LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Continual Learning of Control Primitives: Skill Discovery via Reset-Games
K Xu, S Verma, C Finn, S Levine
[UC Berkeley & Stanford University]
控制基元持续学习:通过游戏发现技能。提出了一种方法,同时解决现实世界强化学习系统面临的两个挑战:在无需手动“重置”的情况下持续学习,以及获得解决长时间内下游任务的多项技能。学习多项技能可实现更有效的无重置学习,而以一种带任务策略的对抗方式学习技能,可使技能本身更有效,更适合解决下游的长期问题。提出了一种通用博弈公式,平衡重置和学习技能的目标,并证明这种方法提高了无重置任务的性能,获得的技能可显著加快下游的学习。**
Reinforcement learning has the potential to automate the acquisition of behavior in complex settings, but in order for it to be successfully deployed, a number of practical challenges must be addressed. First, in real world settings, when an agent attempts a task and fails, the environment must somehow “reset” so that the agent can attempt the task again. While easy in simulation, this could require considerable human effort in the real world, especially if the number of trials is very large. Second, real world learning often involves complex, temporally extended behavior that is often difficult to acquire with random exploration. While these two problems may at first appear unrelated, in this work, we show how a single method can allow an agent to acquire skills with minimal supervision while removing the need for resets. We do this by exploiting the insight that the need to “reset” an agent to a broad set of initial states for a learning task provides a natural setting to learn a diverse set of “reset-skills”. We propose a general-sum game formulation that balances the objectives of resetting and learning skills, and demonstrate that this approach improves performance on reset-free tasks, and additionally show that the skills we obtain can be used to significantly accelerate downstream learning.
https://weibo.com/1402400261/Ju6GTCE1w


2、[LG] **Towards NNGP-guided Neural Architecture Search
D S. Park, J Lee, D Peng, Y Cao, J Sohl-Dickstein
[Google Research]
神经网络高斯过程(NNGP)引导的神经结构搜索。NNGP核的解析形式在许多模型中都是已知的,但计算卷积架构的精确核代价巨大。通过在初始化时用有限网络进行蒙特卡罗估计,可得到这些核的有效逼近。在数据集较小的情况下,与梯度下降训练相比,在FLOPs方面,Monte-Carlo NNGP推理的成本要低几个数量级。NNGP推理提供了一种低成本衡量网络架构性能的方法,本文研究了它作为神经架构搜索(NAS)信号的潜力,发现了基于NNGP度量的比较优势,并讨论了其潜在应用。NNGP性能是一种不依赖于训练中获得度量的低开销信号,既可用于缩小搜索空间,也可用于改进基于训练的性能度量。**
The predictions of wide Bayesian neural networks are described by a Gaussian process, known as the Neural Network Gaussian Process (NNGP). Analytic forms for NNGP kernels are known for many models, but computing the exact kernel for convolutional architectures is prohibitively expensive. One can obtain effective approximations of these kernels through Monte-Carlo estimation using finite networks at initialization. Monte-Carlo NNGP inference is orders-of-magnitude cheaper in FLOPs compared to gradient descent training when the dataset size is small. Since NNGP inference provides a cheap measure of performance of a network architecture, we investigate its potential as a signal for neural architecture search (NAS). We compute the NNGP performance of approximately 423k networks in the NAS-bench 101 dataset on CIFAR-10 and compare its utility against conventional performance measures obtained by shortened gradient-based training. We carry out a similar analysis on 10k randomly sampled networks in the mobile neural architecture search (MNAS) space for ImageNet. We discover comparative advantages of NNGP-based metrics, and discuss potential applications. In particular, we propose that NNGP performance is an inexpensive signal independent of metrics obtained from training that can either be used for reducing big search spaces, or improving training-based performance measures.
https://weibo.com/1402400261/Ju6LAoBnw


3、[LG] **A Transfer Learning Framework for Anomaly Detection Using Model of Normality
S Aburakhia, T Tayeh, R Myers, A Shami
[Western University & National Research Council Canada]
基于正态模型的异常检测迁移学习框架。提出一种基于相似度度量的端到端迁移学习框架,利用迁移学习模型的深度特征表示和正态性模型(MoN)的相似性度量来实现异常检测,提供了一种低复杂度的解决方案,无需进行训练即可实现;采用定义良好的方法来设置异常检测决策阈值,以提高检测精度。实验表明,采用所提出的阈值设置,可显著提高性能。**
Convolutional Neural Network (CNN) techniques have proven to be very useful in image-based anomaly detection applications. CNN can be used as deep features extractor where other anomaly detection techniques are applied on these features. For this scenario, using transfer learning is common since pretrained models provide deep feature representations that are useful for anomaly detection tasks. Consequentially, anomaly can be detected by applying similarly measure between extracted features and a defined model of normality. A key factor in such approaches is the decision threshold used for detecting anomaly. While most of the proposed methods focus on the approach itself, slight attention has been paid to address decision threshold settings. In this paper, we tackle this problem and propose a welldefined method to set the working-point decision threshold that improves detection accuracy. We introduce a transfer learning framework for anomaly detection based on similarity measure with a Model of Normality (MoN) and show that with the proposed threshold settings, a significant performance improvement can be achieved. Moreover, the framework has low complexity with relaxed computational requirements.
https://weibo.com/1402400261/Ju6PGhDru


4、[CL] **Biomedical Named Entity Recognition at Scale
V Kocaman, D Talby
[John Snow Labs Inc.]
大规模生物医学命名实体识别。基于Apache Spark复现了BiLSTM-CNN-Char深度学习架构,提出一种单一的可训练的命名实体识别模型,该模型在7个公共生物医学基准上获得了新的最先进结果,无需使用像BERT这样的重量级上下文嵌入。**
Named entity recognition (NER) is a widely applicable natural language processing task and building block of question answering, topic modeling, information retrieval, etc. In the medical domain, NER plays a crucial role by extracting meaningful chunks from clinical notes and reports, which are then fed to downstream tasks like assertion status detection, entity resolution, relation extraction, and de-identification. Reimplementing a Bi-LSTM-CNN-Char deep learning architecture on top of Apache Spark, we present a single trainable NER model that obtains new state-of-the-art results on seven public biomedical benchmarks without using heavy contextual embeddings like BERT. This includes improving BC4CHEMD to 93.72% (4.1% gain), Species800 to 80.91% (4.6% gain), and JNLPBA to 81.29% (5.2% gain). In addition, this model is freely available within a production-grade code base as part of the open-source Spark NLP library; can scale up for training and inference in any Spark cluster; has GPU support and libraries for popular programming languages such as Python, R, Scala and Java; and can be extended to support other human languages with no code changes.
https://weibo.com/1402400261/Ju6UHpEUd
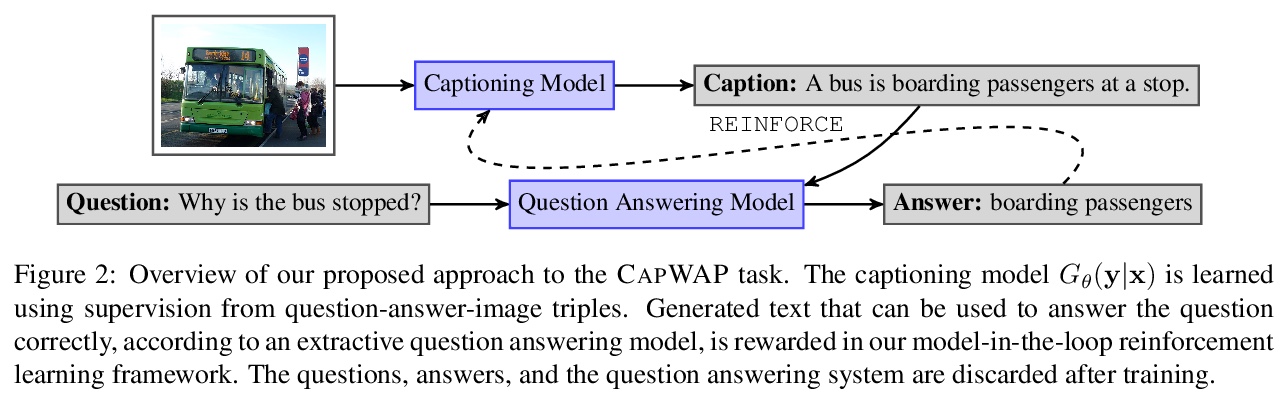
5、[CV] **CapWAP: Captioning with a Purpose
A Fisch, K Lee, M Chang, J H. Clark, R Barzilay
[MIT & Google Research]
CapWAP:带有目的性的描述生成。提出了一个新的任务CapWAP,在这项任务中,用户提供的问题-答案对被用作一种监督源,来学习他们的视觉信息需求。展示了用强化学习直接优化预期的信息需求是可能的,通过对输出的奖励,问答模型可针对采样用户问题提供正确答案。**
The traditional image captioning task uses generic reference captions to provide textual information about images. Different user populations, however, will care about different visual aspects of images. In this paper, we propose a new task, Captioning with a Purpose (CapWAP). Our goal is to develop systems that can be tailored to be useful for the information needs of an intended population, rather than merely provide generic information about an image. In this task, we use question-answer (QA) pairs—-a natural expression of information need—-from users, instead of reference captions, for both training and post-inference evaluation. We show that it is possible to use reinforcement learning to directly optimize for the intended information need, by rewarding outputs that allow a question answering model to provide correct answers to sampled user questions. We convert several visual question answering datasets into CapWAP datasets, and demonstrate that under a variety of scenarios our purposeful captioning system learns to anticipate and fulfill specific information needs better than its generic counterparts, as measured by QA performance on user questions from unseen images, when using the caption alone as context.
https://weibo.com/1402400261/Ju6YJ7f4k


另外几篇值得关注的额论文:
[LG] On Size Generalization in Graph Neural Networks
图神经网络的跨规模泛化
G Yehudai, E Fetaya, E Meirom, G Chechik, H Maron
[NVIDIA & Bar-Ilan University]
https://weibo.com/1402400261/Ju72IrOg8

[LG] Optimal Off-Policy Evaluation from Multiple Logging Policies
多记录策略最佳Off-Policy策略评估
N Kallus, Y Saito, M Uehara
[Cornell University & Tokyo Institute of Technology]
https://weibo.com/1402400261/Ju7551Qy3
[LG] Sampling and Recovery of Graph Signals based on Graph Neural Networks
基于图神经网络的图信号采样与恢复
S Chen, M Li, Y Zhang
[Mitsubishi Electric Research Laboratories (MERL) & Shanghai Jiao Tong University]
https://weibo.com/1402400261/Ju77VEuoo


[CL] Learning from Human Feedback: Challenges for Real-World Reinforcement Learning in NLP
从人类反馈中学习:现实世界自然语言处理强化学习的挑战
J Kreutzer, S Riezler, C Lawrence
[Google Research & Heidelberg University & NEC Laboratories Europe]
https://weibo.com/1402400261/Ju78TEGTf
[LG] Learning and Evaluating Representations for Deep One-class Classification
深度单类分类的学习和表示评价
K Sohn, C Li, J Yoon, M Jin, T Pfister
[Google Cloud AI]
https://weibo.com/1402400261/Ju7aBam9O



若有收获,就点个赞吧
0 人点赞
