- 1、[LG] ZeRO-Offload: Democratizing Billion-Scale Model Training
- 2、[LG] Training Learned Optimizers with Randomly Initialized Learned Optimizers
- 3、[CL] Prefix-Tuning: Optimizing Continuous Prompts for Generation
- 4、[LG] How Does Mixup Help With Robustness and Generalization?
- 5、[CV] Sparse Single Sweep LiDAR Point Cloud Segmentation via Learning Contextual Shape Priors from Scene Completion
- [LG] Topological Deep Learning
- [CV] Quantum Permutation Synchronization
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] ZeRO-Offload: Democratizing Billion-Scale Model Training
J Ren, S Rajbhandari, R Y Aminabadi, O Ruwase, S Yang, M Zhang, D Li, Y He
[Microsoft & University of California, Merced]
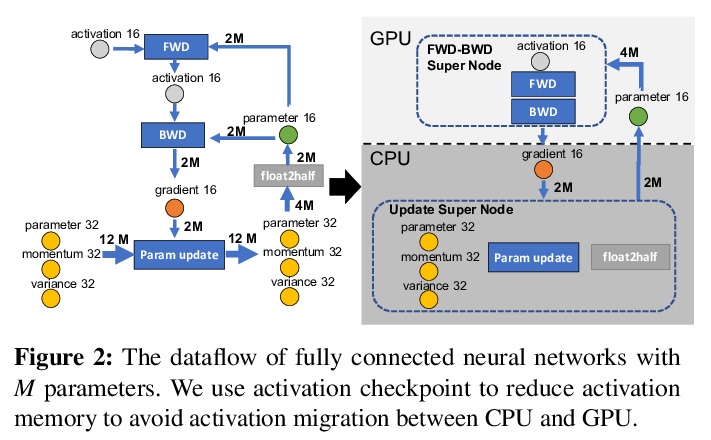
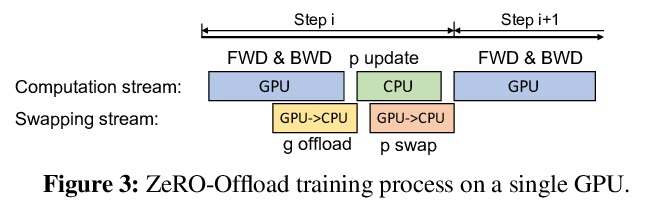
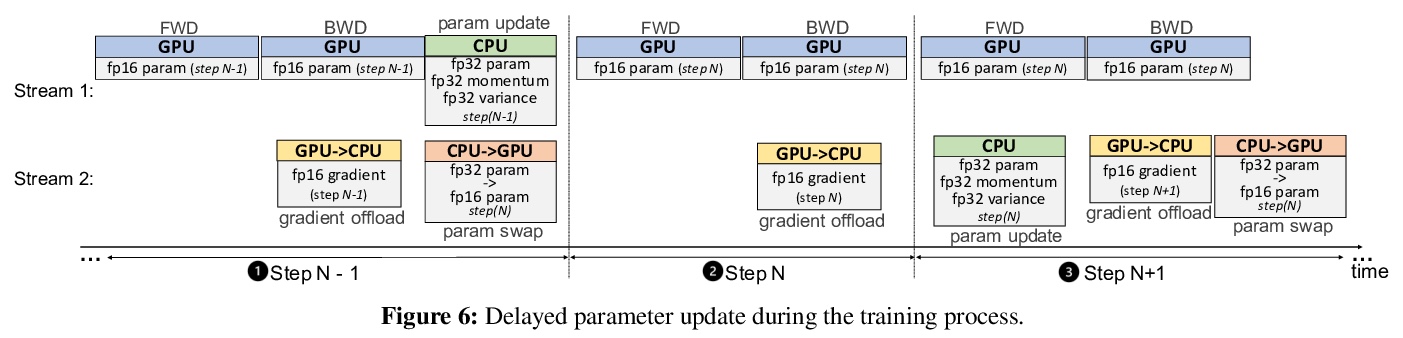
ZeRO-Offload: 十亿级(参数)模型训练大众化。围绕效率、可扩展性和可用性三方面进行优化,目标是让几乎所有人都能进行大型模型的训练,在单个GPU上训练超过130亿参数的模型,与PyTorch等流行框架相比,规模增加10倍,无需对模型进行修改,也不牺牲计算效率。ZeRO-Offload通过将数据和计算分流到CPU,实现了大型模型的训练。为保持计算效率,在最大限度节省GPU内存的同时,最大限度减少GPU的数据移动和计算时间。ZeRO-Offload在单颗NVIDIA V100 GPU上10B参数模型可以实现40 TFlops/GPU,而单独用PyTorch训练1.4B参数模型则需要30TF,这也是在不耗尽内存的情况下可以训练的最大参数模型。ZeRO-Offload还被设计为可在多GPU上进行扩展,最多可在128个GPU上提供近乎线性的加速。此外,它还可以与模型并行化一起工作,在单独的DGX-2上训练超过700亿个参数的模型,与单独使用模型并行化相比,模型规模增加了4.5倍。
Large-scale model training has been a playing ground for a limited few requiring complex model refactoring and access to prohibitively expensive GPU clusters. ZeRO-Offload changes the large model training landscape by making large model training accessible to nearly everyone. It can train models with over 13 billion parameters on a single GPU, a 10x increase in size compared to popular framework such as PyTorch, and it does so without requiring any model change from the data scientists or sacrificing computational efficiency. ZeRO-Offload enables large model training by offloading data and compute to CPU. To preserve compute efficiency, it is designed to minimize the data movement to/from GPU, and reduce CPU compute time while maximizing memory savings on GPU. As a result, ZeRO-Offload can achieve 40 TFlops/GPU on a single NVIDIA V100 GPU for 10B parameter model compared to 30TF using PyTorch alone for a 1.4B parameter model, the largest that can be trained without running out of memory. ZeRO-Offload is also designed to scale on multiple-GPUs when available, offering near linear speedup on up to 128 GPUs. Additionally, it can work together with model parallelism to train models with over 70 billion parameters on a single DGX-2 box, a 4.5x increase in model size compared to using model parallelism alone. By combining compute and memory efficiency with ease-of-use, ZeRO-Offload democratizes large-scale model training making it accessible to even data scientists with access to just a single GPU.
https://weibo.com/1402400261/JEBk6eghr

2、[LG] Training Learned Optimizers with Randomly Initialized Learned Optimizers
L Metz, C. D Freeman, N Maheswaranathan, J Sohl-Dickstein
[Google Research]
用随机初始化习得优化器训练习得优化器。实现了通过自训练加速学习的机器学习系统。随机初始化的习得优化器可用在线方式从头开始自训练,无需在任何部分诉诸手工设计的优化器。基于群体训练的形式被用来协调自训练。虽然随机初始化的优化器最初进展缓慢,但随着其不断改进,会经历一个正反馈循环,迅速提高自训练效率。
Learned optimizers are increasingly effective, with performance exceeding that of hand designed optimizers such as Adam [7] on specific tasks [9]. Despite the potential gains available, in current work the meta-training (or ‘outer-training’) of the learned optimizer is performed by a hand-designed optimizer, or by an optimizer trained by a hand-designed optimizer [11]. We show that a population of randomly initialized learned optimizers can be used to train themselves from scratch in an online fashion, without resorting to a hand designed optimizer in any part of the process. A form of population based training [5] is used to orchestrate this self-training. Although the randomly initialized optimizers initially make slow progress, as they improve they experience a positive feedback loop, and become rapidly more effective at training themselves. We believe feedback loops of this type, where an optimizer improves itself, will be important and powerful in the future of machine learning. These methods not only provide a path towards increased performance, but more importantly relieve research and engineering effort.
https://weibo.com/1402400261/JEBBP75yZ

3、[CL] Prefix-Tuning: Optimizing Continuous Prompts for Generation
X L Li, P Liang
[Stanford University]
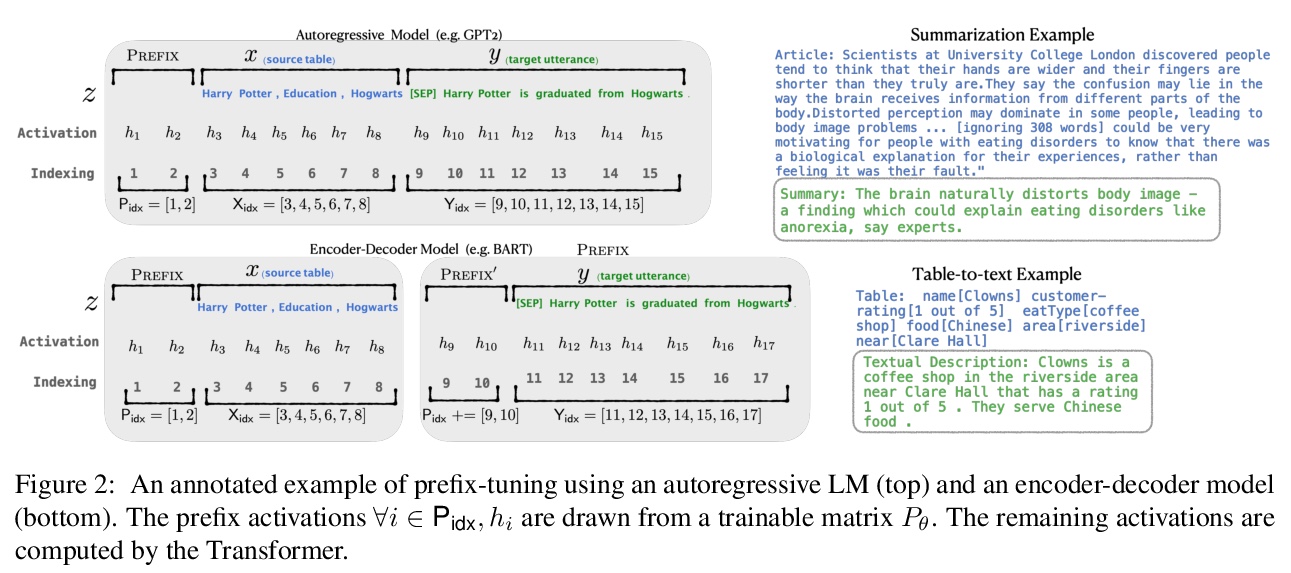
Prefix-Tuning:面向生成的连续提示优化。提出Prefix-Tuning,一种轻量级的自然语言生成任务精细调优替代方案,为自然语言生成任务预置了一个可训练的连续前缀。Prefix-Tuning保持大部分语言模型参数不变,仅优化一个小的连续的任务特定向量(称为前缀prefix)。尽管学习的参数比之前微调方法少了1000倍,但Prefix-Tuning可以在全数据环境下保持相当的性能,并且在低数据和外推环境下都优于之前微调方法。
Fine-tuning is the de facto way to leverage large pretrained language models to perform downstream tasks. However, it modifies all the language model parameters and therefore necessitates storing a full copy for each task. In this paper, we propose prefix-tuning, a lightweight alternative to fine-tuning for natural language generation tasks, which keeps language model parameters frozen, but optimizes a small continuous task-specific vector (called the prefix). Prefix-tuning draws inspiration from prompting, allowing subsequent tokens to attend to this prefix as if it were “virtual tokens”. We apply prefix-tuning to GPT-2 for table-to-text generation and to BART for summarization. We find that by learning only 0.1\% of the parameters, prefix-tuning obtains comparable performance in the full data setting, outperforms fine-tuning in low-data settings, and extrapolates better to examples with topics unseen during training.
https://weibo.com/1402400261/JEBKIwp6B
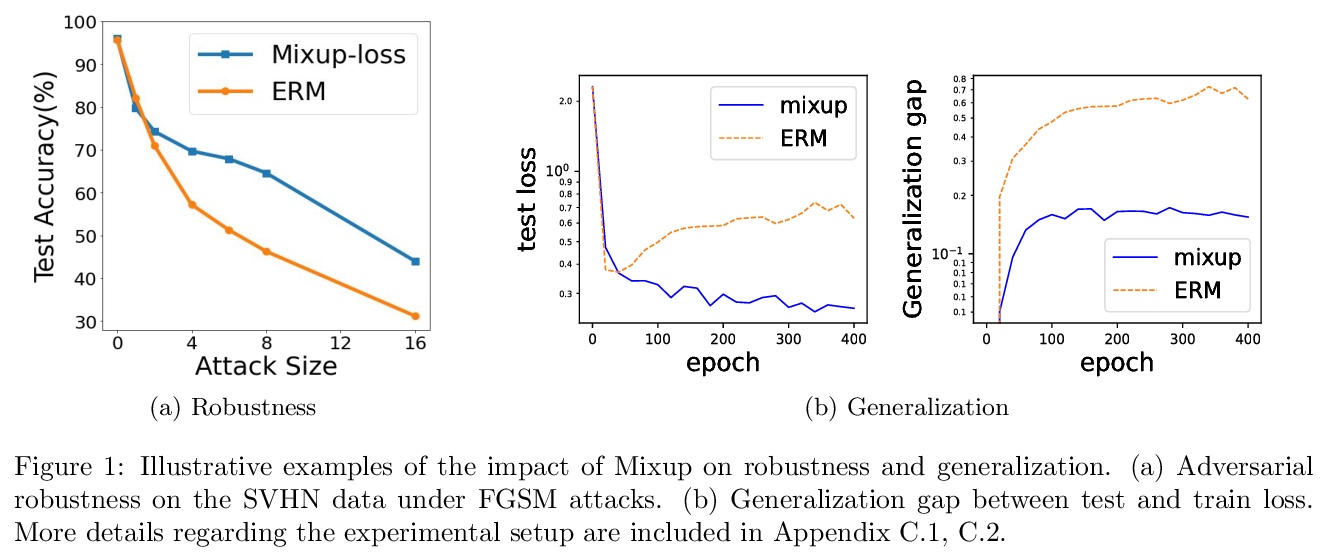
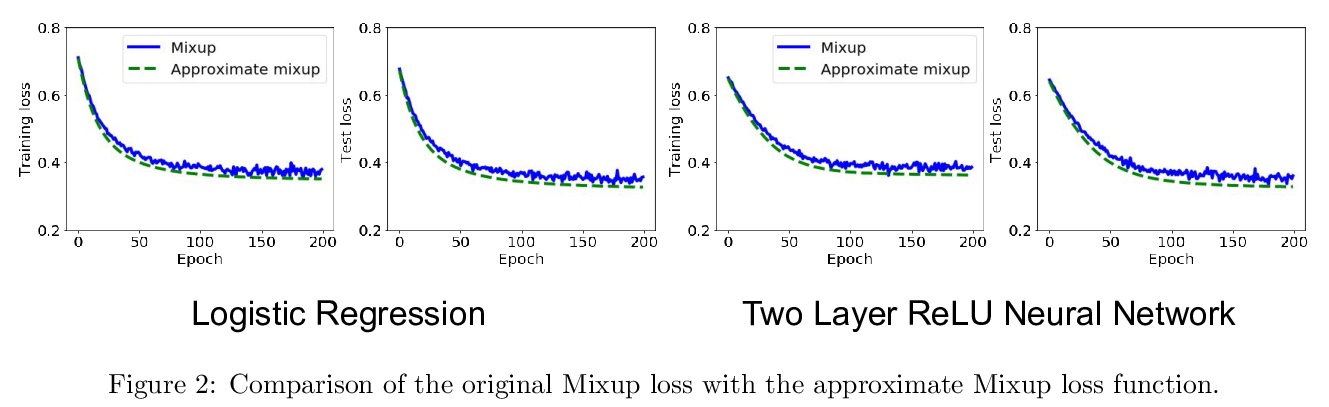
4、[LG] How Does Mixup Help With Robustness and Generalization?
L Zhang, Z Deng, K Kawaguchi, A Ghorbani, J Zou
[Rutgers University & Harvard University & Stanford University]
Mixup提高鲁棒性和泛化性的机制分析。鲁棒性方面,证明了最小化Mixup损失对应于近似最小化对抗损失的上界。这可以解释为什么通过Mixup训练得到的模型表现出对几种对抗性攻击的鲁棒性,如快速梯度符号法(FGSM);在泛化性方面,证明了Mixup增强对应于一种特定类型的数据自适应正则化,可减少过拟合。
Mixup is a popular data augmentation technique based on taking convex combinations of pairs of examples and their labels. This simple technique has been shown to substantially improve both the robustness and the generalization of the trained model. However, it is not well-understood why such improvement occurs. In this paper, we provide theoretical analysis to demonstrate how using Mixup in training helps model robustness and generalization. For robustness, we show that minimizing the Mixup loss corresponds to approximately minimizing an upper bound of the adversarial loss. This explains why models obtained by Mixup training exhibits robustness to several kinds of adversarial attacks such as Fast Gradient Sign Method (FGSM). For generalization, we prove that Mixup augmentation corresponds to a specific type of data-adaptive regularization which reduces overfitting. Our analysis provides new insights and a framework to understand Mixup.
https://weibo.com/1402400261/JEBPh0Xr1
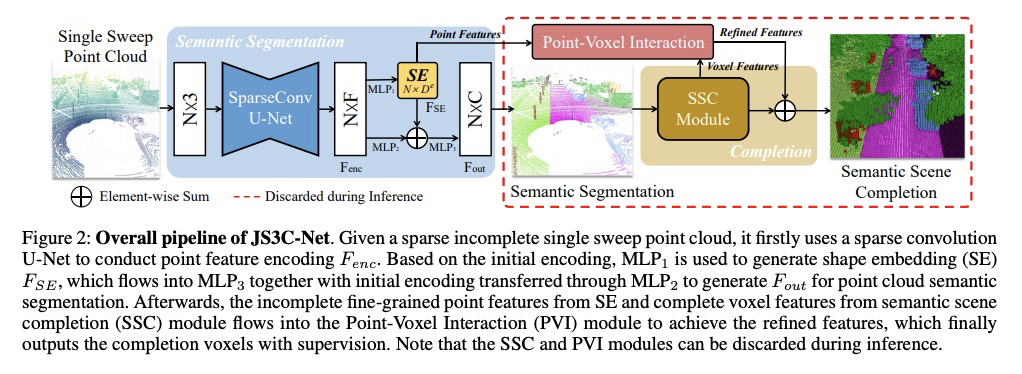
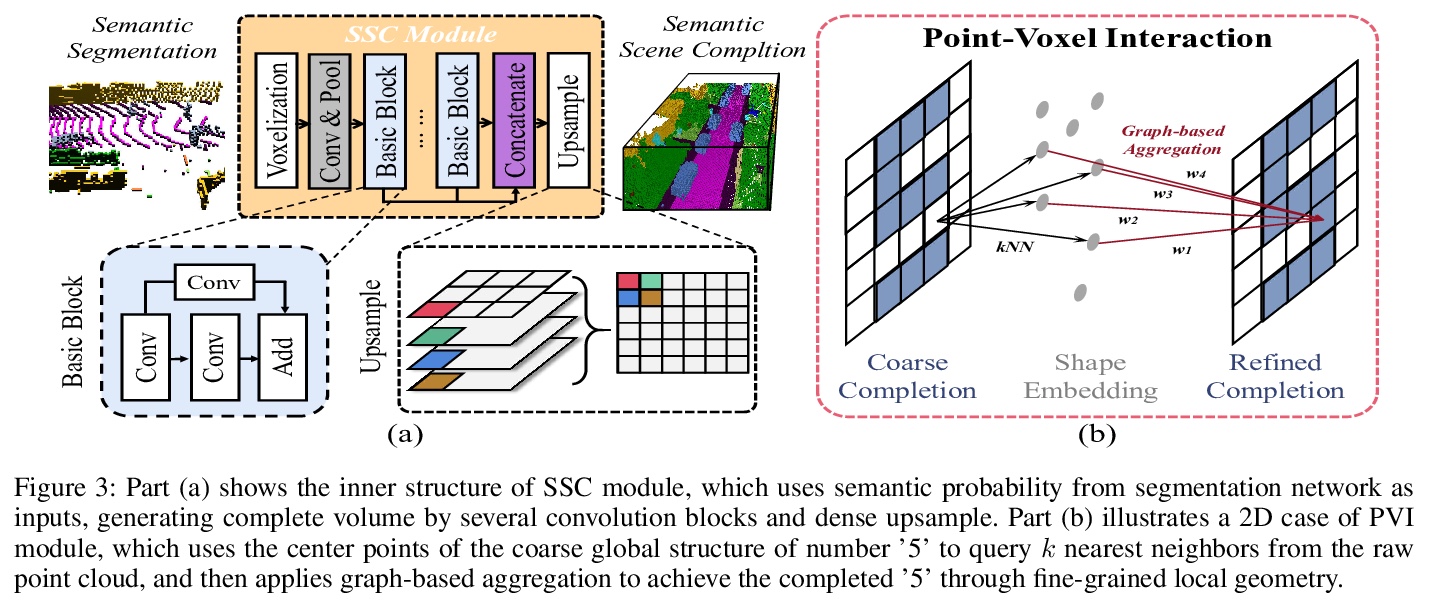
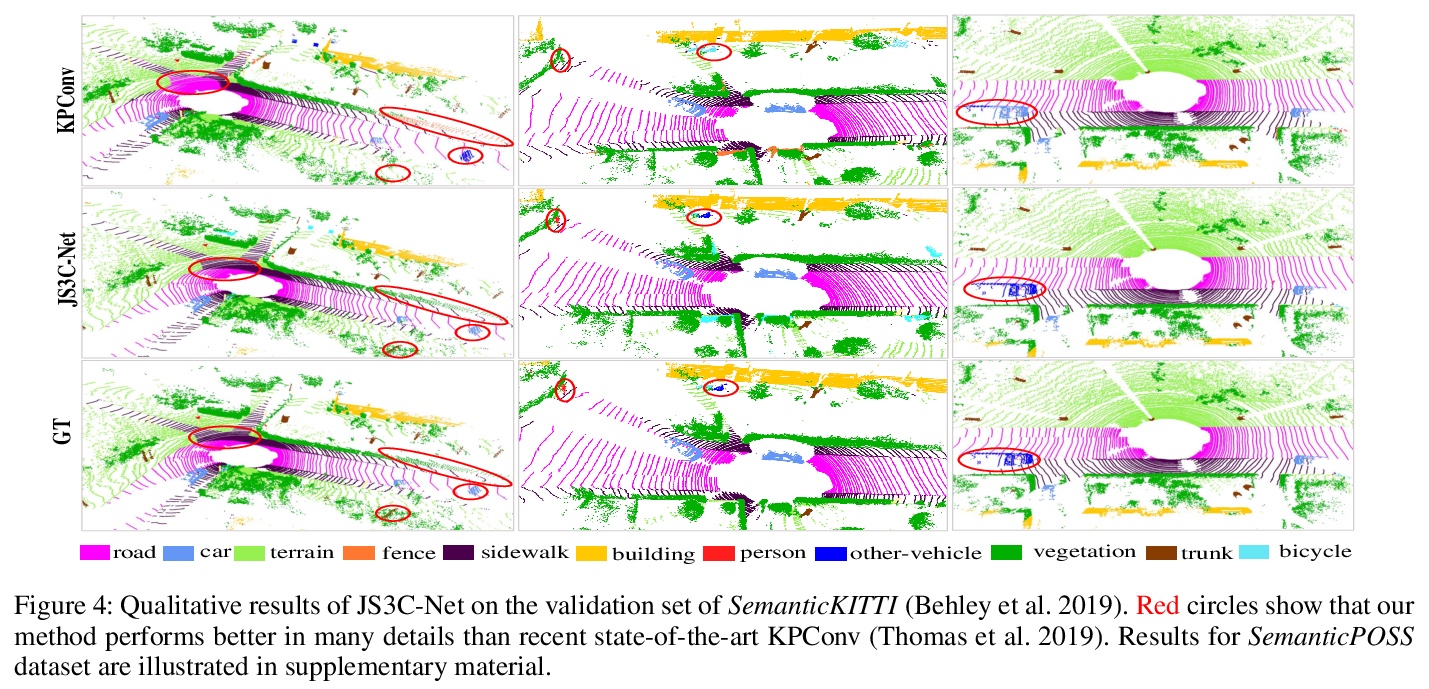
5、[CV] Sparse Single Sweep LiDAR Point Cloud Segmentation via Learning Contextual Shape Priors from Scene Completion
X Yan, J Gao, J Li, R Zhang, Z Li, R Huang, S Cui
[The Chinese University of Hong Kong (Shenzhen) & Shenzhen Research Institute of Big Data]
基于场景补全上下文形状先验学习的稀疏单扫激光雷达点云分割。提出了一种利用从场景补全网络学习到的形状先验,来增强联合单扫激光雷达点云语义分割的方法JS3C-Net。通过利用一些复杂的pipeline、交互模块和合理的损失函数,JS3C-Net模型在语义分割和场景补全任务上都取得了最先进结果,相比之前方法有较大优势。
LiDAR point cloud analysis is a core task for 3D computer vision, especially for autonomous driving. However, due to the severe sparsity and noise interference in the single sweep LiDAR point cloud, the accurate semantic segmentation is non-trivial to achieve. In this paper, we propose a novel sparse LiDAR point cloud semantic segmentation framework assisted by learned contextual shape priors. In practice, an initial semantic segmentation (SS) of a single sweep point cloud can be achieved by any appealing network and then flows into the semantic scene completion (SSC) module as the input. By merging multiple frames in the LiDAR sequence as supervision, the optimized SSC module has learned the contextual shape priors from sequential LiDAR data, completing the sparse single sweep point cloud to the dense one. Thus, it inherently improves SS optimization through fully end-to-end training. Besides, a Point-Voxel Interaction (PVI) module is proposed to further enhance the knowledge fusion between SS and SSC tasks, i.e., promoting the interaction of incomplete local geometry of point cloud and complete voxel-wise global structure. Furthermore, the auxiliary SSC and PVI modules can be discarded during inference without extra burden for SS. Extensive experiments confirm that our JS3C-Net achieves superior performance on both SemanticKITTI and SemanticPOSS benchmarks, i.e., 4% and 3% improvement correspondingly.
https://weibo.com/1402400261/JEBSXrTBo
另外几篇值得关注的论文:
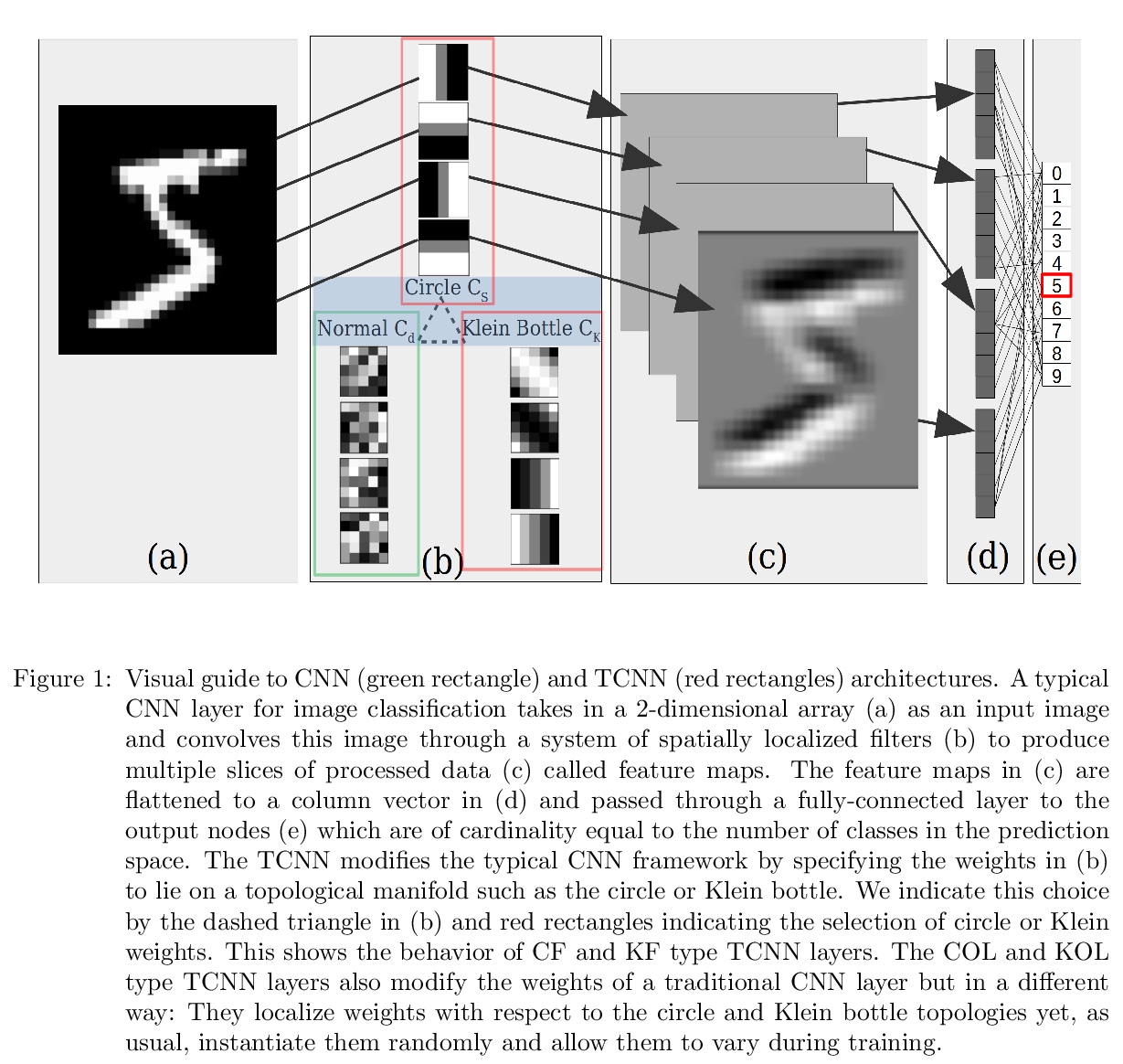
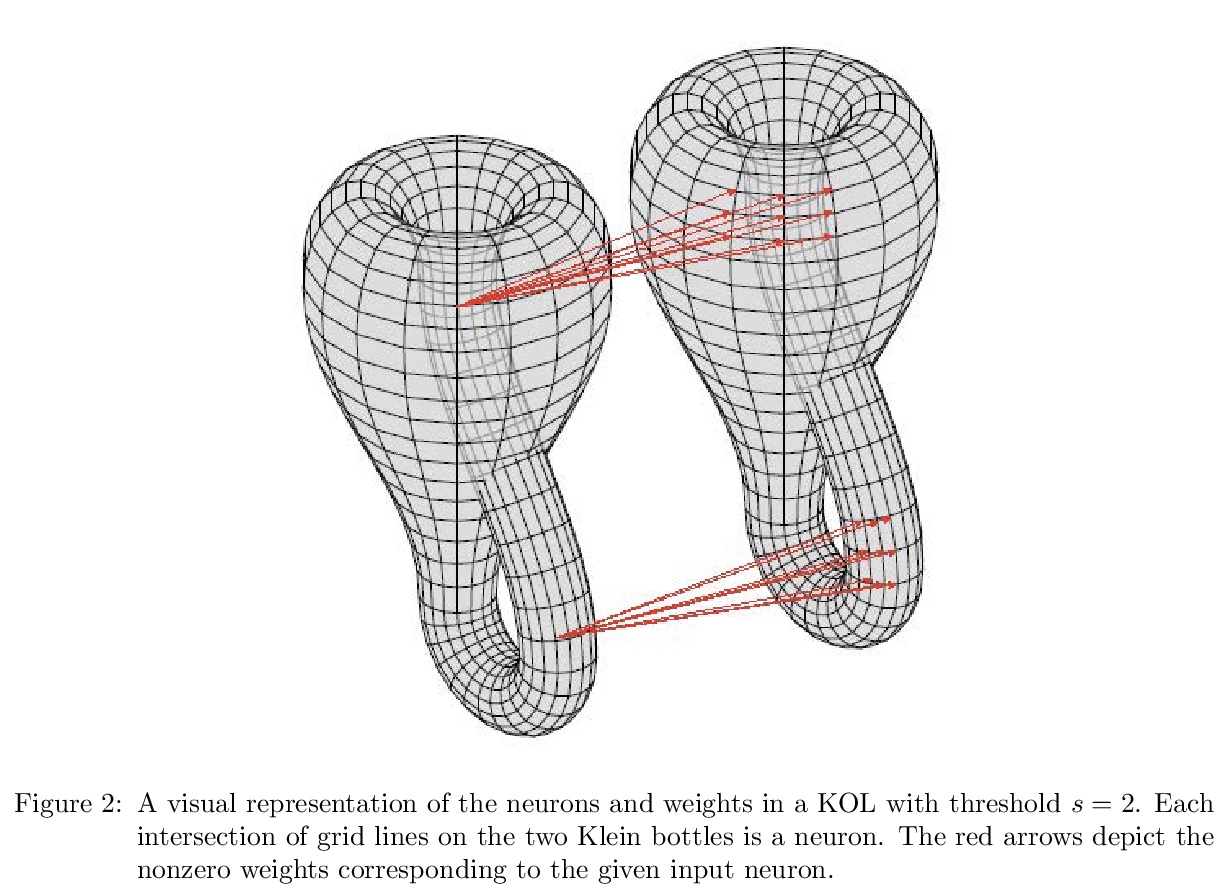
[LG] Topological Deep Learning
拓扑深度学习
E R. Love, B Filippenko, V Maroulas, G Carlsson
[University of Tennessee & Stanford University]
https://weibo.com/1402400261/JEC2qfuto

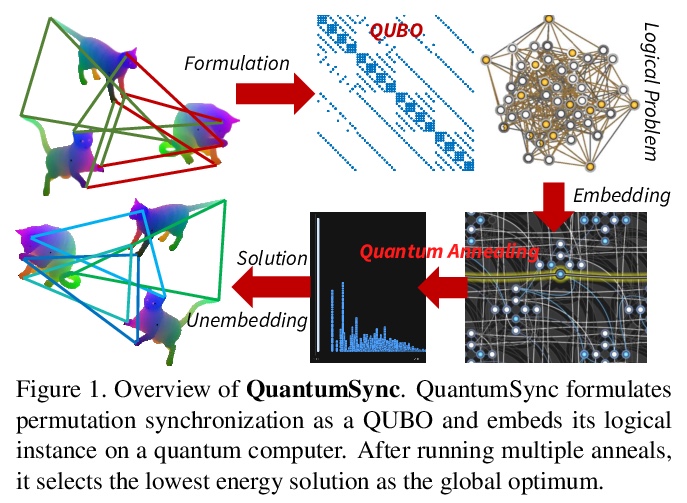
[CV] Quantum Permutation Synchronization
QuantumSync:用来解决计算机视觉同步问题的量子算法
T Birdal, V Golyanik, C Theobalt, L Guibas
[Stanford University & Max Planck Institute for Informatics]
https://weibo.com/1402400261/JEC407lBC



若有收获,就点个赞吧
0 人点赞
