AI - 人工智能 LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音
1、[LG] *Logistic QQ-Learning
J Bas-Serrano, S Curi, A Krause, G Neu
[Universitat Pompeu Fabra & ETH Zurich]
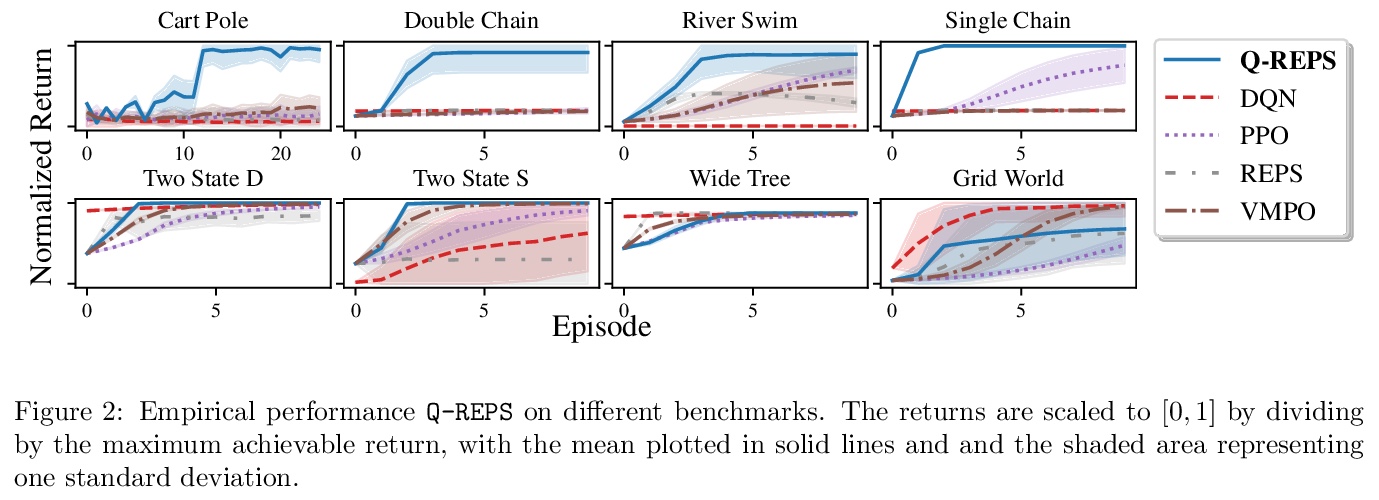
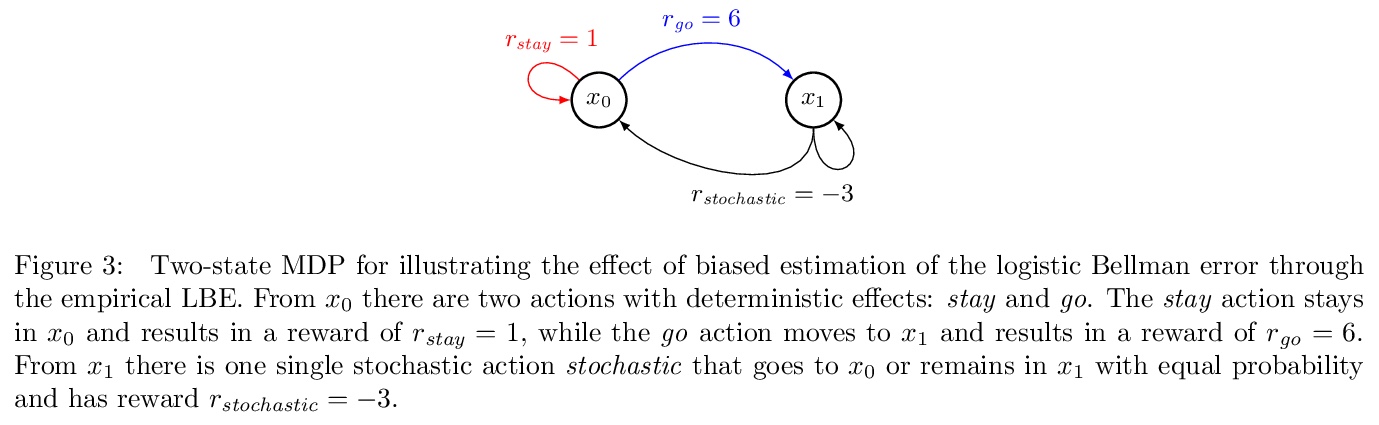
基于Logistic Bellman Error的QREPS强化学习算法,由MDP最优控制的正则化线性规划导出,Logistic Bellman Error是一个用于策略评价的凸损失函数,无需对MDP进行任何近似,理论上可以替代广泛使用的平方Bellman误差。
We propose a new reinforcement learning algorithm derived from a regularized linear-programming formulation of optimal control in MDPs. The method is closely related to the classic Relative Entropy Policy Search (REPS) algorithm of Peters et al. (2010), with the key difference that our method introduces a Q-function that enables efficient exact model-free implementation. The main feature of our algorithm (called QREPS) is a convex loss function for policy evaluation that serves as a theoretically sound alternative to the widely used squared Bellman error. We provide a practical saddle-point optimization method for minimizing this loss function and provide an error-propagation analysis that relates the quality of the individual updates to the performance of the output policy. Finally, we demonstrate the effectiveness of our method on a range of benchmark problems.
https://weibo.com/1402400261/JqsqMjkxY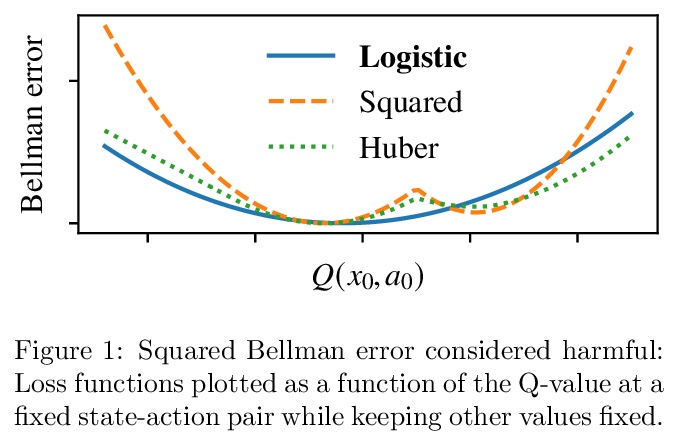
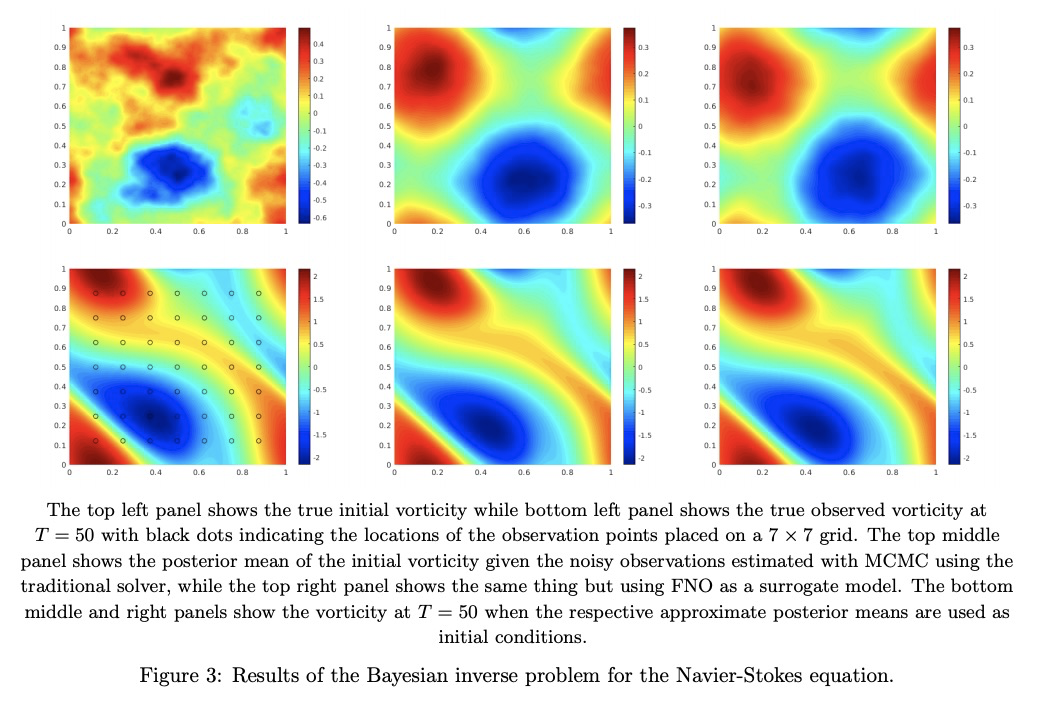
2、[LG] *Fourier Neural Operator for Parametric Partial Differential Equations
Z Li, N Kovachki, K Azizzadenesheli, B Liu, K Bhattacharya, A Stuart, A Anandkumar
[Caltech & Purdue University]
偏微分方程(PDE)傅里叶神经算子,通过在傅里叶空间中直接参数化积分核得到的神经算子,最终解码器网络能学习正确的边界条件,不受周期边界条件限制,能实现更具表达性且更有效的架构。在对伯格斯方程、达西流和纳维-斯托克斯方程进行的实验中,与现有的神经网络方法相比,傅里叶神经算子显示出最先进性能,比传统PDE求解器快1000倍。**
The classical development of neural networks has primarily focused on learning mappings between finite-dimensional Euclidean spaces. Recently, this has been generalized to neural operators that learn mappings between function spaces. For partial differential equations (PDEs), neural operators directly learn the mapping from any functional parametric dependence to the solution. Thus, they learn an entire family of PDEs, in contrast to classical methods which solve one instance of the equation. In this work, we formulate a new neural operator by parameterizing the integral kernel directly in Fourier space, allowing for an expressive and efficient architecture. We perform experiments on Burgers’ equation, Darcy flow, and the Navier-Stokes equation (including the turbulent regime). Our Fourier neural operator shows state-of-the-art performance compared to existing neural network methodologies and it is up to three orders of magnitude faster compared to traditional PDE solvers.
https://weibo.com/1402400261/JqsCHkRfr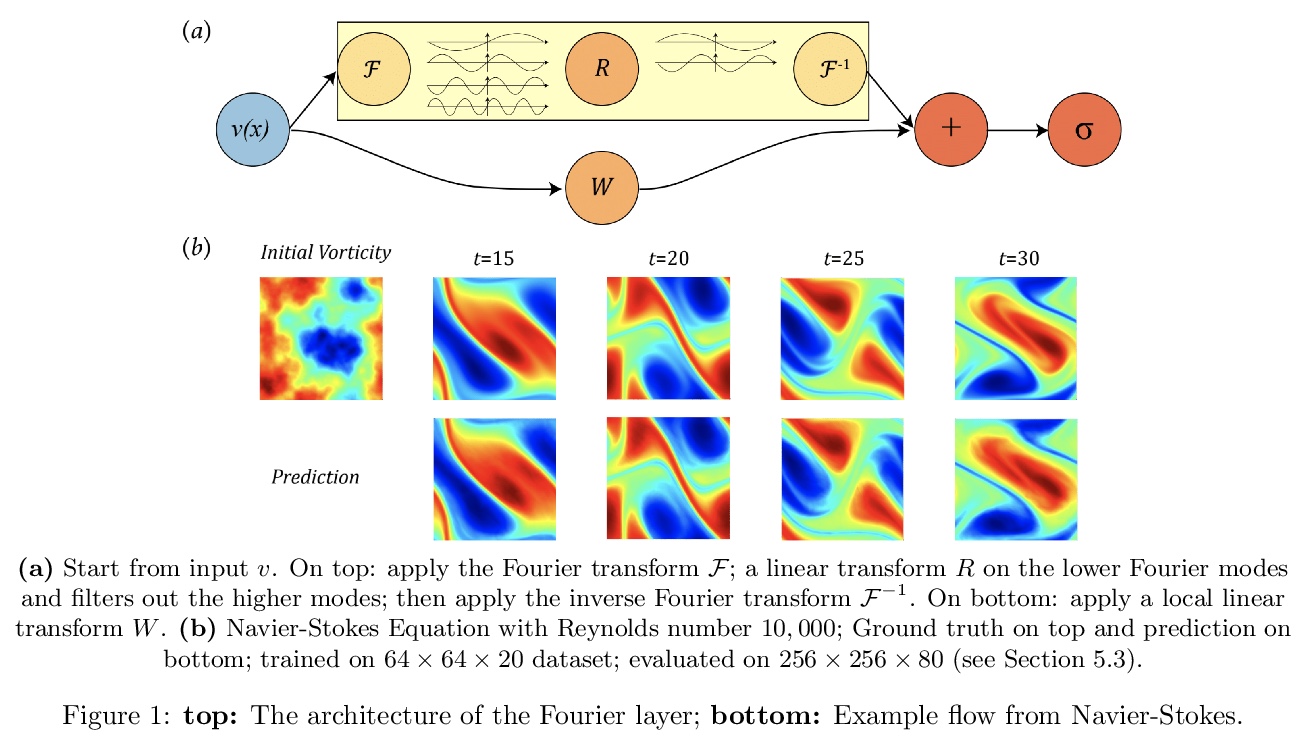
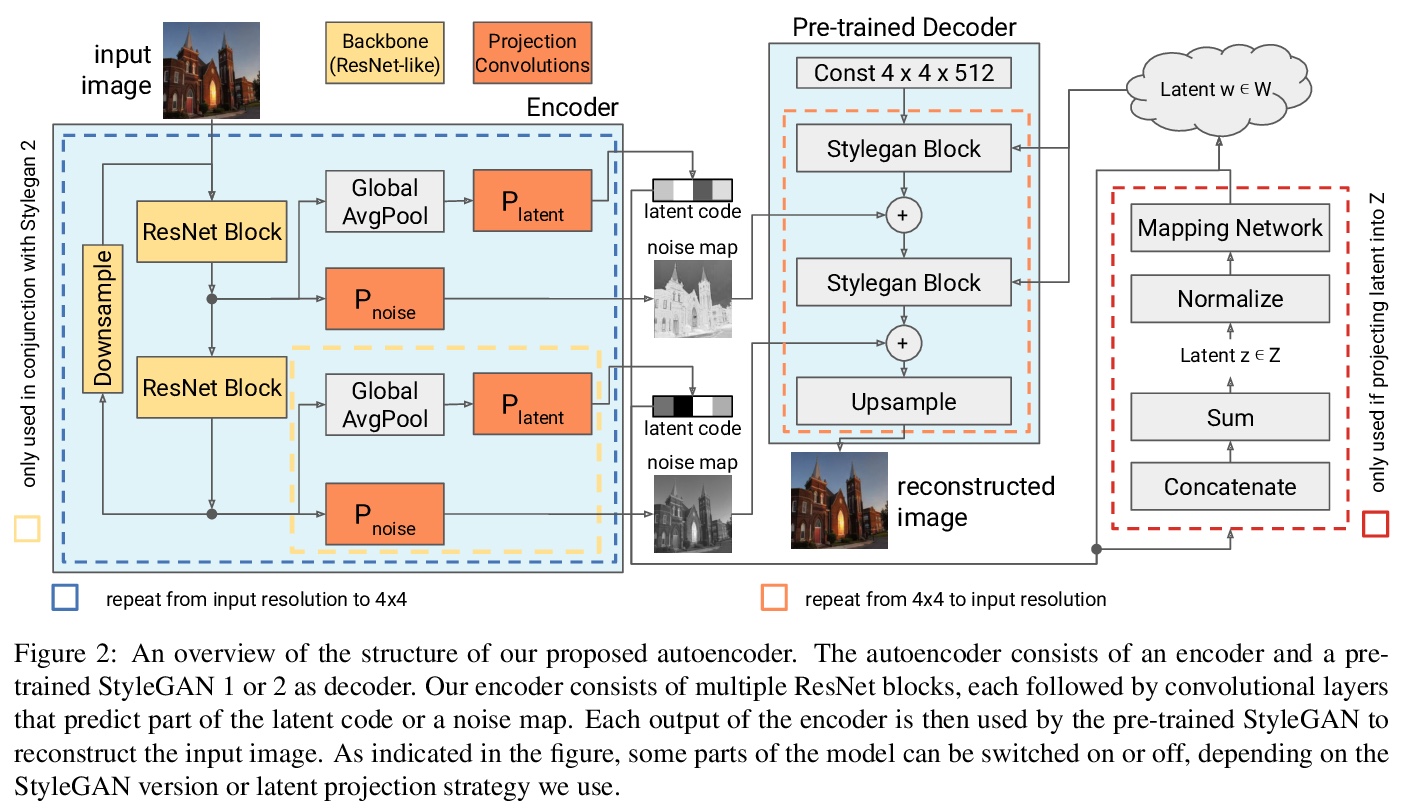
3、[CV] One Model to Reconstruct Them All: A Novel Way to Use the Stochastic Noise in StyleGAN
C Bartz, J Bethge, H Yang, C Meinel [University of Potsdam]
利用随机噪声跨数据域重建高质量图像的StyleGAN自编码器架构,用一个预训练的StyleGAN生成器,可重建几乎所有数据集的图像。利用随机噪声捕获微小细节,操纵StyleGAN生成图像的颜色,而不依赖于潜代码。该架构可以在单个GPU上每秒处理40幅图像,比之前的方法快了大约28倍。
Generative Adversarial Networks (GANs) have achieved state-of-the-art performance for several image generation and manipulation tasks. Different works have improved the limited understanding of the latent space of GANs by embedding images into specific GAN architectures to reconstruct the original images. We present a novel StyleGAN-based autoencoder architecture, which can reconstruct images with very high quality across several data domains. We demonstrate a previously unknown grade of generalizablility by training the encoder and decoder independently and on different datasets. Furthermore, we provide new insights about the significance and capabilities of noise inputs of the well-known StyleGAN architecture. Our proposed architecture can handle up to 40 images per second on a single GPU, which is approximately 28x faster than previous approaches. Finally, our model also shows promising results, when compared to the state-of-the-art on the image denoising task, although it was not explicitly designed for this task.
https://weibo.com/1402400261/JqsLypB8C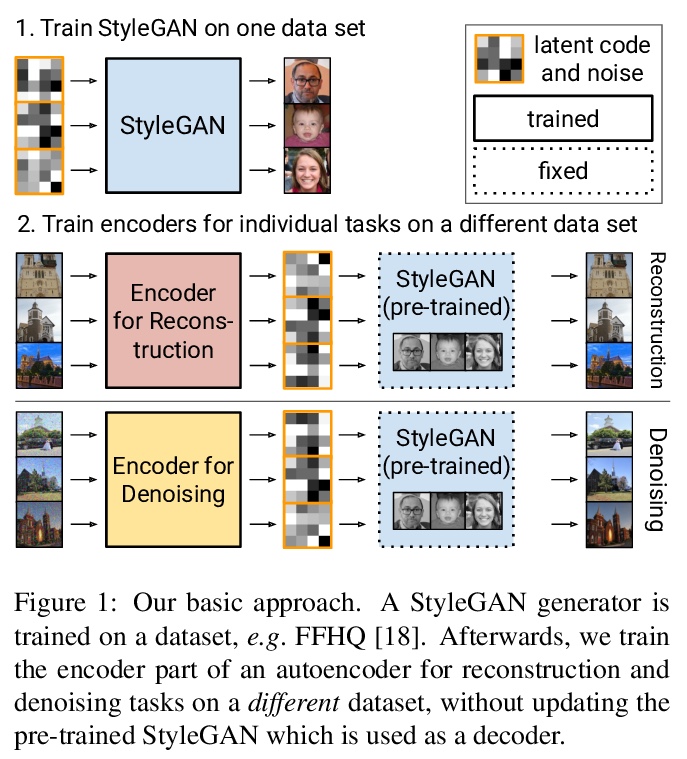

4、[CL] Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
E Voita, R Sennrich, I Titov
[University of Edinburgh & University of Zurich]
用分层关联传播(LRP)变体评价源和目标对神经网络机器翻译(NMT)预测的相对贡献,发现:(1)用更多数据训练的模型更依赖于源信息,有更明显的词条贡献;(2)训练过程是非单调的,分几个不同阶段,与之前验证彩票假说的工作中发现的阶段相一致。
In Neural Machine Translation (and, more generally, conditional language modeling), the generation of a target token is influenced by two types of context: the source and the prefix of the target sequence. While many attempts to understand the internal workings of NMT models have been made, none of them explicitly evaluates relative source and target contributions to a generation decision. We argue that this relative contribution can be evaluated by adopting a variant of Layerwise Relevance Propagation (LRP). Its underlying ‘conservation principle’ makes relevance propagation unique: differently from other methods, it evaluates not an abstract quantity reflecting token importance, but the proportion of each token’s influence. We extend LRP to the Transformer and conduct an analysis of NMT models which explicitly evaluates the source and target relative contributions to the generation process. We analyze changes in these contributions when conditioning on different types of prefixes, when varying the training objective or the amount of training data, and during the training process. We find that models trained with more data tend to rely on source information more and to have more sharp token contributions; the training process is non-monotonic with several stages of different nature.
https://weibo.com/1402400261/JqsRipg0v
5、[LG] **Riemannian Langevin Algorithm for Solving Semidefinite Programs
M (Bill)Li, M A. Erdogdu
[University of Toronto]
基于朗之万扩散的球面积流形非凸优化采样算法,在对数索波列夫不等式下,利用Kullback-Leibler散度,建立了有限次迭代收敛于吉布斯分布的保证。证明了在适当温度选择下,保证了到全局最小的次优性差是任意小且高概率的。**
We propose a Langevin diffusion-based algorithm for non-convex optimization and sampling on a product manifold of spheres. Under a logarithmic Sobolev inequality, we establish a guarantee for finite iteration convergence to the Gibbs distribution in terms of Kullback-Leibler divergence. We show that with an appropriate temperature choice, the suboptimality gap to the global minimum is guaranteed to be arbitrarily small with high probability.As an application, we analyze the proposed Langevin algorithm for solving the Burer-Monteiro relaxation of a semidefinite program (SDP). In particular, we establish a logarithmic Sobolev inequality for the Burer-Monteiro problem when there are no spurious local minima; hence implying a fast escape from saddle points. Combining the results, we then provide a global optimality guarantee for the SDP and the Max-Cut problem. More precisely, we show the Langevin algorithm achieves > ϵ-multiplicative accuracy with high probability in > Ω˜(n2ϵ−3) iterations, where > n is the size of the cost matrix.
https://weibo.com/1402400261/JqsUVlS5r
另外几篇值得关注的论文:
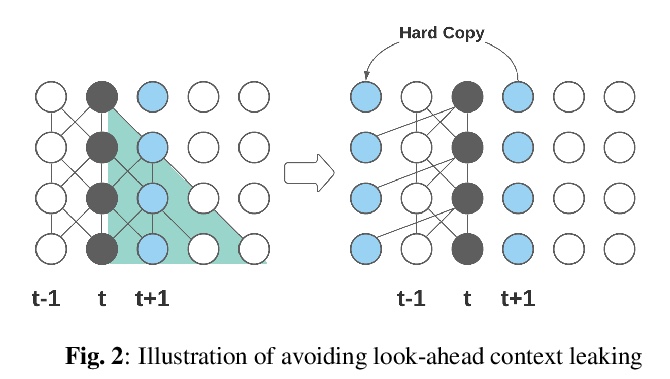
[CL] Emformer: Efficient Memory Transformer Based Acoustic Model For Low Latency Streaming Speech Recognition
Emformer: 面向低延迟流语音识别的记忆Transformer声学模型**
Y Shi, Y Wang, C Wu, C Yeh, J Chan, F Zhang, D Le, M Seltzer
[Facebook AI]
https://weibo.com/1402400261/Jqt0iiDMl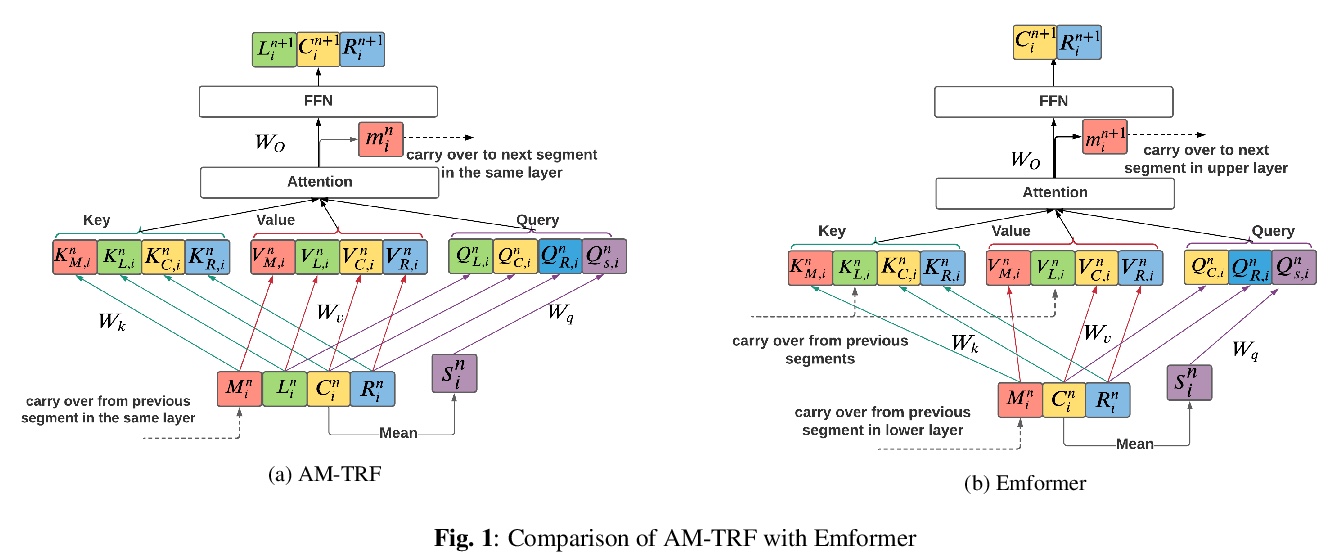
[LG]WaveTransformer: A Novel Architecture for Audio Captioning Based on Learning Temporal and Time-Frequency Information
WaveTransformer: 基于时序和时频信息学习的音频自动描述架构
A Tran, K Drossos, T Virtanen
[Tampere University]
https://weibo.com/1402400261/Jqt134r1P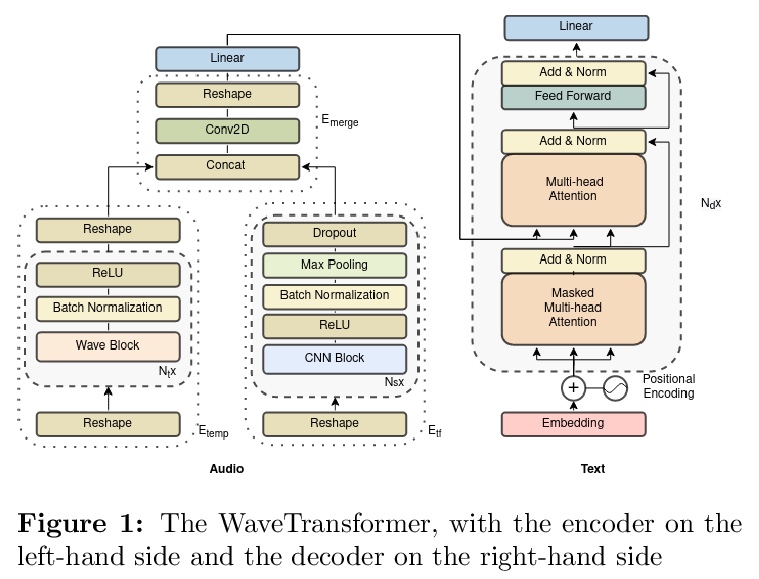
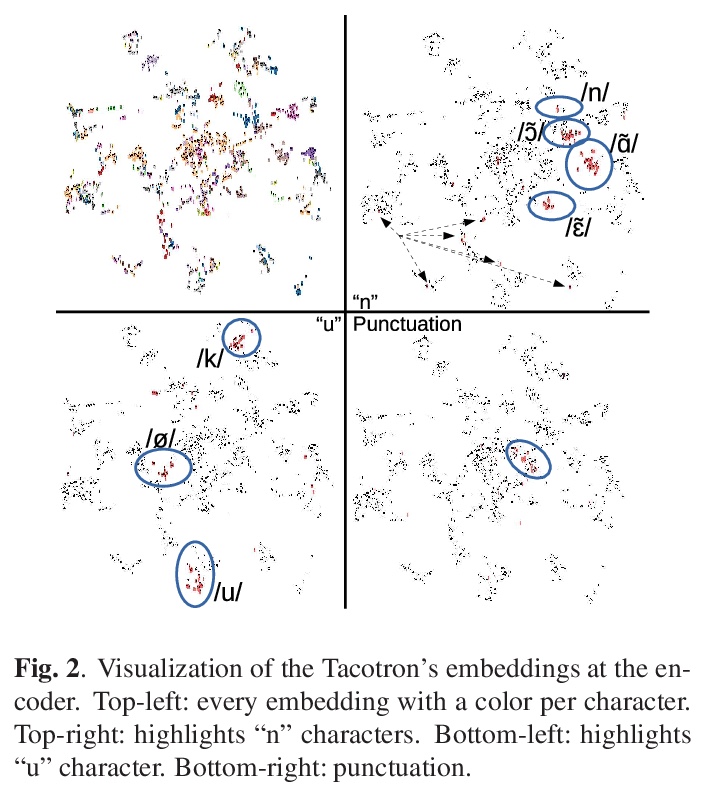
[CL] Grapheme or phoneme? An Analysis of Tacotron’s Embedded Representations
字素还是音素?Tacotron嵌入式表征分析
A Perquin, E Cooper, J Yamagishi
[Univ Rennes & National Institute of Informatics, Japan]
https://weibo.com/1402400261/Jqt5Y1kUA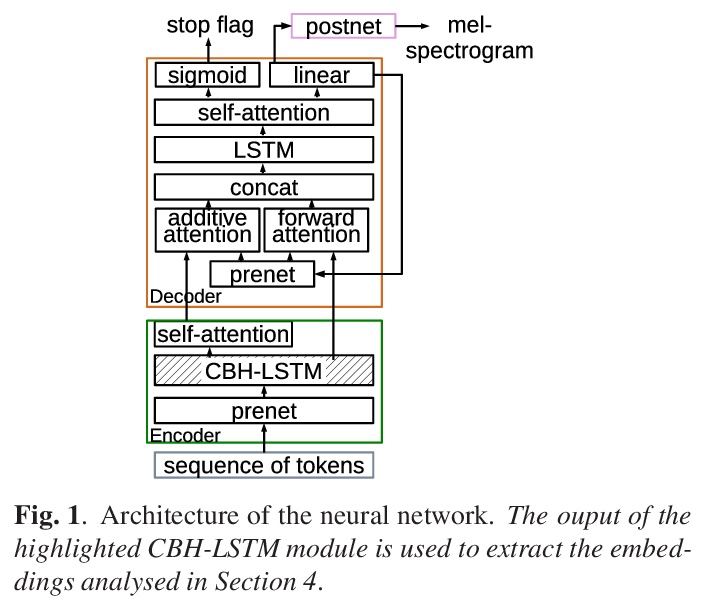
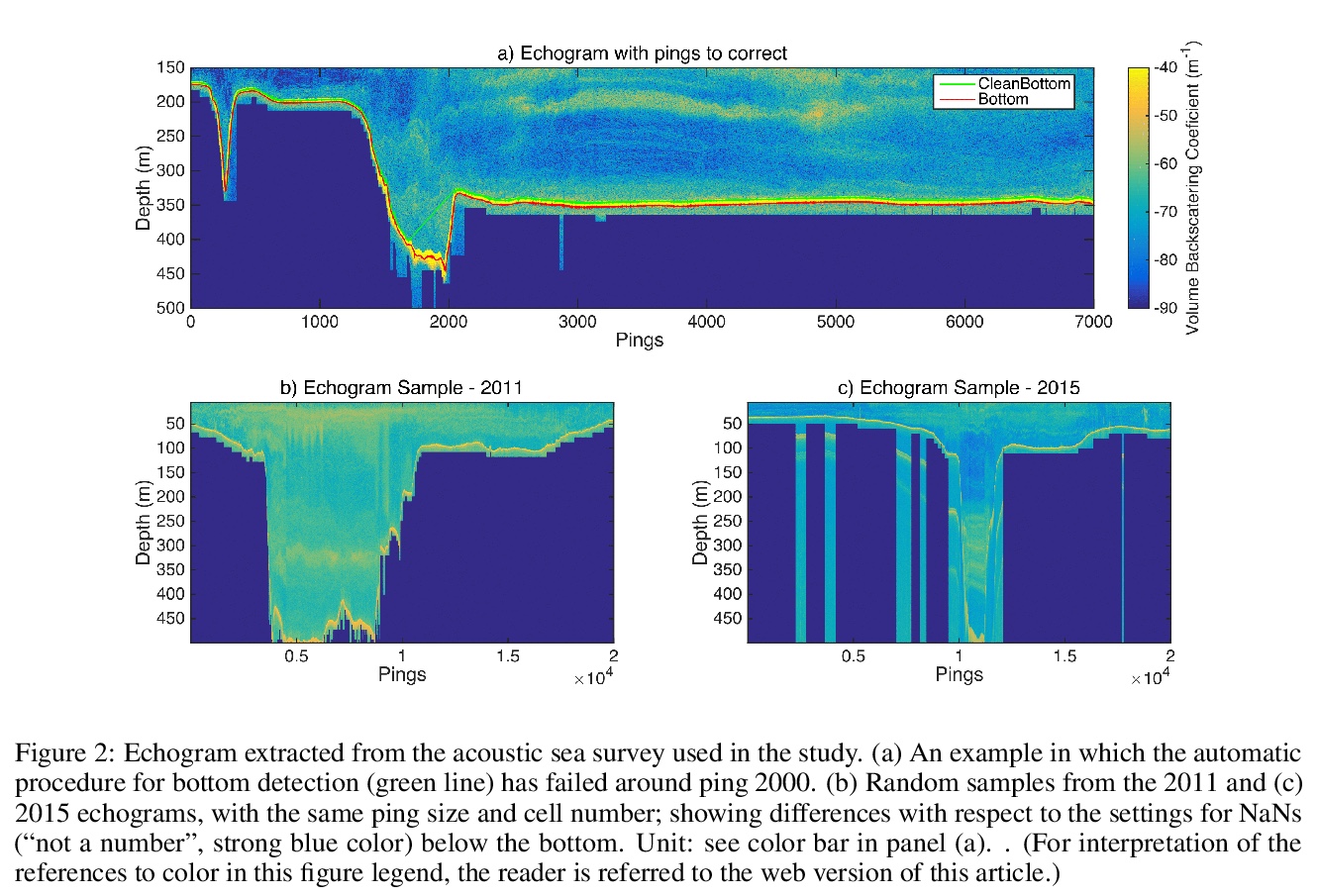
[LG] Complex data labeling with deep learning methods: Lessons from fisheries acoustics
用深度学习方法标记复杂数据: 来自渔业声学的教训
J.M.A.Sarr, T. Brochier, P.Brehmer, Y.Perrot, A.Bah, A.Sarré, M.A.Jeyid, M.Sidibeh, S Ayoub
[Université Cheikh Anta Diop de Dakar UCAD & Univ Brest]
https://weibo.com/1402400261/Jqt8Ibfau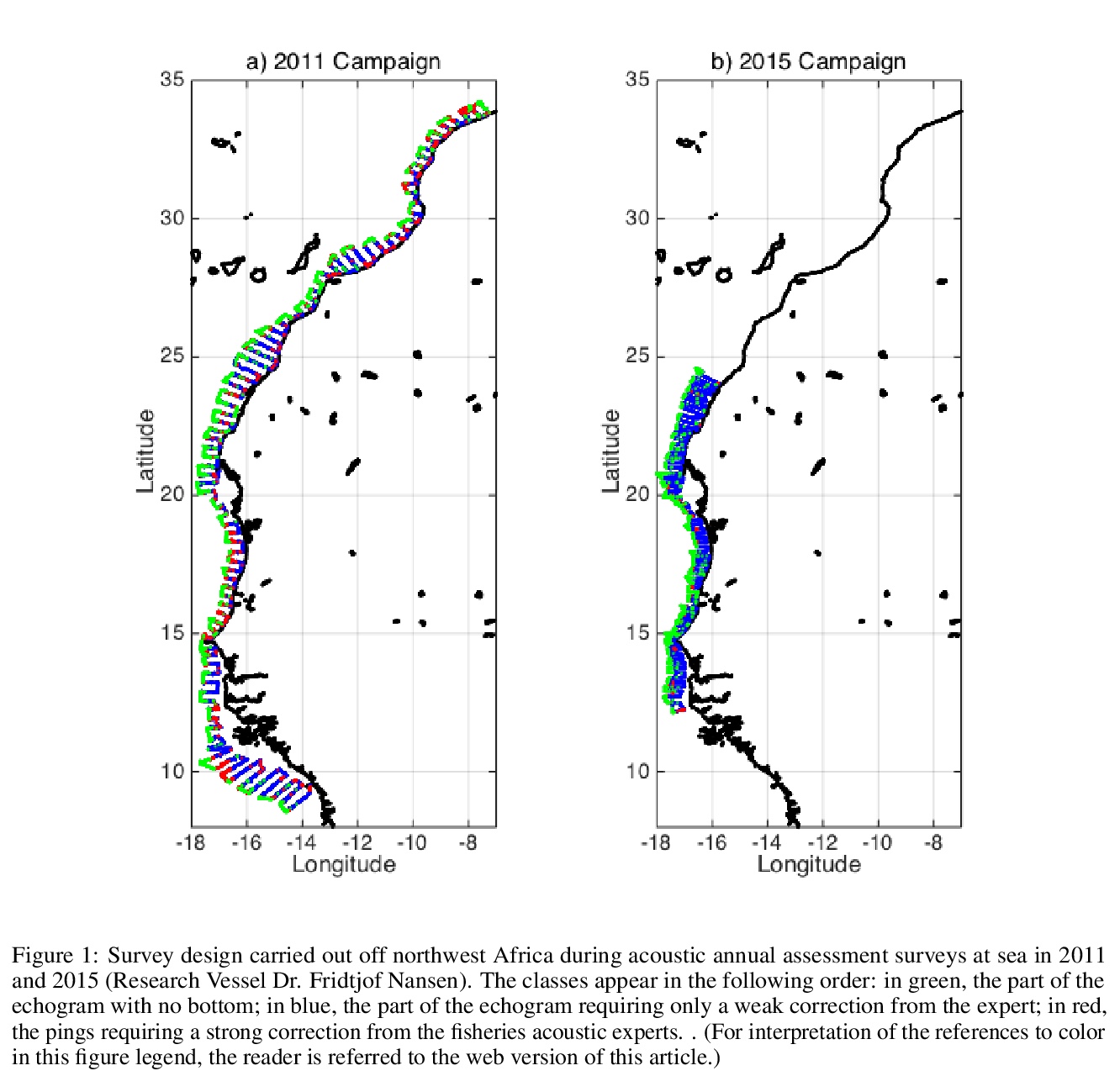
[AS]FastEmit: Low-latency Streaming ASR with Sequence-level Emission Regularization
FastEmit: 序列级发射正则化低延迟流式自动语音识别(ASR)
J Yu, C Chiu, B Li, S Chang, T N. Sainath, Y He, A Narayanan, W Han, A Gulati, Y Wu, R Pang
[Google LLC]
https://weibo.com/1402400261/Jqt9Rqa9T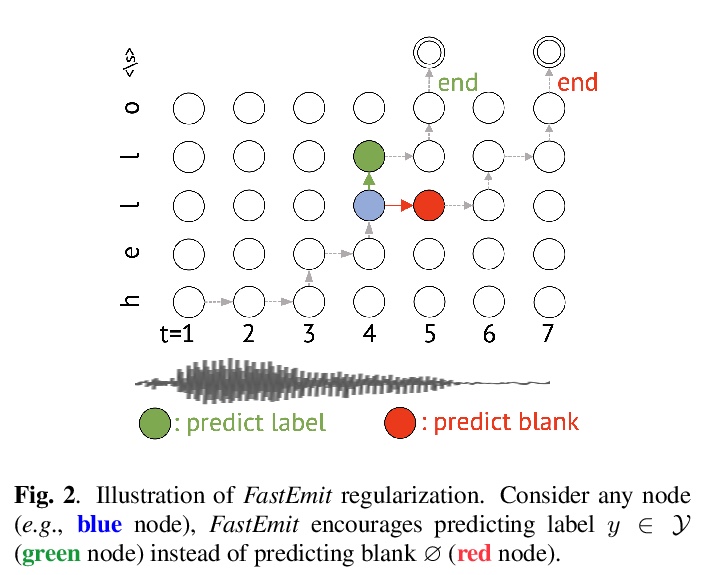

若有收获,就点个赞吧
0 人点赞
