- 1、[LG] Convolutional Neural Nets: Foundations, Computations, and New Applications
- 2、[CV] Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels
- 3、[CL] Robustness Gym: Unifying the NLP Evaluation Landscape
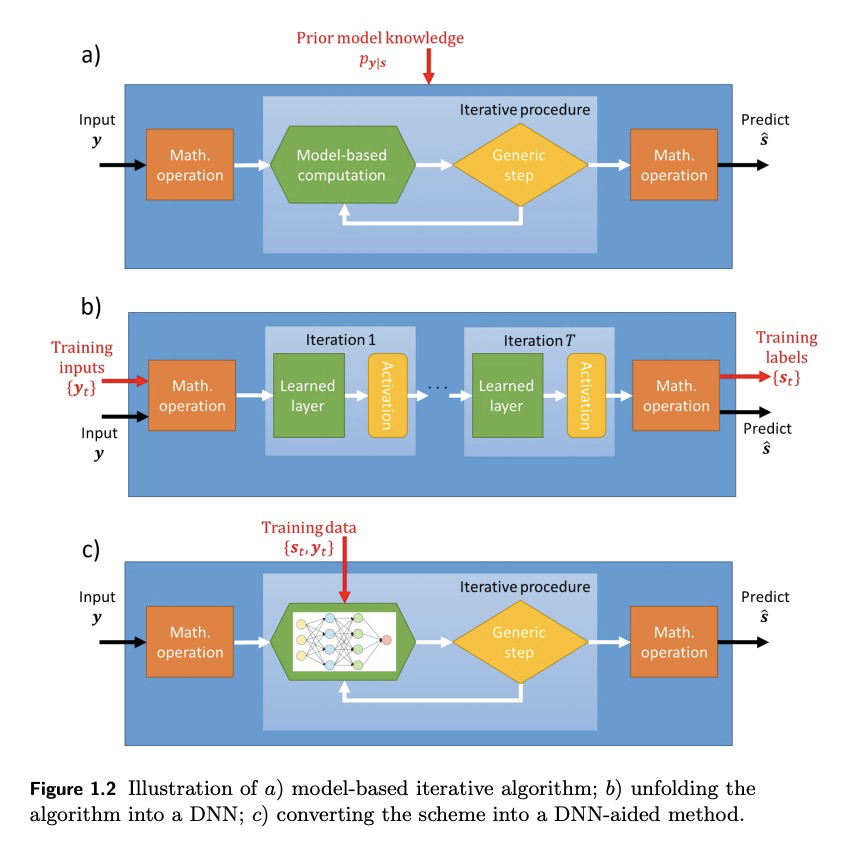
- 4、[LG] Model-Based Machine Learning for Communications
- 5、[CV] Big Self-Supervised Models Advance Medical Image Classification
- [LG] Fast convolutional neural networks on FPGAs with hls4ml
- [CV] This Face Does Not Exist … But It Might Be Yours! Identity Leakage in Generative Models
- [CV] Memory-Augmented Reinforcement Learning for Image-Goal Navigation
- [CV] Estimating and Evaluating Regression Predictive Uncertainty in Deep Object Detectors
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Convolutional Neural Nets: Foundations, Computations, and New Applications
S Jiang, V M. Zavala
[University of Wisconsin-Madison]
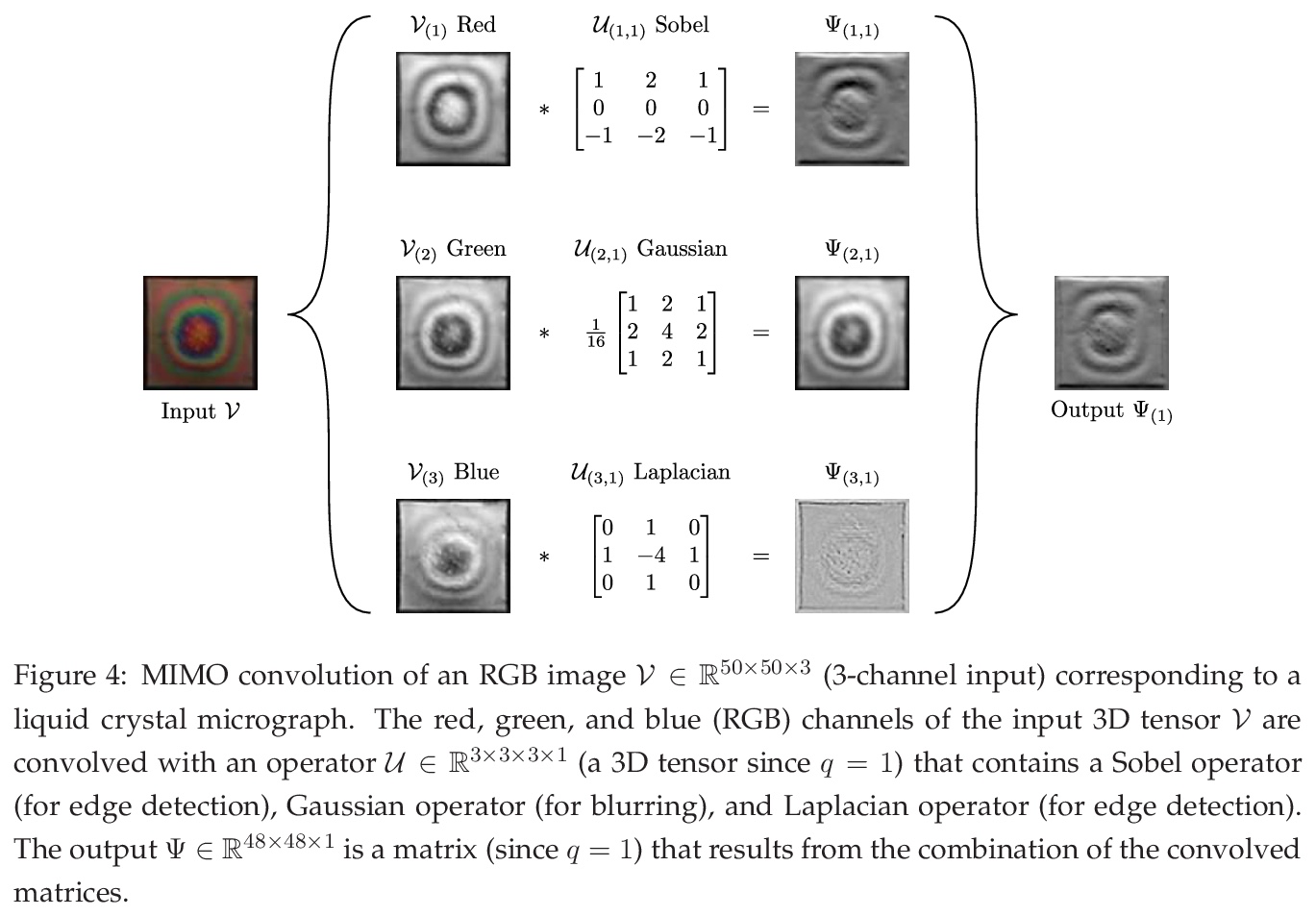
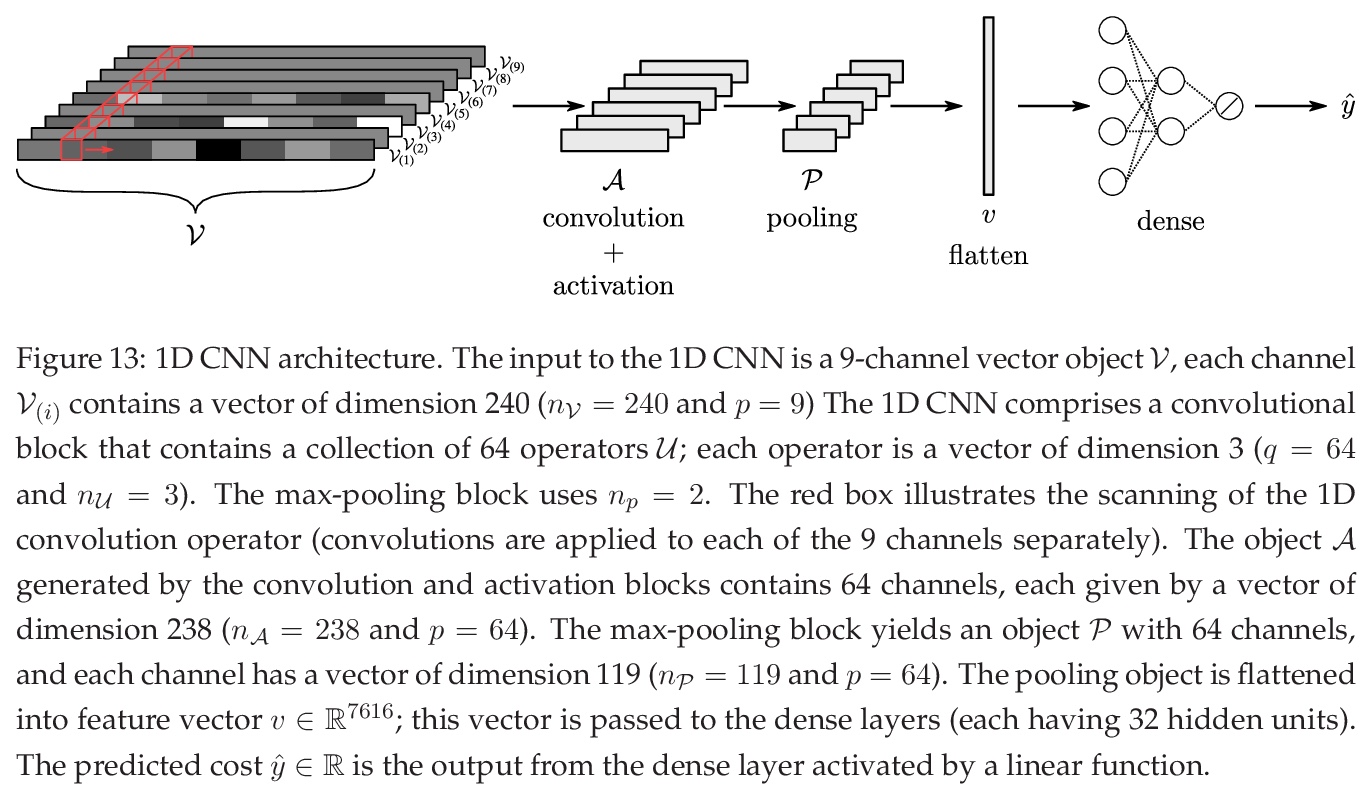
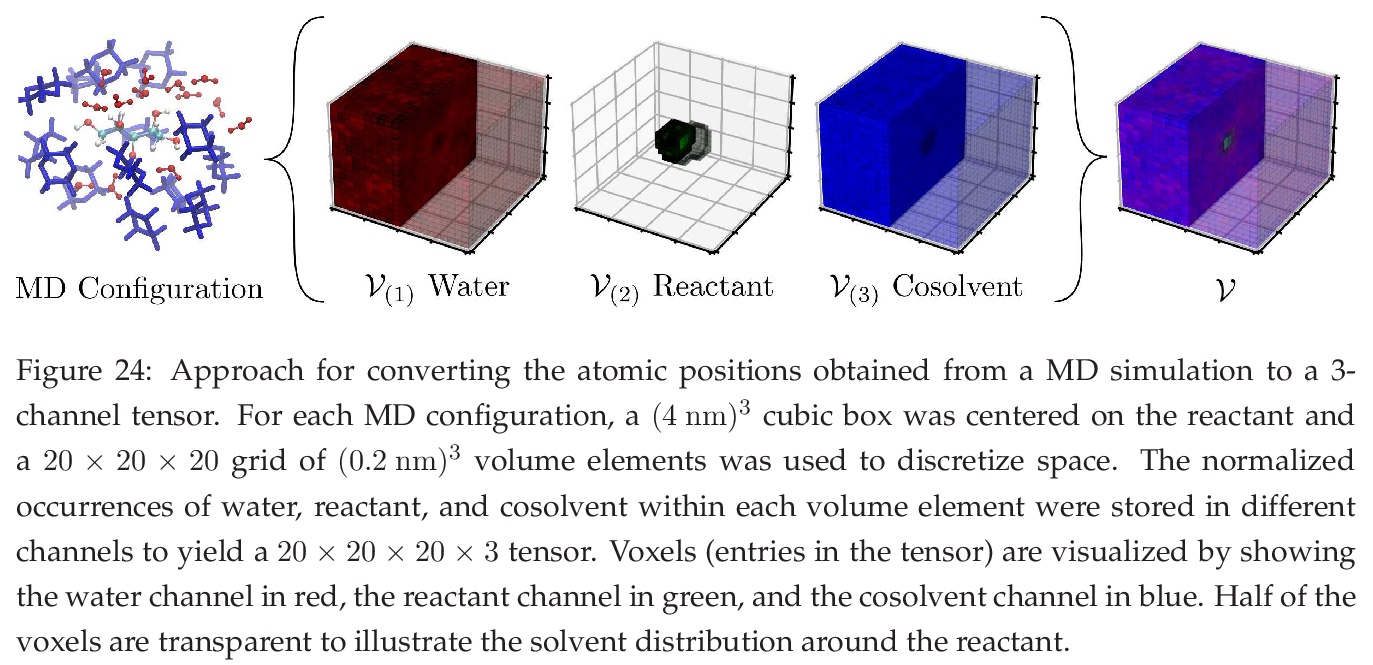
卷积神经网络:基础、计算与新应用。在统一的数学框架下对CNN背后的关键概念(卷积、多通道信号、算子、前向/后向传播和显著性映射)进行了回顾,目标是建立与其他数学领域概念的联系,并强调在这些强大模型中的关键计算。CNN通过用不同类型的算子执行卷积运算来突出网格数据的特征(如图案、梯度、几何特征),并通过优化技术进行学习。展示了如何将CNN应用于新型应用,如优化控制、流式细胞仪、多变量过程监测和分子模拟等。
We review mathematical foundations of convolutional neural nets (CNNs) with the goals of: i) highlighting connections with techniques from statistics, signal processing, linear algebra, differential equations, and optimization, ii) demystifying underlying computations, and iii) identifying new types of applications. CNNs are powerful machine learning models that highlight features from grid data to make predictions (regression and classification). The grid data object can be represented as vectors (in 1D), matrices (in 2D), or tensors (in 3D or higher dimensions) and can incorporate multiple channels (thus providing high flexibility in the input data representation). For example, an image can be represented as a 2D grid data object that contains red, green, and blue (RBG) channels (each channel is a 2D matrix). Similarly, a video can be represented as a 3D grid data object (two spatial dimensions plus time) with RGB channels (each channel is a 3D tensor). CNNs highlight features from the grid data by performing convolution operations with different types of operators. The operators highlight different types of features (e.g., patterns, gradients, geometrical features) and are learned by using optimization techniques. In other words, CNNs seek to identify optimal operators that best map the input data to the output data. A common misconception is that CNNs are only capable of processing image or video data but their application scope is much wider; specifically, datasets encountered in diverse applications can be expressed as grid data. Here, we show how to apply CNNs to new types of applications such as optimal control, flow cytometry, multivariate process monitoring, and molecular simulations.
https://weibo.com/1402400261/JDeitmIy0
2、[CV] Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels
S Yun, S J Oh, B Heo, D Han, J Choe, S Chun
[NAVER AI LAB]
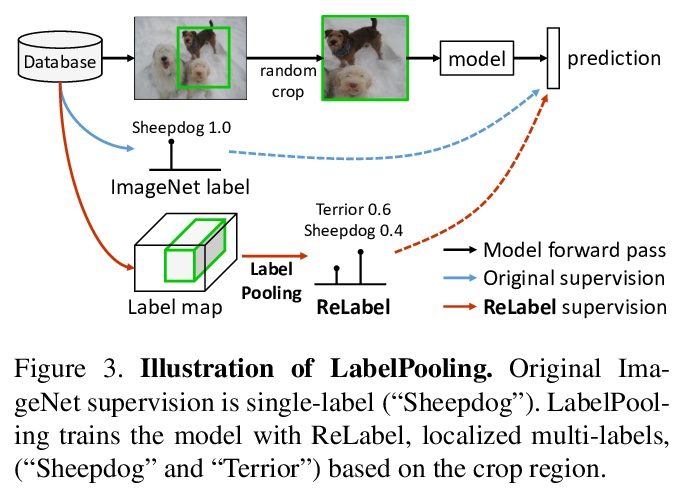
重新标记ImageNet:单标签到多标签,全局标签到局部标签。提出了一个重标注策略ReLabel,用于ImageNet的128万张训练图像。ReLabel将每张图像分配一次的单类标签,变成基于机器标注器为图像各区域分配的多类标签,机器标注器是一个在大量额外的视觉源数据上训练出来的强分类器。提出一种利用局部多类标签(LabelPooling)训练分类器的新方案。通过实验,验证了在重新标记的样本上进行训练,模型性能会得到显著的提升。
ImageNet has been arguably the most popular image classification benchmark, but it is also the one with a significant level of label noise. Recent studies have shown that many samples contain multiple classes, despite being assumed to be a single-label benchmark. They have thus proposed to turn ImageNet evaluation into a multi-label task, with exhaustive multi-label annotations per image. However, they have not fixed the training set, presumably because of a formidable annotation cost. We argue that the mismatch between single-label annotations and effectively multi-label images is equally, if not more, problematic in the training setup, where random crops are applied. With the single-label annotations, a random crop of an image may contain an entirely different object from the ground truth, introducing noisy or even incorrect supervision during training. We thus re-label the ImageNet training set with multi-labels. We address the annotation cost barrier by letting a strong image classifier, trained on an extra source of data, generate the multi-labels. We utilize the pixel-wise multi-label predictions before the final pooling layer, in order to exploit the additional location-specific supervision signals. Training on the re-labeled samples results in improved model performances across the board. ResNet-50 attains the top-1 classification accuracy of 78.9% on ImageNet with our localized multi-labels, which can be further boosted to 80.2% with the CutMix regularization. We show that the models trained with localized multi-labels also outperforms the baselines on transfer learning to object detection and instance segmentation tasks, and various robustness benchmarks. The re-labeled ImageNet training set, pre-trained weights, and the source code are available at {> this https URL}.
https://weibo.com/1402400261/JDeplc9fc

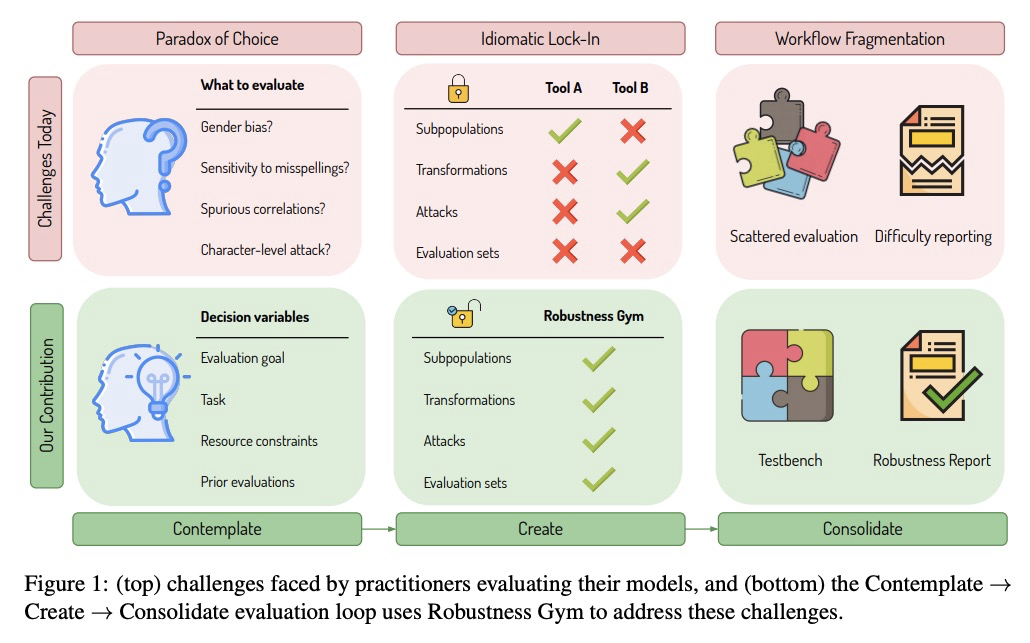
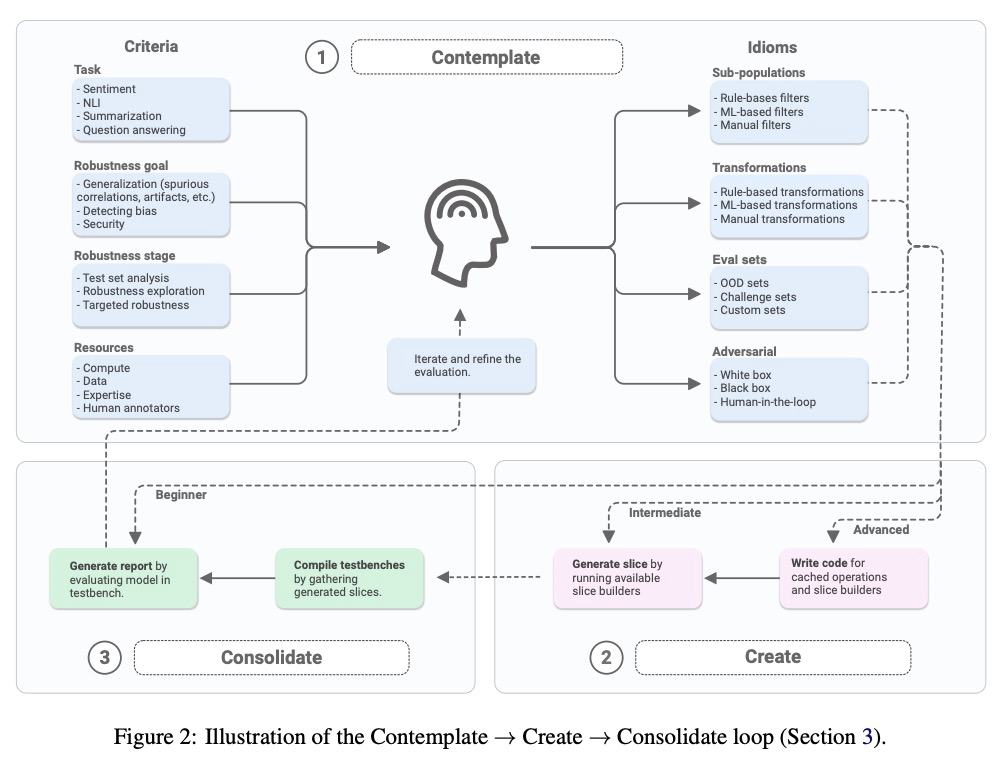
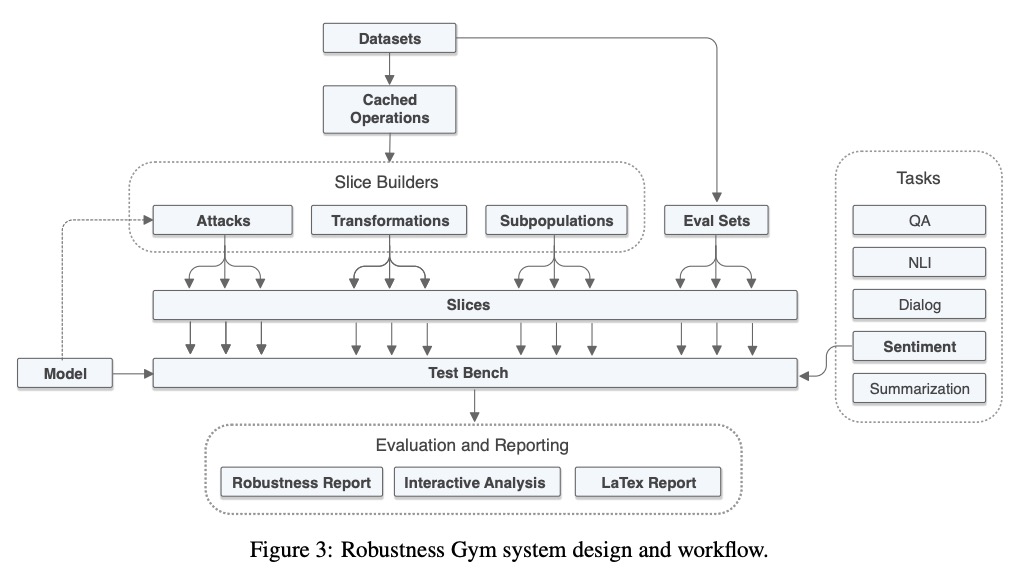
3、[CL] Robustness Gym: Unifying the NLP Evaluation Landscape
K Goel, N Rajani, J Vig, S Tan, J Wu, S Zheng, C Xiong, M Bansal, C Ré
[Stanford University & Salesforce Research & UNC-Chapel Hill]
Robustness Gym:NLP统一评价工具包。以Robustness Gym(RG)的形式提出了一个NLP鲁棒性评价的解决方案,一个简单且可扩展的评价工具包,统一了四种标准的评价范式:子群、转换、评价集和对抗性攻击。RG提供了一个通用的评价平台,使从业者只需几下点击就能比较所有4种评价范式的结果,并用内置的抽象集轻松开发和分享新的评价方法,轻松协同创建和分享评价方法和评价结果。
Despite impressive performance on standard benchmarks, deep neural networks are often brittle when deployed in real-world systems. Consequently, recent research has focused on testing the robustness of such models, resulting in a diverse set of evaluation methodologies ranging from adversarial attacks to rule-based data transformations. In this work, we identify challenges with evaluating NLP systems and propose a solution in the form of Robustness Gym (RG), a simple and extensible evaluation toolkit that unifies 4 standard evaluation paradigms: subpopulations, transformations, evaluation sets, and adversarial attacks. By providing a common platform for evaluation, Robustness Gym enables practitioners to compare results from all 4 evaluation paradigms with just a few clicks, and to easily develop and share novel evaluation methods using a built-in set of abstractions. To validate Robustness Gym’s utility to practitioners, we conducted a real-world case study with a sentiment-modeling team, revealing performance degradations of 18%+. To verify that Robustness Gym can aid novel research analyses, we perform the first study of state-of-the-art commercial and academic named entity linking (NEL) systems, as well as a fine-grained analysis of state-of-the-art summarization models. For NEL, commercial systems struggle to link rare entities and lag their academic counterparts by 10%+, while state-of-the-art summarization models struggle on examples that require abstraction and distillation, degrading by 9%+. Robustness Gym can be found at > this https URL
https://weibo.com/1402400261/JDeum3Fum
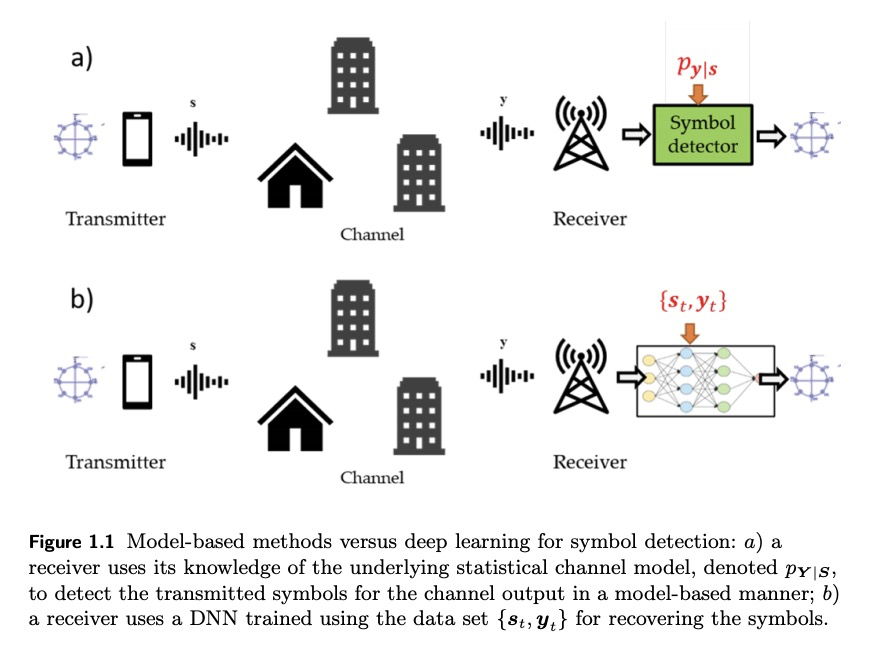
4、[LG] Model-Based Machine Learning for Communications
N Shlezinger, N Farsad, Y C. Eldar, A J. Goldsmith
面向通信的基于模型的机器学习。从高层次回顾了现有的基于模型的算法和机器学习相结合的策略,并将其与传统的深度学习方法进行比较,后者利用已建立的深度神经网络(DNN)架构以端到端方式进行训练。将重点放在符号检测上,这是通信接收机的基本任务之一。展示了传统深度架构、深度展开和DNN辅助混合算法等不同策略的具体应用,后两种方法构成了纯粹基于模型和纯粹基于DNN的接收机之间的中间地带。强调了每种策略的优缺点,并提出了指导方针,以促进未来面向通信基于模型的深度学习系统的设计。
We present an introduction to model-based machine learning for communication systems. We begin by reviewing existing strategies for combining model-based algorithms and machine learning from a high level perspective, and compare them to the conventional deep learning approach which utilizes established deep neural network (DNN) architectures trained in an end-to-end manner. Then, we focus on symbol detection, which is one of the fundamental tasks of communication receivers. We show how the different strategies of conventional deep architectures, deep unfolding, and DNN-aided hybrid algorithms, can be applied to this problem. The last two approaches constitute a middle ground between purely model-based and solely DNN-based receivers. By focusing on this specific task, we highlight the advantages and drawbacks of each strategy, and present guidelines to facilitate the design of future model-based deep learning systems for communications.
https://weibo.com/1402400261/JDeyCcGCB
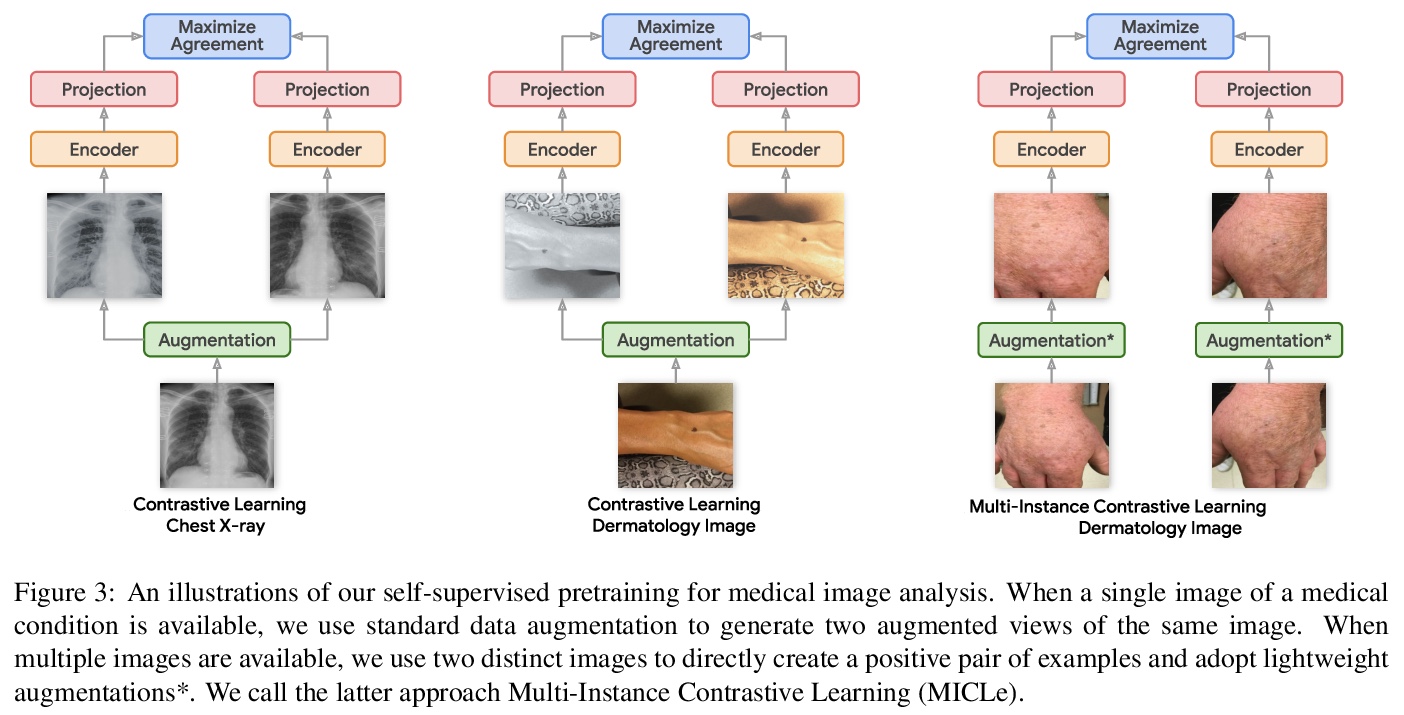
5、[CV] Big Self-Supervised Models Advance Medical Image Classification
S Azizi, B Mustafa, F Ryan, Z Beaver, J Freyberg, J Deaton, A Loh, A Karthikesalingam, S Kornblith, T Chen, V Natarajan, M Norouzi
[Google Research and Health]
面向医学图像分类的大型自监督模型。研究了一种基于在未标记自然图像和医学图像上进行自监督预训练的替代策略,发现自监督预训练的性能显著优于有监督预训练。提出利用每个医疗病例的多幅图像来改善自监督学习数据增强,进一步提升图像分类器的性能。在皮肤和胸部X光片分类上分别实现了6.7%的top-1准确率和1.1%的平均AUC的提升,优于在ImageNet上预训练的强监督基线。由于不需要类标签标注,自监督预训练比有监督预训练的扩展性更强。
Self-supervised pretraining followed by supervised fine-tuning has seen success in image recognition, especially when labeled examples are scarce, but has received limited attention in medical image analysis. This paper studies the effectiveness of self-supervised learning as a pretraining strategy for medical image classification. We conduct experiments on two distinct tasks: dermatology skin condition classification from digital camera images and multi-label chest X-ray classification, and demonstrate that self-supervised learning on ImageNet, followed by additional self-supervised learning on unlabeled domain-specific medical images significantly improves the accuracy of medical image classifiers. We introduce a novel Multi-Instance Contrastive Learning (MICLe) method that uses multiple images of the underlying pathology per patient case, when available, to construct more informative positive pairs for self-supervised learning. Combining our contributions, we achieve an improvement of 6.7% in top-1 accuracy and an improvement of 1.1% in mean AUC on dermatology and chest X-ray classification respectively, outperforming strong supervised baselines pretrained on ImageNet. In addition, we show that big self-supervised models are robust to distribution shift and can learn efficiently with a small number of labeled medical images.
https://weibo.com/1402400261/JDeDlkjND
另外几篇值得关注的论文:
[LG] Fast convolutional neural networks on FPGAs with hls4ml
FPGA上基于hls4ml的快速卷积神经网络
T Aarrestad, V Loncar, M Pierini, S Summers, J Ngadiuba, C Petersson, H Linander, Y Iiyama, G D Guglielmo, J Duarte, P Harris, D Rankin, S Jindariani, K Pedro, N Tran, M Liu, E Kreinar, Z Wu, D Hoang
[European Organization for Nuclear Research (CERN) & California Institute of Technology & Zenseact…]
https://weibo.com/1402400261/JDeHqgOLJ
[CV] This Face Does Not Exist … But It Might Be Yours! Identity Leakage in Generative Models
GAN生成人脸的身份泄漏问题研究
P Tinsley, A Czajka, P Flynn
[University of Notre Dame]
https://weibo.com/1402400261/JDeJpw8gu

[CV] Memory-Augmented Reinforcement Learning for Image-Goal Navigation
面向图像目标导航的记忆增强强化学习
L Mezghani, S Sukhbaatar, T Lavril, O Maksymets, D Batra, P Bojanowski, K Alahari
[Facebook AI Research & Inria]
https://weibo.com/1402400261/JDeLnu0IR


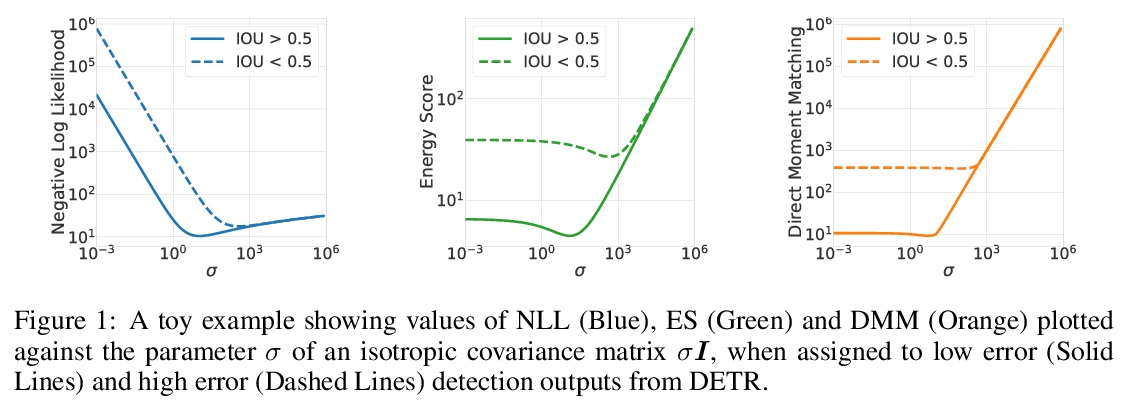
[CV] Estimating and Evaluating Regression Predictive Uncertainty in Deep Object Detectors
深度目标检测器回归预测不确定度的估计和评价
A Harakeh, S L. Waslander
[University Of Toronto]
https://weibo.com/1402400261/JDeMHEX26

若有收获,就点个赞吧
0 人点赞
