- 1、[CV] EfficientNetV2: Smaller Models and Faster Training
- 2、[LG] NeRF-VAE: A Geometry Aware 3D Scene Generative Model
- 3、[CV] LoFTR: Detector-Free Local Feature Matching with Transformers
- 4、[CV] NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video
- 5、[CV] Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis
- [CV] Reconstructing 3D Human Pose by Watching Humans in the Mirror
- [CV] In&Out : Diverse Image Outpainting via GAN Inversion
- [CV] PhySG: Inverse Rendering with Spherical Gaussians for Physics-based Material Editing and Relighting
- [CV] Group-Free 3D Object Detection via Transformers
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] EfficientNetV2: Smaller Models and Faster Training
M Tan, Q V. Le
[Google Research]
EfficientNetV2:模型更小训练更快。提出EfficientNetV2,一个体积更小、速度更快的新模型族。通过采用训练-感知神经架构搜索和缩放相结合,EfficientNetV2在训练速度和参数效率上都优于之前的模型。提出了一种改进的渐进式学习方法,可随着图像大小自适应调整正则化,加快了训练速度,提高了准确度。在ImageNet、CIFAR、Cars和Flowers数据集上展示了比之前技术快11倍的训练速度和高达6.8倍的参数效率。
This paper introduces EfficientNetV2, a new family of convolutional networks that have faster training speed and better parameter efficiency than previous models. To develop this family of models, we use a combination of training-aware neural architecture search and scaling, to jointly optimize training speed and parameter efficiency. The models were searched from the search space enriched with new ops such as Fused-MBConv. Our experiments show that EfficientNetV2 models train much faster than state-of-the-art models while being up to 6.8x smaller.Our training can be further sped up by progressively increasing the image size during training, but it often causes a drop in accuracy. To compensate for this accuracy drop, we propose to adaptively adjust regularization (e.g., dropout and data augmentation) as well, such that we can achieve both fast training and good accuracy.With progressive learning, our EfficientNetV2 significantly outperforms previous models on ImageNet and CIFAR/Cars/Flowers datasets. By pretraining on the same ImageNet21k, our EfficientNetV2 achieves 87.3% top-1 accuracy on ImageNet ILSVRC2012, outperforming the recent ViT by 2.0% accuracy while training 5x-11x faster using the same computing resources. Code will be available at > this https URL.
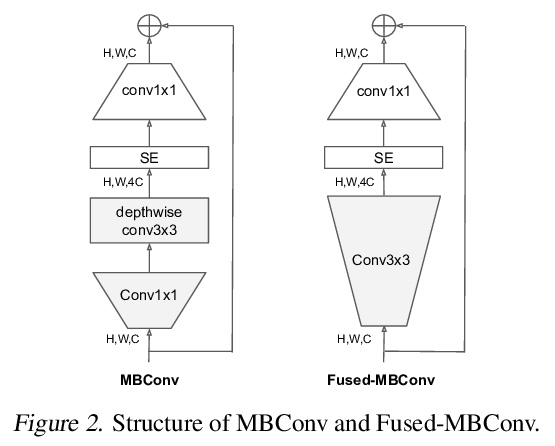
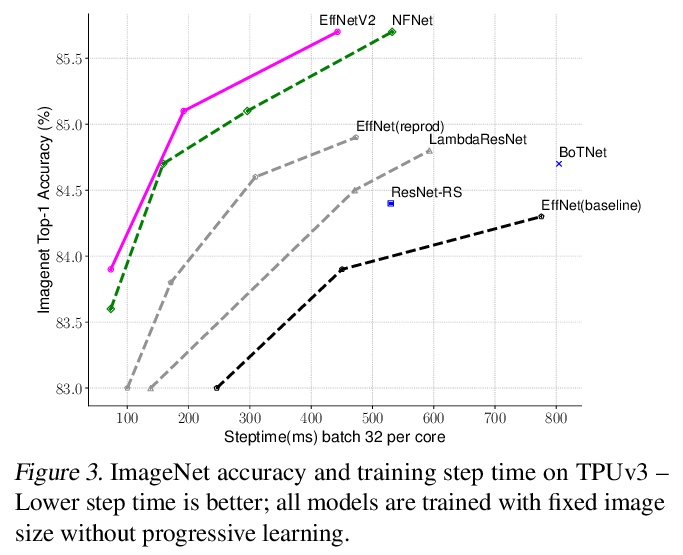
https://weibo.com/1402400261/K989693LL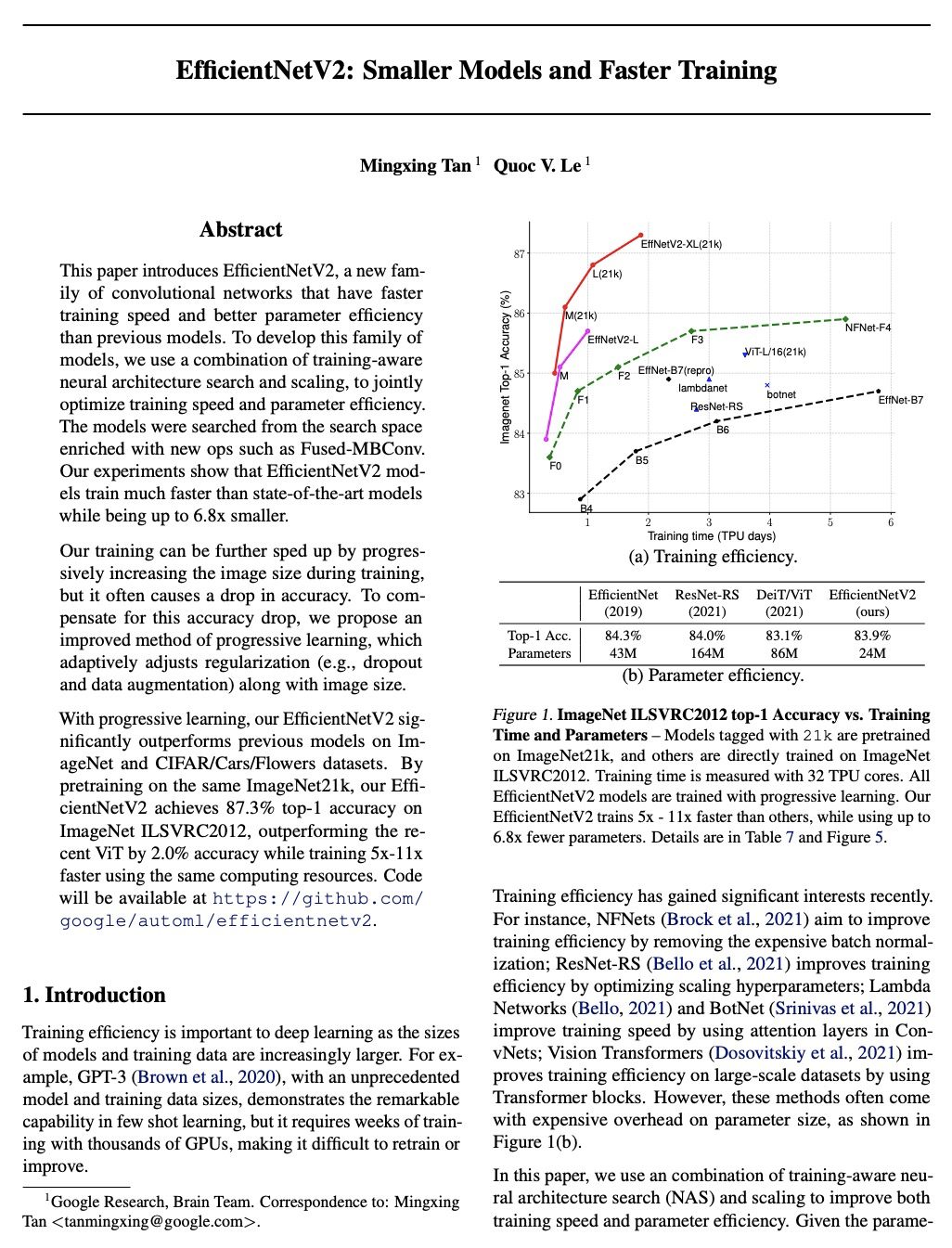

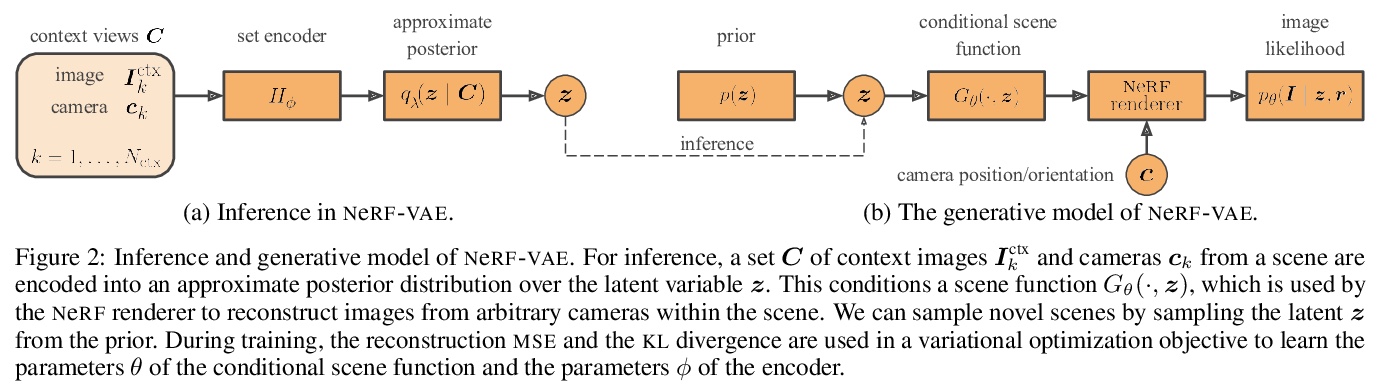
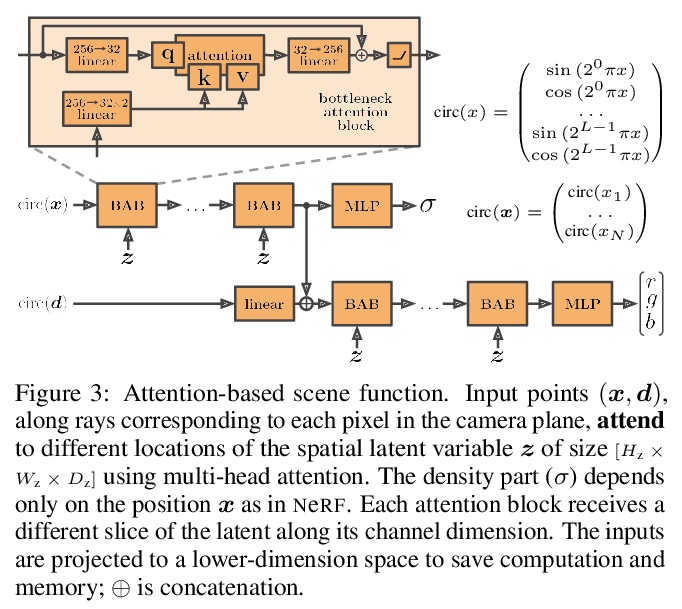
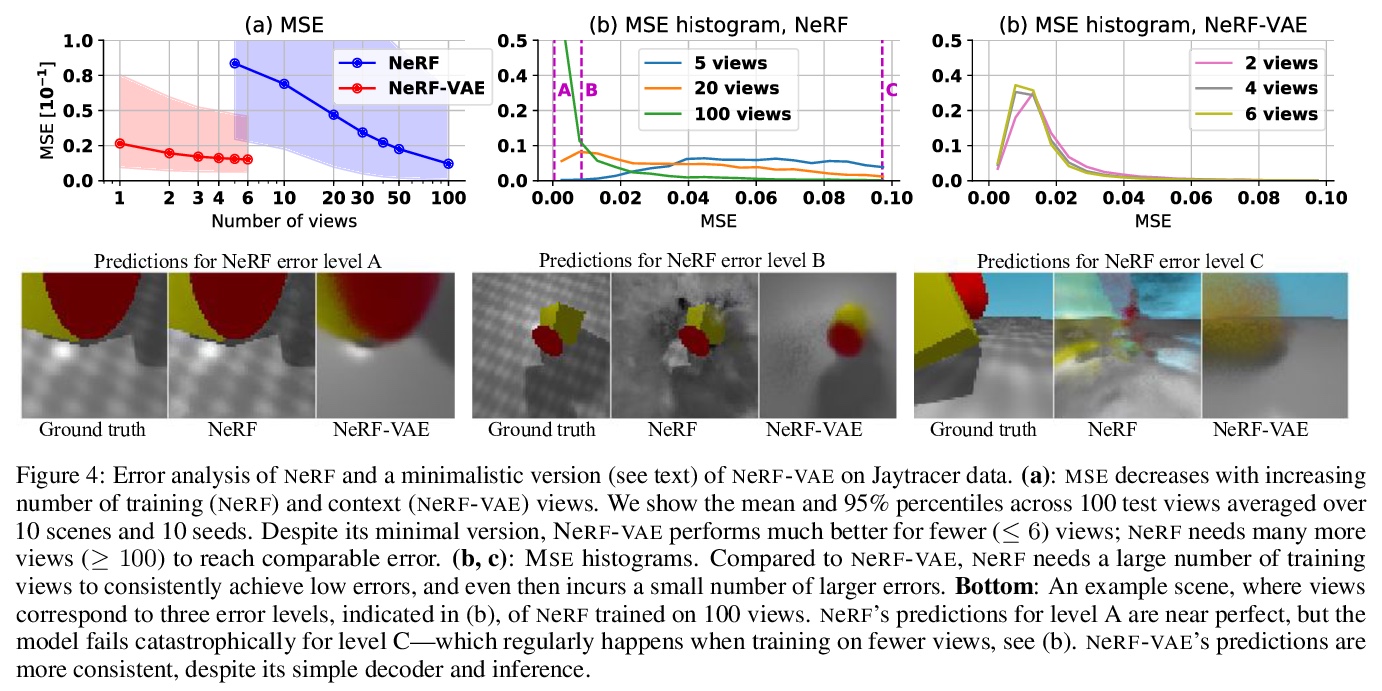
2、[LG] NeRF-VAE: A Geometry Aware 3D Scene Generative Model
A R. Kosiorek, H Strathmann, D Zoran, P Moreno, R Schneider, S Mokrá, D J. Rezende
[DeepMind]
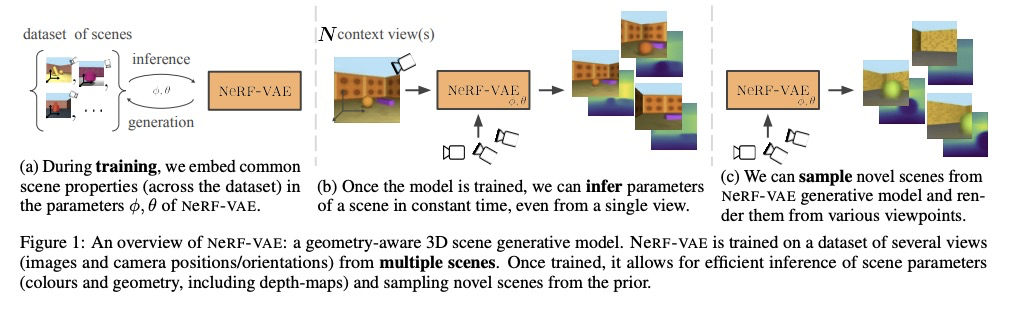
NeRF-VAE:几何感知3D场景生成模型。提出NeRF-VAE,一种通过神经辐射场(NeRF)和可微体渲染结合几何结构的3D场景生成模型。与现有模型相比,NeRF-VAE具有四个关键优势:由于采用分摊推理,不必为每个新场景从头开始进行昂贵优化;由于学习了多场景间共享信息,能从更少的输入视图重建未见场景;与现有用于视图合成的卷积生成模型(如GQN)相比,在评估分布外摄像机视图时泛化性更好;NeRF-VAE是唯一一个分摊NeRF变体,以潜变量的形式使用紧凑的场景表示,可处理输入的不确定性。
We propose NeRF-VAE, a 3D scene generative model that incorporates geometric structure via NeRF and differentiable volume rendering. In contrast to NeRF, our model takes into account shared structure across scenes, and is able to infer the structure of a novel scene — without the need to re-train — using amortized inference. NeRF-VAE’s explicit 3D rendering process further contrasts previous generative models with convolution-based rendering which lacks geometric structure. Our model is a VAE that learns a distribution over radiance fields by conditioning them on a latent scene representation. We show that, once trained, NeRF-VAE is able to infer and render geometrically-consistent scenes from previously unseen 3D environments using very few input images. We further demonstrate that NeRF-VAE generalizes well to out-of-distribution cameras, while convolutional models do not. Finally, we introduce and study an attention-based conditioning mechanism of NeRF-VAE’s decoder, which improves model performance.
https://weibo.com/1402400261/K98dI91nd
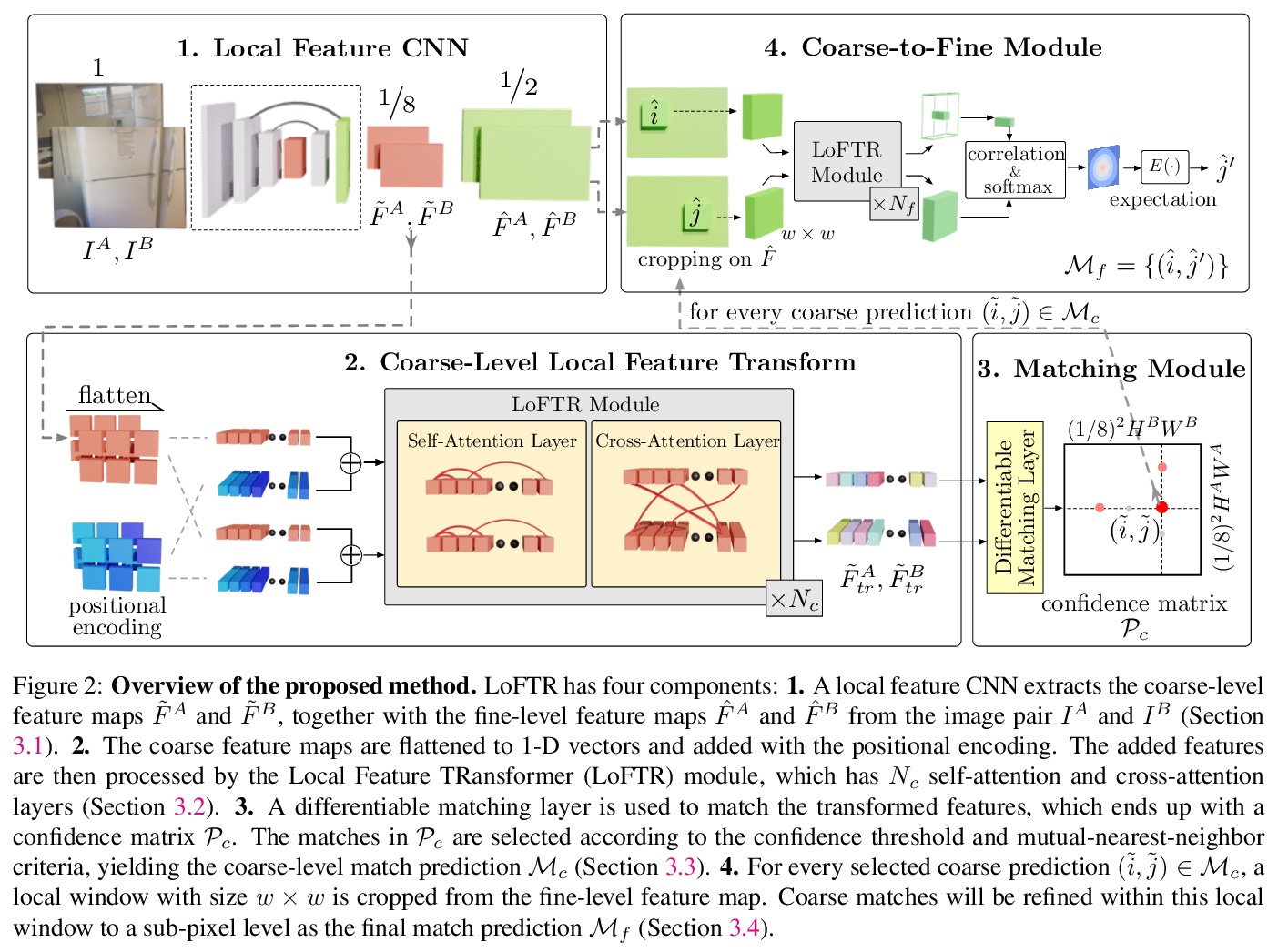
3、[CV] LoFTR: Detector-Free Local Feature Matching with Transformers
J Sun, Z Shen, Y Wang, H Bao, X Zhou
[Zhejiang University Sense & Time Research]
LoFTR:基于Transformer的免检测器局部特征匹配。提出一种新的局部图像特征匹配方法LoFTR,以从粗到细的方式通过Transformer建立精确的准密集匹配。LoFTR模块利用Transformers的自注意层和交叉注意层将局部特征转化为与上下文和位置相关的特征,可在低纹理或重复模式的不清晰区域上获得高质量匹配。实验表明,LoFTR在多个数据集上的相对姿态估计和视觉定位上达到了最先进的性能。
We present a novel method for local image feature matching. Instead of performing image feature detection, description, and matching sequentially, we propose to first establish pixel-wise dense matches at a coarse level and later refine the good matches at a fine level. In contrast to dense methods that use a cost volume to search correspondences, we use self and cross attention layers in Transformer to obtain feature descriptors that are conditioned on both images. The global receptive field provided by Transformer enables our method to produce dense matches in low-texture areas, where feature detectors usually struggle to produce repeatable interest points. The experiments on indoor and outdoor datasets show that LoFTR outperforms state-of-the-art methods by a large margin. LoFTR also ranks first on two public benchmarks of visual localization among the published methods.
https://weibo.com/1402400261/K98hu8AMD
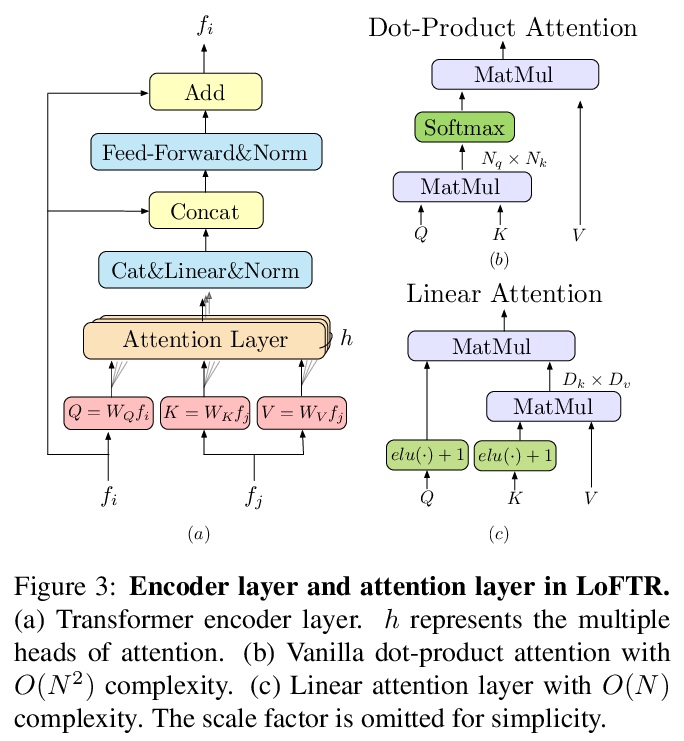
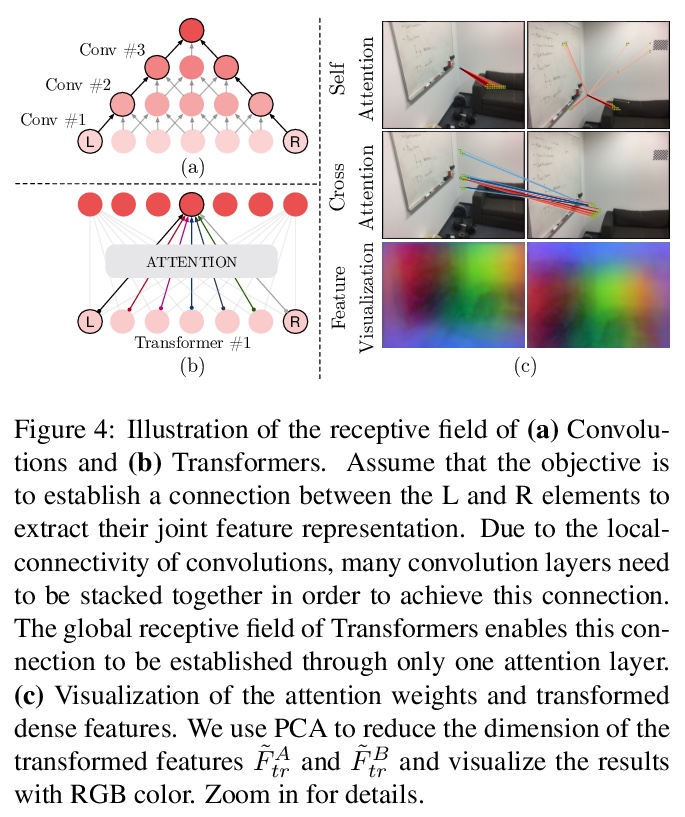
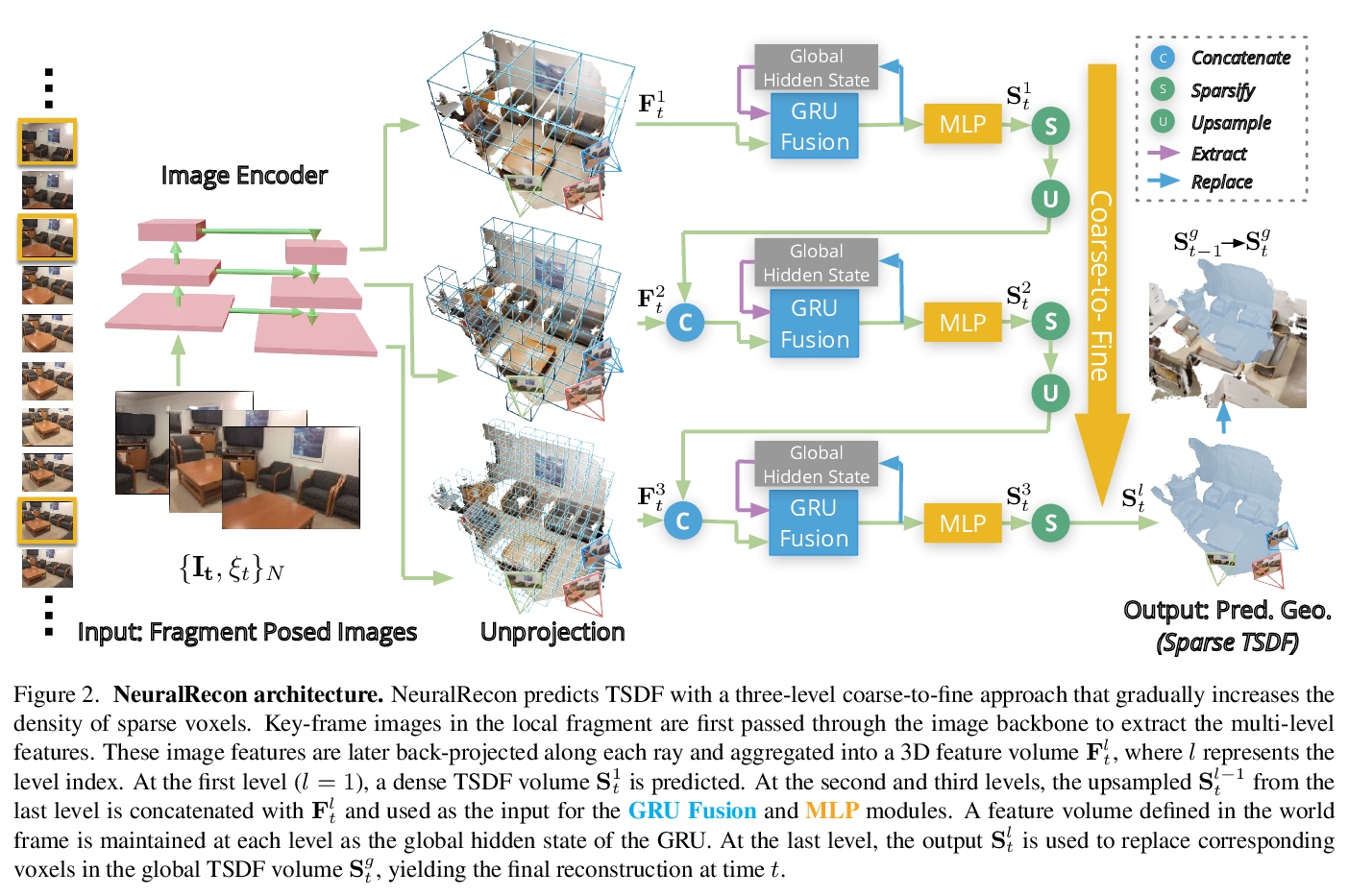
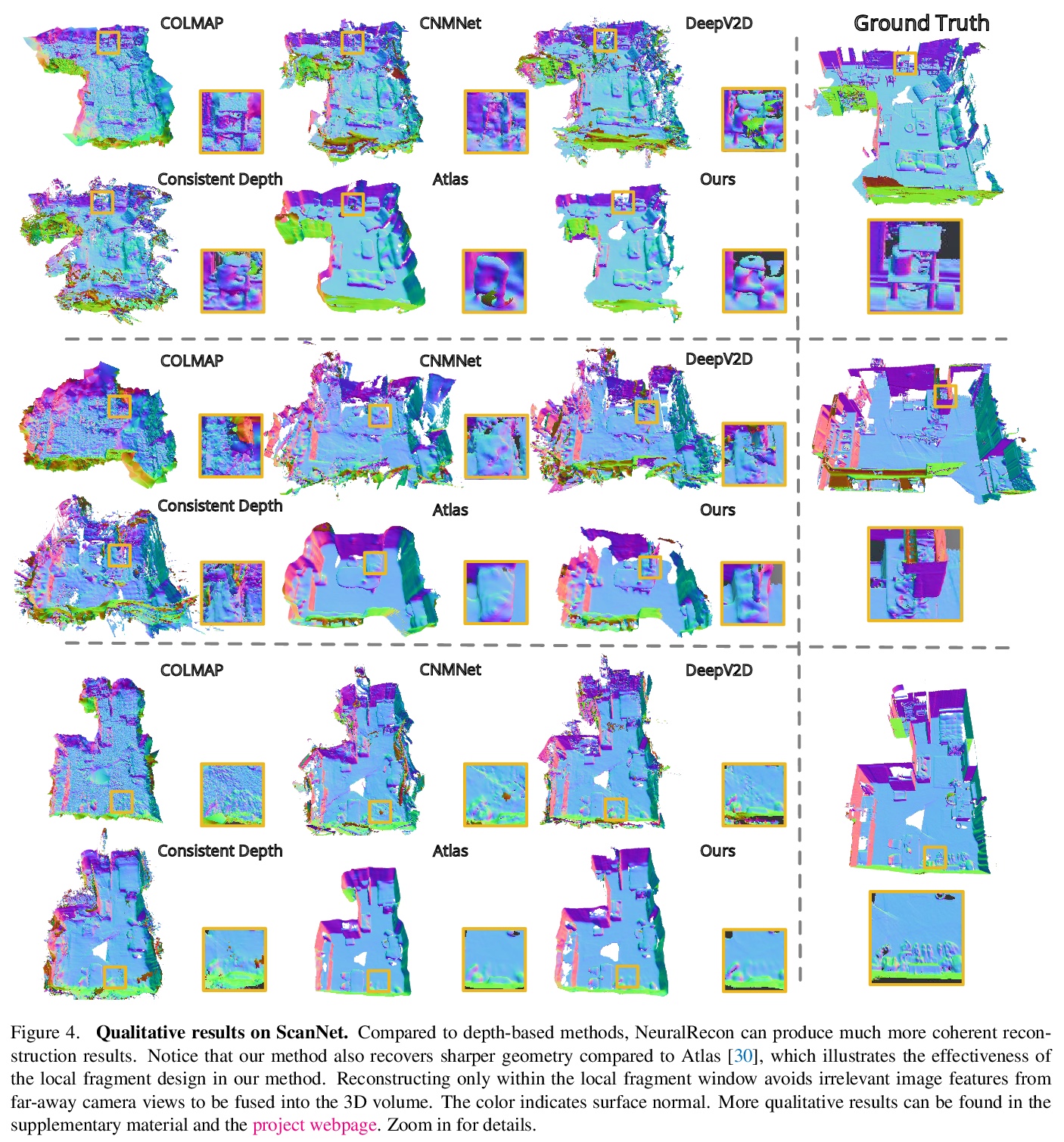
4、[CV] NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video
J Sun, Y Xie, L Chen, X Zhou, H Bao
[Zhejiang University & SenseTime Research]
NeuralRecon:单目视频实时相干3D重建。提出用于从单目视频中进行实时3D场景重建的NeuralRecon框架,通过3D稀疏卷积和GRU,对各视频片段增量式联合重建、融合稀疏TSDF体。基于门控递归单元的学习型TSDF融合模块用于引导网络融合之前片段的特征,在依次重建曲面时能够捕捉到3D曲面的局部平滑度先验和全局形状先验,实现精确、连贯、实时的曲面重建。实验表明,NeuralRecon在重建质量和运行速度上都优于目前最先进的方法。
We present a novel framework named NeuralRecon for real-time 3D scene reconstruction from a monocular video. Unlike previous methods that estimate single-view depth maps separately on each key-frame and fuse them later, we propose to directly reconstruct local surfaces represented as sparse TSDF volumes for each video fragment sequentially by a neural network. A learning-based TSDF fusion module based on gated recurrent units is used to guide the network to fuse features from previous fragments. This design allows the network to capture local smoothness prior and global shape prior of 3D surfaces when sequentially reconstructing the surfaces, resulting in accurate, coherent, and real-time surface reconstruction. The experiments on ScanNet and 7-Scenes datasets show that our system outperforms state-of-the-art methods in terms of both accuracy and speed. To the best of our knowledge, this is the first learning-based system that is able to reconstruct dense coherent 3D geometry in real-time.
https://weibo.com/1402400261/K98kJ6Txw
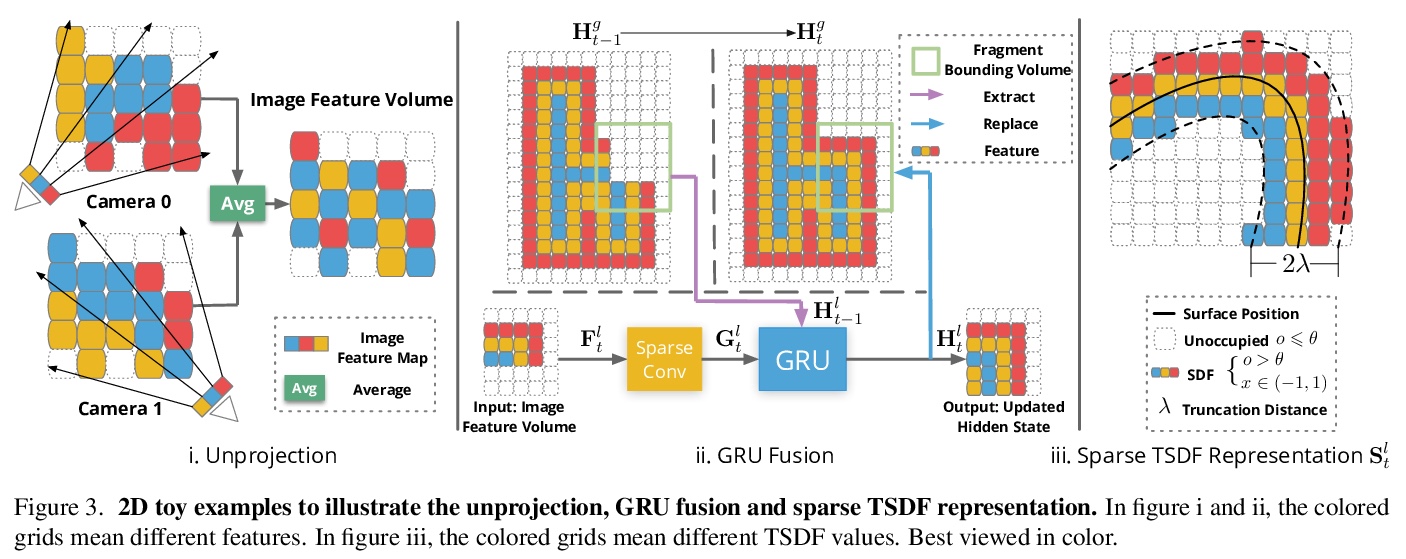
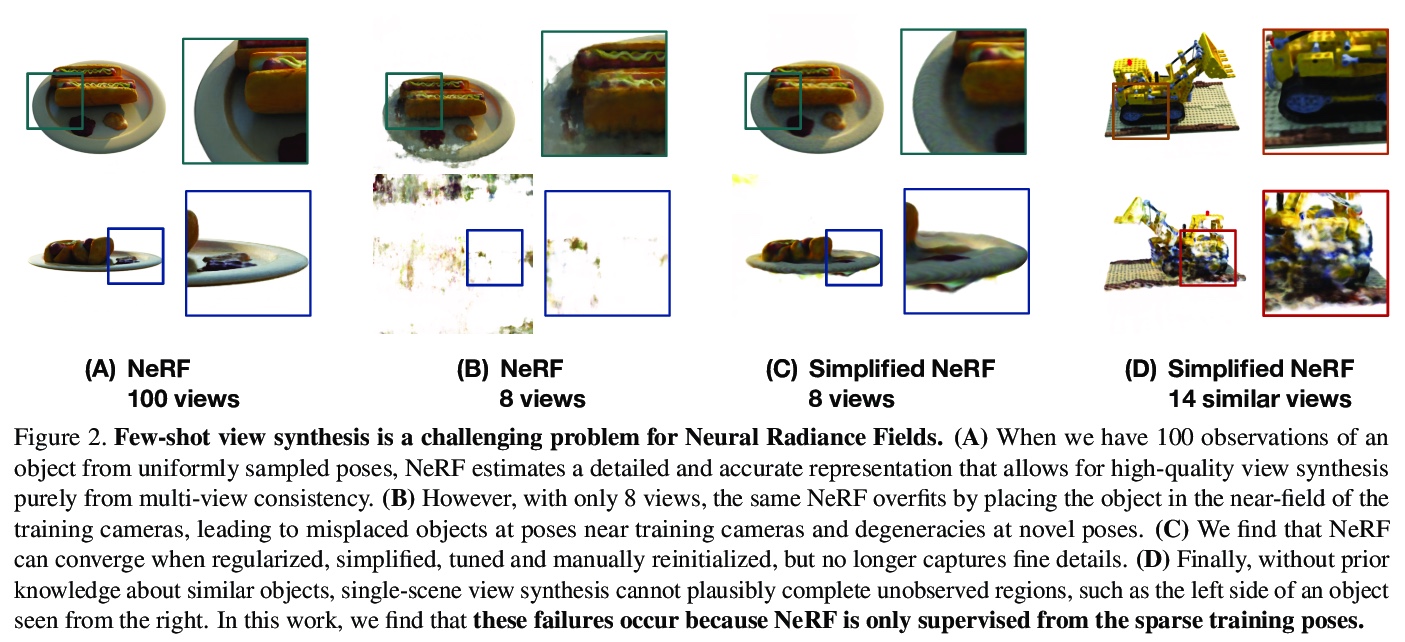
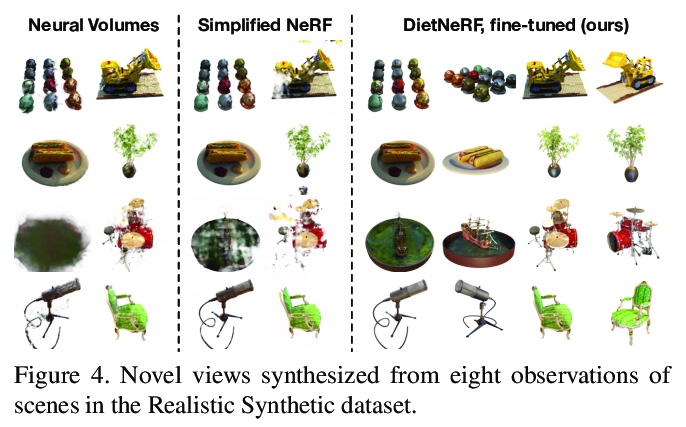
5、[CV] Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis
A Jain, M Tancik, P Abbeel
[UC Berkeley]
为NeRF瘦身:语义一致少样本视图合成。提出DietNeRF,可从少样本图像估计3D神经场景表示。引入辅助的语义一致性损失,鼓励在新姿态下进行逼真渲染。DietNeRF在单个场景上进行训练,以正确渲染同一姿态的给定输入视图,并且在不同的随机姿态上匹配高级语义属性。语义损失可以从任意姿态监督DietNeRF。用预训练好的视觉编码器(如CLIP)来提取这些语义,CLIP是一种视觉Transformer,用自然语言监督的数亿张不同的单视角、2D照片训练得到。在实验中,DietNeRF提高了从头开始学习时少样本视图合成的感知质量,在多视图数据集上预训练时,可用最少的一张观察到图像呈现新视图,对完全未观察区域产生可信的补全。
We present DietNeRF, a 3D neural scene representation estimated from a few images. Neural Radiance Fields (NeRF) learn a continuous volumetric representation of a scene through multi-view consistency, and can be rendered from novel viewpoints by ray casting. While NeRF has an impressive ability to reconstruct geometry and fine details given many images, up to 100 for challenging 360° scenes, it often finds a degenerate solution to its image reconstruction objective when only a few input views are available. To improve few-shot quality, we propose DietNeRF. We introduce an auxiliary semantic consistency loss that encourages realistic renderings at novel poses. DietNeRF is trained on individual scenes to (1) correctly render given input views from the same pose, and (2) match high-level semantic attributes across different, random poses. Our semantic loss allows us to supervise DietNeRF from arbitrary poses. We extract these semantics using a pre-trained visual encoder such as CLIP, a Vision Transformer trained on hundreds of millions of diverse single-view, 2D photographs mined from the web with natural language supervision. In experiments, DietNeRF improves the perceptual quality of few-shot view synthesis when learned from scratch, can render novel views with as few as one observed image when pre-trained on a multi-view dataset, and produces plausible completions of completely unobserved regions.
https://weibo.com/1402400261/K98q0v1ND

另外几篇值得关注的论文:
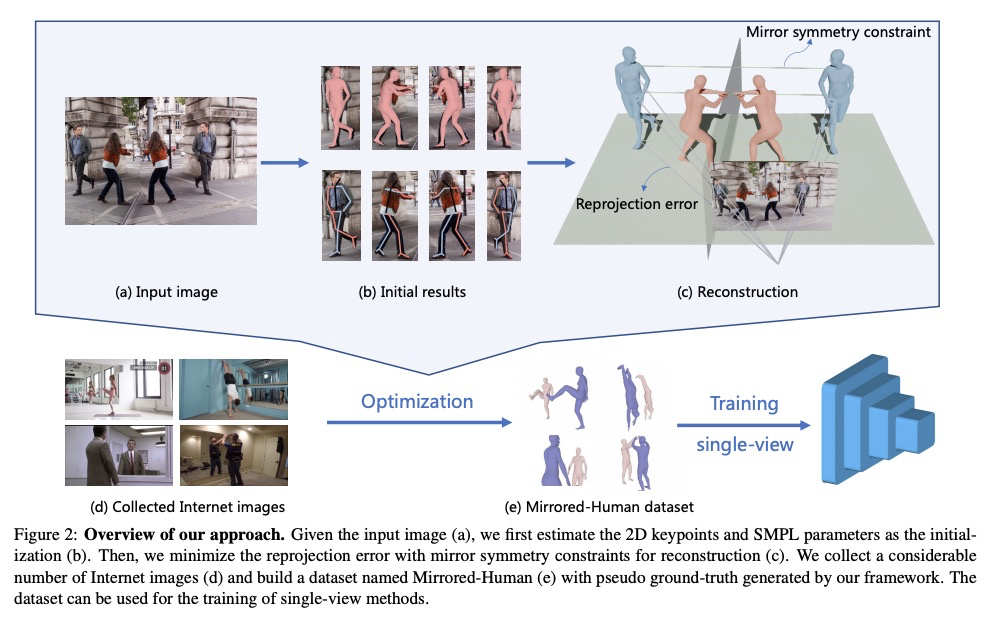
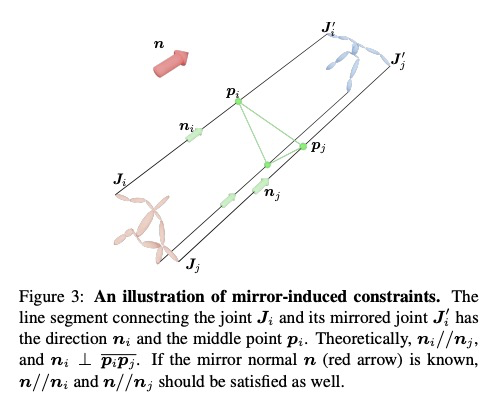
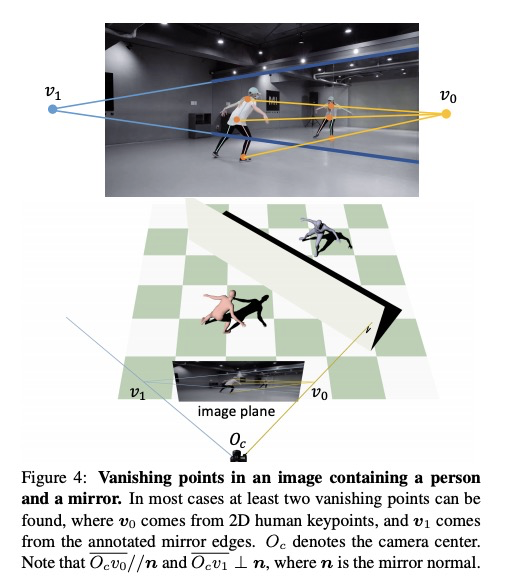
[CV] Reconstructing 3D Human Pose by Watching Humans in the Mirror
通过观察镜中人像重建3D人体姿态
Q Fang, Q Shuai, J Dong, H Bao, X Zhou
[Zhejiang University]
https://weibo.com/1402400261/K98ubl3uI
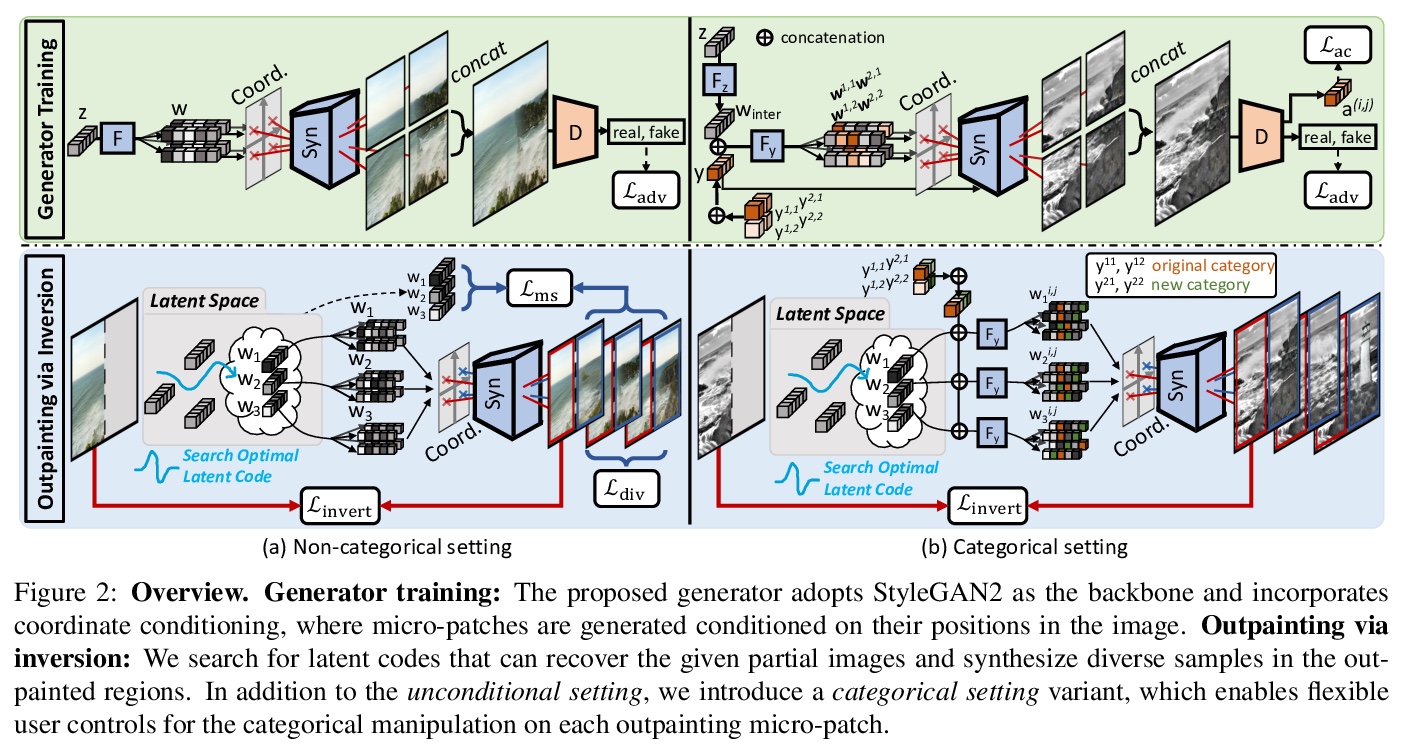
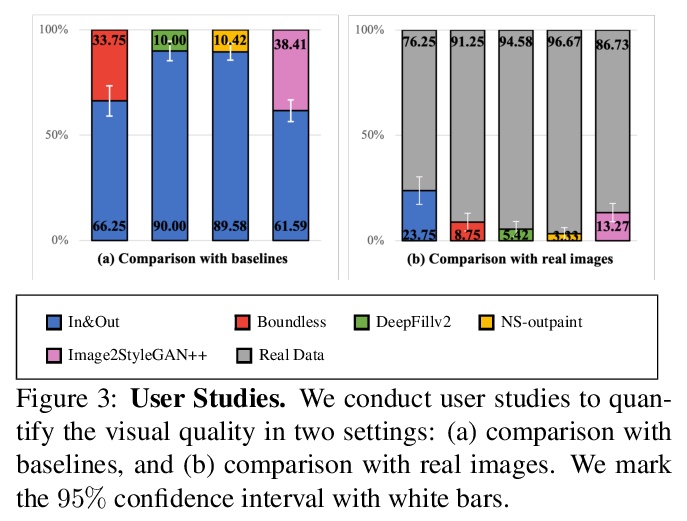
[CV] In&Out : Diverse Image Outpainting via GAN Inversion
通过GAN反转实现多样化图像输出
Y Cheng, C H Lin, H Lee, J Ren, S Tulyakov, M Yang
[CMU & University of California, Merced & Snap Inc]
https://weibo.com/1402400261/K98yJvz9r

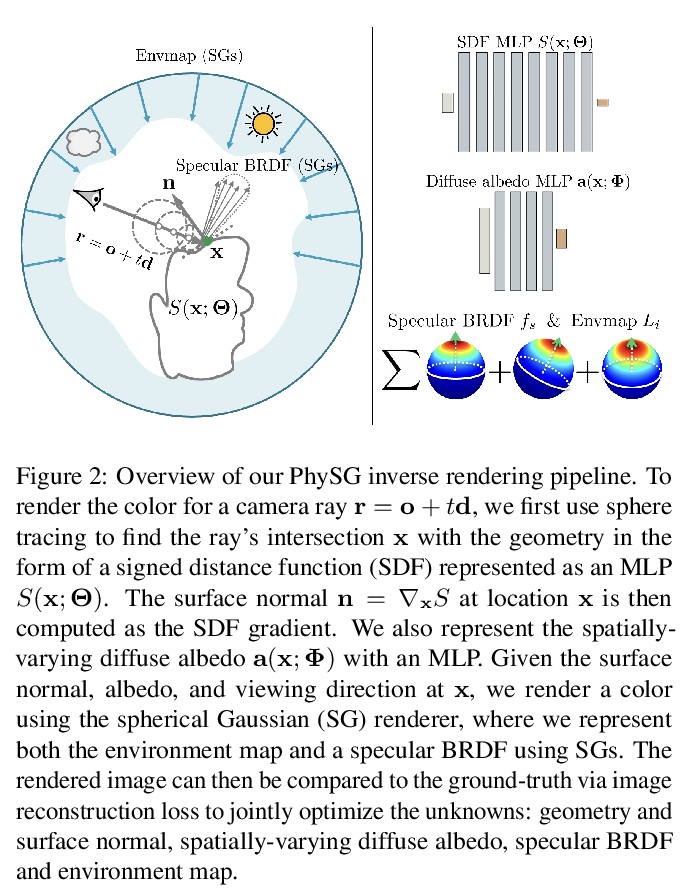
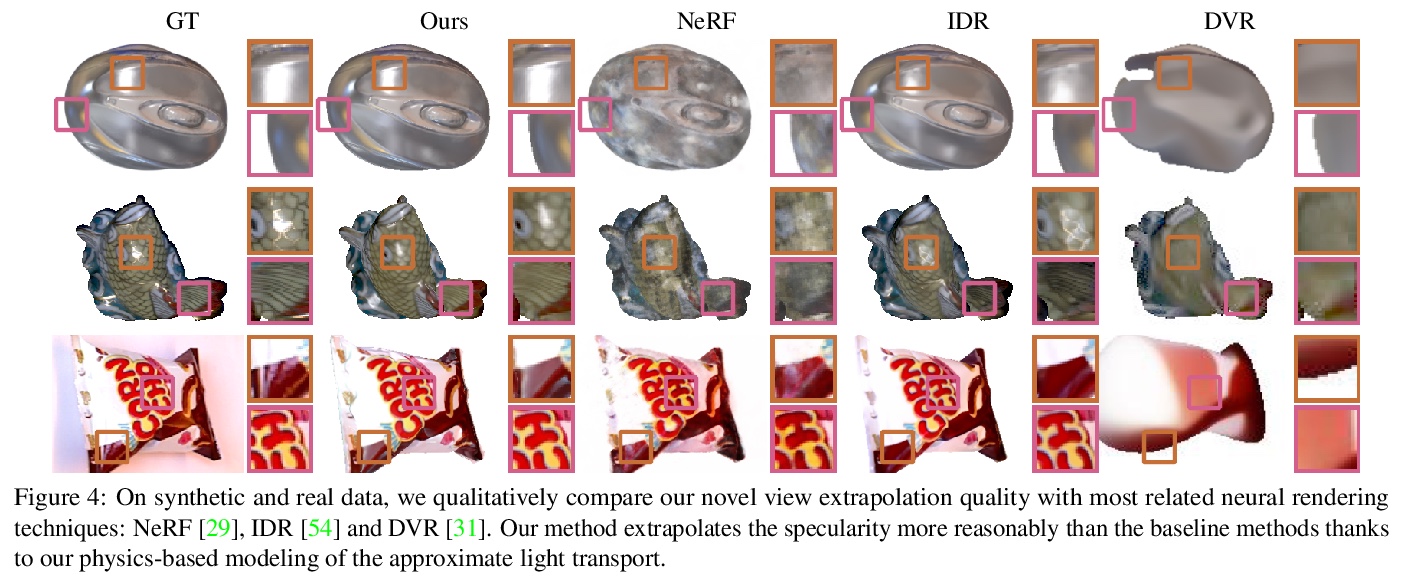
[CV] PhySG: Inverse Rendering with Spherical Gaussians for Physics-based Material Editing and Relighting
PhySG:球面高斯逆渲染的基于物理材质编辑和重打光
K Zhang, F Luan, Q Wang, K Bala, N Snavely
[Cornell University]
https://weibo.com/1402400261/K98B8e4MR

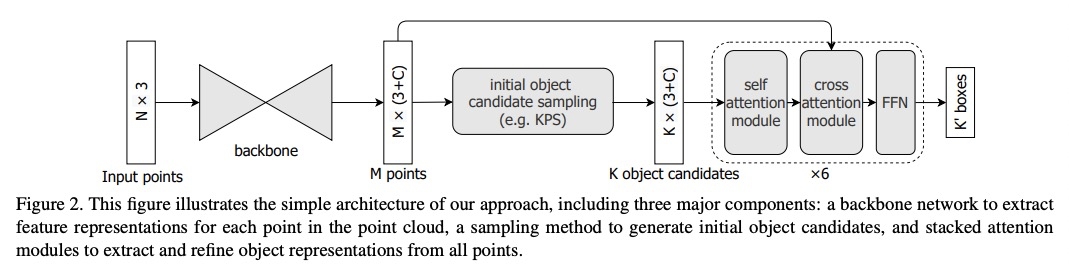
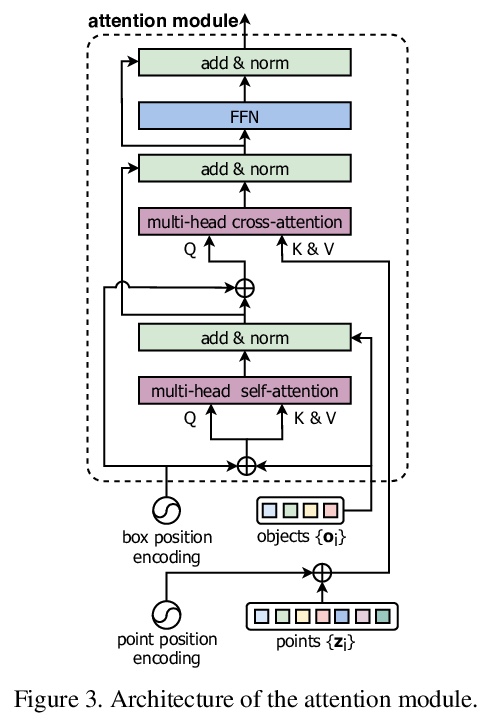
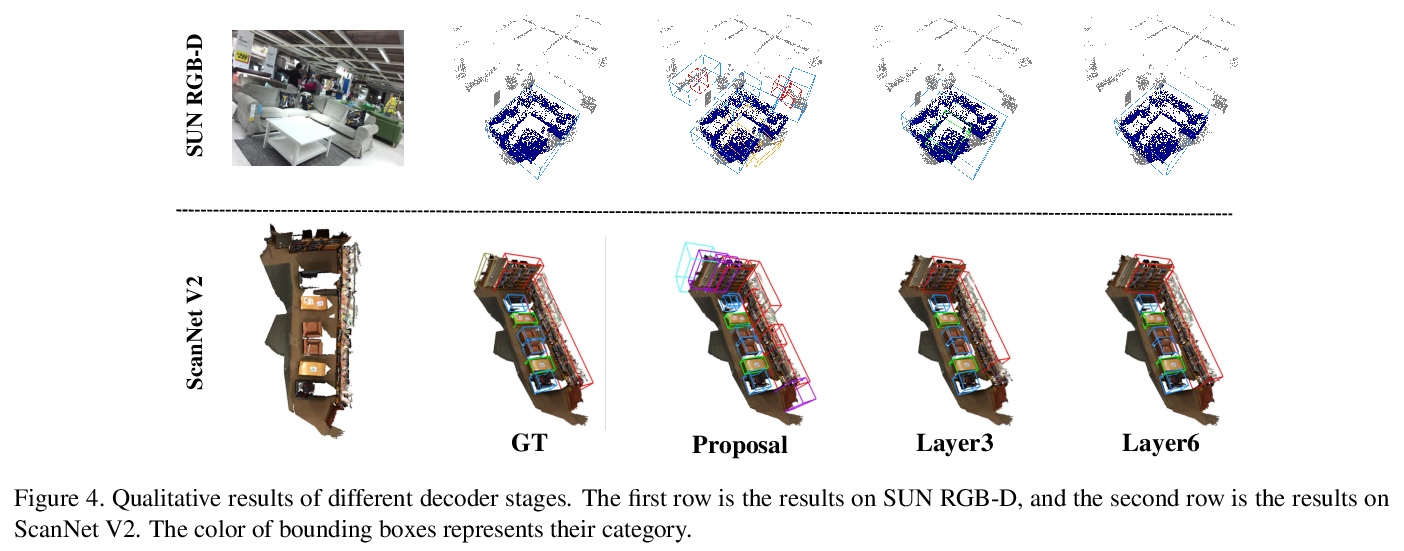
[CV] Group-Free 3D Object Detection via Transformers
基于Transformer的免分组3D物体检测
Z Liu, Z Zhang, Y Cao, H Hu, X Tong
[University of Science and Technology of China & Microsoft Research Asia]
https://weibo.com/1402400261/K98CPnvgW

若有收获,就点个赞吧
0 人点赞
