- 1、[CV] LayoutParser: A Unified Toolkit for Deep Learning Based Document Image Analysis
- 2、[AS] AST: Audio Spectrogram Transformer
- 3、[AS] Keyword Transformer: A Self-Attention Model for Keyword Spotting
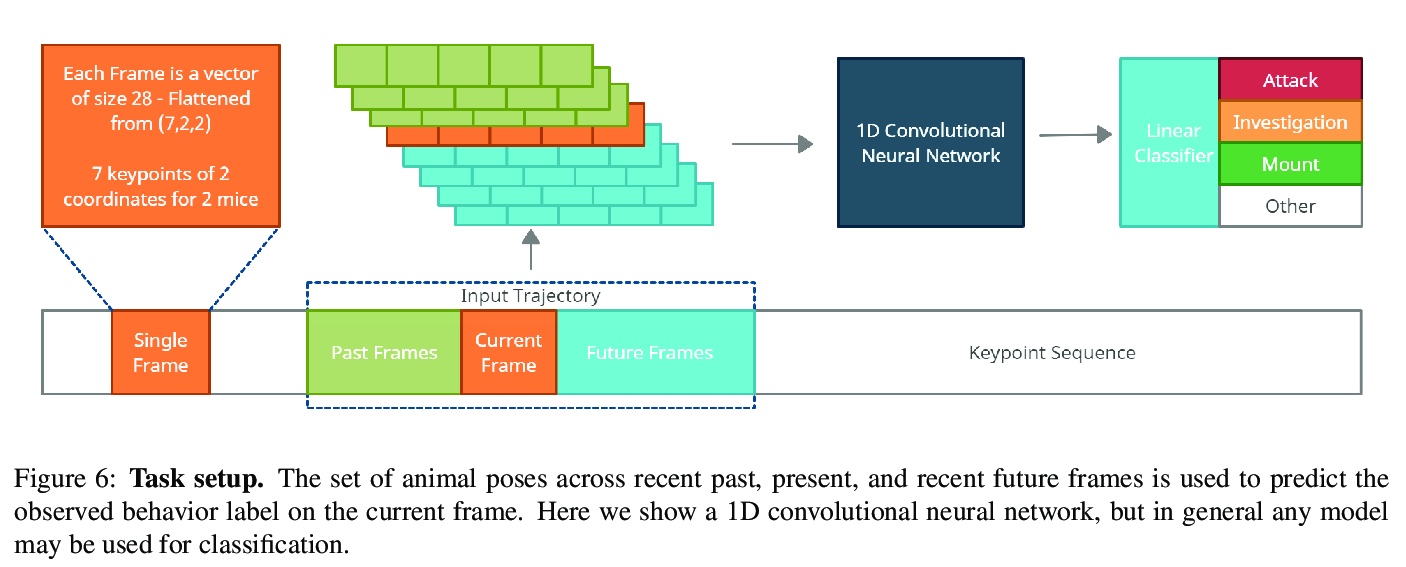
- 4、[LG] The Multi-Agent Behavior Dataset: Mouse Dyadic Social Interactions
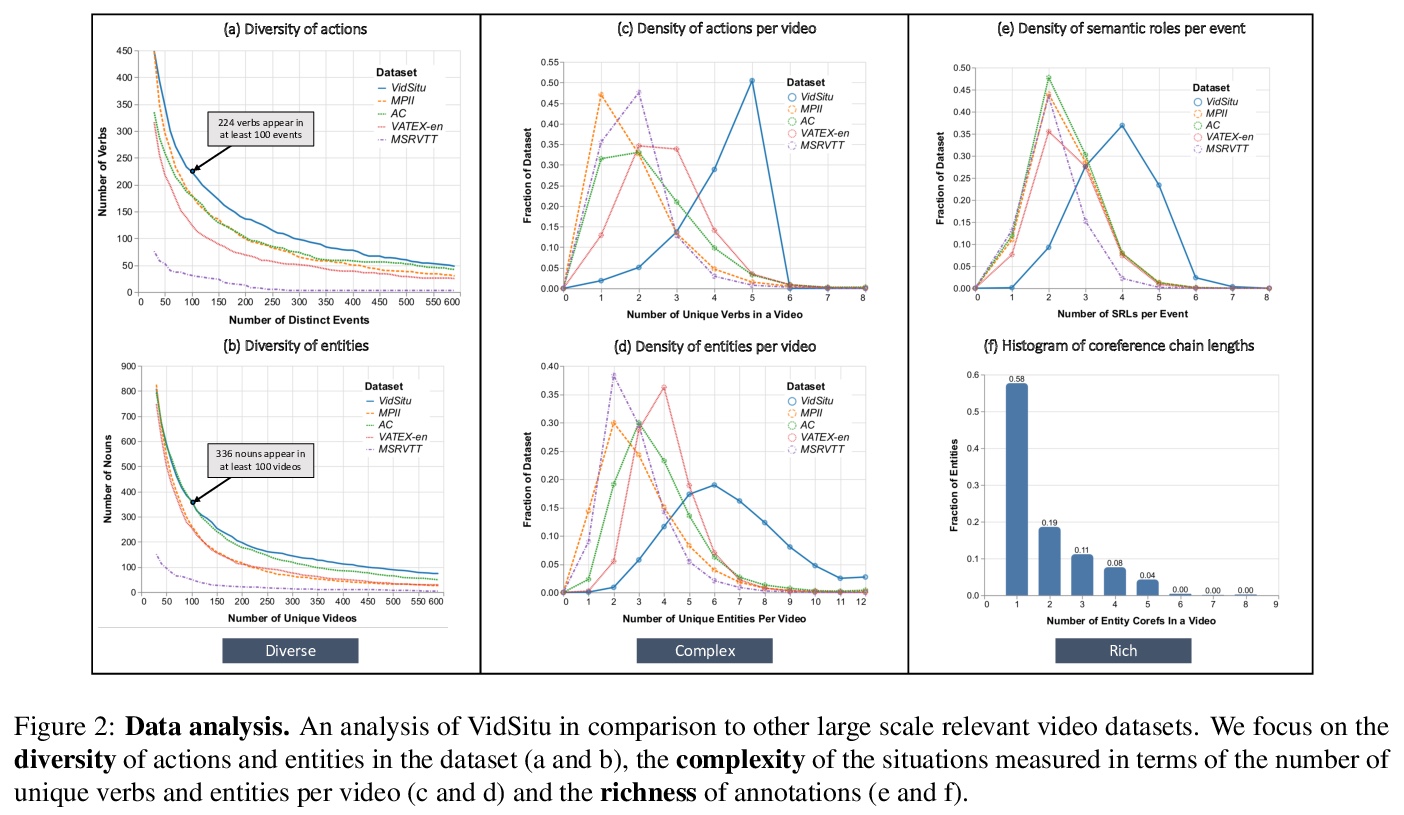
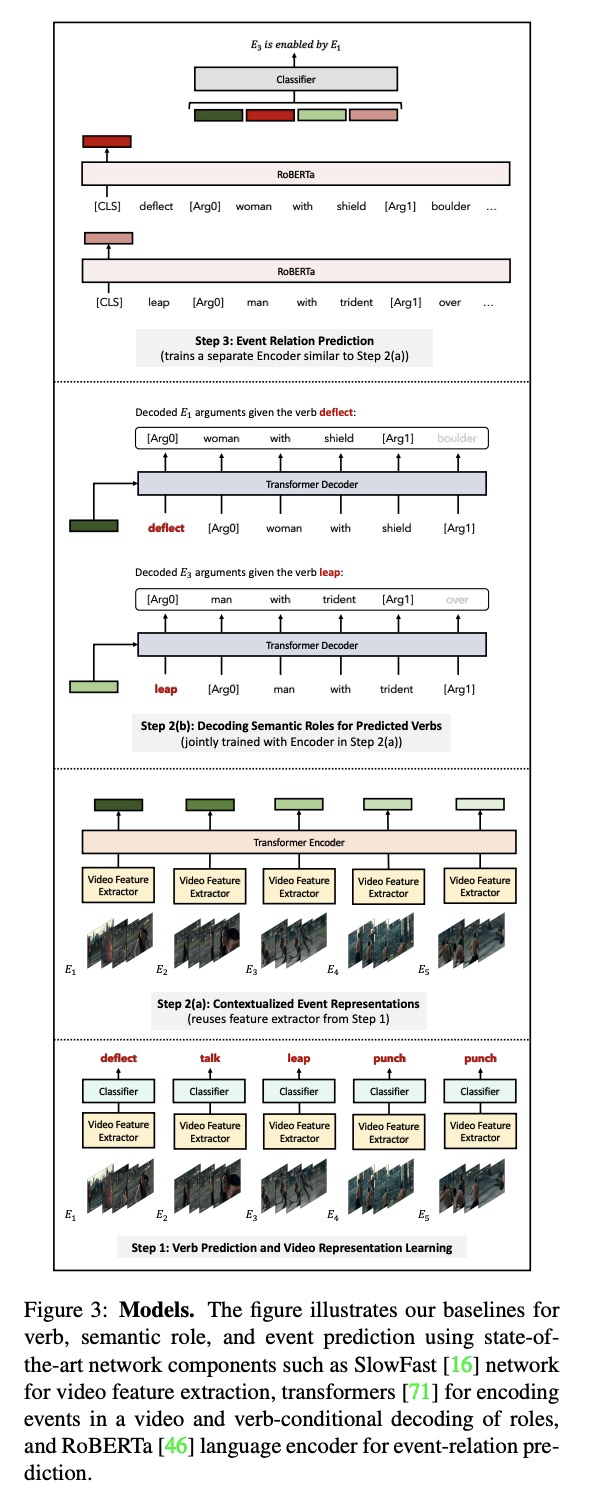
- 5、[CV] Visual Semantic Role Labeling for Video Understanding
- [AS] Speech Resynthesis from Discrete Disentangled Self-Supervised Representations
- [LG] Ranking Neural Checkpoints
- [LG] Active multi-fidelity Bayesian online changepoint detection
- [CV] Learning Generative Models of Textured 3D Meshes from Real-World Images
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] LayoutParser: A Unified Toolkit for Deep Learning Based Document Image Analysis
Z Shen, R Zhang, M Dell, B C G Lee, J Carlson, W Li
[Allen Institute for AI & Brown University & Harvard University & University of Washington & University of Waterloo]
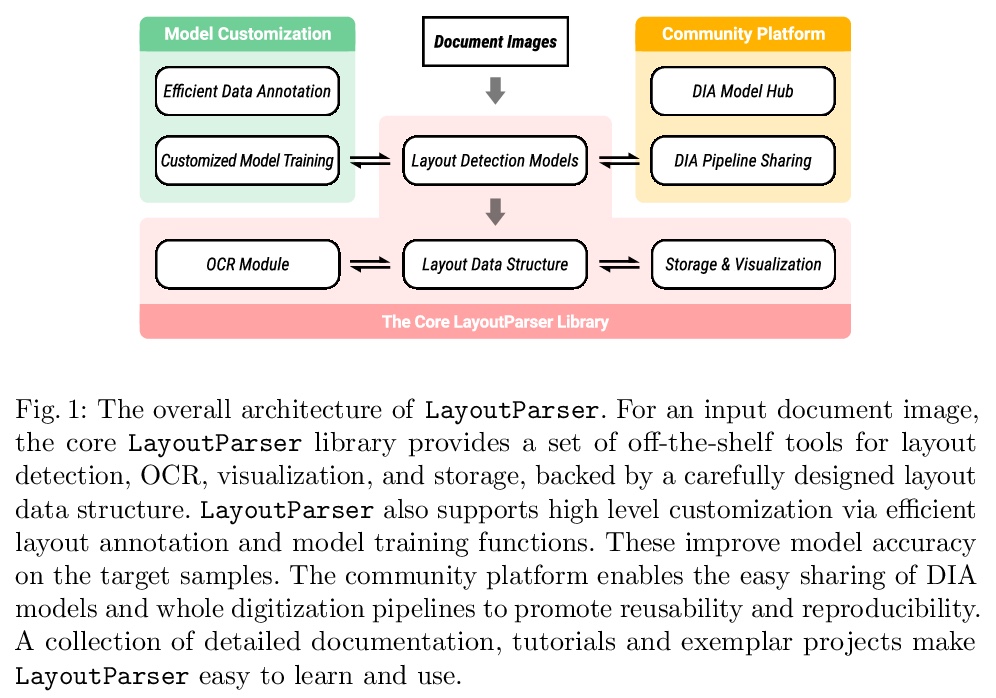
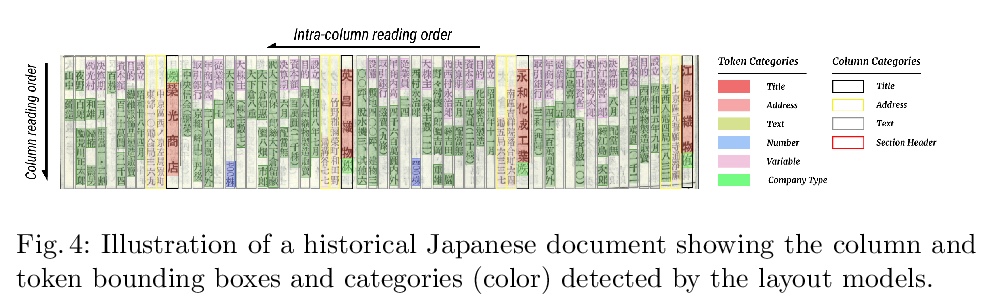
LayoutParser: 统一深度学习文档图像分析工具箱。介绍了LayoutParser,用于简化文档图像分析(DIA)研究和应用中深度学习使用的开源库,易于安装,可用于构建灵活、准确的管线,以处理结构复杂的文档。LayoutParser的核心库带有一套简单直观的接口,能在特定文档图像数据集上轻松标记和训练深度学习模型,以实现布局检测、字符识别和许多其他文档处理任务。为促进可扩展性,LayoutParser还结合了一个社区平台,用于共享预训练模型和完整的文档数字化管线。LayoutParser对于实际文字使用案例中的轻量级和大规模数字化流水线都有帮助。
Recent advances in document image analysis (DIA) have been primarily driven by the application of neural networks. Ideally, research outcomes could be easily deployed in production and extended for further investigation. However, various factors like loosely organized codebases and sophisticated model configurations complicate the easy reuse of important innovations by a wide audience. Though there have been on-going efforts to improve reusability and simplify deep learning (DL) model development in disciplines like natural language processing and computer vision, none of them are optimized for challenges in the domain of DIA. This represents a major gap in the existing toolkit, as DIA is central to academic research across a wide range of disciplines in the social sciences and humanities. This paper introduces layoutparser, an open-source library for streamlining the usage of DL in DIA research and applications. The core layoutparser library comes with a set of simple and intuitive interfaces for applying and customizing DL models for layout detection, character recognition, and many other document processing tasks. To promote extensibility, layoutparser also incorporates a community platform for sharing both pre-trained models and full document digitization pipelines. We demonstrate that layoutparser is helpful for both lightweight and large-scale digitization pipelines in real-word use cases. The library is publicly available at > this https URL.
| Comments: | 16 pages, 6 figures, 2 tables |
| —- | —- |
| Subjects: | Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2103.15348 [cs.CV] |
| | (or arXiv:2103.15348v1 [cs.CV] for this version) |
https://weibo.com/1402400261/KalNccOdY


2、[AS] AST: Audio Spectrogram Transformer
Y Gong, Y Chung, J Glass
[MIT]
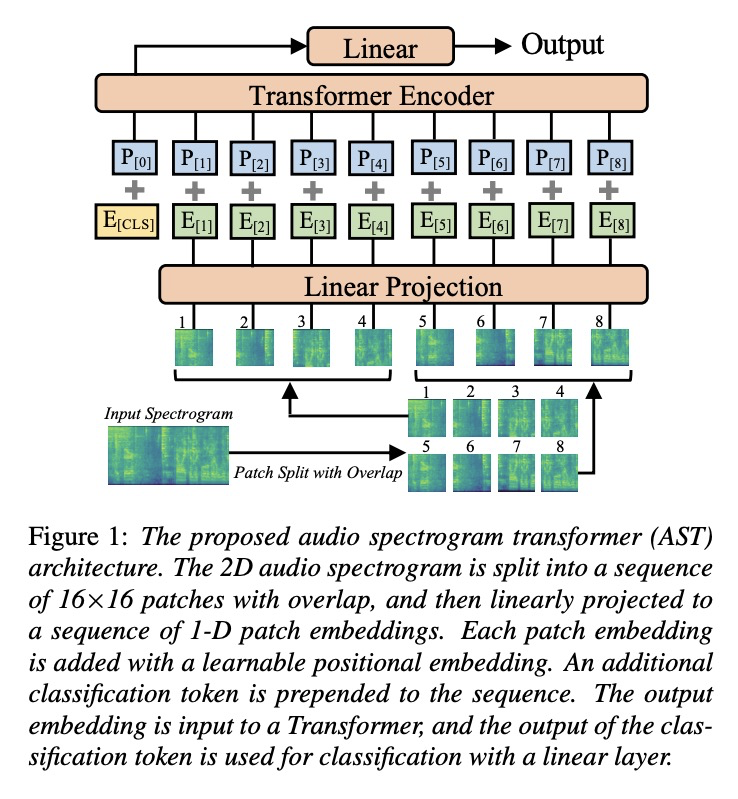
音频频谱Transformer。提出了音频频谱Transformer(AST),一种无卷积、纯基于注意力的音频分类模型,直接应用于音频频谱,即使在最底层也能捕获长距离的全局上下文,其特点是架构简单,性能优越,在训练过程中收敛更快,天然地支持可变长度输入,可应用于不同任务,而不需要改变架构。还提出了一种将在ImageNet上预训练的视觉Transformer(ViT)的知识转移到AST的方法,可显著提高性能。在各种音频分类基准上对AST进行了评估,在AudioSet上达到了0.485 mAP的新的最先进结果,在ESC-50上达到了95.6%的准确率,在Speech Commands V2上达到了98.1%的准确率。
In the past decade, convolutional neural networks (CNNs) have been widely adopted as the main building block for end-to-end audio classification models, which aim to learn a direct mapping from audio spectrograms to corresponding labels. To better capture long-range global context, a recent trend is to add a self-attention mechanism on top of the CNN, forming a CNN-attention hybrid model. However, it is unclear whether the reliance on a CNN is necessary, and if neural networks purely based on attention are sufficient to obtain good performance in audio classification. In this paper, we answer the question by introducing the Audio Spectrogram Transformer (AST), the first convolution-free, purely attention-based model for audio classification. We evaluate AST on various audio classification benchmarks, where it achieves new state-of-the-art results of 0.485 mAP on AudioSet, 95.6% accuracy on ESC-50, and 98.1% accuracy on Speech Commands V2.
https://weibo.com/1402400261/KalUCx2tw
3、[AS] Keyword Transformer: A Self-Attention Model for Keyword Spotting
A Berg, M O’Connor, M T Cruz
[Arm Research]
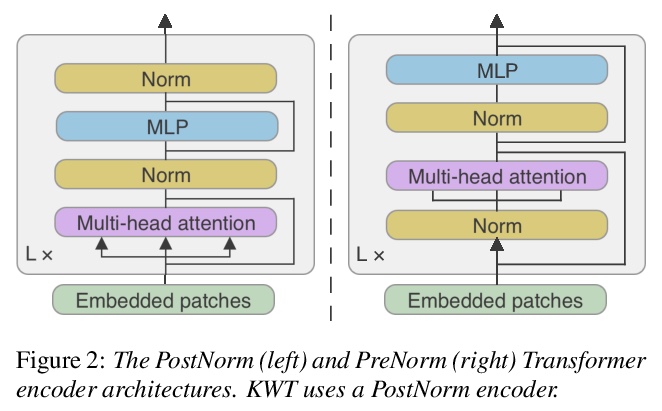
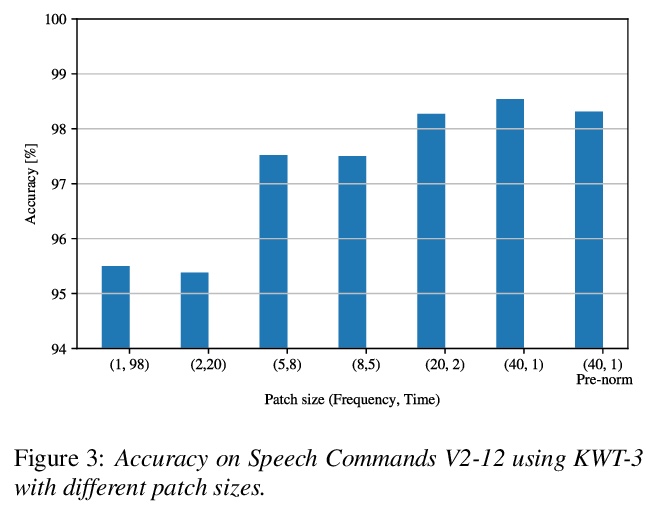
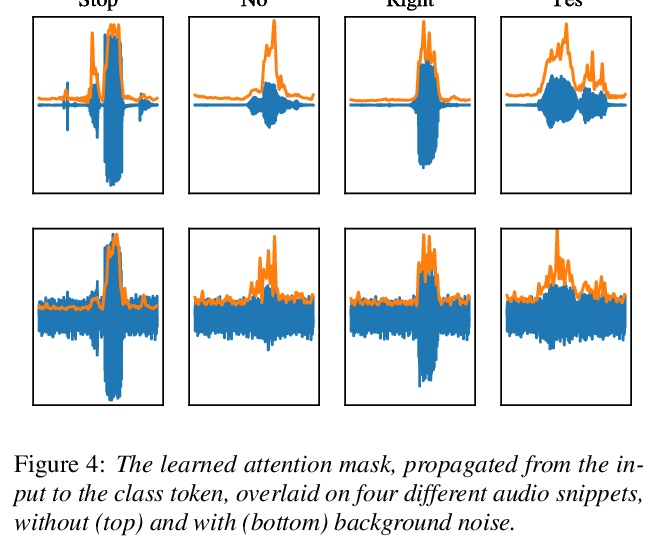
关键词Transformer。研究了Transformer架构在关键词识别中的应用,发现应用自注意力在时域比在频域更有效,提出了关键词Transformer(KWT),一种受视觉Transformer(ViT)启发的全自注意力架构,在多个任务中的性能超过了最先进水平,无需任何预训练或额外数据。该简单架构比混合了卷积层、递归层和注意力层的更复杂的模型表现更好,KWT可以作为这些模型的即插即用式替换,直观展示了学习到的注意力掩模和位置嵌入的效果,在Google语音命令数据集上创造了两项新的基准记录,在12和35命令任务上的准确率分别为98.6%和97.7%。通过对手机上模型延迟的分析,表明关键词Transformer在边缘设备应用中同样具有竞争力。
The Transformer architecture has been successful across many domains, including natural language processing, computer vision and speech recognition. In keyword spotting, self-attention has primarily been used on top of convolutional or recurrent encoders. We investigate a range of ways to adapt the Transformer architecture to keyword spotting and introduce the Keyword Transformer (KWT), a fully self-attentional architecture that exceeds state-of-the-art performance across multiple tasks without any pre-training or additional data. Surprisingly, this simple architecture outperforms more complex models that mix convolutional, recurrent and attentive layers. KWT can be used as a drop-in replacement for these models, setting two new benchmark records on the Google Speech Commands dataset with 98.6% and 97.7% accuracy on the 12 and 35-command tasks respectively.
https://weibo.com/1402400261/KalYKoEuf
4、[LG] The Multi-Agent Behavior Dataset: Mouse Dyadic Social Interactions
J J. Sun, T Karigo, D Chakraborty, S P. Mohanty, D J. Anderson, P Perona, Y Yue, A Kennedy
[Caltech & AICrowd Research & Northwestern University]
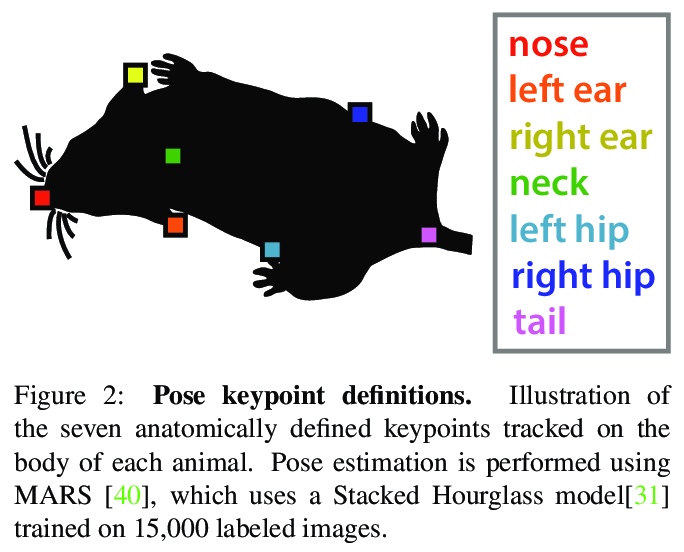
多智能体行为数据集:小鼠二元社交互动。提出了新数据集CalMS21,用于检测在实验室环境中从事自然社交互动的自由行为小鼠的行动,包括对超过70小时成对小鼠姿态的跟踪,以及超过10小时的动物行为的手工逐帧标记。对行为的标记强调了社会行为,这些行为发生在动物靠近的时候,并取决于两个动物的姿态和动作。该数据集为评价多智能体行为分类器性能提供了一个有用的新基准,也是2021年多智能体行为挑战赛的一部分。除了减少人力,自动行为分类与人工标注相比,可以带来更客观、更精确、更可扩展的测量。
Multi-agent behavior modeling aims to understand the interactions that occur between agents. We present a multi-agent dataset from behavioral neuroscience, the Caltech Mouse Social Interactions (CalMS21) Dataset. Our dataset consists of trajectory data of social interactions, recorded from videos of freely behaving mice in a standard resident-intruder assay. The CalMS21 dataset is part of the Multi-Agent Behavior Challenge 2021 and for our next step, our goal is to incorporate datasets from other domains studying multi-agent behavior.To help accelerate behavioral studies, the CalMS21 dataset provides a benchmark to evaluate the performance of automated behavior classification methods in three settings: (1) for training on large behavioral datasets all annotated by a single annotator, (2) for style transfer to learn inter-annotator differences in behavior definitions, and (3) for learning of new behaviors of interest given limited training data. The dataset consists of 6 million frames of unlabelled tracked poses of interacting mice, as well as over 1 million frames with tracked poses and corresponding frame-level behavior annotations. The challenge of our dataset is to be able to classify behaviors accurately using both labelled and unlabelled tracking data, as well as being able to generalize to new annotators and behaviors.
https://weibo.com/1402400261/Kam4w0Smo


5、[CV] Visual Semantic Role Labeling for Video Understanding
A Sadhu, T Gupta, M Yatskar, R Nevatia, A Kembhavi
[University of Southern California & University of Pennsylvania & Allen Institute for AI]
视频理解的视觉语义角色标记。提出一种新框架,利用视觉语义角色标记,来理解和表示视频中的相关突出事件。将视频表示为一组相关事件,其中每个事件由一个动词和多个实体组成,以表现与该事件相关的各种角色。为了研究视频或视频语义角色标注(VidSRL)中的语义角色标注这一具有挑战性的任务,引入了VidSitu基准,一个大规模的视频理解数据源,包括29K个10秒的电影片段,以2秒为单位标注了动词和语义角色。实体在片段各事件中被共同引用,事件之间通过事件-事件关系连接起来。VidSitu中的片段来自于大量的电影集合(3K),并选择了复杂(单个视频中4.2个独特的动词)和多样化(200个动词每个有100多个标记)。提供了全面的分析数据集与其他公开的视频理解基准,几个说明性的基线,评估和比较了一系列的标准视频识别模型。
We propose a new framework for understanding and representing related salient events in a video using visual semantic role labeling. We represent videos as a set of related events, wherein each event consists of a verb and multiple entities that fulfill various roles relevant to that event. To study the challenging task of semantic role labeling in videos or VidSRL, we introduce the VidSitu benchmark, a large-scale video understanding data source with > 29K > 10-second movie clips richly annotated with a verb and semantic-roles every > 2 seconds. Entities are co-referenced across events within a movie clip and events are connected to each other via event-event relations. Clips in VidSitu are drawn from a large collection of movies (> ∼3K) and have been chosen to be both complex (> ∼4.2 unique verbs within a video) as well as diverse (> ∼200 verbs have more than > 100 annotations each). We provide a comprehensive analysis of the dataset in comparison to other publicly available video understanding benchmarks, several illustrative baselines and evaluate a range of standard video recognition models. Our code and dataset is available at > this http URL.
https://weibo.com/1402400261/KamdxFoWx

另外几篇值得关注的论文:
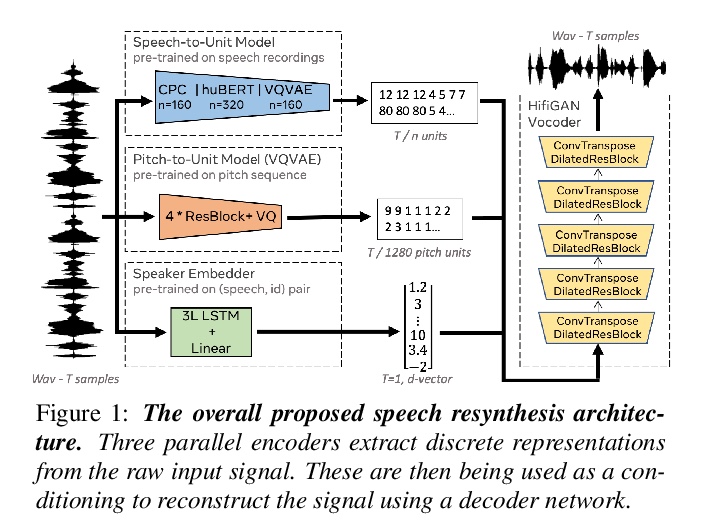
[AS] Speech Resynthesis from Discrete Disentangled Self-Supervised Representations
基于离散解缠自监督表示的语音合成
A Polyak, Y Adi, J Copet, E Kharitonov, K Lakhotia, W Hsu, A Mohamed, E Dupoux
[Facebook AI Research]
https://weibo.com/1402400261/KamjU68YO
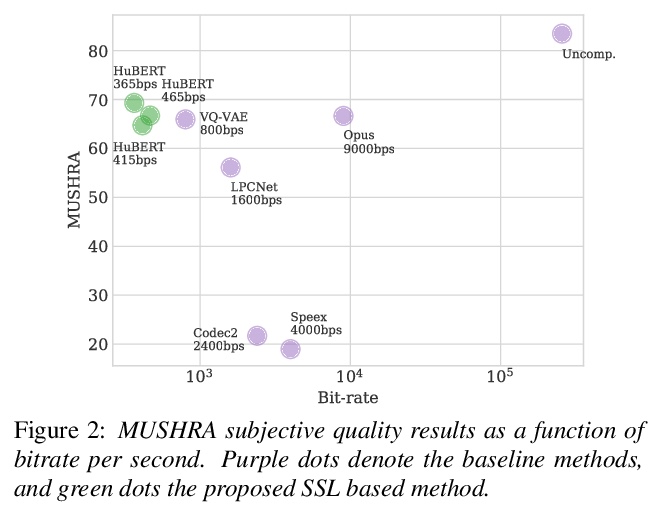
[LG] Ranking Neural Checkpoints
面向迁移学习的预训练深度神经网络(检查点)排序
Y Li, X Jia, R Sang, Y Zhu, B Green, L Wang, B Gong
[University of Central Florida & Google]
https://weibo.com/1402400261/KamlEio0L
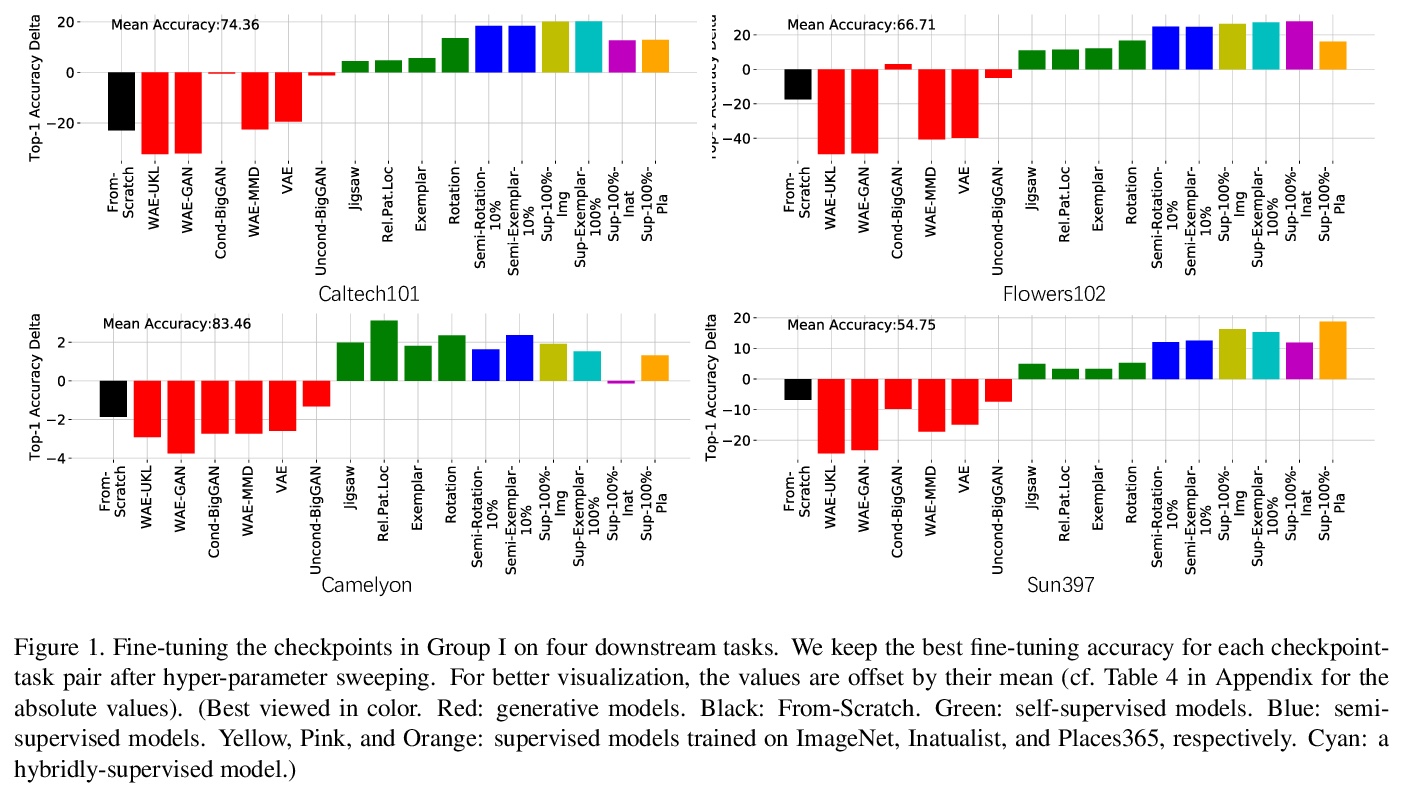
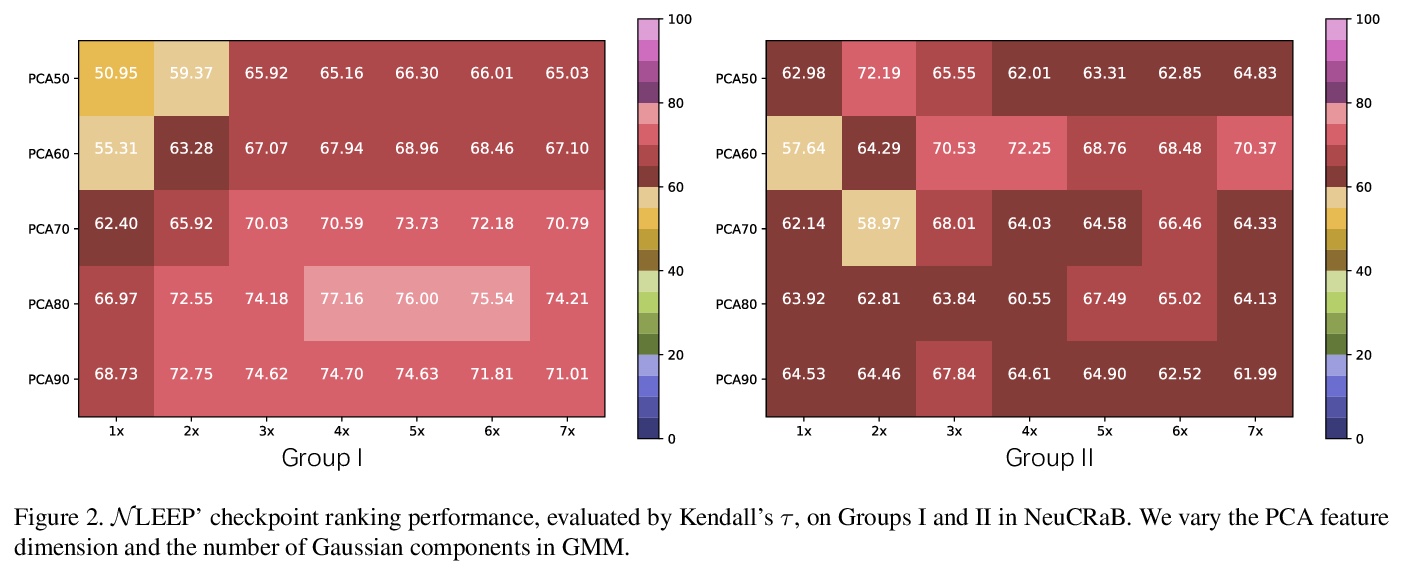
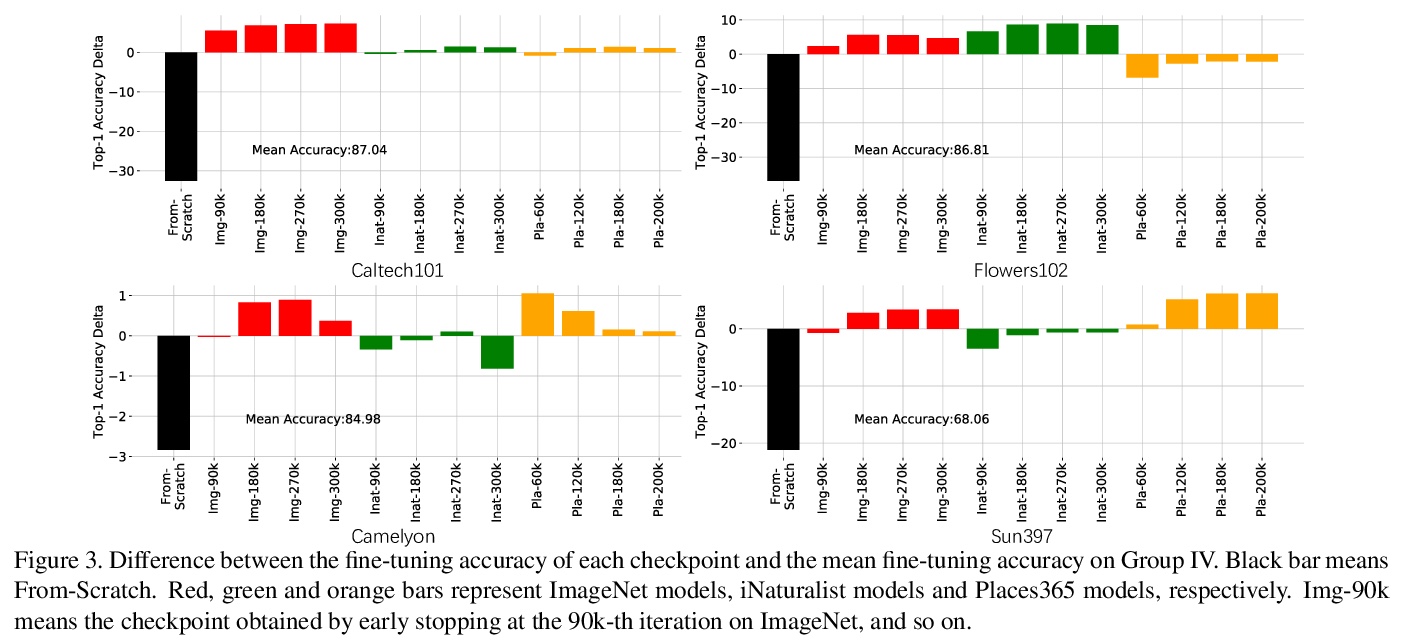
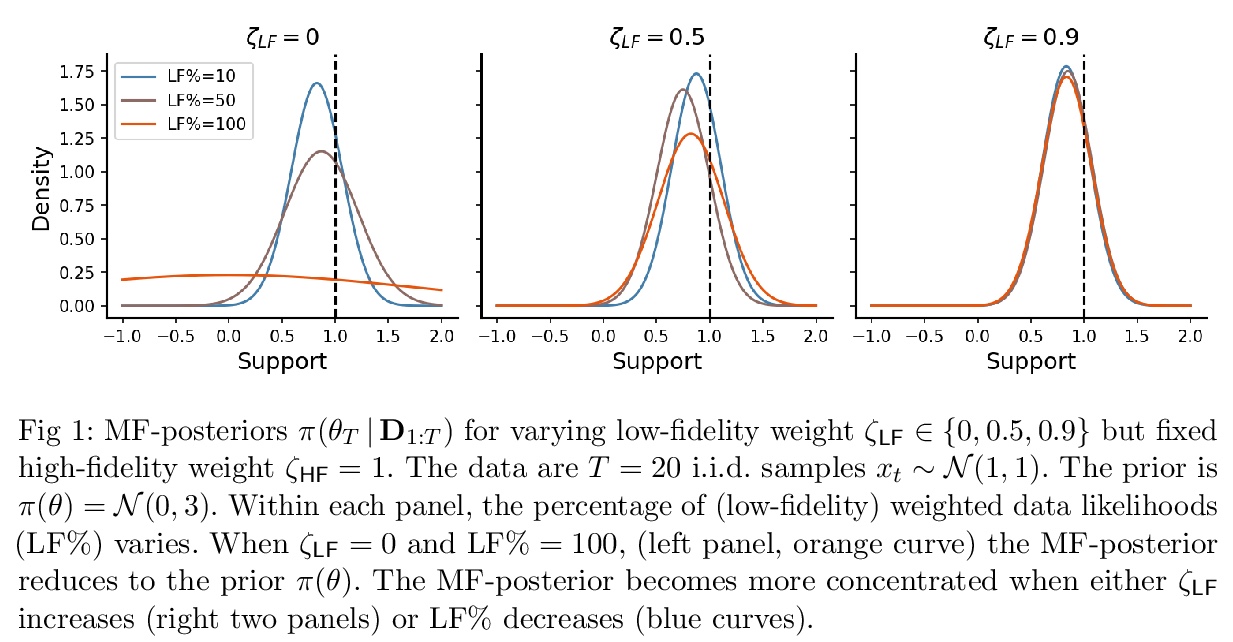
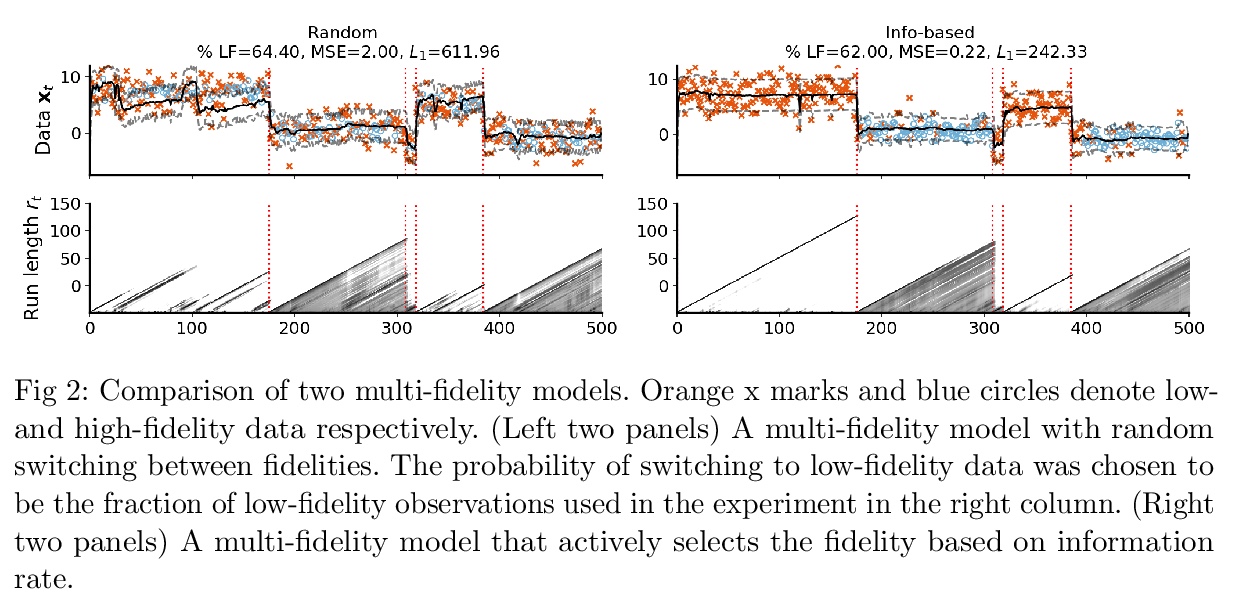
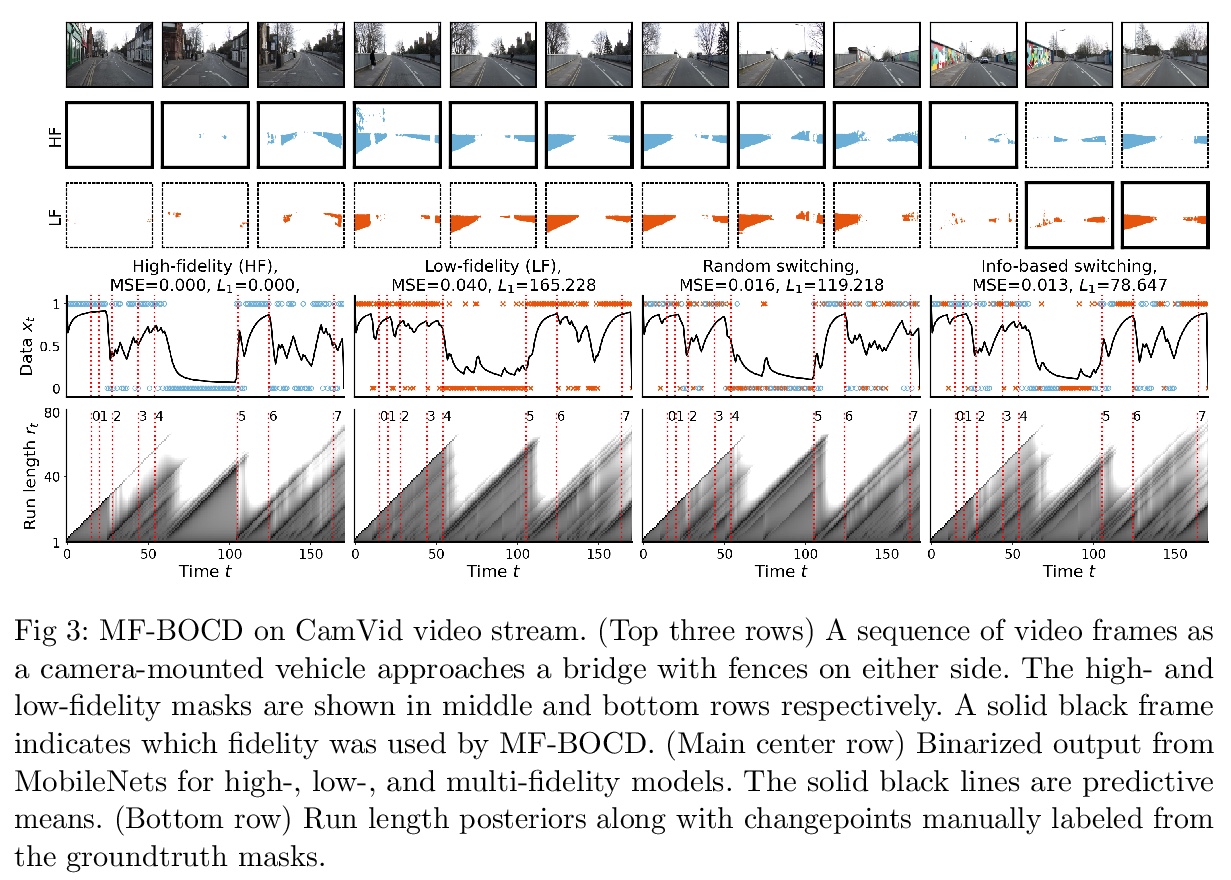
[LG] Active multi-fidelity Bayesian online changepoint detection
主动多保真贝叶斯在线变异点检测
G W. Gundersen, D Cai, C Zhou, B E. Engelhardt, R P. Adams
[ Princeton University & Arm ML Research Lab]
https://weibo.com/1402400261/KamogroqZ
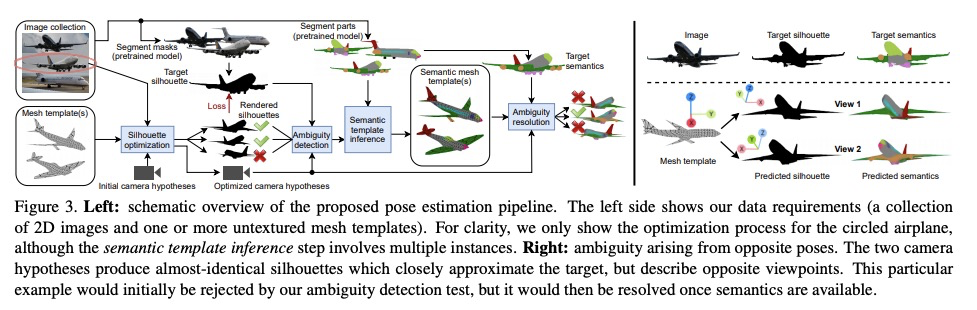
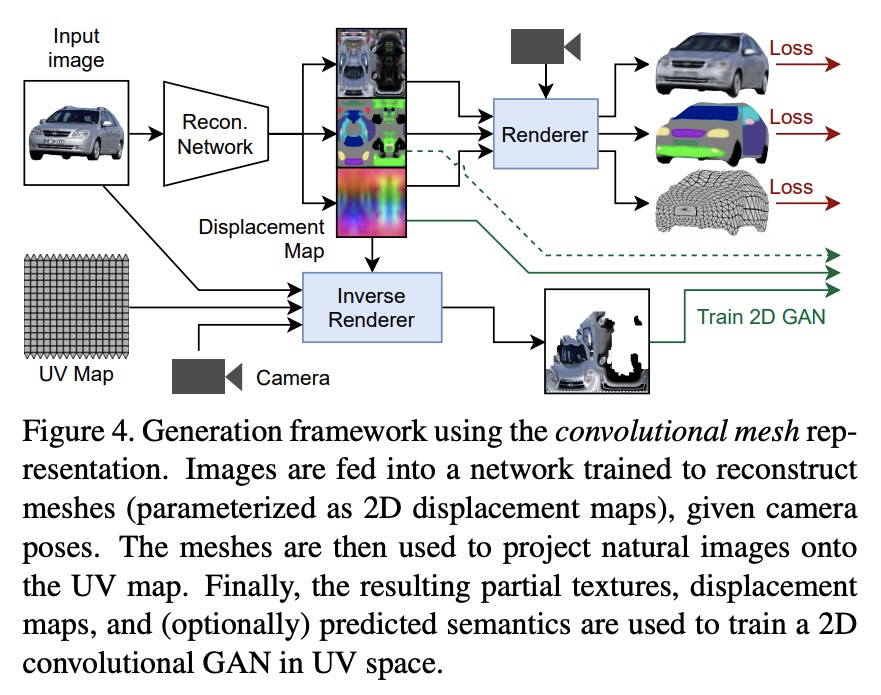
[CV] Learning Generative Models of Textured 3D Meshes from Real-World Images
从真实图像中学习纹理3D网格生成模型
D Pavllo, J Kohler, T Hofmann, A Lucchi
[ETH Zurich]
https://weibo.com/1402400261/Kamue8h1Y


若有收获,就点个赞吧
0 人点赞
