LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] **Modeling Event Salience in Narratives via Barthes’ Cardinal Functions
T Otake, S Yokoi, N Inoue, R Takahashi, T Kuribayashi, K Inui
[Tohoku University]
叙事中的事件显著性建模。叙事中的事件在显著性上有所不同:有些事件对叙事来说比其他事件更重要。受Barthes在叙事学中对基数函数定义的启发,提出用语言模型以无监督方式在叙事中估计事件显著性的方法,从叙事文本中删除事件,通过比较原始叙事文本和删除事件后的叙事文本的连贯性得分来估计事件的显著性。实验发现提出的方法优于基线方法,对叙事文本语言模型的微调是改进本文方法的关键因素。**
Events in a narrative differ in salience: some are more important to the story than others. Estimating event salience is useful for tasks such as story generation, and as a tool for text analysis in narratology and folkloristics. To compute event salience without any annotations, we adopt Barthes’ definition of event salience and propose several unsupervised methods that require only a pre-trained language model. Evaluating the proposed methods on folktales with event salience annotation, we show that the proposed methods outperform baseline methods and find fine-tuning a language model on narrative texts is a key factor in improving the proposed methods.
https://weibo.com/1402400261/JsTkus2Ls
2、[LG] Teaching a GAN What Not to Learn
S Asokan, C S Seelamantula
[Indian Institute of Science]
教GAN不学什么。在GAN框架中,不仅提供GAN必须学会建模的积极样本,还提供它必须学会避免的消极样本——所谓“Rumi框架”,允许鉴别器通过学习惩罚不希望生成的样本,来更好地表示潜在目标分布,以加速生成器的学习过程。在MNIST、Fashion MNIST、CelebA和CIFAR-10数据集上证明了该方法的有效性,与标准GAN框架相比,Rumi框架具有更好的泛化能力的同时,FID得分也显著降低。
Generative adversarial networks (GANs) were originally envisioned as unsupervised generative models that learn to follow a target distribution. Variants such as conditional GANs, auxiliary-classifier GANs (ACGANs) project GANs on to supervised and semi-supervised learning frameworks by providing labelled data and using multi-class discriminators. In this paper, we approach the supervised GAN problem from a different perspective, one that is motivated by the philosophy of the famous Persian poet Rumi who said, “The art of knowing is knowing what to ignore.” In the GAN framework, we not only provide the GAN positive data that it must learn to model, but also present it with so-called negative samples that it must learn to avoid - we call this “The Rumi Framework.” This formulation allows the discriminator to represent the underlying target distribution better by learning to penalize generated samples that are undesirable - we show that this capability accelerates the learning process of the generator. We present a reformulation of the standard GAN (SGAN) and least-squares GAN (LSGAN) within the Rumi setting. The advantage of the reformulation is demonstrated by means of experiments conducted on MNIST, Fashion MNIST, CelebA, and CIFAR-10 datasets. Finally, we consider an application of the proposed formulation to address the important problem of learning an under-represented class in an unbalanced dataset. The Rumi approach results in substantially lower FID scores than the standard GAN frameworks while possessing better generalization capability.
https://weibo.com/1402400261/JsTw6g9gN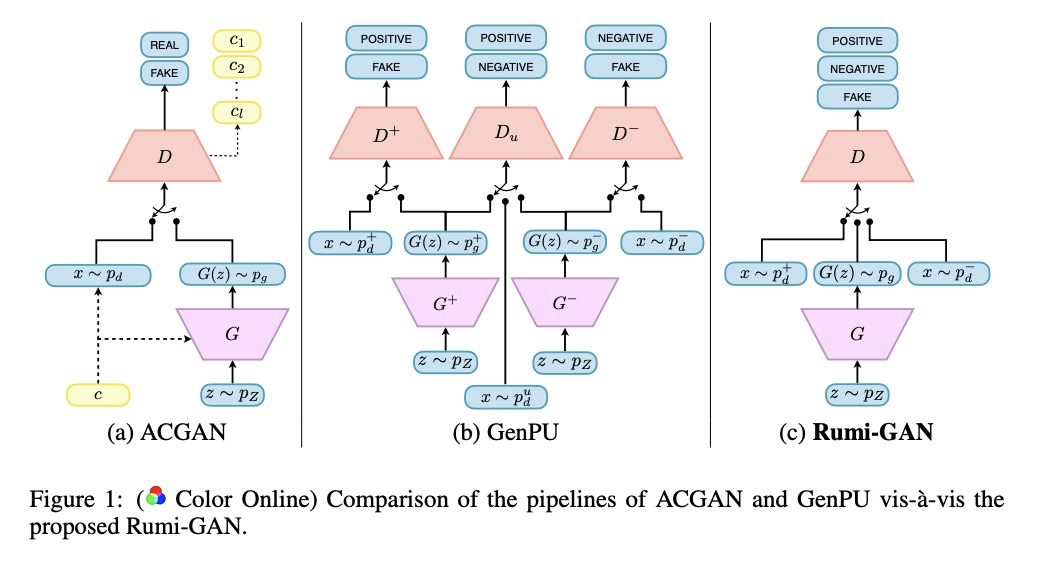

3、[CL] **Biased TextRank: Unsupervised Graph-Based Content Extraction
A Kazemi, V Pérez-Rosas, R Mihalcea
[University of Michigan]
Biased TextRank:基于图的无监督内容提取。提出Biased TextRank,一种基于图的内容提取方法,灵感来自流行的TextRank算法,根据文本在语言处理任务中的重要性和与输入“焦点”的相关性对文本进行排序。Biased TextRank通过修改TextRank执行过程中的随机重启来实现对文本的焦点内容提取。随机重启概率是根据图节点与任务焦点的相关性来分配的。在重点摘要和解释提取任务上的实验表明,Biased TextRank方法比目前最先进的自然语言处理方法更快、更轻量。**
We introduce Biased TextRank, a graph-based content extraction method inspired by the popular TextRank algorithm that ranks text spans according to their importance for language processing tasks and according to their relevance to an input “focus.” Biased TextRank enables focused content extraction for text by modifying the random restarts in the execution of TextRank. The random restart probabilities are assigned based on the relevance of the graph nodes to the focus of the task. We present two applications of Biased TextRank: focused summarization and explanation extraction, and show that our algorithm leads to improved performance on two different datasets by significant ROUGE-N score margins. Much like its predecessor, Biased TextRank is unsupervised, easy to implement and orders of magnitude faster and lighter than current state-of-the-art Natural Language Processing methods for similar tasks.
https://weibo.com/1402400261/JsTC0qgZy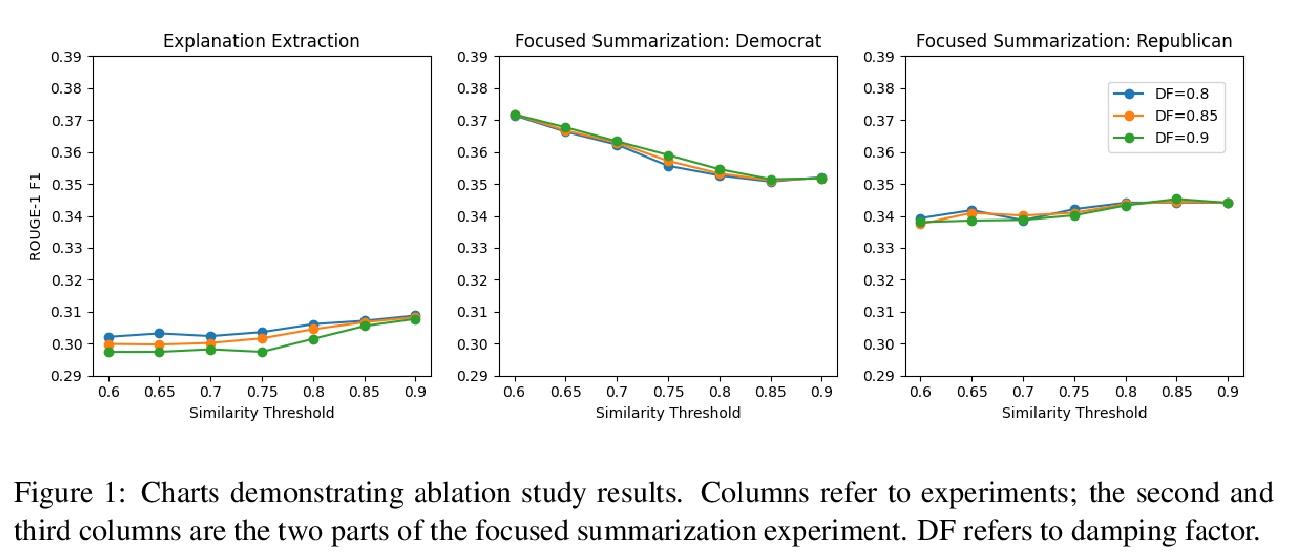
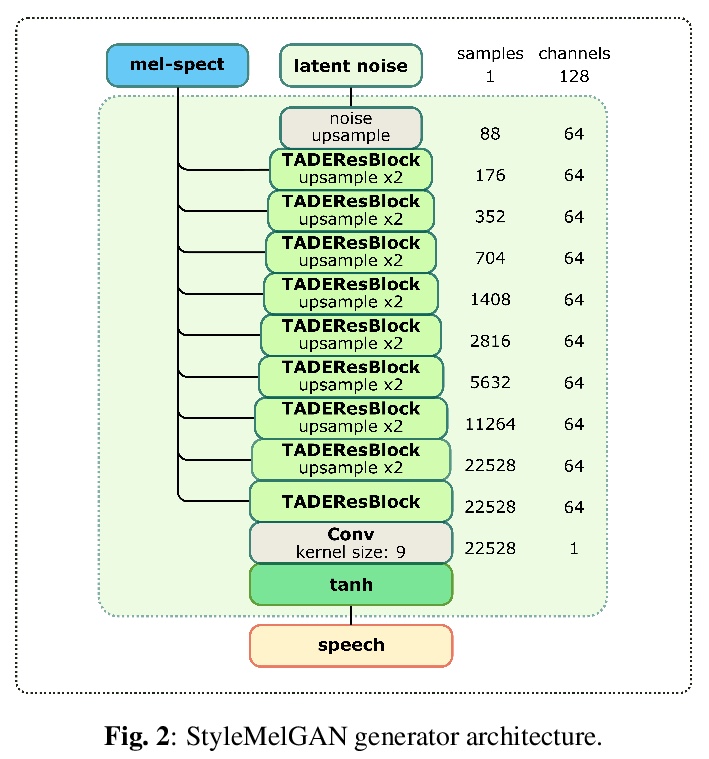
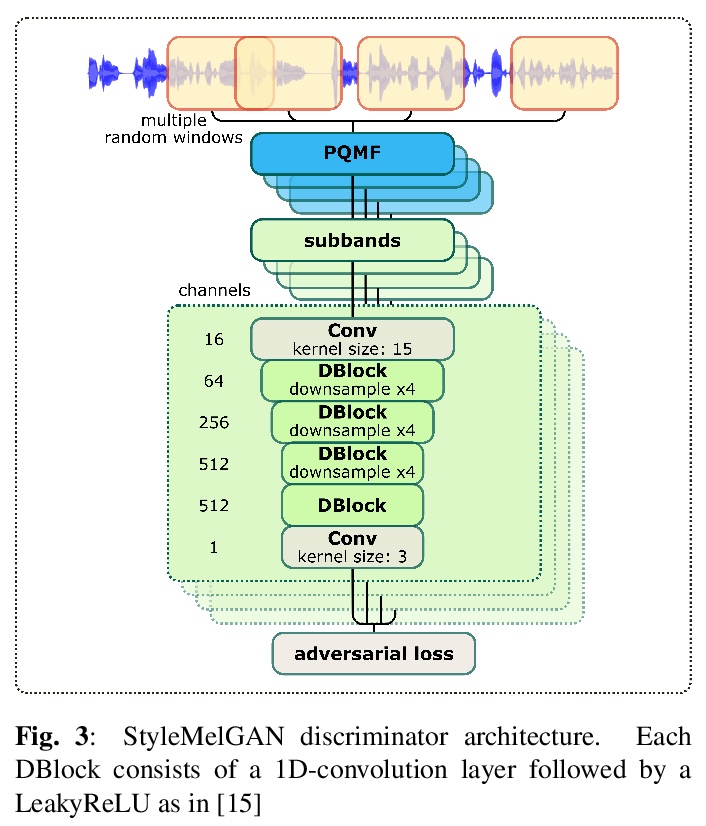
4、[AS] **StyleMelGAN: An Efficient High-Fidelity Adversarial Vocoder with Temporal Adaptive Normalization
A Mustafa, N Pia, G Fuchs
[Fraunhofer IIS]
StyleMelGAN:时间自适应归一化高性能高保真对抗声码器。提出StyleMelGAN,一种轻量神经网络声码器,能以低计算复杂度合成高保真语音。StyleMelGAN用目标语音声学特征的时间自适应归一化风格化低维噪声向量。为了有效训练,多个随机窗口鉴别器对经过滤波器组分析的语音信号进行反向评估,通过多尺度谱重构损失进行正则化。高度并行的语音生成在CPU和GPU上可达到比实时快数倍的速度。**
In recent years, neural vocoders have surpassed classical speech generation approaches in naturalness and perceptual quality of the synthesized speech. Computationally heavy models like WaveNet and WaveGlow achieve best results, while lightweight GAN models, e.g. MelGAN and Parallel WaveGAN, remain inferior in terms of perceptual quality. We therefore propose StyleMelGAN, a lightweight neural vocoder allowing synthesis of high-fidelity speech with low computational complexity. StyleMelGAN employs temporal adaptive normalization to style a low-dimensional noise vector with the acoustic features of the target speech. For efficient training, multiple random-window discriminators adversarially evaluate the speech signal analyzed by a filter bank, with regularization provided by a multi-scale spectral reconstruction loss. The highly parallelizable speech generation is several times faster than real-time on CPUs and GPUs. MUSHRA and P.800 listening tests show that StyleMelGAN outperforms prior neural vocoders in copy-synthesis and Text-to-Speech scenarios.
https://weibo.com/1402400261/JsTKTfi22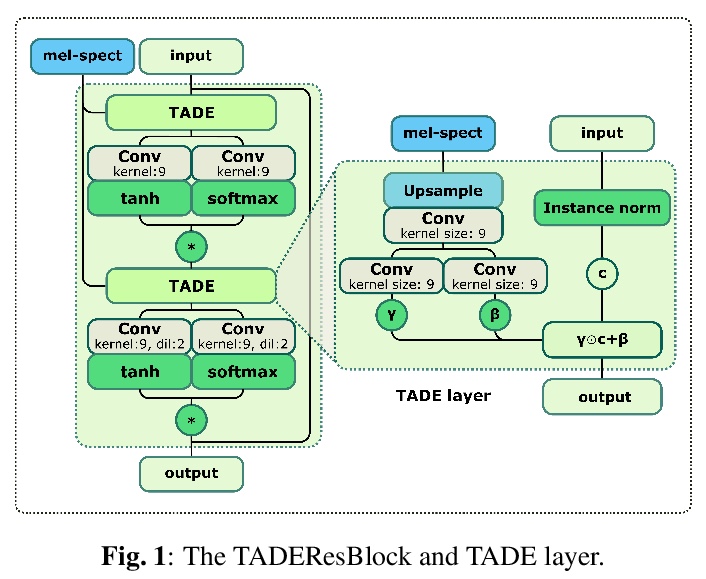
5、[AS] NU-GAN: High resolution neural upsampling with GAN
R Kumar, K Kumar, V Anand, Y Bengio, A Courville
[Descript Inc & Mila]
NU-GAN:GAN神经网络高分辨率音频上采样。提出用于将音频从低采样率到高采样率重新采样(上采样)的NU-GAN,在TTS pipeline中引入音频超分辨率模块,以全前馈和快速采样方式,生成广播质量的语音。ABX偏好测试表明,NU-GAN重采样器能重采样22 kHz到44.1 kHz的音频,与原始音频相比,对单人语音数据集可分辨概率仅比随机高7.4%,对多人语音数据集可分辨概率仅比随机高10.8%。
In this paper, we propose NU-GAN, a new method for resampling audio from lower to higher sampling rates (upsampling). Audio upsampling is an important problem since productionizing generative speech technology requires operating at high sampling rates. Such applications use audio at a resolution of 44.1 kHz or 48 kHz, whereas current speech synthesis methods are equipped to handle a maximum of 24 kHz resolution. NU-GAN takes a leap towards solving audio upsampling as a separate component in the text-to-speech (TTS) pipeline by leveraging techniques for audio generation using GANs. ABX preference tests indicate that our NU-GAN resampler is capable of resampling 22 kHz to 44.1 kHz audio that is distinguishable from original audio only 7.4% higher than random chance for single speaker dataset, and 10.8% higher than chance for multi-speaker dataset.
https://weibo.com/1402400261/JsTQvxPFg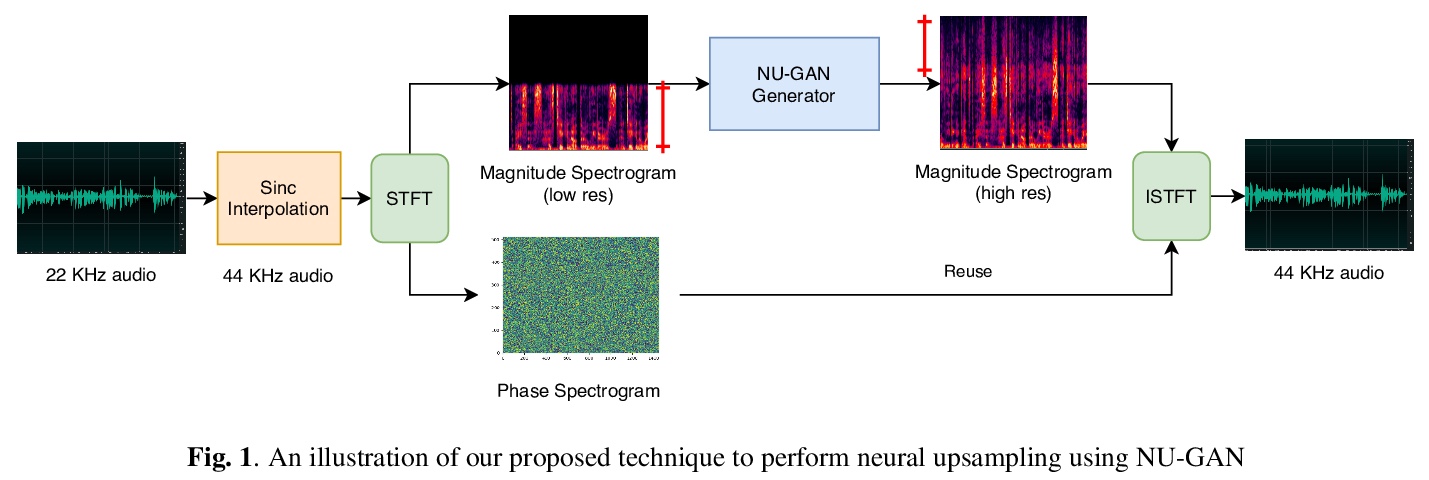
其他几篇值得关注的论文:
[LG] Dos and Don’ts of Machine Learning in Computer Security
计算机安全机器学习的注意事项
D Arp, E Quiring, F Pendlebury, A Warnecke, F Pierazzi, C Wressnegger, L Cavallaro, K Rieck
[Technische Universität Braunschweig & King’s College London]
https://weibo.com/1402400261/JsTYRC5ht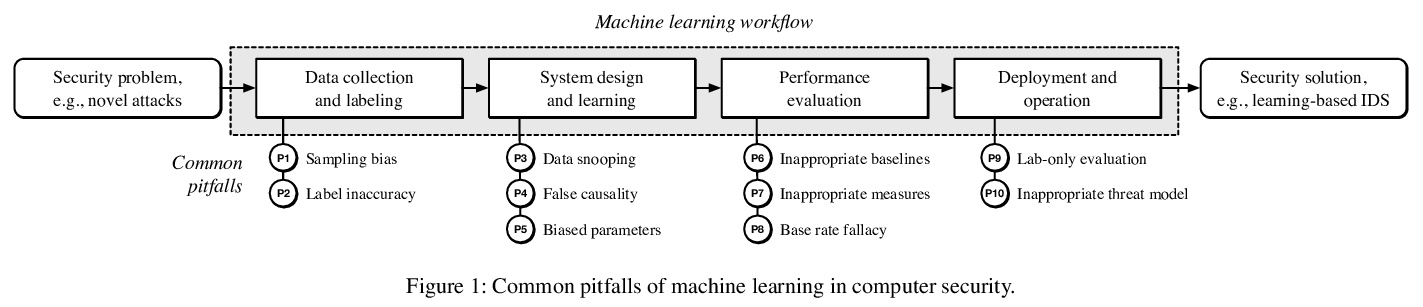
[LG] Multi-task learning for electronic structure to predict and explore molecular potential energy surfaces
用多任务学习预测电子结构、探索分子势能面
Z Qiao, F Ding, M Welborn, P J. Bygrave, A Anandkumar, F R. Manby, T F. M III
[California Institute of Technology & Entos, Inc]
https://weibo.com/1402400261/JsU3y5l6P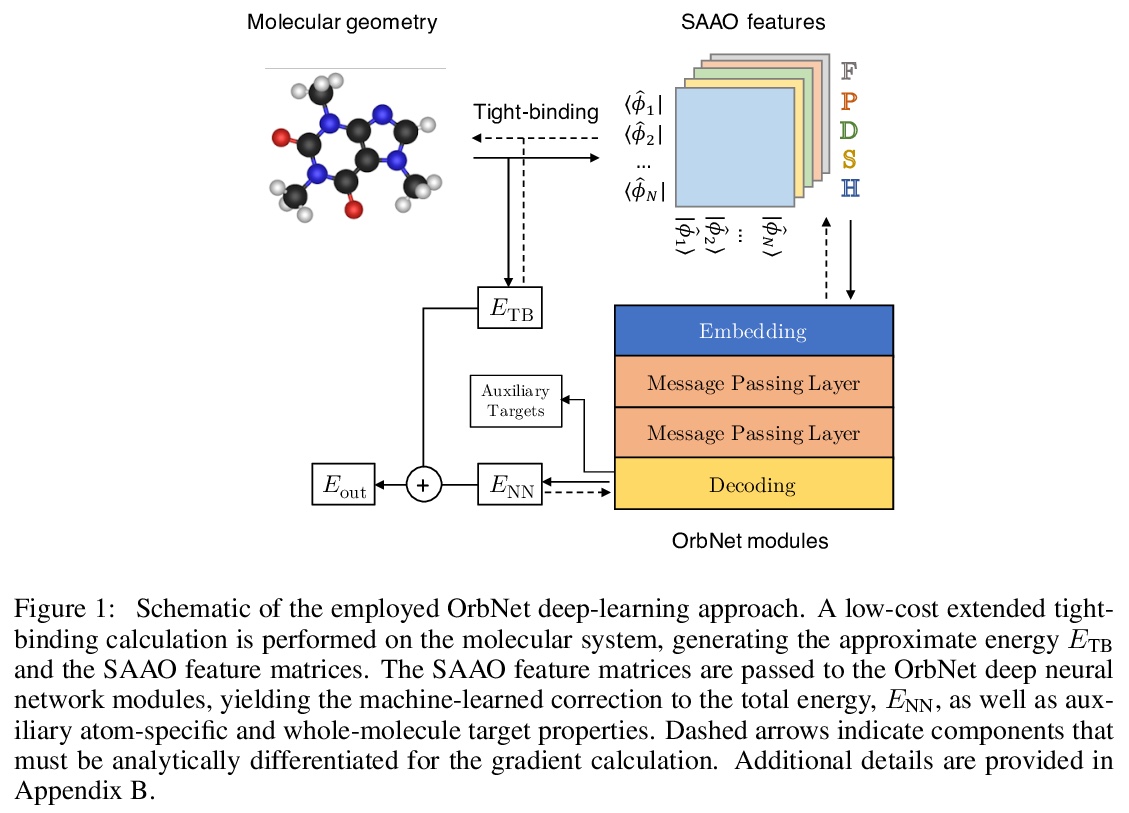
[LG] Machine learning of solvent effects on molecular spectra and reactions
用FieldSchNet研究溶剂效应对分子光谱和Claisen重排反应的影响
M Gastegger, K T. Schütt, K Müller
[Technische Universitat Berlin]
https://weibo.com/1402400261/JsU8qD1OM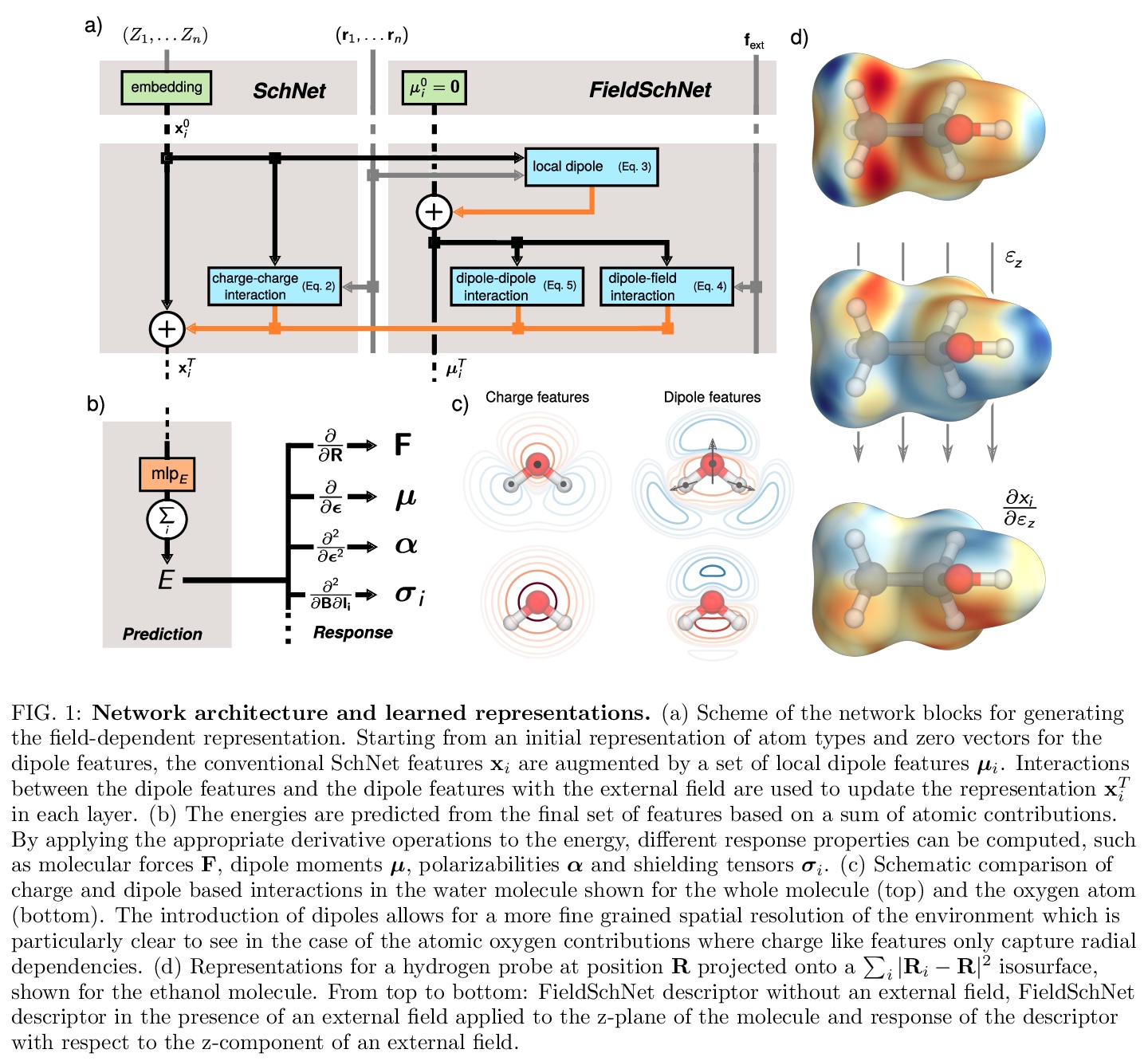
[LG] Towards Reflectivity profile inversion through Artificial Neural Networks
基于神经网络的反射率剖面反演
J M Carmona-Loaiza
[Julich Centre for Neutron Science (JCNS)]
https://weibo.com/1402400261/JsUbs0Wcx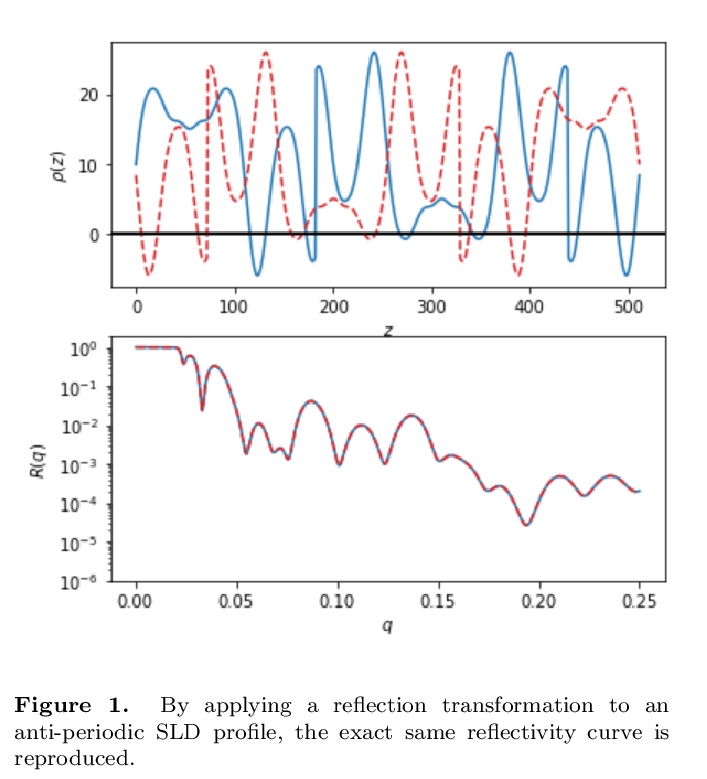

若有收获,就点个赞吧
0 人点赞
