- 1、[CV] Quantum Self-Supervised Learning
- 2、[CV] In-Place Scene Labelling and Understanding with Implicit Scene Representation
- 3、[AI] The General Theory of General Intelligence: A Pragmatic Patternist Perspective
- 4、[CV] Broaden Your Views for Self-Supervised Video Learning
- 5、[CV] Planar Surface Reconstruction from Sparse Views
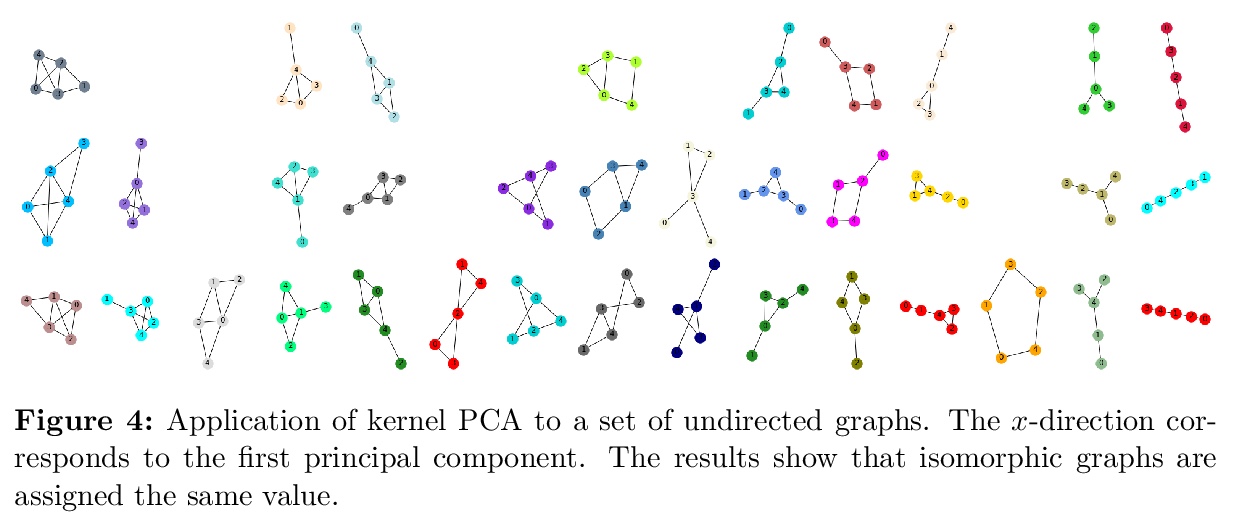
- [LG] Symmetric and antisymmetric kernels for machine learning problems in quantum physics and chemistry
- [CV] On the Adversarial Robustness of Visual Transformers
- [CV] Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers
- [IR] Fairness in Ranking: A Survey
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Quantum Self-Supervised Learning
B Jaderberg, L W. Anderson, W Xie, S Albanie, M Kiffner, D Jaksch
[University of Oxford]
量子自监督学习。提出一种混合量子-经典神经网络架构,用于对比自我监督学习,在原理验证实验中测试其有效性。用小规模量子神经网络对视觉表征的学习相比同等结构的经典网络具有数值上的优势,即使量子电路只采样了100个样本。将最佳量子模型应用于ibmq paris量子计算机上对未见图像进行分类,发现目前含噪设施在下游任务上已经可以达到与等效经典模型同等精度。
The popularisation of neural networks has seen incredible advances in pattern recognition, driven by the supervised learning of human annotations. However, this approach is unsustainable in relation to the dramatically increasing size of real-world datasets. This has led to a resurgence in self-supervised learning, a paradigm whereby the model generates its own supervisory signal from the data. Here we propose a hybrid quantum-classical neural network architecture for contrastive self-supervised learning and test its effectiveness in proof-of-principle experiments. Interestingly, we observe a numerical advantage for the learning of visual representations using small-scale quantum neural networks over equivalently structured classical networks, even when the quantum circuits are sampled with only 100 shots. Furthermore, we apply our best quantum model to classify unseen images on the ibmq_paris quantum computer and find that current noisy devices can already achieve equal accuracy to the equivalent classical model on downstream tasks.
https://weibo.com/1402400261/K9r9CeyOG
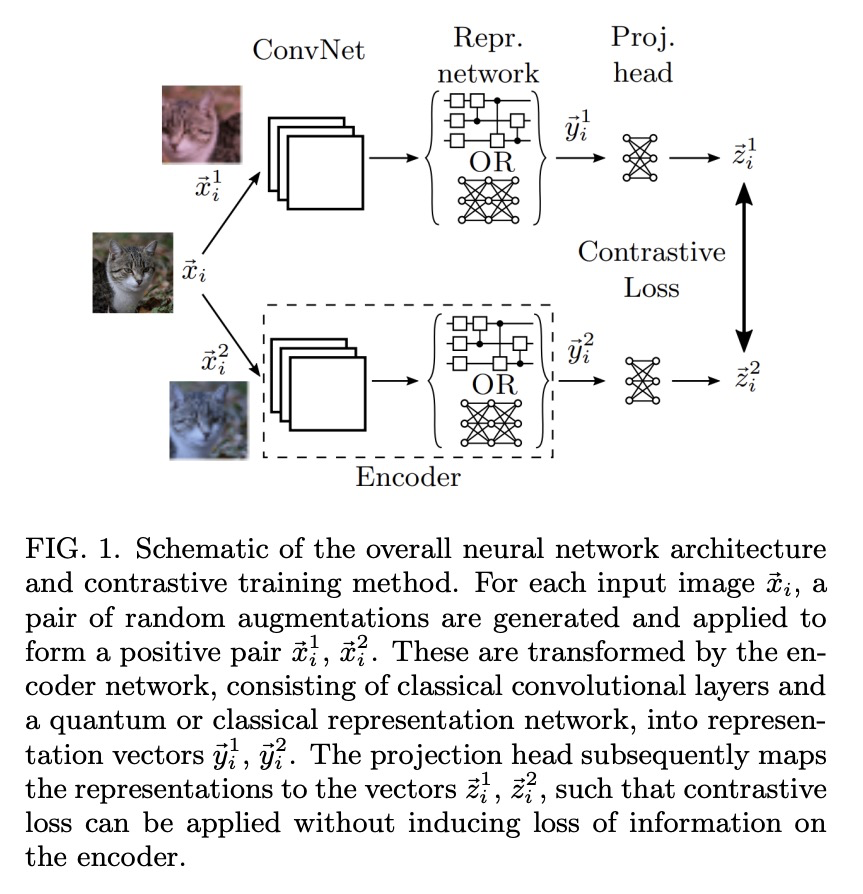
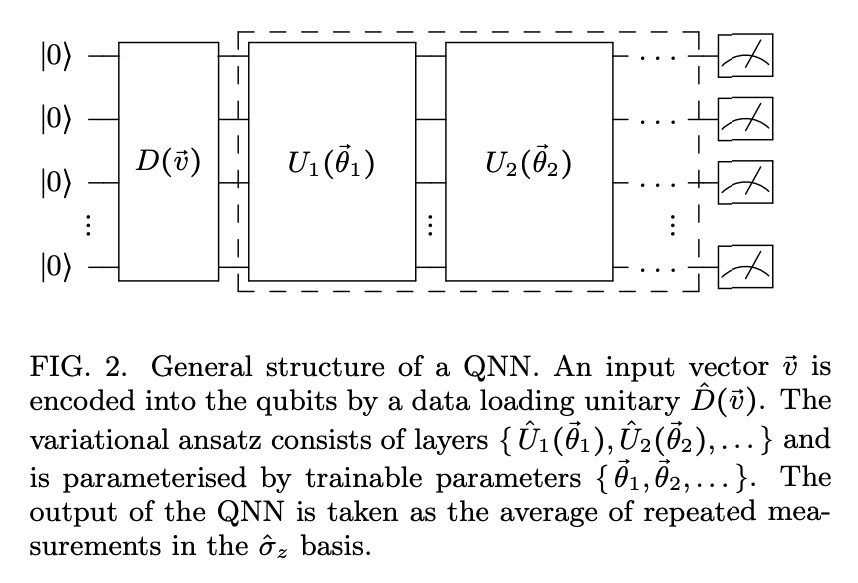
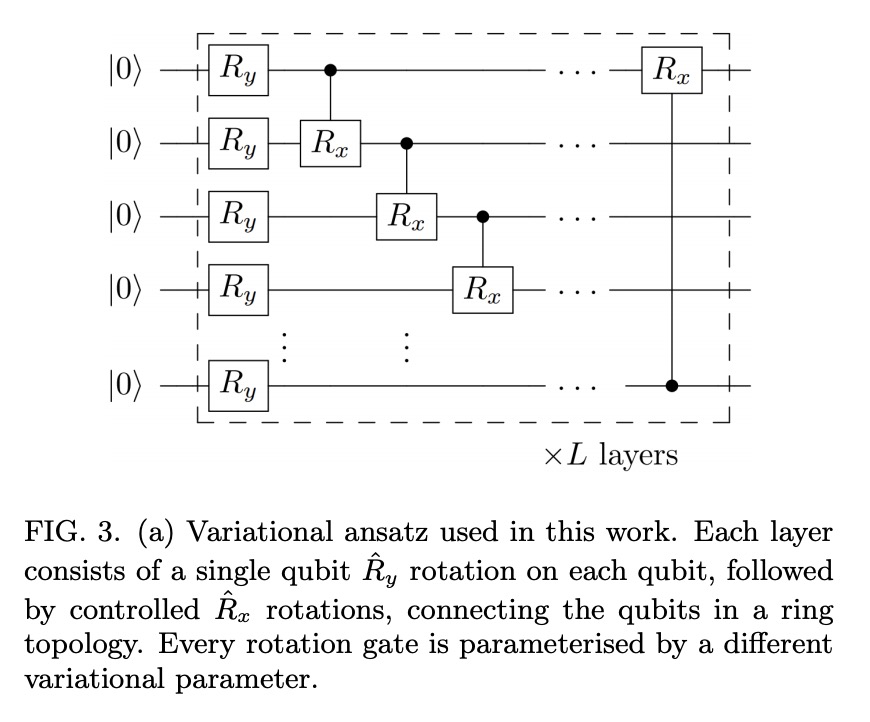
2、[CV] In-Place Scene Labelling and Understanding with Implicit Scene Representation
S Zhi, T Laidlow, S Leutenegger, A J. Davison
[Imperial College London]
基于隐性场景表示的in-place场景标注和理解。扩展了神经辐射场(NeRF),将语义与外观及几何图形联合编码,用少量针对场景的in-place标注来实现完整而准确的二维语义标签。NeRF内在的多视图一致性和平滑性通过使稀疏标签高效传播而使语义受益。展示了这种方法在房间规模场景中标签稀疏或非常嘈杂时的有效性,在各种有趣应用中展示了其优势特性,如高效的场景标签工具、新颖的语义视图合成、标签去噪、超分辨率、标签插值和视觉语义映射系统中的多视图语义标签融合。
Semantic labelling is highly correlated with geometry and radiance reconstruction, as scene entities with similar shape and appearance are more likely to come from similar classes. Recent implicit neural reconstruction techniques are appealing as they do not require prior training data, but the same fully self-supervised approach is not possible for semantics because labels are human-defined properties.We extend neural radiance fields (NeRF) to jointly encode semantics with appearance and geometry, so that complete and accurate 2D semantic labels can be achieved using a small amount of in-place annotations specific to the scene. The intrinsic multi-view consistency and smoothness of NeRF benefit semantics by enabling sparse labels to efficiently propagate. We show the benefit of this approach when labels are either sparse or very noisy in room-scale scenes. We demonstrate its advantageous properties in various interesting applications such as an efficient scene labelling tool, novel semantic view synthesis, label denoising, super-resolution, label interpolation and multi-view semantic label fusion in visual semantic mapping systems.
https://weibo.com/1402400261/K9rfEgNs4

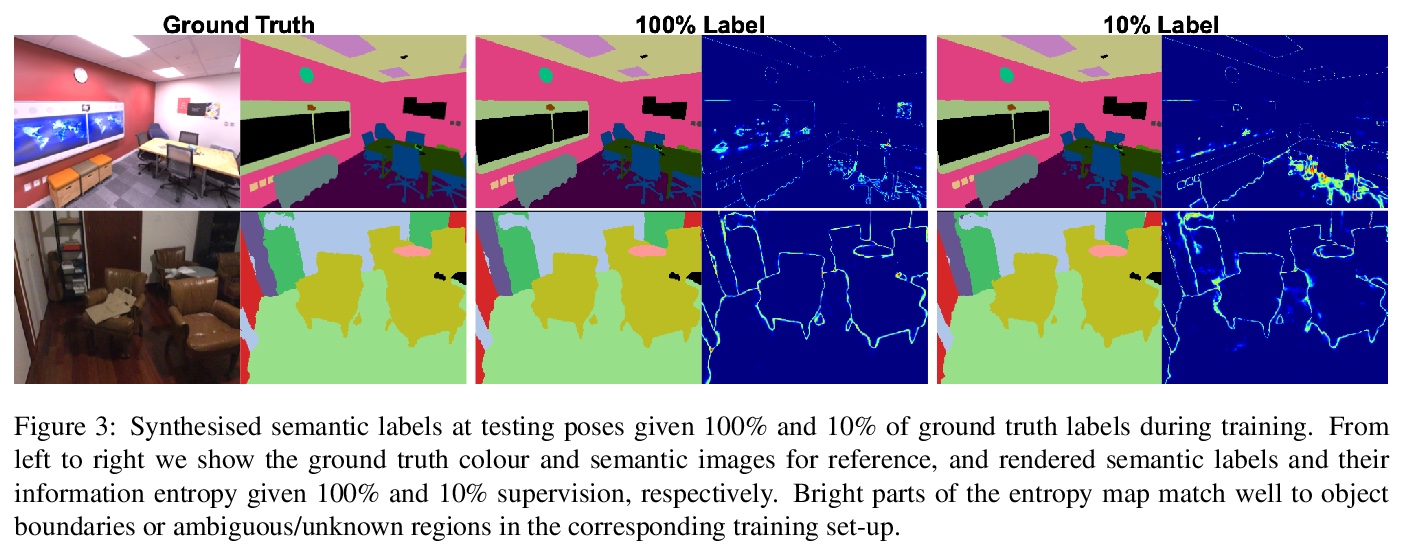

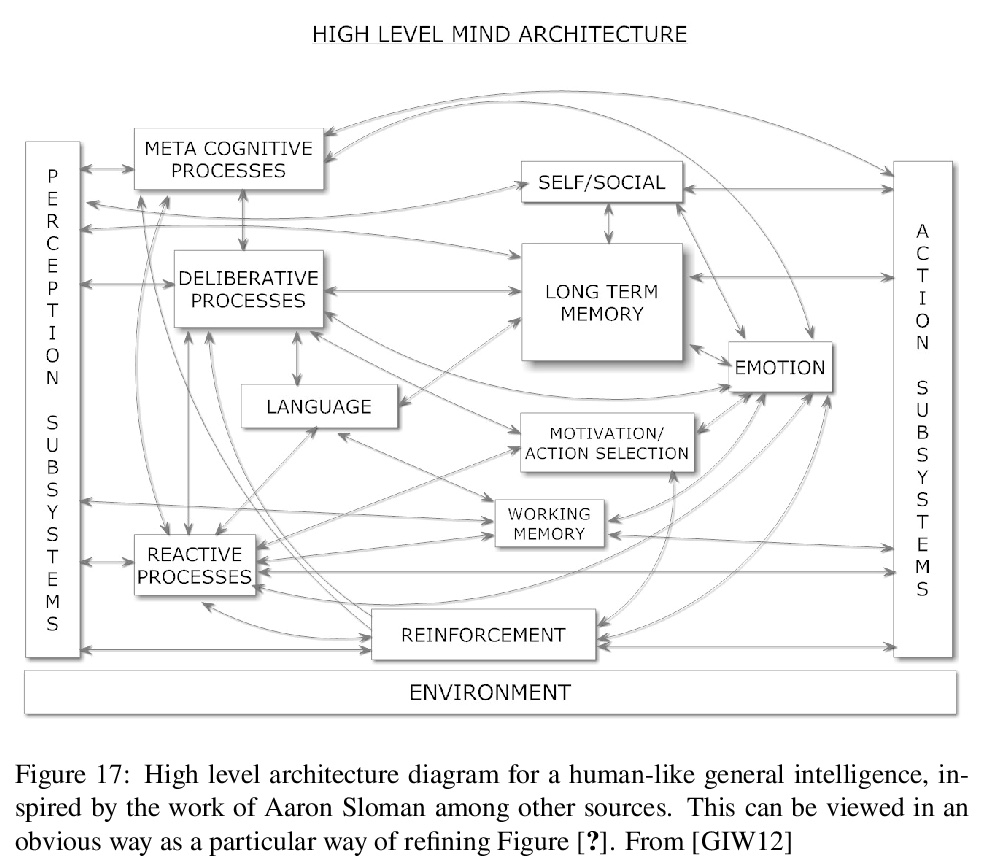
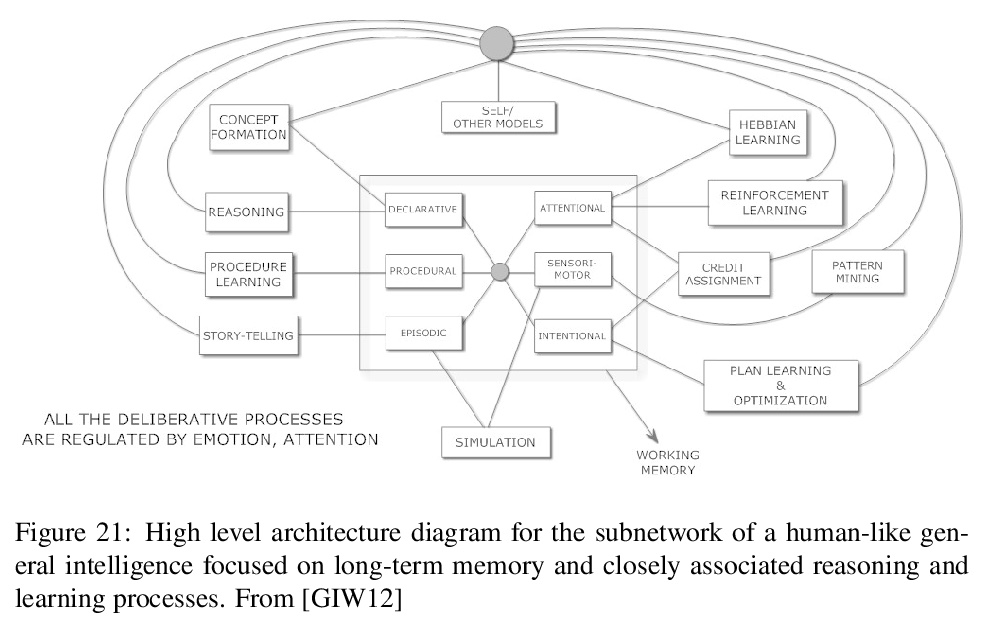
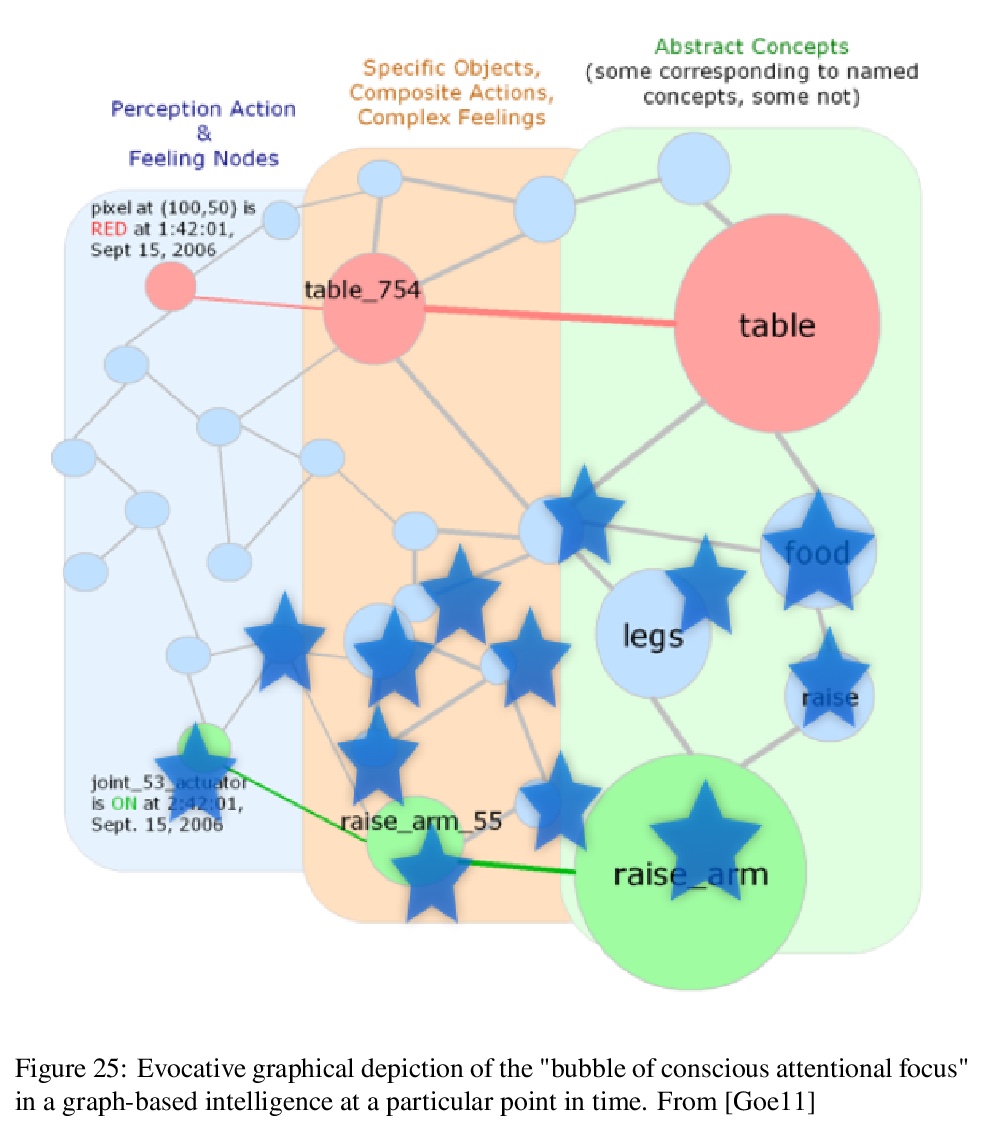
3、[AI] The General Theory of General Intelligence: A Pragmatic Patternist Perspective
B Goertzel
通用智能理论的实用模式主义观点。以适度细节回顾了几十年来对人工和自然通用智能理论基础的探索,这些探索已在一系列书籍和论文中得到体现,并用于指导一系列实用和研究的原型软件系统。综述内容涵盖了基础哲学(模式主义心智哲学、基础现象学和逻辑本体论)、智能概念的形式化,以及部分由这些形式化和哲学驱动的AGI系统的已提出的高层架构。在这个高层架构的语境和语言中,考虑了逻辑推理、程序学习、聚类和注意力分配等具体认知过程的实现,也考虑了一个共同的(如基于typedmetagraph的)知识表征对于实现各种过程之间”认知协同”的重要性。类人认知架构的具体内容是作为这些一般原则的体现,机器意识和机器伦理的关键方面也在此背景下进行了思考。简要讨论了在OpenCog Hyperon等框架中实际实现高级AGI的经验教训。
A multi-decade exploration into the theoretical foundations of artificial and natural general intelligence, which has been expressed in a series of books and papers and used to guide a series of practical and research-prototype software systems, is reviewed at a moderate level of detail. The review covers underlying philosophies (patternist philosophy of mind, foundational phenomenological and logical ontology), formalizations of the concept of intelligence, and a proposed high level architecture for AGI systems partly driven by these formalizations and philosophies. The implementation of specific cognitive processes such as logical reasoning, program learning, clustering and attention allocation in the context and language of this high level architecture is considered, as is the importance of a common (e.g. typed metagraph based) knowledge representation for enabling “cognitive synergy” between the various processes. The specifics of human-like cognitive architecture are presented as manifestations of these general principles, and key aspects of machine consciousness and machine ethics are also treated in this context. Lessons for practical implementation of advanced AGI in frameworks such as OpenCog Hyperon are briefly considered.
https://weibo.com/1402400261/K9rkWhFt7
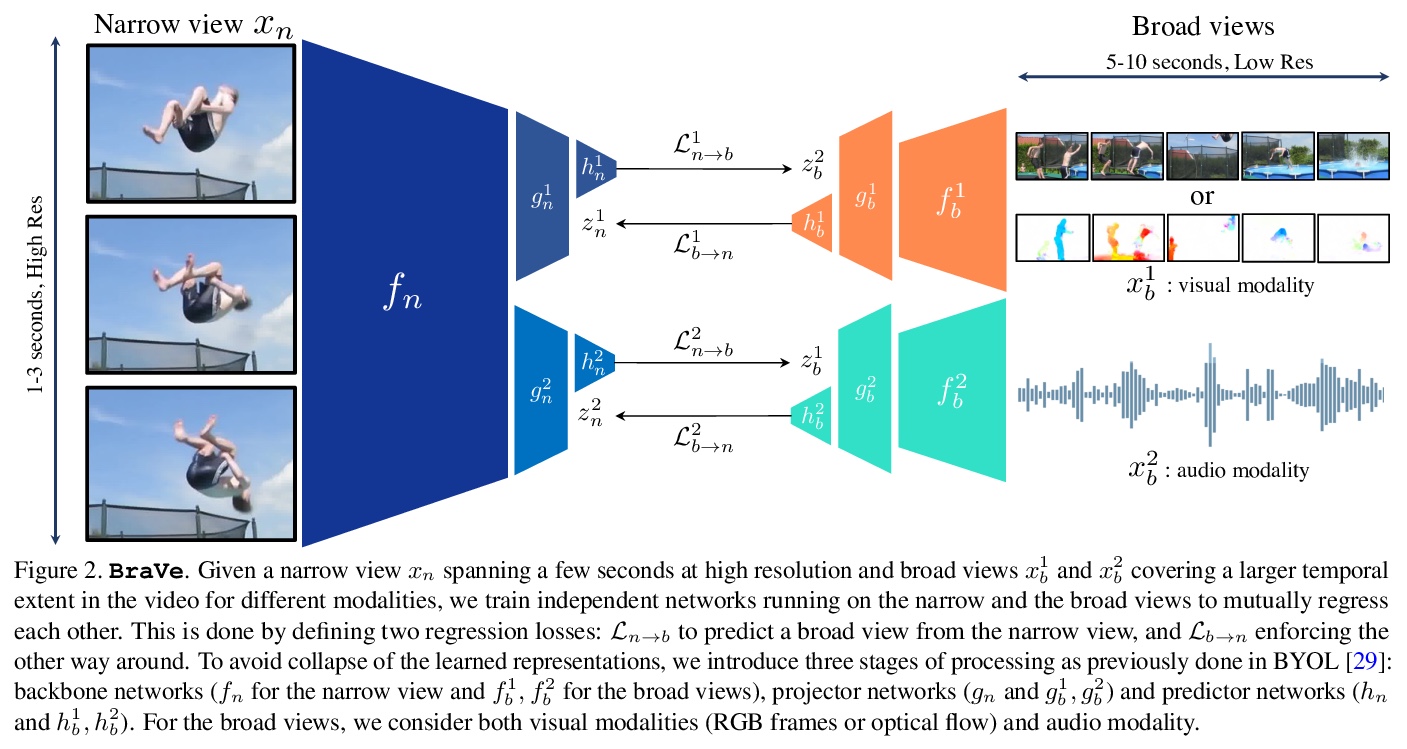
4、[CV] Broaden Your Views for Self-Supervised Video Learning
A Recasens, P Luc, J Alayrac, L Wang, F Strub, C Tallec, M Malinowski, V Patraucean, F Altché, M Valko, J Grill, A v d Oord, A Zisserman
[DeepMind]
拓宽视野的自监督视频学习。提出一种新的表征学习框架BraVe,在不同时间尺度上生成视图,并通过跨视野的简单回归来学习表征,探索在更宽视野如音频、流或随机卷积RGB帧中使用不同的增强和模态。在视频领域评估了该框架,无论有没有音频作为辅助监督信号,在视频和音频分类基准UCF101、HMDB51、Kinetics、ESC-50和AudioSet上获得了最先进的结果。
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
https://weibo.com/1402400261/K9rqKcgE5
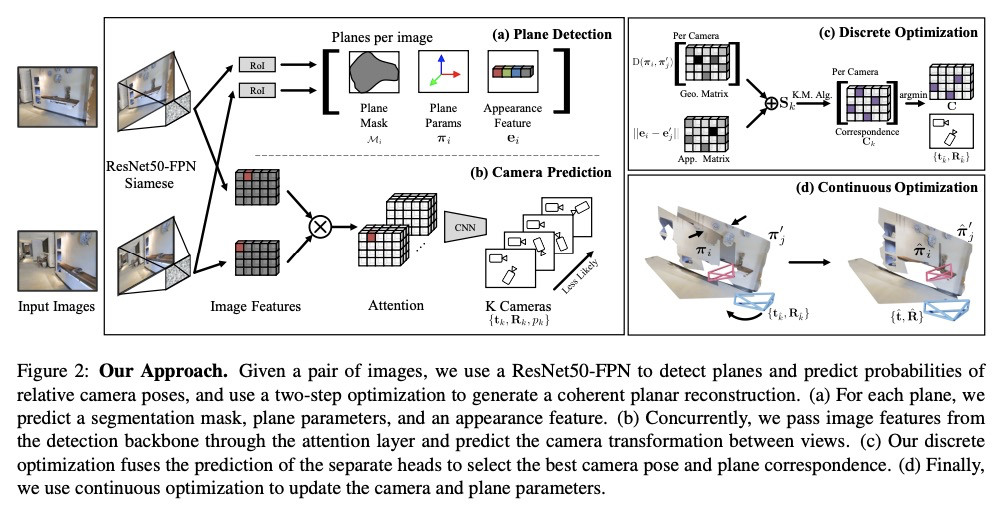
5、[CV] Planar Surface Reconstruction from Sparse Views
L Jin, S Qian, A Owens, D F. Fouhey
[University of Michigan]
稀疏视图平面重建。研究了未知姿态摄像机双视角室内场景的平面重建。提出一种基于学习的系统,从两个未知视图中产生连贯的平面重建。实验结果表明,联合考虑对应与重建可有效改善重建效果。
The paper studies planar surface reconstruction of indoor scenes from two views with unknown camera poses. While prior approaches have successfully created object-centric reconstructions of many scenes, they fail to exploit other structures, such as planes, which are typically the dominant components of indoor scenes. In this paper, we reconstruct planar surfaces from multiple views, while jointly estimating camera pose. Our experiments demonstrate that our method is able to advance the state of the art of reconstruction from sparse views, on challenging scenes from Matterport3D. Project site: > this https URL
https://weibo.com/1402400261/K9ryZ7KTa


另外几篇值得关注的论文:
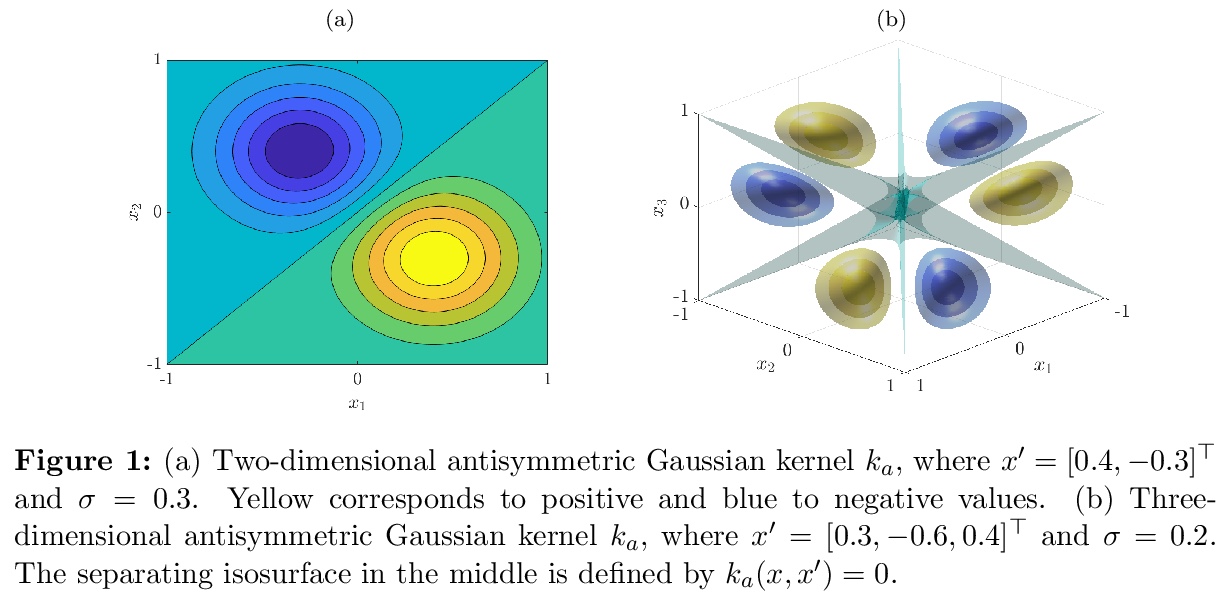
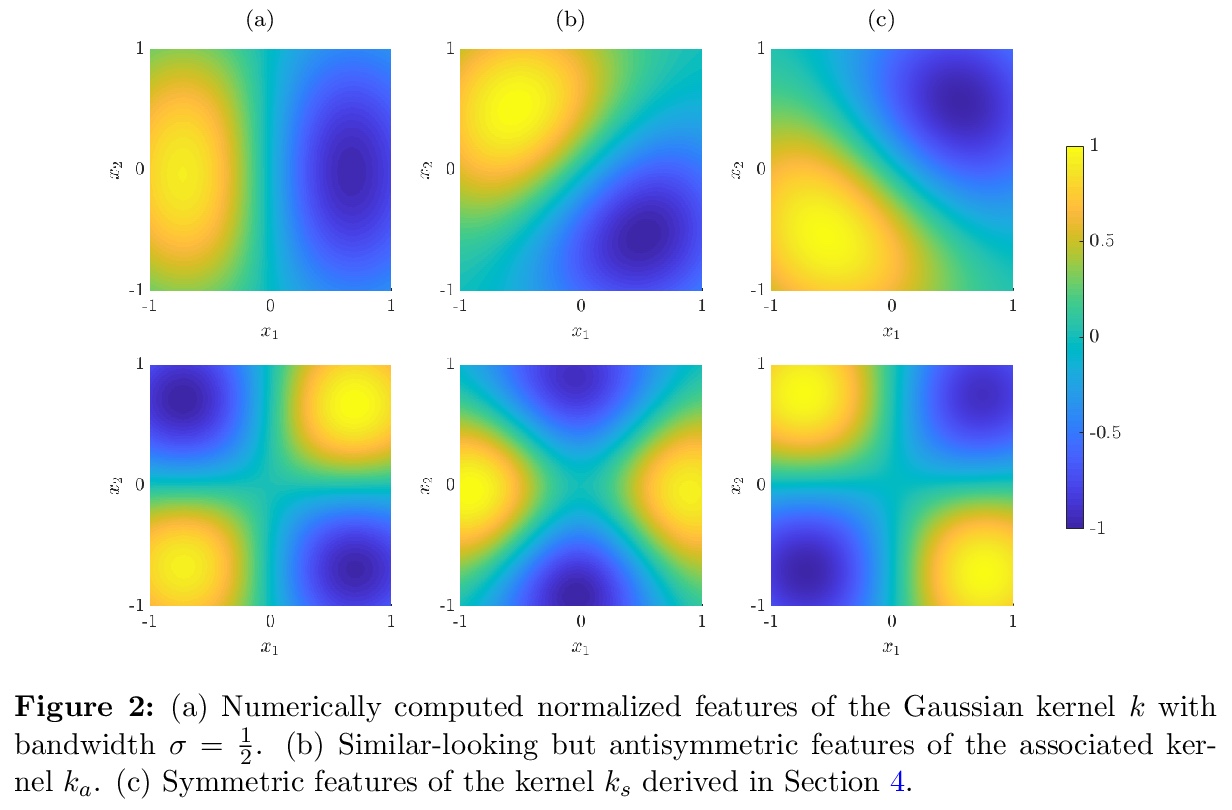
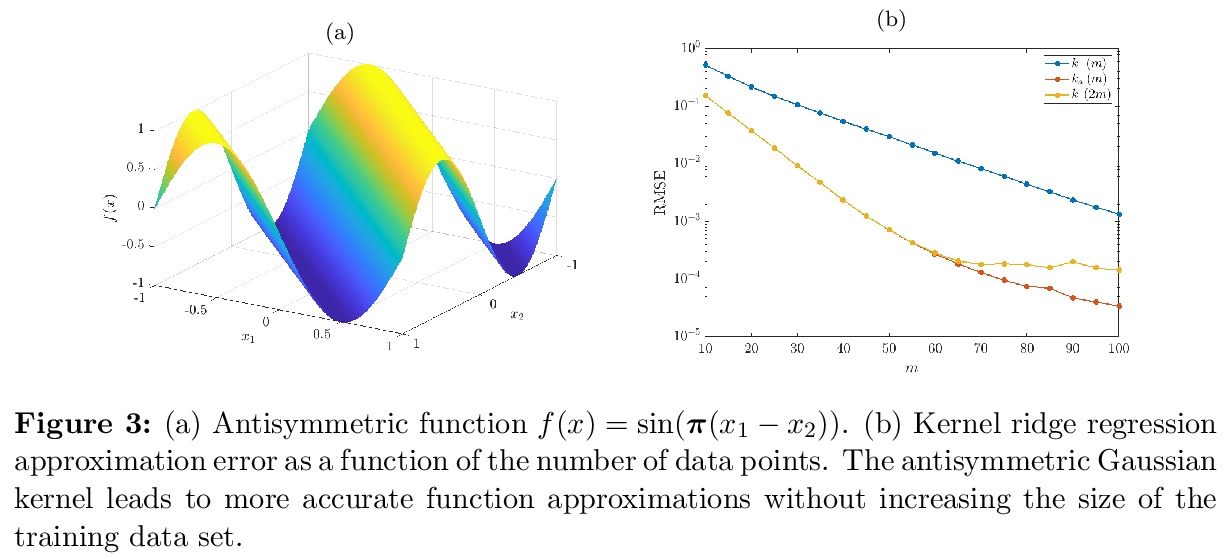
[LG] Symmetric and antisymmetric kernels for machine learning problems in quantum physics and chemistry
面向量子物理化学机器学习问题的对称和反对称核
S Klus, P Gelß, F Nüske, F Noé
[University of Surrey & Freie Universitat Berlin & Paderborn University]
https://weibo.com/1402400261/K9rv6BULR
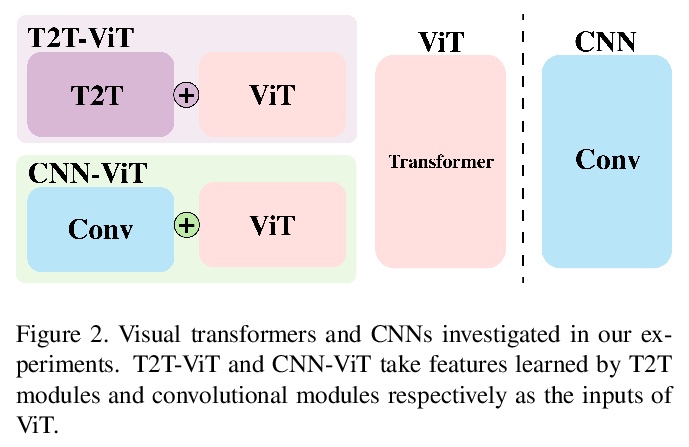
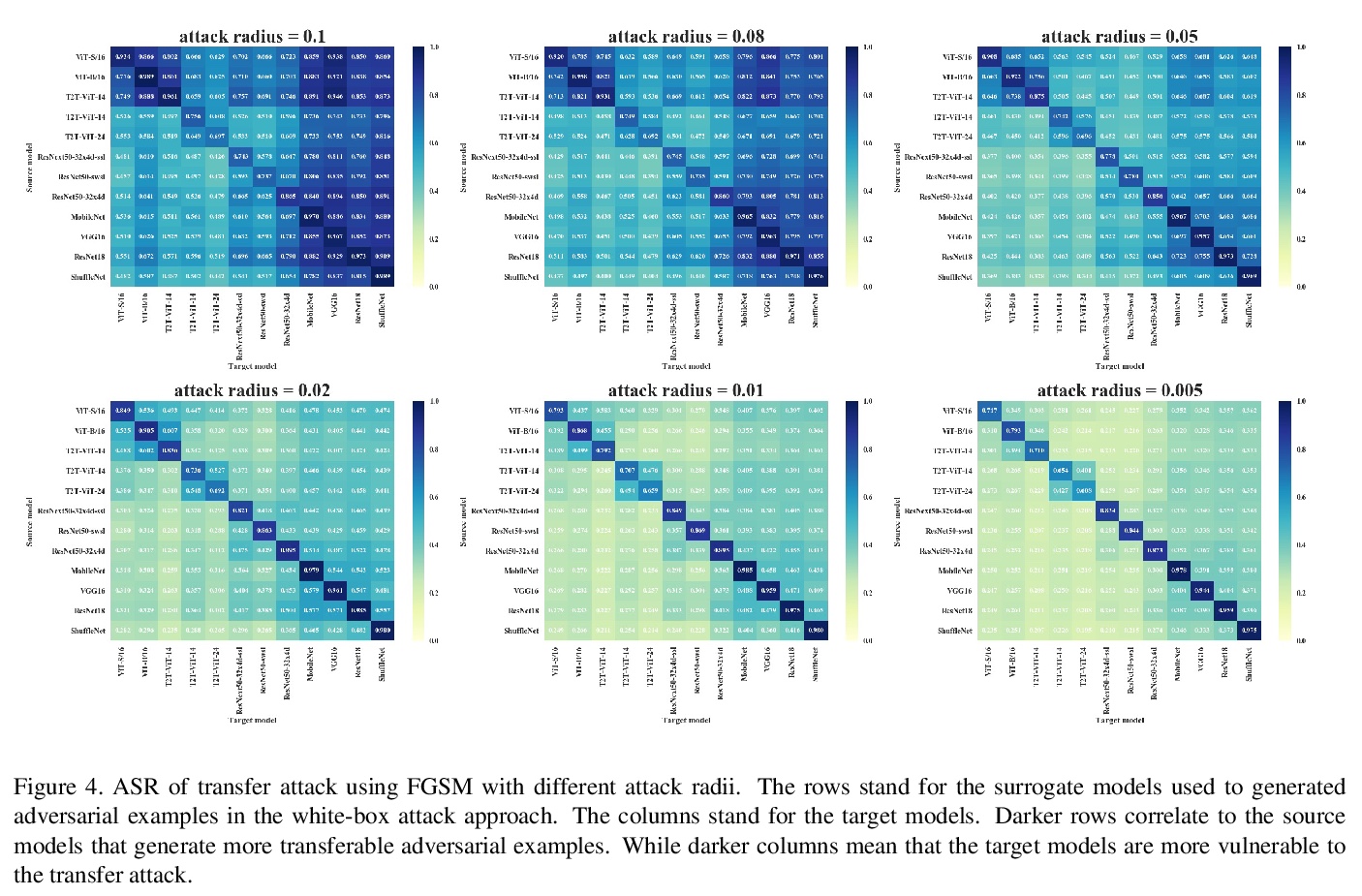
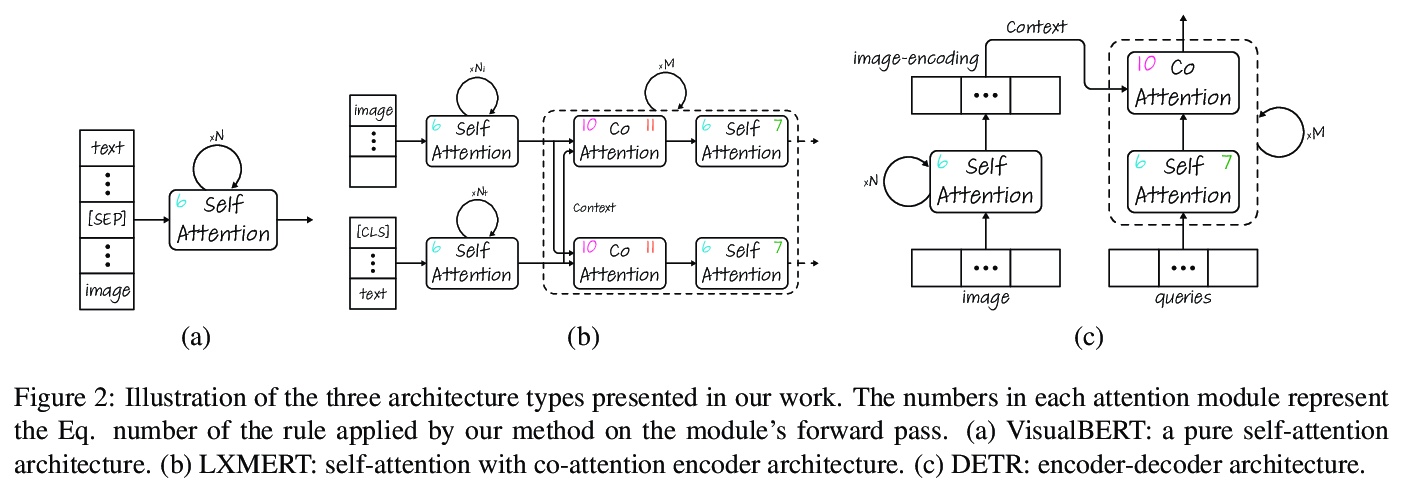
[CV] On the Adversarial Robustness of Visual Transformers
视觉Transformer对抗鲁棒性研究
R Shao, Z Shi, J Yi, P Chen, C Hsieh
[Xi’an Jiaotong University & University of California, Los Angeles & JD AI Research & IBM Research]
https://weibo.com/1402400261/K9rE6pO6E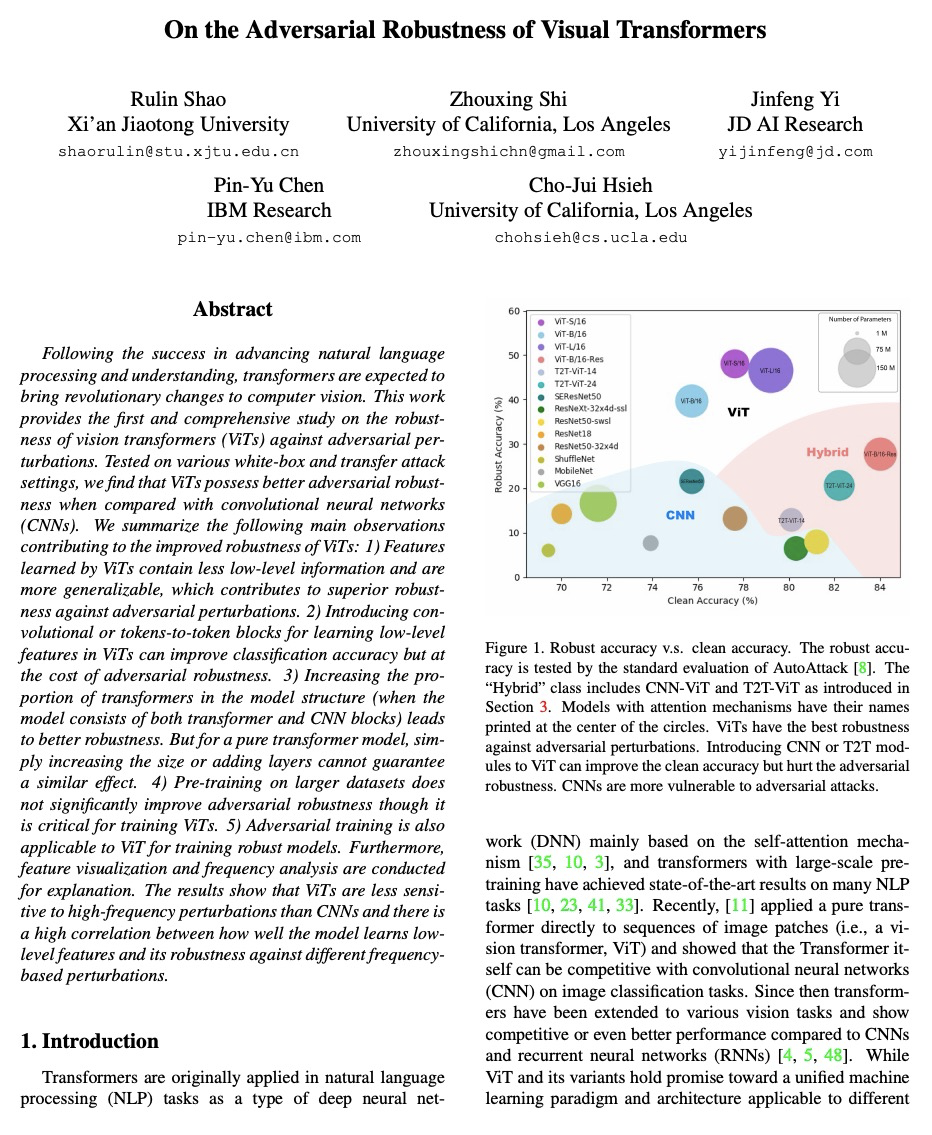

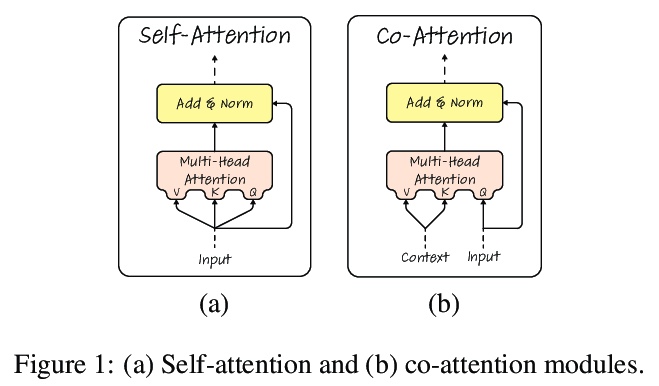
[CV] Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers
解释双模和编-解码Transformer的通用注意力模型可解释性
H Chefer, S Gur, L Wolf
[Tel Aviv University]
https://weibo.com/1402400261/K9rGD3ISH

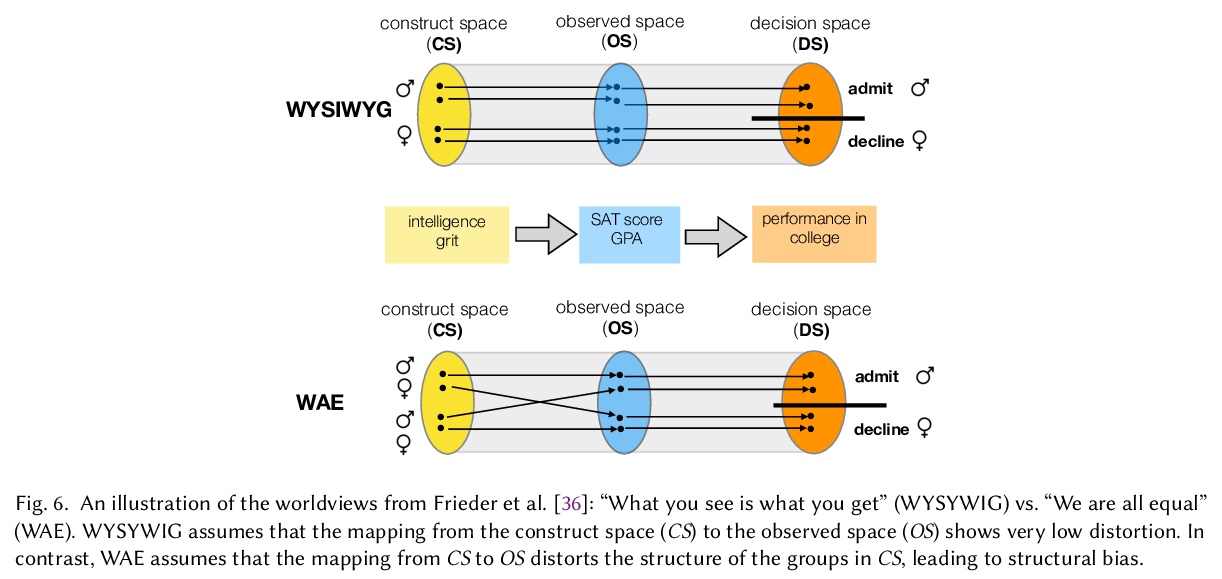
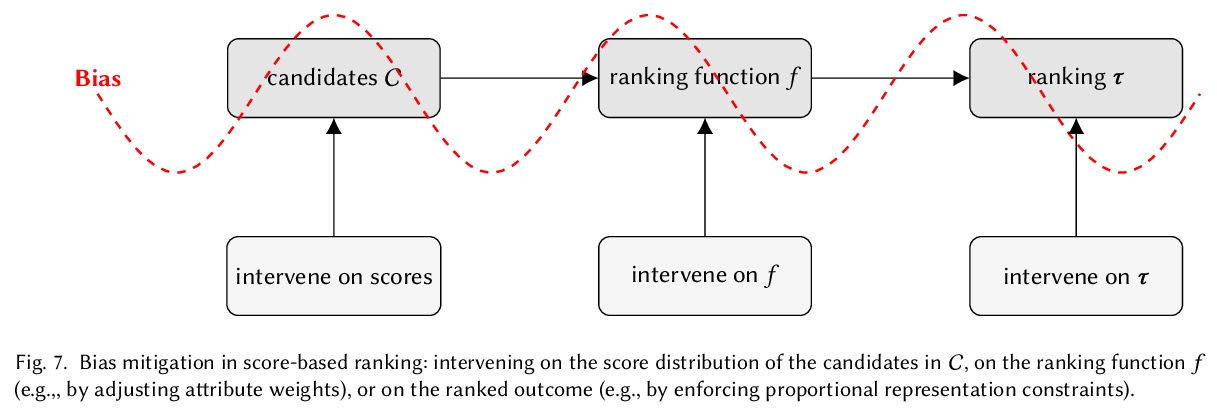
[IR] Fairness in Ranking: A Survey
信息检索排序公平性综述
M Zehlike, K Yang, J Stoyanovich
[New York University]
https://weibo.com/1402400261/K9rNml0yk


若有收获,就点个赞吧
0 人点赞
