- 1、[LG] Accounting for Variance in Machine Learning Benchmarks
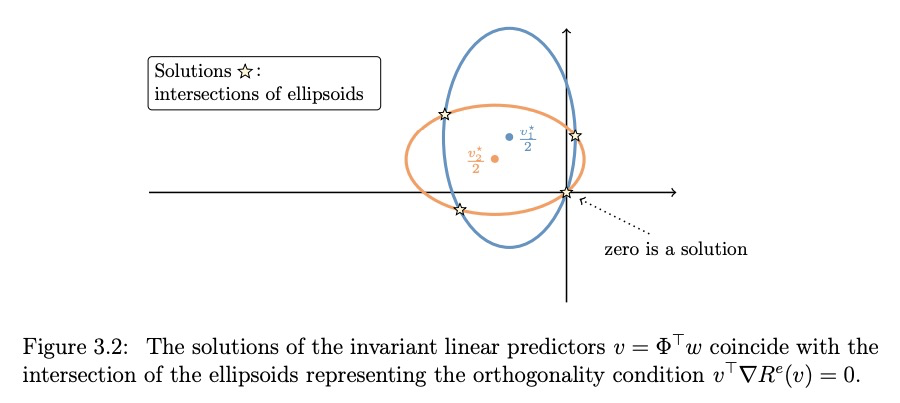
- 2、[LG] Out of Distribution Generalization in Machine Learning
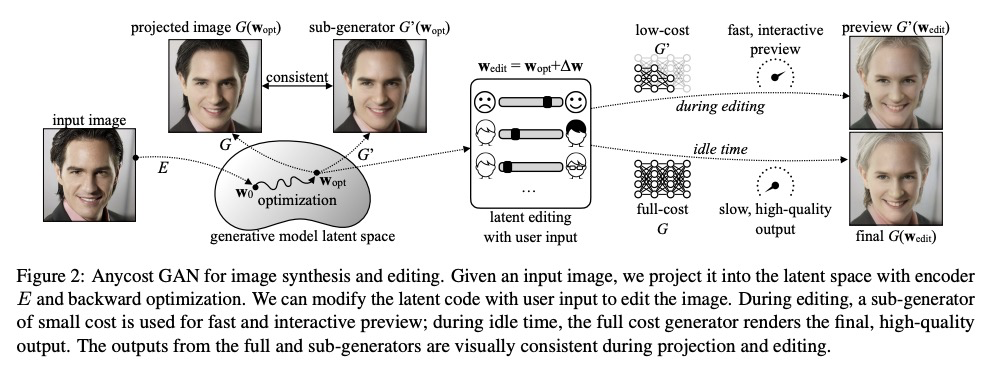
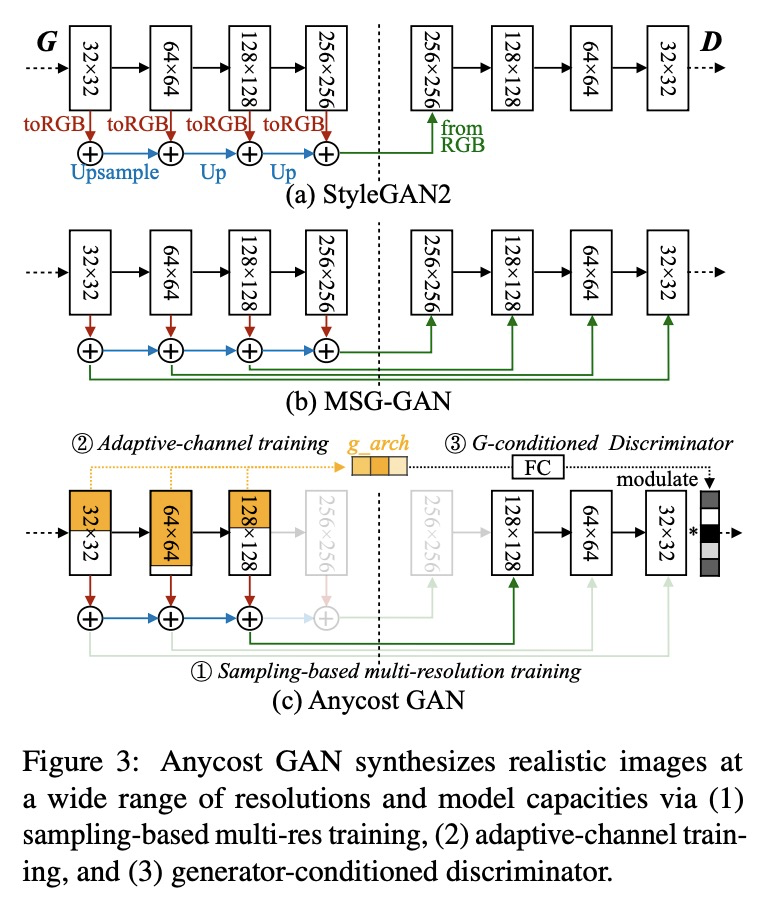
- 3、[CV] Anycost GANs for Interactive Image Synthesis and Editing
- 4、[CV] Self-supervised Geometric Perception
- 5、[CV] Data Augmentation for Object Detection via Differentiable Neural Rendering
- [LG] GenoML: Automated Machine Learning for Genomics
- [CV] MOGAN: Morphologic-structure-aware Generative Learning from a Single Image
- [LG] The Transformer Network for the Traveling Salesman Problem
- [CV] DeepTag: An Unsupervised Deep Learning Method for Motion Tracking on Cardiac Tagging Magnetic Resonance Images
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Accounting for Variance in Machine Learning Benchmarks
X Bouthillier, P Delaunay, M Bronzi, A Trofimov, B Nichyporuk, J Szeto, N Sepah, E Raff, K Madan, V Voleti, S E Kahou, V Michalski, D Serdyuk, T Arbel, C Pal, G Varoquaux, P Vincent
[Mila]
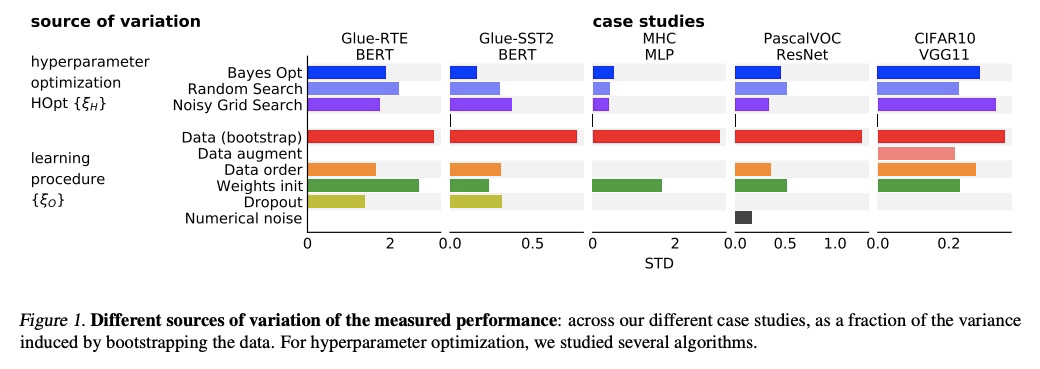
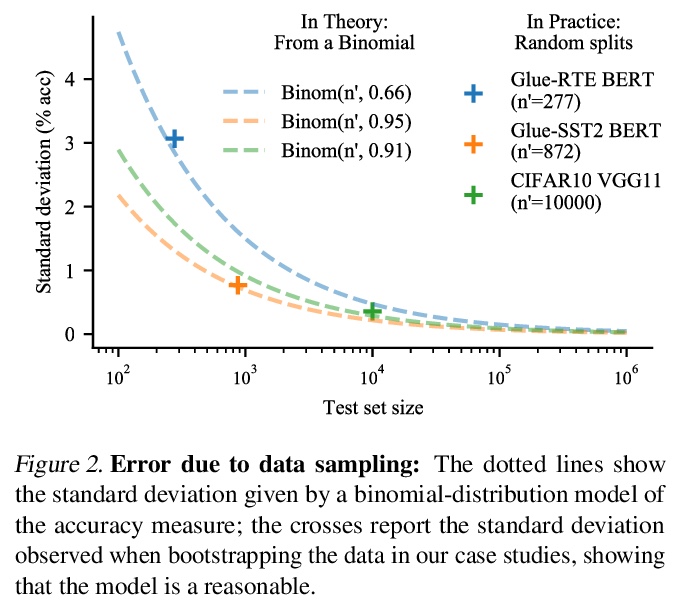
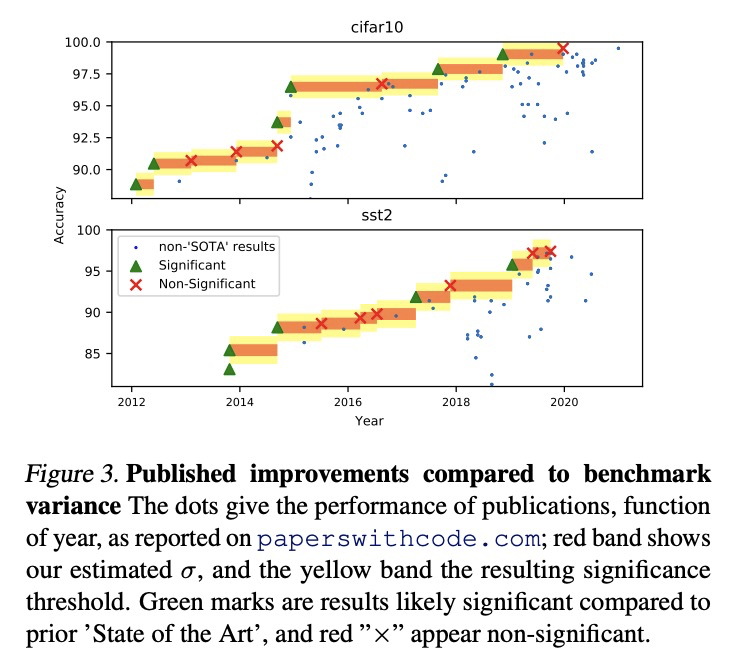
机器学习基准差异核定。对整个机器学习基准测试过程进行建模,揭示了数据采样、参数初始化和超参数选择导致的差异对结果有明显影响。基准测量的性能波动来自于许多不同的来源。在深度学习中,大多数评价集中在随机权重初始化的影响上,这实际上只贡献了一小部分差异,与超参数选择在其优化后的残差波动相当,但比扰动训练集测试集分割所导致的差异小得多。该研究清楚地表明,要给出可靠的基准,必须对这些因素进行核算。基于此考虑,研究了基准差异的估计器以及决策标准,以得出改进的结论。在不完全估计器中加入更多的差异源,可以更好地接近理想估计器,而计算成本却降低了51倍。根据研究结果给出了提高机器学习基准可靠性的建议:1)在性能估计中随机化尽可能多的差异源;2)优选多个随机分割而不是使用固定的测试集;3)当对一个算法比另一个算法的好处下结论时,要考虑由此产生的差异。
Strong empirical evidence that one machine-learning algorithm A outperforms another one B ideally calls for multiple trials optimizing the learning pipeline over sources of variation such as data sampling, data augmentation, parameter initialization, and hyperparameters choices. This is prohibitively expensive, and corners are cut to reach conclusions. We model the whole benchmarking process, revealing that variance due to data sampling, parameter initialization and hyperparameter choice impact markedly the results. We analyze the predominant comparison methods used today in the light of this variance. We show a counter-intuitive result that adding more sources of variation to an imperfect estimator approaches better the ideal estimator at a 51 times reduction in compute cost. Building on these results, we study the error rate of detecting improvements, on five different deep-learning tasks/architectures. This study leads us to propose recommendations for performance comparisons.
https://weibo.com/1402400261/K4Sic9p0e
2、[LG] Out of Distribution Generalization in Machine Learning
M Arjovsky
[New York University]
(博士论文)机器学习分布外泛化。当模型在与训练时稍有不同的数据中进行测试时,机器学习算法可能会出现惊人的失败。本研究试图正式定义这个问题,在数据中做出什么样的假设集是合理的,以及希望从中获得什么样的保证。专注于某一类分布外问题,它们的假设,介绍了这些假设出发的简单算法,这些算法能提供更可靠的泛化。论文的一个中心议题,是发现数据的因果结构,找到无论什么情况下都可靠的特征(在使用这些特征进行预测时)和分布外泛化之间的紧密联系。
Machine learning has achieved tremendous success in a variety of domains in recent years. However, a lot of these success stories have been in places where the training and the testing distributions are extremely similar to each other. In everyday situations when models are tested in slightly different data than they were trained on, ML algorithms can fail spectacularly. This research attempts to formally define this problem, what sets of assumptions are reasonable to make in our data and what kind of guarantees we hope to obtain from them. Then, we focus on a certain class of out of distribution problems, their assumptions, and introduce simple algorithms that follow from these assumptions that are able to provide more reliable generalization. A central topic in the thesis is the strong link between discovering the causal structure of the data, finding features that are reliable (when using them to predict) regardless of their context, and out of distribution generalization.
https://weibo.com/1402400261/K4SsL2vBi
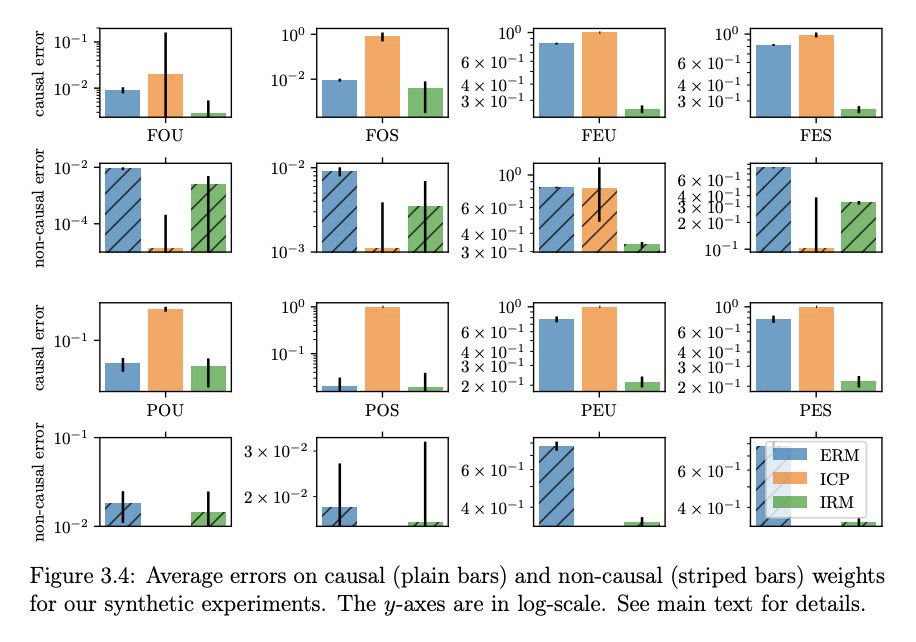
3、[CV] Anycost GANs for Interactive Image Synthesis and Editing
J Lin, R Zhang, F Ganz, S Han, J Zhu
[MIT & Adobe Research]
基于Anycost GAN的交互式图像合成与编辑。受现代渲染软件快速预览功能的启发,提出了Anycost GAN,一种可扩展的训练方法,用于学习无条件生成器,实现交互式自然图像编辑,可适应不同的硬件和用户延迟要求。通过使用基于采样的多分辨率训练、自适应通道训练和生成器条件判别器,Anycost生成器可在各种配置下评价,同时与单独训练的模型相比,实现更好的图像质量。开发了新的编码器训练和潜码优化技术,以促进不同子生成器在图像投射过程的一致性。Anycost GAN可在各种成本预算下执行(最多可减少10倍计算量),并适应广泛的硬件和延迟要求。当部署在桌面CPU和边缘设备上时,该模型可以以6-12倍的速度提供感知上相似的预览,实现交互式图像编辑。
Generative adversarial networks (GANs) have enabled photorealistic image synthesis and editing. However, due to the high computational cost of large-scale generators (e.g., StyleGAN2), it usually takes seconds to see the results of a single edit on edge devices, prohibiting interactive user experience. In this paper, we take inspirations from modern rendering software and propose Anycost GAN for interactive natural image editing. We train the Anycost GAN to support elastic resolutions and channels for faster image generation at versatile speeds. Running subsets of the full generator produce outputs that are perceptually similar to the full generator, making them a good proxy for preview. By using sampling-based multi-resolution training, adaptive-channel training, and a generator-conditioned discriminator, the anycost generator can be evaluated at various configurations while achieving better image quality compared to separately trained models. Furthermore, we develop new encoder training and latent code optimization techniques to encourage consistency between the different sub-generators during image projection. Anycost GAN can be executed at various cost budgets (up to 10x computation reduction) and adapt to a wide range of hardware and latency requirements. When deployed on desktop CPUs and edge devices, our model can provide perceptually similar previews at 6-12x speedup, enabling interactive image editing. The code and demo are publicly available: > this https URL.
https://weibo.com/1402400261/K4SxSC9IW

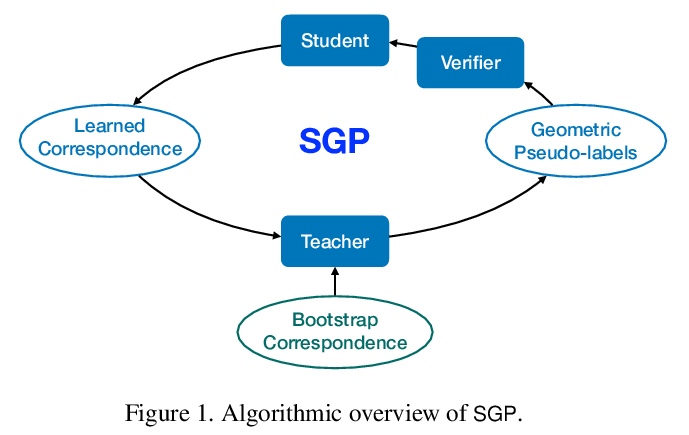
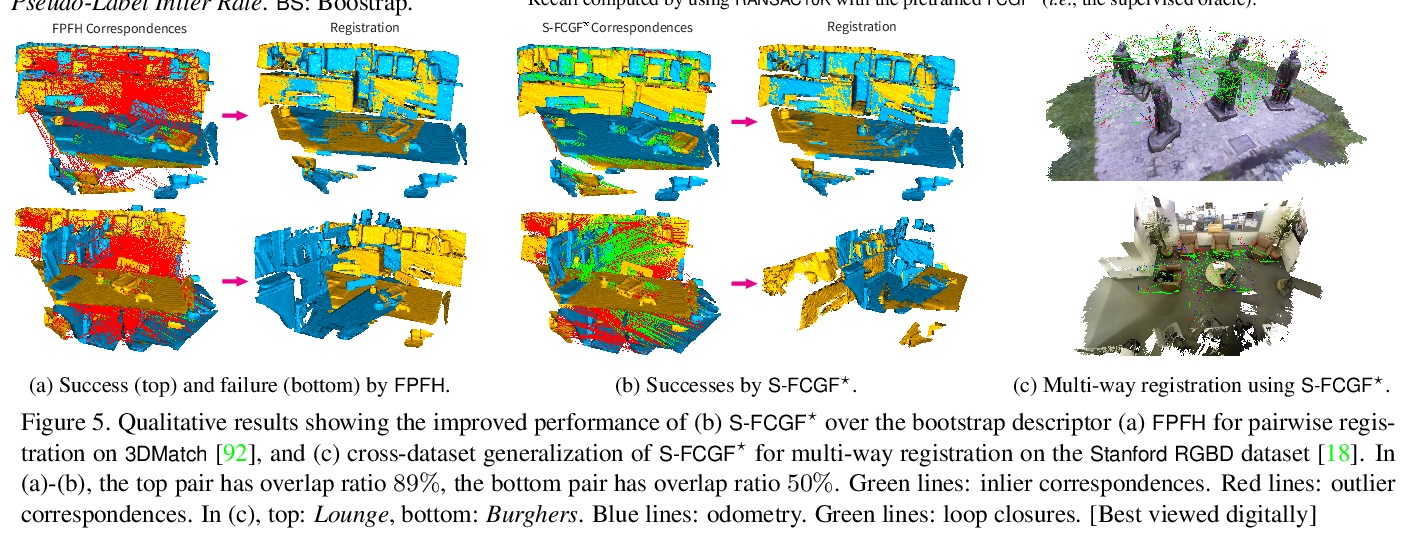
4、[CV] Self-supervised Geometric Perception
H Yang, W Dong, L Carlone, V Koltun
[MIT & CMU & Intel]
自监督几何感知。提出自监督几何感知(SGP),在没有任何真实几何模型标签(如相机姿态,刚性变换)的情况下,学习对应匹配特征描述符的通用框架。SGP迭代执行几何模型鲁棒估计,以生成伪标签,并在噪声伪标签监督下进行特征学习。将SGP应用于相机姿态估计和点云配准,在大规模真实数据集中展示了与有监督相当甚至更优的性能。
We present self-supervised geometric perception (SGP), the first general framework to learn a feature descriptor for correspondence matching without any ground-truth geometric model labels (e.g., camera poses, rigid transformations). Our first contribution is to formulate geometric perception as an optimization problem that jointly optimizes the feature descriptor and the geometric models given a large corpus of visual measurements (e.g., images, point clouds). Under this optimization formulation, we show that two important streams of research in vision, namely robust model fitting and deep feature learning, correspond to optimizing one block of the unknown variables while fixing the other block. This analysis naturally leads to our second contribution — the SGP algorithm that performs alternating minimization to solve the joint optimization. SGP iteratively executes two meta-algorithms: a teacher that performs robust model fitting given learned features to generate geometric pseudo-labels, and a student that performs deep feature learning under noisy supervision of the pseudo-labels. As a third contribution, we apply SGP to two perception problems on large-scale real datasets, namely relative camera pose estimation on MegaDepth and point cloud registration on 3DMatch. We demonstrate that SGP achieves state-of-the-art performance that is on-par or superior to the supervised oracles trained using ground-truth labels.
https://weibo.com/1402400261/K4SCqezcX

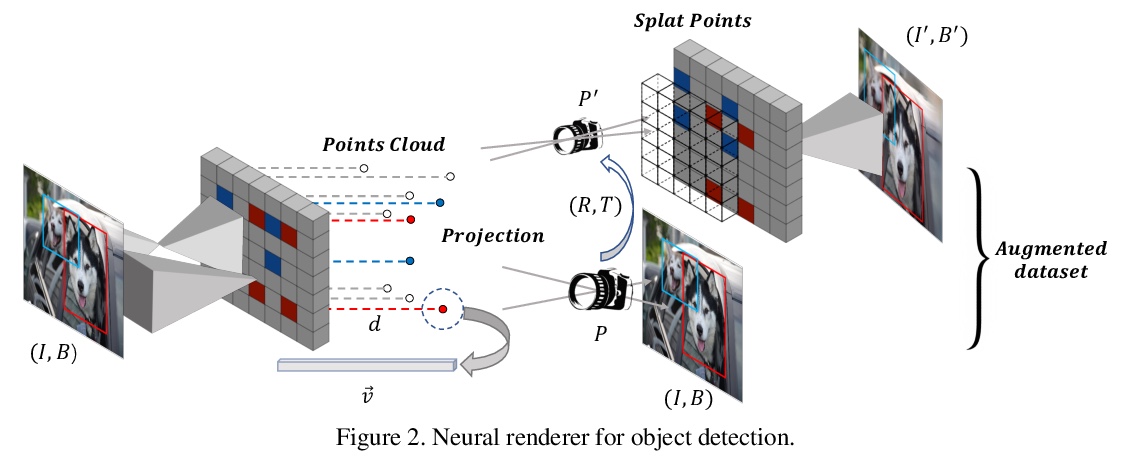
5、[CV] Data Augmentation for Object Detection via Differentiable Neural Rendering
G Ning, G Chen, C Tan, S Luo, L Bo, H Huang
[JD Finance America Corporation]
基于可微神经网络渲染的目标检测数据增强。提出一种用于目标检测的离线数据增强方法,对训练数据进行语义插值,基于可微神经网络渲染生成训练图像的可控视图,及相应的边框标注,无需人工干预。首先提取并将像素对齐的图像特征投射到点云中,同时估计深度图,用目标相机的姿态重新投射,并渲染出新视角二维图像。以关键点形式存在的目标在点云中被标记,以恢复新视图中的标记。该方法完全兼容在线数据增强方法,如仿射变换、图像混合等,作为一种无成本的图像和标签丰富工具,可显著提升训练数据稀缺的目标检测系统的性能。
It is challenging to train a robust object detector when annotated data is scarce. Existing approaches to tackle this problem include semi-supervised learning that interpolates labeled data from unlabeled data, self-supervised learning that exploit signals within unlabeled data via pretext tasks. Without changing the supervised learning paradigm, we introduce an offline data augmentation method for object detection, which semantically interpolates the training data with novel views. Specifically, our proposed system generates controllable views of training images based on differentiable neural rendering, together with corresponding bounding box annotations which involve no human intervention. Firstly, we extract and project pixel-aligned image features into point clouds while estimating depth maps. We then re-project them with a target camera pose and render a novel-view 2d image. Objects in the form of keypoints are marked in point clouds to recover annotations in new views. It is fully compatible with online data augmentation methods, such as affine transform, image mixup, etc. Extensive experiments show that our method, as a cost-free tool to enrich images and labels, can significantly boost the performance of object detection systems with scarce training data. Code is available at \url{> this https URL}.
https://weibo.com/1402400261/K4SNpl4ii


另外几篇值得关注的论文:
[LG] GenoML: Automated Machine Learning for Genomics
GenoML:基因组学自动化机器学习包
M B. Makarious, H L. Leonard, D Vitale, H Iwaki, D Saffo, L Sargent, A Dadu, E S Castaño, J F. Carter, M Maleknia, J A. Botia, C Blauwendraat, R H. Campbell, S H Hashemi, A B. Singleton, M A. Nalls, F Faghri
[National Institutes of Health, Bethesda & Data Tecnica International LLC]
https://weibo.com/1402400261/K4SFU0xYe
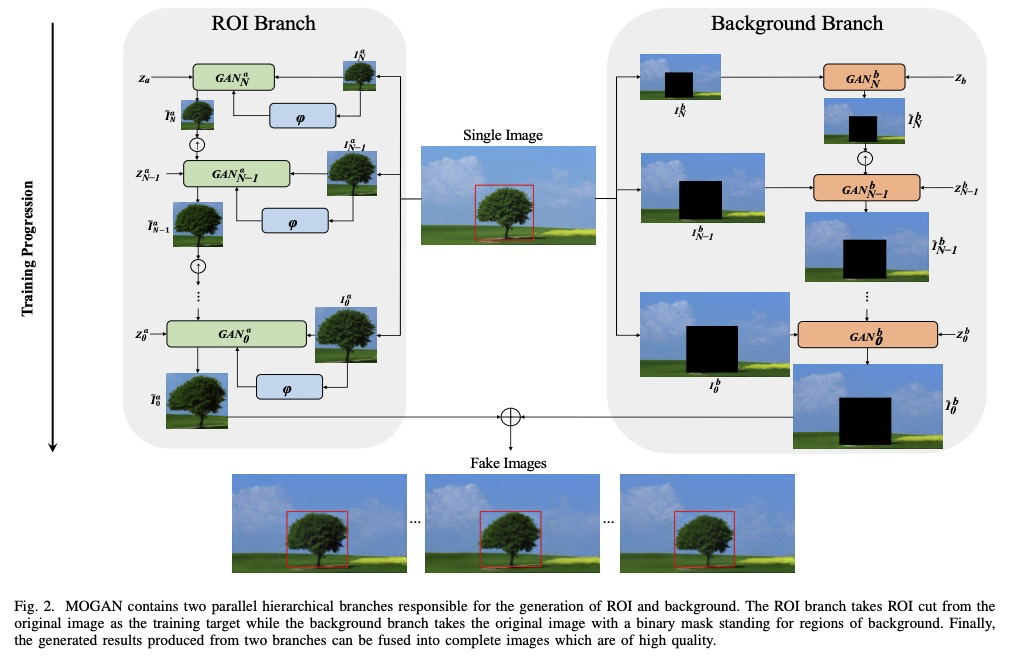
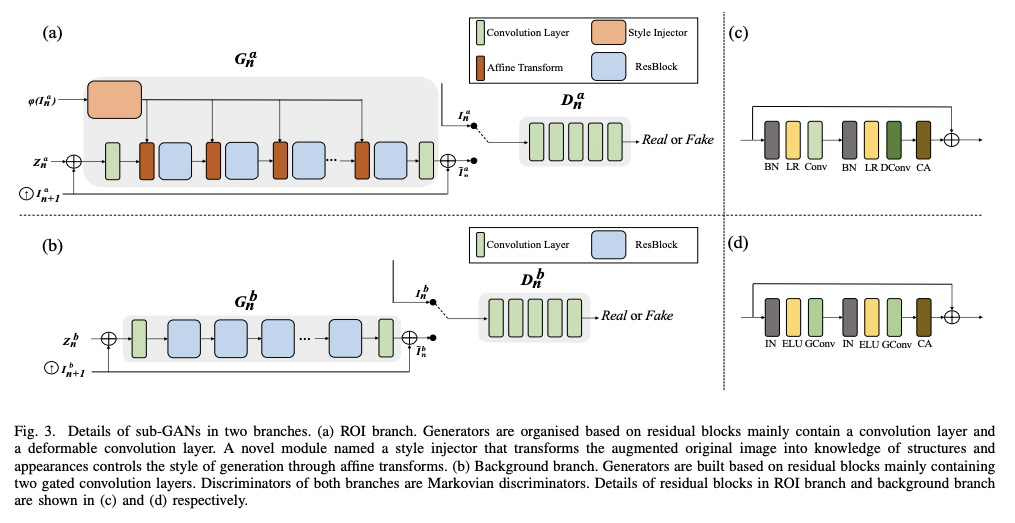
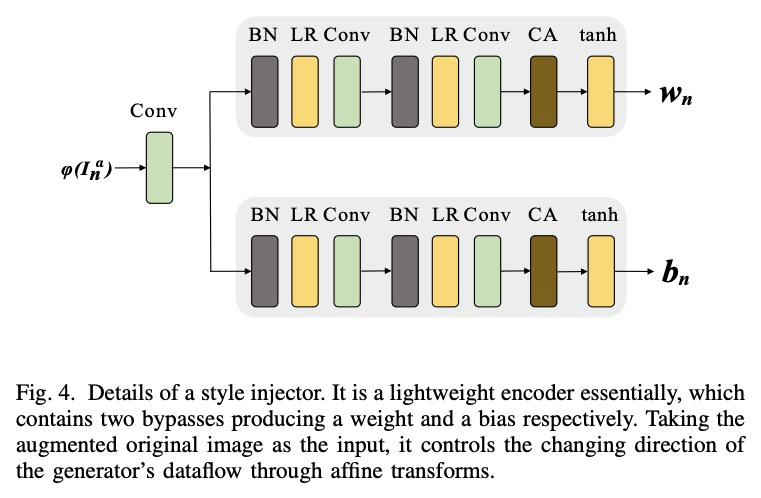
[CV] MOGAN: Morphologic-structure-aware Generative Learning from a Single Image
MOGAN:单幅图像的形态结构感知生成学习
J Chen, Q Xu, Q Kang, M Zhou
[Tongji University]
https://weibo.com/1402400261/K4SRuzakJ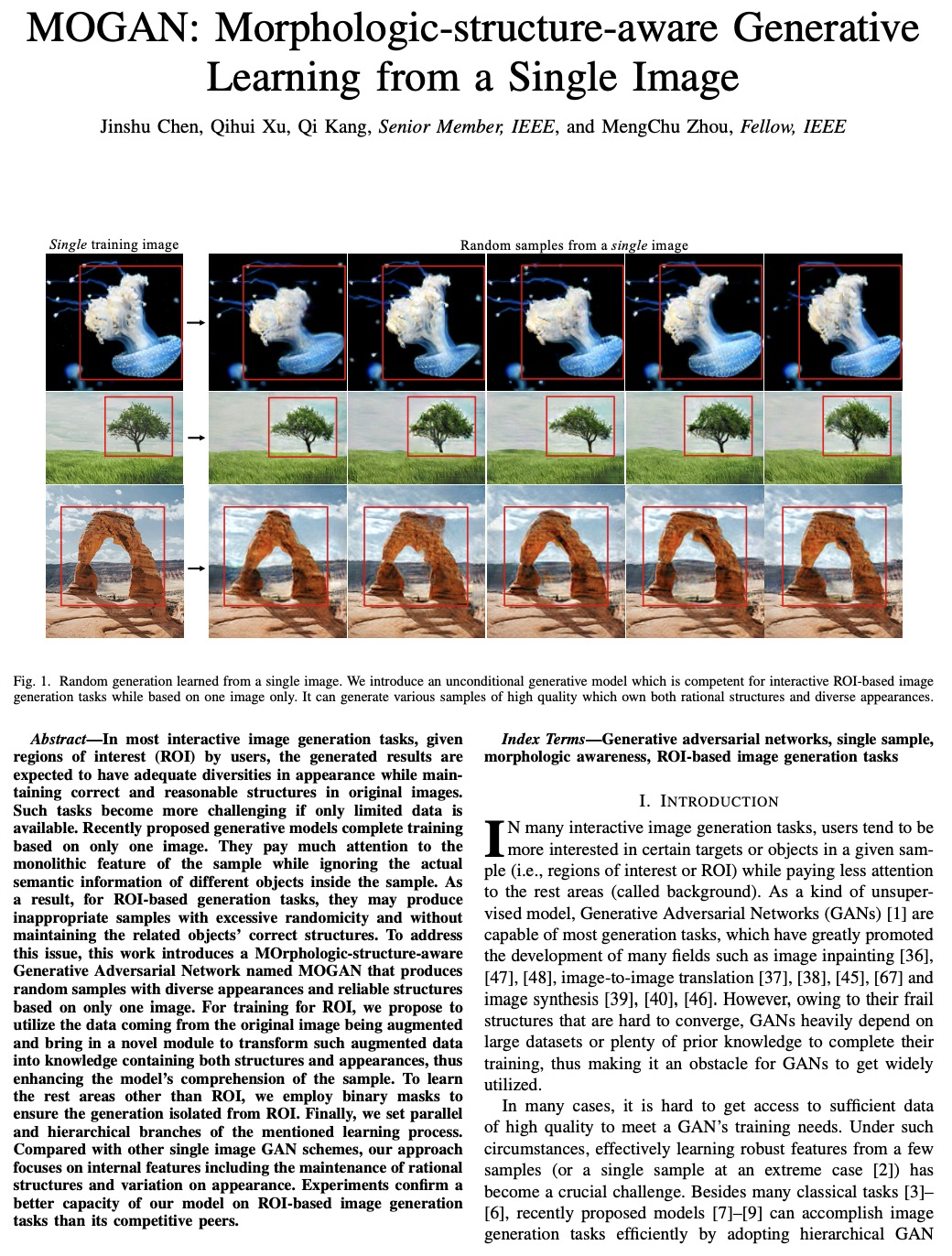
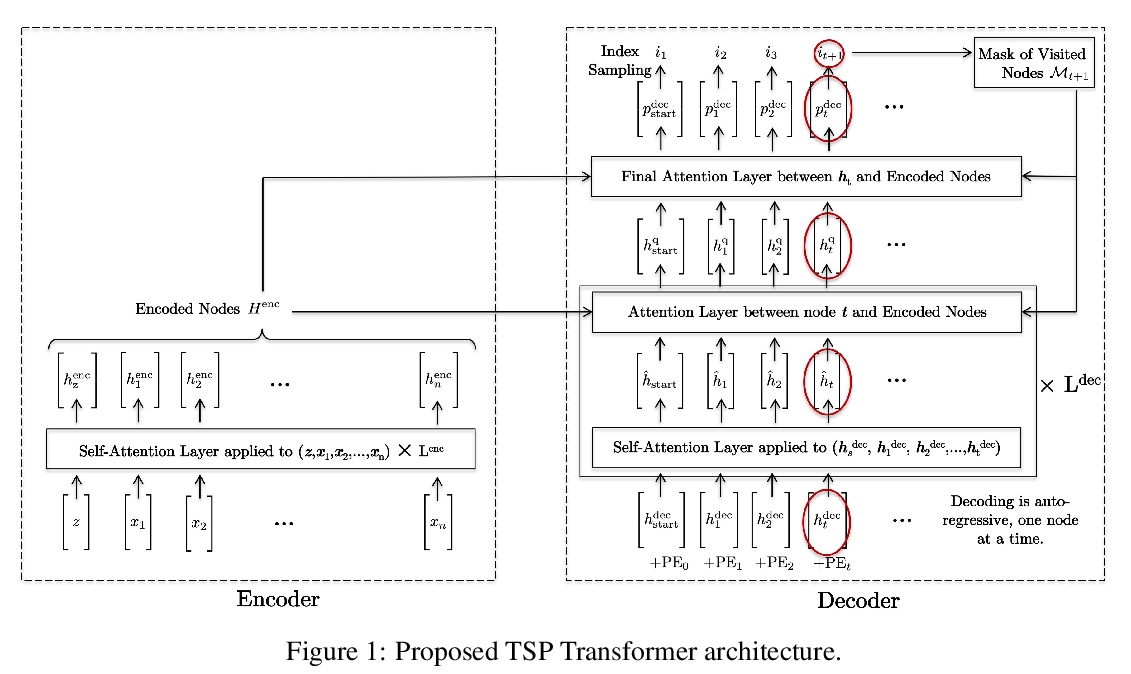
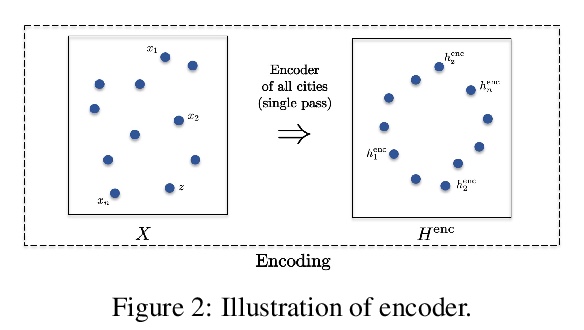
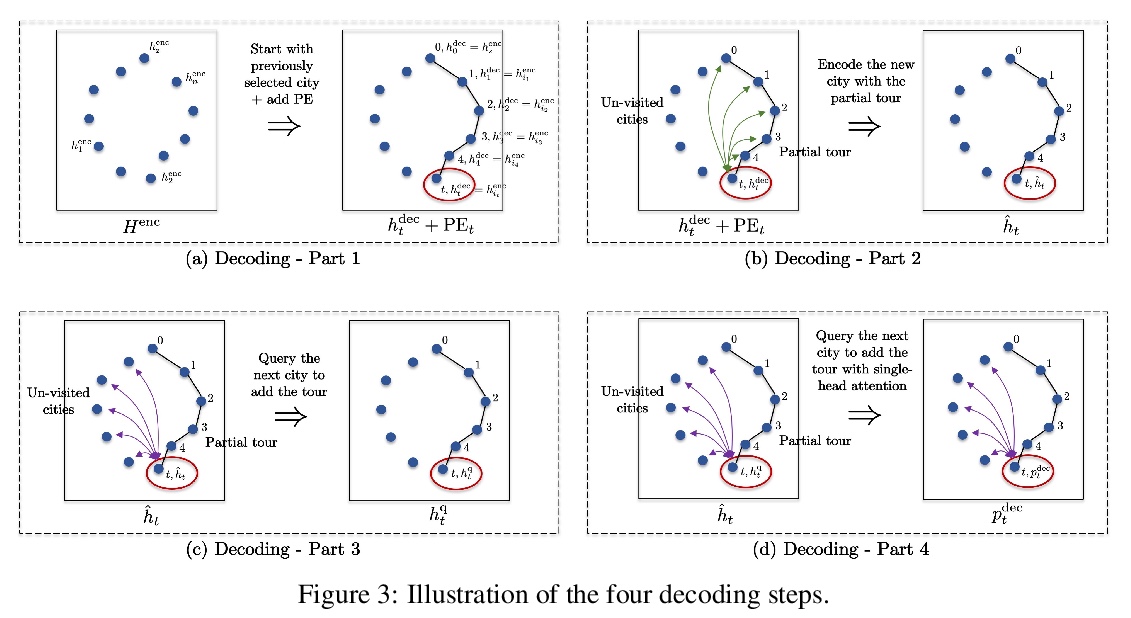
[LG] The Transformer Network for the Traveling Salesman Problem
旅行商问题的Transformer网络
X Bresson, T Laurent
[NTU & Loyola Marymount University]
https://weibo.com/1402400261/K4ST3uu9J
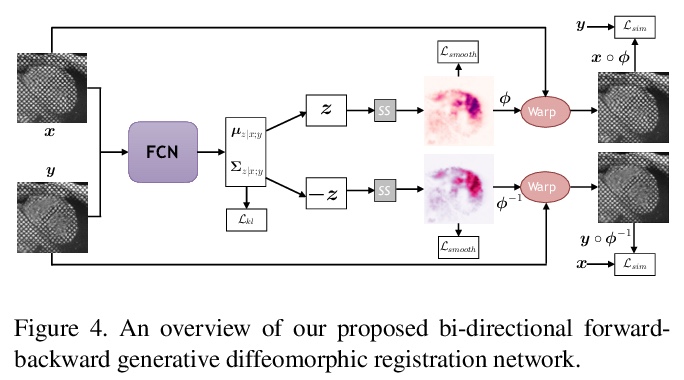
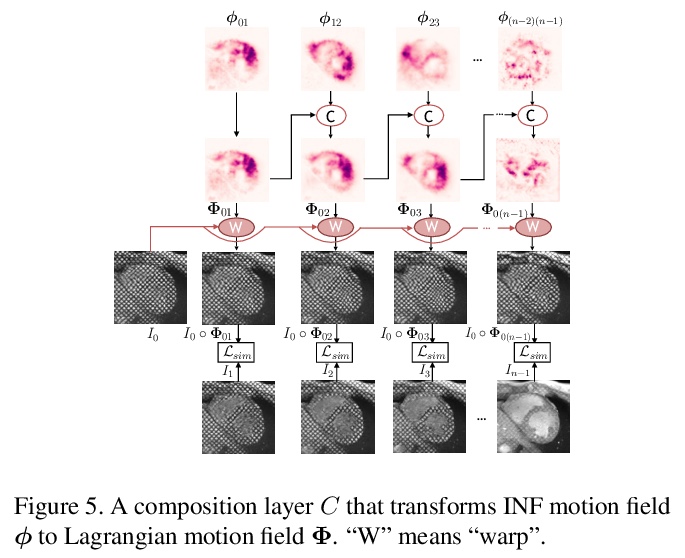
[CV] DeepTag: An Unsupervised Deep Learning Method for Motion Tracking on Cardiac Tagging Magnetic Resonance Images
DeepTag:心脏标记磁共振图像动态跟踪的无监督深度学习方法
M Ye, M Kanski, D Yang, Q Chang, Z Yan, Q Huang, L Axel, D Metaxas
[Rutgers University & New York University School of Medicine & NVIDIA]
https://weibo.com/1402400261/K4SUxopze


若有收获,就点个赞吧
0 人点赞
