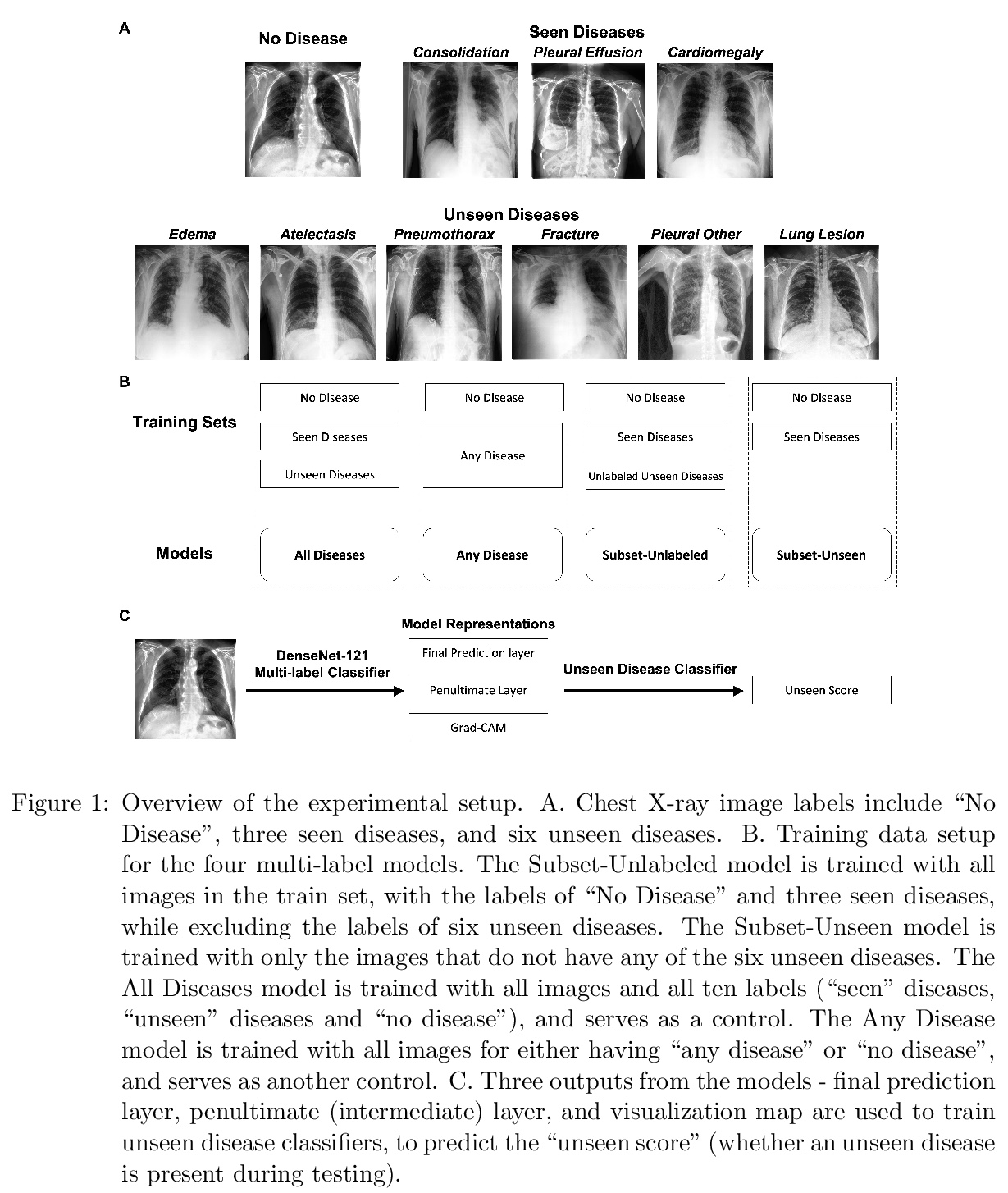
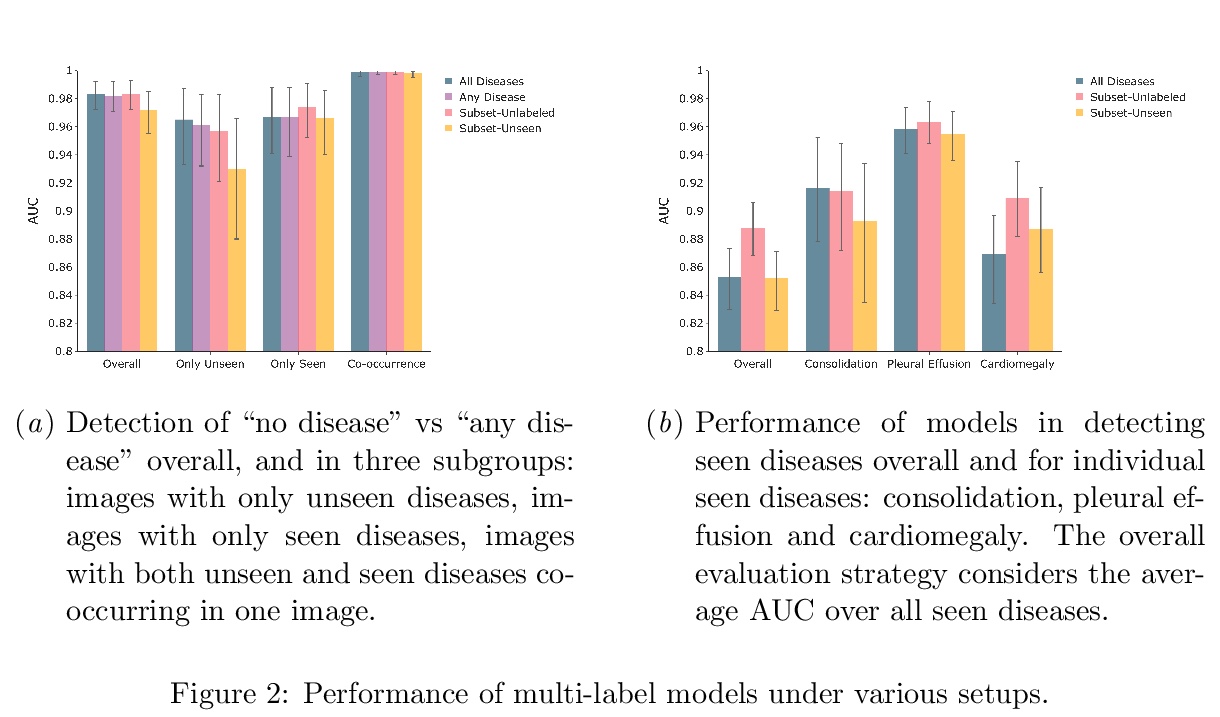
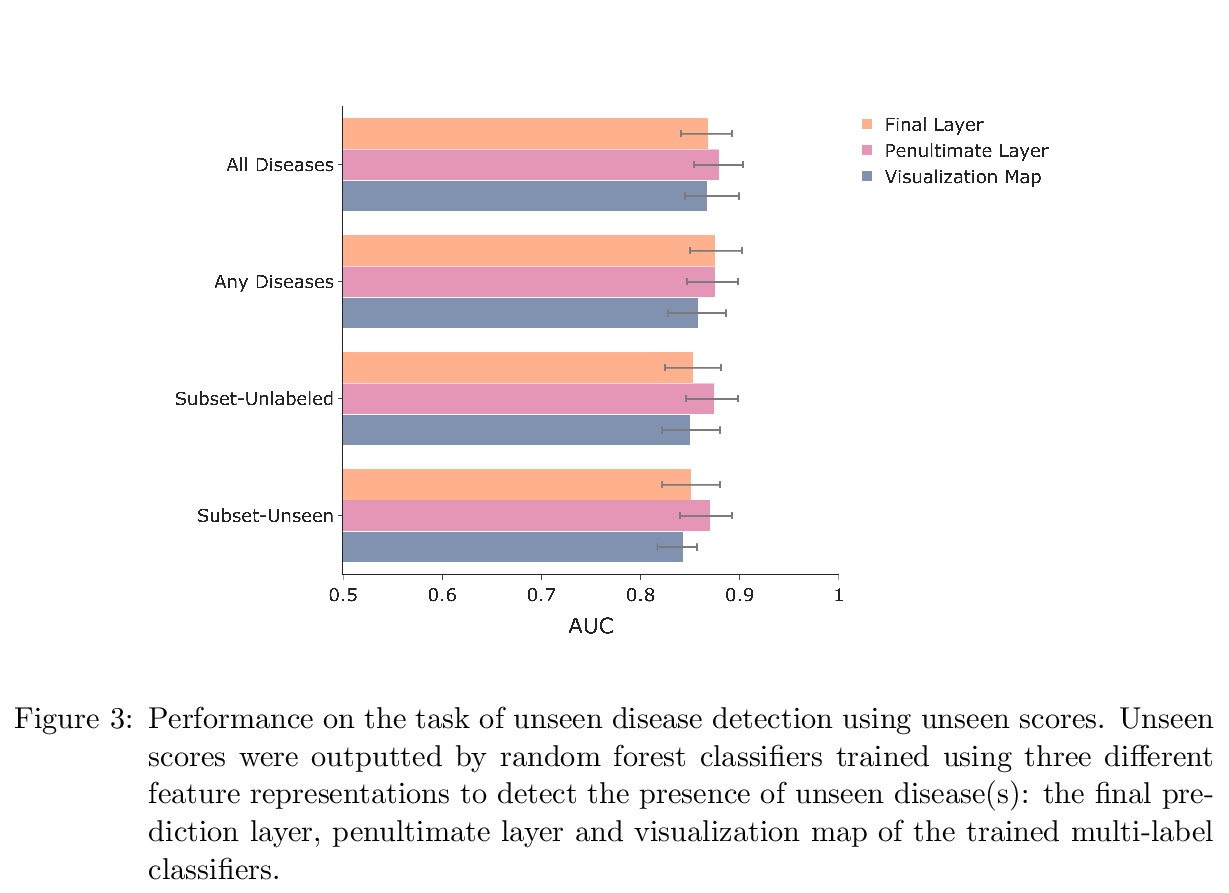
- 1、[CV] CheXseen: Unseen Disease Detection for Deep Learning Interpretation of Chest X-rays
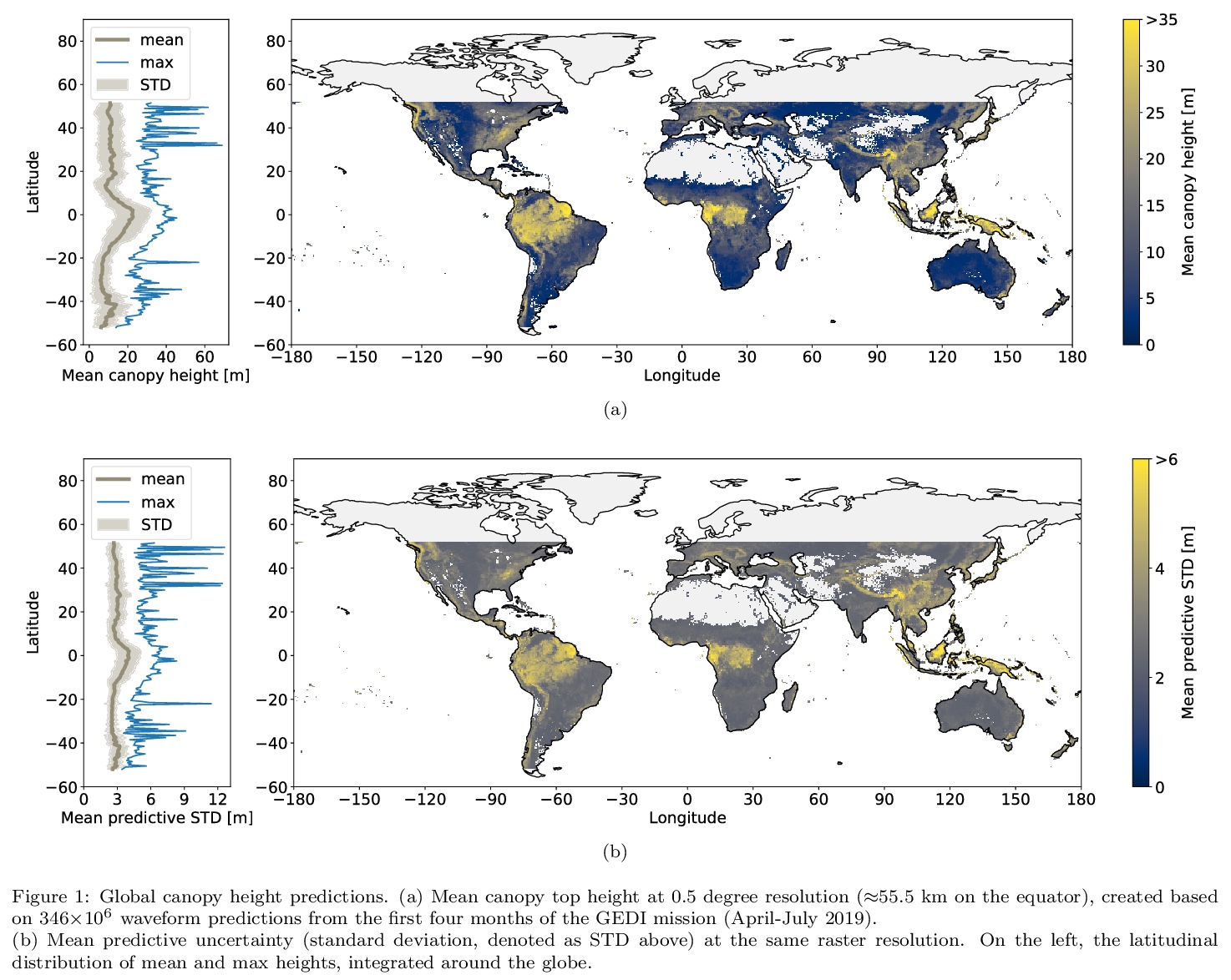
- 2、[LG] Global canopy height estimation with GEDI LIDAR waveforms and Bayesian deep learning
- 3、[LG] Maximum Entropy RL (Provably) Solves Some Robust RL Problems
- 4、[LG] Remember What You Want to Forget: Algorithms for Machine Unlearning
- 5、[CV] High Perceptual Quality Image Denoising with a Posterior Sampling CGAN
- [CL] CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review
- [LG] Kanerva++: extending The Kanerva Machine with differentiable, locally block allocated latent memory
- [LG] Gemini: Dynamic Bias Correction for Autonomous Experimentation and Molecular Simulation
- [CV] Greedy Hierarchical Variational Autoencoders for Large-Scale Video Prediction
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] CheXseen: Unseen Disease Detection for Deep Learning Interpretation of Chest X-rays
S Shi, I Malhi, K Tran, A Y. Ng, P Rajpurkar
[Stanford University]
CheXseen:深度学习胸片解读未见疾病检测。系统评价了深度学习模型在训练过程未标记或不存在疾病的情况下的性能。评价了在疾病子集(见过的疾病)上训练的深度学习模型是否能检测到更大的疾病集中任何一种疾病的存在,发现模型倾向于将子集之外的疾病(未见疾病)错误分类为”无疾病”。评价了在见过的疾病上训练的模型在与子集外疾病(未见疾病)共存时是否能检测到见过的疾病,发现即使与未见疾病共存时,模型仍然能够检测到见过的疾病。评价了给定一个小的未见疾病标签集,模型学习的特征表示是否可用来检测未见疾病的存在,发现深度神经网络的倒数第二层为未见疾病检测提供了有用特征。该结果可为在非详尽疾病类别集上训练的深度学习模型的安全临床部署提供参考。
We systematically evaluate the performance of deep learning models in the presence of diseases not labeled for or present during training. First, we evaluate whether deep learning models trained on a subset of diseases (seen diseases) can detect the presence of any one of a larger set of diseases. We find that models tend to falsely classify diseases outside of the subset (unseen diseases) as “no disease”. Second, we evaluate whether models trained on seen diseases can detect seen diseases when co-occurring with diseases outside the subset (unseen diseases). We find that models are still able to detect seen diseases even when co-occurring with unseen diseases. Third, we evaluate whether feature representations learned by models may be used to detect the presence of unseen diseases given a small labeled set of unseen diseases. We find that the penultimate layer of the deep neural network provides useful features for unseen disease detection. Our results can inform the safe clinical deployment of deep learning models trained on a non-exhaustive set of disease classes.
https://weibo.com/1402400261/K65RzEIEI
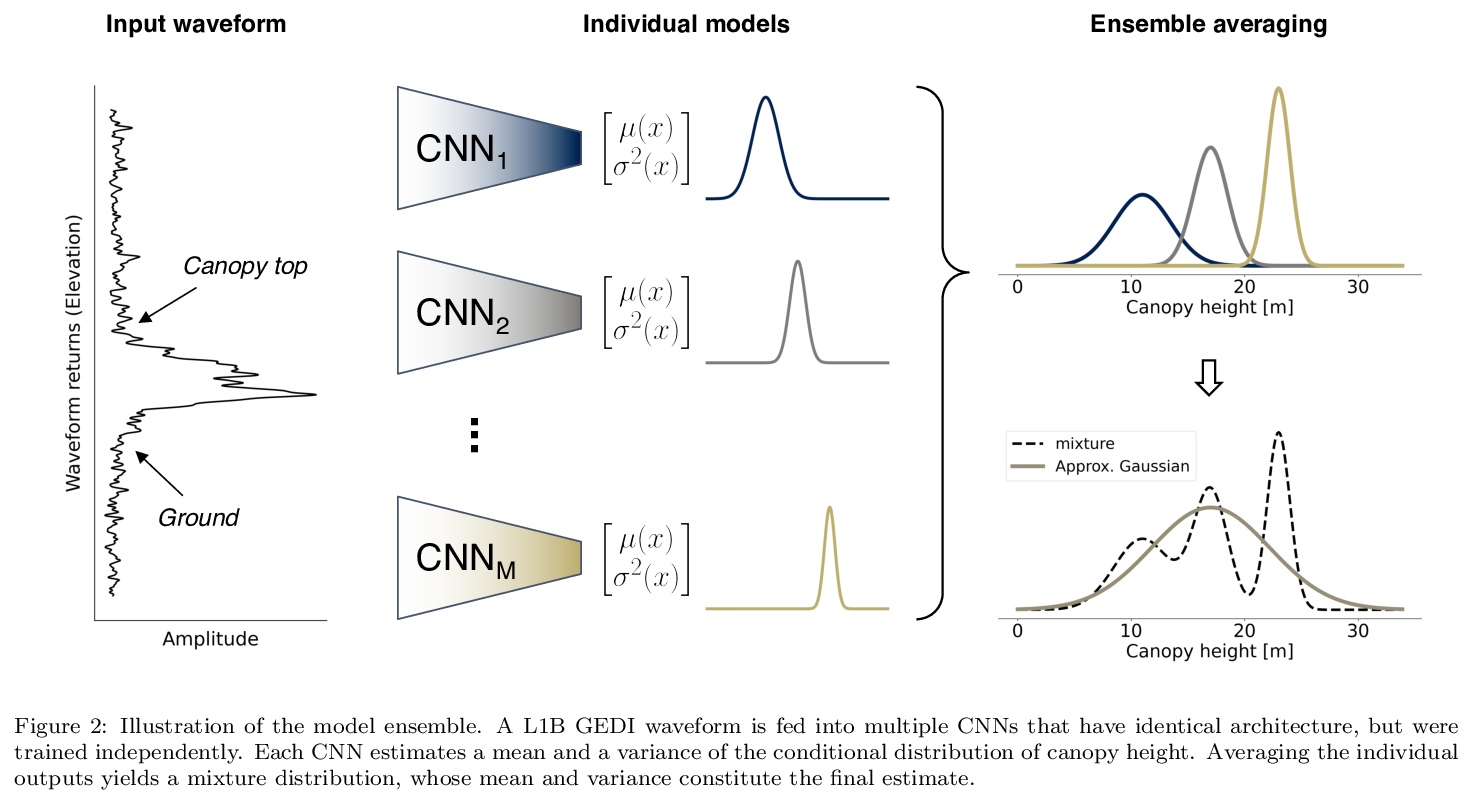
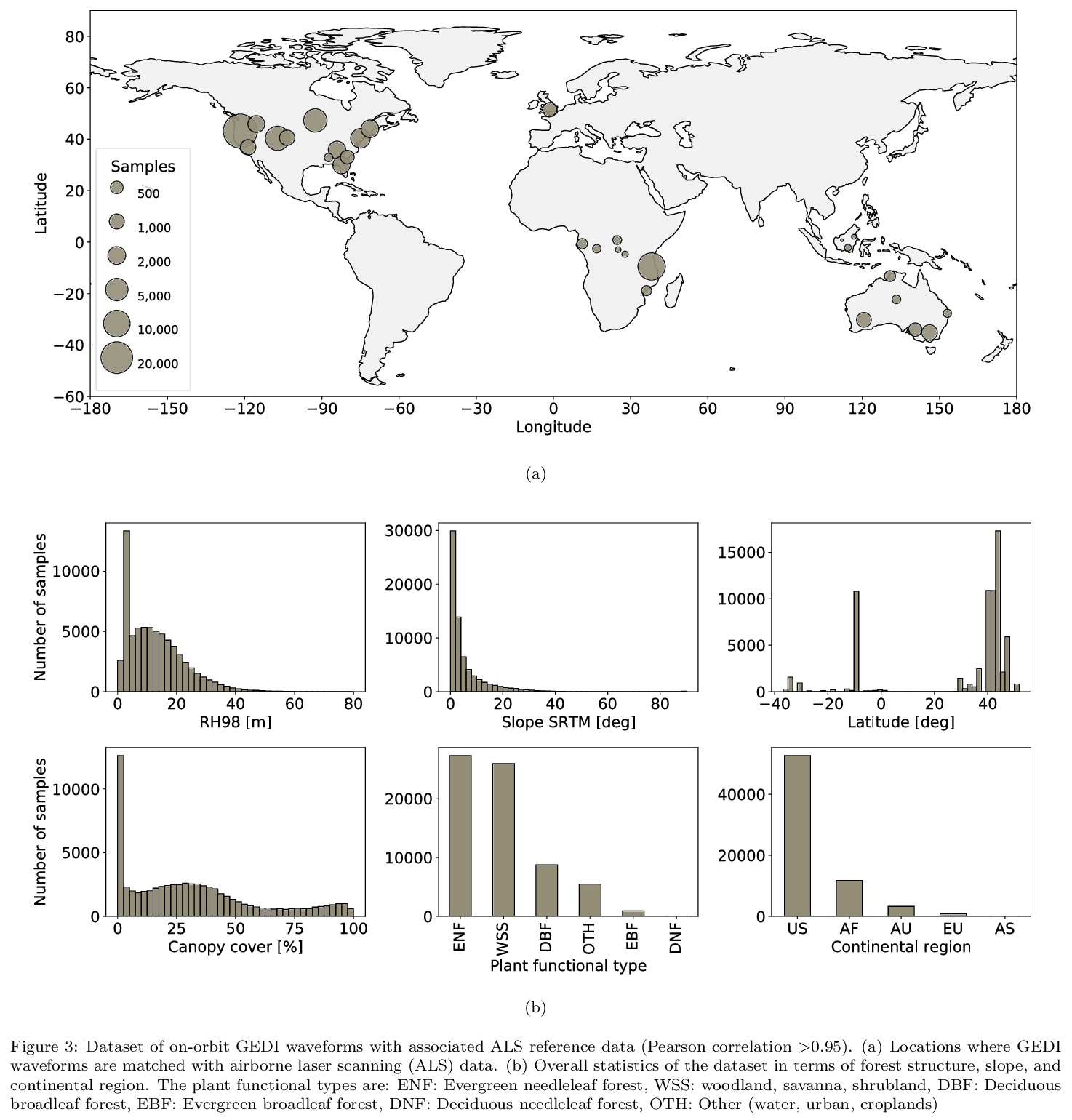
2、[LG] Global canopy height estimation with GEDI LIDAR waveforms and Bayesian deep learning
N Lang, N Kalischek, J Armston, K Schindler, R Dubayah, J D Wegner
[ETH Zurich & University of Maryland]
利用GEDI激光雷达波形和贝叶斯深度学习进行全球树冠高度估计。提出了一种新的有监督机器学习方法来解释GEDI波形,并在全球范围内回归树冠顶部高度。提出一种贝叶斯卷积神经网络,以避免对未知效应(如大气噪声)进行明确建模。CNN方法的一个主要优势是它避免了手动算法校准以找到最佳设置,这可能是一个困难和耗时的过程,并且通常需要根据单光束、植物功能类型、树冠层覆盖和其他观测条件进行调整。所提出的端到端学习是数据驱动的,但在所有可能的情况下都可通用,神经网络编码的自适应波形处理器在这些可变条件下都是有效的。该模型可学习提取可泛化到未见地理区域的稳健特征,还可产生预测不确定性的可靠估计。模型产生的全球树冠高度估计值具有2.7米的预期RMSE,且偏差较低。
https://weibo.com/1402400261/K65Zoipxs
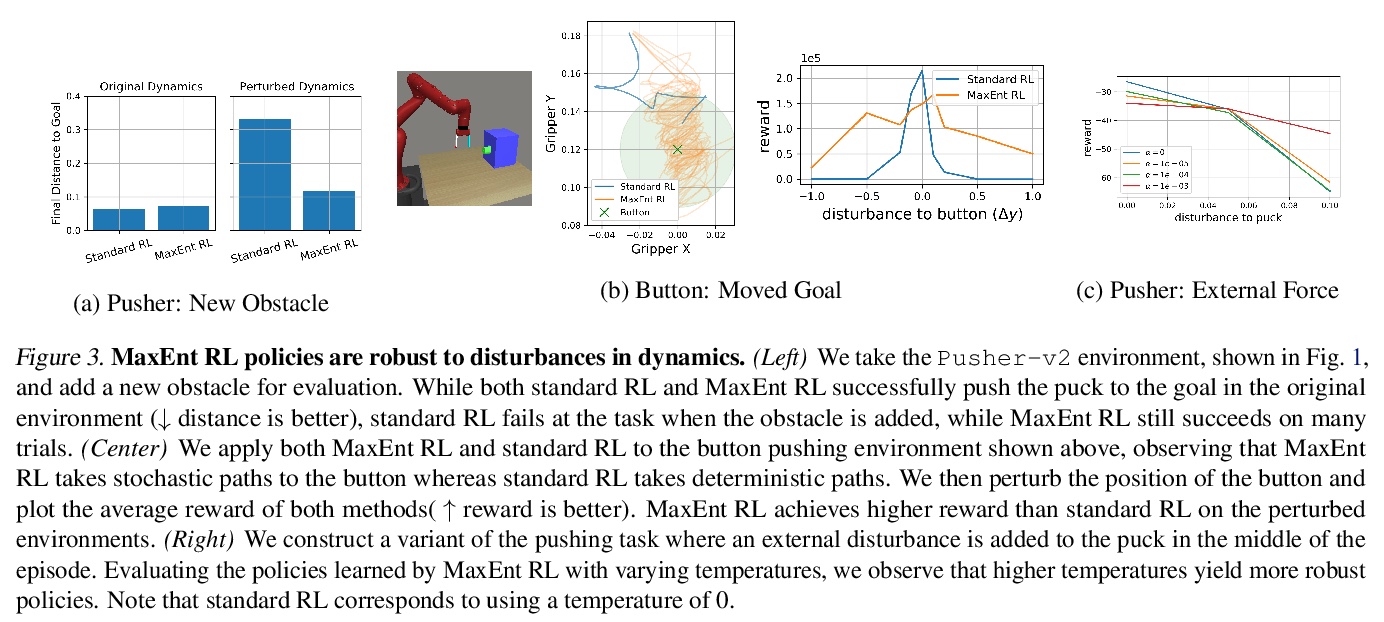
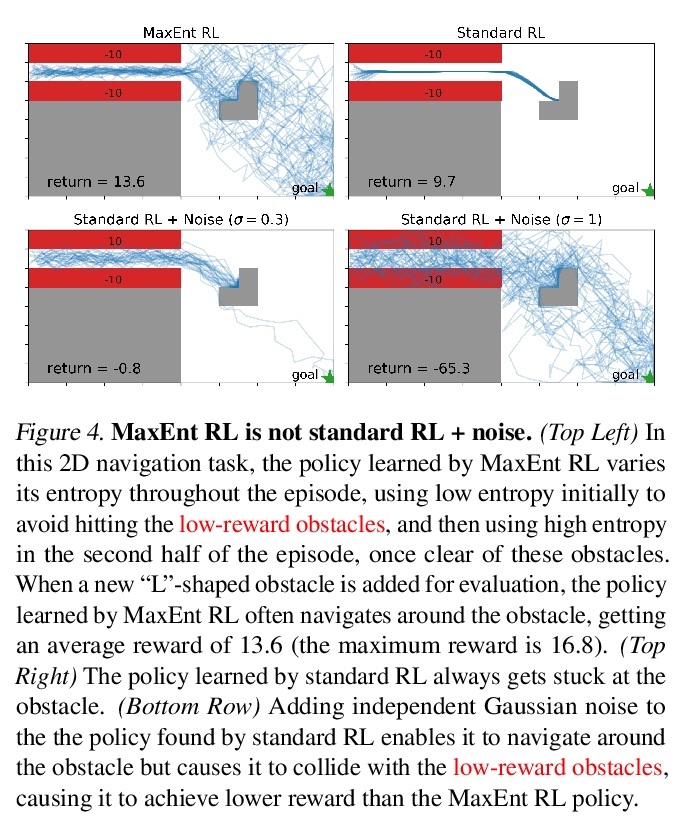
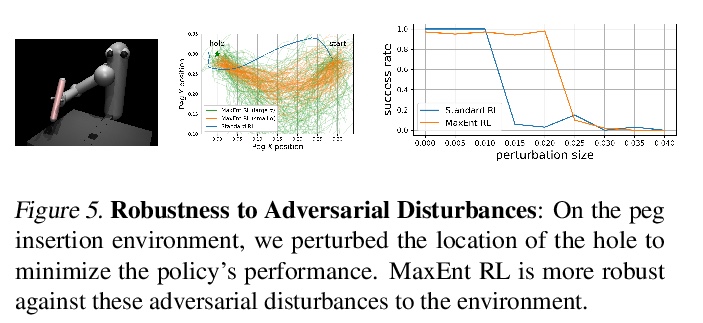
3、[LG] Maximum Entropy RL (Provably) Solves Some Robust RL Problems
B Eysenbach, S Levine
[CMU & UC Berkeley]
最大熵强化学习(可证)能解决部分鲁棒强化学习问题。从理论上证明了标准最大熵强化学习对于动态和奖励函数的一些干扰是鲁棒的,提供了最大熵强化学习鲁棒集的第一个严格的证明和理论阐述。理论结果表明,最大熵强化学习本身对某些干扰是鲁棒的,不需要任何额外修改。最大熵强化学习可能特别适合解决动态和奖励中具有不确定性的问题,不仅包括鲁棒强化学习,还包括具有隐含不确定性的问题,如POMDP、离线强化学习和元学习任务。虽然这并不意味着最大熵强化学习是现有最好的鲁棒强化学习方法,但其确实拥有惊人的简单性和吸引人的形式保证。
Many potential applications of reinforcement learning (RL) require guarantees that the agent will perform well in the face of disturbances to the dynamics or reward function. In this paper, we prove theoretically that standard maximum entropy RL is robust to some disturbances in the dynamics and the reward function. While this capability of MaxEnt RL has been observed empirically in prior work, to the best of our knowledge our work provides the first rigorous proof and theoretical characterization of the MaxEnt RL robust set. While a number of prior robust RL algorithms have been designed to handle similar disturbances to the reward function or dynamics, these methods typically require adding additional moving parts and hyperparameters on top of a base RL algorithm. In contrast, our theoretical results suggest that MaxEnt RL by itself is robust to certain disturbances, without requiring any additional modifications. While this does not imply that MaxEnt RL is the best available robust RL method, MaxEnt RL does possess a striking simplicity and appealing formal guarantees.
https://weibo.com/1402400261/K662NxNxa
4、[LG] Remember What You Want to Forget: Algorithms for Machine Unlearning
A Sekhari, J Acharya, G Kamath, A T Suresh
[Cornell University & University of Waterloo & Google Research]
记住要忘记什么:机器解学习算法。研究从学习模型中遗忘数据点的问题。这种情况下,学习器首先接收从未知分布中提取的数据集S,并输出一个在该分布的未见样本上表现良好的预测器w。但在未来的某时刻,任何训练数据点z∈S都可以请求取消学习,促使学习者在保证相同精度的前提下修改其输出的预测器。本文发起了对此类设置下机器解学习的严格研究,目标是保持未见测试损失的性能,重点是群体风险最小化。对于凸损失函数的情况,提供了一种新的解学习算法,相比使用开箱即用的差分隐私算法进行解学习,在删除容量上至少提高了四倍系数d。
We study the problem of forgetting datapoints from a learnt model. In this case, the learner first receives a dataset > S drawn i.i.d. from an unknown distribution, and outputs a predictor > w that performs well on unseen samples from that distribution. However, at some point in the future, any training data point > z∈S can request to be unlearned, thus prompting the learner to modify its output predictor while still ensuring the same accuracy guarantees. In our work, we initiate a rigorous study of machine unlearning in the population setting, where the goal is to maintain performance on the unseen test loss. We then provide unlearning algorithms for convex loss functions.For the setting of convex losses, we provide an unlearning algorithm that can delete up to > O(n/d1/4) samples, where > d is the problem dimension. In comparison, in general, differentially private learningv(which implies unlearning) only guarantees deletion of > O(n/d1/2) samples. This shows that unlearning is at least polynomially more efficient than learning privately in terms of dependence on > d in the deletion capacity.
https://weibo.com/1402400261/K66609klG
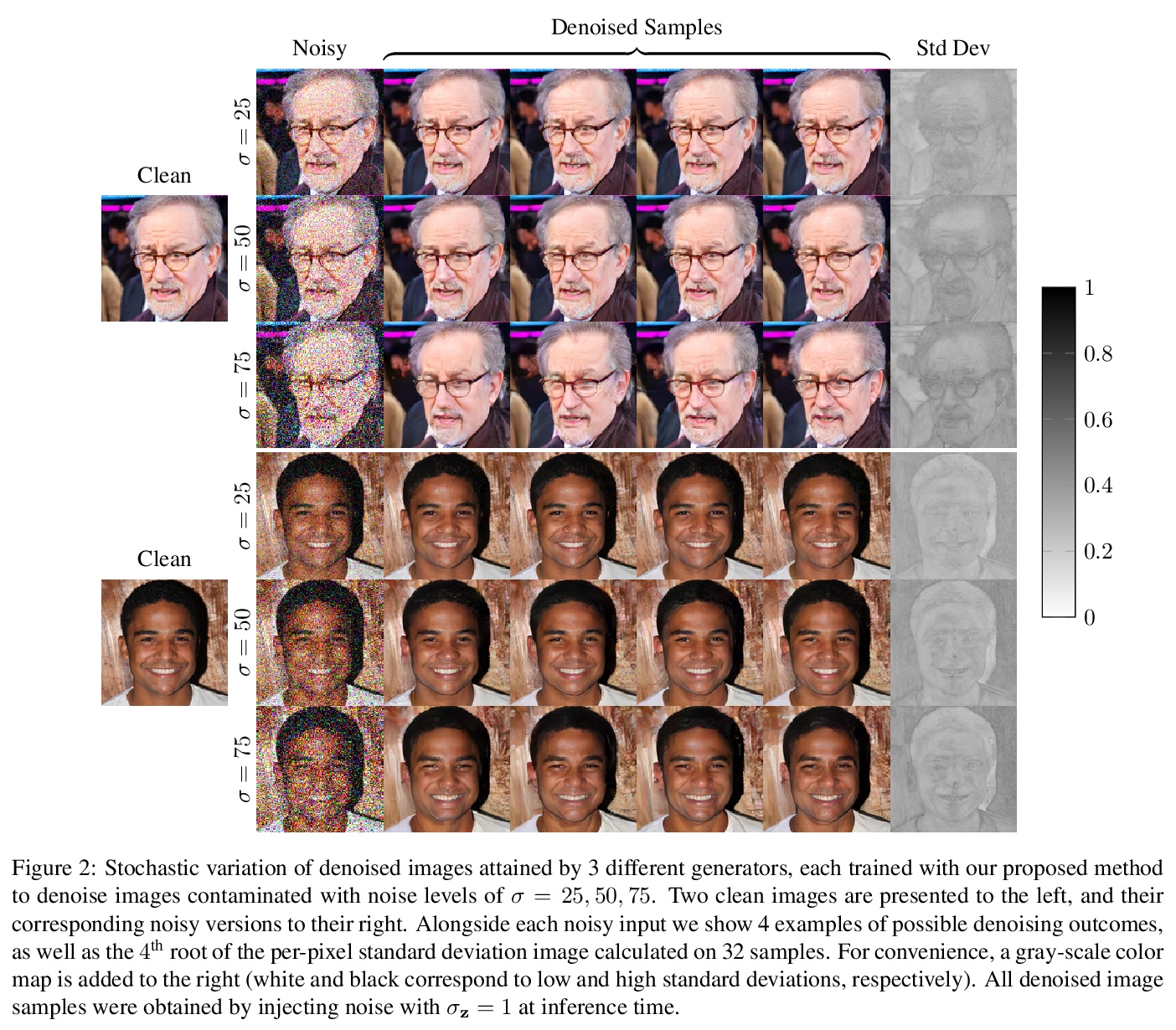
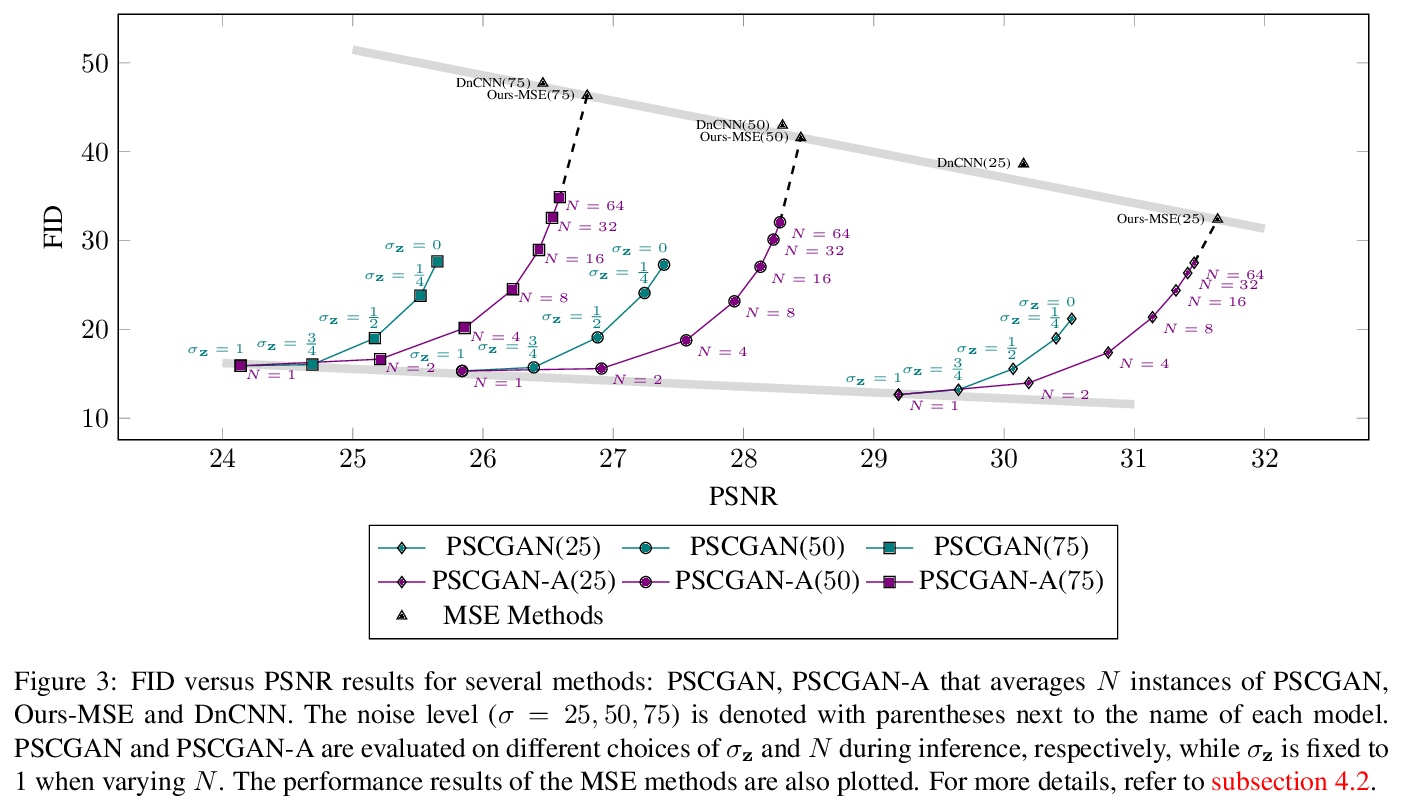
5、[CV] High Perceptual Quality Image Denoising with a Posterior Sampling CGAN
G Ohayon, T Adrai, G Vaksman, M Elad, P Milanfar
[Technion & Google Research]
基于后置采样CGAN的高感知质量图像去噪。重新审视了图像去噪任务,专注于产生视觉上令人愉悦的图像,并仍然忠实于其干净的来源,而不是基于失真的方法,其目标是最佳PSNR。形式上,其目标是在可接受的失真下实现高感知质量,通过随机去噪器来实现,从后置分布中采样,在条件生成对抗网络(CGANs)的框架下作为一个生成器进行训练。与基于失真的正则化项与感知质量冲突相反,在CGANs目标中引入了一个理论上成立的惩罚项,并不强制对单个样本提出失真要求,而是对其平均值提出要求。用一种新的去噪器架构展示了所提方法,实现了新的去噪目标,并在不调和噪声水平下产生了生动而多样的结果。
The vast work in Deep Learning (DL) has led to a leap in image denoising research. Most DL solutions for this task have chosen to put their efforts on the denoiser’s architecture while maximizing distortion performance. However, distortion driven solutions lead to blurry results with sub-optimal perceptual quality, especially in immoderate noise levels. In this paper we propose a different perspective, aiming to produce sharp and visually pleasing denoised images that are still faithful to their clean sources. Formally, our goal is to achieve high perceptual quality with acceptable distortion. This is attained by a stochastic denoiser that samples from the posterior distribution, trained as a generator in the framework of conditional generative adversarial networks (CGANs). Contrary to distortion-based regularization terms that conflict with perceptual quality, we introduce to the CGANs objective a theoretically founded penalty term that does not force a distortion requirement on individual samples, but rather on their mean. We showcase our proposed method with a novel denoiser architecture that achieves the reformed denoising goal and produces vivid and diverse outcomes in immoderate noise levels.
https://weibo.com/1402400261/K66fknGju

另外几篇值得关注的论文:
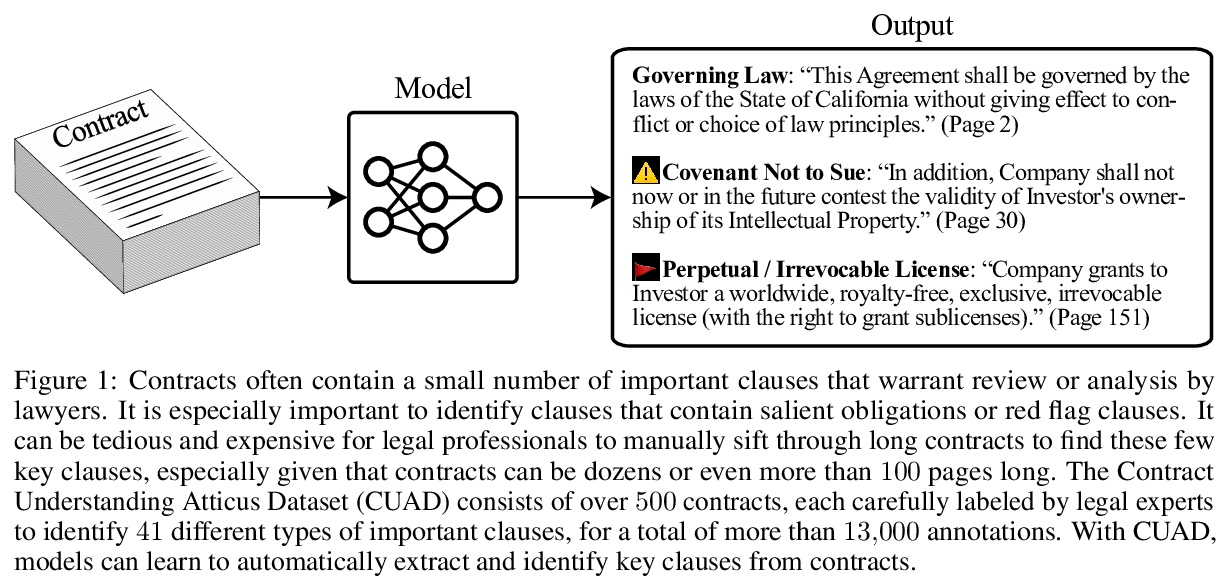
[CL] CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review
CUAD:专家标注法律合同审查自然语言处理数据集
D Hendrycks, C Burns, A Chen, S Ball
[UC Berkeley & The Nueva School]
https://weibo.com/1402400261/K65OccUwb

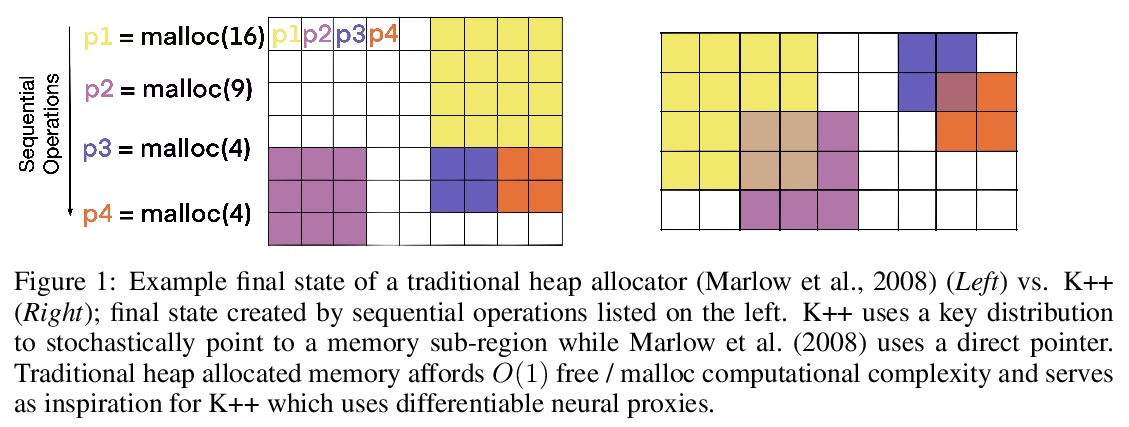
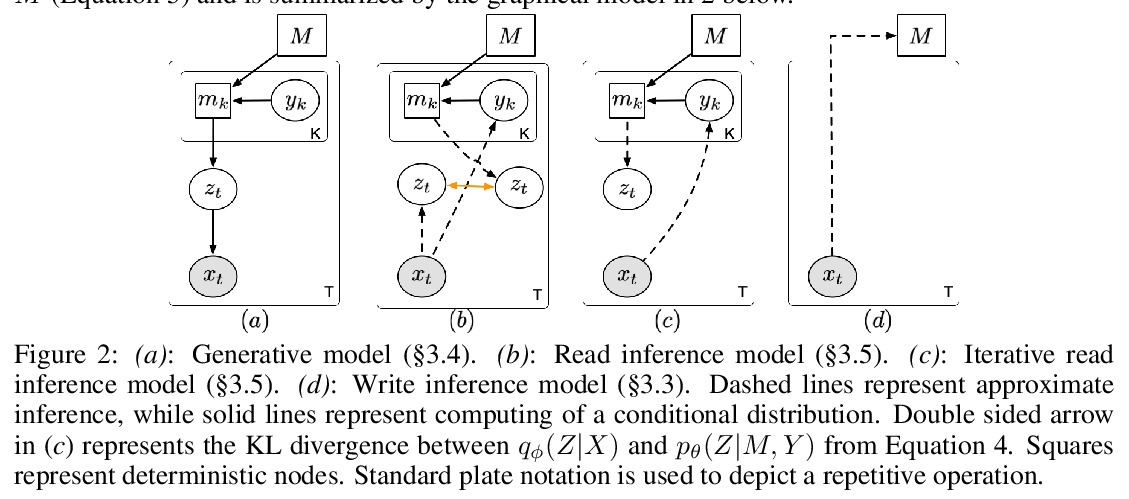
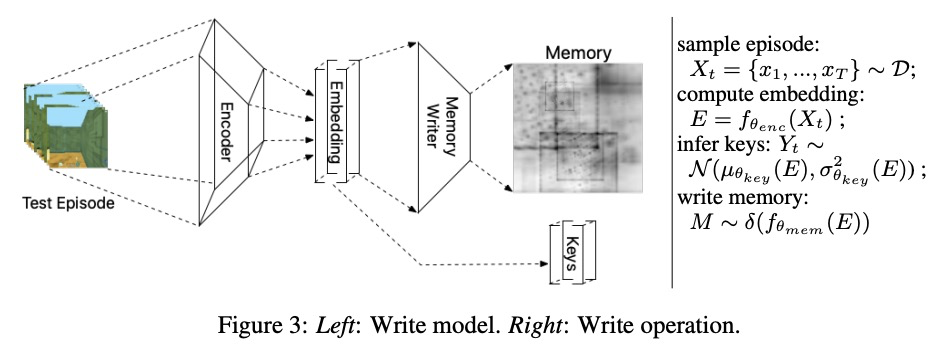
[LG] Kanerva++: extending The Kanerva Machine with differentiable, locally block allocated latent memory
Kanerva++:可微局部块分配潜记忆扩展Kanerva机
J Ramapuram, Y Wu, A Kalousis
[Apple & Deepmind]
https://weibo.com/1402400261/K66d41dw3
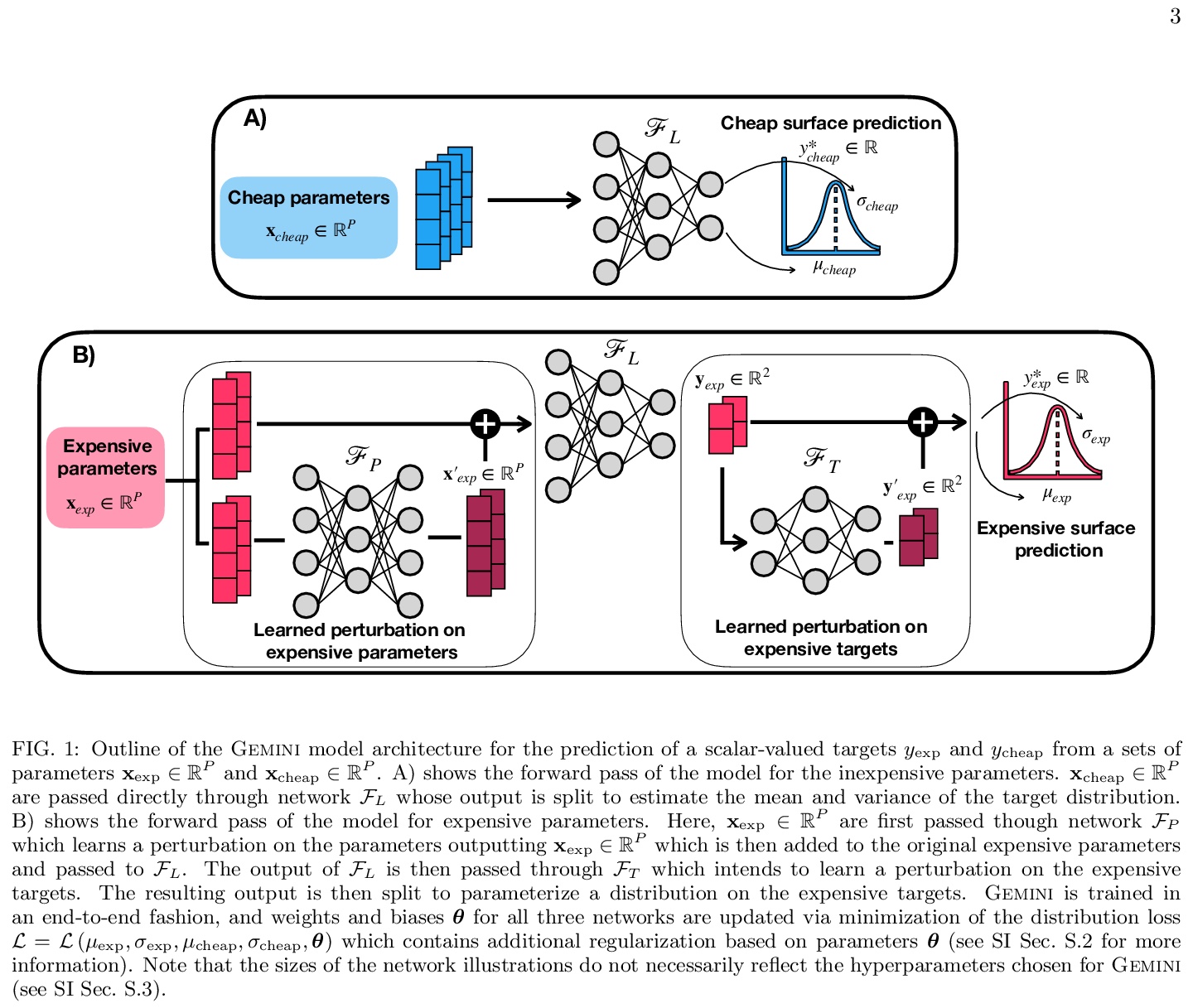
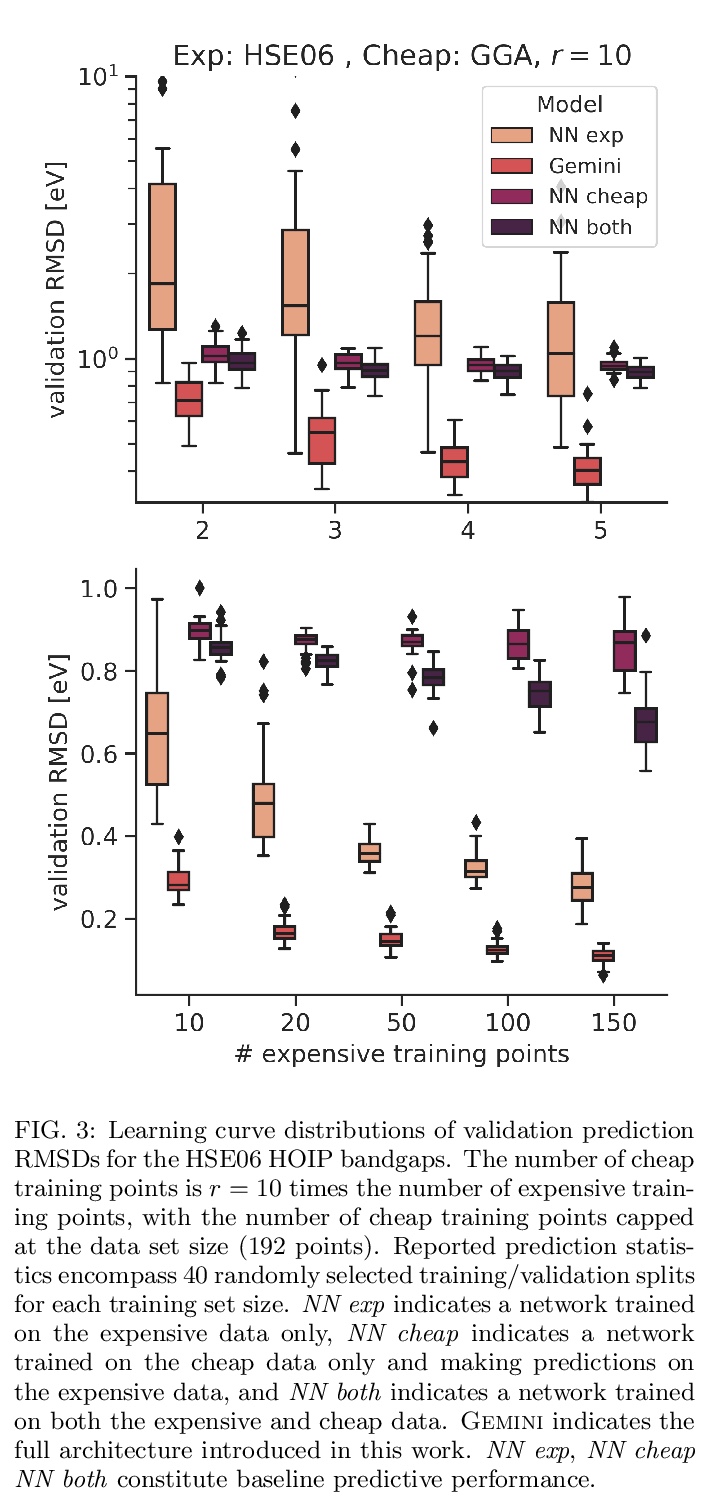
[LG] Gemini: Dynamic Bias Correction for Autonomous Experimentation and Molecular Simulation
Gemini:用于自主实验和分子模拟的动态偏差校正
R J. Hickman, F Häse, L M. Roch, A Aspuru-Guzik
[University of Toronto]
https://weibo.com/1402400261/K66oUBE7D

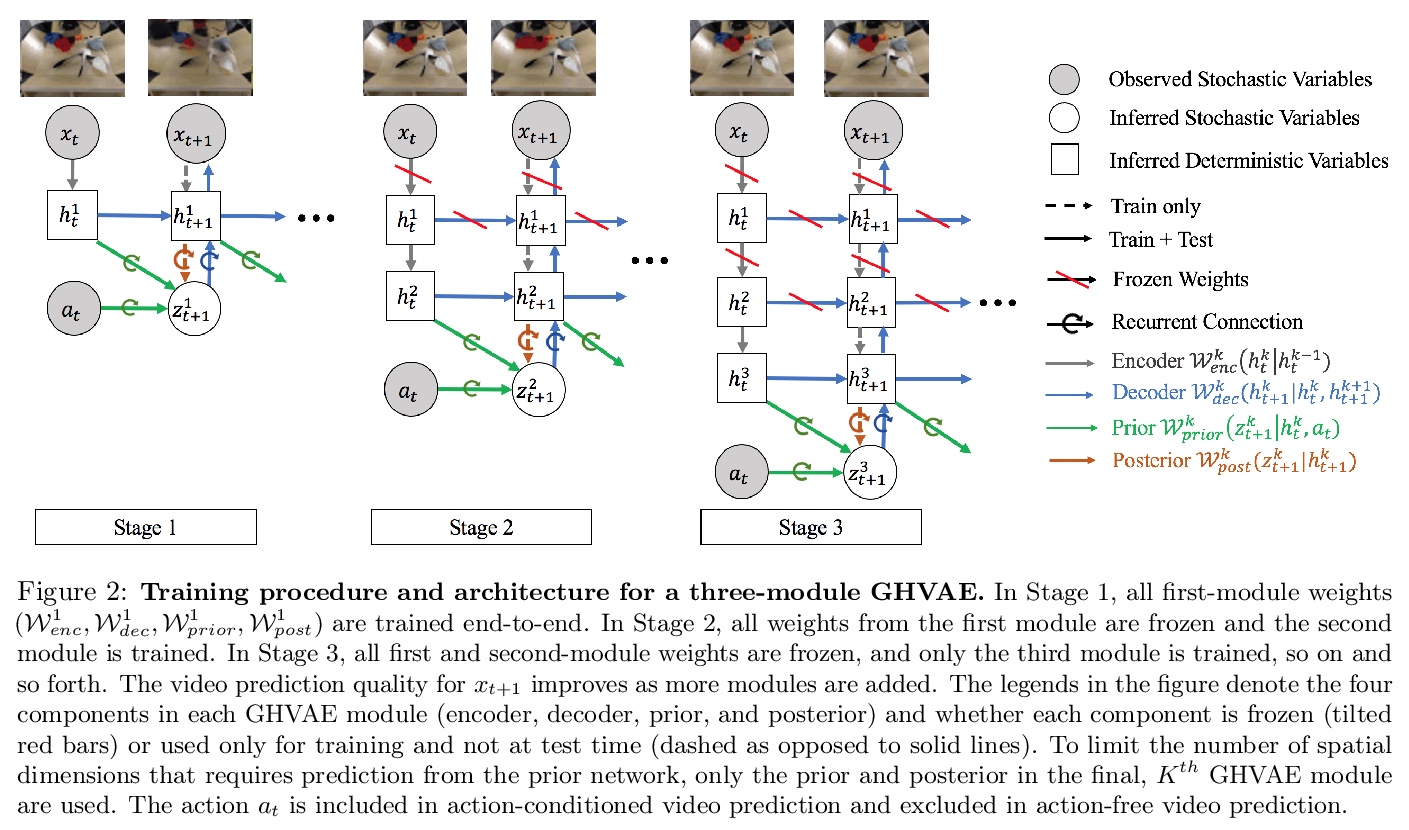
[CV] Greedy Hierarchical Variational Autoencoders for Large-Scale Video Prediction
面向大规模视频预测的贪婪层次变分自编码器
B Wu, S Nair, R Martin-Martin, L Fei-Fei, C Finn
[Stanford University]
https://weibo.com/1402400261/K66qGx4lb



若有收获,就点个赞吧
0 人点赞
