- 1、[CV] RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
- 2、[AI] Generative Art Using Neural Visual Grammars and Dual Encoders
- 3、[CL] Semantic Journeys: Quantifying Change in Emoji Meaning from 2012-2018
- 4、[CV] Self-Supervised Multi-Frame Monocular Scene Flow
- 5、[CV] Texture for Colors: Natural Representations of Colors Using Variable Bit-Depth Textures
- [AI] Foundations of Intelligence in Natural and Artificial Systems: A Workshop Report
- [CV] Visual Composite Set Detection Using Part-and-Sum Transformers
- [AS] Self-Supervised Learning from Automatically Separated Sound Scenes
- [CV] Real-time Deep Dynamic Characters
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
X Ding, X Zhang, J Han, G Ding
[Tsinghua University & MEGVII Technology & Aberystwyth University]
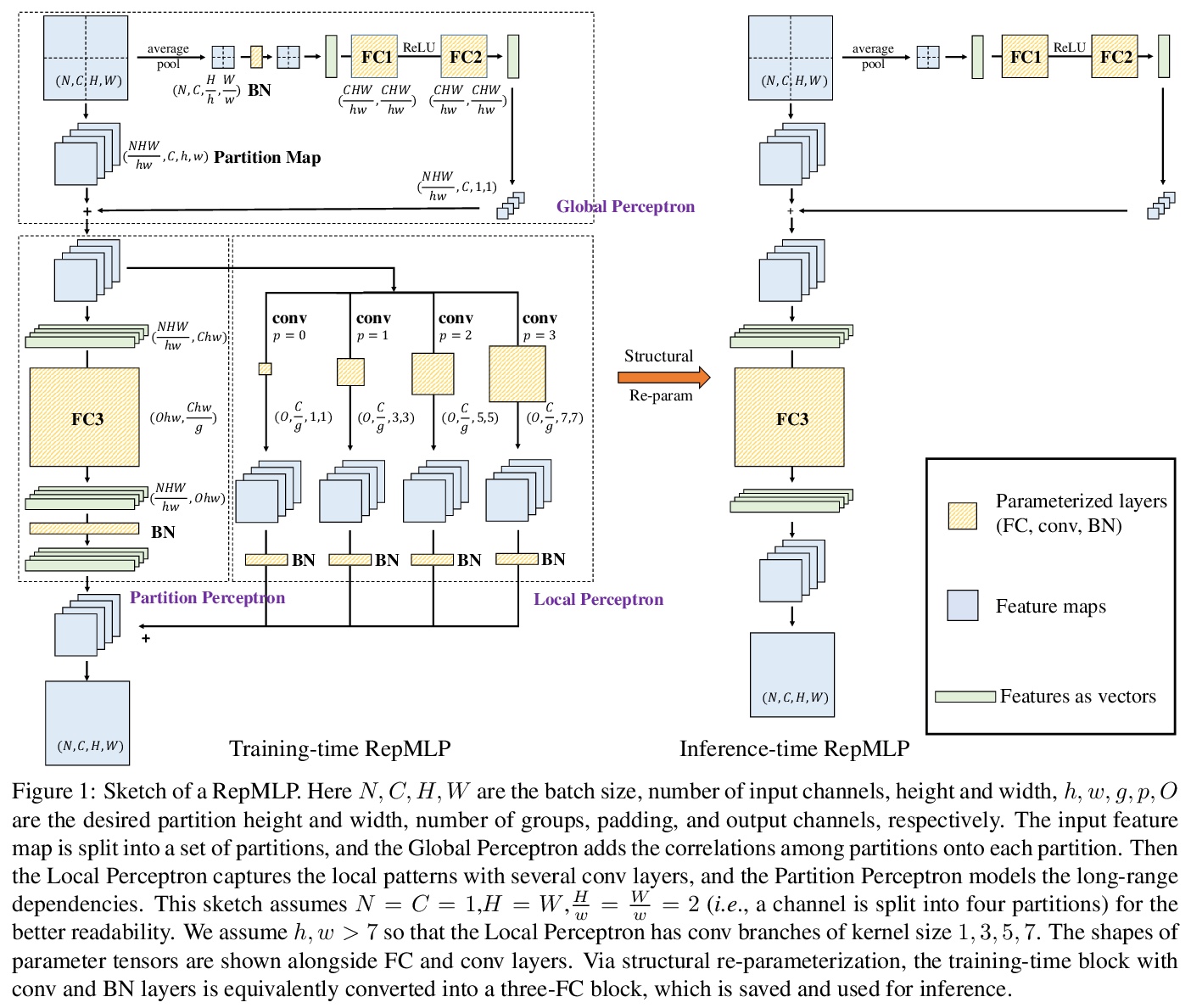
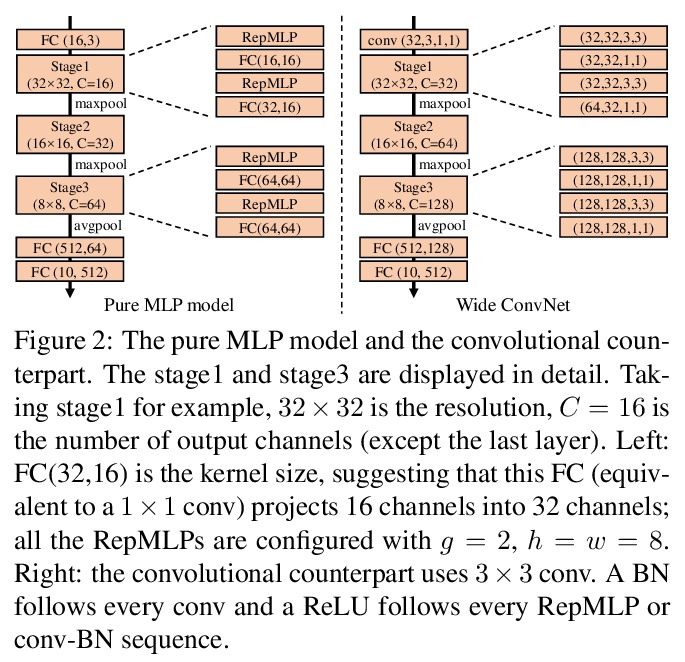
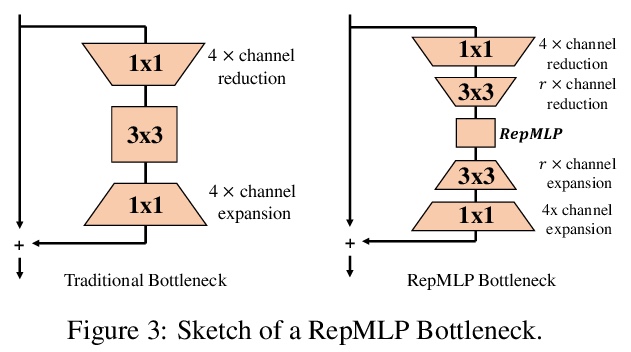
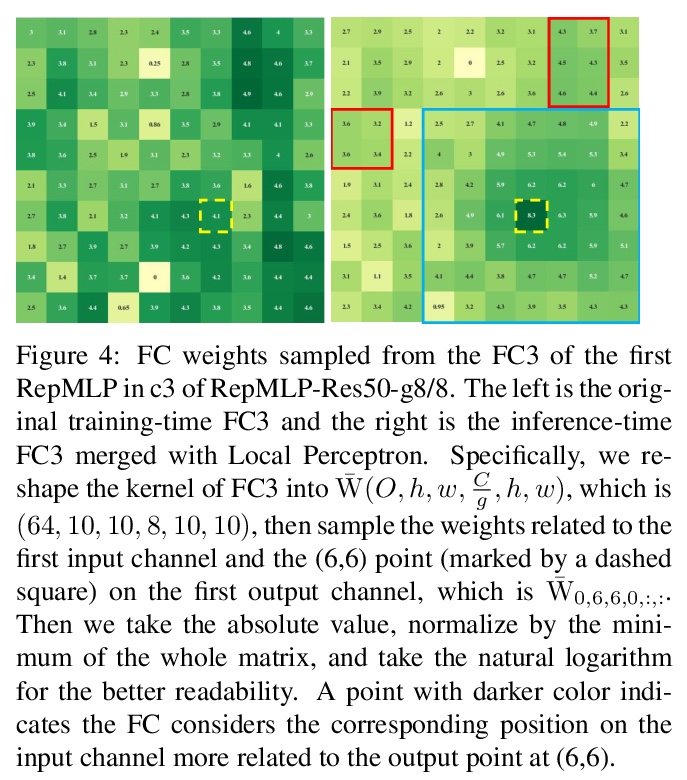
RepMLP:面向图像识别的卷积重参数化全连接层。提出用于图像识别的多层感知器式神经网络构件RepMLP,由一系列全连接(FC)层组成。与卷积层相比,全连接层效率更高,能更好地模拟长程依赖关系和位置模式,但对局部结构的捕捉能力更差,因此通常不太适合用于图像识别。本文提出一种结构重参数化技术,将局部先验添加到全连接层,简单、与平台无关、且可微,没有额外的推理成本,可在图像识别中发挥强大作用。训练期间在RepMLP内构建卷积层,并将其合并到FC中进行推理。在CIFAR上,简单的纯MLP模型显示出与CNN非常接近的性能。通过在传统CNN中插入RepMLP,将ResNets在ImageNet上的准确率提高了1.8%,在人脸识别上提高了2.9%,在Cityscapes上提高了2.3%的mIoU,且FLOPs较低。RepMLP是为那些主要关注推理吞吐量和准确性、而不是参数数量的应用场景而设计的,
We propose RepMLP, a multi-layer-perceptron-style neural network building block for image recognition, which is composed of a series of fully-connected (FC) layers. Compared to convolutional layers, FC layers are more efficient, better at modeling the long-range dependencies and positional patterns, but worse at capturing the local structures, hence usually less favored for image recognition. We propose a structural re-parameterization technique that adds local prior into an FC to make it powerful for image recognition. Specifically, we construct convolutional layers inside a RepMLP during training and merge them into the FC for inference. On CIFAR, a simple pure-MLP model shows performance very close to CNN. By inserting RepMLP in traditional CNN, we improve ResNets by 1.8% accuracy on ImageNet, 2.9% for face recognition, and 2.3% mIoU on Cityscapes with lower FLOPs. Our intriguing findings highlight that combining the global representational capacity and positional perception of FC with the local prior of convolution can improve the performance of neural network with faster speed on both the tasks with translation invariance (e.g., semantic segmentation) and those with aligned images and positional patterns (e.g., face recognition). The code and models are available atthis https URL.
https://weibo.com/1402400261/KeiOx3TqQ
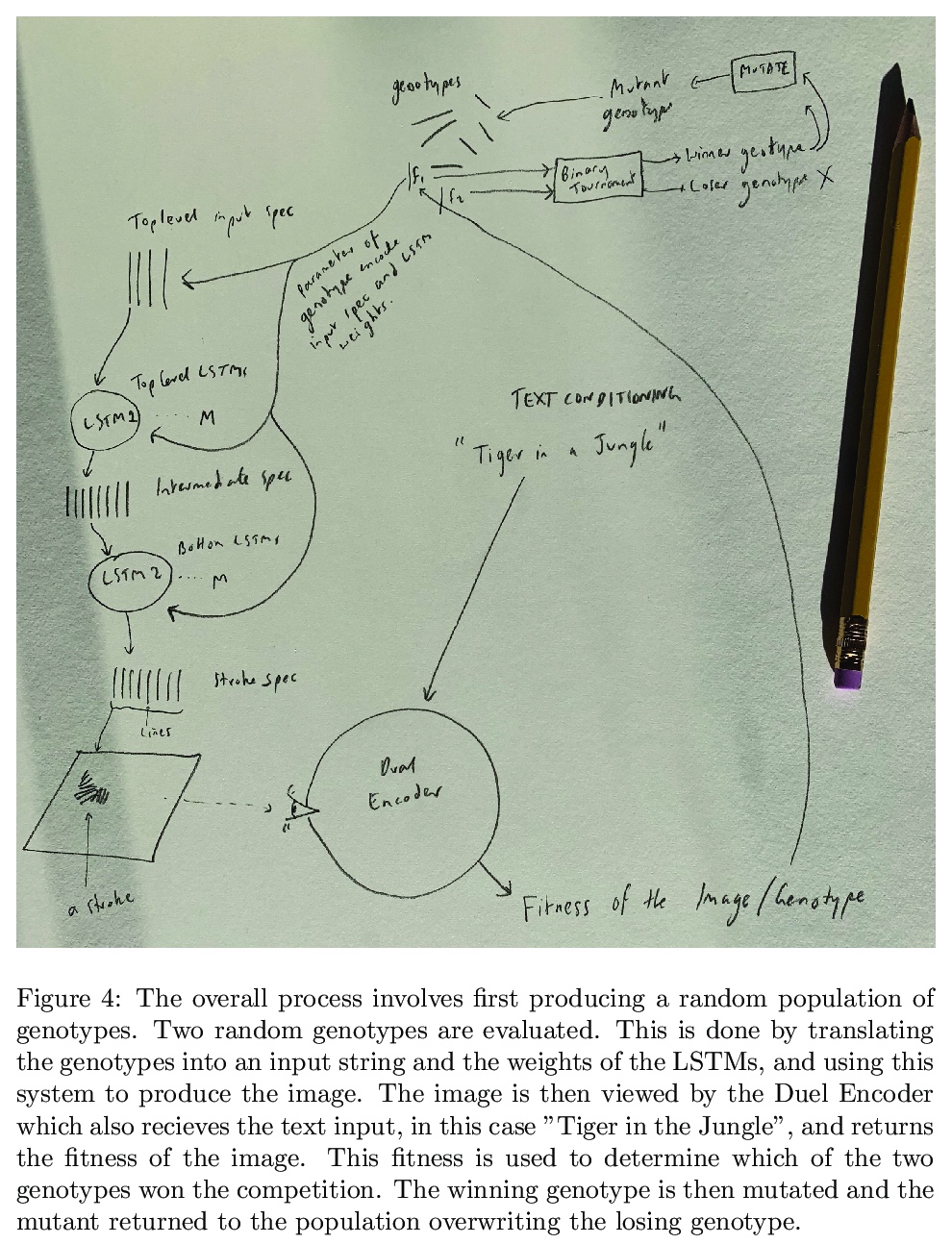
2、[AI] Generative Art Using Neural Visual Grammars and Dual Encoders
C Fernando, S. M. A Eslami, J Alayrac, P Mirowski, D Banarse, S Osindero
[DeepMind]
基于神经视觉语法和双编码器的生成式艺术。虽然科学方法数量有限,但艺术方法的数量几乎与艺术家一样多,艺术过程似乎位于开放性的顶层。为了开始了解艺术创作的部分过程,尝试将其部分自动化是有帮助的。本文描述了一种生成艺术的新算法,允许用户输入一个文本字符串,并对这个字符串做出创造性的反应,输出一个解释该字符串的图像。用分层神经Lindenmeyer系统来演化图像,并用互联网数十亿图像及其相关文本上训练的图像文本双编码器来评估这些图像。这样做的过程中,可以进入并控制一个艺术过程的实例,分析艺术过程的哪些方面成为算法的任务,而哪些元素仍然是艺术家的责任。
Whilst there are perhaps only a few scientific methods, there seem to be almost as many artistic methods as there are artists. Artistic processes appear to inhabit the highest order of open-endedness. To begin to understand some of the processes of art making it is helpful to try to automate them even partially. In this paper, a novel algorithm for producing generative art is described which allows a user to input a text string, and which in a creative response to this string, outputs an image which interprets that string. It does so by evolving images using a hierarchical neural Lindenmeyer system, and evaluating these images along the way using an image text dual encoder trained on billions of images and their associated text from the internet. In doing so we have access to and control over an instance of an artistic process, allowing analysis of which aspects of the artistic process become the task of the algorithm, and which elements remain the responsibility of the artist.
https://weibo.com/1402400261/KeiUgcv3I



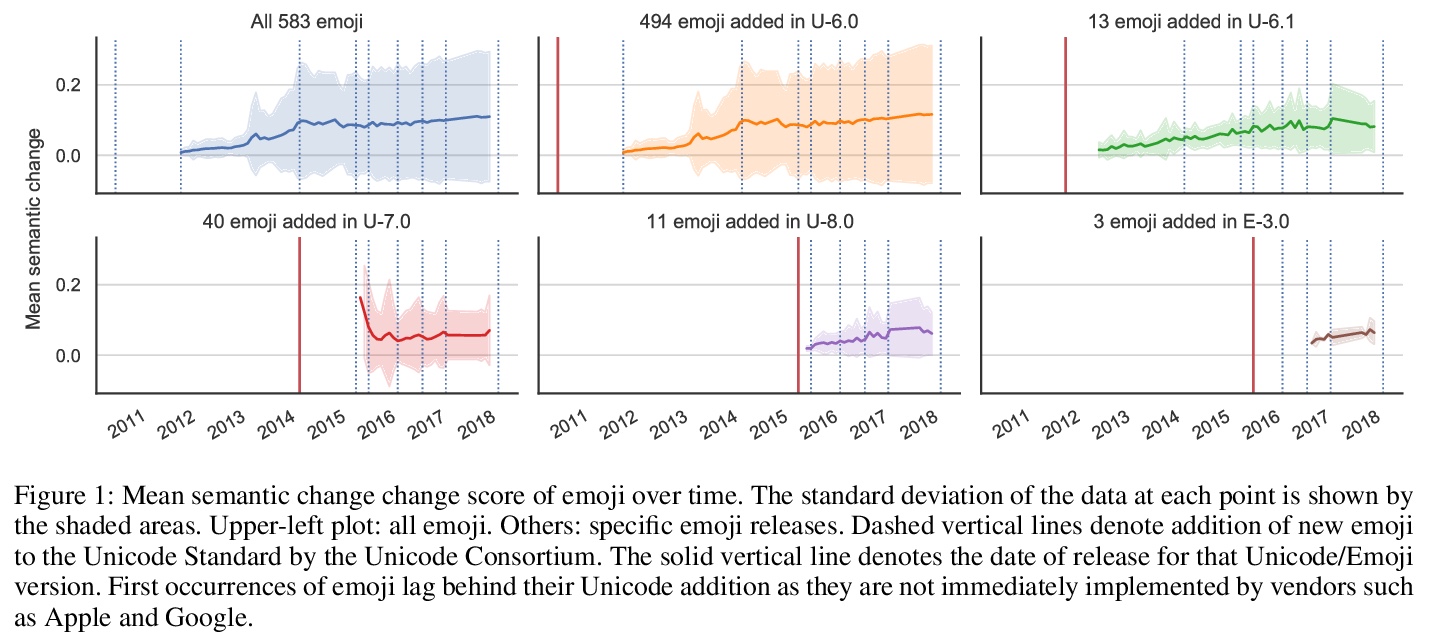
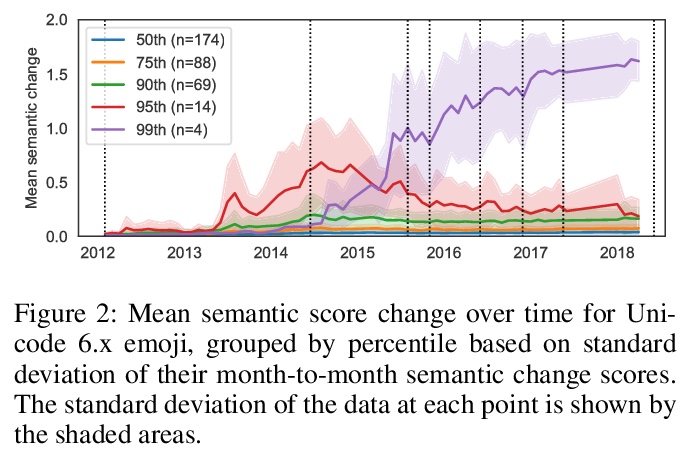
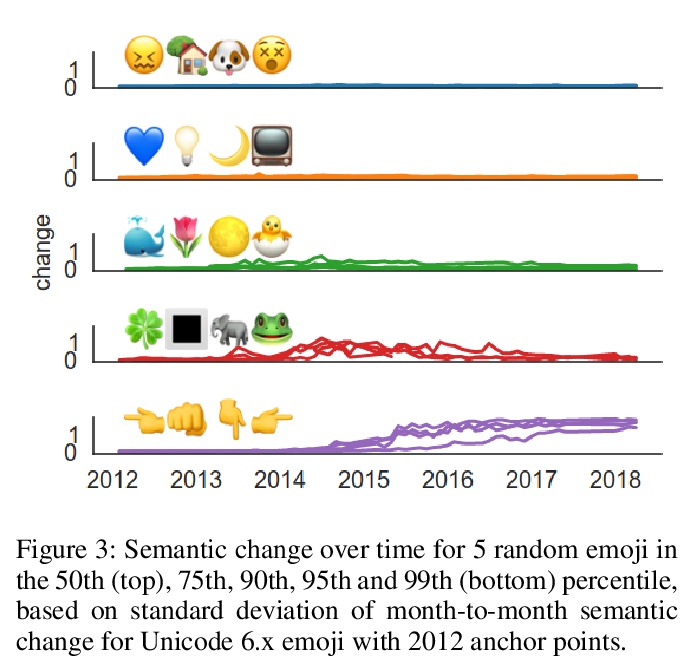
3、[CL] Semantic Journeys: Quantifying Change in Emoji Meaning from 2012-2018
A Robertson, F F Liza, D Nguyen, B McGillivray, S A. Hale
[University of Edinburgh & University of Essex & Utrecht University & University of Cambridge & University of Oxford]
语义之旅:2012-2018年表情符号含义演化量化研究。迄今为止,表情符号的语义一直是从静态角度考虑的。本文对表情符号的语义如何随时间演化进行纵向研究,将计算语言学的技术应用于2012-2018六年的Twitter数据,基于NLP在表征学习方面的进展和测量语义变化的方法。发现大多数表情符号保持稳定,只有少数表情符号在这期间似乎经历了实质性的语义变化。确定了表情符号语义发展的五种模式,并发现有证据表明,表情符号越不抽象,就越有可能发生语义变化。详细分析了选定的表情符号,研究了季节性和世界事件对表情符号语义的影响。
The semantics of emoji has, to date, been considered from a static perspective. We offer the first longitudinal study of how emoji semantics changes over time, applying techniques from computational linguistics to six years of Twitter data. We identify five patterns in emoji semantic development and find evidence that the less abstract an emoji is, the more likely it is to undergo semantic change. In addition, we analyse select emoji in more detail, examining the effect of seasonality and world events on emoji semantics. To aid future work on emoji and semantics, we make our data publicly available along with a web-based interface that anyone can use to explore semantic change in emoji.
https://weibo.com/1402400261/KeiYECVtd

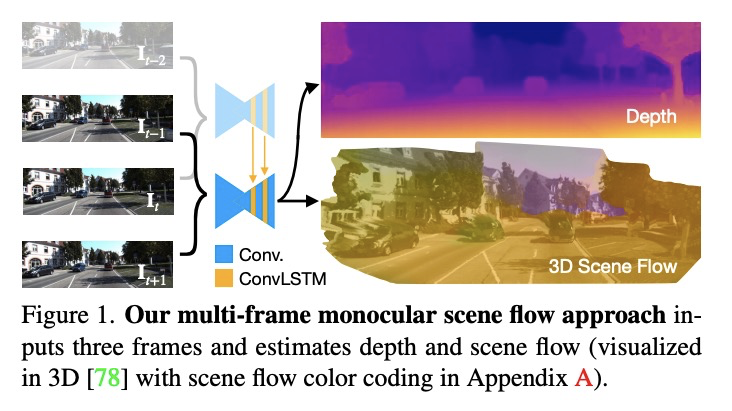
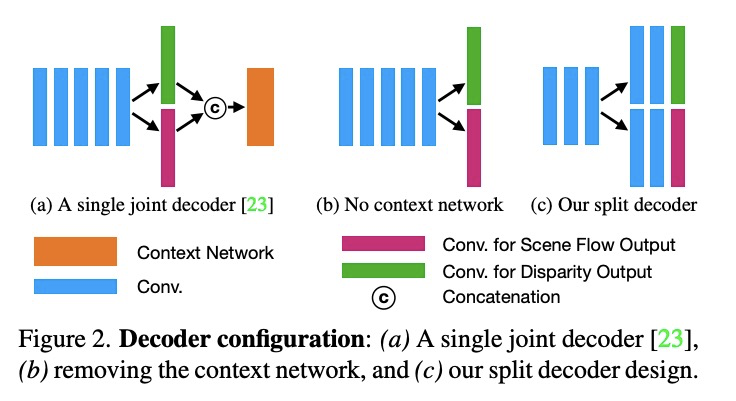
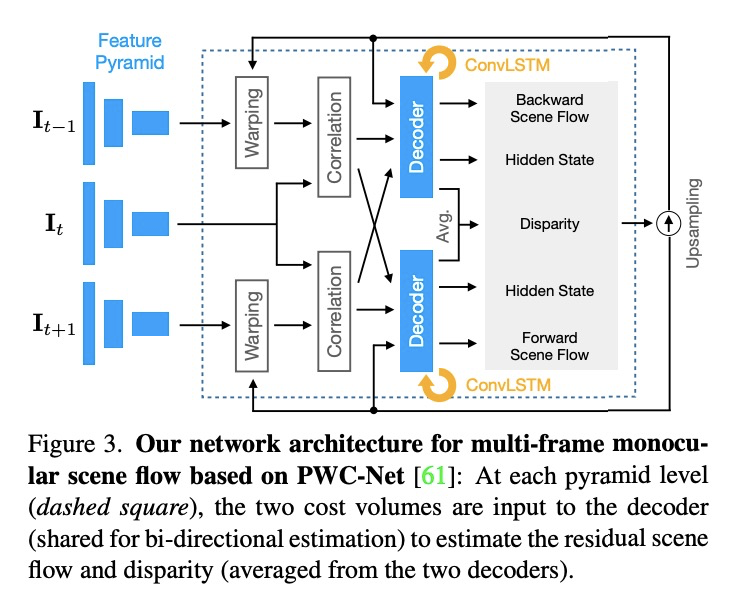
4、[CV] Self-Supervised Multi-Frame Monocular Scene Flow
J Hur, S Roth
[TU Darmstadt]
自监督多帧单目场景流。由于简单、经济的捕捉设置,从单目图像序列估计3D场景流越来越受到关注。由于问题的严重不确定性,当前方法的准确性受到了限制,尤其是高效的实时方法。本文提出一种基于自监督学习的多帧单目场景流网络,在保留实时效率的同时,比之前的网络提高了准确性。基于先进的双帧基线与分割解码器的设计,提出了(i)使用三帧输入和卷积LSTM连接的多帧模型,(ii)采用occlusion-aware census loss以提高准确性,以及(iii)梯度分离策略以提高训练稳定性。在KITTI数据集上,基于自监督学习的单目场景流方法达到了最先进的准确性。
Estimating 3D scene flow from a sequence of monocular images has been gaining increased attention due to the simple, economical capture setup. Owing to the severe illposedness of the problem, the accuracy of current methods has been limited, especially that of efficient, real-time approaches. In this paper, we introduce a multi-frame monocular scene flow network based on self-supervised learning, improving the accuracy over previous networks while retaining real-time efficiency. Based on an advanced twoframe baseline with a split-decoder design, we propose (i) a multi-frame model using a triple frame input and convolutional LSTM connections, (ii) an occlusion-aware census loss for better accuracy, and (iii) a gradient detaching strategy to improve training stability. On the KITTI dataset, we observe state-of-the-art accuracy among monocular scene flow methods based on self-supervised learning.
https://weibo.com/1402400261/Kej31kpxO

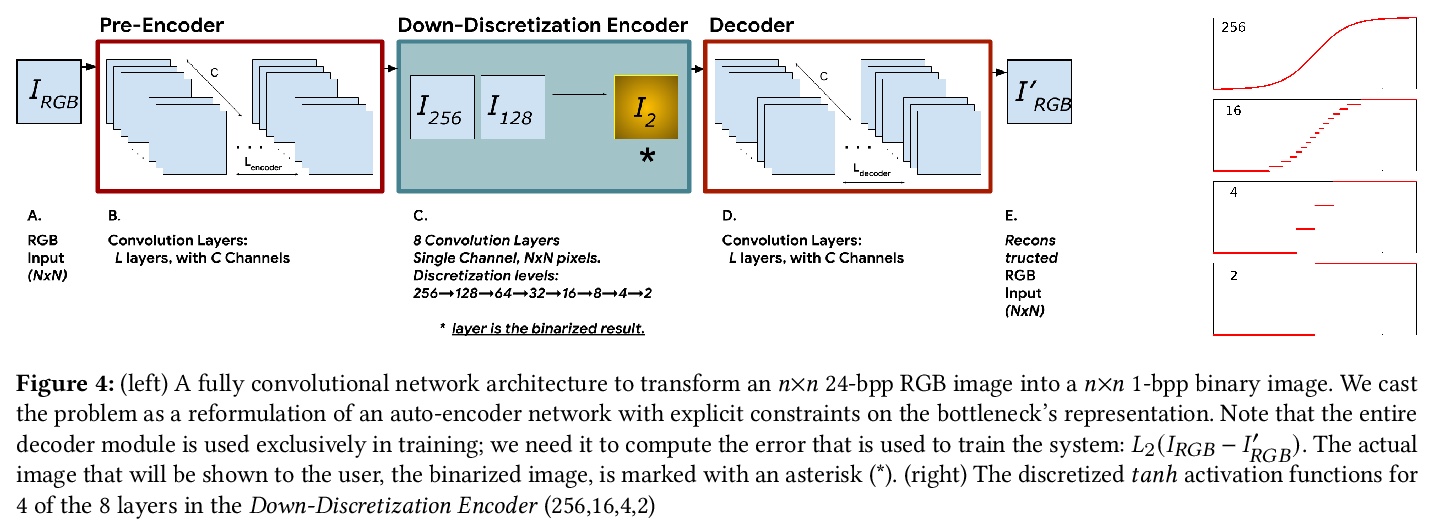
5、[CV] Texture for Colors: Natural Representations of Colors Using Variable Bit-Depth Textures
S Baluja
[Google]
用纹理表示颜色:基于可变比特深度纹理的颜色自然表示。将彩色和灰度图像转换为每像素单比特的二进制对应图像已经有不少方法。通常情况下,目标是增强原始图像的特定属性,使其更适合于分析。而当产生的二进制图像要供人观看时,必须考虑美学问题。半色调等二值化技术,被广泛用于模拟原始图像的强度轮廓。本文提出一种自动化方法,将图像转换为一组二进制纹理,这些纹理不仅代表了原始图像的强度,也代表了原始图像的颜色。该方法的基础是信息留存:创建一组纹理,允许仅从二值化表示中重建原始图像的颜色。提出一些技术,以确保所创建的纹理不会在视觉上产生干扰,保留图像的强度轮廓,并且是自然的,将感知上相似的颜色集映射到相似的图案上。该方法使用深度神经网络,完全自监督,不需要好坏二值化的例子。在对各种图像源进行测试时,该系统产生了具有美感的二进制图像。
Numerous methods have been proposed to transform color and grayscale images to their single bit-per-pixel binary counterparts. Commonly, the goal is to enhance specific attributes of the original image to make it more amenable for analysis. However, when the resulting binarized image is intended for human viewing, aesthetics must also be considered. Binarization techniques, such as half-toning, stippling, and hatching, have been widely used for modeling the original image’s intensity profile. We present an automated method to transform an image to a set of binary textures that represent not only the intensities, but also the colors of the original. The foundation of our method is information preservation: creating a set of textures that allows for the reconstruction of the original image’s colors solely from the binarized representation. We present techniques to ensure that the textures created are not visually distracting, preserve the intensity profile of the images, and are natural in that they map sets of colors that are perceptually similar to patterns that are similar. The approach uses deep-neural networks and is entirely self-supervised; no examples of good vs. bad binarizations are required. The system yields aesthetically pleasing binary images when tested on a variety of image sources.
https://weibo.com/1402400261/Kej9shvmE



另外几篇值得关注的论文:
[AI] Foundations of Intelligence in Natural and Artificial Systems: A Workshop Report
自然和人工系统中的智能基础:研讨会报告
T Millhouse, M Moses, M Mitchell
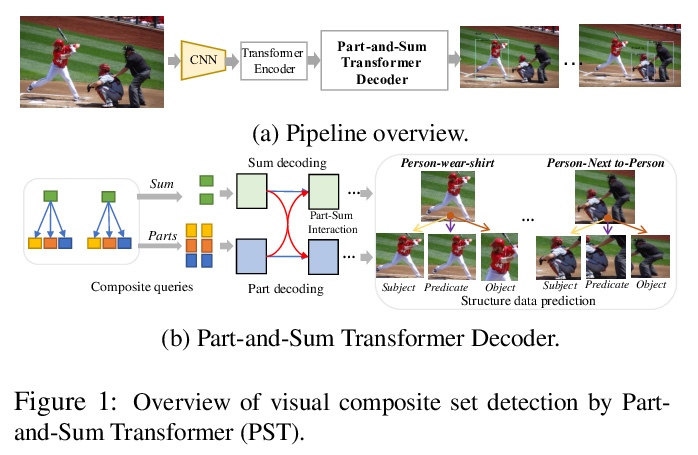
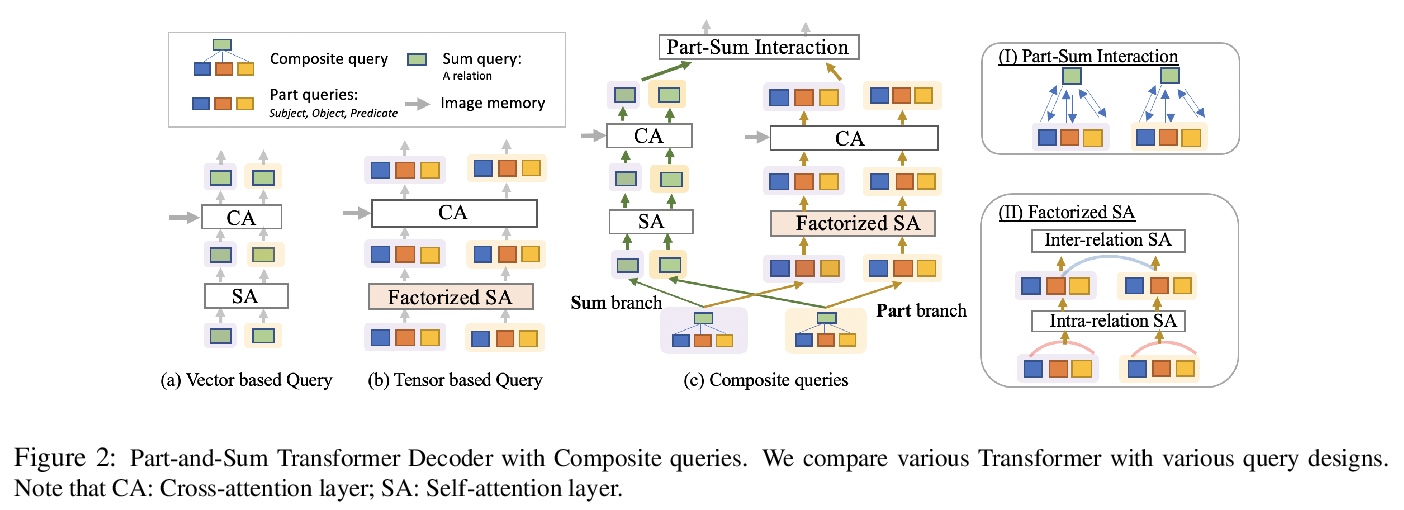
[CV] Visual Composite Set Detection Using Part-and-Sum Transformers
基于部分-相加Transformer的视觉复合集检测
Q Dong, Z Tu, H Liao, Y Zhang, V Mahadevan, S Soatto
[Amazon Web Services]
https://weibo.com/1402400261/KejcLmRBS


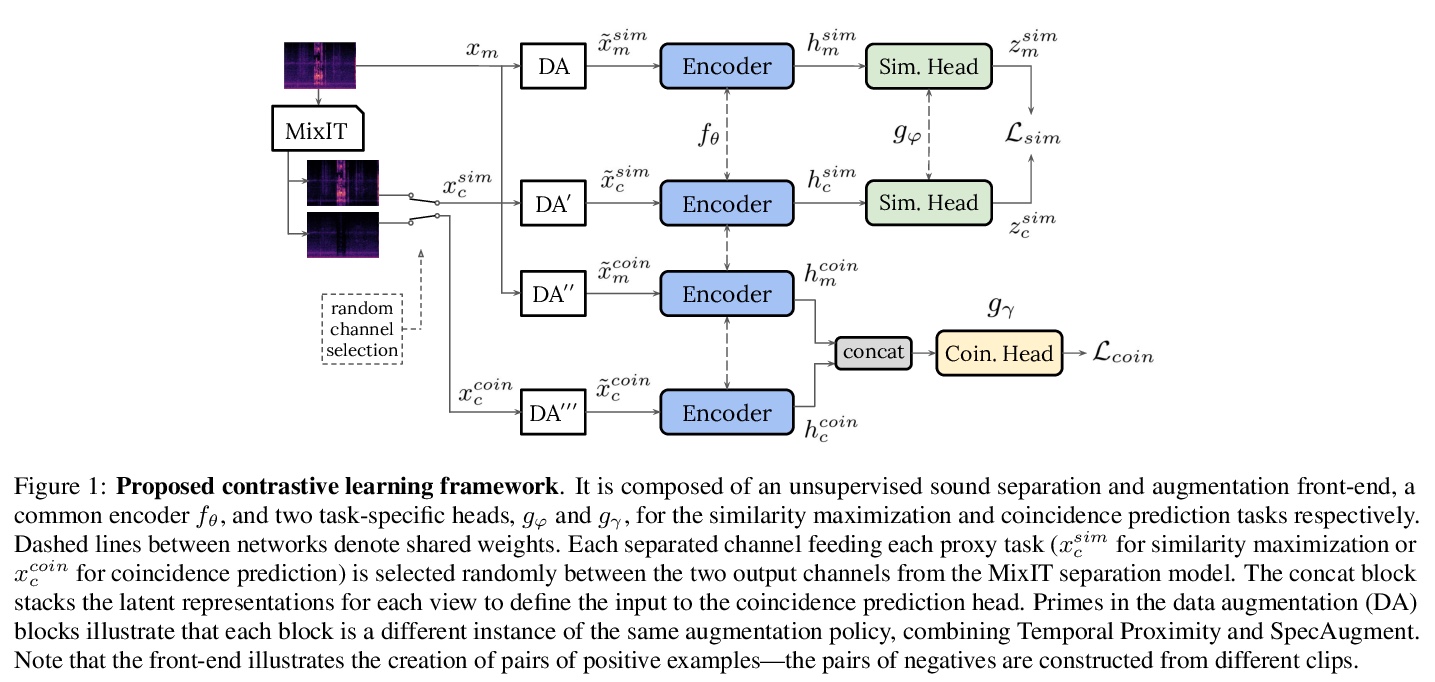
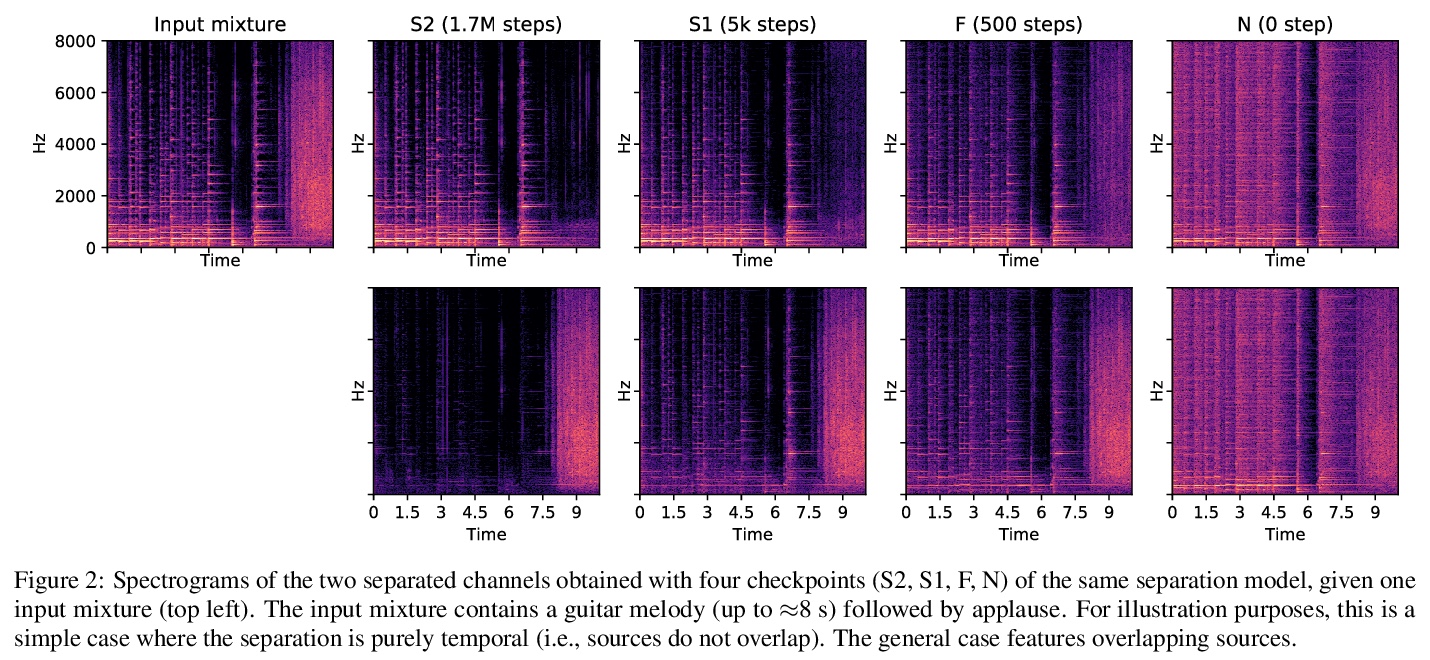
[AS] Self-Supervised Learning from Automatically Separated Sound Scenes
自动分离声音场景自监督学习
E Fonseca, A Jansen, D P. W. Ellis, S Wisdom, M Tagliasacchi, J R. Hershey, M Plakal, S Hershey, R. C Moore, X Serra
[Universitat Pompeu Fabra & Google Research]
https://weibo.com/1402400261/KejeNbiti
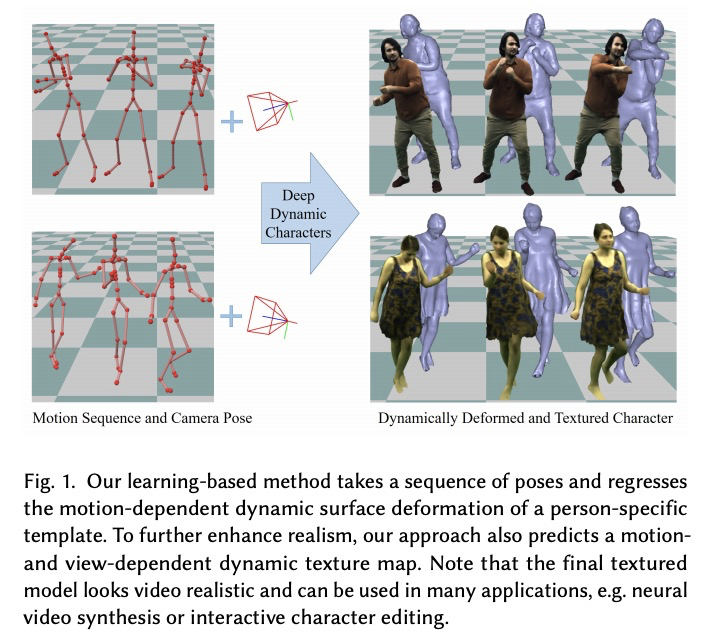
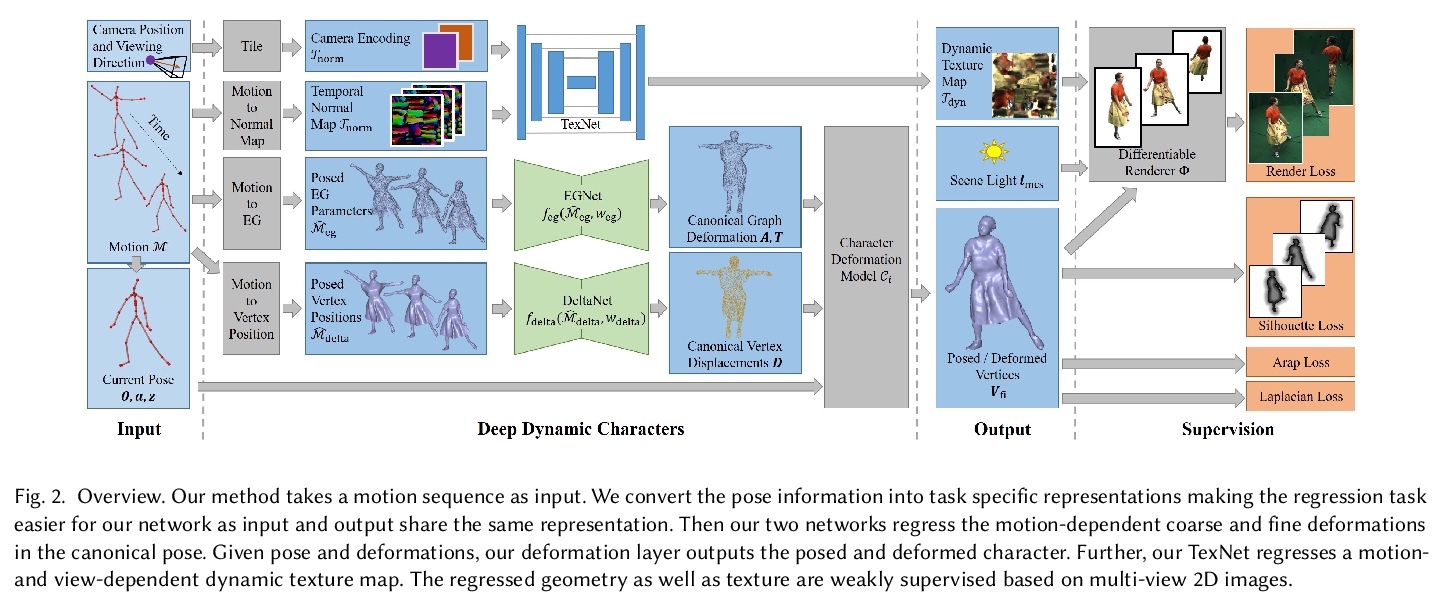
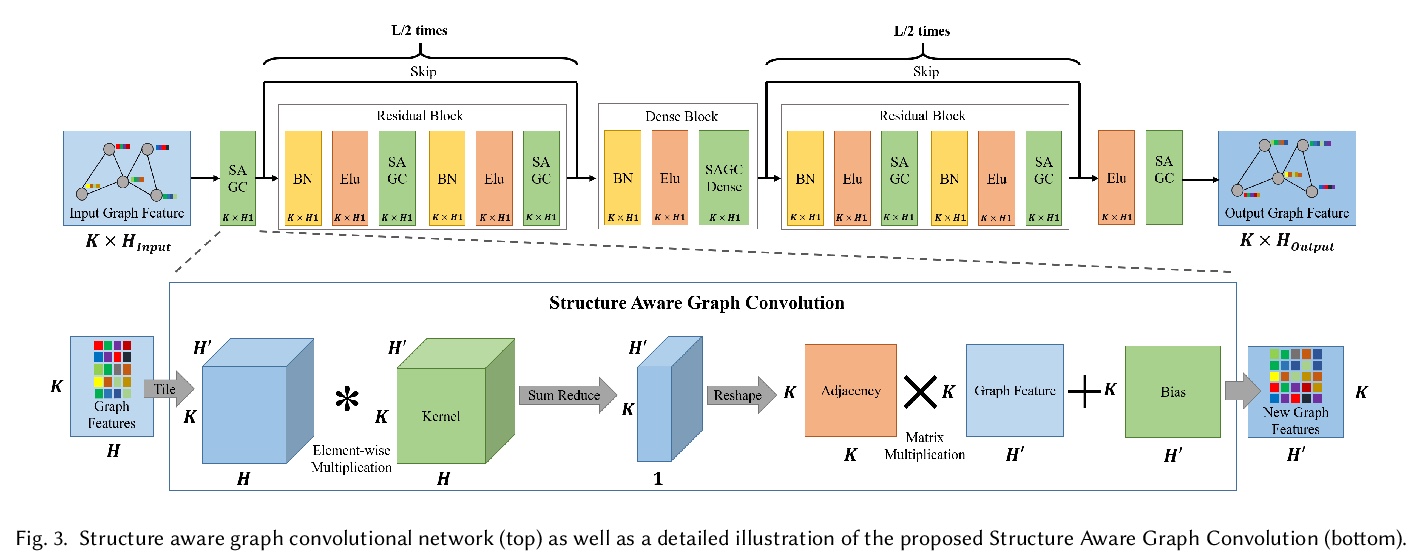
[CV] Real-time Deep Dynamic Characters
实时深度动态角色
M Habermann, L Liu, W Xu, M Zollhoefer, G Pons-Moll, C Theobalt
[Max Planck Institute for Informatics & Facebook Reality Labs]
https://weibo.com/1402400261/KejgH4jP7


若有收获,就点个赞吧
0 人点赞
