- 1、[LG] TT-Rec: Tensor Train Compression for Deep Learning Recommendation Models Embeddings
- 2、[CL] In-IDE Code Generation from Natural Language: Promise and Challenges
- 3、[CV] LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial Recognition
- 4、[CL] The Role of Syntactic Planning in Compositional Image Captioning
- 5、[CV] Exploring Cross-Image Pixel Contrast for Semantic Segmentation
- [LG] Quantum machine learning models are kernel methods
- [CL] Modeling Context in Answer Sentence Selection Systems on a Latency Budget
- [LG] Learning Structural Edits via Incremental Tree Transformations
- [CV] Deep Image Retrieval: A Survey
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] TT-Rec: Tensor Train Compression for Deep Learning Recommendation Models Embeddings
C Yin, B Acun, X Liu, C Wu
[Georgia Institute of Technology & Facebook AI]
TT-REC:深度学习推荐模型嵌入的张量行列压缩。为深度学习推荐模型(DLRM)设计了一种张量行列压缩技术TT-Rec,其核心思想是用矩阵乘积序列代替DLRM中的大型嵌入表,类似于用查找表来权衡内存存储和带宽与计算的技术。由于张量表示是一种“有损”压缩方案,为了补偿精度损失,提出一种新的方式来初始化张量形式的元素分布。为缓解必须对张量形式进行解压时训练时间的增加,引入一种利用DLRM中独特稀疏特征分布的缓存结构。TT-Rec采用一种混合方法来学习特征,在保持与基线相同的模型精度的前提下,平均增加了10%的少量训练时间,将模型的总内存容量需求降低了112倍,使得在线推荐模型训练更加实用。
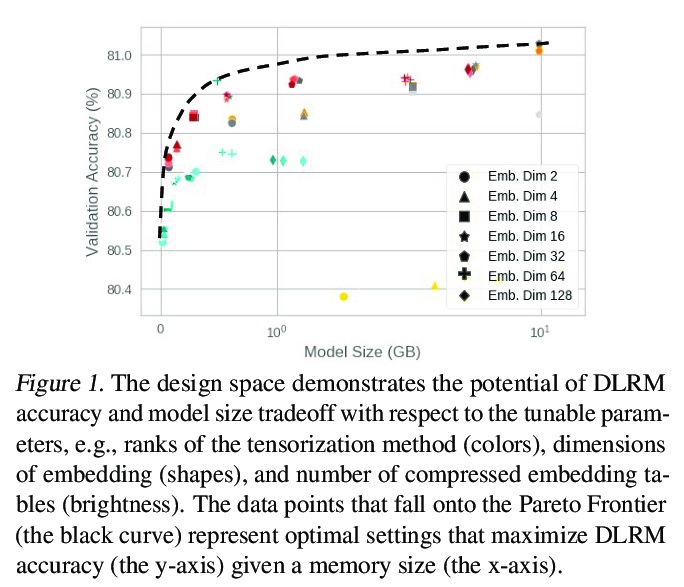
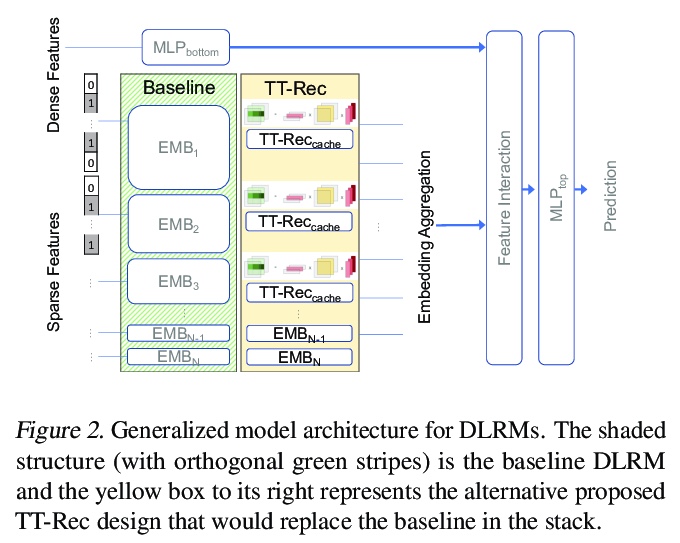
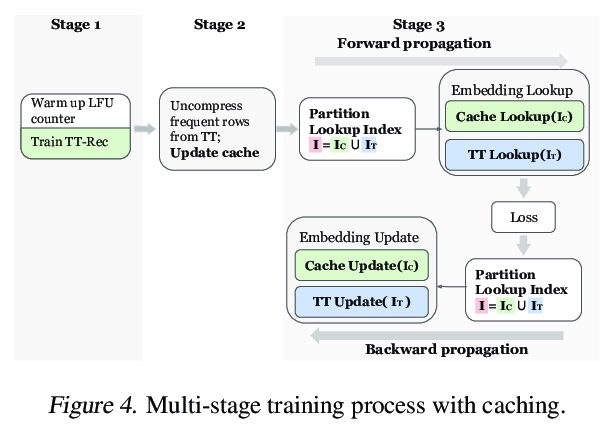
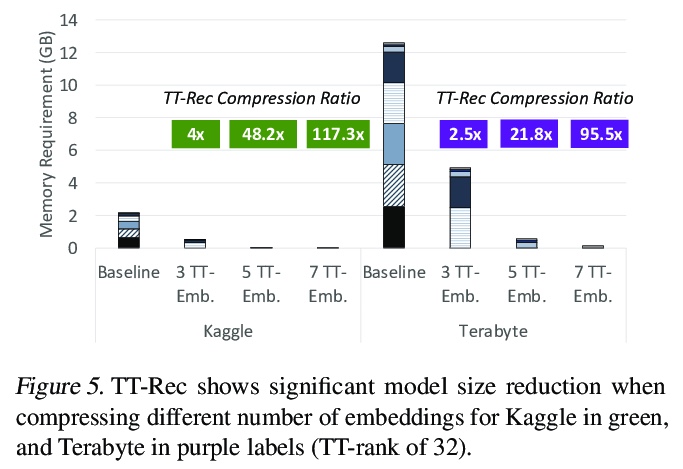
The memory capacity of embedding tables in deep learning recommendation models (DLRMs) is increasing dramatically from tens of GBs to TBs across the industry. Given the fast growth in DLRMs, novel solutions are urgently needed, in order to enable fast and efficient DLRM innovations. At the same time, this must be done without having to exponentially increase infrastructure capacity demands. In this paper, we demonstrate the promising potential of Tensor Train decomposition for DLRMs (TT-Rec), an important yet under-investigated context. We design and implement optimized kernels (TT-EmbeddingBag) to evaluate the proposed TT-Rec design. TT-EmbeddingBag is 3 times faster than the SOTA TT implementation. The performance of TT-Rec is further optimized with the batched matrix multiplication and caching strategies for embedding vector lookup operations. In addition, we present mathematically and empirically the effect of weight initialization distribution on DLRM accuracy and propose to initialize the tensor cores of TT-Rec following the sampled Gaussian distribution. We evaluate TT-Rec across three important design space dimensions — memory capacity, accuracy, and timing performance — by training MLPerf-DLRM with Criteo’s Kaggle and Terabyte data sets. TT-Rec achieves 117 times and 112 times model size compression, for Kaggle and Terabyte, respectively. This impressive model size reduction can come with no accuracy nor training time overhead as compared to the uncompressed baseline.
https://weibo.com/1402400261/JFFfZ259z
2、[CL] In-IDE Code Generation from Natural Language: Promise and Challenges
F F. Xu, B Vasilescu, G Neubig
[CMU]
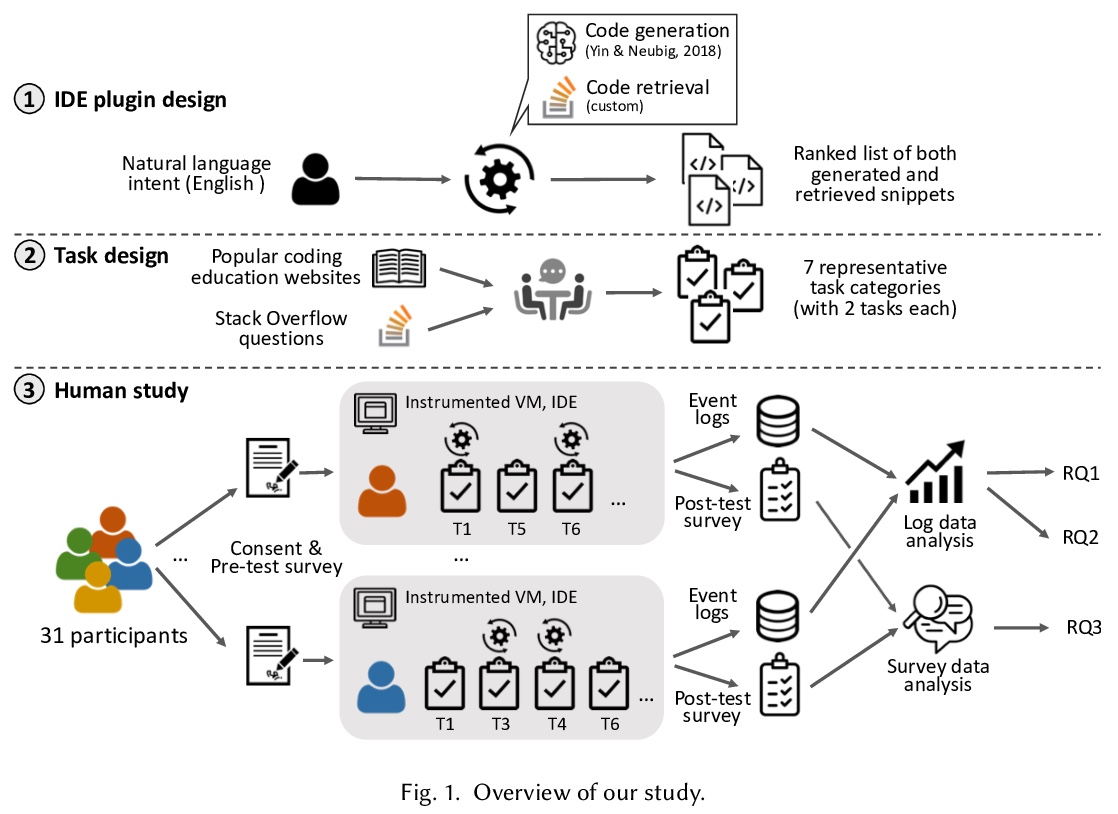
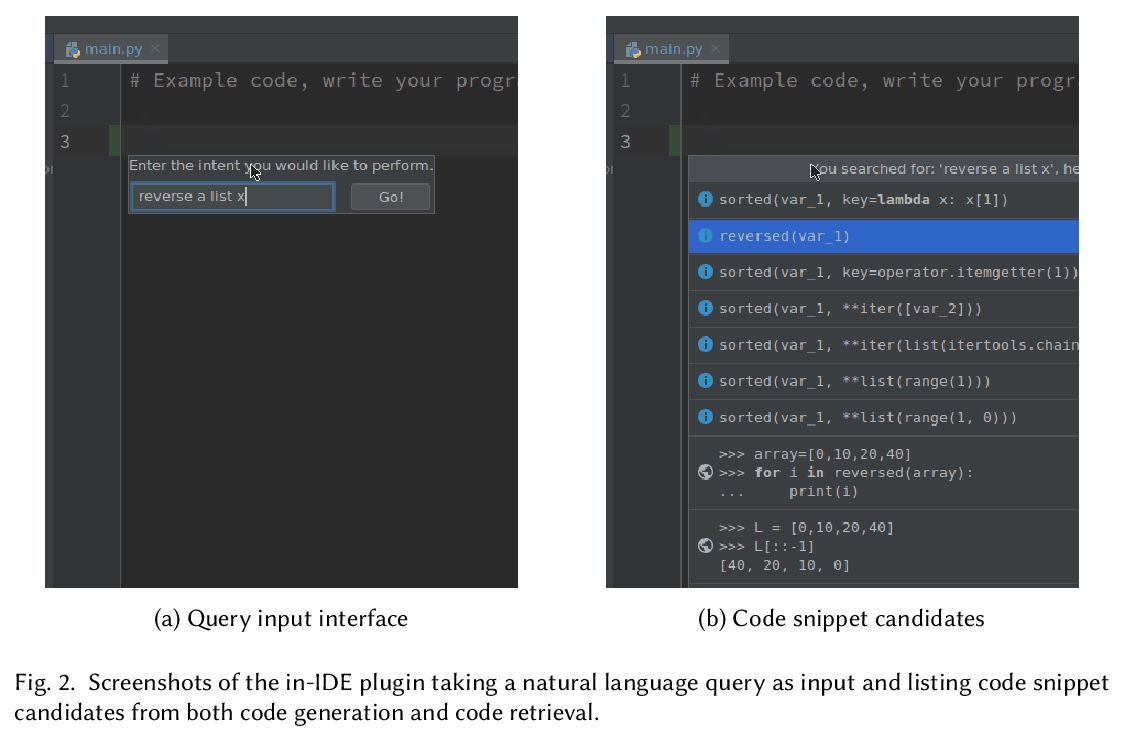
IDE内基于自然语言的程序代码生成:希望与挑战。对IDE内代码生成和检索进行了广泛的用户研究,开发了一个实验插件和分析框架。证明了代码生成和代码检索的现状所面临的挑战和局限性;在对开发者工作流的影响方面,包括时间效率、代码正确性和代码质量,结果喜忧参半。开发者主观上喜欢用IDE内的开发者管理工具体验,并提供了几个具体的改进领域。这些结果将刺激未来在代码生成和检索模型的生产方向上有针对性的发展。
A great part of software development involves conceptualizing or communicating the underlying procedures and logic that needs to be expressed in programs. One major difficulty of programming is turning concept into code, especially when dealing with the APIs of unfamiliar libraries. Recently, there has been a proliferation of machine learning methods for code generation and retrieval from natural language queries, but these have primarily been evaluated purely based on retrieval accuracy or overlap of generated code with developer-written code, and the actual effect of these methods on the developer workflow is surprisingly unattested. We perform the first comprehensive investigation of the promise and challenges of using such technology inside the IDE, asking “at the current state of technology does it improve developer productivity or accuracy, how does it affect the developer experience, and what are the remaining gaps and challenges?” We first develop a plugin for the IDE that implements a hybrid of code generation and code retrieval functionality, and orchestrate virtual environments to enable collection of many user events. We ask developers with various backgrounds to complete 14 Python programming tasks ranging from basic file manipulation to machine learning or data visualization, with or without the help of the plugin. While qualitative surveys of developer experience are largely positive, quantitative results with regards to increased productivity, code quality, or program correctness are inconclusive. Analysis identifies several pain points that could improve the effectiveness of future machine learning based code generation/retrieval developer assistants, and demonstrates when developers prefer code generation over code retrieval and vice versa. We release all data and software to pave the road for future empirical studies and development of better models.
https://weibo.com/1402400261/JFFparN2M
3、[CV] LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial Recognition
V Cherepanova, M Goldblum, H Foley, S Duan, J Dickerson, G Taylor, T Goldstein
[University of Maryland & US Naval Academy]
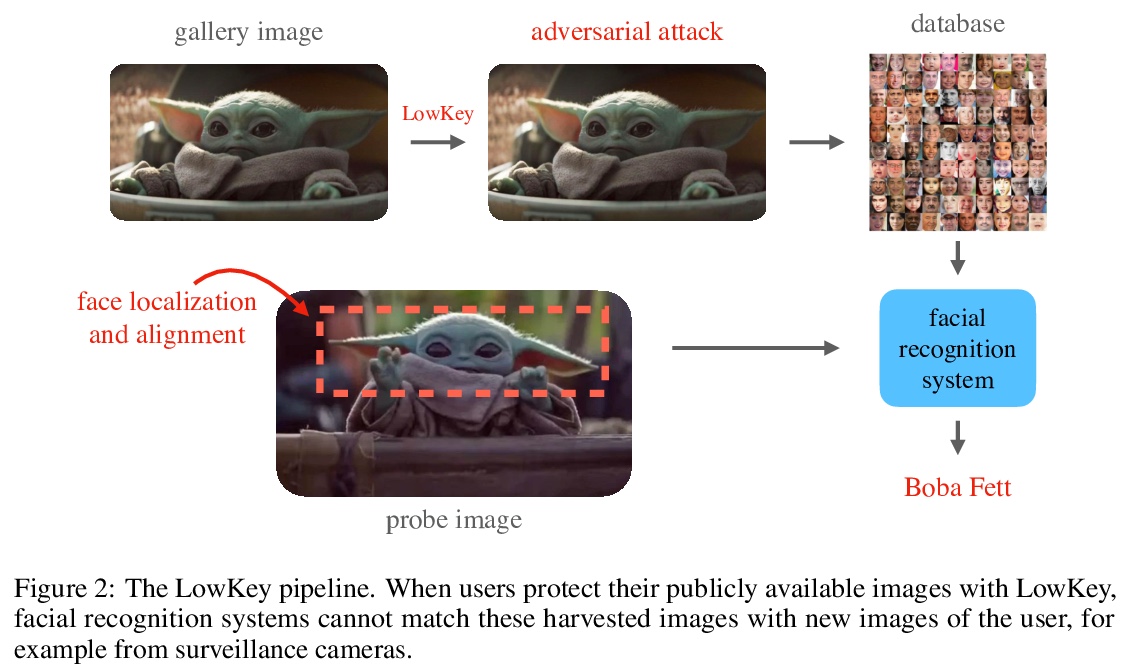
LowKey:用对抗攻击保护社交媒体用户免遭人脸识别。设计了一种针对人脸识别模型的黑盒对抗性攻击,其核心在于改变图库人脸的特征空间表示,使它们不匹配相应的探测图像,同时能够保持图像质量。发布了一个易用的有效对抗商业人脸识别API的网络工具LowKey,可显著降低Amazon Rekognition和微软Azure人脸识别API的准确率,将API准确率降低到1%以下。
https://weibo.com/1402400261/JFFvnr9Ad


4、[CL] The Role of Syntactic Planning in Compositional Image Captioning
E Bugliarello, D Elliott
[University of Copenhagen]
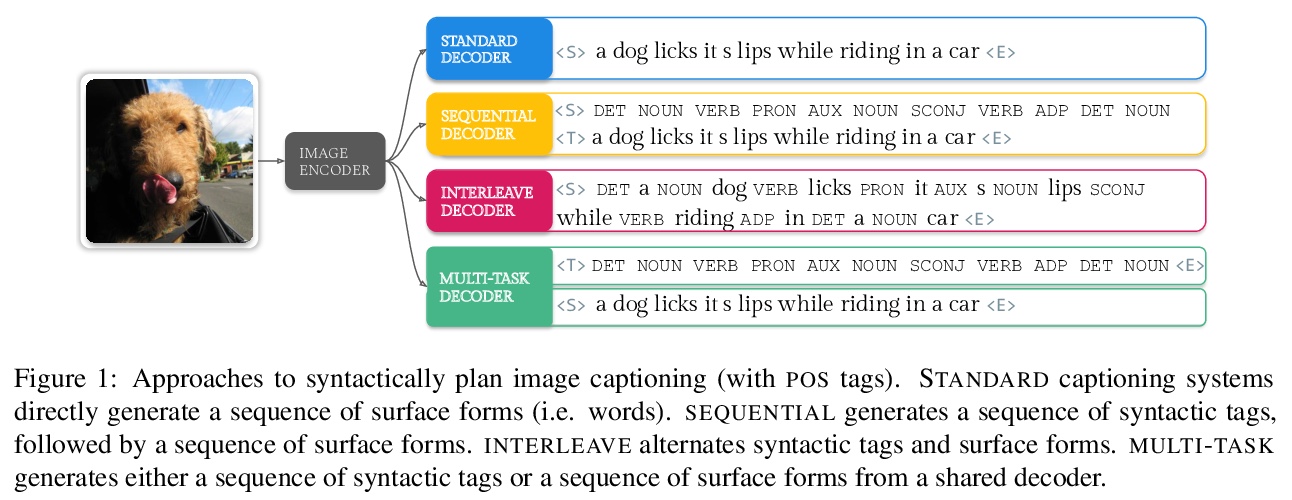
句法规划在合成图像描述中的作用。研究了用句法标签集的多种方法,通过句法规划实现图像描述中的合成泛化。实验表明,联合对标记和句法标签进行建模,可提高基于RNN和Transformer模型的泛化能力,同时也提高了标准指标的性能。虽然这种方法对图像-句子排序模型进行了惩罚,但可通过自适应机制克服这一问题,在合成泛化任务上获得最先进性能。
Image captioning has focused on generalizing to images drawn from the same distribution as the training set, and not to the more challenging problem of generalizing to different distributions of images. Recently, Nikolaus et al. (2019) introduced a dataset to assess compositional generalization in image captioning, where models are evaluated on their ability to describe images with unseen adjective-noun and noun-verb compositions. In this work, we investigate different methods to improve compositional generalization by planning the syntactic structure of a caption. Our experiments show that jointly modeling tokens and syntactic tags enhances generalization in both RNN- and Transformer-based models, while also improving performance on standard metrics.
https://weibo.com/1402400261/JFFCB8Csf


5、[CV] Exploring Cross-Image Pixel Contrast for Semantic Segmentation
W Wang, T Zhou, F Yu, J Dai, E Konukoglu, L V Gool
[ETH Zurich & SenseTime Research]
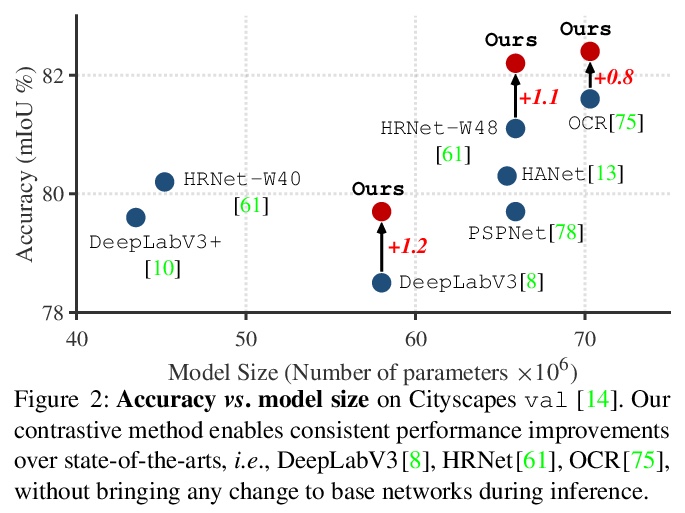
跨图像像素对比语义分割。提出一种用于全监督环境下的语义分割的像素级对比学习框架,一种新的监督学习范式,享有表征学习和度量学习的互补优势,其核心思想是,强制来自同一语义类的像素嵌入,比来自不同语义类的像素嵌入更相似。充分利用了训练像素间的全局语义关系,引导像素嵌入走向跨图像分类辨识的表征,最终提高分割性能。实验表明,在使用著名的分割模型(DeepLabV3,HRNet,OCR)和主干(ResNet,HRNet)时,该方法在不同数据集(Cityscapes,PASCALContext,COCO-Stuff)上带来了一致的性能提升。
Current semantic segmentation methods focus only on mining “local” context, i.e., dependencies between pixels within individual images, by context-aggregation modules (e.g., dilated convolution, neural attention) or structure-aware optimization criteria (e.g., IoU-like loss). However, they ignore “global” context of the training data, i.e., rich semantic relations between pixels across different images. Inspired by the recent advance in unsupervised contrastive representation learning, we propose a pixel-wise contrastive framework for semantic segmentation in the fully supervised setting. The core idea is to enforce pixel embeddings belonging to a same semantic class to be more similar than embeddings from different classes. It raises a pixel-wise metric learning paradigm for semantic segmentation, by explicitly exploring the structures of labeled pixels, which are long ignored in the field. Our method can be effortlessly incorporated into existing segmentation frameworks without extra overhead during testing. We experimentally show that, with famous segmentation models (i.e., DeepLabV3, HRNet, OCR) and backbones (i.e., ResNet, HR-Net), our method brings consistent performance improvements across diverse datasets (i.e., Cityscapes, PASCAL-Context, COCO-Stuff). We expect this work will encourage our community to rethink the current de facto training paradigm in fully supervised semantic segmentation.
https://weibo.com/1402400261/JFFIPFUG2


另外几篇值得关注的论文:
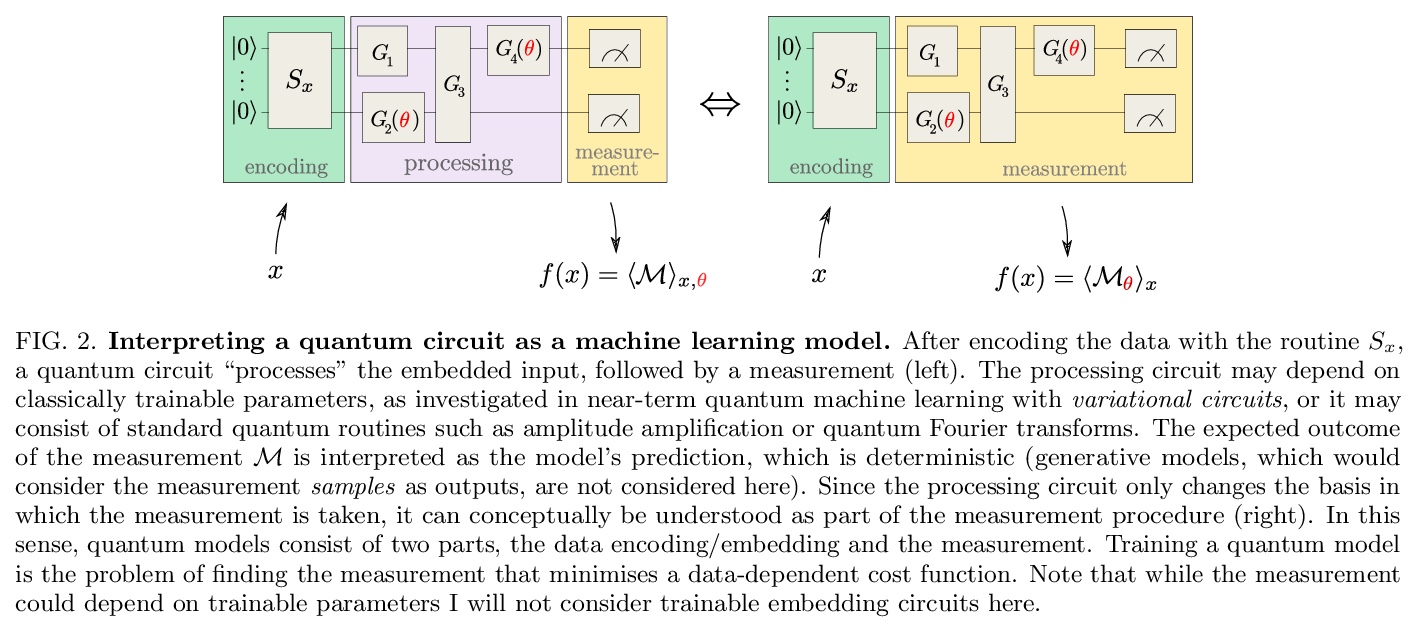
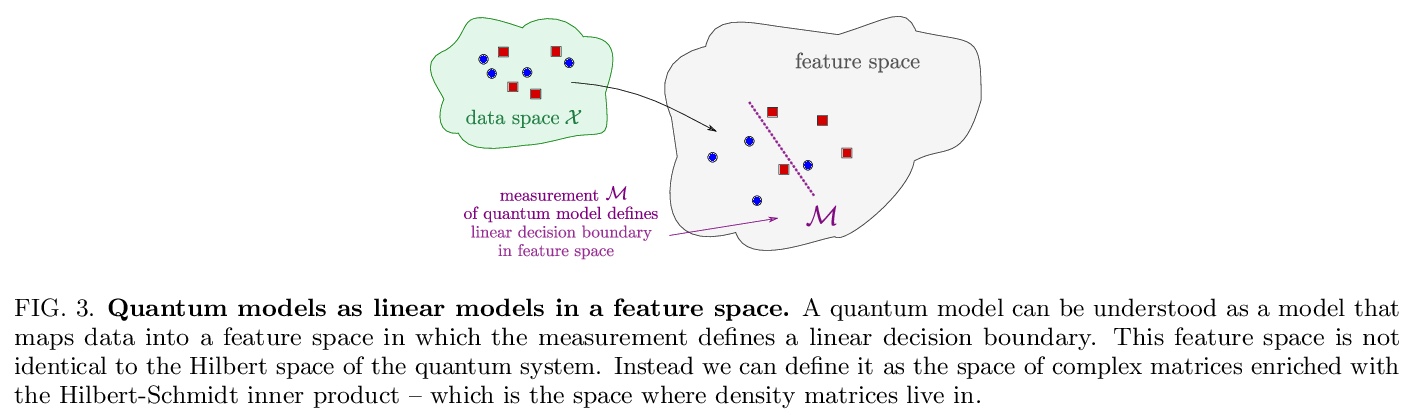
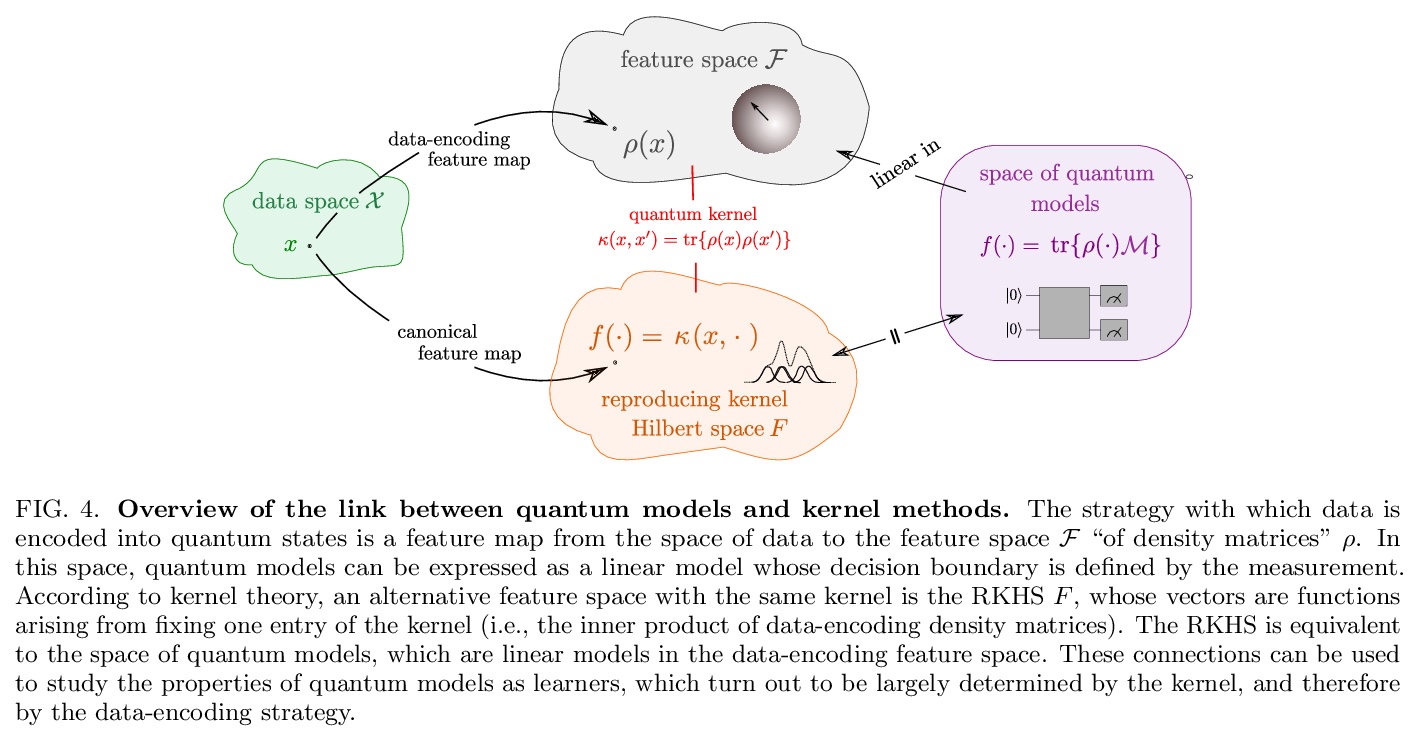
[LG] Quantum machine learning models are kernel methods
量子机器学习模型也是核方法
M Schuld
https://weibo.com/1402400261/JFFAjCb10
[CL] Modeling Context in Answer Sentence Selection Systems on a Latency Budget
低系统延迟的回答句选择系统上下文建模
R Han, L Soldaini, A Moschitti
[University of Southern California & Amazon Alexa]
https://weibo.com/1402400261/JFFNnikg2
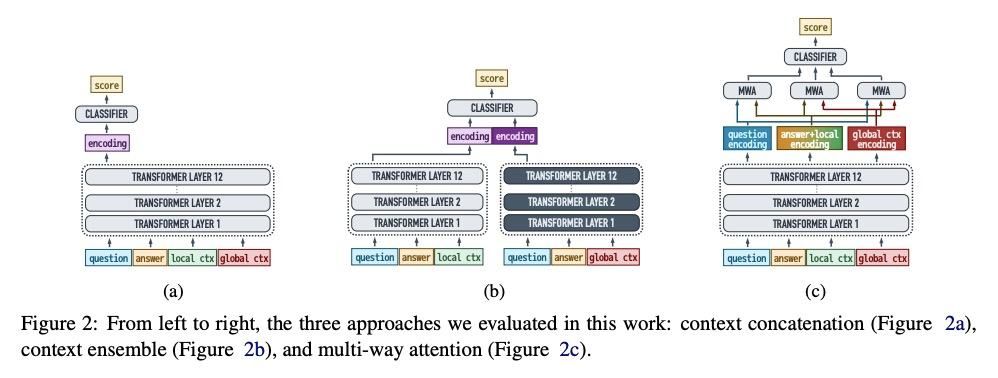
[LG] Learning Structural Edits via Incremental Tree Transformations
基于增量树变换的结构编辑学习
Z Yao, F F. Xu, P Yin, H Sun, G Neubig
[The Ohio State University & CMU]
https://weibo.com/1402400261/JFFRD8EuI
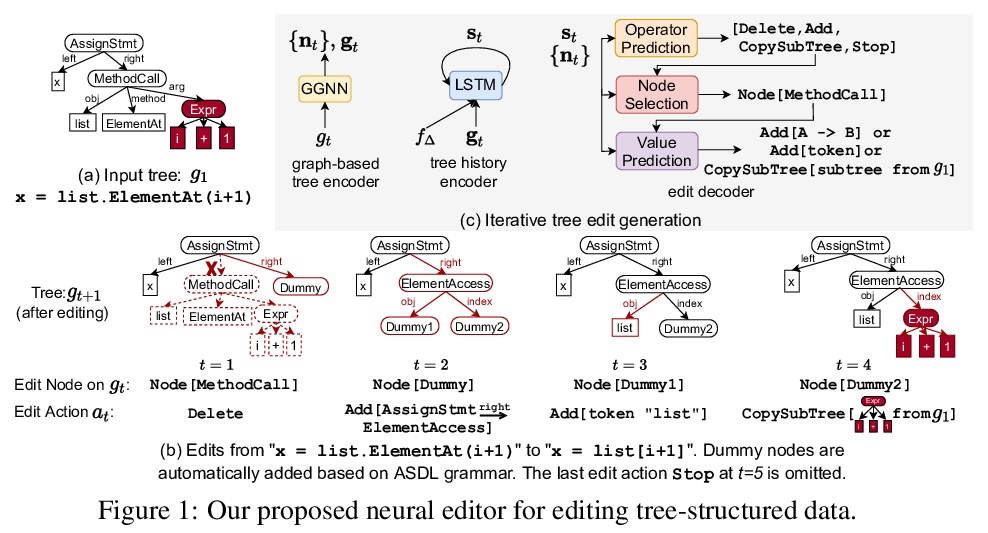
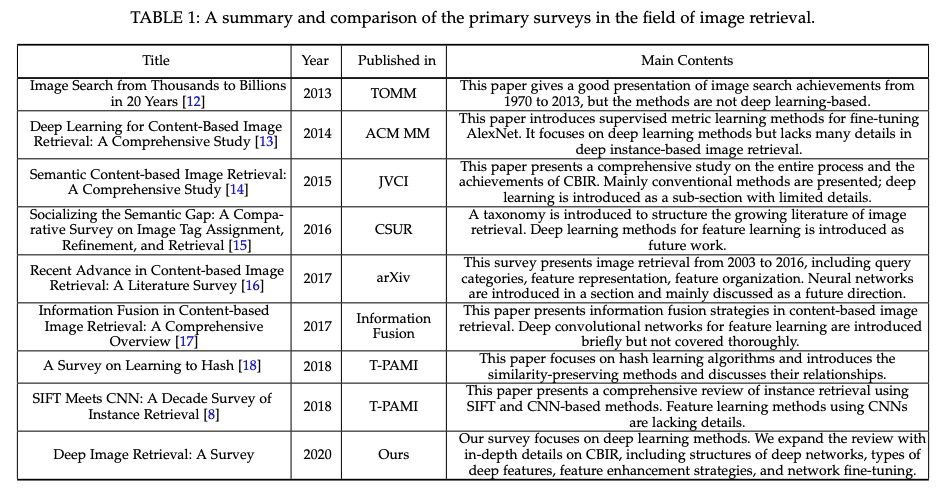
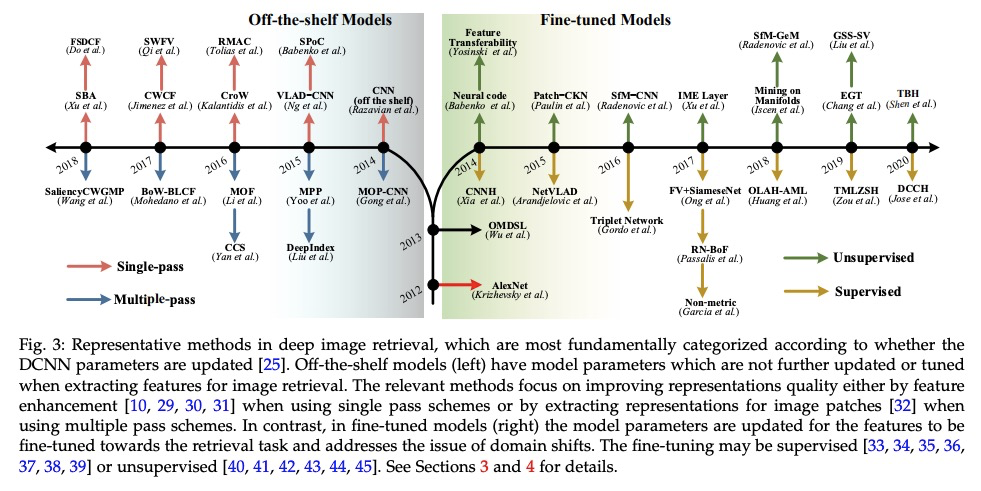
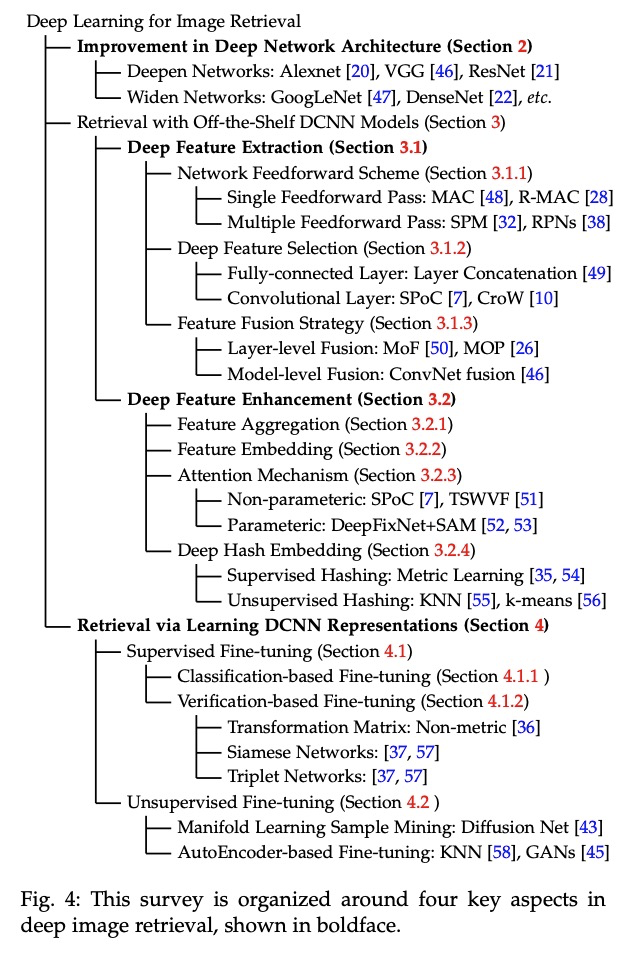
[CV] Deep Image Retrieval: A Survey
深度图像检索综述
W Chen, Y Liu, W Wang, E Bakker, T Georgiou, P Fieguth, L Liu, M S. Lew
[Leiden University & NUDT & University of Waterloo]
https://weibo.com/1402400261/JFFXNaGAK

若有收获,就点个赞吧
0 人点赞
