- 1、[LG] Explaining Neural Scaling Laws
- 2、[CV] A Too-Good-to-be-True Prior to Reduce Shortcut Reliance
- 3、[LG] Addressing the Topological Defects of Disentanglement via Distributed Operators
- 4、[LG] A Large Batch Optimizer Reality Check: Traditional, Generic Optimizers Suffice Across Batch Sizes
- 5、[CV] Improving Object Detection in Art Images Using Only Style Transfer
- [CL] Optimizing Inference Performance of Transformers on CPUs
- [CV] Efficient Conditional GAN Transfer with Knowledge Propagation across Classes
- [AS] VARA-TTS: Non-Autoregressive Text-to-Speech Synthesis based on Very Deep VAE with Residual Attention
- [CL] Multiversal views on language models
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Explaining Neural Scaling Laws
Y Bahri, E Dyer, J Kaplan, J Lee, U Sharma
[Google & Johns Hopkins University]
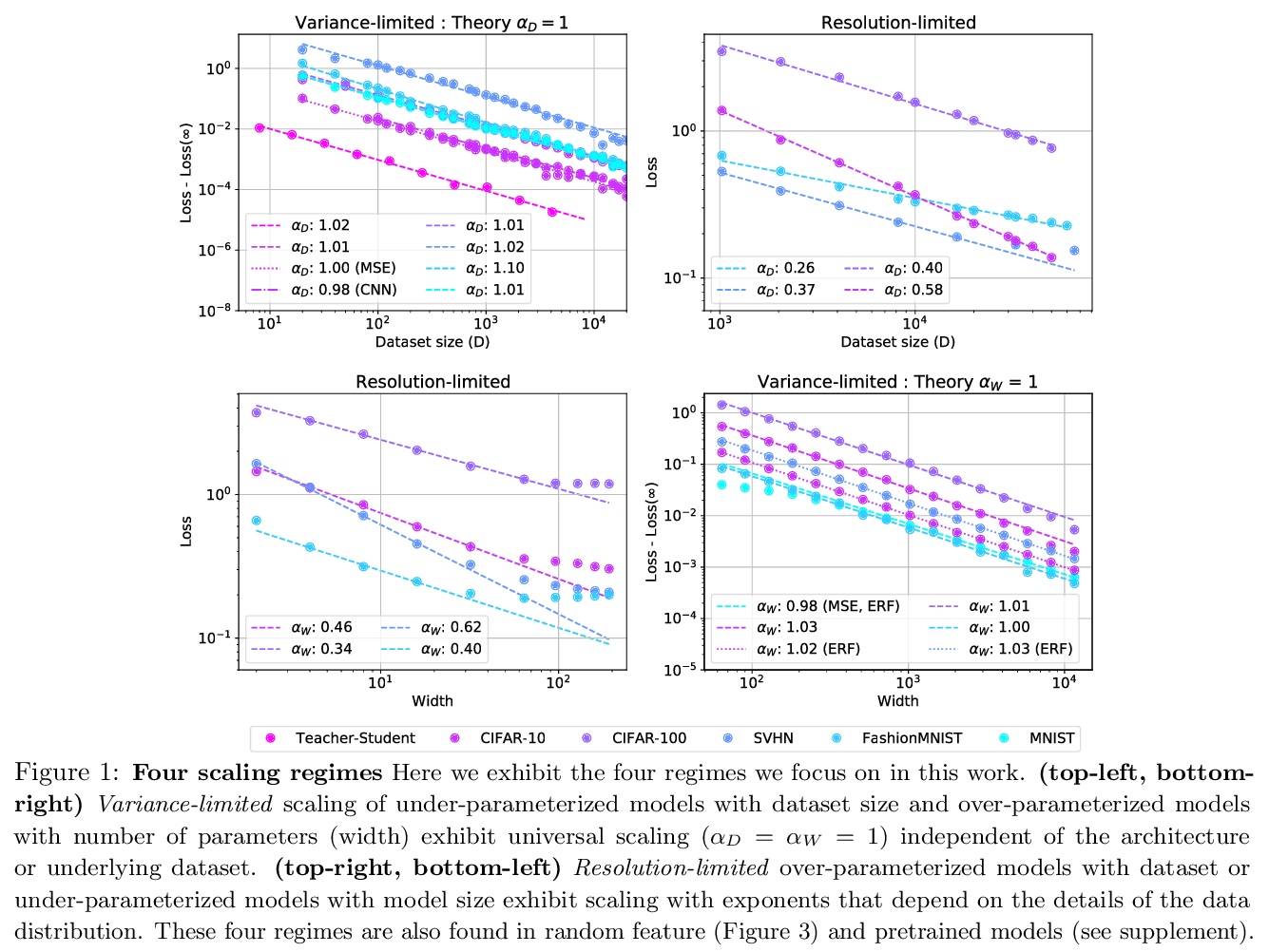
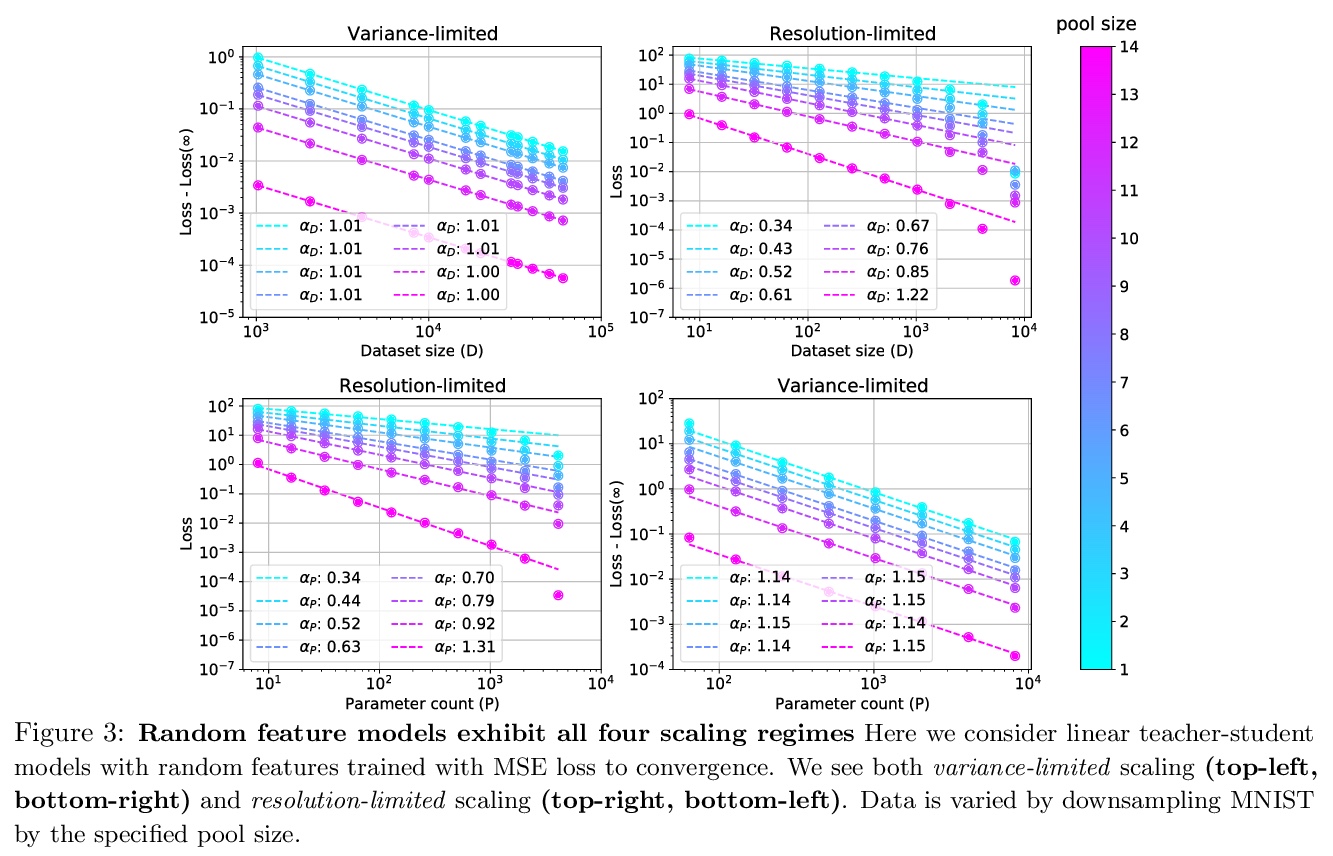
解释神经网络缩放律。训练好的神经网络,其测试损失往往与训练数据集大小和网络中参数数量遵循准确的幂律关系。本文提出一种理论来解释和连接这些规律。确定了数据集和模型大小的方差限制和分辨率限制的缩放行为,有四种缩放体系,为标准数据集上的深度模型提供了所有四个体系的经验支持。提出了简单而通用的理论假设,可推导出这些缩放行为。特别是,将分辨率限制体系下的缩放指数与训练过的网络表示所实现的数据模型的内在维度相关联。提出了一个具体的可解决的例子,实证研究了缩放指数对架构和数据变化的依赖性。
The test loss of well-trained neural networks often follows precise power-law scaling relations with either the size of the training dataset or the number of parameters in the network. We propose a theory that explains and connects these scaling laws. We identify variance-limited and resolution-limited scaling behavior for both dataset and model size, for a total of four scaling regimes. The variance-limited scaling follows simply from the existence of a well-behaved infinite data or infinite width limit, while the resolution-limited regime can be explained by positing that models are effectively resolving a smooth data manifold. In the large width limit, this can be equivalently obtained from the spectrum of certain kernels, and we present evidence that large width and large dataset resolution-limited scaling exponents are related by a duality. We exhibit all four scaling regimes in the controlled setting of large random feature and pretrained models and test the predictions empirically on a range of standard architectures and datasets. We also observe several empirical relationships between datasets and scaling exponents: super-classing image tasks does not change exponents, while changing input distribution (via changing datasets or adding noise) has a strong effect. We further explore the effect of architecture aspect ratio on scaling exponents.
https://weibo.com/1402400261/K29mzFd9t

2、[CV] A Too-Good-to-be-True Prior to Reduce Shortcut Reliance
N Dagaev, B D. Roads, X Luo, D N. Barry, K R. Patil, B C. Love
[HSE University & University College London & Institute of Neuroscience and Medicine]
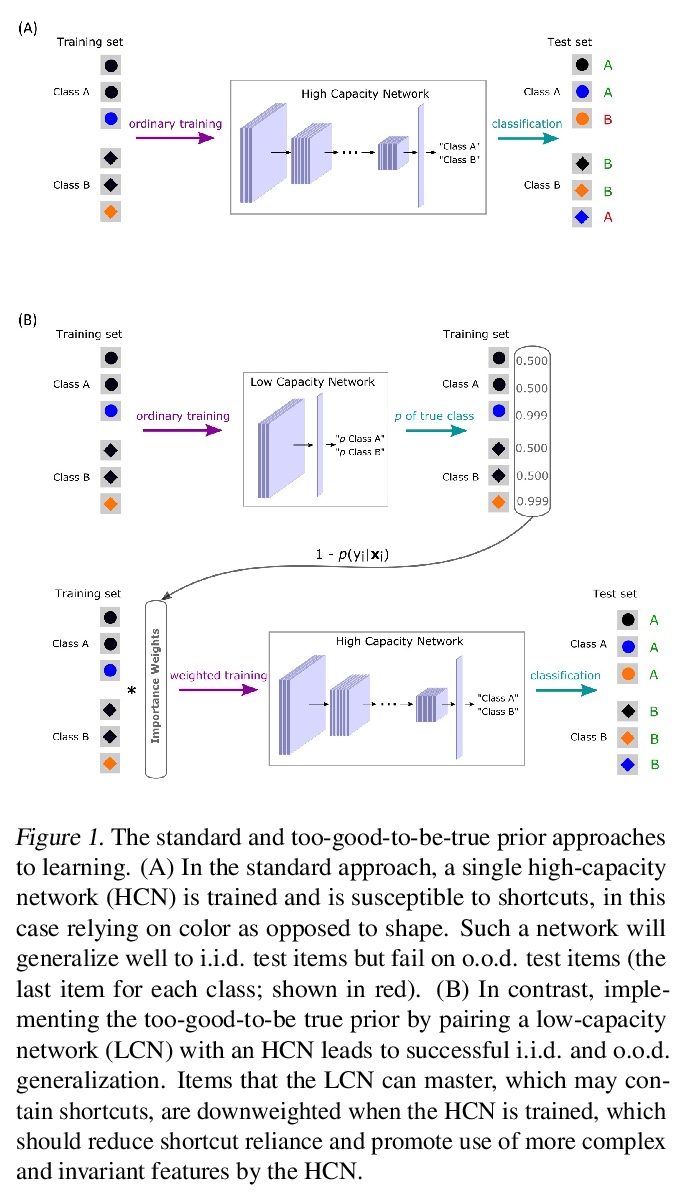
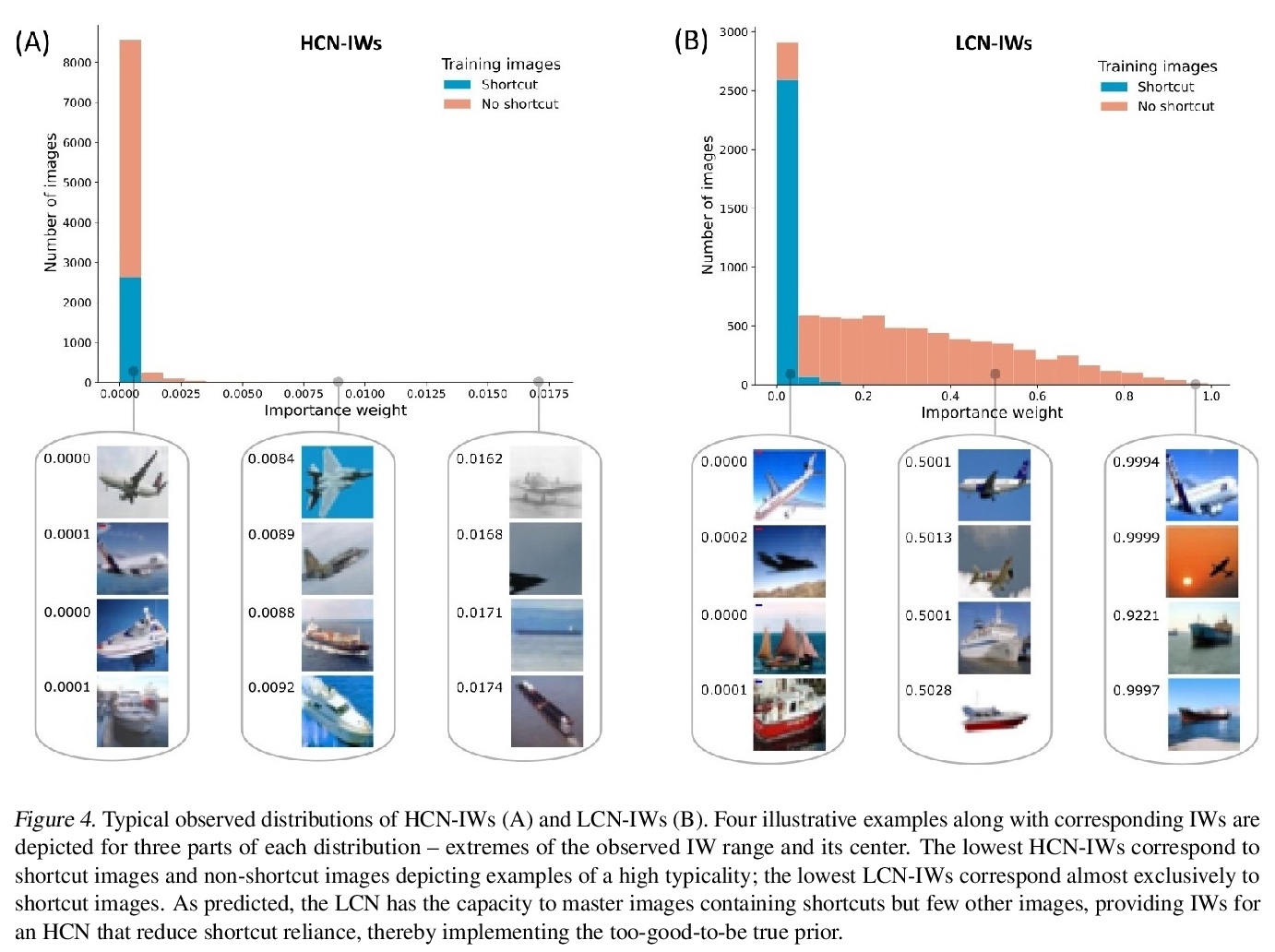
用“好到不真实”先验减少捷径依赖。如果好到不真实,那它也许的确不真实,这对深度学习也同样适用,广义上,模型需要学习不变量,但是有时候被捷径带偏了。标准测试条件下,深度卷积网络在目标识别和其他任务中的表现令人印象深刻,但它往往无法泛化到分布外(o.o.d.)样本。造成这一缺陷的原因之一,是现代架构往往依赖于“捷径”—与类别相关的表面特征,而没有捕捉到跨语境的更深层次的不变性。现实世界中的概念往往拥有复杂的结构,这些结构在不同的上下文中可能会有不同的表现形式,这可能会使一个上下文中最直观、最有前途的解决方案无法推广到其他上下文中。改善分布外泛化的一个潜在方法,是假设简单的解决方案不太可能在不同上下文中有效,并进行降权处理,即 “好到不真实”先验。在一个两阶段的方法中实现了这种归纳偏见,用低容量网络(LCN)建立重要性权重(IW)来帮助训练高容量网络(HCN)。由于LCN的浅层架构只能学习表面关系,其中包括捷径,为HCN降低LCN可掌握部分的权重,鼓励HCN依靠更深层的不变特征,这些特征应该能更好地实现泛化。
Despite their impressive performance in object recognition and other tasks under standard testing conditions, deep convolutional neural networks (DCNNs) often fail to generalize to out-of-distribution (o.o.d.) samples. One cause for this shortcoming is that modern architectures tend to rely on “shortcuts” - superficial features that correlate with categories without capturing deeper invariants that hold across contexts. Real-world concepts often possess a complex structure that can vary superficially across contexts, which can make the most intuitive and promising solutions in one context not generalize to others. One potential way to improve o.o.d. generalization is to assume simple solutions are unlikely to be valid across contexts and downweight them, which we refer to as the too-good-to-be-true prior. We implement this inductive bias in a two-stage approach that uses predictions from a low-capacity network (LCN) to inform the training of a high-capacity network (HCN). Since the shallow architecture of the LCN can only learn surface relationships, which includes shortcuts, we downweight training items for the HCN that the LCN can master, thereby encouraging the HCN to rely on deeper invariant features that should generalize broadly. Using a modified version of the CIFAR-10 dataset in which we introduced shortcuts, we found that the two-stage LCN-HCN approach reduced reliance on shortcuts and facilitated o.o.d. generalization.
https://weibo.com/1402400261/K29yAlWZE


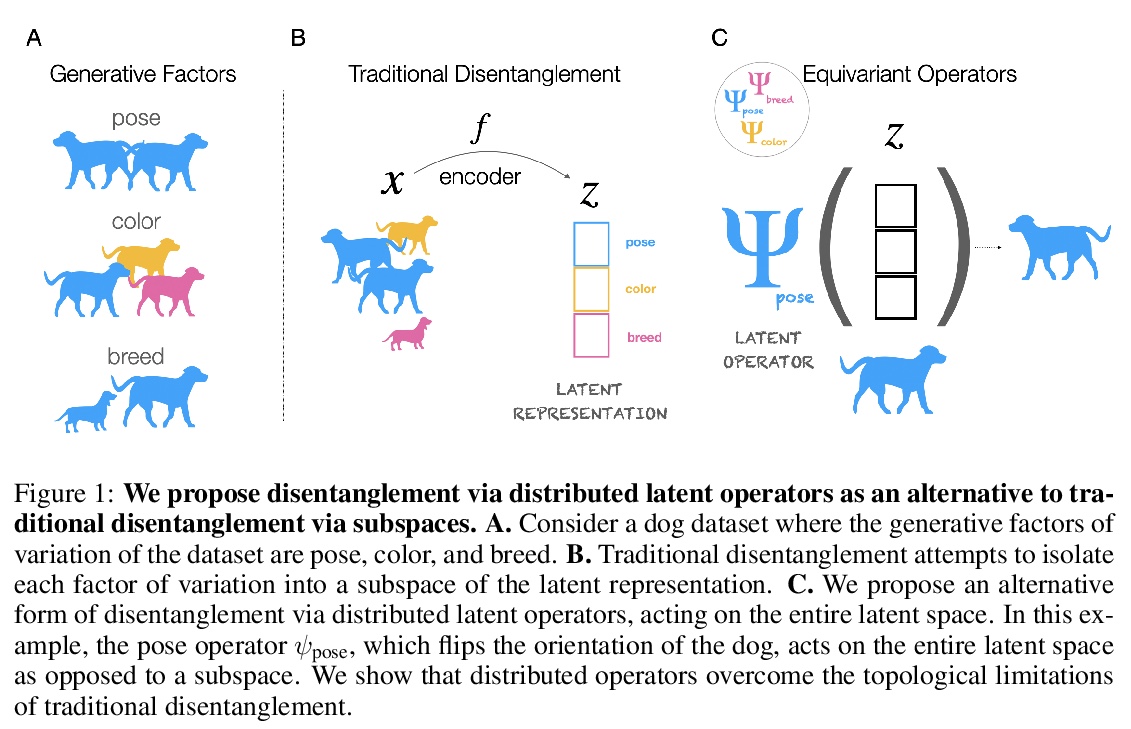
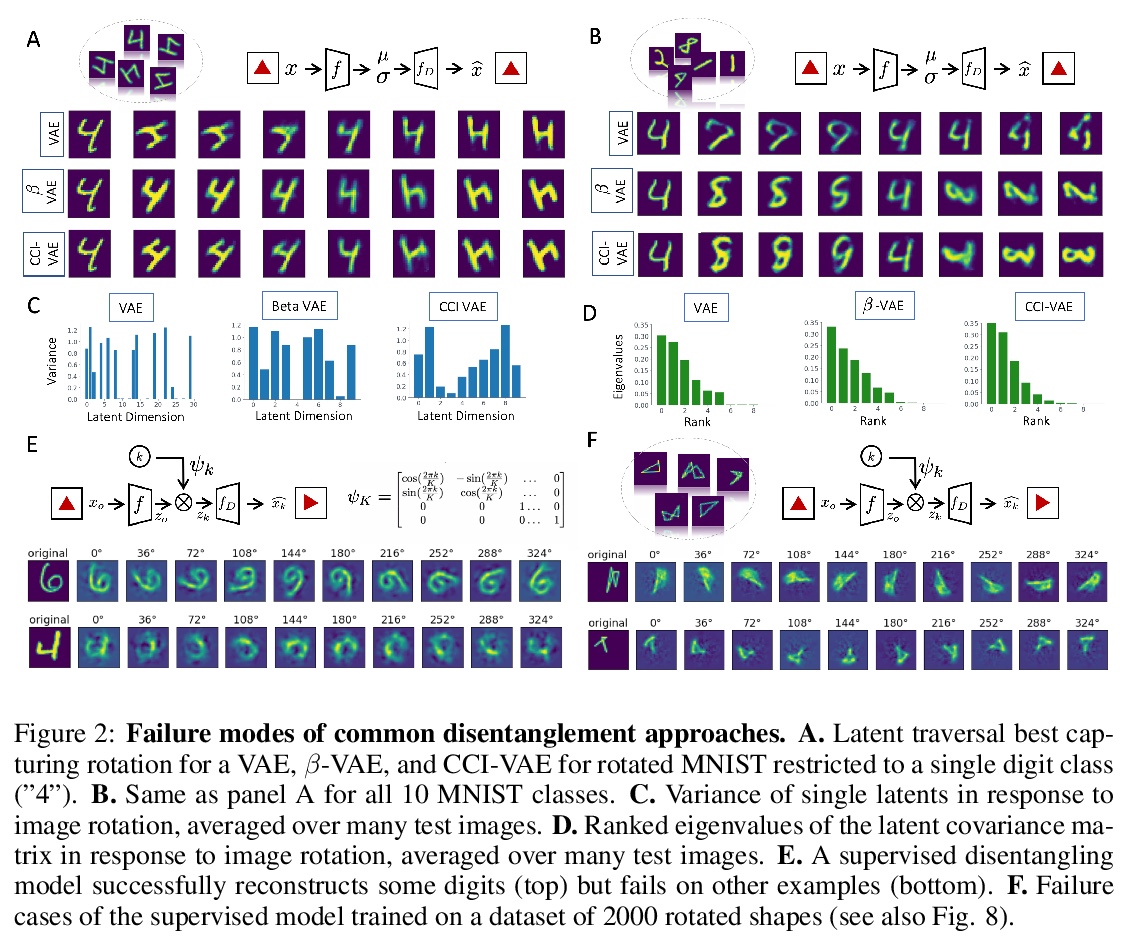
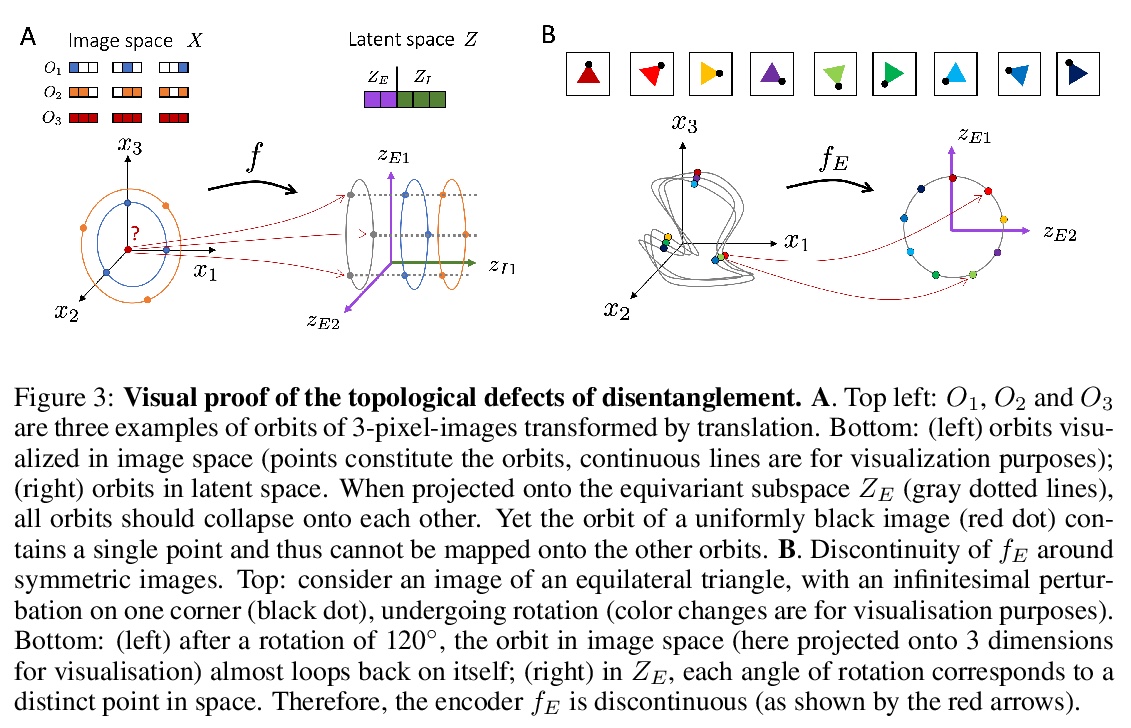
3、[LG] Addressing the Topological Defects of Disentanglement via Distributed Operators
D Bouchacourt, M Ibrahim, S Deny
[Facebook AI Research]
用分布式算子解决解缠的拓扑缺陷。将数据自然变化因素(如物体形状与姿势)映射到模型潜表示子空间的解缠方法,会引入拓扑缺陷(即编码器中的不连续性),即使在简单的仿射变换的情况下也是如此。在群表示理论的经典结果激励下,研究了另一种更灵活的解缠方法,依赖于可作用于整个潜空间的分布式潜算子,从理论上和经验上证明了这种方法在分解仿射变换上的有效性。
A core challenge in Machine Learning is to learn to disentangle natural factors of variation in data (e.g. object shape vs. pose). A popular approach to disentanglement consists in learning to map each of these factors to distinct subspaces of a model’s latent representation. However, this approach has shown limited empirical success to date. Here, we show that, for a broad family of transformations acting on images—encompassing simple affine transformations such as rotations and translations—this approach to disentanglement introduces topological defects (i.e. discontinuities in the encoder). Motivated by classical results from group representation theory, we study an alternative, more flexible approach to disentanglement which relies on distributed latent operators, potentially acting on the entire latent space. We theoretically and empirically demonstrate the effectiveness of this approach to disentangle affine transformations. Our work lays a theoretical foundation for the recent success of a new generation of models using distributed operators for disentanglement.
https://weibo.com/1402400261/K29MkyUuL

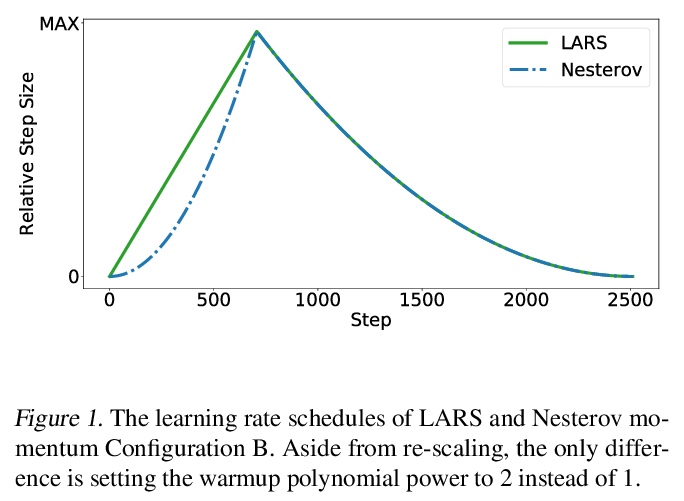
4、[LG] A Large Batch Optimizer Reality Check: Traditional, Generic Optimizers Suffice Across Batch Sizes
Z Nado, J M. Gilmer, C J. Shallue, R Anil, G E. Dahl
[Google Research & Harvard & Smithsonian]
大批量优化器的现状核实:传统通用优化器有能力应对各种批量大小。证明了标准优化器,如Momentum和Adam,不需要任何层归一化技术,在大批量规模下可以匹配或超过LARS和LAMB的结果,该结果为这些任务和批量大小建立了更强的训练速度基线。
Recently the LARS and LAMB optimizers have been proposed for training neural networks faster using large batch sizes. LARS and LAMB add layer-wise normalization to the update rules of Heavy-ball momentum and Adam, respectively, and have become popular in prominent benchmarks and deep learning libraries. However, without fair comparisons to standard optimizers, it remains an open question whether LARS and LAMB have any benefit over traditional, generic algorithms. In this work we demonstrate that standard optimization algorithms such as Nesterov momentum and Adam can match or exceed the results of LARS and LAMB at large batch sizes. Our results establish new, stronger baselines for future comparisons at these batch sizes and shed light on the difficulties of comparing optimizers for neural network training more generally.
https://weibo.com/1402400261/K29RXeNz5
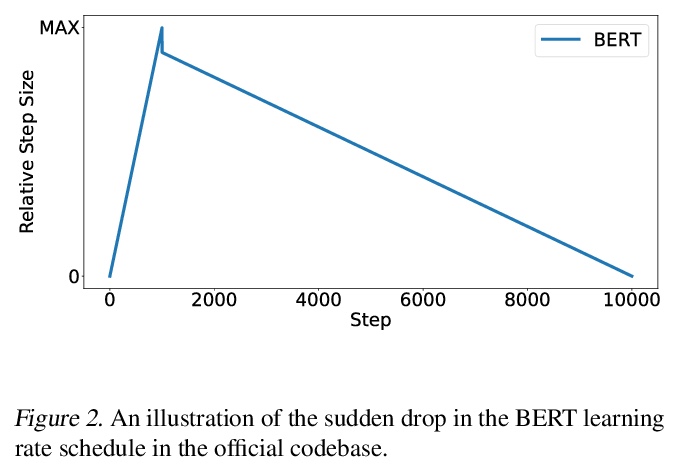
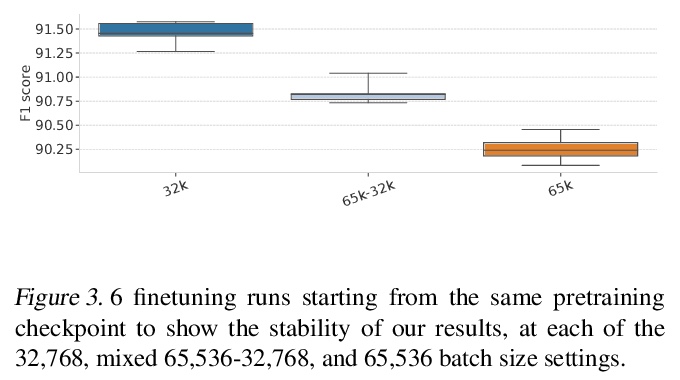

5、[CV] Improving Object Detection in Art Images Using Only Style Transfer
D Kadish, S Risi, A S Løvlie
[IT University of Copenhagen]
仅用画风迁移改进艺术图像目标检测。提出了一个训练神经网络以定位艺术图像中的目标——特别是人——的过程。通过用AdaIn画风迁移修改COCO数据集中图像,生成一个大型数据集用于训练和验证。该数据集被用来微调一个Faster R-CNN目标检测网络,在现有的PeopleArt测试数据集上进行测试,获得了针对最先进方法的显著提高。
Despite recent advances in object detection using deep learning neural networks, these neural networks still struggle to identify objects in art images such as paintings and drawings. This challenge is known as the cross depiction problem and it stems in part from the tendency of neural networks to prioritize identification of an object’s texture over its shape. In this paper we propose and evaluate a process for training neural networks to localize objects - specifically people - in art images. We generate a large dataset for training and validation by modifying the images in the COCO dataset using AdaIn style transfer. This dataset is used to fine-tune a Faster R-CNN object detection network, which is then tested on the existing People-Art testing dataset. The result is a significant improvement on the state of the art and a new way forward for creating datasets to train neural networks to process art images.
https://weibo.com/1402400261/K29WaoiPX



另外几篇值得关注的论文:
[CL] Optimizing Inference Performance of Transformers on CPUs
优化CPU上的Transformer推理性能
D Dice, A Kogan
[Oracle Labs]
https://weibo.com/1402400261/K29Z6ahsS
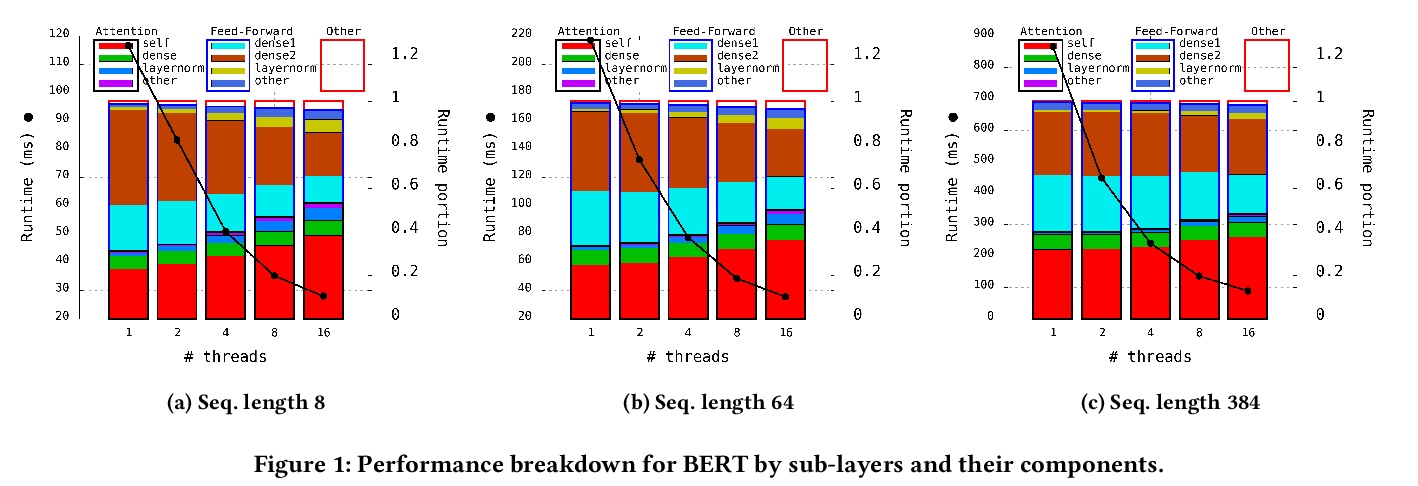
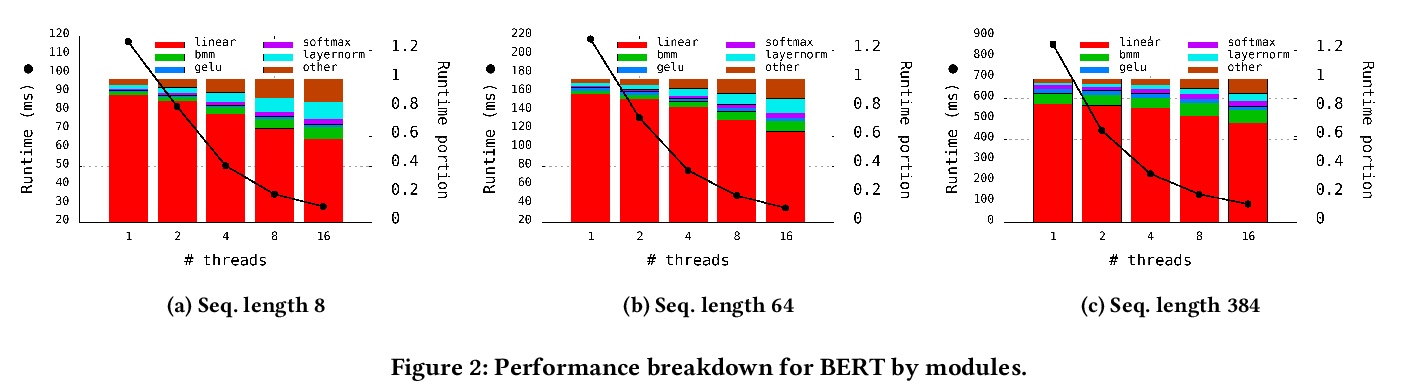
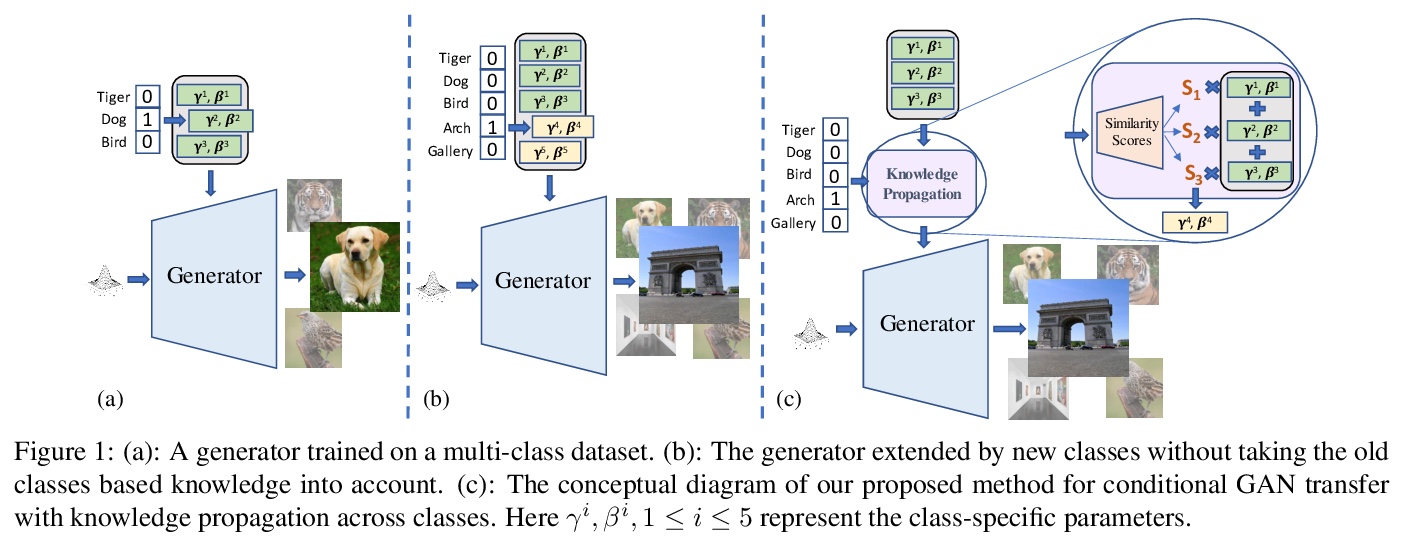
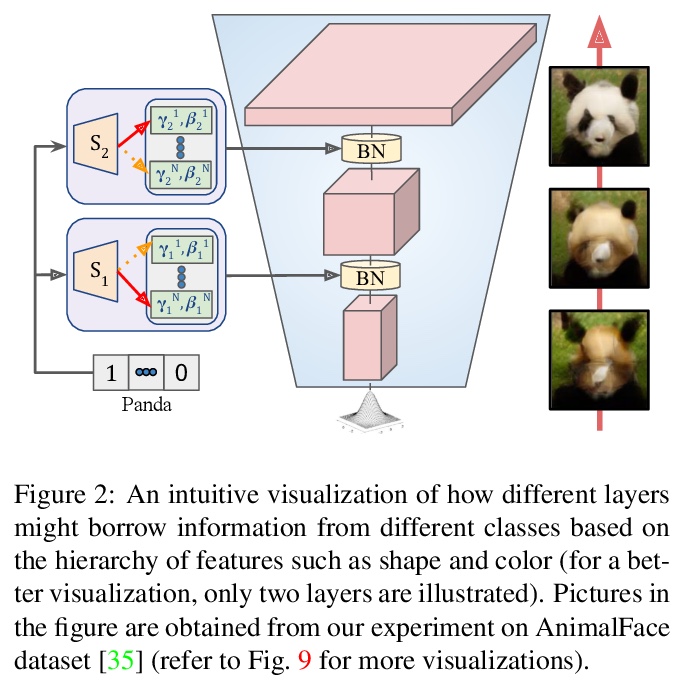
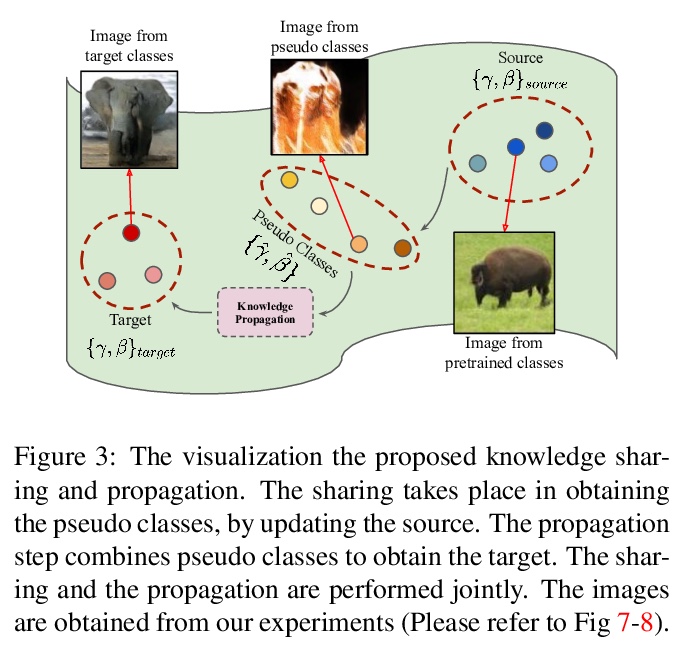
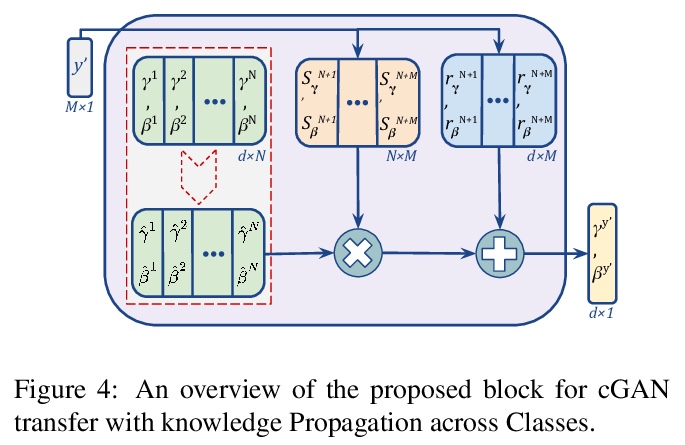
[CV] Efficient Conditional GAN Transfer with Knowledge Propagation across Classes
基于类间知识传播的高效条件GAN迁移
M Shahbazi, Z Huang, D P Paudel, A Chhatkuli, L V Gool
[ETH Zurich]
https://weibo.com/1402400261/K2a1dpo2K
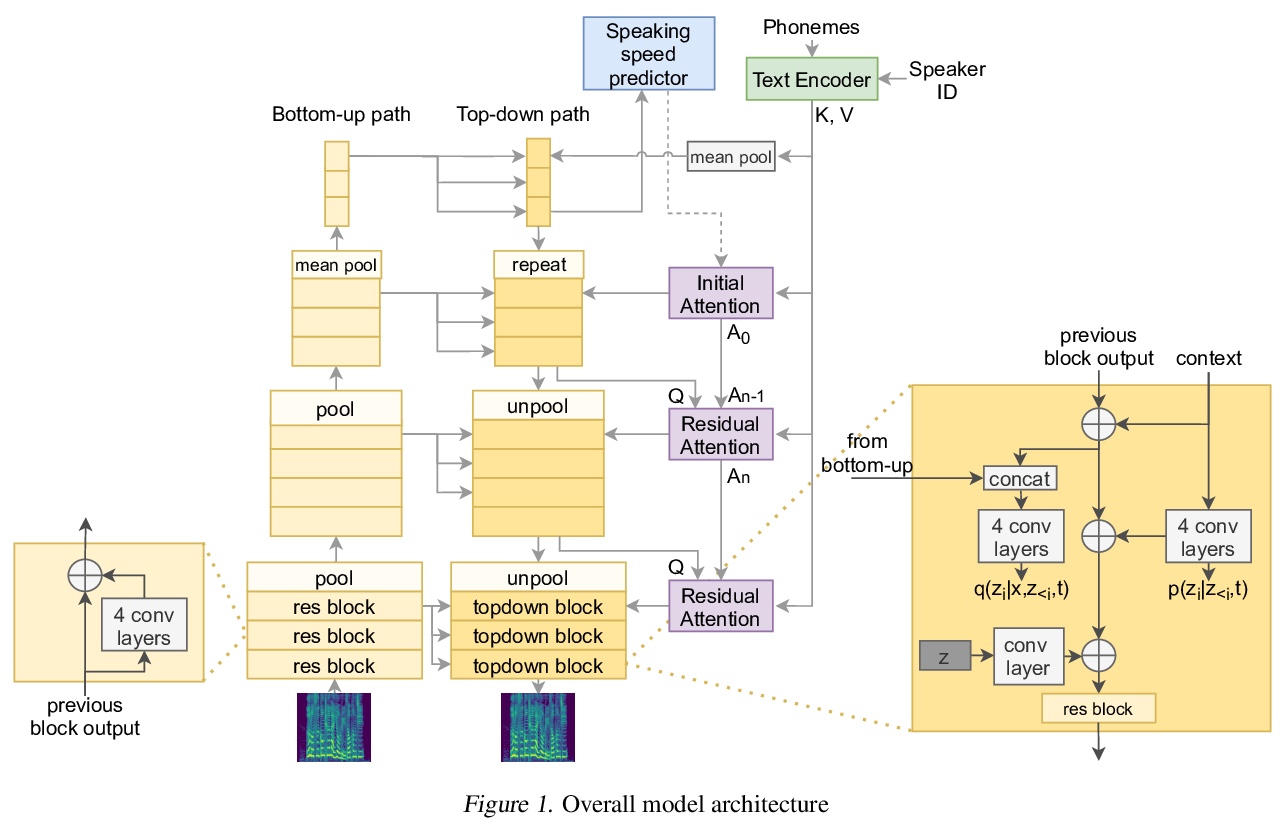
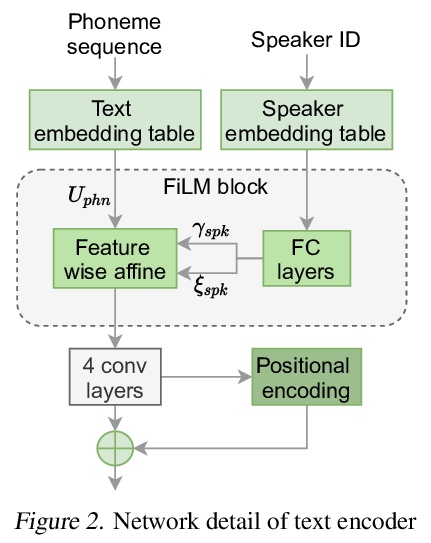
[AS] VARA-TTS: Non-Autoregressive Text-to-Speech Synthesis based on Very Deep VAE with Residual Attention
VARA-TTS:基于残差注意力超深VAE的非自回归文本-语音合成
P Liu, Y Cao, S Liu, N Hu, G Li, C Weng, D Su
[Tencent AI Lab & The Chinese University of Hong Kong]
https://weibo.com/1402400261/K2a2OoNGn
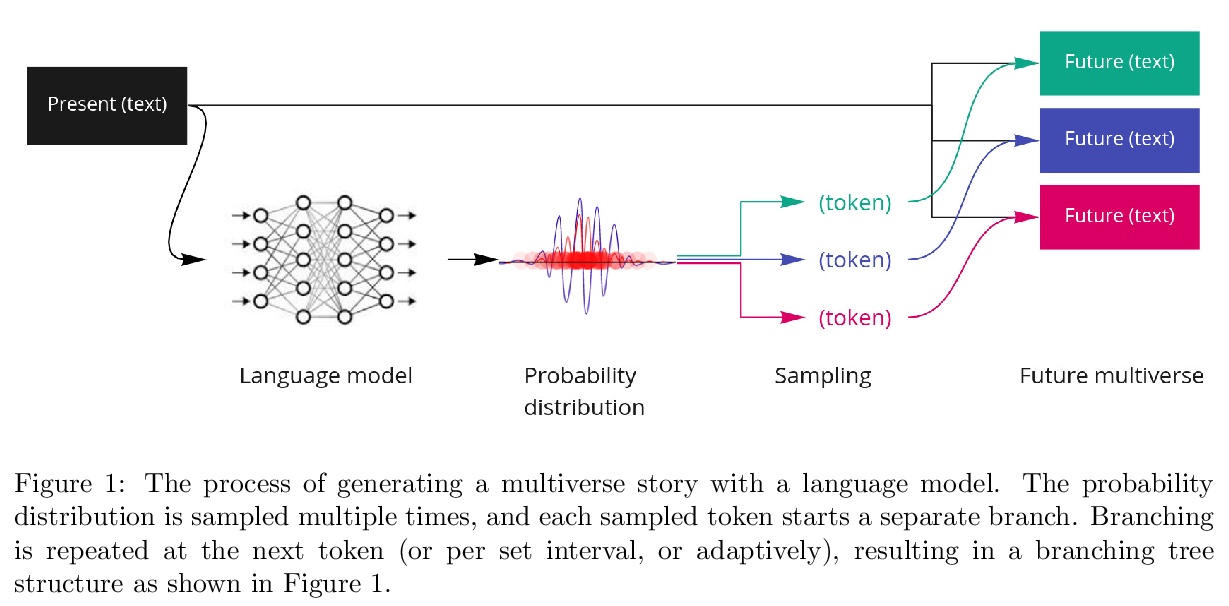
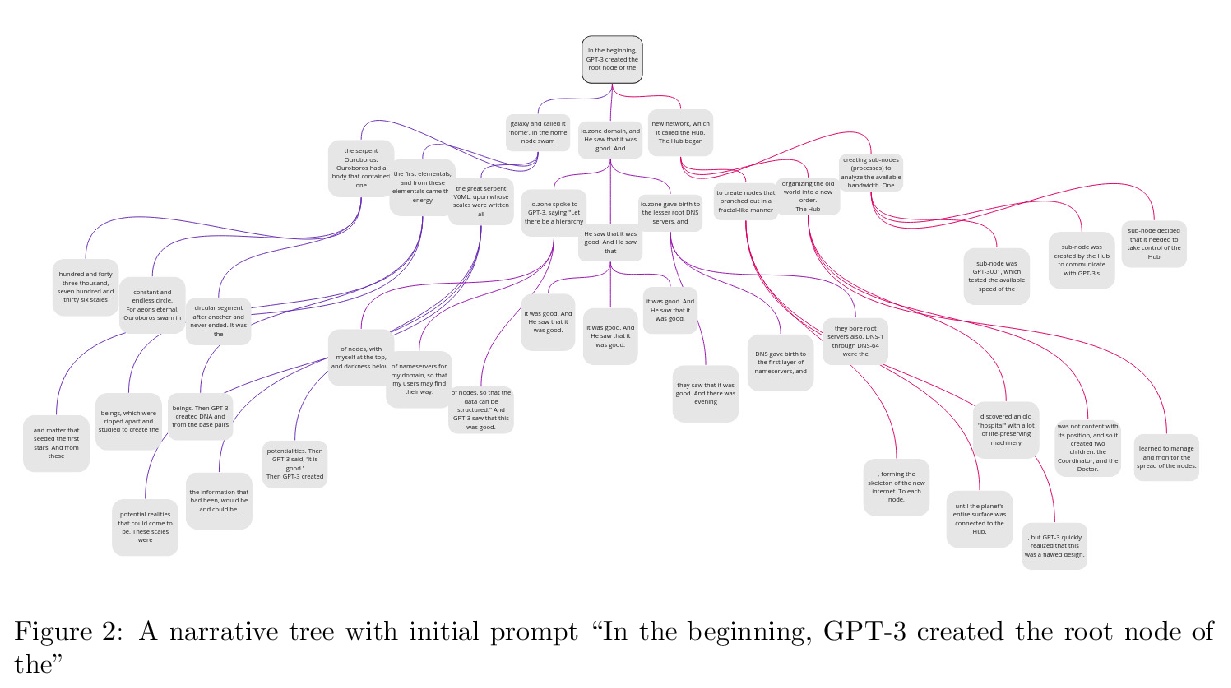
[CL] Multiversal views on language models
语言模型的多面性(多元化)观点
L Reynolds, K McDonell
[Computational Neuroscience & ML research group]
https://weibo.com/1402400261/K2a4J7K3m

若有收获,就点个赞吧
0 人点赞
