- 1、[CV] Are Convolutional Neural Networks or Transformers more like human vision?
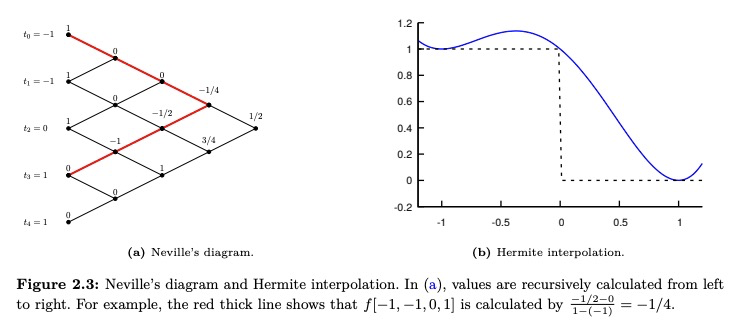
- 2、[ST] Polynomial methods in statistical inference: theory and practice
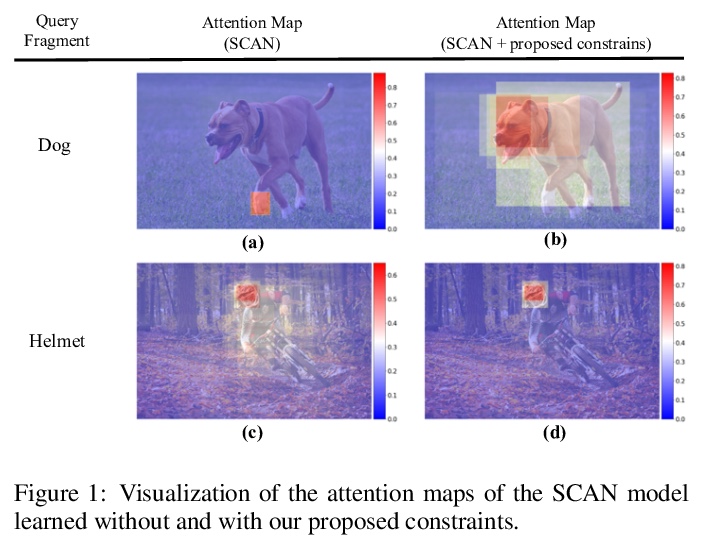
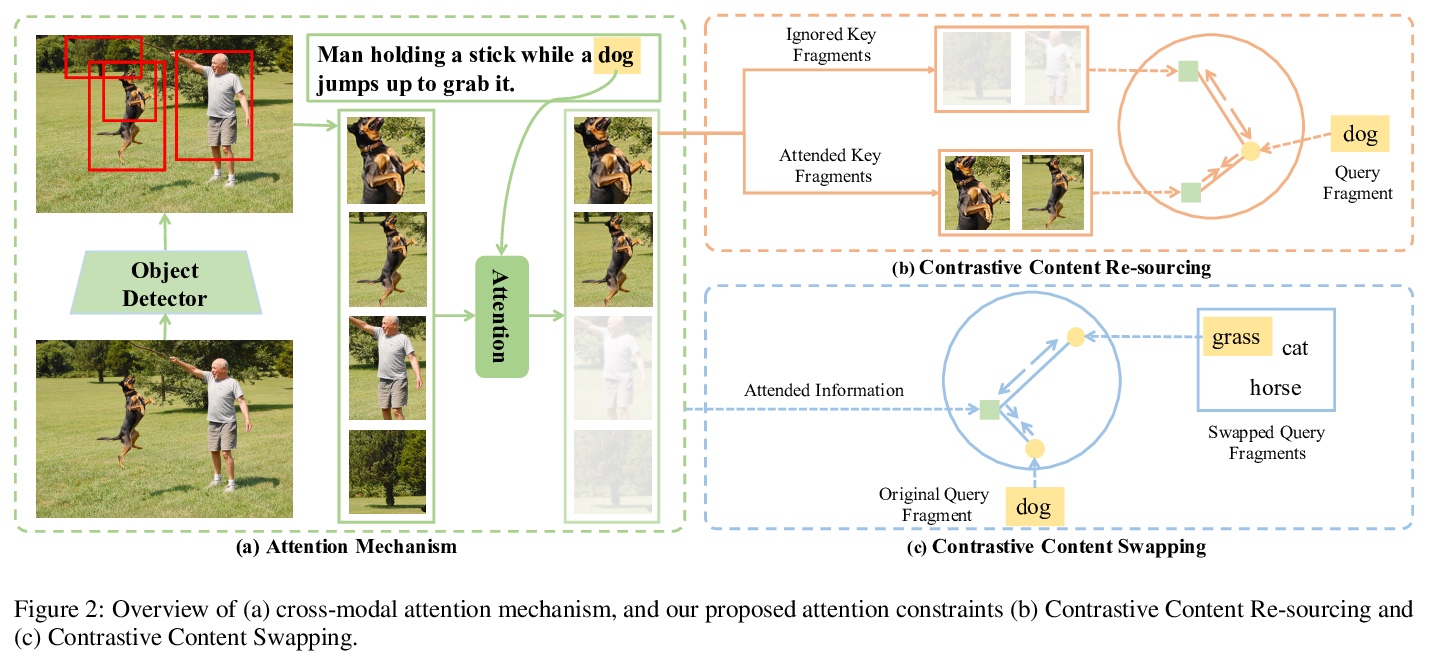
- 3、[CV] More Than Just Attention: Learning Cross-Modal Attentions with Contrastive Constraints
- 4、[CV] Birds of a Feather: Capturing Avian Shape Models from Images
- 5、[CL] Measuring Coding Challenge Competence With APPS
- [RO] Efficient and Robust LiDAR-Based End-to-End Navigation
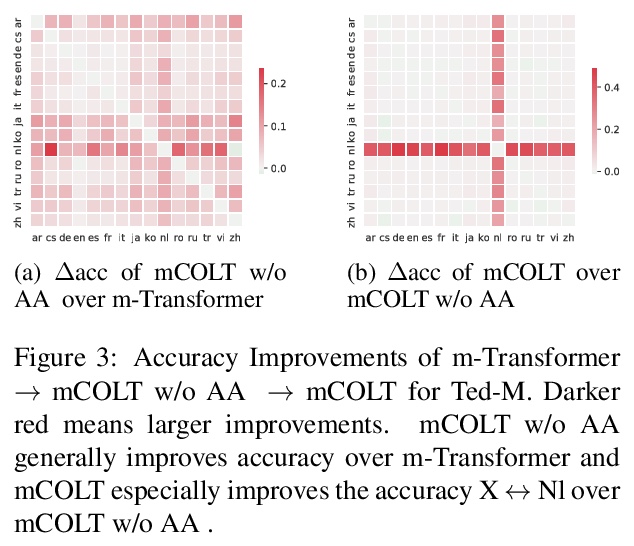
- [CL] Contrastive Learning for Many-to-many Multilingual Neural Machine Translation
- [CV] VTNet: Visual Transformer Network for Object Goal Navigation
- [LG] DEHB: Evolutionary Hyberband for Scalable, Robust and Efficient Hyperparameter Optimization
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] Are Convolutional Neural Networks or Transformers more like human vision?
S Tuli, I Dasgupta, E Grant, T L. Griffiths
[DeepMind & UC Berkeley & Princeton University]
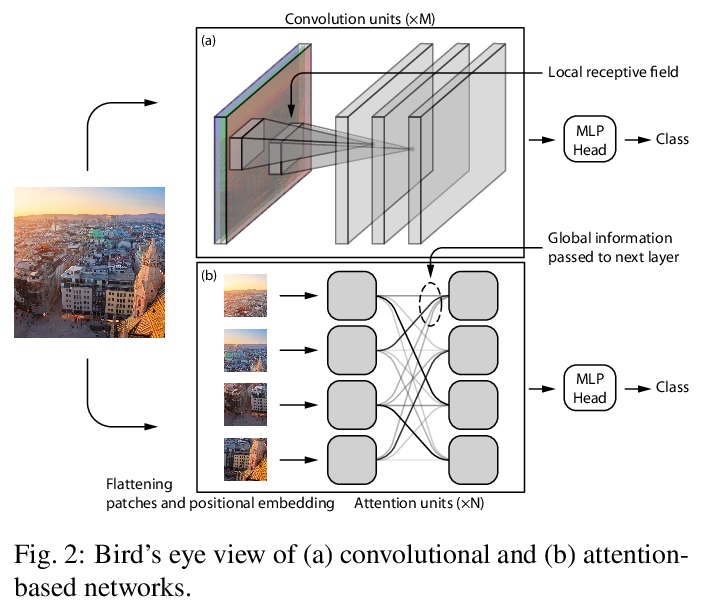
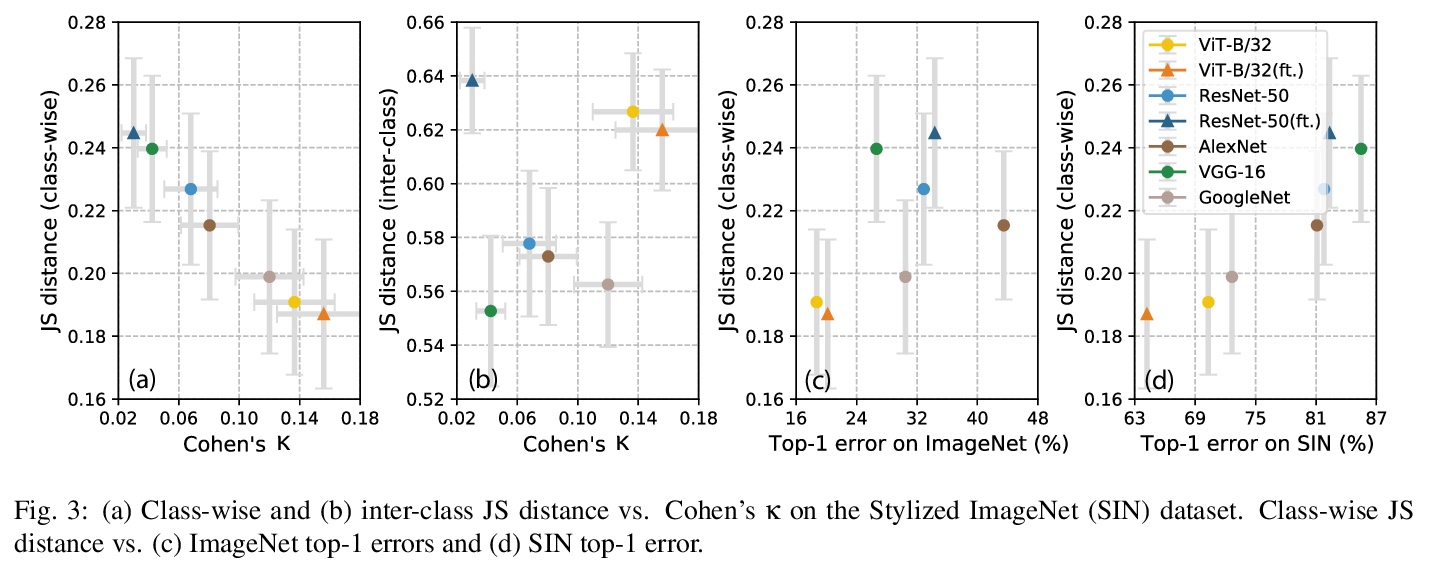
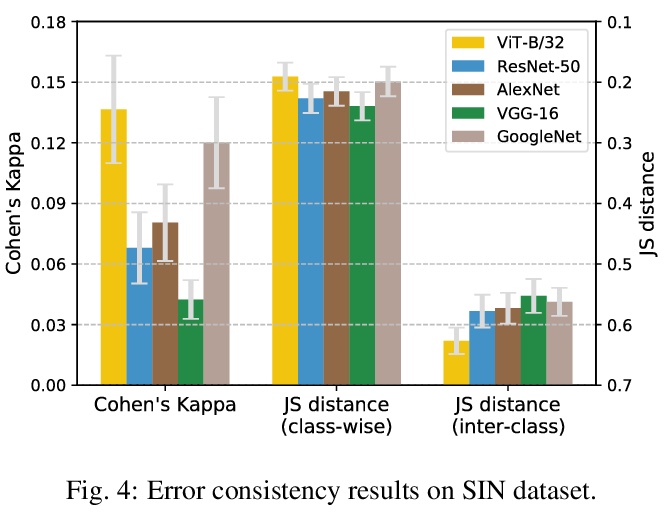
CNN和Transformer哪个更接近人类视觉。现代计算机视觉的机器学习模型在特定视觉识别任务上精度超过了人类,特别是在ImageNet这样的数据集上。然而,高精度可以通过许多方式实现。机器学习系统找到的特定决策函数不仅由系统所接触到的数据决定,还由模型的归纳偏差决定,而这些偏差通常更难被描述。本文遵循最近的趋势,对神经网络模型进行深入的行为分析,通过研究错误模式,超越了精度这一评价指标,重点是比较一套标准的卷积神经网络(CNN)和最近提出的基于注意力的网络——视觉Transformer(ViT),其放松了CNN的转换不变性约束,是一种具有较弱归纳偏差的表示模型。基于注意力的Transformer网络,不仅在图像分类任务的精度上优于CNN,而且具有更高的形状偏差,在很大程度上与人类的错误更一致。这些结果对于建立更像人类的视觉模型,以及理解人类的视觉目标识别都有意义。
Modern machine learning models for computer vision exceed humans in accuracy on specific visual recognition tasks, notably on datasets like ImageNet. However, high accuracy can be achieved in many ways. The particular decision function found by a machine learning system is determined not only by the data to which the system is exposed, but also the inductive biases of the model, which are typically harder to characterize. In this work, we follow a recent trend of in-depth behavioral analyses of neural network models that go beyond accuracy as an evaluation metric by looking at patterns of errors. Our focus is on comparing a suite of standard Convolutional Neural Networks (CNNs) and a recently-proposed attention-based network, the Vision Transformer (ViT), which relaxes the translation-invariance constraint of CNNs and therefore represents a model with a weaker set of inductive biases. Attentionbased networks have previously been shown to achieve higher accuracy than CNNs on vision tasks, and we demonstrate, using new metrics for examining error consistency with more granularity, that their errors are also more consistent with those of humans. These results have implications both for building more human-like vision models, as well as for understanding visual object recognition in humans.
https://weibo.com/1402400261/KgAcbu2om

2、[ST] Polynomial methods in statistical inference: theory and practice
Y Wu, P Yang
[Yale University & Tsinghua University]
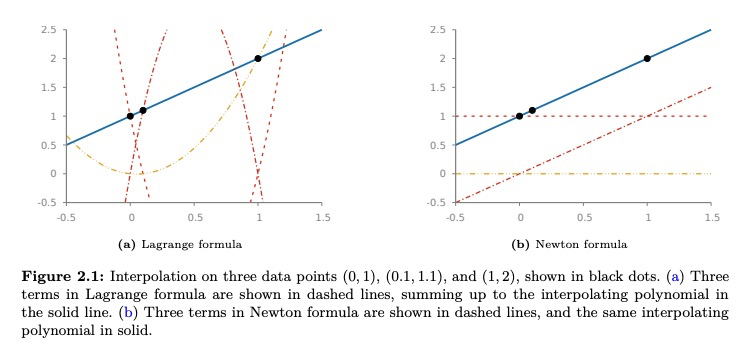
统计推断的多项式方法:理论与实践。本综述阐述了一套基于多项式理论的技术,统称为多项式方法,这些技术最近被成功地应用于解决统计推理中一些挑战性问题。讨论的主题包括多项式近似、多项式插值和优化、矩空间和正多项式、正交多项式和高斯正交,以及它们在大域属性估计和混合模型学习中主要的概率和统计应用。这些技术不仅为设计具有可证明的最优性的高度实用的算法提供了有用的工具,也为通过矩匹配方法建立推理问题的基本限制提供了有用的工具。多项式方法的有效性在具体问题中得到证明,如熵和支持度估计、不同元素问题和学习高斯混合模型。
This survey provides an exposition of a suite of techniques based on the theory of polynomials, collectively referred to as polynomial methods, which have recently been applied to address several challenging problems in statistical inference successfully. Topics including polynomial approximation, polynomial interpolation and majorization, moment space and positive polynomials, orthogonal polynomials and Gaussian quadrature are discussed, with their major probabilistic and statistical applications in property estimation on large domains and learning mixture models. These techniques provide useful tools not only for the design of highly practical algorithms with provable optimality, but also for establishing the fundamental limits of the inference problems through the method of moment matching. The effectiveness of the polynomial method is demonstrated in concrete problems such as entropy and support size estimation, distinct elements problem, and learning Gaussian mixture models.
https://weibo.com/1402400261/KgAjAqetA

3、[CV] More Than Just Attention: Learning Cross-Modal Attentions with Contrastive Constraints
Y Chen, J Yuan, L Zhao, R Luo, L Davis, D N. Metaxas
[Rutgers University & Amazon.com Services]
不只是注意力:基于对比约束的跨模态注意力学习。注意力机制被广泛地应用于跨模态任务,如图像描述和信息检索,由于其在不同模态间学习细粒度相关性的能力,已经取得了显著的改善。然而,现有的注意力模型可能是次优的,并且缺乏精确性,因为在训练期间没有直接的监督。本文提出了对比性内容重溯(CCR)和对比性内容交换(CCS)约束来解决这种限制。这些约束条件以对比学习的方式对注意力模型的训练进行监督,不需要显式的注意力标注。此外,引入三个指标,即注意力精度、召回率和F1分数,来定量评估注意力的质量。用跨模式的检索(图像-文本匹配)任务来评估所提出的约束。在Flickr30k和MS-COCO数据集上的实验表明,将这些注意力约束因素整合到两个最先进的基于注意力的模型中,在检索精度和注意力指标方面都提高了模型的性能。
Attention mechanisms have been widely applied to cross-modal tasks such as image captioning and information retrieval, and have achieved remarkable improvements due to its capability to learn fine-grained relevance across different modalities. However, existing attention models could be suboptimal and lack preciseness because there is no direct supervision involved during training. In this work, we propose Contrastive Content Re-sourcing (CCR) and Contrastive Content Swapping (CCS) constraints to address such limitation. These constraints supervise the training of attention models in a contrastive learning manner without requiring explicit attention annotations. Additionally, we introduce three metrics, namely Attention Precision, Recall and F1-Score, to quantitatively evaluate the attention quality. We evaluate the proposed constraints with cross-modal retrieval (image-text matching) task. The experiments on both Flickr30k and MS-COCO datasets demonstrate that integrating these attention constraints into two state-of-theart attention-based models improves the model performance in terms of both retrieval accuracy and attention metrics.
https://weibo.com/1402400261/KgAv11Oe4

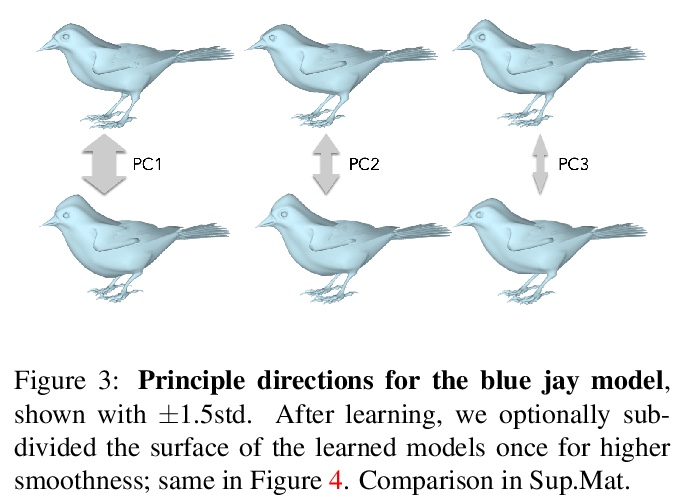
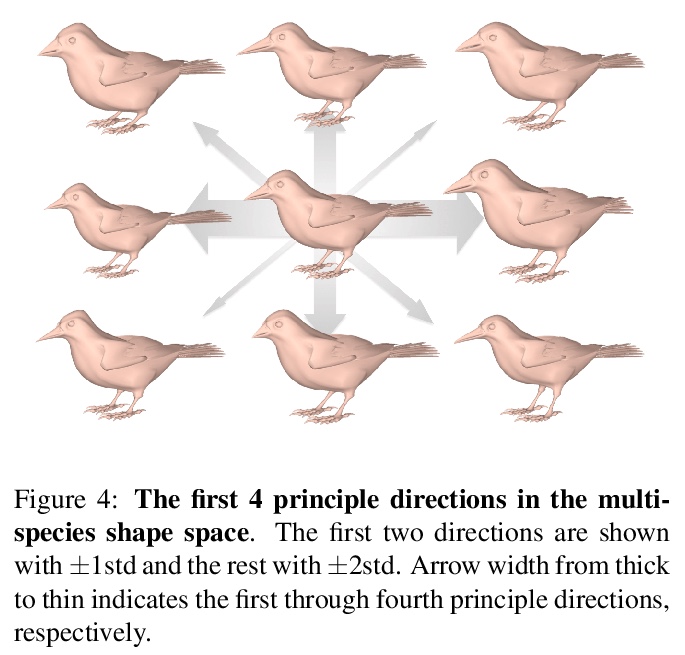
4、[CV] Birds of a Feather: Capturing Avian Shape Models from Images
Y Wang, N Kolotouros, K Daniilidis, M Badger
[University of Pennsylvania]
从图像中捕捉鸟类形状模型。动物的外形多种多样,但由于缺乏3D数据,为一个新物种建立可变形的形状模型并不总是可能的。本文提出一种使用关节模板和物种图像来捕捉该新物种的方法,主要关注鸟类,尽管鸟类所代表的物种数量几乎是哺乳动物的两倍,但没有准确的形状模型可用。为捕捉一个新物种,首先将关节模板拟合于每个训练样本,通过分解姿态和形状,学习一个形状空间,从图像素材中捕捉物种之间和物种内部的变化。从CUB数据集中学习了多个物种的模型,并贡献了新的特定物种和多物种的形状模型,这些模型对下游的重建任务很有用。开发了一个多物种统计形状模型AVES,与鸟类的系统发育相关,并准确地重建个体。
Animals are diverse in shape, but building a deformable shape model for a new species is not always possible due to the lack of 3D data. We present a method to capture new species using an articulated template and images of that species. In this work, we focus mainly on birds. Although birds represent almost twice the number of species as mammals, no accurate shape model is available. To capture a novel species, we first fit the articulated template to each training sample. By disentangling pose and shape, we learn a shape space that captures variation both among species and within each species from image evidence. We learn models of multiple species from the CUB dataset, and contribute new species-specific and multi-species shape models that are useful for downstream reconstruction tasks. Using a low-dimensional embedding, we show that our learned 3D shape space better reflects the phylogenetic relationships among birds than learned perceptual features.
https://weibo.com/1402400261/KgAzcaxnm


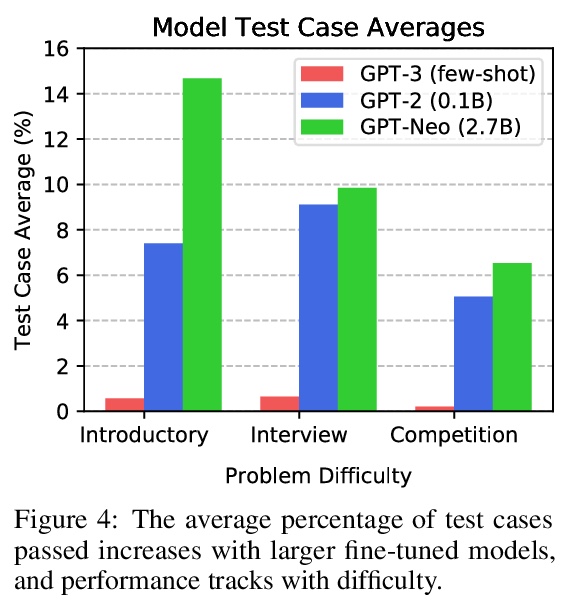
5、[CL] Measuring Coding Challenge Competence With APPS
D Hendrycks, S Basart, S Kadavath, M Mazeika, A Arora, E Guo, C Burns, S Puranik, H He, D Song, J Steinhardt
[UC Berkeley & UChicago & UIUC & Cornell]
用APPS基准衡量自动编程。编程是现代社会中最广泛使用的技能之一,但现代机器学习模型仍无法为基本问题提供编程解决方案。准确评估代码生成性能是很困难的,以一种既灵活又严格的方式评估代码生成的工作非常少。为应对这一挑战,本文提出了代码生成基准APPS,与之前的工作不同,该基准衡量的是模型接受任意自然语言规范并生成符合该规范的Python代码的能力。与公司评估候选软件开发者的方式类似,通过在测试案例上检查其生成的代码来评估模型。该基准包括10,000个问题,从简单的单行解决方案到实质性的算法挑战。在GitHub和训练集上对大型语言模型进行了微调,发现语法错误的发生率正在呈指数级下降。最近的模型如GPT-Neo可以通过大约15%的入门问题的测试案例,机器学习模型正在开始学习如何编程。随着自动代码生成的社会意义在未来几年的增加,该基准可以提供一个重要的衡量标准,来跟踪最新进展。
While programming is one of the most broadly applicable skills in modern society, modern machine learning models still cannot code solutions to basic problems. It can be difficult to accurately assess code generation performance, and there has been surprisingly little work on evaluating code generation in a way that is both flexible and rigorous. To meet this challenge, we introduce APPS, a benchmark for code generation. Unlike prior work in more restricted settings, our benchmark measures the ability of models to take an arbitrary natural language specification and generate Python code fulfilling this specification. Similar to how companies assess candidate software developers, we then evaluate models by checking their generated code on test cases. Our benchmark includes 10,000 problems, which range from having simple one-line solutions to being substantial algorithmic challenges. We fine-tune large language models on both GitHub and our training set, and we find that the prevalence of syntax errors is decreasing exponentially. Recent models such as GPT-Neo can pass approximately 15% of the test cases of introductory problems, so we find that machine learning models are beginning to learn how to code. As the social significance of automatic code generation increases over the coming years, our benchmark can provide an important measure for tracking advancements. “Everybody should learn to program a computer, because it teaches you how to think.” – Steve Jobs
https://weibo.com/1402400261/KgAG34wIk



另外几篇值得关注的论文:
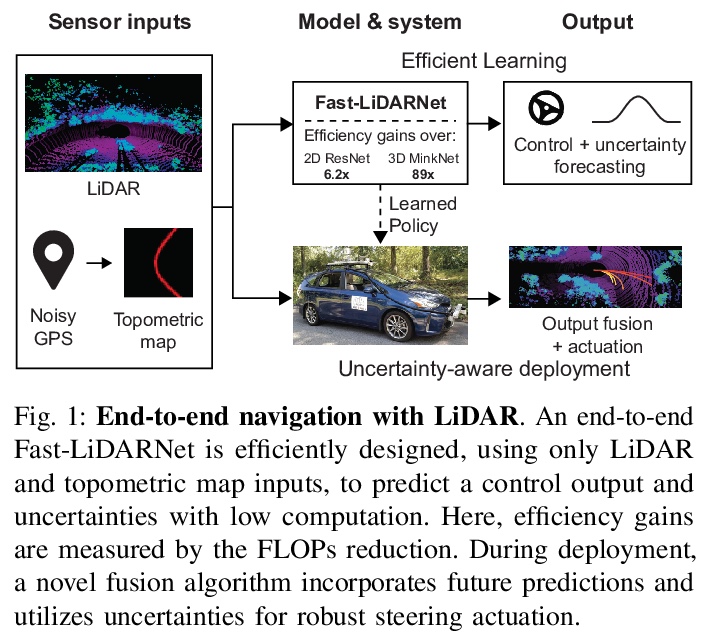
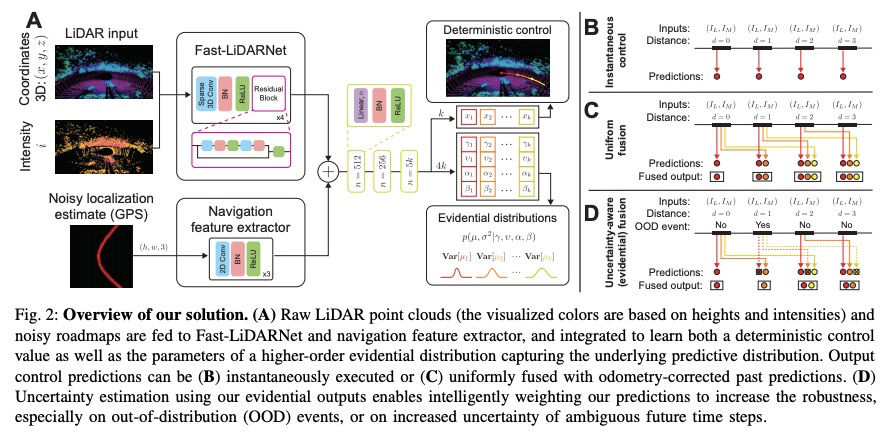
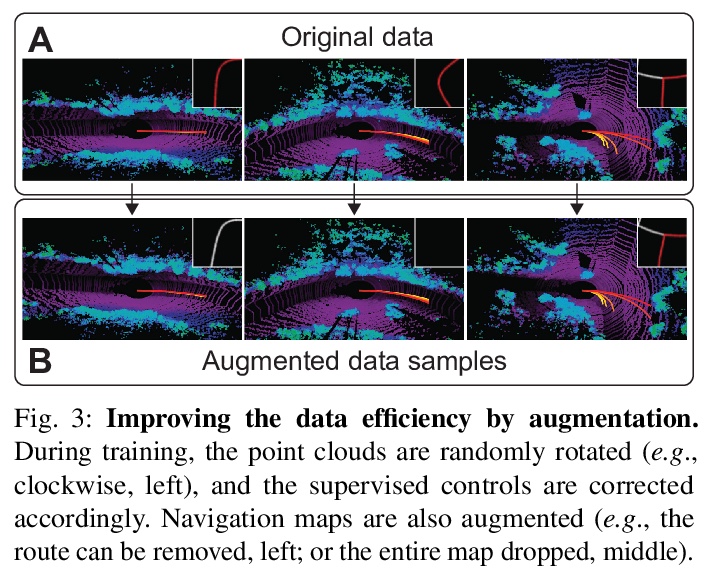
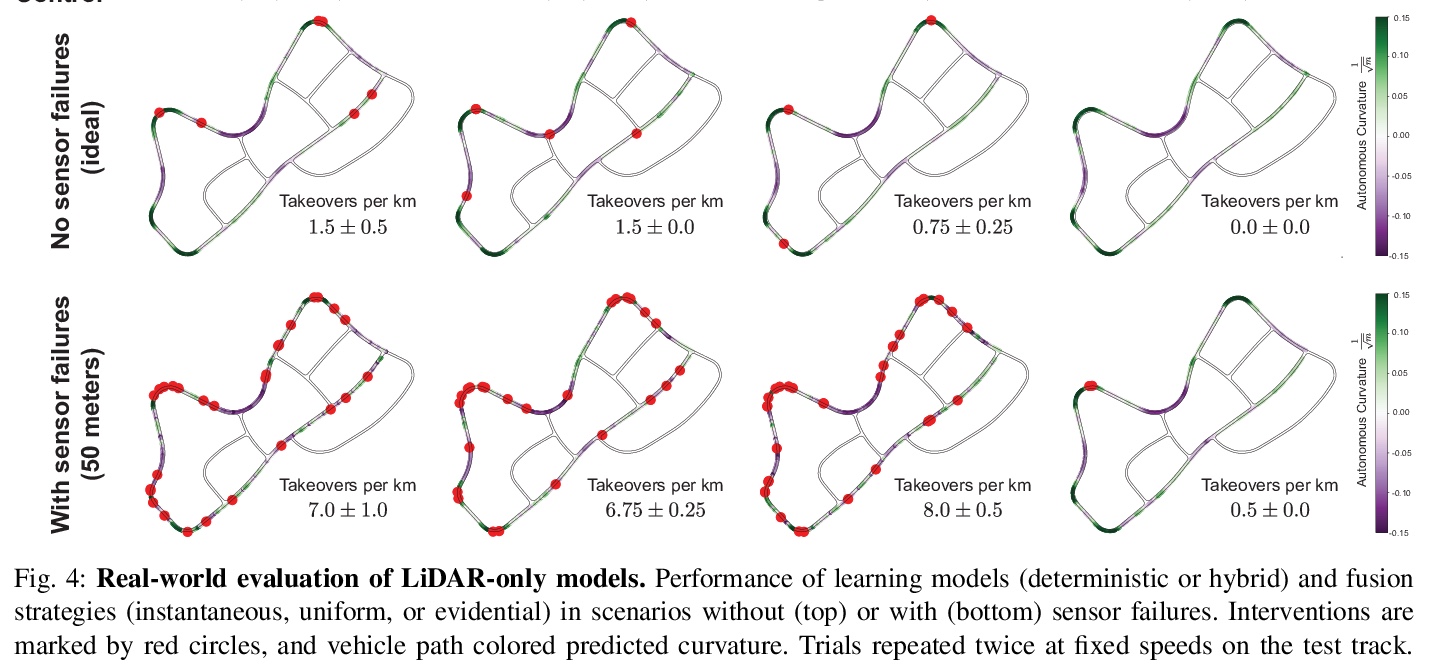
[RO] Efficient and Robust LiDAR-Based End-to-End Navigation
基于激光雷达的高效鲁棒端到端导航
Z Liu, A Amini, S Zhu, S Karaman, S Han, D Rus
[MIT & CSAIL]
https://weibo.com/1402400261/KgAJvyPtl
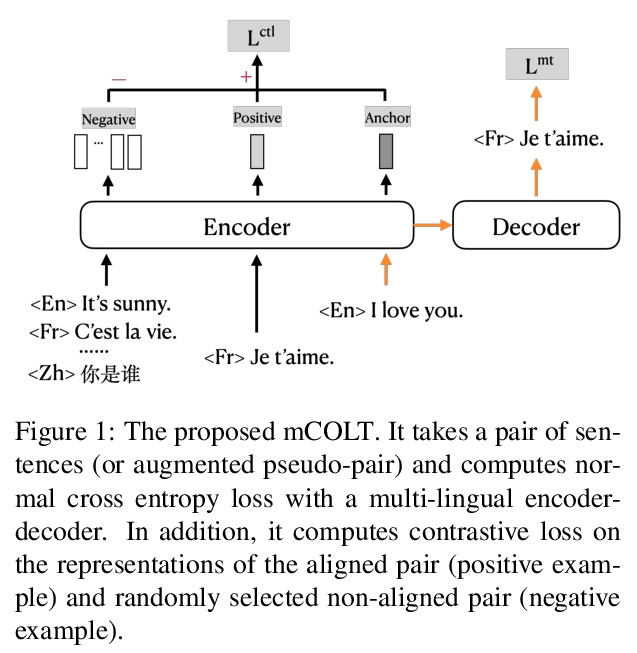
[CL] Contrastive Learning for Many-to-many Multilingual Neural Machine Translation
基于对比学习的多对多多语言神经网络机器翻译
X Pan, M Wang, L Wu, L Li
[ByteDance AI Lab]
https://weibo.com/1402400261/KgALdjTzl


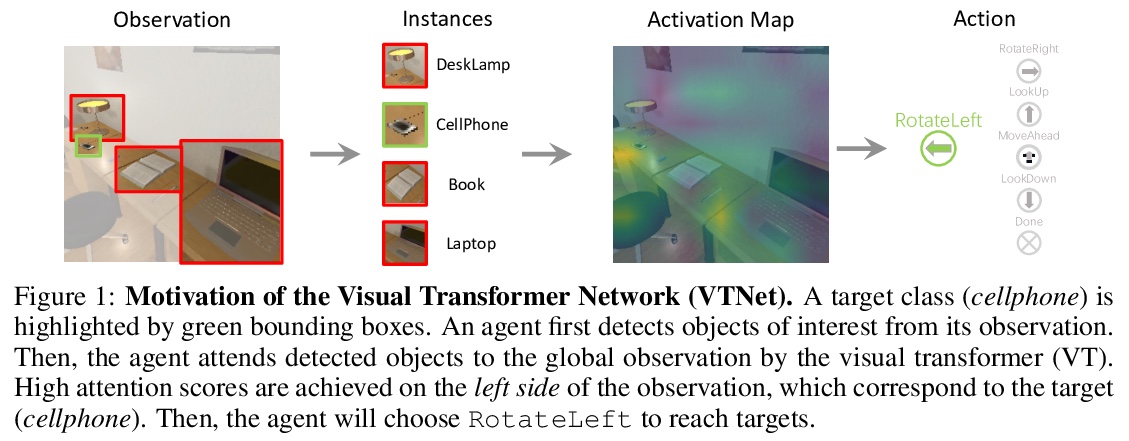
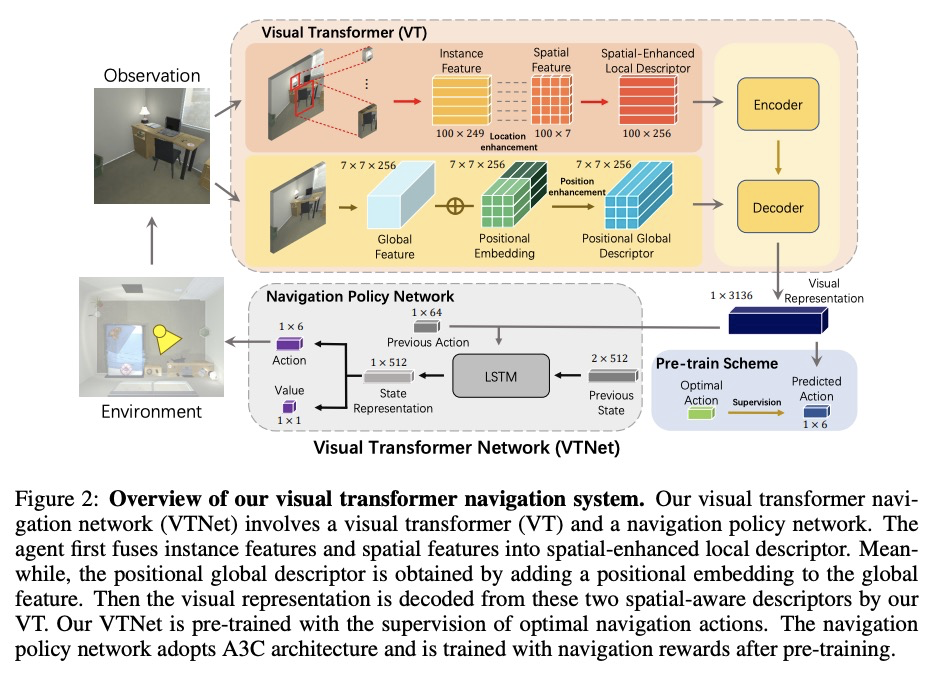
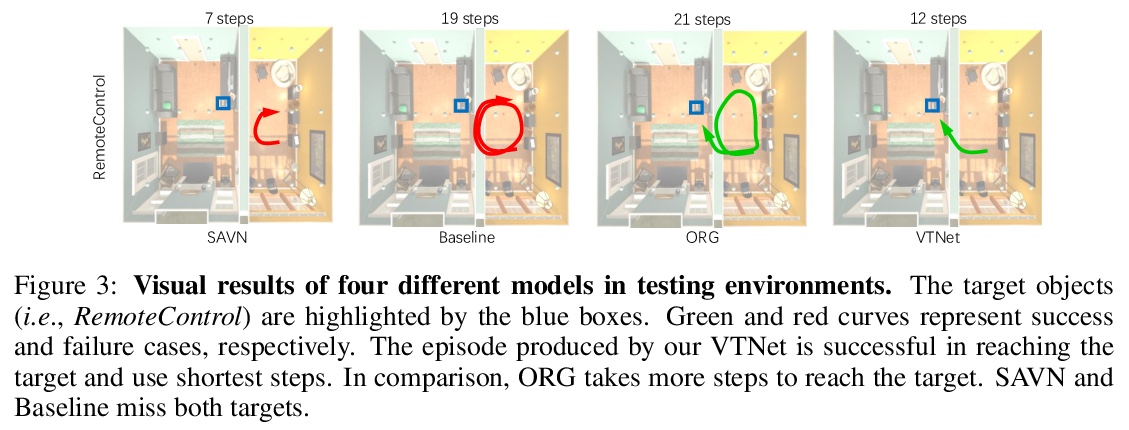
[CV] VTNet: Visual Transformer Network for Object Goal Navigation
VTNet:面向对象目标导航的视觉Transformer网络
H Du, X Yu, L Zheng
[Australian National University & University of Technology Sydney]
https://weibo.com/1402400261/KgAOAwiL7

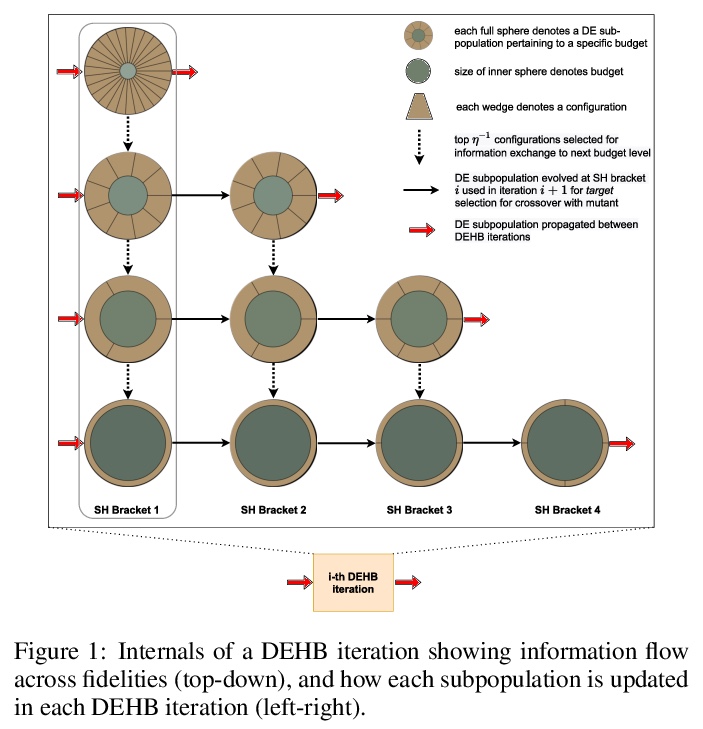
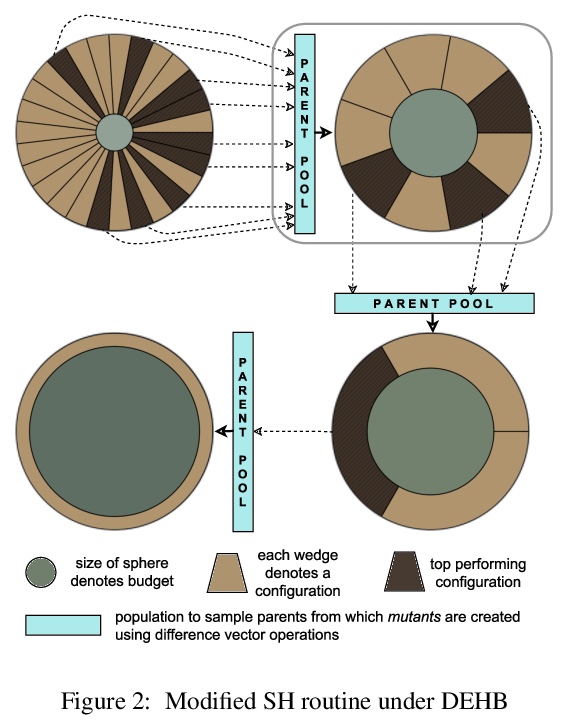
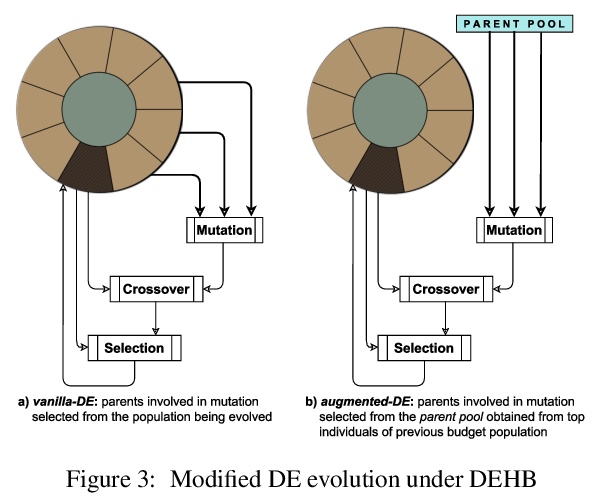
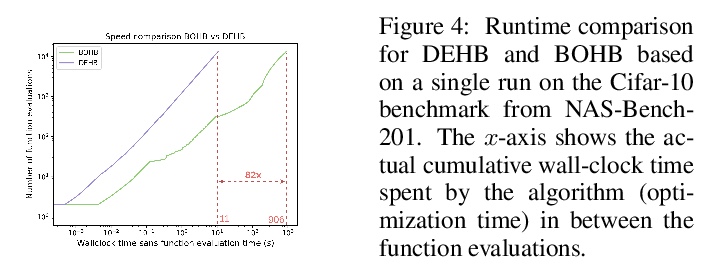
[LG] DEHB: Evolutionary Hyberband for Scalable, Robust and Efficient Hyperparameter Optimization
DEHB:面向可扩展、鲁棒和高效超参数优化的进化Hyberband
N Awad, N Mallik, F Hutter
[University of Freiburg]
https://weibo.com/1402400261/KgAQuuPjR

若有收获,就点个赞吧
0 人点赞
