- 1、[CV] ShaRF: Shape-conditioned Radiance Fields from a Single View
- 2、[LG] Contrastive Learning Inverts the Data Generating Process
- 3、[LG] Differential Privacy Dynamics of Langevin Diffusion and Noisy Gradient Descent
- 4、[LG] Centroid Transformers: Learning to Abstract with Attention
- 5、[CV] Weakly Supervised Learning of Rigid 3D Scene Flow
- [LG] Few-shot Conformal Prediction with Auxiliary Tasks
- [LG] DEUP: Direct Epistemic Uncertainty Prediction
- [CV] Crop mapping from image time series: deep learning with multi-scale label hierarchies
- [LG] Switch Spaces: Learning Product Spaces with Sparse Gating
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] ShaRF: Shape-conditioned Radiance Fields from a Single View
K Rematas, R Martin-Brualla, V Ferrari
[Google Research]
ShaRF:单视图形状条件辐射场。提出一个新模型来表示目标类,可从单一图像中重建目标。提出一种只给定单幅图像的目标神经网络场景表示估计方法,结合中间体形状表示方法调节高保真辐射场,其核心是估计物体的几何支架,并将其作为重建底层辐射场的指导,通过反转该过程,恢复显式和隐式参数,并将它们用于合成新视图。改进了推理过程中的优化和微调策略,允许从真实图像中估计辐射场。在标准的新视图合成数据集上展示了最先进的结果,并展示了对与训练数据有显著差异的图像的泛化。
We present a method for estimating neural scenes representations of objects given only a single image. The core of our method is the estimation of a geometric scaffold for the object and its use as a guide for the reconstruction of the underlying radiance field. Our formulation is based on a generative process that first maps a latent code to a voxelized shape, and then renders it to an image, with the object appearance being controlled by a second latent code. During inference, we optimize both the latent codes and the networks to fit a test image of a new object. The explicit disentanglement of shape and appearance allows our model to be fine-tuned given a single image. We can then render new views in a geometrically consistent manner and they represent faithfully the input object. Additionally, our method is able to generalize to images outside of the training domain (more realistic renderings and even real photographs). Finally, the inferred geometric scaffold is itself an accurate estimate of the object’s 3D shape. We demonstrate in several experiments the effectiveness of our approach in both synthetic and real images.
https://weibo.com/1402400261/K2ASR5JeN
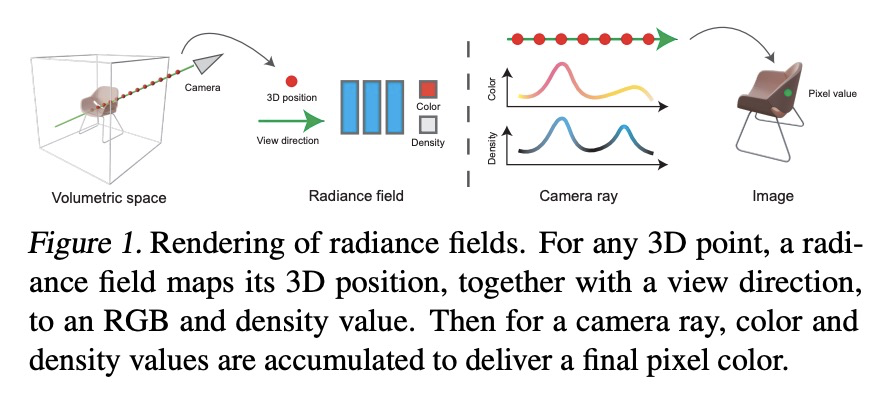
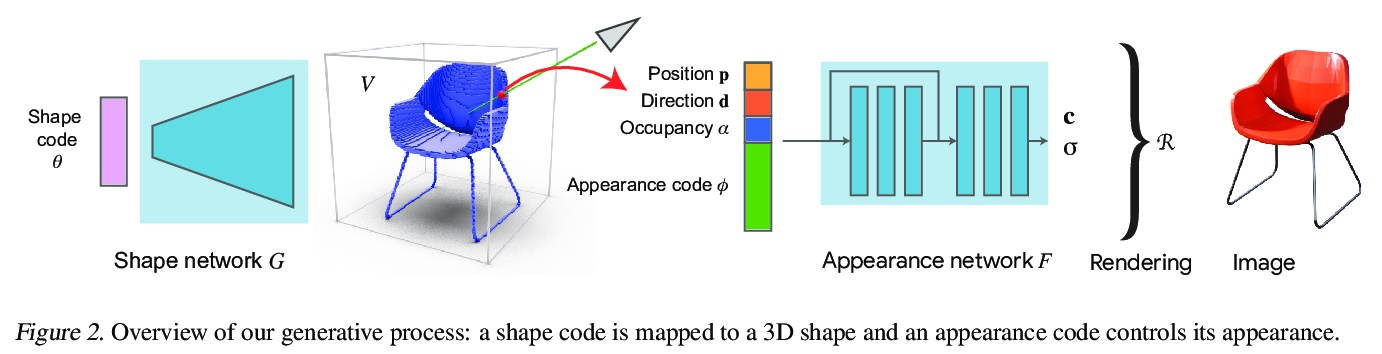
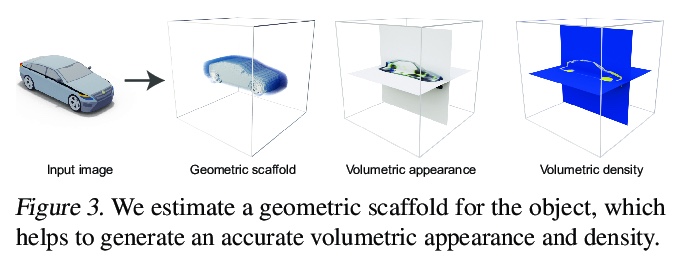
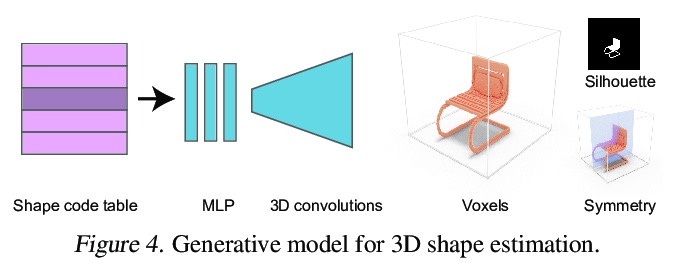
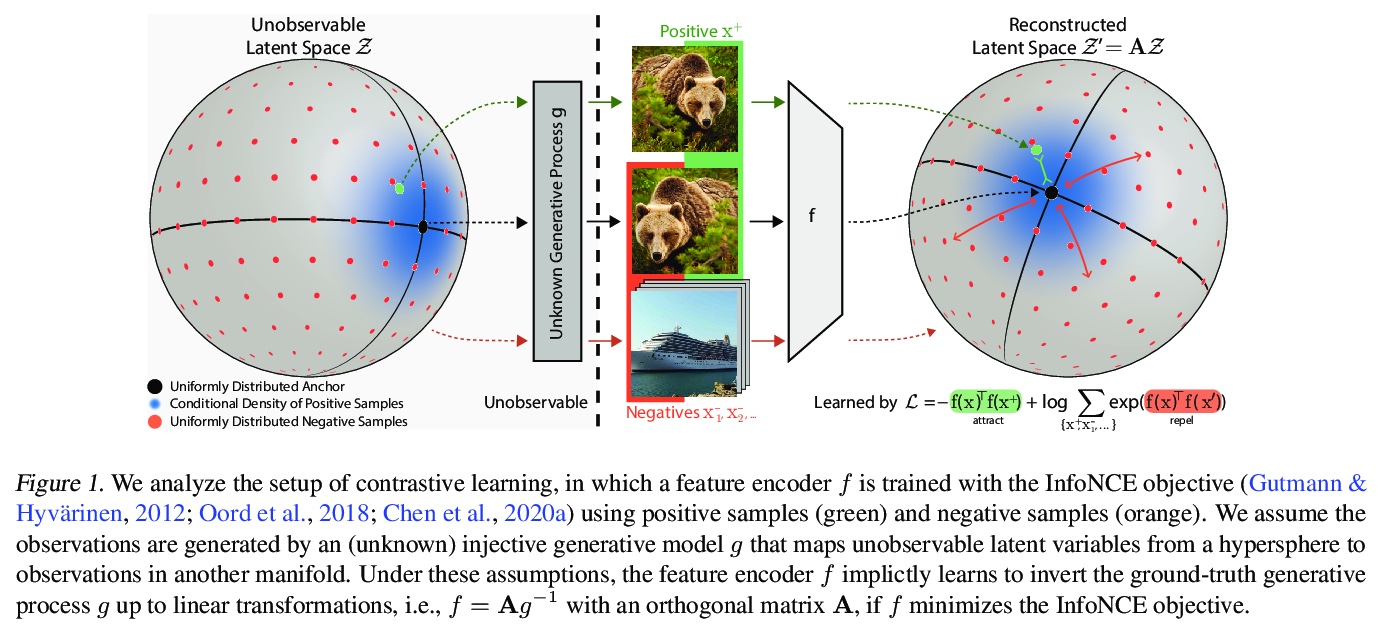
2、[LG] Contrastive Learning Inverts the Data Generating Process
R S. Zimmermann, Y Sharma, S Schneider, M Bethge, W Brendel
[University of Tubingen]
对比学习是数据生成过程的逆转。证明了用InfoNCE族目标训练的前馈模型,可学习到隐式逆转观察数据底层生成模型。即使部分违反理论假设,数据生成过程也能成功逆转。理论和实证结果表明,用对比性学习发现的表示隐含(且近似)了数据生成过程,这可以解释为什么学习到的表示在许多下游任务中如此有效。理论上强调了对比学习、生成式建模和非线性独立成分分析之间的基本联系,进一步加深了对所学表示的理解,也为推导出更有效的对比损失提供了理论基础。
Contrastive learning has recently seen tremendous success in self-supervised learning. So far, however, it is largely unclear why the learned representations generalize so effectively to a large variety of downstream tasks. We here prove that feedforward models trained with objectives belonging to the commonly used InfoNCE family learn to implicitly invert the underlying generative model of the observed data. While the proofs make certain statistical assumptions about the generative model, we observe empirically that our findings hold even if these assumptions are severely violated. Our theory highlights a fundamental connection between contrastive learning, generative modeling, and nonlinear independent component analysis, thereby furthering our understanding of the learned representations as well as providing a theoretical foundation to derive more effective contrastive losses.
https://weibo.com/1402400261/K2B0muEwa

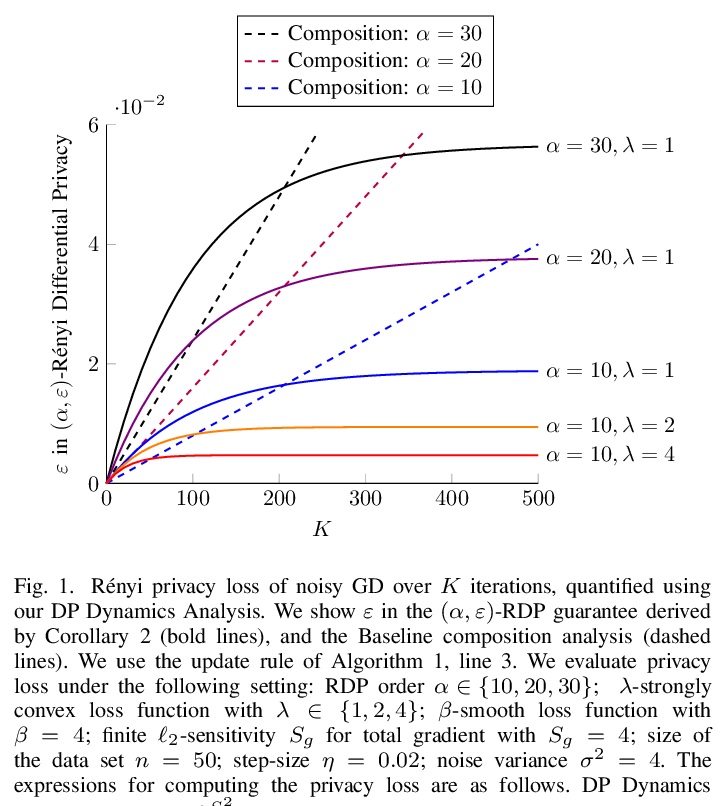
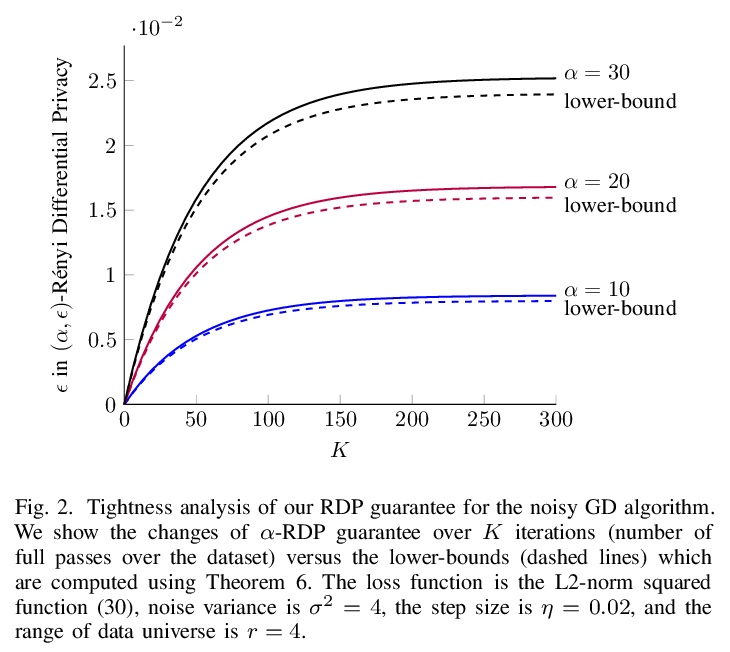
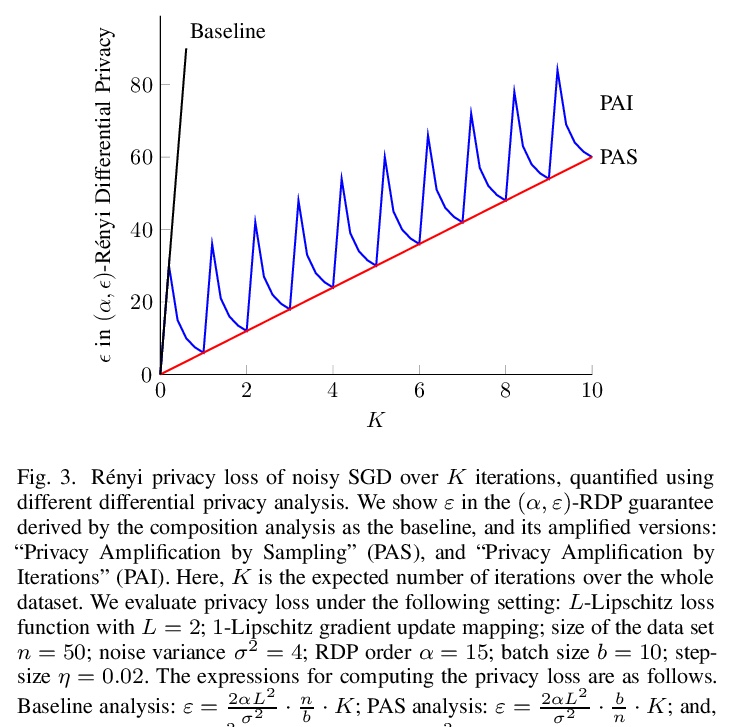
3、[LG] Differential Privacy Dynamics of Langevin Diffusion and Noisy Gradient Descent
R Chourasia, J Ye, R Shokri
[National University of Singapore (NUS)]
朗之万扩散和噪声梯度下降的差分隐私动态。开发了一种新理论框架,用于分析机器学习中隐私损失的动态。模拟了朗之万扩散中隐私损失的动态,并将其扩展到含噪的梯度下降算法中,计算了Rényi差分隐私的紧界及其在整个学习过程中的变化率,证明隐私损失以指数速度收敛,可显著改善之前对差分私有(随机)梯度下降算法的隐私分析,其中(Rényi)隐私损失在训练迭代中不断增加。理论结果表明,隐藏训练算法内部状态可使微分隐私约束指数快速收敛到紧界。
We model the dynamics of privacy loss in Langevin diffusion and extend it to the noisy gradient descent algorithm: we compute a tight bound on Rényi differential privacy and the rate of its change throughout the learning process. We prove that the privacy loss converges exponentially fast. This significantly improves the prior privacy analysis of differentially private (stochastic) gradient descent algorithms, where (Rényi) privacy loss constantly increases over the training iterations. Unlike composition-based methods in differential privacy, our privacy analysis does not assume that the noisy gradients (or parameters) during the training could be revealed to the adversary. Our analysis tracks the dynamics of privacy loss through the algorithm’s intermediate parameter distributions, thus allowing us to account for privacy amplification due to convergence. We prove that our privacy analysis is tight, and also provide a utility analysis for strongly convex, smooth and Lipshitz loss functions.
https://weibo.com/1402400261/K2B50ji55
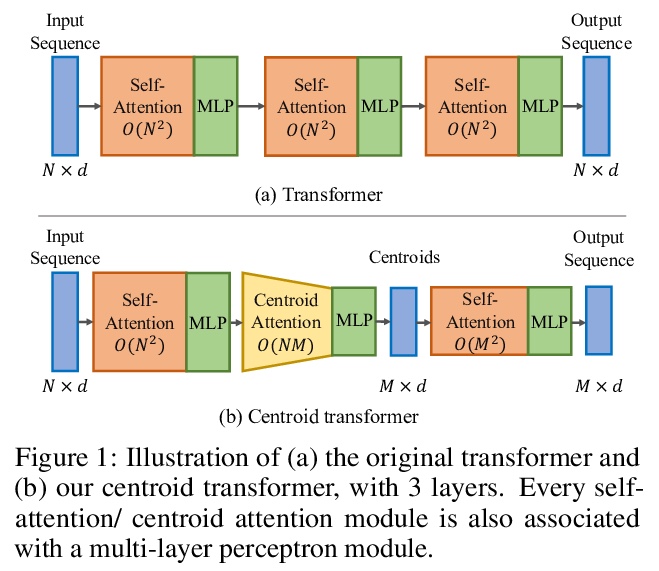
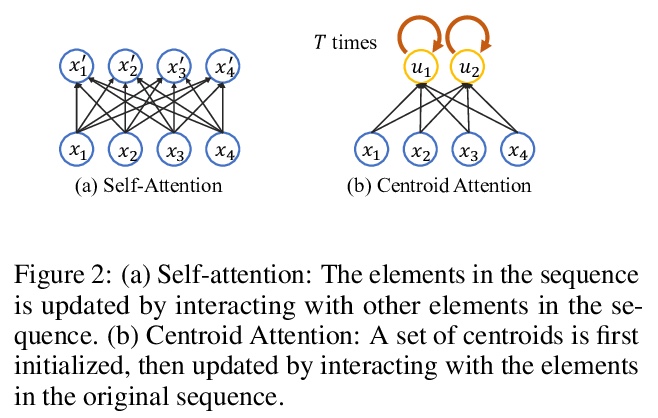
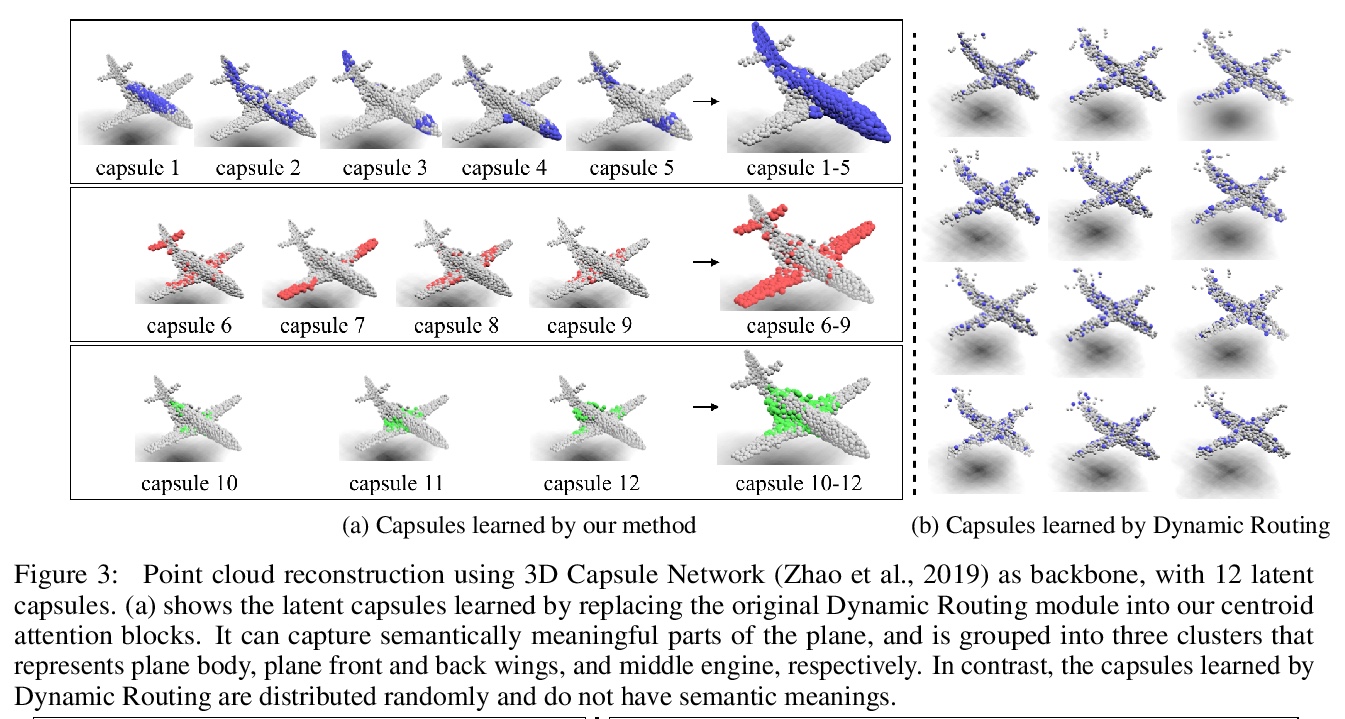
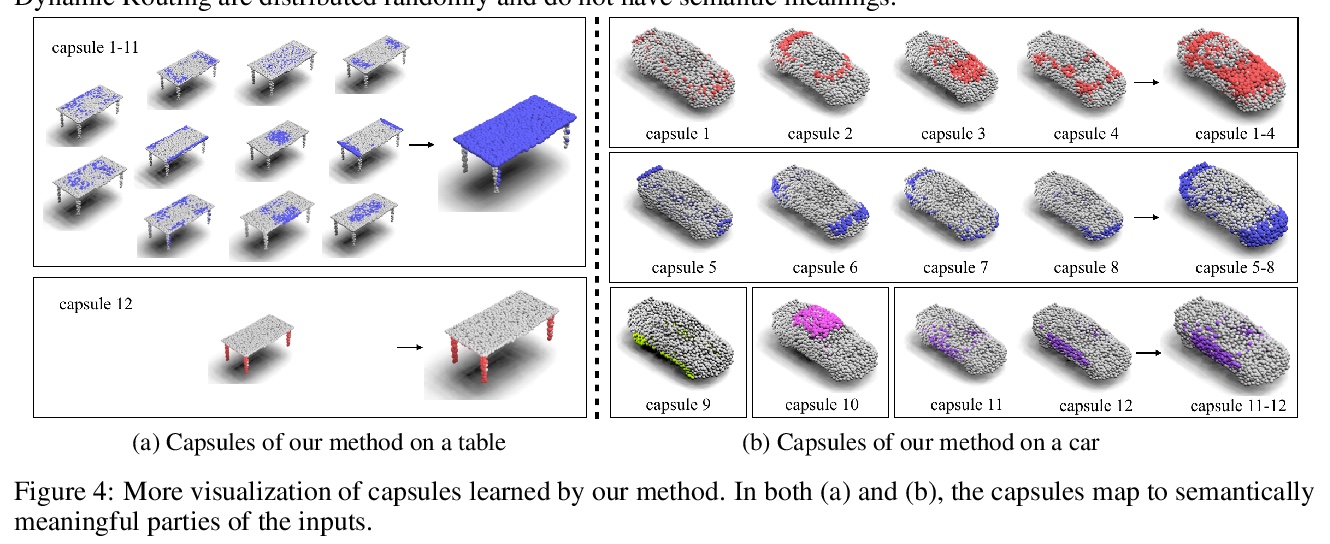
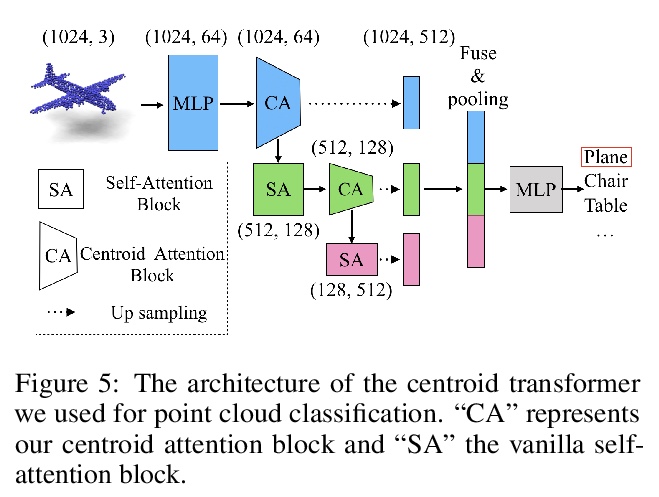
4、[LG] Centroid Transformers: Learning to Abstract with Attention
L Wu, X Liu, Q Liu
[UT Austin]
中心Transformer:基于注意力的抽象学习。提出了中心子注意力,一种自注意力的泛化,将N个输入映射到M个输出(M≤N),输入中的关键信息被归纳到较少的输出中(称为中心子)。通过对输入的聚类目标函数的梯度下降更新规则进行分摊,设计出中心注意力,揭示了注意力和聚类之间的潜在联系。通过对中心的输入进行压缩,提取了对预测有用的关键信息,减少了注意力模块和后续层的计算量。将该方法用于各领域,包括抽象文本摘要、3D视觉和图像处理,实证结果证明该方法相比标准Transformer的有效性。
Self-attention, as the key block of transformers, is a powerful mechanism for extracting features from the inputs. In essence, what self-attention does to infer the pairwise relations between the elements of the inputs, and modify the inputs by propagating information between input pairs. As a result, it maps inputs to N outputs and casts a quadratic > O(N2) memory and time complexity. We propose centroid attention, a generalization of self-attention that maps N inputs to M outputs > (M≤N), such that the key information in the inputs are summarized in the smaller number of outputs (called centroids). We design centroid attention by amortizing the gradient descent update rule of a clustering objective function on the inputs, which reveals an underlying connection between attention and clustering. By compressing the inputs to the centroids, we extract the key information useful for prediction and also reduce the computation of the attention module and the subsequent layers. We apply our method to various applications, including abstractive text summarization, 3D vision, and image processing. Empirical results demonstrate the effectiveness of our method over the standard transformers.
https://weibo.com/1402400261/K2Ba5AzdX
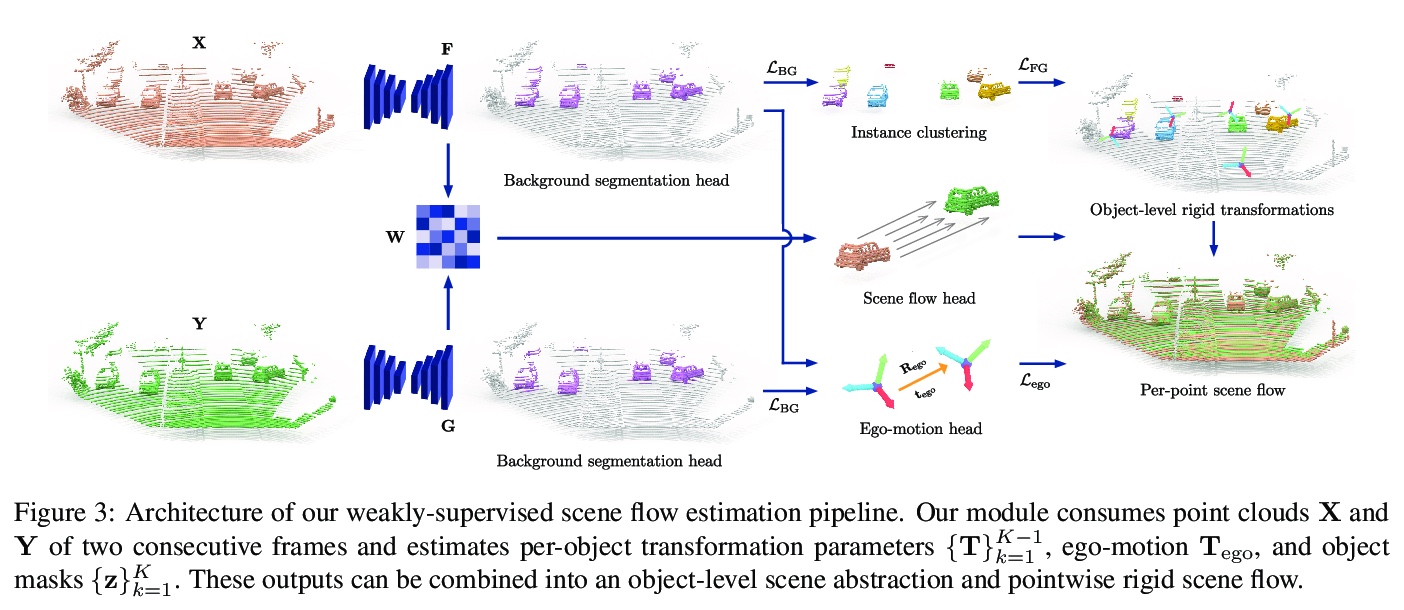
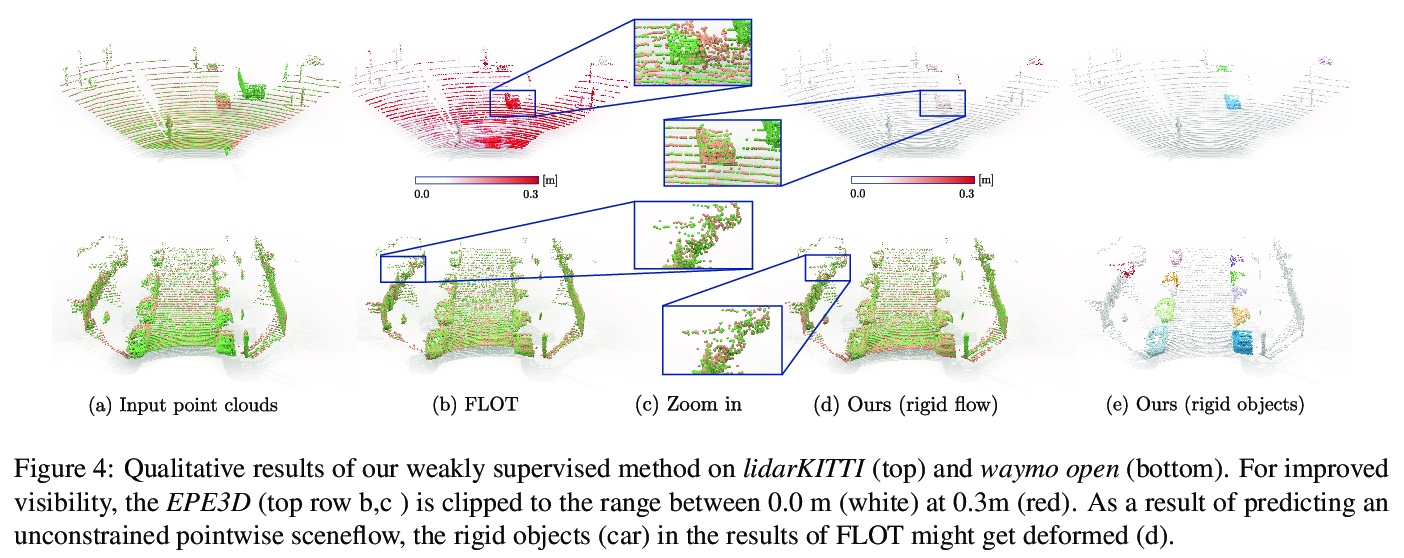
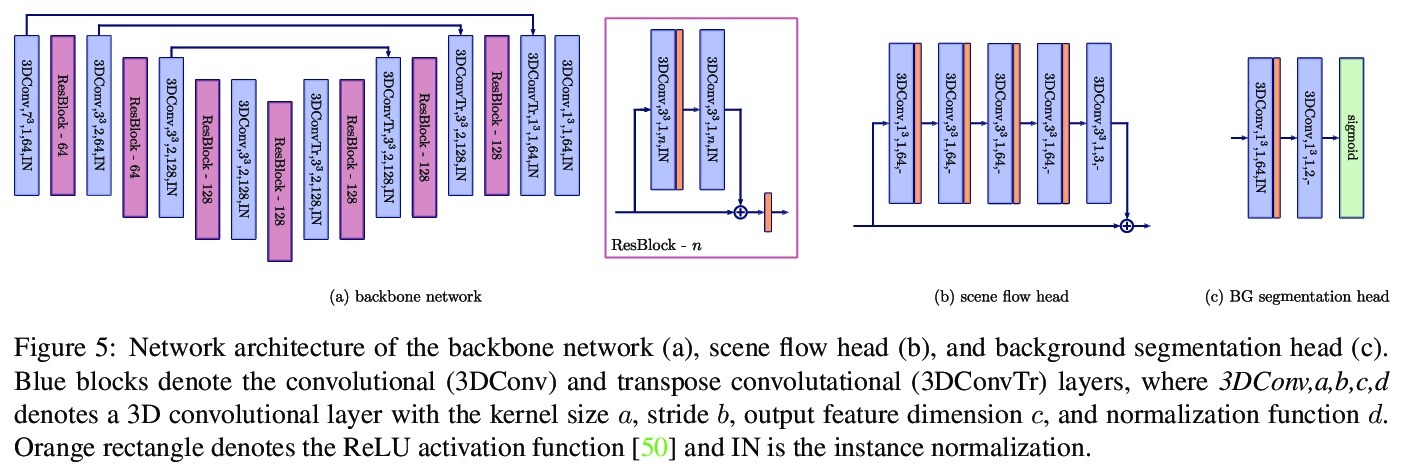
5、[CV] Weakly Supervised Learning of Rigid 3D Scene Flow
Z Gojcic, O Litany, A Wieser, L J. Guibas, T Birdal
[ETH Zurich & Stanford University]
刚性3D场景流弱监督学习方法。提出一种数据驱动的场景流估计算法,通过将流整合到更高层次的场景抽象中,以多刚体运动的形式来放松密集监督,核心在于一个深度架构,利用刚性场景流问题的几何形状将感应偏差引入到网络中,考虑3D场景流与其他3D任务相结合,在对象层面进行推理,结果是一个先进的流估计网络,还输出了一个简洁的动态场景表示。进一步提出了一个测试时的优化方法来完善预测的刚性场景流。该方法由一个新颖的、灵活的、场景流动骨干支持,可用于解决各种任务。在四个不同的自动驾驶数据集上展示了方法的有效性和泛化能力。
We propose a data-driven scene flow estimation algorithm exploiting the observation that many 3D scenes can be explained by a collection of agents moving as rigid bodies. At the core of our method lies a deep architecture able to reason at the \textbf{object-level} by considering 3D scene flow in conjunction with other 3D tasks. This object level abstraction, enables us to relax the requirement for dense scene flow supervision with simpler binary background segmentation mask and ego-motion annotations. Our mild supervision requirements make our method well suited for recently released massive data collections for autonomous driving, which do not contain dense scene flow annotations. As output, our model provides low-level cues like pointwise flow and higher-level cues such as holistic scene understanding at the level of rigid objects. We further propose a test-time optimization refining the predicted rigid scene flow. We showcase the effectiveness and generalization capacity of our method on four different autonomous driving datasets. We release our source code and pre-trained models under \url{> this http URL}.
https://weibo.com/1402400261/K2BkKhHTp

另外几篇值得关注的论文:
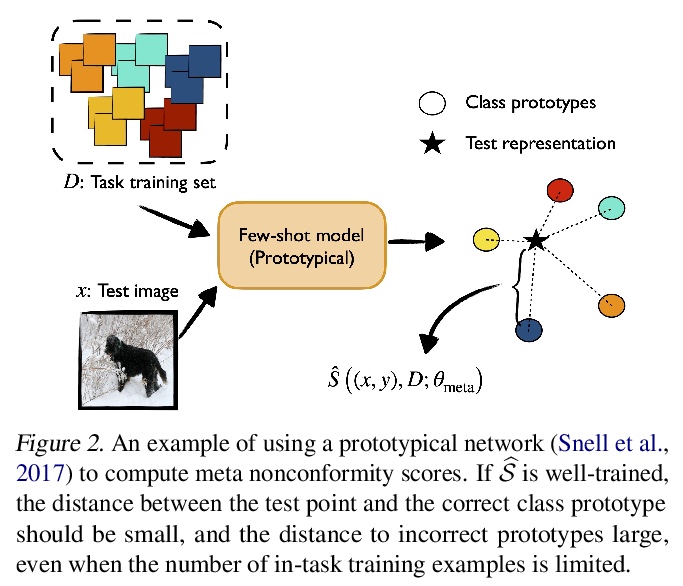
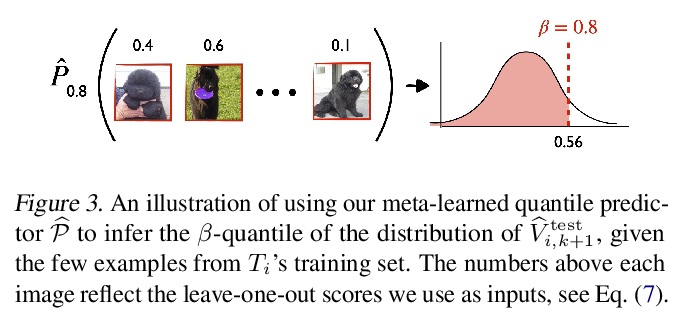
[LG] Few-shot Conformal Prediction with Auxiliary Tasks
辅助任务少样本共形预测
A Fisch, T Schuster, T Jaakkola, R Barzilay
[MIT]
https://weibo.com/1402400261/K2BtLFJ57

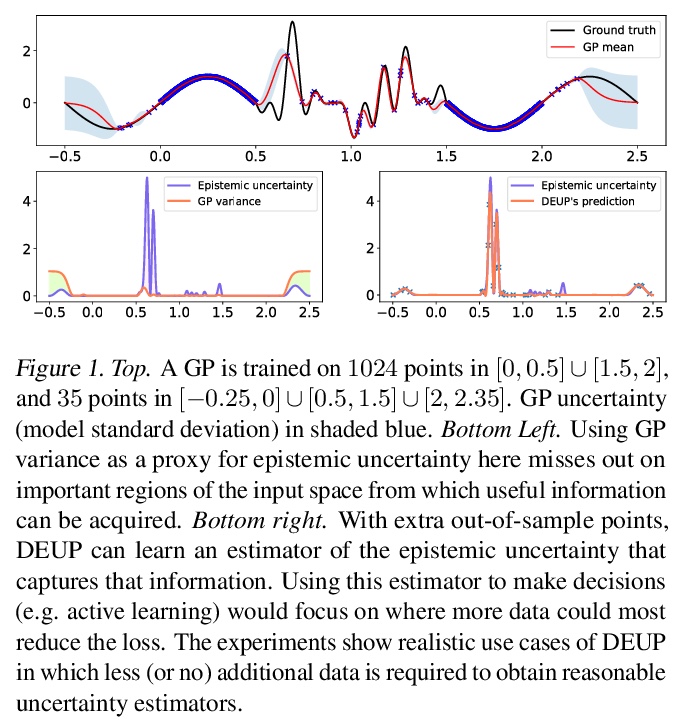
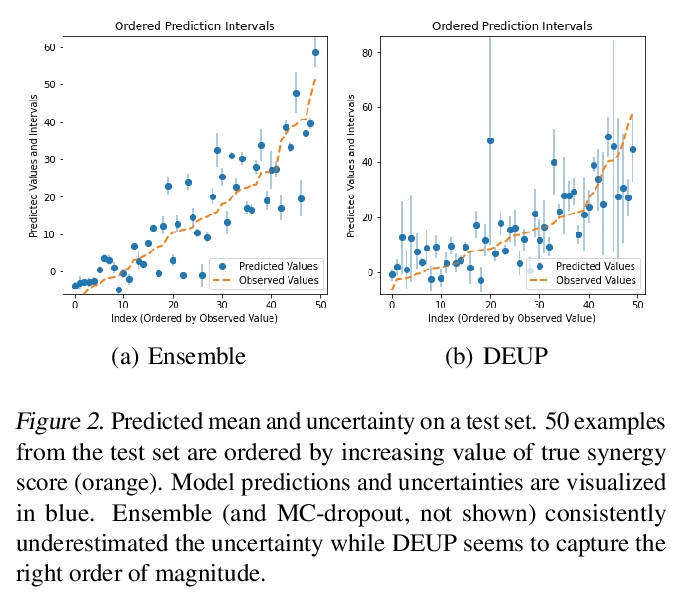
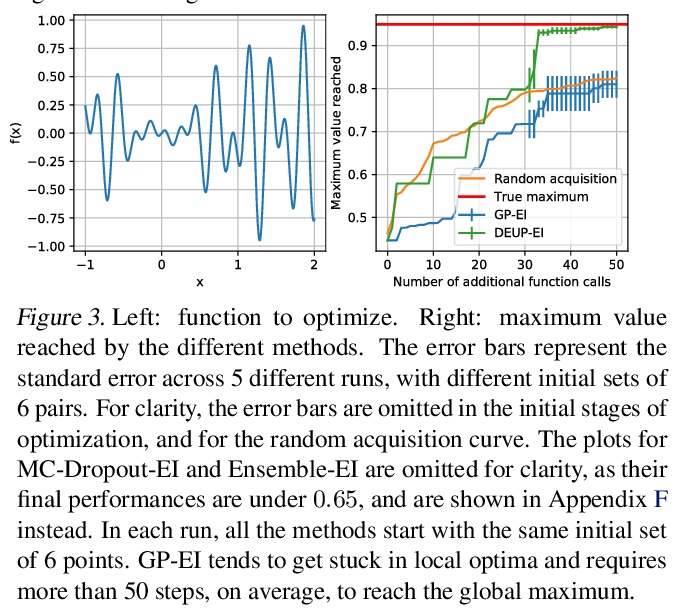
[LG] DEUP: Direct Epistemic Uncertainty Prediction
DEUP:直接认知不确定性预测(端到端样本外预测误差预测)
M Jain, S Lahlou, H Nekoei, V Butoi, P Bertin, J Rector-Brooks, M Korablyov, Y Bengio
[Mila & Cornell University]
https://weibo.com/1402400261/K2BvIw4vp
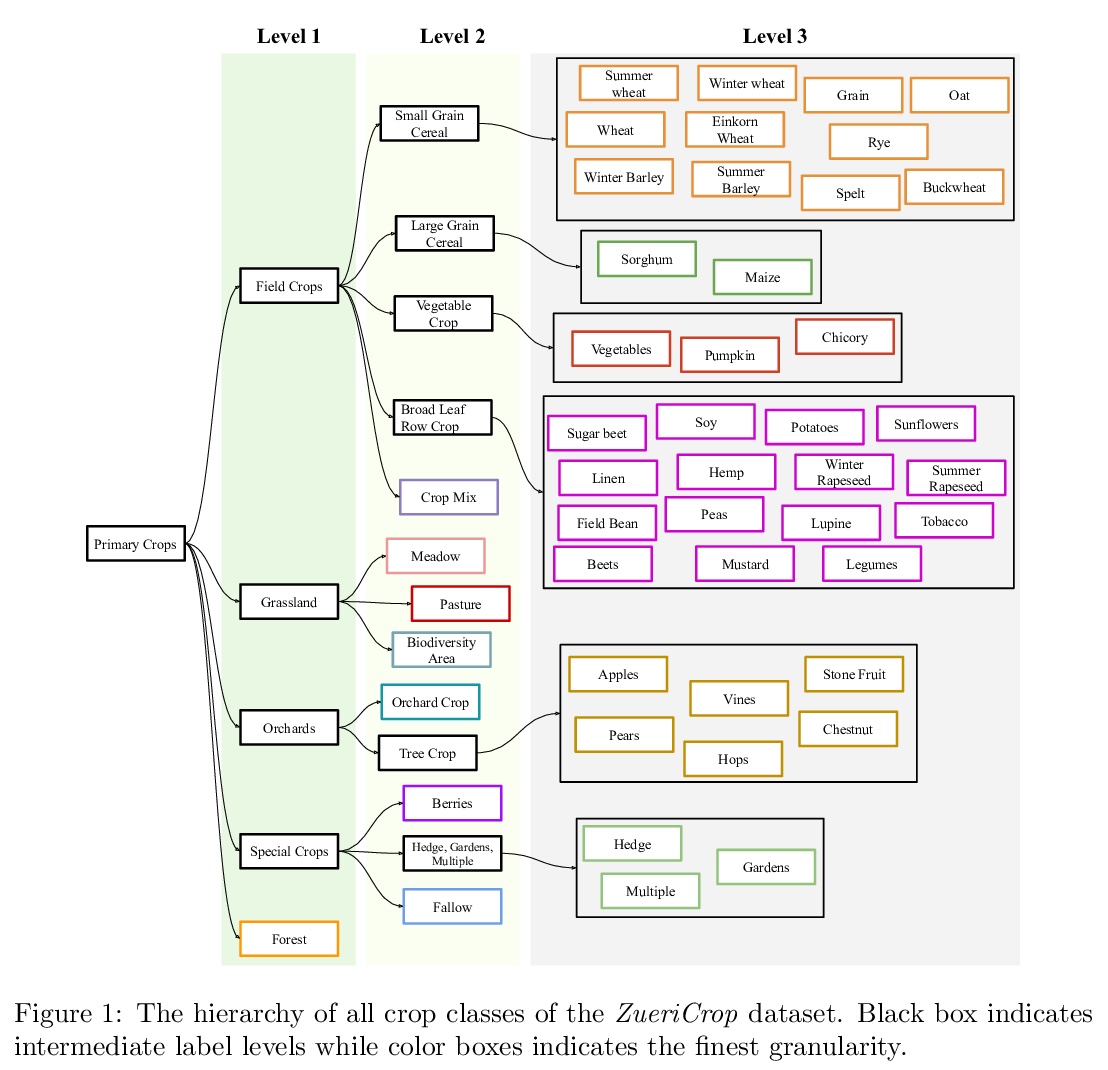
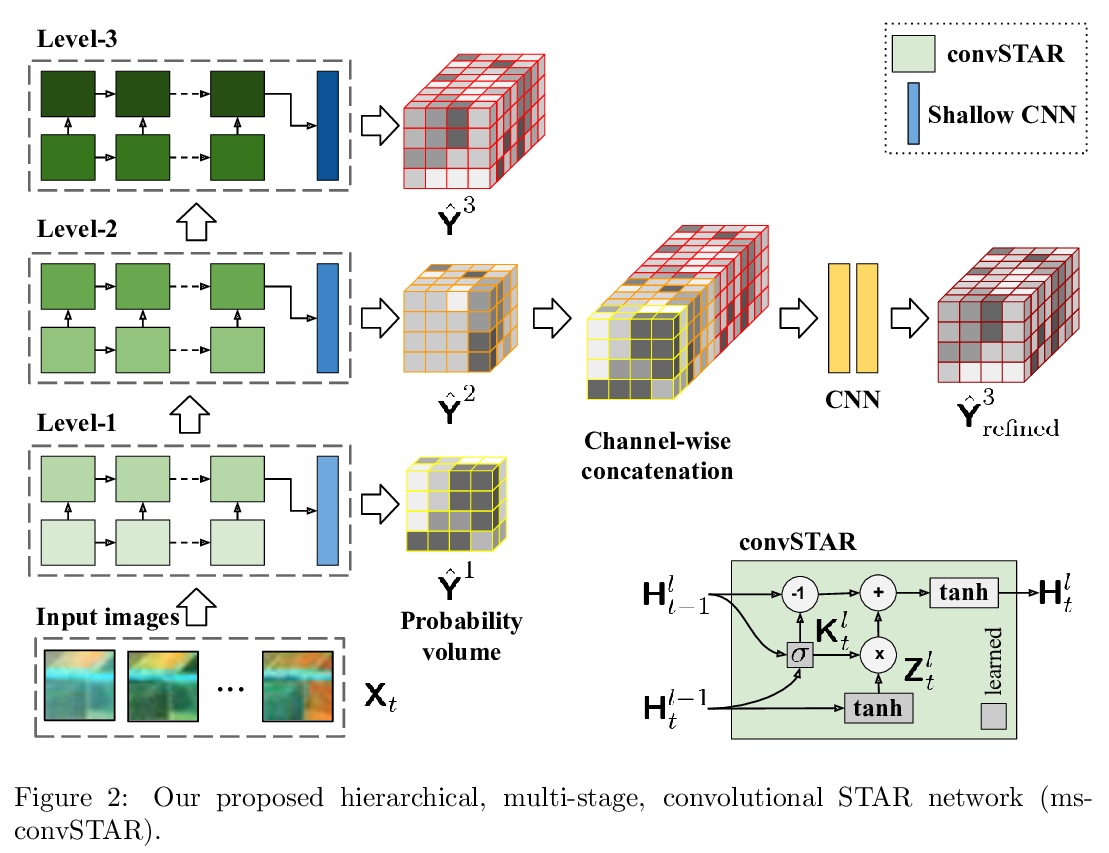
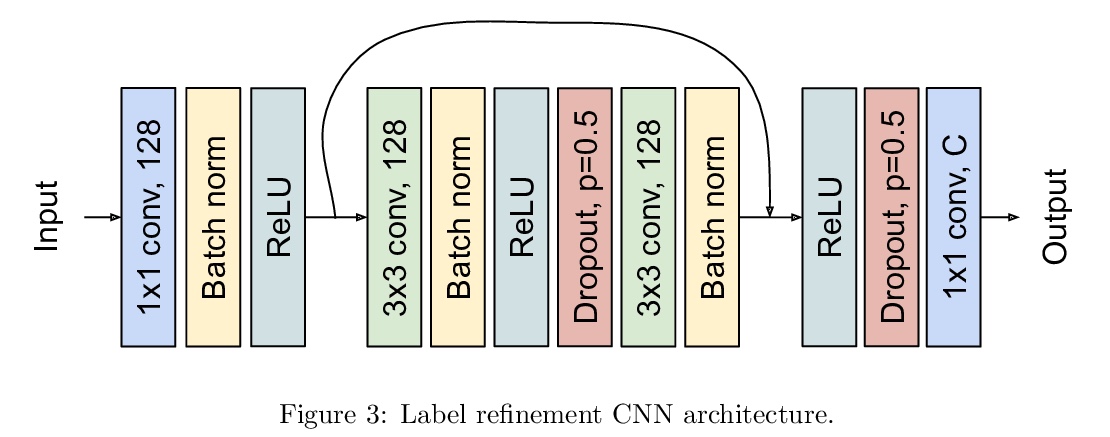
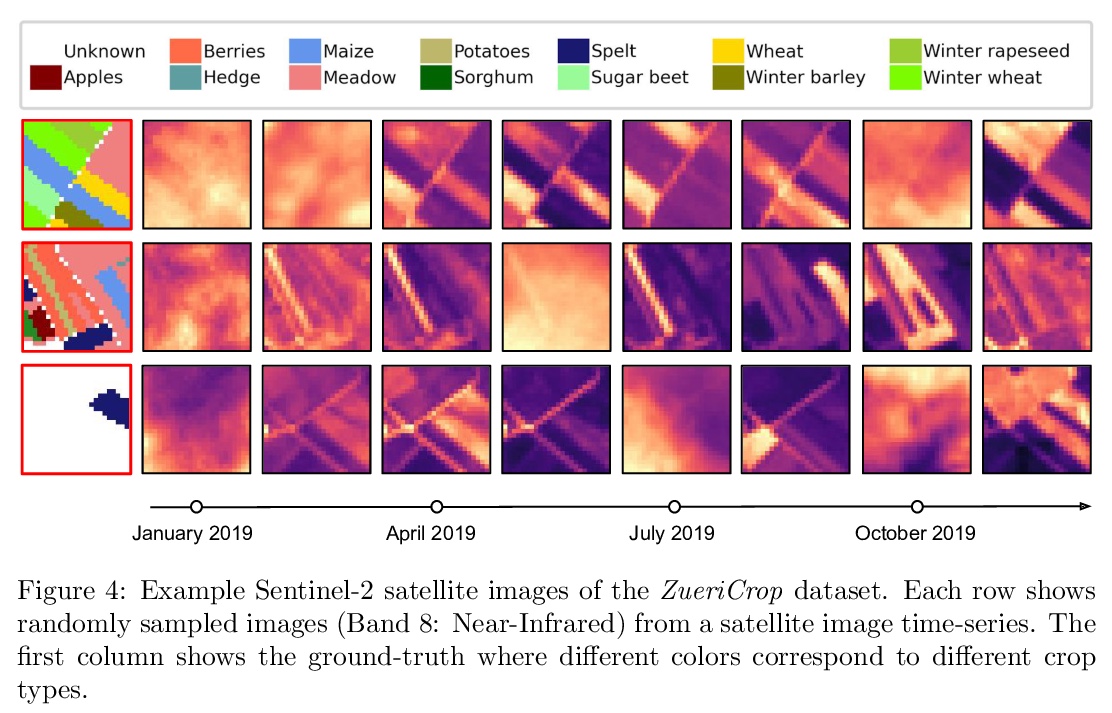
[CV] Crop mapping from image time series: deep learning with multi-scale label hierarchies
卫星图像时间序列农作物地图绘制:多尺度标签层次深度学习
M O Turkoglu, S D’Aronco, G Perich, F Liebisch, C Streit, K Schindler, J D Wegner
[ETH Zurich & Federal Office for Agriculture]
https://weibo.com/1402400261/K2ByYE6Kt
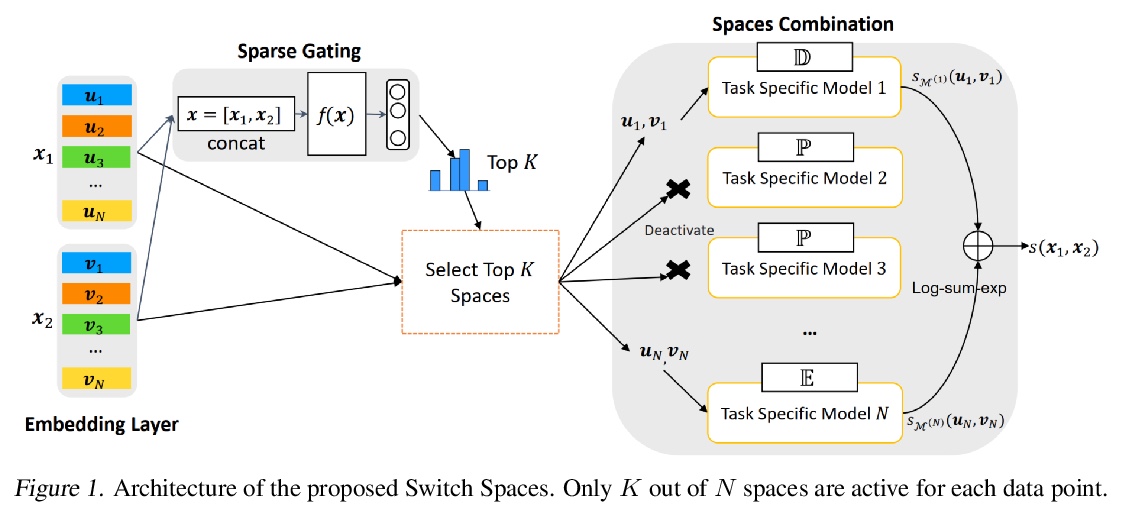
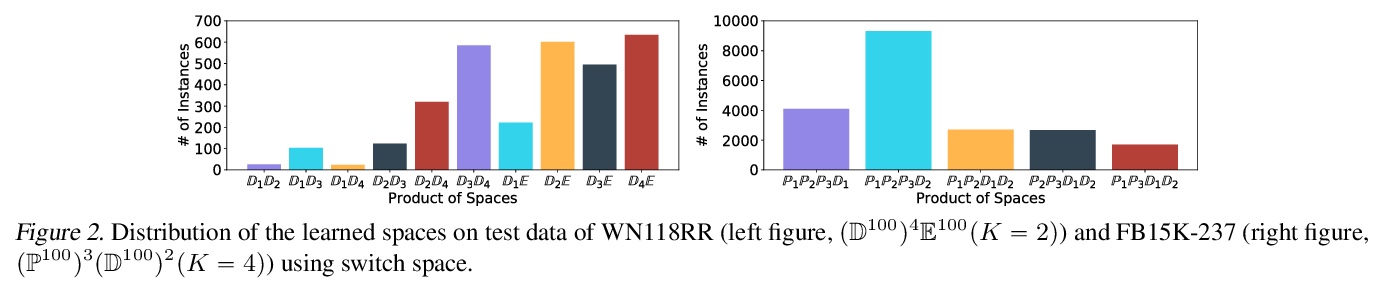
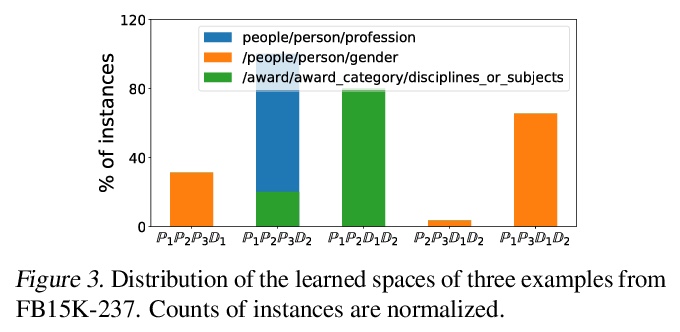
[LG] Switch Spaces: Learning Product Spaces with Sparse Gating
Switch Spaces:基于稀疏门控的积空间学习
S Zhang, Y Tay, W Jiang, D Juan, C Zhang
[ETH Zurich & Google Research]
https://weibo.com/1402400261/K2BBh9ilj

若有收获,就点个赞吧
0 人点赞
