LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
(*表示值得重点关注)
1、[CL] Attention is Not Only a Weight: Analyzing Transformers with Vector Norms
G Kobayashi, T Kuribayashi, S Yokoi, K Inui
[Tohoku University]
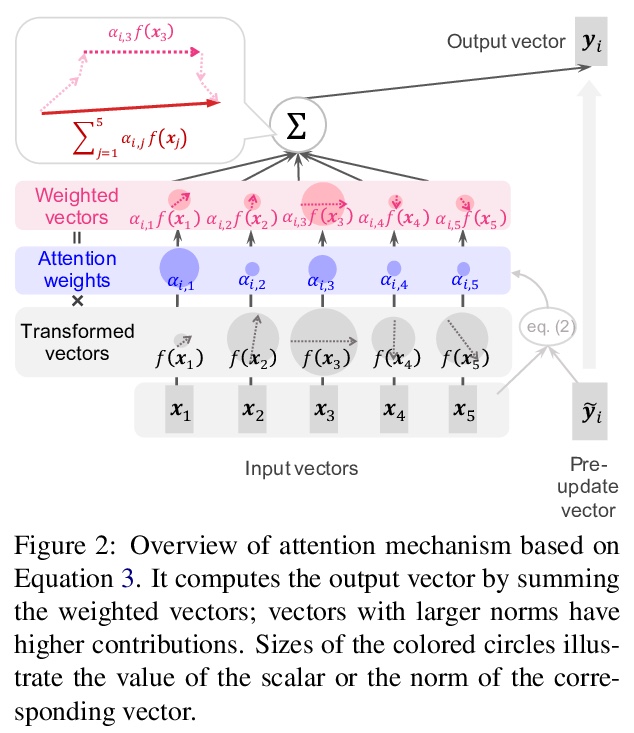
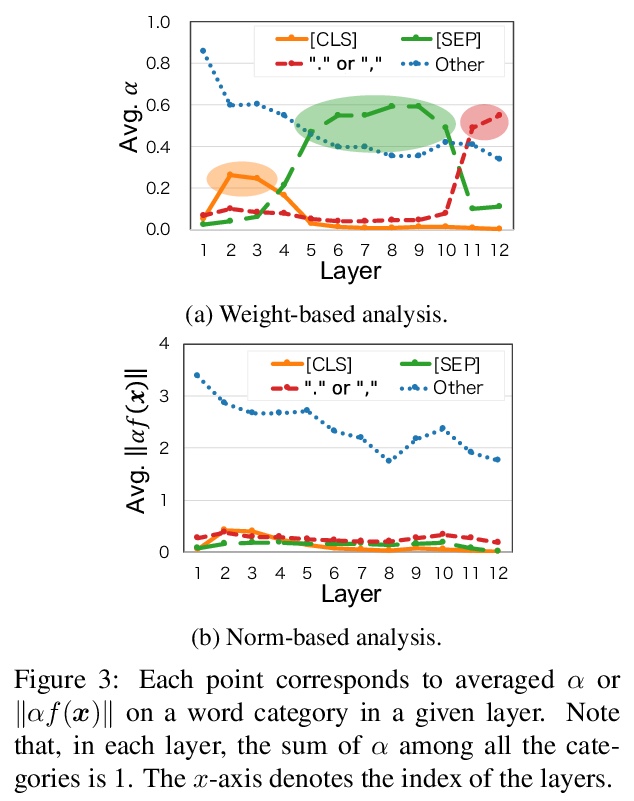
注意力不仅仅是权重:用向量范数分析Transformer。提出一种基于范数的分析方法,结合注意力输出中,除权重以外另一个重要因素,即转换后的输入向量范数,对Transformer内部工作原理提供了更详细的解释。基于范数对BERT和基于Transformer的神经网络机器翻译系统进行分析,发现:(i)BERT对特殊标记的重视程度较低,(ii)可以从Transformer的注意机制中提取出合理的词对齐。
Attention is a key component of Transformers, which have recently achieved considerable success in natural language processing. Hence, attention is being extensively studied to investigate various linguistic capabilities of Transformers, focusing on analyzing the parallels between attention weights and specific linguistic phenomena. This paper shows that attention weights alone are only one of the two factors that determine the output of attention and proposes a norm-based analysis that incorporates the second factor, the norm of the transformed input vectors. The findings of our norm-based analyses of BERT and a Transformer-based neural machine translation system include the following: (i) contrary to previous studies, BERT pays poor attention to special tokens, and (ii) reasonable word alignment can be extracted from attention mechanisms of Transformer. These findings provide insights into the inner workings of Transformers.
https://weibo.com/1402400261/JweHr4rbN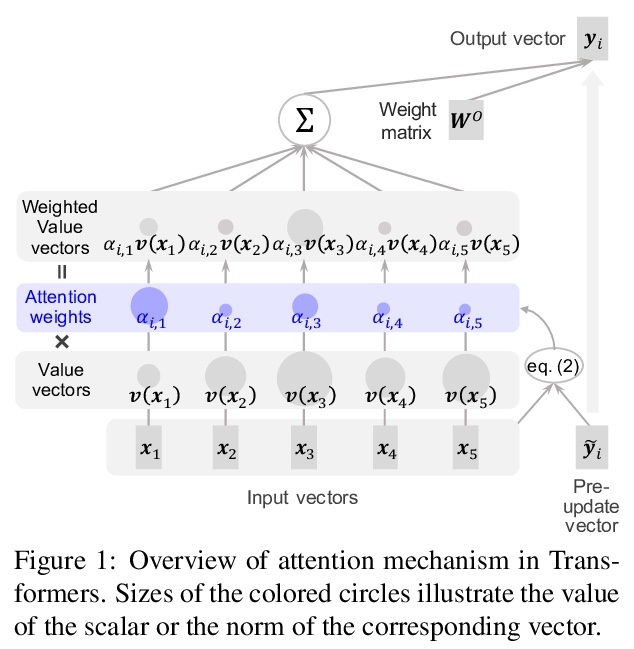
2、** **[CL] OCR Post Correction for Endangered Language Texts
S Rijhwani, A Anastasopoulos, G Neubig
[CMU & George Mason University]
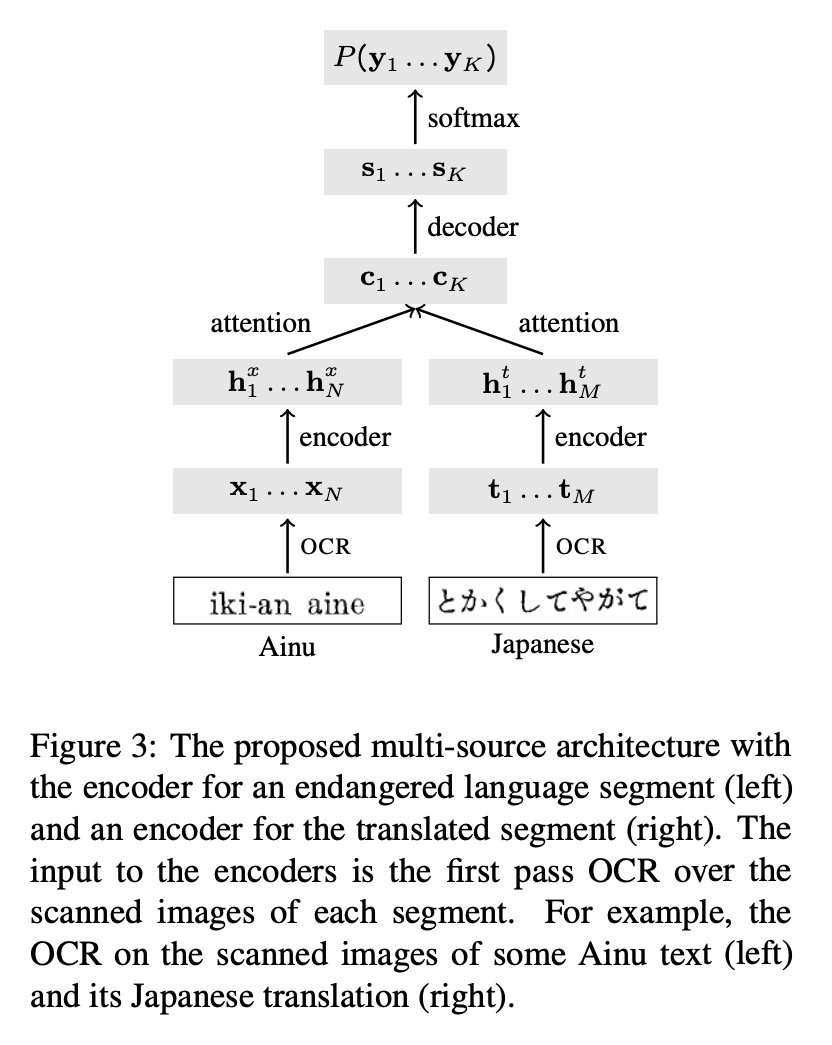
针对濒危语言文本的OCR后校正。对大多数濒危语言来说,几乎没有数据可用来构建自然语言处理模型,本文解决了从濒危语言纸质书籍和扫描图像资源中提取文本的任务,为三种濒危语言(阿伊努语、格里科语和雅克哈语)的扫描图书创建了转录基准数据集,对使用OCR工具在濒危语言的数据稀缺设置方面的不足进行了系统分析,开发了一种OCR后校正方法,以简化在数据稀缺场景下的训练,在三种语言中识别错误率平均降低34%。
There is little to no data available to build natural language processing models for most endangered languages. However, textual data in these languages often exists in formats that are not machine-readable, such as paper books and scanned images. In this work, we address the task of extracting text from these resources. We create a benchmark dataset of transcriptions for scanned books in three critically endangered languages and present a systematic analysis of how general-purpose OCR tools are not robust to the data-scarce setting of endangered languages. We develop an OCR post-correction method tailored to ease training in this data-scarce setting, reducing the recognition error rate by 34% on average across the three languages.
https://weibo.com/1402400261/JweNH3jdT


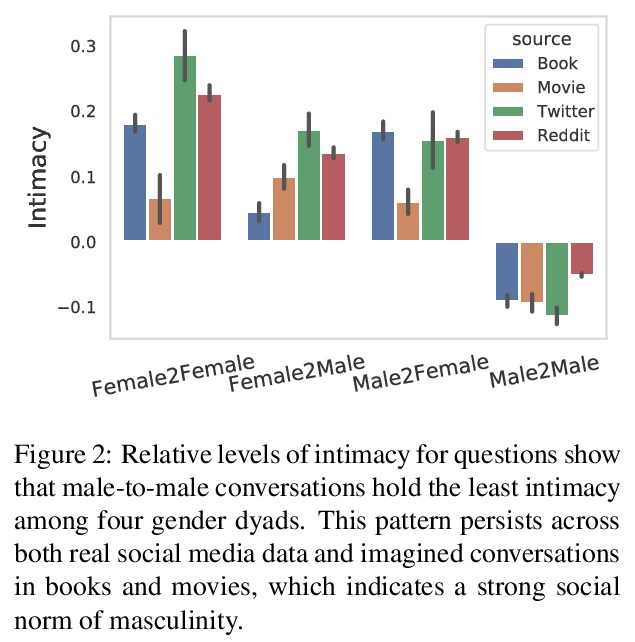
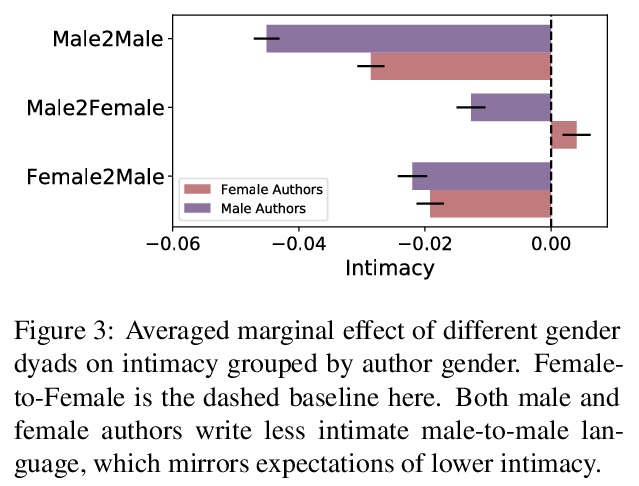
3、** **[CL] Quantifying Intimacy in Language
J Pei, D Jurgens
[University of Michigan]
言语亲密度的量化。通过新的数据和模型来研究语言中的亲密关系,开发了一个高质量的问题数据集,提出一种与人类判断密切相关的相应模型,研究了来自社交媒体、书籍和电影的8050万个问题,以揭示个体如何通过选择亲密性言语来塑造和响应其所在的社交环境。发现语言的亲密性不仅是个人选择,人们可能会用不同的语言策略来表达亲密性,同时反映出社会规范的约束,包括性别和社会距离。
Intimacy is a fundamental aspect of how we relate to others in social settings. Language encodes the social information of intimacy through both topics and other more subtle cues (such as linguistic hedging and swearing). Here, we introduce a new computational framework for studying expressions of the intimacy in language with an accompanying dataset and deep learning model for accurately predicting the intimacy level of questions (Pearson r = 0.87). Through analyzing a dataset of 80.5M questions across social media, books, and films, we show that individuals employ interpersonal pragmatic moves in their language to align their intimacy with social settings. Then, in three studies, we further demonstrate how individuals modulate their intimacy to match social norms around gender, social distance, and audience, each validating key findings from studies in social psychology. Our work demonstrates that intimacy is a pervasive and impactful social dimension of language.
https://weibo.com/1402400261/JweRUdUYZ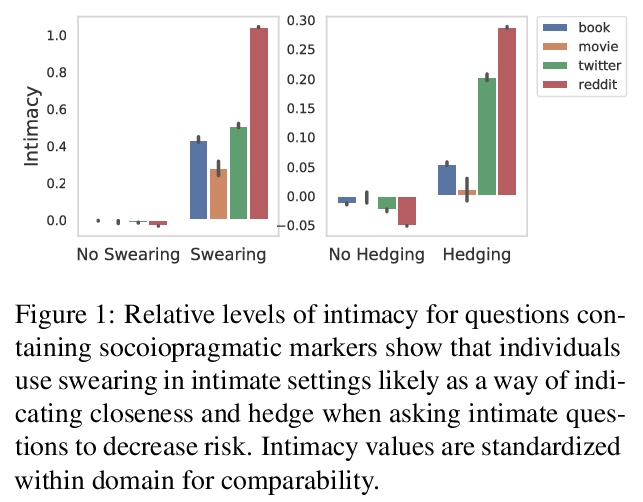
4、**[CL] Reformulating Unsupervised Style Transfer as Paraphrase Generation
K Krishna, J Wieting, M Iyyer
[University of Massachusetts Amherst & CMU]
用意译生成实现无监督文体迁移。现代自然语言处理将文体迁移任务定义为,在不明显改变句子语义的情况下,修改句子的文体,这意味着文体迁移系统的输出应该是对输入内容的改写。本文将无监督文体迁移,作为受控的意译生成问题,重新进行阐述,提出一种用自动生成的转述数据,对预训练语言模型进行微调的简单方法。通过对23篇文献的调研,对目前的文体迁移评价进行了批评,并提出对常见缺陷的修正。**
Modern NLP defines the task of style transfer as modifying the style of a given sentence without appreciably changing its semantics, which implies that the outputs of style transfer systems should be paraphrases of their inputs. However, many existing systems purportedly designed for style transfer inherently warp the input’s meaning through attribute transfer, which changes semantic properties such as sentiment. In this paper, we reformulate unsupervised style transfer as a paraphrase generation problem, and present a simple methodology based on fine-tuning pretrained language models on automatically generated paraphrase data. Despite its simplicity, our method significantly outperforms state-of-the-art style transfer systems on both human and automatic evaluations. We also survey 23 style transfer papers and discover that existing automatic metrics can be easily gamed and propose fixed variants. Finally, we pivot to a more real-world style transfer setting by collecting a large dataset of 15M sentences in 11 diverse styles, which we use for an in-depth analysis of our system.
https://weibo.com/1402400261/JweWGhL9G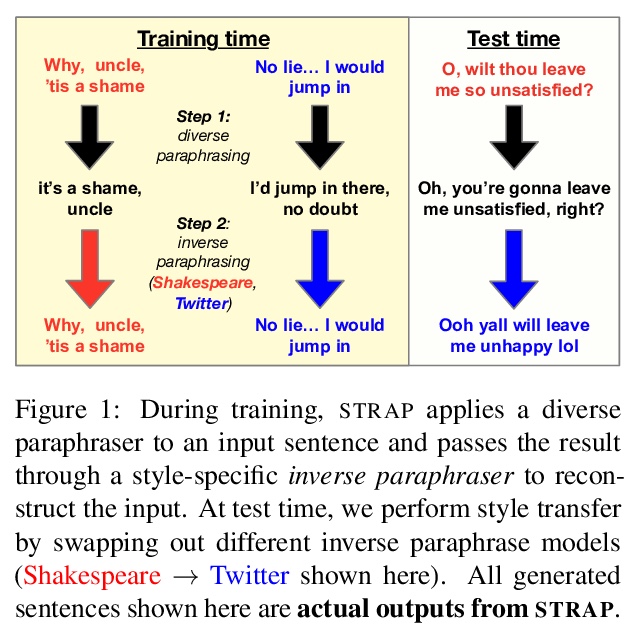


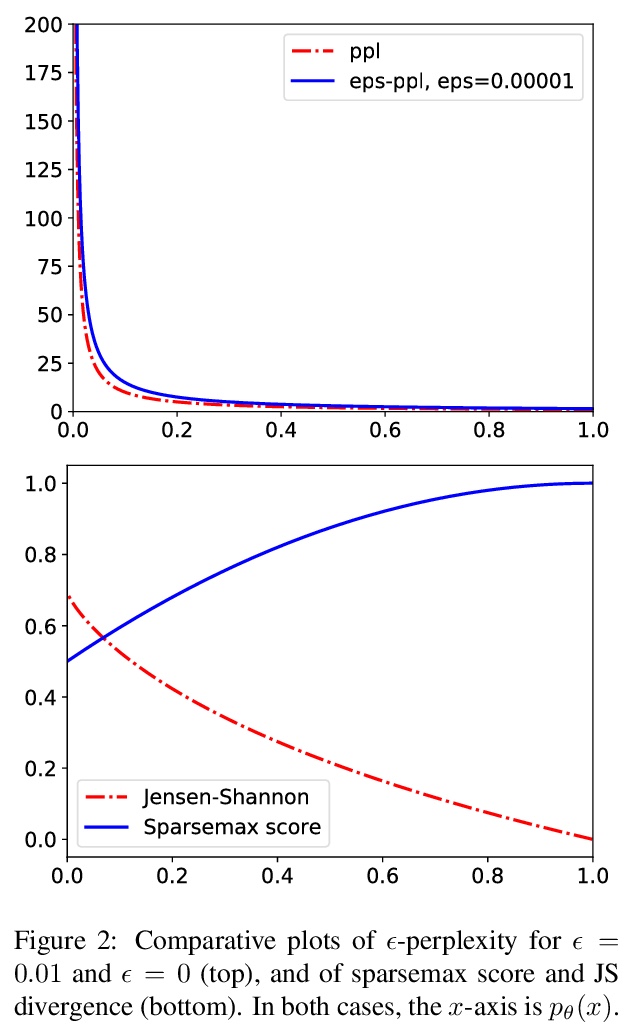
5、**[CL] Sparse Text Generation
PH Martins, Z Marinho, AFT Martins
稀疏文本生成。提出一种新的基于稀疏概率分布的文本生成策略——entmax采样,具有三个主要优点:(i)提供一种直接从输出概率分布进行采样的自然方法;(ii)训练时对分布稀疏度进行建模,避免训练时和运行时之间的稀疏度不匹配;(iii)用entmax采样时,所考虑词数随上下文不同而不同。提出了新的语言模型评价指标,可产生稀疏和截断概率分布。**
Current state-of-the-art text generators build on powerful language models such as GPT-2, achieving impressive performance. However, to avoid degenerate text, they require sampling from a modified softmax, via temperature parameters or ad-hoc truncation techniques, as in top-k or nucleus sampling. This creates a mismatch between training and testing conditions. In this paper, we use the recently introduced entmax transformation to train and sample from a natively sparse language model, avoiding this mismatch. The result is a text generator with favorable performance in terms of fluency and consistency, fewer repetitions, and n-gram diversity closer to human text. In order to evaluate our model, we propose three new metrics for comparing sparse or truncated distributions: 𝜖-perplexity, sparsemax score, and Jensen-Shannon divergence. Human-evaluated experiments in story completion and dialogue generation show that entmax sampling leads to more engaging and coherent stories and conversations.
https://weibo.com/1402400261/Jwf3Ib4CZ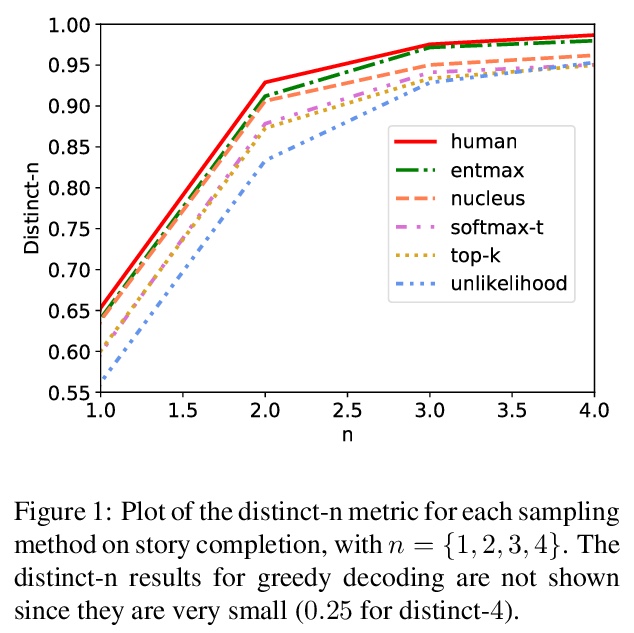

其他几篇值得关注的论文:
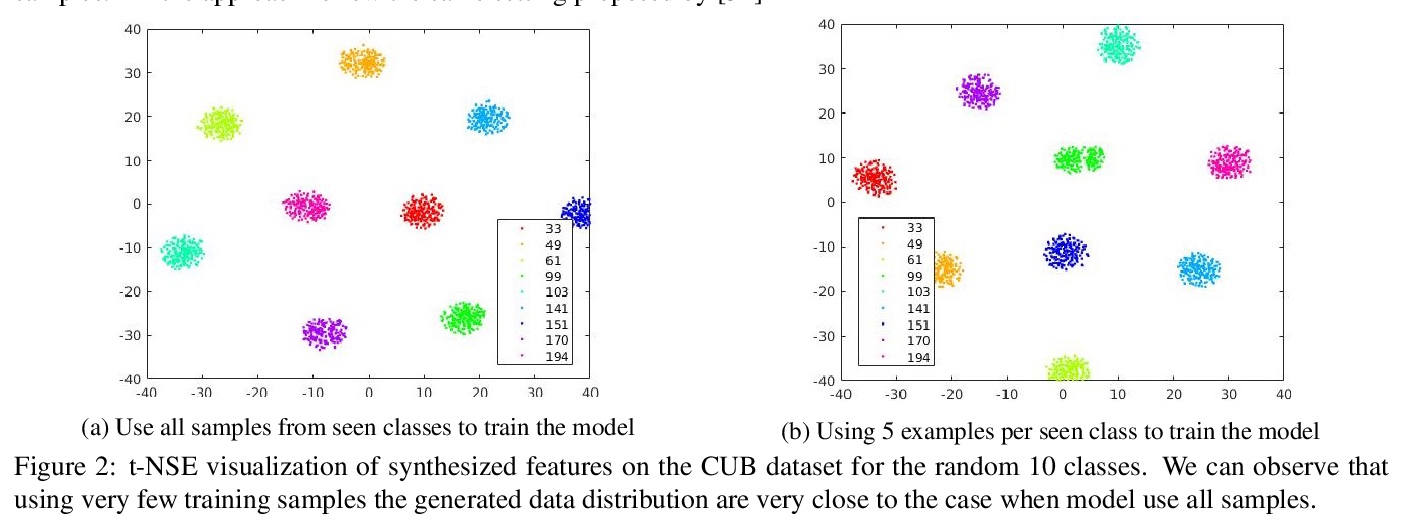
[CV] Towards Zero-Shot Learning with Fewer Seen Class Examples
用较少的可见类样本实现零样本学习
V K Verma, A Mishra, A Pandey, H A. Murthy, P Rai
[IIT Madras]
https://weibo.com/1402400261/Jwf6NDAOs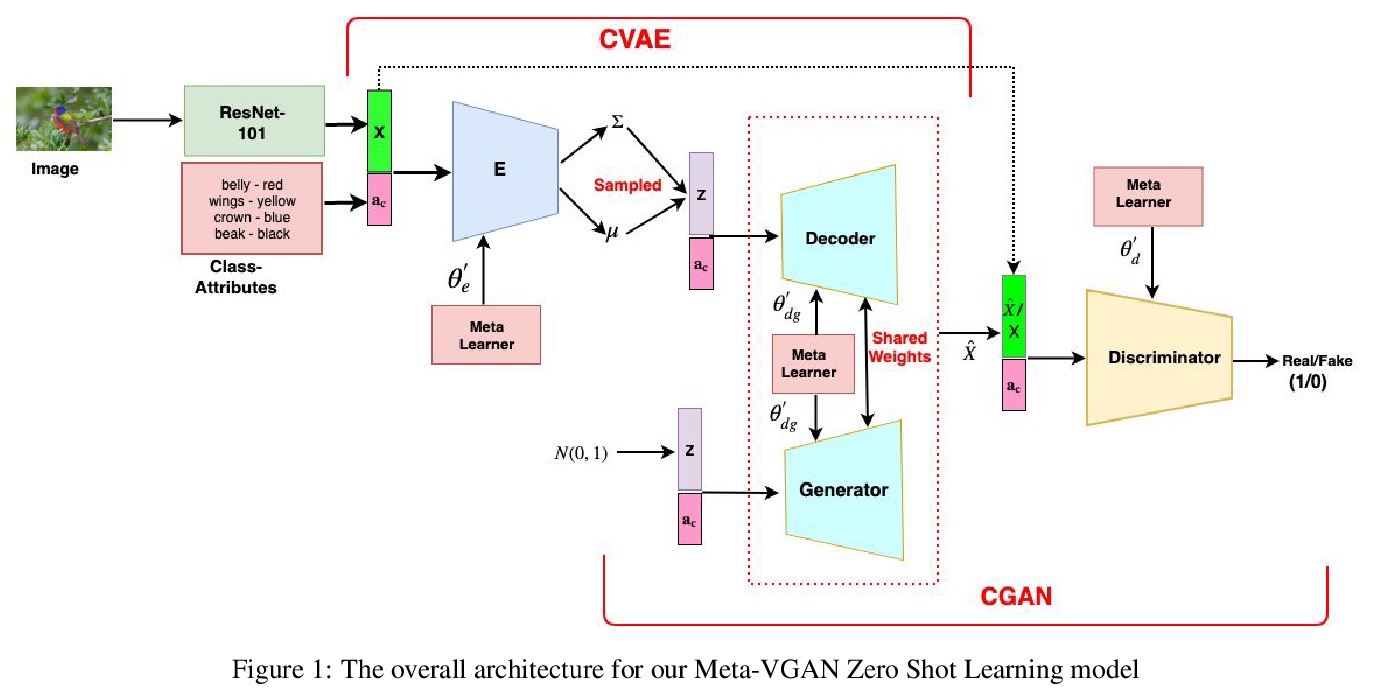
[LG] Challenges in Deploying Machine Learning: a Survey of Case Studies
机器学习部署挑战:案例研究综述
A Paleyes, R Urma, N D. Lawrence
[University of Cambridge & Cambridge Spark]
https://weibo.com/1402400261/Jwf8BFhYQ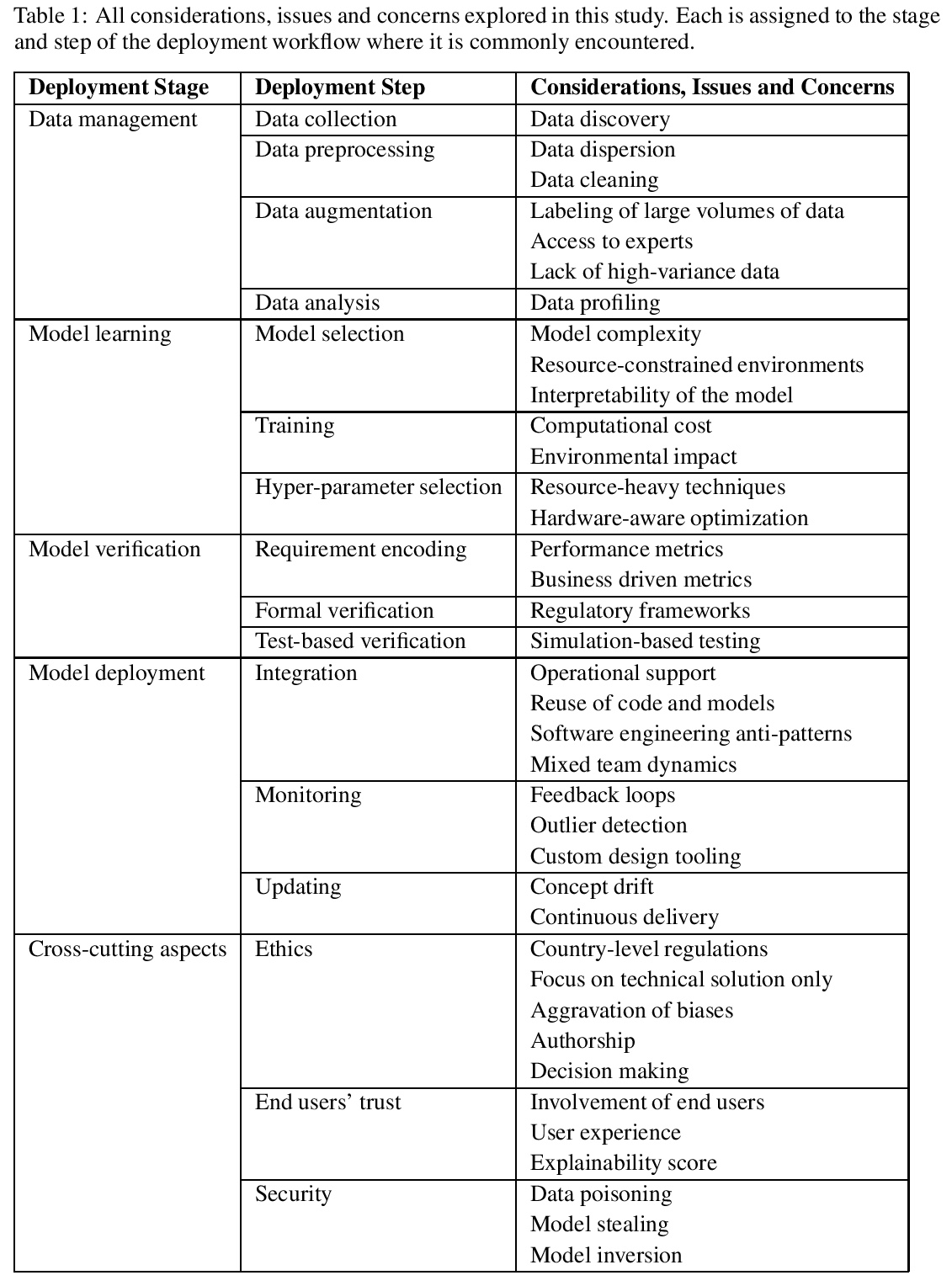

若有收获,就点个赞吧
0 人点赞
