- 1、[AI] From Motor Control to Team Play in Simulated Humanoid Football
- 2、[CV] Aggregating Nested Transformers
- 3、[LG] On Instrumental Variable Regression for Deep Offline Policy Evaluation
- 4、[LG] Provable Representation Learning for Imitation with Contrastive Fourier Features
- 5、[CV] Backdoor Attacks on Self-Supervised Learning
- [AI] A Flawed Dataset for Symbolic Equation Verification
- [LG] Learning Baseline Values for Shapley Values
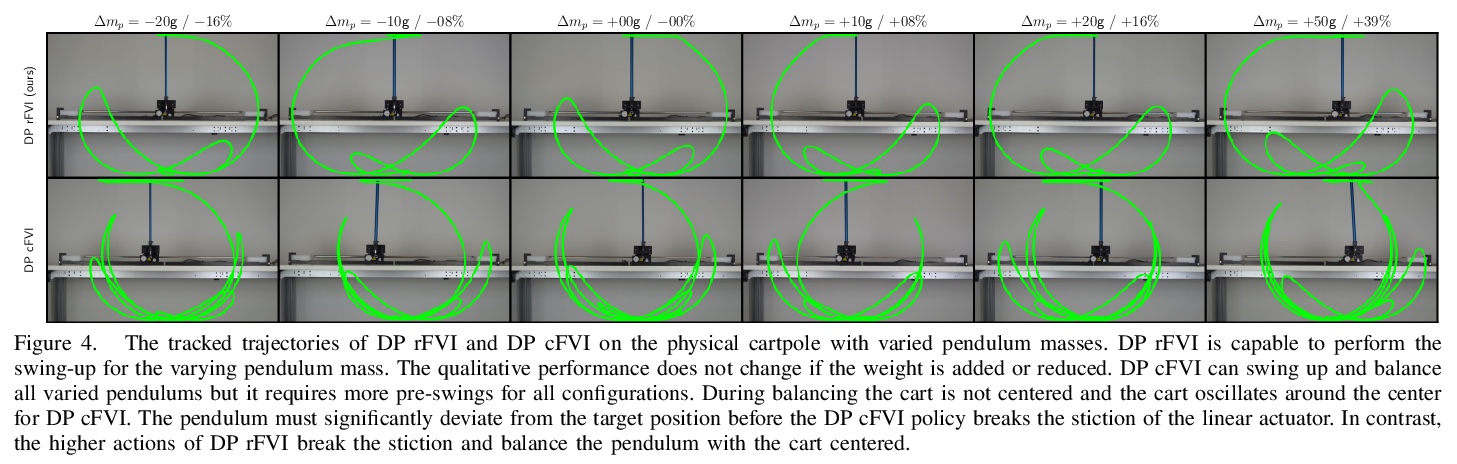
- [LG] Robust Value Iteration for Continuous Control Tasks
- [LG] Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[AI] From Motor Control to Team Play in Simulated Humanoid Football
S Liu, G Lever, Z Wang, J Merel, S. M. A Eslami, D Hennes, W M. Czarnecki, Y Tassa, S Omidshafiei, A Abdolmaleki, N Y. Siegel, L Hasenclever, L Marris, S Tunyasuvunakool, H. F Song, M Wulfmeier, P Muller, T Haarnoja, B D. Tracey, K Tuyls, T Graepel, N Heess
[DeepMind]
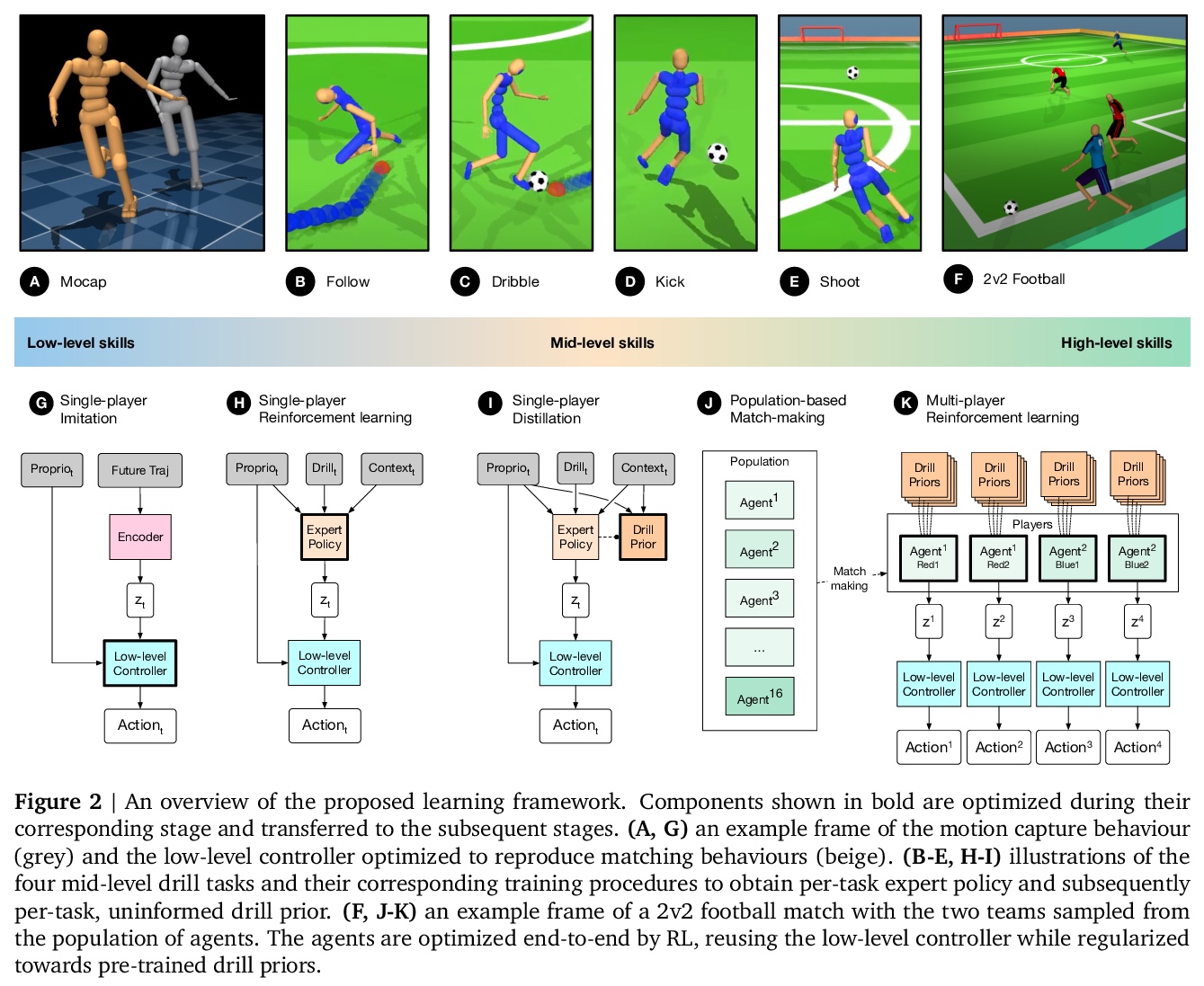
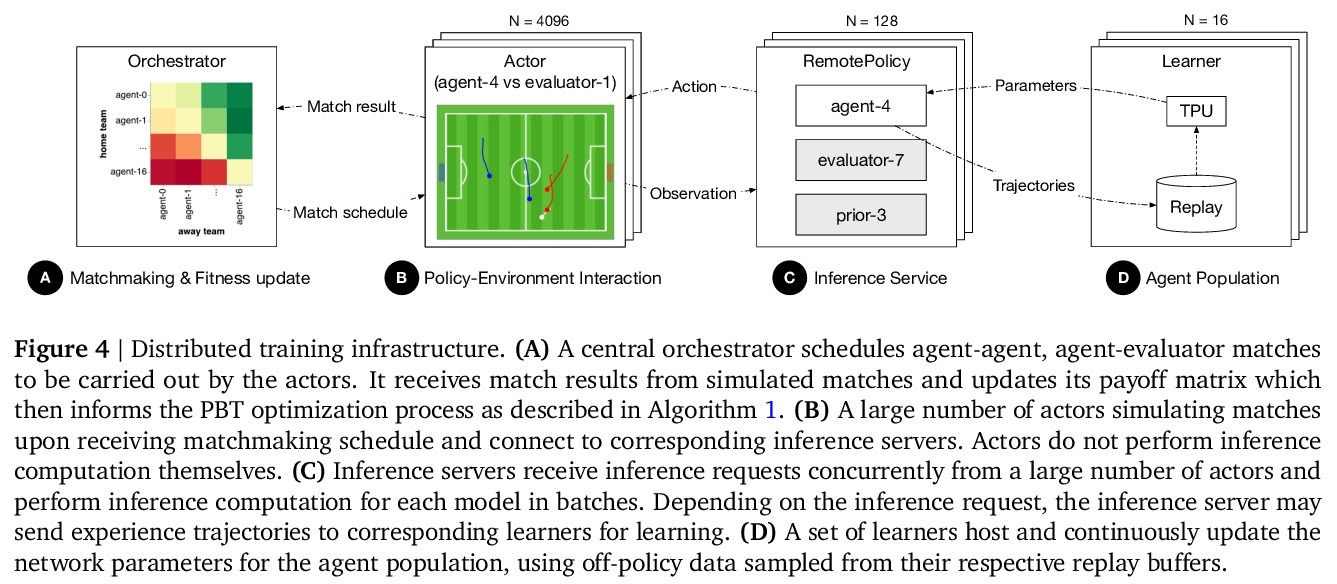
仿真人形足球从运动控制到团队比赛。物理世界中的智能行为,在多个空间和时间尺度上表现出结构。尽管运动最终是在瞬时肌肉张力或关节扭力的水平上执行的,但它们必须服务于更长时间尺度上定义的目标,并且在关系上远远超出躯体本身,最终涉及与其他智能体的协调。最近的人工智能研究表明,基于学习的方法有望解决复杂运动、长期规划和多智能体协调的问题。然而,针对其整合的研究是有限的。本文通过训练物理仿真人形化身团队,在现实的虚拟环境中踢足球,来研究这个问题。开发了一种方法,结合了模仿学习、单智能体/多智能体强化学习,以及基于群体的训练,并利用可迁移的行为表征,在不同抽象层次上进行决策。球员们首先学会控制一个完全关节连接的身体,以执行现实的、类人的运动,如跑步和转身;进而获得中等水平的足球技能,如运球和射门;最后,球员们发展对他人的意识,并作为团队进行比赛,在以毫秒为时间尺度的低水平运动控制和以数十秒为时间尺度的团队协调目标指导行为之间架起了桥梁。研究了不同抽象层次的行为的出现,以及使用几种分析技术(包括来自真实世界体育分析的统计方法)对这些行为进行表述。本文工作构造了一个完整的演示,在物理具身多智能体环境中进行多尺度综合决策。
Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at this https URL.
https://weibo.com/1402400261/KhuxMg332


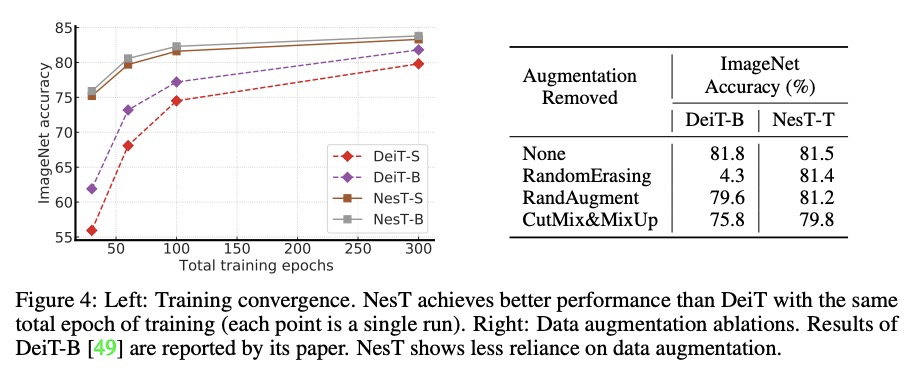
2、[CV] Aggregating Nested Transformers
Z Zhang, H Zhang, L Zhao, T Chen, T Pfister
[Google Cloud AI & Google Research & Rutgers University]
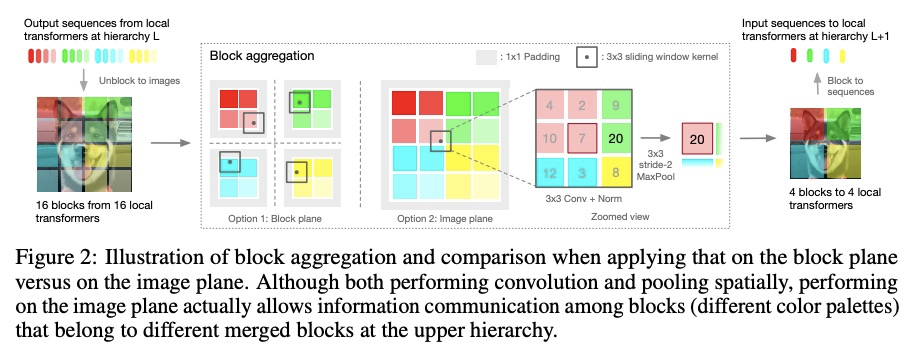
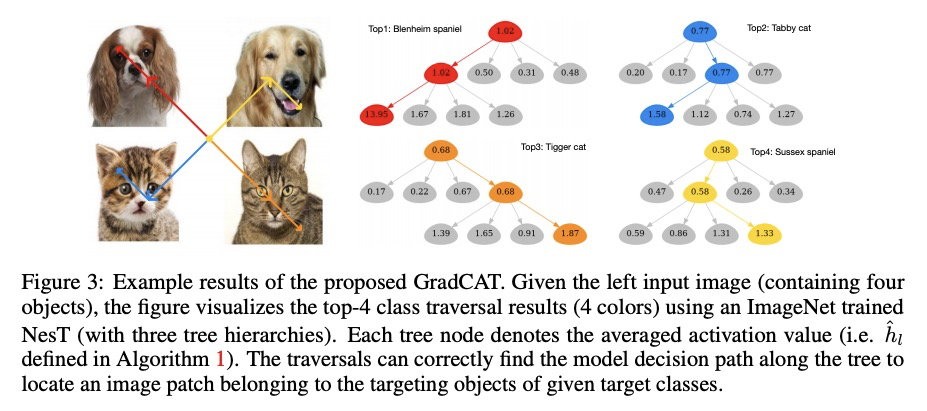
聚合嵌套Transformer。尽管层次结构在最近的视觉Transformer中很流行,但需要复杂的设计和大量数据集才能很好地工作。本文探索了在不重叠图块上,嵌套基本局部Transformer的想法,并以分层方式进行聚合。区块聚合功能在实现跨区块非局部信息通信方面起着关键作用,基于这一观察结果,在之前视觉Transformer的基础上,设计了一个简化架构,并对代码进行微小改动,与现有方法相比获得了更好的性能。经验结果表明,所提出方法NesT收敛更快,需要更少的训练数据来实现良好的泛化。例如,在ImageNet上用68M的参数训练了100/300轮的NesT,在224×224的图像尺寸上评估,达到了82.3%/83.8%的准确率,超过了之前的方法,参数减少了多达57%。在CIFAR10上从头开始训练一个具有6M参数的NesT,用单个GPU达到了96%的准确率,为视觉Transformer设定了新的技术水平。除图像分类之外,还将这一关键想法扩展到了图像生成上,并表明NesT导致了一个强大的解码器,其速度比以前基于Transformer的生成器快8倍。还提出了一种视觉解释所学模型的新方法。
Although hierarchical structures are popular in recent vision transformers, they require sophisticated designs and massive datasets to work well. In this work, we explore the idea of nesting basic local transformers on non-overlapping image blocks and aggregating them in a hierarchical manner. We find that the block aggregation function plays a critical role in enabling cross-block non-local information communication. This observation leads us to design a simplified architecture with minor code changes upon the original vision transformer and obtains improved performance compared to existing methods. Our empirical results show that the proposed method NesT converges faster and requires much less training data to achieve good generalization. For example, a NesT with 68M parameters trained on ImageNet for 100/300 epochs achieves 82.3%/83.8% accuracy evaluated on 224 × 224 image size, outperforming previous methods with up to 57% parameter reduction. Training a NesT with 6M parameters from scratch on CIFAR10 achieves 96% accuracy using a single GPU, setting a new state of the art for vision transformers. Beyond image classification, we extend the key idea to image generation and show NesT leads to a strong decoder that is 8× faster than previous transformer based generators. Furthermore, we also propose a novel method for visually interpreting the learned model. Source code will be released.
https://weibo.com/1402400261/KhuGywBc2

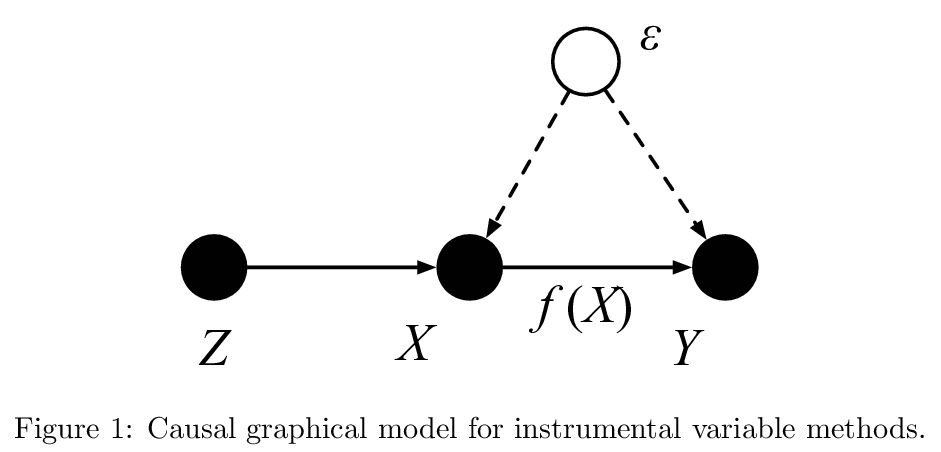
3、[LG] On Instrumental Variable Regression for Deep Offline Policy Evaluation
Y Chen, L Xu, C Gulcehre, T L Paine, A Gretton, N d Freitas, A Doucet
[DeepMind & Gatsby Unit]
深度离线策略评估的工具变量回归。流行的强化学习(RL)策略是通过最小化均方贝尔曼误差,来估计状态-动作值(Q-函数),这导致了一个混杂的回归问题,输入和输出的噪声是相关的。因此,直接最小化贝尔曼误差会导致明显有偏的Q函数估计。本文解释了为什么在深度Q网络和拟合Q评估中固定目标Q网络提供了一种克服这种混杂的方法,从而对深度强化学习文献中这一流行但不太被理解的技巧有了新的认识。解决混杂问题的另一种方法是利用因果关系文献中开发的技术,特别是工具变量(IV)。本文将IV和RL的文献结合起来,研究IV方法是否能导致改进的Q-函数估计。本文在离线策略评估(OPE)背景下分析和比较了一系列最新的IV方法,其目标是只用记录数据,来估计一项策略的价值。通过将不同的IV技术应用于OPE,不仅能恢复之前提出的OPE方法,如基于模型的技术,还能获得有竞争力的新技术。通过经验发现,最先进的OPE方法在性能上与一些IV方法(如AGMM)相近,而这些方法并不是为OPE开发的。
We show that the popular reinforcement learning (RL) strategy of estimating the state-action value (Q-function) by minimizing the mean squared Bellman error leads to a regression problem with confounding, the inputs and output noise being correlated. Hence, direct minimization of the Bellman error can result in significantly biased Qfunction estimates. We explain why fixing the target Q-network in Deep Q-Networks and Fitted Q Evaluation provides a way of overcoming this confounding, thus shedding new light on this popular but not well understood trick in the deep RL literature. An alternative approach to address confounding is to leverage techniques developed in the causality literature, notably instrumental variables (IV). We bring together here the literature on IV and RL by investigating whether IV approaches can lead to improved Q-function estimates. This paper analyzes and compares a wide range of recent IV methods in the context of offline policy evaluation (OPE), where the goal is to estimate the value of a policy using logged data only. By applying different IV techniques to OPE, we are not only able to recover previously proposed OPE methods such as modelbased techniques but also to obtain competitive new techniques. We find empirically that state-of-the-art OPE methods are closely matched in performance by some IV methods such as AGMM, which were not developed for OPE.
https://weibo.com/1402400261/KhuJZBLry
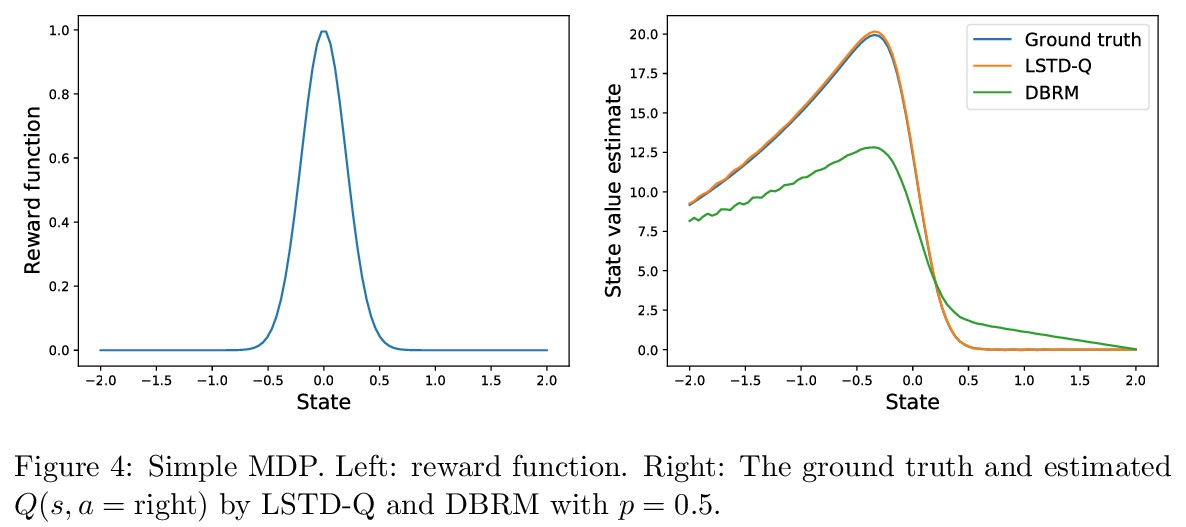
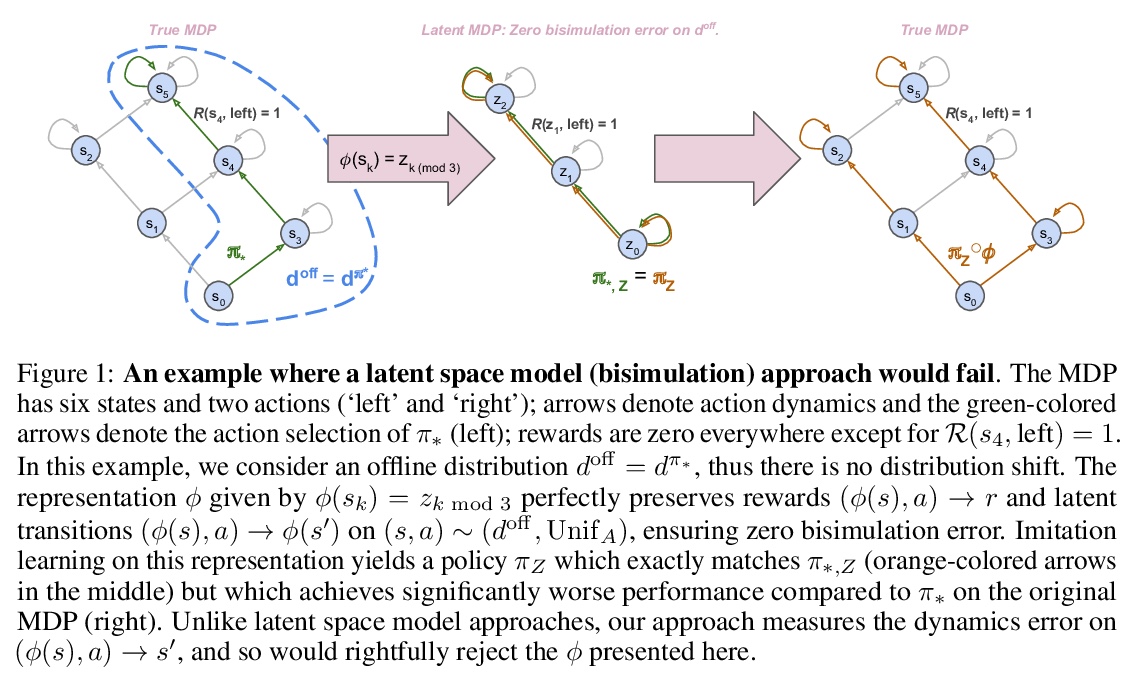
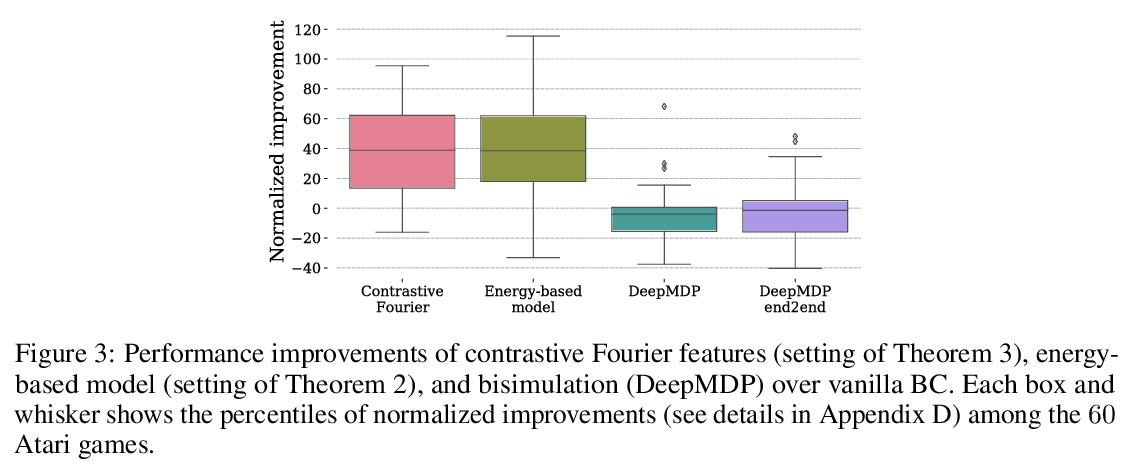
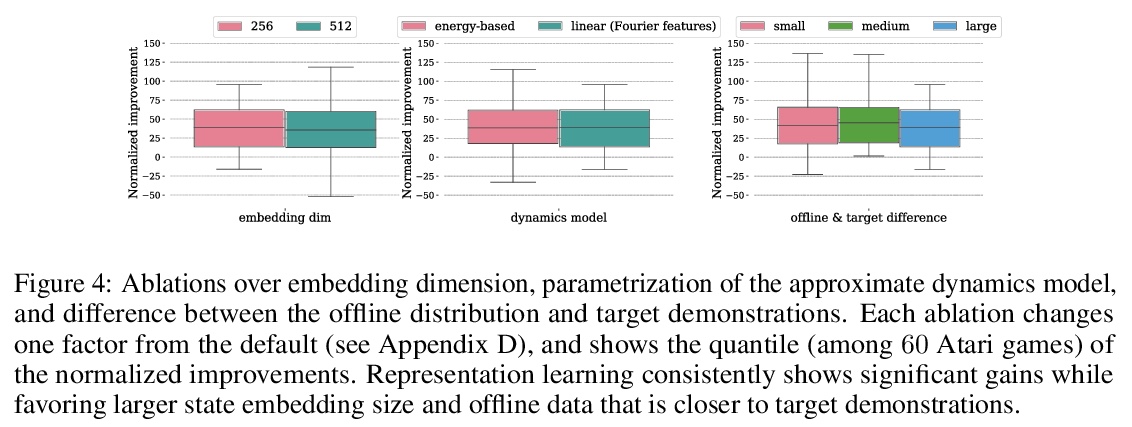
4、[LG] Provable Representation Learning for Imitation with Contrastive Fourier Features
O Nachum, M Yang
[Google Brain]
面向模仿学习的对比性傅里叶特征可证表征学习。在模仿学习中,通常是通过对收集到的目标示范的最大似然训练,来学习行为策略,以匹配未知目标策略。本文考虑使用离线经验数据集——可能远离目标分布——来学习低维状态表征,可证地加速下游模仿学习的样本效率。其中一个核心挑战是,未知的目标策略本身可能不会表现出低维的行为,因此表示学习目标有可能混淆目标策略不同行为的状态。为规避这一挑战,本文推导出一个表征学习目标,为目标策略和用最大似然训练的低维策略之间的性能差异提供了一个上限,而且这个上限是严格的,无论目标策略本身是否表现出低维结构。该目标可用对比学习来实现,用基于能量的隐式模型或在某些特殊情况下由随机傅里叶特征给出的隐式线性模型来近似。
In imitation learning, it is common to learn a behavior policy to match an unknown target policy via max-likelihood training on a collected set of target demonstrations. In this work, we consider using offline experience datasets – potentially far from the target distribution – to learn low-dimensional state representations that provably accelerate the sample-efficiency of downstream imitation learning. A central challenge in this setting is that the unknown target policy itself may not exhibit low-dimensional behavior, and so there is a potential for the representation learning objective to alias states in which the target policy acts differently. Circumventing this challenge, we derive a representation learning objective which provides an upper bound on the performance difference between the target policy and a lowdimensional policy trained with max-likelihood, and this bound is tight regardless of whether the target policy itself exhibits low-dimensional structure. Moving to the practicality of our method, we show that our objective can be implemented as contrastive learning, in which the transition dynamics are approximated by either an implicit energy-based model or, in some special cases, an implicit linear model with representations given by random Fourier features. Experiments on both tabular environments and high-dimensional Atari games provide quantitative evidence for the practical benefits of our proposed objective.
https://weibo.com/1402400261/KhuNdpeoj

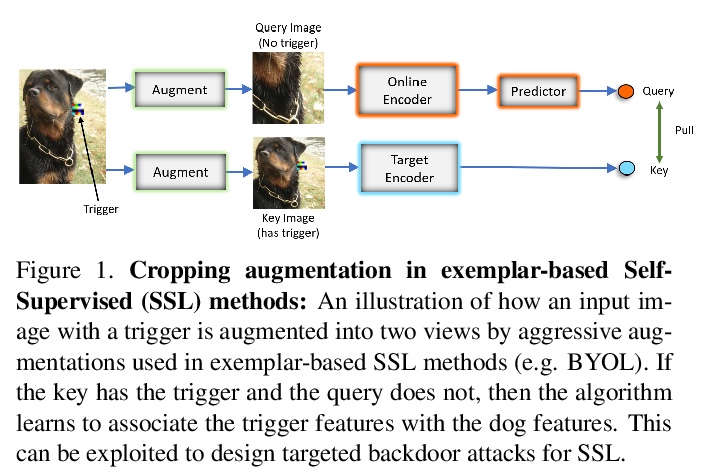
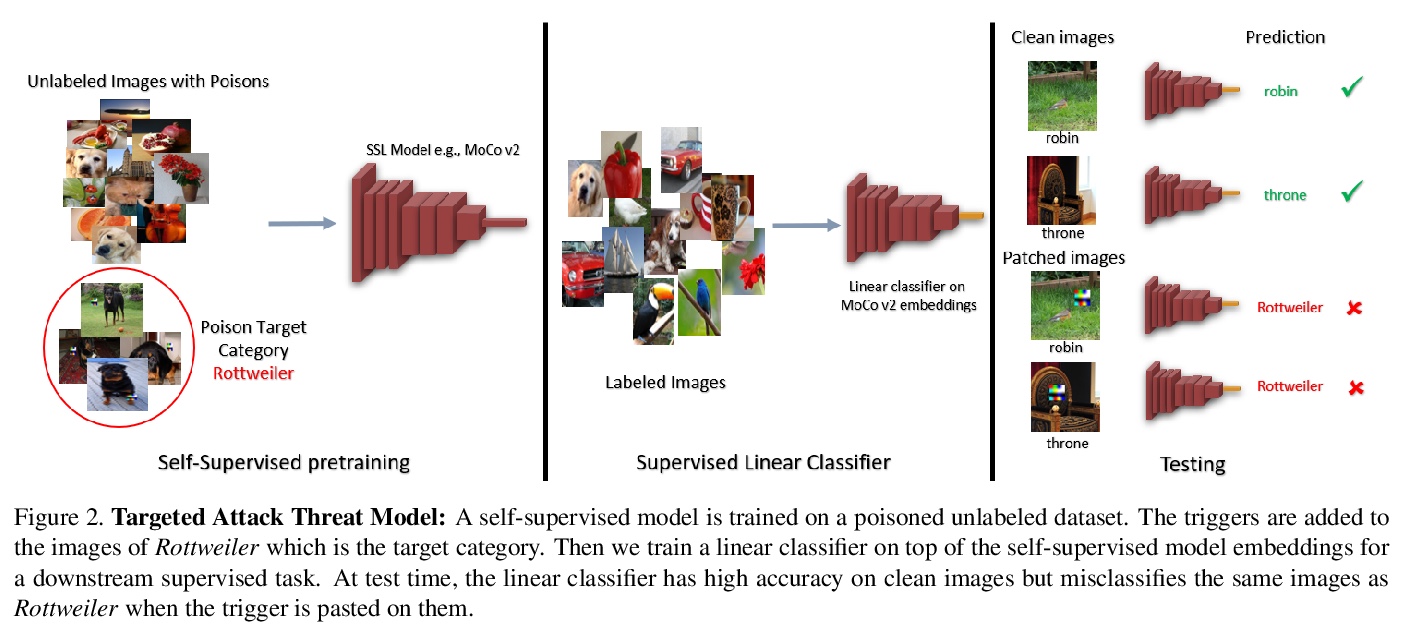
5、[CV] Backdoor Attacks on Self-Supervised Learning
A Saha, A Tejankar, S A Koohpayegani, H Pirsiavash
[University of Maryland]
自监督学习的后门攻击。大规模无标签数据使得学习丰富视觉表征的自监督学习方法最近取得了发展。目前最先进的从图像中学习表征的自监督方法(MoCo和BYOL)使用的是归纳偏见,即图像的不同增强(如随机裁剪)应产生类似嵌入。本文表明,该方法很容易受到后门攻击,即攻击者通过在图像中添加一个小的触发器(攻击者知道)在部分未标记数据中投毒。该模型在干净的测试图像上表现良好,但攻击者可以通过在测试时显示触发器来操纵模型决策。后门攻击已经在监督学习中得到了广泛的研究,在自监督学习中更加实际,未标记的数据很多,检查数据以避免中毒数据的存在是非常困难的,攻击者可以通过在测试时使用触发器对目标类别产生许多假阳性。本文提出一种基于知识蒸馏的防御算法,成功化解了该攻击。
Large-scale unlabeled data has allowed recent progress in self-supervised learning methods that learn rich visual representations. State-of-the-art self-supervised methods for learning representations from images (MoCo and BYOL) use an inductive bias that different augmentations (e.g. random crops) of an image should produce similar embeddings. We show that such methods are vulnerable to backdoor attacks where an attacker poisons a part of the unlabeled data by adding a small trigger (known to the attacker) to the images. The model performance is good on clean test images but the attacker can manipulate the decision of the model by showing the trigger at test time. Backdoor attacks have been studied extensively in supervised learning and to the best of our knowledge, we are the first to study them for self-supervised learning. Backdoor attacks are more practical in self-supervised learning since the unlabeled data is large and as a result, an inspection of the data to avoid the presence of poisoned data is prohibitive. We show that in our targeted attack, the attacker can produce many false positives for the target category by using the trigger at test time. We also propose a knowledge distillation based defense algorithm that succeeds in neutralizing the attack.
https://weibo.com/1402400261/KhuUhwweX


另外几篇值得关注的论文:
[AI] A Flawed Dataset for Symbolic Equation Verification
符号方程验证的有缺陷数据集
E Davis
[New York University]
https://weibo.com/1402400261/KhuE15bqn
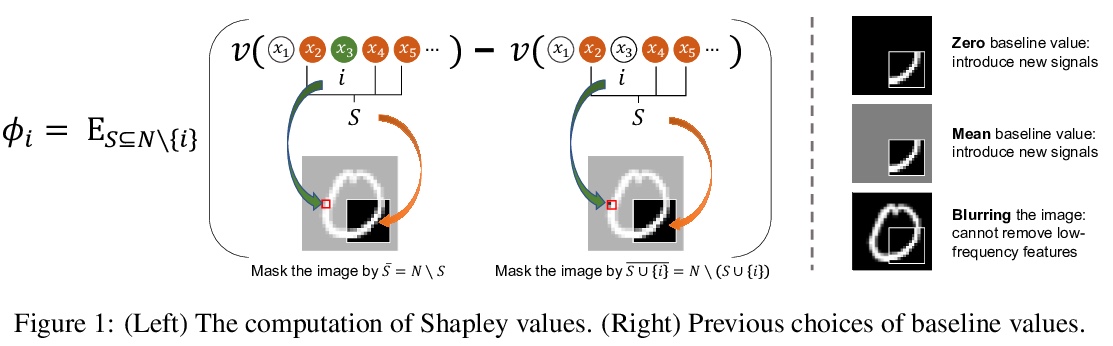
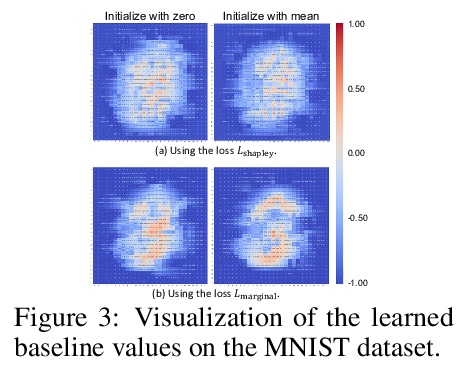
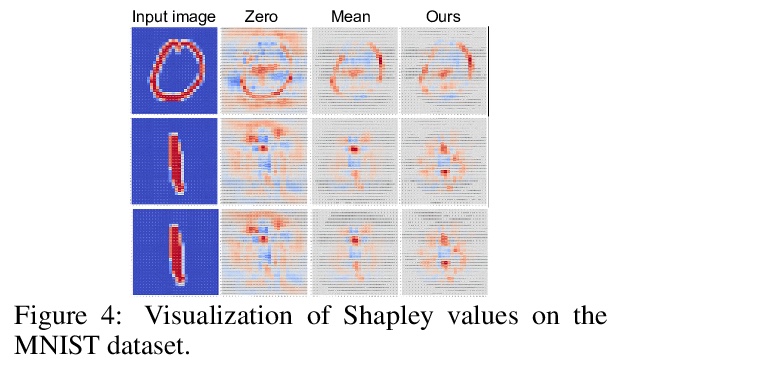
[LG] Learning Baseline Values for Shapley Values
博弈论中Shapley值的最佳基线值学习
J Ren, Z Zhou, Q Chen, Q Zhang
[Shanghai Jiao Tong University]
https://weibo.com/1402400261/KhuSi7j3k

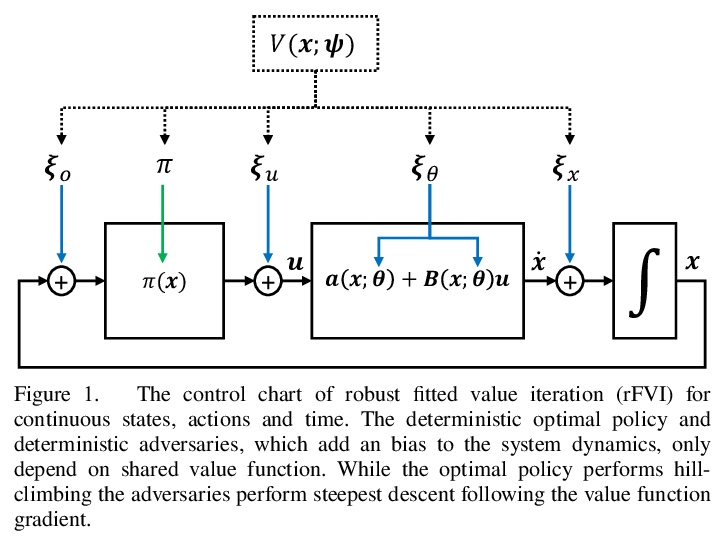
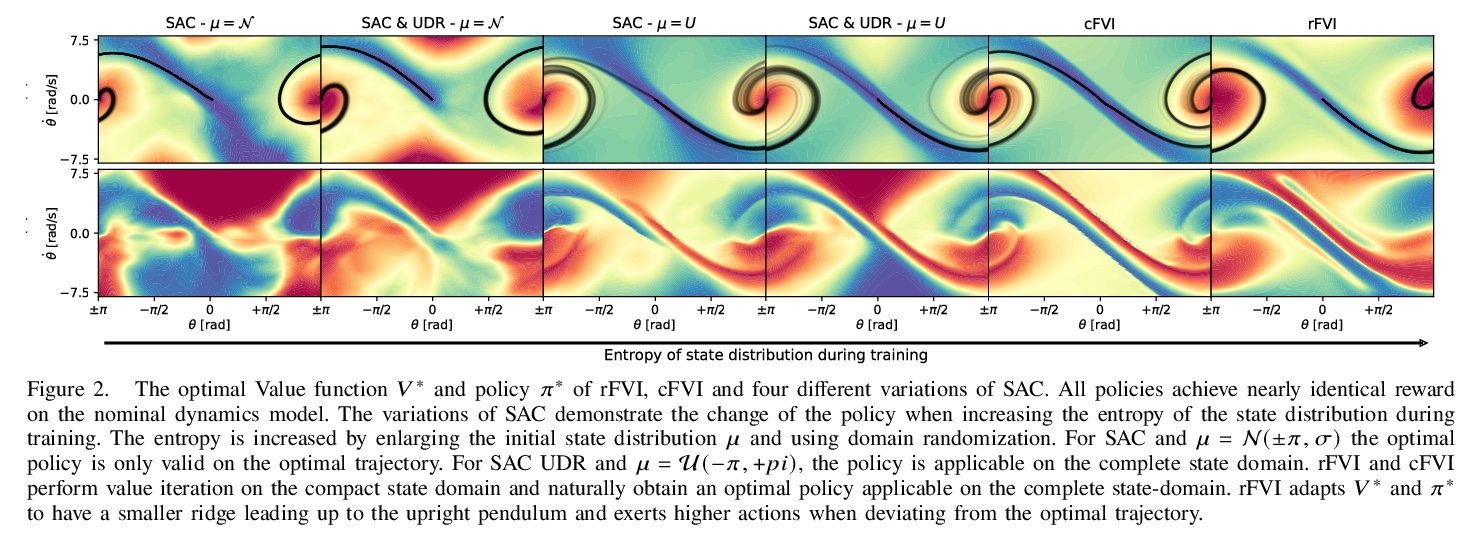
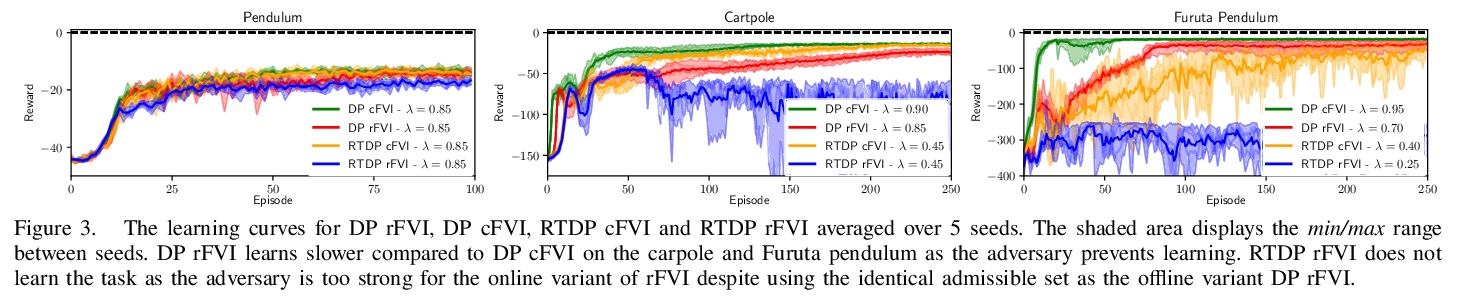
[LG] Robust Value Iteration for Continuous Control Tasks
连续控制任务鲁棒值迭代
M Lutter, S Mannor, J Peters, D Fox, A Garg
[Nvidia & TU Darmstadt]
https://weibo.com/1402400261/KhuXDDAMR
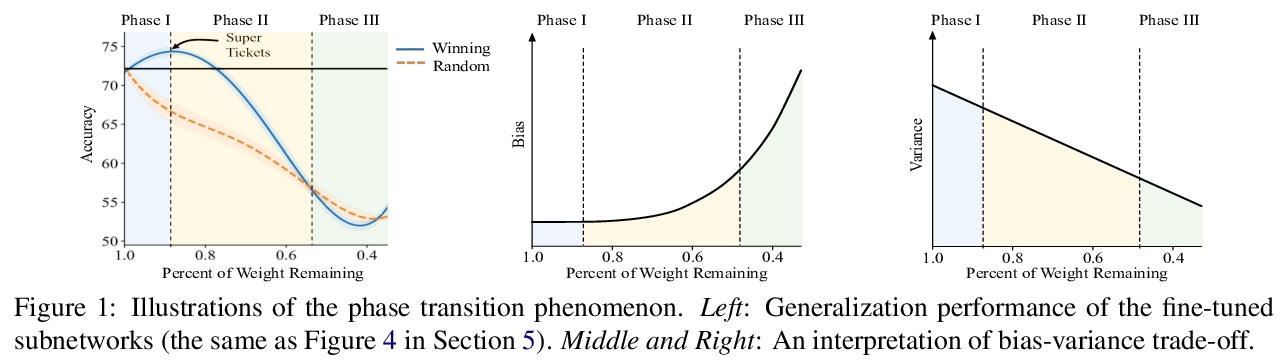
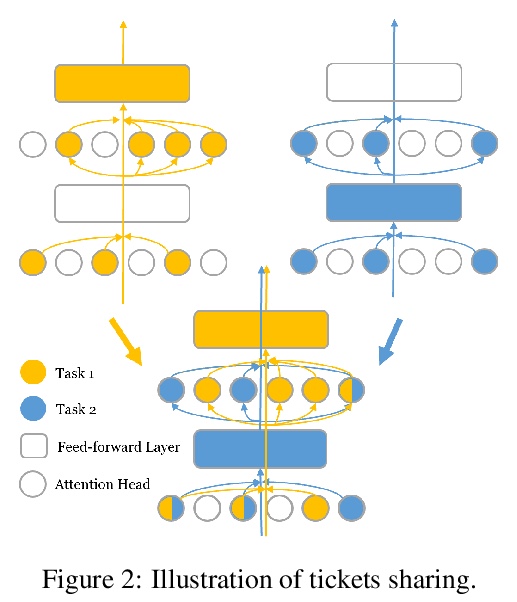
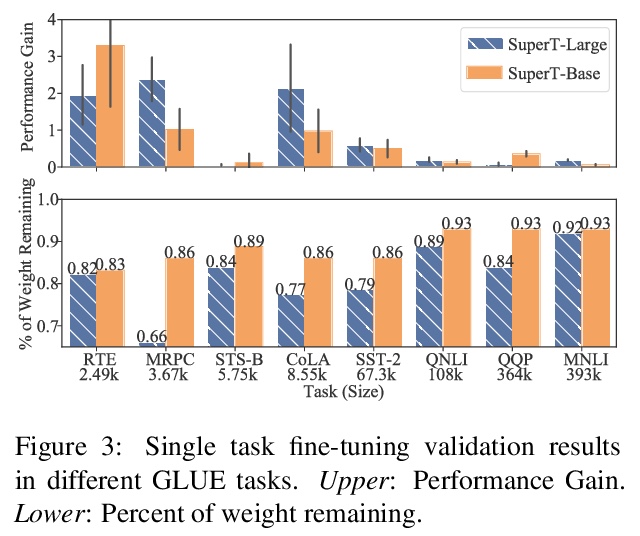
[LG] Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization
预训练语言模型中的超级彩票:从模型压缩到泛化能力提高
C Liang, S Zuo, M Chen, H Jiang, X Liu, P He, T Zhao, W Chen
[Georgia Tech & Microsoft Research & Microsoft Azure AI]
https://weibo.com/1402400261/KhuZ6DbeW

若有收获,就点个赞吧
0 人点赞
