- 1、[AI] Player-AI Interaction: What Neural Network Games Reveal About AI as Play
- 2、[LG] Does Continual Learning = Catastrophic Forgetting?
- 3、[CV] U-Noise: Learnable Noise Masks for Interpretable Image Segmentation
- 4、[CV] ArtEmis: Affective Language for Visual Art
- 5、[CV] Fast Convergence of DETR with Spatially Modulated Co-Attention
- [LG] A Unifying Generative Model for Graph Learning Algorithms: Label Propagation, Graph Convolutions, and Combinations
- [CV] GO-Finder: A Registration-Free Wearable System for Assisting Users in Finding Lost Objects via Hand-Held Object Discovery
- [CV] Using Shape to Categorize: Low-Shot Learning with an Explicit Shape Bias
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
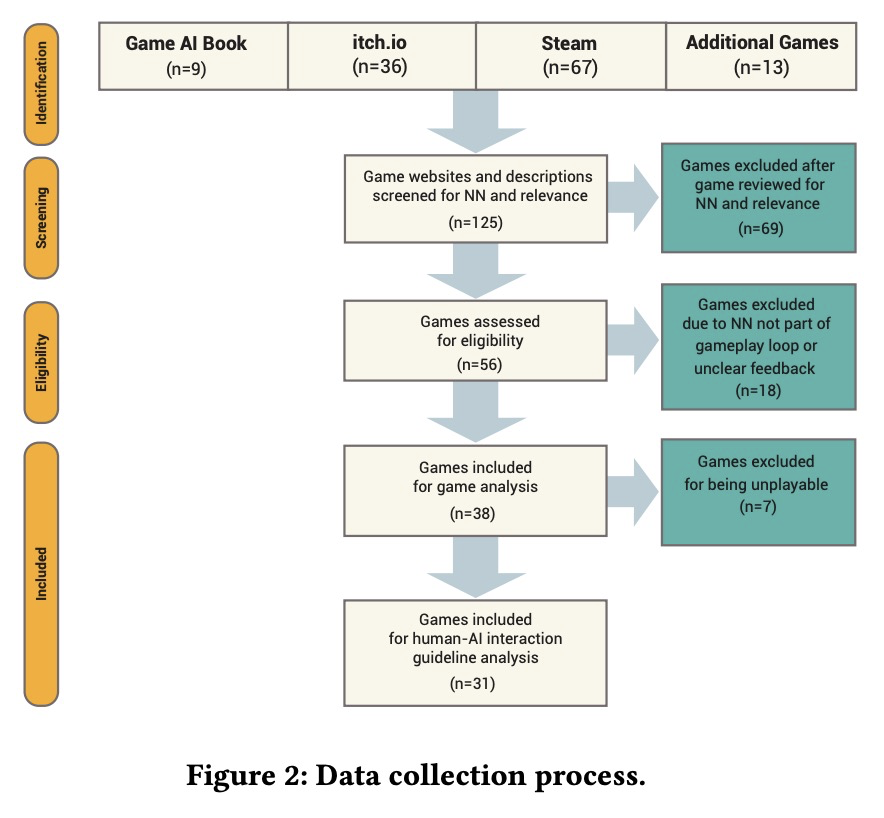
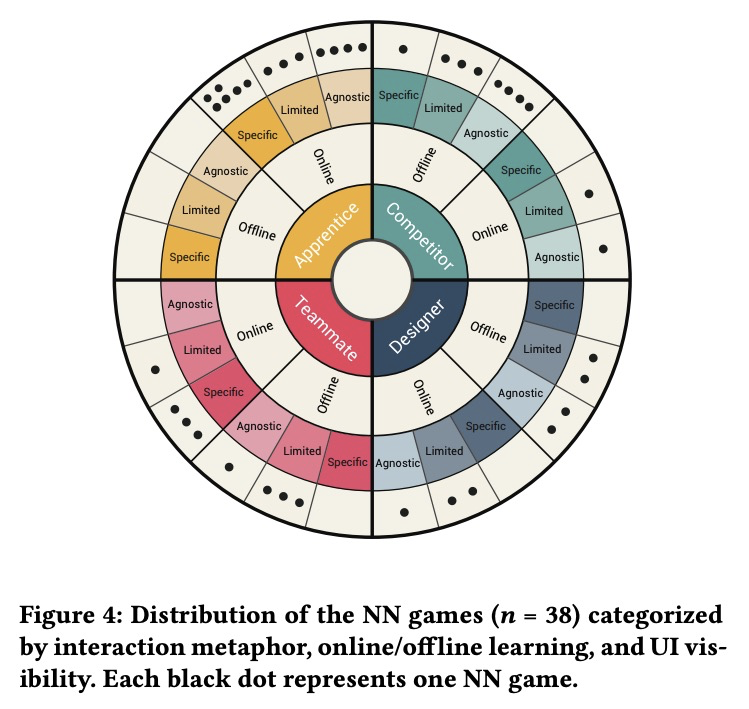
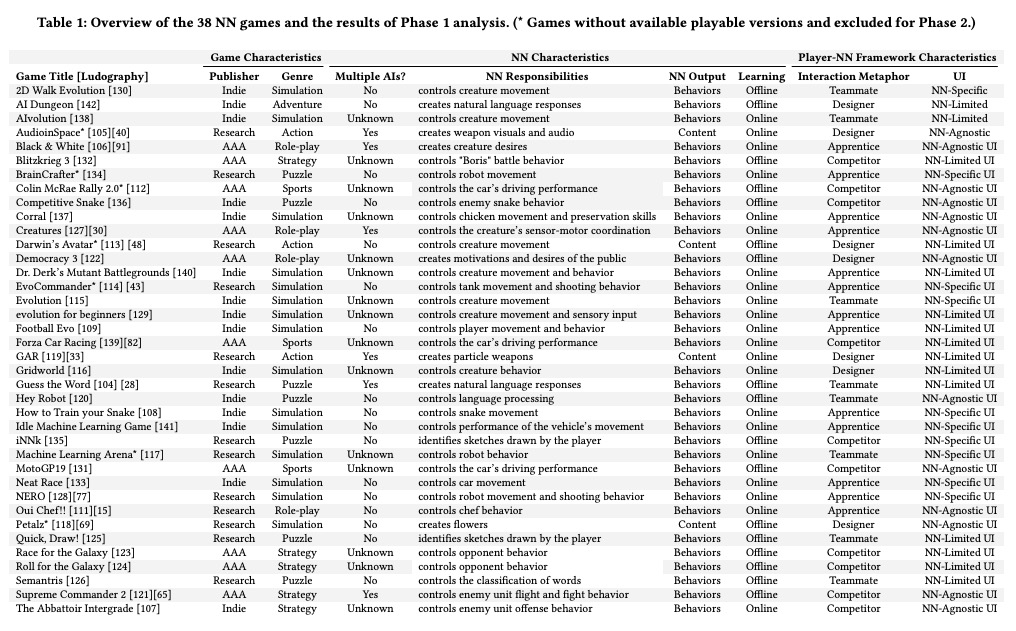
1、[AI] Player-AI Interaction: What Neural Network Games Reveal About AI as Play
J Zhu, J Villareale, N Javvaji, S Risi, M Löwe, R Weigelt, C Harteveld
[Drexel University & Northeastern University & IT University Copenhagen]
玩家-AI交互:神经网络游戏揭示了AI即游戏。引入了玩家-AI交互这个新研究领域,研究人类玩家如何在游戏中与AI交互,以强调在游戏环境中,特别是通过电脑游戏,人们如何与AI交互。通过对神经网络游戏的系统调查,确定了这些游戏中的主导交互象征和AI交互模式。应用现有的人-AI交互准则,阐明了在AI注入系统的背景下玩家与AI的交互。
The advent of artificial intelligence (AI) and machine learning (ML) bring human-AI interaction to the forefront of HCI research. This paper argues that games are an ideal domain for studying and experimenting with how humans interact with AI. Through a systematic survey of neural network games (n = 38), we identified the dominant interaction metaphors and AI interaction patterns in these games. In addition, we applied existing human-AI interaction guidelines to further shed light on player-AI interaction in the context of AI-infused systems. Our core finding is that AI as play can expand current notions of human-AI interaction, which are predominantly productivity-based. In particular, our work suggests that game and UX designers should consider flow to structure the learning curve of human-AI interaction, incorporate discovery-based learning to play around with the AI and observe the consequences, and offer users an invitation to play to explore new forms of human-AI interaction.
https://weibo.com/1402400261/JE8T507dA
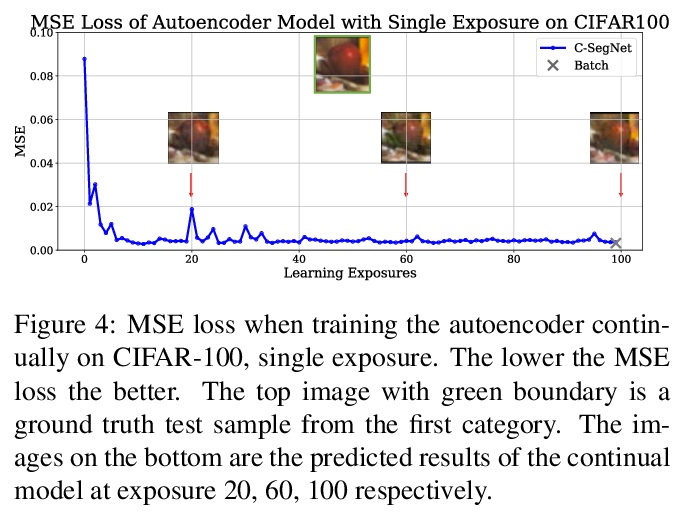
2、[LG] Does Continual Learning = Catastrophic Forgetting?
A Thai, S Stojanov, I Rehg, J M. Rehg
[Georgia Institute of Technology]
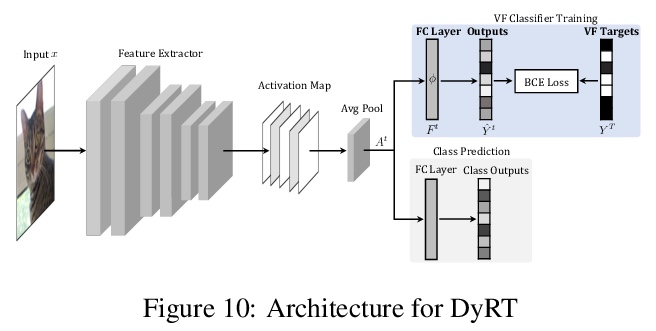
持续学习就意味着灾难性遗忘吗?对持续学习与灾难性遗忘必然相关的假设发起了挑战,发现有一类重建任务不会表现出灾难性遗忘,灾难性遗忘是否发生取决于任务和环境设置。提出了一种新的简单算法YASS,在类-增量分类学习任务中表现优于最先进方法。提出了DyRT,一个用于跟踪持续模型中特征学习动态的新工具。
Continual learning is known for suffering from catastrophic forgetting, a phenomenon where earlier learned concepts are forgotten at the expense of more recent samples. In this work, we challenge the assumption that continual learning is inevitably associated with catastrophic forgetting by presenting a set of tasks that surprisingly do not suffer from catastrophic forgetting when learned continually. We attempt to provide an insight into the property of these tasks that make them robust to catastrophic forgetting and the potential of having a proxy representation learning task for continual classification. We further introduce a novel yet simple algorithm, YASS that outperforms state-of-the-art methods in the class-incremental categorization learning task. Finally, we present DyRT, a novel tool for tracking the dynamics of representation learning in continual models. The codebase, dataset and pre-trained models released with this article can be found at > this https URL.
https://weibo.com/1402400261/JE98M2jop
3、[CV] U-Noise: Learnable Noise Masks for Interpretable Image Segmentation
T Koker, F Mireshghallah, T Titcombe, G Kaissis
[Grid AI & University of California San Diego & Tessella]
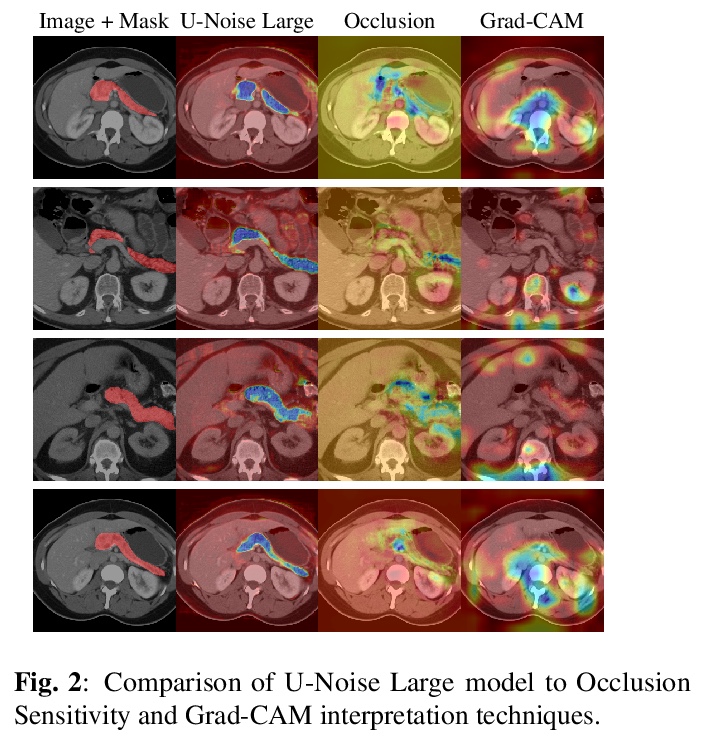
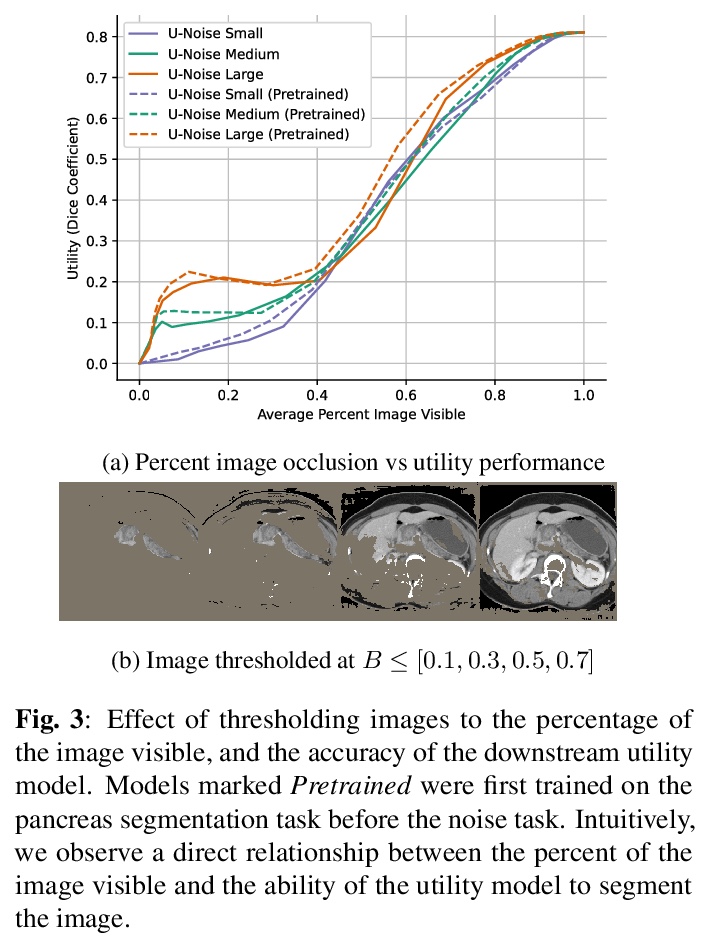
U-Noise:基于可学习噪声掩模的可解释图像分割。提出U-Noise,基于噪声的图像分割模型解释框架。U-Noise通过应用加性噪声,观察模型效用对每个像素值变化的敏感程度,来发现分割模型赖以决策的像素。所提出的架构提供了一种轻量方法,可在不严重影响任务实用性的情况下对图像的部分进行遮挡。与现有的隐私方法(如局部差分隐私)相比,可被用来以更直接的方式遮蔽设备端的用户数据。
Deep Neural Networks (DNNs) are widely used for decision making in a myriad of critical applications, ranging from medical to societal and even judicial. Given the importance of these decisions, it is crucial for us to be able to interpret these models. We introduce a new method for interpreting image segmentation models by learning regions of images in which noise can be applied without hindering downstream model performance. We apply this method to segmentation of the pancreas in CT scans, and qualitatively compare the quality of the method to existing explainability techniques, such as Grad-CAM and occlusion sensitivity. Additionally we show that, unlike other methods, our interpretability model can be quantitatively evaluated based on the downstream performance over obscured images.
https://weibo.com/1402400261/JE9eqtkhd

4、[CV] ArtEmis: Affective Language for Visual Art
P Achlioptas, M Ovsjanikov, K Haydarov, M Elhoseiny, L Guibas
[Stanford University & Ecole Polytechnique & King Abdullah University of Science and Technology (KAUST)]
ArtEmis:视觉艺术情感语言数据集。提出一个新的大规模数据集和配套的机器学习模型,旨在详细了解视觉内容、情感效应及语言对其的解释之间的相互作用。与计算机视觉领域现有的大多数标注数据集不同,该数据集专注于视觉艺术作品引发的情感体验,并要求标注者指出他们对给定图像的主要情感,并为其情感选择提供语言解释依据。ArtEmis数据集包含对WikiArt上81K件艺术作品的439K条人工标注的情感归因和解释。在这些数据的基础上,训练并展示了一系列能够从视觉刺激中表达和解释情感的描述系统,其产生的描述往往能成功反映图像的语义和抽象内容,远远超出在现有数据集上训练的系统。
We present a novel large-scale dataset and accompanying machine learning models aimed at providing a detailed understanding of the interplay between visual content, its emotional effect, and explanations for the latter in language. In contrast to most existing annotation datasets in computer vision, we focus on the affective experience triggered by visual artworks and ask the annotators to indicate the dominant emotion they feel for a given image and, crucially, to also provide a grounded verbal explanation for their emotion choice. As we demonstrate below, this leads to a rich set of signals for both the objective content and the affective impact of an image, creating associations with abstract concepts (e.g., “freedom” or “love”), or references that go beyond what is directly visible, including visual similes and metaphors, or subjective references to personal experiences. We focus on visual art (e.g., paintings, artistic photographs) as it is a prime example of imagery created to elicit emotional responses from its viewers. Our dataset, termed ArtEmis, contains 439K emotion attributions and explanations from humans, on 81K artworks from WikiArt. Building on this data, we train and demonstrate a series of captioning systems capable of expressing and explaining emotions from visual stimuli. Remarkably, the captions produced by these systems often succeed in reflecting the semantic and abstract content of the image, going well beyond systems trained on existing datasets. The collected dataset and developed methods are available at > this https URL.
https://weibo.com/1402400261/JE9kTbNsD



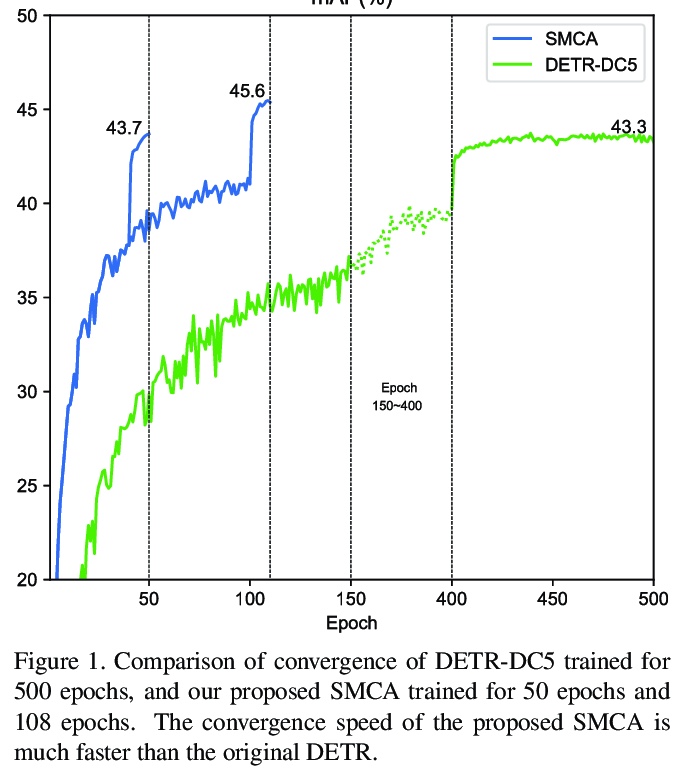
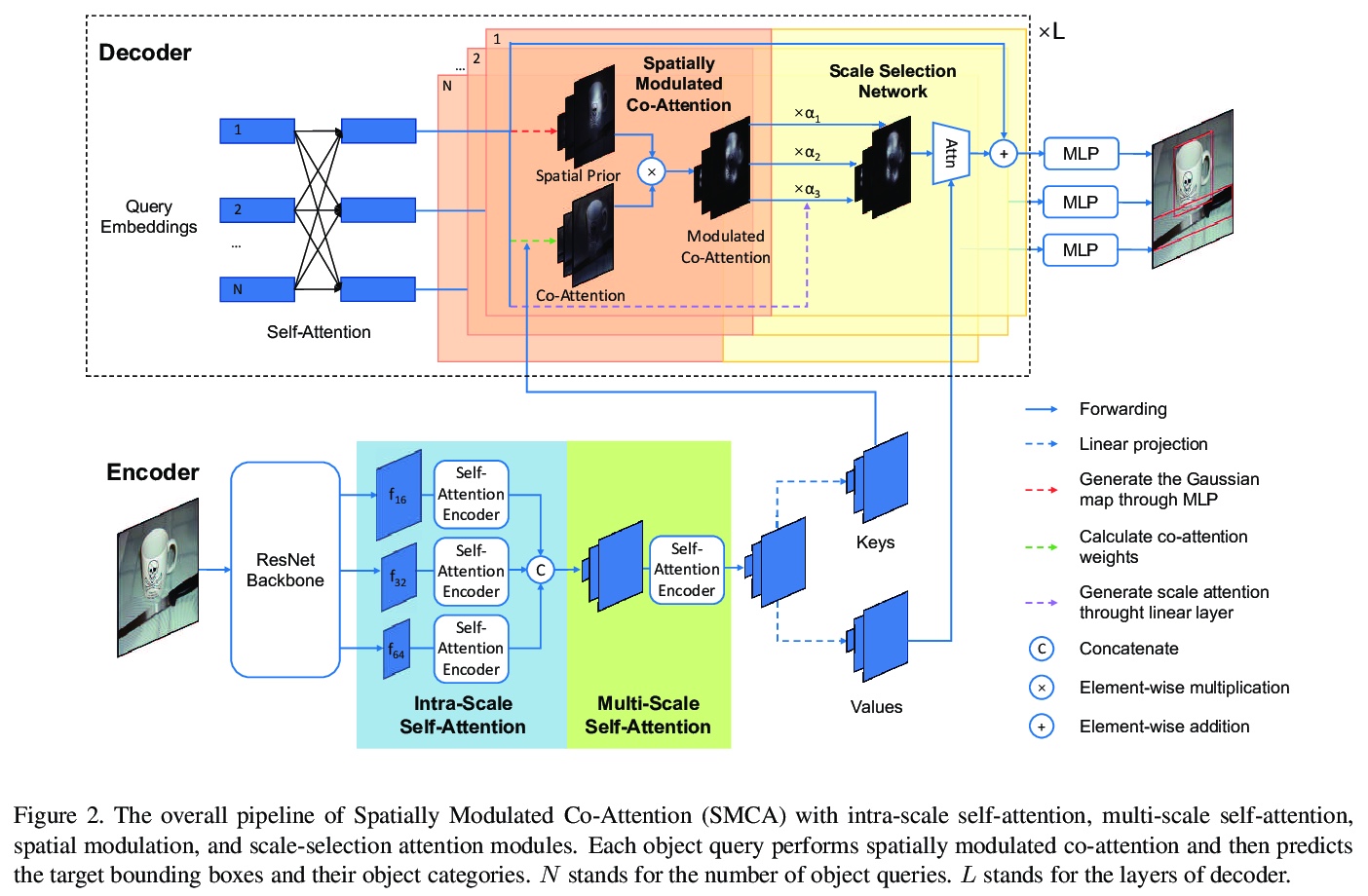
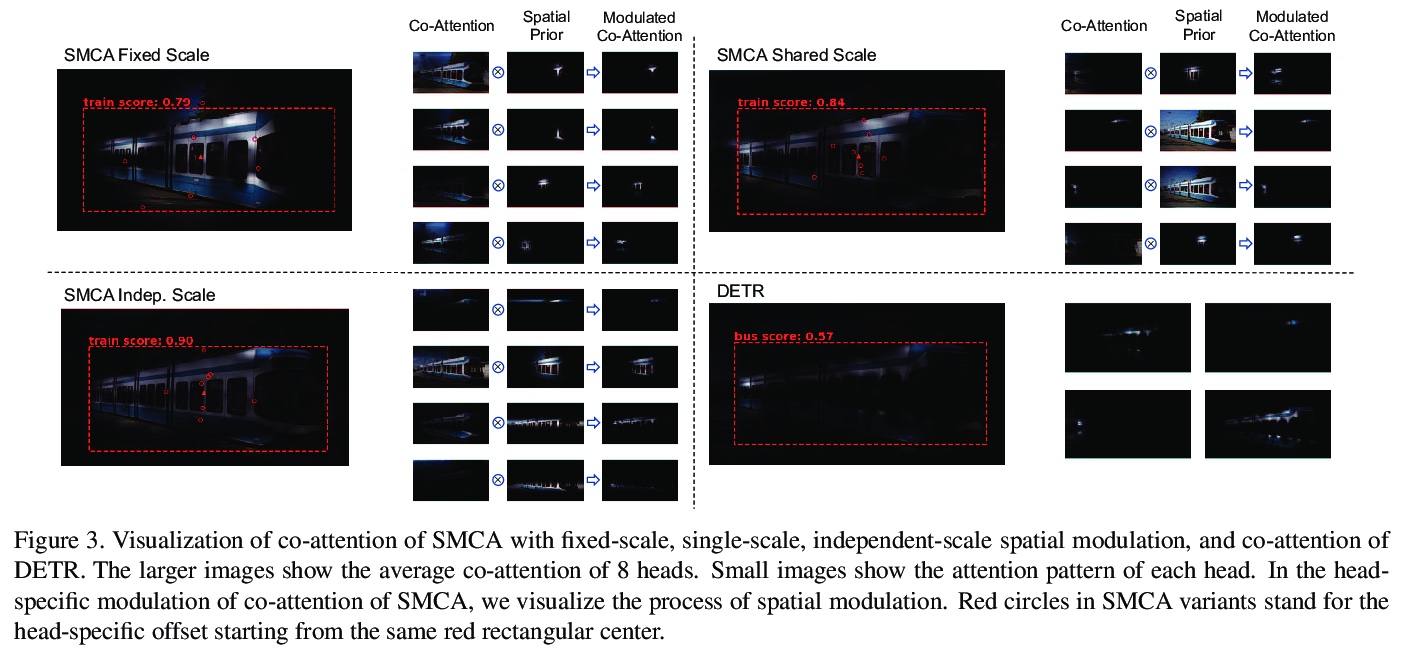
5、[CV] Fast Convergence of DETR with Spatially Modulated Co-Attention
P Gao, M Zheng, X Wang, J Dai, H Li
[The Chinese University of Hong Kong & SenseTime Research & Peking University]
基于空间调制共同注意力的DETR快速收敛。提出一种超越以往两阶段和单阶段方法的端到端目标检测解决方案。通过将空间调制协同注意力(SMCA)集成到DETR中,在推理成本相当的情况下,原来500个epochs的训练可以减少到108个epochs,mAP从43.4提高到45.6。SMCA展示了探索全局信息实现高质量目标检测的潜力。
The recently proposed Detection Transformer (DETR) model successfully applies Transformer to objects detection and achieves comparable performance with two-stage object detection frameworks, such as Faster-RCNN. However, DETR suffers from its slow convergence. Training DETR \cite{carion2020end} from scratch needs 500 epochs to achieve a high accuracy. To accelerate its convergence, we propose a simple yet effective scheme for improving the DETR framework, namely Spatially Modulated Co-Attention (SMCA) mechanism. The core idea of SMCA is to conduct regression-aware co-attention in DETR by constraining co-attention responses to be high near initially estimated bounding box locations. Our proposed SMCA increases DETR’s convergence speed by replacing the original co-attention mechanism in the decoder while keeping other operations in DETR unchanged. Furthermore, by integrating multi-head and scale-selection attention designs into SMCA, our fully-fledged SMCA can achieve better performance compared to DETR with a dilated convolution-based backbone (45.6 mAP at 108 epochs vs. 43.3 mAP at 500 epochs). We perform extensive ablation studies on COCO dataset to validate the effectiveness of the proposed SMCA.
https://weibo.com/1402400261/JE9qNwVOc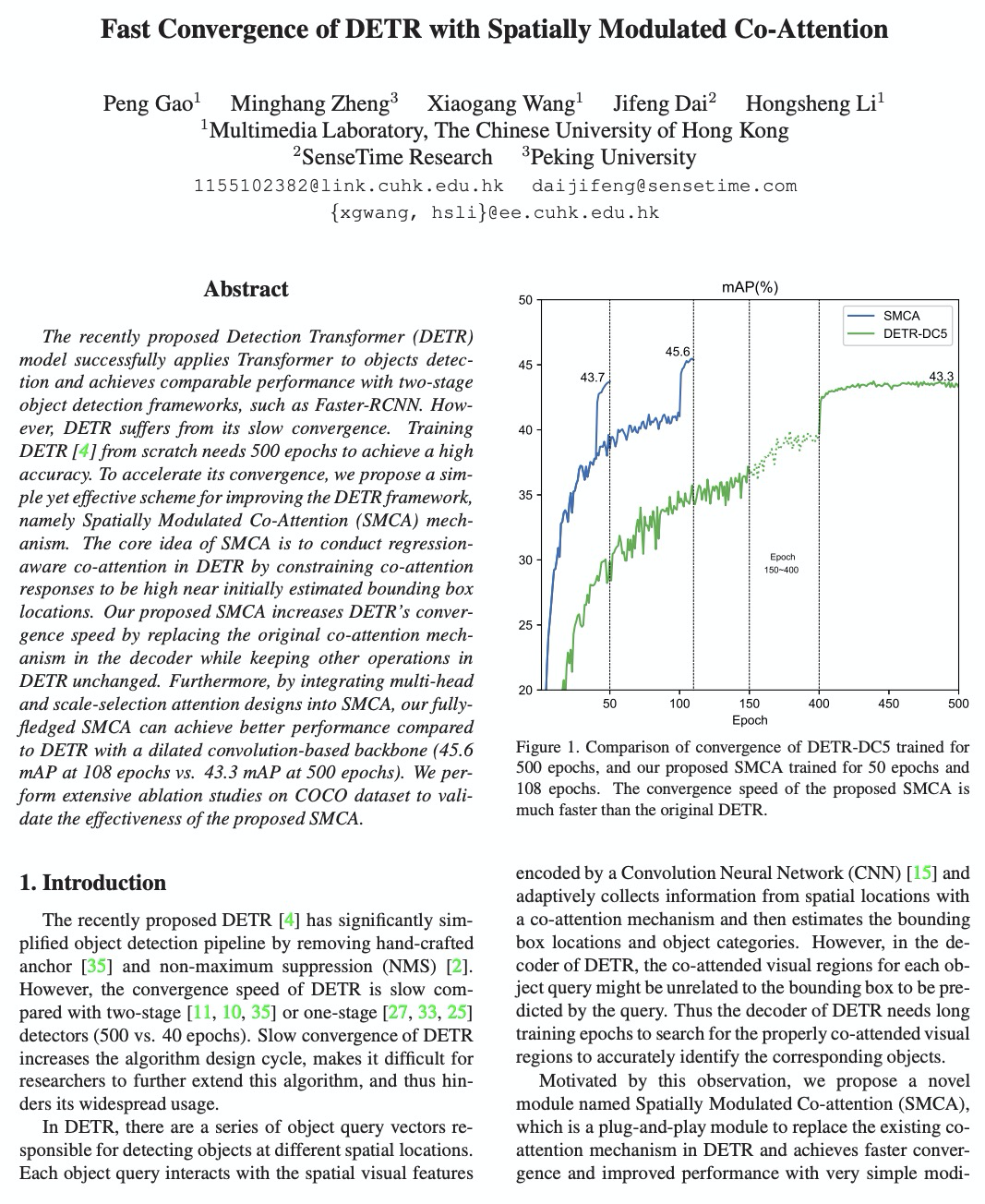
另外几篇值得关注的论文:
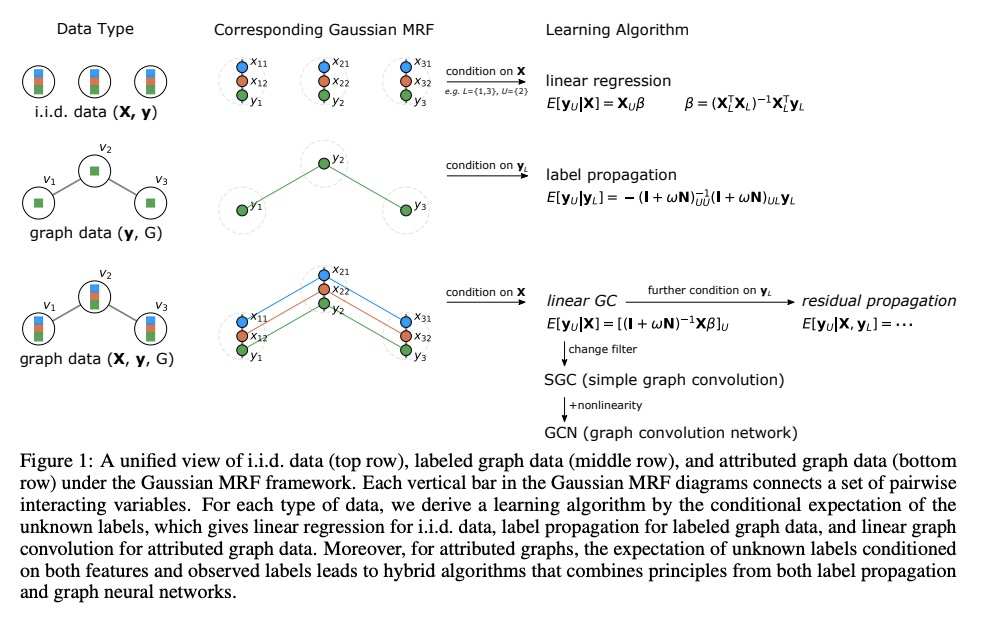
[LG] A Unifying Generative Model for Graph Learning Algorithms: Label Propagation, Graph Convolutions, and Combinations
图学习算法统一生成模型:标签传播、图卷积和组合
J Jia, A R. Benson
[Cornell University]
https://weibo.com/1402400261/JE9xbe12s
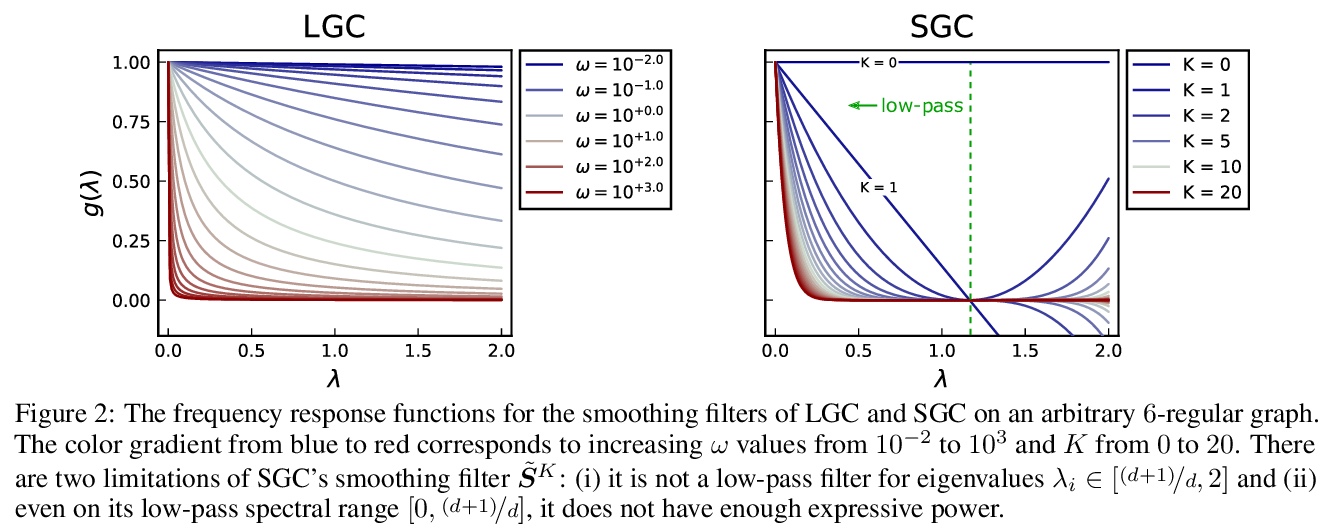

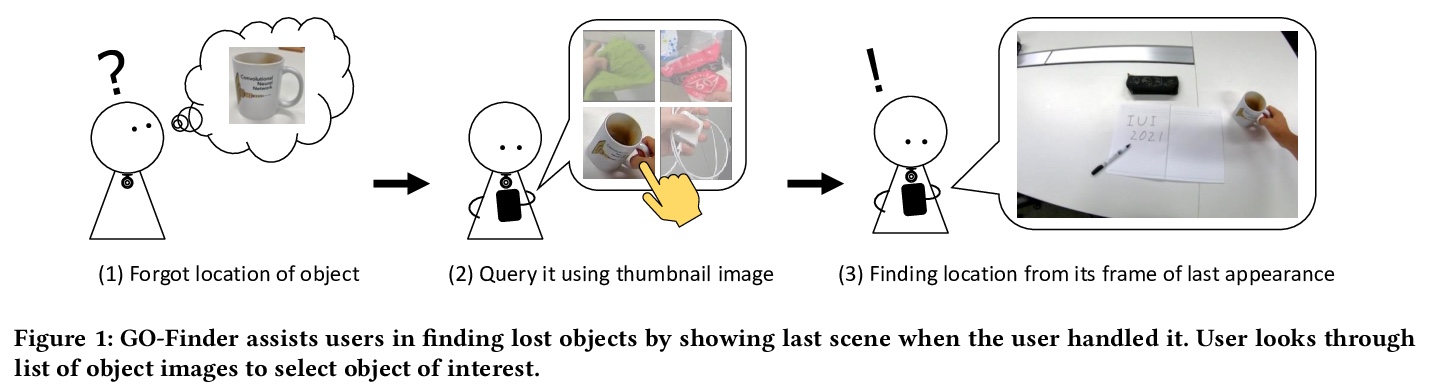
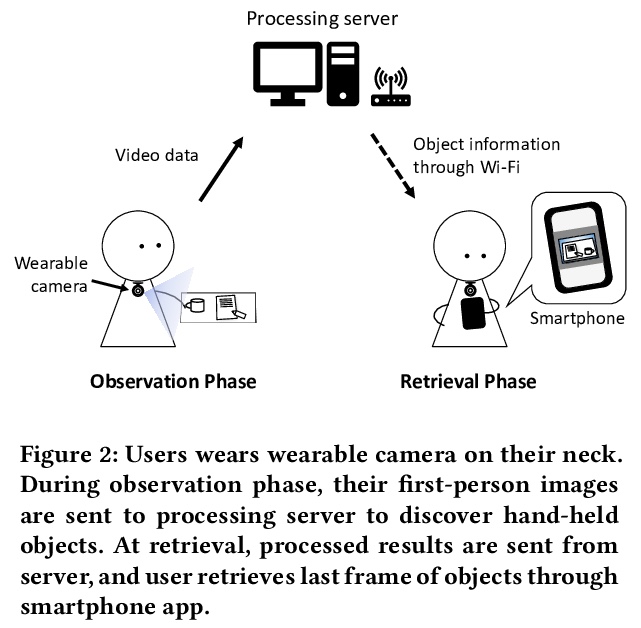
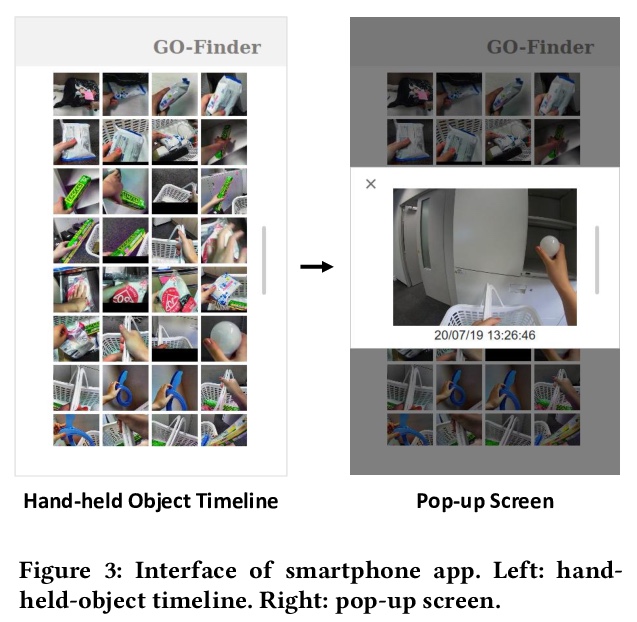
[CV] GO-Finder: A Registration-Free Wearable System for Assisting Users in Finding Lost Objects via Hand-Held Object Discovery
GO-Finder:用于帮用户寻找丢失物品的无需注册目标的手持目标发现可穿戴系统
T Yagi, T Nishiyasu, K Kawasaki, M Matsuki, Y Sato
[The University of Tokyo & FUJITSU LABORATORIES LTD & SoftBank Corp]
https://weibo.com/1402400261/JE9ASdhEf
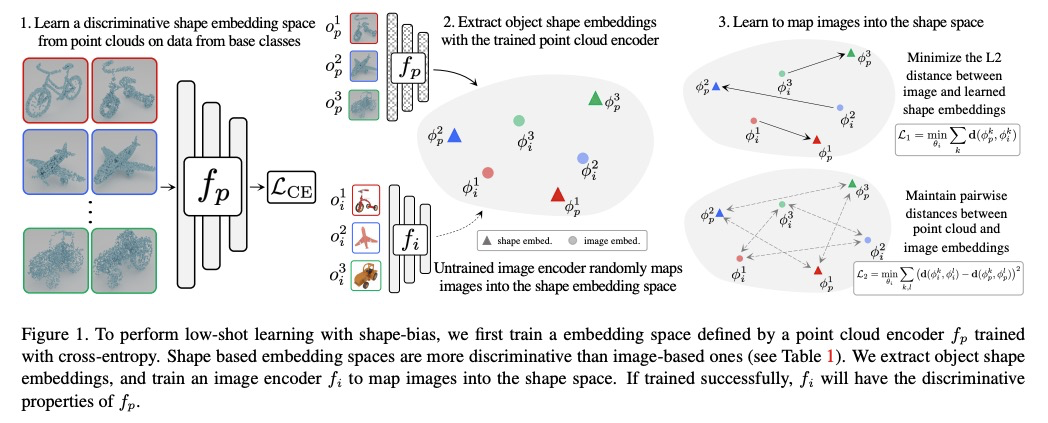
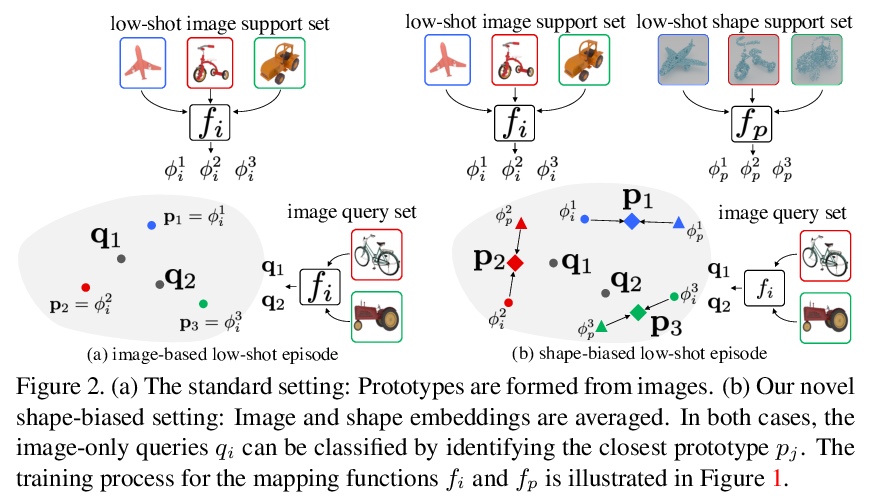
[CV] Using Shape to Categorize: Low-Shot Learning with an Explicit Shape Bias
用形状分类:基于显性形状偏差的少样本学习
S Stojanov, A Thai, J M. Rehg
[Georgia Institute of Technology]
https://weibo.com/1402400261/JE9FR0JKv


若有收获,就点个赞吧
0 人点赞
