LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
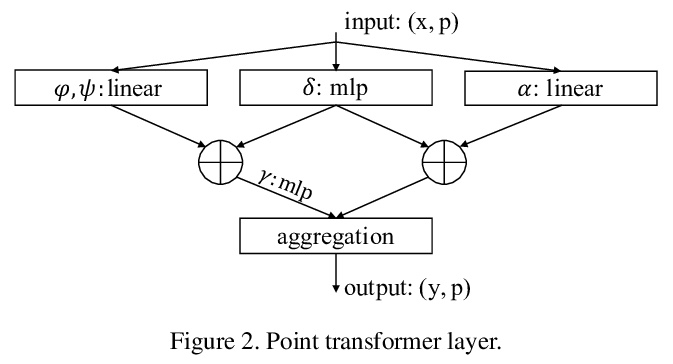
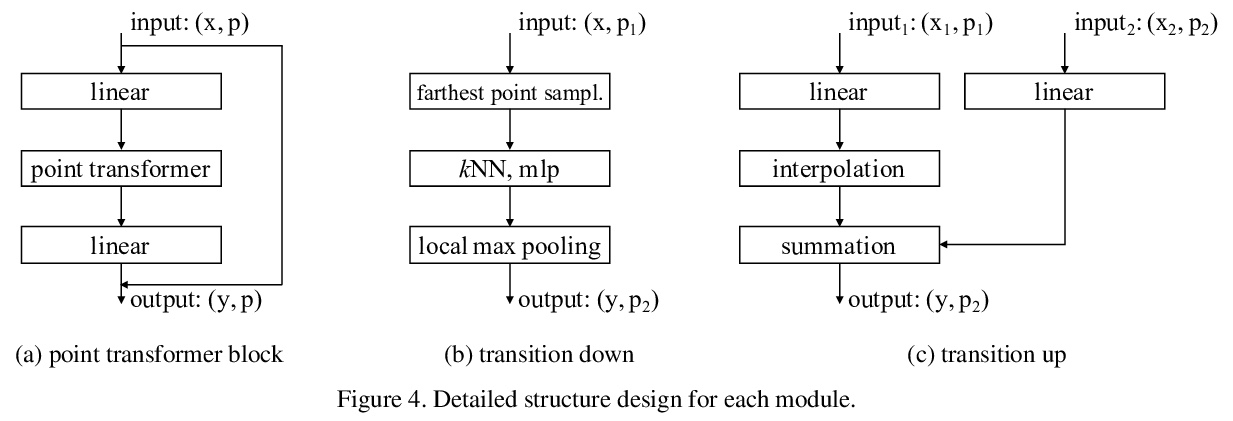
1、[CV] *Point Transformer
H Zhao, L Jiang, J Jia, P Torr, V Koltun
[University of Oxford & The Chinese University of Hong Kong & Intel Labs]
自注意力网络在3D点云处理中的应用。提出了用于3D点云的Transformer架构,与语言或图像处理相比,Transformer或许更适合于点云处理,因为点云本质上是嵌入在度量空间中的集合,而Transformer网络核心的自注意力算子,从根本上来说是一个集合算子。为点云设计了自注意力层,利用这些自注意力层构建自注意力网络Point Transformer,用于诸如语义场景分割、目标部分分割和物体分类等任务。在具有挑战性的大规模语义场景分割的S3DIS数据集上,Point Transformer在Area 5上达到了70.4%的mIoU,比之前最强模型高出3.3个百分点,首次突破了70%的mIoU阈值。
Self-attention networks have revolutionized natural language processing and are making impressive strides in image analysis tasks such as image classification and object detection. Inspired by this success, we investigate the application of self-attention networks to 3D point cloud processing. We design self-attention layers for point clouds and use these to construct self-attention networks for tasks such as semantic scene segmentation, object part segmentation, and object classification. Our Point Transformer design improves upon prior work across domains and tasks. For example, on the challenging S3DIS dataset for large-scale semantic scene segmentation, the Point Transformer attains an mIoU of 70.4% on Area 5, outperforming the strongest prior model by 3.3 absolute percentage points and crossing the 70% mIoU threshold for the first time.
https://weibo.com/1402400261/JyYoUfDGw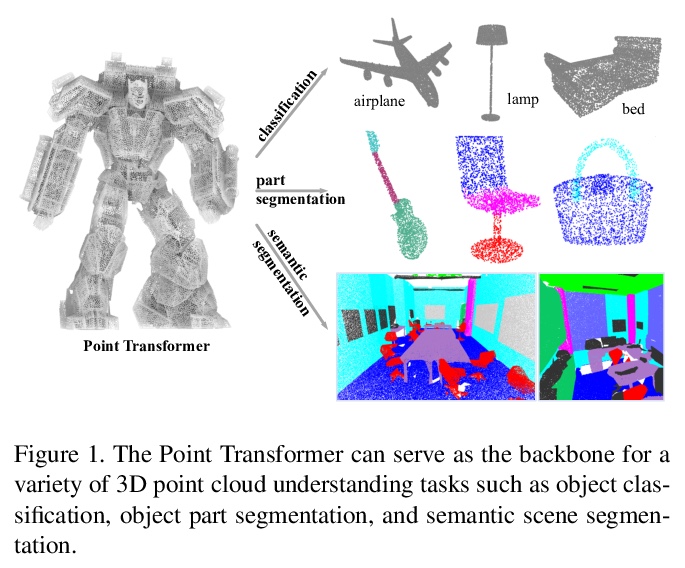


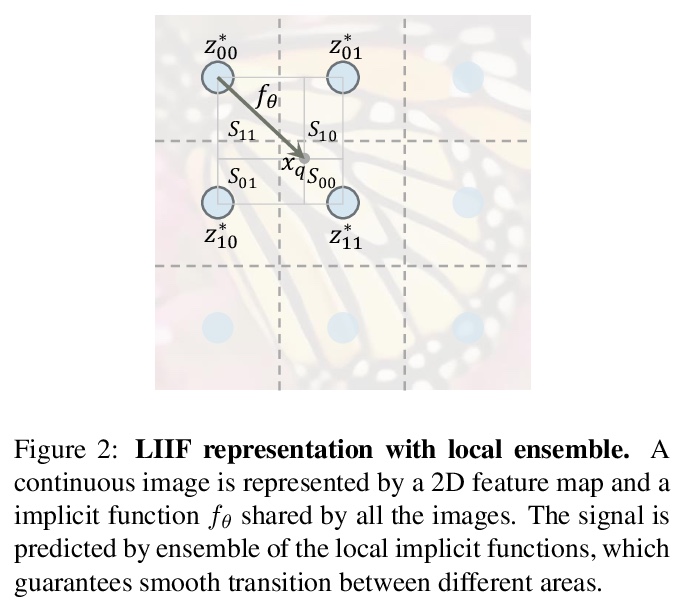
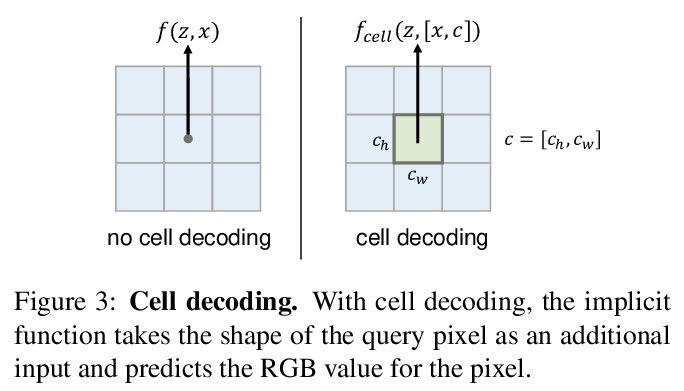
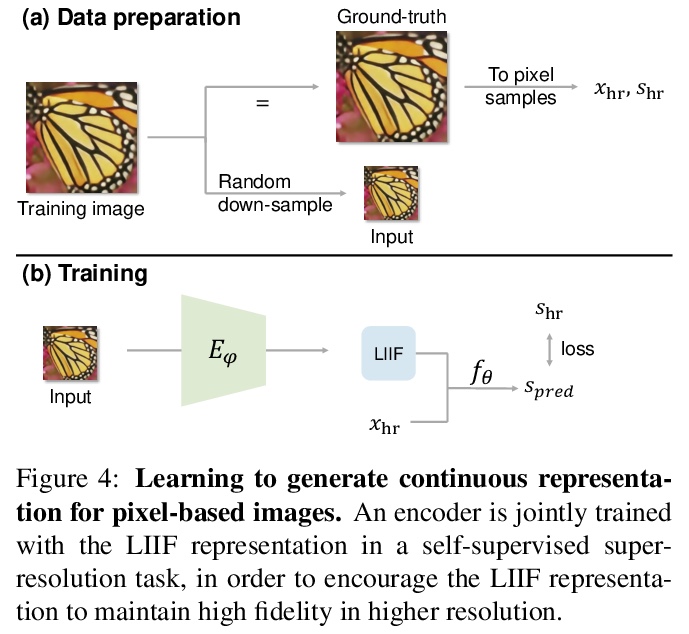
2、** *[CV] Learning Continuous Image Representation with Local Implicit Image Function
Y Chen, S Liu, X Wang
[UC San Diego & NVIDIA]
基于局部隐图像函数的连续图像表示学习。提出了局部隐函数(Local Implicit Image Function,LIIF),以图像坐标和坐标周围的二维深度特征作为输入,预测给定坐标处RGB值作为输出。在LIIF表示中,每幅图像由一个二维特征映射表示,所有图像共享一个神经隐式函数,根据输入坐标和邻近特征向量输出RGB值。通过用超分辨率自监督任务训练具有LIIF表示的编码器,可为基于像素的图像生成连续的LIIF表示。连续表示可在超高分辨率下呈现,可推广到×30的更高分辨率,同时保持高保真度,无需额外训练。LIIF表示法在二维离散表示法和连续表示法之间架起了一座桥梁,可自然有效地利用不同分辨率下的图像真实信息。
How to represent an image? While the visual world is presented in a continuous manner, machines store and see the images in a discrete way with 2D arrays of pixels. In this paper, we seek to learn a continuous representation for images. Inspired by the recent progress in 3D reconstruction with implicit function, we propose Local Implicit Image Function (LIIF), which takes an image coordinate and the 2D deep features around the coordinate as inputs, predicts the RGB value at a given coordinate as an output. Since the coordinates are continuous, LIIF can be presented in an arbitrary resolution. To generate the continuous representation for pixel-based images, we train an encoder and LIIF representation via a self-supervised task with super-resolution. The learned continuous representation can be presented in arbitrary resolution even extrapolate to > ×30 higher resolution, where the training tasks are not provided. We further show that LIIF representation builds a bridge between discrete and continuous representation in 2D, it naturally supports the learning tasks with size-varied image ground-truths and significantly outperforms the method with resizing the ground-truths. Our project page with code is at > this https URL .
https://weibo.com/1402400261/JyYtsaKgB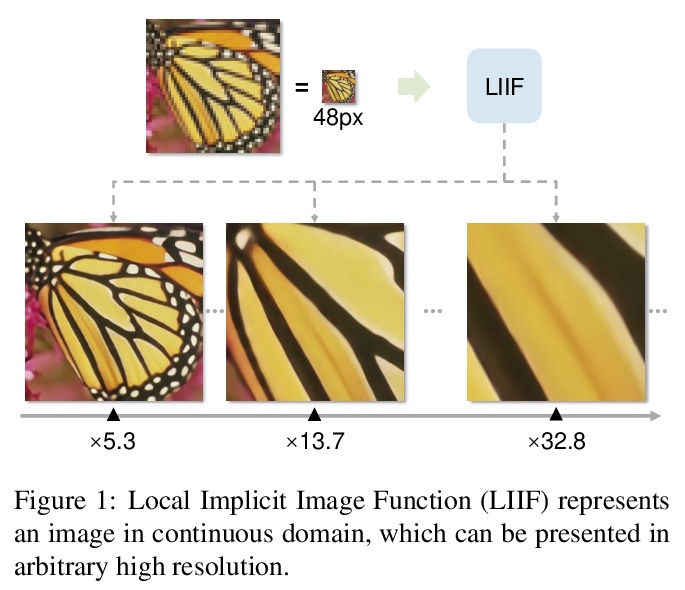
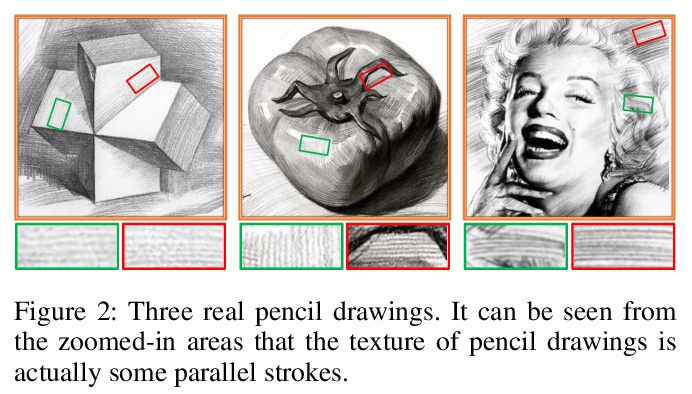
3、**[CV] Sketch Generation with Drawing Process Guided by Vector Flow and Grayscale
Z Tong, X Chen, B Ni, X Wang
[Shanghai Jiao Tong University]
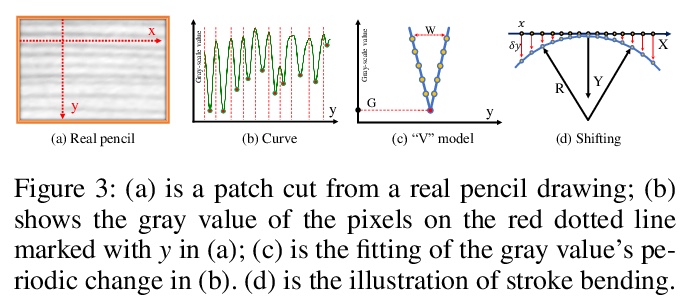
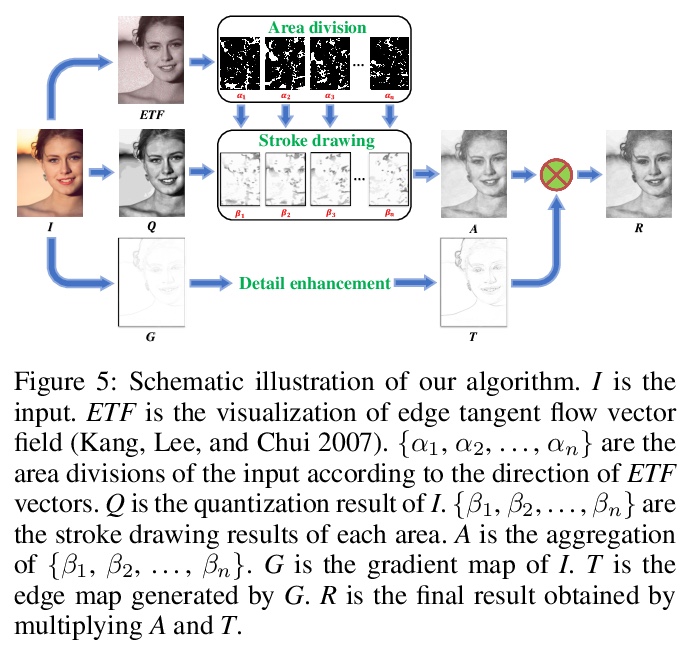
以矢量流和灰度为指导的带有绘画过程的草图生成。提出一种新的图像到素描画的转换方法,不仅可生成高质量铅笔素描草图,还能提供绘画过程。建立了铅笔笔画模仿机制,用边缘切线流矢量场来引导笔画方向,用灰度图像确定位置、长度和笔画阴影,用边缘贴图来增强细节。采用该框架,可产生每次画一笔的铅笔素描,且过程完全可解释。**
We propose a novel image-to-pencil translation method that could not only generate high-quality pencil sketches but also offer the drawing process. Existing pencil sketch algorithms are based on texture rendering rather than the direct imitation of strokes, making them unable to show the drawing process but only a final result. To address this challenge, we first establish a pencil stroke imitation mechanism. Next, we develop a framework with three branches to guide stroke drawing: the first branch guides the direction of the strokes, the second branch determines the shade of the strokes, and the third branch enhances the details further. Under this framework’s guidance, we can produce a pencil sketch by drawing one stroke every time. Our method is fully interpretable. Comparison with existing pencil drawing algorithms shows that our method is superior to others in terms of texture quality, style, and user evaluation.
https://weibo.com/1402400261/JyYyImWnP
4、[CV] C2F-FWN: Coarse-to-Fine Flow Warping Network for Spatial-Temporal Consistent Motion Transfer
D Wei, X Xu, H Shen, K Huang
[Zhejiang University & Guangdong Provincial People’s Hospital]
基于由粗到精流扭曲网络的空-时一致运动迁移。提出Coarse-to-Fine Flow Warping Network(C2F-FWN)来实现人体视频运动转移的空间和时间一致性,保留范例外观的同时提高了视频一致性。C2F-FWN可精确模拟由运动引起的几何变形,确保空间一致性,用LayoutConstrained Deformable Convolution(LC-DConv)来改善变换流估计特征。提出流时间一致性(FTC)损失,以学习连续变换流之间的显式时间一致性,提高视频连贯性。
Human video motion transfer (HVMT) aims to synthesize videos that one person imitates other persons’ actions. Although existing GAN-based HVMT methods have achieved great success, they either fail to preserve appearance details due to the loss of spatial consistency between synthesized and exemplary images, or generate incoherent video results due to the lack of temporal consistency among video frames. In this paper, we propose Coarse-to-Fine Flow Warping Network (C2F-FWN) for spatial-temporal consistent HVMT. Particularly, C2F-FWN utilizes coarse-to-fine flow warping and Layout-Constrained Deformable Convolution (LC-DConv) to improve spatial consistency, and employs Flow Temporal Consistency (FTC) Loss to enhance temporal consistency. In addition, provided with multi-source appearance inputs, C2F-FWN can support appearance attribute editing with great flexibility and efficiency. Besides public datasets, we also collected a large-scale HVMT dataset named SoloDance for evaluation. Extensive experiments conducted on our SoloDance dataset and the iPER dataset show that our approach outperforms state-of-art HVMT methods in terms of both spatial and temporal consistency. Source code and the SoloDance dataset are available at > this https URL.
https://weibo.com/1402400261/JyYE6jxOF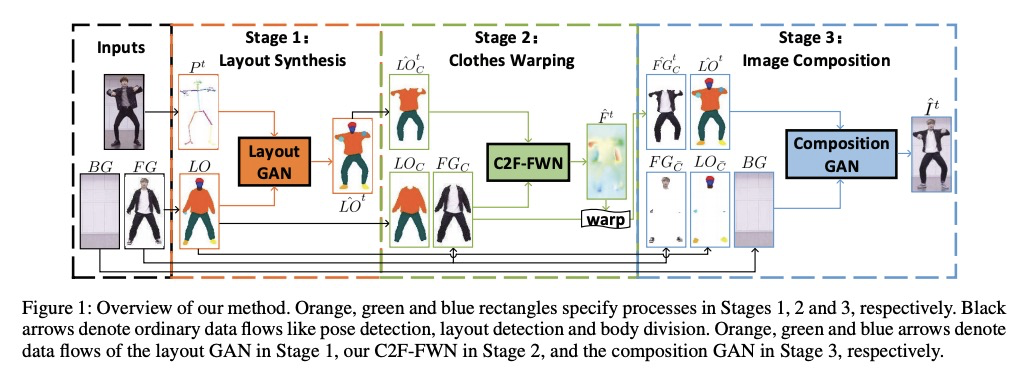


5、**[CL] Pre-Training Transformers as Energy-Based Cloze Models
K Clark, M Luong, Q V. Le, C D. Manning
[Stanford University & Google Brain]
用预训练Transformers实现基于能量的完形填空模型。提出了基于能量的完形填空模型Electric,并为其设计了基于噪声对比估计的高效训练算法。Electric给每个输入的词条分配一个标量能量分数,表示给定上下文其可能性有多大。当迁移到下游任务时,Electric表现良好,在为文本产生似然分数方面特别有效:可比语言模型更好地重排语音识别n-best列表,比掩蔽语言模型快得多。**
We introduce Electric, an energy-based cloze model for representation learning over text. Like BERT, it is a conditional generative model of tokens given their contexts. However, Electric does not use masking or output a full distribution over tokens that could occur in a context. Instead, it assigns a scalar energy score to each input token indicating how likely it is given its context. We train Electric using an algorithm based on noise-contrastive estimation and elucidate how this learning objective is closely related to the recently proposed ELECTRA pre-training method. Electric performs well when transferred to downstream tasks and is particularly effective at producing likelihood scores for text: it re-ranks speech recognition n-best lists better than language models and much faster than masked language models. Furthermore, it offers a clearer and more principled view of what ELECTRA learns during pre-training.
https://weibo.com/1402400261/JyYIObWKd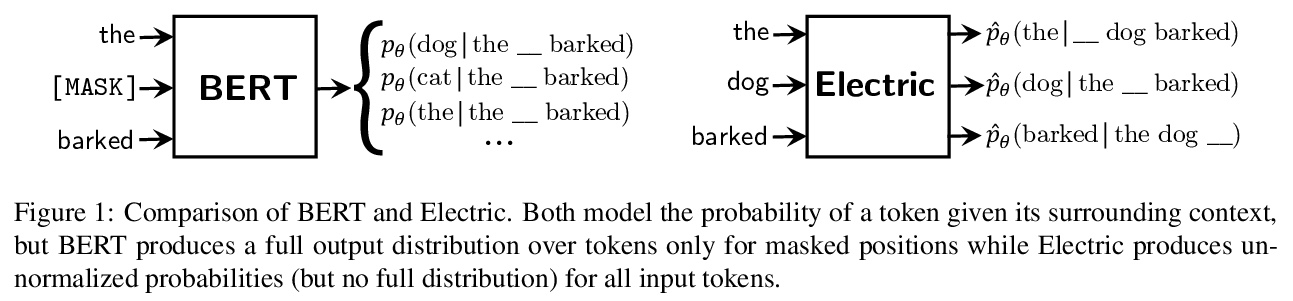
另外几篇值得关注的论文:
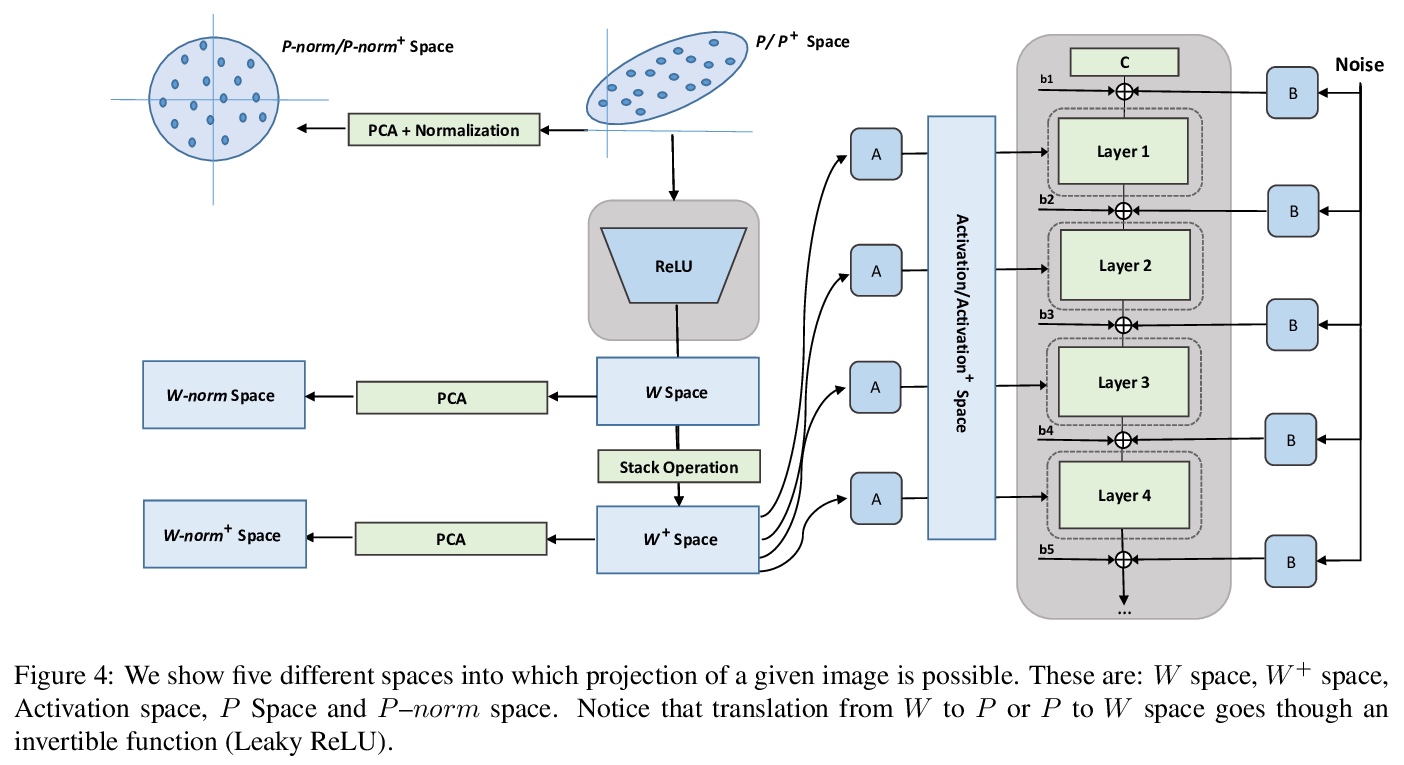
[CV] Improved StyleGAN Embedding: Where are the Good Latents?
改善StyleGAN嵌入:好的潜码在哪里?
P Zhu, R Abdal, Y Qin, P Wonka
[KAUST & Cardiff University]
https://weibo.com/1402400261/JyYO31cq9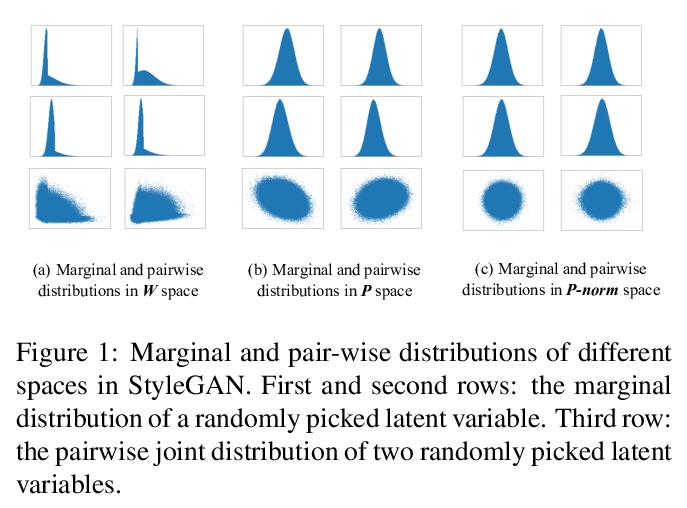


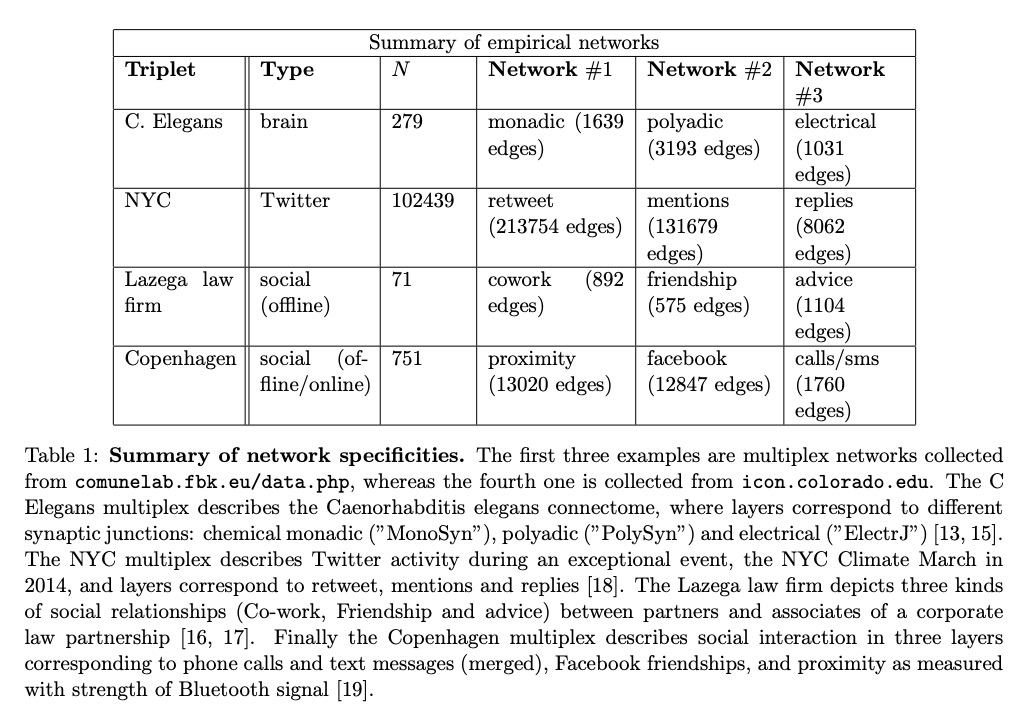
[SI] Beyond pairwise network similarity: exploring Mediation and Suppression between networks
超越网络成对相似性:探索网络间的间接关联与抑制
L Lacasa, S Stramaglia, D Marinazzo
[Queen Mary University of London & Universita Degli Studi di Bari & Ghent University]
https://weibo.com/1402400261/JyYQtkWQJ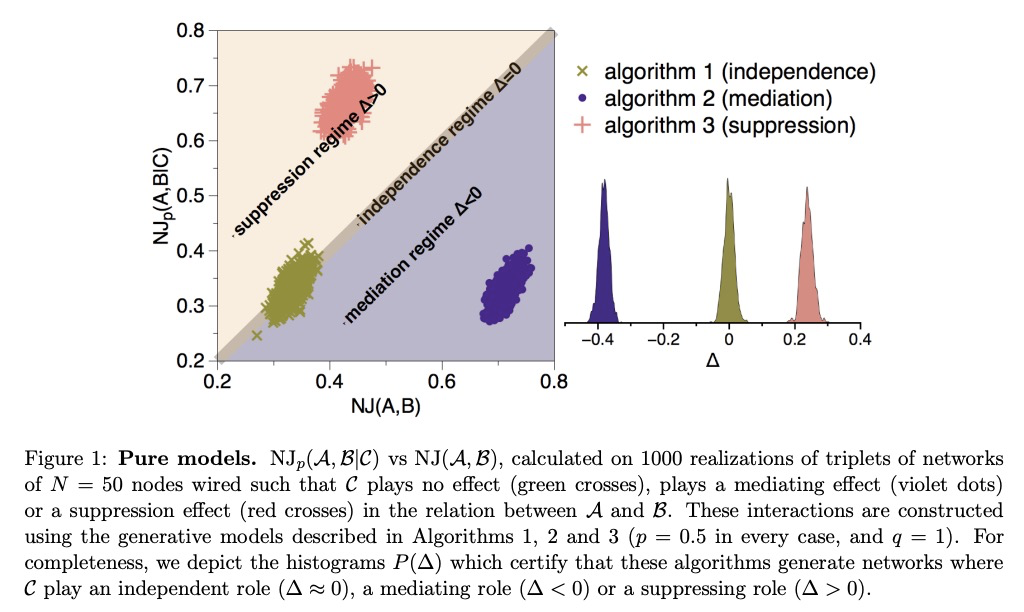
[CV] DECOR-GAN: 3D Shape Detailization by Conditional Refinement
通过条件细化实现3D形状细节化
Z Chen, V Kim, M Fisher, N Aigerman, H Zhang, S Chaudhuri
[Simon Fraser University & Adobe Research]
https://weibo.com/1402400261/JyYTyiFHa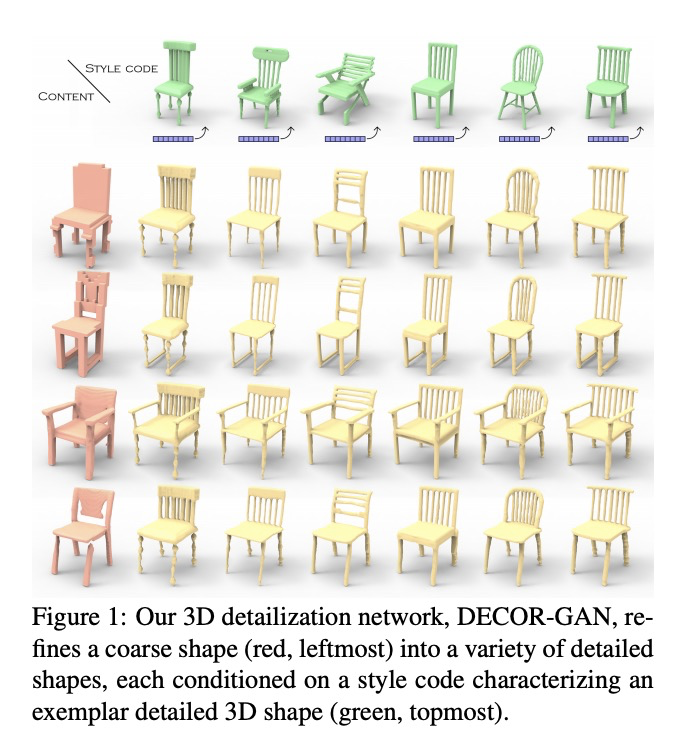

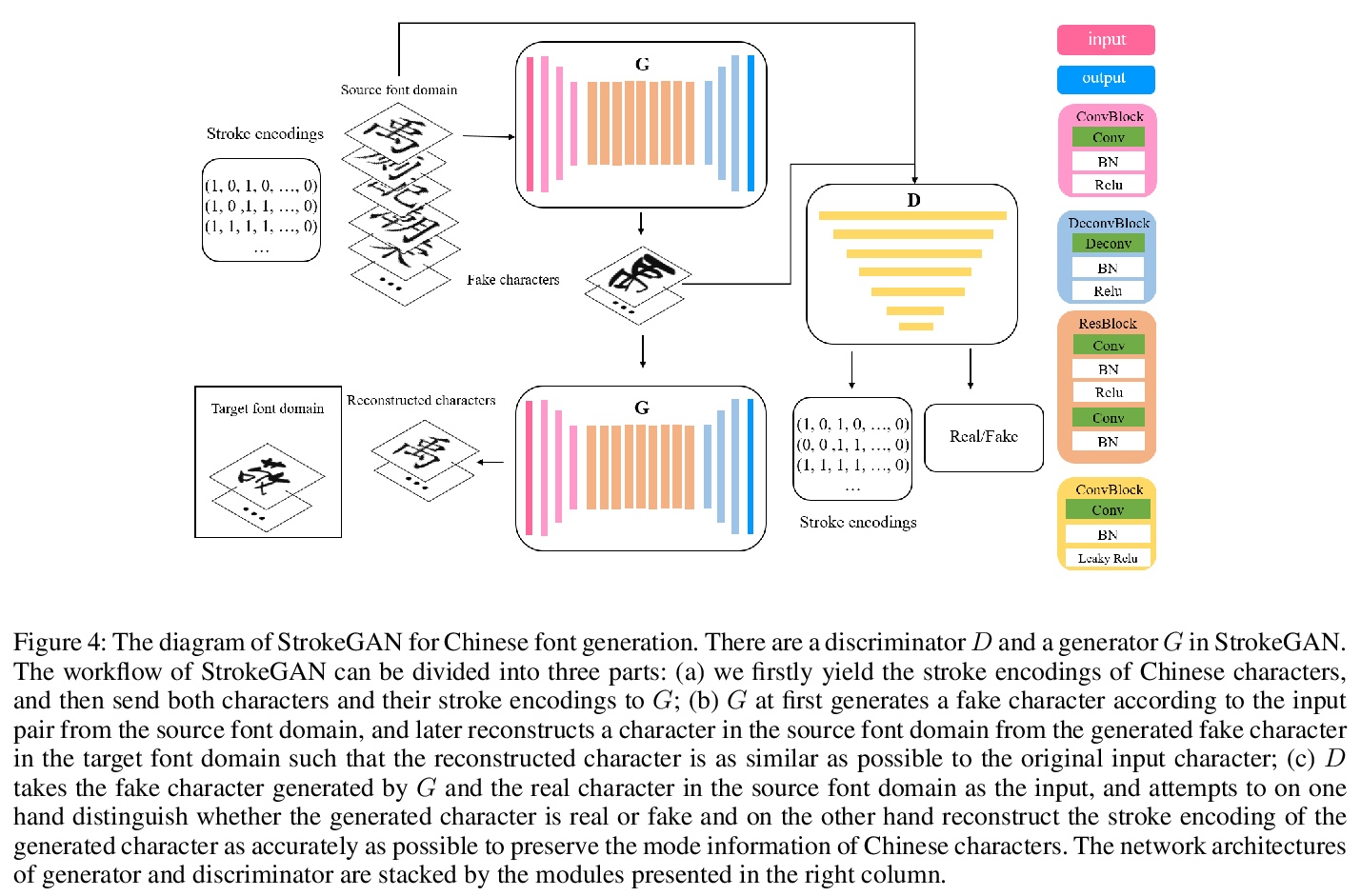
[CV] StrokeGAN: Reducing Mode Collapse in Chinese Font Generation via Stroke Encoding
StrokeGAN:通过笔画编码减少中文字体生成中的模式崩溃
J Zeng, Q Chen, Y Liu, M Wang, Y Yao
[Jiangxi Normal University & Hong Kong University of Science and Technology]
https://weibo.com/1402400261/JyYUjzgqR


若有收获,就点个赞吧
0 人点赞
