原文链接:https://jelly.jd.com/article/5e8191f810f7500156d46ccf
电商红利其核心就是流量红利期,具体指用户平均消费额随着访问流量中新用户的不断增加而增加,这是电商产生红利最主要的支撑因素。
前言:电商红利褪去的时代
什么是电商红利?电商红利其核心就是流量红利期,具体指用户平均消费额随着访问流量中新用户的不断增加而增加。这是电商产生红利最主要的支撑因素。
在流量红利时代,用低价流量来获取利润是所有企业的不二选择,这种逻辑也被几乎所有入局互联网的玩家视为真理。在享受了10多年红利之后,现在的电商人都能比较深刻的感觉到流量红利的消退,最直观的感受就是08年一个UV一毛钱,现在涨到了几块钱甚至两位数,这些成本的增加在如今竞争激烈的市场上给企业也带来了不小的压力。为此电商人都在尝试各种提升流量利用率的方式,除了深挖用户场景(如下沉市场)以外,如何通过数据分析去压缩运营成本,从而稀释上升的流量成本,是急需要做的事情。
数据分析对电商的影响
电商模式归根结底无外乎几个场景:人通过平台直接找货、人在平台通过跟人一起再找到货(团购、拼团)、人在平台通过人找到货(直播)、人在平台找服务(以旧换新、回收)、人在平台通过信息找货(小红书等内容平台)。
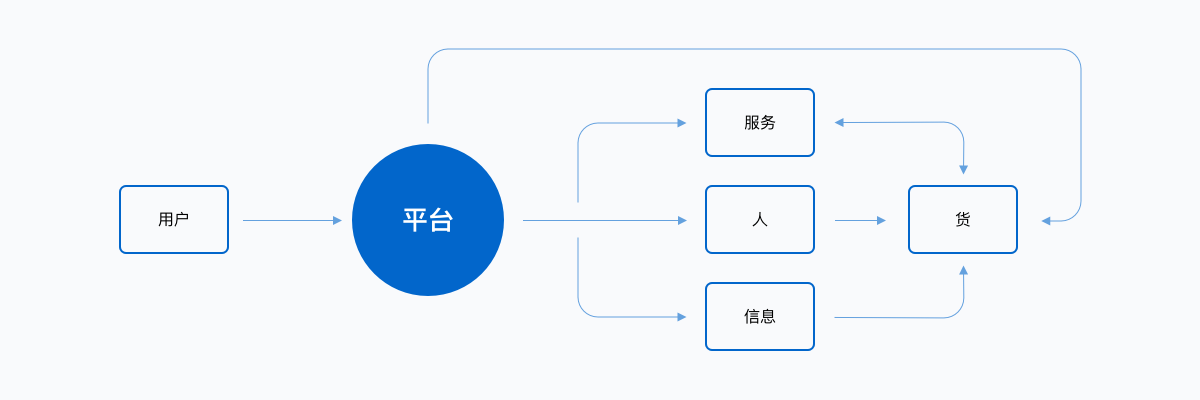
传统的电商运营都是基于管理化模式,在资源信息的分配、整合、共享上都处于碎片化阶段,特别是流量红利时代,大多数互联网公司都是流量驱动的企业,他们的整个运营重心在流量的引入上,对于整个模式环节中造成的流量损耗比(流失率和留存率)并不重视,由此造成企业运作成本较高,利润摊薄甚至负利润。例如:库存和销售的信息不对称容易造成库存积压,影响运作资金运转,造成企业压力过大。而当库存和配送成本变高之后,要想维系企业的正常运转,这些成本最终转嫁到用户身上,导致消大量用户在环节中流失,从根本上对企业产生了更大的压力。
随着社会信息化程度的加深,企业对于数据的重视程度也在逐步加深。特别是电商行业,数据的深挖和分析对于整个内部运作的效率有着明显的帮助。
一方面,数据的运用,会将传统管理化运营模式变为以信息为主体的数据化运营模式,管理与各类经济环节都会变得数据化,小到基础材料采购,大到资产运行以及订单的完成。通过数据,可以清晰的看到所有环节有哪些是互相联系的,哪些是缺失不合理的,哪些是可以复用和保留的,类似前面提到的库存积压问题,再也不会因为信息的不对称而导致企业的成本上升。
另一方面,通过数据分析,可以对用户的消费习惯及消费心理进行归纳分析与预测,从而对产品的市场调度供需程度进行一系列的建议指导,并且利用数据的整合处理技术,在产品生产供应环节中实现各种数据信息的及时共享,从而更好地吸引消费者,促进产品销售,实现产业结构转型优化与完善。
自动化处理在数据分析中的作用
电商企业在运用数据后发现,由于数据量过于庞大,人为处理数据的时间成本耗费严重,且人为过失导致数据失准的问题频繁出现。因此,经过一系列公式和逻辑的沉淀,通过机器分析,也就是自动化处理,成为企业在处理数据过程中的一个核心功能,也是最紧迫的功能。
什么是自动化?自动化(Automation)是指机器设备、系统或过程(生产、管理过程)在没有人或较少人的直接参与下,按照人的要求,经过自动检测、信息处理、分析判断、操纵控制,实现预期的目标的过程。谷歌公司企业基础设施首席技术官GengLi表示,自动化是保持数据中心一切设施融合在一起的粘合剂。
以数懒(lan.jd.com)为例。京东每年都会举行高频率多样化的营销活动,在每次活动结束后,活动的复盘对于后期的优化至关重要,因此无论是视觉、交互、产品、业务都会对这些数据进行自我分析。在整个数据分析过程中,需要针对大批量数据进行手动计算和分析校验,就会占用到大量的时间成本,而不同角色所分析的数据结论也并不统一。
为了解决这些高额运作成本,数懒小组专门针对性去做了一些调研,通过访谈去了解有哪些是有规可循却占据着大量时间成本的节点工作。例如:批量数据的计算、从数据中剥离出想看的数据结果、历史时期的多维度数据比较、同一页面不同活动时期的楼层对比分析等等。我们将调研到的这些问题一一记录,并通过大量的案例找到其中的规律和公式,通过技术打包进数懒平台,使用者可以将活动数据表上传至平台,平台就会自动生成可视化的数据对比结果和分析结论,供使用者参考。
数懒平台上线后,通过对使用者的调研反馈所得,使用数懒后可以节省50%的人效果。

自动化数据处理的弊端
虽然自动化数据处理能帮助节省不少时间成本,但也存在不同时期的一些弊端。
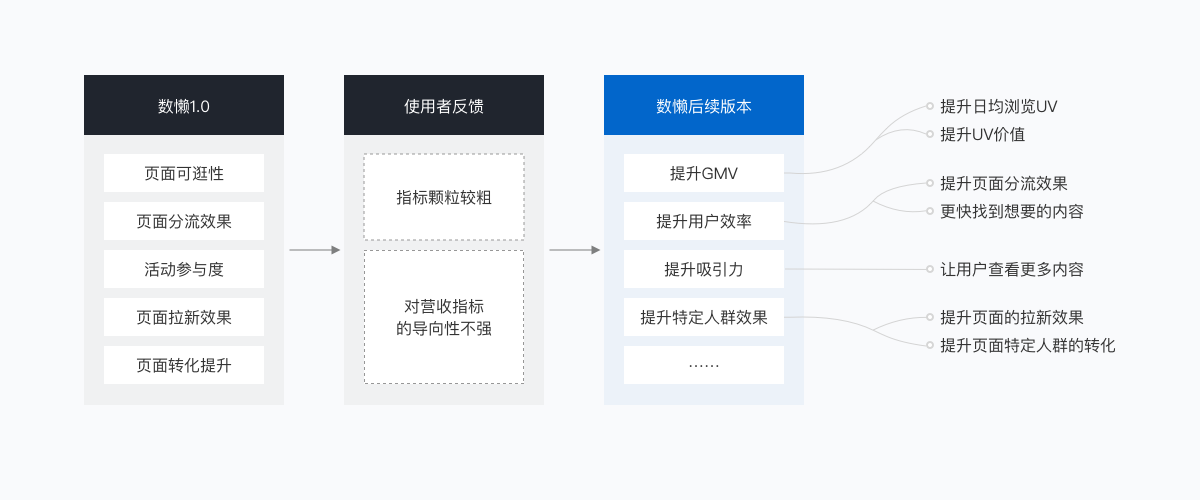
前期:核心数据指标不全
在自动化数据处理前期,由于对整个数据源的沉淀并不充分,对于业务的针对性指标预判不足,会出现无法判断的未知数据而导致无法自动化处理。例如:在数懒1.0版本中,我们的分析目标只有“页面可逛性”、“页面分流效果”、“活动参与度”、“页面拉新效果”、“页面转化提升”,数据目标颗粒比较粗,无法满足实际运营中业务上的一些数据需求,比如页面的分流效果、让用户更快找到想要的内容,提升UV价值等等。
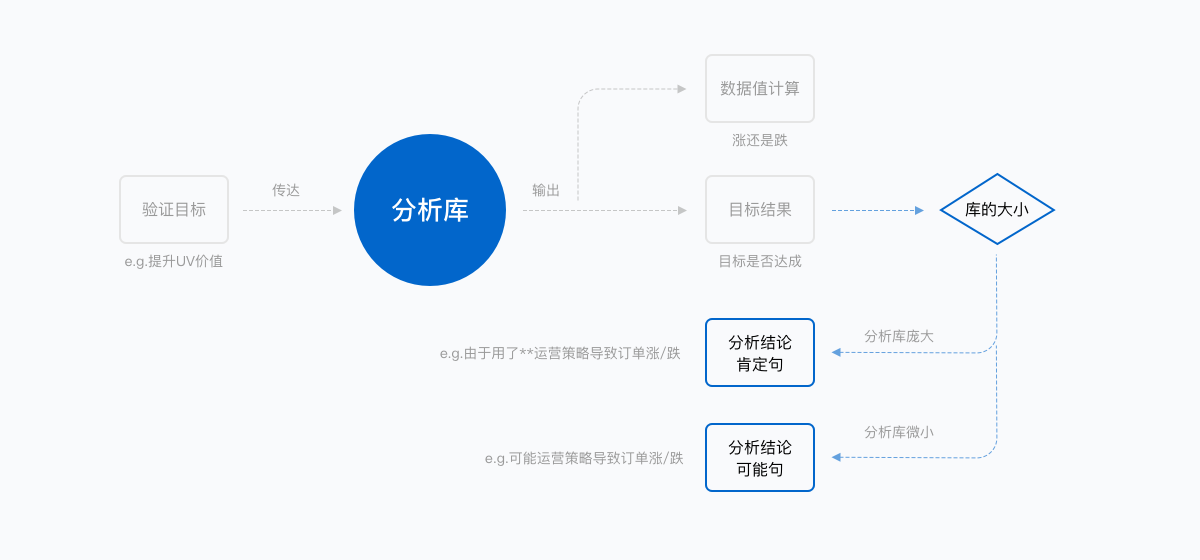
中期:后台分析库量级小
由于自动化较长一段时间都依赖库的存在,而分析库的量级前期基本靠人为的积累,所以在自动化数据处理中期会因时间问题存在局限性风险,无法在短期内满足不同场景不同数据细节的处理,从而无法得出较为精确的数据处理结果。例如:数懒2.0因库的局限性,在整体数据结论的输出上颗粒度比较大,暂时无法给出很精准的结论内容,参考价值就会比较薄弱。
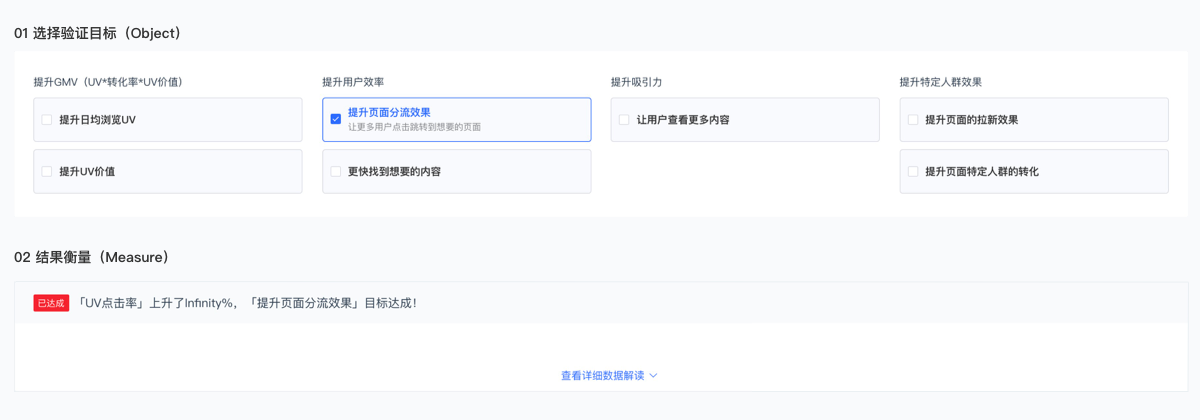
后期:涟漪效应风险
由于后期数据库越来越庞大,自动化介入的信息量也越来越多,在一个高度自动化的系统中,每一件事都是相互关联的,一个单一的缺陷可以引起连锁反应,如果没有被发现的话,将会引发广泛的服务中断,这就是涟漪效应风险。频繁的服务中断就会导致用户体验下降,间接造成用户群体的流失,从而影响企业营收。例如:数懒2.0运作中发现,有时候会出现数据结论出现空值,在问题追寻过程中会看到,因后端代码的缺陷或者是在处理新功能时存在和现有功能代码冲突的代码片断,导致展示给用户看的前台出现数据错误问题。
云提供商Joyent公司首席技术官布莱恩•卡特瑞警告说,在整个数据中心基础设施中,自动化程度越高,就会面临着一个微小错误造成灾难性后果的局面。而这种局面也是所有企业不愿意看到的。
结语
虽然自动化在信息化发展的前期存在一些未知弊端,但还是无法掩盖它在降低成本和改造企业迭代上的光芒。Salesforce公司基础设施工程副总裁TJKniveton称,自动化方法意味着需要更多的思考,如何避免数据中心实现自动化后小错酿大祸,权力越大意味着责任越大。
我们不能因为弊端的存在而退却,反而更应该去更多的思考如何去分时期的避免和解决这些弊端。例如:数懒目前存在的这些自动化弊端,我们在进行迭代的时候需要跟数据分析的同事进行更多的沟通,在实操中去发现问题,需要将分析师日常的分析步骤,包括业务方对活动数据的一些人工分析行为进行记录和细分,去扩大库的量级。另外在迭代版本上线前的细致走查,需要更多的严谨和规范,以达到上线后不会对用户的使用造成大的影响。

若有收获,就点个赞吧
0 人点赞
