- 1、 [CV] *Training data-efficient image transformers & distillation through attention
- 2、 [CV] *Focal Frequency Loss for Generative Models
- 3、 [CV] Vid2Actor: Free-viewpoint Animatable Person Synthesis from Video in the Wild
- 4、 [CL] Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing
- 5、[CV] Efficient video annotation with visual interpolation and frame selection guidance
- [CL] TicketTalk: Toward human-level performance with end-to-end, transaction-based dialog systems
- [CV] ANR: Articulated Neural Rendering for Virtual Avatars
- [CL] ActionBert: Leveraging User Actions for Semantic Understanding of User Interfaces
- [CV] Pit30M: A Benchmark for Global Localization in the Age of Self-Driving Cars
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、 [CV] *Training data-efficient image transformers & distillation through attention
H Touvron, M Cord, M Douze, F Massa, A Sablayrolles, H Jégou
[Facebook AI & Sorbonne University]
基于注意力的数据高效transformer训练和蒸馏。提出DeiT,改进了训练和蒸馏过程,对已有数据增强和正则化策略进行优化,不需要大量数据就能进行训练出性能较好的图像transformer。通过充分设计的方案,只用Imagenet进行训练,就能产生性能不错的非卷积transformer,单台计算机上训练时间不超过3天,在不引入外部数据的情况下,在ImageNet上可实现83.1%的top-1精度。
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. However, these visual transformers are pre-trained with hundreds of millions of images using an expensive infrastructure, thereby limiting their adoption by the larger community.In this work, with an adequate training scheme, we produce a competitive convolution-free transformer by training on Imagenet only. We train it on a single computer in less than 3 days. Our reference vision transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop evaluation) on ImageNet with no external data. We share our code and models to accelerate community advances on this line of research.Additionally, we introduce a teacher-student strategy specific to transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention. We show the interest of this token-based distillation, especially when using a convnet as a teacher. This leads us to report results competitive with convnets for both Imagenet (where we obtain up to 84.4% accuracy) and when transferring to other tasks.
https://weibo.com/1402400261/JA2icBbpQ


2、 [CV] *Focal Frequency Loss for Generative Models
L Jiang, B Dai, W Wu, C C Loy
[Nanyang Technological Universit & SenseTime Research]
生成模型的焦频损失。进行了在频域优化生成模型的初步探索,提出了焦点频率损失,一种新的目标函数,可以使模型动态关注那些难以合成的频率成分,对容易合成的频率进行降权。是对现有的各种基线的空间损失的补充,将生成模型的优化带入频域,很大程度上减轻了由于神经网络固有问题而导致的重要频率信息丢失问题,改善了合成质量。**
Despite the remarkable success of generative models in creating photorealistic images using deep neural networks, gaps could still exist between the real and generated images, especially in the frequency domain. In this study, we find that narrowing the frequency domain gap can ameliorate the image synthesis quality further. To this end, we propose the focal frequency loss, a novel objective function that brings optimization of generative models into the frequency domain. The proposed loss allows the model to dynamically focus on the frequency components that are hard to synthesize by down-weighting the easy frequencies. This objective function is complementary to existing spatial losses, offering great impedance against the loss of important frequency information due to the inherent crux of neural networks. We demonstrate the versatility and effectiveness of focal frequency loss to improve various baselines in both perceptual quality and quantitative performance.
https://weibo.com/1402400261/JA2p55yrx


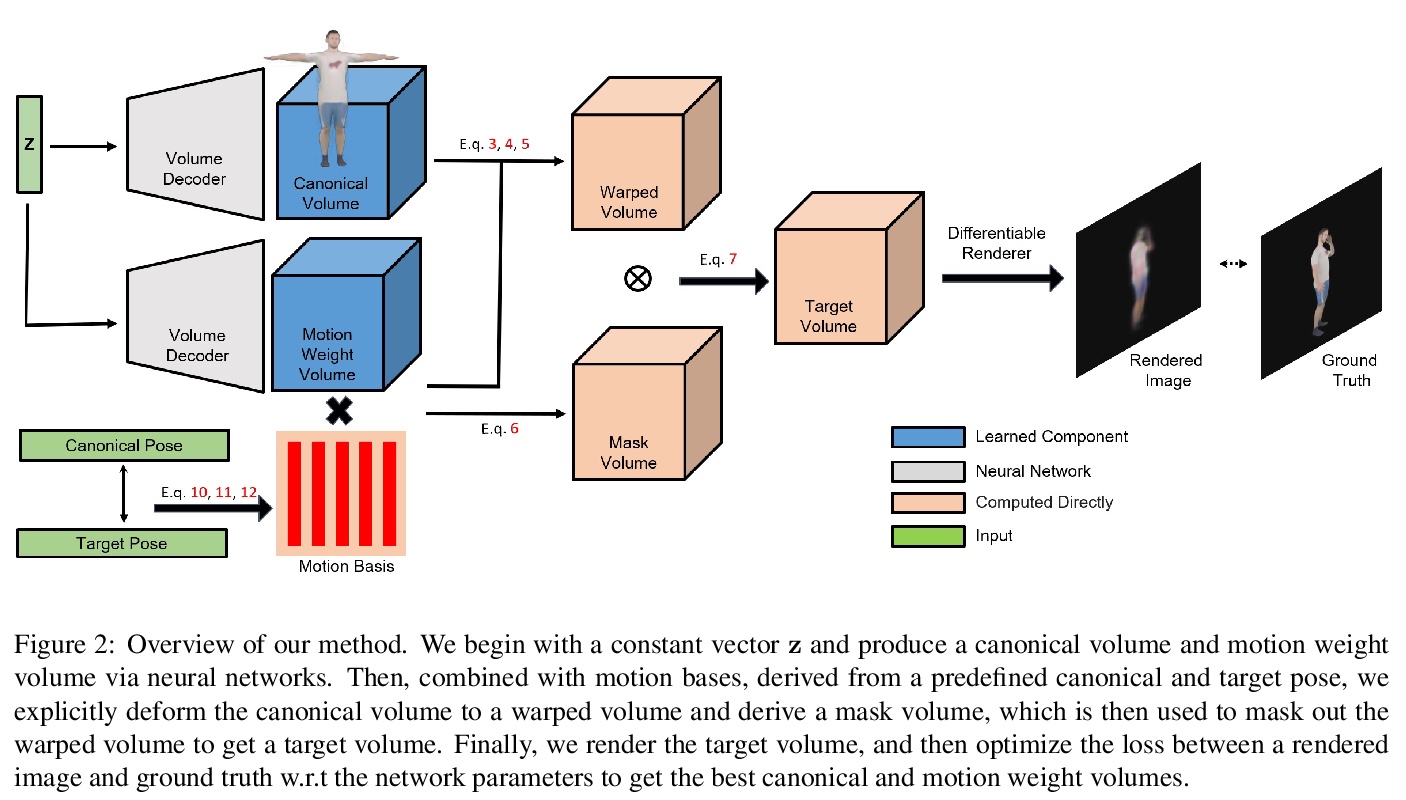
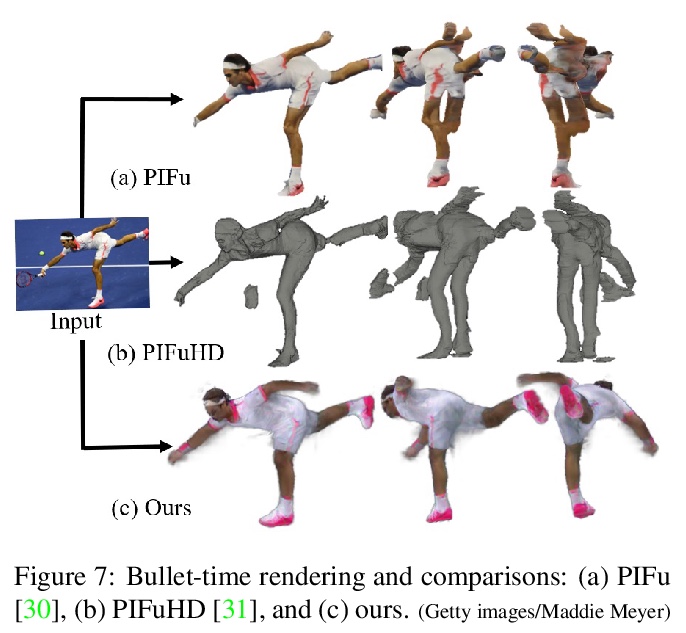
3、 [CV] Vid2Actor: Free-viewpoint Animatable Person Synthesis from Video in the Wild
C Weng, B Curless, I Kemelmacher-Shlizerman
[University of Washington]
Vid2Actor:基于自然场景视频的自由视角动画人物合成。提出一种新的简单的可动画化的人体表示,仅从图像观测中学习,可以从任意视角以任何姿态进行人物合成,无需明确的3D网格重建,其核心是用输入视频训练深度网络进行体3D人体表示重建,通过内部3D表示对任意姿态和相机进行图像合成,不需要预先设置模型或基于网格学习的标准网格来进行训练。
Given an “in-the-wild” video of a person, we reconstruct an animatable model of the person in the video. The output model can be rendered in any body pose to any camera view, via the learned controls, without explicit 3D mesh reconstruction. At the core of our method is a volumetric 3D human representation reconstructed with a deep network trained on input video, enabling novel pose/view synthesis. Our method is an advance over GAN-based image-to-image translation since it allows image synthesis for any pose and camera via the internal 3D representation, while at the same time it does not require a pre-rigged model or ground truth meshes for training, as in mesh-based learning. Experiments validate the design choices and yield results on synthetic data and on real videos of diverse people performing unconstrained activities (e.g. dancing or playing tennis). Finally, we demonstrate motion re-targeting and bullet-time rendering with the learned models.
https://weibo.com/1402400261/JA2tCDjSb

4、 [CL] Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing
X V Lin, R Socher, C Xiong
[Salesforce Research]
跨文本数据和表格数据建模的跨域文本到SQL语义解析。提出BRIDGE,一个强大的序列化架构,用于对自然语言问题和关系数据库之间依赖关系进行建模,实现跨数据库语义解析。BRIDGE将问题和数据库模式序列化为标签序列,最大限度利用预训练语言模型(如BERT)捕捉文本提及和数据库模式组件之间的联系,采用锚文本进一步提高跨模态输入之间的一致性,结合简单的顺序指针生成器解码器和模式一致性驱动的搜索空间修剪,在广泛使用的Spider和WikiSQL文本到SQL基准上达到了最先进性能。
We present BRIDGE, a powerful sequential architecture for modeling dependencies between natural language questions and relational databases in cross-DB semantic parsing. BRIDGE represents the question and DB schema in a tagged sequence where a subset of the fields are augmented with cell values mentioned in the question. The hybrid sequence is encoded by BERT with minimal subsequent layers and the text-DB contextualization is realized via the fine-tuned deep attention in BERT. Combined with a pointer-generator decoder with schema-consistency driven search space pruning, BRIDGE attained state-of-the-art performance on popular cross-DB text-to-SQL benchmarks, Spider (71.1\% dev, 67.5\% test with ensemble model) and WikiSQL (92.6\% dev, 91.9\% test). Our analysis shows that BRIDGE effectively captures the desired cross-modal dependencies and has the potential to generalize to more text-DB related tasks. Our implementation is available at > this URL.
https://weibo.com/1402400261/JA2yhABln

5、[CV] Efficient video annotation with visual interpolation and frame selection guidance
A. Kuznetsova, A. Talati, Y. Luo, K. Simmons, V. Ferrari
[Google Research]
基于视觉插值和帧选择引导的高效视频标记。提出了用于交互式视频边框标记的统一框架,引入了一种视觉插值算法,基于最先进的跟踪器,可进行轨迹校正;提出了帧选择引导模块,通过实验证明了其在标记过程中的重要性。解决了视频标记的两个重要挑战:(1)在所有帧的子集上对人工标记的边框进行自动时间插值和外推;(2)自动选择需要手动标记的帧。实验表明,用视觉信号可比传统的线性插值法少60%的边框,并保持相同的质量,标记时间可减少50%以上。
We introduce a unified framework for generic video annotation with bounding boxes. Video annotation is a longstanding problem, as it is a tedious and time-consuming process. We tackle two important challenges of video annotation: (1) automatic temporal interpolation and extrapolation of bounding boxes provided by a human annotator on a subset of all frames, and (2) automatic selection of frames to annotate manually. Our contribution is two-fold: first, we propose a model that has both interpolating and extrapolating capabilities; second, we propose a guiding mechanism that sequentially generates suggestions for what frame to annotate next, based on the annotations made previously. We extensively evaluate our approach on several challenging datasets in simulation and demonstrate a reduction in terms of the number of manual bounding boxes drawn by 60% over linear interpolation and by 35% over an off-the-shelf tracker. Moreover, we also show 10% annotation time improvement over a state-of-the-art method for video annotation with bounding boxes [25]. Finally, we run human annotation experiments and provide extensive analysis of the results, showing that our approach reduces actual measured annotation time by 50% compared to commonly used linear interpolation.
https://weibo.com/1402400261/JA2E4nF2q


另外几篇值得关注的论文:
[CL] TicketTalk: Toward human-level performance with end-to-end, transaction-based dialog systems
TicketTalk:通过端到端、基于事务的对话系统实现人工水平(对话)性能
B Byrne, K Krishnamoorthi, S Ganesh, M S Kale
[Google] 



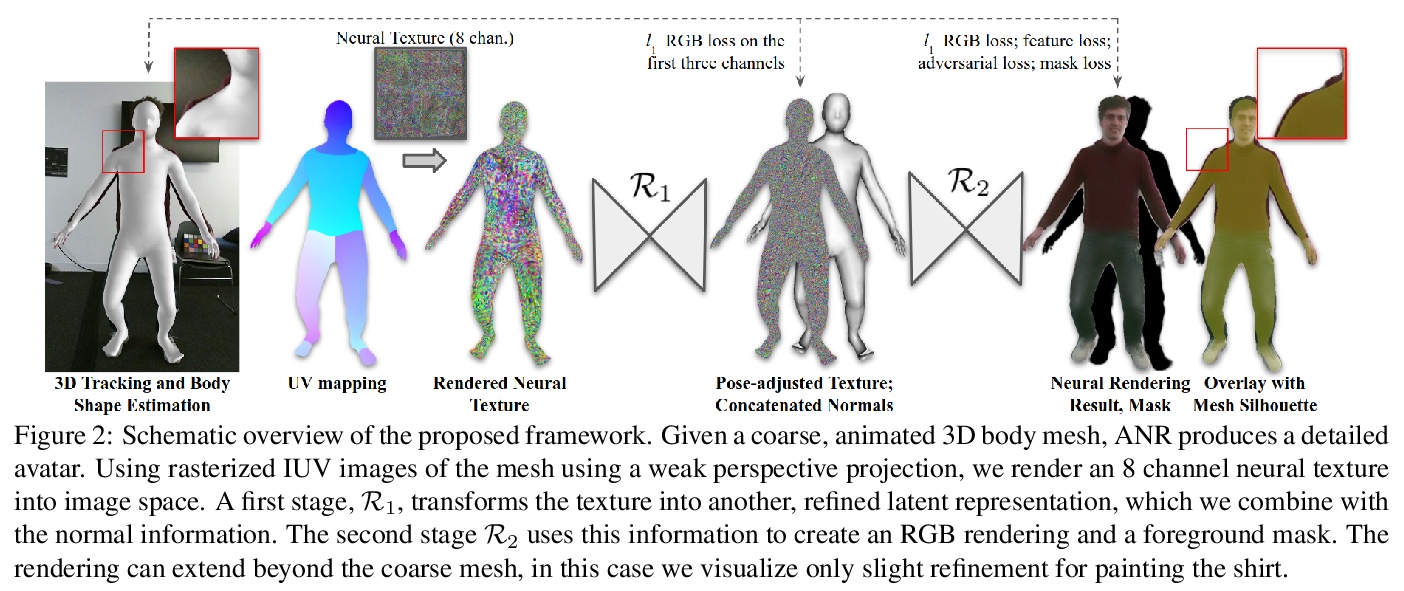
[CV] ANR: Articulated Neural Rendering for Virtual Avatars
ANR:虚拟化身关节式神经渲染
A Raj, J Tanke, J Hays, M Vo, C Stoll, C Lassner
[Georgia Tech & University of Bonn & Facebook Reality Labs & Epic Games]
https://weibo.com/1402400261/JA2Ly1rL7

[CL] ActionBert: Leveraging User Actions for Semantic Understanding of User Interfaces
ActionBert:基于用户行为的用户界面语义理解
Z He, S Sunkara, X Zang, Y Xu, L Liu, N Wichers, G Schubiner, R Lee, J Chen
[Princeton University & Google Research]
https://weibo.com/1402400261/JA2N08TOx





[CV] Pit30M: A Benchmark for Global Localization in the Age of Self-Driving Cars
Pit30M:无人驾驶汽车时代的全局定位基准
J Martinez, S Doubov, J Fan, I A Bârsan, S Wang, G Máttyus, R Urtasun
[Uber Advanced Technologies Group]
https://weibo.com/1402400261/JA2Ph5U2e




若有收获,就点个赞吧
0 人点赞
