- 1、[CV] When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations
- 2、[LG] Decision Transformer: Reinforcement Learning via Sequence Modeling
- 3、[CL] PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World
- 4、[CV] Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control
- 5、[CV] Barbershop: GAN-based Image Compositing using Segmentation Masks
- [RO] Towards Learning to Play Piano with Dexterous Hands and Touch
- [CV] Container: Context Aggregation Network
- [CV] NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination
- [CV] Robust Reference-based Super-Resolution via C2-Matching
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations
X Chen, C Hsieh, B Gong
[Google Research & UCLA]
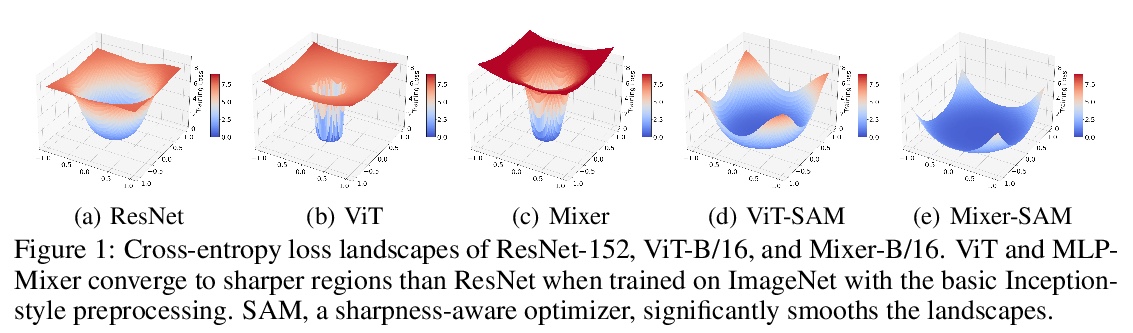
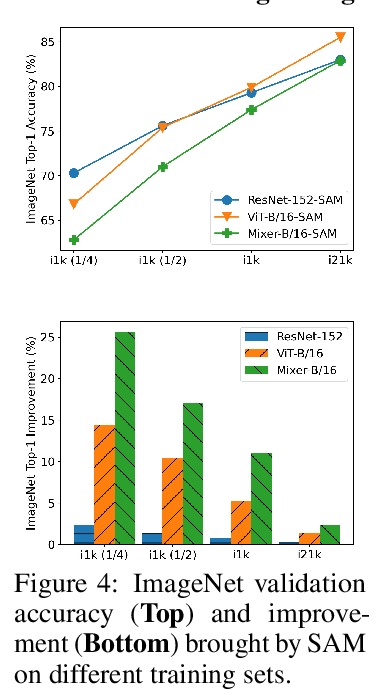
没有预训练或强数据增强的视觉Transformer表现能否超过ResNets。视觉Transformer(ViT)和MLP标志着在用通用神经网络架构取代手工特征或归纳偏见方面的进一步努力。现有的工作通过大规模预训练和/或重复的强数据增强来增强模型能力,仍存在与优化相关的问题(例如,对初始化和学习率的敏感性)。本文从损失几何和损失景观的角度,研究ViT和MLP-Mixer,旨在提高模型在训练时的数据效率和推理时的泛化能力,减少模型对大规模预训练和/或强数据增强的依赖性。可视化和Hessian揭示了已收敛模型的极其尖锐的局部最小值。用最近提出的锐度感知优化器(SAM)来提高平滑度,大幅提高了ViT和MLP-Mixer在各种任务中的准确性和鲁棒性,包括监督学习、对抗学习、对比学习和迁移学习。通过SAM对损失几何进行显式正则化处理,使模型拥有更平坦的损失景观,在准确性和鲁棒性方面有更好的通用性。平滑度的提高归因于前几层激活神经元的稀疏。由此产生的ViT在ImageNet上从头开始训练时,在没有大规模预训练或强大数据增强的情况下,其表现优于类似规模和吞吐量的ResNets。还拥有更敏锐的注意力图。
Vision Transformers (ViTs) and MLPs signal further efforts on replacing handwired features or inductive biases with general-purpose neural architectures. Existing works empower the models by massive data, such as large-scale pretraining and/or repeated strong data augmentations, and still report optimization-related problems (e.g., sensitivity to initialization and learning rate). Hence, this paper investigates ViTs and MLP-Mixers from the lens of loss geometry, intending to improve the models’ data efficiency at training and generalization at inference. Visualization and Hessian reveal extremely sharp local minima of converged models. By promoting smoothness with a recently proposed sharpness-aware optimizer, we substantially improve the accuracy and robustness of ViTs and MLP-Mixers on various tasks spanning supervised, adversarial, contrastive, and transfer learning (e.g., +5.3% and +11.0% top-1 accuracy on ImageNet for ViT-B/16 and MixerB/16, respectively, with the simple Inception-style preprocessing). We show that the improved smoothness attributes to sparser active neurons in the first few layers. The resultant ViTs outperform ResNets of similar size and throughput when trained from scratch on ImageNet without large-scale pretraining or strong data augmentations. They also possess more perceptive attention maps.
https://weibo.com/1402400261/KiIcNFnIy


2、[LG] Decision Transformer: Reinforcement Learning via Sequence Modeling
L Chen, K Lu, A Rajeswaran, K Lee, A Grover, M Laskin, P Abbeel, A Srinivas, I Mordatch
[UC Berkeley & Facebook AI Research & Google Brain]
决策Transformer:序列建模强化学习。提出一种将强化学习(RL)抽象为序列建模问题的框架,可利用Transformer架构的简单性和可扩展性,以及语言建模的相关进展,如GPT-x和BERT。提出决策Transformer,一种将强化学习问题作为条件序列建模的体系结构。不同于之前拟合价值函数或计算策略梯度的强化学习方法,决策Transformer利用因果掩蔽Transformer简单输出最佳行动。通过对期望回报(奖励) 、过去状态和行动的自回归模型进行调节,决策Transformer模型能生成实现期望回报的未来行动。尽管简单,但决策Transformer符合或超过了Atari、OpenAI Gym和Key-to-Door任务上最先进的无模型离线强化学习基线的性能。
We introduce a framework that abstracts Reinforcement Learning (RL) as a sequence modeling problem. This allows us to draw upon the simplicity and scalability of the Transformer architecture, and associated advances in language modeling such as GPT-x and BERT. In particular, we present Decision Transformer, an architecture that casts the problem of RL as conditional sequence modeling. Unlike prior approaches to RL that fit value functions or compute policy gradients, Decision Transformer simply outputs the optimal actions by leveraging a causally masked Transformer. By conditioning an autoregressive model on the desired return (reward), past states, and actions, our Decision Transformer model can generate future actions that achieve the desired return. Despite the simplicity, Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on Atari, OpenAI Gym, and Key-to-Door tasks.
https://weibo.com/1402400261/KiIi5E3ts




3、[CL] PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World
R Zellers, A Holtzman, M Peters, R Mottaghi, A Kembhavi, A Farhadi, Y Choi
[University of Washington & Allen Institute for Artificial Intelligence]
PIGLeT:3D世界神经-符号交互语言建模。提出PIGLeT,一种通过互动学习物理常识知识,然后将这些知识用于基础语言的模型。将PIGLeT分解为物理动力学模型和单独的语言模型。动力学模型不仅学习了什么是物体,还学习了它们的作用: 玻璃杯扔出去会破裂、塑料杯子不会。用动力学模型作为语言模型的接口,形成语言形式和基本意义的统一模型。PIGLeT可以阅读一个句子,用神经网络模拟接下来可能发生的事情,通过文字符号表示或自然语言传达结果。实验结果表明,模型有效学习了世界动力学以及如何与其交流。在超过80%的时间里,能正确预测并给出英语表达的“接下来会怎样”,比100倍大的文本到文本方法超出10%。
We propose PIGLeT: a model that learns physical commonsense knowledge through interaction, and then uses this knowledge to ground language. We factorize PIGLeT into a physical dynamics model, and a separate language model. Our dynamics model learns not just what objects are but also what they do: glass cups break when thrown, plastic ones don’t. We then use it as the interface to our language model, giving us a unified model of linguistic form and grounded meaning. PIGLeT can read a sentence, simulate neurally what might happen next, and then communicate that result through a literal symbolic representation, or natural language. Experimental results show that our model effectively learns world dynamics, along with how to communicate them. It is able to correctly forecast “what happens next” given an English sentence over 80% of the time, outperforming a 100x larger, text-to-text approach by over 10%. Likewise, its natural language summaries of physical interactions are also judged by humans as more accurate than LM alternatives. We present comprehensive analysis showing room for future work.
https://weibo.com/1402400261/KiIlVdGga




4、[CV] Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control
L Liu, M Habermann, V Rudnev, K Sarkar, J Gu, C Theobalt
[Max Planck Institute for Informatics & Facebook AI Research]
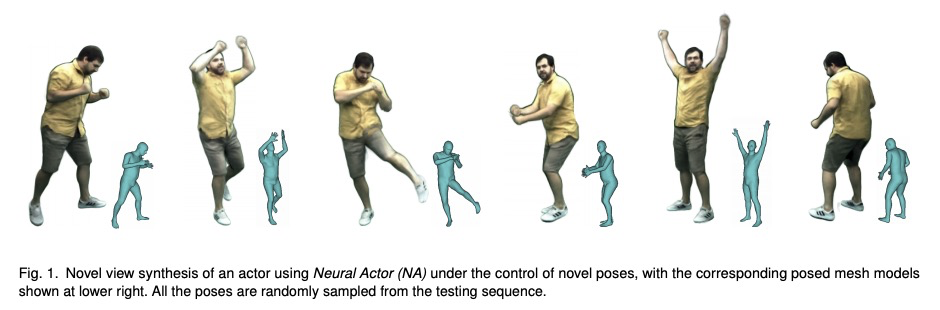
带姿态控制的演员神经网络自由视角合成。提出了”神经演员”(NA),从任意视角和任意可控姿态进行高质量人体图像合成的新方法。该方法建立在最近的神经场景表示和渲染工作之上,这些工作仅从2D图像中学习几何和外观表示。虽然现有工作展示了引人注目的静态场景的渲染和动态场景的回放,但用神经隐方法对人体进行照片级真实重建和渲染,特别是由用户控制的新姿态下,仍然很困难。为解决该问题,本文用粗略身体模型作为代理,将周围3D空间展开成标准姿态。用神经辐射场从多视角视频输入中,学习姿态依赖的几何变形,以及姿态和视角依赖的外观效果。为合成高保真动态几何和外观的新视图,利用定义在身体模型上的2D纹理图作为潜变量预测残余变形和动态外观。实验表明,该方法在回放和新姿态合成方面,取得了比先进技术更好的质量,可以很好地推广到与训练姿态截然不同的新姿势,还支持对合成结果的体形控制。
We propose Neural Actor (NA), a new method for high-quality synthesis of humans from arbitrary viewpoints and under arbitrary controllable poses. Our method is built upon recent neural scene representation and rendering works which learn representations of geometry and appearance from only 2D images. While existing works demonstrated compelling rendering of static scenes and playback of dynamic scenes, photo-realistic reconstruction and rendering of humans with neural implicit methods, in particular under user-controlled novel poses, is still difficult. To address this problem, we utilize a coarse body model as the proxy to unwarp the surrounding 3D space into a canonical pose. A neural radiance field learns pose-dependent geometric deformations and poseand view-dependent appearance effects in the canonical space from multi-view video input. To synthesize novel views of high-fidelity dynamic geometry and appearance, we leverage 2D texture maps defined on the body model as latent variables for predicting residual deformations and the dynamic appearance. Experiments demonstrate that our method achieves better quality than the state-of-the-arts on playback as well as novel pose synthesis, and can even generalize well to new poses that starkly differ from the training poses. Furthermore, our method also supports body shape control of the synthesized results.
https://weibo.com/1402400261/KiIta4Tfp



5、[CV] Barbershop: GAN-based Image Compositing using Segmentation Masks
P Zhu, R Abdal, J Femiani, P Wonka
[KAUST & Miami University]
Barbershop:基于GAN分割蒙版的图像合成。由于光照、几何和部分遮挡的复杂关系,导致了图像不同部分之间的耦合,因此无缝融合来自多个图像的特征是极具挑战性的。即使最近的GAN工作能够合成逼真的头发或面孔,但要把它们组合成一个单一的、一致的、可信的图像,而不是一组不相干的图块,仍然很困难。本文提出一种新的图像融合解决方案,特别针对发型迁移问题,基于GAN逆映射。提出一种用于图像融合的潜空间,能更好地保留细节和编码空间信息,提出一种新的GAN嵌入算法,能稍微修改图像以符合共同的分割蒙版。该新型表征能从多个参考图像中迁移视觉属性,包括痣和皱纹等具体细节,由于是在潜空间进行图像融合,可以合成一致的图像。该方法避免了其他方法中存在的融合假象,并找到一个全局一致的图像。
Seamlessly blending features from multiple images is extremely challenging because of complex relationships in lighting, geometry, and partial occlusion which cause coupling between different parts of the image. Even though recent work on GANs enables synthesis of realistic hair or faces, it remains difficult to combine them into a single, coherent, and plausible image rather than a disjointed set of image patches. We present a novel solution to image blending, particularly for the problem of hairstyle transfer, based on GAN-inversion. We propose a novel latent space for image blending which is better at preserving detail and encoding spatial information, and propose a new GAN-embedding algorithm which is able to slightly modify images to conform to a common segmentation mask. Our novel representation enables the transfer of the visual properties from multiple reference images including specific details such as moles and wrinkles, and because we do image blending in a latent-space we are able to synthesize images that are coherent. Our approach avoids blending artifacts present in other approaches and finds a globally consistent image. Our results demonstrate a significant improvement over the current state of the art in a user study, with users preferring our blending solution over 95 percent of the time.
https://weibo.com/1402400261/KiIyk4R4m




另外几篇值得关注的论文:
[RO] Towards Learning to Play Piano with Dexterous Hands and Touch
用灵巧的手和触觉学习弹钢琴
H Xu, Y Luo, S Wang, T Darrell, R Calandra
[UC Berkeley & Facebook AI Research & Princeton University & MIT]
https://weibo.com/1402400261/KiICh5WSs




[CV] Container: Context Aggregation Network
Container:上下文聚合网络
P Gao, J Lu, H Li, R Mottaghi, A Kembhavi
[The Chinese University of Hong Kong & University of Washington]
https://weibo.com/1402400261/KiIDIwfZ4

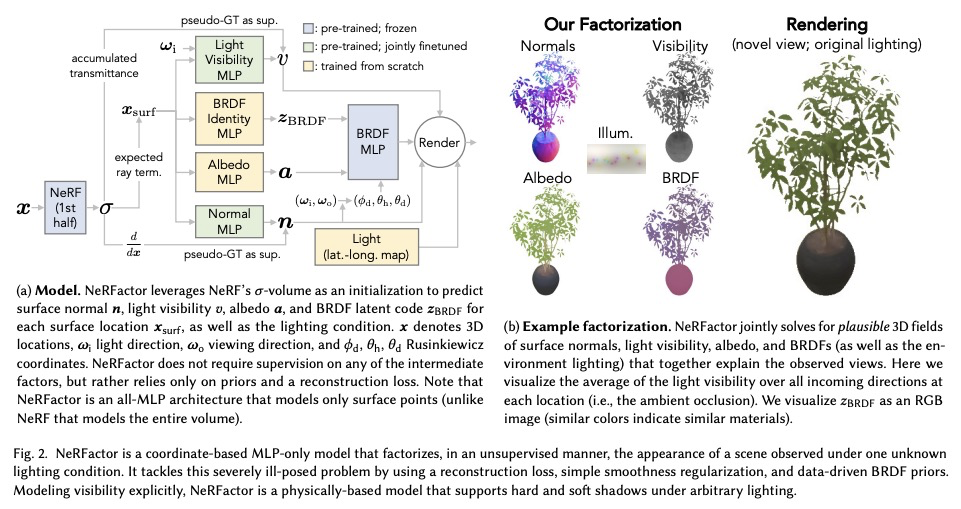
[CV] NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination
NeRFactor:未知光照下形状和反射率的神经网络因子分解
X Zhang, P P. Srinivasan, B Deng, P Debevec, W T. Freeman, J T. Barron
[MIT CSAIL & Google Research]
https://weibo.com/1402400261/KiIFhb4G9



[CV] Robust Reference-based Super-Resolution via C2-Matching
C2-Matching基于参考鲁棒超分辨率
Y Jiang, K C.K. Chan, X Wang, C C Loy, Z Liu
[Nanyang Technological University & Tencent PCG]
https://weibo.com/1402400261/KiIGWAdJy





若有收获,就点个赞吧
0 人点赞
