LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[AS] *Wave-Tacotron: Spectrogram-free end-to-end text-to-speech synthesis
R J. Weiss, R Skerry-Ryan, E Battenberg, S Mariooryad, D P. Kingma
[Google Research]
Wave-Tacotron:免声谱端到端文本-语音合成。提出一种端到端(归一化)文本-语音波形合成模型,将归一化流纳入自回归Tacotron解码器环路。Wave-Tacotron以文本为条件直接生成高质量的语音波形,使用单一模型,无需单独的声码器,其训练不需要手工设计声谱图或其他中间特征上复杂损失的估计,只需要训练数据上的最大似然。该混合模型结构结合了基于注意力的TTS模型的简单性和归一化流的并行生成能力,可直接生成波形样本。实验表明,该模型生成的语音质量接近于最先进的神经网络TTS系统,生成速度显著提高。**
We describe a sequence-to-sequence neural network which can directly generate speech waveforms from text inputs. The architecture extends the Tacotron model by incorporating a normalizing flow into the autoregressive decoder loop. Output waveforms are modeled as a sequence of non-overlapping fixed-length frames, each one containing hundreds of samples. The interdependencies of waveform samples within each frame are modeled using the normalizing flow, enabling parallel training and synthesis. Longer-term dependencies are handled autoregressively by conditioning each flow on preceding frames. This model can be optimized directly with maximum likelihood, without using intermediate, hand-designed features nor additional loss terms. Contemporary state-of-the-art text-to-speech (TTS) systems use a cascade of separately learned models: one (such as Tacotron) which generates intermediate features (such as spectrograms) from text, followed by a vocoder (such as WaveRNN) which generates waveform samples from the intermediate features. The proposed system, in contrast, does not use a fixed intermediate representation, and learns all parameters end-to-end. Experiments show that the proposed model generates speech with quality approaching a state-of-the-art neural TTS system, with significantly improved generation speed.
https://weibo.com/1402400261/Jtv0NdAWq

2、[CV] *An Attack on InstaHide: Is Private Learning Possible with Instance Encoding?
N Carlini, S Deng, S Garg, S Jha, S Mahloujifar, M Mahmoody, S Song, A Thakurta, F Tramer
[Google & Columbia University & UC Berkeley]
针对InstaHide的隐私重建攻击。InstaHide通过一种编码机制来保护数据隐私,在被学习之前会修改输入信息,以防生成模型泄漏其训练集的隐私信息。本文提出一种针对nstaHide的重建攻击,用编码图像恢复原始图像的视觉可识别版本。该攻击是有效和高效的,根据实证可在CIFAR-10、CIFAR-100和最近发布的InstaHide挑战上破解InstaHide。通过实例编码进一步形式化了各种隐私学习概念,研究了实现这些概念的可能性。**
A learning algorithm is private if the produced model does not reveal (too much) about its training set. InstaHide [Huang, Song, Li, Arora, ICML’20] is a recent proposal that claims to preserve privacy by an encoding mechanism that modifies the inputs before being processed by the normal learner.We present a reconstruction attack on InstaHide that is able to use the encoded images to recover visually recognizable versions of the original images. Our attack is effective and efficient, and empirically breaks InstaHide on CIFAR-10, CIFAR-100, and the recently released InstaHide Challenge.We further formalize various privacy notions of learning through instance encoding and investigate the possibility of achieving these notions. We prove barriers against achieving (indistinguishability based notions of) privacy through any learning protocol that uses instance encoding.
https://weibo.com/1402400261/Jtv84dhBE


3、[LG] **Deep Reinforcement Learning for Navigation in AAA Video Games
E Alonso, M Peter, D Goumard, J Romoff
[Ubisoft La Forge]
基于深度强化学习的AAA游戏漫游。无需导航网格(NavMesh),用深度强化学习来学习如何在大规模3D地图上漫游,以解决游戏中非玩家角色(NPC)的自由移动问题。在Unity游戏引擎中复杂的3D环境中进行了测试,这些环境比深强化学习文献中通常使用的地图大一个数量级,其中一种地图是直接模仿育碧AAA级游戏制作的。实验表明,该方法执行效果很好,在所有测试场景中都达到了至少90%的成功率。**
In video games, non-player characters (NPCs) are used to enhance the players’ experience in a variety of ways, e.g., as enemies, allies, or innocent bystanders. A crucial component of NPCs is navigation, which allows them to move from one point to another on the map. The most popular approach for NPC navigation in the video game industry is to use a navigation mesh (NavMesh), which is a graph representation of the map, with nodes and edges indicating traversable areas. Unfortunately, complex navigation abilities that extend the character’s capacity for movement, e.g., grappling hooks, jetpacks, teleportation, or double-jumps, increases the complexity of the NavMesh, making it intractable in many practical scenarios. Game designers are thus constrained to only add abilities that can be handled by a NavMesh if they want to have NPC navigation. As an alternative, we propose to use Deep Reinforcement Learning (Deep RL) to learn how to navigate 3D maps using any navigation ability. We test our approach on complex 3D environments in the Unity game engine that are notably an order of magnitude larger than maps typically used in the Deep RL literature. One of these maps is directly modeled after a Ubisoft AAA game. We find that our approach performs surprisingly well, achieving at least > 90% success rate on all tested scenarios. A video of our results is available at > this https URL.
https://weibo.com/1402400261/JtvdtjCP2

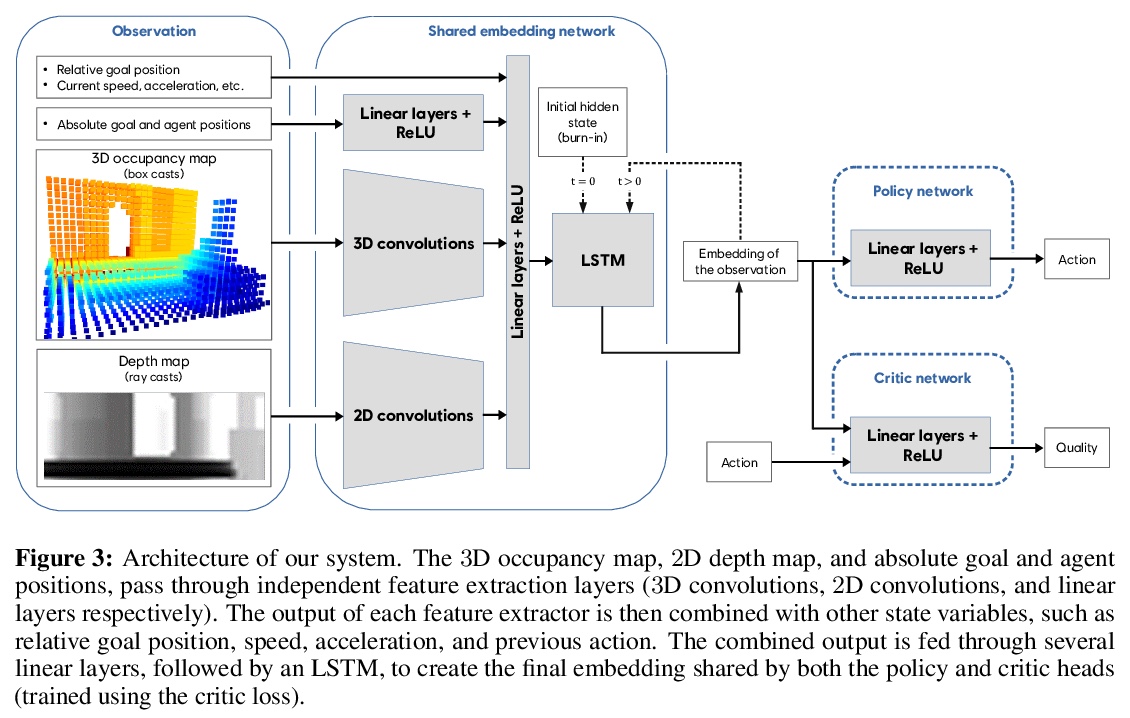
4、[CL] **Weakly- and Semi-supervised Evidence Extraction
D Pruthi, B Dhingra, G Neubig, Z C. Lipton
[CMU]
弱监督和半监督证据提取。试图阐明“预测背后的原因”,为预测补充证据,用来验证预测的正确性。提出了联合建模文本分类和证据序列标记任务的方法,将少量证据标记(强半监督)与大量文档级标签(弱监督)相结合进行证据提取。实验表明,在“先分类再提取”的框架下,根据预测标签对证据提取进行调整,可以提高基线性能,只需要几百个证据标记就能带来实质性的增益。**
For many prediction tasks, stakeholders desire not only predictions but also supporting evidence that a human can use to verify its correctness. However, in practice, additional annotations marking supporting evidence may only be available for a minority of training examples (if available at all). In this paper, we propose new methods to combine few evidence annotations (strong semi-supervision) with abundant document-level labels (weak supervision) for the task of evidence extraction. Evaluating on two classification tasks that feature evidence annotations, we find that our methods outperform baselines adapted from the interpretability literature to our task. Our approach yields substantial gains with as few as hundred evidence annotations. Code and datasets to reproduce our work are available at > this https URL.
https://weibo.com/1402400261/Jtvid1N5m

5、[LG] **Generative Neurosymbolic Machines
J Jiang, S Ahn
[Rutgers University]
生成式神经符号机(GNM),在生成式潜变量模型中,结合了分布式表示和符号表示的优点,不仅提供可解释的、模块化的、组合的结构化符号表示,还可以根据观测数据密度生成图像,这是建模世界的关键能力。实验表明,该模型在学习生成清晰的图像和遵循观察结构密度的复杂场景结构显著优于基线。**
Reconciling symbolic and distributed representations is a crucial challenge that can potentially resolve the limitations of current deep learning. Remarkable advances in this direction have been achieved recently via generative object-centric representation models. While learning a recognition model that infers object-centric symbolic representations like bounding boxes from raw images in an unsupervised way, no such model can provide another important ability of a generative model, i.e., generating (sampling) according to the structure of learned world density. In this paper, we propose Generative Neurosymbolic Machines, a generative model that combines the benefits of distributed and symbolic representations to support both structured representations of symbolic components and density-based generation. These two crucial properties are achieved by a two-layer latent hierarchy with the global distributed latent for flexible density modeling and the structured symbolic latent map. To increase the model flexibility in this hierarchical structure, we also propose the StructDRAW prior. In experiments, we show that the proposed model significantly outperforms the previous structured representation models as well as the state-of-the-art non-structured generative models in terms of both structure accuracy and image generation quality.
https://weibo.com/1402400261/JtvnowoQ7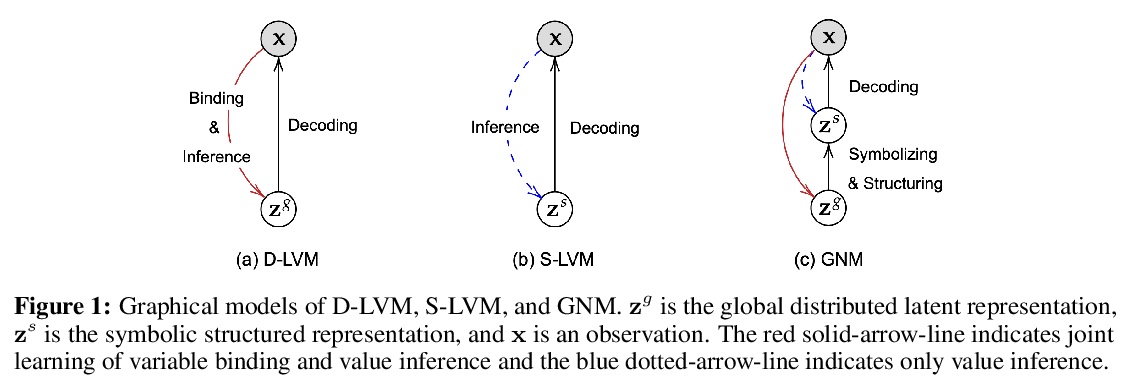


其他几篇值得关注的论文:
[LG] The power of quantum neural networks
量子神经网络
A Abbas, D Sutter, C Zoufal, A Lucchi, A Figalli, S Woerner
[IBM Research & ETH Zurich]
https://weibo.com/1402400261/JtvqUj9tN
[LG] Deep Learning is Singular, and That’s Good
奇异学习理论与深度学习
D Murfet, S Wei, M Gong, H Li, J Gell-Redman, T Quella
[University of Melbourne]
https://weibo.com/1402400261/Jtvs5xKMX

[LG] Function Contrastive Learning of Transferable Representations
可迁移表示的函数对比学习
M W Gondal, S Joshi, N Rahaman, S Bauer, M Wüthrich, B Schölkopf
[Max Planck Institute for Intelligent Systems]
https://weibo.com/1402400261/JtvuurgFj

[CL] When Do You Need Billions of Words of Pretraining Data?
要得到效果不错的预训练语言模型至少需要多少词
Y Zhang, A Warstadt, H Li, S R. Bowman
[New York University]
https://weibo.com/1402400261/JtvwE3oMz


[CV] CompressAI: a PyTorch library and evaluation platform for end-to-end compression research
CompressAI:用于端到端压缩研究的PyTorch库和评价平台
J Bégaint, F Racapé, S Feltman, A Pushparaja
[InterDigital AI Lab]
https://weibo.com/1402400261/JtvF2lCWc


[LG] Margins are Insufficient for Explaining Gradient Boosting
A Grønlund, L Kamma, K G Larsen
[Aarhus University]
https://weibo.com/1402400261/JtvGNFpFN


若有收获,就点个赞吧
0 人点赞
