- 1、 [LG] Offline Reinforcement Learning from Images with Latent Space Models
- 2、[LG] RealFormer: Transformer Likes Residual Attention
- 3、[LG] Soft-IntroVAE: Analyzing and Improving the Introspective Variational Autoencoder
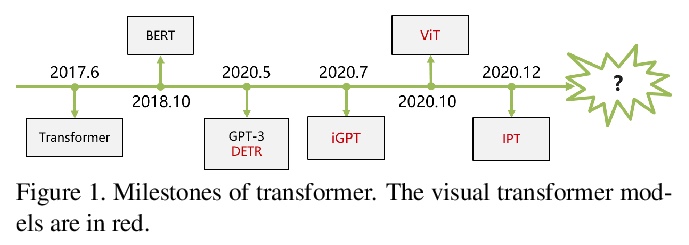
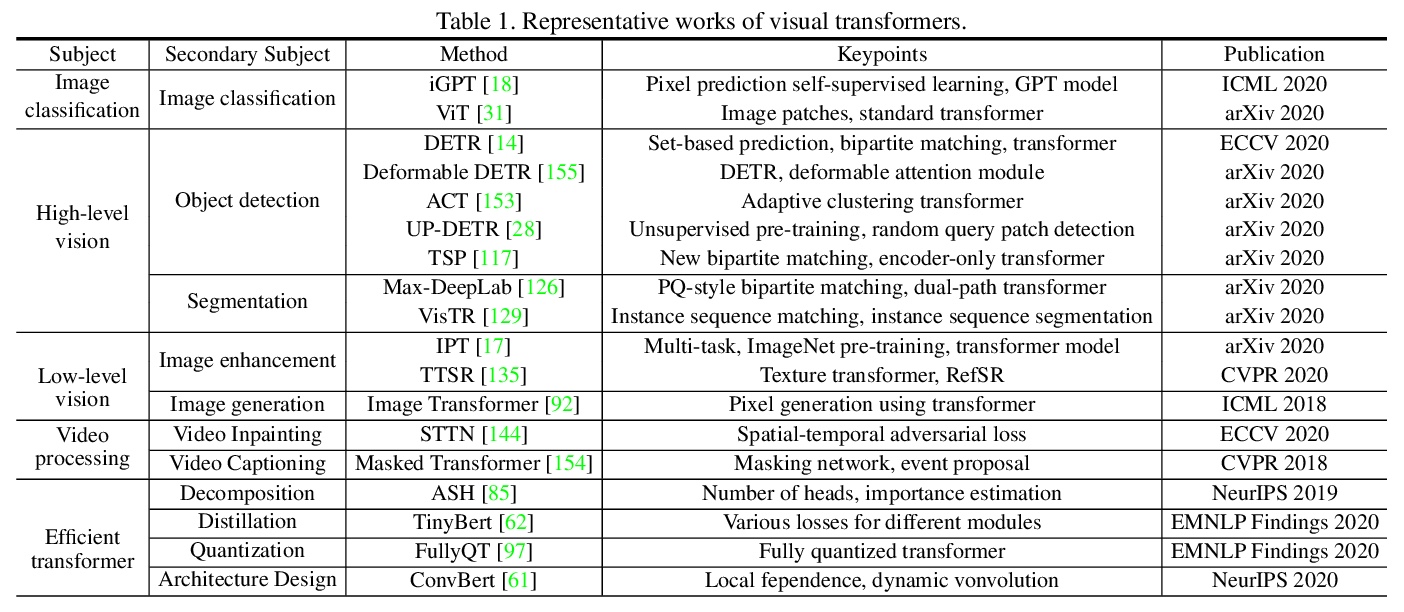
- 4、 [CV] A Survey on Visual Transformer
- 5、 [CV] MobileSal: Extremely Efficient RGB-D Salient Object Detection
- [AI] Leveraging GPT-2 for Classifying Spam Reviews with Limited Labeled Data via Adversarial Training
- [SI] Concurrency measures in the era of temporal network epidemiology: A review
- [CV] Seesaw Loss for Long-Tailed Instance Segmentation
- [LG] SCC: an efficient deep reinforcement learning agent mastering the game of StarCraft II
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、 [LG] Offline Reinforcement Learning from Images with Latent Space Models
R Rafailov, T Yu, A Rajeswaran, C Finn
[Stanford University & University of Washington]
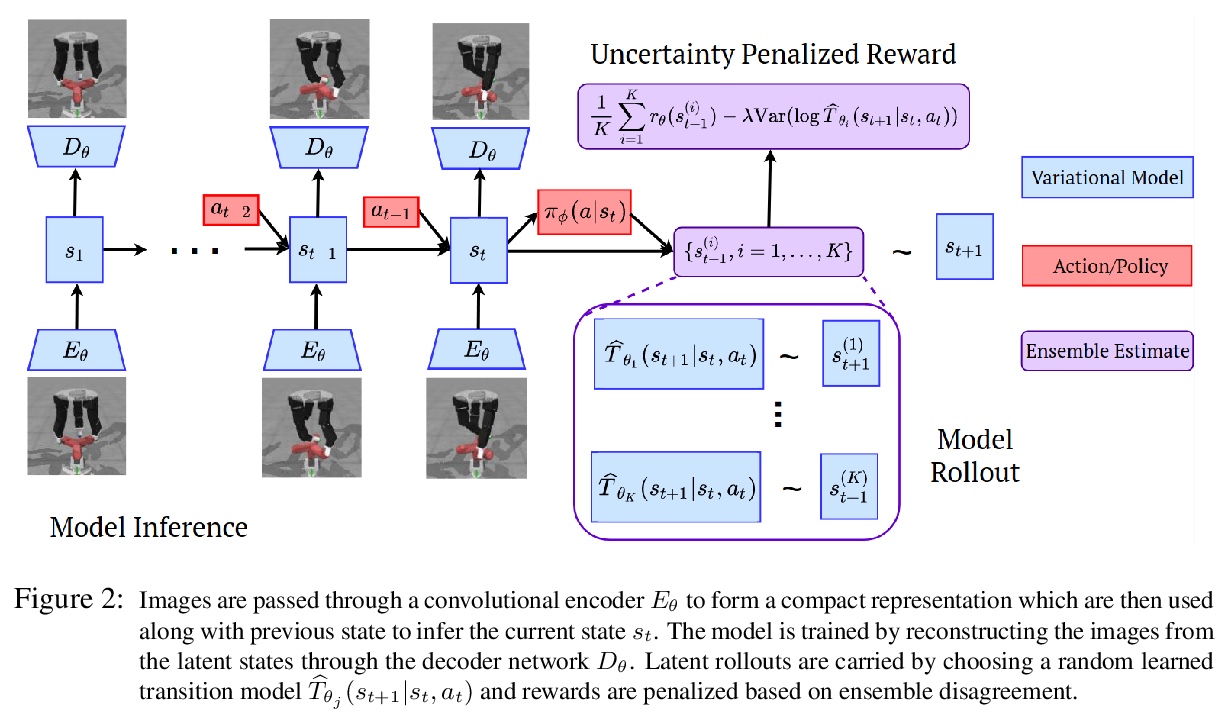
基于潜空间模型的图像离线强化学习。提出一种基于模型的离线强化学习算法,基于潜动态模型和不确定性量化来学习高维观测。视觉动态模型学习很困难,像素空间不确定性的量化开销巨大,本方法通过学习潜空间来解决这些挑战,并在潜空间中量化模型的不确定性。所用的LOMPO算法,通过潜模型集成解缠,用潜模型不确定性惩罚潜在状态。实验表明,该算法显著优于之前的离线无模型强化学习方法,以及最先进的在线基于视觉模型的强化学习方法。
Offline reinforcement learning (RL) refers to the problem of learning policies from a static dataset of environment interactions. Offline RL enables extensive use and re-use of historical datasets, while also alleviating safety concerns associated with online exploration, thereby expanding the real-world applicability of RL. Most prior work in offline RL has focused on tasks with compact state representations. However, the ability to learn directly from rich observation spaces like images is critical for real-world applications such as robotics. In this work, we build on recent advances in model-based algorithms for offline RL, and extend them to high-dimensional visual observation spaces. Model-based offline RL algorithms have achieved state of the art results in state based tasks and have strong theoretical guarantees. However, they rely crucially on the ability to quantify uncertainty in the model predictions, which is particularly challenging with image observations. To overcome this challenge, we propose to learn a latent-state dynamics model, and represent the uncertainty in the latent space. Our approach is both tractable in practice and corresponds to maximizing a lower bound of the ELBO in the unknown POMDP. In experiments on a range of challenging image-based locomotion and manipulation tasks, we find that our algorithm significantly outperforms previous offline model-free RL methods as well as state-of-the-art online visual model-based RL methods. Moreover, we also find that our approach excels on an image-based drawer closing task on a real robot using a pre-existing dataset. All results including videos can be found online at > this https URL .
https://weibo.com/1402400261/JAbLZ8rWB

2、[LG] RealFormer: Transformer Likes Residual Attention
R He, A Ravula, B Kanagal, J Ainslie
[Google Research]
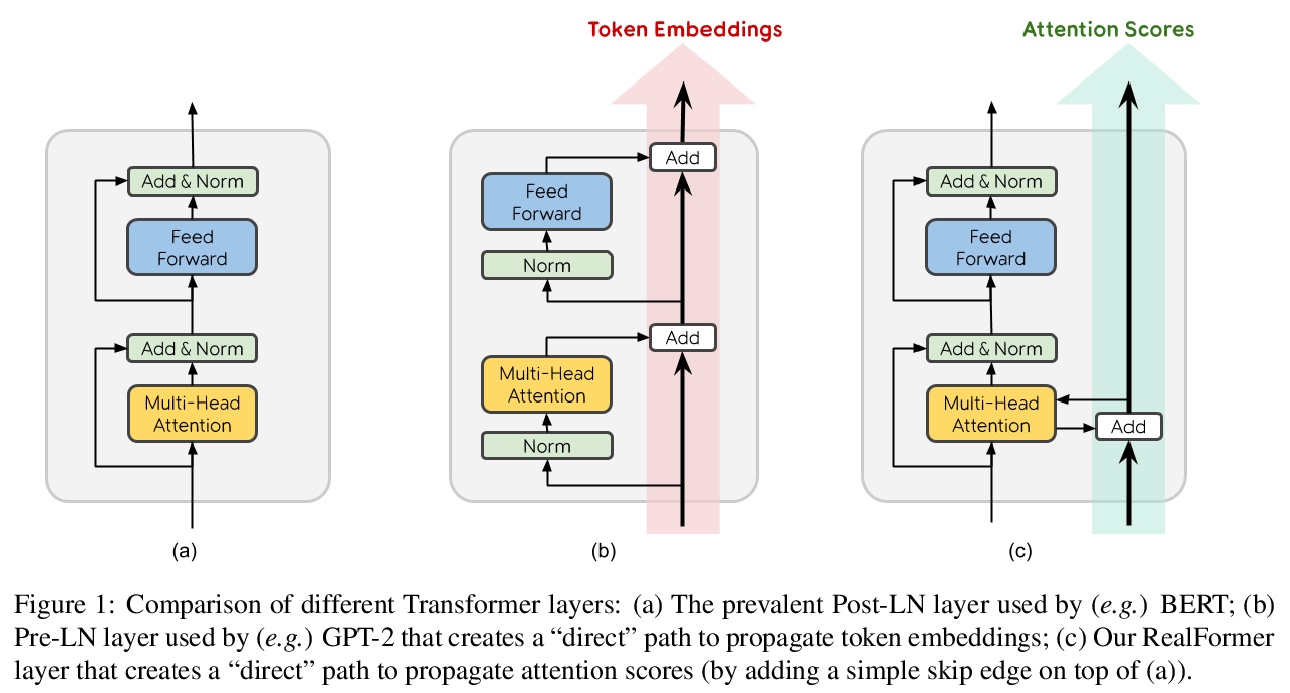
RealFormer: 残差注意力Transformer。提出RealFormer,一个简单的残差注意力层Transformer体系结构,在包括掩蔽语言建模、GLUE和SQuAD在内的一系列任务上显著优于标准Transformer。RealFormer很容易实现,只需要最小化的超参数调优过程。
Transformer is the backbone of modern NLP models. In this paper, we propose RealFormer, a simple Residual Attention Layer Transformer architecture that significantly outperforms canonical Transformers on a spectrum of tasks including Masked Language Modeling, GLUE, and SQuAD. Qualitatively, RealFormer is easy to implement and requires minimal hyper-parameter tuning. It also stabilizes training and leads to models with sparser attentions. Code will be open-sourced upon paper acceptance.
https://weibo.com/1402400261/JAbUIrGsl
3、[LG] Soft-IntroVAE: Analyzing and Improving the Introspective Variational Autoencoder
T Daniel, A Tamar
[Technion]
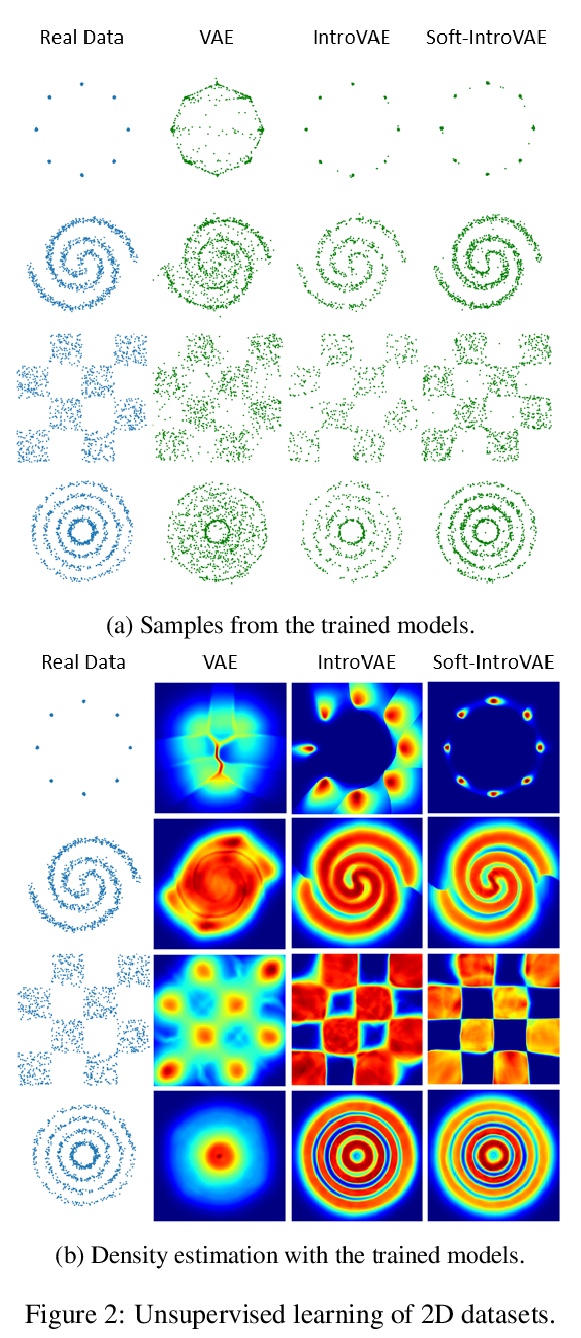
Soft-IntroVAE:自省变分自编码器的分析与改进。提出SoftIntroVAE,在生成样本上以平滑指数损失代替合页损失项,大大提高了训练的稳定性,也使完整算法的理论分析成为可能。IntroVAE可收敛到一个分布,使数据分布与熵项的KL距离之和最小化。
The recently introduced introspective variational autoencoder (IntroVAE) exhibits outstanding image generations, and allows for amortized inference using an image encoder. The main idea in IntroVAE is to train a VAE adversarially, using the VAE encoder to discriminate between generated and real data samples. However, the original IntroVAE loss function relied on a particular hinge-loss formulation that is very hard to stabilize in practice, and its theoretical convergence analysis ignored important terms in the loss. In this work, we take a step towards better understanding of the IntroVAE model, its practical implementation, and its applications. We propose the Soft-IntroVAE, a modified IntroVAE that replaces the hinge-loss terms with a smooth exponential loss on generated samples. This change significantly improves training stability, and also enables theoretical analysis of the complete algorithm. Interestingly, we show that the IntroVAE converges to a distribution that minimizes a sum of KL distance from the data distribution and an entropy term. We discuss the implications of this result, and demonstrate that it induces competitive image generation and reconstruction. Finally, we describe two applications of Soft-IntroVAE to unsupervised image translation and out-of-distribution detection, and demonstrate compelling results. Code and additional information is available on the project website — > this https URL
https://weibo.com/1402400261/JAbZBDceM

4、 [CV] A Survey on Visual Transformer
K Han, Y Wang, H Chen, X Chen, J Guo, Z Liu, Y Tang, A Xiao, C Xu, Y Xu, Z Yang, Y Zhang, D Tao
[Noah’s Ark Lab & University of Sydney]
视觉Transformer综述。对视觉Transformer模型进行了分类,并分析其优缺点。具体来说,主要分类包括基本图像分类、高级视觉、低级视觉和视频处理。介绍了将Transformer推向实际应用的有效Transformer方法。虽然研究者们已经提出了许多基于Transformer的模型来处理计算机视觉任务,但这些工作只是初步的解决方案,还有很大的改进空间。Transformer需要应用在更多的任务上;现有的视觉Transformer模型大多是针对单一任务而设计;开发高效的视觉Transformer模型也是一个有待解决的问题。
Transformer is a type of deep neural network mainly based on self-attention mechanism which is originally applied in natural language processing field. Inspired by the strong representation ability of transformer, researchers propose to extend transformer for computer vision tasks. Transformer-based models show competitive and even better performance on various visual benchmarks compared to other network types such as convolutional networks and recurrent networks. In this paper we provide a literature review of these visual transformer models by categorizing them in different tasks and analyze the advantages and disadvantages of these methods. In particular, the main categories include the basic image classification, high-level vision, low-level vision and video processing. Self-attention in computer vision is also briefly revisited as self-attention is the base component in transformer. Efficient transformer methods are included for pushing transformer into real applications. Finally, we give a discussion about the further research directions for visual transformer.
https://weibo.com/1402400261/JAc9g1L9e
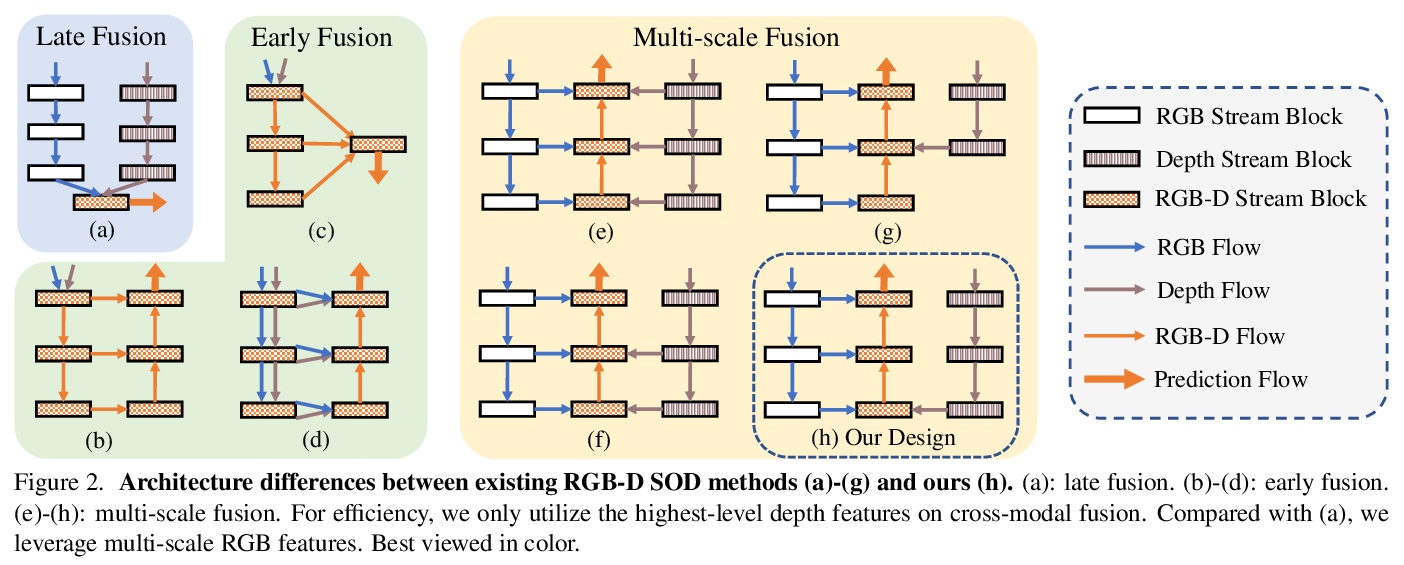
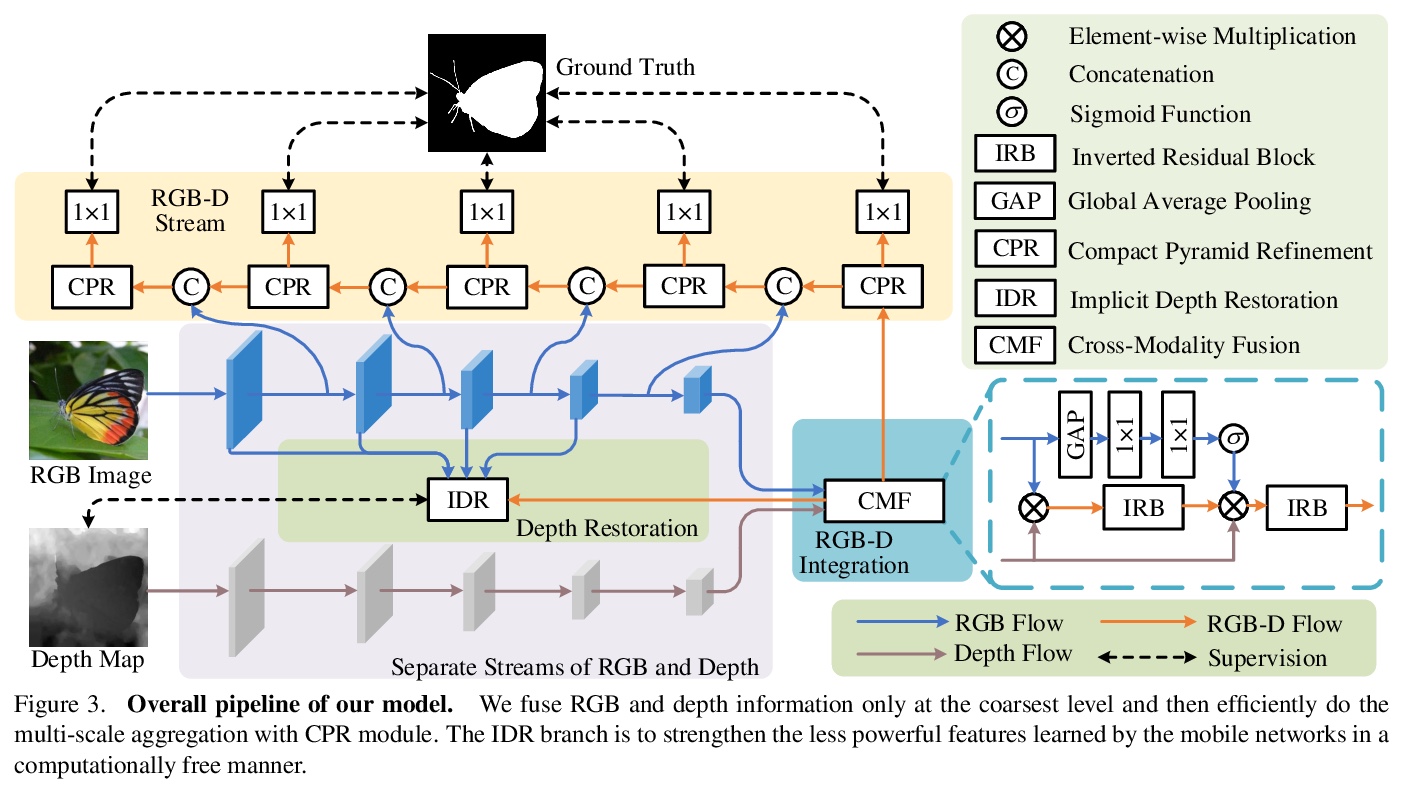
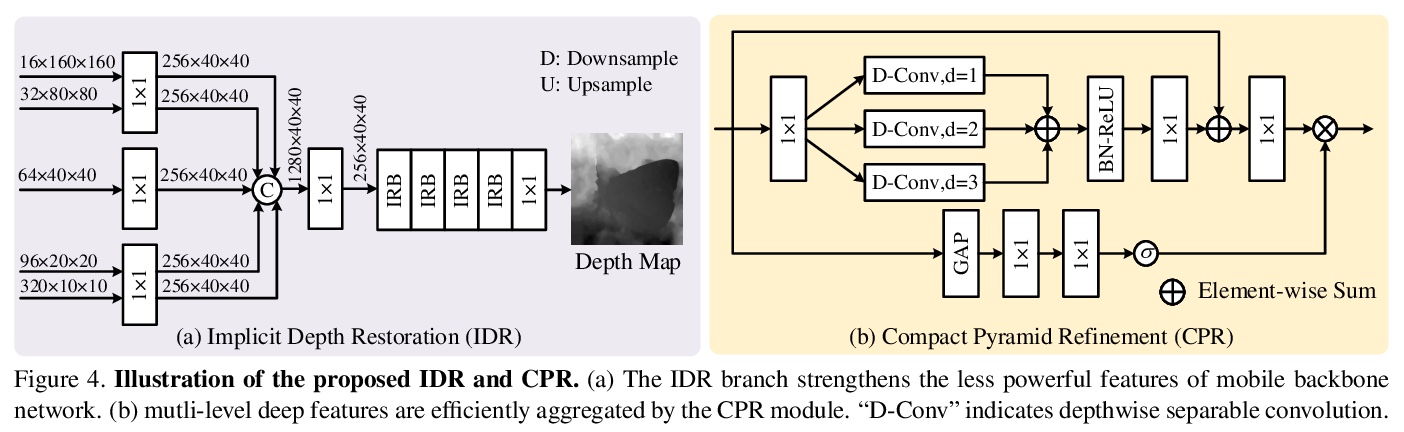
5、 [CV] MobileSal: Extremely Efficient RGB-D Salient Object Detection
Y Wu, Y Liu, J Xu, J Bian, Y Gu, M Cheng
[Nankai University & University of Adelaide]
MobileSal: 极高效RGB-D显著目标检测。提出MobileSal,利用移动网络面向高效RGB-D显著目标检测提取深度特征。用隐式深度恢复(IDR)技术,增强移动网络对RGB-D显著目标检测的特征表示能力。采用高效的多层特征聚合方法,以获得边界清晰的显著目标。结合IDR和CPR, MobileSal在7个具有挑战性的RGB-D SOD数据集上以更快的速度(450fps)和更少的参数(6.5M)达到最先进方法性能。
The high computational cost of neural networks has prevented recent successes in RGB-D salient object detection (SOD) from benefiting real-world applications. Hence, this paper introduces a novel network, MobileSal, which focuses on efficient RGB-D SOD by using mobile networks for deep feature extraction. The problem is that mobile networks are less powerful in feature representation than cumbersome networks. To this end, we observe that the depth information of color images can strengthen the feature representation related to SOD if leveraged properly. Therefore, we propose an implicit depth restoration (IDR) technique to strengthen the feature representation capability of mobile networks for RGB-D SOD. IDR is only adopted in the training phase and is omitted during testing, so it is computationally free. Besides, we propose compact pyramid refinement (CPR) for efficient multi-level feature aggregation so that we can derive salient objects with clear boundaries. With IDR and CPR incorporated, MobileSal performs favorably against state-of-the-art methods on seven challenging RGB-D SOD datasets with much faster speed (450fps) and fewer parameters (6.5M). The code will be released.
https://weibo.com/1402400261/JAcd72IXA
另外几篇值得关注的论文:
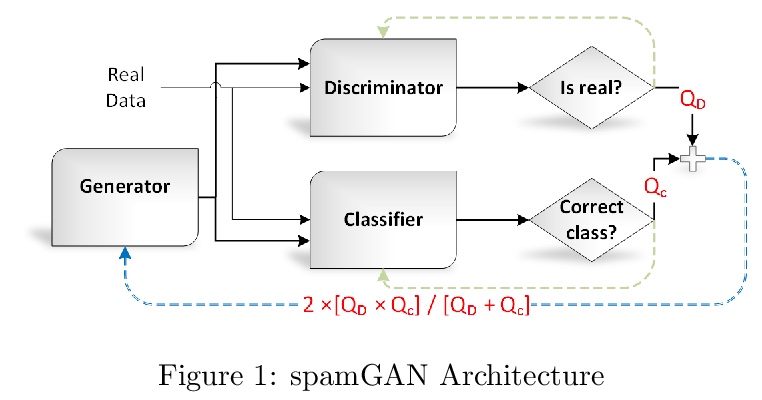
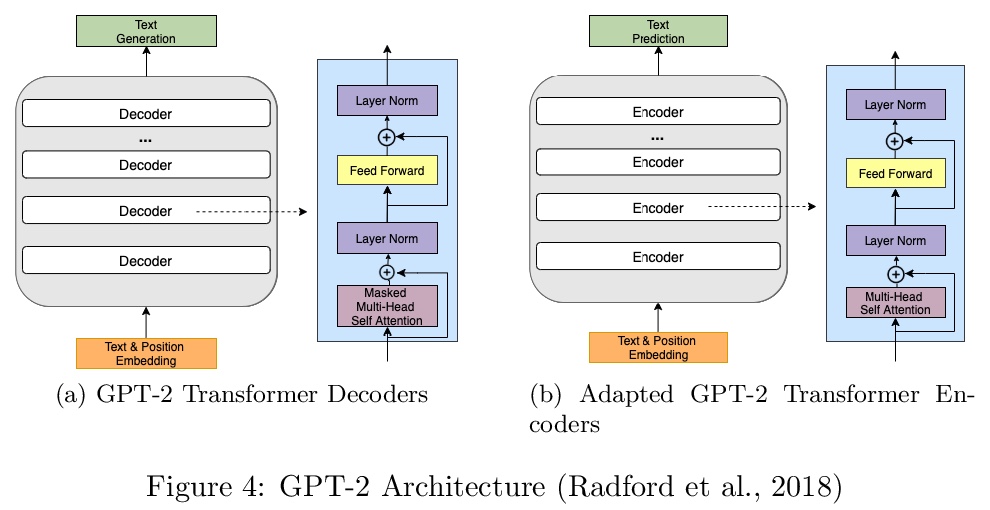
[AI] Leveraging GPT-2 for Classifying Spam Reviews with Limited Labeled Data via Adversarial Training
基于GPT-2对抗训练的有限标签数据垃圾评论分类
A A. Irissappane, H Yu, Y Shen, A Agrawal, G Stanton
[University of Washington & Colorado State University]
https://weibo.com/1402400261/JAcjou2av
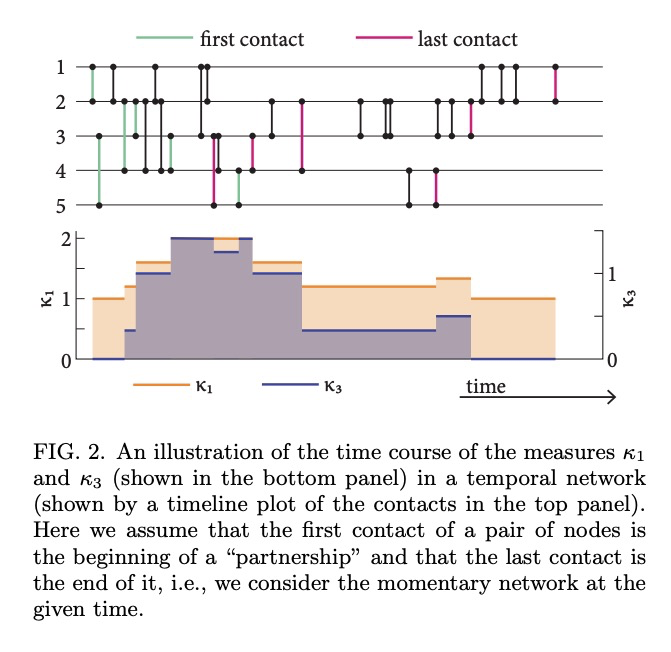
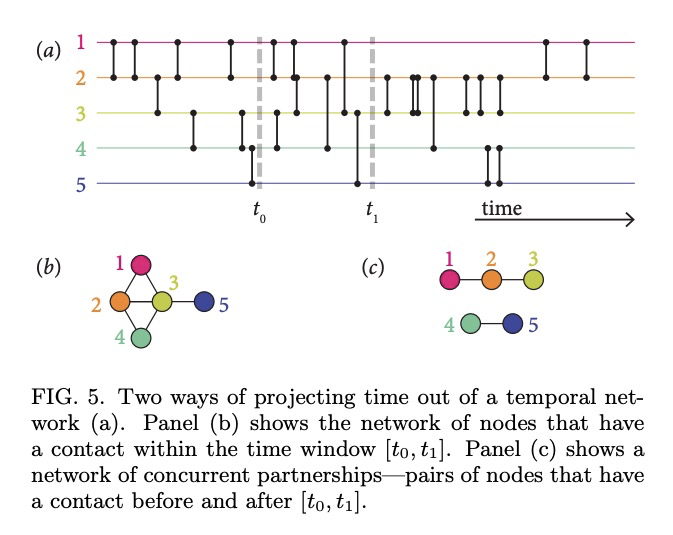
[SI] Concurrency measures in the era of temporal network epidemiology: A review
时间网络流行病学时代的并发性度量综述
N Masuda, J C. Miller, P Holme
[State University of New York at Buffalo & La Trobe University & Tokyo Institute of Technology]
https://weibo.com/1402400261/JAcmj0MdP
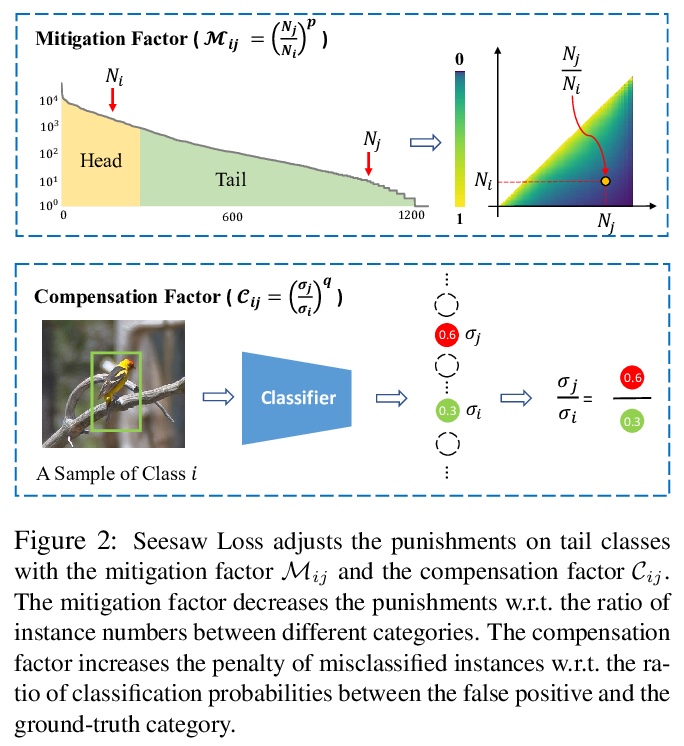
[CV] Seesaw Loss for Long-Tailed Instance Segmentation
Seesaw损失长尾实例分割
J Wang, W Zhang, Y Zang, Y Cao, J Pang, T Gong, K Chen, Z Liu, C C Loy, D Lin
[The Chinese University of Hong Kong & Nanyang Technological University & Zhejiang University & University of Science and Technology of China]
https://weibo.com/1402400261/JAco9qkPf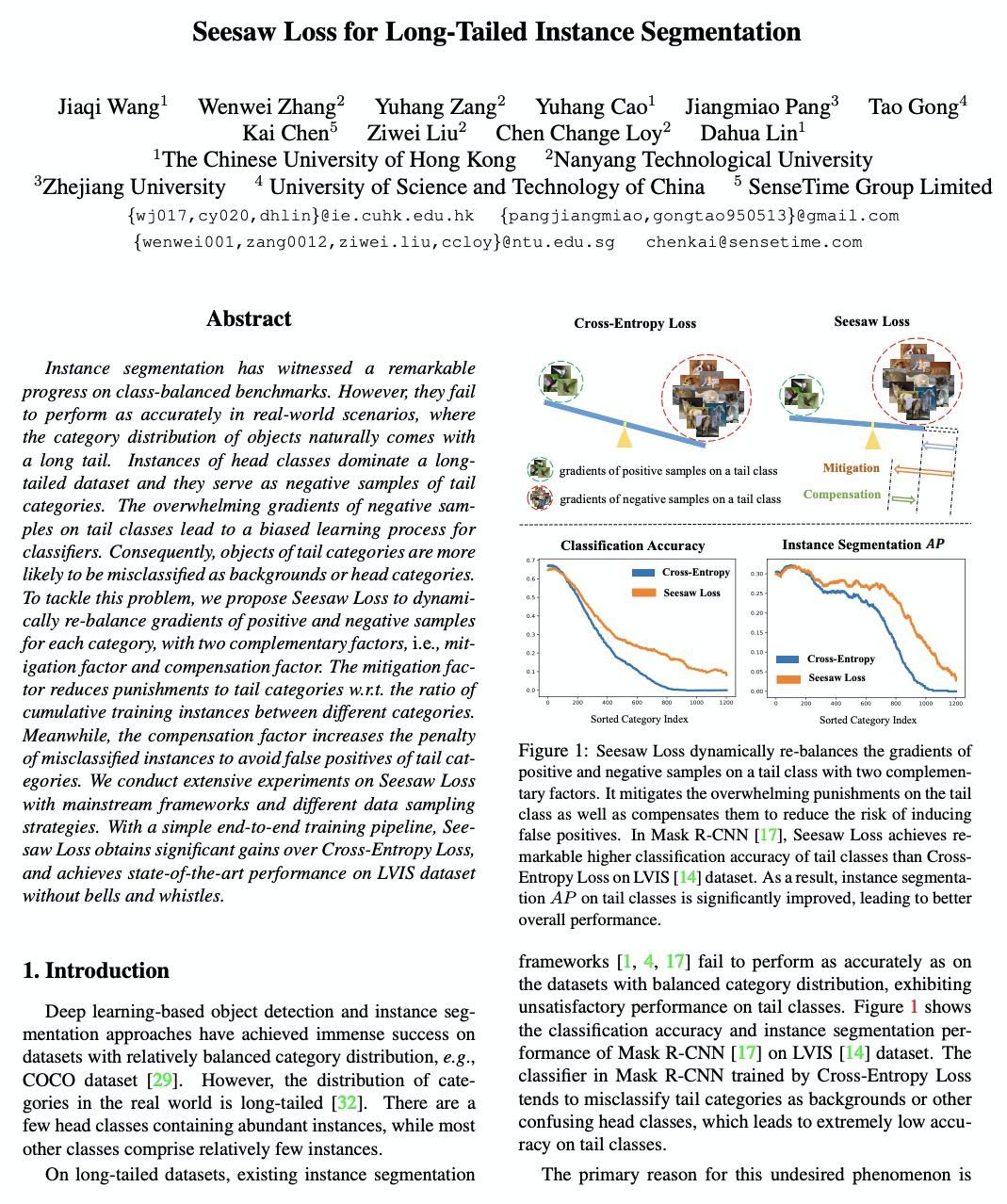
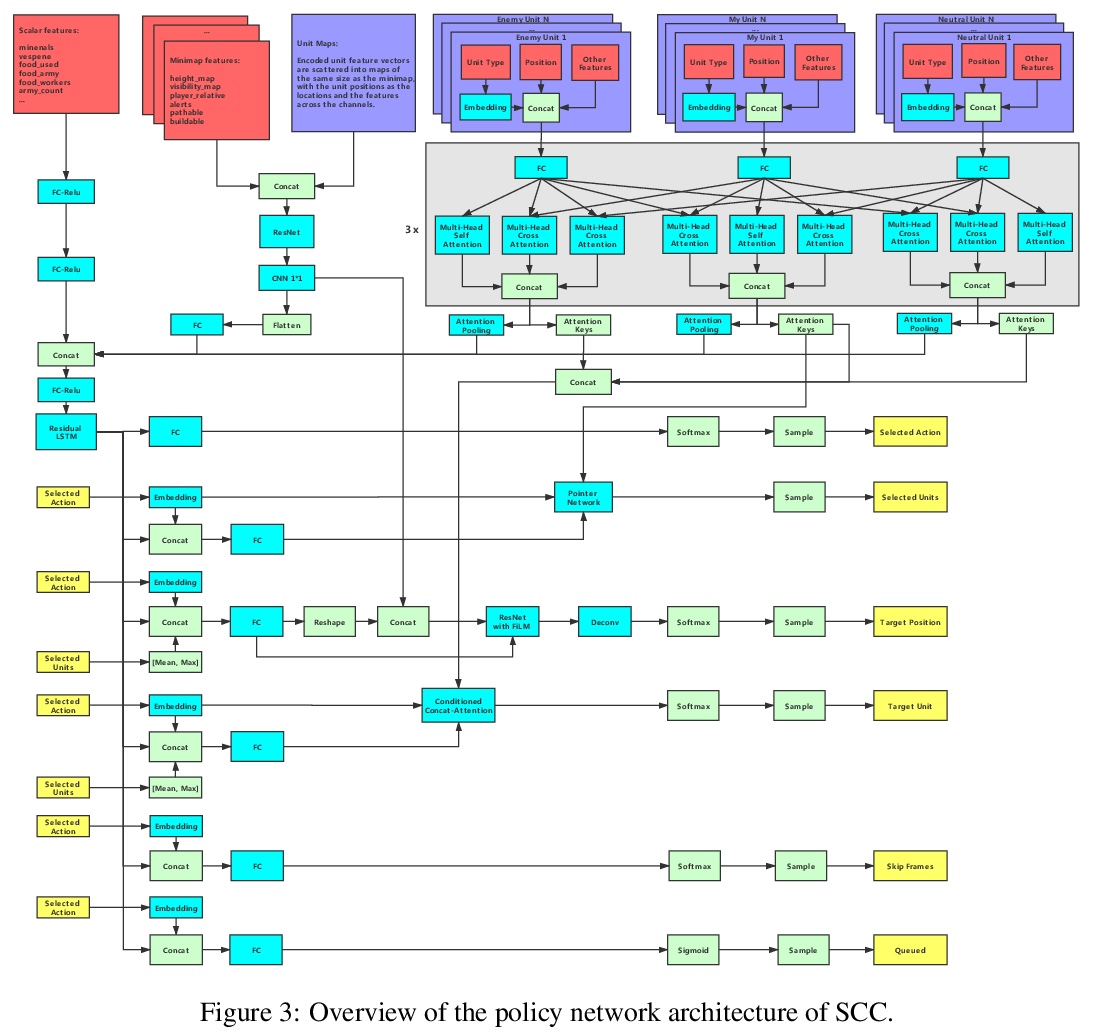
[LG] SCC: an efficient deep reinforcement learning agent mastering the game of StarCraft II
SCC:高效深度强化学习玩转星际争霸2
X Wang, J Song, P Qi, P Peng, Z Tang, W Zhang, W Li, X Pi, J He, C Gao, H Long, Q Yuan
[inspir.ai]
https://weibo.com/1402400261/JAcpFCDR9

若有收获,就点个赞吧
0 人点赞
