- 1、[CV] Training Vision Transformers for Image Retrieval
- 2、[CV] Is Space-Time Attention All You Need for Video Understanding?
- 3、[LG] NAST: Non-Autoregressive Spatial-Temporal Transformer for Time Series Forecasting
- 4、[CV] Unsupervised Novel View Synthesis from a Single Image
- 5、[CV] Self-Supervised Representation Learning from Flow Equivariance
- [LG] Introduction to Machine Learning for the Sciences
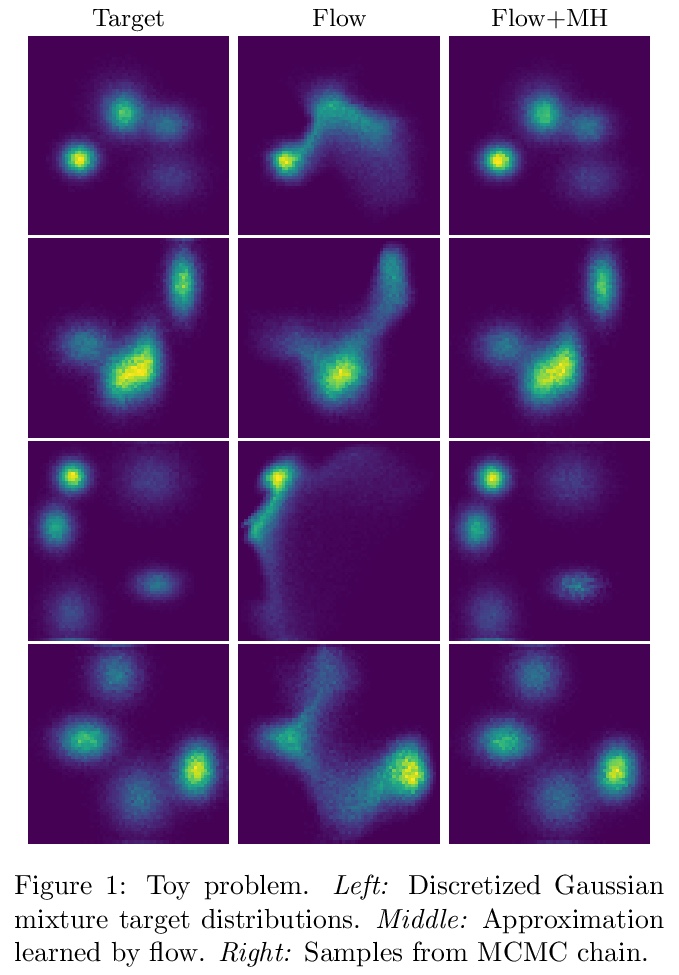
- [LG] Sampling in Combinatorial Spaces with SurVAE Flow Augmented MCMC
- [CV] H3D: Benchmark on Semantic Segmentation of High-Resolution 3D Point Clouds and textured Meshes from UAV LiDAR and Multi-View-Stereo
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
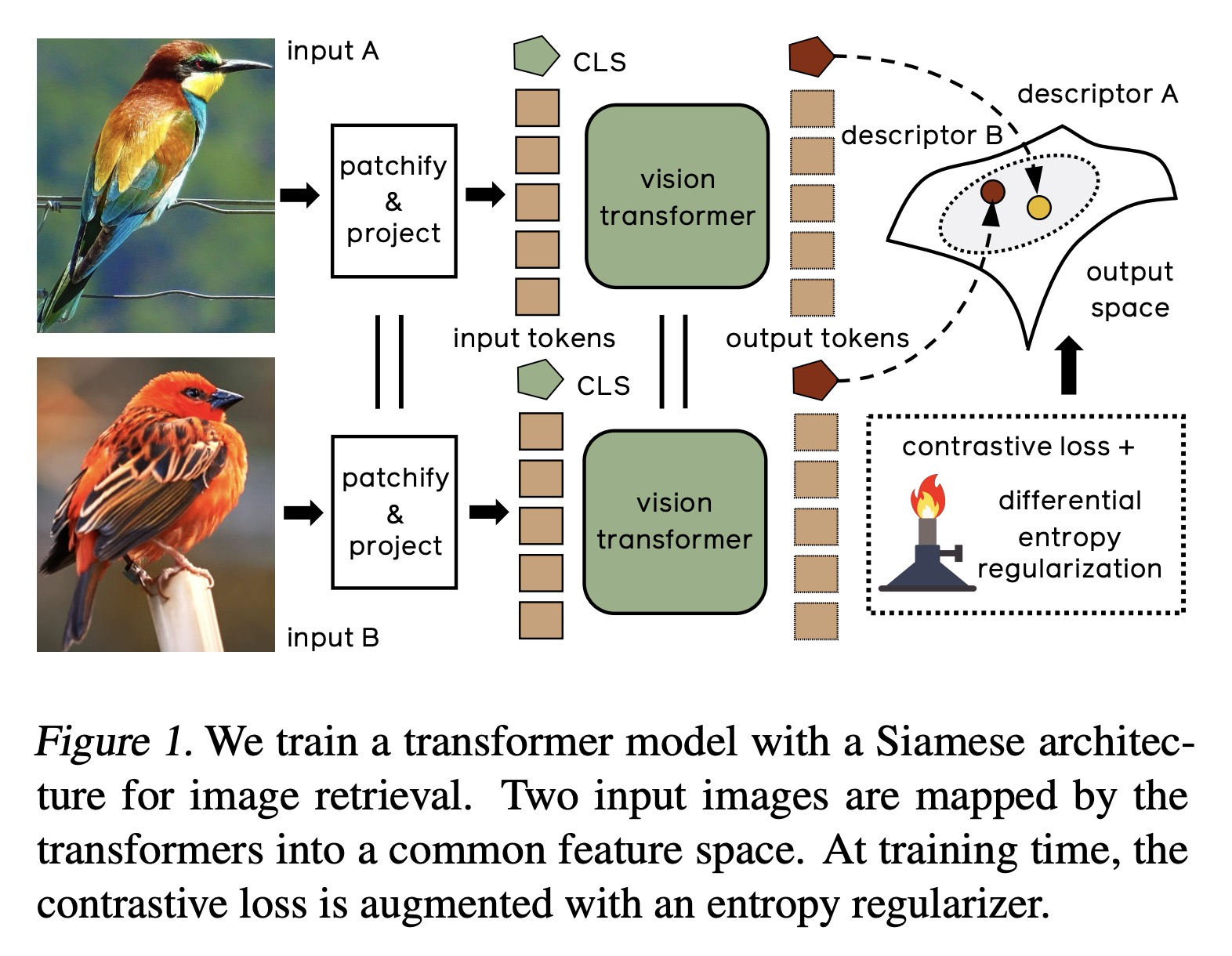
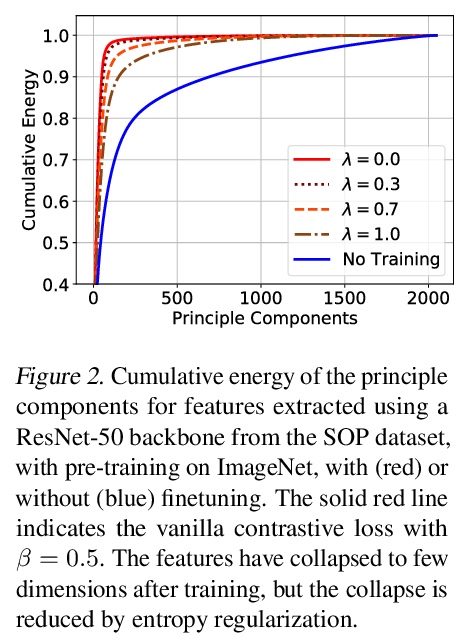
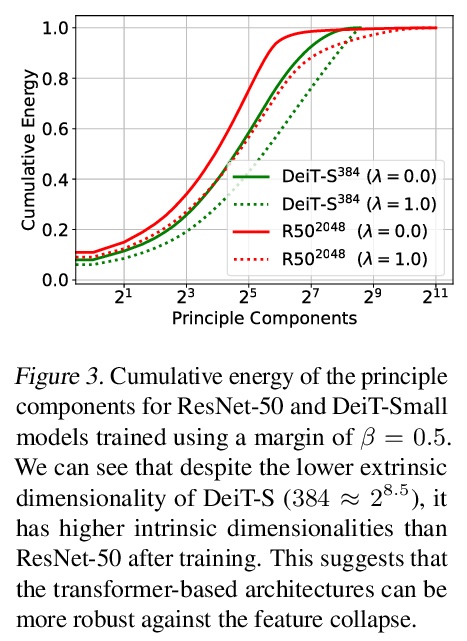
1、[CV] Training Vision Transformers for Image Retrieval
A El-Nouby, N Neverova, I Laptev, H Jégou
[Facebook AI & ENS/Inria]
面向图像检索的Vision Transformer。提出一种简单方法来训练Vision Transformer,可用于类别级,也可以用于特定目标检索,与具有类似容量的卷积模型相比,性能更具竞争力。采用Vision Transformer生成图像描述子,以度量学习目标训练所产生模型,重新审视了对比损失公式,表明基于微分熵损失在单位超球上传播向量的正则化器,改善了基于Transformer的模型以及卷积模型的性能。在类别级检索的三个流行基准上达到了新水平。对于特定目标检索,在短向量表示(128分量)时,在ROxford和RParis上的结果与在更高的分辨率和FLOPS下运行的卷积模型相当。微分熵规整器增强了对比损失,提高了整体性能。
Transformers have shown outstanding results for natural language understanding and, more recently, for image classification. We here extend this work and propose a transformer-based approach for image retrieval: we adopt vision transformers for generating image descriptors and train the resulting model with a metric learning objective, which combines a contrastive loss with a differential entropy regularizer. Our results show consistent and significant improvements of transformers over convolution-based approaches. In particular, our method outperforms the state of the art on several public benchmarks for category-level retrieval, namely Stanford Online Product, In-Shop and CUB-200. Furthermore, our experiments on ROxford and RParis also show that, in comparable settings, transformers are competitive for particular object retrieval, especially in the regime of short vector representations and low-resolution images.
https://weibo.com/1402400261/K1xLYlwXv
2、[CV] Is Space-Time Attention All You Need for Video Understanding?
G Bertasius, H Wang, L Torresani
[Facebook AI]
基于时-空注意力的视频理解。提出一种完全建立在空间和时间上的自注意力上的视频分类的无卷积方法TimeSformer,直接从帧级区块序列中实现时-空特征学习,将标准的Transformer架构适应于视频。通过实验研究比较了不同的自注意力方案,表明“分割注意力”,即在每个块内分别应用时间注意力和空间注意力,在所考虑的设计选择中,导致了最佳的视频分类精度。与既有的基于卷积的视频模型范式相比,这是一种根本不同的视频建模方法。TimeSformer是一种完全建立在时空自洽上的有效、高效和可扩展的视频架构。其主要特点:(1)概念简单,(2)在主要动作识别基准上取得了最先进的结果,(3)推理成本低,(4)适合长期的视频建模。
We present a convolution-free approach to video classification built exclusively on self-attention over space and time. Our method, named “TimeSformer,” adapts the standard Transformer architecture to video by enabling spatiotemporal feature learning directly from a sequence of frame-level patches. Our experimental study compares different self-attention schemes and suggests that “divided attention,” where temporal attention and spatial attention are separately applied within each block, leads to the best video classification accuracy among the design choices considered. Despite the radically different design compared to the prominent paradigm of 3D convolutional architectures for video, TimeSformer achieves state-of-the-art results on several major action recognition benchmarks, including the best reported accuracy on Kinetics-400 and Kinetics-600. Furthermore, our model is faster to train and has higher test-time efficiency compared to competing architectures. Code and pretrained models will be made publicly available.
https://weibo.com/1402400261/K1xTkvoJN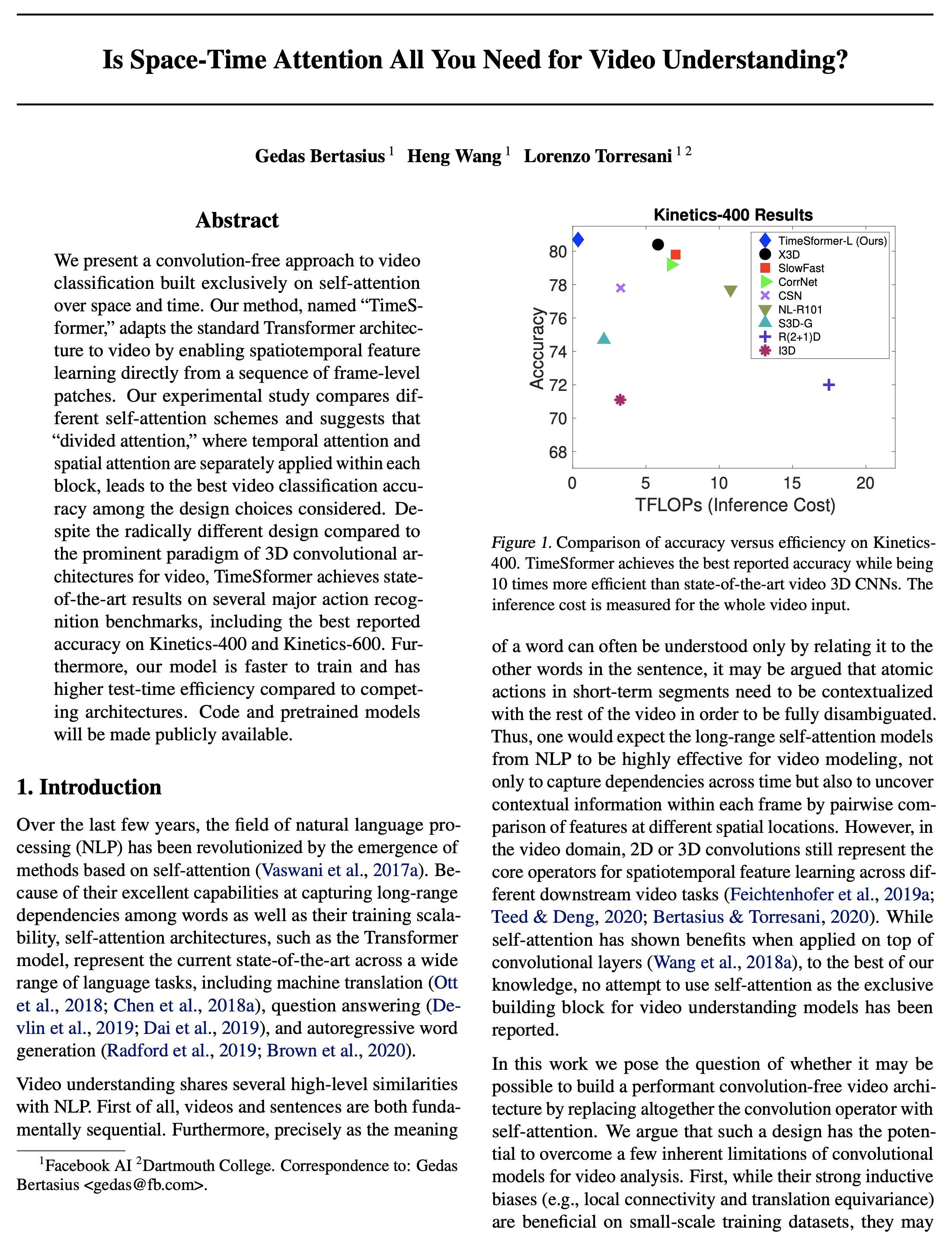
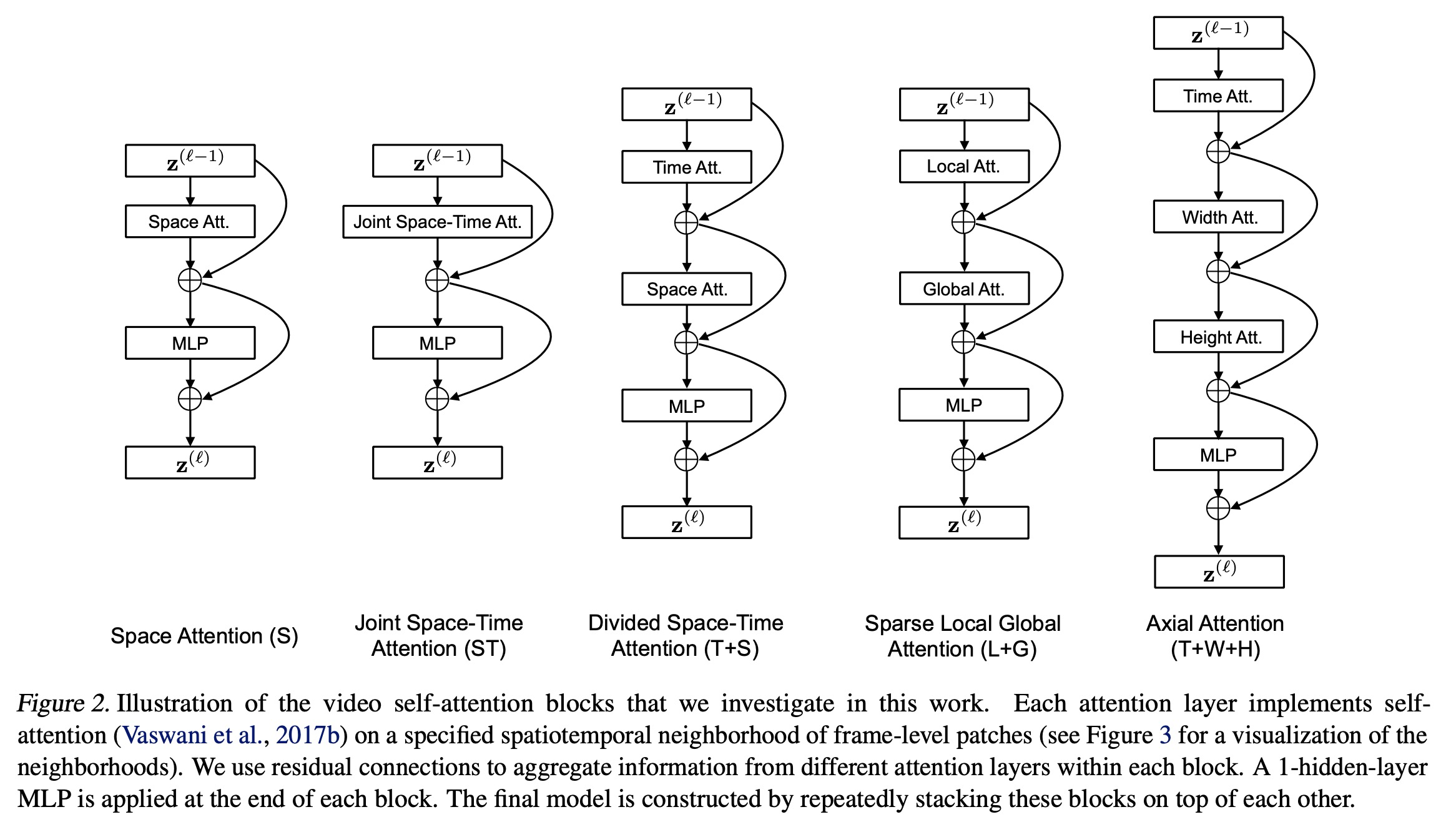

3、[LG] NAST: Non-Autoregressive Spatial-Temporal Transformer for Time Series Forecasting
K Chen, G Chen, D Xu, L Zhang, Y Huang, A Knoll
[Tongji University & The Hong Kong University of Science and Technology & Technical University of Munich]
NAST:面向时序预测的非自回归时空Transformer。提出了一种非自回归Transformer解码,设计了一种新的空间-时间注意力机制,联合处理空间和时间注意力。尝试将非自回归Transformer模型引入具有空间和时间依赖性的时间序列预测中。实验结果表明,时空注意力机制和非自回归解码方式都是必要和有益的。模型表现远优于其他基于Transformer的方法,实现了优于基于RNN的方法的有效性能。
Although Transformer has made breakthrough success in widespread domains especially in Natural Language Processing (NLP), applying it to time series forecasting is still a great challenge. In time series forecasting, the autoregressive decoding of canonical Transformer models could introduce huge accumulative errors inevitably. Besides, utilizing Transformer to deal with spatial-temporal dependencies in the problem still faces tough difficulties.~To tackle these limitations, this work is the first attempt to propose a Non-Autoregressive Transformer architecture for time series forecasting, aiming at overcoming the time delay and accumulative error issues in the canonical Transformer. Moreover, we present a novel spatial-temporal attention mechanism, building a bridge by a learned temporal influence map to fill the gaps between the spatial and temporal attention, so that spatial and temporal dependencies can be processed integrally. Empirically, we evaluate our model on diversified ego-centric future localization datasets and demonstrate state-of-the-art performance on both real-time and accuracy.
https://weibo.com/1402400261/K1xZECrKx
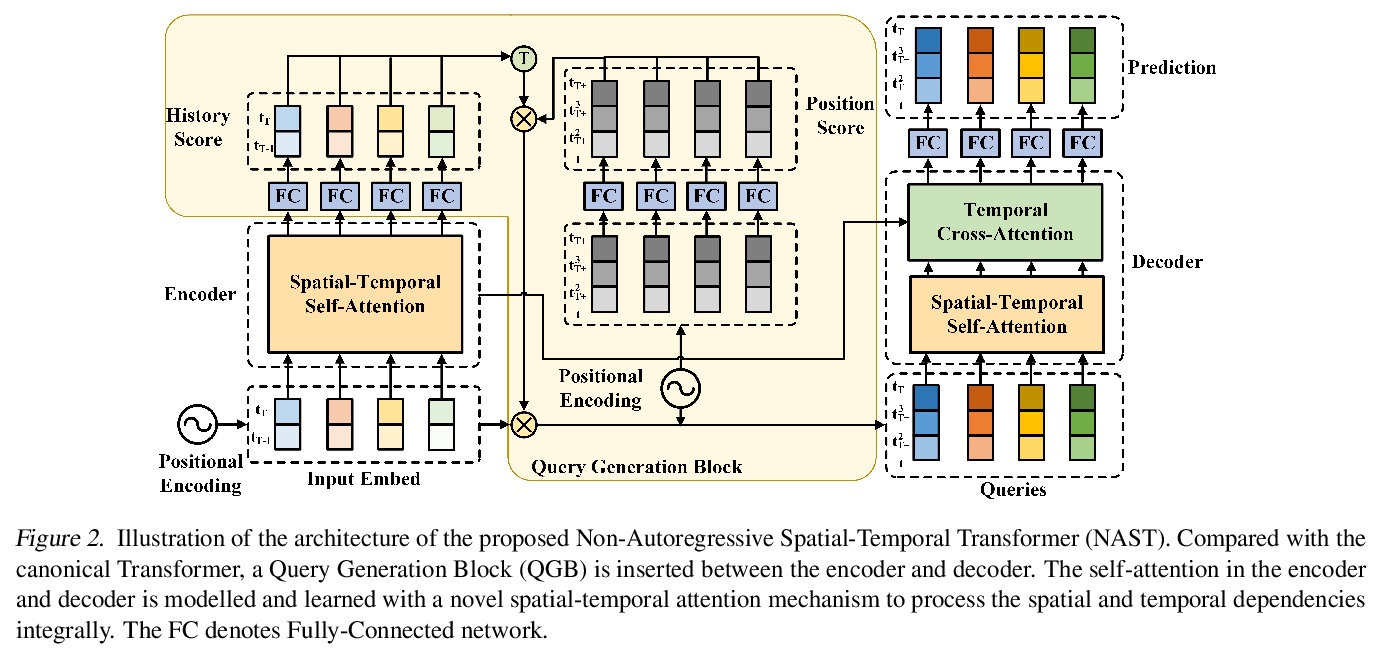
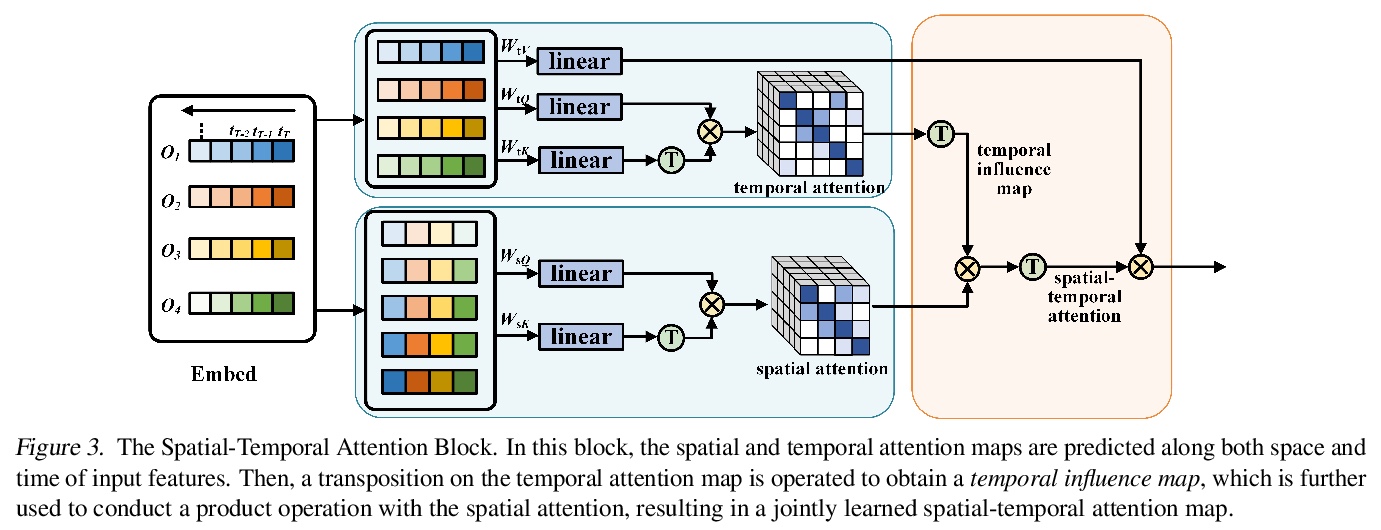
4、[CV] Unsupervised Novel View Synthesis from a Single Image
P Z Ramirez, A Tonioni, F Tombari
[University of Bologna & Google]
从单图像中无监督合成新视图。提出一种新的从单视图中进行新视图合成的方法,不需要任何形式的标注或训练集配对就可进行训练,唯一的要求是属于同一宏观类别的对象图像集合。用GAN预训练一个纯生成式解码器模型,同时训练一个编码器网络来反转从潜码到图像的映射。将编码器和解码器交换,并将网络训练成一个条件GAN,混合自编码器类目标和自分裂。提出一种两阶段训练方法,对3D感知生成模型的知识进行自蒸馏,将其作为条件,同时保留姿态和内容的解缠。
Novel view synthesis from a single image aims at generating novel views from a single input image of an object. Several works recently achieved remarkable results, though require some form of multi-view supervision at training time, therefore limiting their deployment in real scenarios. This work aims at relaxing this assumption enabling training of conditional generative model for novel view synthesis in a completely unsupervised manner. We first pre-train a purely generative decoder model using a GAN formulation while at the same time training an encoder network to invert the mapping from latent code to images. Then we swap encoder and decoder and train the network as a conditioned GAN with a mixture of auto-encoder-like objective and self-distillation. At test time, given a view of an object, our model first embeds the image content in a latent code and regresses its pose w.r.t. a canonical reference system, then generates novel views of it by keeping the code and varying the pose. We show that our framework achieves results comparable to the state of the art on ShapeNet and that it can be employed on unconstrained collections of natural images, where no competing method can be trained.
https://weibo.com/1402400261/K1yaSzTf0

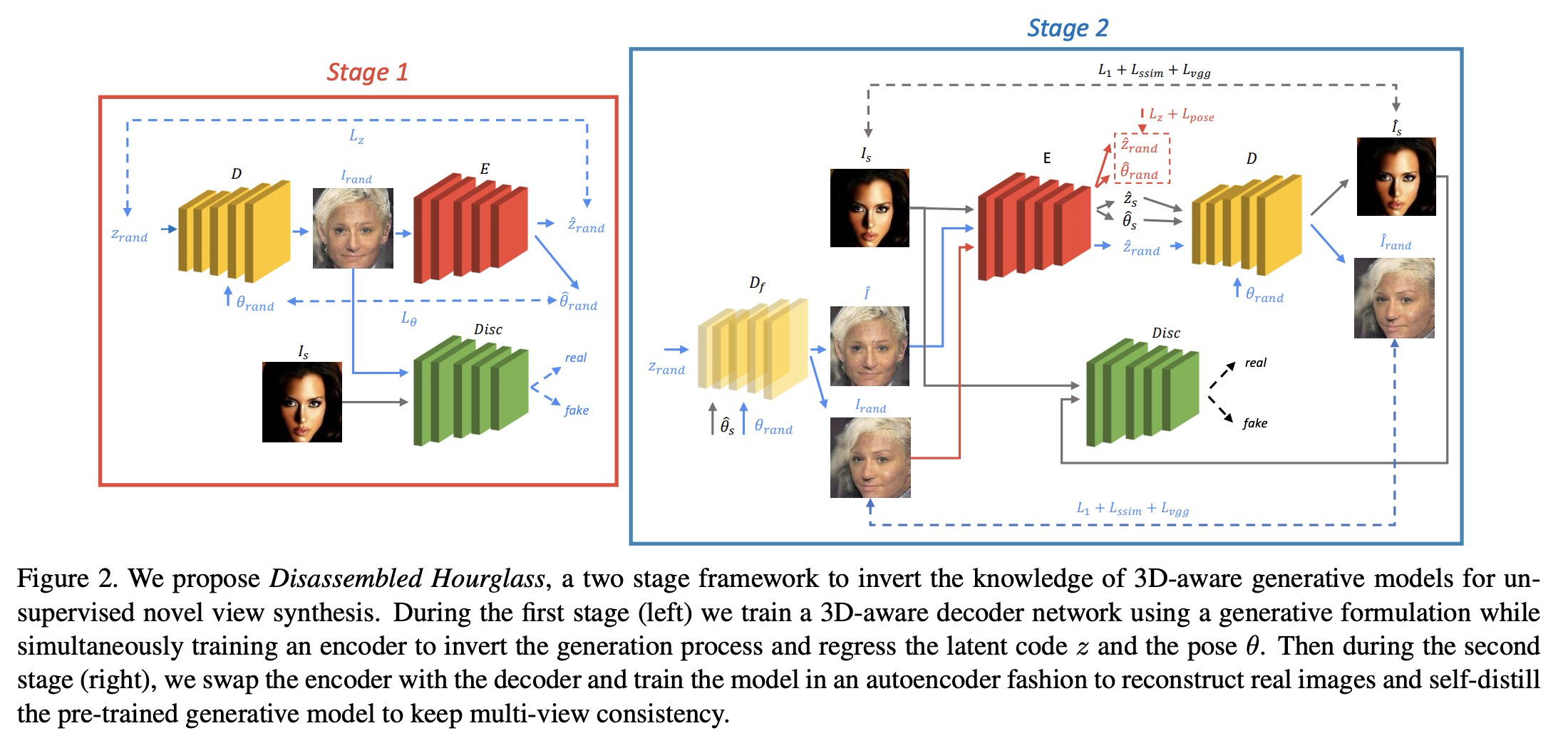

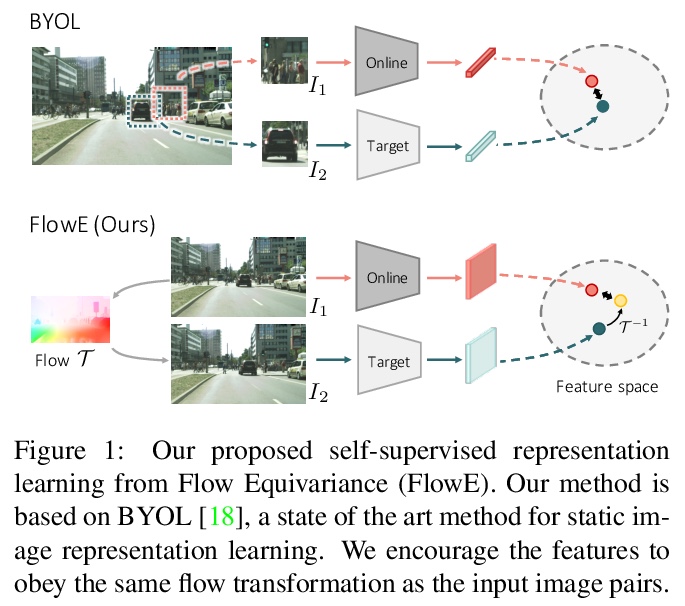
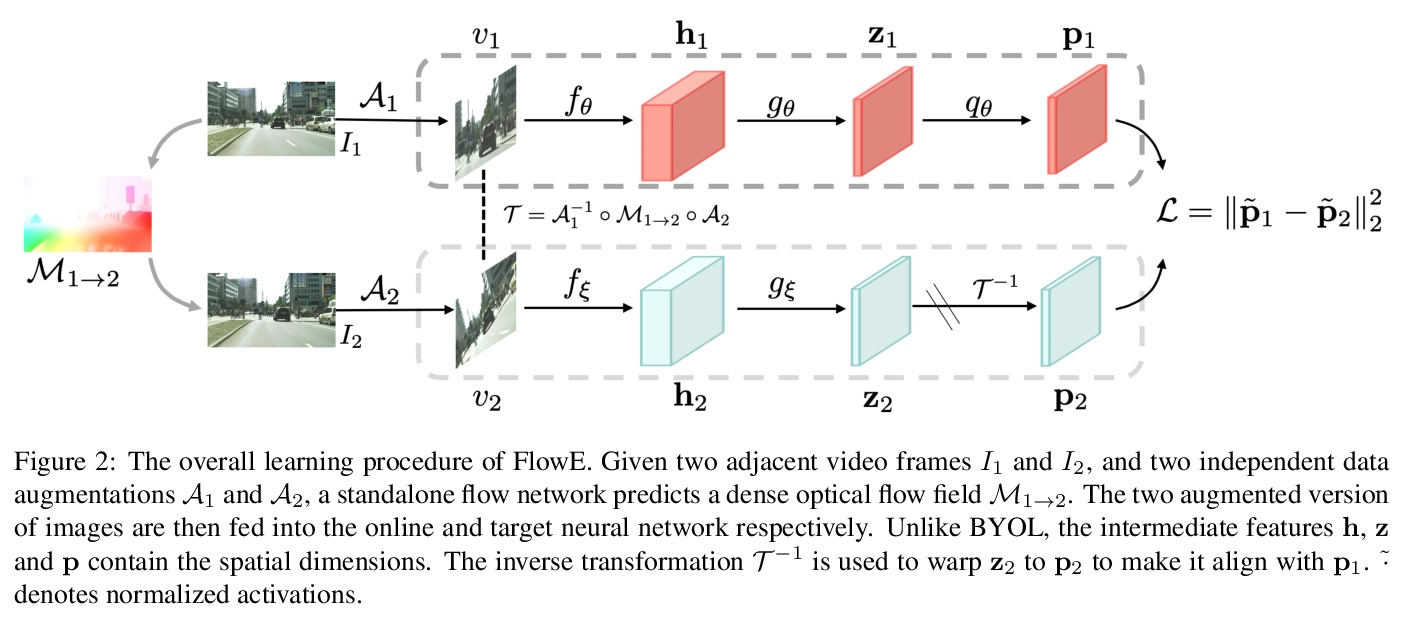
5、[CV] Self-Supervised Representation Learning from Flow Equivariance
Y Xiong, M Ren, W Zeng, R Urtasun
[Uber ATG & University of Toronto]
流等变自监督表示学习。提出一种新的基于流等变目标的自监督表示学习框架,能从具有复杂场景的原始高分辨率视频中学习像素级表示。该框架鼓励网络通过对当前帧的特征应用流转换来预测另一帧的特征,从高分辨率原始视频中学习,可以很容易地用于静态图像的下游任务。在驾驶视频上的大规模实验表明,该无监督表示对对象检测、语义和实例分割非常有用,在许多情况下优于从ImageNet获得的最先进表示。
Self-supervised representation learning is able to learn semantically meaningful features; however, much of its recent success relies on multiple crops of an image with very few objects. Instead of learning view-invariant representation from simple images, humans learn representations in a complex world with changing scenes by observing object movement, deformation, pose variation, and ego motion. Motivated by this ability, we present a new self-supervised learning representation framework that can be directly deployed on a video stream of complex scenes with many moving objects. Our framework features a simple flow equivariance objective that encourages the network to predict the features of another frame by applying a flow transformation to the features of the current frame. Our representations, learned from high-resolution raw video, can be readily used for downstream tasks on static images. Readout experiments on challenging semantic segmentation, instance segmentation, and object detection benchmarks show that we are able to outperform representations obtained from previous state-of-the-art methods including SimCLR and BYOL.
https://weibo.com/1402400261/K1yfu0FKN

另外几篇值得关注的论文:
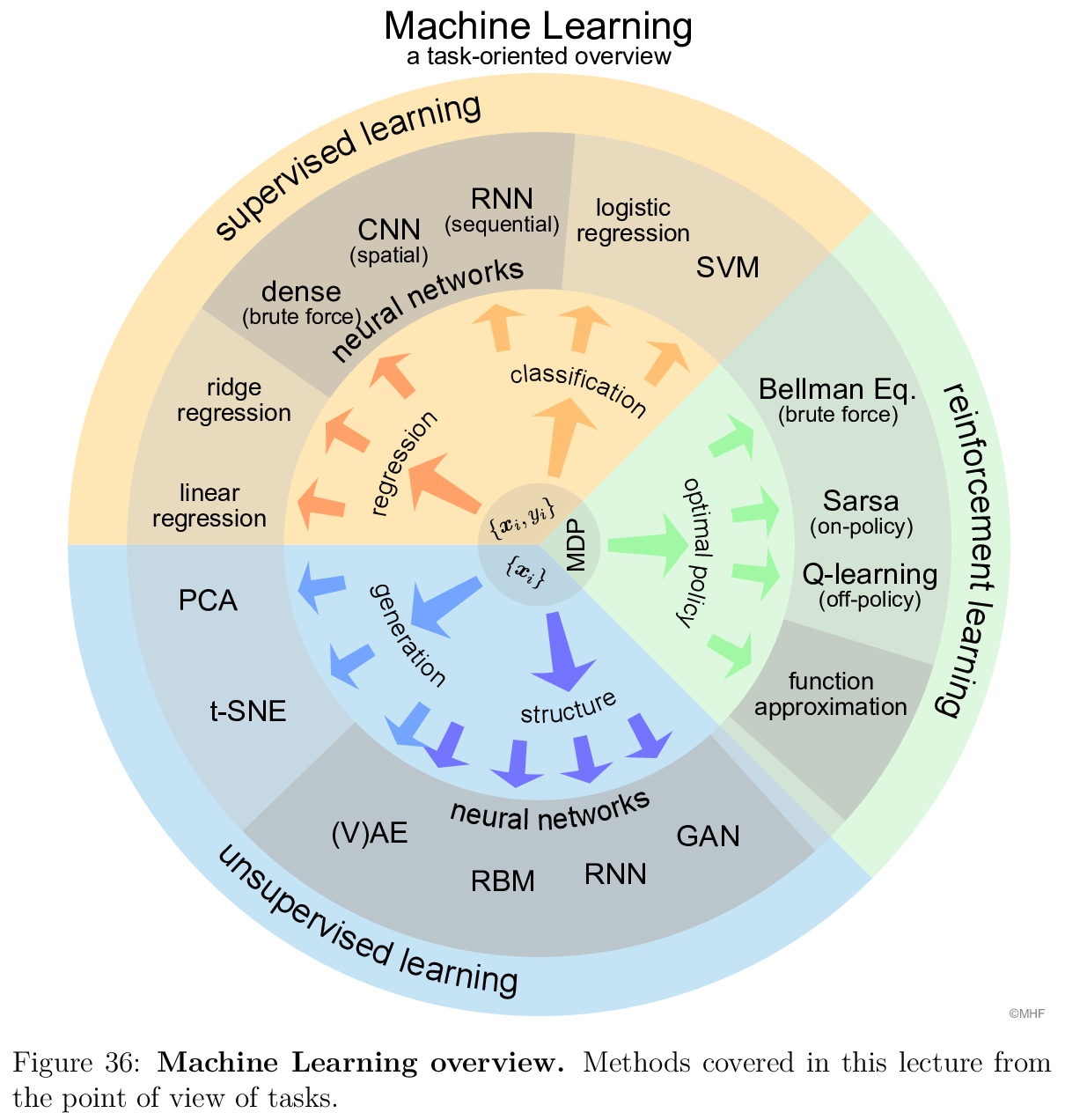
[LG] Introduction to Machine Learning for the Sciences
面向科学研究的机器学习介绍
T Neupert, M H Fischer, E Greplova, K Choo, M Denner
[University of Zurich & Delft University of Technology]
https://weibo.com/1402400261/K1ymHCpQT

[LG] Sampling in Combinatorial Spaces with SurVAE Flow Augmented MCMC
SurVAE流增强MCMC组合空间采样
P Jaini, D Nielsen, M Welling
[University of Amsterdam & Technical University of Denmark]
https://weibo.com/1402400261/K1yrK26o9


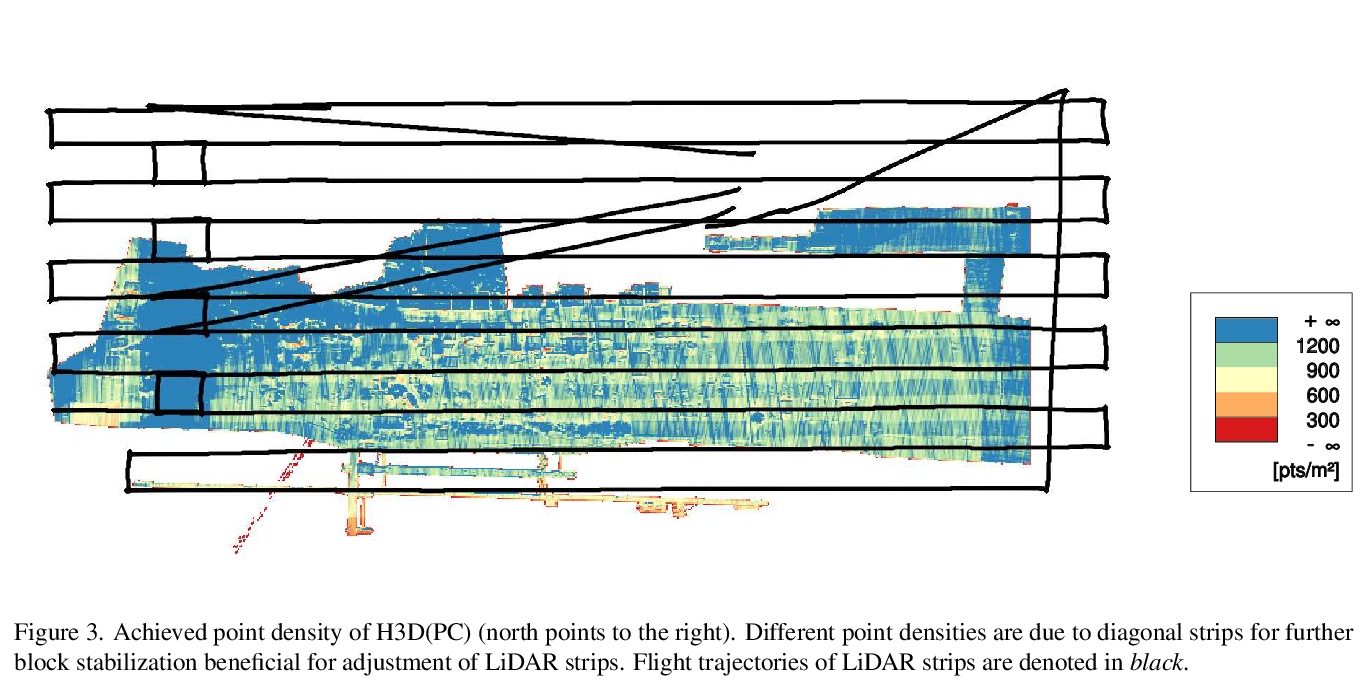
[CV] H3D: Benchmark on Semantic Segmentation of High-Resolution 3D Point Clouds and textured Meshes from UAV LiDAR and Multi-View-Stereo
H3D:无人机激光雷达和多视点立体高分辨率三维点云和纹理网格语义分割基准
M Kölle, D Laupheimer, S Schmohl, N Haala, F Rottensteiner, J D Wegner, H Ledoux
[University of Stuttgart & Leibniz University Hannover]
https://weibo.com/1402400261/K1yvffoVX



若有收获,就点个赞吧
0 人点赞
