- 1、[LG] Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth
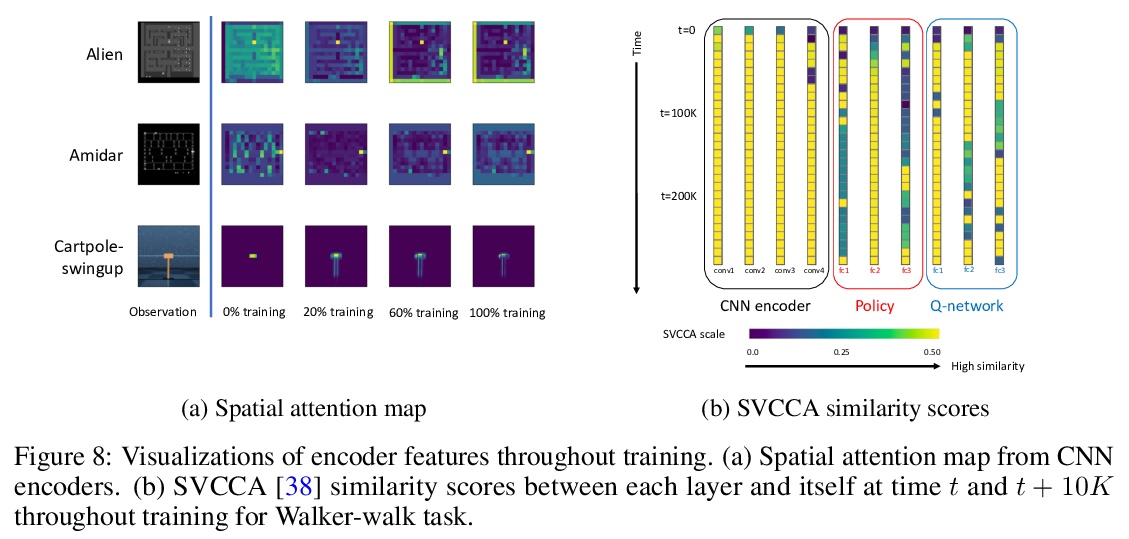
- 2、[LG] Improving Computational Efficiency in Visual Reinforcement Learning via Stored Embeddings
- 3、[RO] Scale invariant robot behavior with fractals
- 4、[CV] Multimodal Representation Learning via Maximization of Local Mutual Information
- 5、[CV] Parser-Free Virtual Try-on via Distilling Appearance Flows
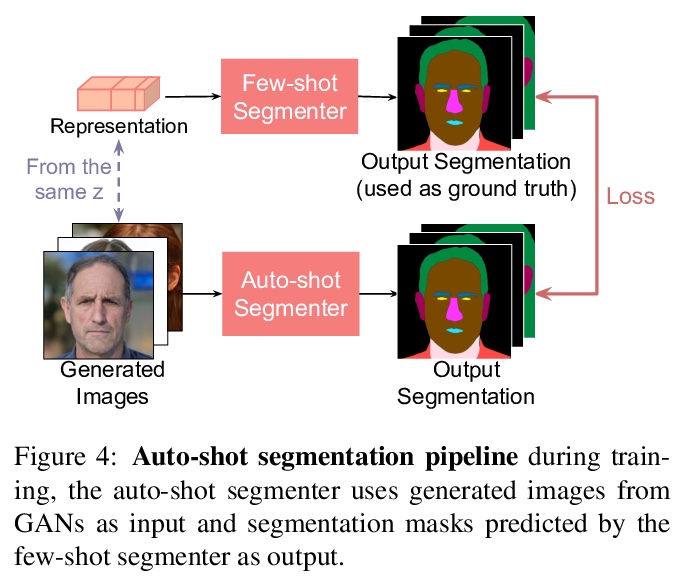
- [CV] Repurposing GANs for One-shot Semantic Part Segmentation
- [LG] The Hintons in your Neural Network: a Quantum Field Theory View of Deep Learning
- [CL] Syntax-BERT: Improving Pre-trained Transformers with Syntax Trees
- [CV] End-to-End Human Object Interaction Detection with HOI Transformer
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth
Y Dong, J Cordonnier, A Loukas
[Google & EPFL]
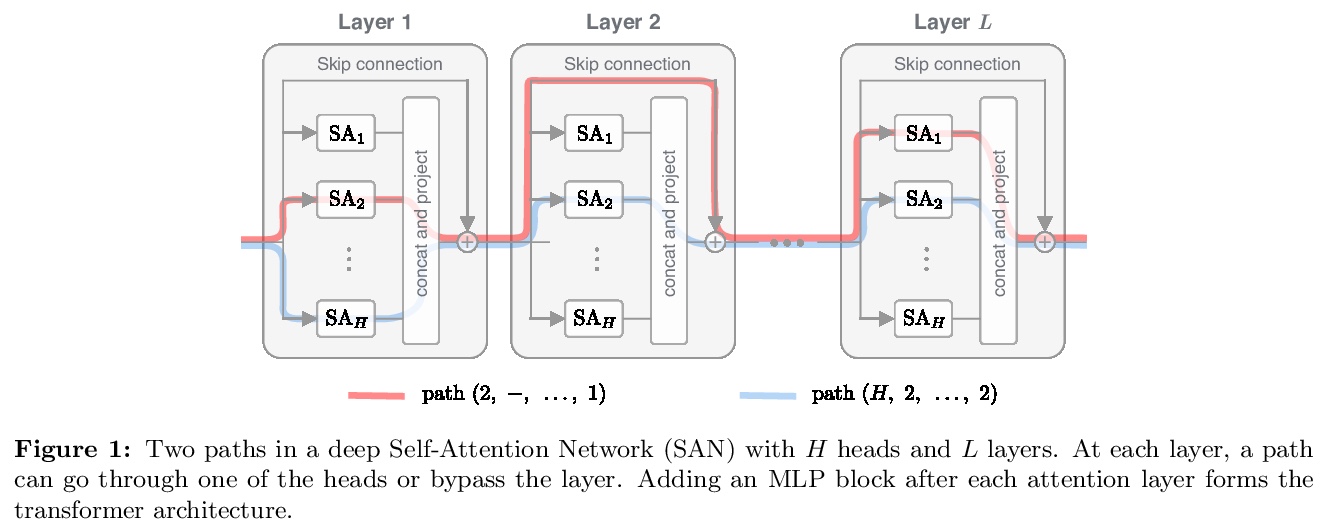
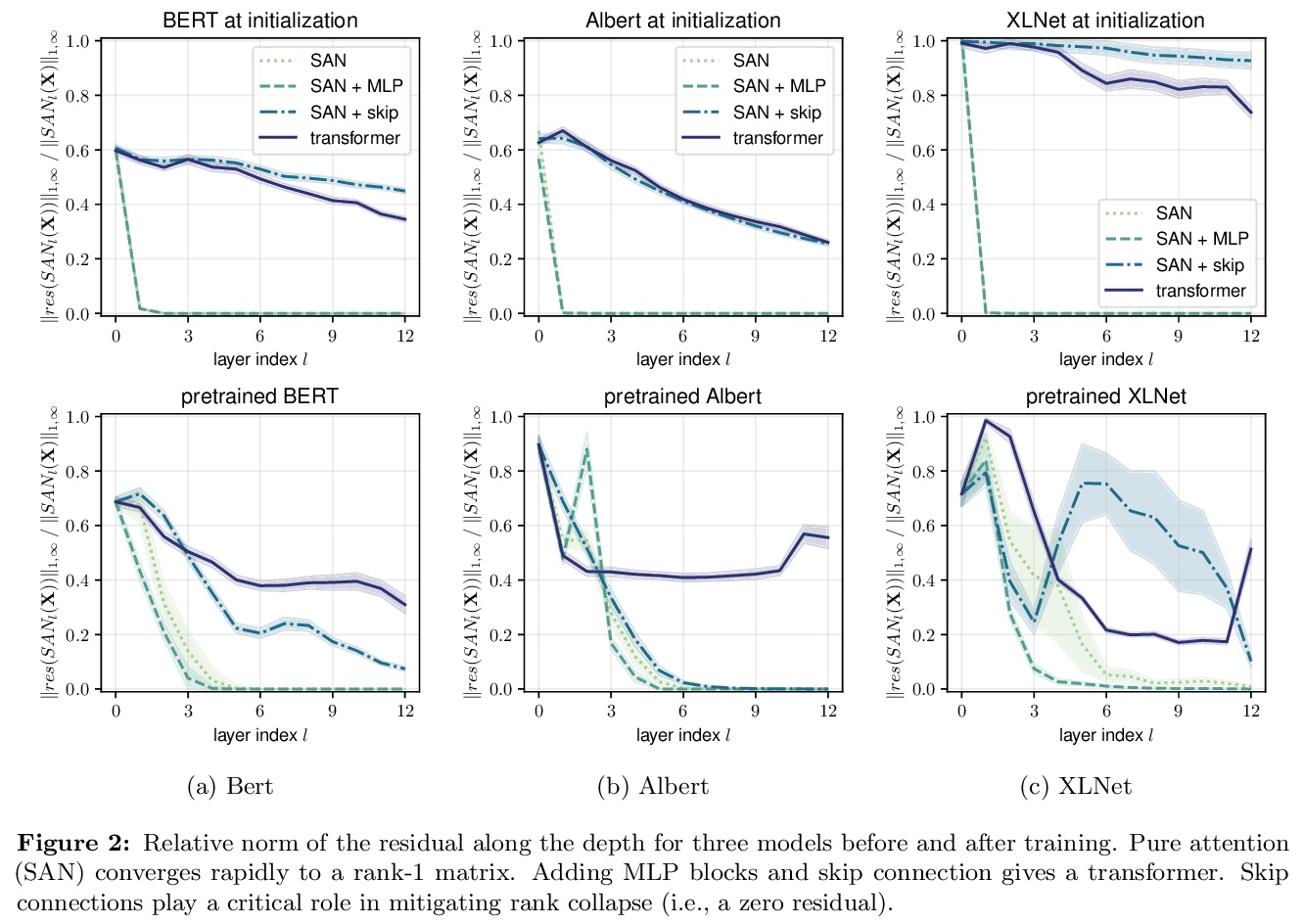
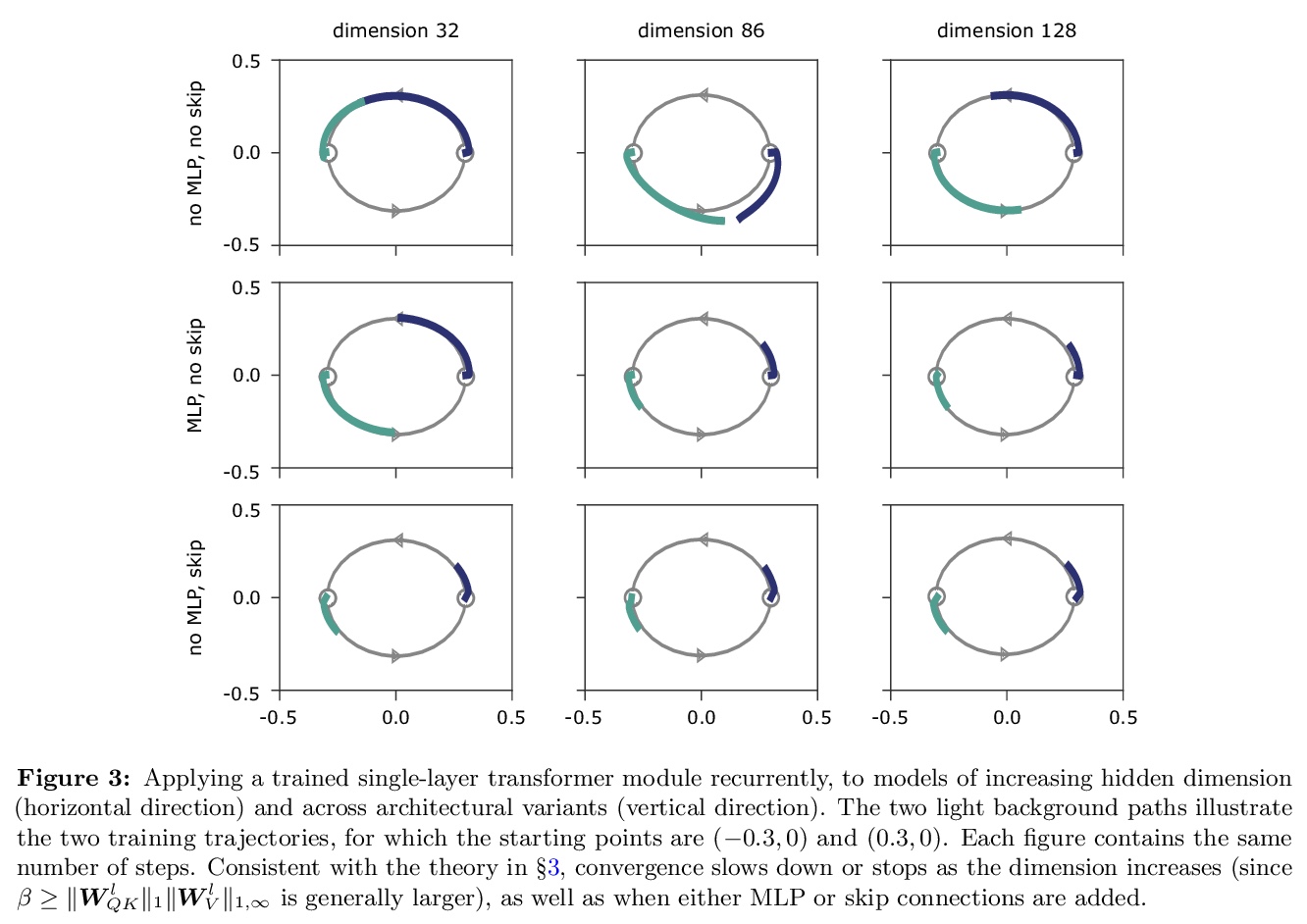
注意力并不是万能的:随深度增加单纯注意力的秩会出现坍缩。提出一种理解自注意力网络的新方法:其输出可分解成一个个更小的项的和,每个项都涉及对跨层的注意力头序列的操作。利用这种分解,证明了自注意力有强烈的 “token统一性”归纳偏向。在没有跳接和多层感知器(MLPs)的情况下,输出会双指数级收敛到秩为1的矩阵。另一方面,跳接和多层感知器可以阻止输出的退化。通过对transformer构件的系统研究,揭示了自注意力及其反作用力——跳接和多层感知器——之间的对立影响,会促进或防止transformer秩的坍缩。作为一个必然结果,揭示了跳接除了有助于优化之外,另一个以前未知的重要用途。提出一种通过路径分解来分析SAN的新方法,SAN是浅层网络的集成。
Attention-based architectures have become ubiquitous in machine learning, yet our understanding of the reasons for their effectiveness remains limited. This work proposes a new way to understand self-attention networks: we show that their output can be decomposed into a sum of smaller terms, each involving the operation of a sequence of attention heads across layers. Using this decomposition, we prove that self-attention possesses a strong inductive bias towards “token uniformity”. Specifically, without skip connections or multi-layer perceptrons (MLPs), the output converges doubly exponentially to a rank-1 matrix. On the other hand, skip connections and MLPs stop the output from degeneration. Our experiments verify the identified convergence phenomena on different variants of standard transformer architectures.
https://weibo.com/1402400261/K5tUA2l2c
2、[LG] Improving Computational Efficiency in Visual Reinforcement Learning via Stored Embeddings
L Chen, K Lee, A Srinivas, P Abbeel
[UC Berkeley]
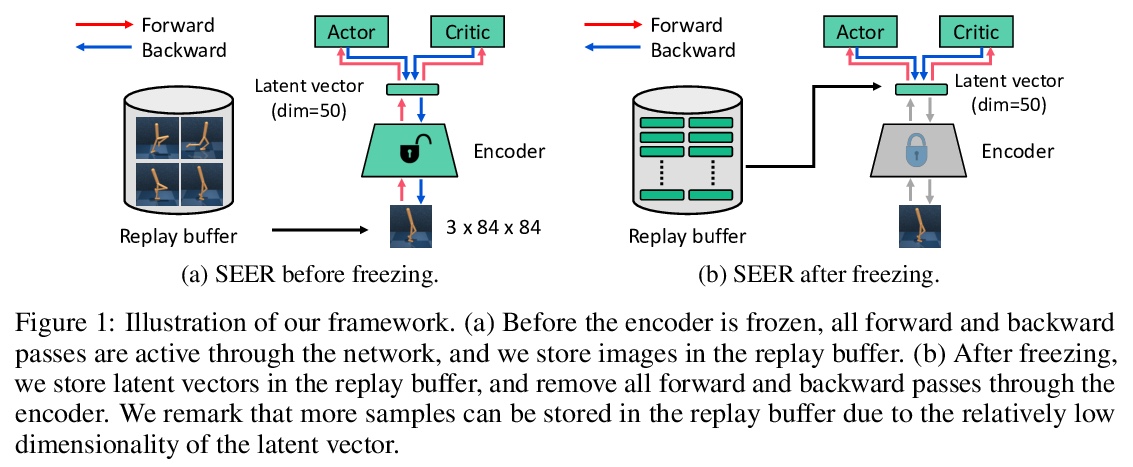
用嵌入保存提高视觉强化学习计算效率。提出了面向高效强化学习的嵌入保存(Stored Embeddings for Efficient Reinforcement Learning,SEER),对现有非策略强化学习方法进行简单修改,以降低计算和内存需求,可与大多数现代非策略强化学习算法结合使用。为减少CNN中梯度更新的计算开销,在训练初期冻结CNN编码器底层,其参数会早期收敛。通过存储低维潜向量的经验重放、而不是高维图像来降低内存需求,从而实现重放缓冲区容量的自适应增加,这是一种在受限内存环境下的有用技术。SEER通过增加重放缓冲区容量,提高了约束内存环境下强化学习智能体的样本效率。实验表明,SEER不会降低强化学习智能体性能,在不同的DeepMind Control环境和Atari游戏中显著节省了计算和内存。SEER对于强化学习实现计算高效的迁移学习是有用的,从CNN底层提取可泛化特征,这些特征可用于不同的任务和领域。
Recent advances in off-policy deep reinforcement learning (RL) have led to impressive success in complex tasks from visual observations. Experience replay improves sample-efficiency by reusing experiences from the past, and convolutional neural networks (CNNs) process high-dimensional inputs effectively. However, such techniques demand high memory and computational bandwidth. In this paper, we present Stored Embeddings for Efficient Reinforcement Learning (SEER), a simple modification of existing off-policy RL methods, to address these computational and memory requirements. To reduce the computational overhead of gradient updates in CNNs, we freeze the lower layers of CNN encoders early in training due to early convergence of their parameters. Additionally, we reduce memory requirements by storing the low-dimensional latent vectors for experience replay instead of high-dimensional images, enabling an adaptive increase in the replay buffer capacity, a useful technique in constrained-memory settings. In our experiments, we show that SEER does not degrade the performance of RL agents while significantly saving computation and memory across a diverse set of DeepMind Control environments and Atari games. Finally, we show that SEER is useful for computation-efficient transfer learning in RL because lower layers of CNNs extract generalizable features, which can be used for different tasks and domains.
https://weibo.com/1402400261/K5u2mypvD
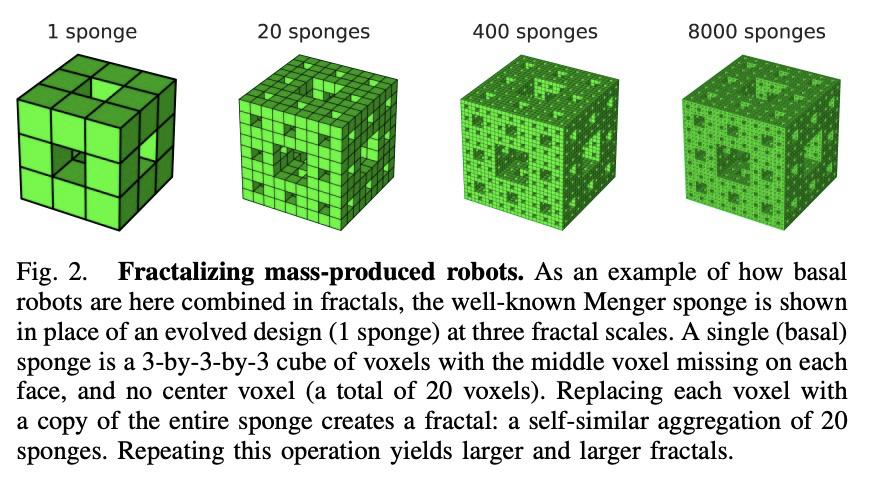
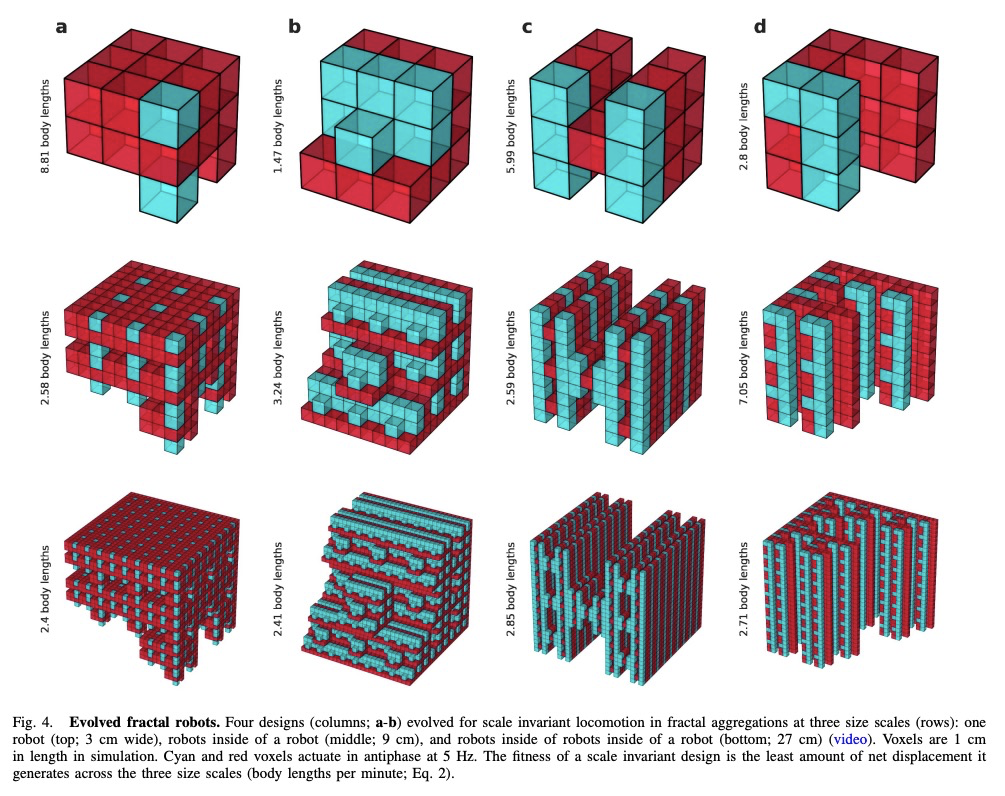
3、[RO] Scale invariant robot behavior with fractals
S Kriegman, A M Nasab, D Blackiston, H Steele, M Levin, R Kramer-Bottiglio, J Bongard
[University of Vermont & Yale University & Tufts University]
基于分形的尺度不变机器人行为。由于自然界中自相似结构经常在不同尺度上表现出自相似行为,假设可能存在具有类似属性的机器人设计。证明了对某些但不是所有的模块化软体机器人来说,情况确实如此:某些机器人设计在小尺寸尺度上表现出所需的行为,如果将该机器人的复制体连在一起,在更高尺度上实现相同的设计,则那些更大的机器人会表现出相似行为。展示了如何用进化算法在模拟中找到这样的设计。当不假设分形附着,因而附着几何结构必须随着基础机器人单元的设计而演化时,尺度不变行为无法实现,表明结构自相似性当与适当的设计相结合时,是实现尺度不变的机器人行为的有用路径。通过证明将自相似结构和行为成功迁移到气动控制的软体机器人,来验证该发现。表明生物机器人可自发地表现出自相似附着几何结构,通过自相似结构的自相似行为可能在未来的广泛机器人平台上实现。
Robots deployed at orders of magnitude different size scales, and that retain the same desired behavior at any of those scales, would greatly expand the environments in which the robots could operate. However it is currently not known whether such robots exist, and, if they do, how to design them. Since self similar structures in nature often exhibit self similar behavior at different scales, we hypothesize that there may exist robot designs that have the same property. Here we demonstrate that this is indeed the case for some, but not all, modular soft robots: there are robot designs that exhibit a desired behavior at a small size scale, and if copies of that robot are attached together to realize the same design at higher scales, those larger robots exhibit similar behavior. We show how to find such designs in simulation using an evolutionary algorithm. Further, when fractal attachment is not assumed and attachment geometries must thus be evolved along with the design of the base robot unit, scale invariant behavior is not achieved, demonstrating that structural self similarity, when combined with appropriate designs, is a useful path to realizing scale invariant robot behavior. We validate our findings by demonstrating successful transferal of self similar structure and behavior to pneumatically-controlled soft robots. Finally, we show that biobots can spontaneously exhibit self similar attachment geometries, thereby suggesting that self similar behavior via self similar structure may be realizable across a wide range of robot platforms in future.
https://weibo.com/1402400261/K5u9UFfuf

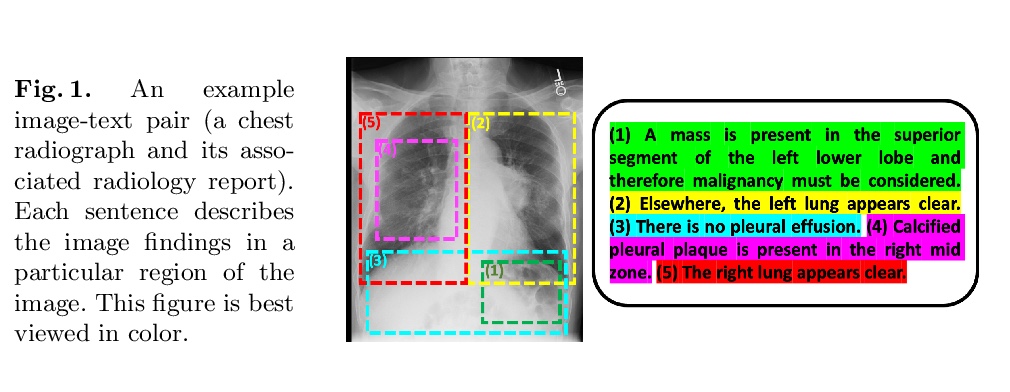
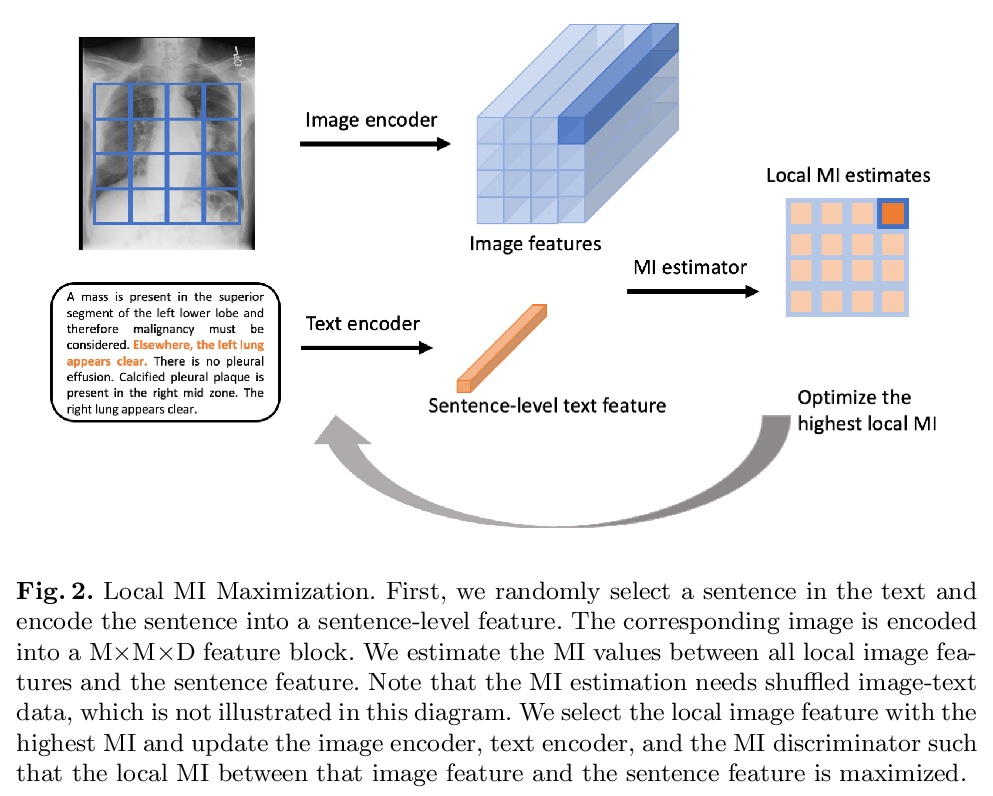
4、[CV] Multimodal Representation Learning via Maximization of Local Mutual Information
R Liao, D Moyer, M Cha, K Quigley, S Berkowitz, S Horng, P Golland, W M. Wells
[MIT & Harvard Medical School]
基于局部互信息最大化的多模态表示学习。通过最大化图像和文本局部特征间的互信息,提出一种针对图像和文本的多模态表示学习框架。通过鼓励文本中的句子级特征与局部图像特征表现出高互信息,图像编码器学习提取有用的特征表示,用于后续的图像分析,通过鼓励产生的表征表现出高的局部互信息来学习图像和文本编码器,利用了神经网络判别器在互信息估计方面的最新进展。证明了在马尔可夫条件下,局部互信息最大化等同于全局互信息最大化,进一步深入了解了局部互信息。
We propose and demonstrate a representation learning approach by maximizing the mutual information between local features of images and text. The goal of this approach is to learn useful image representations by taking advantage of the rich information contained in the free text that describes the findings in the image. Our method learns image and text encoders by encouraging the resulting representations to exhibit high local mutual information. We make use of recent advances in mutual information estimation with neural network discriminators. We argue that, typically, the sum of local mutual information is a lower bound on the global mutual information. Our experimental results in the downstream image classification tasks demonstrate the advantages of using local features for image-text representation learning.
https://weibo.com/1402400261/K5udv9BgO
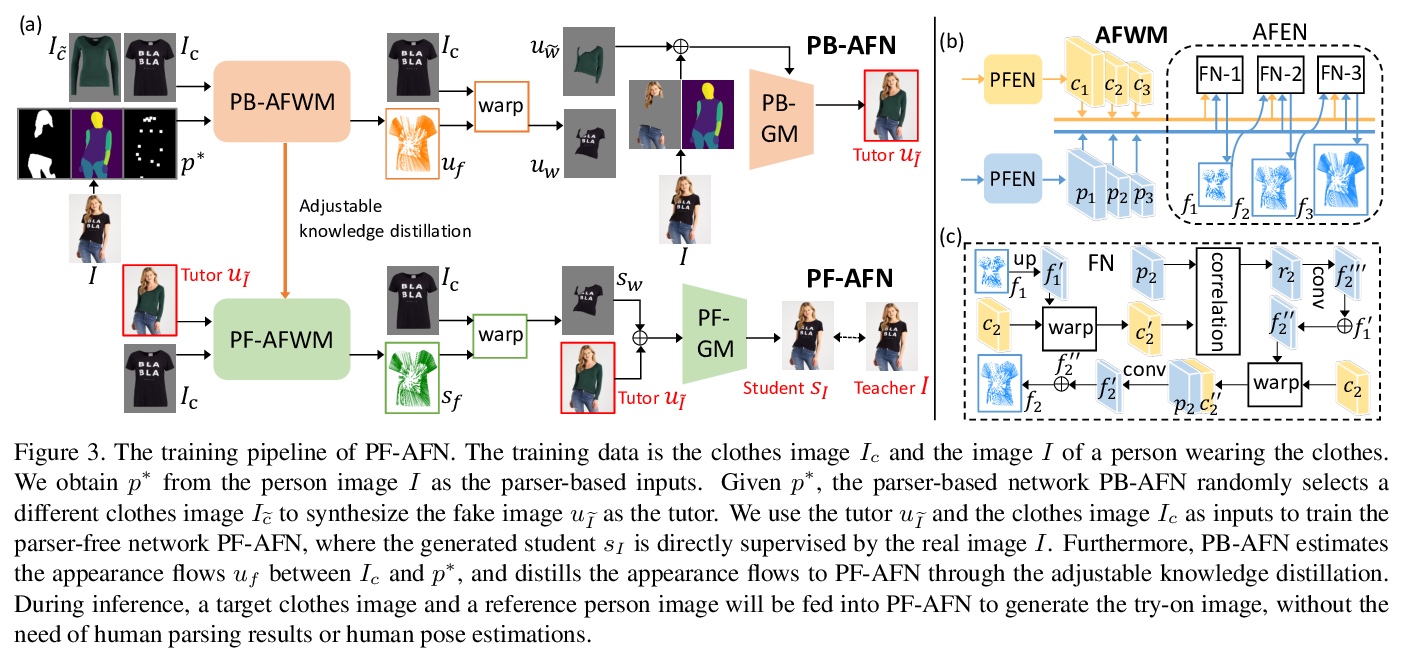
5、[CV] Parser-Free Virtual Try-on via Distilling Appearance Flows
Y Ge, Y Song, R Zhang, C Ge, W Liu, P Luo
[The University of Hong Kong & Tencent AI Lab & The Chinese University of Hong Kong]
基于外观流蒸馏的免解析虚拟试穿。提出一种新方法—“教师-导师-学生”知识蒸馏,以生成逼真的照片级试穿图像,无需人工解析。该方法将基于解析器的网络产生的假图像(导师知识)作为无解析器的学生网络的输入,学生网络以自监督方式对原始真人图像(教师知识)进行监督,伪影可通过真实的”教师知识”进行修正。除使用真实图像作为监督外,进一步蒸馏了人物图像和服装图像之间的外观流,以找到它们之间的精确密集对应关系,从而实现高质量的图像生成。
Image virtual try-on aims to fit a garment image (target clothes) to a person image. Prior methods are heavily based on human parsing. However, slightly-wrong segmentation results would lead to unrealistic try-on images with large artifacts. Inaccurate parsing misleads parser-based methods to produce visually unrealistic results where artifacts usually occur. A recent pioneering work employed knowledge distillation to reduce the dependency of human parsing, where the try-on images produced by a parser-based method are used as supervisions to train a “student” network without relying on segmentation, making the student mimic the try-on ability of the parser-based model. However, the image quality of the student is bounded by the parser-based model. To address this problem, we propose a novel approach, “teacher-tutor-student” knowledge distillation, which is able to produce highly photo-realistic images without human parsing, possessing several appealing advantages compared to prior arts. (1) Unlike existing work, our approach treats the fake images produced by the parser-based method as “tutor knowledge”, where the artifacts can be corrected by real “teacher knowledge”, which is extracted from the real person images in a self-supervised way. (2) Other than using real images as supervisions, we formulate knowledge distillation in the try-on problem as distilling the appearance flows between the person image and the garment image, enabling us to find accurate dense correspondences between them to produce high-quality results. (3) Extensive evaluations show large superiority of our method (see Fig. 1).
https://weibo.com/1402400261/K5uhEflLW


另外几篇值得关注的论文:
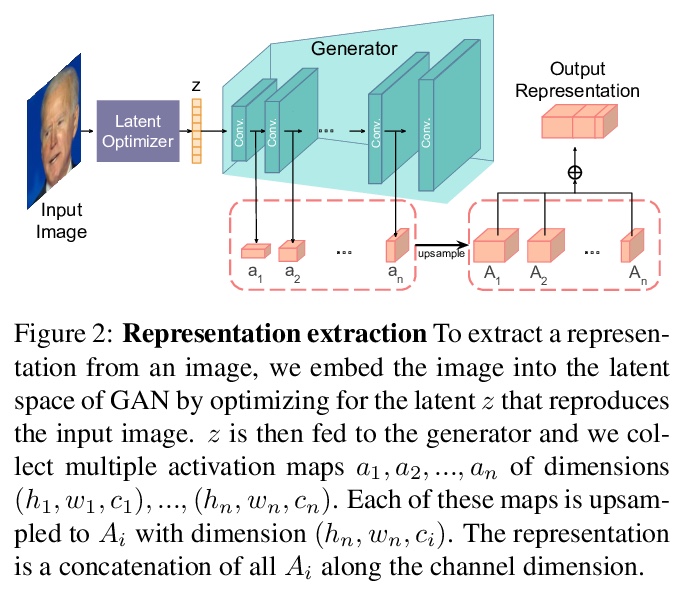
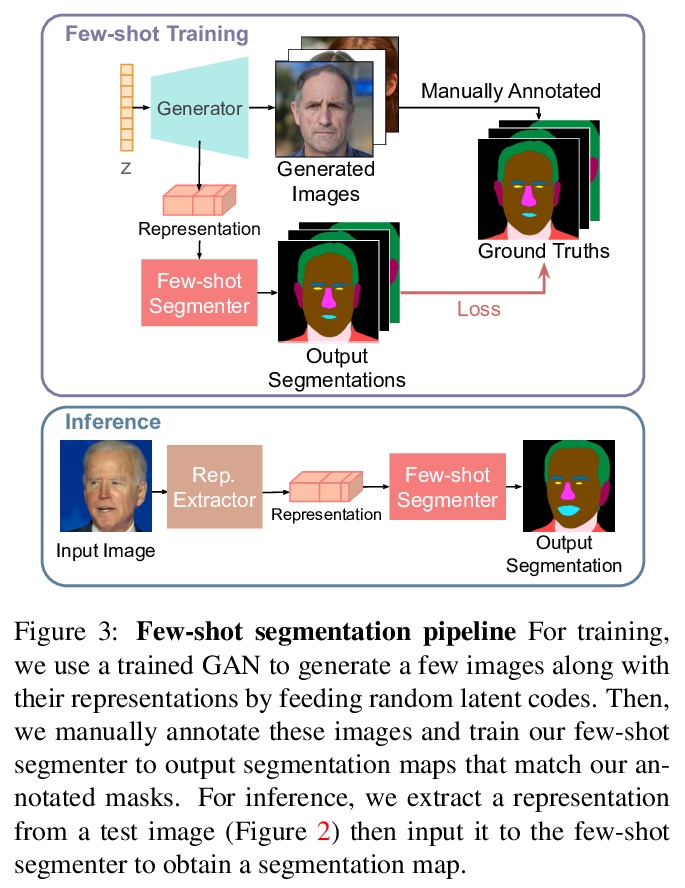
[CV] Repurposing GANs for One-shot Semantic Part Segmentation
面向单样本语义部分分割的再利用GAN
N Tritrong, P Rewatbowornwong, S Suwajanakorn
[VISTEC]
https://weibo.com/1402400261/K5ulKFnQ8


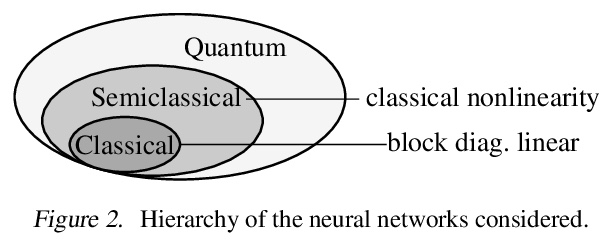
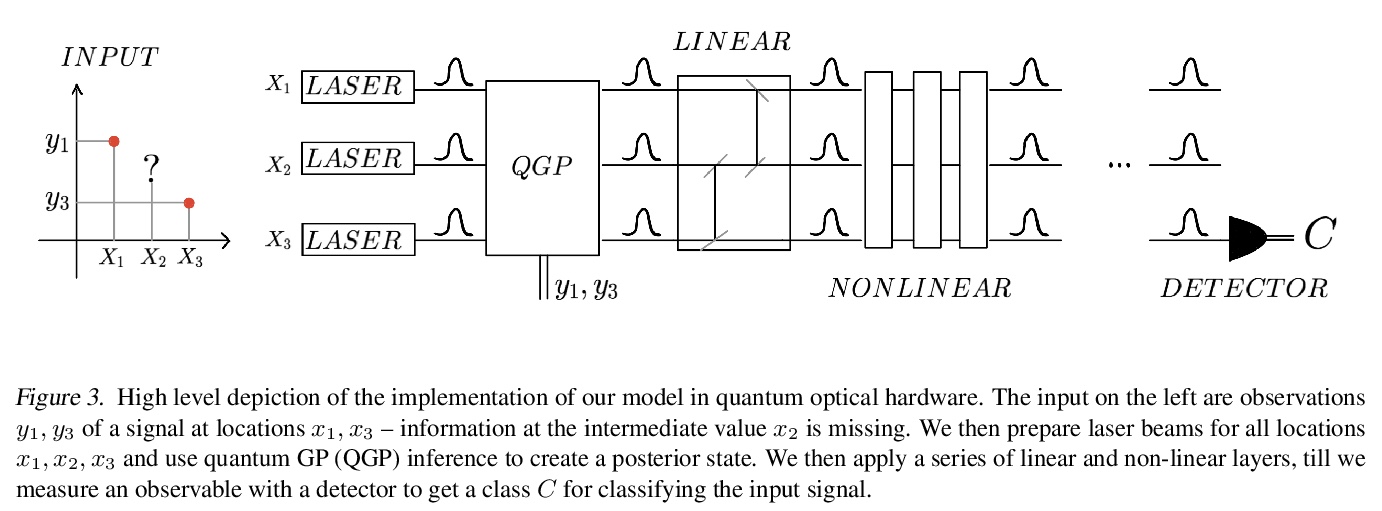
[LG] The Hintons in your Neural Network: a Quantum Field Theory View of Deep Learning
神经网络中的信元(Hintons)粒子:用量子场论看深度学习
R Bondesan, M Welling
[Qualcomm AI Research]
https://weibo.com/1402400261/K5unBioDW

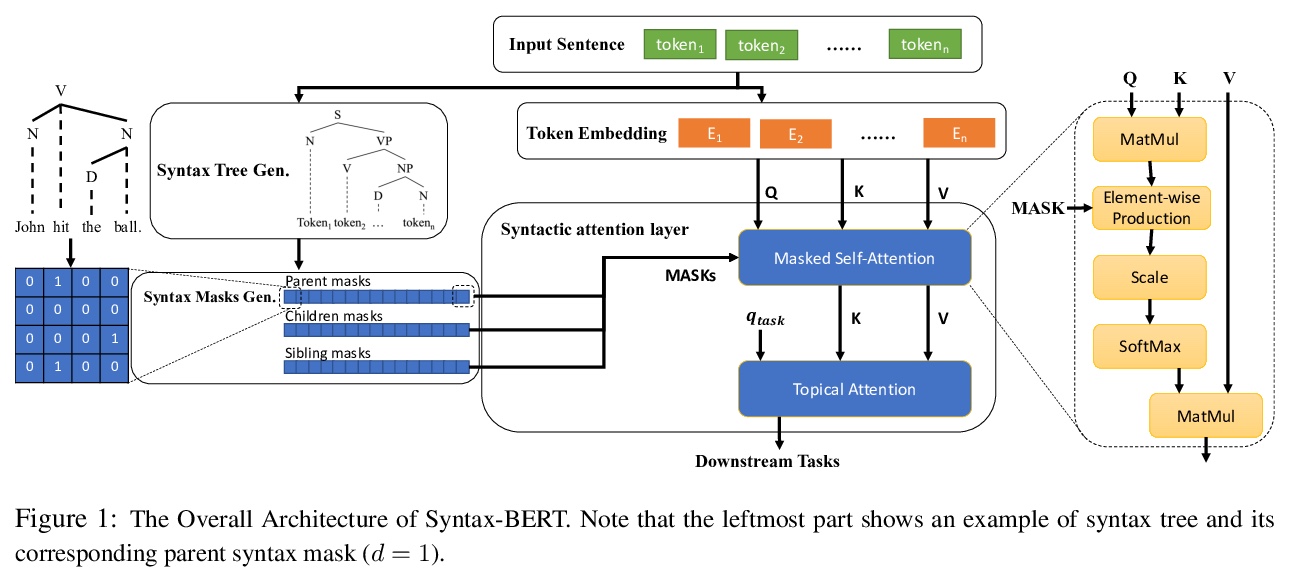
[CL] Syntax-BERT: Improving Pre-trained Transformers with Syntax Trees
Syntax-BERT;用语法树改进预训练Transformer
J Bai, Y Wang, Y Chen, Y Yang, J Bai, J Yu, Y Tong
[Peking University & Microsoft Research Asia & Chinese Academy of Sciences]
https://weibo.com/1402400261/K5uqWsVy1

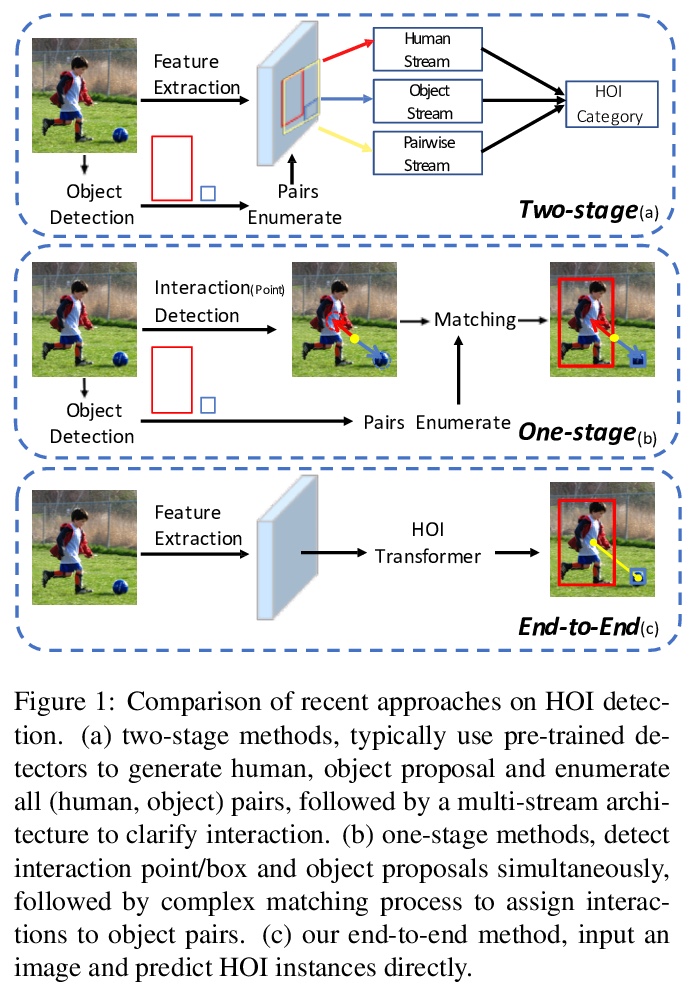
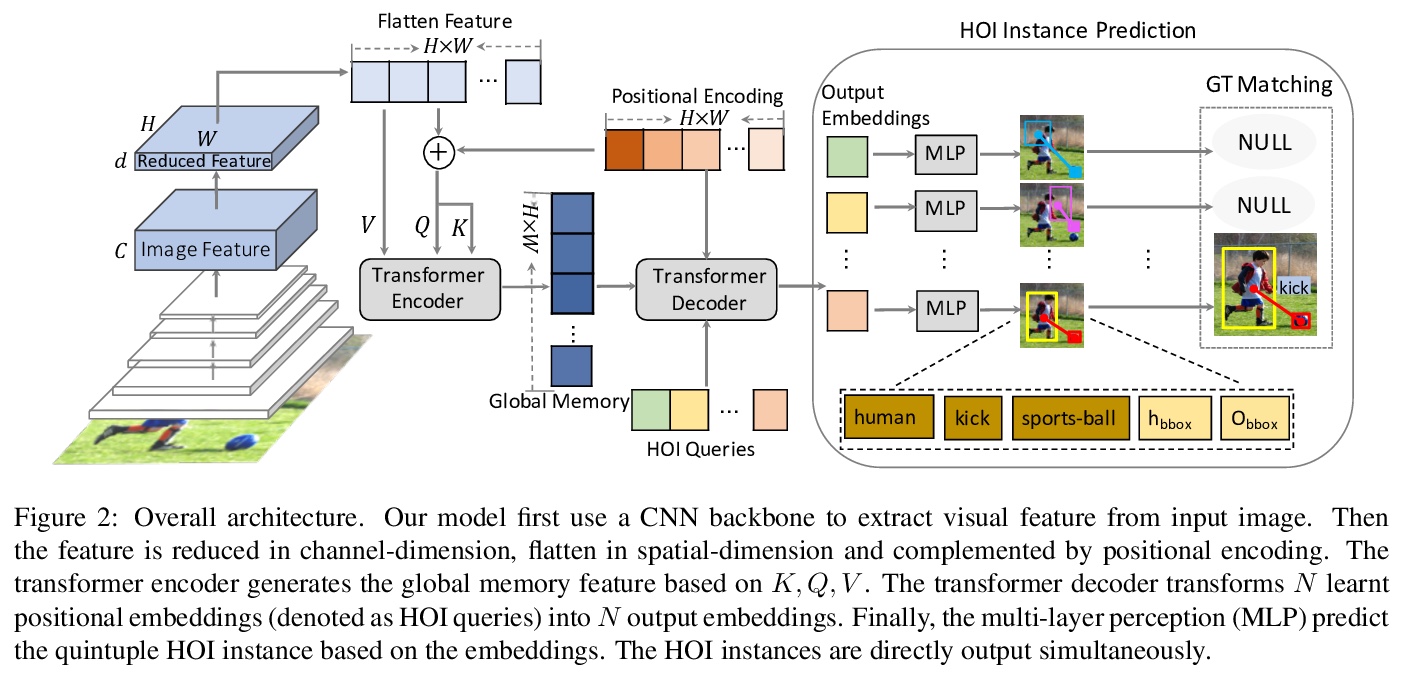
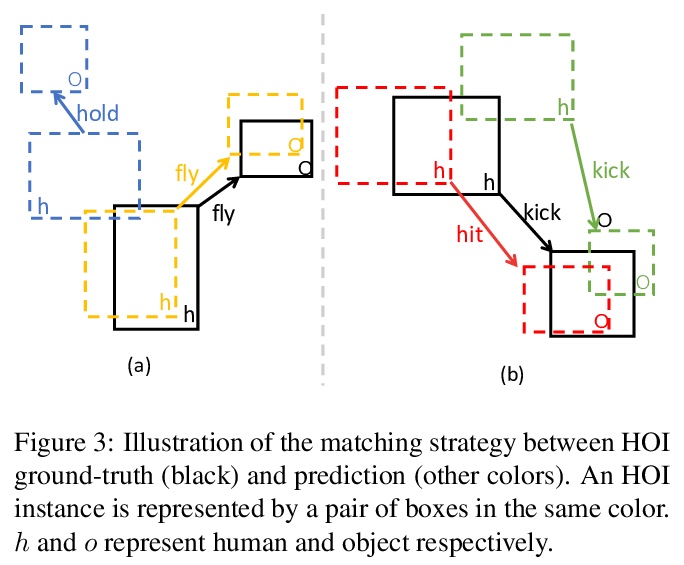
[CV] End-to-End Human Object Interaction Detection with HOI Transformer
基于HOI Transformer的端到端人体交互检测
C Zou, B Wang, Y Hu, J Liu, Q Wu, Y Zhao, B Li, C Zhang, C Zhang, Y Wei, J Sun
[MEGVII Technology]
https://weibo.com/1402400261/K5usqFym0

若有收获,就点个赞吧
0 人点赞
