- 1、[LG] CombOptNet: Fit the Right NP-Hard Problem by Learning Integer Programming Constraints
- 2、[LG] GSPMD: General and Scalable Parallelization for ML Computation Graphs
- 3、[CL] SCoRe: Pre-Training for Context Representation in Conversational Semantic Parsing
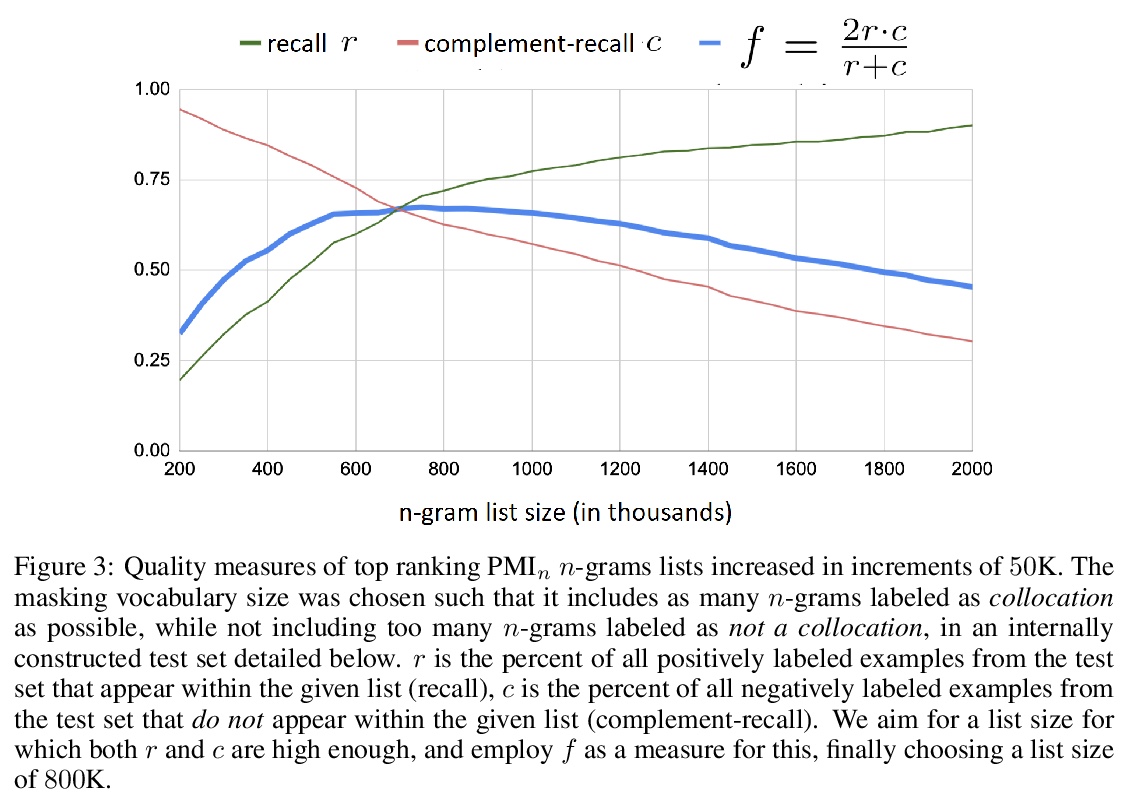
- 4、[CL] PMI-Masking: Principled masking of correlated spans
- 5、[LG] Learning Controllable Content Generators
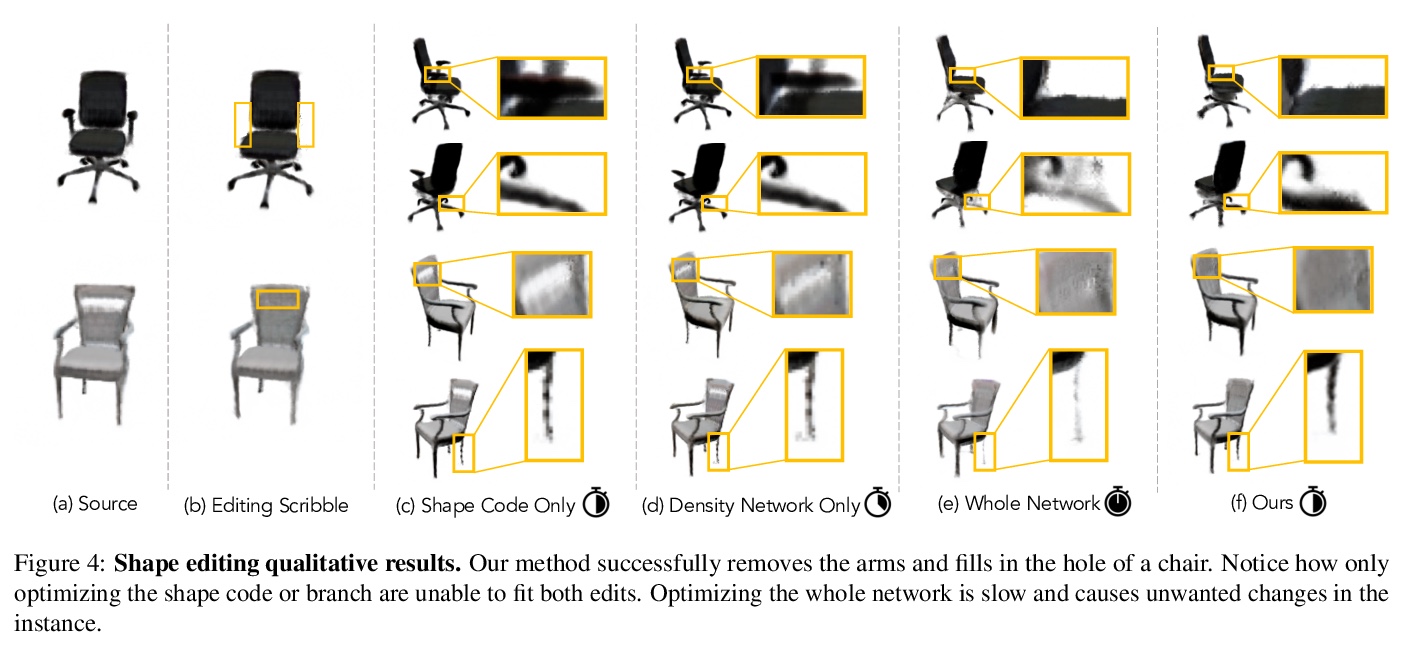
- [CV] Editing Conditional Radiance Fields
- [LG] Value Iteration in Continuous Actions, States and Time
- [LG] baller2vec++: A Look-Ahead Multi-Entity Transformer For Modeling Coordinated Agents
- [CL] What’s in the Box? An Analysis of Undesirable Content in the Common Crawl Corpus
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] CombOptNet: Fit the Right NP-Hard Problem by Learning Integer Programming Constraints
A Paulus, M Rolínek, V Musil, B Amos, G Martius
[Max-Planck-Institute for Intelligent Systems & Masaryk University & Facebook AI Research]
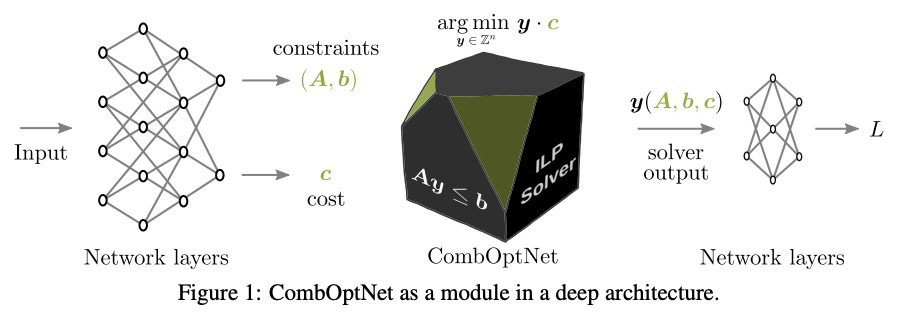
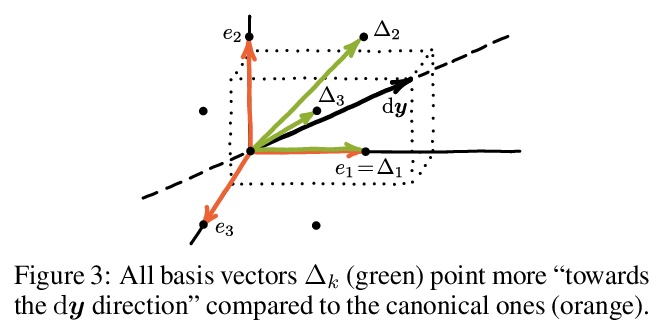
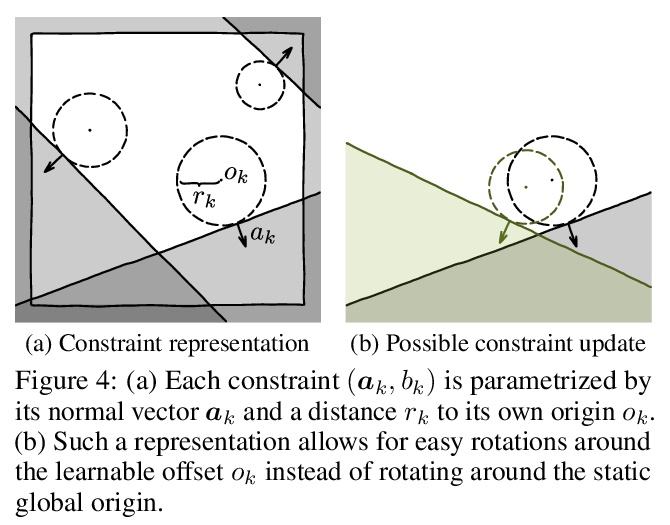
CombOptNet:将整数线性规划求解器作为层集成到神经网络架构。将逻辑和算法推理与现代机器学习技术联系起来,是具有潜在变革性影响的基本挑战。算法方面,许多NP-HARD问题可以表达为整数规划,其中约束起到了”组合规范”的作用。本文旨在将整数规划求解器整合到神经网络架构,作为能学习损失项和约束的层。由此产生的端到端可训练架构从原始数据中联合提取特征,用最先进的整数规划求解器解决一个合适的(习得)组合问题,学习拟合用于解决任务所需的正确的NP-hard问题。通过对合成数据进行广泛的性能分析,并在一个有竞争力的计算机视觉关键点匹配基准上进行演示,证明了这种层的潜力。
Bridging logical and algorithmic reasoning with modern machine learning techniques is a fundamental challenge with potentially transformative impact. On the algorithmic side, many NP-HARD problems can be expressed as integer programs, in which the constraints play the role of their “combinatorial specification.” In this work, we aim to integrate integer programming solvers into neural network architectures as layers capable of learning both the cost terms and the constraints. The resulting end-to-end trainable architectures jointly extract features from raw data and solve a suitable (learned) combinatorial problem with state-of-the-art integer programming solvers. We demonstrate the potential of such layers with an extensive performance analysis on synthetic data and with a demonstration on a competitive computer vision keypoint matching benchmark.
https://weibo.com/1402400261/KfP2Nojs6

2、[LG] GSPMD: General and Scalable Parallelization for ML Computation Graphs
Y Xu, H Lee, D Chen, B Hechtman, Y Huang, R Joshi, M Krikun, D Lepikhin, A Ly, M Maggioni, R Pang, N Shazeer, S Wang, T Wang, Y Wu, Z Chen
[Google]
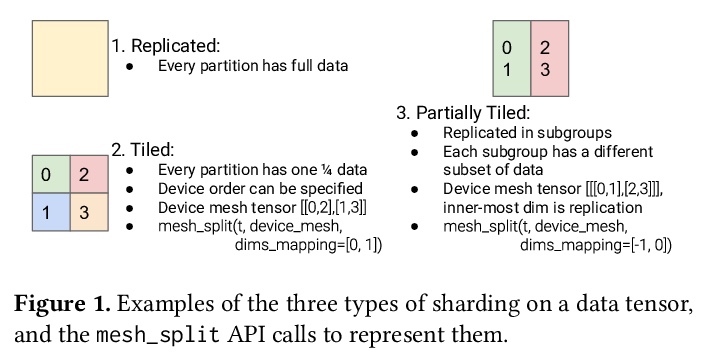
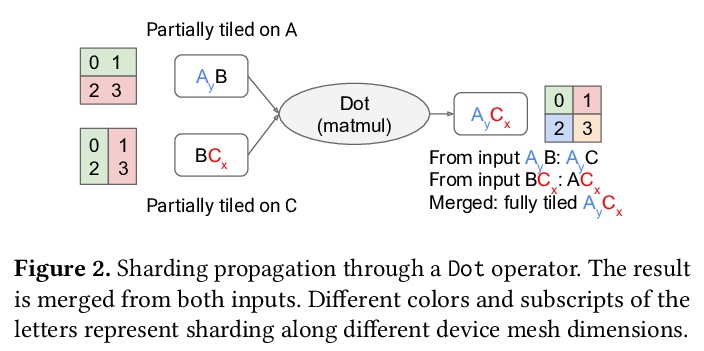
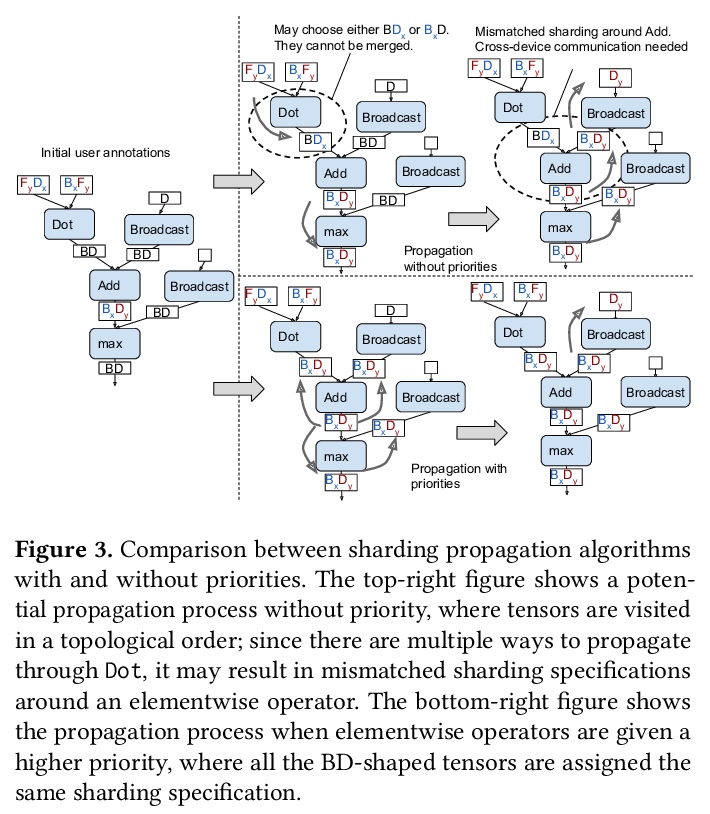
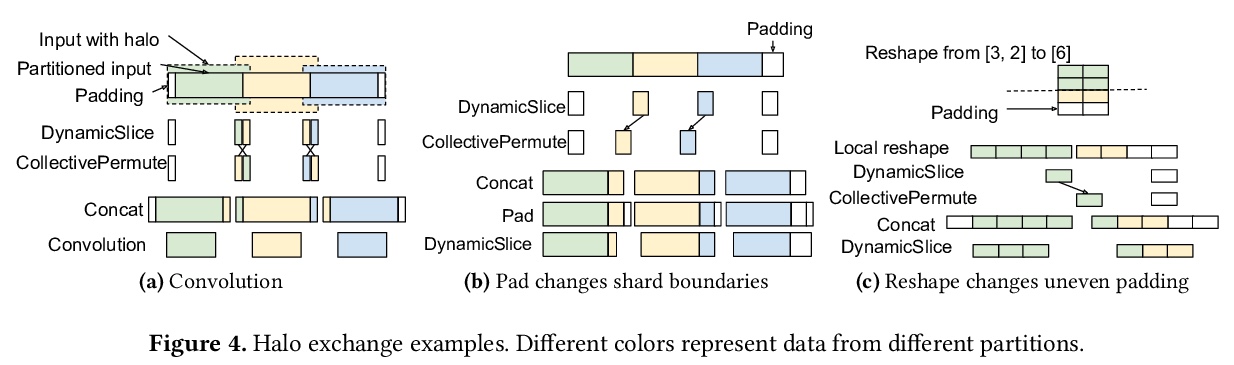
GSPMD:机器学习计算图的通用和可扩展并行化。提出GSPMD,一种自动的、基于编译器的并行化系统,用于通用机器学习计算图,允许用户以与在单个设备上相同的方式编写程序,通过注释来提示如何分配张量,在此基础上由GSPMD对计算进行并行化。GSPMD对划分的表述简单、通用,可在各种模型上表达不同的或混合的并行范式。GSPMD基于有限的用户注释,推断出图中各运算符的划分,能方便地扩展现有的单设备程序。它解决了生产使用中的几个技术难题,如静态形状约束、不均匀划分、halo数据交换和嵌套运算符分区。这些技术使GSPMD在128至2048个云计算TPUv3内核上实现了50%至62%的计算利用率,模型的参数高达1万亿。GSPMD为所有设备产生单一的程序,根据运行时的划分ID调整其行为,并使用集体运算符进行跨设备通信。这一特性使系统本身具有可扩展性:随着设备数量的增加,编译时间保持不变。
We present GSPMD, an automatic, compiler-based parallelization system for commonmachine learning computation graphs. It allows users to write programs in the same way as for a single device, then give hints through a few annotations on how to distribute tensors, based on which GSPMD will parallelize the computation. Its representation of partitioning is simple yet general, allowing it to express different or mixed paradigms of parallelism on a wide variety of models. GSPMD infers the partitioning for every operator in the graph based on limited user annotations, making it convenient to scale up existing single-device programs. It solves several technical challenges for production usage, such as static shape constraints, uneven partitioning, exchange of halo data, and nested operator partitioning. These techniques allow GSPMD to achieve 50% to 62% compute utilization on 128 to 2048 Cloud TPUv3 cores for models with up to one trillion parameters. GSPMD produces a single program for all devices, which adjusts its behavior based on a run-time partition ID, and uses collective operators for cross-device communication. This property allows the system itself to be scalable: the compilation time stays constant with increasing number of devices.
https://weibo.com/1402400261/KfP7xrnBp
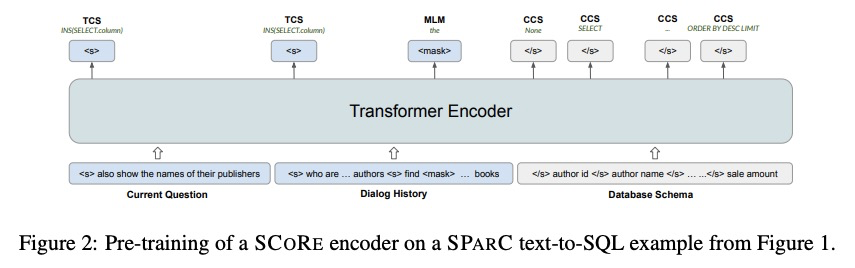
3、[CL] SCoRe: Pre-Training for Context Representation in Conversational Semantic Parsing
T Yu, R Zhang, O Polozov, C Meek, AH Awadallah
[Yale University & The Pennsylvania State University & Microsoft Research]
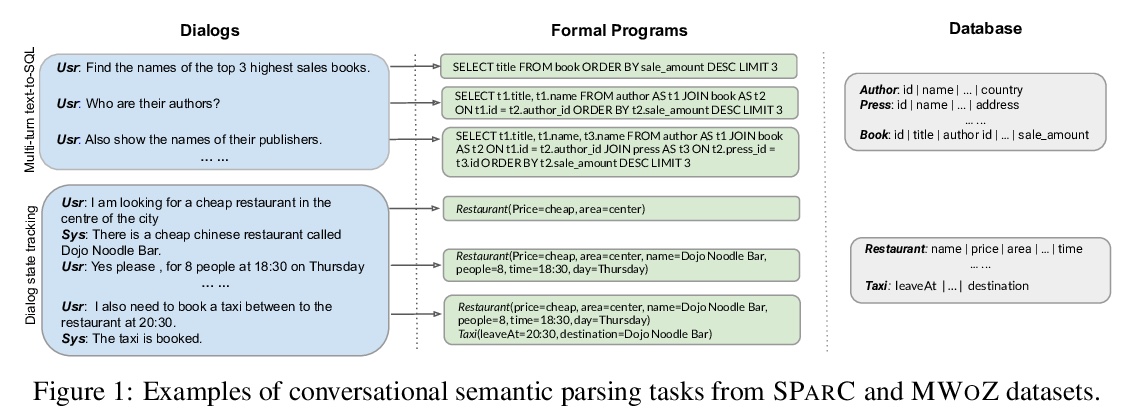
SCoRe:对话语义解析中的语境表示预训练。对话语义解析(CSP)任务,是将一连串自然语言查询,转换为可针对结构化本体(如数据库、知识库)执行的形式语言(如SQL、SPARQL)。 为完成这一任务,CSP系统需要对非结构化语言语料和结构化本体之间的关系进行建模,同时表示对话的多轮动态。预训练语言模型是各种自然语言处理任务的最先进技术,然而现有的预训练语言模型,在自由形式文本上用语言建模训练目标,在表示自然语言对上下文结构数据的引用方面能力有限。本文提出SCORE,一种用于CSP任务的新的预训练方法,旨在诱导能捕捉对话流和结构背景之间的一致性的表示。通过将SCORE与四个不同任务(SPARC、COSQL、MWOZ和SQA)的强大基础系统相结合,证明了SCORE对CSP任务的广泛适用性。SCORE可比所有这些基础系统的性能提高很多,并在其中三个任务上取得了最先进的结果。
Conversational Semantic Parsing (CSP) is the task of converting a sequence of natural language queries to formal language (e.g., SQL, SPARQL) that can be executed against a structured ontology (e.g. databases, knowledge bases). To accomplish this task, a CSP system needs to model the relation between the unstructured language utterance and the structured ontology while representing the multi-turn dynamics of the dialog. Pre-trained language models (LMs) are the state-of-the-art for various natural language processing tasks. However, existing pre-trained LMs that use language modeling training objectives over free-form text have limited ability to represent natural language references to contextual structural data. In this work, we present SCORE, a new pre-training approach for CSP tasks designed to induce representations that capture the alignment between the dialogue flow and the structural context. We demonstrate the broad applicability of SCORE to CSP tasks by combining SCORE with strong base systems on four different tasks (SPARC, COSQL, MWOZ, and SQA). We show that SCORE can improve the performance over all these base systems by a significant margin and achieves state-of-the-art results on three of them.
https://weibo.com/1402400261/KfPb3uDyJ
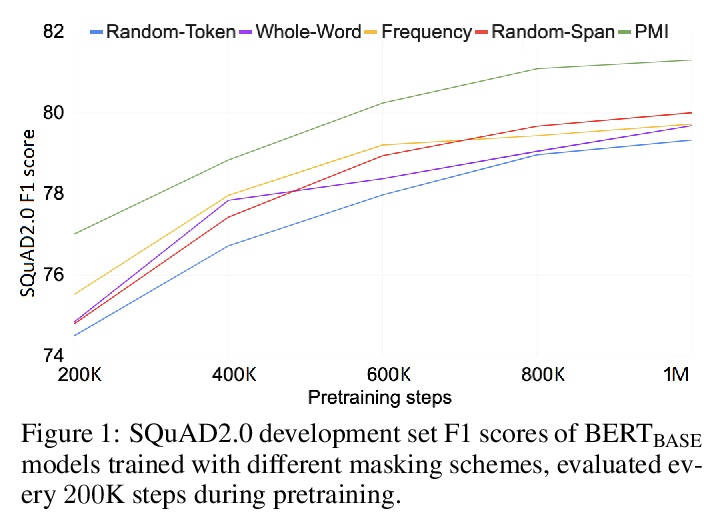
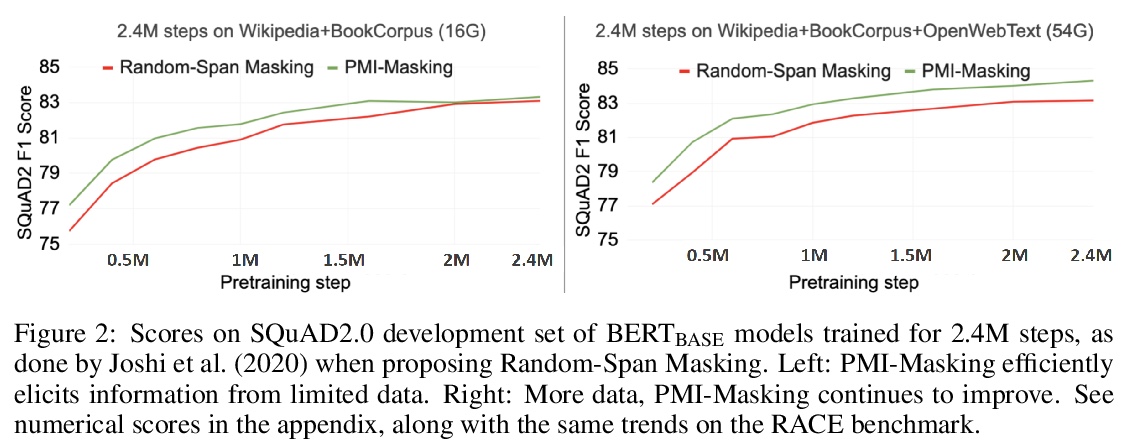
4、[CL] PMI-Masking: Principled masking of correlated spans
Y Levine, B Lenz, O Lieber, O Abend, K Leyton-Brown…
[AI21 Labs]
PMI-Masking:相关区间原则性掩码。随机均匀掩蔽token构成了掩码语言模型(如BERT)预训练中的一个常见缺陷。这种均匀的掩码允许掩码语言模型通过捕捉浅层局部信号来最小化训练目标,导致预训练的低效率和次优的下游性能。为解决这一缺陷,本文提出PMI-Masking,一种基于点互信息(PMI)概念的原则性掩码策略,如果一个token n-gram在语料库中表现出较高的搭配性,就会被联合掩码。PMI-Masking激励、统一并改进了之前的启发式方法,这些方法试图解决随机统一token掩蔽的缺点,如全词掩蔽、实体/短语掩蔽和随机区间掩蔽。通过实验表明,PMI-Masking在一半的训练时间内就达到了先前的掩码方法的性能,并在训练收尾阶段不断提高性能。
Masking tokens uniformly at random constitutes a common flaw in the pretraining of Masked Language Models (MLMs) such as BERT. We show that such uniform masking allows an MLM to minimize its training objective by latching onto shallow local signals, leading to pretraining inefficiency and suboptimal downstream performance. To address this flaw, we propose PMI-Masking, a principled masking strategy based on the concept of Pointwise Mutual Information (PMI), which jointly masks a token n-gram if it exhibits high collocation over the corpus. PMIMasking motivates, unifies, and improves upon prior more heuristic approaches that attempt to address the drawback of random uniform token masking, such as whole-word masking, entity/phrase masking, and random-span masking. Specifically, we show experimentally that PMI-Masking reaches the performance of prior masking approaches in half the training time, and consistently improves performance at the end of training.
https://weibo.com/1402400261/KfPfb5KIz
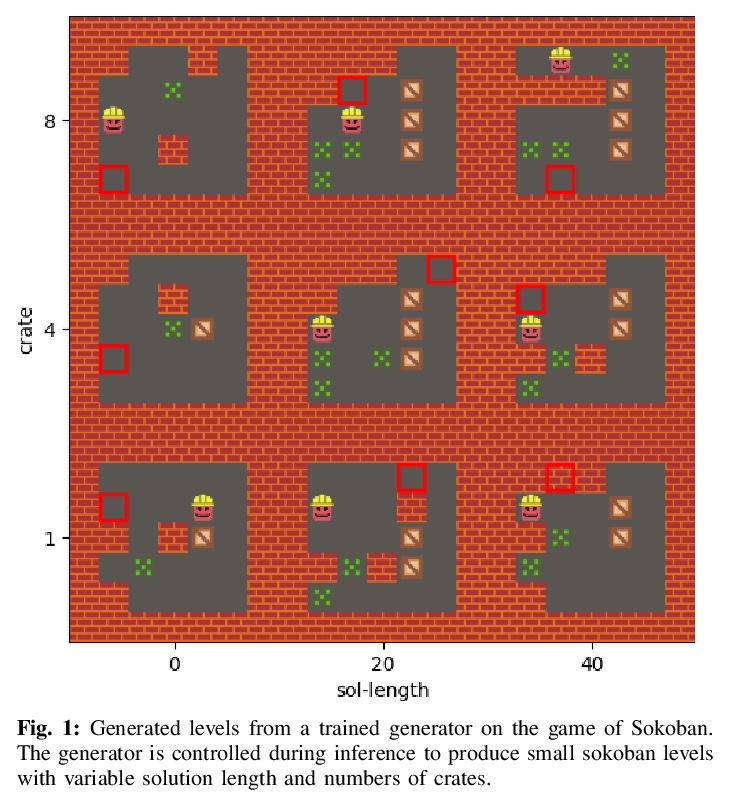
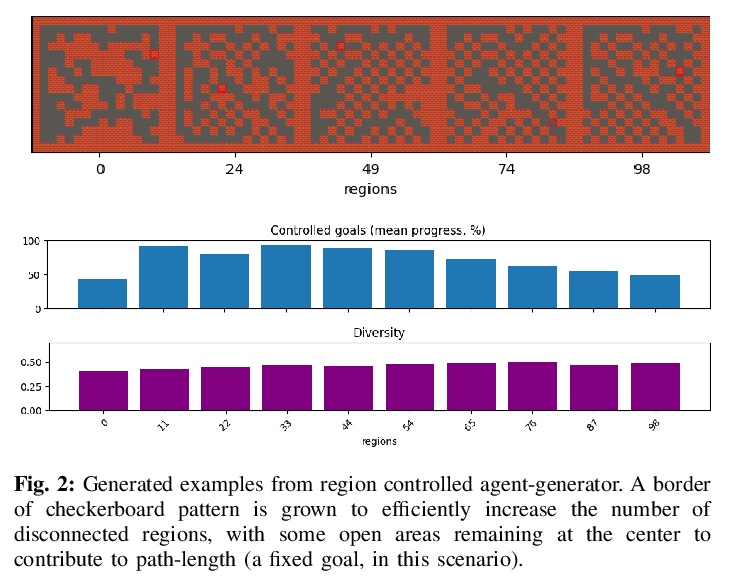
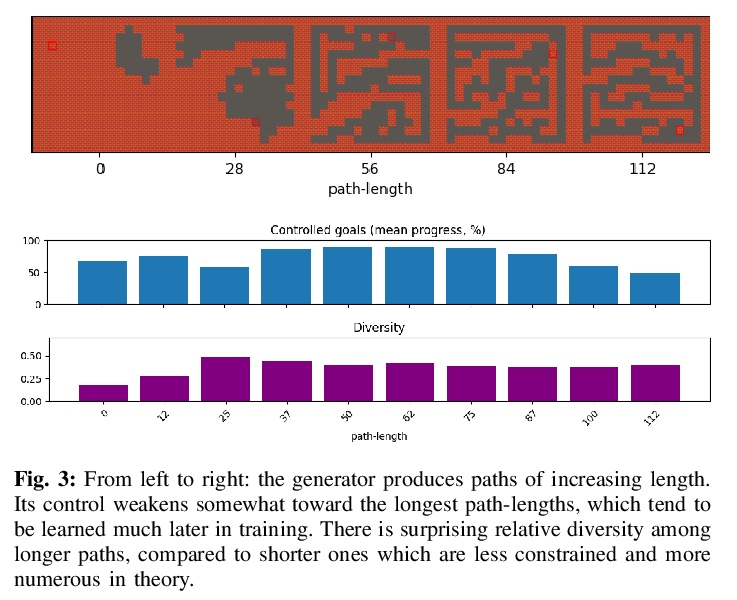
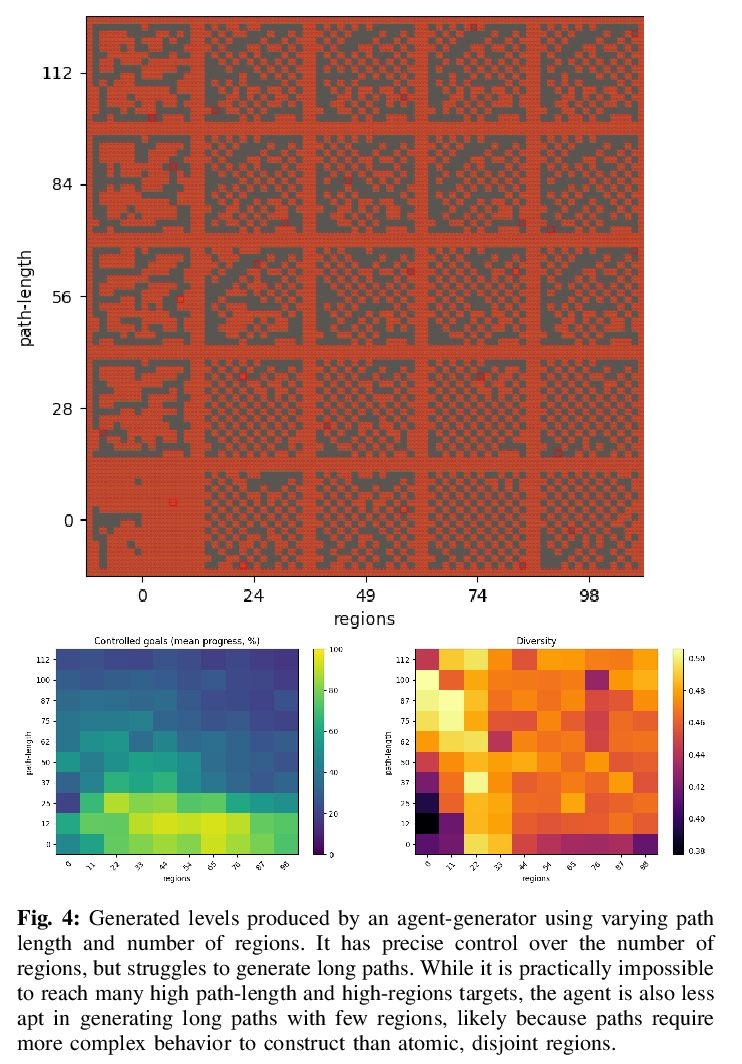
5、[LG] Learning Controllable Content Generators
S Earle, M Edwards, A Khalifa, P Bontrager, J Togelius
[New York University & TheTake]
可控内容生成器学习。最近有研究表明,强化学习可用来训练能产生高质量游戏关卡的生成器,其质量以用户指定的启发式方法来定义。为确保这些生成器的输出有足够的多样性(不等同于复制单一的最佳关卡配置),生成过程受到限制,使初始种子导致生成器的输出有一定的差异。然而,这导致人类用户失去了对生成内容的控制。本文建议通过使生成器具有”目标意识”来训练生成器,使其能产生可控的多样化输出。为此,本文增加了条件输入,代表生成器与某些启发式的接近程度,并修改奖励机制以纳入该值。在多个领域的测试中,所产生的关卡生成器能够以一种有针对性的、可控制的方式探索可能的关卡空间,产生与没有目标意识的同类关卡质量相当的关卡,这些关卡沿着设计者指定的维度是多样化的。
It has recently been shown that reinforcement learning can be used to train generators capable of producing highquality game levels, with quality defined in terms of some userspecified heuristic. To ensure that these generators’ output is sufficiently diverse (that is, not amounting to the reproduction of a single optimal level configuration), the generation process is constrained such that the initial seed results in some variance in the generator’s output. However, this results in a loss of control over the generated content for the human user. We propose to train generators capable of producing controllably diverse output, by making them “goal-aware.” To this end, we add conditional inputs representing how close a generator is to some heuristic, and also modify the reward mechanism to incorporate that value. Testing on multiple domains, we show that the resulting level generators are capable of exploring the space of possible levels in a targeted, controllable manner, producing levels of comparable quality as their goal-unaware counterparts, that are diverse along designer-specified dimensions.
https://weibo.com/1402400261/KfPiZeTGP
另外几篇值得关注的论文:
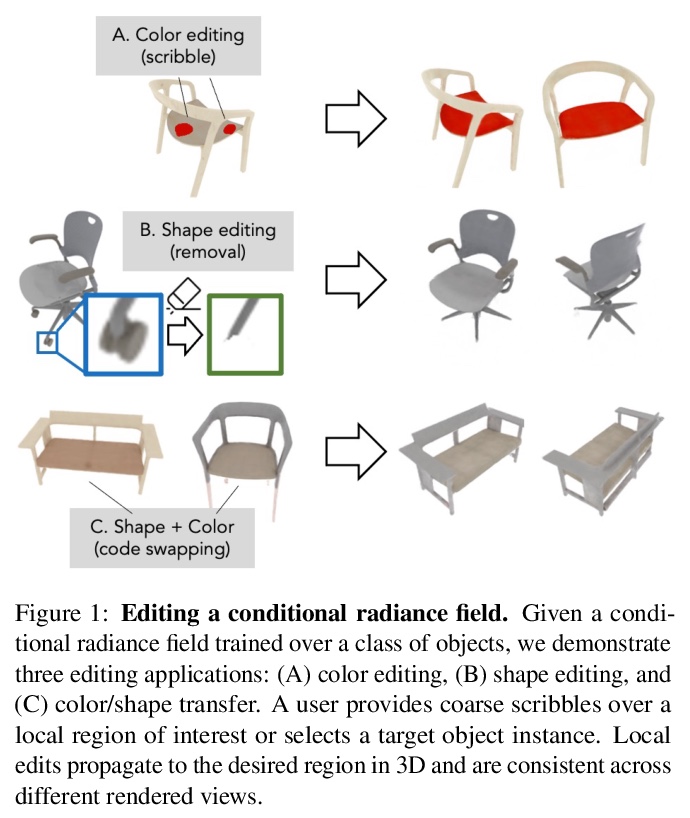
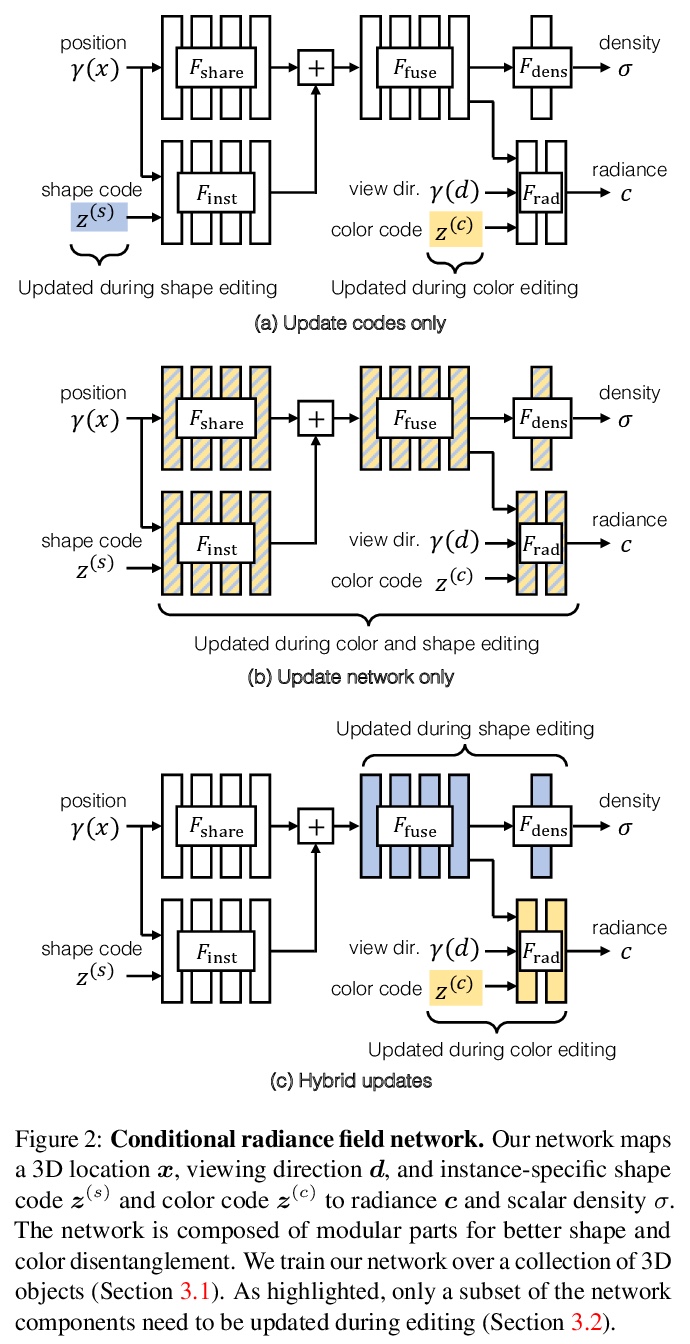
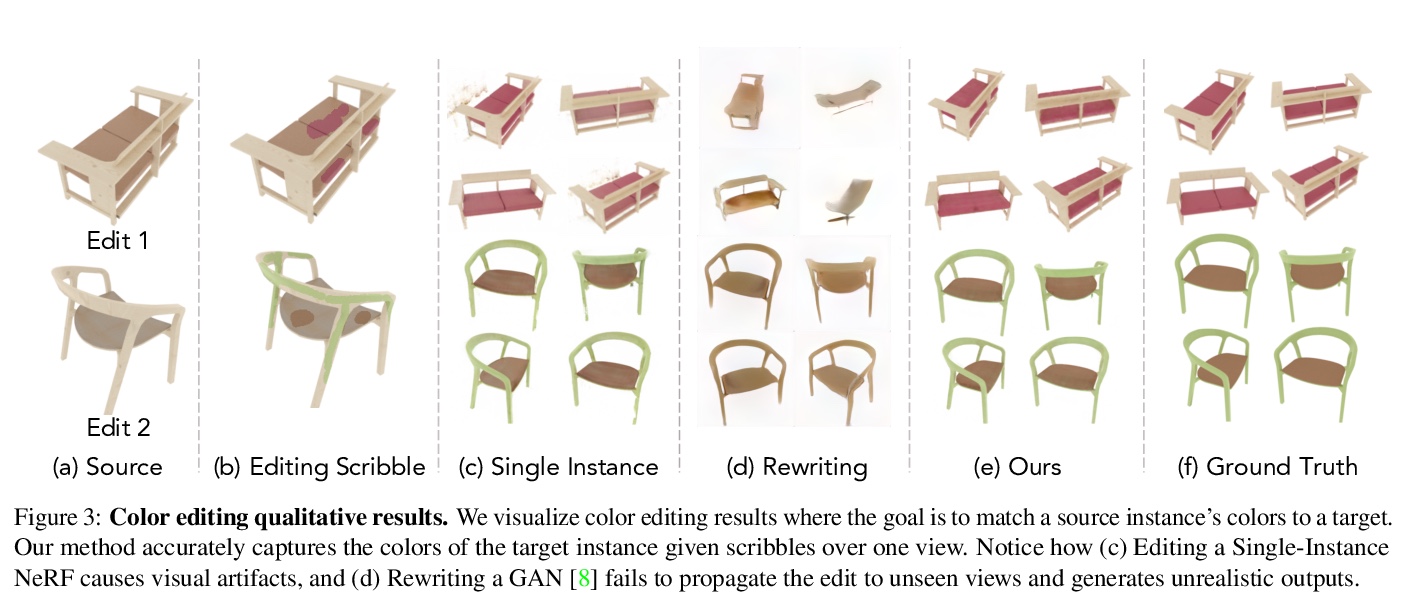
[CV] Editing Conditional Radiance Fields
可编辑条件辐射场
S Liu, X Zhang, Z Zhang, R Zhang, J Zhu, B Russell
[MIT & Adobe Research]
https://weibo.com/1402400261/KfPlJpUzR
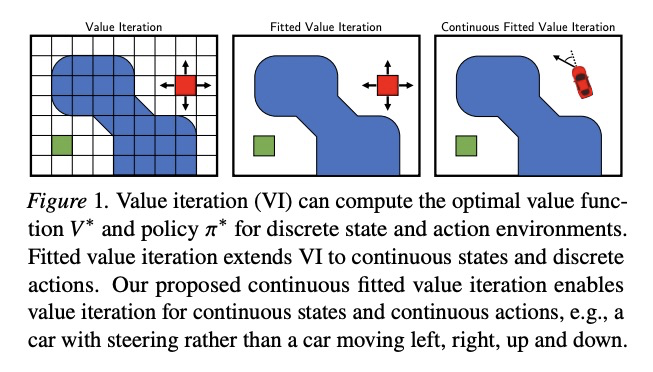
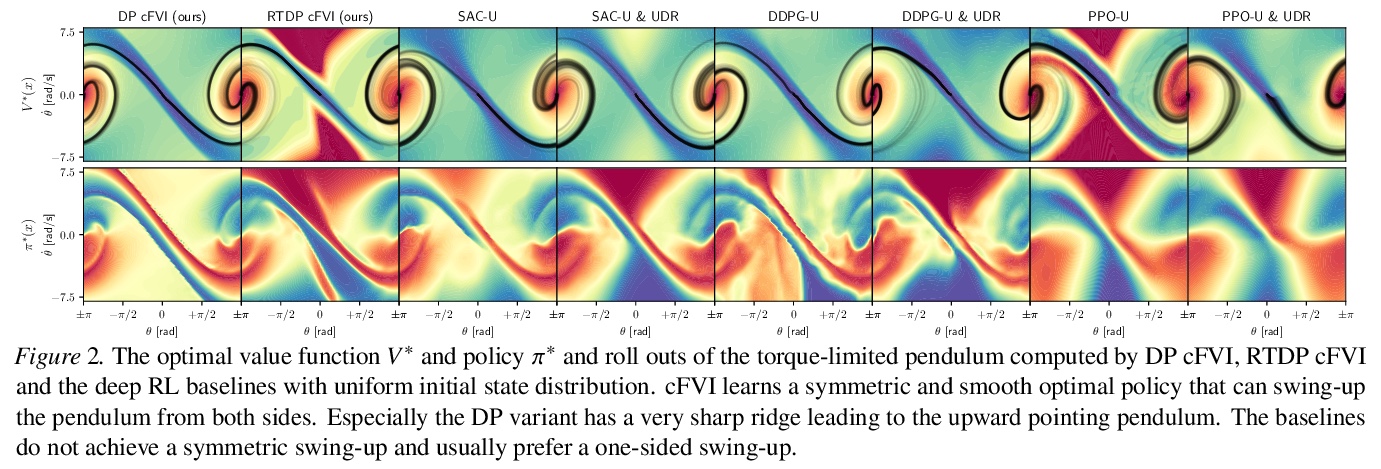
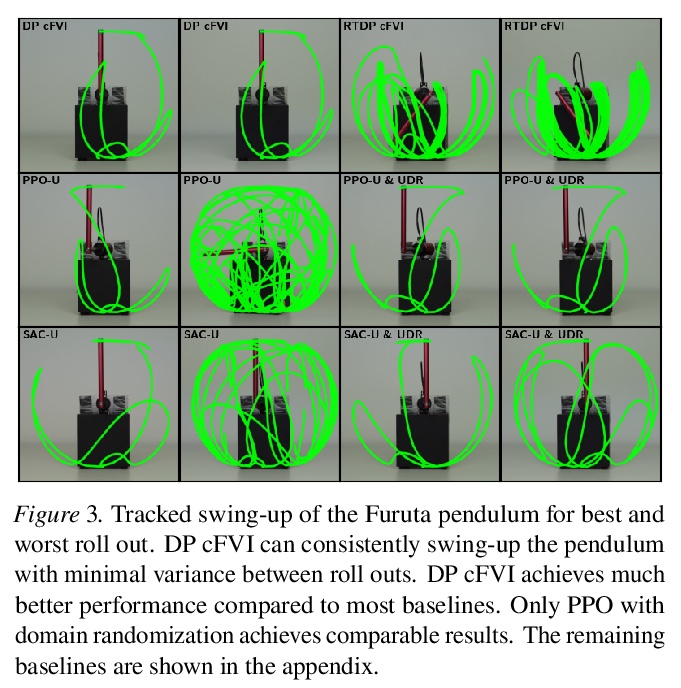
[LG] Value Iteration in Continuous Actions, States and Time
连续动作、状态和时间中的价值迭代
M Lutter, S Mannor, J Peters, D Fox, A Garg
[NVIDIA & Technical University of Darmstadt]
https://weibo.com/1402400261/KfPoKpnHz

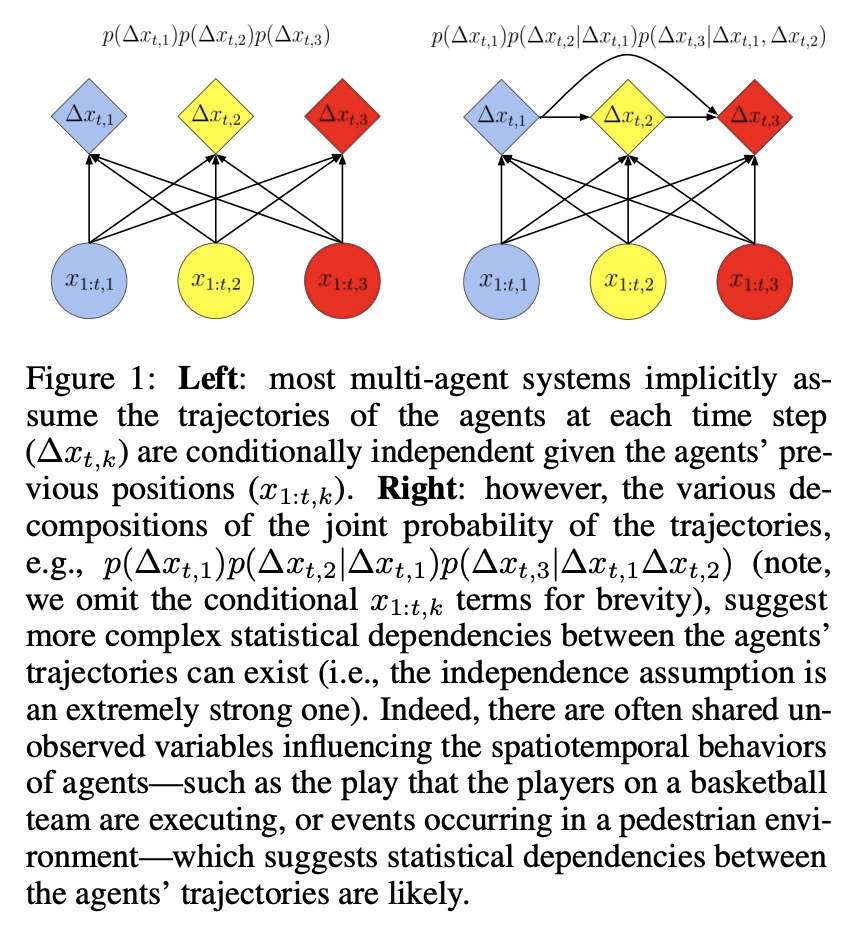
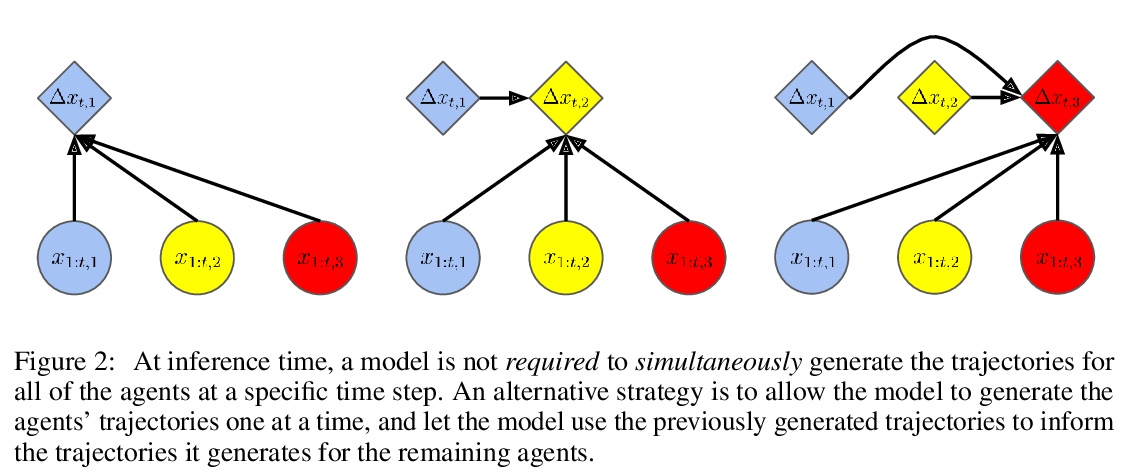
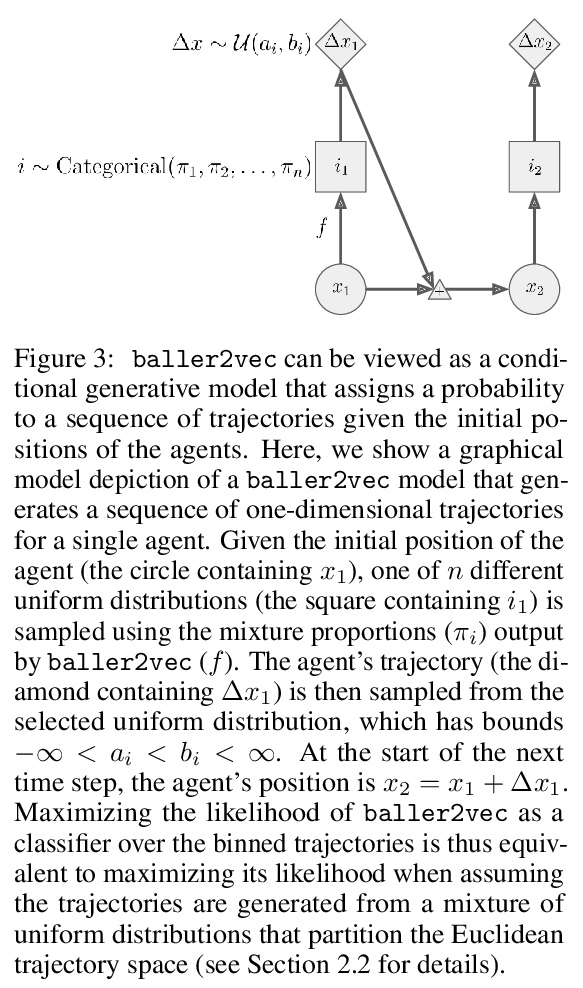
[LG] baller2vec++: A Look-Ahead Multi-Entity Transformer For Modeling Coordinated Agents
baller2vec++:面向协调智能体建模的前瞻多实体Transformer
M A. Alcorn, A Nguyen
[Auburn University]
https://weibo.com/1402400261/KfPq7g2lf

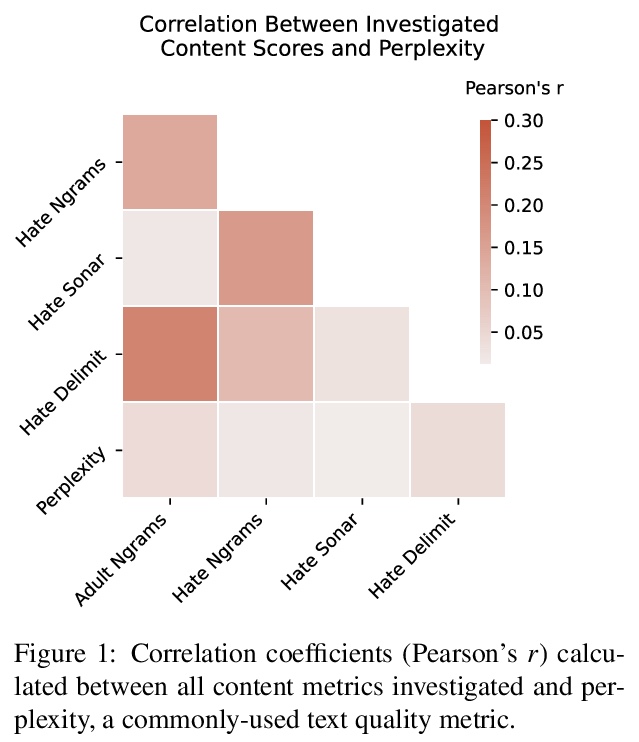
[CL] What’s in the Box? An Analysis of Undesirable Content in the Common Crawl Corpus
Common Crawl语料库不良内容分析
A S Luccioni, J D. Viviano
[Mila Quebec AI Institute]
https://weibo.com/1402400261/KfPt8x6Cr

若有收获,就点个赞吧
0 人点赞
