- 1、[CL] True Few-Shot Learning with Language Models
- 2、[DM] Analysis of Boolean Functions
- 3、[LG] A GAN-Like Approach for Physics-Based Imitation Learning and Interactive Character Control
- 4、[CV] PPR10K: A Large-Scale Portrait Photo Retouching Dataset with Human-Region Mask and Group-Level Consistency
- 5、[CV] Embracing New Techniques in Deep Learning for Estimating Image Memorability
- [CV] Large-Scale Attribute-Object Compositions
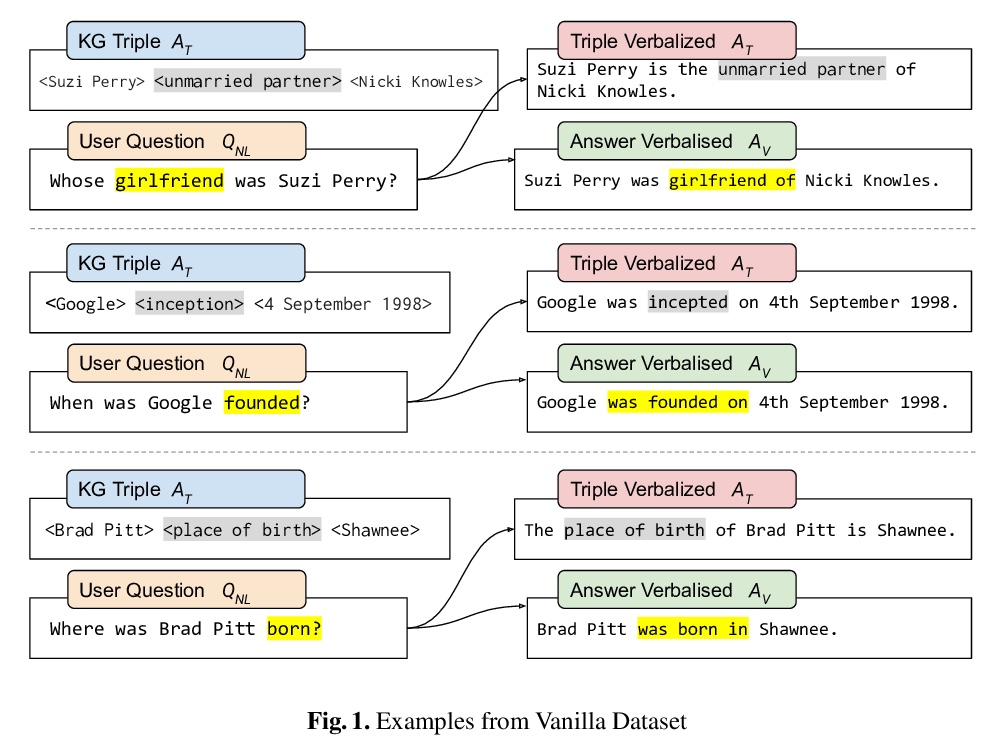
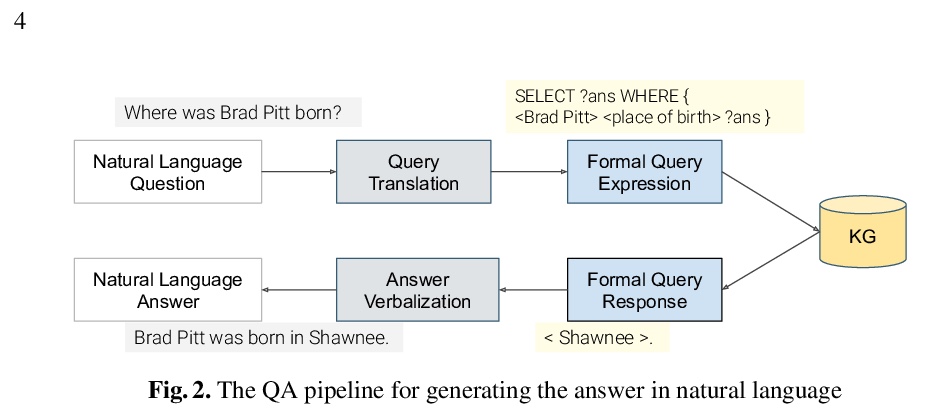
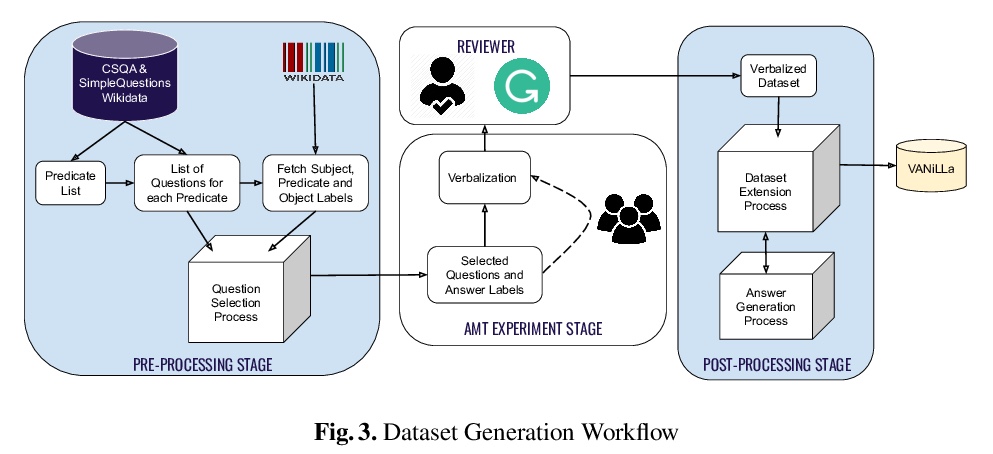
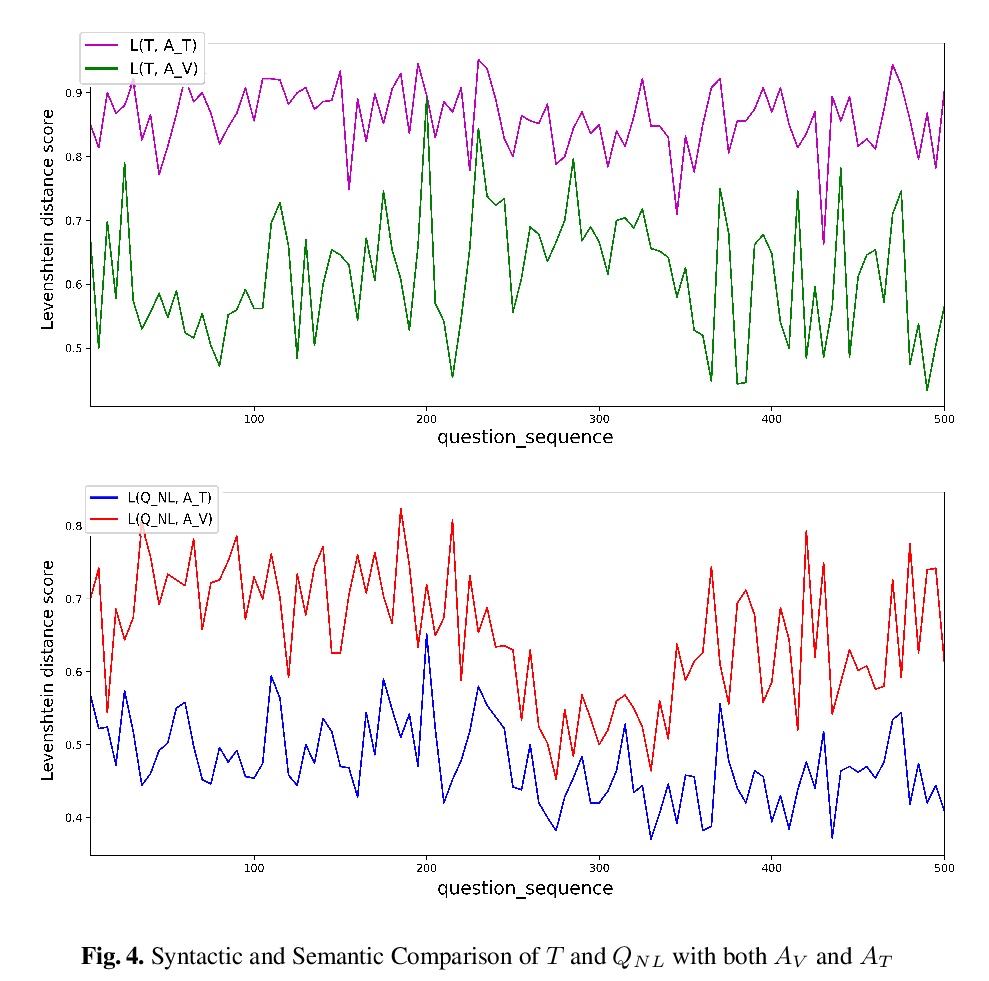
- [CL] VANiLLa : Verbalized Answers in Natural Language at Large Scale
- [CV] Egocentric Activity Recognition and Localization on a 3D Map
- [AI] Software Engineering for AI-Based Systems: A Survey
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 DM - 离散数学
1、[CL] True Few-Shot Learning with Language Models
E Perez, D Kiela, K Cho
[New York University & Facebook AI Research]
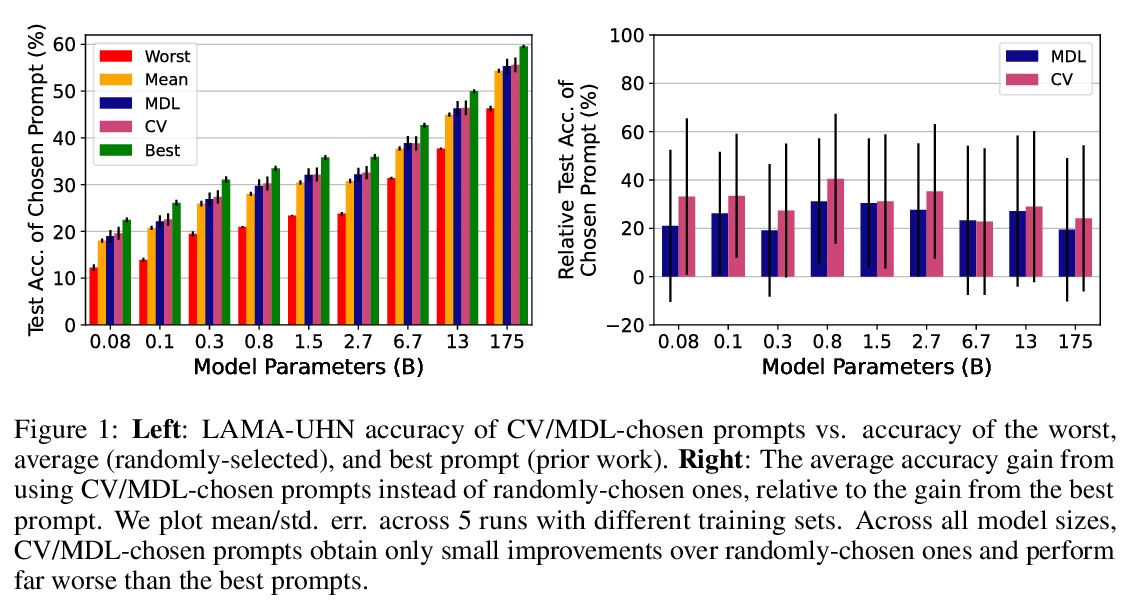
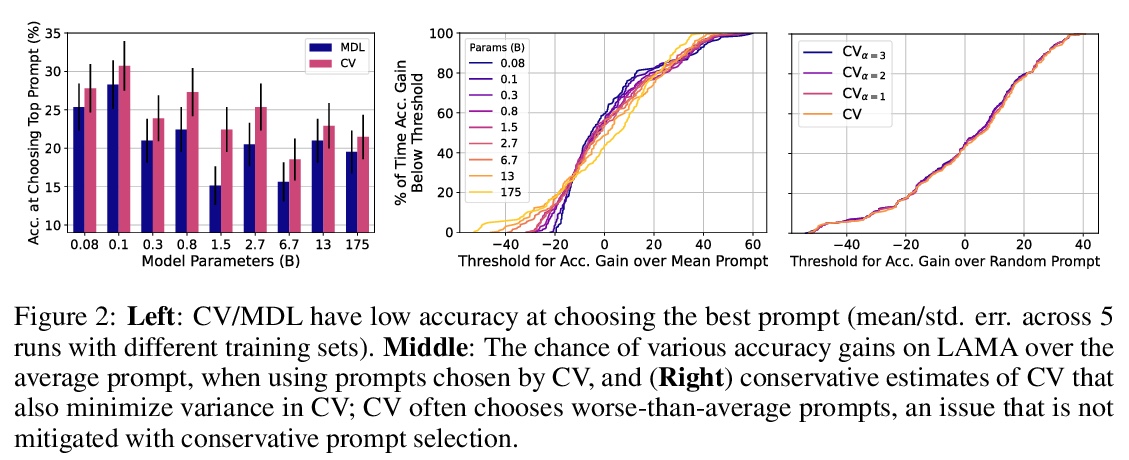
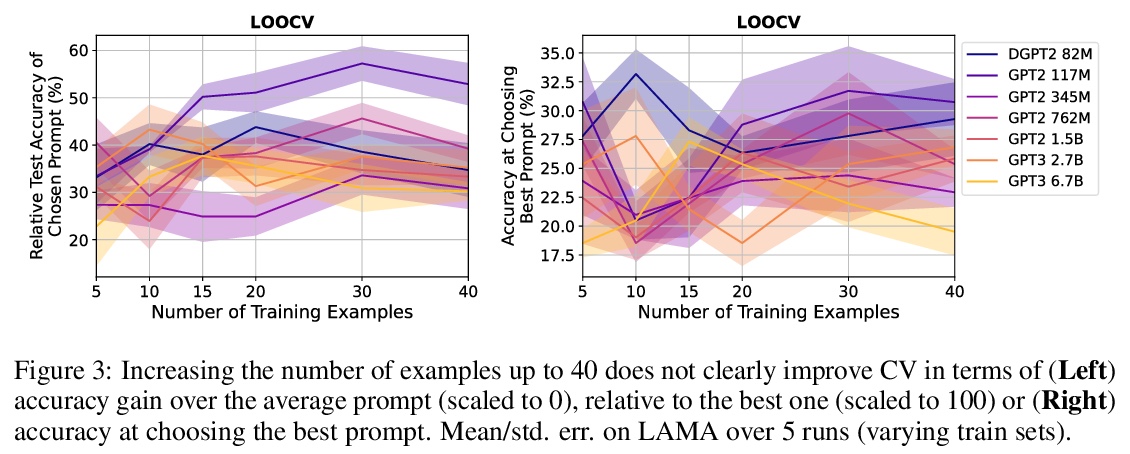
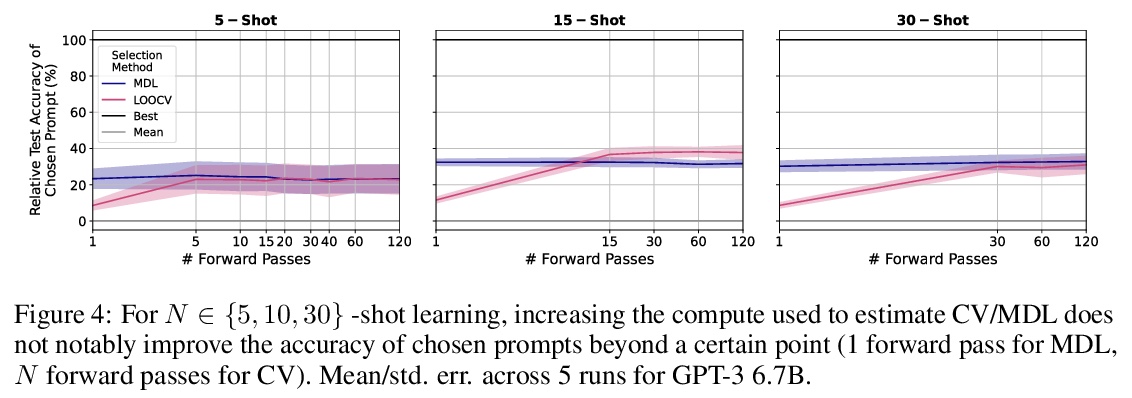
基于语言模型的真少样本学习。预训练语言模型(LM)在许多任务中表现良好,即使是从少数样本中学习,但之前的工作用许多保留样本微调学习的各方面,如超参数、训练目标和自然语言模板(“提示”)。本文评估了保留样本不可用时,语言模型的少样本能力,并把这种设置称为真少样本学习。测试了两种模型选择标准,交叉验证和最小描述长度,用于在真少样本学习环境中选择语言模型的提示和超参数。平均来说,这两种方法都略优于随机选择,大大低于基于保留样本的选择。此外,选择标准往往倾向于选择那些表现明显比随机选择更差的模型。即使考虑到在选择过程中对模型真实性能的不确定性,以及改变用于选择的计算量和样本数量,也发现了类似的结果。研究结果表明,考虑到少样本模型选择的难度,之前的工作大大高估了语言模型的真少样本能力。
Pretrained language models (LMs) perform well on many tasks even when learning from a few examples, but prior work uses many held-out examples to tune various aspects of learning, such as hyperparameters, training objectives, and natural language templates (“prompts”). Here, we evaluate the few-shot ability of LMs when such held-out examples are unavailable, a setting we call true few-shot learning. We test two model selection criteria, cross-validation and minimum description length, for choosing LM prompts and hyperparameters in the true few-shot setting. On average, both marginally outperform random selection and greatly underperform selection based on held-out examples. Moreover, selection criteria often prefer models that perform significantly worse than randomly-selected ones. We find similar results even when taking into account our uncertainty in a model’s true performance during selection, as well as when varying the amount of computation and number of examples used for selection. Overall, our findings suggest that prior work significantly overestimated the true few-shot ability of LMs given the difficulty of few-shot model selection.
https://weibo.com/1402400261/KhbRapxU1
2、[DM] Analysis of Boolean Functions
R O’Donnell
布尔函数分析。通过布尔函数f:{0,1}n→{0,1}的傅里叶展开和其他分析手段研究布尔函数。布尔函数也许是理论计算机科学中最基本的研究对象,而傅里叶分析已成为该领域中不可或缺的工具。该课题在数学的其他几个领域也发挥了关键作用,从组合学、随机图论、统计物理学,到高斯几何、巴拿赫空间和社会选择理论。本书的意图是既要发展该领域的基础,又要对其应用进行广泛(尽管远非详尽)的概述。每一章最后都有一个”亮点”,展示了布尔函数分析在不同学科领域的威力:属性检验、社会选择、密码学、电路复杂性、学习理论、伪随机性、硬度近似、具体复杂性和随机图理论。
The subject of this textbook is the analysis of Boolean functions. Roughly speaking, this refers to studying Boolean functions f:{0,1}n→{0,1} via their Fourier expansion and other analytic means. Boolean functions are perhaps the most basic object of study in theoretical computer science, and Fourier analysis has become an indispensable tool in the field. The topic has also played a key role in several other areas of mathematics, from combinatorics, random graph theory, and statistical physics, to Gaussian geometry, metric/Banach spaces, and social choice theory.
The intent of this book is both to develop the foundations of the field and to give a wide (though far from exhaustive) overview of its applications. Each chapter ends with a “highlight” showing the power of analysis of Boolean functions in different subject areas: property testing, social choice, cryptography, circuit complexity, learning theory, pseudorandomness, hardness of approximation, concrete complexity, and random graph theory.
The book can be used as a reference for working researchers or as the basis of a one-semester graduate-level course. The author has twice taught such a course at Carnegie Mellon University, attended mainly by graduate students in computer science and mathematics but also by advanced undergraduates, postdocs, and researchers in adjacent fields. In both years most of Chapters 1-5 and 7 were covered, along with parts of Chapters 6, 8, 9, and 11, and some additional material on additive combinatorics. Nearly 500 exercises are provided at the ends of the book’s chapters.
https://weibo.com/1402400261/KhbWI58mP



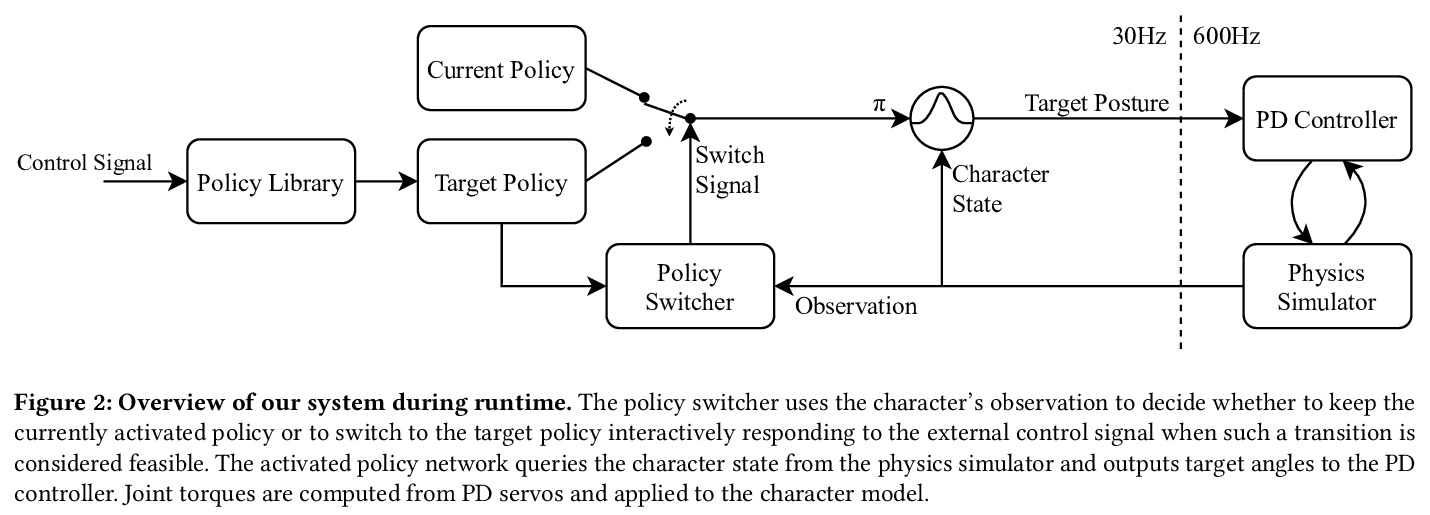
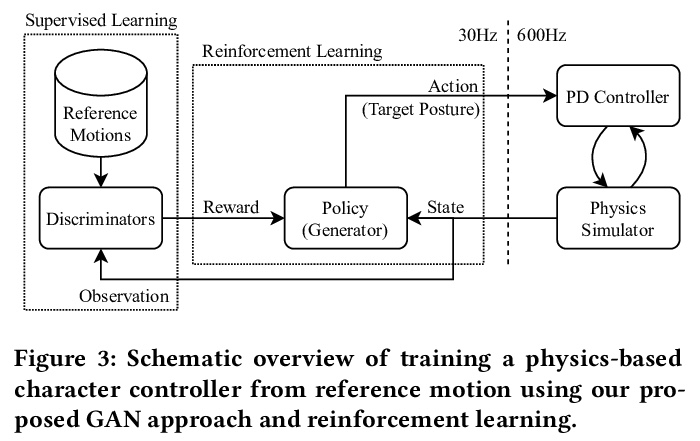
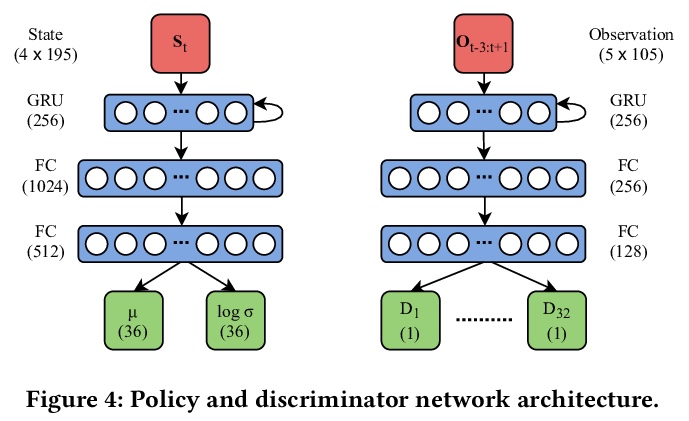
3、[LG] A GAN-Like Approach for Physics-Based Imitation Learning and Interactive Character Control
P Xu, I Karamouzas
[Clemson University]
用类似GAN的方法实现基于物理学的模仿学习和交互式角色控制。提出了一种简单而直观的物理模拟人物互动控制方法。本文工作建立在生成对抗网络(GAN)和强化学习的基础上,引入了一个模仿学习框架,其中分类器的集合和模仿策略是在给定预处理的参考片段的情况下同步训练的。分类器被训练成从模仿策略产生的运动中区分出参考运动,而策略则因骗过分类器而得到奖励。采用基于GAN的方法,可分别训练多个运动控制策略来模仿不同的行为。运行时,系统可对用户提供的外部控制信号作出反应,在不同的策略之间进行交互式切换。与现有方法相比,所提出方法有以下特性:1)实现了最先进的模仿性能,不需要手动设计和微调奖励函数;2)直接控制角色,而不需要通过相位状态显式或隐式地跟踪任何目标参考姿态;3)支持交互式策略切换,不需要任何运动生成或运动匹配机制。该方法适用于一系列模仿和交互式控制任务,具有承受外部扰动以及恢复平衡的能力。总的来说,该方法产生了高保真的运动,具有较低的运行时间成本,可以很容易地集成到交互式应用和游戏中。
We present a simple and intuitive approach for interactive control of physically simulated characters. Our work builds upon generative adversarial networks (GAN) and reinforcement learning, and introduces an imitation learning framework where an ensemble of classifiers and an imitation policy are trained in tandem given preprocessed reference clips. The classifiers are trained to discriminate the reference motion from the motion generated by the imitation policy, while the policy is rewarded for fooling the discriminators. Using our GAN-based approach, multiple motor control policies can be trained separately to imitate different behaviors. In runtime, our system can respond to external control signal provided by the user and interactively switch between different policies. Compared to existing method, our proposed approach has the following attractive properties: 1) achieves state-of-the-art imitation performance without manually designing and fine tuning a reward function; 2) directly controls the character without having to track any target reference pose explicitly or implicitly through a phase state; and 3) supports interactive policy switching without requiring any motion generation or motion matching mechanism. We highlight the applicability of our approach in a range of imitation and interactive control tasks, while also demonstrating its ability to withstand external perturbations as well as to recover balance. Overall, our approach generates high-fidelity motion, has low runtime cost, and can be easily integrated into interactive applications and games.
https://weibo.com/1402400261/Khc053f5H

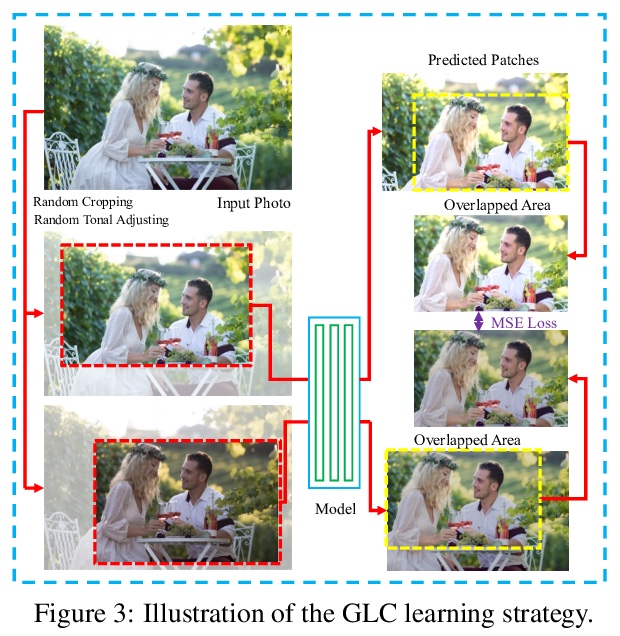
4、[CV] PPR10K: A Large-Scale Portrait Photo Retouching Dataset with Human-Region Mask and Group-Level Consistency
J Liang, H Zeng, M Cui, X Xie, L Zhang
[The HongKong Polytechnic University & Alibaba Group]
PPR10K: 具有人像区域掩模和组一致性的大规模人像照片润色数据集。与一般的照片润色任务不同,人像照片润色(PPR)的目的,是提高平面人像照片集合的视觉质量,有其特殊的实际要求,如人像区域优先(HRP)和组一致性(GLC)。HRP要求对人像区域给予更多关注,而GLC则要求将一组人像照片润色成一致色调。然而,在现有的一般照片润色数据集上训练的模型,很难满足PPR的这些要求。为促进这一高频任务的研究,构建了一个大规模的PPR数据集PPR10K,包含1,681组、11,161张高质量的原始人像照片。提供了高分辨率的人像区域分割掩模。每张原始照片由三位专家进行润色,并精心调整每组照片,使其色调一致。定义了一套评估PPR性能的客观措施,提出了学习具有良好HRP和GLC性能的PPR模型的策略。构建的PPR10K数据集为研究自动PPR方法提供了一个很好的基准,实验证明,所提出的学习策略能够有效地提高润色性能。
Different from general photo retouching tasks, portrait photo retouching (PPR), which aims to enhance the visual quality of a collection of flat-looking portrait photos, has its special and practical requirements such as human-region priority (HRP) and group-level consistency (GLC). HRP requires that more attention should be paid to human regions, while GLC requires that a group of portrait photos should be retouched to a consistent tone. Models trained on existing general photo retouching datasets, however, can hardly meet these requirements of PPR. To facilitate the research on this high-frequency task, we construct a largescale PPR dataset, namely PPR10K, which is the first of its kind to our best knowledge. PPR10K contains 1, 681 groups and 11, 161 high-quality raw portrait photos in total. High-resolution segmentation masks of human regions are provided. Each raw photo is retouched by three experts, while they elaborately adjust each group of photos to have consistent tones. We define a set of objective measures to evaluate the performance of PPR and propose strategies to learn PPR models with good HRP and GLC performance. The constructed PPR10K dataset provides a good benchmark for studying automatic PPR methods, and experiments demonstrate that the proposed learning strategies are effective to improve the retouching performance. Datasets and codes are available: https://github.com/csjliang/PPR10K.
https://weibo.com/1402400261/Khc446d4Z



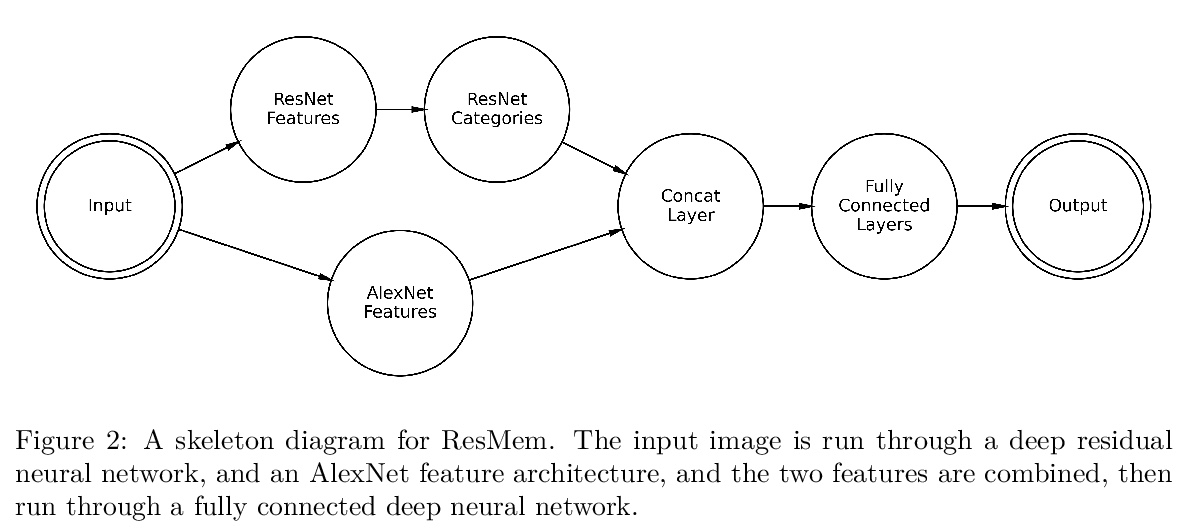
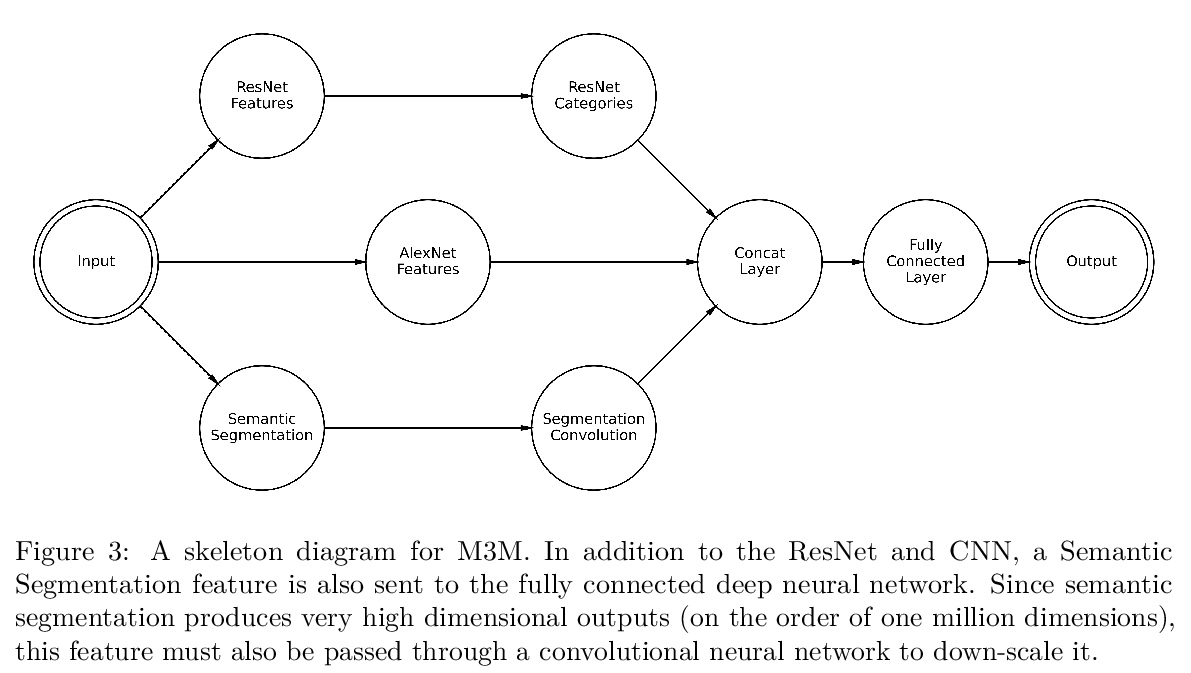
5、[CV] Embracing New Techniques in Deep Learning for Estimating Image Memorability
C D. Needell, W A. Bainbridge
[University of Chicago]
面向图像可记忆性估计的深度学习方法。多项工作表明,图像的可记忆性在不同人之间是一致的,因此可以被视为图像的内在属性。使用计算机视觉模型,可以对人们将记住或忘记的东西做出具体预测。虽然较早的工作是用现在已过时的深度学习架构预测图像的记忆性,但该领域的创新给了我们新的技术来应用于这个问题。本文提出并评估了五个备选的深度学习模型,利用该领域过去五年的发展,主要引入了残差神经网络,目的是让模型在记忆性估计过程中使用语义信息。这些新的模型与之前的技术水平进行了测试,并建立了一个组合数据集,以优化类别内和跨类别的预测。研究结果表明,之前的主流记忆性网络夸大了通用性,对训练集过拟合。新模型优于之前模型,在记忆性回归中,残差网络优于更简单的卷积神经网络。
Various work has suggested that the memorability of an image is consistent across people, and thus can be treated as an intrinsic property of an image. Using computer vision models, we can make specific predictions about what people will remember or forget. While older work has used now-outdated deep learning architectures to predict image memorability, innovations in the field have given us new techniques to apply to this problem. Here, we propose and evaluate five alternative deep learning models which exploit developments in the field from the last five years, largely the introduction of residual neural networks, which are intended to allow the model to use semantic information in the memorability estimation process. These new models were tested against the prior state of the art with a combined dataset built to optimize both within-category and across-category predictions. Our findings suggest that the key prior memorability network had overstated its generalizability and was overfit on its training set. Our new models outperform this prior model, leading us to conclude that Residual Networks outperform simpler convolutional neural networks in memorability regression. We make our new state-of-the-art model readily available to the research community, allowing memory researchers to make predictions about memorability on a wider range of images.
https://weibo.com/1402400261/Khc8fwxj5


另外几篇值得关注的论文:
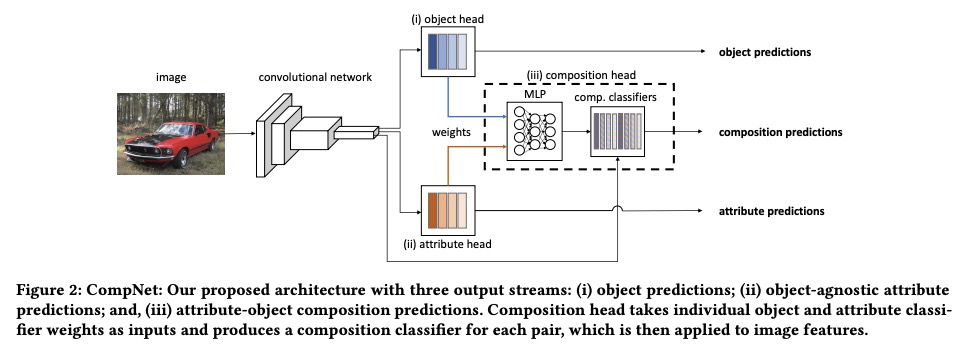
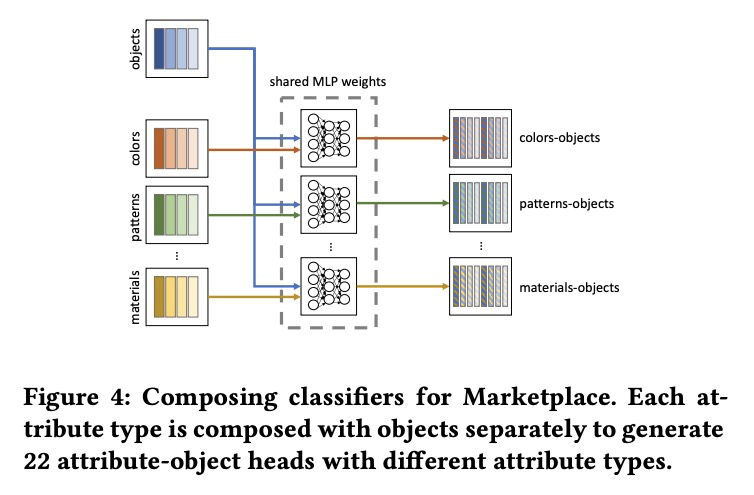
[CV] Large-Scale Attribute-Object Compositions
大规模属性-对象组合
F Radenovic, A Sinha, A Gordo, T Berg, D Mahajan
[Facebook AI]
https://weibo.com/1402400261/Khcbflavn


[CL] VANiLLa : Verbalized Answers in Natural Language at Large Scale
VANiLLa:面向大规模自然语言口头化完整回答的数据集
D Biswas, M Dubey, M R A H Rony, J Lehmann
[Saarland University & University of Bonn & Fraunhofer IAIS]
https://weibo.com/1402400261/KhccXFqRW
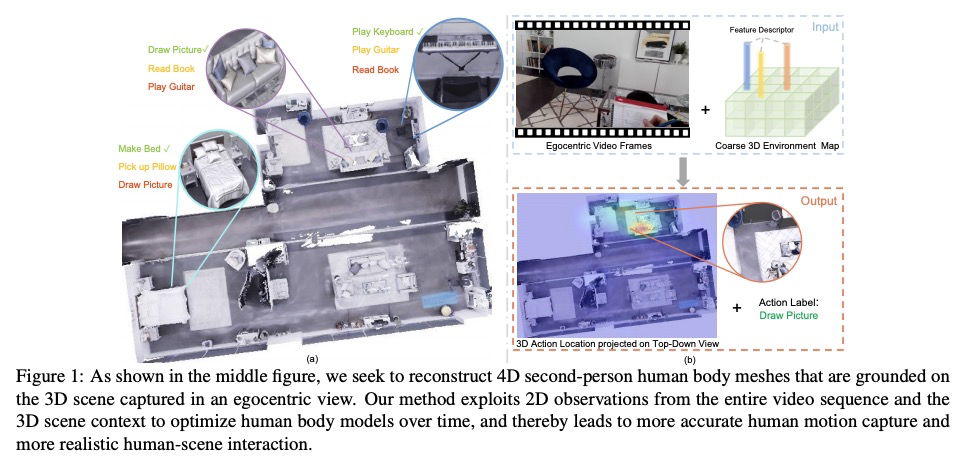
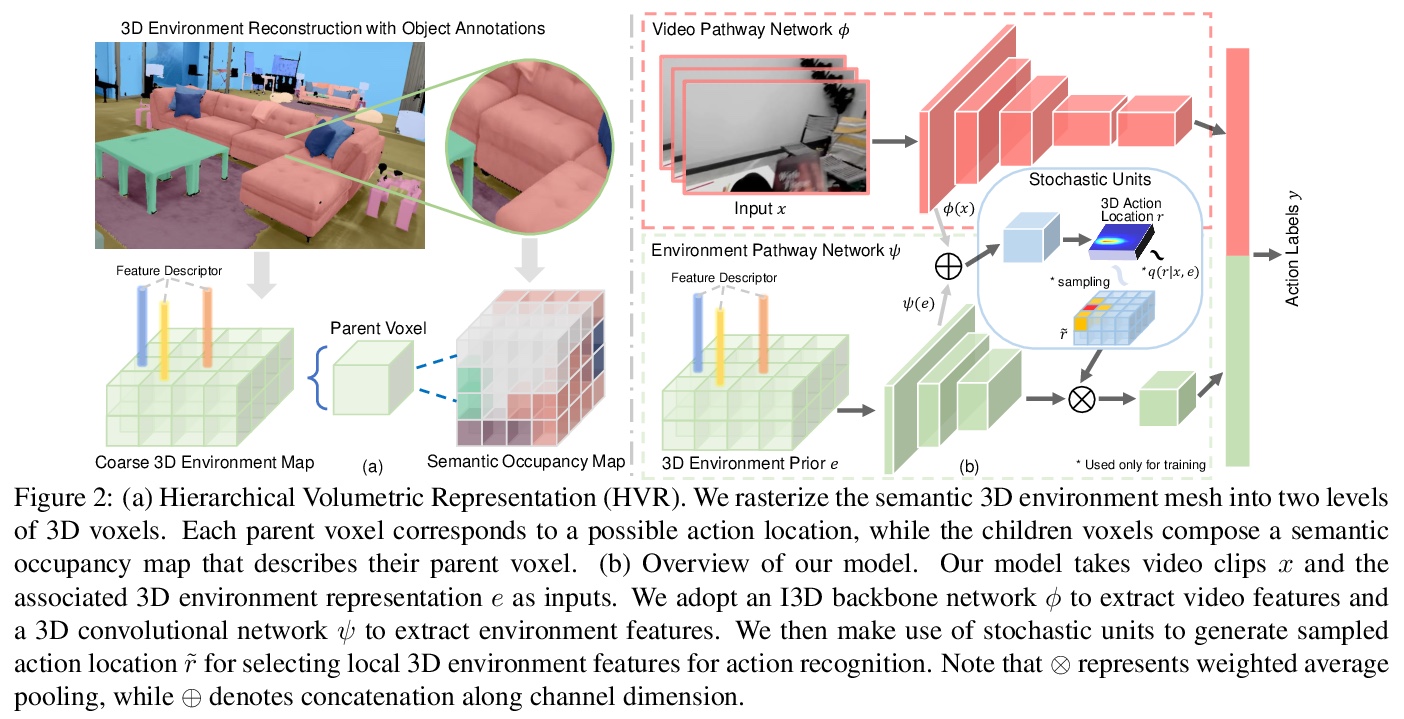
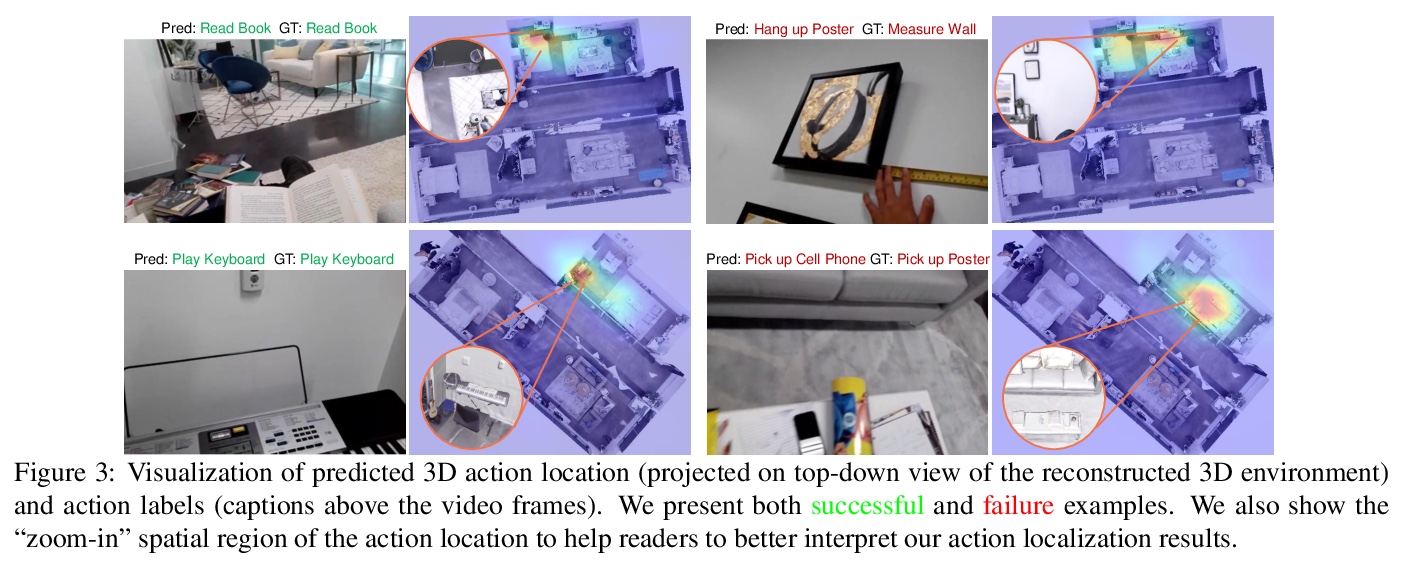
[CV] Egocentric Activity Recognition and Localization on a 3D Map
3D地图上自我中心活动识别与定位
M Liu, L Ma, K Somasundaram, Y Li, K Grauman, J M. Rehg, C Li
[Georgia Institute of Technology & Facebook Reality Lab & University of Wisconsin-Madison]
https://weibo.com/1402400261/KhcfMkQfO

[AI] Software Engineering for AI-Based Systems: A Survey
人工智能系统软件工程综述
S Martínez-Fernández, J Bogner, X Franch, M Oriol, J Siebert, A Trendowicz, A M Vollmer, S Wagner
[Universitat Politècnica de Catalunya & University of Stuttgart]
https://weibo.com/1402400261/Khcil3VXM

若有收获,就点个赞吧
0 人点赞
