- 1、[CL] SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
- 2、[CL] What Will it Take to Fix Benchmarking in Natural Language Understanding?
- 3、[LG] Efficient Transformers in Reinforcement Learning using Actor-Learner Distillation
- 4、[CL] CodeTrans: Towards Cracking the Language of Silicone’s Code Through Self-Supervised Deep Learning and High Performance Computing
- 5、[LG] Sparse Algorithms for Markovian Gaussian Processes
- [CV] LIFE: Lighting Invariant Flow Estimation
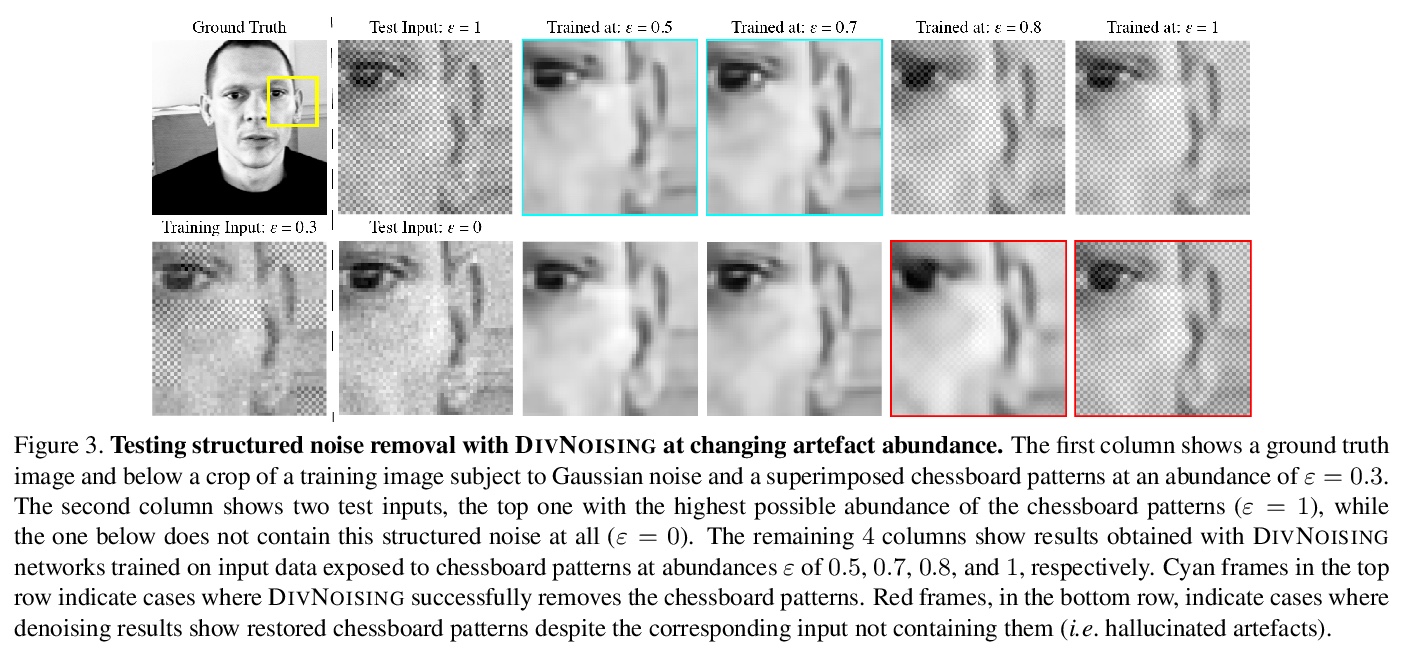
- [CV] Removing Pixel Noises and Spatial Artifacts with Generative Diversity Denoising Methods
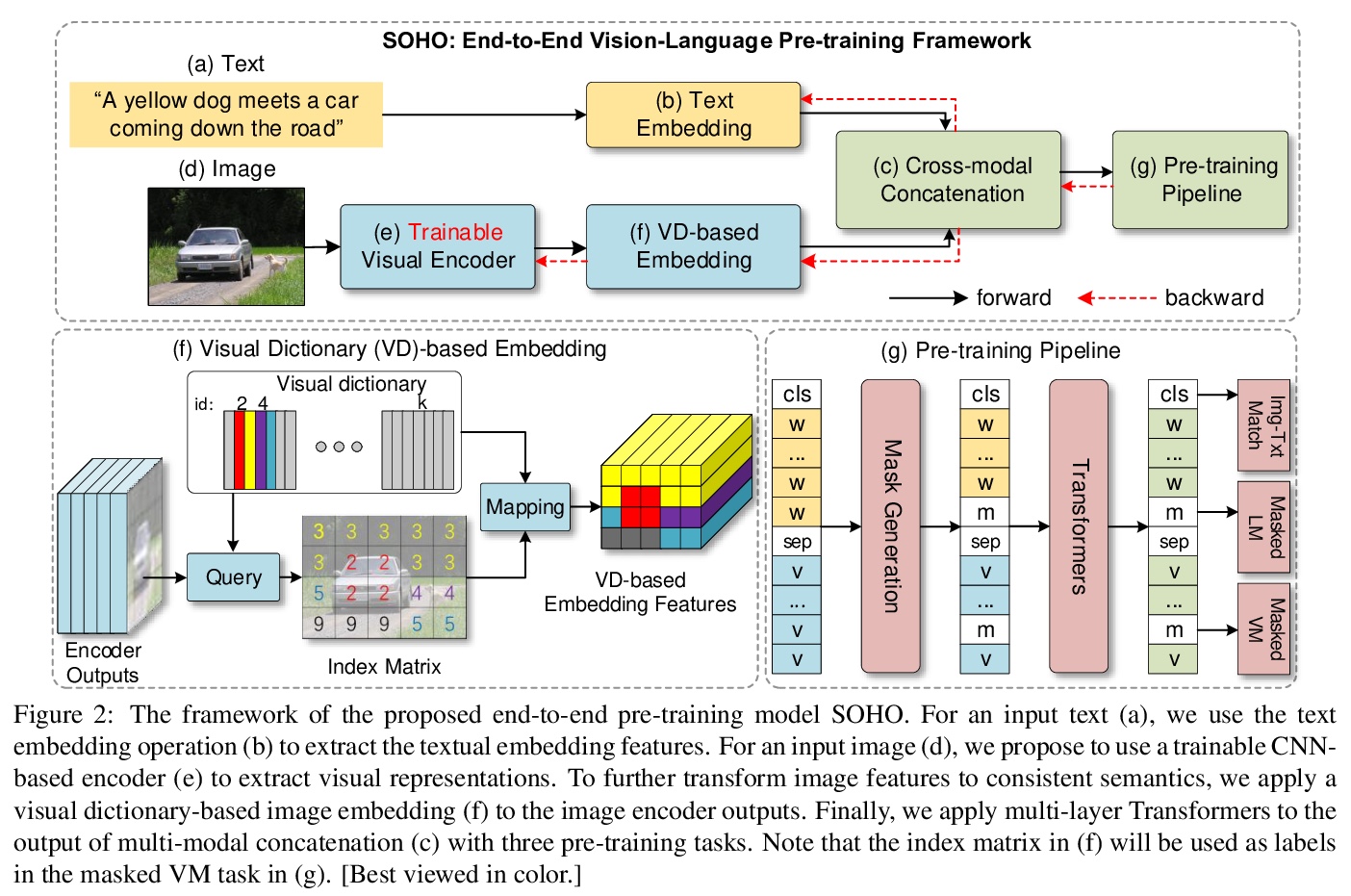
- [CV] Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
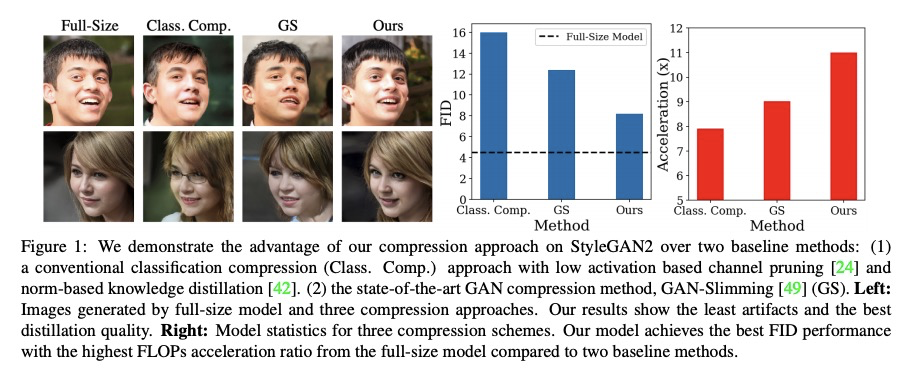
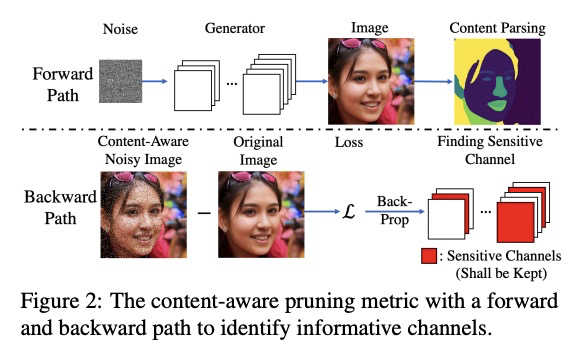
- [CV] Content-Aware GAN Compression
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
W Chan, D Park, C Lee, Y Zhang, Q Le, M Norouzi
[Google Research]
SpeechStew:简单混合所有可用语音识别数据来训练一个大型神经网络。提出SpeechStew,一种在各种公开语音识别数据集组合上训练的语音识别模型,只简单地将所有数据集混合,不对数据集进行任何特殊的重新加权或重新平衡。SpeechStew在各种任务中实现了SoTA或接近SoTA的结果,无需使用外部语言模型。证明了SpeechStew可以学习强大的迁移学习表征。当遇到新数据集时,可简单地在未见过的数据上微调一个通用的预训练模型,以产生强大的经验结果。
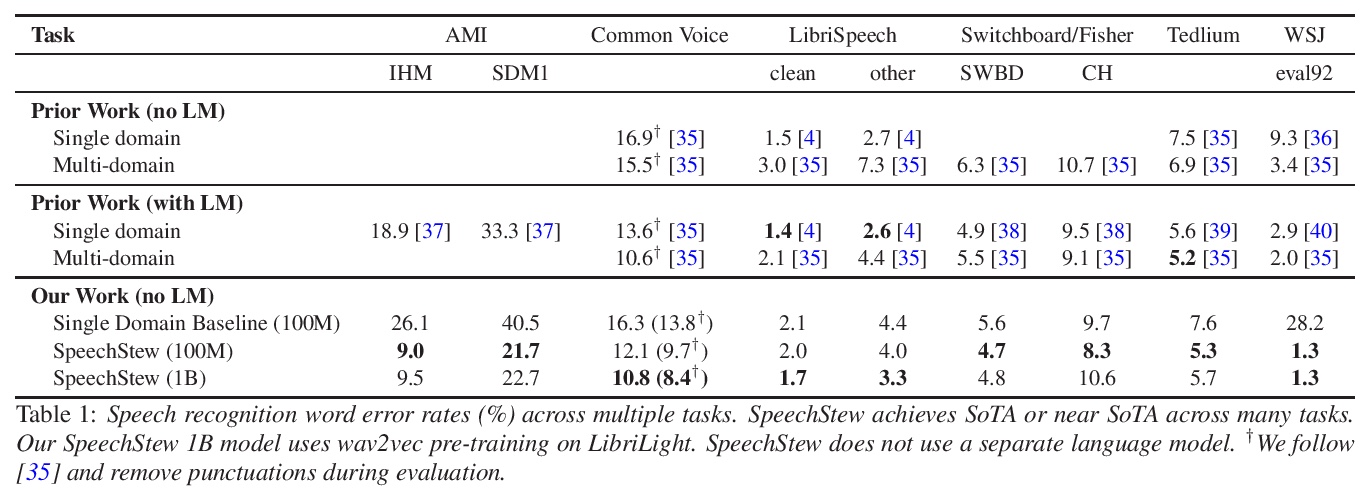
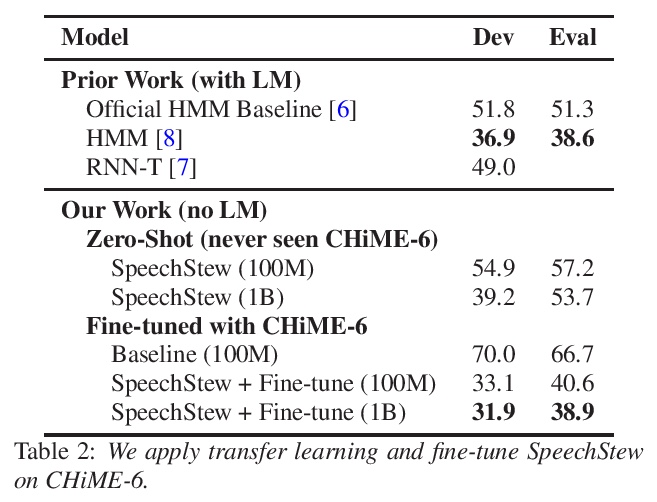
We present SpeechStew, a speech recognition model that is trained on a combination of various publicly available speech recognition datasets: AMI, Broadcast News, Common Voice, LibriSpeech, Switchboard/Fisher, Tedlium, and Wall Street Journal. SpeechStew simply mixes all of these datasets together, without any special re-weighting or re-balancing of the datasets. SpeechStew achieves SoTA or near SoTA results across a variety of tasks, without the use of an external language model. Our results include 9.0\% WER on AMI-IHM, 4.7\% WER on Switchboard, 8.3\% WER on CallHome, and 1.3\% on WSJ, which significantly outperforms prior work with strong external language models. We also demonstrate that SpeechStew learns powerful transfer learning representations. We fine-tune SpeechStew on a noisy low resource speech dataset, CHiME-6. We achieve 38.9\% WER without a language model, which compares to 38.6\% WER to a strong HMM baseline with a language model.
https://weibo.com/1402400261/Kav8J5fqD
2、[CL] What Will it Take to Fix Benchmarking in Natural Language Understanding?
S R. Bowman, G E. Dahl
[New York University & Google Research]
如何才能解决自然语言理解的基准问题?提出了自然语言理解(NLU)基准应该满足的四个主要标准,基准应满足对语言能力提供忠实、有用和负责任的度量。背离IID评估(正如通过对抗性过滤收集的基准数据集所看到的那样)无助于解决这些标准,但概括地列出了如何直接解决每个标准。恢复健康的评估生态需要在基准数据集的设计、数据集标记的可靠性、数据集大小以及处理社会偏见的方式上取得重大进展。
Evaluation for many natural language understanding (NLU) tasks is broken: Unreliable and biased systems score so highly on standard benchmarks that there is little room for researchers who develop better systems to demonstrate their improvements. The recent trend to abandon IID benchmarks in favor of adversarially-constructed, out-of-distribution test sets ensures that current models will perform poorly, but ultimately only obscures the abilities that we want our benchmarks to measure. In this position paper, we lay out four criteria that we argue NLU benchmarks should meet. We argue most current benchmarks fail at these criteria, and that adversarial data collection does not meaningfully address the causes of these failures. Instead, restoring a healthy evaluation ecosystem will require significant progress in the design of benchmark datasets, the reliability with which they are annotated, their size, and the ways they handle social bias.
https://weibo.com/1402400261/Kavce246C

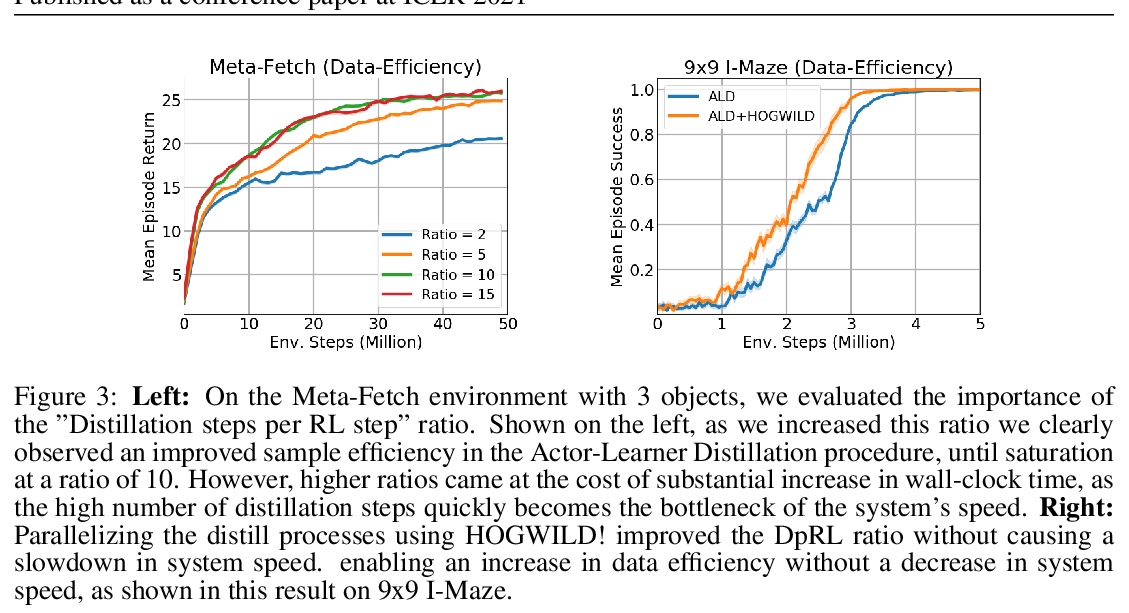
3、[LG] Efficient Transformers in Reinforcement Learning using Actor-Learner Distillation
E Parisotto, R Salakhutdinov
[CMU]
基于Actor-Learner蒸馏的强化学习中的高效Transformer。提出一种针对Actor-延迟约束设置的解决方案,”Actor-Learner蒸馏(ALD)”,利用策略蒸馏的持续形式,将更大的”Learner模型”在线压缩,来实现可驯服的”Actor模型”。聚焦用于部分可观测环境的分布式强化学习环境,目标是利用Transformer模型优越的样本效率,同时在演算过程中仍然与LSTM模型的计算效率持平。在具有挑战性的内存环境中,Transformer比LSTM具有明显优势,证明了我们的Actor-Learner蒸馏提供了大幅提高的样本效率,同时仍然具有与较小的LSTM相当的实验运行时间。
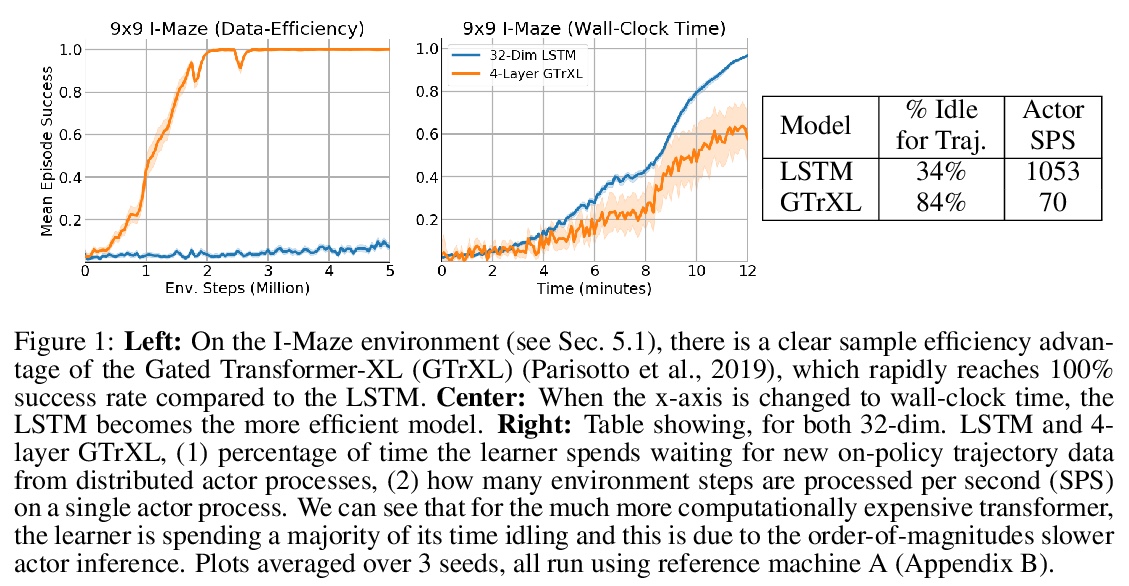
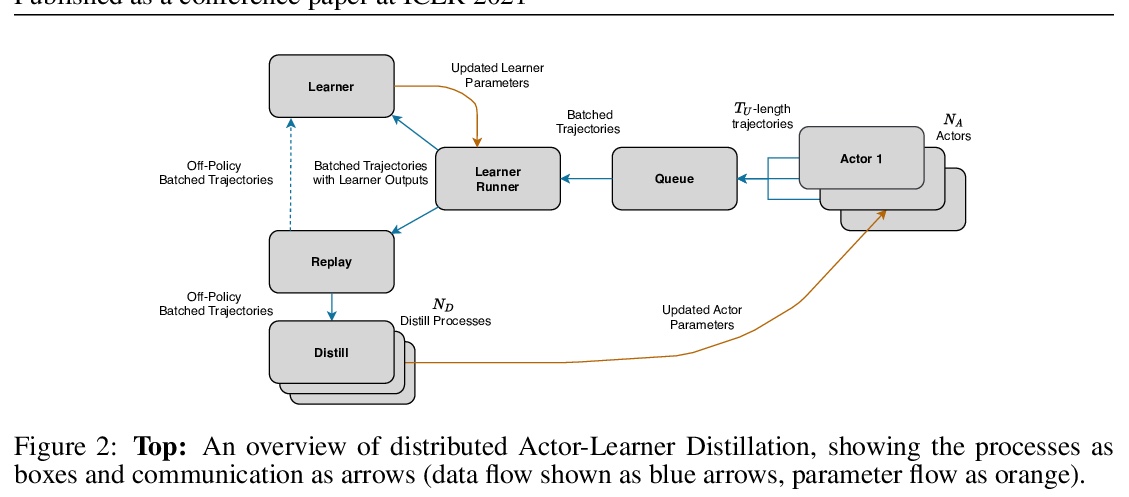
Many real-world applications such as robotics provide hard constraints on power and compute that limit the viable model complexity of Reinforcement Learning (RL) agents. Similarly, in many distributed RL settings, acting is done on un-accelerated hardware such as CPUs, which likewise restricts model size to prevent intractable experiment run times. These “actor-latency” constrained settings present a major obstruction to the scaling up of model complexity that has recently been extremely successful in supervised learning. To be able to utilize large model capacity while still operating within the limits imposed by the system during acting, we develop an “Actor-Learner Distillation” (ALD) procedure that leverages a continual form of distillation that transfers learning progress from a large capacity learner model to a small capacity actor model. As a case study, we develop this procedure in the context of partially-observable environments, where transformer models have had large improvements over LSTMs recently, at the cost of significantly higher computational complexity. With transformer models as the learner and LSTMs as the actor, we demonstrate in several challenging memory environments that using Actor-Learner Distillation recovers the clear sample-efficiency gains of the transformer learner model while maintaining the fast inference and reduced total training time of the LSTM actor model.
https://weibo.com/1402400261/Kavfx1VpJ
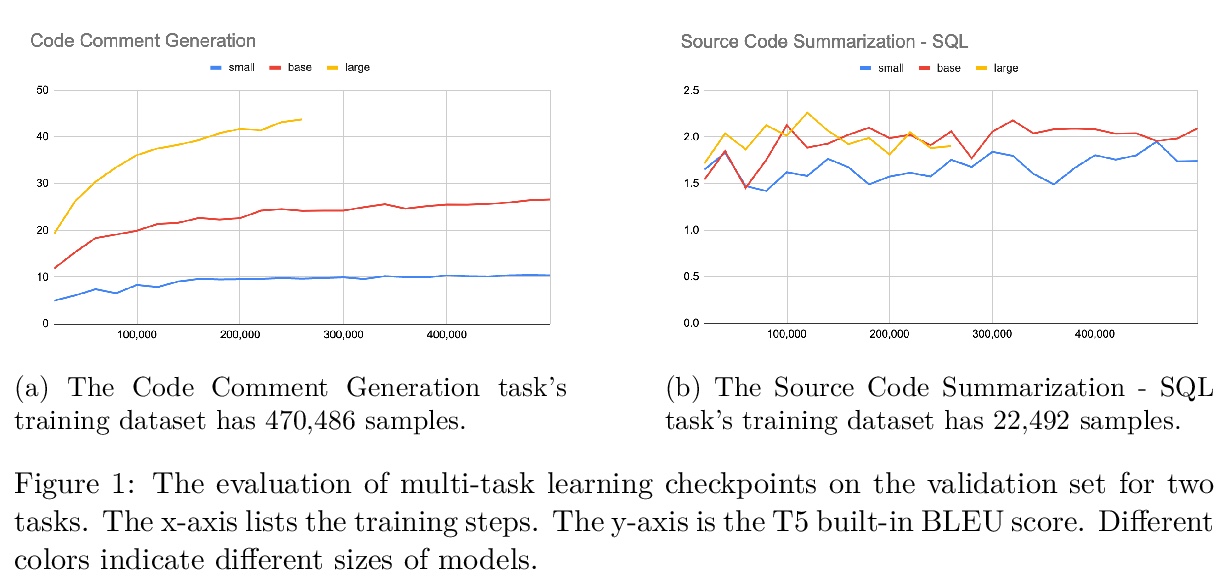
4、[CL] CodeTrans: Towards Cracking the Language of Silicone’s Code Through Self-Supervised Deep Learning and High Performance Computing
A Elnaggar, W Ding, L Jones, T Gibbs, T Feher, C Angerer, S Severini, F Matthes, B Rost
[TUM (Technical University of Munich) & Google AI & Ludwig-Maximilians-Universit¨at M¨unchen]
CodeTrans: 面向软件工程领域任务的编-解码器transformer模型。提出了基于编-解码器transformer架构、面向软件工程任务的CodeTrans模型。将CodeTrans应用于6种不同任务,包括代码文档生成、源代码摘要、代码注释生成、Git提交消息生成、API序列推荐和程序合成。在一个NVIDIA GPU和Google Cloud TPU上使用单任务学习、迁移学习和多任务学习来训练CodeTrans。用有监督任务和自监督任务来构建软件工程领域的语言模型,在所有任务上达到了最先进性能。当在不同数据集上对不同大小的模型用不同的训练策略时,模型的性能有一定差异,模型大小对模型性能起着至关重要的作用。对于单任务学习来说,数据集越大,大模型需要的训练步骤越少。在应用多任务学习或迁移学习策略时,在相同的batch大小和评估步骤下,更大的模型达到的损失更低。虽然对于更大的模型来说,前期的训练可能会花费更多的时间,但是在每个任务的微调过程中,它们需要的迭代步骤比小模型少。对于大多数任务来说,模型越大,即使微调时间越少,模型也能达到更好的评价分数。
Currently, a growing number of mature natural language processing applications make people’s life more convenient. Such applications are built by source code - the language in software engineering. However, the applications for understanding source code language to ease the software engineering process are under-researched. Simultaneously, the transformer model, especially its combination with transfer learning, has been proven to be a powerful technique for natural language processing tasks. These breakthroughs point out a promising direction for process source code and crack software engineering tasks. This paper describes CodeTrans - an encoder-decoder transformer model for tasks in the software engineering domain, that explores the effectiveness of encoder-decoder transformer models for six software engineering tasks, including thirteen sub-tasks. Moreover, we have investigated the effect of different training strategies, including single-task learning, transfer learning, multi-task learning, and multi-task learning with fine-tuning. CodeTrans outperforms the state-of-the-art models on all the tasks. To expedite future works in the software engineering domain, we have published our pre-trained models of CodeTrans.
https://weibo.com/1402400261/KavkOq3Hx
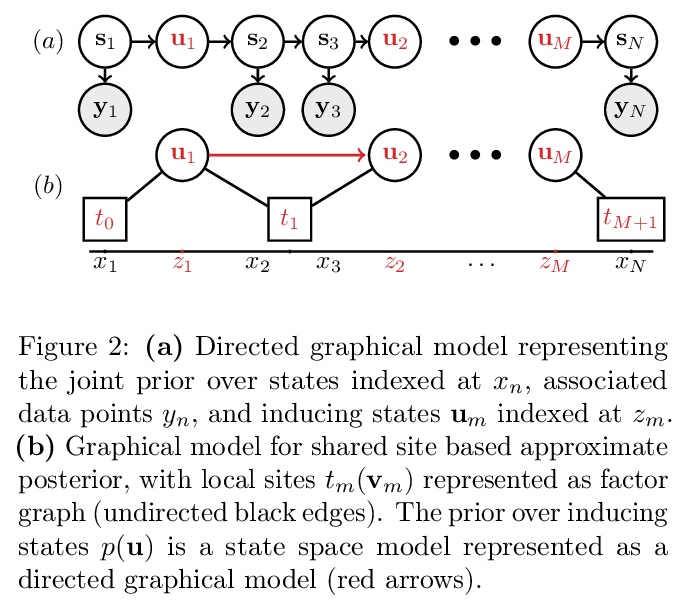
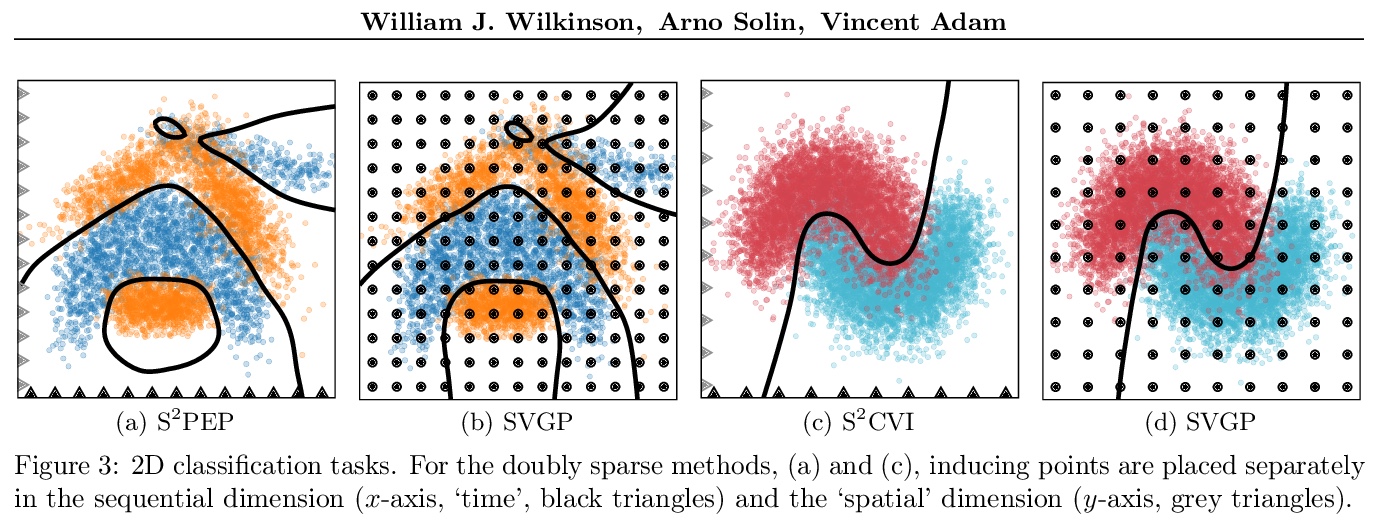
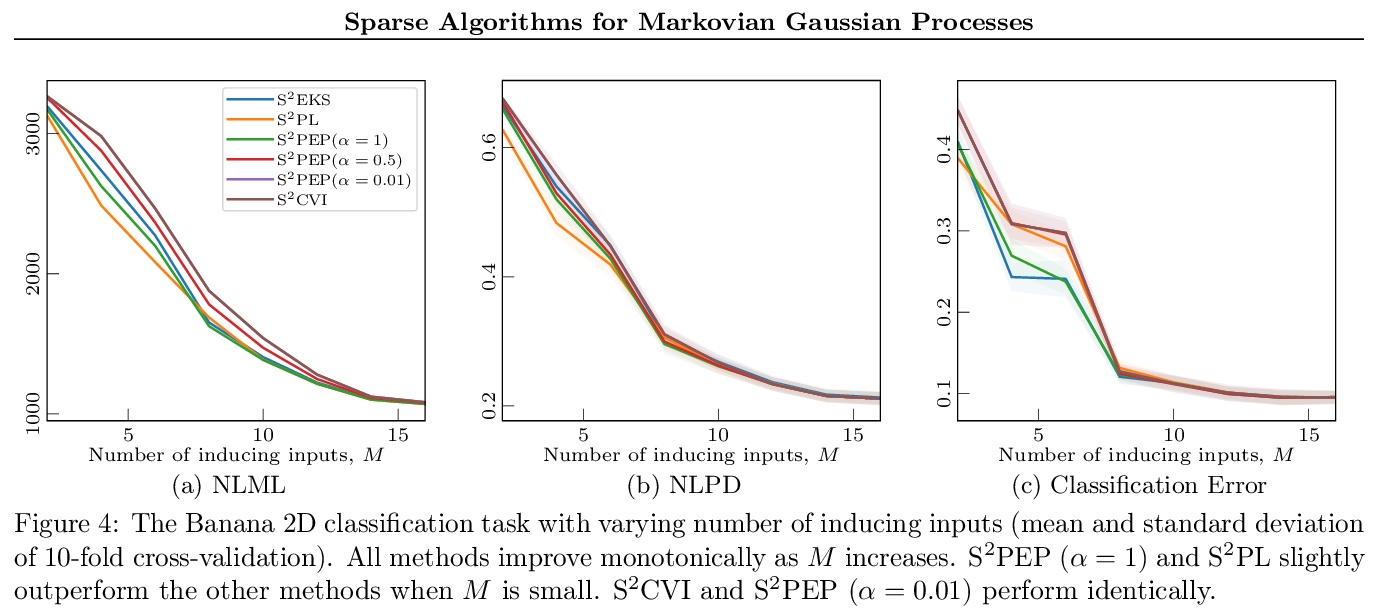
5、[LG] Sparse Algorithms for Markovian Gaussian Processes
W J. Wilkinson, A Solin, V Adam
[Aalto University & Secondmind.ai]
马尔科夫高斯过程稀疏算法。稀疏马尔科夫高斯过程将诱导变量的使用与高效的卡尔曼滤波器式递归结合起来,导致算法的计算和内存需求随诱导点的数量线性扩展,同时还能实现并行参数更新和随机优化。在该范式下,推导出一种基于地点的近似推理方法,即用局部高斯项(称为地点)来近似非高斯似然。该方法导致了对机器学习和信号处理文献中算法的一套新的稀疏扩展,包括变异推理、期望传播和经典的非线性卡尔曼平滑器。衍生方法适用于大型时间序列,证明了它们对时空数据的适用性。
Approximate Bayesian inference methods that scale to very large datasets are crucial in leveraging probabilistic models for real-world time series. Sparse Markovian Gaussian processes combine the use of inducing variables with efficient Kalman filter-like recursions, resulting in algorithms whose computational and memory requirements scale linearly in the number of inducing points, whilst also enabling parallel parameter updates and stochastic optimisation. Under this paradigm, we derive a general site-based approach to approximate inference, whereby we approximate the non-Gaussian likelihood with local Gaussian terms, called sites. Our approach results in a suite of novel sparse extensions to algorithms from both the machine learning and signal processing literature, including variational inference, expectation propagation, and the classical nonlinear Kalman smoothers. The derived methods are suited to large time series, and we also demonstrate their applicability to spatio-temporal data, where the model has separate inducing points in both time and space.
https://weibo.com/1402400261/KavtBC2VU
另外几篇值得关注的论文:
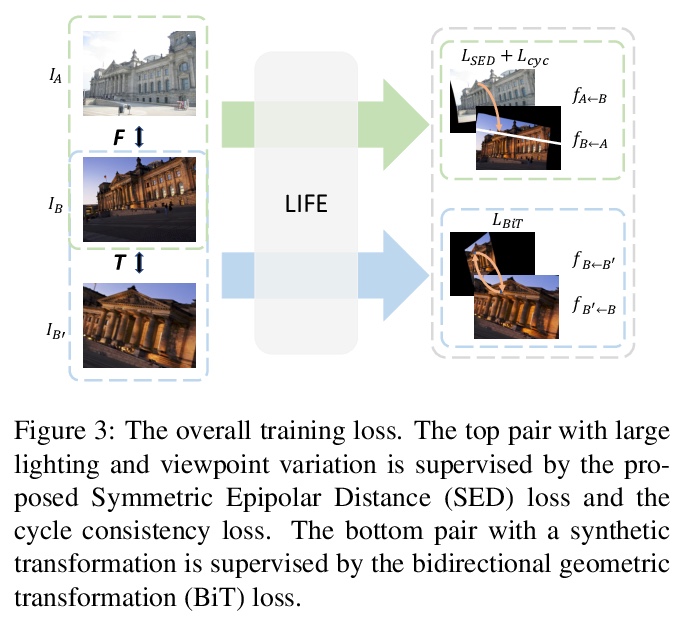
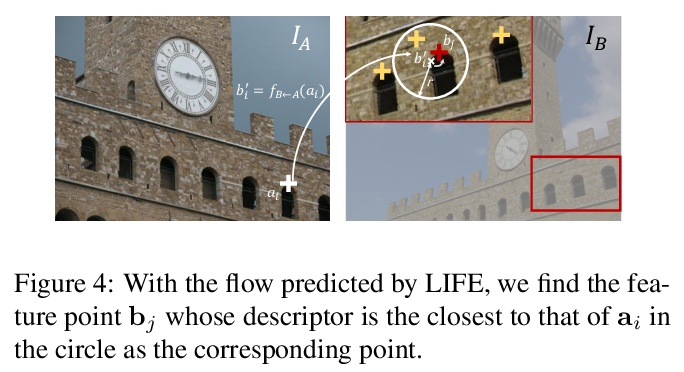
[CV] LIFE: Lighting Invariant Flow Estimation
LIFE:光照不变流估计
Z Huang, X Pan, R Xu, Y Xu, K Cheung, G Zhang, H Li
[The Chinese University of Hong Kong & Zhejiang University & NVIDIA]
https://weibo.com/1402400261/KavqdyB68

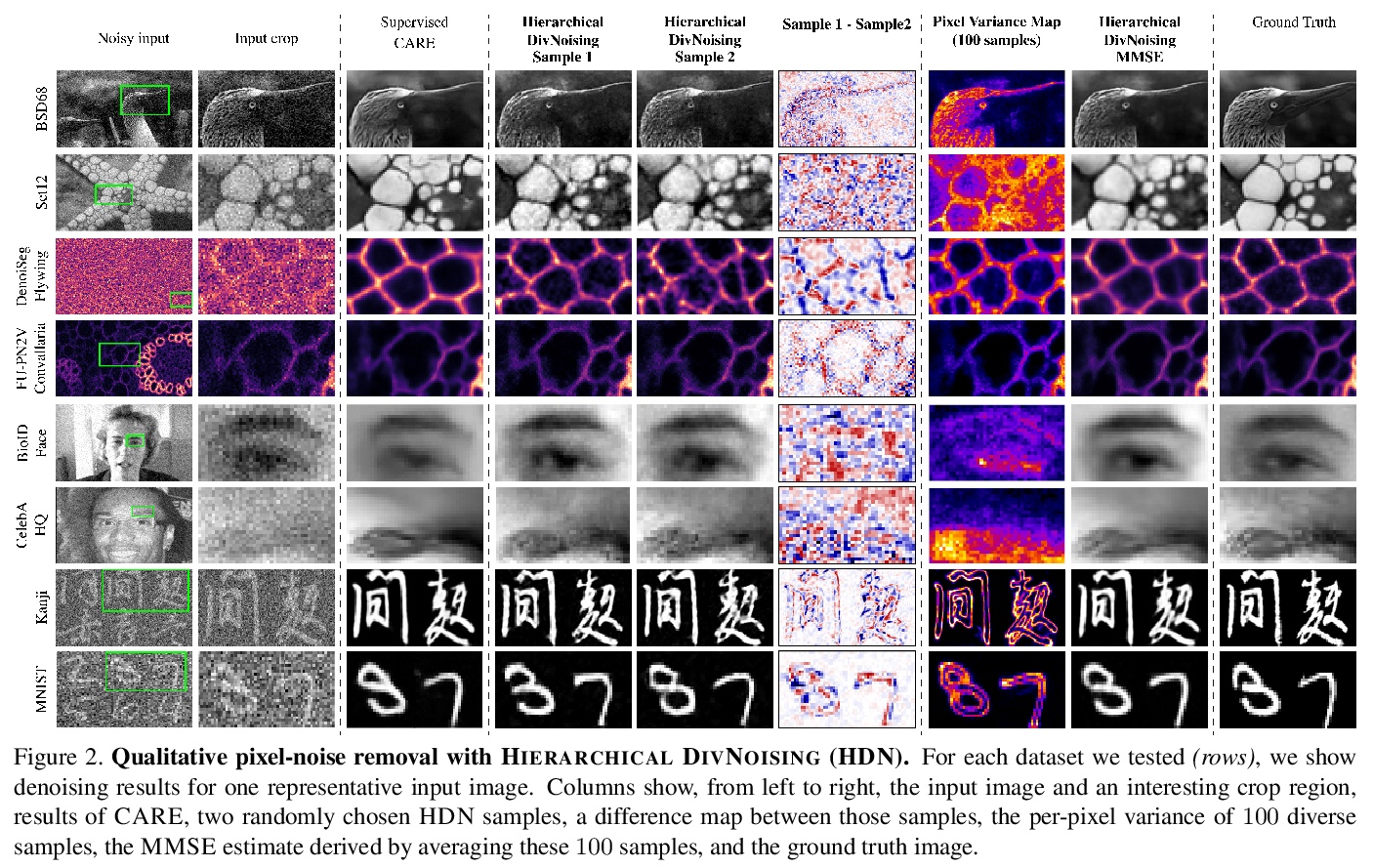
[CV] Removing Pixel Noises and Spatial Artifacts with Generative Diversity Denoising Methods
用生成式多样性去噪方法去除像素噪声和空间伪影
M Prakash, M Delbracio, P Milanfar, F Jug
[Max-Planck Institute CBG & Google Research]
https://weibo.com/1402400261/KavxnnjNl

[CV] Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
视觉-语言表征学习的端到端预训练
Z Huang, Z Zeng, Y Huang, B Liu, D Fu, J Fu
[University of Science and Technology Beijing & Sun Yat-sen University & Microsoft Research Asia]
https://weibo.com/1402400261/Kavz1CJ3u


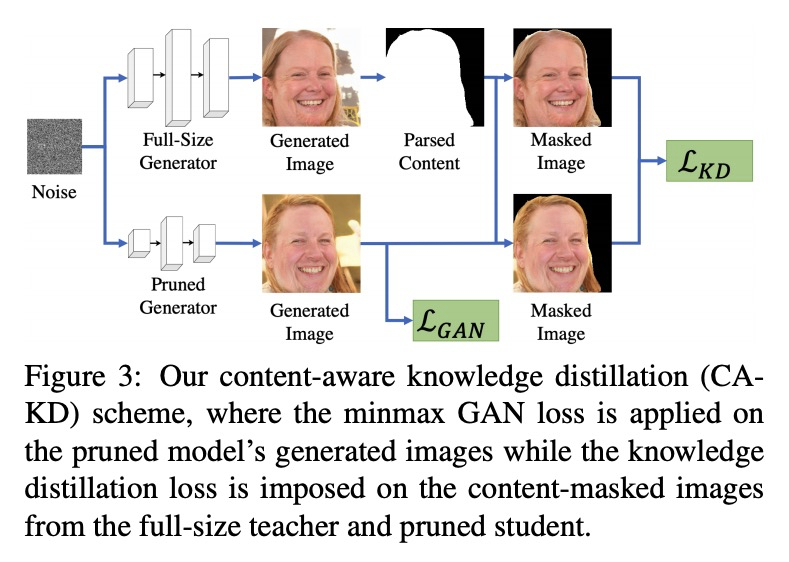
[CV] Content-Aware GAN Compression
内容感知GAN压缩
Y Liu, Z Shu, Y Li, Z Lin, F Perazzi, S.Y. Kung
[Princeton University & Adobe Research]
https://weibo.com/1402400261/KavDkda4m

若有收获,就点个赞吧
0 人点赞
