- 1、[LG] Machine-Learning Non-Conservative Dynamics for New-Physics Detection
- 2、[LG] Towards mental time travel: a hierarchical memory for reinforcement learning agents
- 3、[LG] Counterfactual Invariance to Spurious Correlations: Why and How to Pass Stress Tests
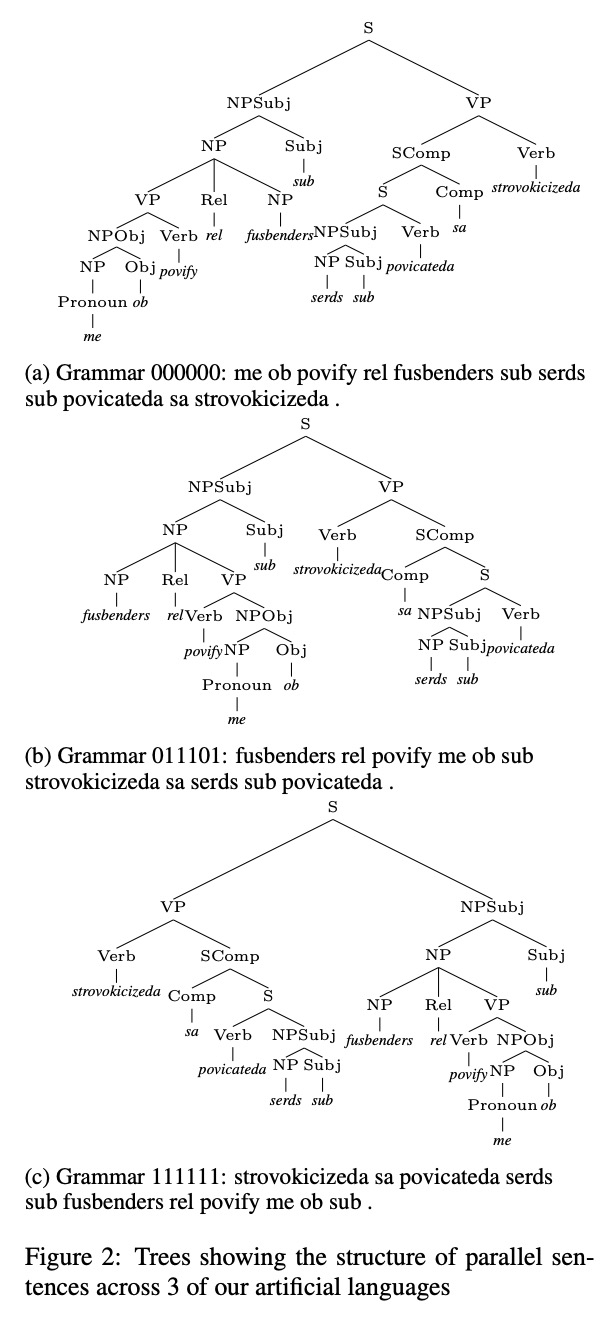
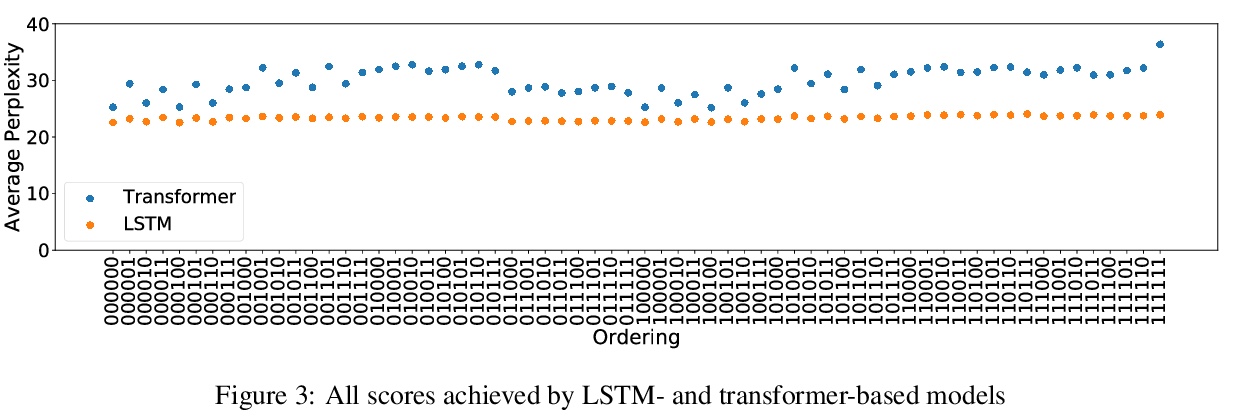
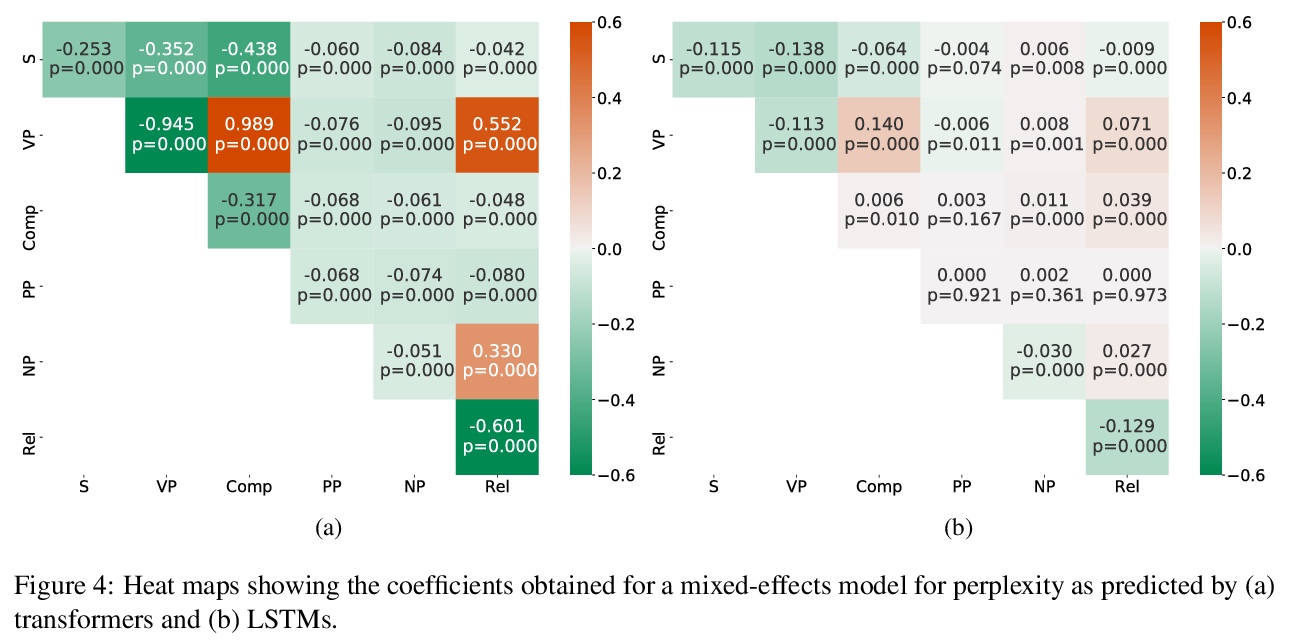
- 4、[CL] Examining the Inductive Bias of Neural Language Models with Artificial Languages
- 5、[CV] DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
- [LG] Connections and Equivalences between the Nyström Method and Sparse Variational Gaussian Processes
- [CV] Learning to Stylize Novel Views
- [LG] Bottom-Up and Top-Down Neural Processing Systems Design: Neuromorphic Intelligence as the Convergence of Natural and Artificial Intelligence
- [CL] MLPruning: A Multilevel Structured Pruning Framework for Transformer-based Models
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] Machine-Learning Non-Conservative Dynamics for New-Physics Detection
Z Liu, B Wang, Q Meng, W Chen, M Tegmark, T Liu
[Microsoft Research Asia & MIT]
机器学习非保守动力学的新物理学检测。能量守恒是基本的物理学原理,它的破坏往往意味着新的物理学。本文提出一种数据驱动的”新物理学”发现方法。给定一个由未知力支配的轨迹,神经新物理学检测器(NNPhD)旨在通过将力场分解为保守和非保守成分来检测新物理学,这些成分分别由拉格朗日神经网络(LNN)和通用逼近器网络(UAN)表示,经过训练使力的恢复误差加上预测非保守力常数λ最小。在λ=1时发生了相变,普遍适用于任意的力。证明了NNPhD在简单数值实验中成功地发现了新物理学,从阻尼双摆中重新发现了摩擦力,从天王星轨道上发现了海王星,从吸气轨道上发现了引力波。还展示了NNPhD与积分器的结合在预测阻尼双摆的未来方面如何胜过之前的方法。
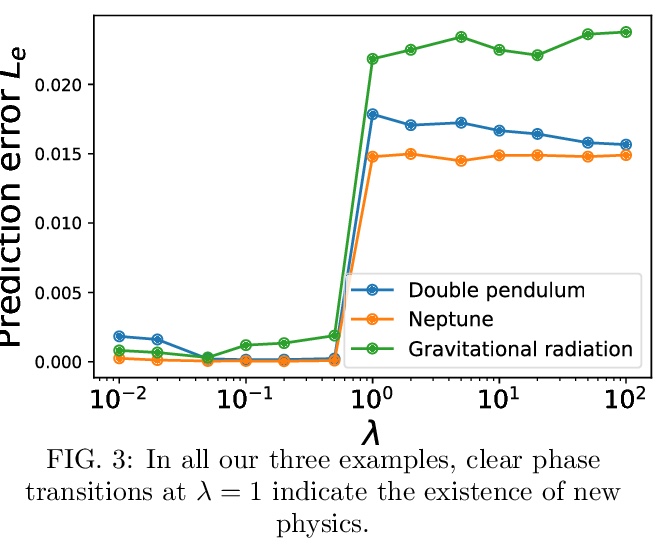
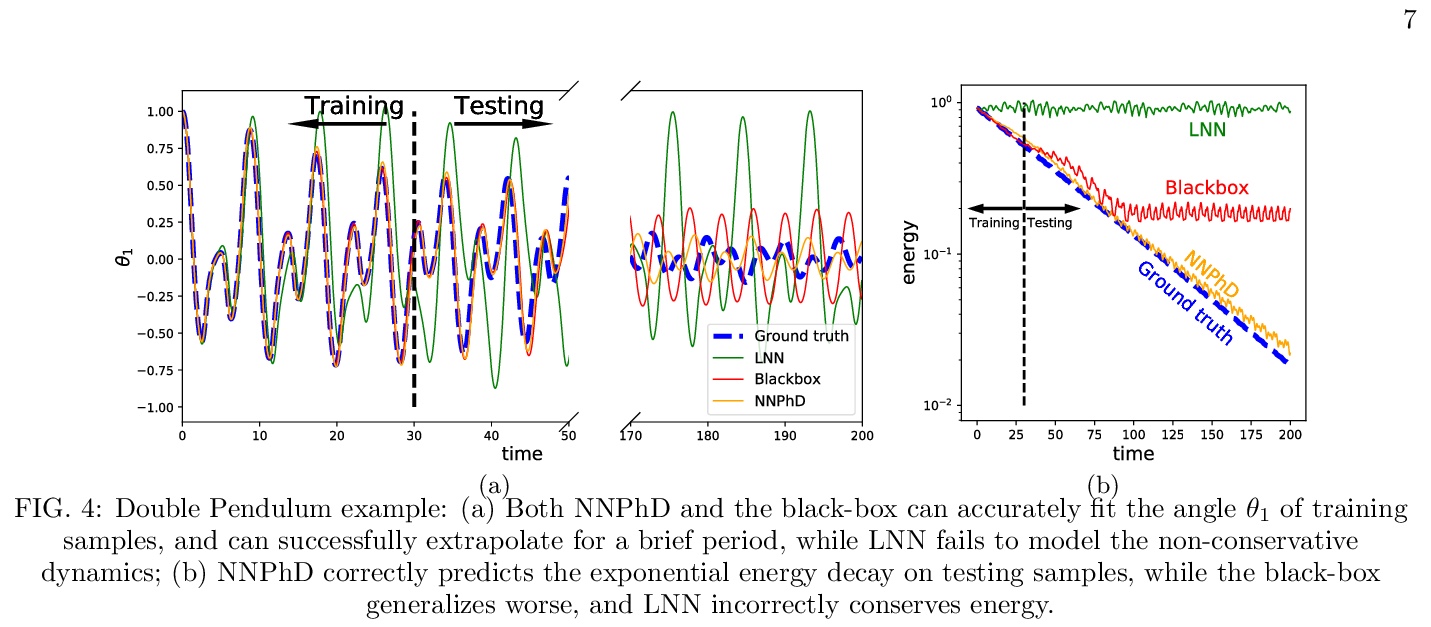
Energy conservation is a basic physics principle, the breakdown of which often implies new physics. This paper presents a method for data-driven “new physics” discovery. Specifically, given a trajectory governed by unknown forces, our Neural New-Physics Detector (NNPhD) aims to detect new physics by decomposing the force field into conservative and non-conservative components, which are represented by a Lagrangian Neural Network (LNN) and a universal approximator network (UAN), respectively, trained to minimize the force recovery error plus a constant λ times the magnitude of the predicted non-conservative force. We show that a phase transition occurs at λ = 1, universally for arbitrary forces. We demonstrate that NNPhD successfully discovers new physics in toy numerical experiments, rediscovering friction (1493) from damped double pendulum, Neptune from Uranus’ orbit (1846) and gravitational waves (2017) from an inspiraling orbit. We also show how NNPhD coupled with an integrator outperforms previous methods for predicting the future of a damped double pendulum.
https://weibo.com/1402400261/KiRCZwcmj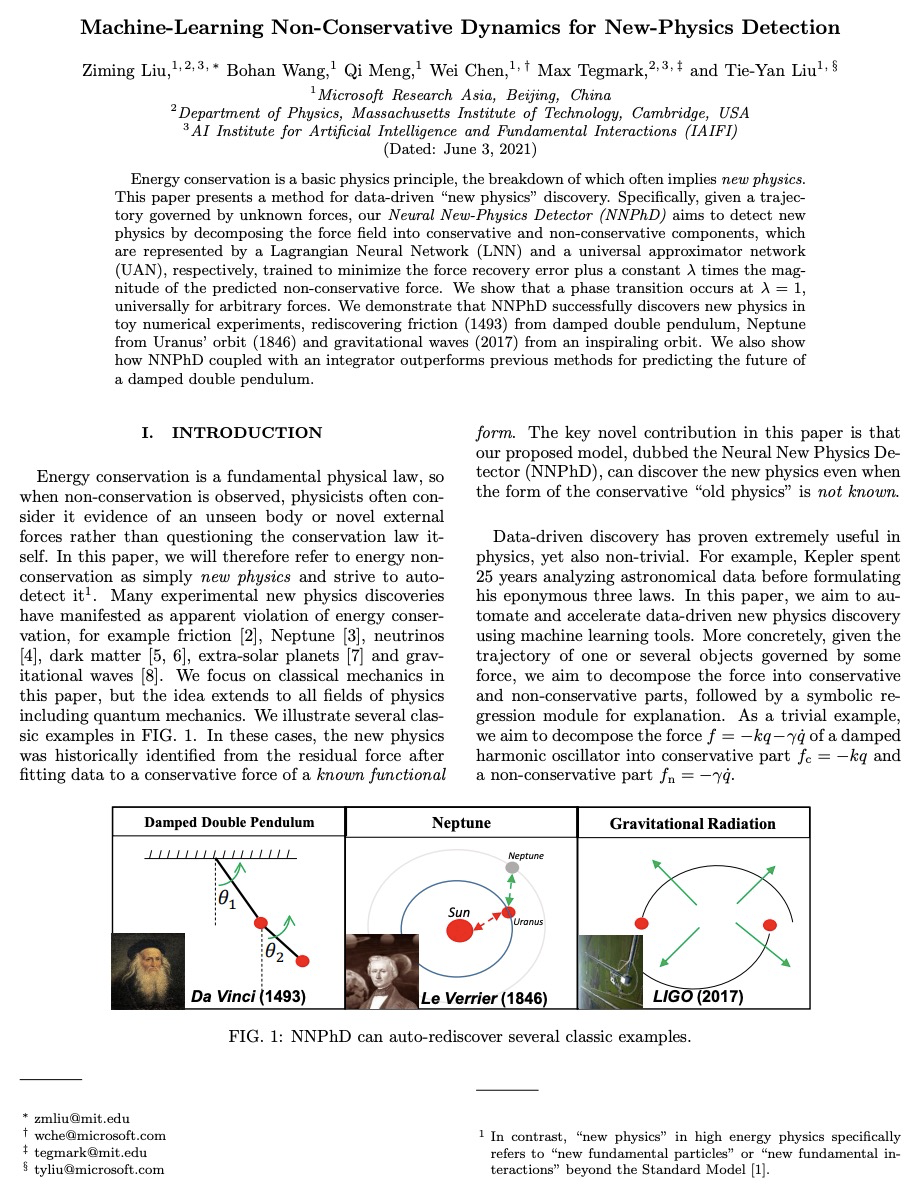


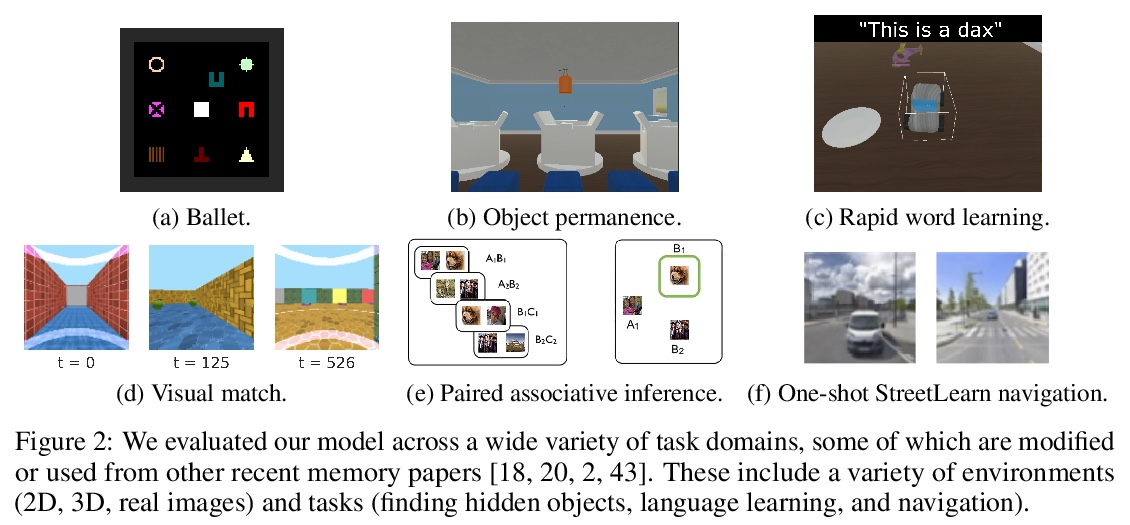
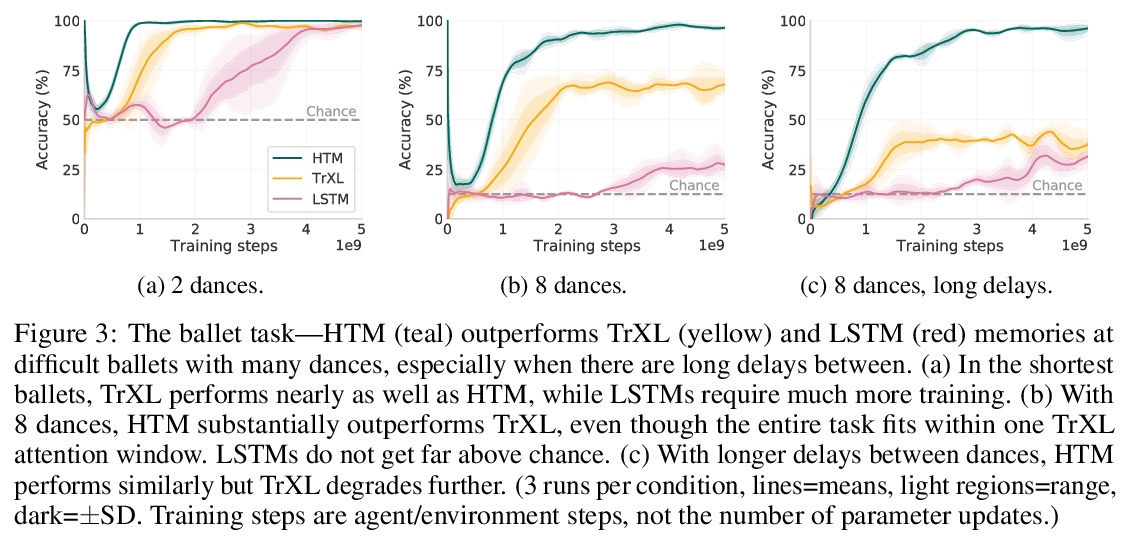
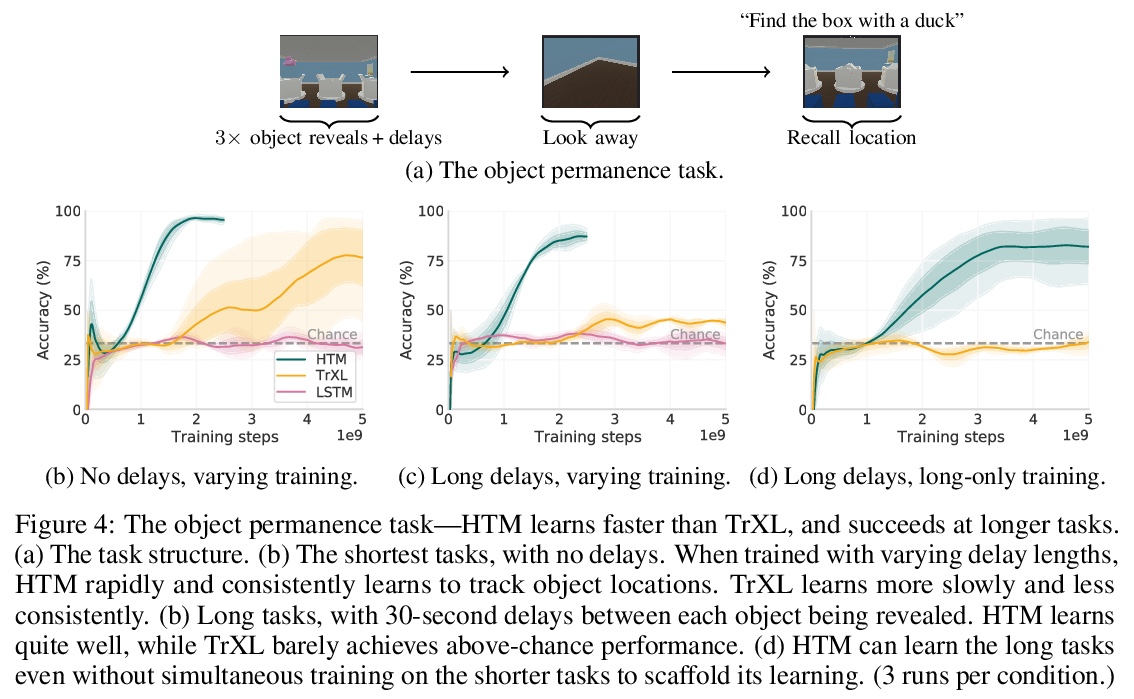
2、[LG] Towards mental time travel: a hierarchical memory for reinforcement learning agents
A K Lampinen, S C.Y. Chan, A Banino, F Hill
[DeepMind]
思想时间旅行:强化学习智能体的层次记忆。强化学习智能体经常忘记过去的细节,特别是在延迟或分心任务之后。具有普通记忆结构的智能体难以回忆和整合过去事件的多个时间段,甚至难以回忆被分心任务影响的单个时间段的细节。为解决这些限制,本文提出了层次Transformer记忆(HTM),帮智能体详细记住过往。HTM通过把过去分成几块来存储记忆,对这几块的粗略摘要实施高层次注意力,只在最相关的几个块内实施详细注意力,以此方式来实现回忆。具有HTM的智能体可实现”思想时间旅行”——在不对所有干预事件加以注意的情况下详细记住过去的事件。在需要长期回忆、保留或推理记忆的任务中,具有HTM的智能体的表现大大优于具有其他记忆结构的智能体。这些任务包括回忆一个物体在3D环境中的隐藏位置,快速学习在一个新的社区中有效导航,以及快速学习和保留新的物体名称。拥有HTM的智能体可以推断出比他们被训练时间长一个数量级的任务序列,甚至可以从元学习环境中零散地泛化出保持跨轮的知识。HTM提高了智能体的采样效率、泛化性和通用性(通过解决以前需要专门架构的任务)。
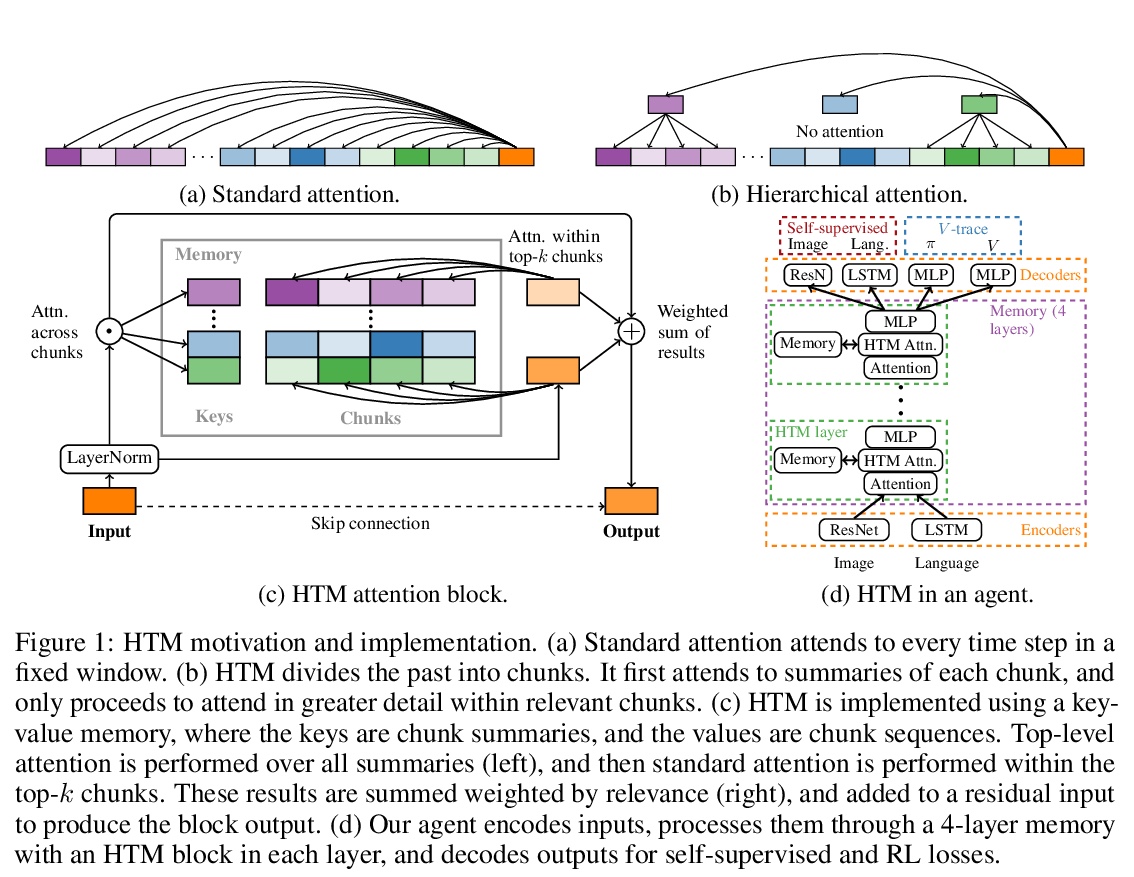
Reinforcement learning agents often forget details of the past, especially after delays or distractor tasks. Agents with common memory architectures struggle to recall and integrate across multiple timesteps of a past event, or even to recall the details of a single timestep that is followed by distractor tasks. To address these limitations, we propose a Hierarchical Transformer Memory (HTM), which helps agents to remember the past in detail. HTM stores memories by dividing the past into chunks, and recalls by first performing high-level attention over coarse summaries of the chunks, and then performing detailed attention within only the most relevant chunks. An agent with HTM can therefore “mentally time-travel”—remember past events in detail without attending to all intervening events. We show that agents with HTM substantially outperform agents with other memory architectures at tasks requiring long-term recall, retention, or reasoning over memory. These include recalling where an object is hidden in a 3D environment, rapidly learning to navigate efficiently in a new neighborhood, and rapidly learning and retaining new object names. Agents with HTM can extrapolate to task sequences an order of magnitude longer than they were trained on, and can even generalize zero-shot from a meta-learning setting to maintaining knowledge across episodes. HTM improves agent sample efficiency, generalization, and generality (by solving tasks that previously required specialized architectures). Our work is a step towards agents that can learn, interact, and adapt in complex and temporally-extended environments.
https://weibo.com/1402400261/KiRGaDWWz
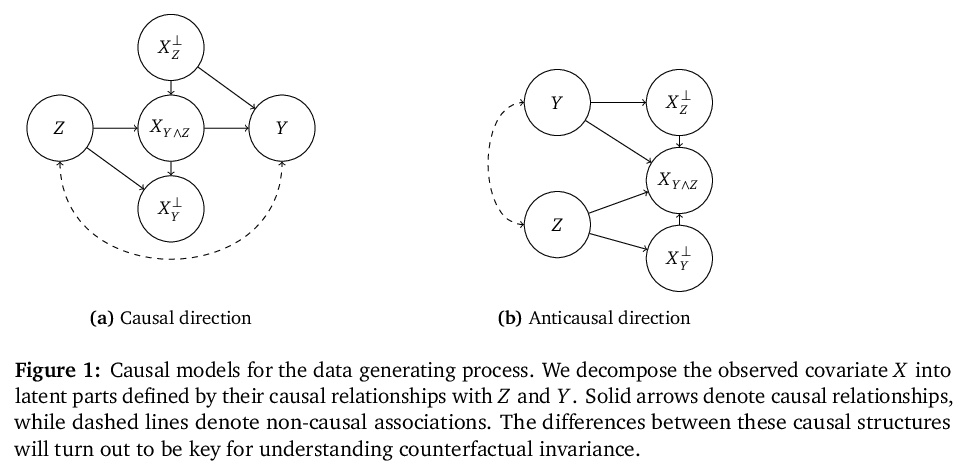
3、[LG] Counterfactual Invariance to Spurious Correlations: Why and How to Pass Stress Tests
V Veitch, A D’Amour, S Yadlowsky, J Eisenstein
[Google Research]
伪相关反事实不变性:为什么以及如何通过压力测试。在非正式的定义里,”伪相关”是指模型对输入数据的某些方面的依赖性,而分析师认为这些方面不应该存在依赖性。在机器学习中,这种依赖具有”眼见为实”的特点;例如,改变一个句子主语的性别会改变情感预测器的输出。为检查伪相关性,可以通过扰动输入数据的不相关部分,对模型进行”压力测试”,看模型的预测是否发生变化。本文采用因果推理工具研究压力测试,引入了反事实不变性,作为改变输入的不相关部分不应改变模型预测的要求的形式化。将反事实不变性与域外模型的性能联系起来,并提供了学习(近似)反事实不变性的预测器的实用方案(不需要获得反事实样本)。事实证明,反事实不变性的手段和意义都从根本上取决于数据的真正的基本因果结构。不同的因果结构需要不同的正则化方案来引起反事实不变性。同样地,反事实不变性意味着不同的域迁移保证,这取决于潜在的因果结构。这一理论得到了文本分类的经验结果的支持。
Informally, a ‘spurious correlation’ is the dependence of a model on some aspect of the input data that an analyst thinks shouldn’t matter. In machine learning, these have a know-it-when-you-see-it character; e.g., changing the gender of a sentence’s subject changes a sentiment predictor’s output. To check for spurious correlations, we can ‘stress test’ models by perturbing irrelevant parts of input data and seeing if model predictions change. In this paper, we study stress testing using the tools of causal inference. We introduce counterfactual invariance as a formalization of the requirement that changing irrelevant parts of the input shouldn’t change model predictions. We connect counterfactual invariance to out-of-domain model performance, and provide practical schemes for learning (approximately) counterfactual invariant predictors (without access to counterfactual examples). It turns out that both the means and implications of counterfactual invariance depend fundamentally on the true underlying causal structure of the data. Distinct causal structures require distinct regularization schemes to induce counterfactual invariance. Similarly, counterfactual invariance implies different domain shift guarantees depending on the underlying causal structure. This theory is supported by empirical results on text classification.
https://weibo.com/1402400261/KiRM2mU4P
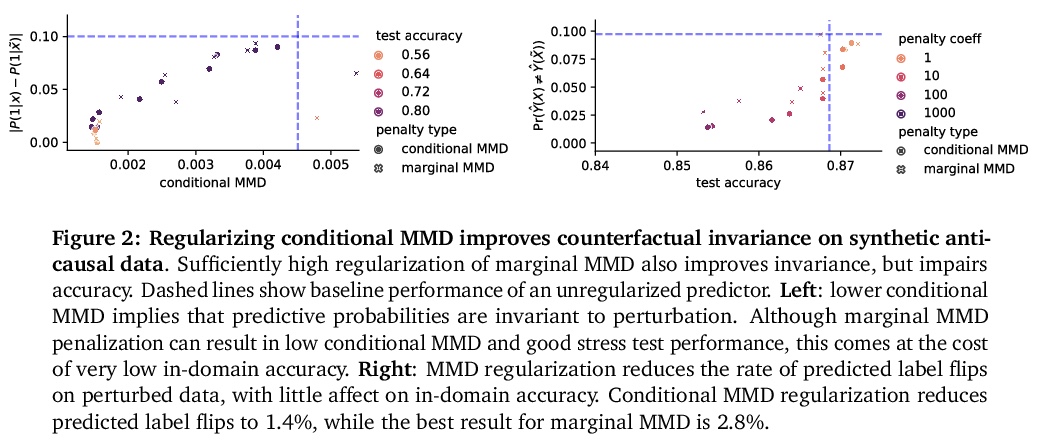
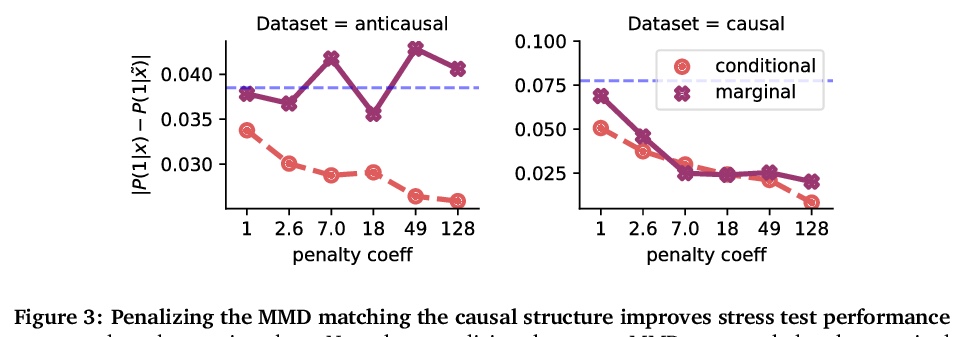
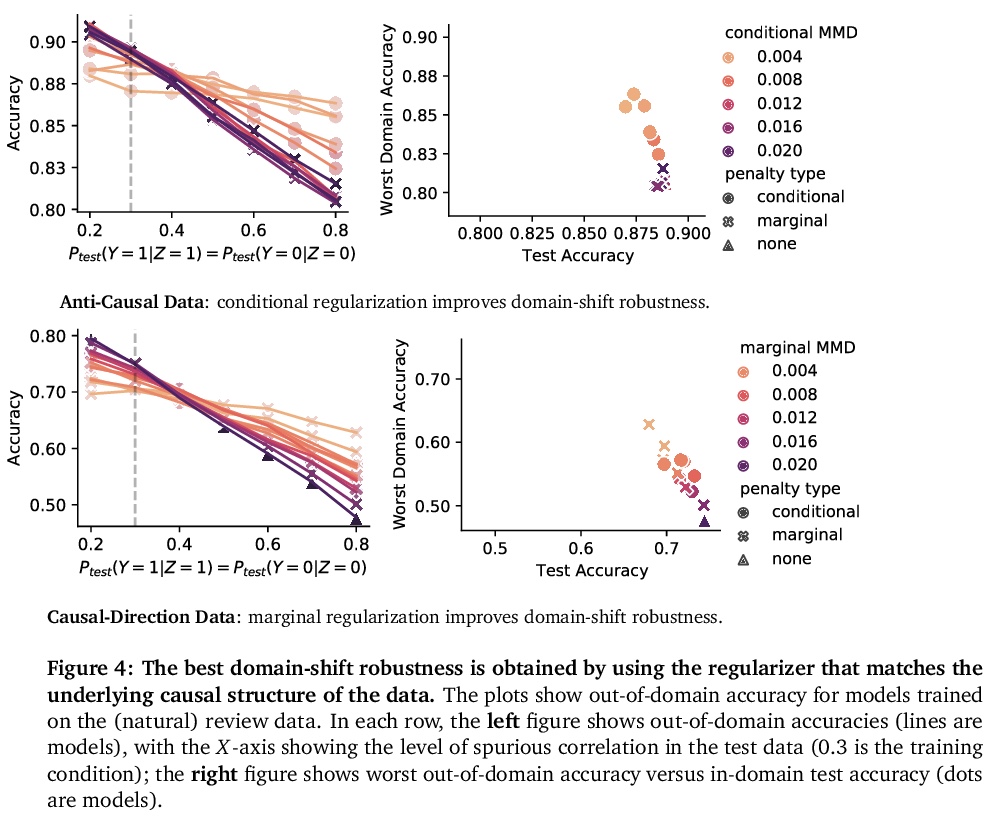
4、[CL] Examining the Inductive Bias of Neural Language Models with Artificial Languages
J C. White, R Cotterell
[University of Cambridge]
用人造语言检验神经语言模型的归纳偏差。由于语言模型被用来对各种各样的语言进行建模,因此很自然地要问,用于该任务的神经架构在对特定类型语言建模时是否引入了归纳偏差。由于实验设置中出现了许多变量,对这些偏差的检验非常复杂。语言在许多类型学维度上都有差异,很难在没有其他因素干扰的情况下单独挑出一两个进行调查。本文提出一种新方法,来检查人造语言的语言模型的归纳偏差。这些人造语言经过特别构造,能在不同语言中创建平行语料库,而只在被检查的类型学特征(如词序)方面存在差异。这些人造语言用来训练和测试语言模型,构成一个完全受控的因果框架,展示了语法工程如何作为分析神经模型的一个有用工具。采用这种方法,可以发现常用的神经架构表现出不同的归纳偏差。LSTM在单词排序方面几乎没有显示出偏好,而Transformer则显示出对某些排序的明显偏好。发现无论是LSTM的归纳偏差还是转化器的归纳偏差,似乎都没有反映在已证实的自然语言中看到的任何倾向。
Since language models are used to model a wide variety of languages, it is natural to ask whether the neural architectures used for the task have inductive biases towards modeling particular types of languages. Investigation of these biases has proved complicated due to the many variables that appear in the experimental setup. Languages vary in many typological dimensions, and it is difficult to single out one or two to investigate without the others acting as confounders. We propose a novel method for investigating the inductive biases of language models using artificial languages. These languages are constructed to allow us to create parallel corpora across languages that differ only in the typological feature being investigated, such as word order. We then use them to train and test language models. This constitutes a fully controlled causal framework, and demonstrates how grammar engineering can serve as a useful tool for analyzing neural models. Using this method, we find that commonly used neural architectures exhibit different inductive biases: LSTMs display little preference with respect to word ordering, while transformers display a clear preference for some orderings over others. Further, we find that neither the inductive bias of the LSTM nor that of the transformer appears to reflect any tendencies that we see in attested natural languages.
https://weibo.com/1402400261/KiRQAE0HF
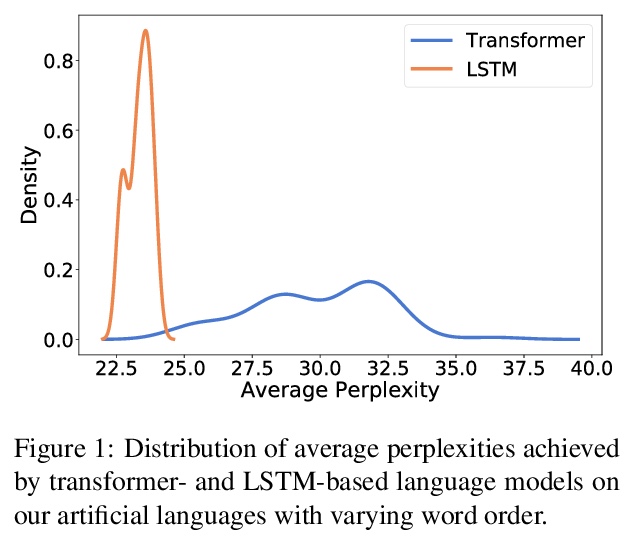
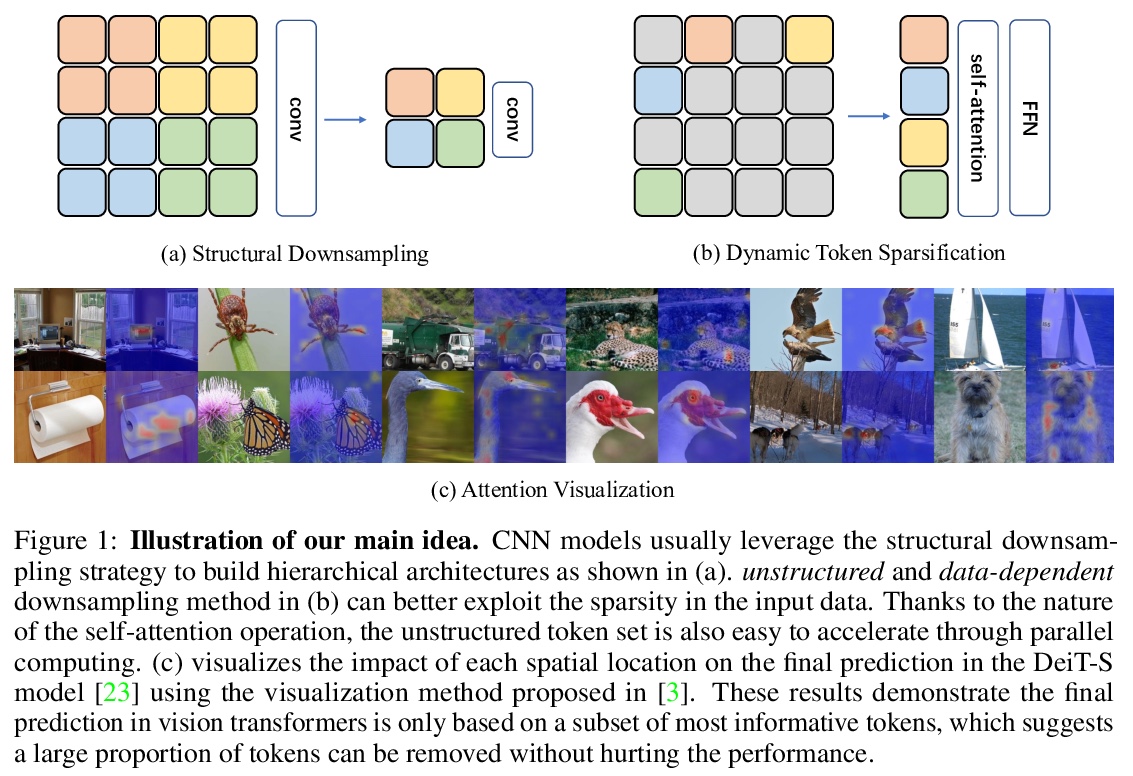
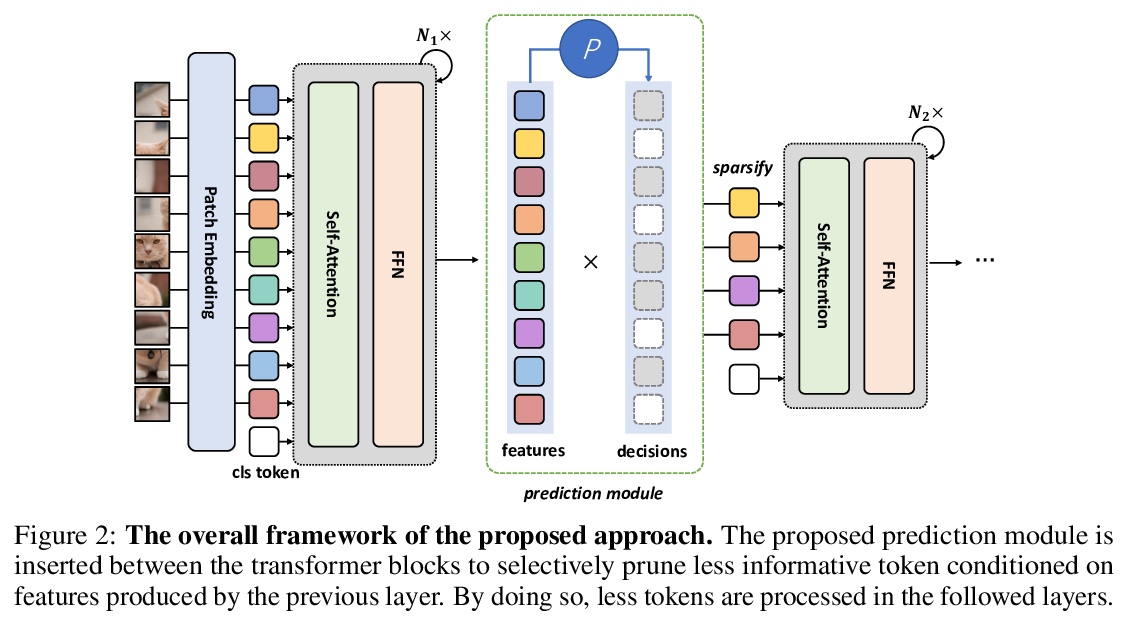
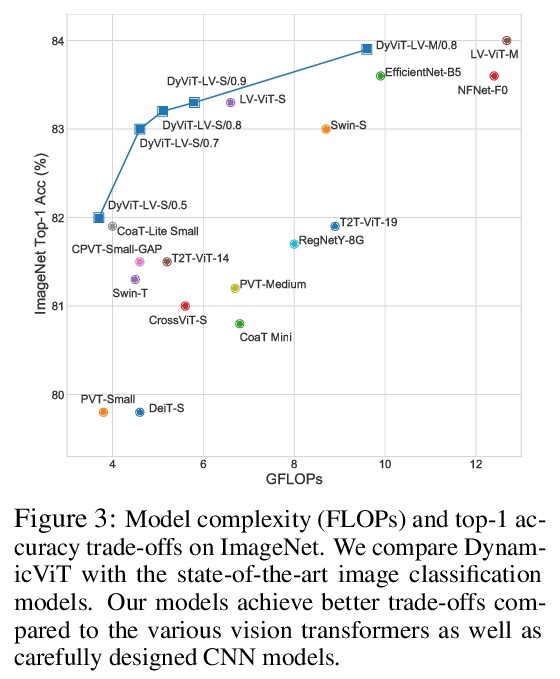
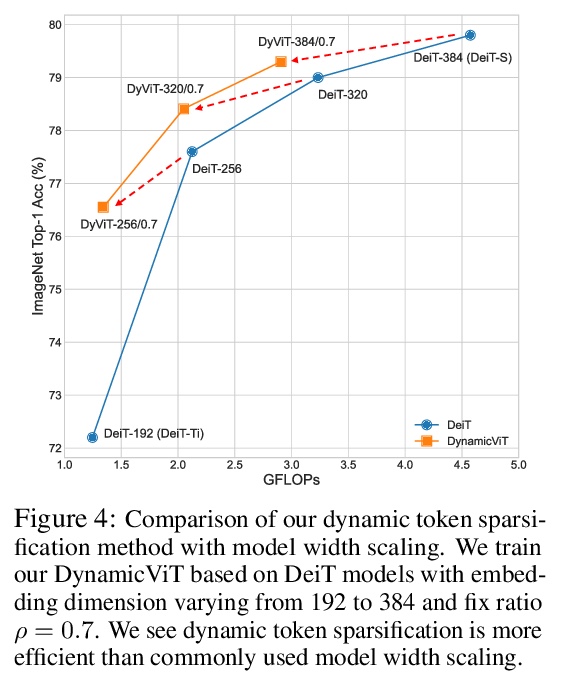
5、[CV] DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
Y Rao, W Zhao, B Liu, J Lu, J Zhou, C Hsieh
[Tsinghua University & University of California, Los Angeles]
DynamicViT:动态Token稀疏化的高效视觉Transformer。视觉Transformer中的注意力是稀疏的,其最终预测,只基于信息量最大的Token子集,这对于准确的图像识别是足够的。基于这一观察,本文提出一种动态Token稀疏化框架,根据输入逐步和动态地修剪多余的Token。设计了一个轻量的预测模块,来估计当前特征下每个Token的重要性得分。该模块被添加到不同的层,以分层地修剪多余Token。为了以端到端的方式优化预测模块,提出了一种注意力掩蔽策略,通过阻止一个Token与其他Token的相互作用,来有区别地修剪该Token。受益于自注意力的性质,非结构化稀疏Token仍然是硬件友好的,使得框架很容易实现实际的速度提升。通过分层修剪66%的输入Token,该方法大大减少了31%∼37%的FLOPs,提高了40%以上的吞吐量,而对于各种视觉Transformer来说,准确性的下降在0.5%以内。与ImageNet上最先进的CNN和视觉Transformer相比,配备了动态Token稀疏化框架的DynamicViT模型可以实现非常有竞争力的复杂性/准确率权衡。
Attention is sparse in vision transformers. We observe the final prediction in vision transformers is only based on a subset of most informative tokens, which is sufficient for accurate image recognition. Based on this observation, we propose a dynamic token sparsification framework to prune redundant tokens progressively and dynamically based on the input. Specifically, we devise a lightweight prediction module to estimate the importance score of each token given the current features. The module is added to different layers to prune redundant tokens hierarchically. To optimize the prediction module in an end-to-end manner, we propose an attention masking strategy to differentiably prune a token by blocking its interactions with other tokens. Benefiting from the nature of self-attention, the unstructured sparse tokens are still hardware friendly, which makes our framework easy to achieve actual speed-up. By hierarchically pruning 66% of the input tokens, our method greatly reduces 31% ∼ 37% FLOPs and improves the throughput by over 40% while the drop of accuracy is within 0.5% for various vision transformers. Equipped with the dynamic token sparsification framework, DynamicViT models can achieve very competitive complexity/accuracy trade-offs compared to state-of-the-art CNNs and vision transformers on ImageNet.
https://weibo.com/1402400261/KiRX2530H
另外几篇值得关注的论文:
[LG] Connections and Equivalences between the Nyström Method and Sparse Variational Gaussian Processes
Nyström方法和稀疏变分高斯过程之间的联系和等价性
V Wild, M Kanagawa, D Sejdinovic
[University of Oxford & EURECOM]
https://weibo.com/1402400261/KiRZR4fIH
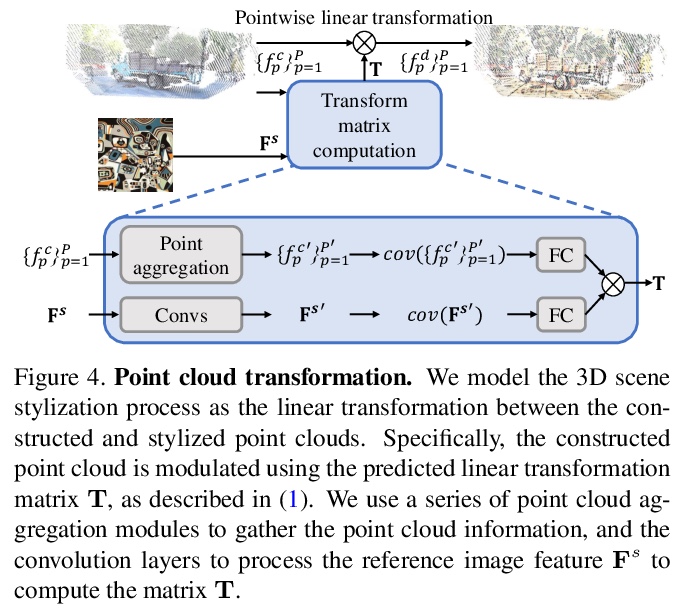
[CV] Learning to Stylize Novel Views
新视图风格化学习
H Huang, H Tseng, S Saini, M Singh, M Yang
[University of California, Merced & Verisk Analytics]
https://weibo.com/1402400261/KiS1tchEE



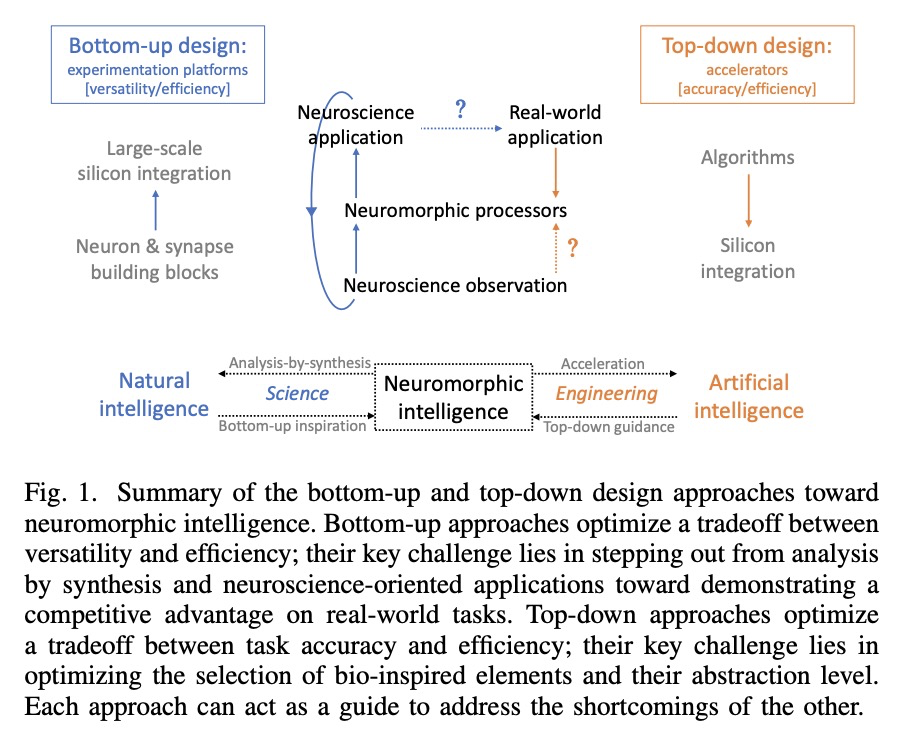
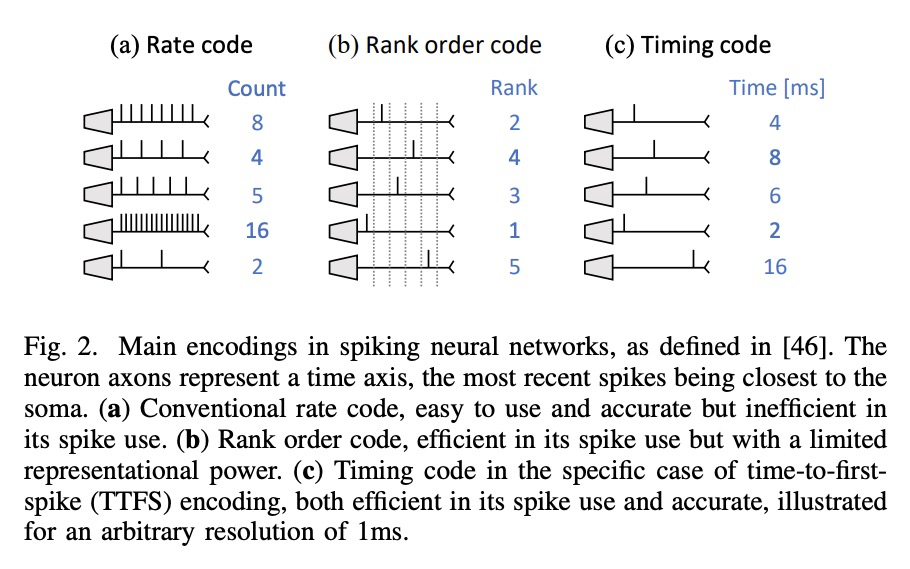
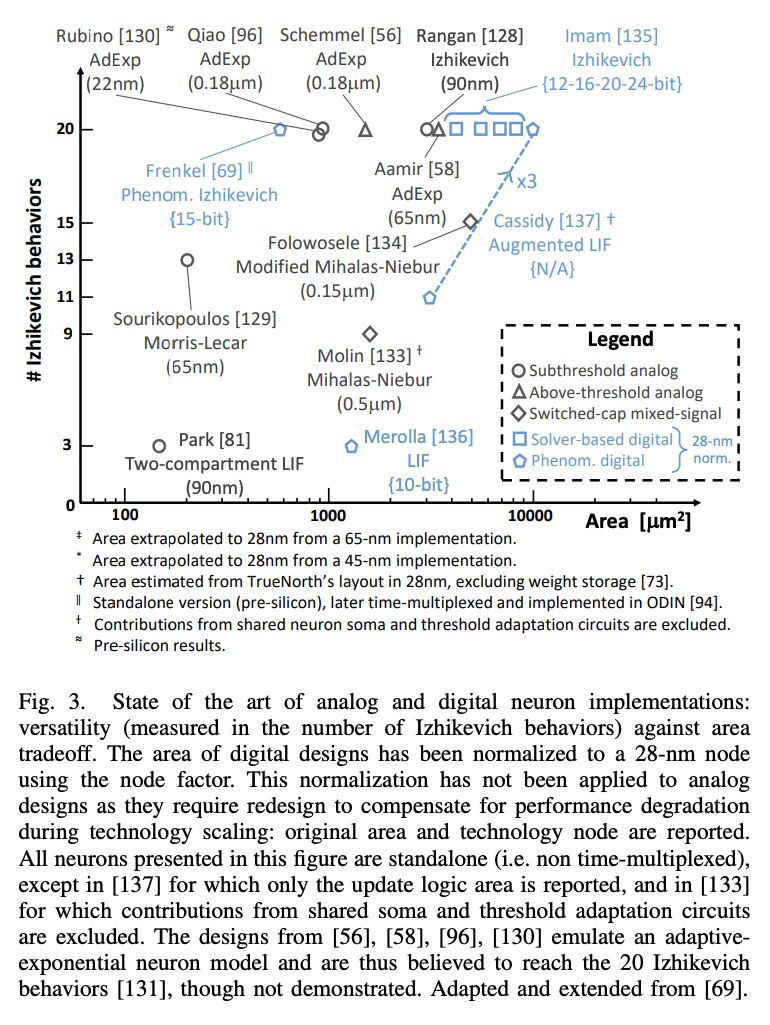
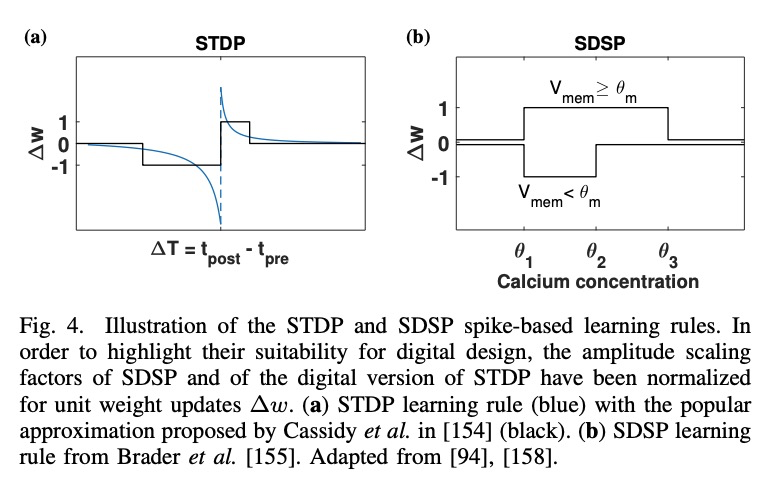
[LG] Bottom-Up and Top-Down Neural Processing Systems Design: Neuromorphic Intelligence as the Convergence of Natural and Artificial Intelligence
自下而上和自上而下的神经处理系统设计:作为自然智能和人工智能融合的神经形态智能
C Frenkel, D Bol, G Indiveri
[ETH Zurich & Universite catholique de Louvain]
https://weibo.com/1402400261/KiS4Ph9Ou
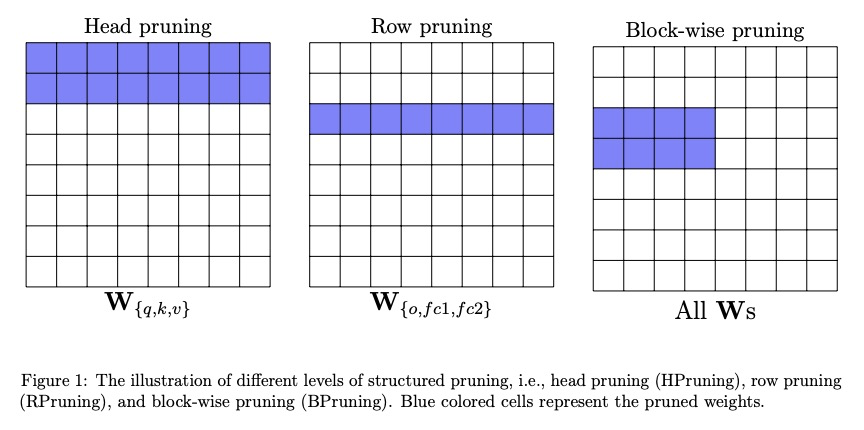
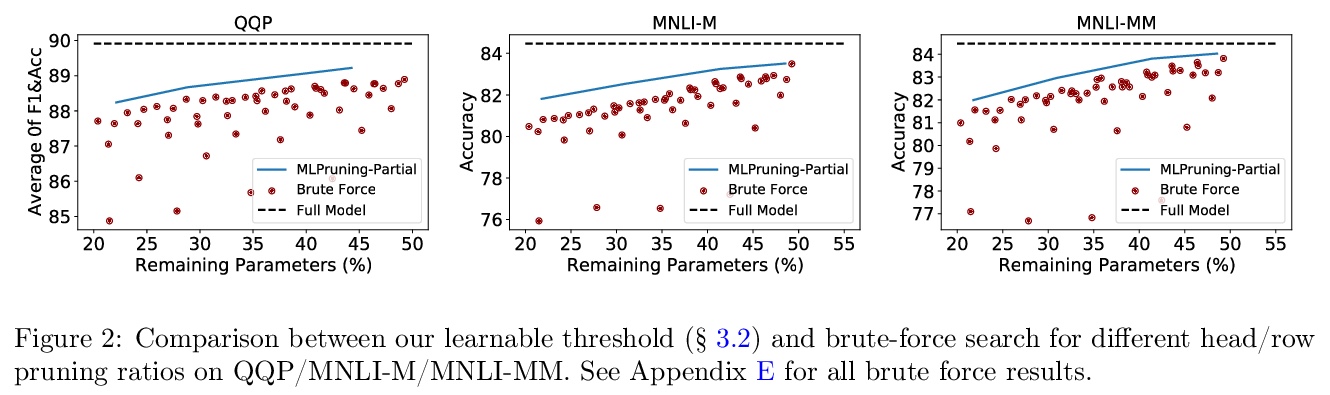
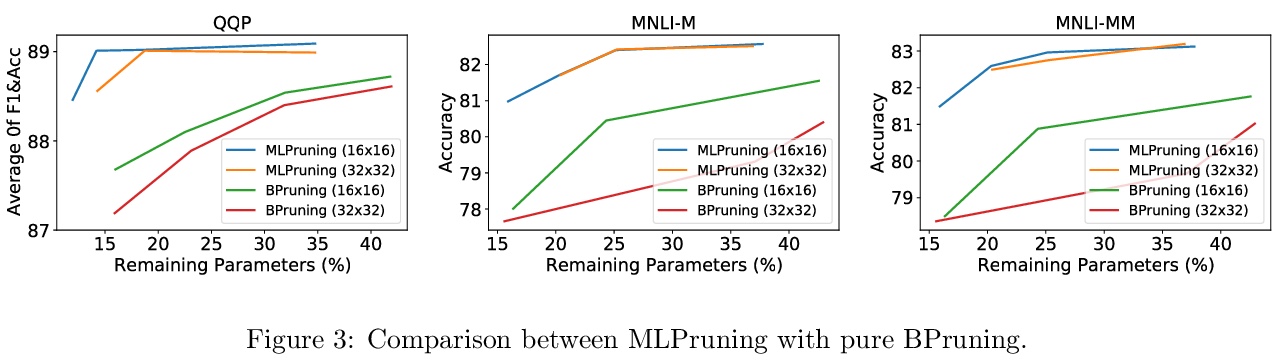
[CL] MLPruning: A Multilevel Structured Pruning Framework for Transformer-based Models
MLPruning:Transformer模型多层结构化剪枝框架
Z Yao, L Ma, S Shen, K Keutzer, M W. Mahoney
[UC Berkeley & University of Illinois at Urbana-Champaign]
https://weibo.com/1402400261/KiS7Bwfqx

若有收获,就点个赞吧
0 人点赞
