LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
(*表示值得重点关注)
1、[CL] *CoMatch: Semi-supervised Learning with Contrastive Graph Regularization
J Li, C Xiong, S Hoi
[Salesforce Research]
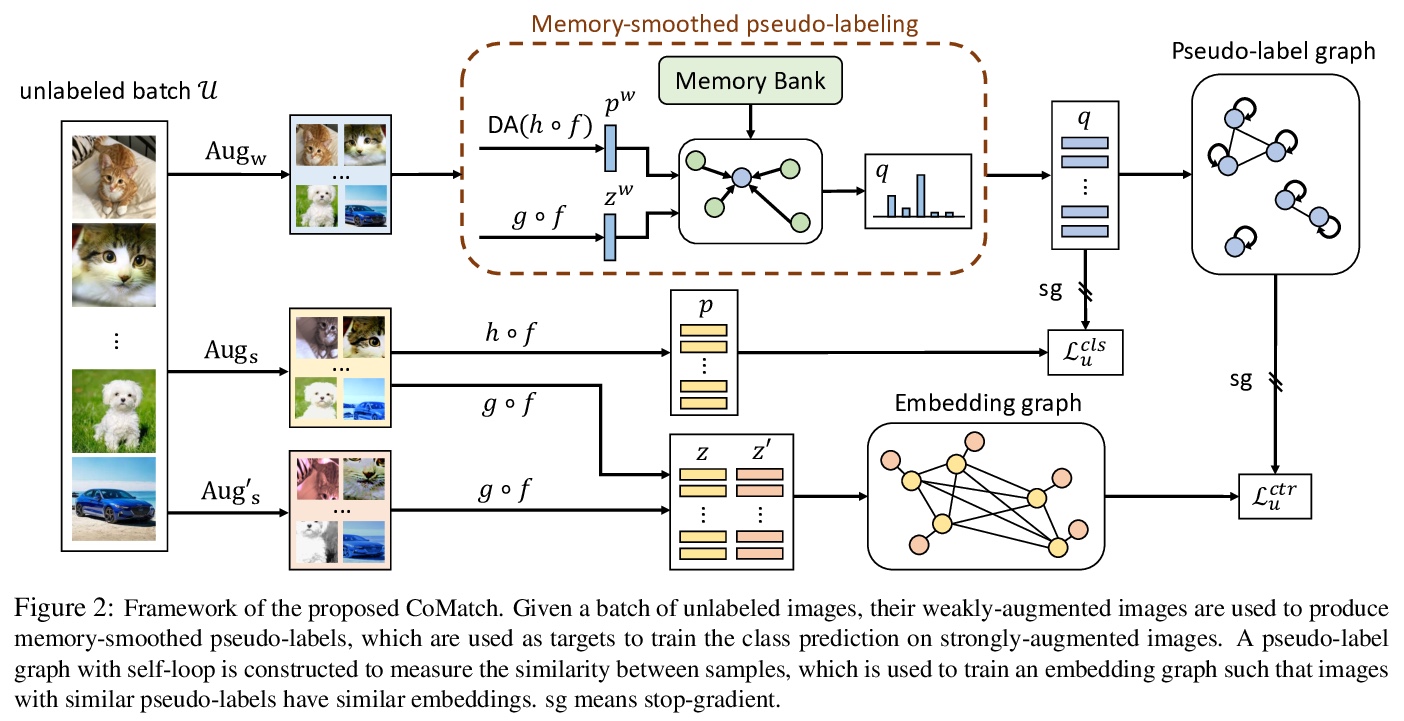
对比图正则化半监督学习。提出了新的半监督学习方法CoMatch,联合学习训练数据的类概率和低维嵌入两种表示,两种表示相互作用,共同进化:嵌入对类概率施加光滑性约束来改进伪标记,而伪标记通过基于图的对比学习来正则化嵌入结构。CoMatch在多个数据集上实现了最先进性能,在下游任务上取得了更好的表示学习性能,优于监督学习和自监督学习。
Semi-supervised learning has been an effective paradigm for leveraging unlabeled data to reduce the reliance on labeled data. We propose CoMatch, a new semi-supervised learning method that unifies dominant approaches and addresses their limitations. CoMatch jointly learns two representations of the training data, their class probabilities and low-dimensional embeddings. The two representations interact with each other to jointly evolve. The embeddings impose a smoothness constraint on the class probabilities to improve the pseudo-labels, whereas the pseudo-labels regularize the structure of the embeddings through graph-based contrastive learning. CoMatch achieves state-of-the-art performance on multiple datasets. It achieves ~20% accuracy improvement on the label-scarce CIFAR-10 and STL-10. On ImageNet with 1% labels, CoMatch achieves a top-1 accuracy of 66.0%, outperforming FixMatch by 12.6%. The accuracy further increases to 67.1% with self-supervised pre-training. Furthermore, CoMatch achieves better representation learning performance on downstream tasks, outperforming both supervised learning and self-supervised learning.
https://weibo.com/1402400261/JvVLH4Zav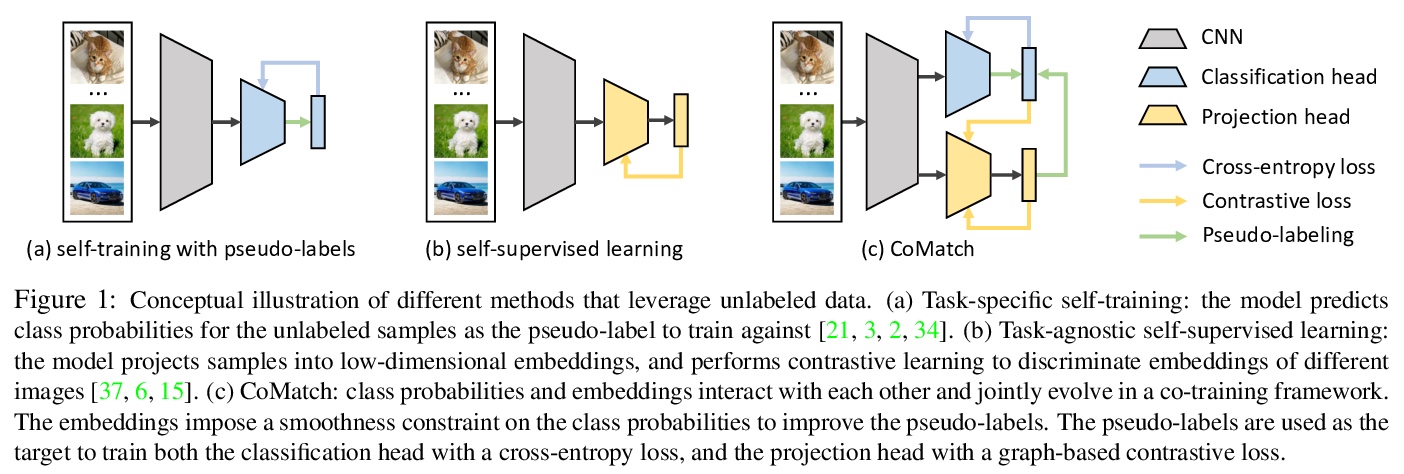
2、[CV] **Enriching ImageNet with Human Similarity Judgments and Psychological Embeddings
B D. Roads, B C. Love
[University College London]
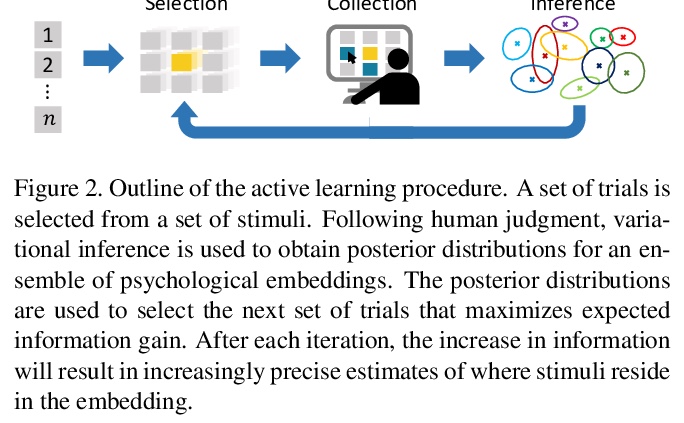
用人工相似性判断和心理嵌入丰富ImageNet。评价一个模型的内在表示与人工判断的一致性,可提供一个有用的评价指标。本文提出一种方法,用人工对大量目标的判断高效推断嵌入空间。用变分推理、集成模型和主动学习,考虑一个比之前工作大一个数量级的问题。该方法收集的人工相似度判断,可有效评价模型表示,用来评价用监督或无监督方法训练的模型。
Advances in object recognition flourished in part because of the availability of high-quality datasets and associated benchmarks. However, these benchmarks—-such as ILSVRC—-are relatively task-specific, focusing predominately on predicting class labels. We introduce a publicly-available dataset that embodies the task-general capabilities of human perception and reasoning. The Human Similarity Judgments extension to ImageNet (ImageNet-HSJ) is composed of human similarity judgments that supplement the ILSVRC validation set. The new dataset supports a range of task and performance metrics, including the evaluation of unsupervised learning algorithms. We demonstrate two methods of assessment: using the similarity judgments directly and using a psychological embedding trained on the similarity judgments. This embedding space contains an order of magnitude more points (i.e., images) than previous efforts based on human judgments. Scaling to the full 50,000 image set was made possible through a selective sampling process that used variational Bayesian inference and model ensembles to sample aspects of the embedding space that were most uncertain. This methodological innovation not only enables scaling, but should also improve the quality of solutions by focusing sampling where it is needed. To demonstrate the utility of ImageNet-HSJ, we used the similarity ratings and the embedding space to evaluate how well several popular models conform to human similarity judgments. One finding is that more complex models that perform better on task-specific benchmarks do not better conform to human semantic judgments. In addition to the human similarity judgments, pre-trained psychological embeddings and code for inferring variational embeddings are made publicly available. Collectively, ImageNet-HSJ assets support the appraisal of internal representations and the development of more human-like models.
https://weibo.com/1402400261/JvVP1ztwJ
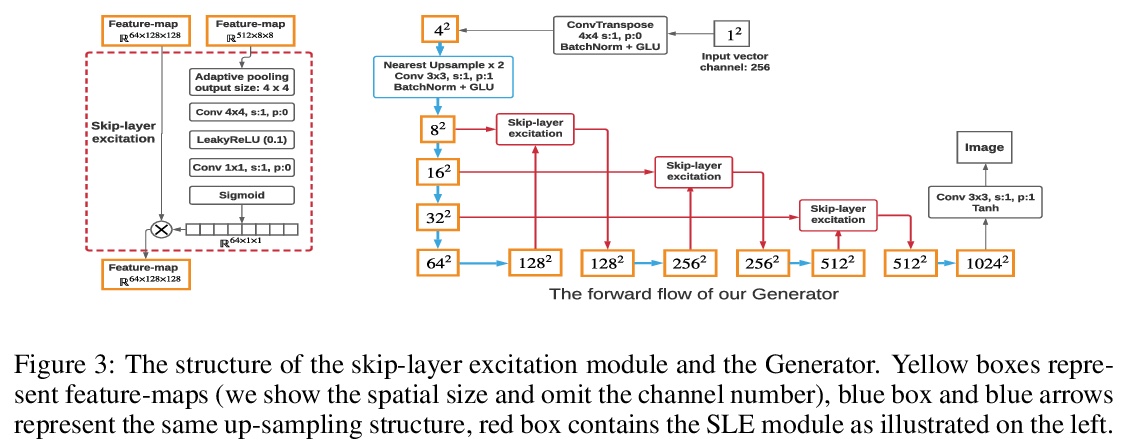
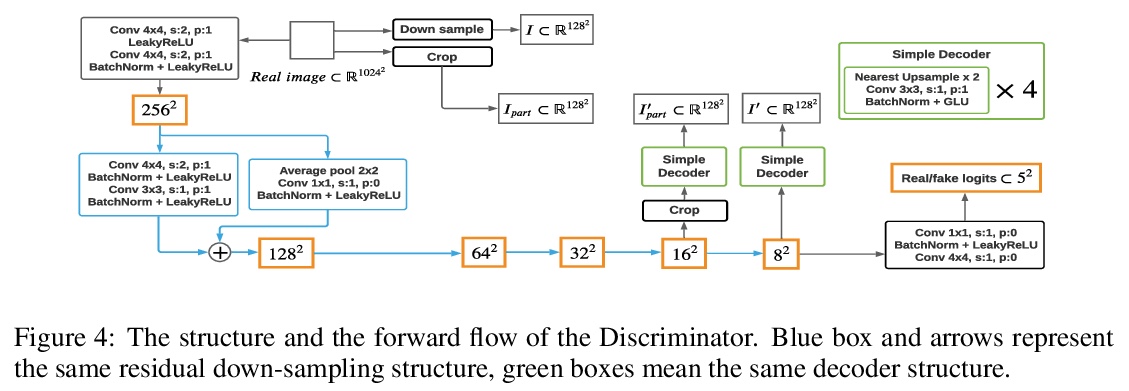
3、[CV] **Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis
(ICLR 2021 Blind Submission)
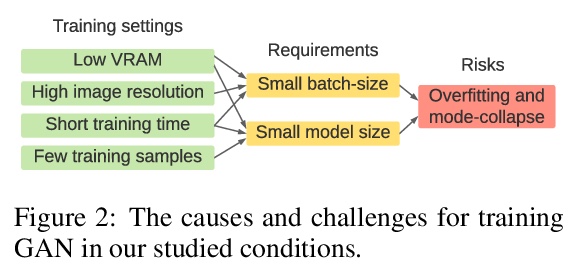
面向高保真少样本图像合成的更快更稳定的GAN训练。研究了基于最小计算代价GAN算法的少样本图像合成任务,提出一种轻量GAN结构,采用跃层通道级激发机制(SLE)和鉴别器自监督正则化,显著提高GAN的合成性能,在1024x1024分辨率上获得优异质量。只需单块RTX-2080 GPU上训练几个小时,就可以从头开始收敛,即使在不到100个训练样本的情况下,也具有一致的性能。**
Training Generative Adversarial Networks (GAN) on high-fidelity images usually requires large-scale GPU-clusters and a vast number of training images. In this paper, we study the few-shot image synthesis task for GAN with minimum computing cost. We propose a light-weight GAN structure that gains superior quality on 1024x1024 resolution. Notably, the model converges from scratch with just a few hours of training on a single RTX-2080 GPU; and has a consistent performance, even with less than 100 training samples. Two technique designs constitute our work, a skip-layer channel-wise excitation module and a self-supervised discriminator trained as a feature-encoder. With thirteen datasets covering a wide variety of image domains, we show our model’s robustness and its superior performance compared to the state-of-the-art StyleGAN2.
https://weibo.com/1402400261/JvVUbgKly
4、[CV] **Rotation-Only Bundle Adjustment
S H Lee, J Civera
[University of Zaragoza]
Rotation-Only束调整多视图全局旋转估计方法。当两个校准过的摄像机观察五个或五个以上相同的点时,其相对旋转可独立于平移恢复,本文将此思想扩展到多个视点,将旋转估计从平移估计和结构估计中解耦出来,通过扩展双视图rotation-only方法来表达优化问题,用Adam优化器进行优化。
We propose a novel method for estimating the global rotations of the cameras independently of their positions and the scene structure. When two calibrated cameras observe five or more of the same points, their relative rotation can be recovered independently of the translation. We extend this idea to multiple views, thereby decoupling the rotation estimation from the translation and structure estimation. Our approach provides several benefits such as complete immunity to inaccurate translations and structure, and the accuracy improvement when used with rotation averaging. We perform extensive evaluations on both synthetic and real datasets, demonstrating consistent and significant gains in accuracy when used with the state-of-the-art rotation averaging method.
https://weibo.com/1402400261/JvW0ZAw6V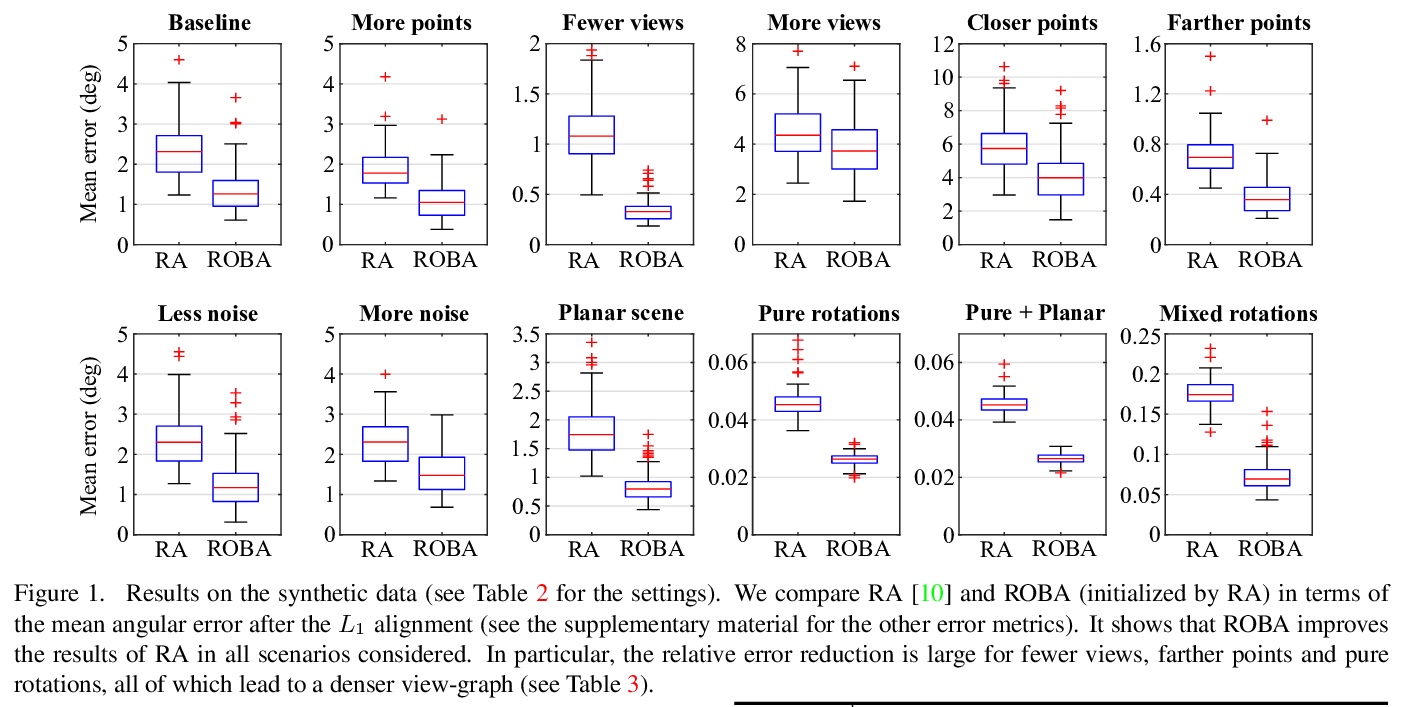
5、[LG] **Online Model Selection for Reinforcement Learning with Function Approximation
J N. Lee, A Pacchiano, V Muthukumar, W Kong, E Brunskill
[Stanford University & UC Berkeley & Simons Institute & University of Washington]
函数逼近强化学习在线模型选择。提出一种基于函数逼近的强化学习模型选择元算法,给定一组基本算法,元算法通过简单的、可解释的统计检验,来适应最优算法的遗憾。元算法的遗憾保留了对模型复杂度的最优依赖,同时增加了对集数T的依赖。与以往工作相比,元算法提供了类似强的最坏情况的遗憾边界,计算效率是基于基础算法的效率,只用最小假设,提供了新的实例依赖的结果。
Deep reinforcement learning has achieved impressive successes yet often requires a very large amount of interaction data. This result is perhaps unsurprising, as using complicated function approximation often requires more data to fit, and early theoretical results on linear Markov decision processes provide regret bounds that scale with the dimension of the linear approximation. Ideally, we would like to automatically identify the minimal dimension of the approximation that is sufficient to encode an optimal policy. Towards this end, we consider the problem of model selection in RL with function approximation, given a set of candidate RL algorithms with known regret guarantees. The learner’s goal is to adapt to the complexity of the optimal algorithm without knowing it \textit{a priori}. We present a meta-algorithm that successively rejects increasingly complex models using a simple statistical test. Given at least one candidate that satisfies realizability, we prove the meta-algorithm adapts to the optimal complexity with > Õ (L5/6T2/3) regret compared to the optimal candidate’s > Õ (T‾‾√) regret, where > T is the number of episodes and > L is the number of algorithms. The dimension and horizon dependencies remain optimal with respect to the best candidate, and our meta-algorithmic approach is flexible to incorporate multiple candidate algorithms and models. Finally, we show that the meta-algorithm automatically admits significantly improved instance-dependent regret bounds that depend on the gaps between the maximal values attainable by the candidates.
https://weibo.com/1402400261/JvW5McHwb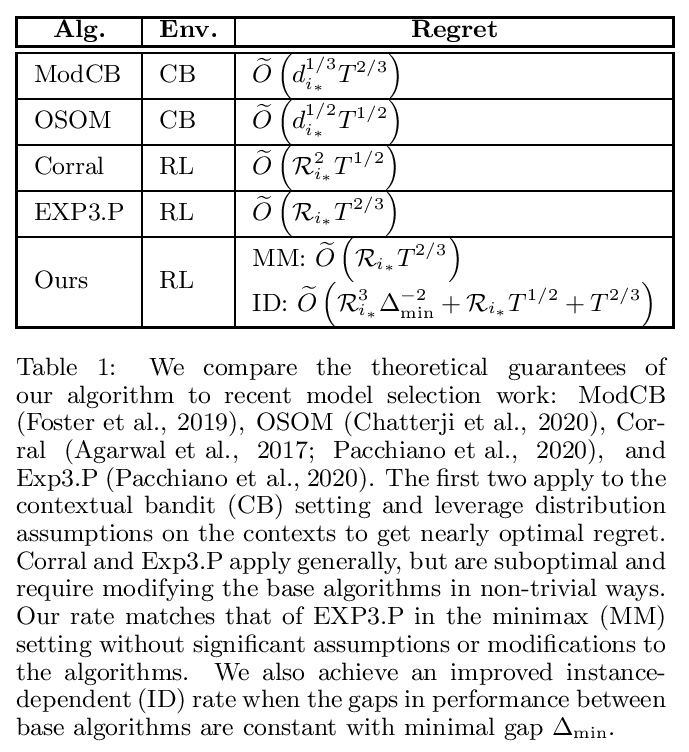
其他几篇值得关注的论文:
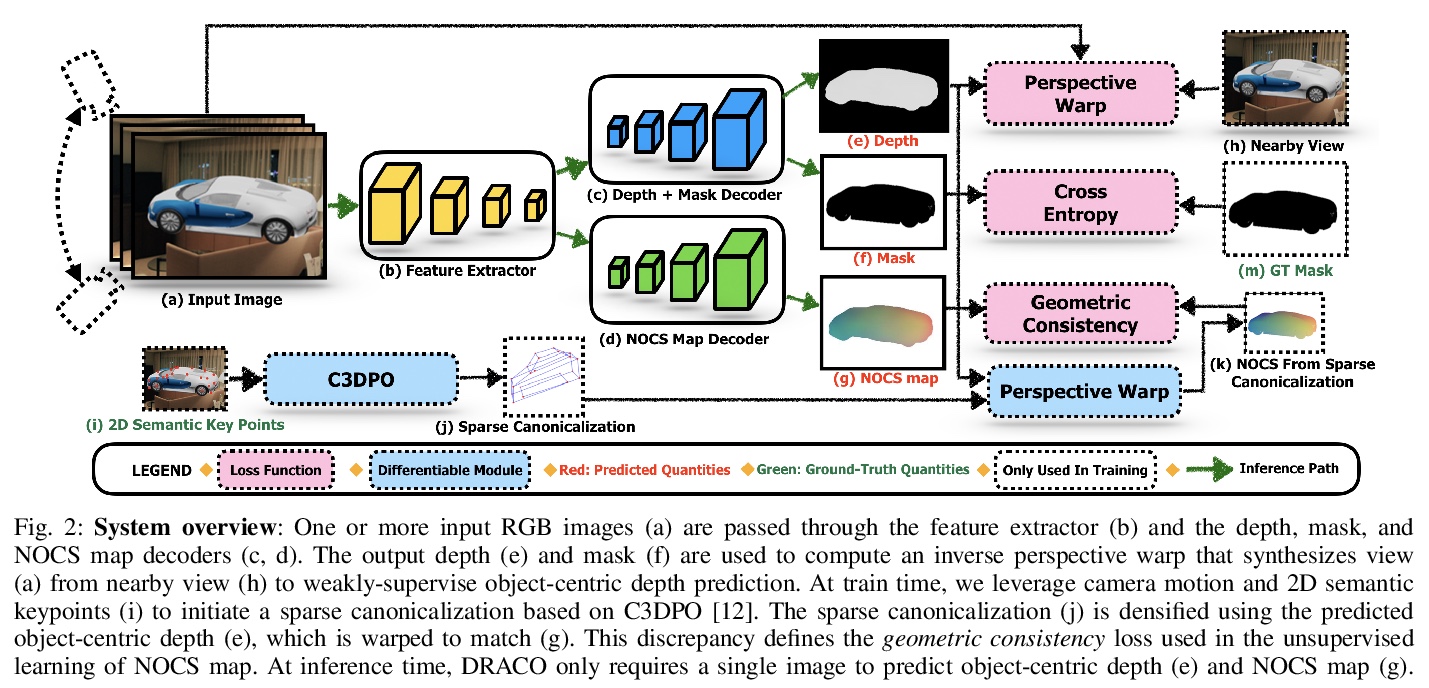
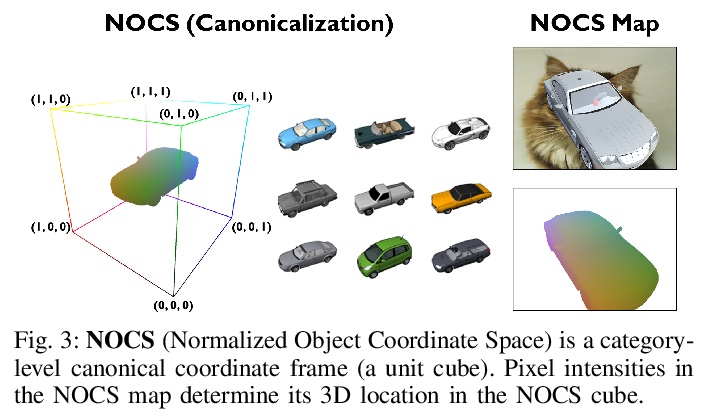
[CV] DRACO: Weakly Supervised Dense Reconstruction And Canonicalization of Objects
DRACO:弱监督密集重建与对象规范化
R Sajnani, A Sanchawala, K M Jatavallabhula, S Sridhar, K. M Krishna
[KCIS & Mila & Brown University]
https://weibo.com/1402400261/JvW9v0FfF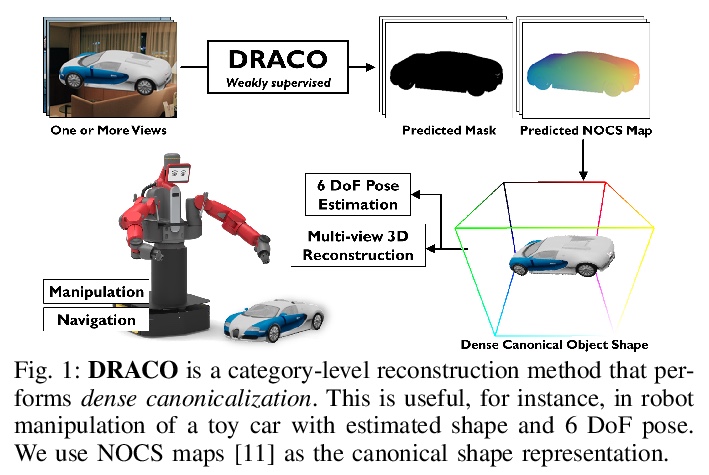
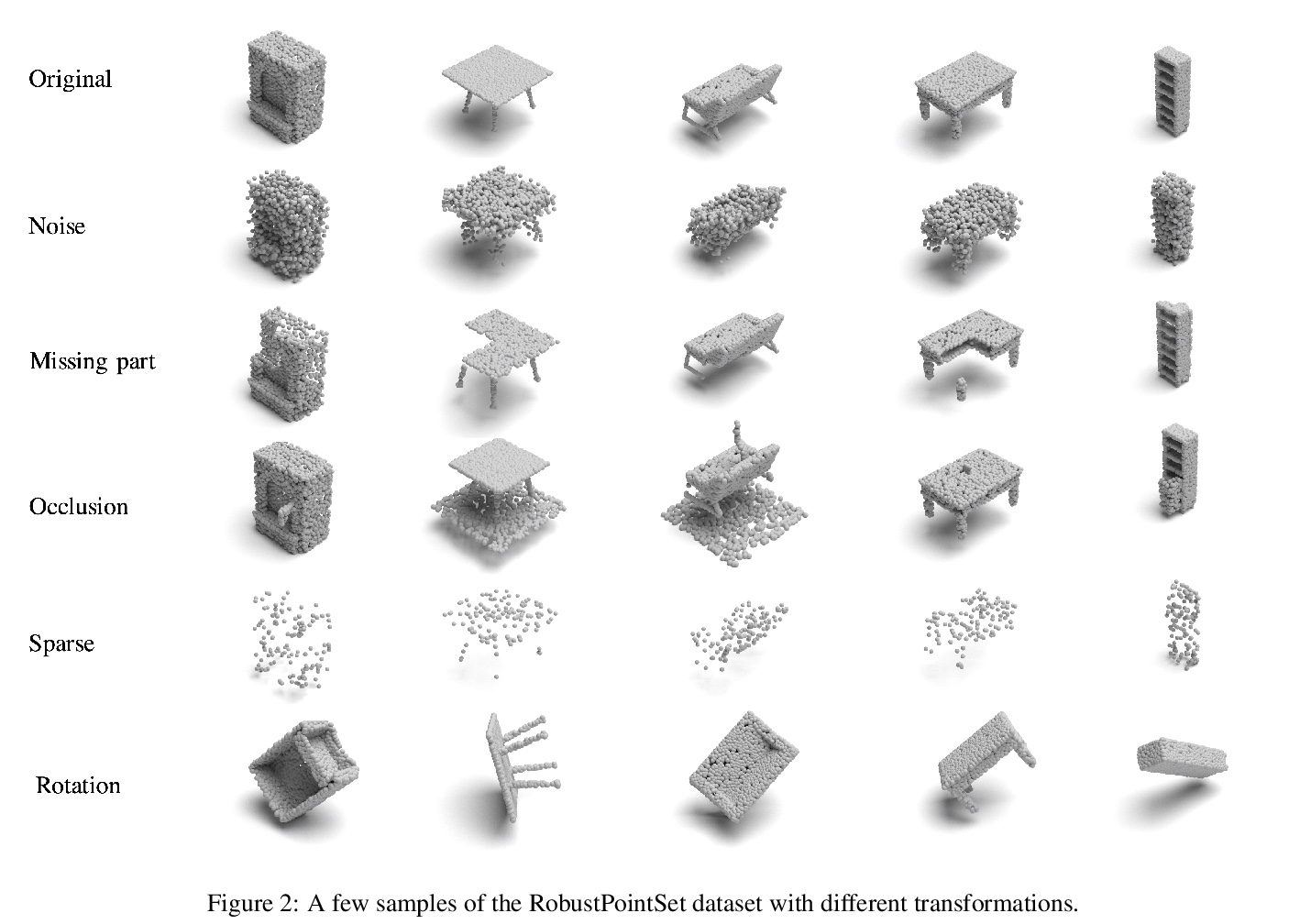
[CV] RobustPointSet: A Dataset for Benchmarking Robustness of Point Cloud Classifiers
RobustPointSet:点云分类器鲁棒性基准数据集
S A Taghanaki, J Luo, R Zhang, Y Wang, P K Jayaraman, K M Jatavallabhula
[Autodesk AI Lab & Autodesk Research & Mila]
https://weibo.com/1402400261/JvWb5rIdE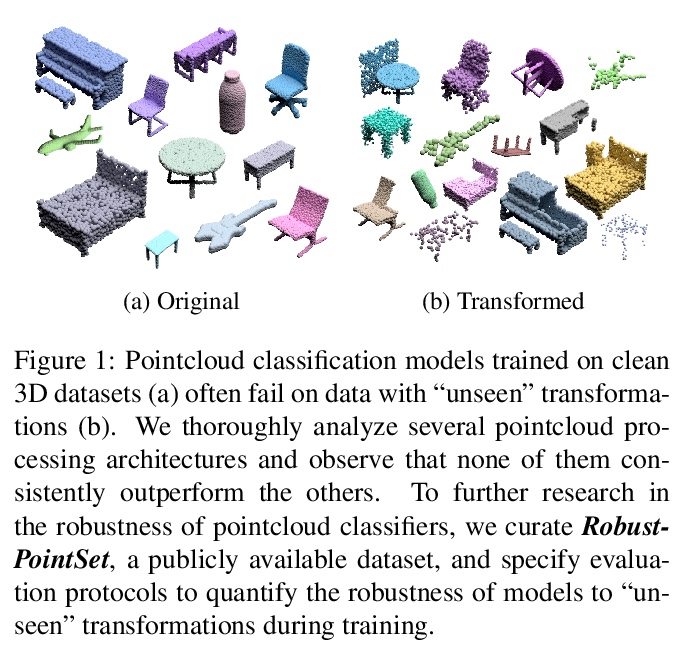
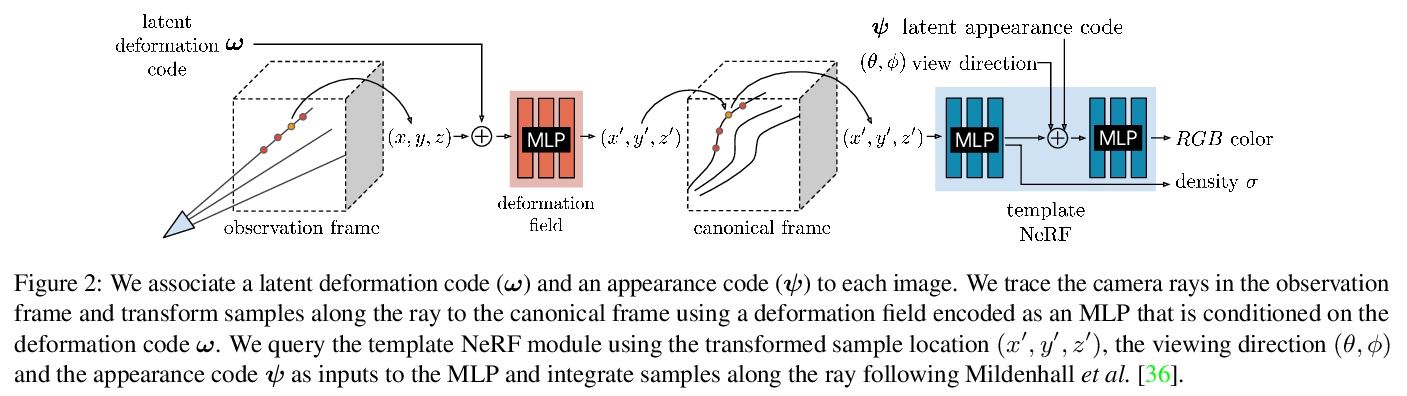
[CV] Deformable Neural Radiance Fields
可变形神经网络辐射场
K Park, U Sinha, J T. Barron, S Bouaziz, D B Goldman, S M. Seitz, R Brualla
[University of Washington & Google Research]
https://weibo.com/1402400261/JvWd0wFMh


若有收获,就点个赞吧
0 人点赞
