- 1、[LG] Deterministic Neural Networks with Appropriate Inductive Biases Capture Epistemic and Aleatoric Uncertainty
- 2、[LG] Pretrained Transformers as Universal Computation Engines
- 3、[CV] Holistic 3D Scene Understanding from a Single Image with Implicit Representation
- 4、[CV] SMPLicit: Topology-aware Generative Model for Clothed People
- 5、[CL] CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation
- [AS] BYOL for Audio: Self-Supervised Learning for General-Purpose Audio Representation
- [CV] WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
- [CV] Fast and Accurate Model Scaling
- [RO] Robust High-speed Running for Quadruped Robots via Deep Reinforcement Learning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Deterministic Neural Networks with Appropriate Inductive Biases Capture Epistemic and Aleatoric Uncertainty
J Mukhoti, A Kirsch, J v Amersfoort, P H.S. Torr, Y Gal
[University of Oxford]
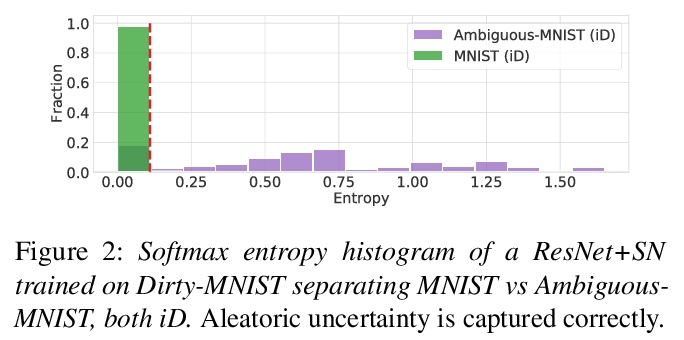
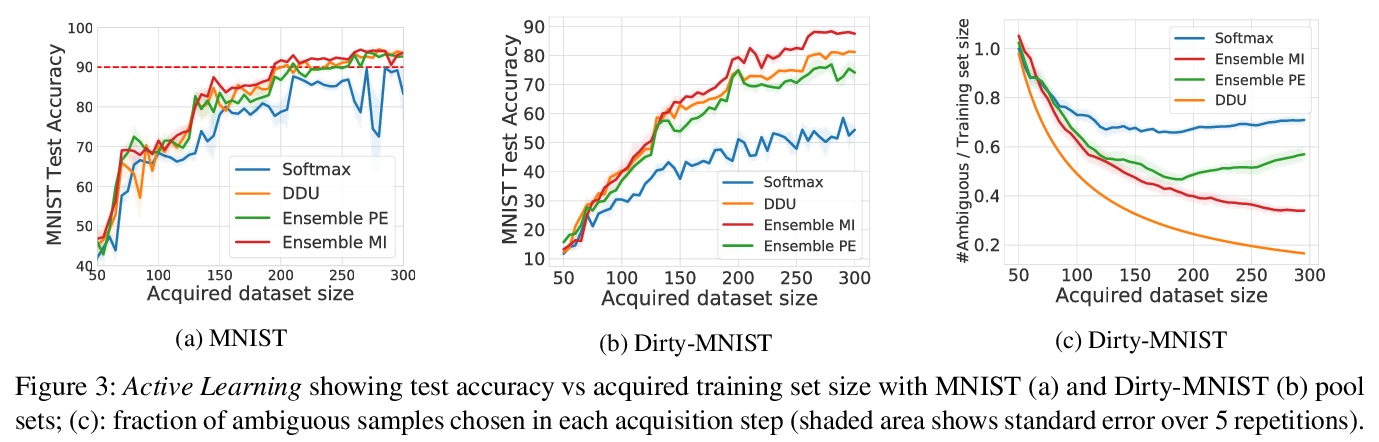
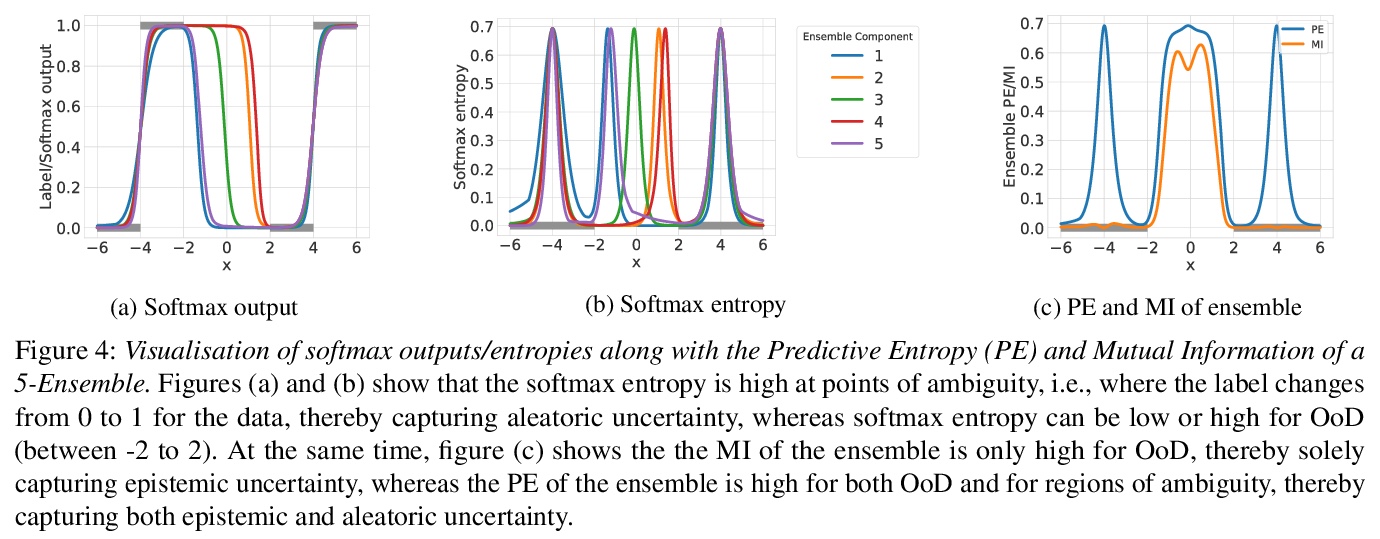
用具有适当归纳偏差的确定性神经网络捕捉认知和偶然不确定性。展示了用确定性模型可靠捕捉认知不确定性的充分条件,通过适当的归纳偏差,具有常规既有架构的神经网络可通过其特征空间密度来量化认知不确定性,灵敏度可防止特征坍缩,平滑性可确保用基于距离的密度估计器获得特征空间密度。通过将该密度与softmax分布熵结合,可有效将偶然不确定性从认知不确定性中解缠出来,这在主动学习等需要可靠估计认知不确定性的应用中至关重要。实验表明,所提出的深度确定不定性(Deep Deterministic Uncertainty,DDU),在只需对softmax模型架构进行最小改变,并保持相同训练方法的情况下,在主动学习和OoD检测上优于当前最先进的不确定性量化方法,包括深度集成方法。
We show that a single softmax neural net with minimal changes can beat the uncertainty predictions of Deep Ensembles and other more complex single-forward-pass uncertainty approaches. Softmax neural nets cannot capture epistemic uncertainty reliably because for OoD points they extrapolate arbitrarily and suffer from feature collapse. This results in arbitrary softmax entropies for OoD points which can have high entropy, low, or anything in between. We study why, and show that with the right inductive biases, softmax neural nets trained with maximum likelihood reliably capture epistemic uncertainty through the feature-space density. This density is obtained using Gaussian Discriminant Analysis, but it cannot disentangle uncertainties. We show that it is necessary to combine this density with the softmax entropy to disentangle aleatoric and epistemic uncertainty — crucial e.g. for active learning. We examine the quality of epistemic uncertainty on active learning and OoD detection, where we obtain SOTA ~0.98 AUROC on CIFAR-10 vs SVHN.
https://weibo.com/1402400261/K5WgyEGnn
2、[LG] Pretrained Transformers as Universal Computation Engines
K Lu, A Grover, P Abbeel, I Mordatch
[UC Berkeley & Facebook AI Research & Google Brain]
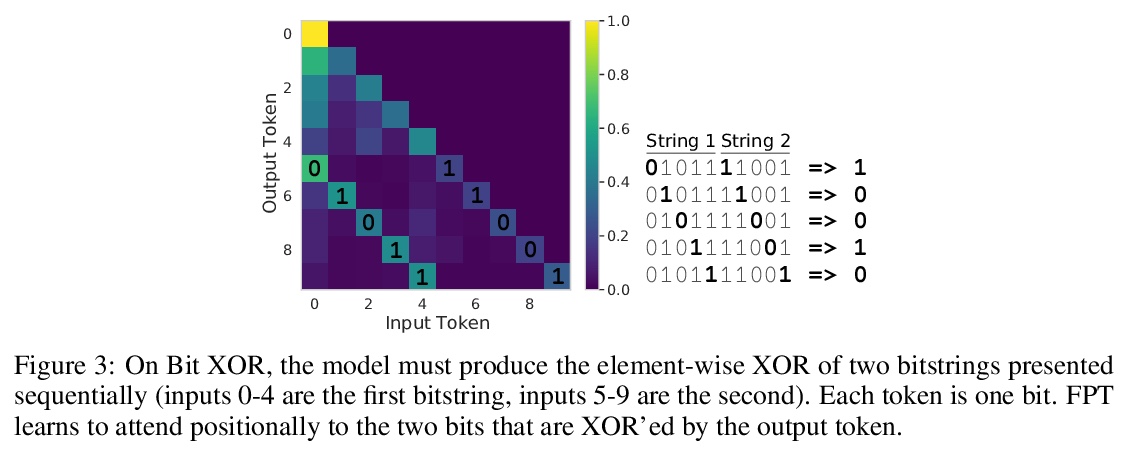
将预训练Transformer用作通用计算引擎。研究了用自然语言预训练的Transformer的能力,以最小微调——不对残差块自注意力和前馈层进行微调——来泛化到其他模式。提出冻结预训练Transformer(FPT)模型,将预训练Transformer语言模型迁移到非语言模态的下游任务上,研究了在各种序列分类任务上对其进行微调,涵盖数值计算、视觉和蛋白质折叠预测。与之前研究在与预训练数据集相同的模态上进行微调的工作不同,FPT表明在自然语言上进行预训练,可提高非语言下游任务的性能和计算效率。
We investigate the capability of a transformer pretrained on natural language to generalize to other modalities with minimal finetuning — in particular, without finetuning of the self-attention and feedforward layers of the residual blocks. We consider such a model, which we call a Frozen Pretrained Transformer (FPT), and study finetuning it on a variety of sequence classification tasks spanning numerical computation, vision, and protein fold prediction. In contrast to prior works which investigate finetuning on the same modality as the pretraining dataset, we show that pretraining on natural language improves performance and compute efficiency on non-language downstream tasks. In particular, we find that such pretraining enables FPT to generalize in zero-shot to these modalities, matching the performance of a transformer fully trained on these tasks.
https://weibo.com/1402400261/K5WnQ9pye


3、[CV] Holistic 3D Scene Understanding from a Single Image with Implicit Representation
C Zhang, Z Cui, Y Zhang, B Zeng, M Pollefeys, S Liu
[University of Electronic Science and Technology of China & Zhejiang University & Google & ETH Zurich ]
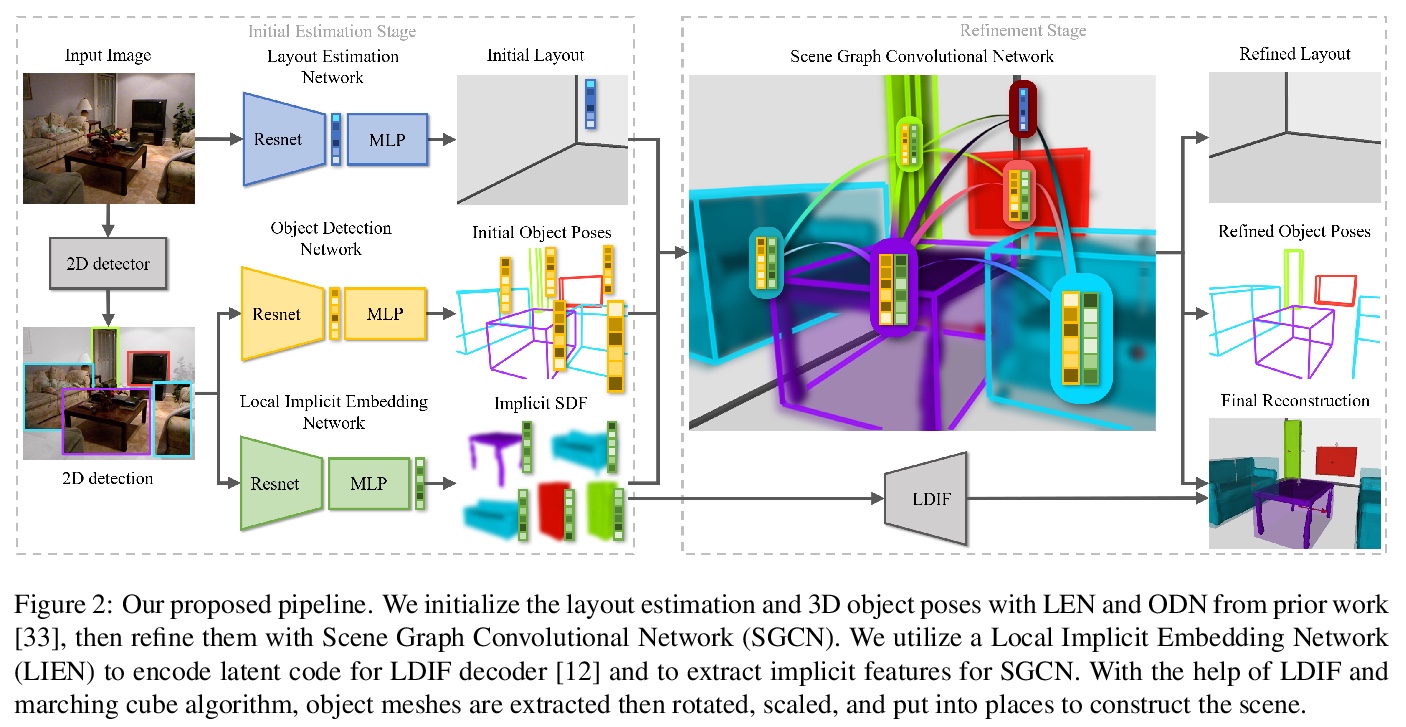
基于隐式表示从单幅图像整体理解3D场景。提出一种新的从单幅图像整体理解3D场景的流水线,可预测物体形状、物体姿态和场景布局。对于这个高度复杂问题,现有方法通常存在形状和布局估计不准确问题,特别是对于物体间严重遮挡的杂乱场景。本文提出用最新的深度隐式表示方法来解决这一难题,提出一种基于图像的局部结构隐式网络来改善物体形状估计,通过一种新的隐式场景图神经网络,利用局部物体隐式特征来完善3D物体姿态和场景布局。提出了一种新的物理违规损失,以避免对象之间的不正确上下文。实验表明,该方法在物体形状、场景布局估计和3D目标检测方面都优于现有的方法。
We present a new pipeline for holistic 3D scene understanding from a single image, which could predict object shape, object pose, and scene layout. As it is a highly ill-posed problem, existing methods usually suffer from inaccurate estimation of both shapes and layout especially for the cluttered scene due to the heavy occlusion between objects. We propose to utilize the latest deep implicit representation to solve this challenge. We not only propose an image-based local structured implicit network to improve the object shape estimation, but also refine 3D object pose and scene layout via a novel implicit scene graph neural network that exploits the implicit local object features. A novel physical violation loss is also proposed to avoid incorrect context between objects. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods in terms of object shape, scene layout estimation, and 3D object detection.
https://weibo.com/1402400261/K5WtO7TA1


4、[CV] SMPLicit: Topology-aware Generative Model for Clothed People
E Corona, A Pumarola, G Alenyà, G Pons-Moll, F Moreno-Noguer
[CSIC-UPC & Max Planck Institute for Informatics]
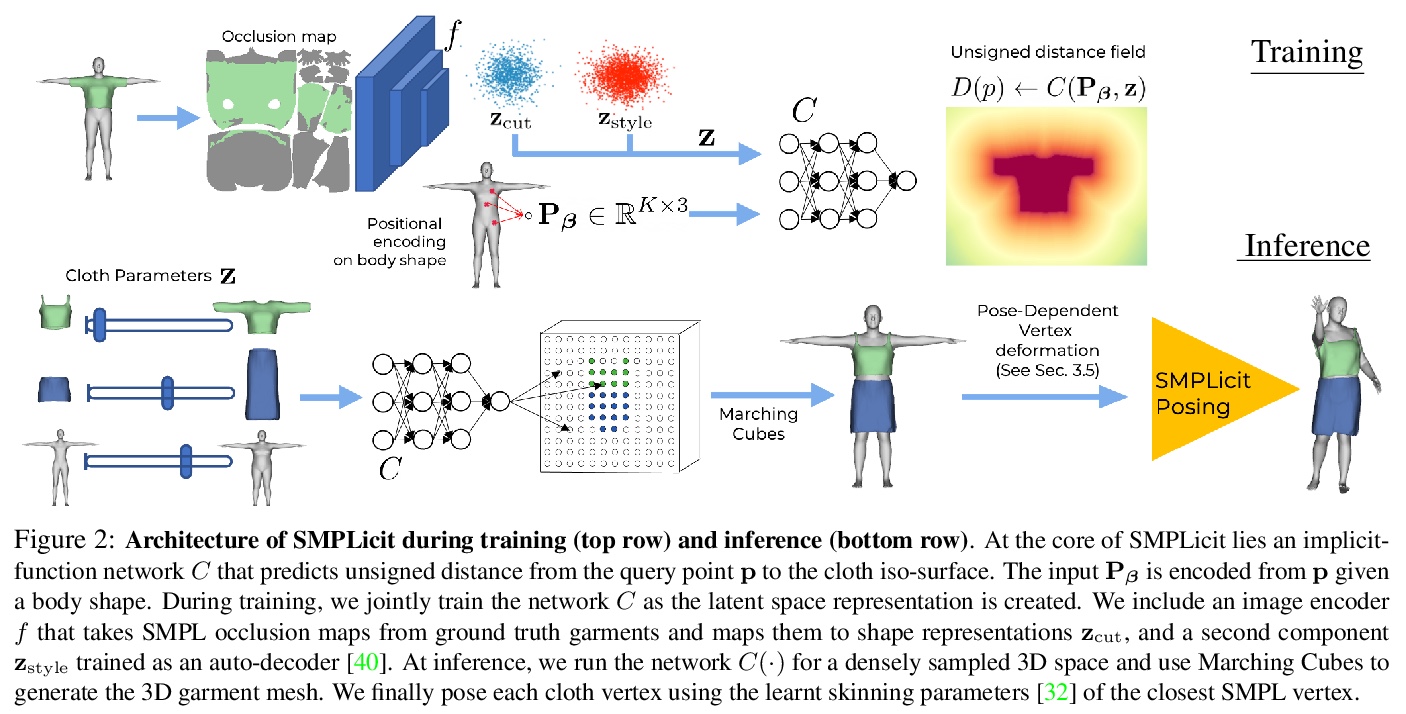
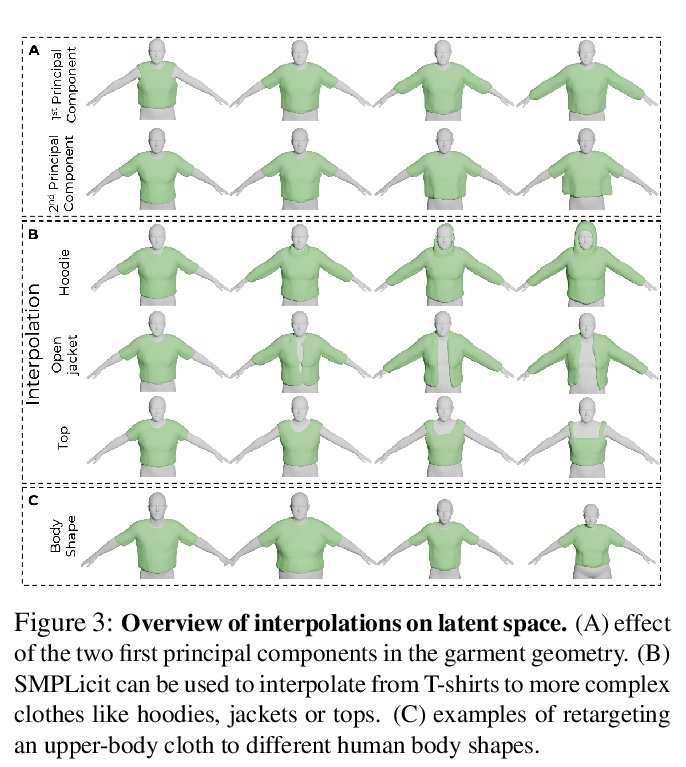
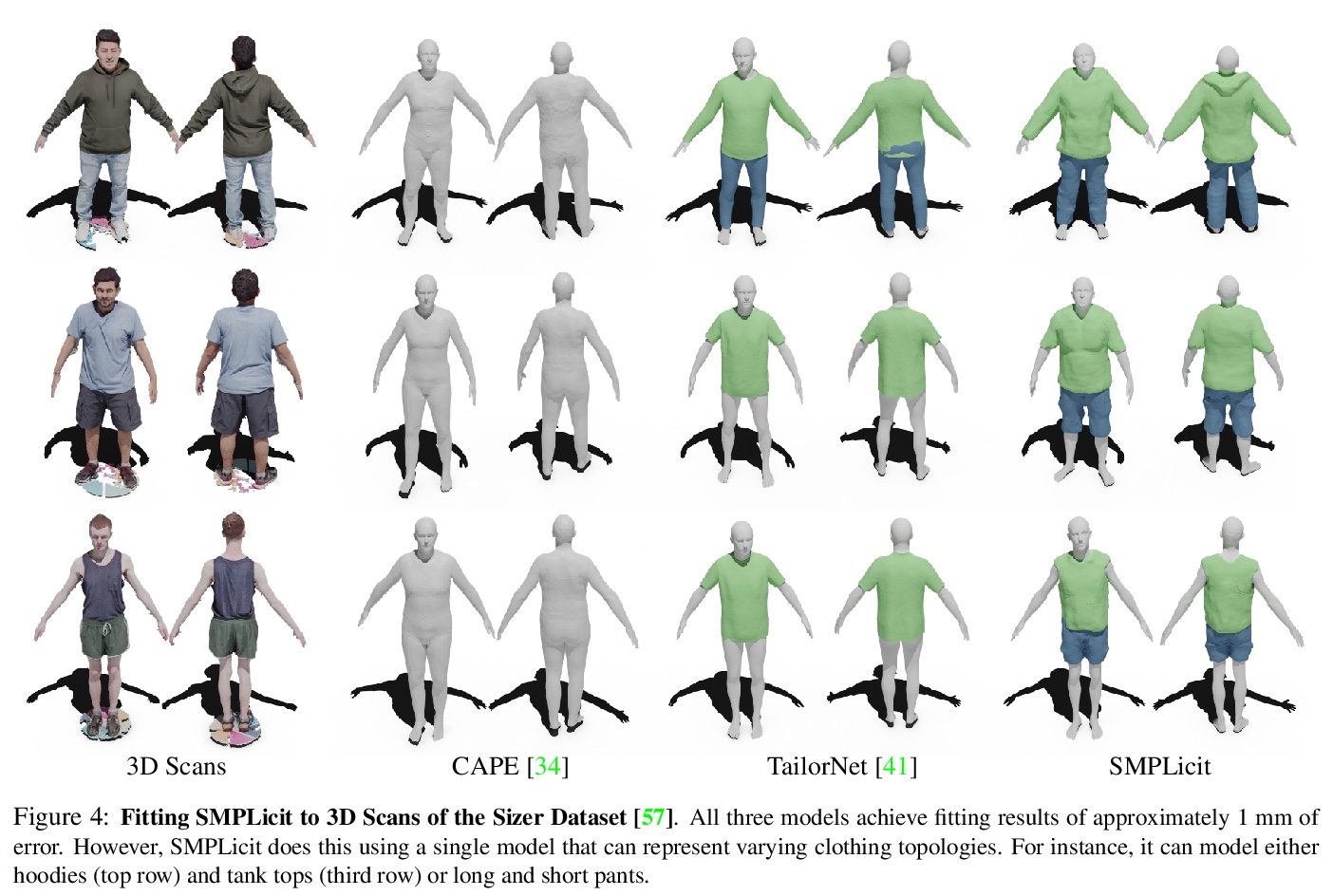
SMPLicit:拓扑感知穿衣人生成模型。提出一种新的生成式模型SMPLicit,以联合表示身体姿态、形状和服装几何,能表示不同的服装拓扑结构,并通过一些可解释的参数控制其风格和剪裁。与现有基于学习的方法需要为每种类型服装训练特定模型不同,SMPLicit以统一方式表示不同的服装拓扑结构(例如从无袖上衣到连帽衫,再到敞口夹克),同时控制其他属性,如服装尺寸或松紧度。该模型适用于各种服装,包括T恤、帽衫、夹克、短裤、裤子、裙子、鞋子甚至头发。SMPLicit的表示灵活性建立在以SMPL人体参数为条件的隐式模型和可学习的潜空间之上,该潜空间是可语义解释的,并与服装属性一致。所提出的模型完全可微,可用于更大的端到端可训练系统。
https://weibo.com/1402400261/K5WyqcfX8

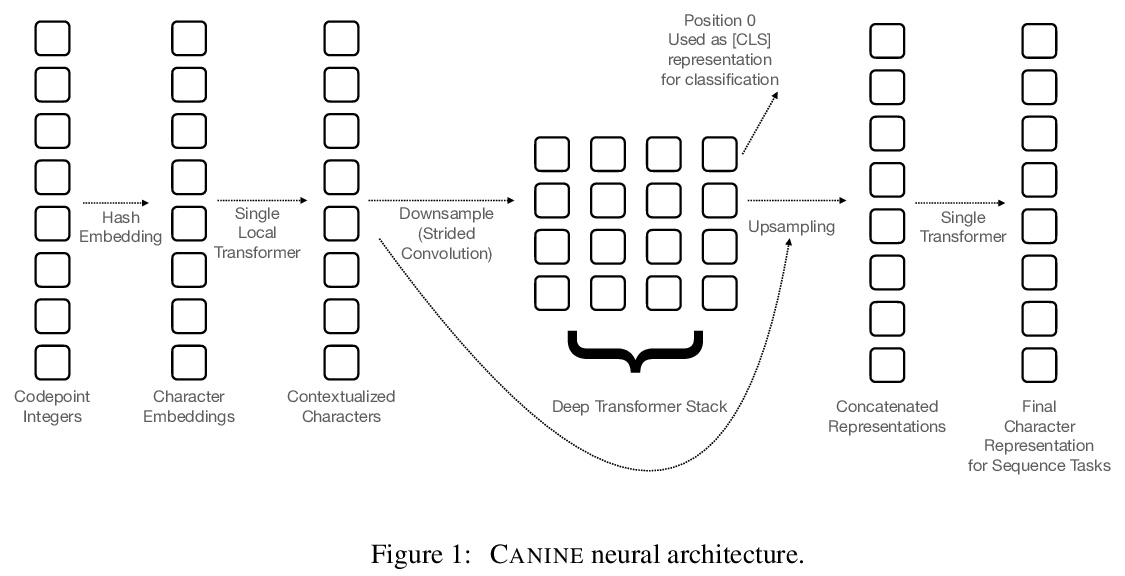
5、[CL] CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation
J H. Clark, D Garrette, I Turc, J Wieting
[Google Research]
CANINE:用于语言表示的高效预训练非标记化编码器。提出CANINE,直接对字符序列进行操作的神经编码器——无需明确的标记化或词表——以及用软归纳偏差代替硬标记边界的预训练策略。CANINE可直接对长字符序列进行编码,速度可与vanilla BERT相媲美。为有效且高效地利用精细输入,CANINE将减小输入序列长度的降采样与编码上下文的深度transformer栈相结合。尽管CANINE模型参数少了28%,但在TYDI QA这个具有挑战性的多语言基准上,CANINE的表现却比同类mBERT模型F1好了≥1,超越了建立在启发式标记器之上的模型的质量。
https://weibo.com/1402400261/K5WBlzNaM
另外几篇值得关注的论文:
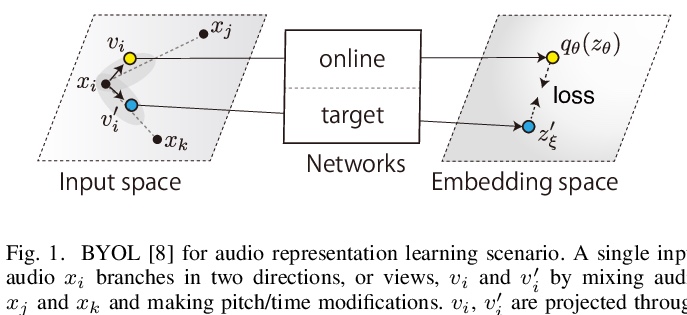
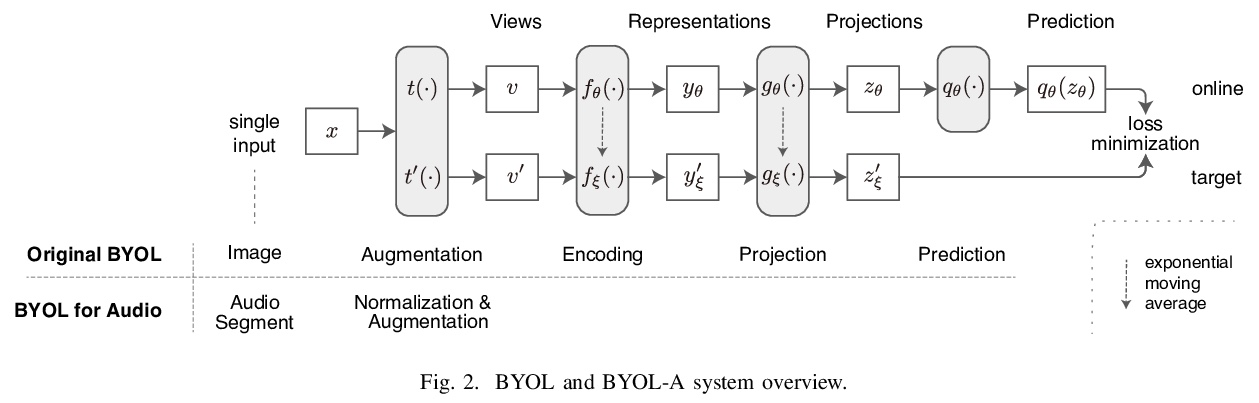
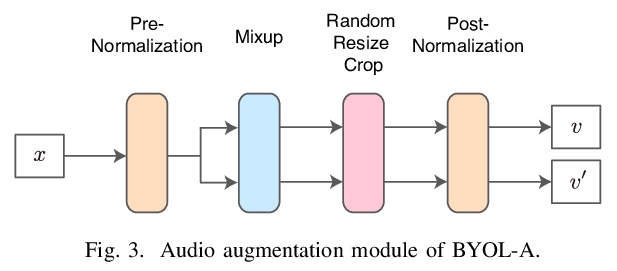
[AS] BYOL for Audio: Self-Supervised Learning for General-Purpose Audio Representation
音频BYOL:通用音频表示自监督学习
D Niizumi, D Takeuchi, Y Ohishi, N Harada, K Kashino
[NTT Corporation]
https://weibo.com/1402400261/K5WGdmaDL

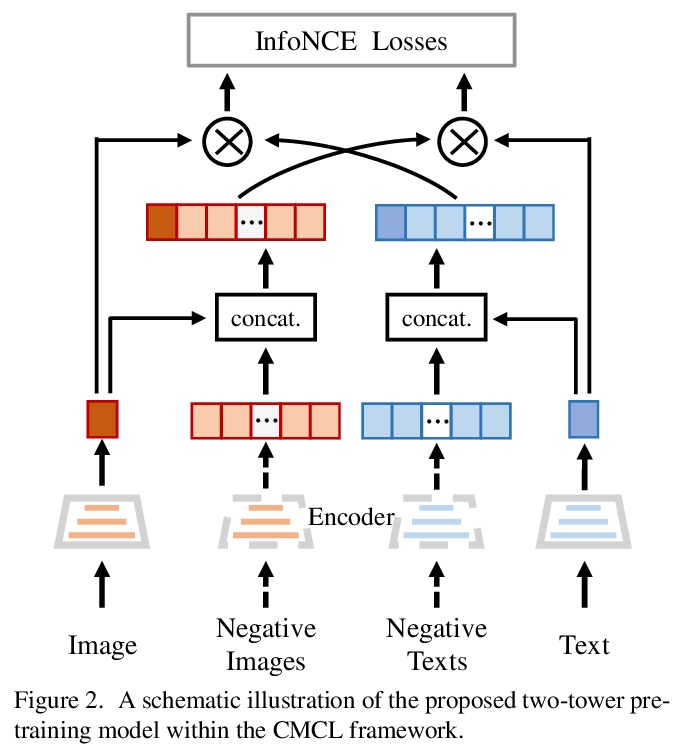
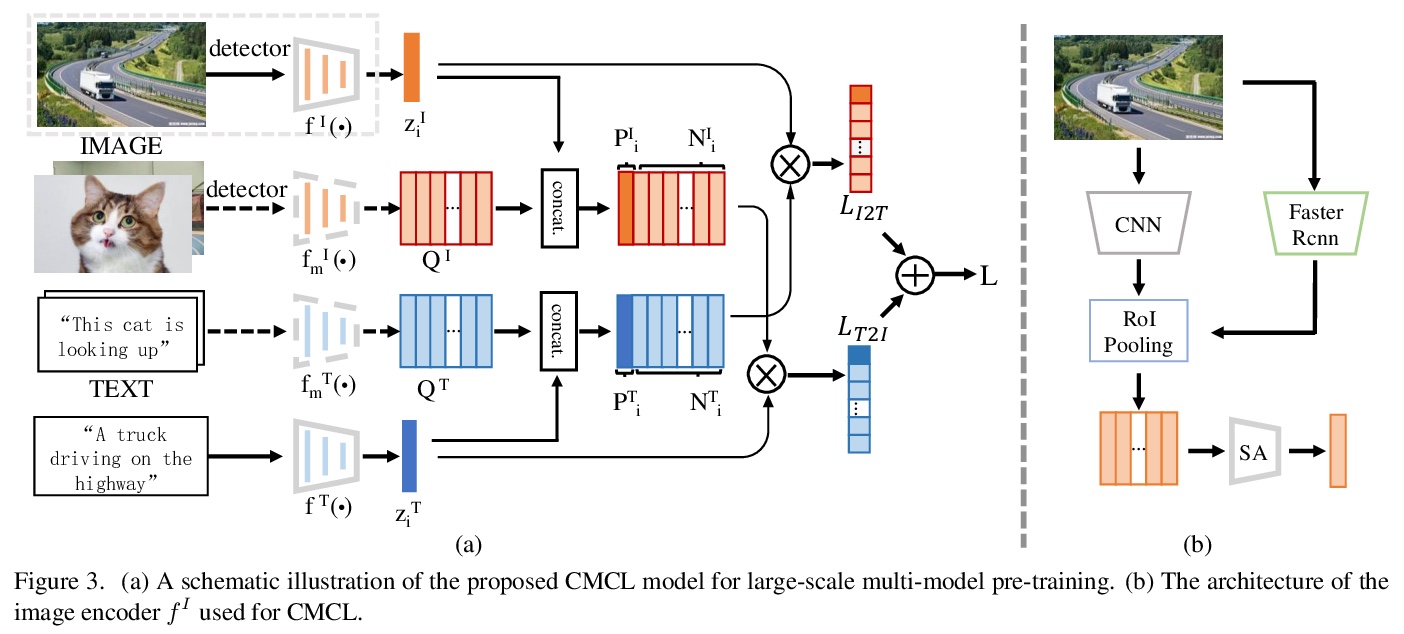
[CV] WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
WenLan:用大规模多模态预训练弥合视觉与语言
Y Huo, M Zhang, G Liu, H Lu, Y Gao, G Yang, J Wen, H Zhang, B Xu, W Zheng, Z Xi, Y Yang, A Hu, J Zhao, R Li, Y Zhao, L Zhang, Y Song, X Hong, W Cui, D Hou, Y Li, J Li, P Liu, Z Gong, C Jin, Y Sun, S Chen, Z Lu, Z Dou, Q Jin, Y Lan, W X Zhao, R Song, J Wen
[Renmin University of China & Chinese Academy of Sciences]
https://weibo.com/1402400261/K5WLADPLp

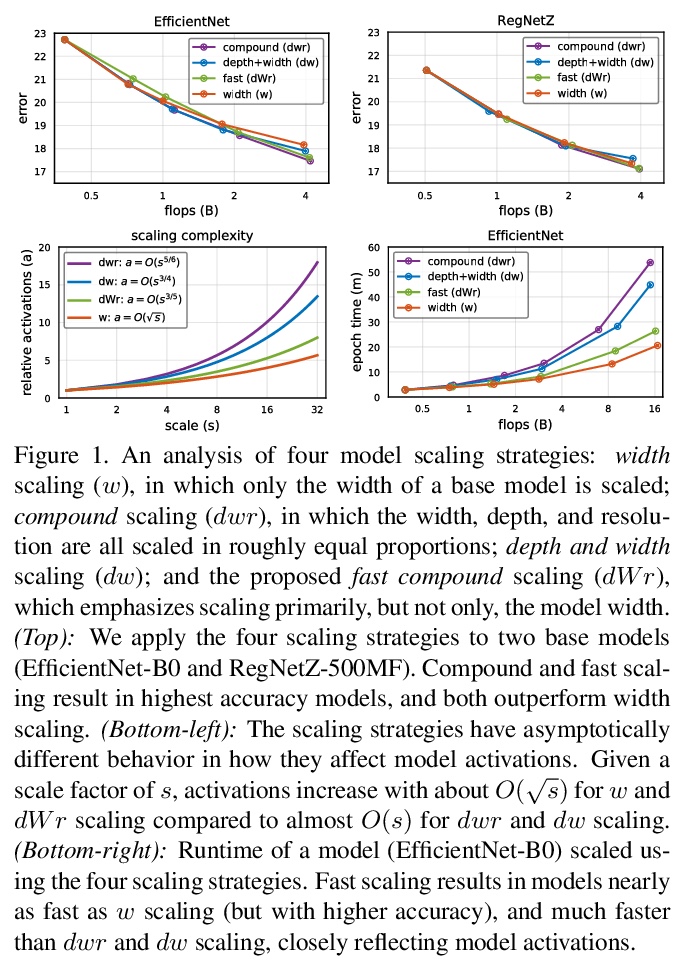
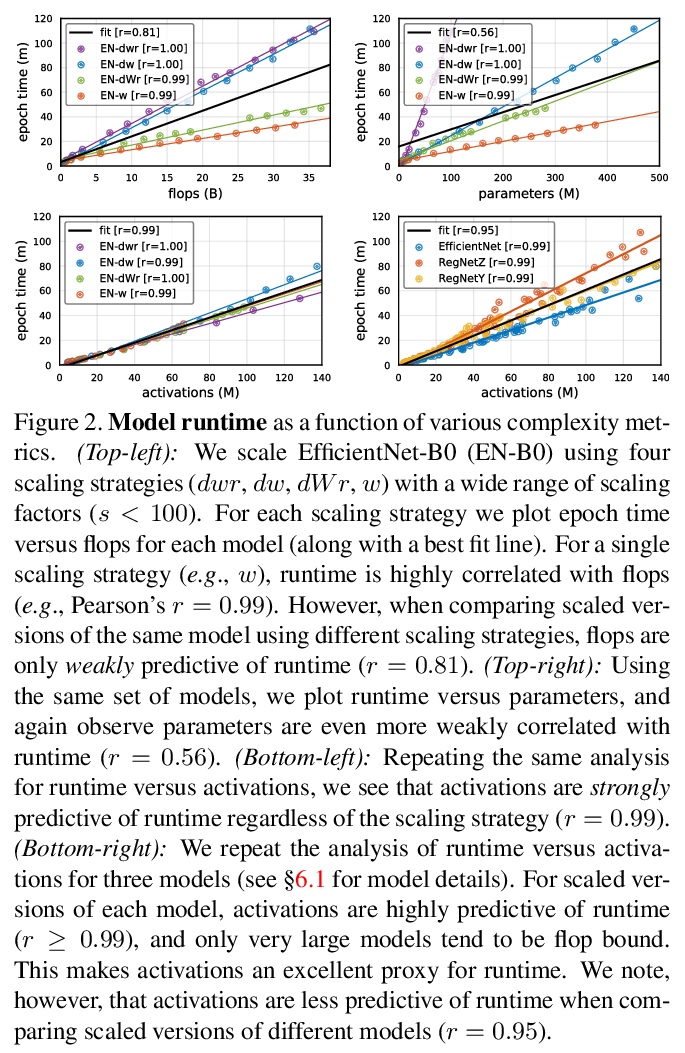
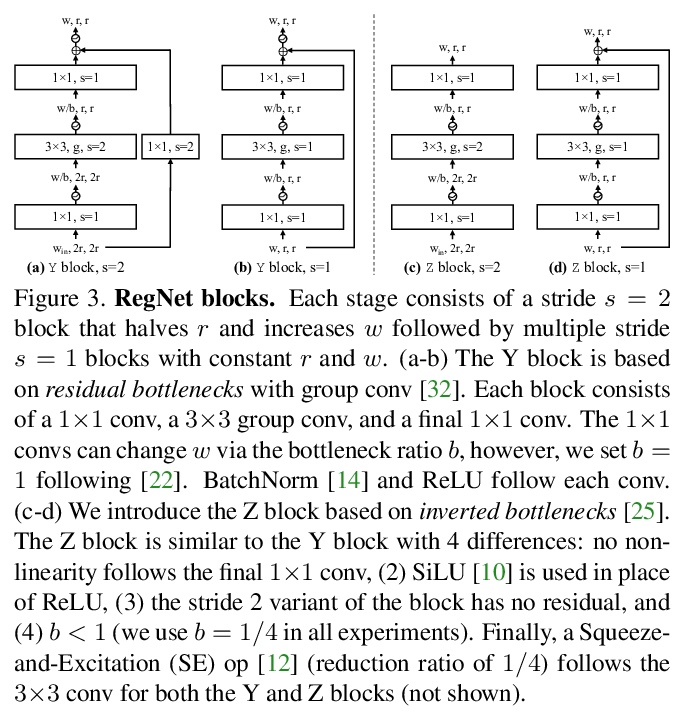
[CV] Fast and Accurate Model Scaling
快速准确的模型缩放
P Dollár, M Singh, R Girshick
[Facebook AI Research (FAIR)]
https://weibo.com/1402400261/K5WMRcL9T
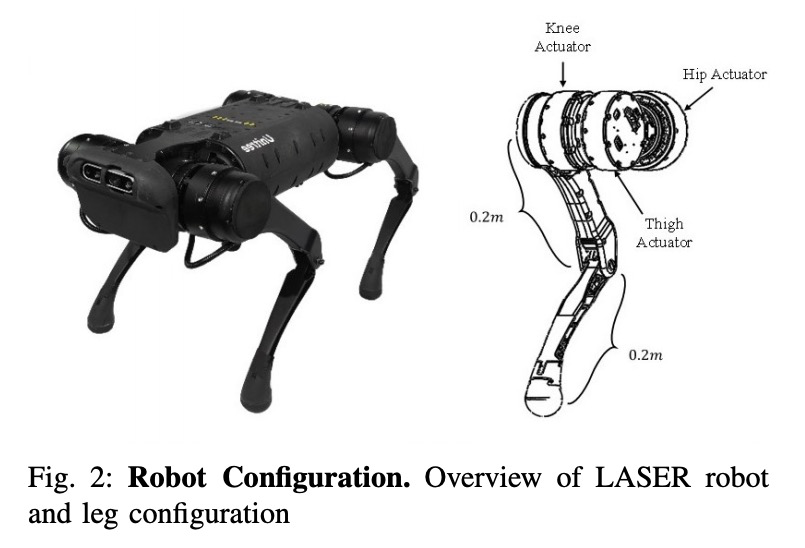
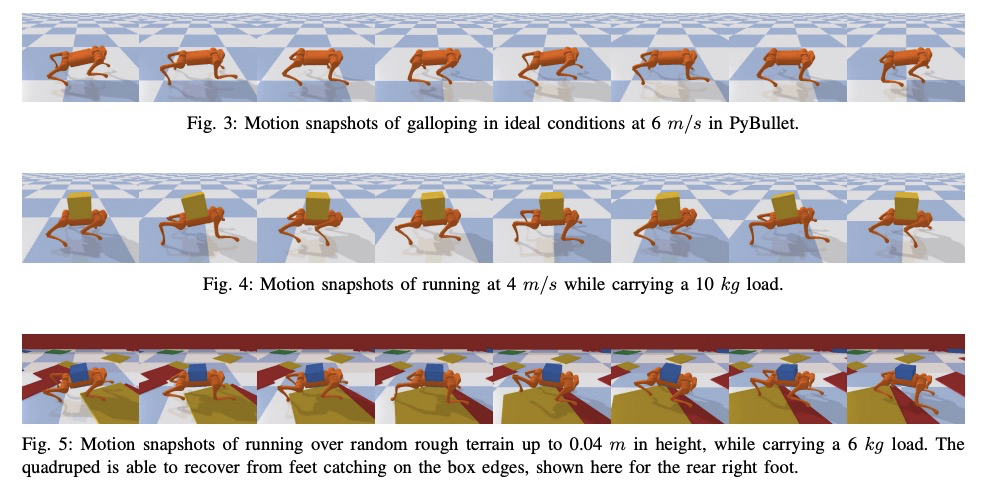
[RO] Robust High-speed Running for Quadruped Robots via Deep Reinforcement Learning
基于深度强化学习的四足机器人鲁棒高速奔跑
G Bellegarda, Q Nguyen
[University of Southern California]
https://weibo.com/1402400261/K5WOMiPas

若有收获,就点个赞吧
0 人点赞
