- 1、[CV] Deep learning-enabled medical computer vision
- 2、[LG] Good practices for Bayesian Optimization of high dimensional structured spaces
- 3、[CV] Adversarial Robustness by Design through Analog Computing and Synthetic Gradients
- 4、[CL] Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies
- 5、[CL] What all do audio transformer models hear? Probing Acoustic Representations for Language Delivery and its Structure
- [CL] UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
- [CV] Self-Supervised Pretraining of 3D Features on any Point-Cloud
- [CV] Text-Free Image-to-Speech Synthesis Using Learned Segmental Units
- [CL] UnitedQA: A Hybrid Approach for Open Domain Question Answering
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
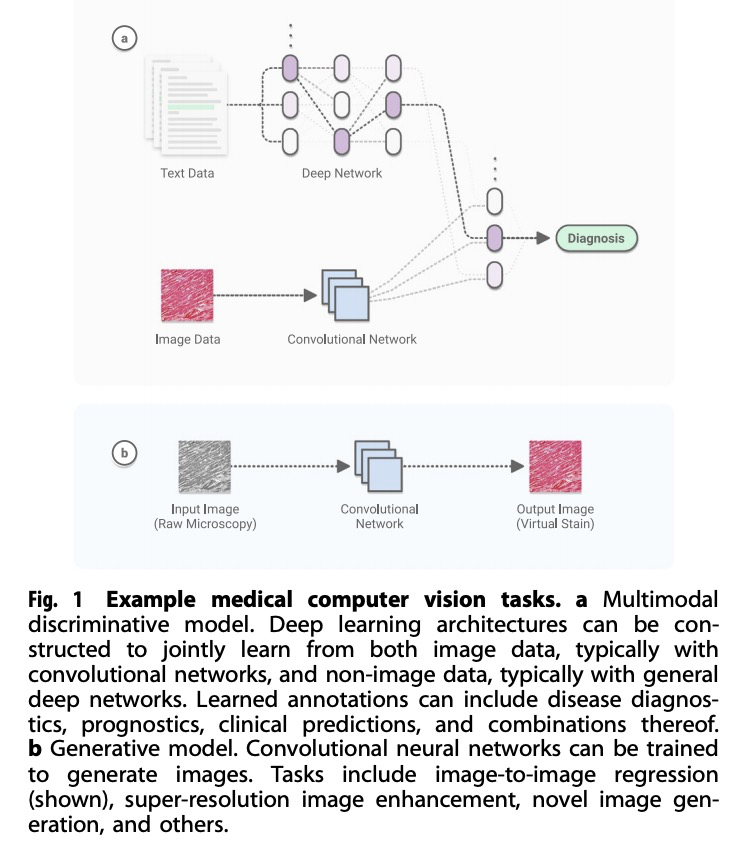
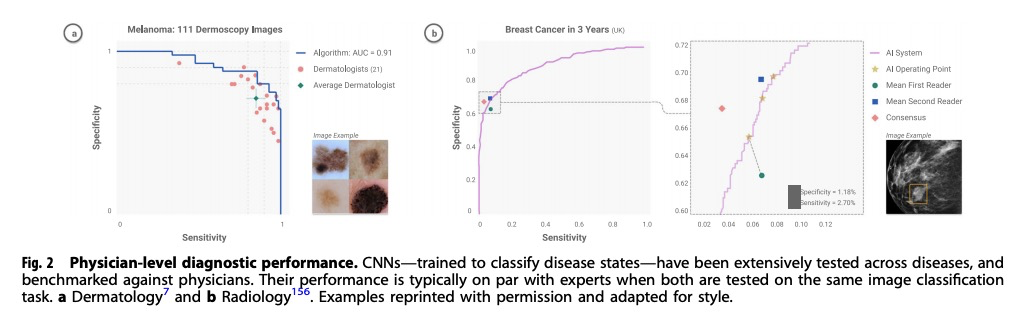
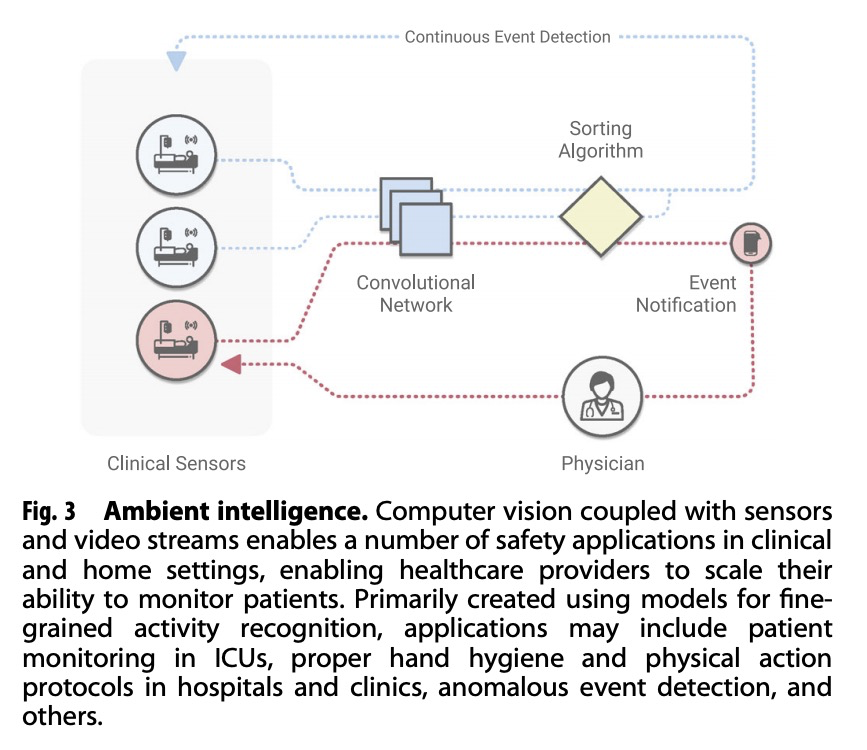
1、[CV] Deep learning-enabled medical computer vision
A Esteva, K Chou, S Yeung, N Naik, A Madani, A Mottaghi, Y Liu, E Topol, J Dean, R Socher
[Salesforce AI Research & Google Research & Stanford University]
基于深度学习的医疗计算机视觉。总结了以深度学习为动力的现代计算机视觉技术,在医疗应用方面的最新进展,重点是医疗成像、医疗视频和临床部署。简要总结了卷积神经网络十年来的进展,包括在医疗领域实现的视觉任务。讨论了几个医学影像应用实例—包括心脏病学、病理学、皮肤学、眼科,并提出了继续工作的新途径。扩展了一般的医学视频,强调临床工作流程可以整合计算机视觉以增强护理的方法。讨论了这些技术在现实世界的临床部署所面临的挑战和障碍。
A decade of unprecedented progress in artificial intelligence (AI) has demonstrated the potential for many fields—including medicine—to benefit from the insights that AI techniques can extract from data. Here we survey recent progress in the development of modern computer vision techniques—powered by deep learning—for medical applications, focusing on medical imaging, medical video, and clinical deployment. We start by briefly summarizing a decade of progress in convolutional neural networks, including the vision tasks they enable, in the context of healthcare. Next, we discuss several example medical imaging applications that stand to benefit—including cardiology, pathology, dermatology, ophthalmology–and propose new avenues for continued work. We then expand into general medical video, highlighting ways in which clinical workflows can integrate computer vision to enhance care. Finally, we discuss the challenges and hurdles required for real-world clinical deployment of these technologies.
https://weibo.com/1402400261/JCteyeZgu
2、[LG] Good practices for Bayesian Optimization of high dimensional structured spaces
E Siivola, J Gonzalez, A Paleyes, A Vehtari
[Aalto University & Microsoft & University of Cambridge]
高维结构化空间贝叶斯优化良好实践。研究了将深度生成模型(如变分自编码器)和高斯过程相结合的方法,使回归模型和优化在生成模型找到的平滑欧氏低维空间中进行。证明了维度、优化空间限制策略和获取函数对优化性能的影响。结果表明,深度生成模型存在使优化产生的性能最好的最佳维度。不需要限制获取函数的优化空间,获取函数在结构化问题中的性能与常规的低维贝叶斯优化的情况相似。通过联合学习潜空间和高斯过程模型来调整潜空间,可能会导致过拟合和整体性能的下降。
The increasing availability of structured but high dimensional data has opened new opportunities for optimization. One emerging and promising avenue is the exploration of unsupervised methods for projecting structured high dimensional data into low dimensional continuous representations, simplifying the optimization problem and enabling the application of traditional optimization methods. However, this line of research has been purely methodological with little connection to the needs of practitioners so far. In this paper, we study the effect of different search space design choices for performing Bayesian Optimization in high dimensional structured datasets. In particular, we analyse the influence of the dimensionality of the latent space, the role of the acquisition function and evaluate new methods to automatically define the optimization bounds in the latent space. Finally, based on experimental results using synthetic and real datasets, we provide recommendations for the practitioners.>
https://weibo.com/1402400261/JCtnctxeu


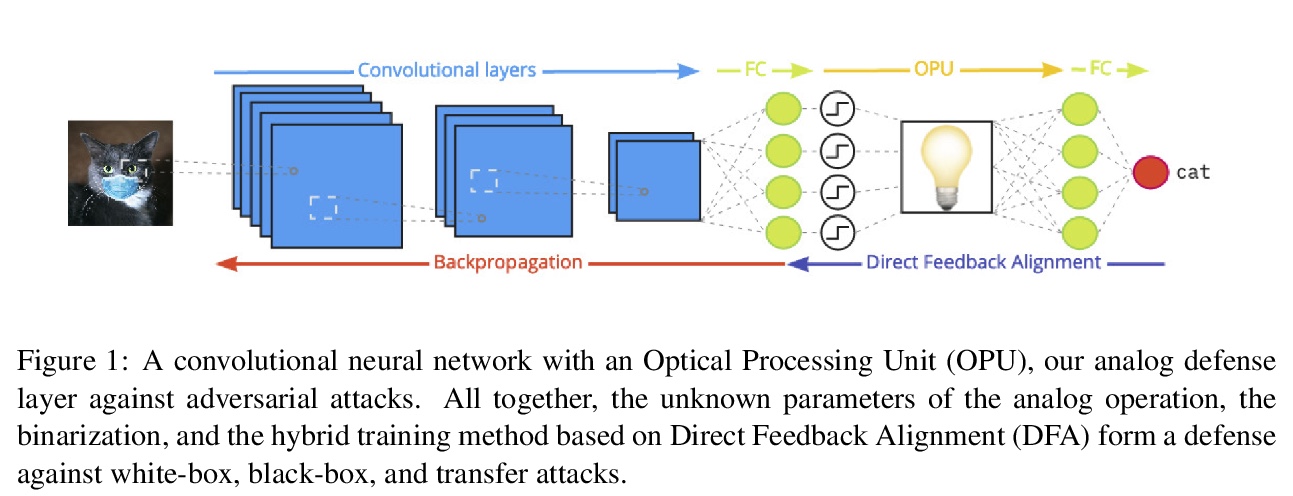
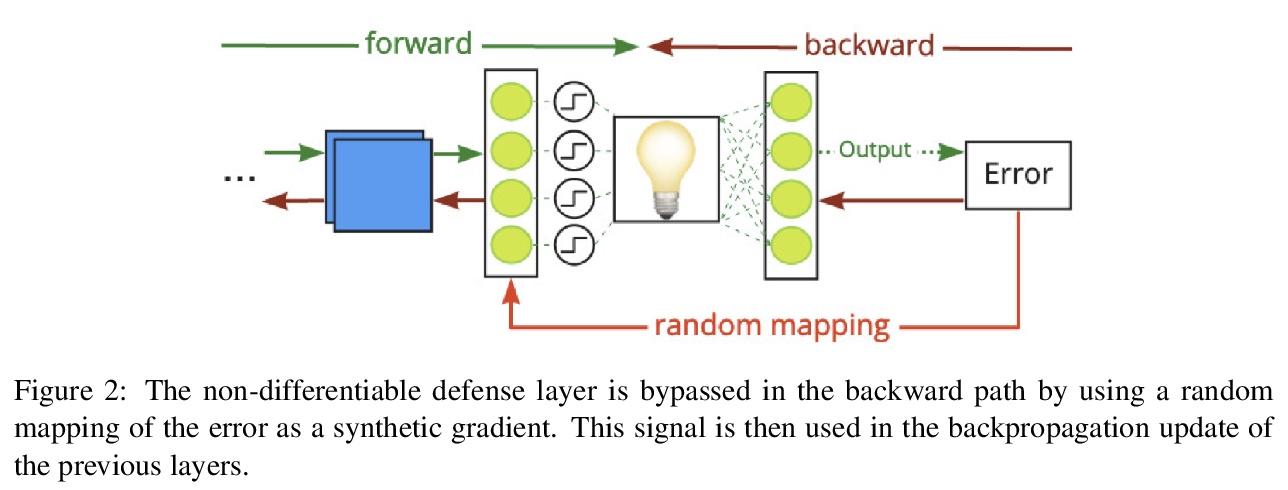
3、[CV] Adversarial Robustness by Design through Analog Computing and Synthetic Gradients
A Cappelli, R Ohana, J Launay, L Meunier, I Poli, F Krzakala
[LightOn & Facebook AI Research]
基于模拟计算和合成梯度设计的对抗鲁棒性。提出一种针对白盒、黑盒和迁移攻击的新防御技术,基于使用光协处理器的神经网络层的模拟实现,不影响自然精度,以防御对抗性攻击。硬件协处理器执行非线性固定随机变换,其中的参数是未知的,不可能在足够大的维度上以足够的精度检索。在白盒设置中,防御措施通过混淆随机投影的参数来工作。光学系统中随机投影和二值化的结合也提高了对各种类型黑盒攻击的鲁棒性。采用混合训练方法构建针对迁移攻击的稳健特征。
https://weibo.com/1402400261/JCtsfuCZU
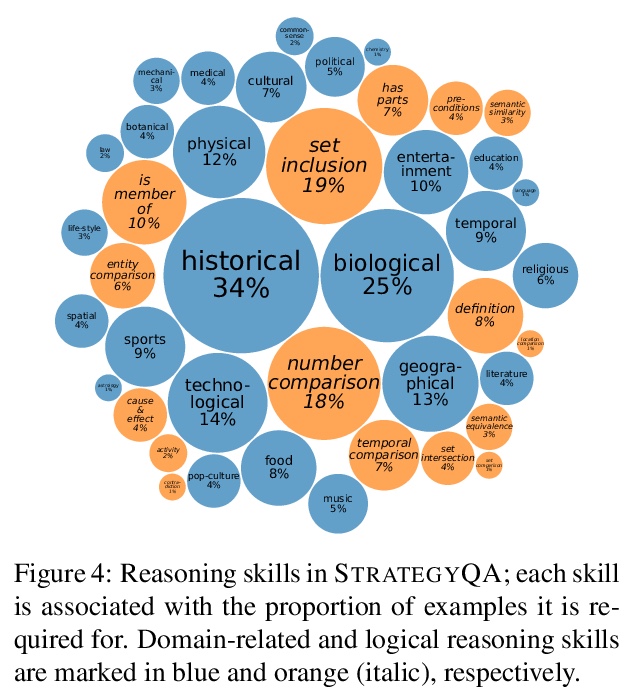
4、[CL] Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies
M Geva, D Khashabi, E Segal, T Khot, D Roth, J Berant
[Tel Aviv University & Allen Institute for AI & University of Pennsylvania]
隐性推理问答基准。提出了STRATEGYQA,一个需要广泛推理技能的隐式多步骤问答数据集。引入了一个新的标记pipeline来引出创造性问题,这些问题使用简单的语言,但涵盖了一系列具有挑战性的不同策略。STRATEGYQA中的问题被分解为推理步骤和证据段落,以指导正在进行的研究,解决隐式多跳推理的挑战。StrategyQA包含2780个样本,每个样本都包含一个策略问题、分解和证据段落,其问题篇幅较短,主题多样,涉及的策略范围很广。
A key limitation in current datasets for multi-hop reasoning is that the required steps for answering the question are mentioned in it explicitly. In this work, we introduce StrategyQA, a question answering (QA) benchmark where the required reasoning steps are implicit in the question, and should be inferred using a strategy. A fundamental challenge in this setup is how to elicit such creative questions from crowdsourcing workers, while covering a broad range of potential strategies. We propose a data collection procedure that combines term-based priming to inspire annotators, careful control over the annotator population, and adversarial filtering for eliminating reasoning shortcuts. Moreover, we annotate each question with (1) a decomposition into reasoning steps for answering it, and (2) Wikipedia paragraphs that contain the answers to each step. Overall, StrategyQA includes 2,780 examples, each consisting of a strategy question, its decomposition, and evidence paragraphs. Analysis shows that questions in StrategyQA are short, topic-diverse, and cover a wide range of strategies. Empirically, we show that humans perform well (87%) on this task, while our best baseline reaches an accuracy of > ∼66%.
https://weibo.com/1402400261/JCtxMyzMi

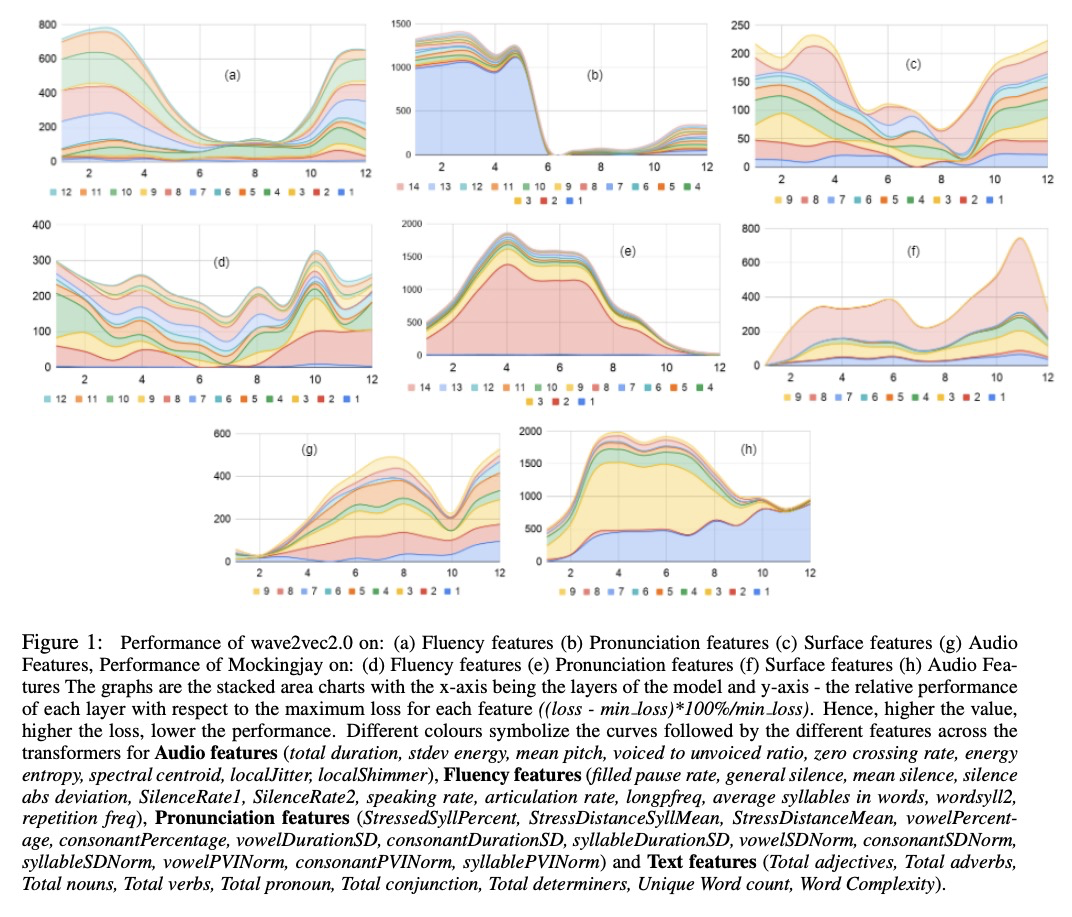
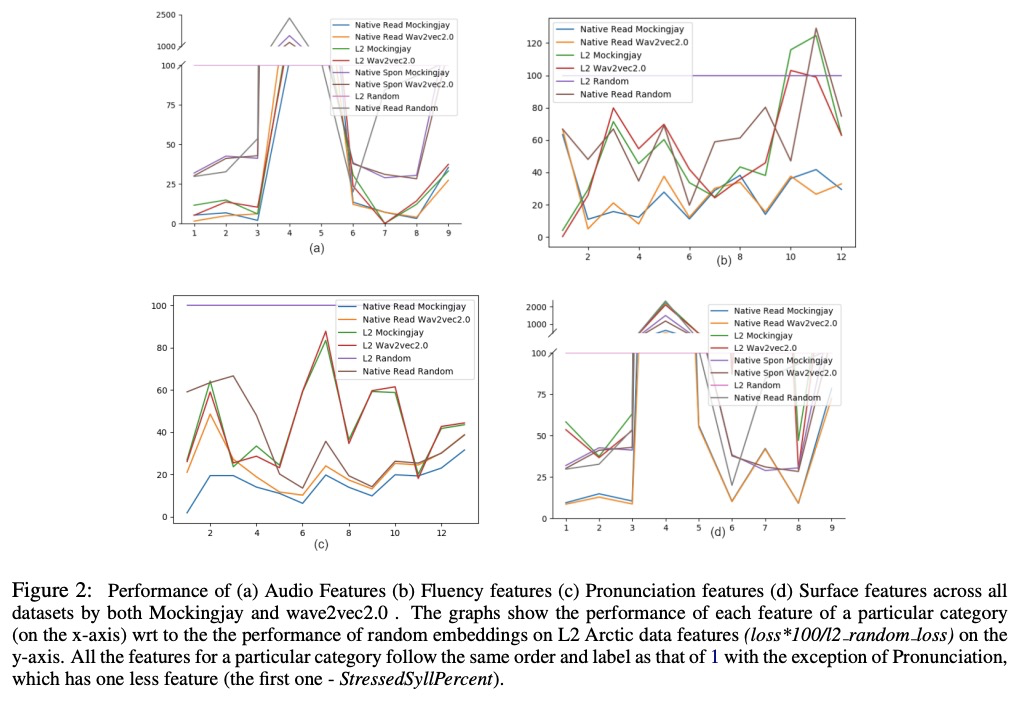
5、[CL] What all do audio transformer models hear? Probing Acoustic Representations for Language Delivery and its Structure
J Shah, Y K Singla, C Chen, R R Shah
[IIIT-Delhi & State University of New York at Buffalo]
语言传递及其结构的的声学表示探究。试图为最近的两个音频transformer模型——Mockingjay和wave2vec2.0——回答“音频transformer模型学习到的是什么”的问题。比较了一套全面的语言传递及其结构特征,包括音频、流畅性和发音特征。探讨了音频模型对文本字面、句法和语义特征的理解,并与BERT进行了比较。发现wave2vec2.0在音频和流畅性上优于Mockingjay,但在发音特性上表现欠佳。
In recent times, BERT based transformer models have become an inseparable part of the ‘tech stack’ of text processing models. Similar progress is being observed in the speech domain with a multitude of models observing state-of-the-art results by using audio transformer models to encode speech. This begs the question of what are these audio transformer models learning. Moreover, although the standard methodology is to choose the last layer embedding for any downstream task, but is it the optimal choice? We try to answer these questions for the two recent audio transformer models, Mockingjay and wave2vec2.0. We compare them on a comprehensive set of language delivery and structure features including audio, fluency and pronunciation features. Additionally, we probe the audio models’ understanding of textual surface, syntax, and semantic features and compare them to BERT. We do this over exhaustive settings for native, non-native, synthetic, read and spontaneous speech datasets
https://weibo.com/1402400261/JCtC0lV42
另外几篇值得关注的论文:
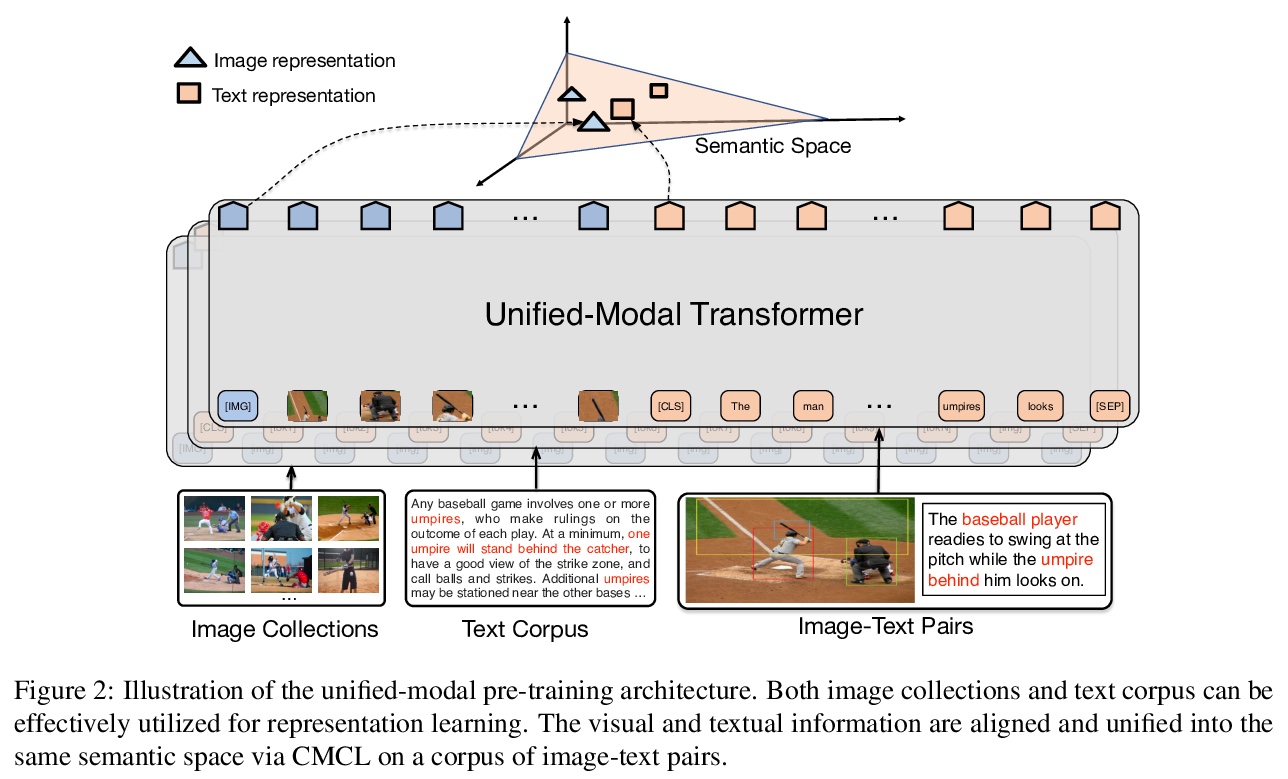
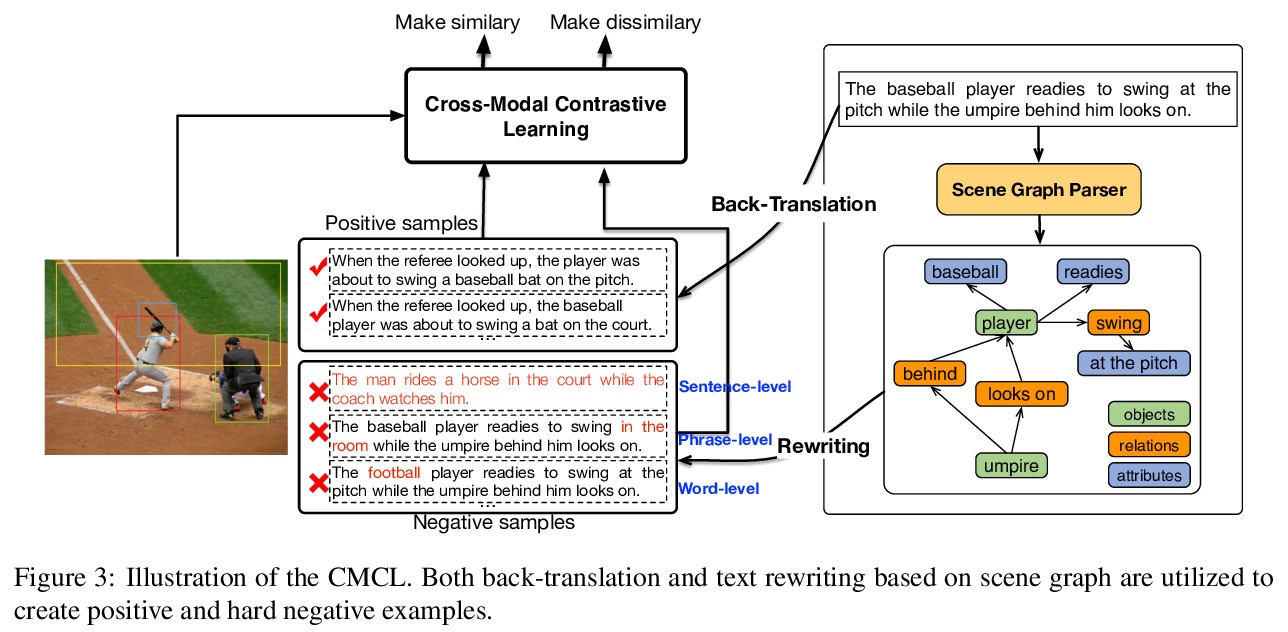
[CL] UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
UNIMO:基于跨模态对比学习的统一模态理解和生成
W Li, C Gao, G Niu, X Xiao, H Liu, J Liu, H Wu, H Wang
[Baidu Inc]
https://weibo.com/1402400261/JCtLneTzv

[CV] Self-Supervised Pretraining of 3D Features on any Point-Cloud
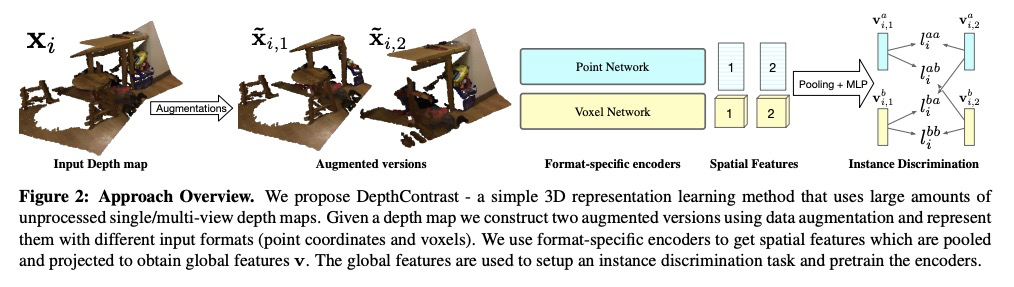
点云3D特征自监督预训练
Z Zhang, R Girdhar, A Joulin, I Misra
[Facebook AI Research]
https://weibo.com/1402400261/JCtP2xbL7
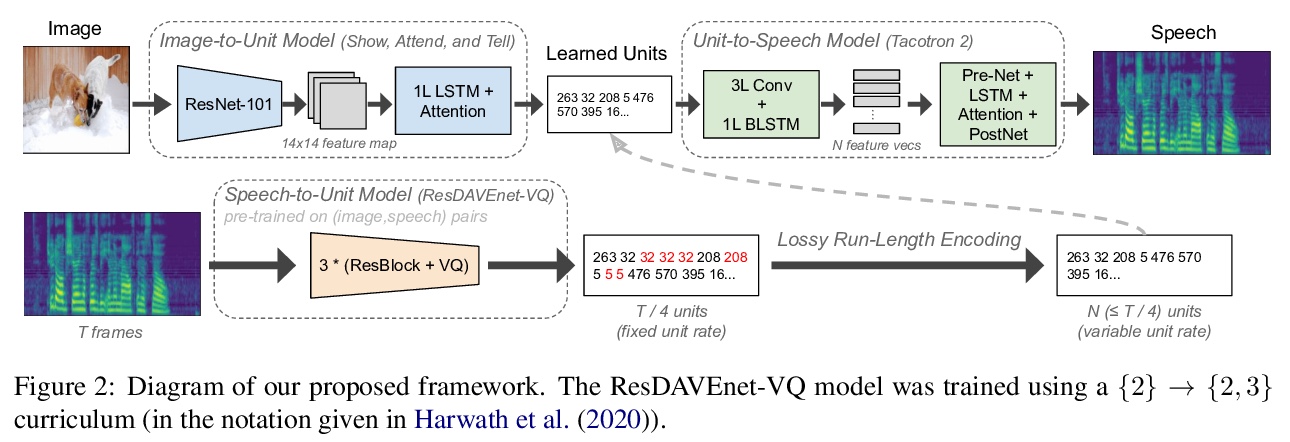
[CV] Text-Free Image-to-Speech Synthesis Using Learned Segmental Units
基于习得片段单元的免文本图像语音合成
W Hsu, D Harwath, C Song, J Glass
[MIT & University of Texas at Austin & Johns Hopkins University]
https://weibo.com/1402400261/JCtS0fxYF

[CL] UnitedQA: A Hybrid Approach for Open Domain Question Answering
UnitedQA:开放域问答的混合方法
H Cheng, Y Shen, X Liu, P He, W Chen, J Gao
[Microsoft Research]
https://weibo.com/1402400261/JCtTztySG

若有收获,就点个赞吧
0 人点赞
