- 1、[CV] Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Shapes
- 2、[CL] English Machine Reading Comprehension Datasets: A Survey
- 3、[LG] GUIGAN: Learning to Generate GUI Designs Using Generative Adversarial Networks
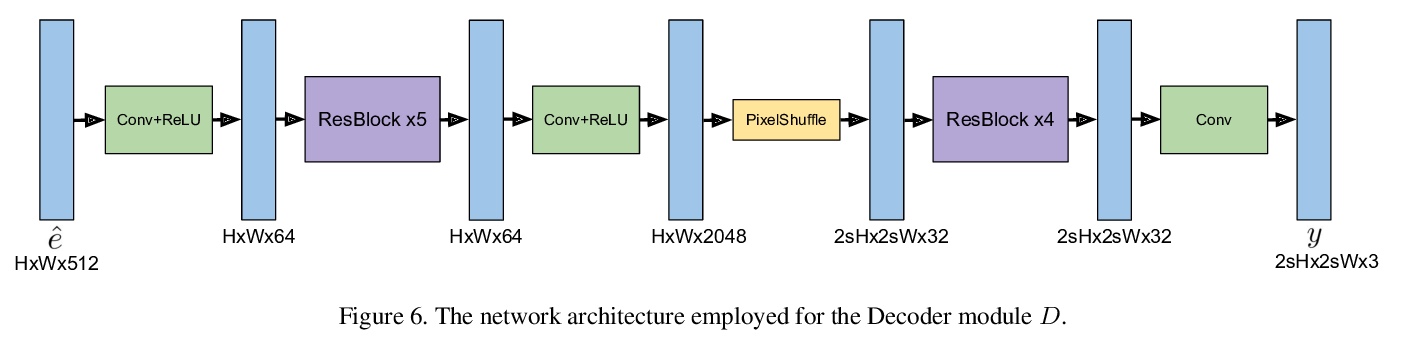
- 4、[CV] Deep Burst Super-Resolution
- 5、[CV] CPTR: Full Transformer Network for Image Captioning
- [Cl] Summarising Historical Text in Modern Languages
- [CV] Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning
- [AI] On the Evaluation of Vision-and-Language Navigation Instructions
- [LG] Predicting Patient Outcomes with Graph Representation Learning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Shapes
T Takikawa, J Litalien, K Yin, K Kreis, C Loop, D Nowrouzezahrai, A Jacobson, M McGuire, S Fidler
[NVIDIA & University of Toronto & McGill University]
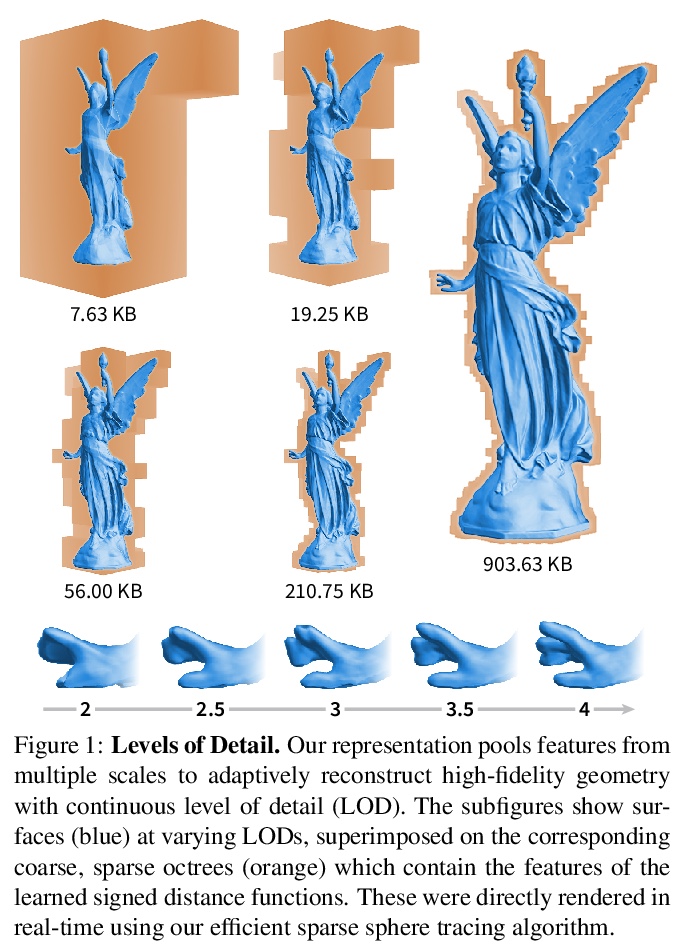
神经几何细节级别:隐式3D形状实时渲染。提出一种新的高效3D形状神经符号距离函数(SDF)表示方法,实现了高保真神经SDF实时渲染,可自适应扩展到不同细节水平(LOD),重建高度细节的几何形状,达到了最先进的几何重建质量。该方法可在不同尺度的几何体之间平滑插值,在合理内存占用下实现实时渲染。使用稀疏体素八叉树对空间进行离散化,存储学到的特征向量而不是有符号距离值,可自适应地拟合具有多个离散细节级别(LOD)的形状,并实现连续LOD与SDF插值。开发了为架构量身打造的射线遍历算法,使得几何体渲染速度比DeepSDF快了近100倍。该架构可用压缩格式表示3D形状,比传统方法具有更高的视觉保真度,即使从单个样本学习也能在不同几何形状间实现泛化。
Neural signed distance functions (SDFs) are emerging as an effective representation for 3D shapes. State-of-the-art methods typically encode the SDF with a large, fixed-size neural network to approximate complex shapes with implicit surfaces. Rendering with these large networks is, however, computationally expensive since it requires many forward passes through the network for every pixel, making these representations impractical for real-time graphics. We introduce an efficient neural representation that, for the first time, enables real-time rendering of high-fidelity neural SDFs, while achieving state-of-the-art geometry reconstruction quality. We represent implicit surfaces using an octree-based feature volume which adaptively fits shapes with multiple discrete levels of detail (LODs), and enables continuous LOD with SDF interpolation. We further develop an efficient algorithm to directly render our novel neural SDF representation in real-time by querying only the necessary LODs with sparse octree traversal. We show that our representation is 2-3 orders of magnitude more efficient in terms of rendering speed compared to previous works. Furthermore, it produces state-of-the-art reconstruction quality for complex shapes under both 3D geometric and 2D image-space metrics.
https://weibo.com/1402400261/JFcXpESZG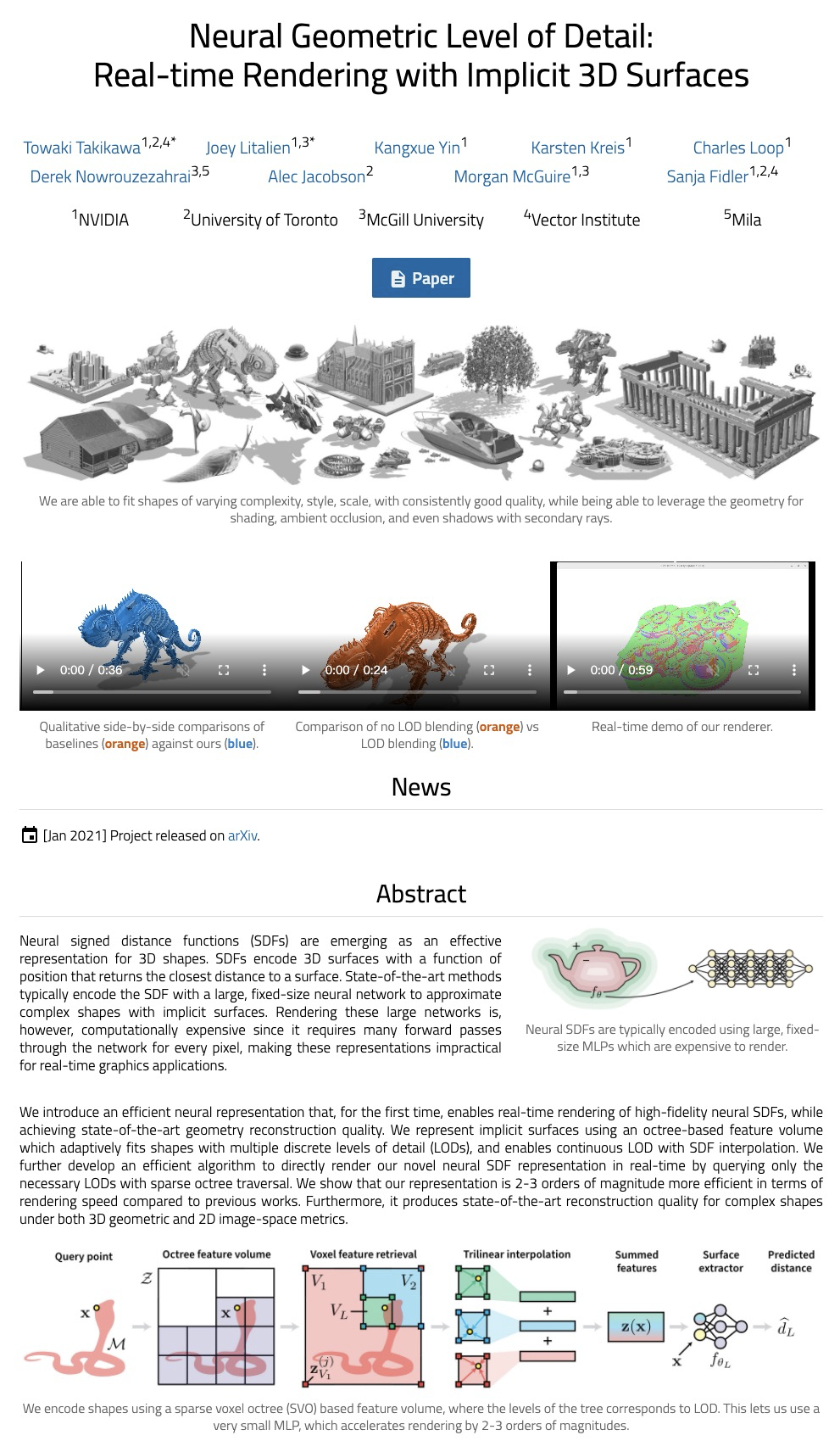
2、[CL] English Machine Reading Comprehension Datasets: A Survey
D Dzendzik, C Vogel, J Foster
[Dublin City University & Trinity College Dublin]
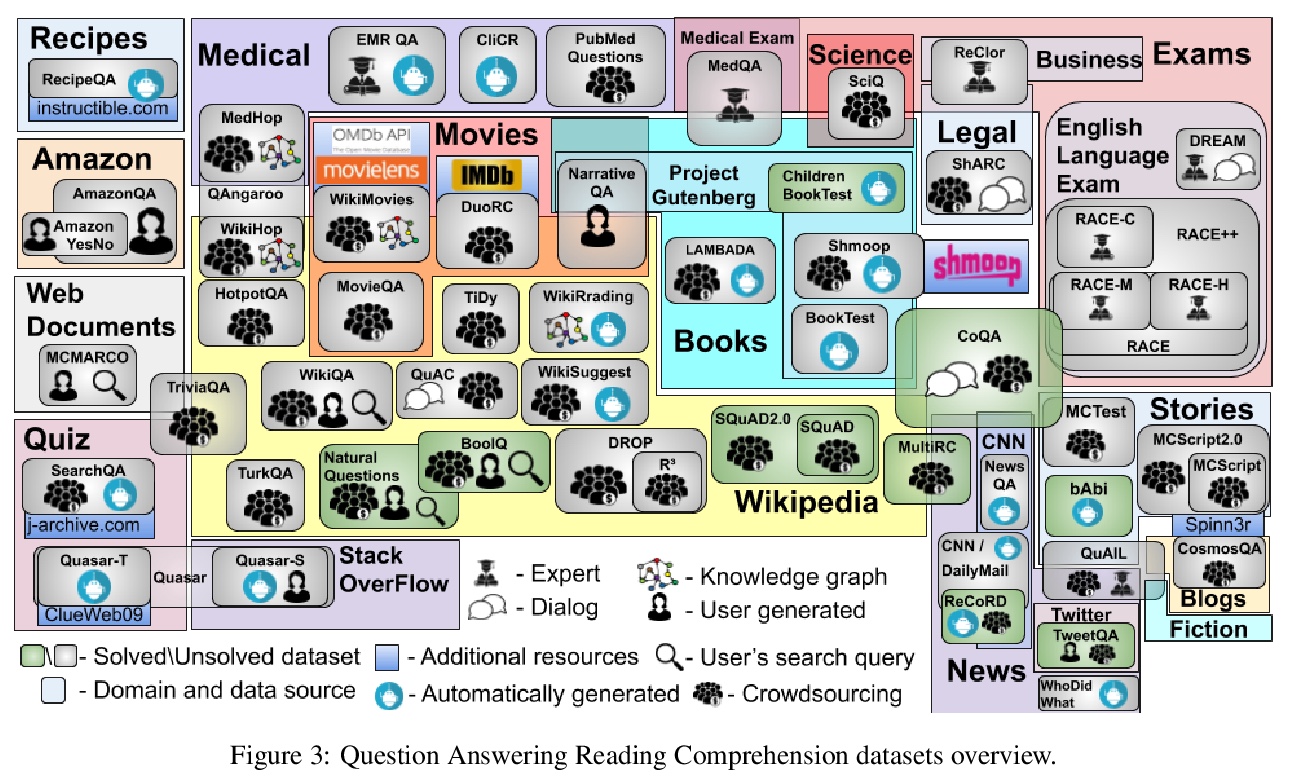
英语机器阅读理解数据集综述。对54个英语机器阅读理解数据集进行了调研,根据数据集的问答形式对其进行分类,从大小、词汇量、数据来源、创建方法、人工表现水平和第一问题词等多个维度进行比较。观察到从较小数据集向大型问题集合发展的趋势,以及从众包合成数据向自发创建数据发展的趋势。分析显示,维基百科是目前最常见的数据源,而各数据集中的why、when、where问题相对缺乏。
This paper surveys 54 English Machine Reading Comprehension datasets, with a view to providing a convenient resource for other researchers interested in this problem. We categorize the datasets according to their question and answer form and compare them across various dimensions including size, vocabulary, data source, method of creation, human performance level, and first question word. Our analysis reveals that Wikipedia is by far the most common data source and that there is a relative lack of why, when, and where questions across datasets.
https://weibo.com/1402400261/JFd5ZCtny

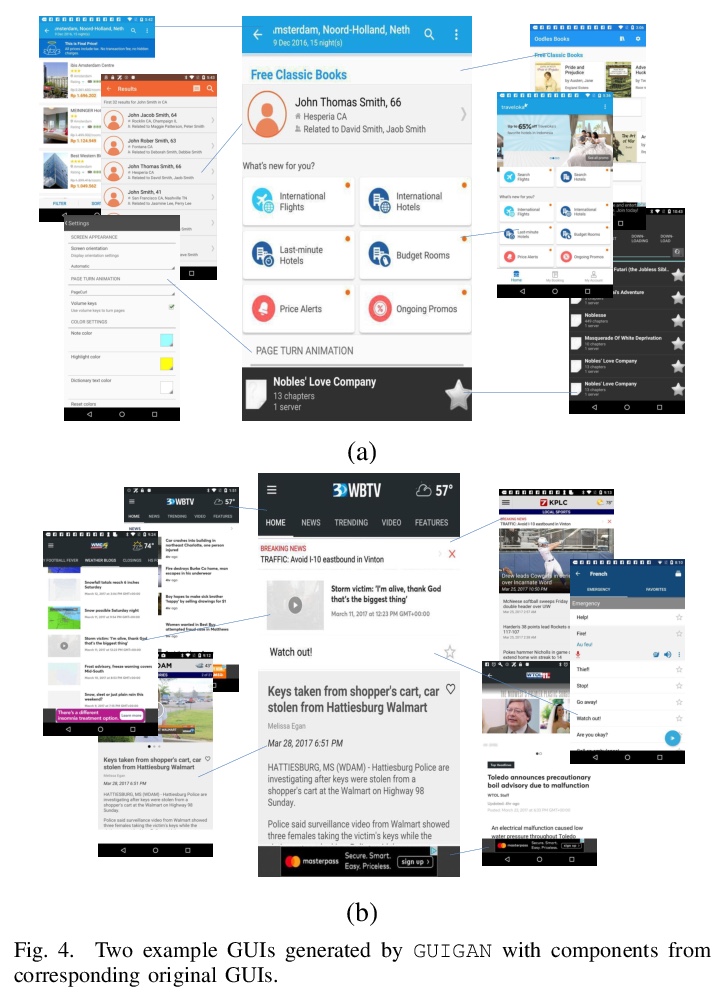
3、[LG] GUIGAN: Learning to Generate GUI Designs Using Generative Adversarial Networks
T Zhao, C Chen, Y Liu, X Zhu
[Jilin University & Monash University]
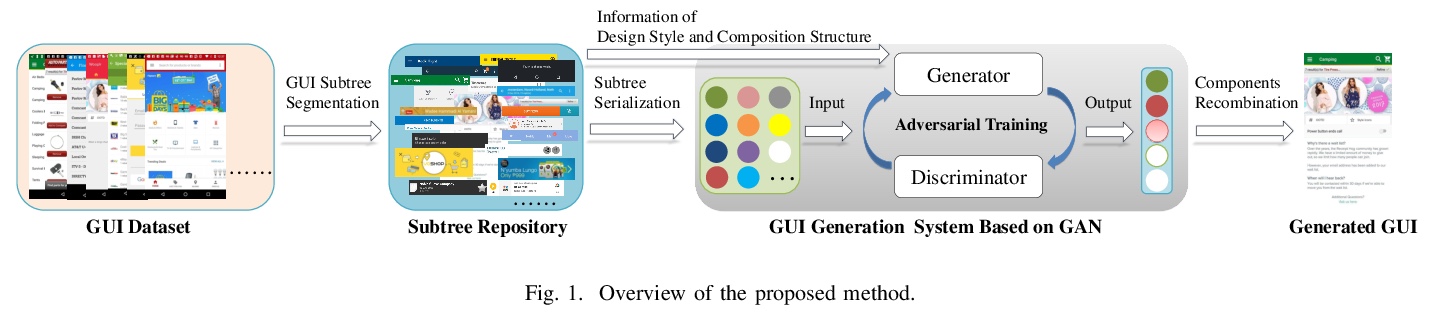
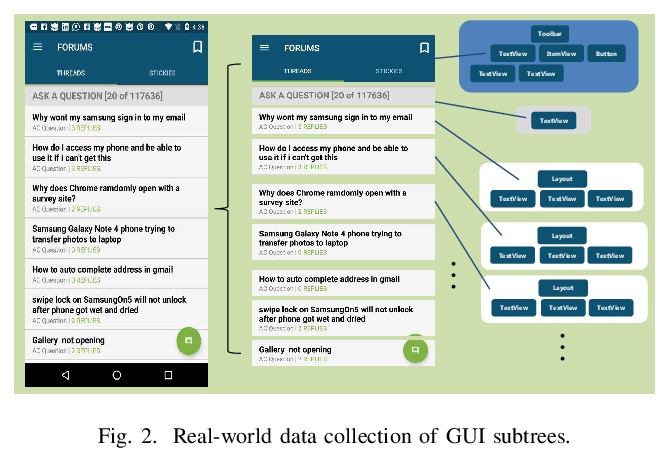
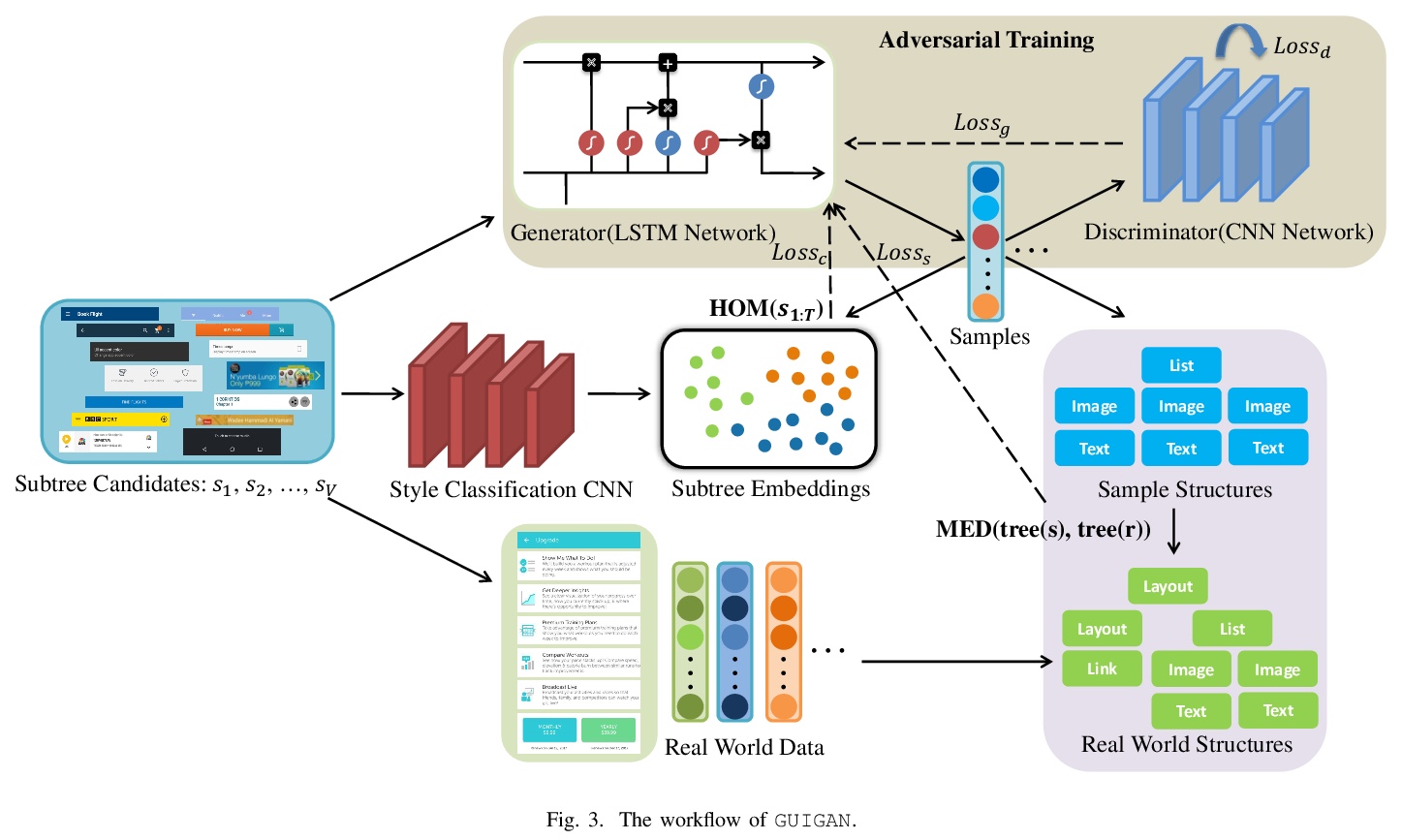
GUIGAN:用生成式对抗网络学习生成图形用户界面(GUI)设计。开发了自动生成GUI设计的模型GUIGAN。不同于传统基于图像像素的图像生成模型,GUIGAN对既有移动应用GUI中收集的GUI组件进行再利用,组成新的设计,类似于自然语言生成。GUIGAN在SeqGAN的基础上,对GUI组件风格兼容性和GUI结构进行了建模。构建了一个人机协作系统,模型中生成的GUI仅用于启发开发者/设计者。
Graphical User Interface (GUI) is ubiquitous in almost all modern desktop software, mobile applications, and online websites. A good GUI design is crucial to the success of the software in the market, but designing a good GUI which requires much innovation and creativity is difficult even to well-trained designers. Besides, the requirement of the rapid development of GUI design also aggravates designers’ working load. So, the availability of various automated generated GUIs can help enhance the design personalization and specialization as they can cater to the taste of different designers. To assist designers, we develop a model GUIGAN to automatically generate GUI designs. Different from conventional image generation models based on image pixels, our GUIGAN is to reuse GUI components collected from existing mobile app GUIs for composing a new design that is similar to natural-language generation. Our GUIGAN is based on SeqGAN by modeling the GUI component style compatibility and GUI structure. The evaluation demonstrates that our model significantly outperforms the best of the baseline methods by 30.77% in Frechet Inception distance (FID) and 12.35% in 1-Nearest Neighbor Accuracy (1-NNA). Through a pilot user study, we provide initial evidence of the usefulness of our approach for generating acceptable brand new GUI designs.
https://weibo.com/1402400261/JFd9JhsRZ
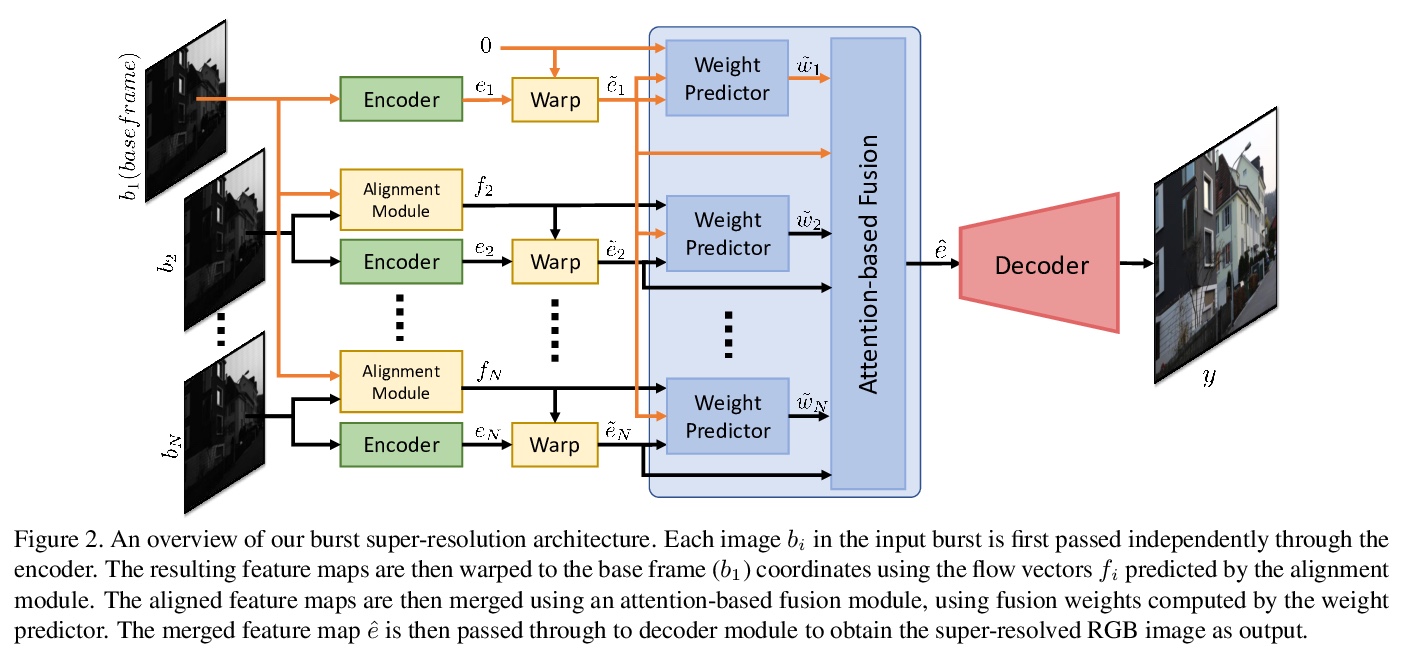
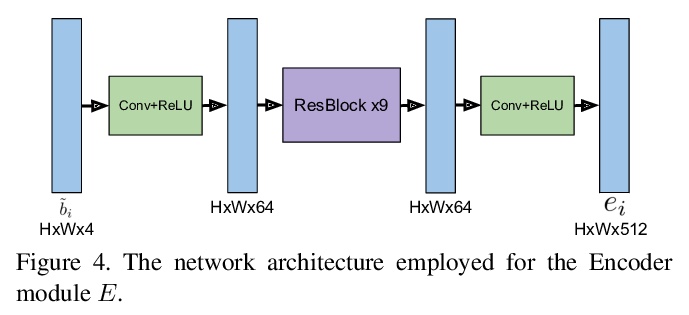
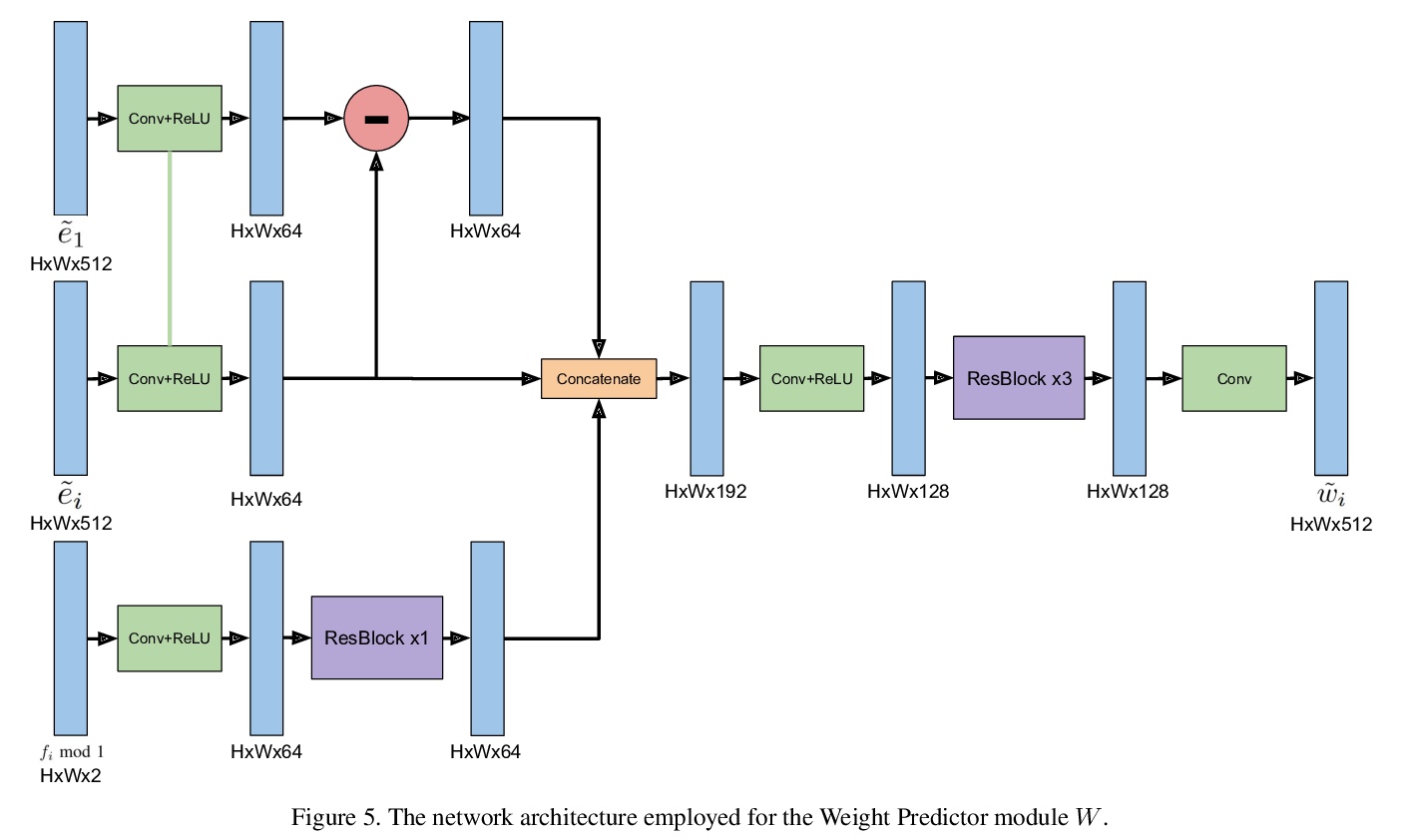
4、[CV] Deep Burst Super-Resolution
G Bhat, M Danelljan, L V Gool, R Timofte
[ETH Zurich]
针对移动抓拍的深度多帧超分辨率(MFSR)。提出一种新型的基于深度学习的多帧超分辨率方法,将多张含有噪声的RAW图像作为输入,生成去噪、超分辨率的RGB图像作为输出,通过像素化光流显式对齐深度嵌入来实现,用基于注意力的融合模块对所有帧的信息进行自适应合并,可自适应合并任意数量的输入帧,以产生高质量输出。该方法不限于图像间的简单运动,如平移或同构,通过计算元素级融合权重来合并各帧的对齐表示,能自适应地从每幅图像中选择可靠的、信息量大的内容,同时丢弃例如错位的区域。引入一个新的数据集BurstSR,包含从手持相机捕获的RAW抓拍序列,以及用变焦镜头获得的相应的高分辨率真值。
While single-image super-resolution (SISR) has attracted substantial interest in recent years, the proposed approaches are limited to learning image priors in order to add high frequency details. In contrast, multi-frame super-resolution (MFSR) offers the possibility of reconstructing rich details by combining signal information from multiple shifted images. This key advantage, along with the increasing popularity of burst photography, have made MFSR an important problem for real-world applications.We propose a novel architecture for the burst super-resolution task. Our network takes multiple noisy RAW images as input, and generates a denoised, super-resolved RGB image as output. This is achieved by explicitly aligning deep embeddings of the input frames using pixel-wise optical flow. The information from all frames are then adaptively merged using an attention-based fusion module. In order to enable training and evaluation on real-world data, we additionally introduce the BurstSR dataset, consisting of smartphone bursts and high-resolution DSLR ground-truth. We perform comprehensive experimental analysis, demonstrating the effectiveness of the proposed architecture.
https://weibo.com/1402400261/JFdcMDIjB
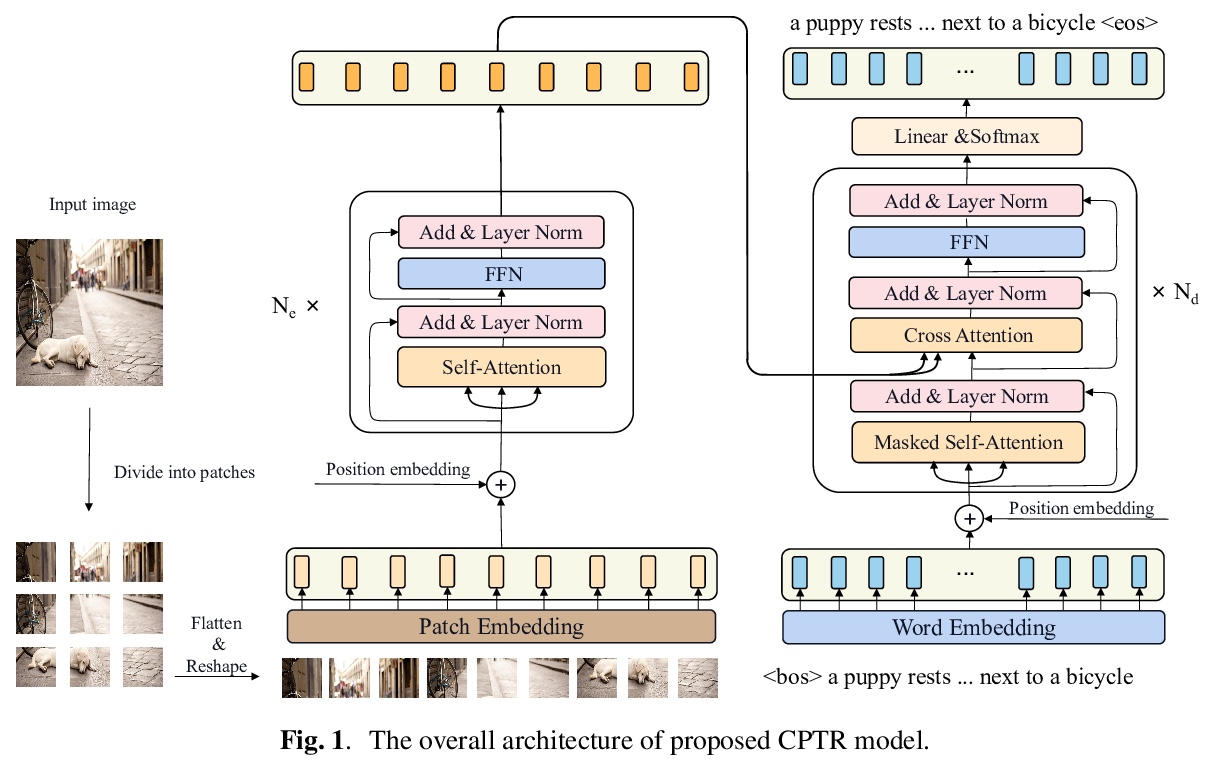
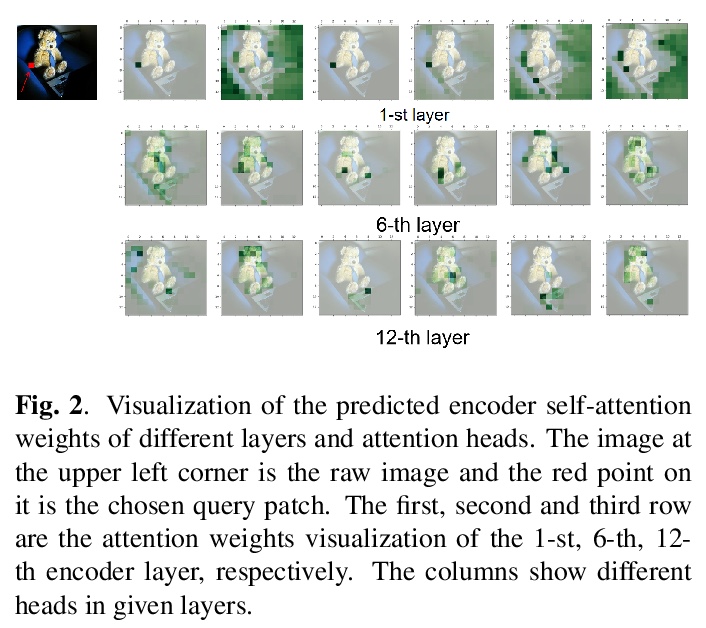
5、[CV] CPTR: Full Transformer Network for Image Captioning
W Liu, S Chen, L Guo, X Zhu, J Liu
[Chinese Academy of Sciences]
CPTR:面向图像描述的全Transformer网络。将图像描述生成作为序列对序列的预测任务重新思考,提出全Transformer模型CPTR,以取代传统的”CNN+Transformer”模型。该网络完全无卷积,具有从头在编码器每一层建模全局上下文信息的能力。在MS COCO数据集上的评价结果证明了该方法的有效性,其效果超越了 “CNN+Transformer”网络。
In this paper, we consider the image captioning task from a new sequence-to-sequence prediction perspective and propose Caption TransformeR (CPTR) which takes the sequentialized raw images as the input to Transformer. Compared to the “CNN+Transformer” design paradigm, our model can model global context at every encoder layer from the beginning and is totally convolution-free. Extensive experiments demonstrate the effectiveness of the proposed model and we surpass the conventional “CNN+Transformer” methods on the MSCOCO dataset. Besides, we provide detailed visualizations of the self-attention between patches in the encoder and the “words-to-patches” attention in the decoder thanks to the full Transformer architecture.
https://weibo.com/1402400261/JFdjX44xc
另外几篇值得关注的论文:
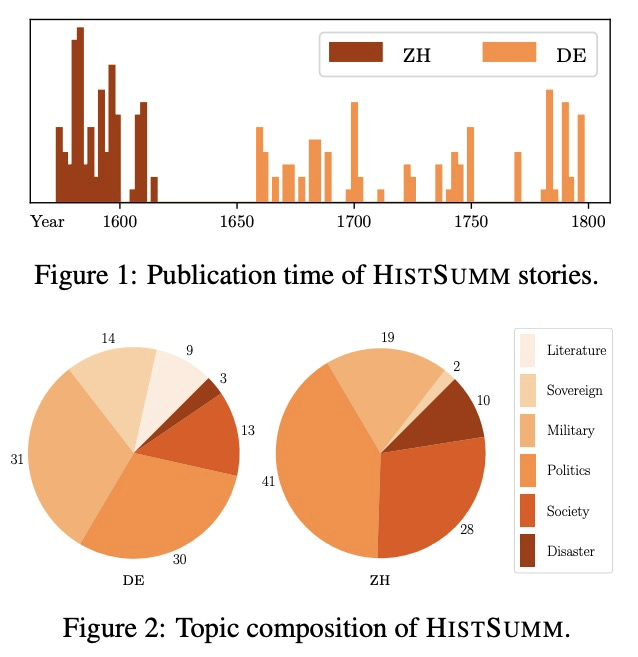
[Cl] Summarising Historical Text in Modern Languages
古文的现代文摘要生成
X Peng, Y Zheng, C Lin, A Siddharthan
[The University of Sheffield & Beihang University & The Open University]
We introduce the task of historical text summarisation, where documents in historical forms of a language are summarised in the corresponding modern language. This is a fundamentally important routine to historians and digital humanities researchers but has never been automated. We compile a high-quality gold-standard text summarisation dataset, which consists of historical German and Chinese news from hundreds of year ago summarised in modern German or Chinese. Based on cross-lingual transfer learning techniques, we propose a summarisation model which can be trained even with no cross-lingual (historical to modern) parallel data, and further benchmark it against state-of-the-art algorithms. We report automatic and human evaluations that distinguish the historic to modern language summarisation task from standard cross-lingual summarisation (i.e., modern to modern language), highlight the distinctness and value of our dataset, and demonstrate that our transfer learning approach outperforms standard cross-lingual benchmarks on this task.
https://weibo.com/1402400261/JFdoyfbNJ

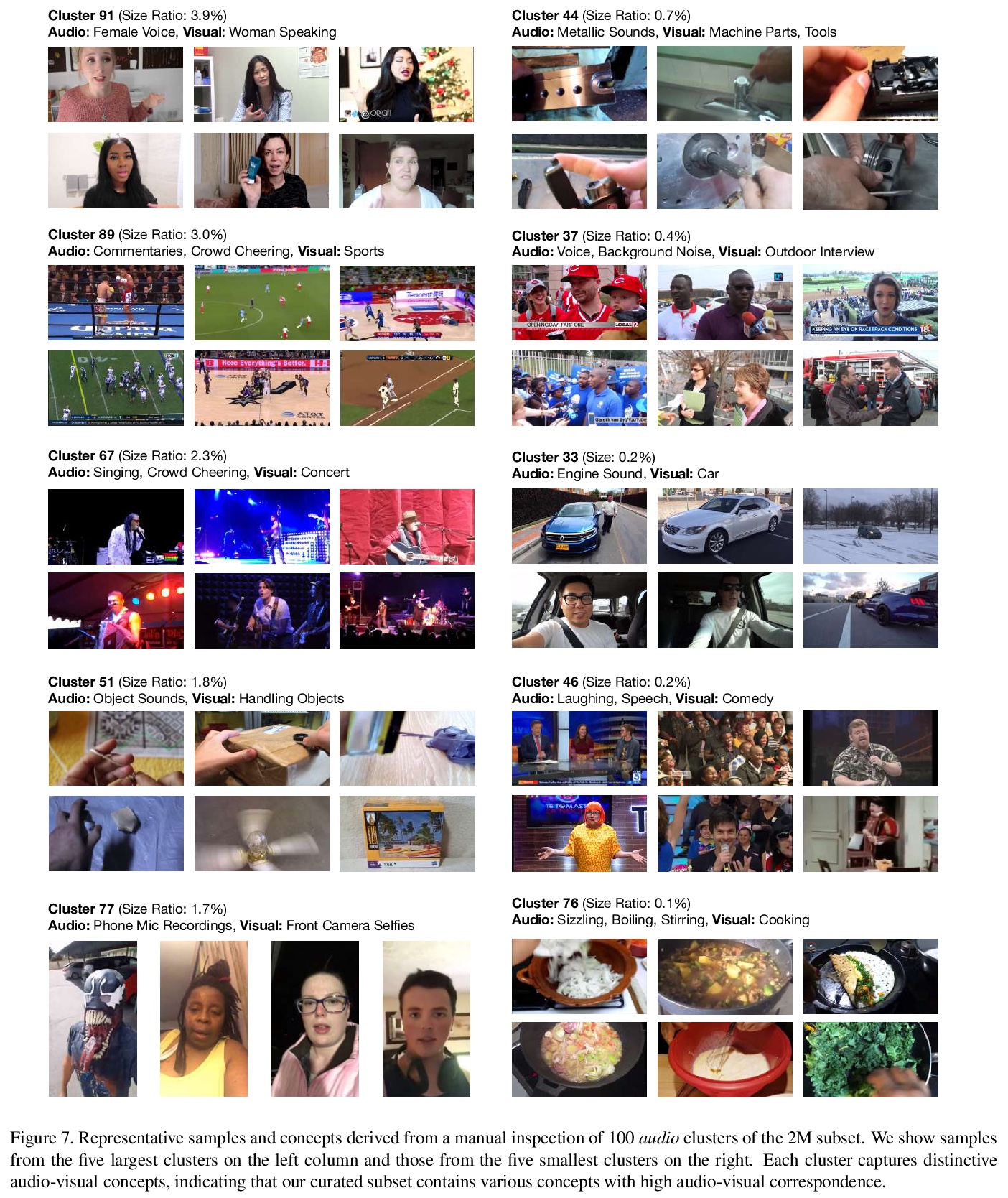
[CV] Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning
面向视-听表示学习的大规模数据集自动策管
S Lee, J Chung, Y Yu, G Kim, T Breuel, G Chechik, Y Song
[NVIDIA Research & Microsoft Research]**
https://weibo.com/1402400261/JFdtwqZGm
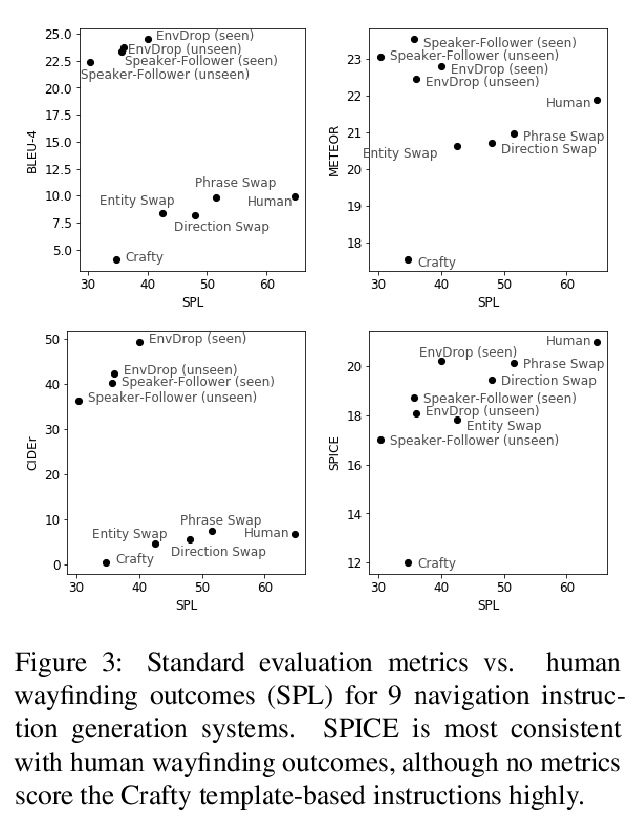
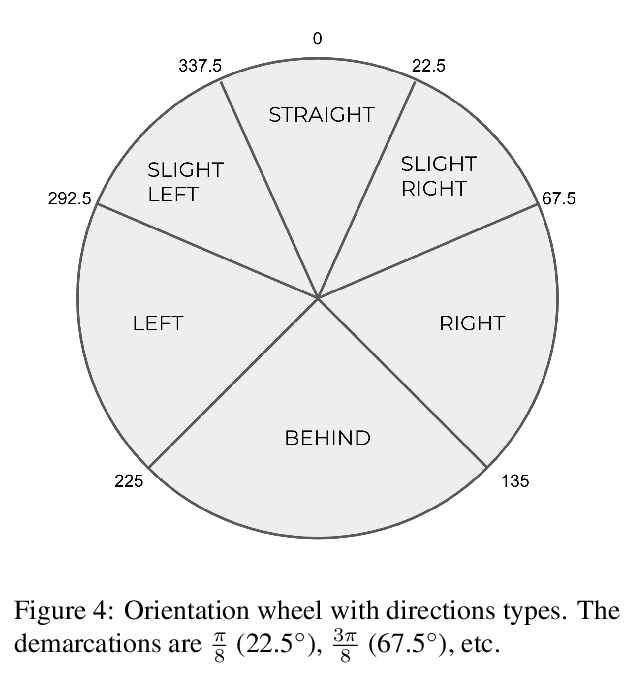
[AI] On the Evaluation of Vision-and-Language Navigation Instructions
视觉-语言导航指令评价
M Zhao, P Anderson, V Jain, S Wang, A Ku, J Baldridge, E Ie
[Google Research]
https://weibo.com/1402400261/JFdvi3Ii0
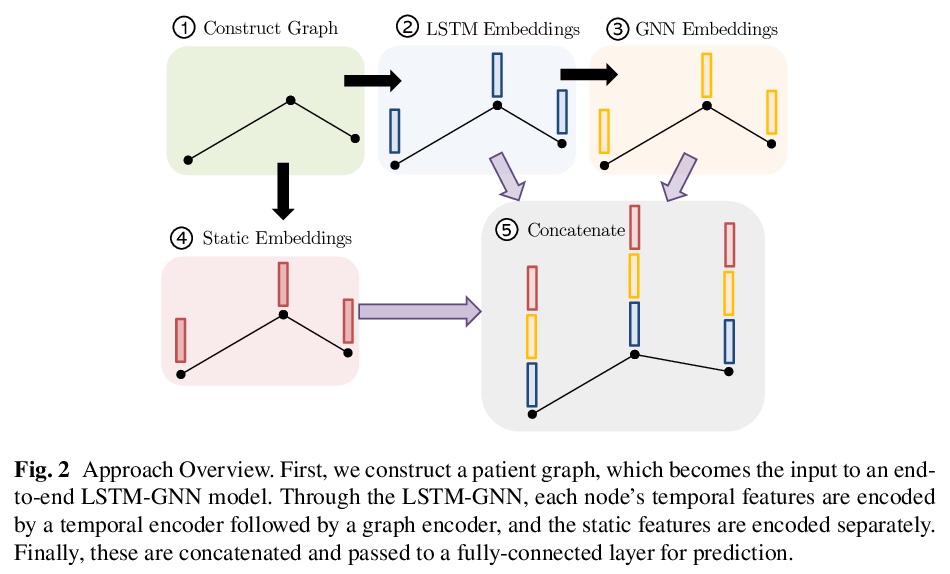
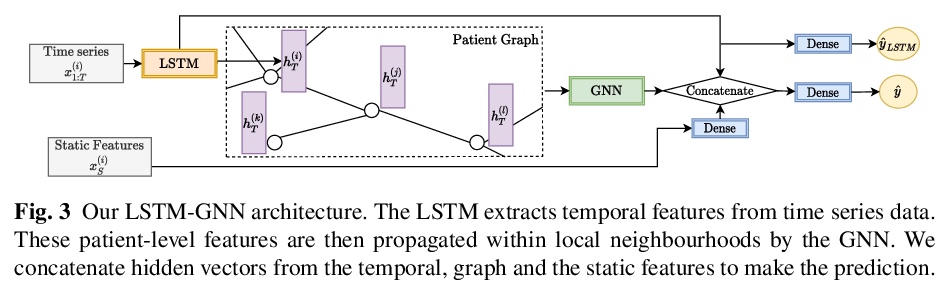
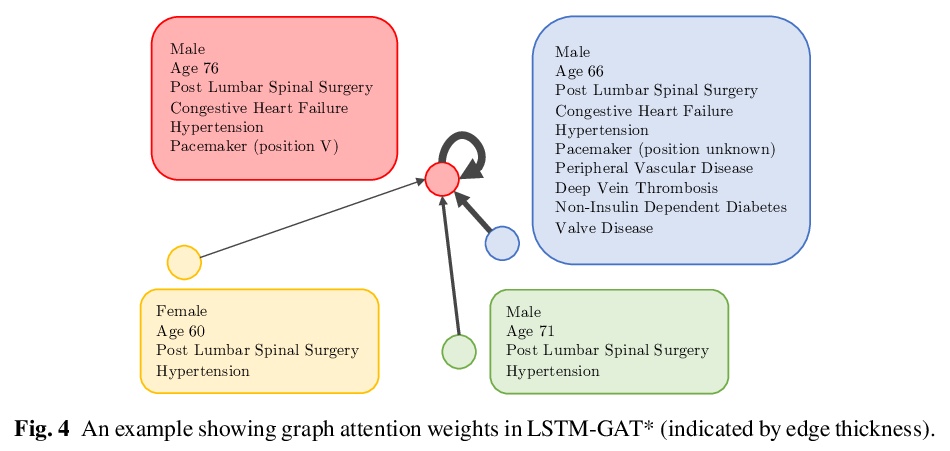
[LG] Predicting Patient Outcomes with Graph Representation Learning
图表示学习患者预后预测
E Rocheteau, C Tong, P Veličković, N Lane, P Liò
[University of Cambridge & University of Oxford]
https://weibo.com/1402400261/JFdyC1d5T

若有收获,就点个赞吧
0 人点赞
