产品设计全局观——谈一个搜索长尾流量项目的反思 | 人人都是产品经理
每一做一个项目都应当有所收获,面对千变万化的长尾问题,如何提供更优解?作者复盘了其一个搜索长尾流量项目,谈谈当中所做和所思,希望对你有所启发。

你好,我是柠梦百香果,做过大厂交互、普通公司资深UI和小组长、创业合伙人、入门自媒体等。
介绍是为了让你愿意听听这样的我,是怎么被项目碾压的。
这是个复杂项目复盘反思文。文章较长,因为不仅从设计角度来分析,预估17-25min阅读吧。
毕竟复盘它,从思维整理+脑暴上就花了熟悉项目的我2天时间,还只是输出了个简单的解决方案雏形。
前置一下这个复盘最重要的收获——复杂需求产品设计的全局思维。
一个复杂需求的解决方案,先定义好要解决的问题,然后从工程化开始思考解决方案;从工程出发,找到不同角色更适合赋能的地方,最终合并成一个综合解决方案。
这里的复杂,主要在于解决方案的复杂性。可能是信息量、服务量、物件量、角色量等。 我涉及的主要是信息量。
其他还有一些额外的跟项目、技术、设计、内容更结合的感触,放在了具体项目拆解中。
文章节奏分为:Foreword前言 – Star伊始 – Think思考 – Solution工程方案 – Design设计 – Expand扩展 – Summary总结。
我且烹茶煮酒,各位看官,去留随意。
一、Foreword:一顿操作猛如虎,一看输出0.5的项目,倒逼解决方案的思考
这是一个复杂的搜索问答项目。当时投入了好几个老板、一群产品、技术、设计,涉及20人+了(记不清了)。疯狂加班,输出+修改了n次设计,开n次会,看n个文档,做n次调研。
可以看下图设计侧部分文件,每个文件至少page有8个以上,多则25+,每个page都很大。图为保密做了缩放+模糊处理 ⬇️(注:非我一人输出,是团队总体输出)
图1 设计侧部分文件

图2 随便找了个设计文件(缩放了很多倍,右侧有20个pages)
还没放产品侧一堆文档。当时文档已经多到找文件都很困难了。看到这里会不会觉得:哇!好多好多,666!
No!它只是个成果很难应用的输出。也就是这里的输出,大部分当时没找到合适的落地方式。
也正因它价值难判,却又如此的占用时间,倒逼我在离开这个项目后重新反省这个需求的解决方案。
二、Star:需求定义
搜索问答项目,听起来太学术了。换一个说法介绍一下:
用多了谷歌的,相信都对精选摘要有印象。em···没印象就看下图3,其实就是谷歌搜索引擎整理网页内容,提炼出的第一个搜索结果,直达问题的答案。让用户更快Get到有效信息。
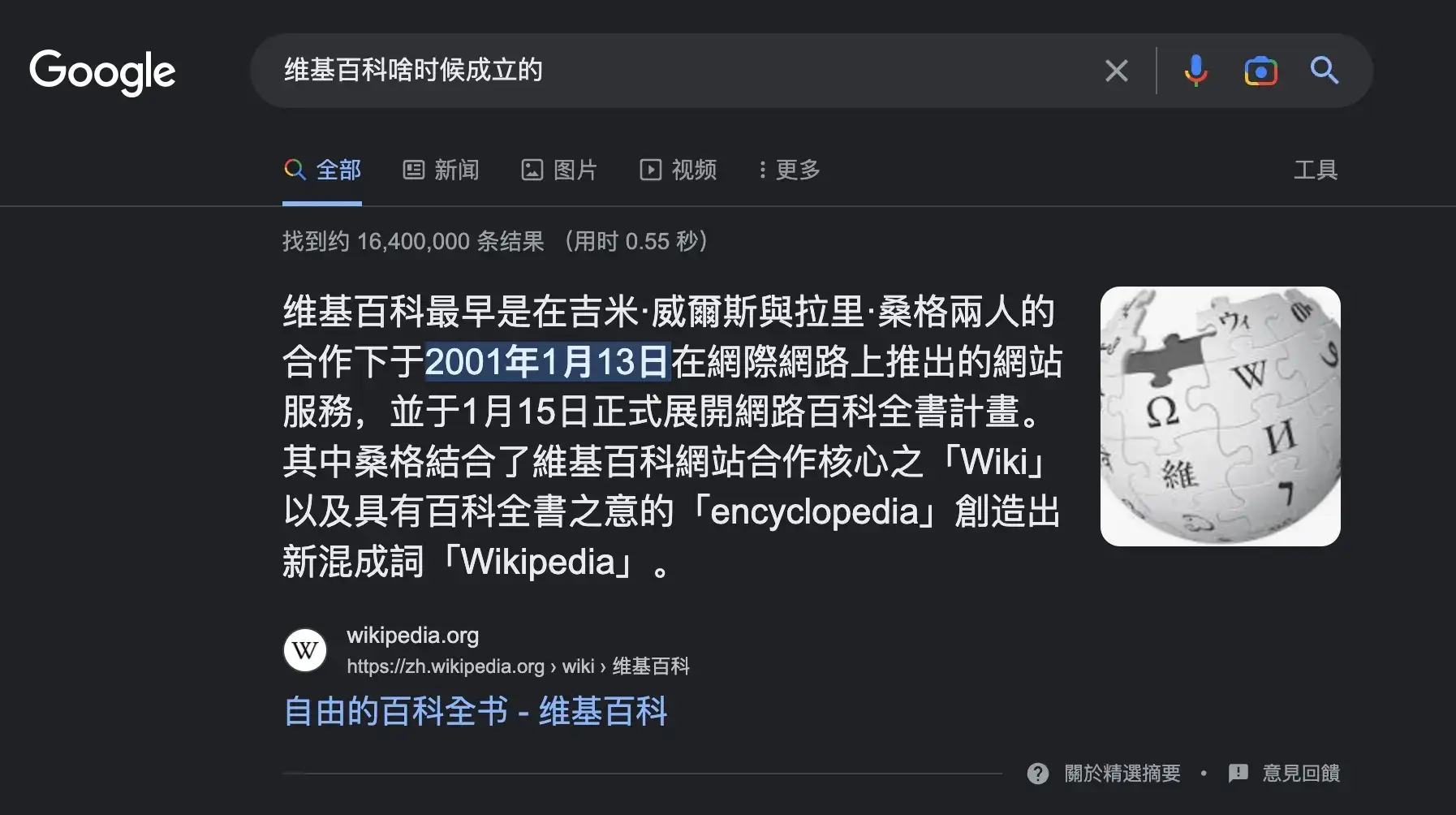
图3 谷歌的精选摘要
我们当时要做的就是类似优化这块精选摘要的工作,只是产品是其他浏览器(名字保密,不影响复盘)。
项目目标在文档中的说法是:高效解决用户疑惑。关键词有可信、直观、有用。数据指标就是提升问答覆盖率和满意度。
说到这里,初步对这个需求重新定义问题:
针对用户的搜索问题,怎么提供更优质的解答?
这里做一个重要申明,定义问题非常非常非常重要!
定义问题其实就是怎么去拆解看待问题的角度,会影响你解决方案的出发点。
不得不说做项目踩的认知第一坑——我们没有定义问题。也是我觉得费力不讨好的关键因素。
当时拿到项目,我们就很着急去分析搜索答案的框架,划分了单维多维、唯一不唯一、有趣或专业什么象限图,最后发现应用的时候很难套上用处,因为它很难对应的用户真实数据覆盖面统计,必须继续细分,但又很难判断细分度。尴尬到我跟产品介绍框架、框架设计case时都要抠脚指甲了!

图4 分析时做的框架最后很难应用
更糟糕的是,因为我们花了很多时间做了分析,导致我们后面一直被这个分析思维缠住了,没办法很好的跳出不好的框架来看。现在看来,有点歪了路。
额外多嘴:
- 项目特意摘出问答来做项目,其实也让我有点不解。因为用户搜索的,都是用户的疑惑需求,只是不一定用问题的方式作为关键词,谷歌搜索引擎研究中是搜索的都合并分析。这算后话了。
- 项目文档中部分说法,其实有些常规项目执行的坑点。等后面分解。
三、Think:定义的问题在项目中的特性
问题:针对用户的搜索问题,怎么提供更优质的解答?
这个问题,在这个项目中,有什么特性呢?这些特性会影响整体解决方案及后续验证的输出。
1. 搜索问题是长尾流量,难以统计出有共性设计需求的大覆盖面比例
这其实也是是项目上踩的认知第二坑。当时项目从用户的问题进行分类:是什么、为什么、怎么办这些角度,确实可以得到数据占比。
但是,“水果篮子是什么时候播出的?”、“天官赐福是哪些人在拍”、“女生主动给男生发消息是啥意思?”这三个“是什么”的答案可是不一样的。前者是一个具体时间,中间是涉及多个主体,后者则是行为代表的多种含义猜测。对应的是单答案、多答案不同结构呈现。
所以我现在重新翻看数据分析,发现它难以产生足够有效的参考。 为此,我暂时放弃的数据的参考,回归问题本质之一——回答各种各样、千变万化的问题。
好在这个千变万化长尾的烦恼,搜索技术是可以解决的。
搜索引擎技术可以通过分析用户输入的搜索词,进行分词、词性判断等,通过贝叶斯概率、向量分析等方法来处理识别用户问问题的意图,也就是长尾问题是可以习得分析的。这个解释起来比较复杂,认真解释的话可以扯出另一篇技术文章来。隐约记得吴军的《数学之美》有提到过类似的技术解答,感兴趣可以去看,或是查阅论文、解析什么的~
如果你耐心看到这,你也发现了——技术在这里面,是绝对的大王。 这也是后文工程化最主要的地方。我也一直疑惑,当时为啥不是技术来主导···
pps,数据永远不绝对,如果它无效,就要回归问题本质思考解决方案。
2. 搜索引擎工具主打信息浏览服务,追求高效满足,链接第三方网页
这是很搜索的特性了,也是项目踩的认知第三坑——无法在短期通过数据验证方案的结果。
代入细想一下,如果真的做了优化,能让用户获得更优质的解答(比如更高效、更好用),用户会在浏览器搜索数据上表现出什么呢?
(1)单次搜索问答浏览时长缩减量。更短时间浏览就能找到答案——这个对于业务来说,并不一定是一个好消息,虽然长期来看可能增加了用户使用生命周期。
(2)相关问题搜索频率增量。会更常在这里搜索相关问题——这个要考虑验证的时间窗口是一周还是一个月内?毕竟长尾需求刚性有,但弱,随机性较强,而团队跟进能否支持得了拉长的时间窗口。
(3)答案摘要的点击率。这个指标,到底用户是因为满意想看更多所以想点击,还是因为不满意想看更多才点击呢?——不知道,所以不算得好指标。
所以,当时项目文档提到的提高用户满意度,是什么呢?
很难定义,一直在讨论,没有很好定下来数据指标。唯一比较肯定的就是,可以通过用户访谈、问卷来进行简易验证。
这就是我在前面Star多嘴处说到文档执行坑点:数据指标量化有困难。
客观来说,这个特性导致追求短平快的团队难以验证设计。但这个也正是需要辩证考虑的,到底要不要追求长期主义?短期难以验证,但长期是可以的,比如你的用户量会增多,你的搜索频率会增高,你的LTV会增长,你的广告收入会拉高,窗口拉得足够长,确实是存在可验证性的。
3. 最优答案的呈现形态是动态变动的
团队当时有从信息可视化、动态化、海报、贴纸、互动等等角度去优化一些答案Case,Case做的很完美(大家都很有设计力),可惜到了落地都是遇到了技术实现、影响覆盖面问题,无法很好继续谈下去。
回看一番,这些解答不一定就是最好的设计方式。因为哪怕整个产品团队去优化特定类型问题的解决方案,在海量长尾面前,无异于螳臂当车。
图5 鲜活直观信息呈现的方式的调研收集(Case就不放出来啦,团队Case涉及保密问题)
那么最优答案是怎么样的呢?
答案就是知识。知识的传播,最开始是死记硬背,再演变到讲故事更容易让人记住、漫画讲解有图示、视频讲解更有临场感、游戏化寓教于乐,同一个知识有完全不同的解释方式,被不同时代的不同人所喜爱。
同样的,我在观察社区类竞品时发现:UGC知识的好处是每个人解答方式或角度的不一样,活灵活现,总有适合不同人的最优解。
我不禁反思,或许解决这个问题真正一劳永逸的方法,就是要设计一个可动态变化追寻最优解的工程。
啊!Bingo!就是这个——可动态变化追寻最优解的工程。这就是我的答案。
四、Solution:可动态变化追寻最优解的工程
动态变化,就意味着要存在对答案内容的解析、提炼、评分。而且评分的等级是一直变化的。我修修改改,简陋的弄了一个工程流程图。
图6 设想的解答背后工程构想
构想画的比较粗糙,背后技术省略了很多,原谅我一个没啥技术背景的小白的表达方式。
这个构想是需要一整个大团队才可以完成的事情。但私以为,不要觉得动态变化如此大成本投入不可靠。说一个个人的感触,在高中时期,我还觉得百度搜索中文结果特别方便,等到我大学毕业后,反而觉得谷歌搜索非常精准,而百度搜索出来一堆无用的解答。
这是因为谷歌专注于对于中文的搜索理解优化以及对应的中文内容匹配抓取,它专心优化的是自己的搜索技术;而百度是专注于做中文内容结构化铺开,比如百度经验、百度知道、百度文档,所以搜索内容时,匹配结果时部分依赖自己搭建的结构化内容,导致搜索引擎看着可用但实际上寻找的不够精准问题被掩饰了。
而当初谷歌离开中国市场时,互联网上的中文内容还太少了,谷歌跑不出数据量训练自己的模型。现在随着互联网跑了十年,这两个搜索引擎就出现了区别——海量中文内容加持下,谷歌是越找越精准,百度却是越找越乏力。
所以要做好,跑长期工程,或许更适合。验证也走长期思路。长远来看,用户对于搜索的评价是上升还是下降,使用频率增高还是降低,使用时长是增高还是降低,用户量是增高还是降低等等。
工程出来,每个角色适合赋能位置就清晰许多了。 拆解一下如图7。
技术主导整个流程,其中产品设计可以参与设计答案框架,涵盖所有适合的答案框架。内容或活动运营可以考虑在建立优秀答案内容池上做运营活动,比如“答案点评官活动”投放活动到福利中心,让用户实际参与点评筛选,持续丰富内容池等等。
图7 角色赋能拆解
五、Design:设计赋能清晰化的框架呈现
图7建议设计工作落到设计更适合的答案框架上。
答案框架一直是我们当时在研究的重点,Star 部分讲的图4 已经表明前期框架我们将其分类做的复杂了。后来我们按照单答案、多答案分别细分,虽然分得较为杂乱,但算是较合理的处理方式。如图8。
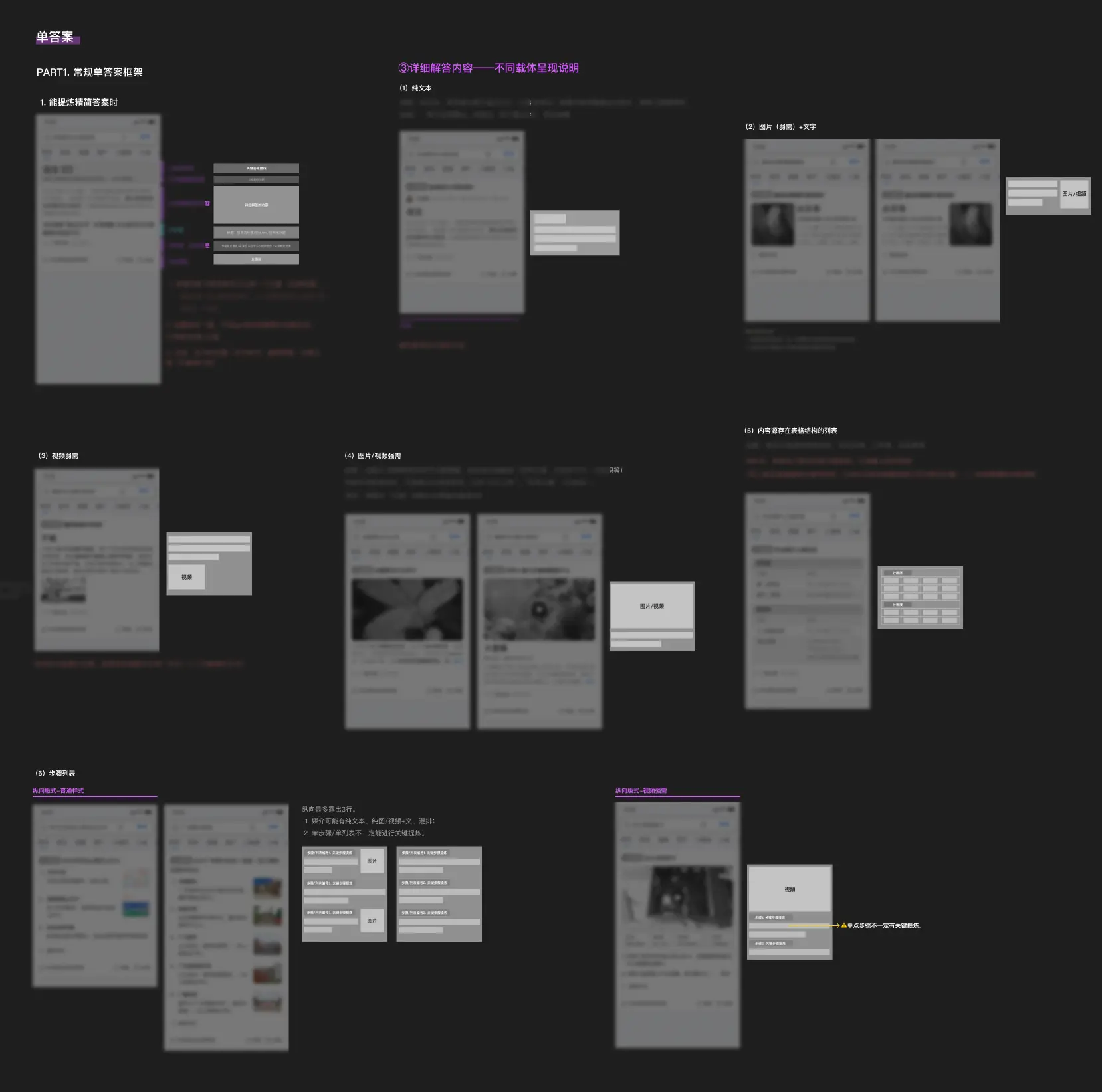
图8 单答案部分框架提取
这里提一下我们当时认知上的第四坑——将单答案、多答案分开看待的,但实际上在技术侧不是这么分的。
答案框架的应用取决于答案内容。如果答案提炼到是多维答案框架(多维=多角度、多分类),那么就是用多维答案框架,如果没有多维,技术只能爬到单答案,那就按照单答案展示。其实就是类似“自主适配”。
综合思考后,我觉得需要设计的是一个递进交合结构的基础答案框架。 初步构想如下图9。
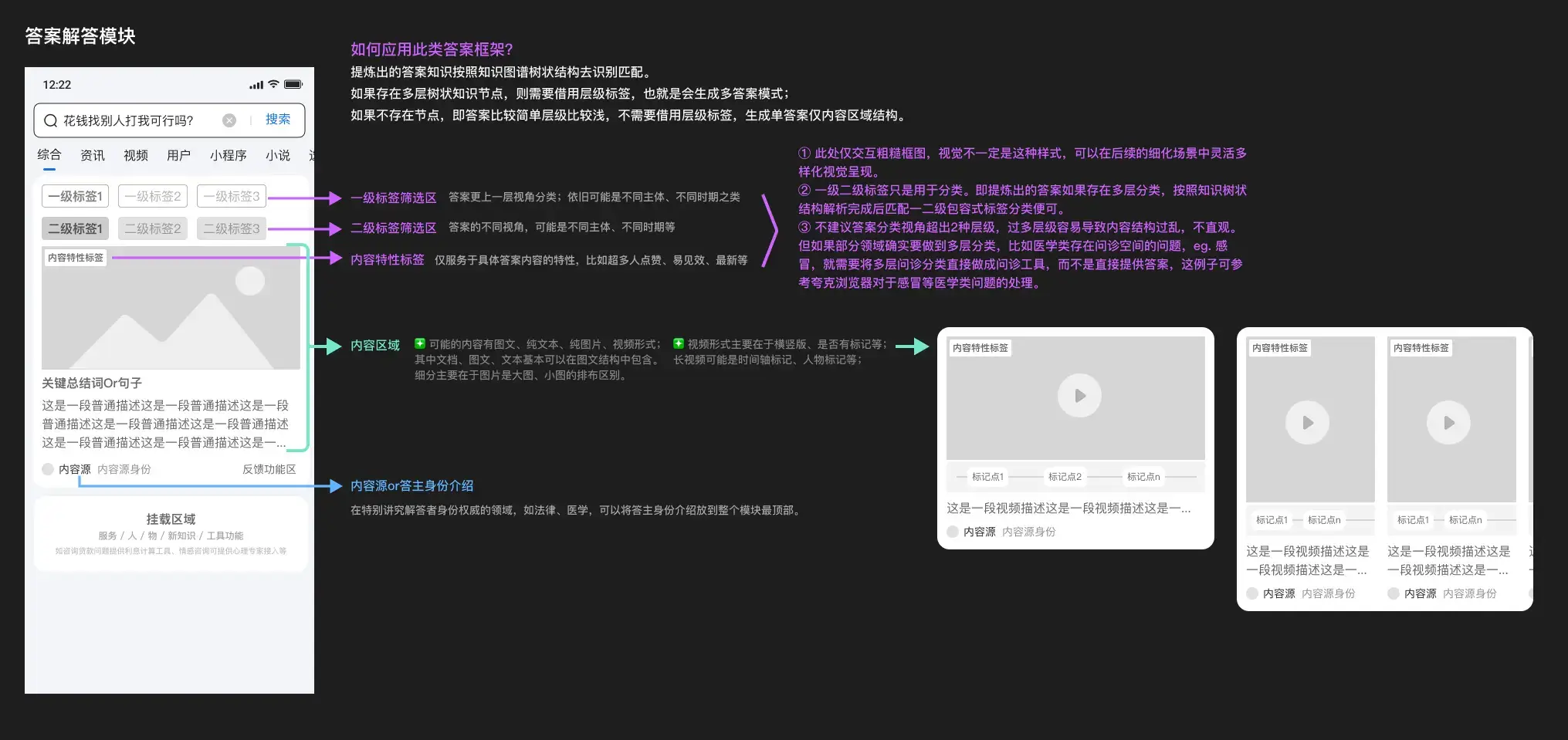
图9 基础答案框架
递进交合应用取决于答案内容的知识图谱节点识别。
如果存在多层节点,就套上一二级标签结构去应用,就会变成一个多答案结构;如果是没有节点,就是只有答案内容的单答案结构。
初步构想很粗糙,还可以细分,比如一个级别的标签下可能有多个内容、图片大小不同的情况、视频横竖+不同时长+是否可自动播放情况、文档存在下载操作按钮、内容为操作步骤有流程性、内容是表格如何呈现比较好等等;
甚至再细分一些特殊模式,比如二级标签只是2个比较的情况,可以直接用PK模式呈现。展开的话也是一大设计文件说明,图9基本已经把我的主要思维体现了,所以细节就先不展开了。
提一个框架设计中体验的关键点:
(1)增强答案的认同感
其实用户寻找问题,得到答案,是为了得到自己更认同的答案。
那么影响认同感的因素有哪些呢?——答主身份、用户认同数。 后者其实比较难抓取,但前者属于内容源,是可以固定下来的。当时团队对专业领域的答主就很看重其身份的展示。
故我在图9的结构末尾加了内容源的身份解析,但是这个为不干扰主体答案画的比较弱,必要情况下可以加强视觉呈现,比如特别专业领域使用内容源or答主身份前置到顶部,或是直接把这块的头像面积变大修改版式。
(2)服务于答案内容的情绪感知
在工程图6的设想中有提到答案的情绪感知。
当时团队讨论观察提到的方式是该怎么去回答一个问题,有些适合搞梗,比如互联网热词,有些适合专业比如法律咨询,有些适合安抚比如伤心情感问题。
只是当时切入的应用角度是垂直领域细分,比如安抚就是情感领域。但实际上这样还不够严谨。因为有些情感是向上的,不一定需要安抚。
所以我倾向于直接解析答案内容的情绪,这需要借助机器模型学习。
识别内容判定总体情绪,是否安抚性强。比如是否出现安抚性词语“抱抱”、“加油”、“你可以的”等等字眼。如果判断出答案的情绪属于这一类,那么就可以在挂载区增加一些互动安抚功能。比如类似壹心理的抱抱互动按钮,增加xx人在这里与你拥抱、xxx位陌生人给你鼓励+鼓励弹幕;
同类扩展,搞梗有趣的可以增加热词段子弹幕到扩展区;不过专业的更建议提供咨询的挂在服务了。
当然体验关键点还有其他,比如统一简洁化呈现,这些属于基础要求,就不细提啦~
六、Expand:项目复盘的可复用性讨论
写这篇文章之前就在想,做这个复盘,除了给自己一个交代外,还能有什么复用扩展?
1. 复杂需求产品设计的全局思维
与开篇呼应,这是最重要的思维收获。面对一个复杂的需求,定义问题是基础,它可以避免费力不讨好的尝试。然后从工程化角度去思考解决方案,而不是一下子就从细节入手。工程化可以让自己从全局角度来看待这件事,也能找到每个角色更好赋能的方式。
2. 这种搜索设计思路能否用于社区类搜索逻辑?
社区类App链接的是人和产生内容的人,也就是至少存在KOL和粉丝两种角色。两者之间存在情感联结。如果使用了提取答案摘要的能力,平台自己生成一个答案,可能会减少KOL的SEO搜索导量,引起KOL流失、粉丝流失,损益过重。
所以精选摘要更多是在搜索工具这种纯粹的工具中存在,因为搜索工具链接的是网页。
当然也有一种折中解决方案,也就是官方自己下场到社区中,成为社区的某一类生产内容的人。 比如小红书的运营官建了很多官方账号,比如吃货薯、知识薯,且会做部分小专题内容。搜索一些相关内容可能就会看到官方的结果也混在SEO之中。
不过这种官方不会做的太过,怕抢占KOL的盘面,或是即使做多了,也是会给提供对应内容KOL引流。
总体来说,现在这个搜索工具的复盘,更多适合在工具属性强的产品中的搜索应用。如果是在社区中应用,可以建立官方账号,以官方账号人这个角色去产出精选摘要内容呈现。
3. 这种动态工程化解决设计的思维就是AI背后的工作
随着 ChatGPT 大火,深感未来搜索革新之重。昨晚甚至觉得,我做的复盘,其实是AI的工作,而现在国内大家都集体搬用API,其实就是直接借用了国外的工程化结果。
记得去年 leader 说过,现在搜索引擎其实我们是在用机器的方式跟机器对话,未来也许会用跟人对话的方式跟机器对话。目前看来已经走在这条新路之上。
图6的工程化 = AI背后的工作,技术设定优化好好学习模型,基于标记好的内容库训练机器,最后得到一个可动态学习自我更新的 AI 。想想 Open AI 2015年成立,2022年底引爆行业,近乎8年的投入,确实有勇有谋。侧面也可看出:但凡需要考虑工程化去解决一件事的需求,要么是长期主义的需求,要么是需要投入大量人力的需求。 筚路褴褛,以启山林。不过人多本来也就意味着时间长,因为沟通边际效益就高很多了。
活久见,也幸得活久见。
不过多嘴一下:私以为,AI和搜索引擎,或是说和任何一个信息传播的平台都具备的问题,就是信息茧房或是头部效应。哪怕是机器,也逃不开这个问题,这跟机器的数据源、处理方式、传递给人类时人类的学习能力有关。我其实在设计问答时也在思考,如何让少数或是说厚数据也能被人看到?暂未有解,只能先记着。
看,写到这里就会发现,其实还是解决方案思维上的学习。
Summary:最后一杯茶
回顾一下:
项目复盘从一开始介绍了需求背景后,开始定义问题——如何面对千变万化的长尾问题,提供更优解?
然后确定问题的特性,也就是把问题放到项目中去判断它的特性,推断解决方案可以落在工程化思路上。
之后设计工程化解决思路,从整体流程出现确定每个角色更适合赋能的地方。围绕其中产品设计的赋能之处,思考设计构想与体验关键点并体现在设计框架之中。
最后反思复盘的扩展应用可能,除开最重要的工程化解决思路外,也谈及如果要应用到社区内容搜索的可能方式,也感慨其实这个就是AI背后思路。
作者:柠梦百香果,思考与走路两个都不想放弃的设计师。公众号:柠梦百香果
本文由 @柠梦百香果 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。

若有收获,就点个赞吧
0 人点赞
