LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] *Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the Neural Tangent Kernel
S Fort, G K Dziugaite, M Paul, S Kharaghani, D M. Roy, S Ganguli
[Stanford University & Element AI & University of Toronto]
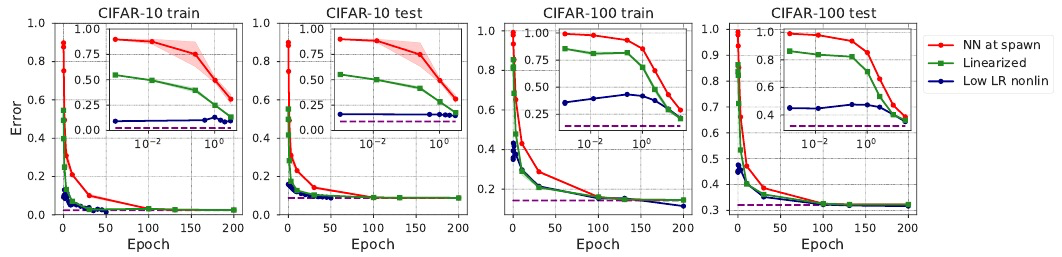
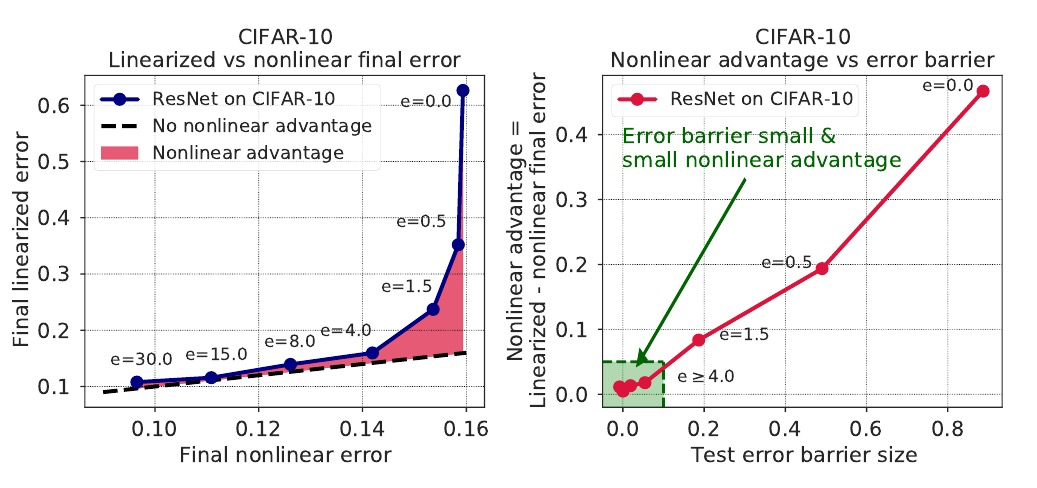
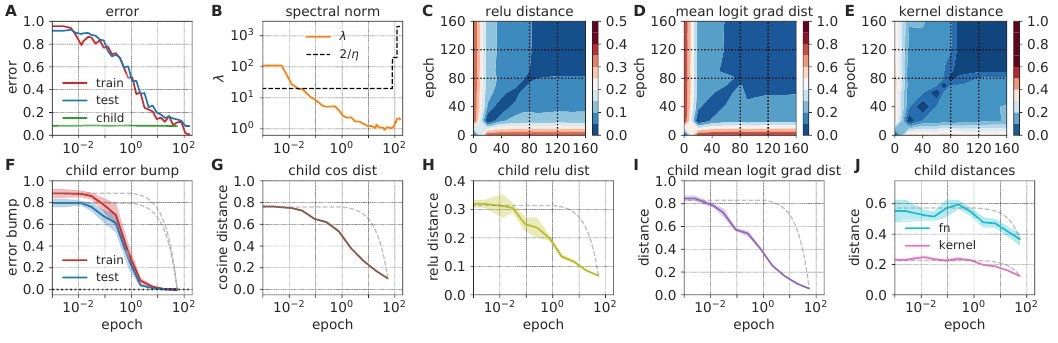
深度学习与核学习:损失景观几何与神经切内切核时间演化的实证研究。研究了非线性深度网络的训练动力学、损失景观的几何形状和依赖数据的神经内切核(NTK)的时间演化之间的关系,通过对训练的大规模现象分析,综合各种方法来刻画损失景观几何和NTK动态,揭示了快速的混沌到稳定过渡的深度学习动力学,在2-3轮更新中,损失盆地确定下来,NTK迅速变化和改进,从训练数据中学习有用的特征。
In suitably initialized wide networks, small learning rates transform deep neural networks (DNNs) into neural tangent kernel (NTK) machines, whose training dynamics is well-approximated by a linear weight expansion of the network at initialization. Standard training, however, diverges from its linearization in ways that are poorly understood. We study the relationship between the training dynamics of nonlinear deep networks, the geometry of the loss landscape, and the time evolution of a data-dependent NTK. We do so through a large-scale phenomenological analysis of training, synthesizing diverse measures characterizing loss landscape geometry and NTK dynamics. In multiple neural architectures and datasets, we find these diverse measures evolve in a highly correlated manner, revealing a universal picture of the deep learning process. In this picture, deep network training exhibits a highly chaotic rapid initial transient that within 2 to 3 epochs determines the final linearly connected basin of low loss containing the end point of training. During this chaotic transient, the NTK changes rapidly, learning useful features from the training data that enables it to outperform the standard initial NTK by a factor of 3 in less than 3 to 4 epochs. After this rapid chaotic transient, the NTK changes at constant velocity, and its performance matches that of full network training in 15% to 45% of training time. Overall, our analysis reveals a striking correlation between a diverse set of metrics over training time, governed by a rapid chaotic to stable transition in the first few epochs, that together poses challenges and opportunities for the development of more accurate theories of deep learning.
https://weibo.com/1402400261/JrPmobMeQ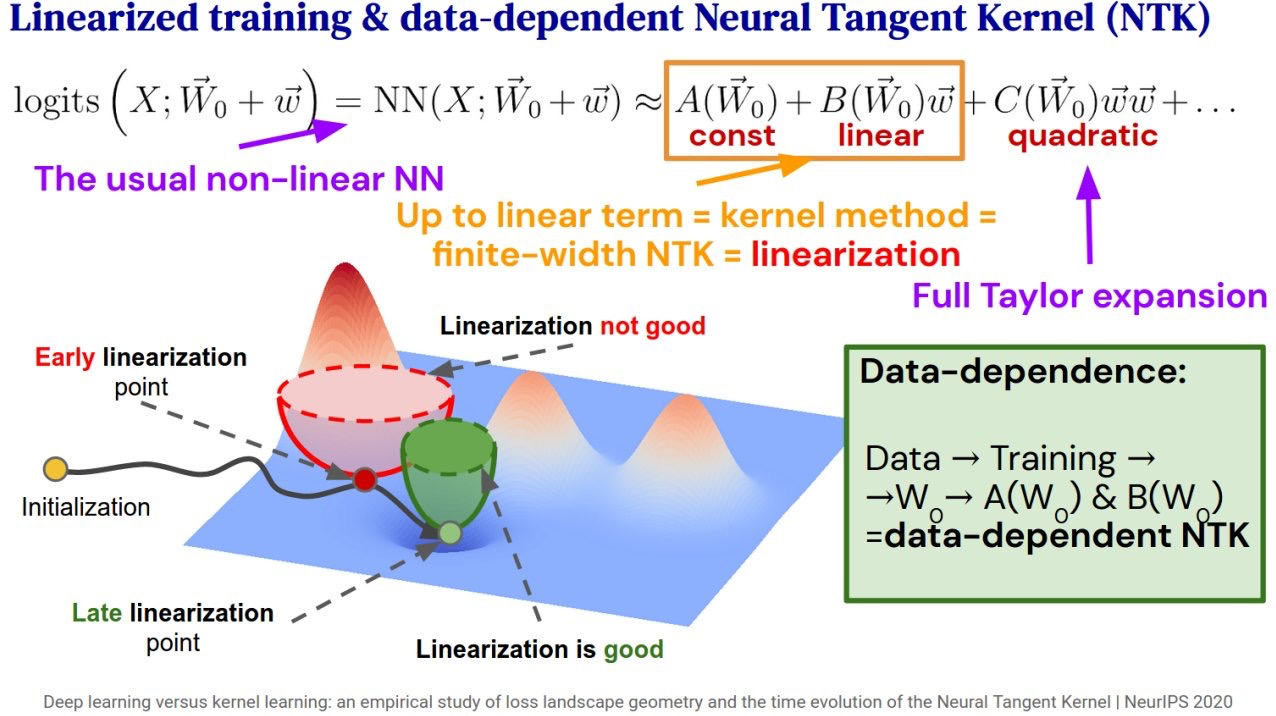
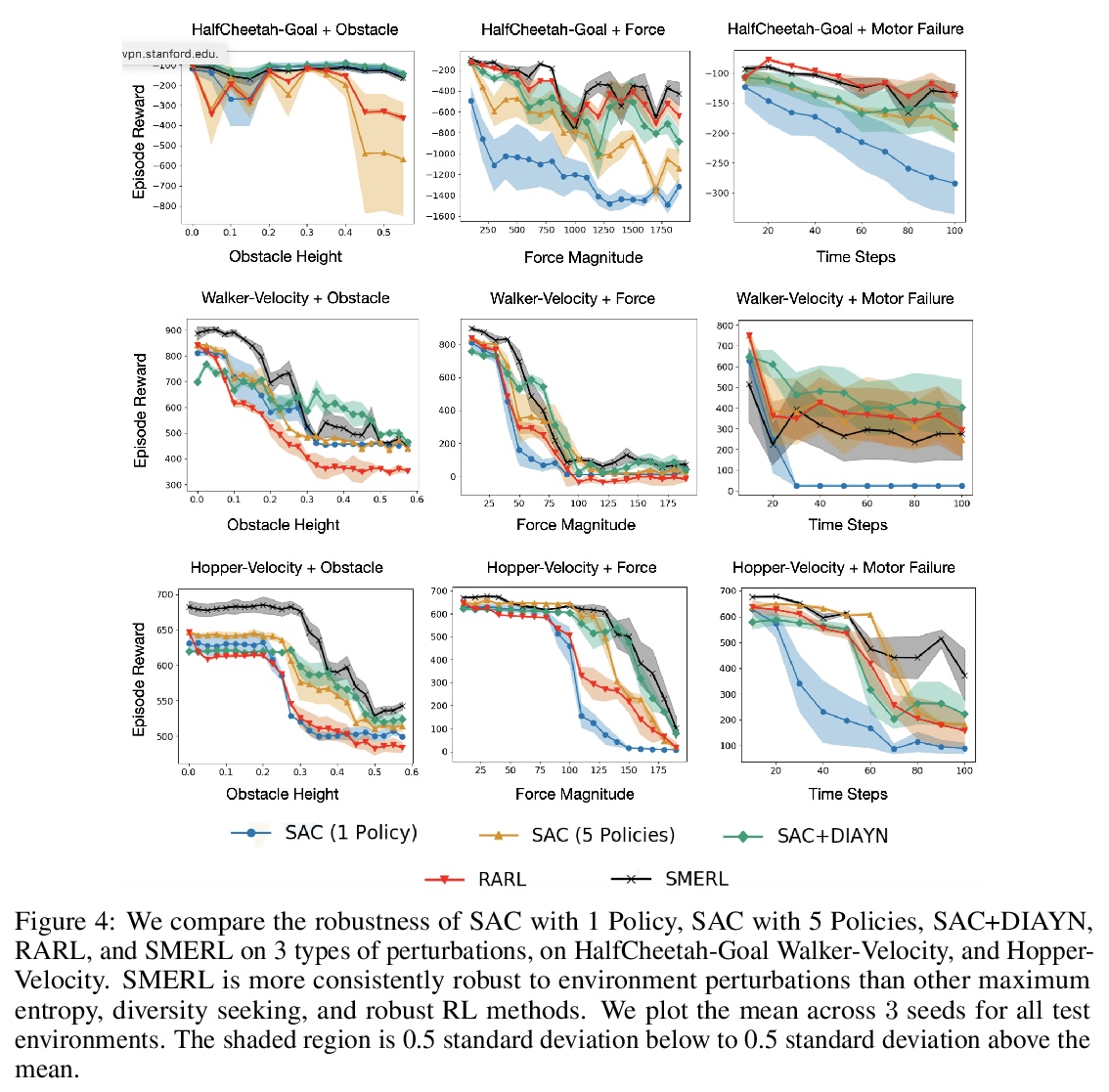
2、[LG] *One Solution is Not All You Need: Few-Shot Extrapolation via Structured MaxEnt RL
S Kumar, A Kumar, S Levine, C Finn
[Stanford University & UC Berkeley]
用结构化最大熵强化学习(MaxEnt RL)实现少样本外推。提出鲁棒的SMERL强化学习算法,用于学习强化学习策略,可以通过少量实验推断分布外的测试条件。核心思想是,可以学习一组策略,为单个任务找到多种不同的解决方案,用潜变量进行控制。训练过程中,通过在单一环境中识别任务的多个解决方案,放弃不再有效的解决方案、采用有效的解决方案来泛化新情况。**
While reinforcement learning algorithms can learn effective policies for complex tasks, these policies are often brittle to even minor task variations, especially when variations are not explicitly provided during training. One natural approach to this problem is to train agents with manually specified variation in the training task or environment. However, this may be infeasible in practical situations, either because making perturbations is not possible, or because it is unclear how to choose suitable perturbation strategies without sacrificing performance. The key insight of this work is that learning diverse behaviors for accomplishing a task can directly lead to behavior that generalizes to varying environments, without needing to perform explicit perturbations during training. By identifying multiple solutions for the task in a single environment during training, our approach can generalize to new situations by abandoning solutions that are no longer effective and adopting those that are. We theoretically characterize a robustness set of environments that arises from our algorithm and empirically find that our diversity-driven approach can extrapolate to various changes in the environment and task.
https://weibo.com/1402400261/JrPAcebws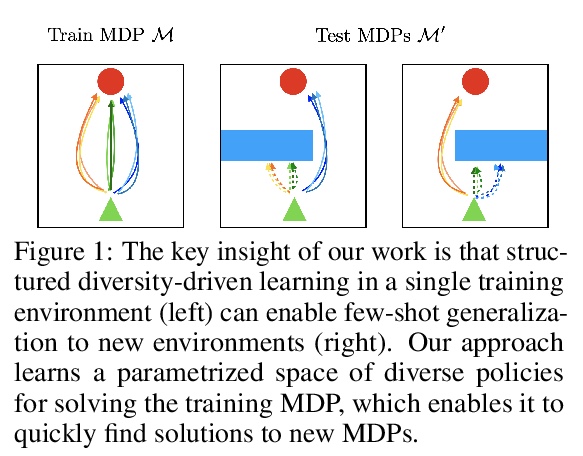
3、[LG] *Implicit Under-Parameterization Inhibits Data-Efficient Deep Reinforcement Learning
A Kumar, R Agarwal, D Ghosh, S Levine
[UC Berkeley & Google Research]
深度强化学习中抑制数据效率的隐式欠参数化。在bootstrapping深度强化学习中,基于梯度的目标优化会导致价值网络表达能力的降低。这种效应表现为价值网络学到特征的秩坍缩、状态混叠,并导致糟糕的性能。分析表明,这种现象是由目标的梯度下降导致的隐式正则化造成的,通过简单的正则化方案,可缓解这一问题,提高深度Q-learning方法的性能。**
We identify an implicit under-parameterization phenomenon in value-based deep RL methods that use bootstrapping: when value functions, approximated using deep neural networks, are trained with gradient descent using iterated regression onto target values generated by previous instances of the value network, more gradient updates decrease the expressivity of the current value network. We characterize this loss of expressivity in terms of a drop in the rank of the learned value network features, and show that this corresponds to a drop in performance. We demonstrate this phenomenon on widely studies domains, including Atari and Gym benchmarks, in both offline and online RL settings. We formally analyze this phenomenon and show that it results from a pathological interaction between bootstrapping and gradient-based optimization. We further show that mitigating implicit under-parameterization by controlling rank collapse improves performance.
https://weibo.com/1402400261/JrPGh1DqC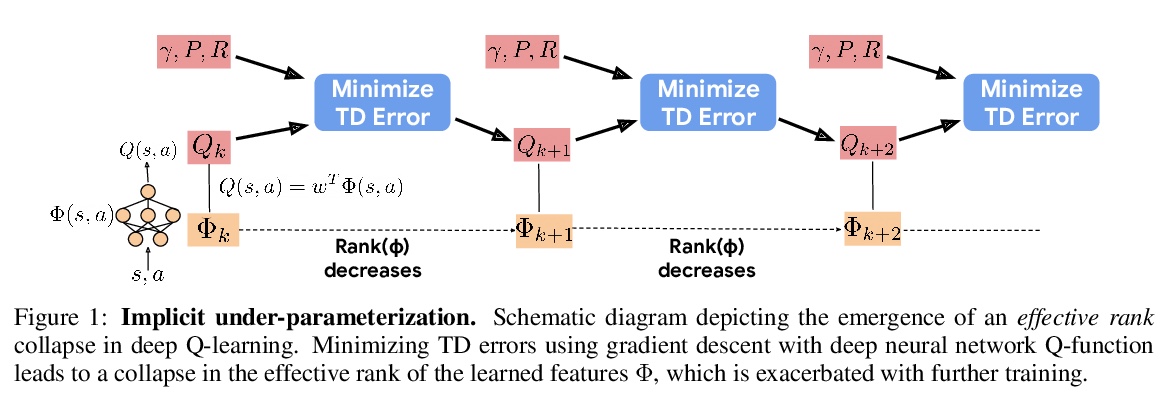
4、[LG] **Conservative Safety Critics for Exploration
H Bharadhwaj, A Kumar, N Rhinehart, S Levine, F Shkurti, A Garg
[University of Toronto & UC Berkeley]
通过对安全状态保守估计的批判器学习实现强化学习的安全探索。引入了一个安全探索算法来学习一个保守的安全状态估计评批判器,估计每个候选状态-动作元组的失败概率,用来约束策略评价和策略改进,证明了在每次训练迭代中灾难性失败的概率是有界的。从理论上刻画了安全性和策略改进之间的权衡关系,证明了在训练过程中,安全性约束可以以较高的概率得到满足,并给出了可证明的收敛性保证。**
Safe exploration presents a major challenge in reinforcement learning (RL): when active data collection requires deploying partially trained policies, we must ensure that these policies avoid catastrophically unsafe regions, while still enabling trial and error learning. In this paper, we target the problem of safe exploration in RL by learning a conservative safety estimate of environment states through a critic, and provably upper bound the likelihood of catastrophic failures at every training iteration. We theoretically characterize the tradeoff between safety and policy improvement, show that the safety constraints are likely to be satisfied with high probability during training, derive provable convergence guarantees for our approach, which is no worse asymptotically than standard RL, and demonstrate the efficacy of the proposed approach on a suite of challenging navigation, manipulation, and locomotion tasks. Empirically, we show that the proposed approach can achieve competitive task performance while incurring significantly lower catastrophic failure rates during training than prior methods. Videos are at this url > this https URL
https://weibo.com/1402400261/JrPPEzj4s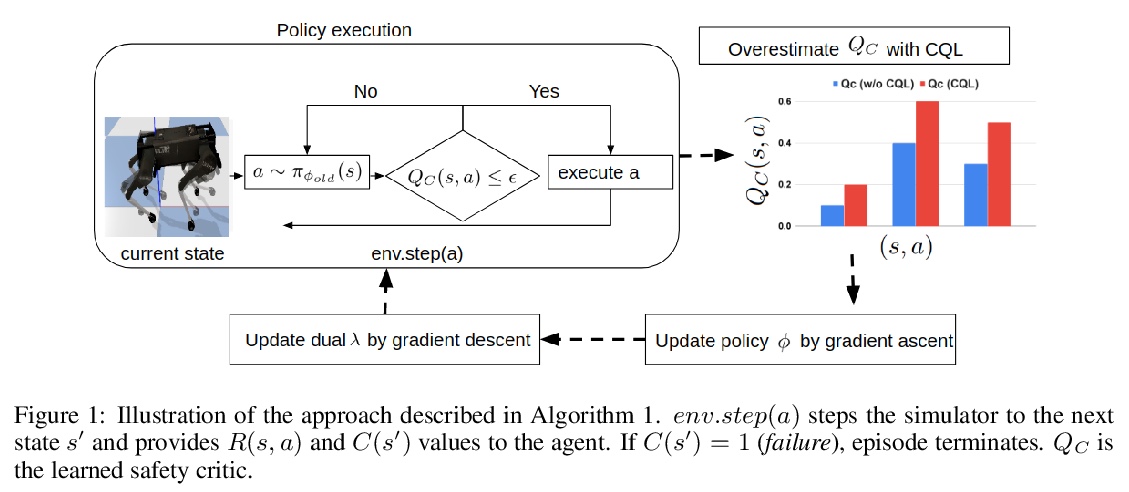

5、[CL] **On the Importance of Adaptive Data Collection for Extremely Imbalanced Pairwise Tasks
S Mussmann, R Jia, P Liang
[Stanford University]
自适应数据收集对极度不平衡成对任务的重要性。启发式样本选择方法会导致模型泛化性差,本文用主动学习来收集训练数据,用基于BERT的嵌入模型来有效地从巨大的未标记话语对池中检索非确定点。通过创建含有更多反面例子的平衡训练数据,主动学习极大提高了QQP和WikiQA上的平均准确。**
Many pairwise classification tasks, such as paraphrase detection and open-domain question answering, naturally have extreme label imbalance (e.g., > 99.99% of examples are negatives). In contrast, many recent datasets heuristically choose examples to ensure label balance. We show that these heuristics lead to trained models that generalize poorly: State-of-the art models trained on QQP and WikiQA each have only > 2.4% average precision when evaluated on realistically imbalanced test data. We instead collect training data with active learning, using a BERT-based embedding model to efficiently retrieve uncertain points from a very large pool of unlabeled utterance pairs. By creating balanced training data with more informative negative examples, active learning greatly improves average precision to > 32.5% on QQP and > 20.1% on WikiQA.
https://weibo.com/1402400261/JrQ4p8nt2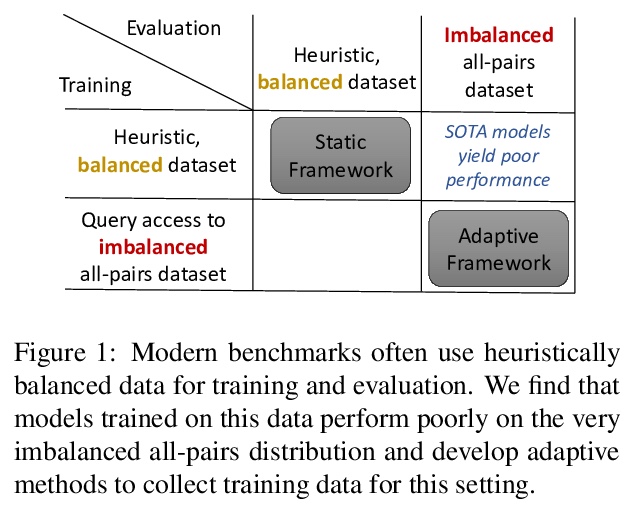

其他几篇值得关注的论文:
[LG] Scientific intuition inspired by machine learning generated hypotheses
受机器学习生成假设启发的科学直觉
P Friederich, M Krenn, I Tamblyn, A Aspuru-Guzik
[University of Toronto]
https://weibo.com/1402400261/JrPZPmowU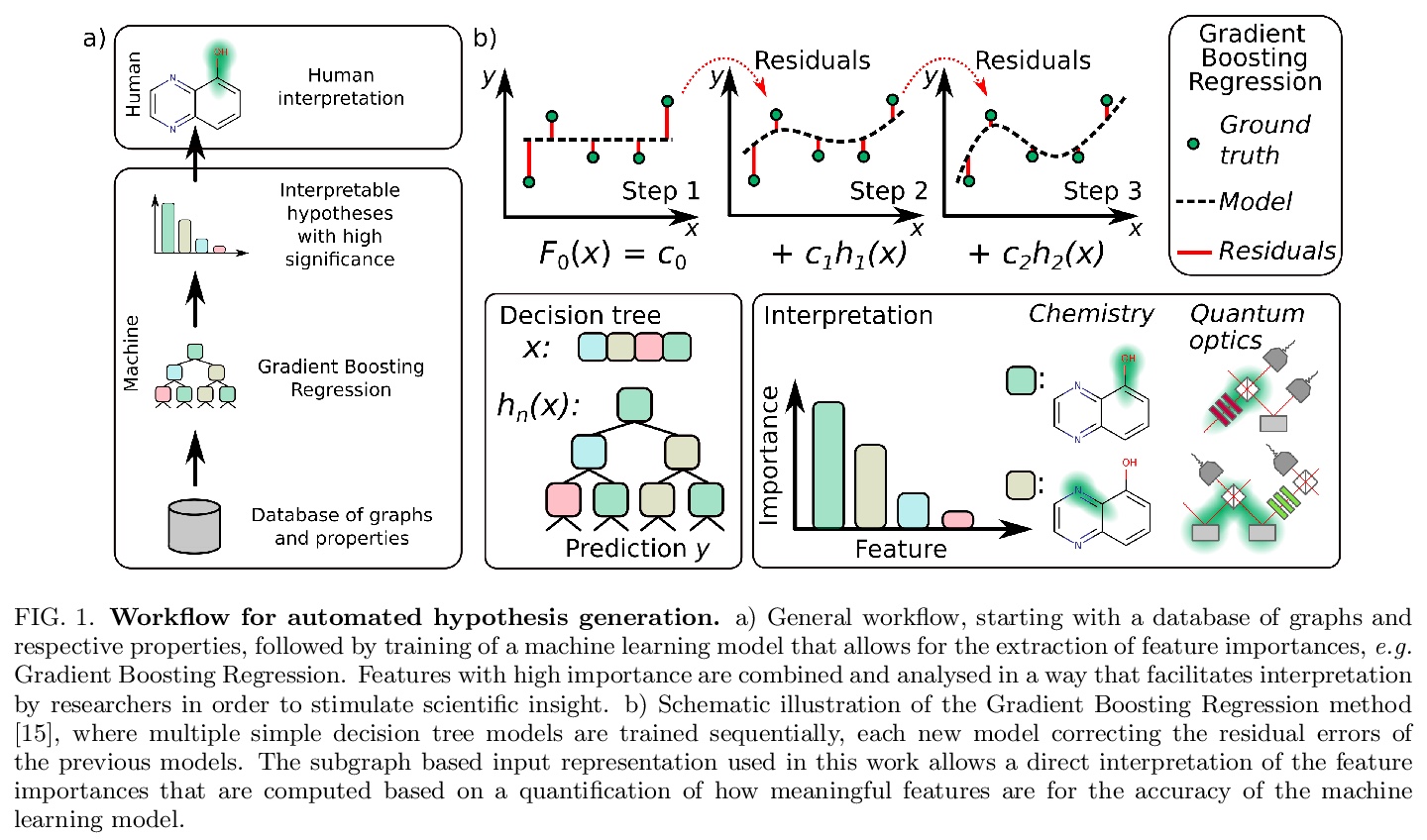
[LG]Tree-structured Ising models can be learned efficiently
树结构Ising模型的高效学习
C Daskalakis, Q Pan
[MIT]
https://weibo.com/1402400261/JrQ2OnijD
[CV] Show and Speak: Directly Synthesize Spoken Description of Images
图像语音描述的直接合成
X Wang, S Feng, J Zhu, M Hasegawa-Johnson, O Scharenborg
[Xi’an Jiaotong University & Delft University of Technology & University of Illinois at Urbana-Champaign]
https://weibo.com/1402400261/JrQ7Z2c2B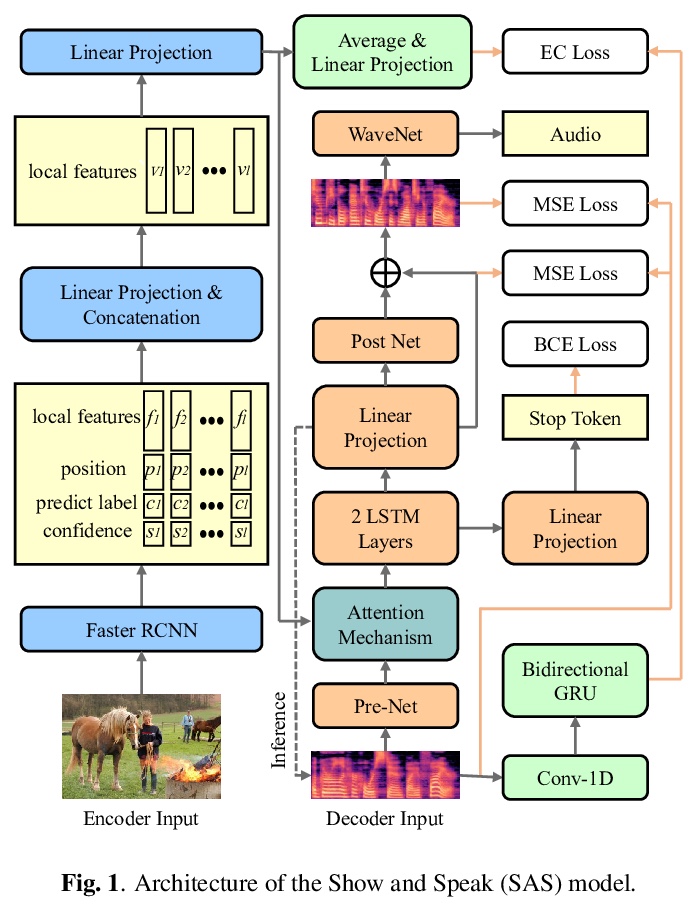


若有收获,就点个赞吧
0 人点赞
