- LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
- 1、[CV] Playable Video Generation
- 2、[CV] DOC2PPT: Automatic Presentation Slides Generation from Scientific Documents
- 3、[CV] Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
- 4、[LG] On the Origin of Implicit Regularization in Stochastic Gradient Descent
- 5、[CV] Multi-Modal Aesthetic Assessment for MObile Gaming Image
- [CV] Object Detection Made Simpler by Eliminating Heuristic NMS
- [CV] Vx2Text: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs
- [CL] Disembodied Machine Learning: On the Illusion of Objectivity in NLP
- [CL] Syntactic Nuclei in Dependency Parsing — A Multilingual Exploration
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
(*表示值得重点关注)
1、[CV] Playable Video Generation
W Menapace, S Lathuilière, S Tulyakov, A Siarohin, E Ricci
[University of Trento & Telecom Paris & Snap Inc]
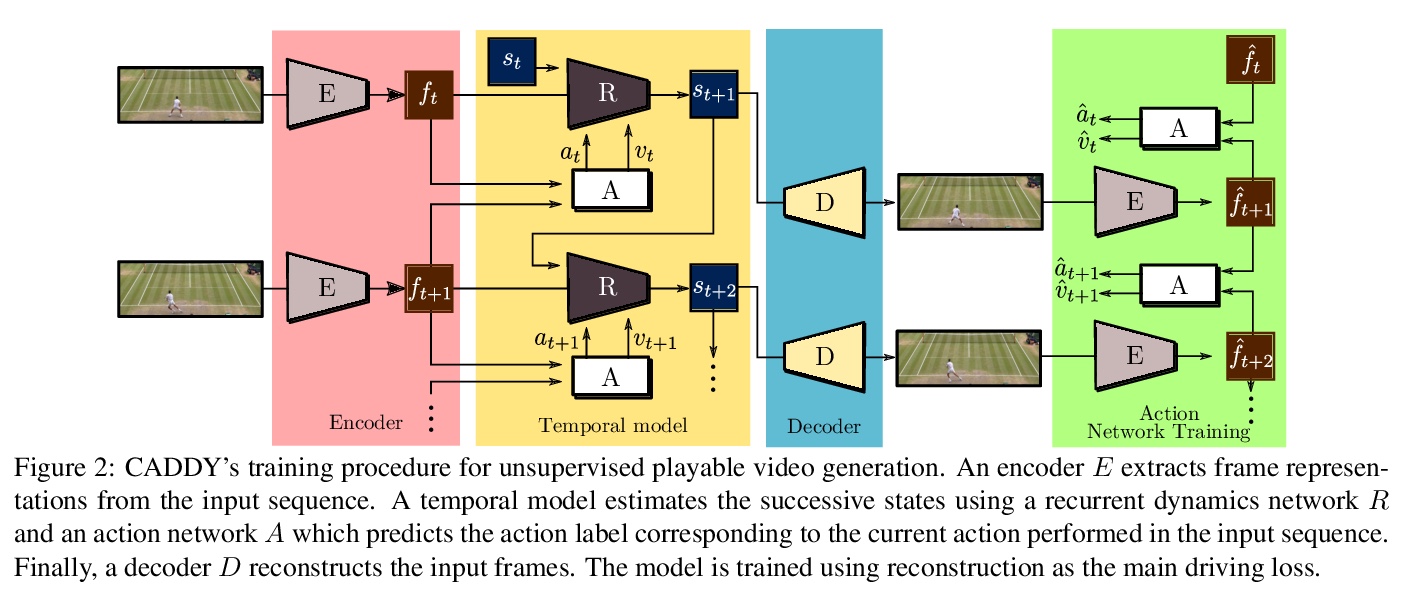
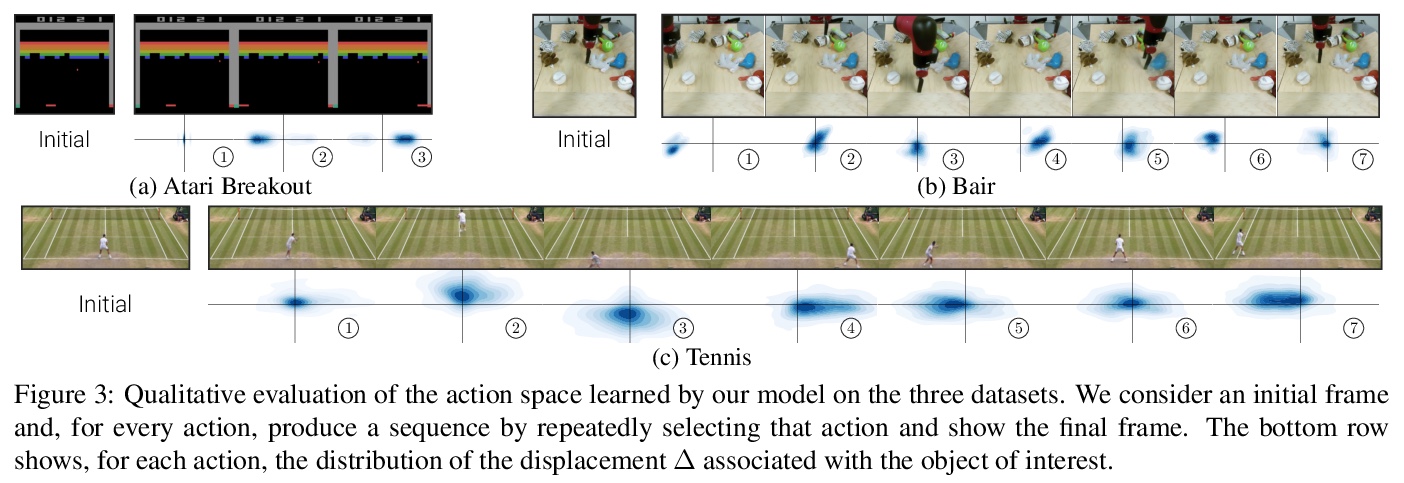
像打游戏一样可操控的视频生成。介绍了可操控视频生成(PVG)无监督学习问题。在PVG中,目标是让用户通过在每个时间步骤选择一个离散动作,控制生成的视频,像玩视频游戏一样,其难度在于学习语义一致的动作,以及根据用户输入生成逼真视频。提出一种新的基于编-解码器架构的自监督PVG框架CADDY,将预测的动作标签作为瓶颈,在大型未标记视频数据集上以自监督方式进行训练。约束网络学习一个丰富的动作空间,将生成视频重建损失作为主要驱动损失。在三个不同的数据集上对CADDY进行了评价,展示了最先进性能,可学习一组丰富动作,为用户提供类似游戏的体验来控制生成视频。
This paper introduces the unsupervised learning problem of playable video generation (PVG). In PVG, we aim at allowing a user to control the generated video by selecting a discrete action at every time step as when playing a video game. The difficulty of the task lies both in learning semantically consistent actions and in generating realistic videos conditioned on the user input. We propose a novel framework for PVG that is trained in a self-supervised manner on a large dataset of unlabelled videos. We employ an encoder-decoder architecture where the predicted action labels act as bottleneck. The network is constrained to learn a rich action space using, as main driving loss, a reconstruction loss on the generated video. We demonstrate the effectiveness of the proposed approach on several datasets with wide environment variety. Further details, code and examples are available on our project page > this http URL.
https://weibo.com/1402400261/JFvMgt4t2


2、[CV] DOC2PPT: Automatic Presentation Slides Generation from Scientific Documents
T Fu, W Y Wang, D McDuff, Y Song
[UC Santa Barbara & Microsoft Research]
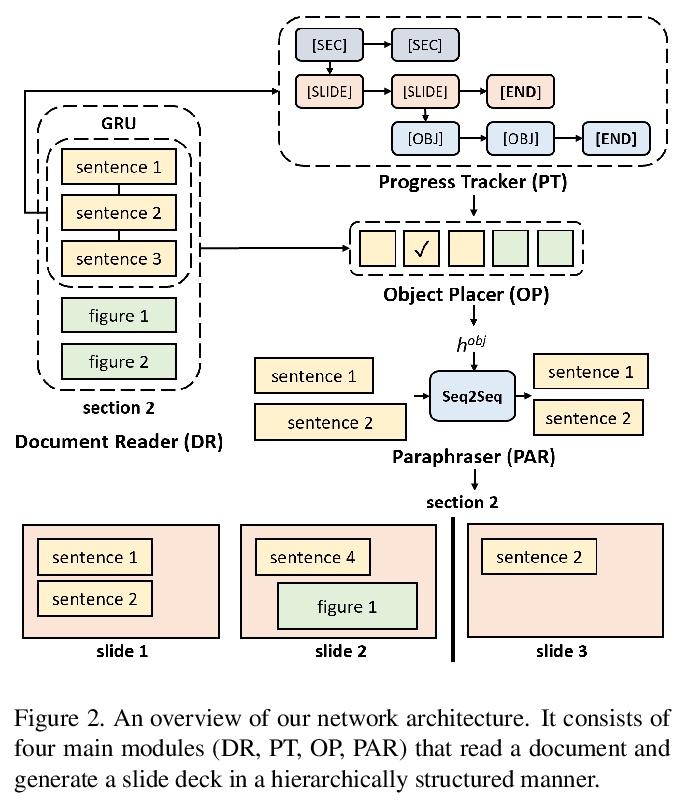
DOC2PPT: 从科研论文自动生成PPT。提出一种新的文档到幻灯片生成的任务和方法。解决该问题涉及到文档摘要、图像和文本检索、幻灯片结构和布局预测,以将关键元素安排成适合演示的形式。提出了一种分层递归序列到序列的方法,通过在章节级(针对文档)和卡片级(针对幻灯片)进行推理,利用文档和幻灯片的固有结构,结合转述和布局预测模块,以端到端方式生成幻灯片。为加速该领域研究,发布了一个6K规模的文档-幻灯片配对数据集。
Creating presentation materials requires complex multimodal reasoning skills to summarize key concepts and arrange them in a logical and visually pleasing manner. Can machines learn to emulate this laborious process? We present a novel task and approach for document-to-slide generation. Solving this involves document summarization, image and text retrieval, slide structure, and layout prediction to arrange key elements in a form suitable for presentation. We propose a hierarchical sequence-to-sequence approach to tackle our task in an end-to-end manner. Our approach exploits the inherent structures within documents and slides and incorporates paraphrasing and layout prediction modules to generate slides. To help accelerate research in this domain, we release a dataset about 6K paired documents and slide decks used in our experiments. We show that our approach outperforms strong baselines and produces slides with rich content and aligned imagery.
https://weibo.com/1402400261/JFvWq8Coo

3、[CV] Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
L Yuan, Y Chen, T Wang, W Yu, Y Shi, F E Tay, J Feng, S Yan
[National University of Singapore & YITU Technology]
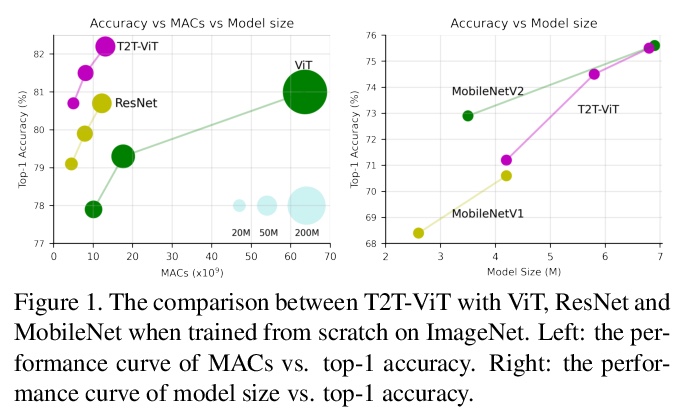
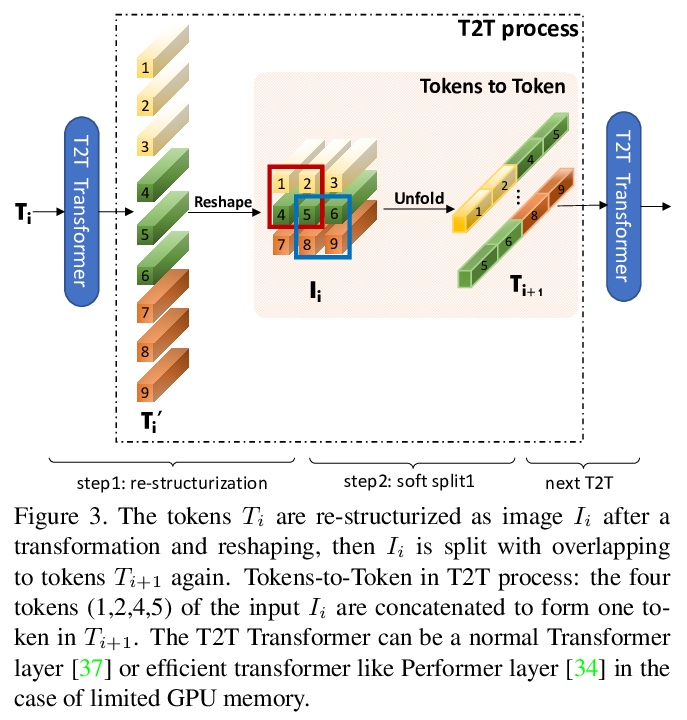
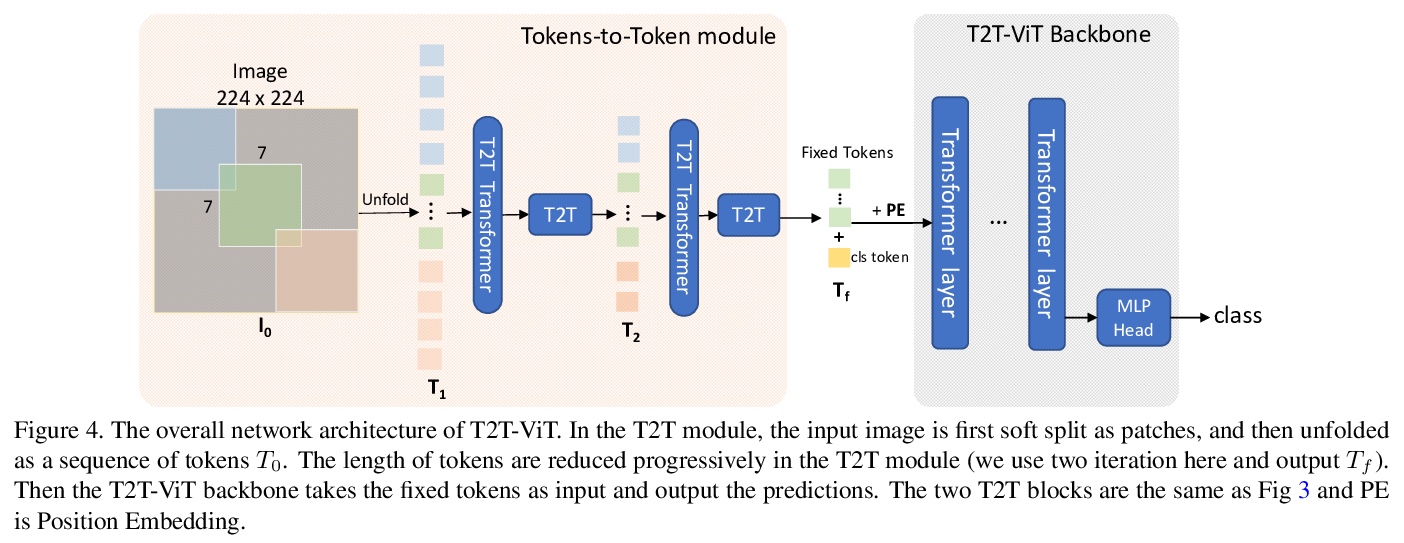
T2T-ViT:用ImageNet从头训练Vision Transformers。提出了一种新的T2T-ViT模型,可在ImageNet上从头训练,并实现与CNN相当甚至更好的性能。T2T-ViT有效地对图像结构信息进行建模,增强了特征的丰富性,克服了ViT的局限性。引入新的Tokens-to-Token(T2T)过程,将图像逐步转化为tokens,并对其进行结构化聚合。研究了CNN的各种架构设计选择,以提高T2TViT的性能,实证发现,深窄结构比浅宽结构性能更好。T2T-ViT在ImageNet上从头开始训练时,取得了优于ResNets的性能,并与相似模型大小的MobileNetV1性能相当。
Transformers, which are popular for language modeling, have been explored for solving vision tasks recently, e.g., the Vision Transformers (ViT) for image classification. The ViT model splits each image into a sequence of tokens with fixed length and then applies multiple Transformer layers to model their global relation for classification. However, ViT achieves inferior performance compared with CNNs when trained from scratch on a midsize dataset (e.g., ImageNet). We find it is because: 1) the simple tokenization of input images fails to model the important local structure (e.g., edges, lines) among neighboring pixels, leading to its low training sample efficiency; 2) the redundant attention backbone design of ViT leads to limited feature richness in fixed computation budgets and limited training samples.To overcome such limitations, we propose a new Tokens-To-Token Vision Transformers (T2T-ViT), which introduces 1) a layer-wise Tokens-to-Token (T2T) transformation to progressively structurize the image to tokens by recursively aggregating neighboring Tokens into one Token (Tokens-to-Token), such that local structure presented by surrounding tokens can be modeled and tokens length can be reduced; 2) an efficient backbone with a deep-narrow structure for vision transformers motivated by CNN architecture design after extensive study. Notably, T2T-ViT reduces the parameter counts and MACs of vanilla ViT by 200\%, while achieving more than 2.5\% improvement when trained from scratch on ImageNet. It also outperforms ResNets and achieves comparable performance with MobileNets when directly training on ImageNet. For example, T2T-ViT with ResNet50 comparable size can achieve 80.7\% top-1 accuracy on ImageNet. (Code: > this https URL)
https://weibo.com/1402400261/JFw2Kxf54

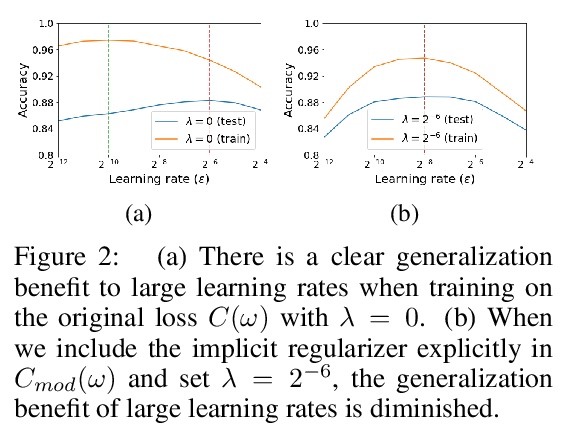
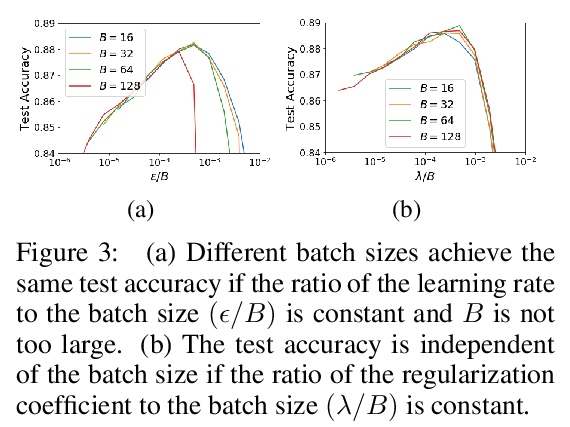
4、[LG] On the Origin of Implicit Regularization in Stochastic Gradient Descent
S L. Smith, B Dherin, D G. T. Barrett, S De
[DeepMind & Google]
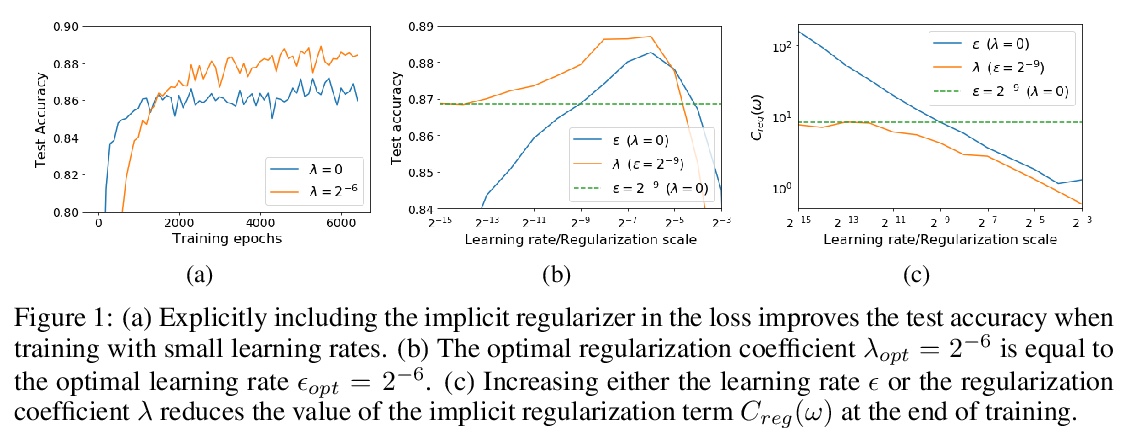
随机梯度下降中隐式正则化的来源。对于无穷小的学习率,随机梯度下降(SGD)遵循的是整批损失函数上的梯度流路径。适度加大学习率,可获得更高的测试准确率,这种泛化优势并不能用收敛界来解释,因为测试准确率最大化的学习率,往往大于训练损失最小化的学习率。为解释该现象,本文证明了对随机重排SGD,如果学习率小且有限,平均SGD迭代也会保持接近梯度流路径,但是在一个修正的损失上,该损失由原始损失函数和一个隐式正则化器组成,对minibatch梯度的范数进行惩罚。在温和假设下,当批次规模较小时,隐式正则化项的大小,与学习率和批次规模之比成正比。实证验证了当学习率较小时,在损失中明确包含隐式正则化项可以提高测试精度。
For infinitesimal learning rates, stochastic gradient descent (SGD) follows the path of gradient flow on the full batch loss function. However moderately large learning rates can achieve higher test accuracies, and this generalization benefit is not explained by convergence bounds, since the learning rate which maximizes test accuracy is often larger than the learning rate which minimizes training loss. To interpret this phenomenon we prove that for SGD with random shuffling, the mean SGD iterate also stays close to the path of gradient flow if the learning rate is small and finite, but on a modified loss. This modified loss is composed of the original loss function and an implicit regularizer, which penalizes the norms of the minibatch gradients. Under mild assumptions, when the batch size is small the scale of the implicit regularization term is proportional to the ratio of the learning rate to the batch size. We verify empirically that explicitly including the implicit regularizer in the loss can enhance the test accuracy when the learning rate is small.
https://weibo.com/1402400261/JFwkYfyv0
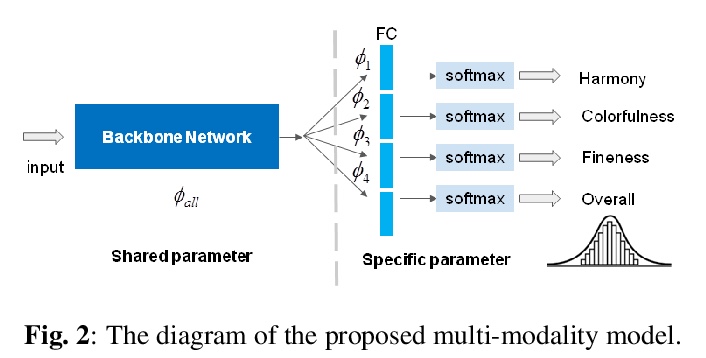
5、[CV] Multi-Modal Aesthetic Assessment for MObile Gaming Image
Z Lei, Y Xie, S Ling, A Pastor, J Wang, P L Callet
[University of Nantes & Tencent & Ocean University of China]
手机游戏图像多模态审美评价。通过观察不同审美维度之间的相关性,开发了一种基于多任务学习的手机游戏图像评价模型。该模型倾向于寻找和学习不同美学相关维度之间的相关性,以进一步提升预测所有美学维度的泛化性能。通过利用其他维度的互补资源,共享各维度的训练信息,间接增强训练数据,解除在有限标注数据下获得单独维度良好预测的 “瓶颈”。根据实验结果,所提出的模型在预测四个游戏美学维度方面明显优于最先进的美学指标。
With the proliferation of various gaming technology, services, game styles, and platforms, multi-dimensional aesthetic assessment of the gaming contents is becoming more and more important for the gaming industry. Depending on the diverse needs of diversified game players, game designers, graphical developers, etc. in particular conditions, multi-modal aesthetic assessment is required to consider different aesthetic dimensions/perspectives. Since there are different underlying relationships between different aesthetic dimensions, e.g., between the Colorfulness' andColor Harmony’, it could be advantageous to leverage effective information attached in multiple relevant dimensions. To this end, we solve this problem via multi-task learning. Our inclination is to seek and learn the correlations between different aesthetic relevant dimensions to further boost the generalization performance in predicting all the aesthetic dimensions. Therefore, the `bottleneck’ of obtaining good predictions with limited labeled data for one individual dimension could be unplugged by harnessing complementary sources of other dimensions, i.e., augment the training data indirectly by sharing training information across dimensions. According to experimental results, the proposed model outperforms state-of-the-art aesthetic metrics significantly in predicting four gaming aesthetic dimensions.
https://weibo.com/1402400261/JFwpAhIJ8
另外几篇值得关注的论文:
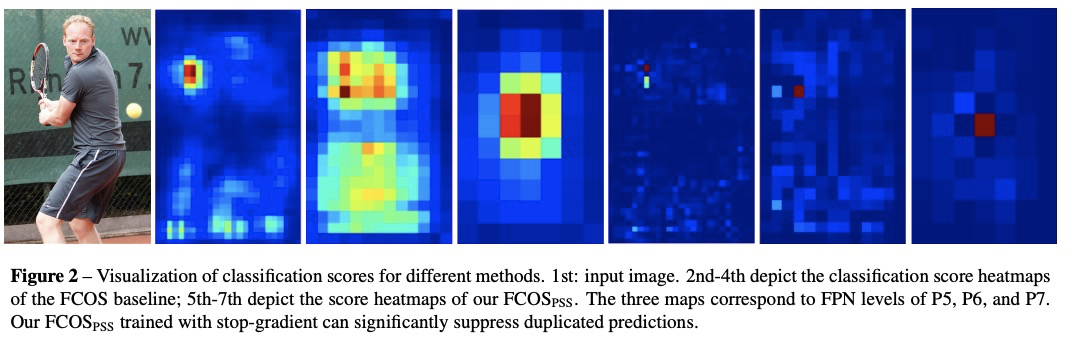
[CV] Object Detection Made Simpler by Eliminating Heuristic NMS
无NMS的端到端目标检测框架
Q Zhou, C Yu, C Shen, Z Wang, H Li
[Alibaba Group & Monash University]
https://weibo.com/1402400261/JFwtZ15WH

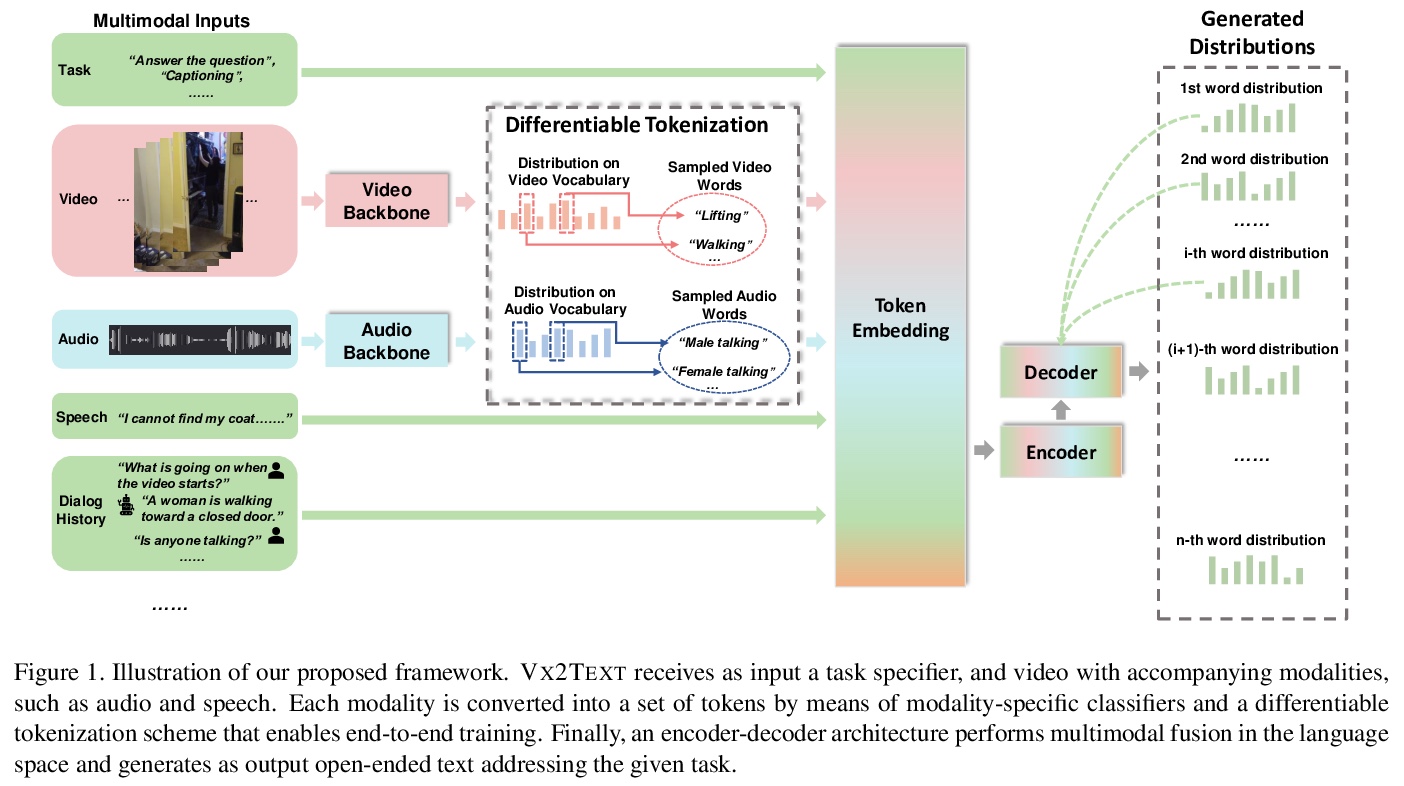
[CV] Vx2Text: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs
Vx2Text:视频多模输入文本生成的端到端学习
X Lin, G Bertasius, J Wang, S Chang, D Parikh, L Torresani
[Columbia University & Facebook AI]
https://weibo.com/1402400261/JFwwXFKsv

[CL] Disembodied Machine Learning: On the Illusion of Objectivity in NLP
无身机器学习:NLP的客观性错觉
Z Waseem, S Lulz, J Bingel, I Augenstein
[University of Sheffield & Humboldt University & Hero I/S & University of Copenhagen]
https://weibo.com/1402400261/JFwyFt0Dh
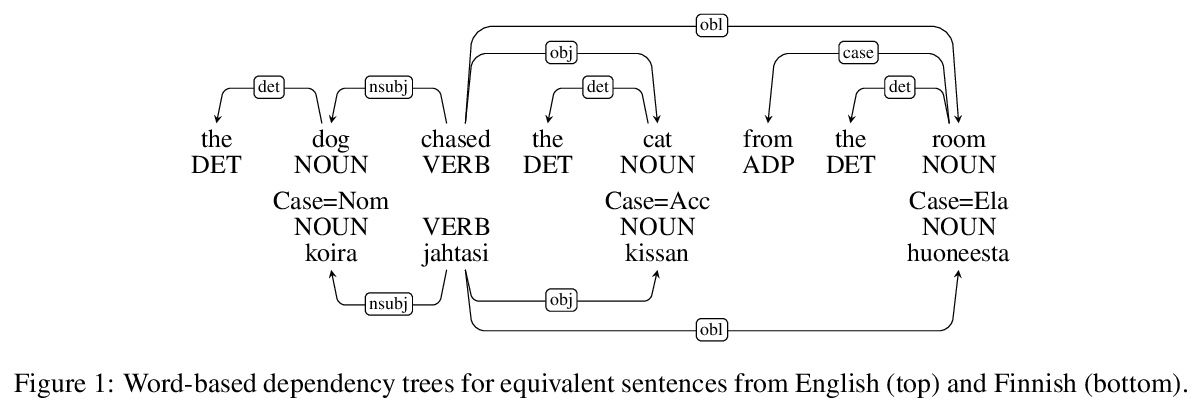
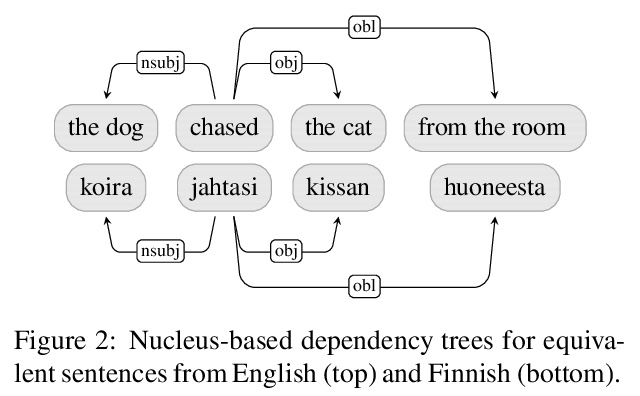
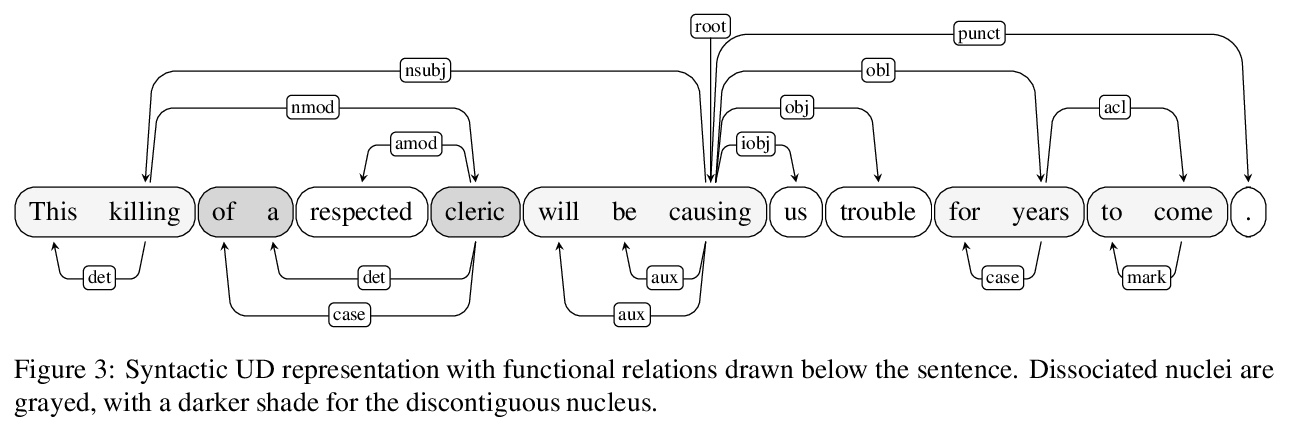
[CL] Syntactic Nuclei in Dependency Parsing — A Multilingual Exploration
依存句法分析中的句法核:多语言探索
A Basirat, J Nivre
[Uppsala University]
https://weibo.com/1402400261/JFwFq7toM

若有收获,就点个赞吧
0 人点赞
