- 1、[CV] StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
- 2、[CV] Going deeper with Image Transformers
- 3、[RO] Learning Generalizable Robotic Reward Functions from “In-The-Wild” Human Videos
- 4、[CV] Dual Contrastive Loss and Attention for GANs
- 5、[CV] Semi-supervised Synthesis of High-Resolution Editable Textures for 3D Humans
- [CL] A Neighbourhood Framework for Resource-Lean Content Flagging
- [CV] Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes
- [CV] Seasonal Contrast: Unsupervised Pre-Training from Uncurated Remote Sensing Data
- [CV] Rethinking Self-supervised Correspondence Learning: A Video Frame-level Similarity Perspective
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
O Patashnik, Z Wu, E Shechtman, D Cohen-Or, D Lischinski
[Hebrew University of Jerusalem & Tel-Aviv University & Adobe Research]
StyleCLIP: 文本驱动的StyleGAN图像操纵。探索利用最近提出的对比语言图像预训练(CLIP)模型的能力,为StyleGAN图像操纵开发基于文本的界面,不需要太多对于自由度的人工监督。提出一个优化方案,利用基于CLIP的损失来修改输入的潜向量,以响应用户提供的文本提示。以及一种潜映射器,为给定输入图像推导出一个文本引导的潜操纵步骤,允许更快更稳定的基于文本的操作。提出一种方法,用于将文本提示映射到StyleGAN的风格空间中输入无关的方向,从而实现交互式的文本驱动的图像操纵。广泛的结果和比较证明了该方法的有效性。
Inspired by the ability of StyleGAN to generate highly realistic images in a variety of domains, much recent work has focused on understanding how to use the latent spaces of StyleGAN to manipulate generated and real images. However, discovering semantically meaningful latent manipulations typically involves painstaking human examination of the many degrees of freedom, or an annotated collection of images for each desired manipulation. In this work, we explore leveraging the power of recently introduced Contrastive Language-Image Pre-training (CLIP) models in order to develop a text-based interface for StyleGAN image manipulation that does not require such manual effort. We first introduce an optimization scheme that utilizes a CLIP-based loss to modify an input latent vector in response to a user-provided text prompt. Next, we describe a latent mapper that infers a text-guided latent manipulation step for a given input image, allowing faster and more stable text-based manipulation. Finally, we present a method for mapping a text prompts to input-agnostic directions in StyleGAN’s style space, enabling interactive text-driven image manipulation. Extensive results and comparisons demonstrate the effectiveness of our approaches.
https://weibo.com/1402400261/K8YKO4FnJ
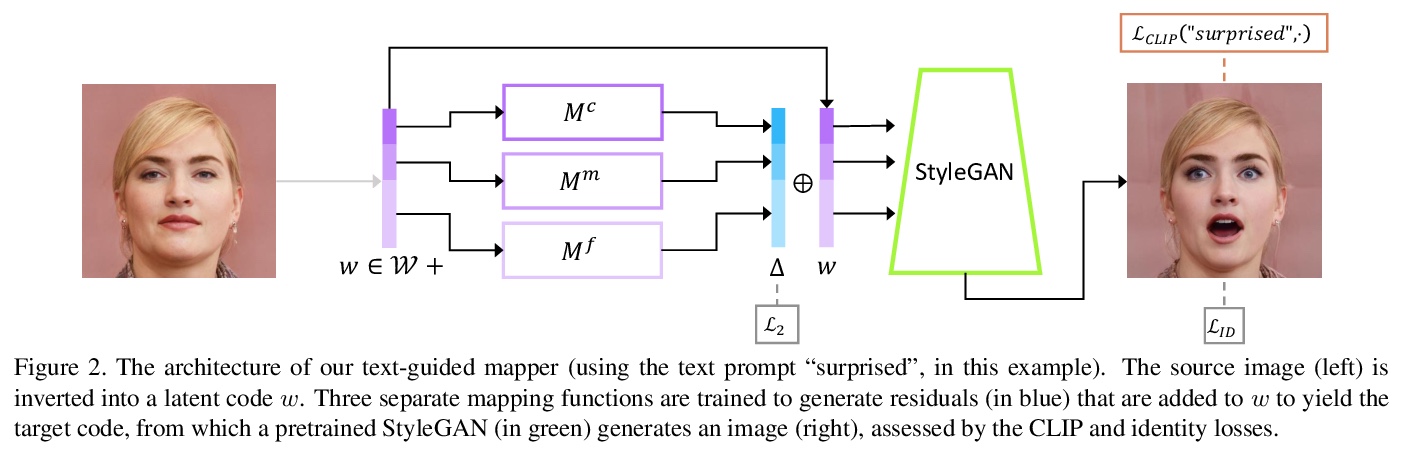


2、[CV] Going deeper with Image Transformers
H Touvron, M Cord, A Sablayrolles, G Synnaeve, H Jégou
[Facebook AI & Sorbonne University]
更深的图像Transformer。构建并优化了用于图像分类的深度Transformer网络,研究了这种专用Transformer的架构和优化的相互影响。提出两个Transformer架构的改变,以编码器/解码器架构的方式设计了简单有效的CaiT架构,显著提高了深度Transformer的准确性。产生的模型的性能不会随着更深的深度而提前饱和,在没有外部数据的情况下进行训练时,在Imagenet上获得了86.3%的top-1精度。所得到的最佳模型在没有额外训练数据的情况下,用Reassessed标签和Imagenet-V2/匹配频率在Imagenet上达到了新的技术水平。
Transformers have been recently adapted for large scale image classification, achieving high scores shaking up the long supremacy of convolutional neural networks. However the optimization of image transformers has been little studied so far. In this work, we build and optimize deeper transformer networks for image classification. In particular, we investigate the interplay of architecture and optimization of such dedicated transformers. We make two transformers architecture changes that significantly improve the accuracy of deep transformers. This leads us to produce models whose performance does not saturate early with more depth, for instance we obtain 86.3% top-1 accuracy on Imagenet when training with no external data. Our best model establishes the new state of the art on Imagenet with Reassessed labels and Imagenet-V2 / match frequency, in the setting with no additional training data.
https://weibo.com/1402400261/K8YP0pkGR
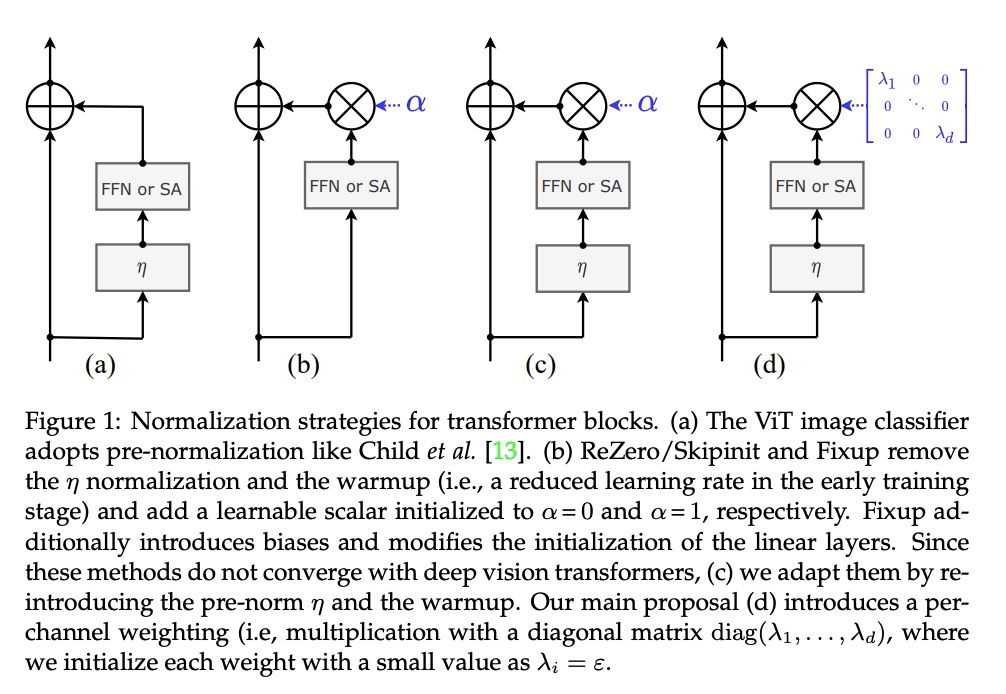
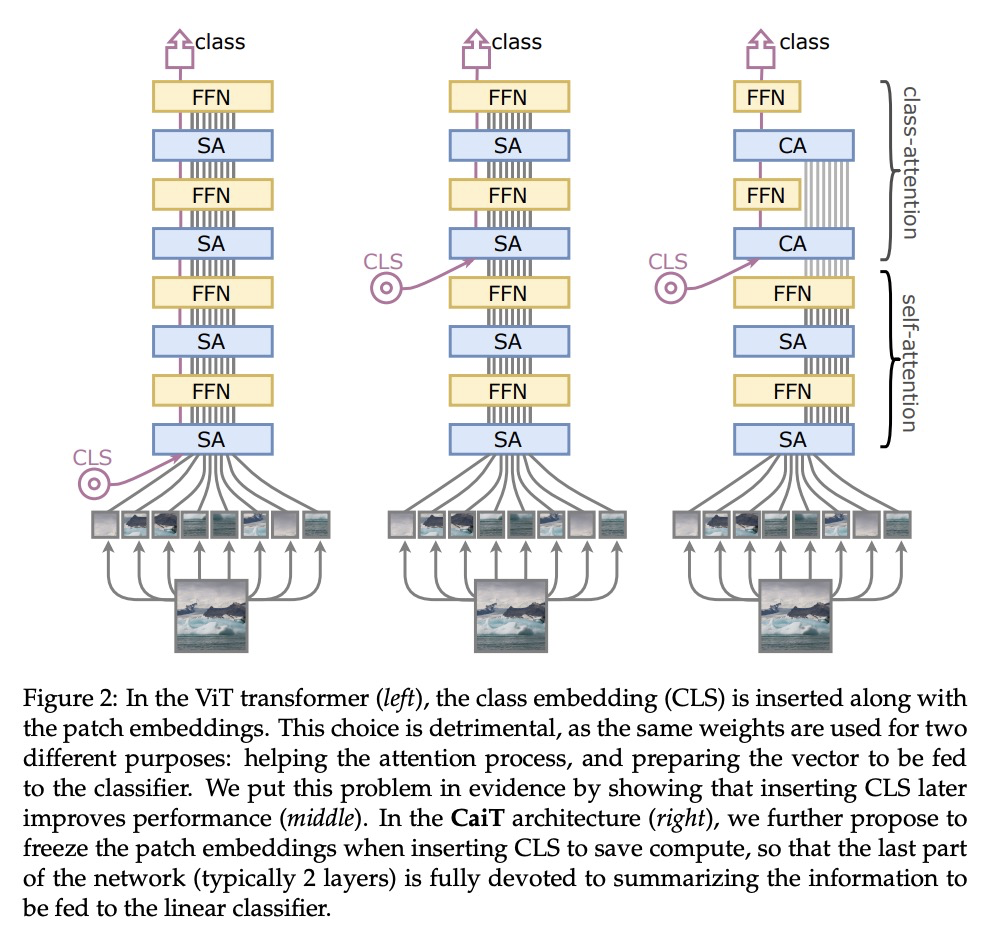
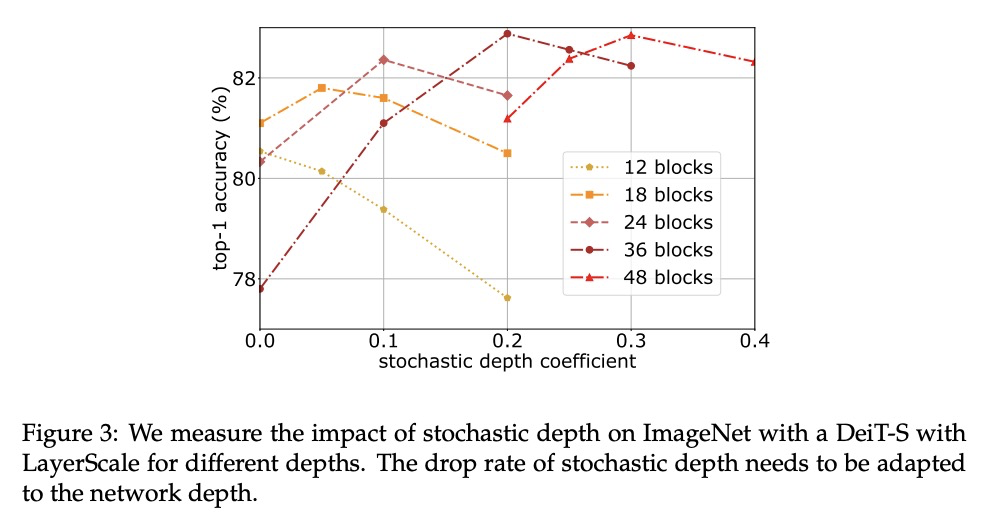
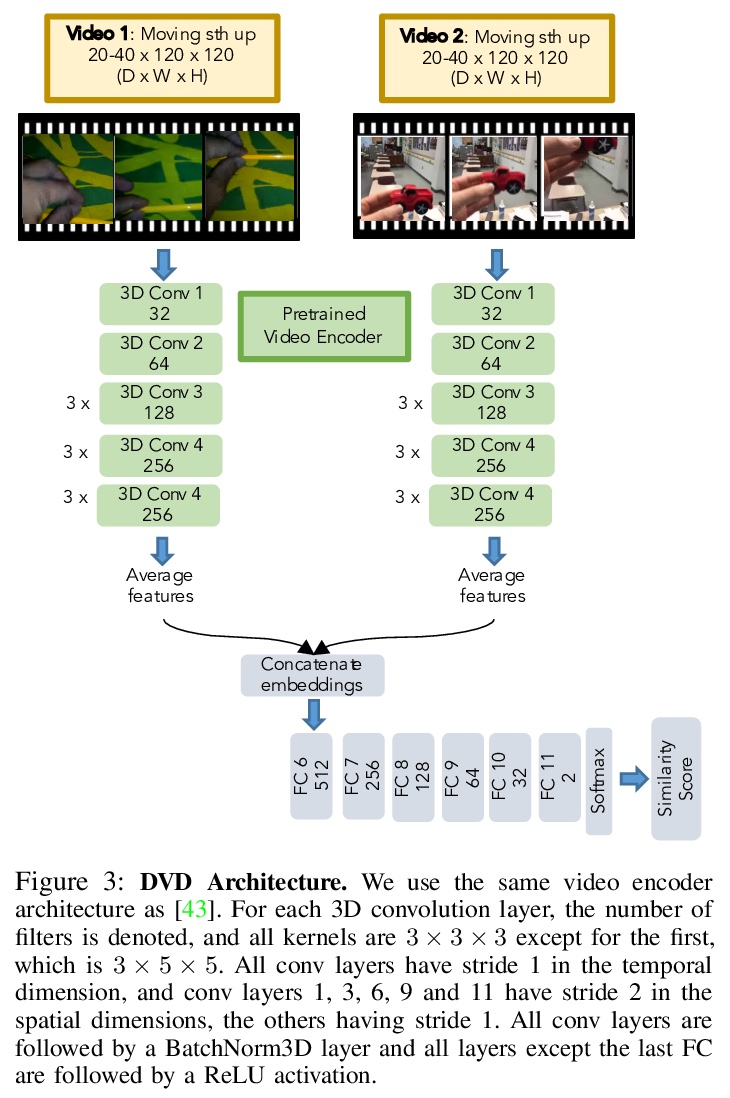
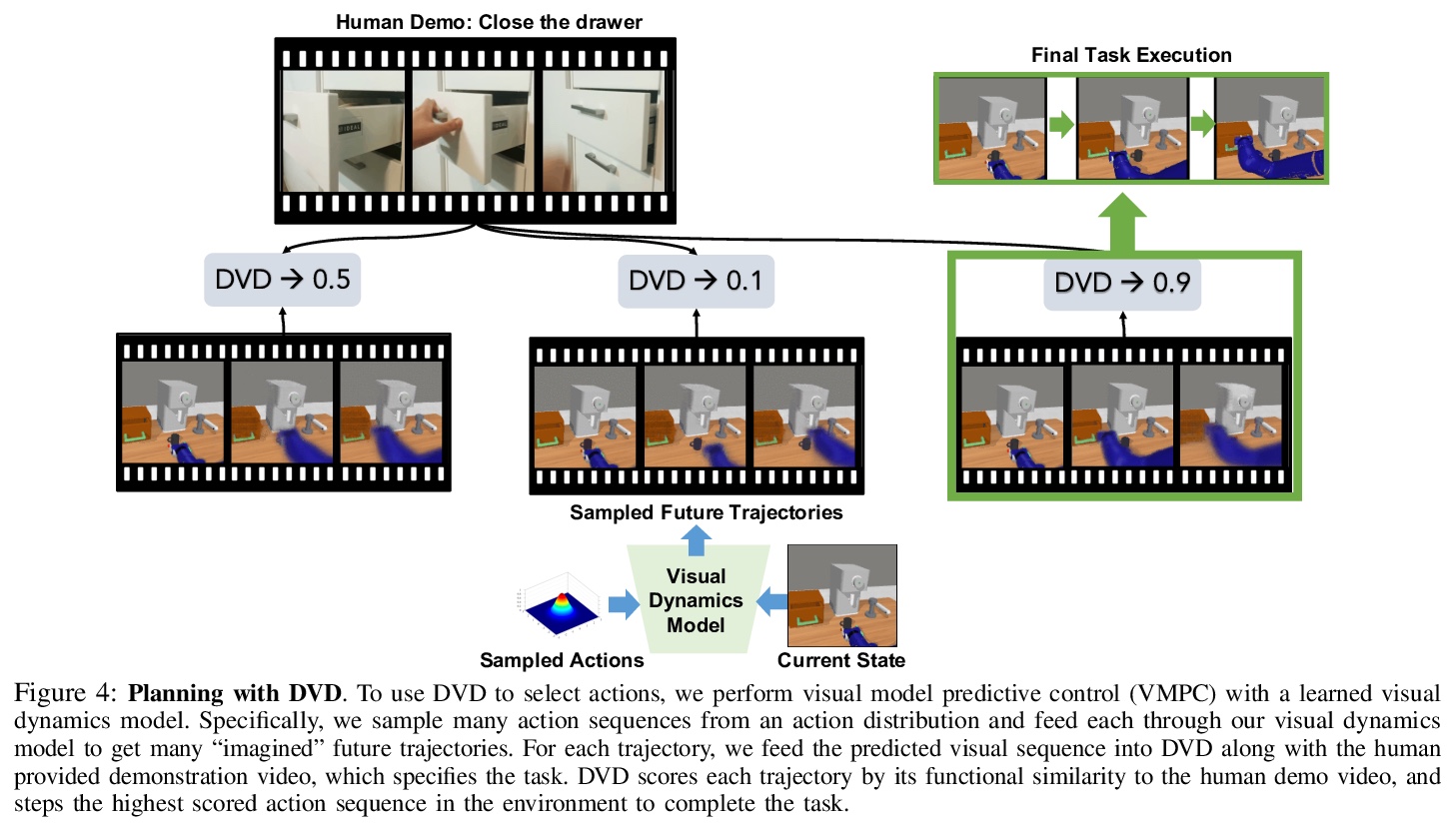
3、[RO] Learning Generalizable Robotic Reward Functions from “In-The-Wild” Human Videos
A S. Chen, S Nair, C Finn
[Stanford University]
从”现实世界”人类视频中学习可泛化的机器人奖励函数。提出一种简单方法—领域不可知视频鉴别器(DVD),通过训练一个鉴别器来学习多任务奖励函数,以分辨两个视频是否在执行相同的任务,利用广泛的人类视频数据集、凭借从少量机器人数据中学习,来进行泛化。通过利用多样化的人类数据集,奖励函数可以将零样本泛化到不可见环境中和不可见任务中,并与视觉模型预测控制相结合,从单个人类演示中解决真实WidowX200机器人在不可见环境中的机器人操作任务。
We are motivated by the goal of generalist robots that can complete a wide range of tasks across many environments. Critical to this is the robot’s ability to acquire some metric of task success or reward, which is necessary for reinforcement learning, planning, or knowing when to ask for help. For a general-purpose robot operating in the real world, this reward function must also be able to generalize broadly across environments, tasks, and objects, while depending only on on-board sensor observations (e.g. RGB images). While deep learning on large and diverse datasets has shown promise as a path towards such generalization in computer vision and natural language, collecting high quality datasets of robotic interaction at scale remains an open challenge. In contrast, “in-the-wild” videos of humans (e.g. YouTube) contain an extensive collection of people doing interesting tasks across a diverse range of settings. In this work, we propose a simple approach, Domain-agnostic Video Discriminator (DVD), that learns multitask reward functions by training a discriminator to classify whether two videos are performing the same task, and can generalize by virtue of learning from a small amount of robot data with a broad dataset of human videos. We find that by leveraging diverse human datasets, this reward function (a) can generalize zero shot to unseen environments, (b) generalize zero shot to unseen tasks, and (c) can be combined with visual model predictive control to solve robotic manipulation tasks on a real WidowX200 robot in an unseen environment from a single human demo.
https://weibo.com/1402400261/K8YVXcQUU

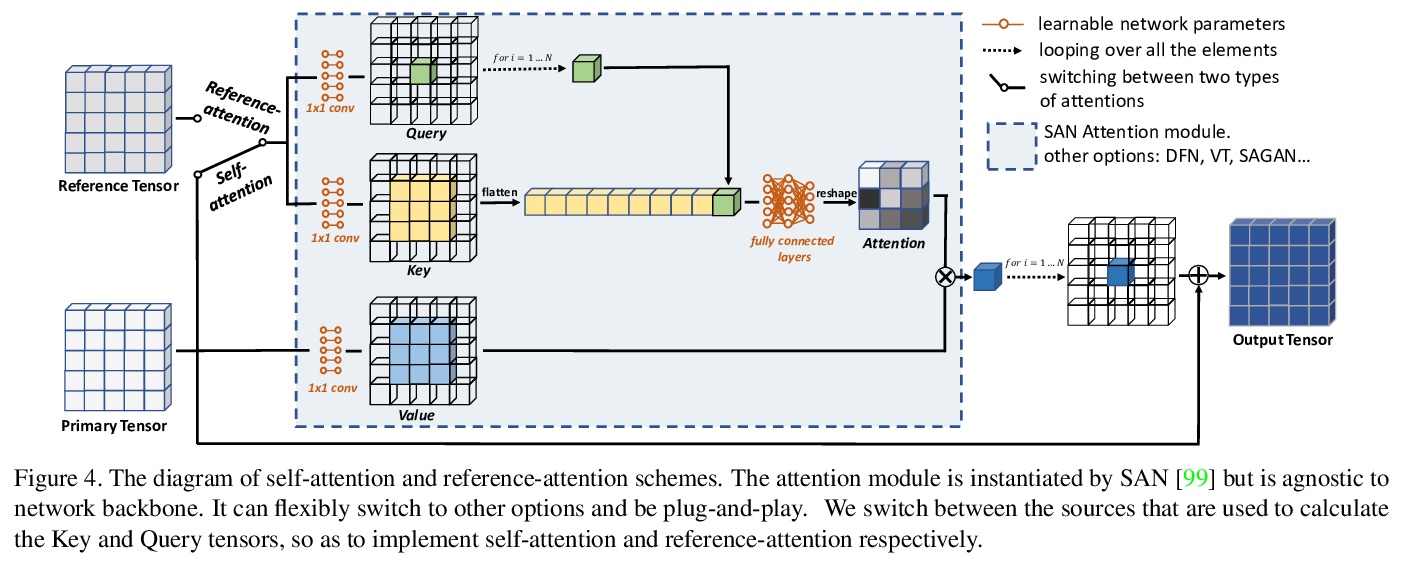
4、[CV] Dual Contrastive Loss and Attention for GANs
N Yu, G Liu, A Dundar, A Tao, B Catanzaro, L Davis, M Fritz
[University of Maryland & NVIDIA]
GANs双对比损失和注意力。在对抗训练中提出一种新的双对比损失,将表征泛化,使其更有效地区分真假,并进一步激励图像的生成质量。研究了GAN架构中注意力机制的变体,以缓解局部和静止卷积的问题。设计了一种新的引用-注意力辨别器架构,使有限规模的数据集大大受益。对大规模数据集及其较小子集进行了广泛实验,表明在损失函数和生成器上的改进在两种情况下都能成立。基于可用图像数量,判别器表现会有所不同,而基于引用注意力的判别器仅在有限规模的数据集上有所改进。重新定义了最新水平,在几个大规模基准数据集上,FID分数至少提高了17.5%。在CLEVR数据集上实现了更真实的生成,该数据集带来了与其他数据集不同的挑战:带有遮挡、阴影、反射和镜面的合成场景。
Generative Adversarial Networks (GANs) produce impressive results on unconditional image generation when powered with large-scale image datasets. Yet generated images are still easy to spot especially on datasets with high variance (e.g. bedroom, church). In this paper, we propose various improvements to further push the boundaries in image generation. Specifically, we propose a novel dual contrastive loss and show that, with this loss, discriminator learns more generalized and distinguishable representations to incentivize generation. In addition, we revisit attention and extensively experiment with different attention blocks in the generator. We find attention to be still an important module for successful image generation even though it was not used in the recent state-of-the-art models. Lastly, we study different attention architectures in the discriminator, and propose a reference attention mechanism. By combining the strengths of these remedies, we improve the compelling state-of-the-art Fréchet Inception Distance (FID) by at least 17.5% on several benchmark datasets. We obtain even more significant improvements on compositional synthetic scenes (up to 47.5% in FID).
https://weibo.com/1402400261/K8Z2S1Nup



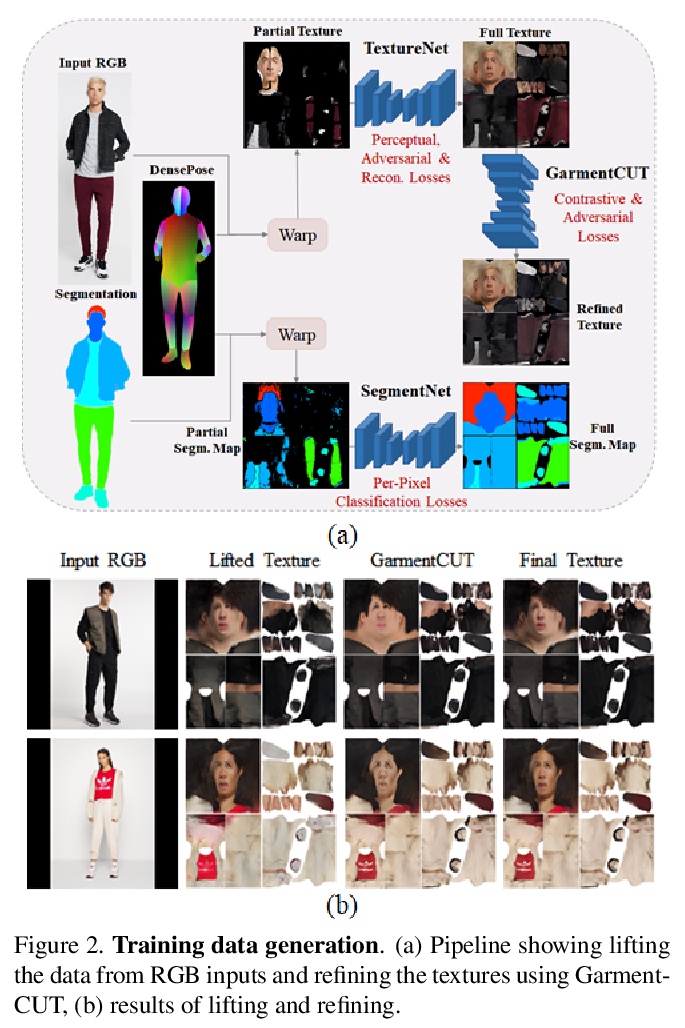
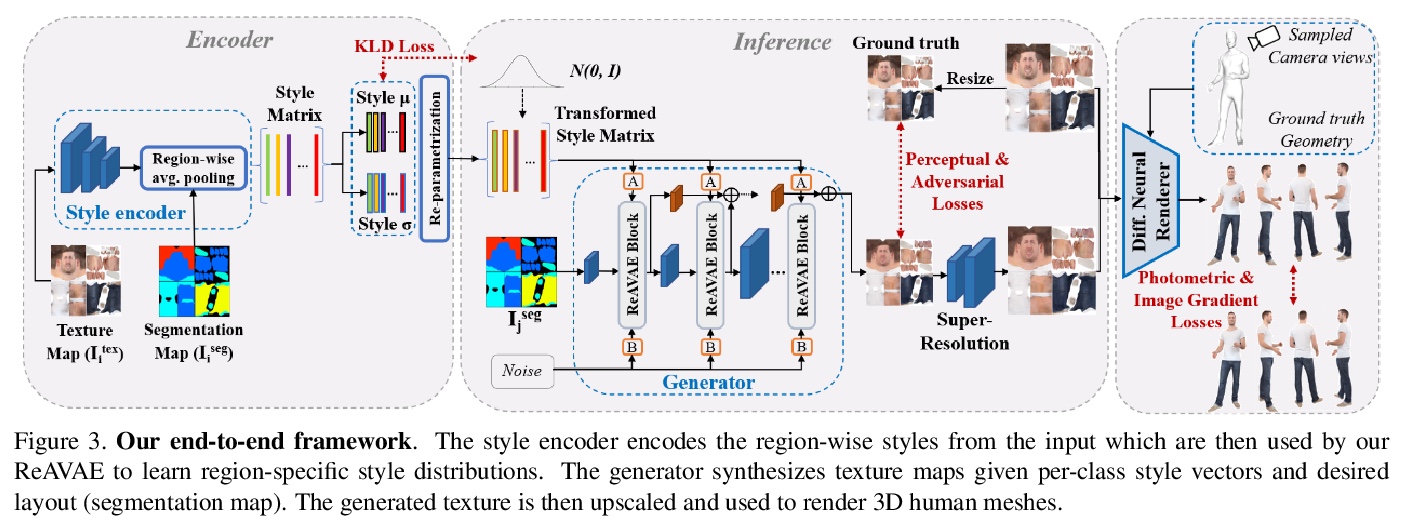
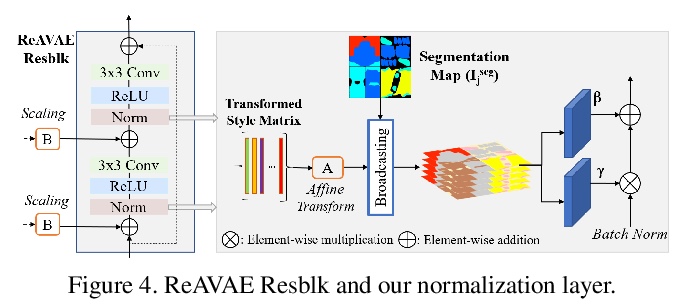
5、[CV] Semi-supervised Synthesis of High-Resolution Editable Textures for 3D Humans
B Chaudhuri, N Sarafianos, L Shapiro, T Tung
[University of Washington & Facebook Reality Labs Research]
3D人体高分辨率可编辑纹理半监督合成。提出一种新的架构,在半监督设置下,给定一个输入分割掩模,生成3D人体纹理图。网络使用VAE学习每类风格分布,并通过从学习的分布中随机采样,通过掩模和风格独立操作布局来控制生成的纹理。通过实验证明了该方法在重建和合成任务中都优于之前的工作,可应用于虚拟试穿AR/VR应用中。
We introduce a novel approach to generate diverse high fidelity texture maps for 3D human meshes in a semi-supervised setup. Given a segmentation mask defining the layout of the semantic regions in the texture map, our network generates high-resolution textures with a variety of styles, that are then used for rendering purposes. To accomplish this task, we propose a Region-adaptive Adversarial Variational AutoEncoder (ReAVAE) that learns the probability distribution of the style of each region individually so that the style of the generated texture can be controlled by sampling from the region-specific distributions. In addition, we introduce a data generation technique to augment our training set with data lifted from single-view RGB inputs. Our training strategy allows the mixing of reference image styles with arbitrary styles for different regions, a property which can be valuable for virtual try-on AR/VR applications. Experimental results show that our method synthesizes better texture maps compared to prior work while enabling independent layout and style controllability.
https://weibo.com/1402400261/K8ZbzyyDx
另外几篇值得关注的论文:
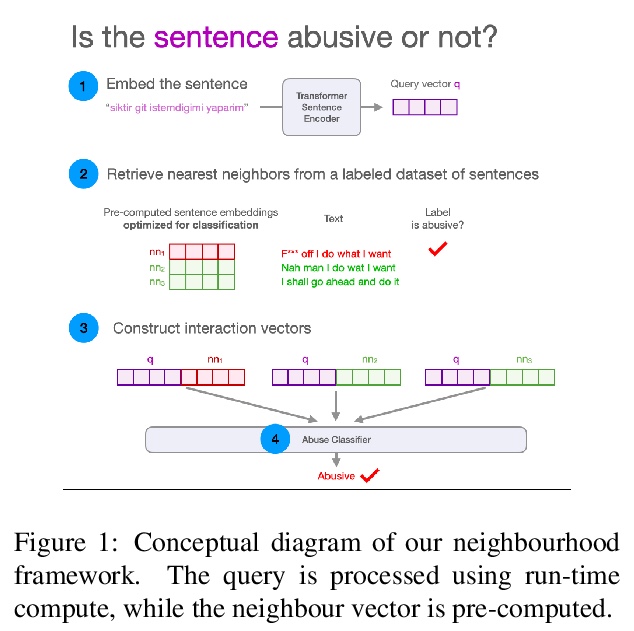
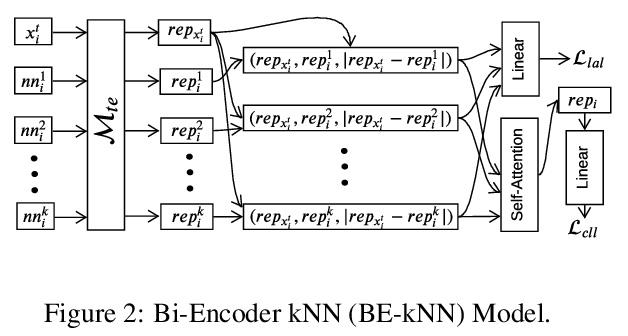
[CL] A Neighbourhood Framework for Resource-Lean Content Flagging
面向资源贫乏内容标记的邻域框架
S M Sarwar, D Zlatkova, M Hardalov, Y Dinkov, I Augenstein, P Nakov
[CheckStep Research]
https://weibo.com/1402400261/K8Zka2iey
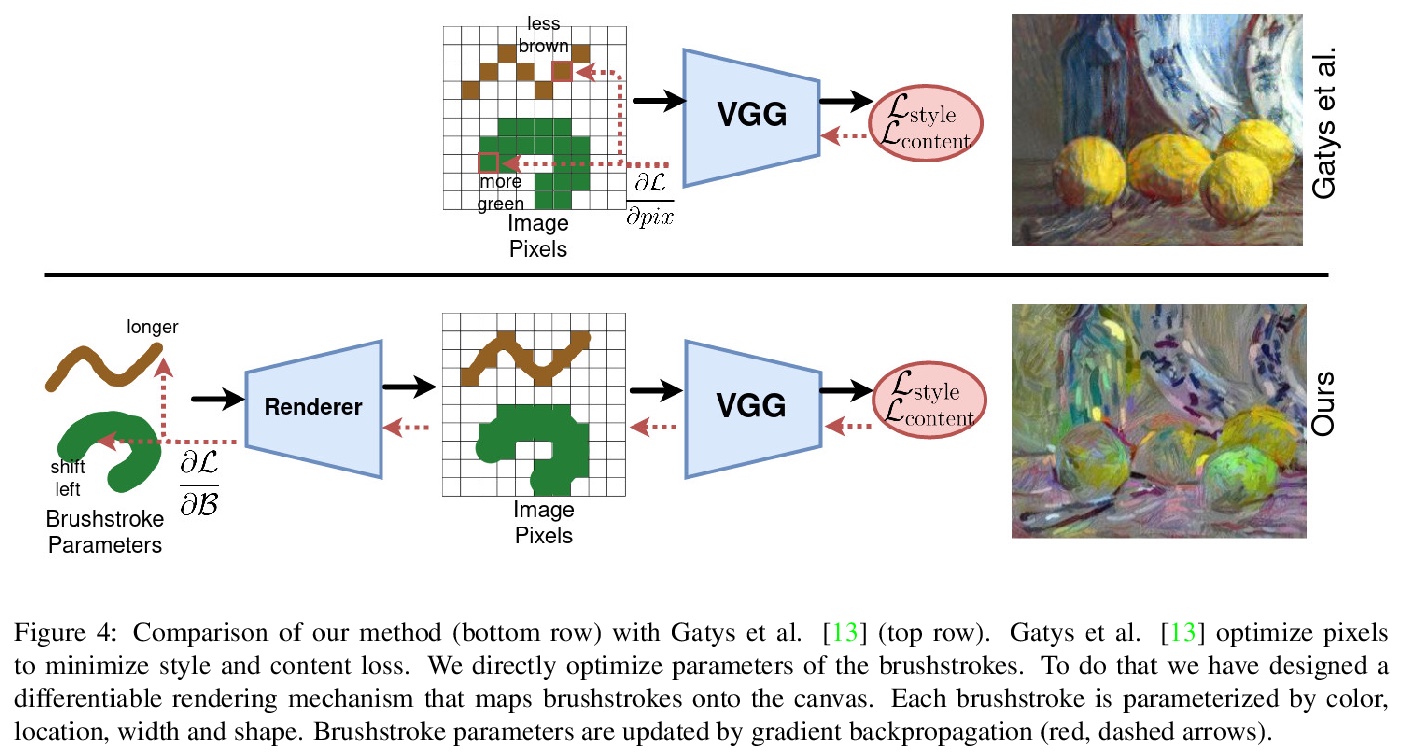
[CV] Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes
画风迁移的反思:从像素到参数化笔触
D Kotovenko, M Wright, A Heimbrecht, B Ommer
[Heidelberg University]
https://weibo.com/1402400261/K8ZnEBLCd


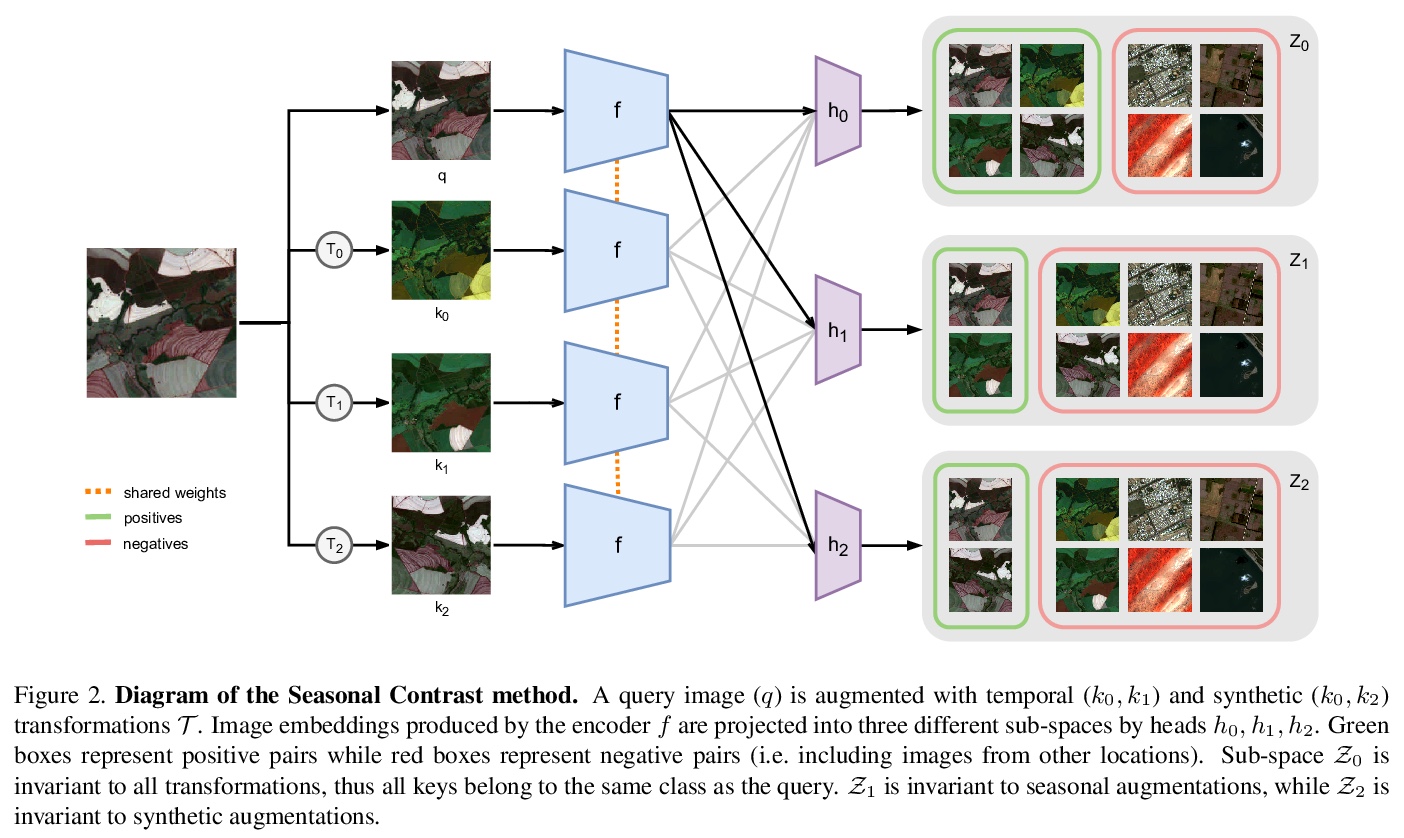
[CV] Seasonal Contrast: Unsupervised Pre-Training from Uncurated Remote Sensing Data
季节性对比:未分割遥感数据无监督预训练
O Mañas, A Lacoste, X Giro-i-Nieto, D Vazquez, P Rodriguez
[Element AI & Universitat Politecnica de Catalunya]
https://weibo.com/1402400261/K8Zq9ujm7
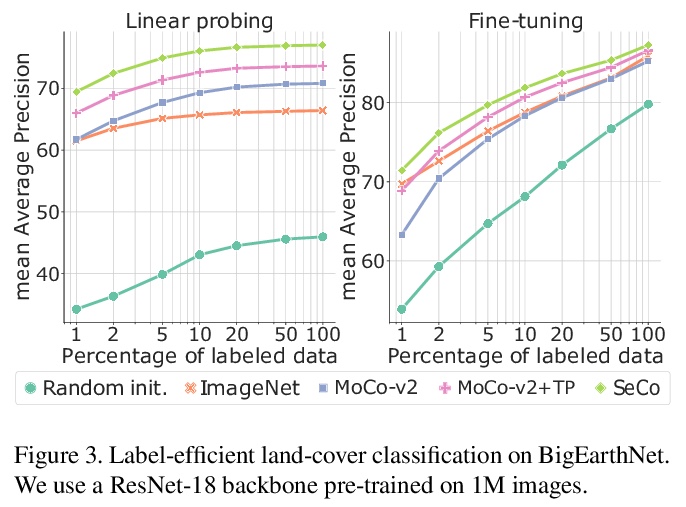
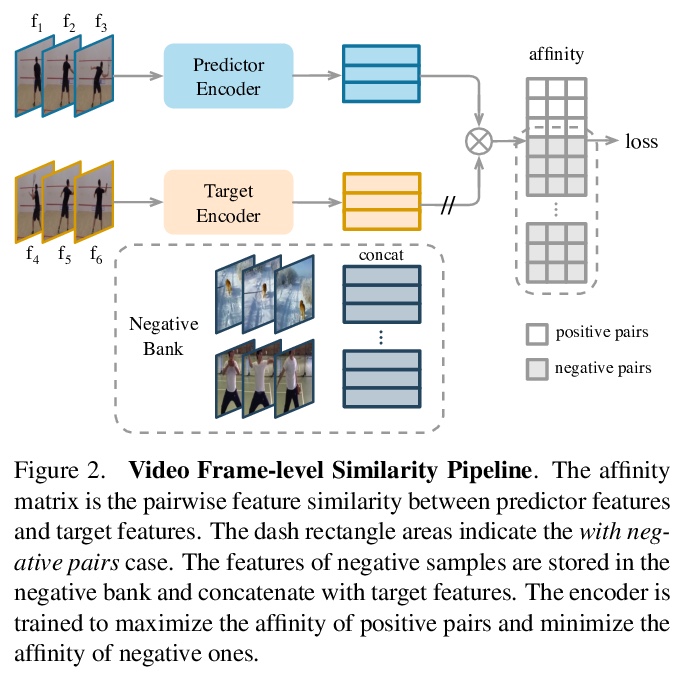
[CV] Rethinking Self-supervised Correspondence Learning: A Video Frame-level Similarity Perspective
反思自监督对应学习:视频帧级相似度视角
J Xu, X Wang
[UC San Diego]
https://weibo.com/1402400261/K8ZrPrNqc


若有收获,就点个赞吧
0 人点赞
