LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] *pixelNeRF: Neural Radiance Fields from One or Few Images
A Yu, V Ye, M Tancik, A Kanazawa
[UC Berkeley]
单图/少图神经辐射场。提出学习框架pixelNeRF,基于单幅或少幅输入图像,预测连续神经场景表示。现有构建神经辐射场的方法,对各场景单独优化表示,需要大量校准视图和运算时间,pixelNeRF通过引入以全卷积方式对图像输入进行压缩的架构来解决这些缺点,网络可在多场景间进行训练,学习场景先验,以前馈方式从稀疏视图集(甚至是单一视图)合成新视图。利用NeRF的体绘制方法,可直接从图像训练,无需明确的3D监督。通过实验,证明了pixelNeRF的灵活性,在新视图合成和单图像3D重建方面,优于目前最先进方法。
We propose pixelNeRF, a learning framework that predicts a continuous neural scene representation conditioned on one or few input images. The existing approach for constructing neural radiance fields involves optimizing the representation to every scene independently, requiring many calibrated views and significant compute time. We take a step towards resolving these shortcomings by introducing an architecture that conditions a NeRF on image inputs in a fully convolutional manner. This allows the network to be trained across multiple scenes to learn a scene prior, enabling it to perform novel view synthesis in a feed-forward manner from a sparse set of views (as few as one). Leveraging the volume rendering approach of NeRF, our model can be trained directly from images with no explicit 3D supervision. We conduct extensive experiments on ShapeNet benchmarks for single image novel view synthesis tasks with held-out objects as well as entire unseen categories. We further demonstrate the flexibility of pixelNeRF by demonstrating it on multi-object ShapeNet scenes and real scenes from the DTU dataset. In all cases, pixelNeRF outperforms current state-of-the-art baselines for novel view synthesis and single image 3D reconstruction. For the video and code, please visit the project website: > this https URL
https://weibo.com/1402400261/JwZQ75baU

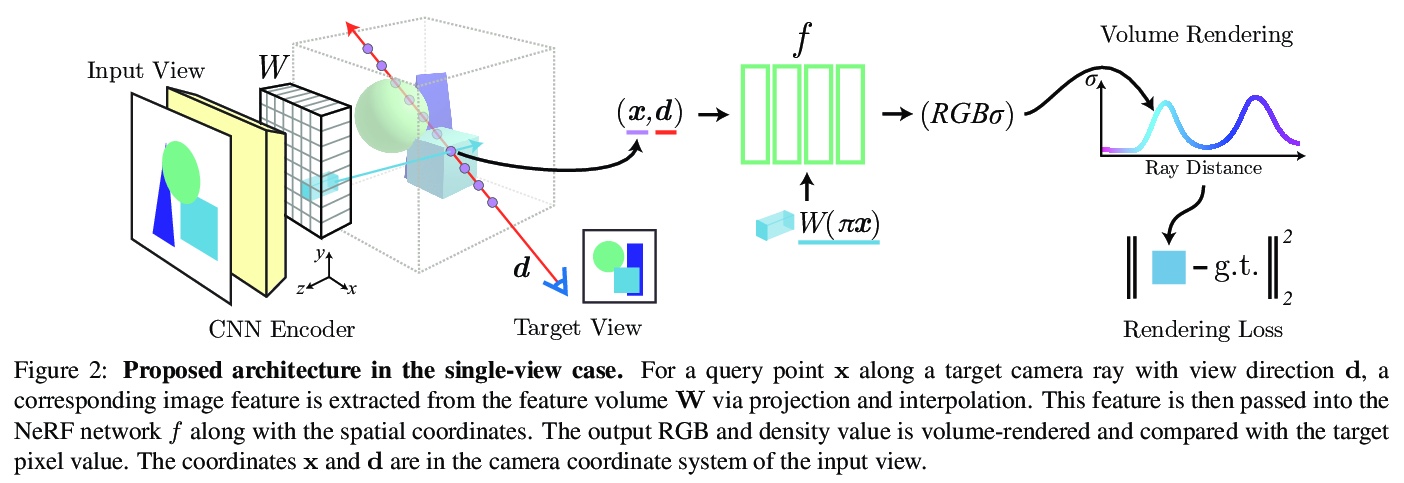
2、**[CV] Neural Deformation Graphs for Globally-consistent Non-rigid Reconstruction
A Božič, P Palafox, M Zollhöfer, J Thies, A Dai, M Nießner
[Technical University of Munich & Facebook Reality Labs]
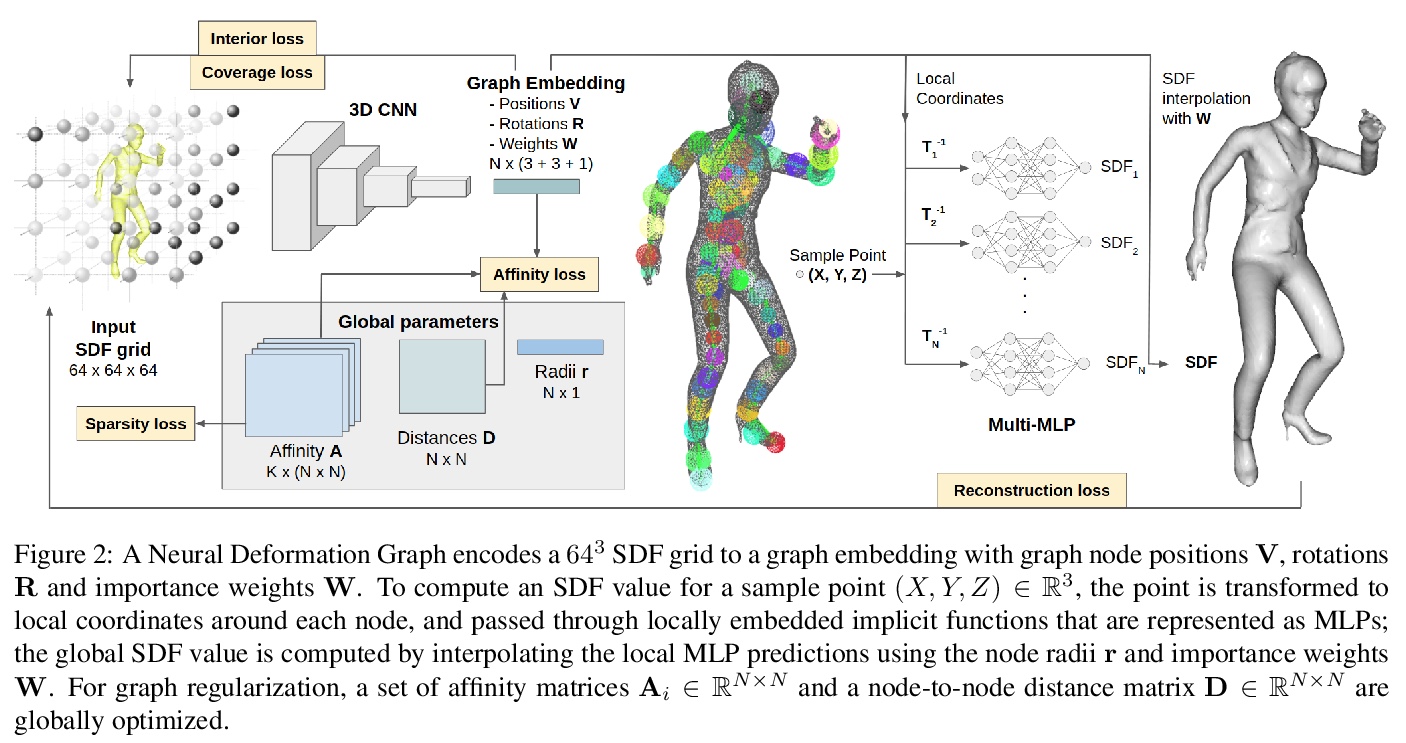
基于神经变形图的全局一致非刚性重建。提出了神经变形图(Neural Deformation Graph),以全局一致的方式,实现对非刚性变形对象的重建和跟踪,用深度神经网络隐式地建立变形图模型,不依赖于任何对象特定结构,可用于一般的非刚性变形跟踪。神经变形图在给定非刚性运动目标深度摄像机观察序列上,全局优化神经图。基于明确的视点一致性,及帧间图和表面一致性约束,以自监督方式训练底层网络,其跟踪与重构质量超出现有技术60%以上。*
We introduce Neural Deformation Graphs for globally-consistent deformation tracking and 3D reconstruction of non-rigid objects. Specifically, we implicitly model a deformation graph via a deep neural network. This neural deformation graph does not rely on any object-specific structure and, thus, can be applied to general non-rigid deformation tracking. Our method globally optimizes this neural graph on a given sequence of depth camera observations of a non-rigidly moving object. Based on explicit viewpoint consistency as well as inter-frame graph and surface consistency constraints, the underlying network is trained in a self-supervised fashion. We additionally optimize for the geometry of the object with an implicit deformable multi-MLP shape representation. Our approach does not assume sequential input data, thus enabling robust tracking of fast motions or even temporally disconnected recordings. Our experiments demonstrate that our Neural Deformation Graphs outperform state-of-the-art non-rigid reconstruction approaches both qualitatively and quantitatively, with 64% improved reconstruction and 62% improved deformation tracking performance.
https://weibo.com/1402400261/JwZWAq9lg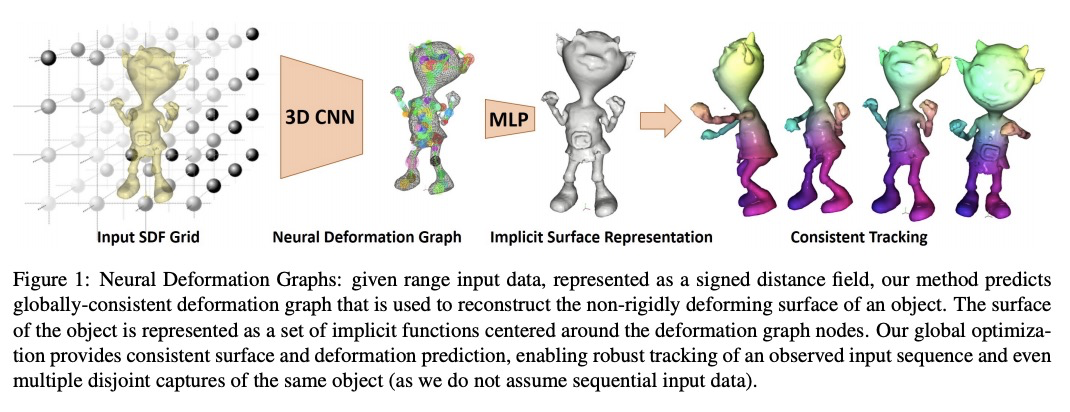

3、**[CV] Full-Resolution Correspondence Learning for Image Translation
X Zhou, B Zhang, T Zhang, P Zhang, J Bao, D Chen, Z Zhang, F Wen
[Zhejiang University & Microsoft Research Asia & USTC & Binghamton University]
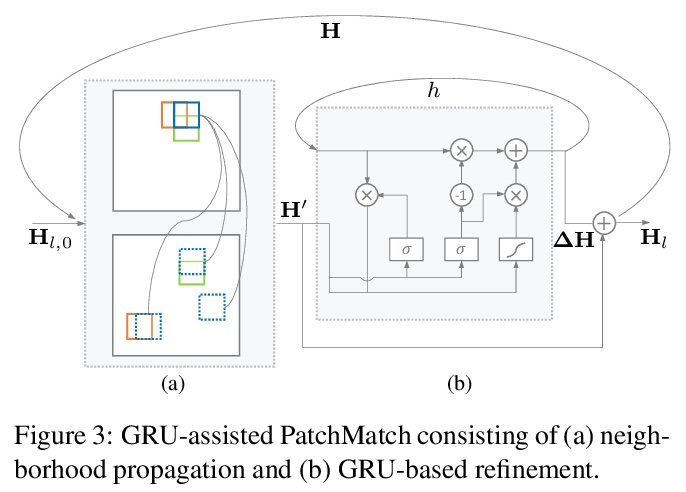
全分辨率对应学习图像变换。提出跨域图像全分辨率对应学习方法,通过在由粗到细的层次结构中迭代细化,有效建立对应关系,在每一层,交替执行邻域传播和GRU传播。该方法完全可微,效率很高。当与图像变换共同训练时,可在无监督情况下建立全分辨率的语义对应。使用该方法,可产生具有精细纹理的逼真输出,以及在高分辨率(5122和10242)下具有视觉吸引力的图像。**
We present the full-resolution correspondence learning for cross-domain images, which aids image translation. We adopt a hierarchical strategy that uses the correspondence from coarse level to guide the finer levels. In each hierarchy, the correspondence can be efficiently computed via PatchMatch that iteratively leverages the matchings from the neighborhood. Within each PatchMatch iteration, the ConvGRU module is employed to refine the current correspondence considering not only the matchings of larger context but also the historic estimates. The proposed GRU-assisted PatchMatch is fully differentiable and highly efficient. When jointly trained with image translation, full-resolution semantic correspondence can be established in an unsupervised manner, which in turn facilitates the exemplar-based image translation. Experiments on diverse translation tasks show our approach performs considerably better than state-of-the-arts on producing high-resolution images.
https://weibo.com/1402400261/Jx03Mk2MM


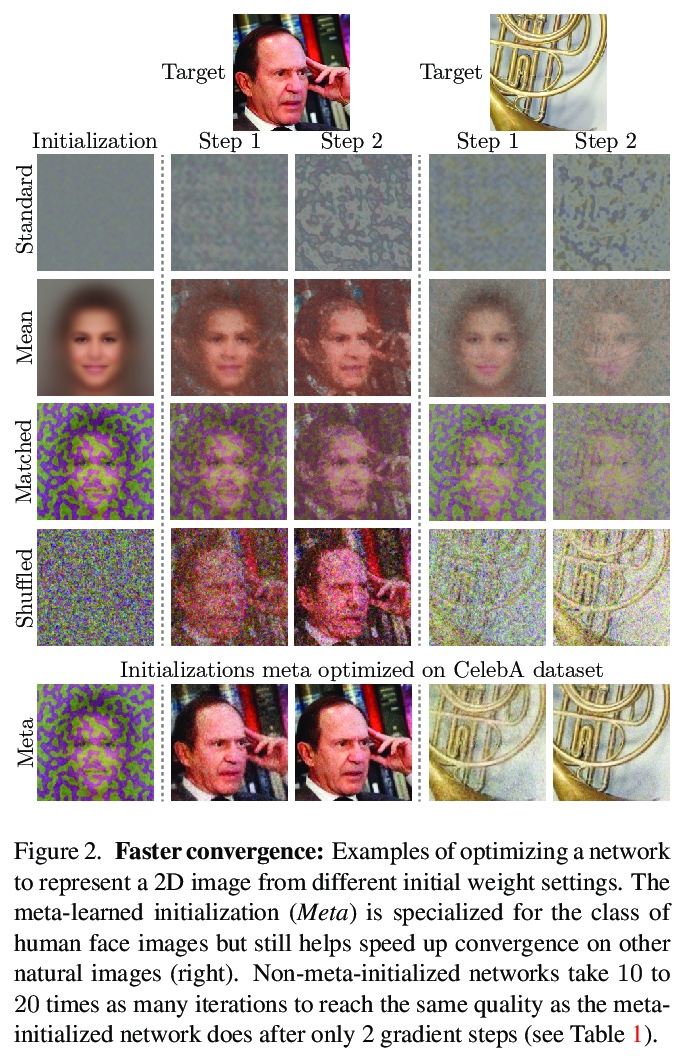
4、** **[CV] Learned Initializations for Optimizing Coordinate-Based Neural Representations
M Tancik, B Mildenhall, T Wang, D Schmidt, P P. Srinivasan, J T. Barron, R Ng
[UC Berkeley & Google Research]
协调神经表示优化的习得初始化。对于复杂低维信号,基于协调的神经表示法,已成为作为离散的基于数组表示法的重要替代方案。然而,随机初始化新信号权值来优化基于协调网络的方法是低效的。本文建议采用标准的元学习算法,来学习基于被表示信号底层类别的全连接网络初始权值参数。在实现中,只需要一个小的变化,用这些习得初始权值,可在优化过程实现更快的收敛,同时,当给定信号部分观察可用时,可作为较强的先验信号进行建模,实现更好的泛化。
Coordinate-based neural representations have shown significant promise as an alternative to discrete, array-based representations for complex low dimensional signals. However, optimizing a coordinate-based network from randomly initialized weights for each new signal is inefficient. We propose applying standard meta-learning algorithms to learn the initial weight parameters for these fully-connected networks based on the underlying class of signals being represented (e.g., images of faces or 3D models of chairs). Despite requiring only a minor change in implementation, using these learned initial weights enables faster convergence during optimization and can serve as a strong prior over the signal class being modeled, resulting in better generalization when only partial observations of a given signal are available. We explore these benefits across a variety of tasks, including representing 2D images, reconstructing CT scans, and recovering 3D shapes and scenes from 2D image observations.
https://weibo.com/1402400261/Jx0alqQqa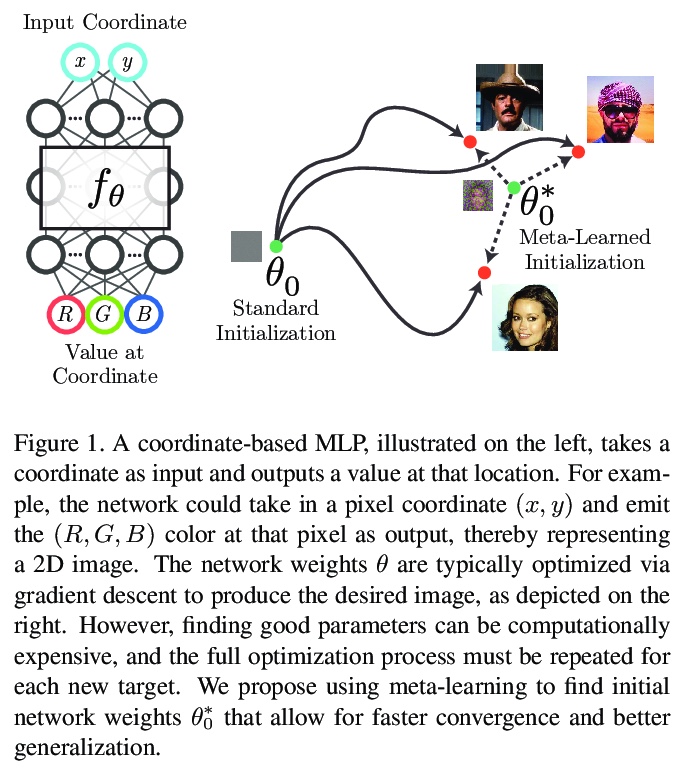

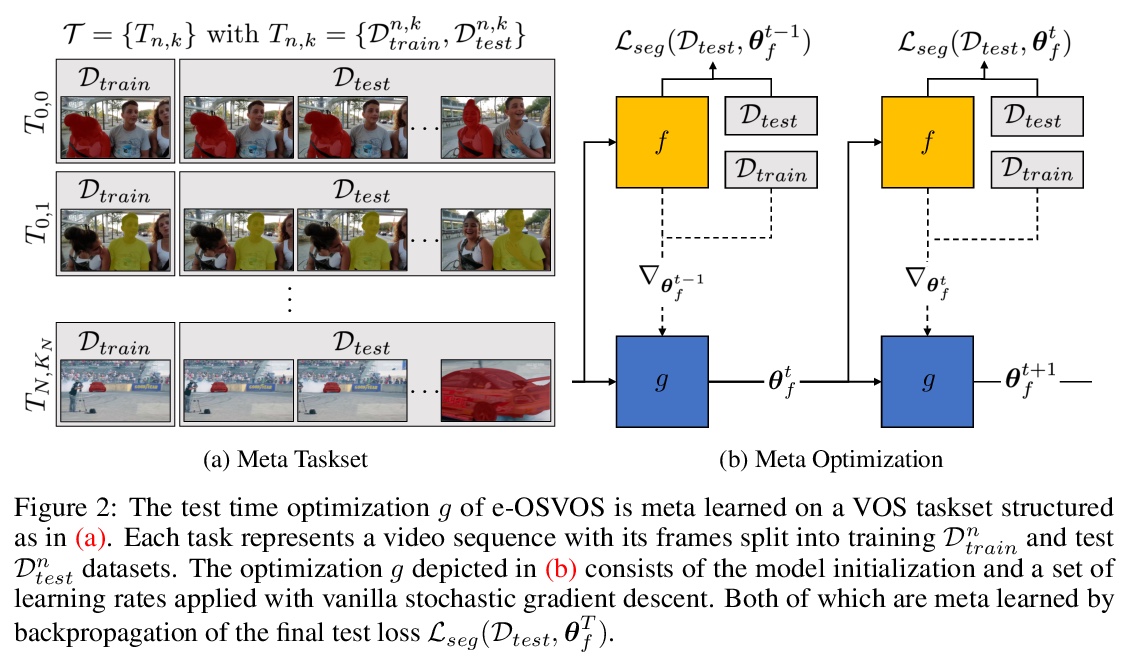
5、**[CV] Make One-Shot Video Object Segmentation Efficient Again
T Meinhardt, L Leal-Taixe
[Technical University of Munich]
高效单样本视频目标分割。展示了元学习在视频目标分割(VOS)微调中的应用,提出了有效的单样本视频目标分割(e-OSVOS),用修改版的Mask R-CNN解耦目标检测任务,并预测局部分割掩膜。无需费力手工超参数搜索即可优化单样本测试运行时和性能。通过元学习指导模型初始化和学习速率,在神经元水平上预测个体学习速率。用在线自适应解决整个序列中常见的性能退化问题。**
Video object segmentation (VOS) describes the task of segmenting a set of objects in each frame of a video. In the semi-supervised setting, the first mask of each object is provided at test time. Following the one-shot principle, fine-tuning VOS methods train a segmentation model separately on each given object mask. However, recently the VOS community has deemed such a test time optimization and its impact on the test runtime as unfeasible. To mitigate the inefficiencies of previous fine-tuning approaches, we present efficient One-Shot Video Object Segmentation (e-OSVOS). In contrast to most VOS approaches, e-OSVOS decouples the object detection task and predicts only local segmentation masks by applying a modified version of Mask R-CNN. The one-shot test runtime and performance are optimized without a laborious and handcrafted hyperparameter search. To this end, we meta learn the model initialization and learning rates for the test time optimization. To achieve optimal learning behavior, we predict individual learning rates at a neuron level. Furthermore, we apply an online adaptation to address the common performance degradation throughout a sequence by continuously fine-tuning the model on previous mask predictions supported by a frame-to-frame bounding box propagation. e-OSVOS provides state-of-the-art results on DAVIS 2016, DAVIS 2017, and YouTube-VOS for one-shot fine-tuning methods while reducing the test runtime substantially.
https://weibo.com/1402400261/Jx0izaoBP
另外几篇值得关注的论文:
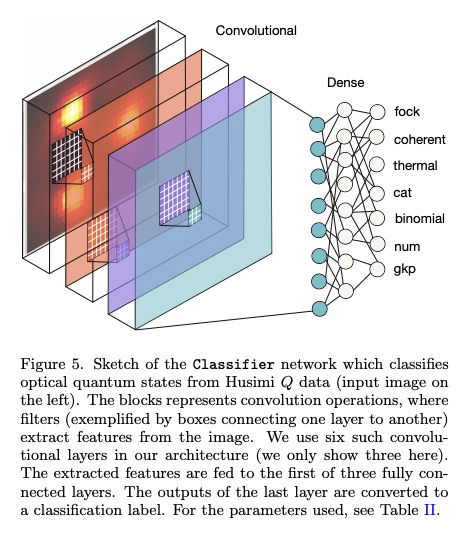
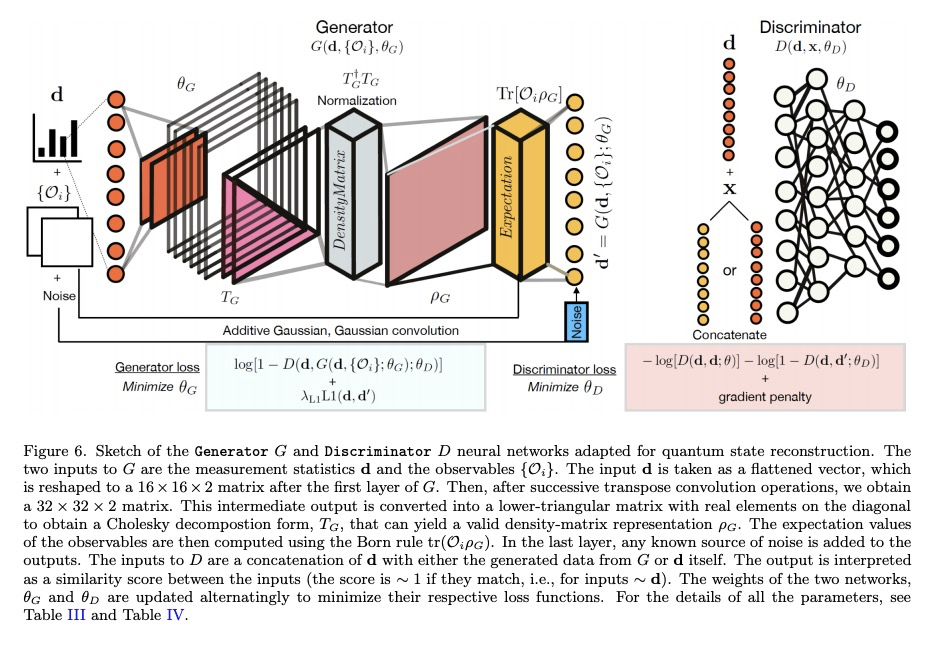
[LG] Classification and reconstruction of optical quantum states with deep neural networks
深度网络光量子态分类与重构
S Ahmed, C S Muñoz, F Nori, A F Kockum
[Chalmers University of Technology & Universidad Autonoma de Madrid & RIKEN Cluster for Pioneering Research]
https://weibo.com/1402400261/Jx0oBBVLj

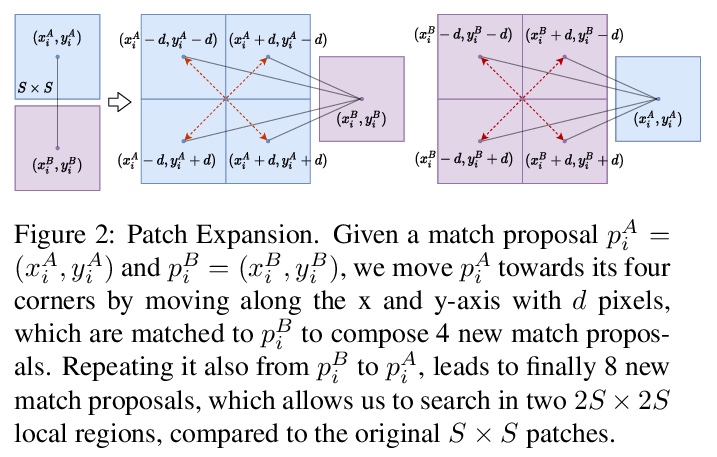
[CV] Patch2Pix: Epipolar-Guided Pixel-Level Correspondences
Patch2Pix:极线引导的像素级对应
Q Zhou, T Sattler, L Leal-Taixe
[Technical University of Munich & Chalmers University of Technology]
https://weibo.com/1402400261/Jx0r2k7ce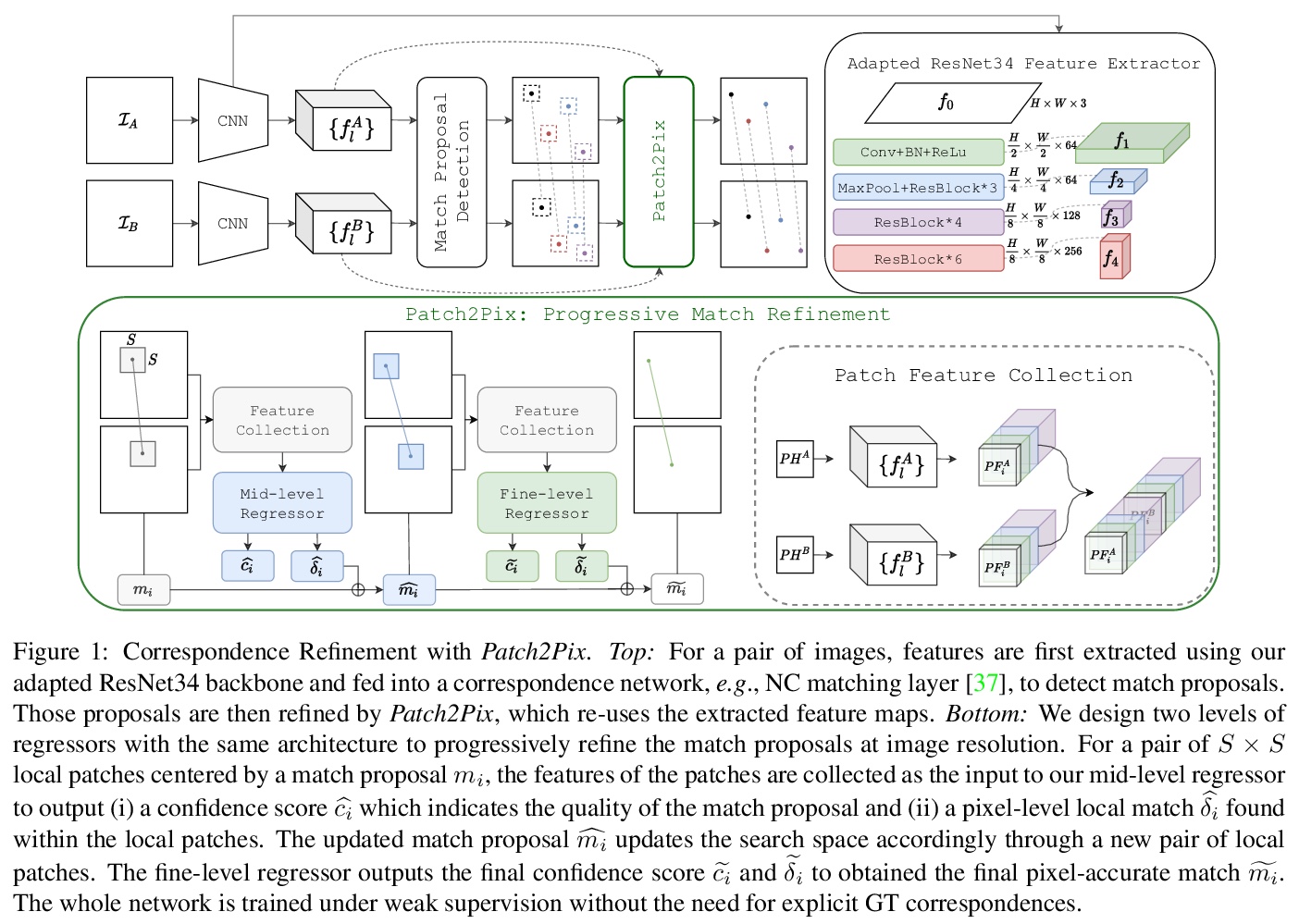

[CV] Attribute-Guided Adversarial Training for Robustness to Natural Perturbations
对自然扰动的属性引导鲁棒对抗训练
T Gokhale, R Anirudh, B Kailkhura, J J. Thiagarajan, C Baral, Y Yang
[Arizona State University & Lawrence Livermore National Laboratory]
https://weibo.com/1402400261/Jx0sq1Omk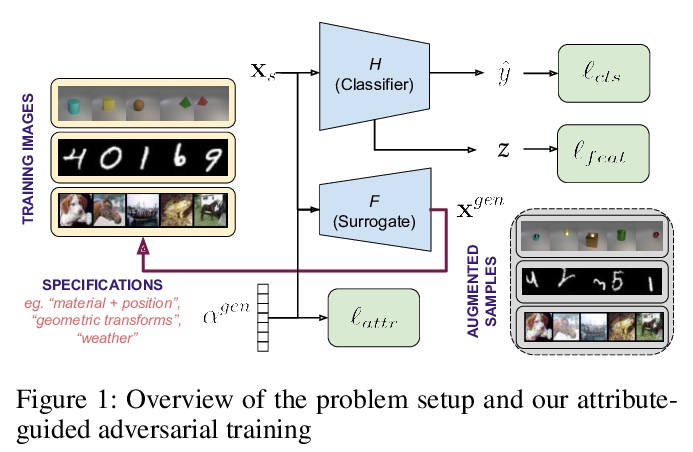


若有收获,就点个赞吧
0 人点赞
