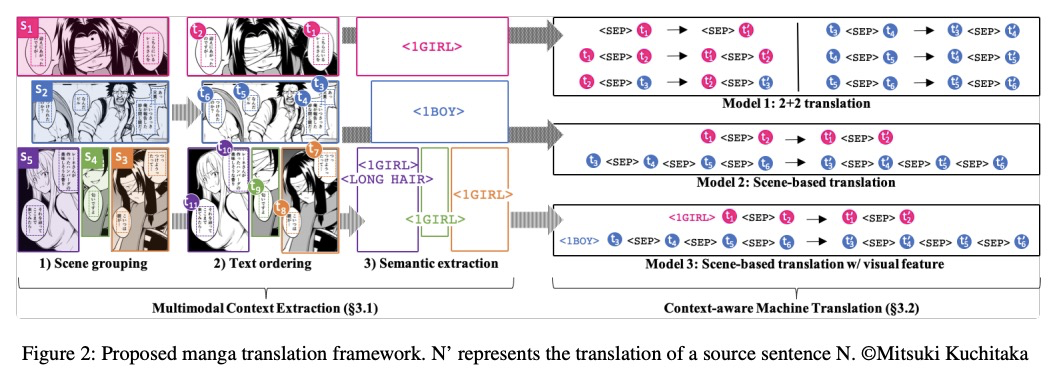
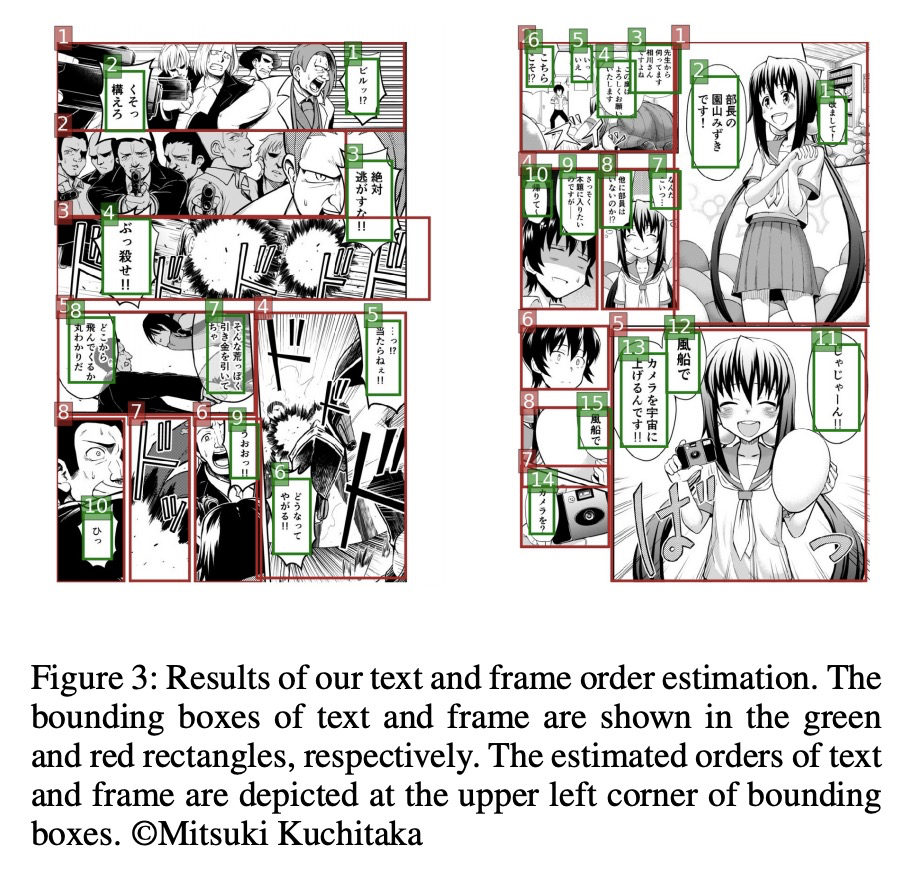
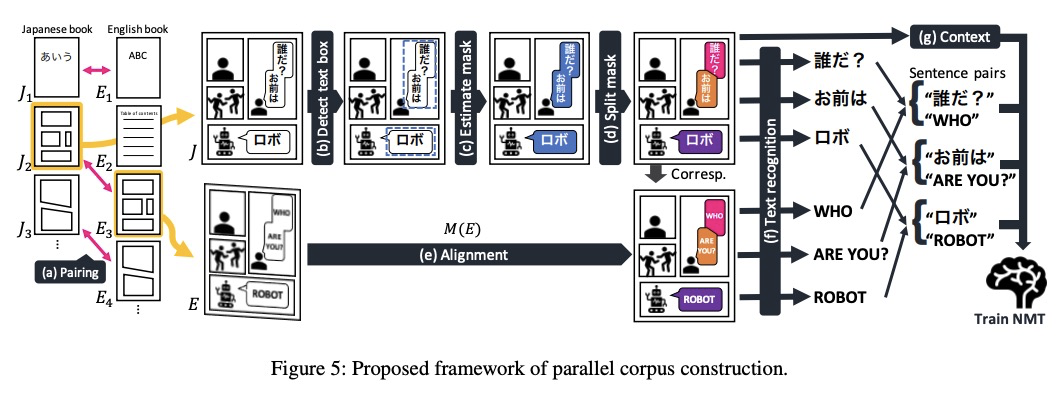
- 1、[CL] Towards Fully Automated Manga Translation
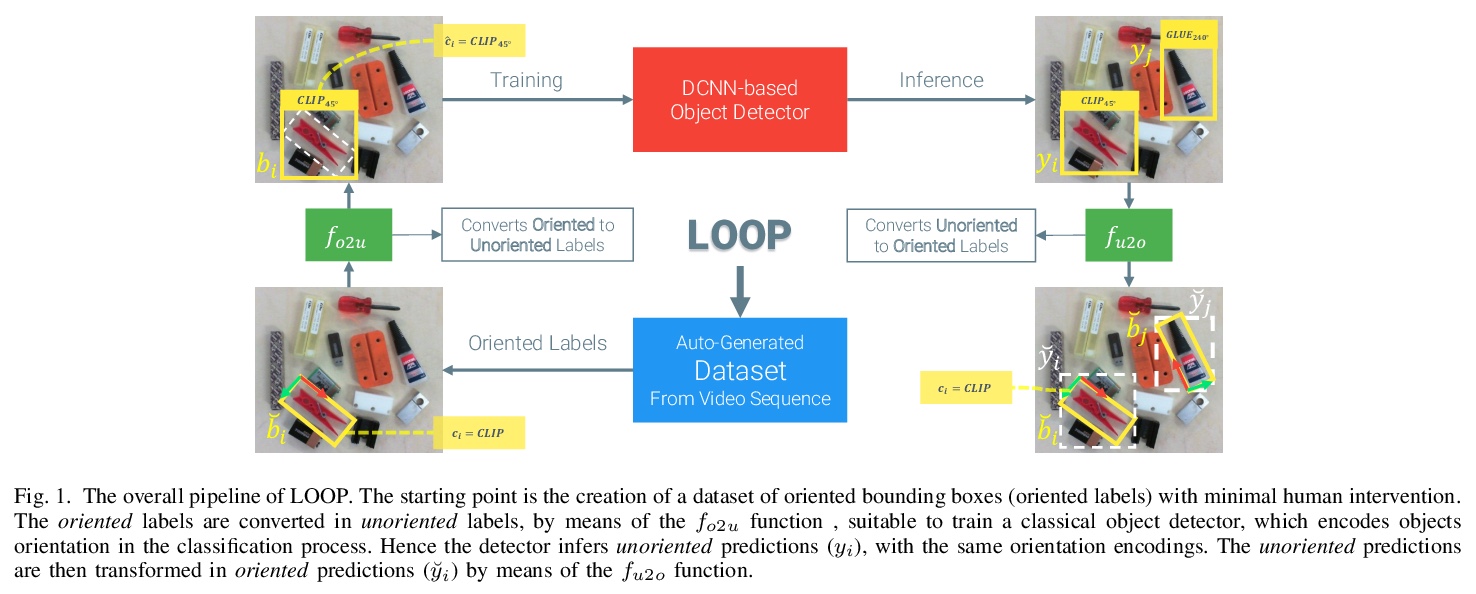
- 2、[RO] Effective Deployment of CNNs for 3DoF Pose Estimation and Grasping in Industrial Settings
- 3、[LG] Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
- 4、[LG] Evolution Is All You Need: Phylogenetic Augmentation for Contrastive Learning
- 5、[CL] Explaining NLP Models via Minimal Contrastive Editing (MiCE)
- [CV] Modeling Deep Learning Based Privacy Attacks on Physical Mail
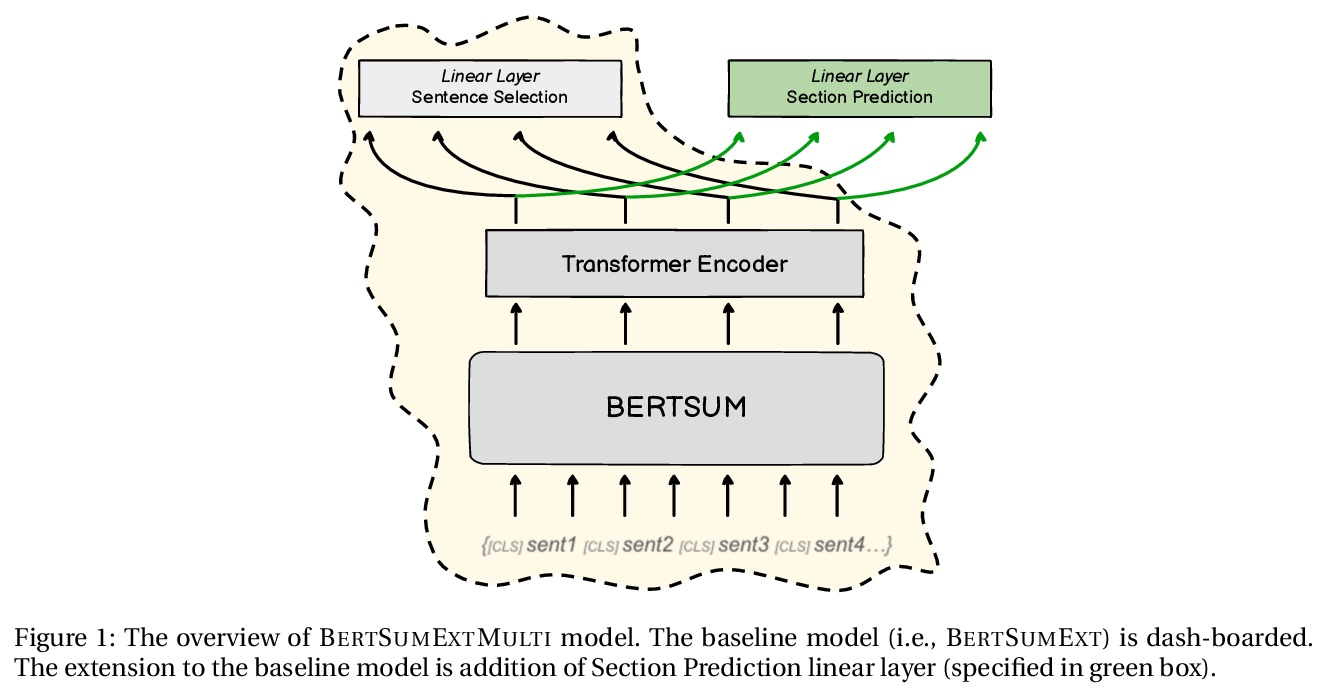
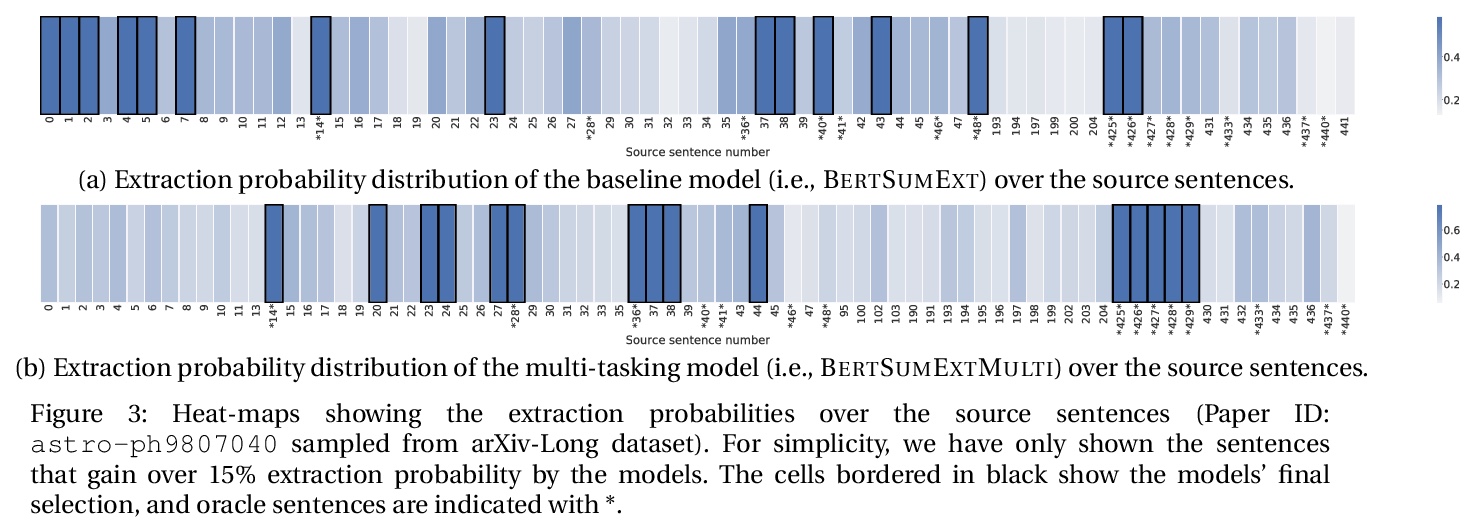
- [CL] On Generating Extended Summaries of Long Documents
- [CL] I like fish, especially dolphins: Addressing Contradictions in Dialogue Modeling
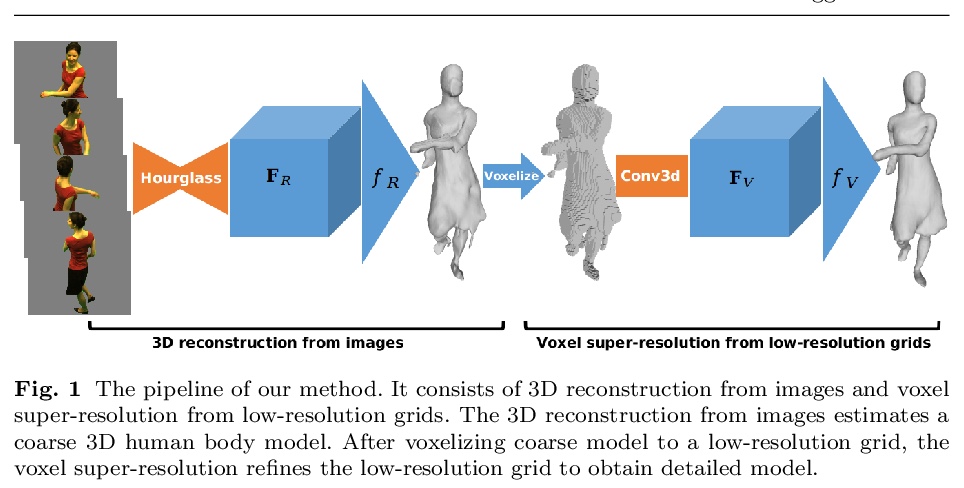
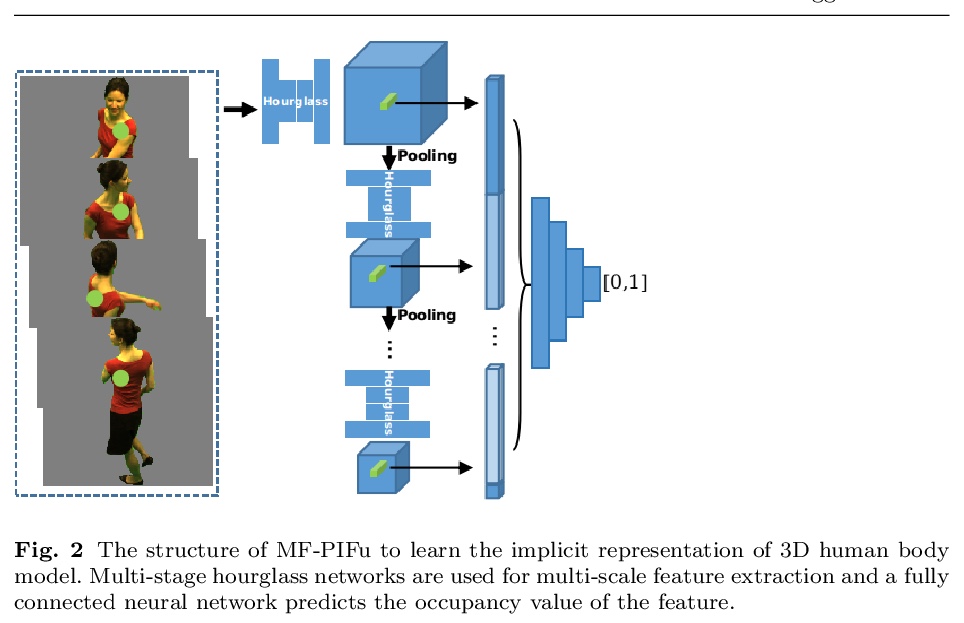
- [CV] Detailed 3D Human Body Reconstruction from Multi-view Images Combining Voxel Super-Resolution and Learned Implicit Representation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] Towards Fully Automated Manga Translation
R Hinami, S Ishiwatari, K Yasuda, Y Matsui
[Mantra Inc & Yahoo Japan Corporation & The University of Tokyo]
漫画全自动机器翻译探索。针对漫画机器翻译的两个关键问题——上下文感知和多模态翻译,通过 1)提出多模态上下文感知翻译方法 2)自动平行语料库构建 3)建立基准 4)开发全自动翻译系统,为漫画翻译研究奠定了基础。
https://weibo.com/1402400261/JAWTP7HmQ

2、[RO] Effective Deployment of CNNs for 3DoF Pose Estimation and Grasping in Industrial Settings
D D Gregorio, R Zanella, G Palli, L D Stefano
[EYECAN.ai & University of Bologna]
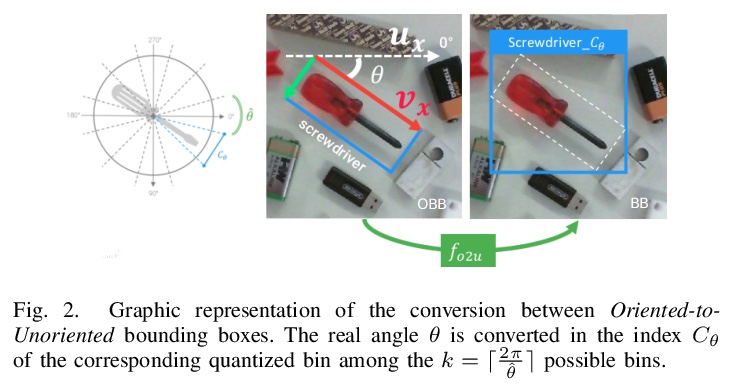
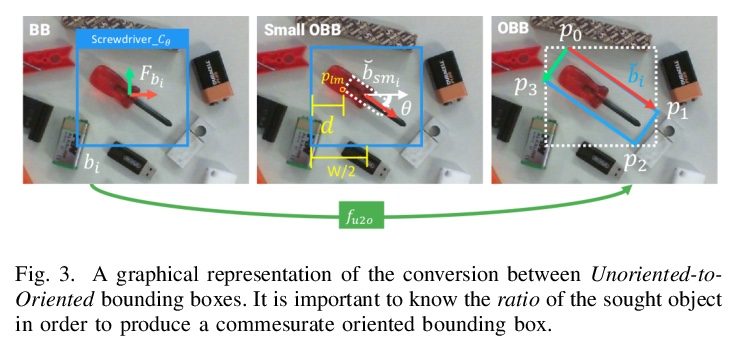
面向工业环境3DoF姿态估计与抓取的CNN高效部署。提出经典CNN目标检测器的一种扩展,能产生适合3-DoF姿态估计任务的定向边界框。为检测器提供了简化程序,可在现场收集大量训练数据,只需极少的人工干预。展示了如何利用所提出技术,在真实工业环境中有效使用深度学习,利用神经网络作为更复杂的控制方案的模块。
In this paper we investigate how to effectively deploy deep learning in practical industrial settings, such as robotic grasping applications. When a deep-learning based solution is proposed, usually lacks of any simple method to generate the training data. In the industrial field, where automation is the main goal, not bridging this gap is one of the main reasons why deep learning is not as widespread as it is in the academic world. For this reason, in this work we developed a system composed by a 3-DoF Pose Estimator based on Convolutional Neural Networks (CNNs) and an effective procedure to gather massive amounts of training images in the field with minimal human intervention. By automating the labeling stage, we also obtain very robust systems suitable for production-level usage. An open source implementation of our solution is provided, alongside with the dataset used for the experimental evaluation.
https://weibo.com/1402400261/JAX0kbQjr
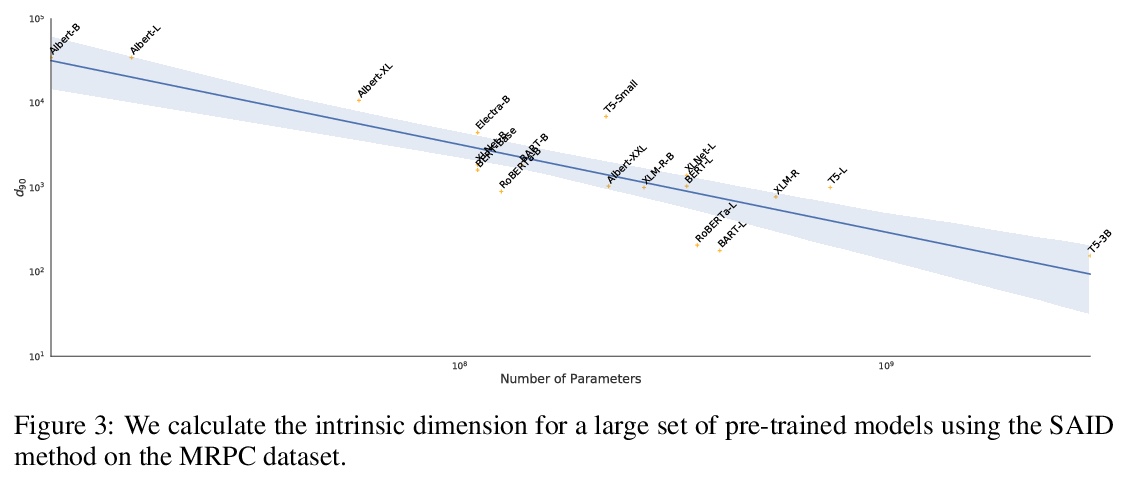
3、[LG] Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
A Aghajanyan, L Zettlemoyer, S Gupta
[Facebook]
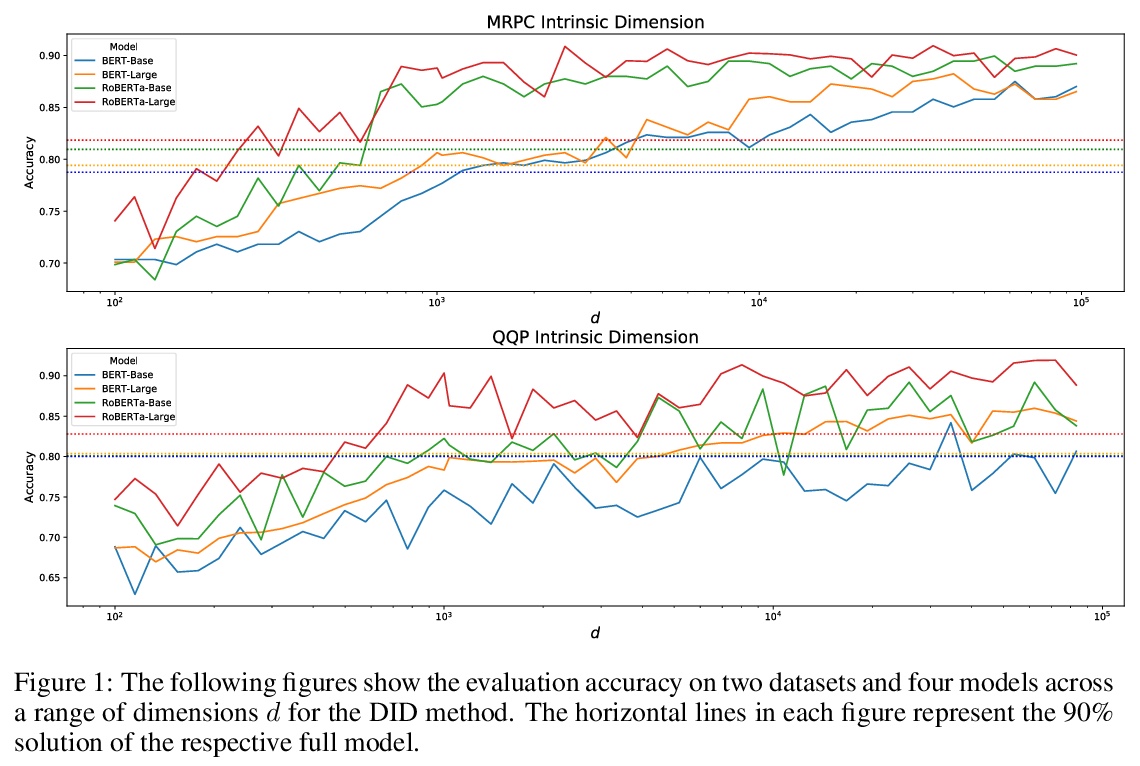
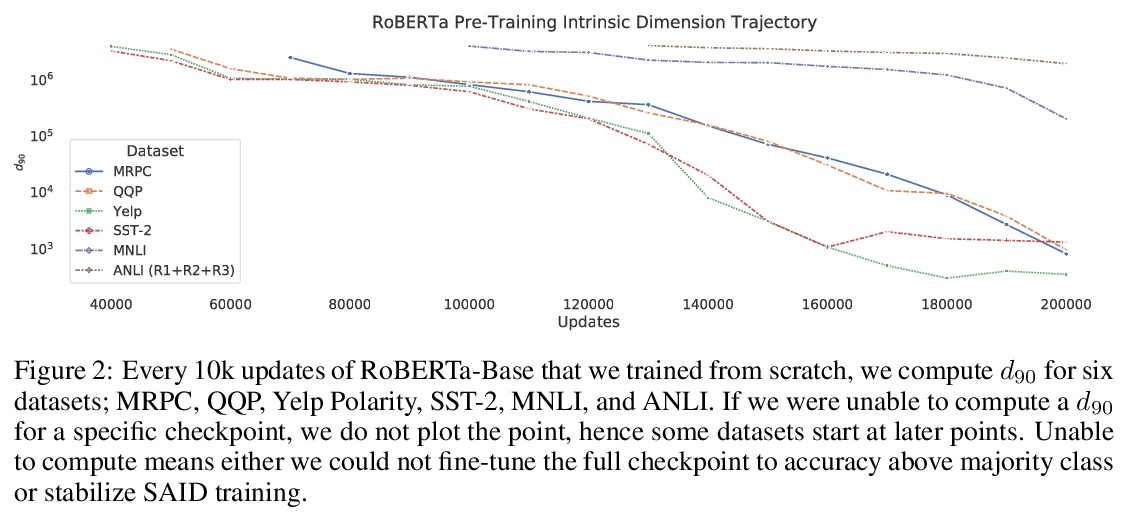
用本征维解释语言模型微调效果。提出通过本征维视角,看待关于微调和预训练的各种现象。实证表明,用预训练表示时,常见的自然语言任务可以用极少参数,有时甚至是数百个参数来学习。将预训练解释为提供压缩框架,以最小化自然语言任务平均描述长度,并表明预训练隐性最小化了该平均描述长度。随着增加预训练表示参数的数量,本征维会出现下降,这一现象为预训练表示的增长趋势提供了一些直观认识。将本征维与泛化联系起来,在各种任务中,本征维较低的预训练模型,可实现更高的评价精度和更低的相对泛化差距。通过将泛化边界应用于本征维来解释这些经验结果,从而得到泛化边界,其增长的顺序是本征维,而不是预训练模型的参数个数。本征维是理解大型模型复杂行为的有用工具。
Although pretrained language models can be fine-tuned to produce state-of-the-art results for a very wide range of language understanding tasks, the dynamics of this process are not well understood, especially in the low data regime. Why can we use relatively vanilla gradient descent algorithms (e.g., without strong regularization) to tune a model with hundreds of millions of parameters on datasets with only hundreds or thousands of labeled examples? In this paper, we argue that analyzing fine-tuning through the lens of intrinsic dimension provides us with empirical and theoretical intuitions to explain this remarkable phenomenon. We empirically show that common pre-trained models have a very low intrinsic dimension; in other words, there exists a low dimension reparameterization that is as effective for fine-tuning as the full parameter space. For example, by optimizing only 200 trainable parameters randomly projected back into the full space, we can tune a RoBERTa model to achieve 90\% of the full parameter performance levels on MRPC. Furthermore, we empirically show that pre-training implicitly minimizes intrinsic dimension and, perhaps surprisingly, larger models tend to have lower intrinsic dimension after a fixed number of pre-training updates, at least in part explaining their extreme effectiveness. Lastly, we connect intrinsic dimensionality with low dimensional task representations and compression based generalization bounds to provide intrinsic-dimension-based generalization bounds that are independent of the full parameter count.
https://weibo.com/1402400261/JAX4n8FbH
4、[LG] Evolution Is All You Need: Phylogenetic Augmentation for Contrastive Learning
A X. Lu, A X. Lu, A Moses
[University of Toronto]
对比学习的进化序列增强策略。目前生物学中的自监督表示学习方法,多改编自为NLP设计的大型语言模型,而不是以生物信息学的理念为出发点。对比学习在图像模态中取得了最先进结果,具有理想的理论属性,本文将进化作为对比学习的序列增强策略,在系统性”噪声通道”实现信息最大化,并从生物学和理论的角度提供了这样做的理由。
https://weibo.com/1402400261/JAX9b05tg

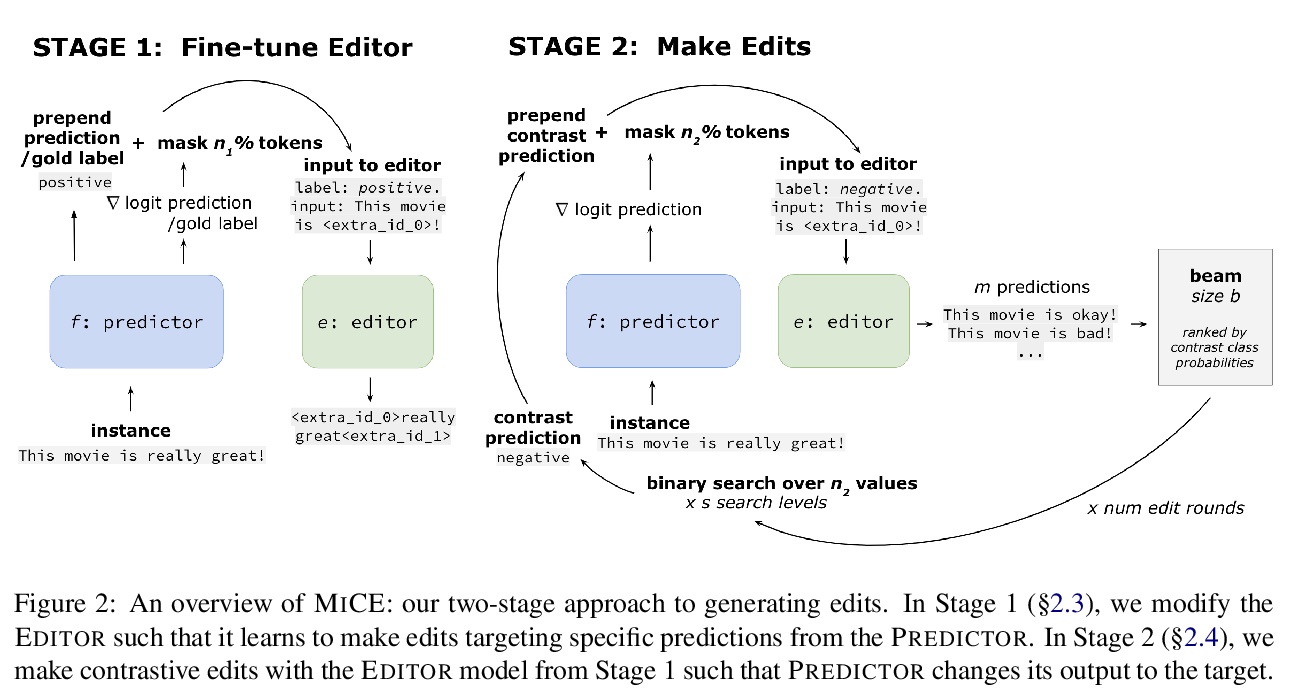
5、[CL] Explaining NLP Models via Minimal Contrastive Editing (MiCE)
A Ross, A Marasović, M E. Peters
[Allen Institute for Artificial Intelligence & University of Washington]
通过最小对比编辑(MiCE)解释NLP模型。提出了最小对比编辑(MiCE),一种对模型预测产生对比解释的方法,其形式是对输入进行编辑,将模型输出变为对比信息。在三个任务中的实验—二元情感分类、话题分类和多选题回答—表明MiCE能够产生的编辑不仅是对比性的,而且是最小的和流畅的,与人类的对比性编辑一致。
Humans give contrastive explanations that explain why an observed event happened rather than some other counterfactual event (the contrast case). Despite the important role that contrastivity plays in how people generate and evaluate explanations, this property is largely missing from current methods for explaining NLP models. We present Minimal Contrastive Editing (MiCE), a method for generating contrastive explanations of model predictions in the form of edits to inputs that change model outputs to the contrast case. Our experiments across three tasks — binary sentiment classification, topic classification, and multiple-choice question answering — show that MiCE is able to produce edits that are not only contrastive, but also minimal and fluent, consistent with human contrastive edits. We demonstrate how MiCE edits can be used for two use cases in NLP system development — uncovering dataset artifacts and debugging incorrect model predictions — and thereby illustrate that generating contrastive explanations is a promising research direction for model interpretability.
https://weibo.com/1402400261/JAXe2o1pp

另外几篇值得关注的论文:
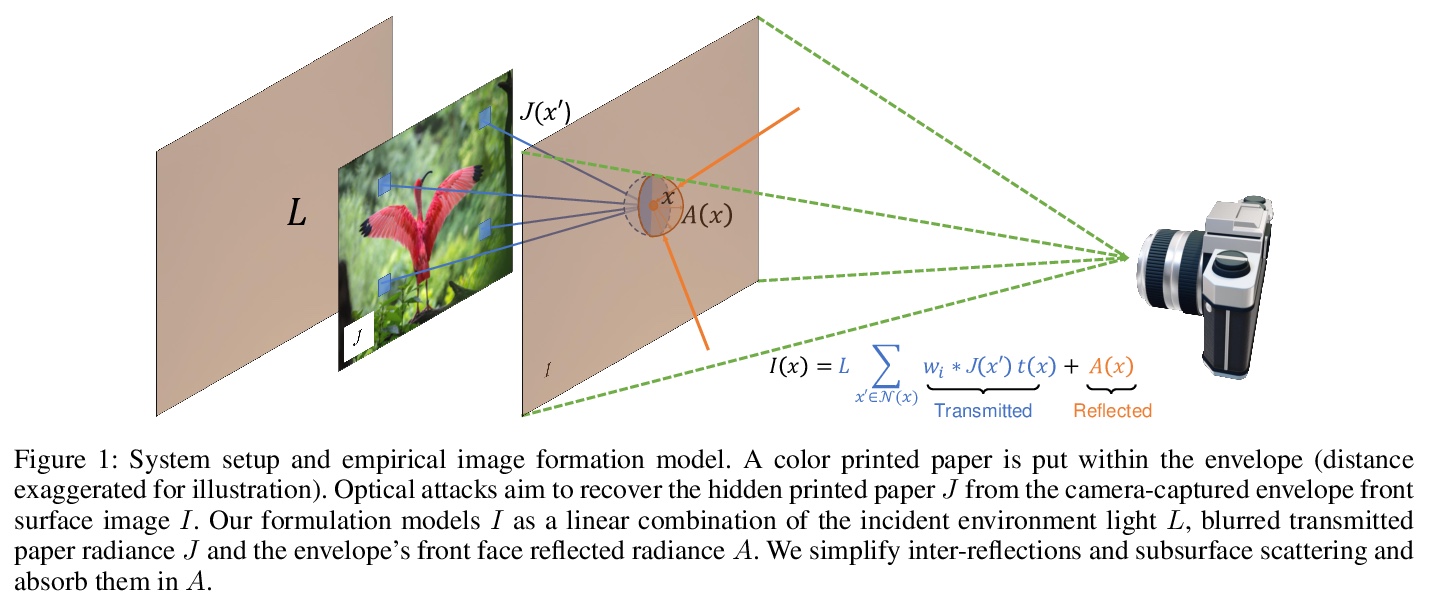
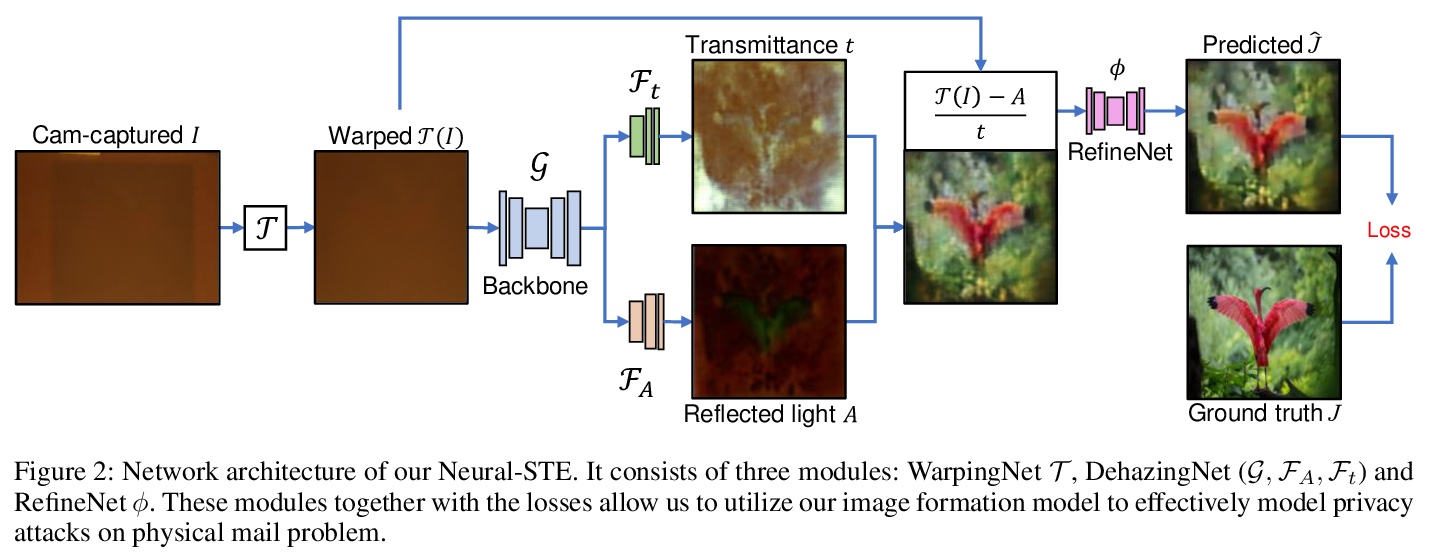
[CV] Modeling Deep Learning Based Privacy Attacks on Physical Mail
基于深度学习的物理邮件隐私攻击建模
B Huang, R Lian, D Samaras, H Ling
[Stony Brook University]
https://weibo.com/1402400261/JAXje9mHZ
[CL] On Generating Extended Summaries of Long Documents
长文档扩展摘要生成
S Sotudeh, A Cohan, N Goharian
[Georgetown University & Allen Institute for Artificial]
https://weibo.com/1402400261/JAXkF4SP2

[CL] I like fish, especially dolphins: Addressing Contradictions in Dialogue Modeling
对话矛盾检测
Y Nie, M Williamson, M Bansal, D Kiela, J Weston
[UNC Chapel Hill & Facebook AI Research]
https://weibo.com/1402400261/JAXmW5bt4


[CV] Detailed 3D Human Body Reconstruction from Multi-view Images Combining Voxel Super-Resolution and Learned Implicit Representation
结合体素超分辨率和隐式表示学习的多视图人体细节3D重建
Z Li, M Oskarsson, A Heyden
https://weibo.com/1402400261/JAXpOtczZ


若有收获,就点个赞吧
0 人点赞
