- 1、[CL] Approximating How Single Head Attention Learns
- 2、[LG] Growing 3D Artefacts and Functional Machines with Neural Cellular Automata
- 3、[CV] Back to the Feature: Learning Robust Camera Localization from Pixels to Pose
- 4、[CV] Is it Enough to Optimize CNN Architectures on ImageNet?
- 5、[LG] Deep learning: a statistical viewpoint
- [AS] Flow-based Self-supervised Density Estimation for Anomalous Sound Detection
- [CV] Multilingual Multimodal Pre-training for Zero-Shot Cross-Lingual Transfer of Vision-Language Models
- [CL] LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] Approximating How Single Head Attention Learns
C Snell, R Zhong, D Klein, J Steinhardt
[UC Berkeley]
理解单头注意力的学习方式。试图理解注意力训练的黑盒,在训练早期,LSTM Seq2Seq注意力模型首先学习如何从词袋的共现统计中翻译单个词,然后驱动注意力的学习。文中框架解释了为什么通过标准训练获得的注意力权重往往与显著性相关,以及多头注意力如何通过改善训练动态而不是表现力来提高性能。
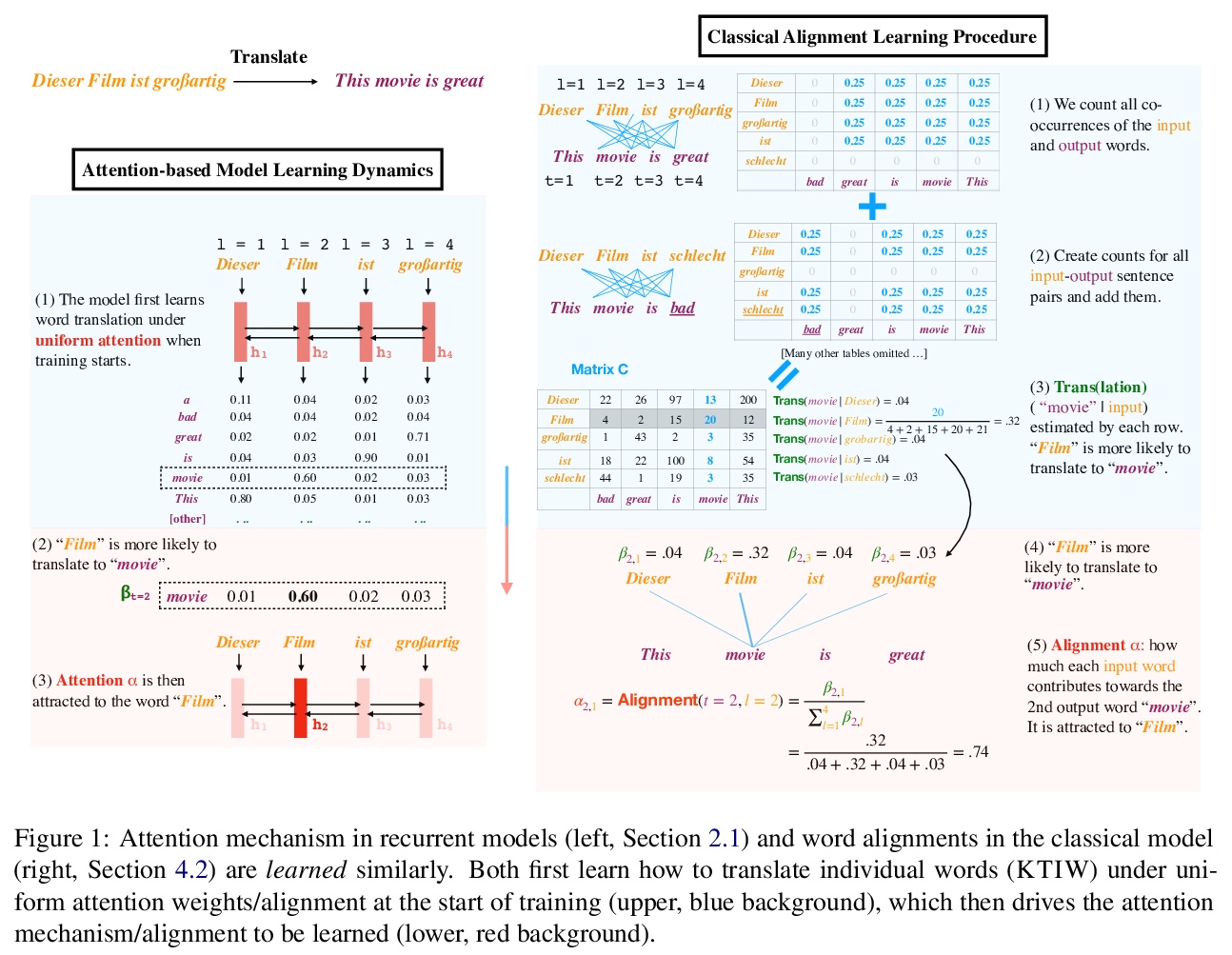
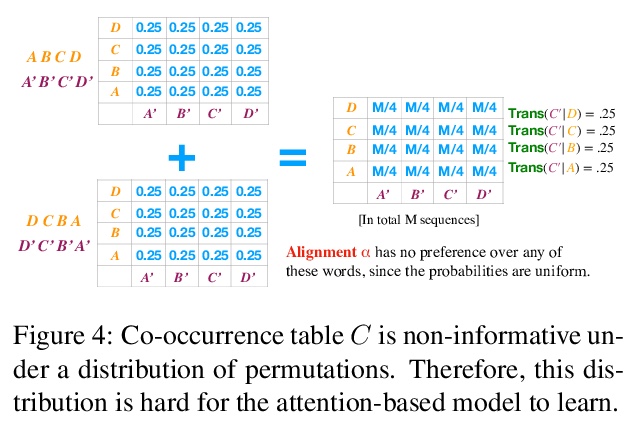
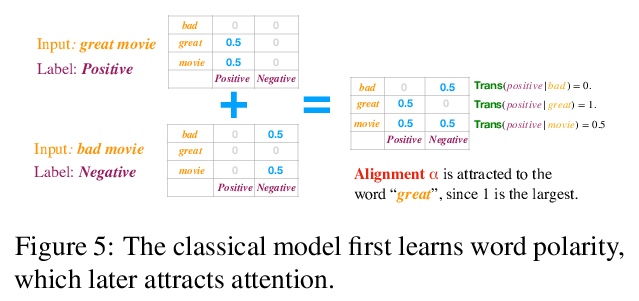
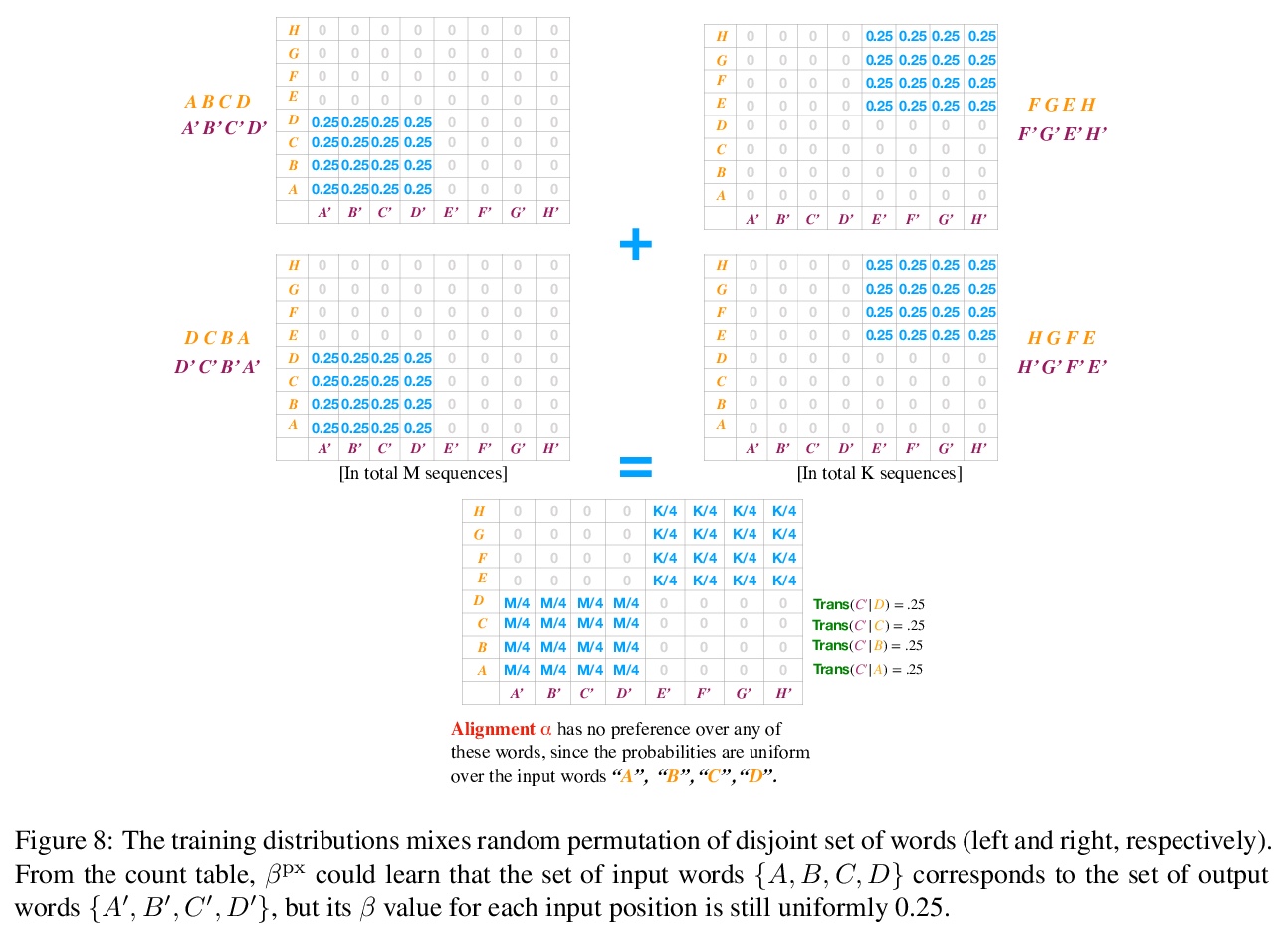
Why do models often attend to salient words, and how does this evolve throughout training? We approximate model training as a two stage process: early on in training when the attention weights are uniform, the model learns to translate individual input word i to o if they co-occur frequently. Later, the model learns to attend to i while the correct output is > o because it knows i translates to o. To formalize, we define a model property, Knowledge to Translate Individual Words (KTIW) (e.g. knowing that i translates to o), and claim that it drives the learning of the attention. This claim is supported by the fact that before the attention mechanism is learned, KTIW can be learned from word co-occurrence statistics, but not the other way around. Particularly, we can construct a training distribution that makes KTIW hard to learn, the learning of the attention fails, and the model cannot even learn the simple task of copying the input words to the output. Our approximation explains why models sometimes attend to salient words, and inspires a toy example where a multi-head attention model can overcome the above hard training distribution by improving learning dynamics rather than expressiveness.
https://weibo.com/1402400261/K6HbLE1ai
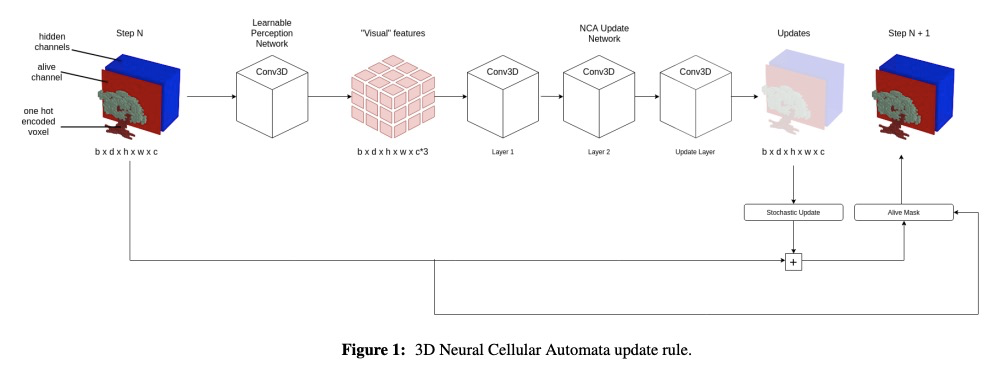
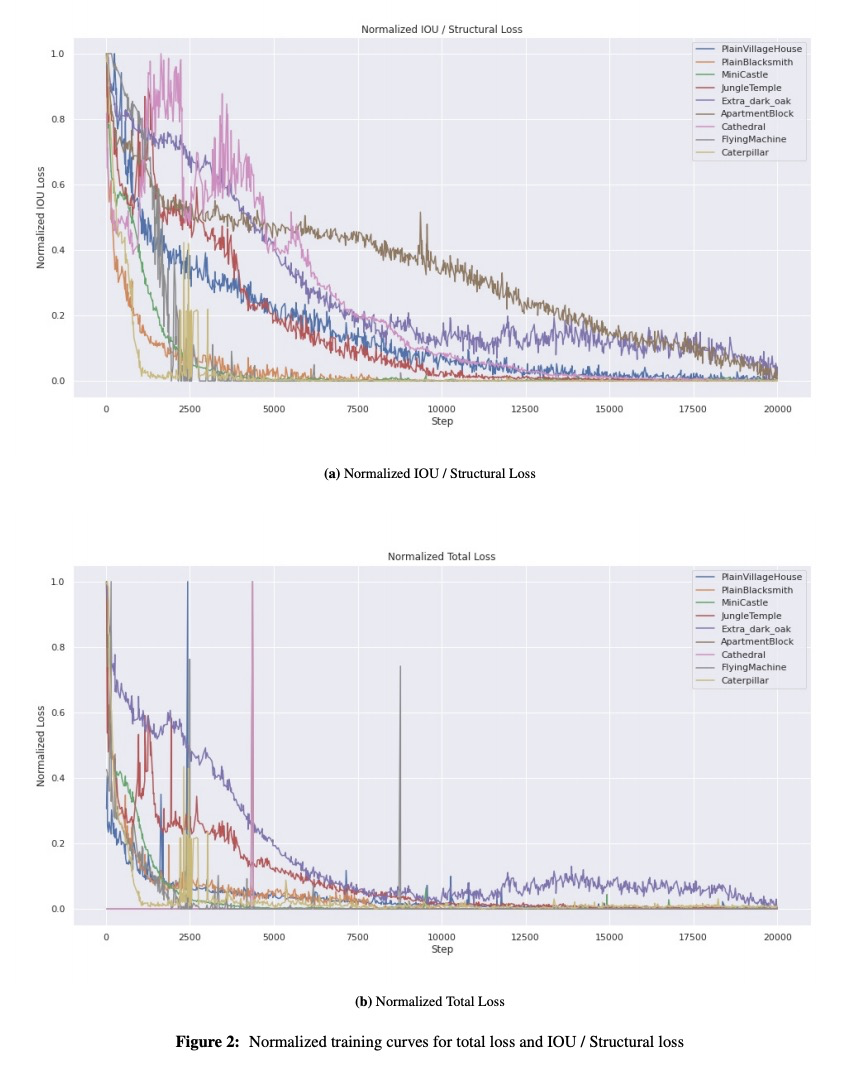
2、[LG] Growing 3D Artefacts and Functional Machines with Neural Cellular Automata
S Sudhakaran, D Grbic, S Li, A Katona, E Najarro, C Glanois, S Risi
[IT University of Copenhagen & University of York & Shanghai University]
基于神经元胞自动机自生长的3D构建和功能机。神经元胞自动机(NCA)已被证明在形态发生过程模拟中是有效的,即从极少的起始元胞连续构建复杂结构。最近NCA的发展在于二维领域,即从单个像素或无限增长的二维纹理重建目标图像。本文提出了NCA向3D领域的扩展,在提出的神经网络架构中利用了3D卷积、与环境兼容的元胞状态向量表示、以及强调与目标结构相似性的组合损失函数。Minecraft被选为自动机环境,因其可生成静态结构和行动机。尽管很简单,但NCA能生长出复杂的实体,如城堡,公寓楼和树木,其中一些是由超过3000块组成。此外,当训练再生时,该系统能够重新生长简单功能机的部分,极大扩展了模拟形态发生系统的能力。
Neural Cellular Automata (NCAs) have been proven effective in simulating morphogenetic processes, the continuous construction of complex structures from very few starting cells. Recent developments in NCAs lie in the 2D domain, namely reconstructing target images from a single pixel or infinitely growing 2D textures. In this work, we propose an extension of NCAs to 3D, utilizing 3D convolutions in the proposed neural network architecture. Minecraft is selected as the environment for our automaton since it allows the generation of both static structures and moving machines. We show that despite their simplicity, NCAs are capable of growing complex entities such as castles, apartment blocks, and trees, some of which are composed of over 3,000 blocks. Additionally, when trained for regeneration, the system is able to regrow parts of simple functional machines, significantly expanding the capabilities of simulated morphogenetic systems.
https://weibo.com/1402400261/K6HkklgX9

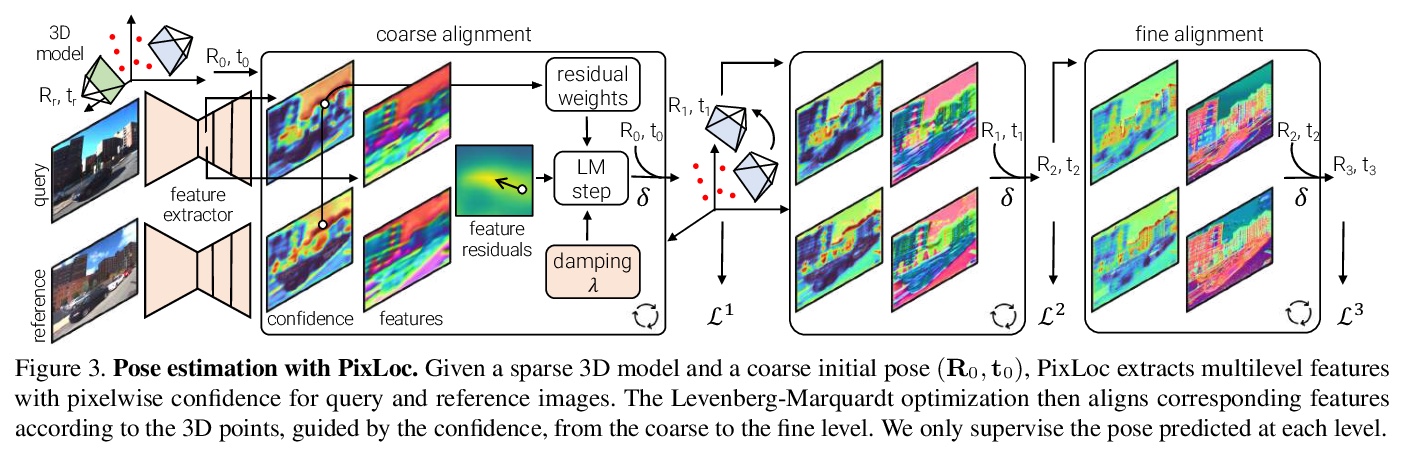
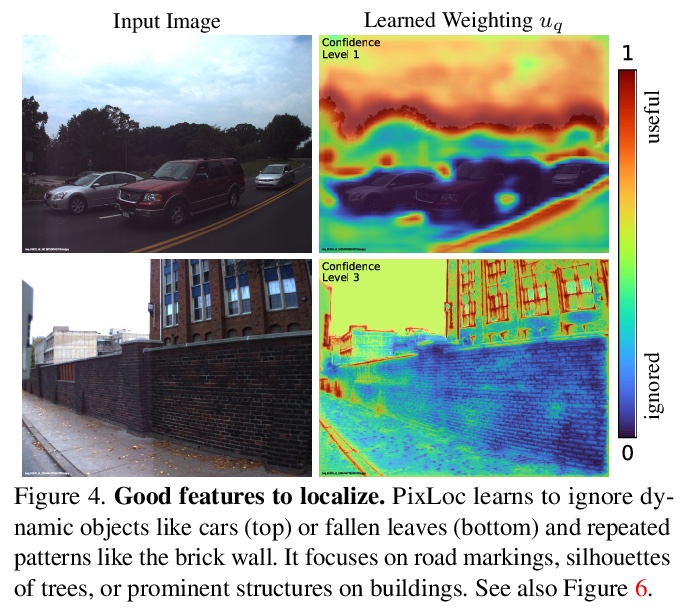
3、[CV] Back to the Feature: Learning Robust Camera Localization from Pixels to Pose
P Sarlin, A Unagar, M Larsson, H Germain, C Toft, V Larsson, M Pollefeys, V Lepetit, L Hammarstrand, F Kahl, T Sattler
[ETH Zurich & Chalmers University of Technology & Ecole des Ponts]
回到特征:从像素到姿态的鲁棒相机定位学习。提出一个简单方案,用于相机姿态估计的端到端学习。与之前回归几何量的方法不同,不是尝试教给深度网络基本的几何原理或3D图编码,而是回到特征:认为深度网络应该专注于学习鲁棒和不变的视觉特征,而几何估计应该留给原则性的算法,基于多尺度深度特征的直接对齐,将相机定位看作是度量学习,学习鲁棒和通用的特征,以实现精确定位。由此产生的系统PixLoc,是第一个端到端可训练的方法,用以从图像和3D模型中估算出精确的6-DoF姿态,通过从像素到姿态的端到端训练,来学习强大的数据先验,并通过分离模型参数和场景几何,表现出对新场景的优秀泛化能力,可部署到与其训练数据差异很大的新场景中,无需重新训练或微调。PixLoc实现了与更复杂的最先进的流水线竞争的姿态估计精度。端到端训练与不确定性建模相结合,使PixLoc能够学习复杂但可解释的先验。
Camera pose estimation in known scenes is a 3D geometry task recently tackled by multiple learning algorithms. Many regress precise geometric quantities, like poses or 3D points, from an input image. This either fails to generalize to new viewpoints or ties the model parameters to a specific scene. In this paper, we go Back to the Feature: we argue that deep networks should focus on learning robust and invariant visual features, while the geometric estimation should be left to principled algorithms. We introduce PixLoc, a scene-agnostic neural network that estimates an accurate 6-DoF pose from an image and a 3D model. Our approach is based on the direct alignment of multiscale deep features, casting camera localization as metric learning. PixLoc learns strong data priors by end-to-end training from pixels to pose and exhibits exceptional generalization to new scenes by separating model parameters and scene geometry. The system can localize in large environments given coarse pose priors but also improve the accuracy of sparse feature matching by jointly refining keypoints and poses with little overhead. The code will be publicly available at > this https URL.
https://weibo.com/1402400261/K6Hra7J5W

4、[CV] Is it Enough to Optimize CNN Architectures on ImageNet?
L Tuggener, J Schmidhuber, T Stadelmann
[ZHAW Datalab & The Swiss AI Lab IDSIA]
在ImageNet上优化CNN架构就够了吗?现代计算机视觉研究的一个隐含但普遍的假设是,在ImageNet上表现更好的卷积神经网络(CNN)架构在其他视觉数据集上也会有更好的表现。本文通过一项广泛的实证研究来挑战该假说,在ImageNet以及其他8个来自广泛应用领域的图像分类数据集上训练了500个采样CNN架构。根据不同的数据集,架构和性能之间的关系差异很大。对于其中一些数据集,与ImageNet的性能相关性甚至是负的。显然,当目标是要取得与所有应用相关的进展时,仅仅针对ImageNet优化架构是不够的。因此,确定了两个针对数据集的性能指标:跨层累积宽度和网络总深度。ImageNet所覆盖的数据集变化范围可以通过添加ImageNet子集,限制在少数类中,而显著扩展。
An implicit but pervasive hypothesis of modern computer vision research is that convolutional neural network (CNN) architectures that perform better on ImageNet will also perform better on other vision datasets. We challenge this hypothesis through an extensive empirical study for which we train 500 sampled CNN architectures on ImageNet as well as 8 other image classification datasets from a wide array of application domains. The relationship between architecture and performance varies wildly, depending on the datasets. For some of them, the performance correlation with ImageNet is even negative. Clearly, it is not enough to optimize architectures solely for ImageNet when aiming for progress that is relevant for all applications. Therefore, we identify two dataset-specific performance indicators: the cumulative width across layers as well as the total depth of the network. Lastly, we show that the range of dataset variability covered by ImageNet can be significantly extended by adding ImageNet subsets restricted to few classes.
https://weibo.com/1402400261/K6Hxbl7ys
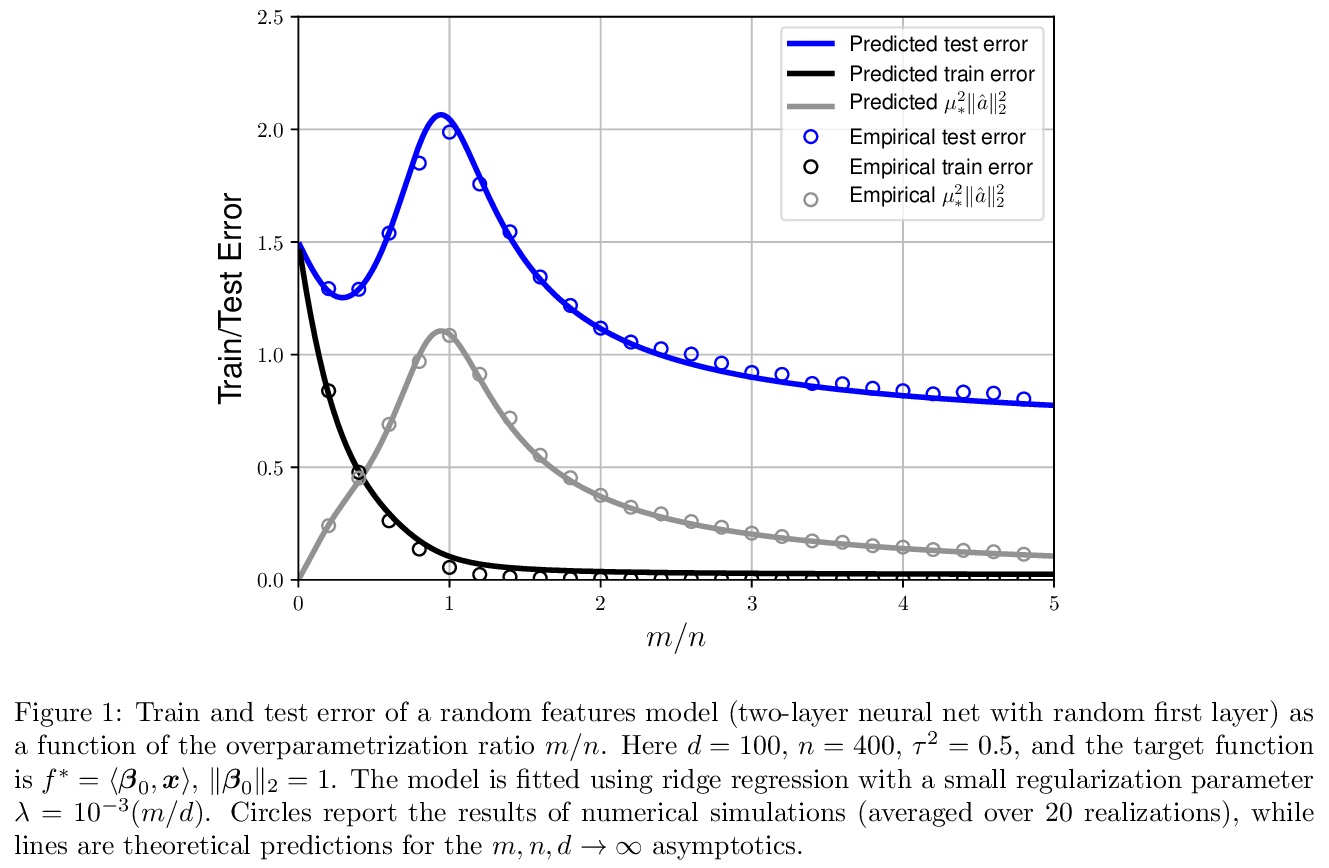
5、[LG] Deep learning: a statistical viewpoint
P L. Bartlett, A Montanari, A Rakhlin
[UC Berkeley & Stanford University & MIT]
深度学习的统计学观点。这篇综述中,着重于理解什么时候以及为什么即使在有噪声的数据中,插值也能达到最优或接近最优。回顾了经典的统一收敛结果,以及为什么它们不能解释深度学习方法行为的各个方面。给出了简单环境下隐式正则化的例子,其中梯度方法导致最小的正则函数,能完美拟合训练数据。回顾了表现出良性过拟合的预测方法,重点是具有二次损失的回归问题。对于这些方法,可以将预测规则分解为一个对预测有用的简单分量和一个对过拟合有用的尖峰分量,但在有利的环境下,不会损害预测精度。特别关注神经网络的线性特性,即网络可以用线性模型来近似。在该体系下,展示了梯度流的成功,考虑了两层网络的良性过拟合,给出了精确的渐变分析,精确展示了过拟合的影响。最后,强调了将这些见解扩展到现实的深度学习环境中所面临的关键挑战。
The remarkable practical success of deep learning has revealed some major surprises from a theoretical perspective. In particular, simple gradient methods easily find near-optimal solutions to non-convex optimization problems, and despite giving a near-perfect fit to training data without any explicit effort to control model complexity, these methods exhibit excellent predictive accuracy. We conjecture that specific principles underlie these phenomena: that overparametrization allows gradient methods to find interpolating solutions, that these methods implicitly impose regularization, and that overparametrization leads to benign overfitting. We survey recent theoretical progress that provides examples illustrating these principles in simpler settings. We first review classical uniform convergence results and why they fall short of explaining aspects of the behavior of deep learning methods. We give examples of implicit regularization in simple settings, where gradient methods lead to minimal norm functions that perfectly fit the training data. Then we review prediction methods that exhibit benign overfitting, focusing on regression problems with quadratic loss. For these methods, we can decompose the prediction rule into a simple component that is useful for prediction and a spiky component that is useful for overfitting but, in a favorable setting, does not harm prediction accuracy. We focus specifically on the linear regime for neural networks, where the network can be approximated by a linear model. In this regime, we demonstrate the success of gradient flow, and we consider benign overfitting with two-layer networks, giving an exact asymptotic analysis that precisely demonstrates the impact of overparametrization. We conclude by highlighting the key challenges that arise in extending these insights to realistic deep learning settings.
https://weibo.com/1402400261/K6HB1drBM
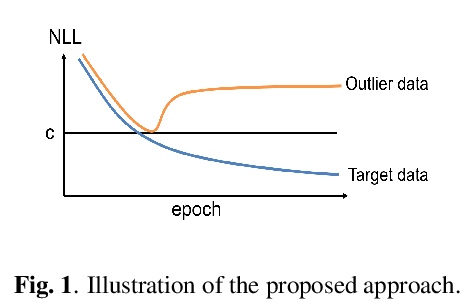
另外几篇值得关注的论文:
[AS] Flow-based Self-supervised Density Estimation for Anomalous Sound Detection
基于流的自监督密度估计异常声音检测
K Dohi, T Endo, H Purohit, R Tanabe, Y Kawaguchi
[Hitachi]
https://weibo.com/1402400261/K6HEkgBve
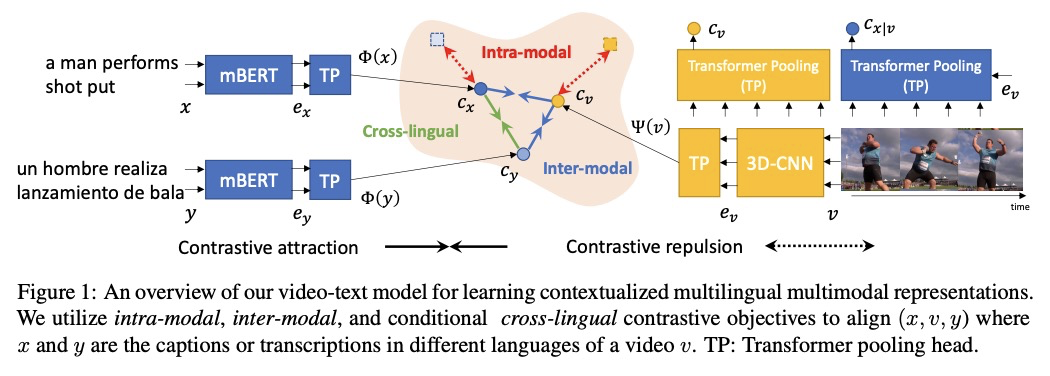
[CV] Multilingual Multimodal Pre-training for Zero-Shot Cross-Lingual Transfer of Vision-Language Models
面向视觉语言模型零样本跨语言迁移的多语言多模态预训练
P Huang, M Patrick, J Hu, G Neubig, F Metze, A Hauptmann
[CMU & University of Oxford & Facebook AI]
https://weibo.com/1402400261/K6HG7lL0F


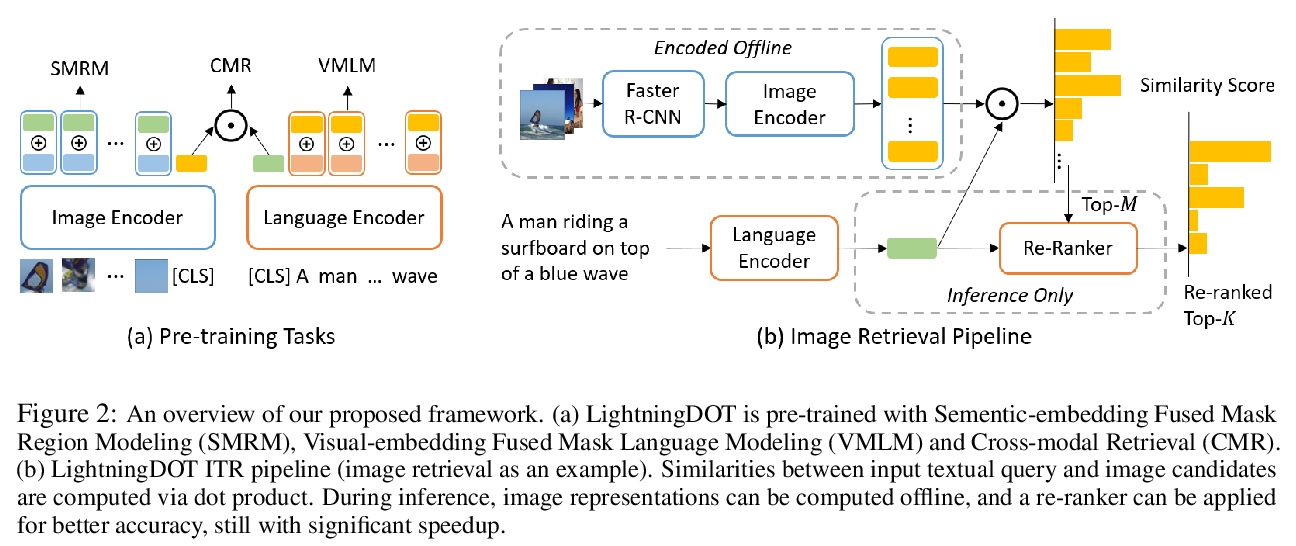
[CL] LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval
LightningDOT:面向实时图像-文本检索的预训练视觉-语义嵌入
S Sun, Y Chen, L Li, S Wang, Y Fang, J Liu
[Microsoft Corporation]
https://weibo.com/1402400261/K6HIO4EZD



若有收获,就点个赞吧
0 人点赞
