LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、** **[CV] Object-based attention for spatio-temporal reasoning: Outperforming neuro-symbolic models with flexible distributed architectures
D Ding, F Hill, A Santoro, M Botvinick
[DeepMind]
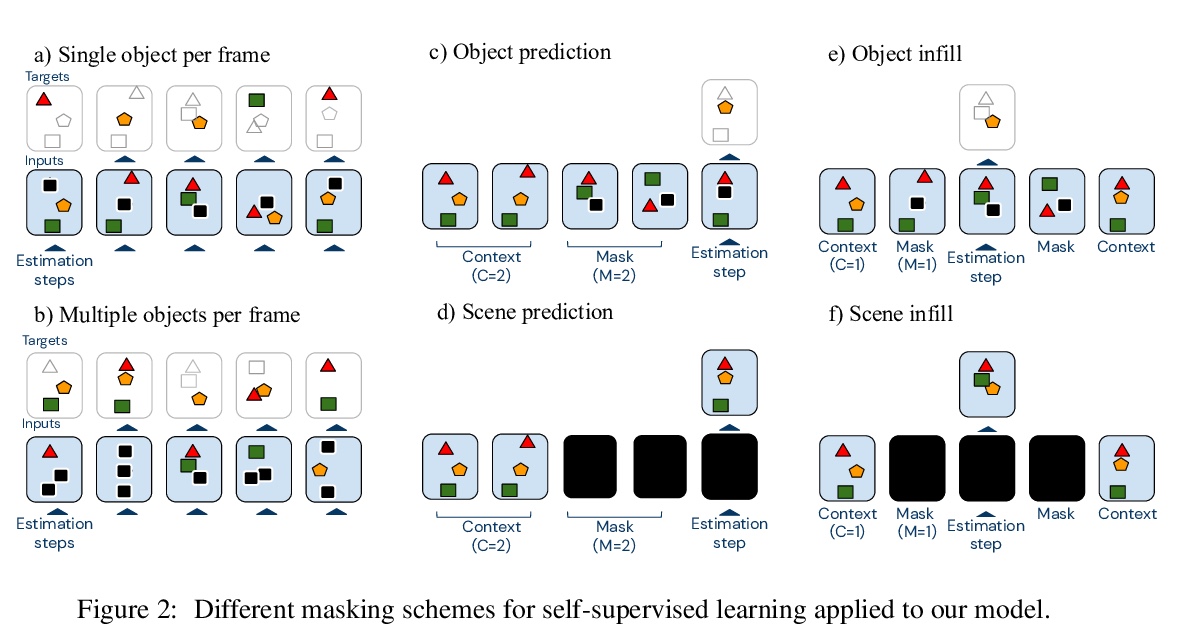
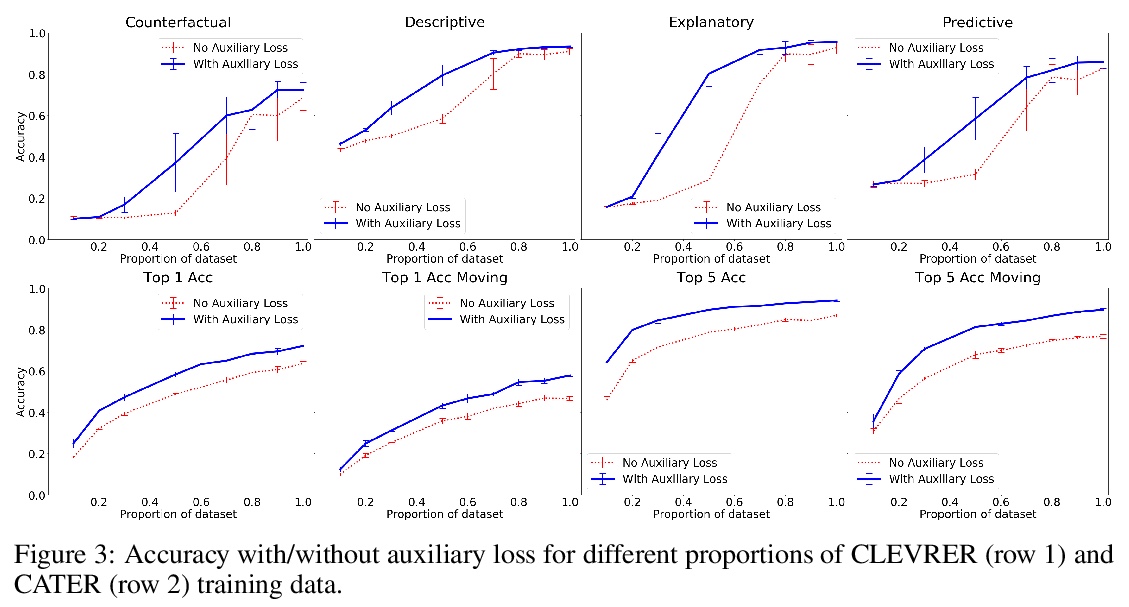
对象注意力时空推理。提出用于解释物理对象相互作用视频的模型,在两个最近提出的数据集CLEVRER和CATER上,表现大大优于之前的神经符号模型。包含明确为相关任务定制的手工编码组件的神经-符号混合架构,对强大性能来说是必要的。模型完全依赖于分布式—而不是符号或局部式—内在表示,少用40%的标记数据,实现了与现存最佳神经-符号模型相同的性能,在相同数据量情况下大幅超越所有现有方法。三个要素对模型性能至关重要:自注意力,在对象层次对输入的柔性(准)离散化,以及自监督学习。
Neural networks have achieved success in a wide array of perceptual tasks, but it is often stated that they are incapable of solving tasks that require higher-level reasoning. Two new task domains, CLEVRER and CATER, have recently been developed to focus on reasoning, as opposed to perception, in the context of spatio-temporal interactions between objects. Initial experiments on these domains found that neuro-symbolic approaches, which couple a logic engine and language parser with a neural perceptual front-end, substantially outperform fully-learned distributed networks, a finding that was taken to support the above thesis. Here, we show on the contrary that a fully-learned neural network with the right inductive biases can perform substantially better than all previous neural-symbolic models on both of these tasks, particularly on questions that most emphasize reasoning over perception. Our model makes critical use of both self-attention and learned “soft” object-centric representations, as well as BERT-style semi-supervised predictive losses. These flexible biases allow our model to surpass the previous neuro-symbolic state-of-the-art using less than 60% of available labelled data. Together, these results refute the neuro-symbolic thesis laid out by previous work involving these datasets, and they provide evidence that neural networks can indeed learn to reason effectively about the causal, dynamic structure of physical events.
https://weibo.com/1402400261/JyOWLahCg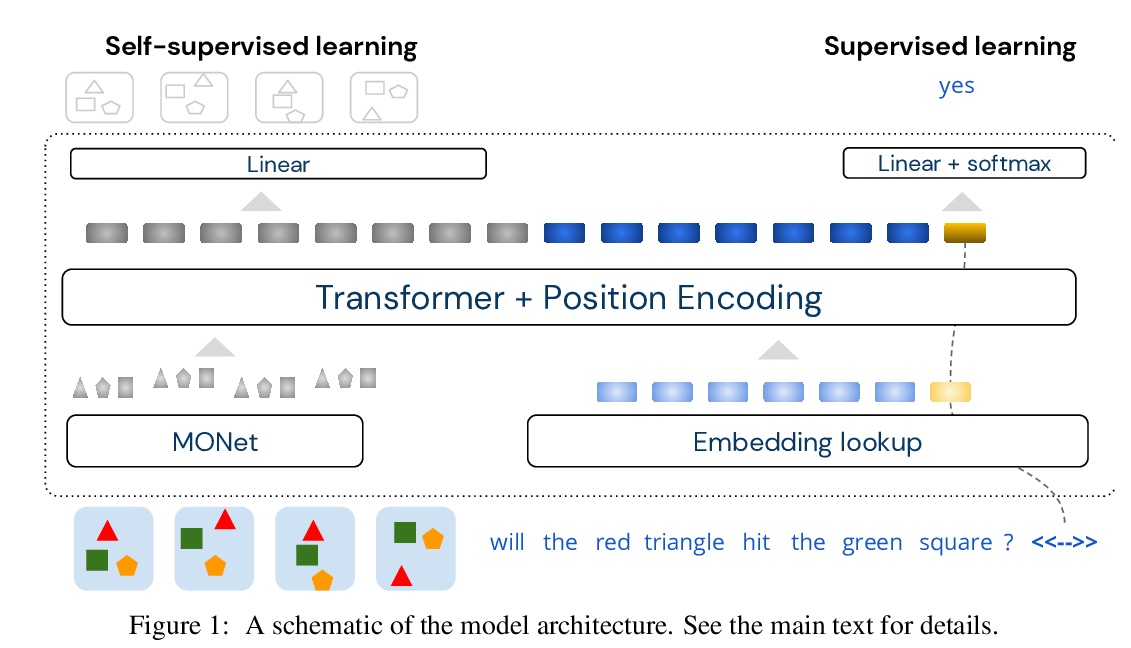
2、** **[CV] Detecting Invisible People
T Khurana, A Dave, D Ramanan
[CMU]
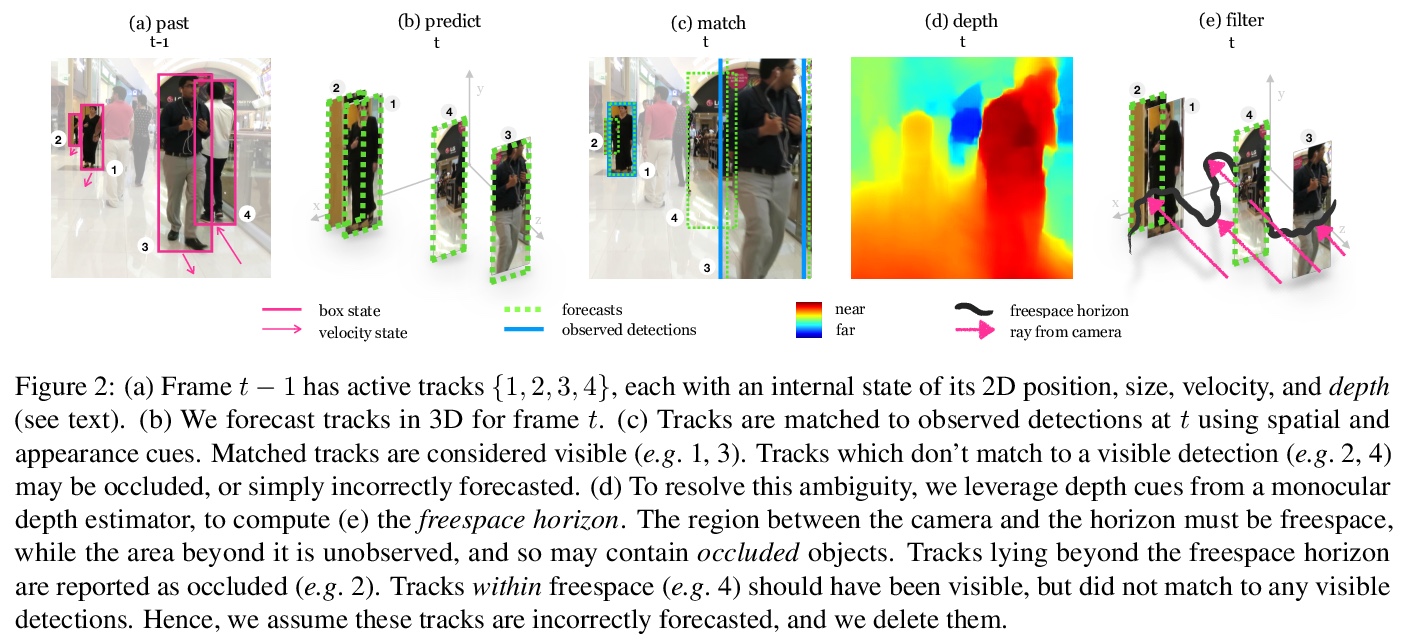
隐蔽人物检测。提出以在线方式从单目相机中检测完全被遮挡目标的任务,提出一种在线方法,预测被遮挡人物轨迹,将时间序列中的隐蔽目标检测作为短期预测挑战,引入动态序列预测工具,利用最先进的单目深度估计网络所产生的观测结果,建立明确的3D推理动态模型,更好地推理潜在遮挡。该方法可用于已有检测器和跟踪器的输出,准确度比基线提高11%,比最先进水平提高5%。
Monocular object detection and tracking have improved drastically in recent years, but rely on a key assumption: that objects are visible to the camera. Many offline tracking approaches reason about occluded objects post-hoc, by linking together tracklets after the object re-appears, making use of reidentification (ReID). However, online tracking in embodied robotic agents (such as a self-driving vehicle) fundamentally requires object permanence, which is the ability to reason about occluded objects before they re-appear. In this work, we re-purpose tracking benchmarks and propose new metrics for the task of detecting invisible objects, focusing on the illustrative case of people. We demonstrate that current detection and tracking systems perform dramatically worse on this task. We introduce two key innovations to recover much of this performance drop. We treat occluded object detection in temporal sequences as a short-term forecasting challenge, bringing to bear tools from dynamic sequence prediction. Second, we build dynamic models that explicitly reason in 3D, making use of observations produced by state-of-the-art monocular depth estimation networks. To our knowledge, ours is the first work to demonstrate the effectiveness of monocular depth estimation for the task of tracking and detecting occluded objects. Our approach strongly improves by 11.4% over the baseline in ablations and by 5.0% over the state-of-the-art in F1 score.
https://weibo.com/1402400261/JyP2M4YRI
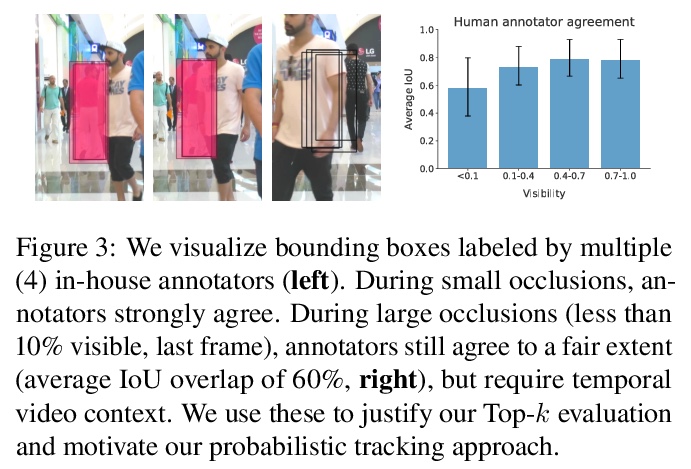
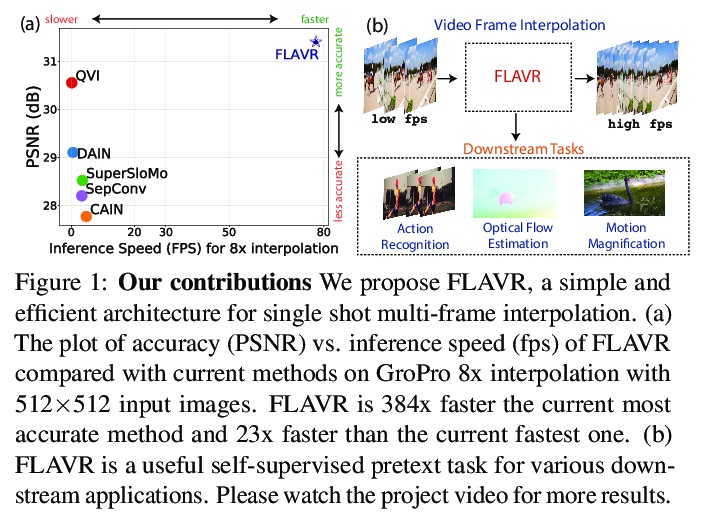
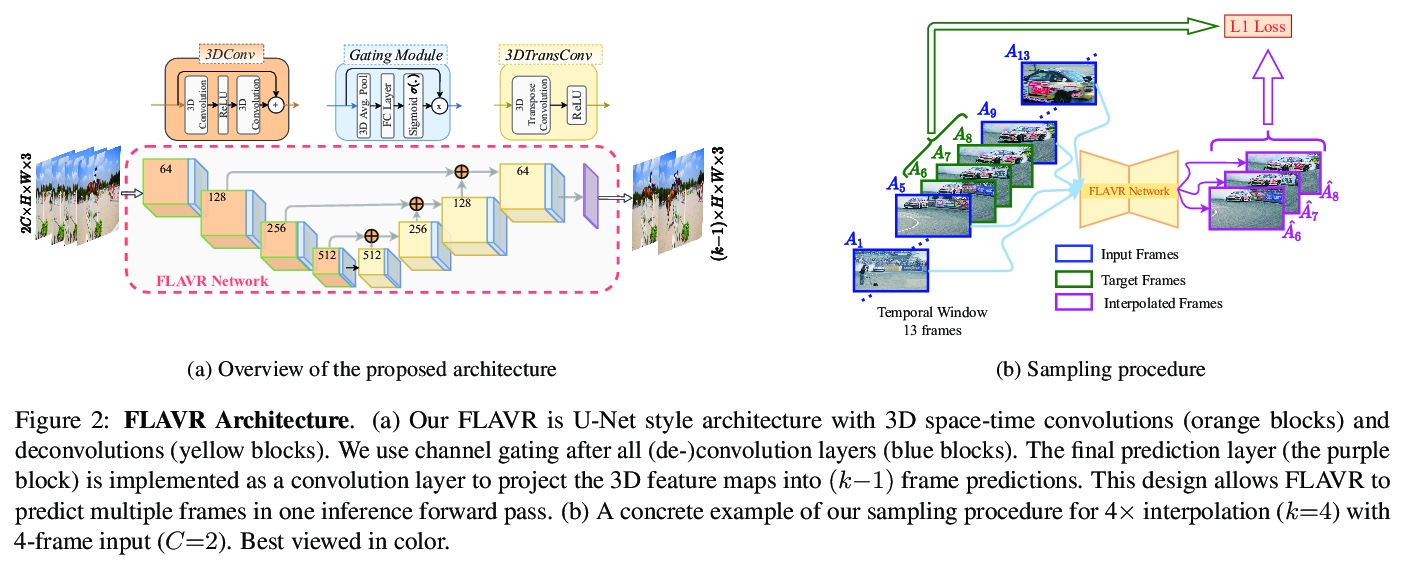
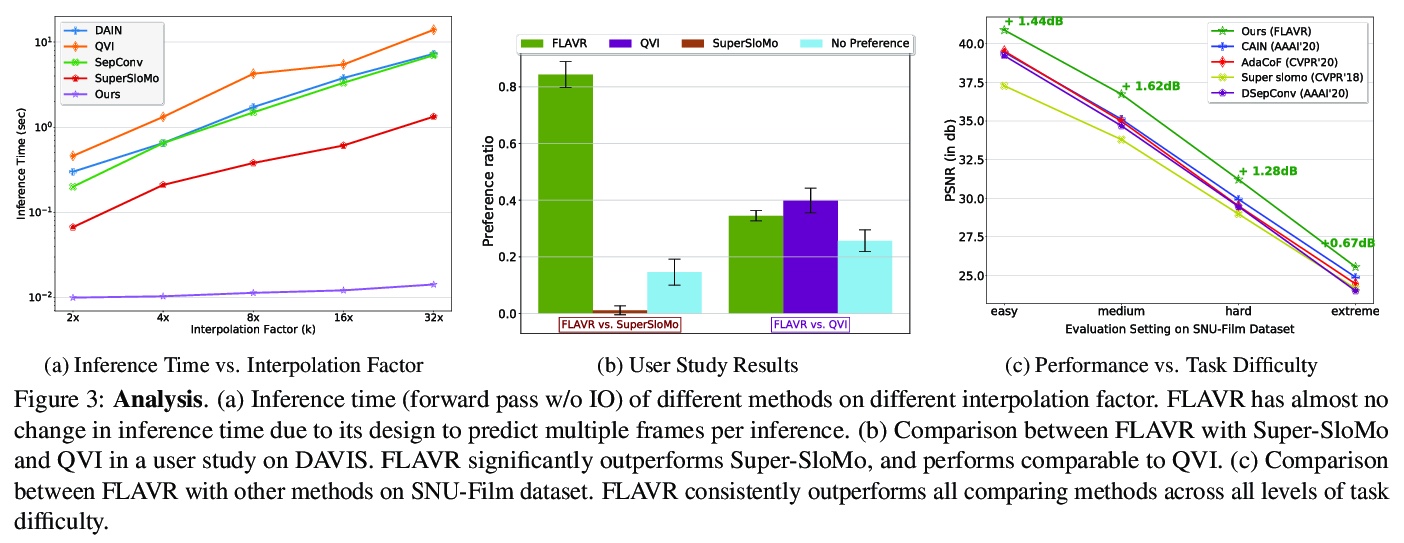
3、** **[CV] FLAVR: Flow-Agnostic Video Representations for Fast Frame Interpolation
T Kalluri, D Pathak, M Chandraker, D Tran
[UCSD & CMU & Facebook AI]
面向快速帧插值的光流无关视频表示。提出FLAVR,一种光流无关、简单且高效的端到端帧插值架构,采用3D卷积来明显式建模输入帧之间的时空关系,提高了各种输入帧速率下复杂运动曲线的插值精度。FLAVR比当前最精确的方法快384倍,比当前最快的方法快23倍,与当前的方法相比性能更好。
A majority of approaches solve the problem of video frame interpolation by computing bidirectional optical flow between adjacent frames of a video followed by a suitable warping algorithm to generate the output frames. However, methods relying on optical flow often fail to model occlusions and complex non-linear motions directly from the video and introduce additional bottlenecks unsuitable for real time deployment. To overcome these limitations, we propose a flexible and efficient architecture that makes use of 3D space-time convolutions to enable end to end learning and inference for the task of video frame interpolation. Our method efficiently learns to reason about non-linear motions, complex occlusions and temporal abstractions resulting in improved performance on video interpolation, while requiring no additional inputs in the form of optical flow or depth maps. Due to its simplicity, our proposed method improves the inference speed by 384x compared to the current most accurate method and 23x compared to the current fastest on 8x interpolation. In addition, we evaluate our model on a wide range of challenging settings and consistently demonstrate superior qualitative and quantitative results compared with current methods on various popular benchmarks including Vimeo-90K, UCF101, DAVIS, Adobe, and GoPro. Finally, we demonstrate that video frame interpolation can serve as a useful self-supervised pretext task for action recognition, optical flow estimation, and motion magnification.
https://weibo.com/1402400261/JyP78qe9E
4、** **[LG] Amazon SageMaker Autopilot: a white box AutoML solution at scale
P Das, V Perrone, N Ivkin, T Bansal, Z Karnin, H Shen, I Shcherbatyi, Y Elor, W Wu, A Zolic, T Lienart, A Tang, A Ahmed, J B Faddoul, R Jenatton, F Winkelmolen, P Gautier, L Dirac, A Perunicic, M Miladinovic, G Zappella, C Archambeau, M Seeger, B Dutt, L Rouesnel
[Amazon Web Services]
Amazon SageMaker Autopilot:规模化白盒AutoML解决方案。介绍了Amazon SageMaker Autopilot,一个全托管系统,提供自动化的机器学习解决方案,可在需要时进行修改。给定表格数据集和目标列名,Autopilot会识别问题类型,分析数据,并生成一套多样化的完整机器学习pipeline,包括特征预处理和机器学习算法,经调整后生成候选模型排行。性能不达标时,可查看和编辑所提出的机器学习pipeline,以注入人工的专业知识和业务知识,而不必重新回到全手工解决方案。
AutoML systems provide a black-box solution to machine learning problems by selecting the right way of processing features, choosing an algorithm and tuning the hyperparameters of the entire pipeline. Although these systems perform well on many datasets, there is still a non-negligible number of datasets for which the one-shot solution produced by each particular system would provide sub-par performance. In this paper, we present Amazon SageMaker Autopilot: a fully managed system providing an automated ML solution that can be modified when needed. Given a tabular dataset and the target column name, Autopilot identifies the problem type, analyzes the data and produces a diverse set of complete ML pipelines including feature preprocessing and ML algorithms, which are tuned to generate a leaderboard of candidate models. In the scenario where the performance is not satisfactory, a data scientist is able to view and edit the proposed ML pipelines in order to infuse their expertise and business knowledge without having to revert to a fully manual solution. This paper describes the different components %in the eco-system of Autopilot, emphasizing the infrastructure choices that allow scalability, high quality models, editable ML pipelines, consumption of artifacts of offline meta-learning, and a convenient integration with the entire SageMaker suite allowing these trained models to be used in a production setting.
https://weibo.com/1402400261/JyPcac5JQ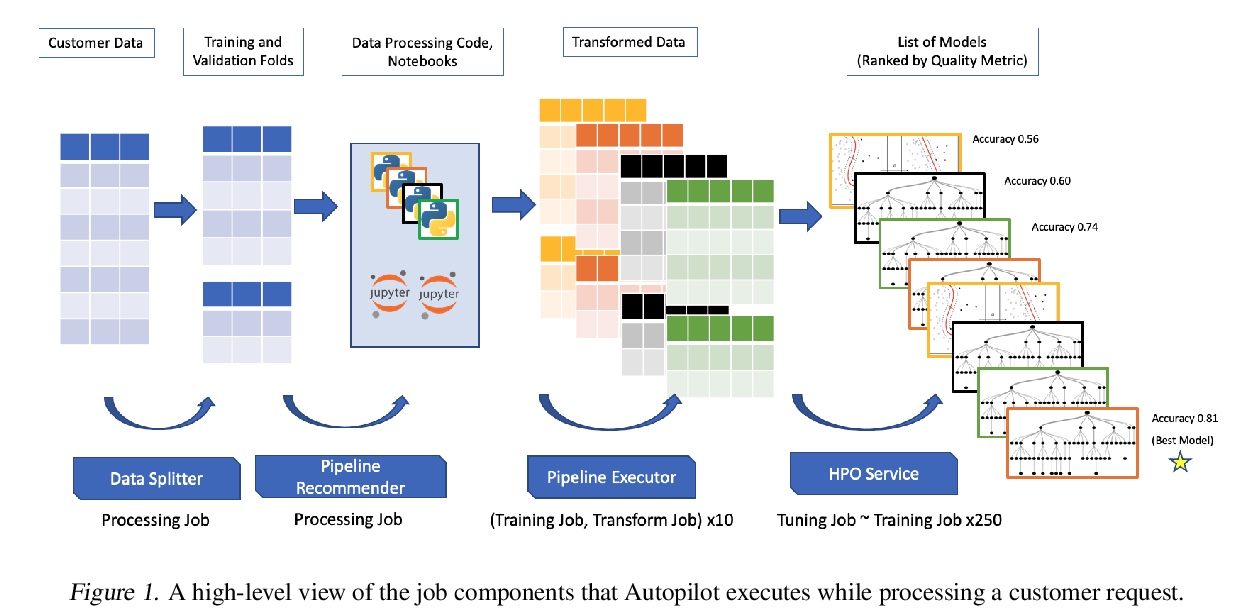


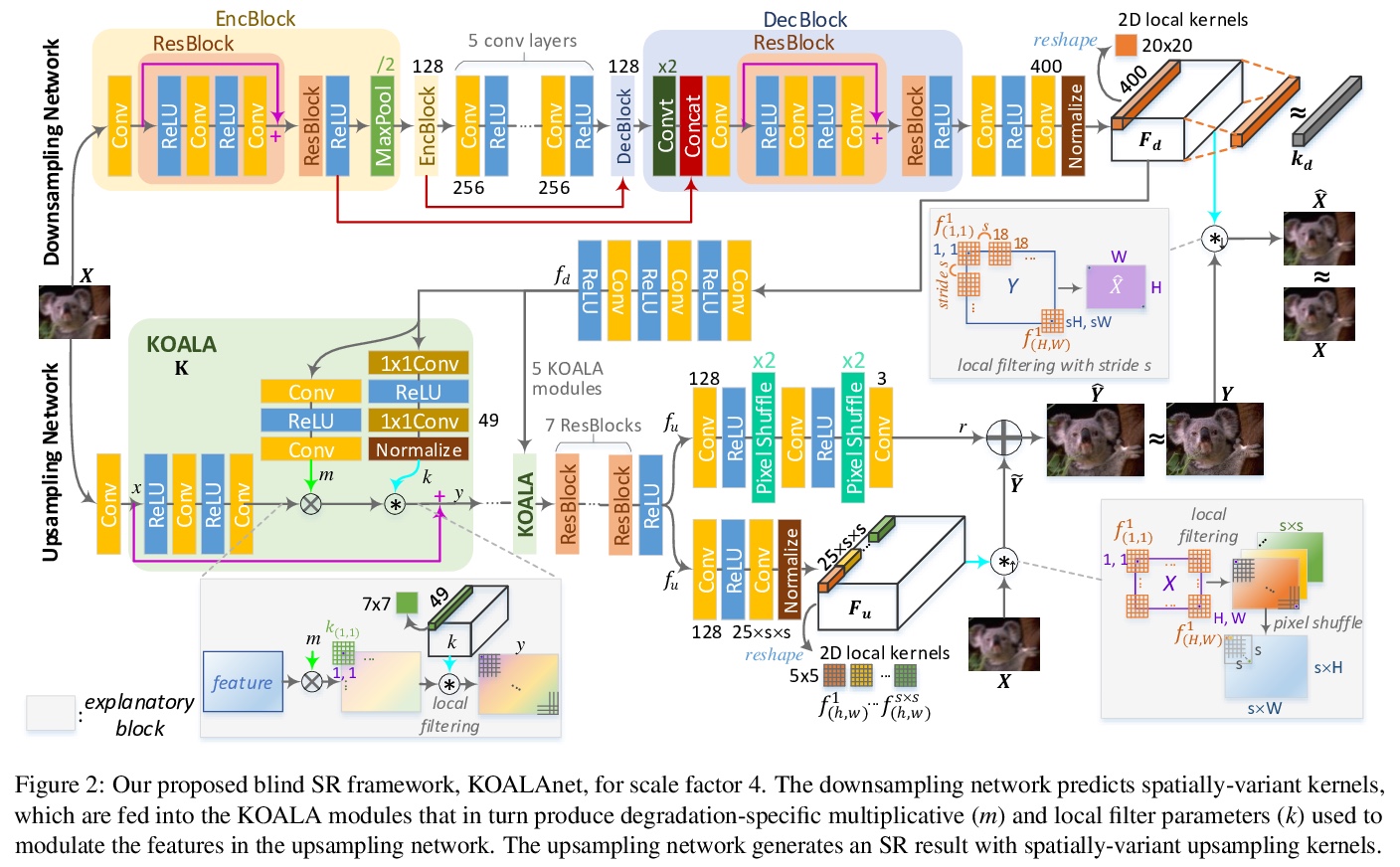
5、[CV] KOALAnet: Blind Super-Resolution using Kernel-Oriented Adaptive Local Adjustment
S Y Kim, H Sim, M Kim
[Korea Advanced Institute of Science and Technology]
基于核自适应局部调整的盲超分辨率。提出一种基于面向核的超分辨率特征自适应局部调整(KOALA)的新型盲超分辨率框架,称为KOALAnet,包括能预测空间变化的下采样网络和能有效利用这些信息的上采样网络,应用这些核作为局部滤波操作来调制基于退化信息的早期超分辨率特征,联合学习空间变异退化和恢复核,以适应真实图像中空间变化的模糊特征。KOALAnet对随机退化得到的合成低分辨率图像的性能优于最新的盲超分辨率方法,通过有效处理混合焦内和焦外区域的图像,对有意模糊的艺术照片产生了最自然的结果,没有过度锐化。
Blind super-resolution (SR) methods aim to generate a high quality high resolution image from a low resolution image containing unknown degradations. However, natural images contain various types and amounts of blur: some may be due to the inherent degradation characteristics of the camera, but some may even be intentional, for aesthetic purposes (eg. Bokeh effect). In the case of the latter, it becomes highly difficult for SR methods to disentangle the blur to remove, and that to leave as is. In this paper, we propose a novel blind SR framework based on kernel-oriented adaptive local adjustment (KOALA) of SR features, called KOALAnet, which jointly learns spatially-variant degradation and restoration kernels in order to adapt to the spatially-variant blur characteristics in real images. Our KOALAnet outperforms recent blind SR methods for synthesized LR images obtained with randomized degradations, and we further show that the proposed KOALAnet produces the most natural results for artistic photographs with intentional blur, which are not over-sharpened, by effectively handling images mixed with in-focus and out-of-focus areas.
https://weibo.com/1402400261/JyPfs5vPl

另外几篇值得关注的论文:
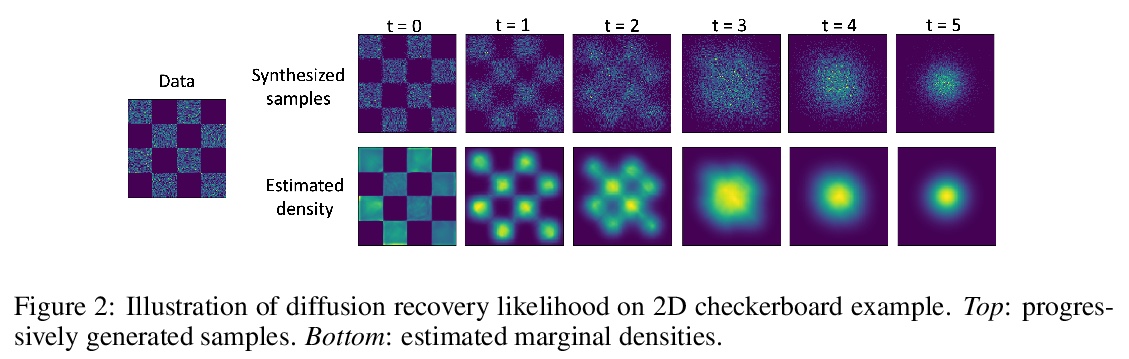
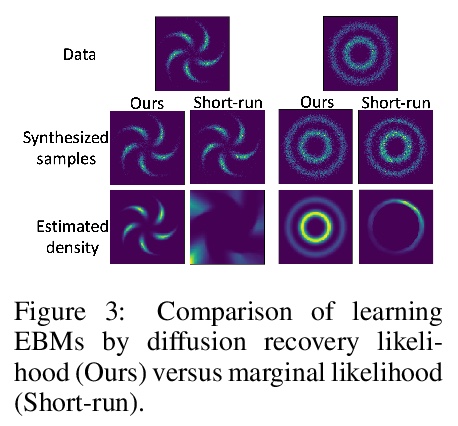
[LG] Learning Energy-Based Models by Diffusion Recovery Likelihood
基于扩散恢复似然的能量模型学习
R Gao, Y Song, B Poole, Y N Wu, D P. Kingma
[UCLA & Stanford University & Google Brain]
https://weibo.com/1402400261/JyPkovWkt
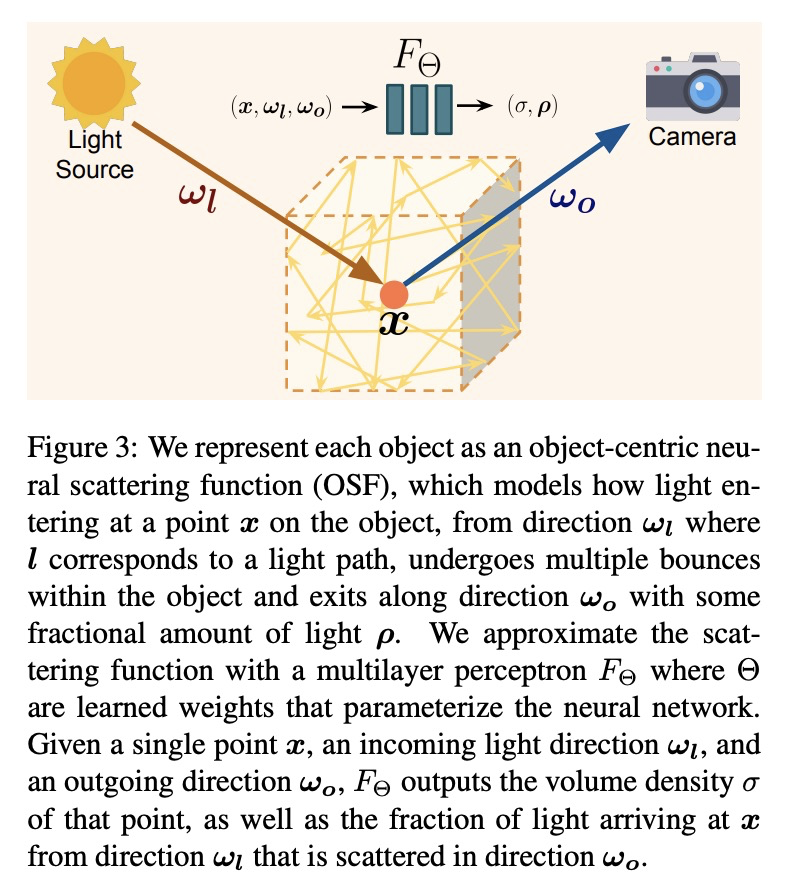
[CV] Object-Centric Neural Scene Rendering
以对象为中心的神经场景渲染
M Guo, A Fathi, J Wu, T Funkhouser
[Stanford University & Google Research]
https://weibo.com/1402400261/JyPmkdDwQ

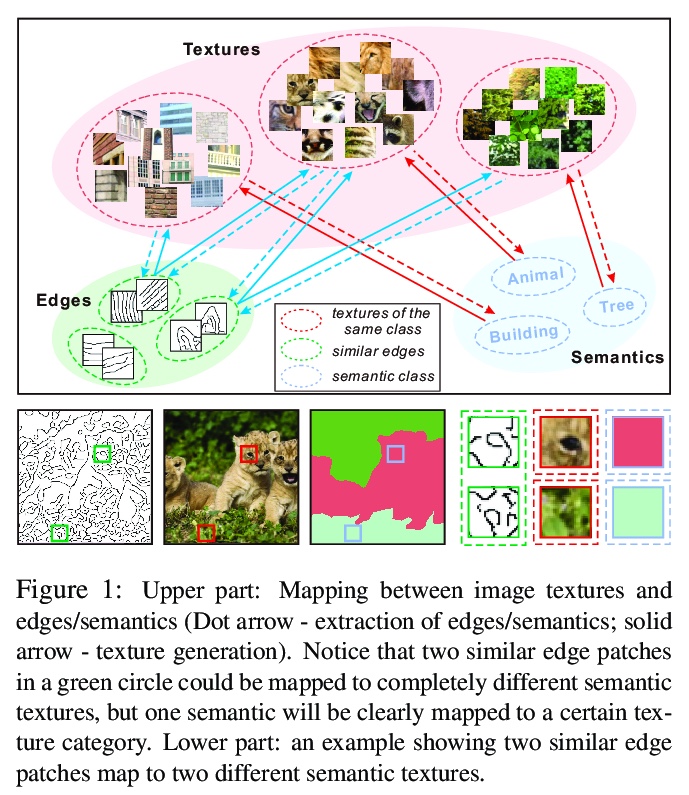
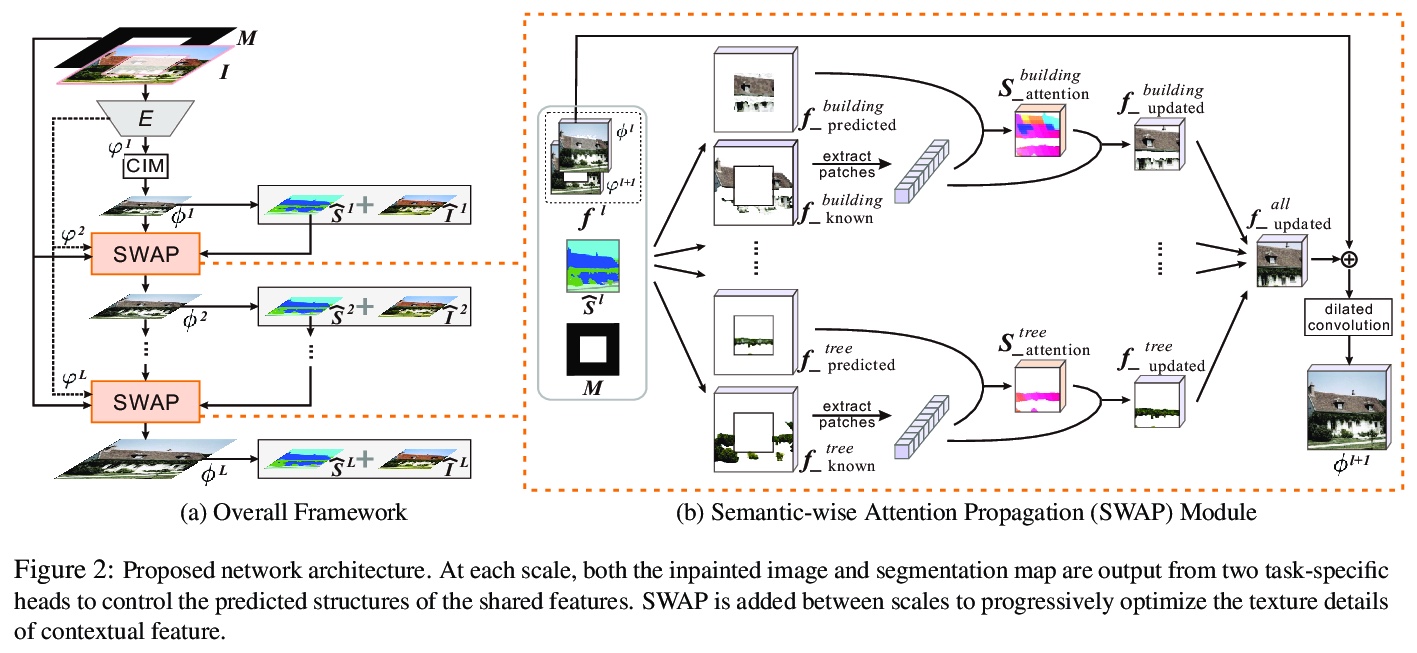
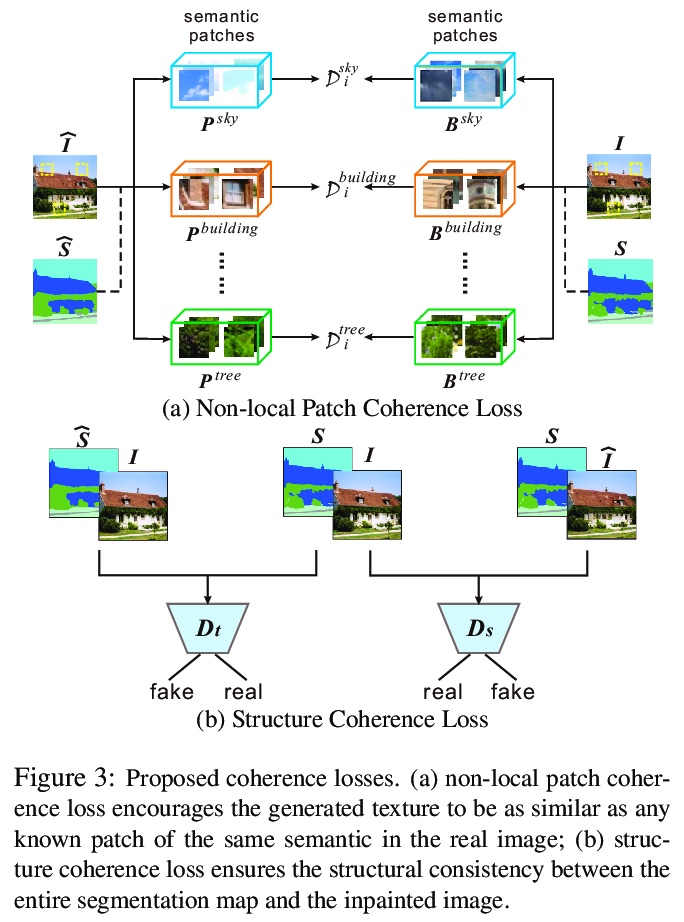
[CV] Image Inpainting Guided by Coherence Priors of Semantics and Textures
语义纹理一致先验指导下的图像补全
L Liao, J Xiao, Z Wang, C Lin, S Satoh
[National Institute of Informatics & Wuhan University]
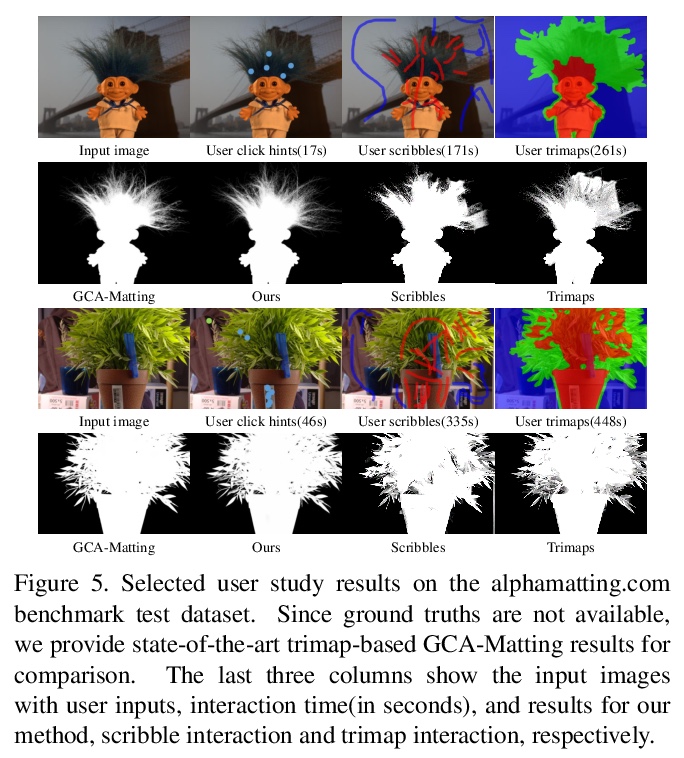
[CV] Improved Image Matting via Real-time User Clicks and Uncertainty Estimation
通过实时用户点击和不确定性估计改进的图像抠图
T Wei, D Chen, W Zhou, J Liao, H Zhao, W Zhang, N Yu
[University of Science and Technology in China & Microsoft Cloud AI & City University of Hong Kong]
https://weibo.com/1402400261/JyPpClm2d

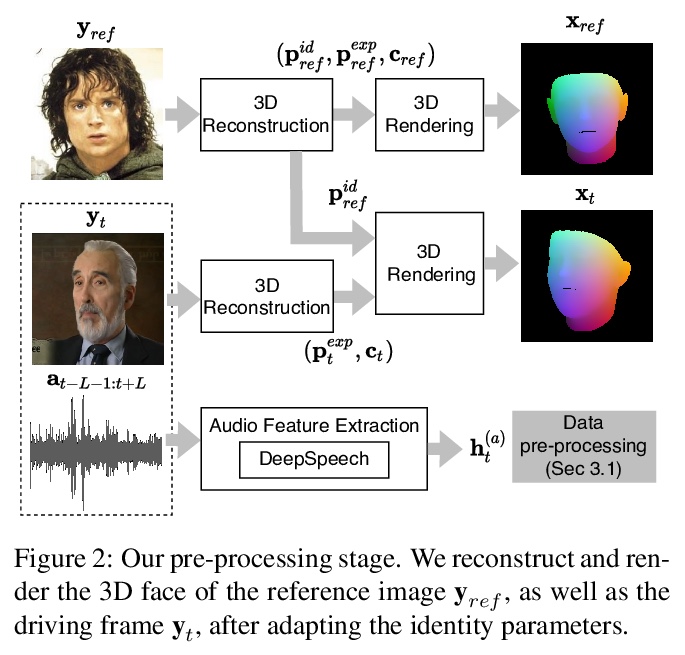
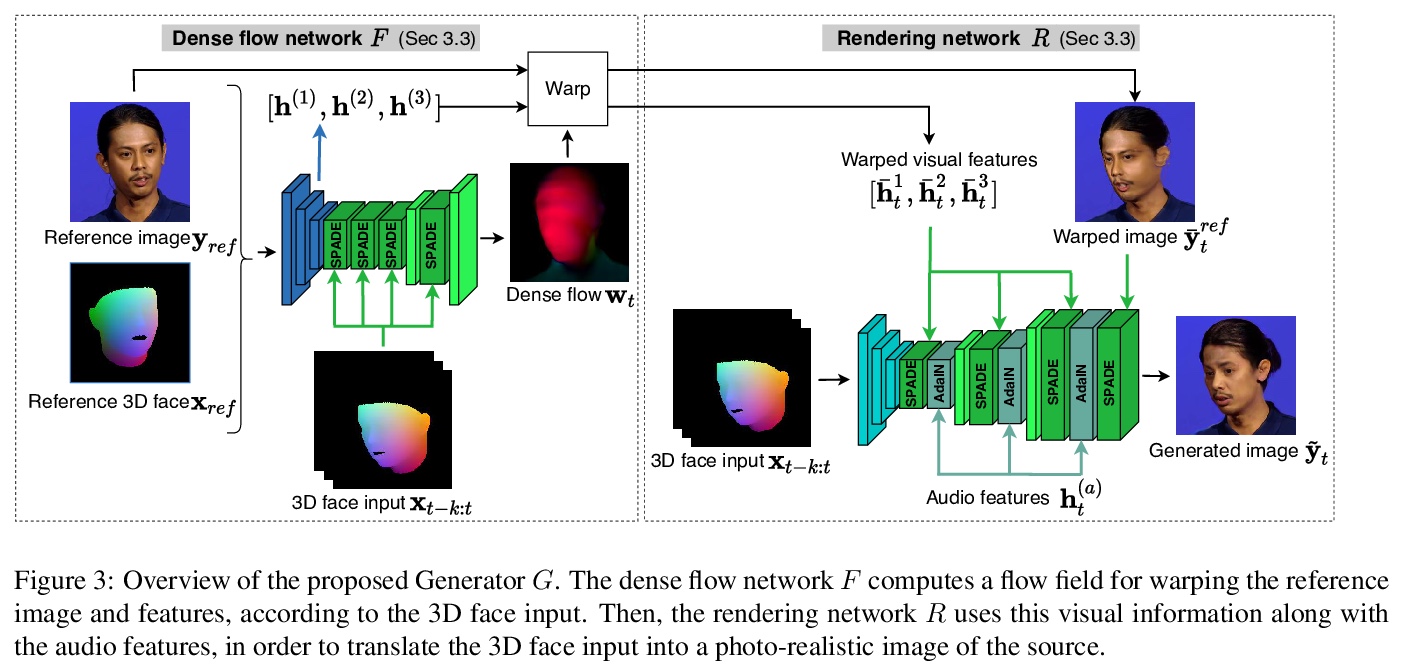
[CV] HeadGAN: Video-and-Audio-Driven Talking Head Synthesis
HeadGAN:视-音频驱动的说话人头部合成
M C Doukas, S Zafeiriou, V Sharmanska
[Imperial College London]
https://weibo.com/1402400261/JyPrt4YbG
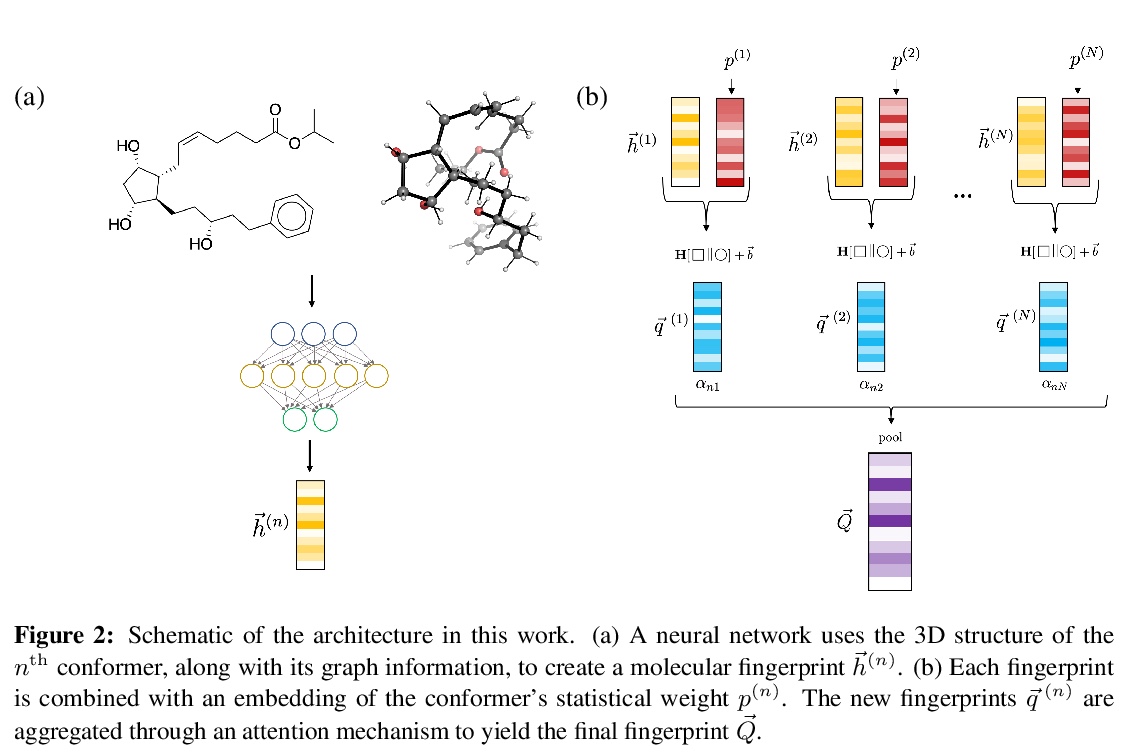
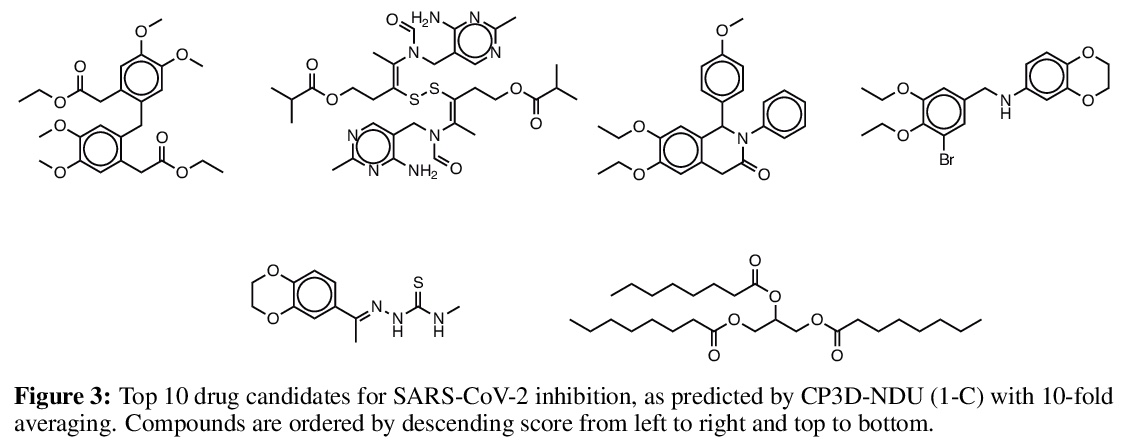
[LG] Molecular machine learning with conformer ensembles
整合器集成分子机器学习
S Axelrod, R Gomez-Bombarelli
[Harvard University & MIT]
https://weibo.com/1402400261/JyPsyq1WB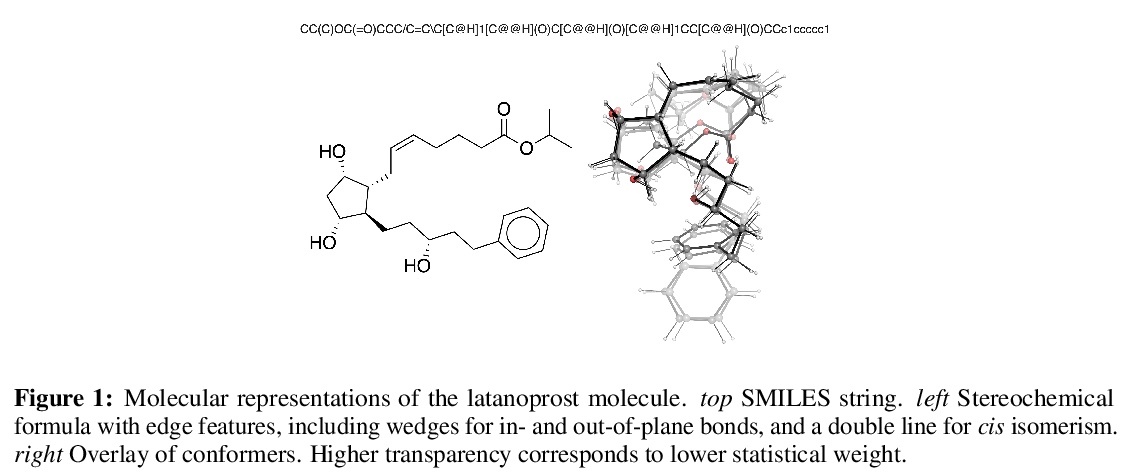

若有收获,就点个赞吧
0 人点赞
