- 1、[CV] Memory-Efficient Semi-Supervised Continual Learning: The World is its Own Replay Buffer
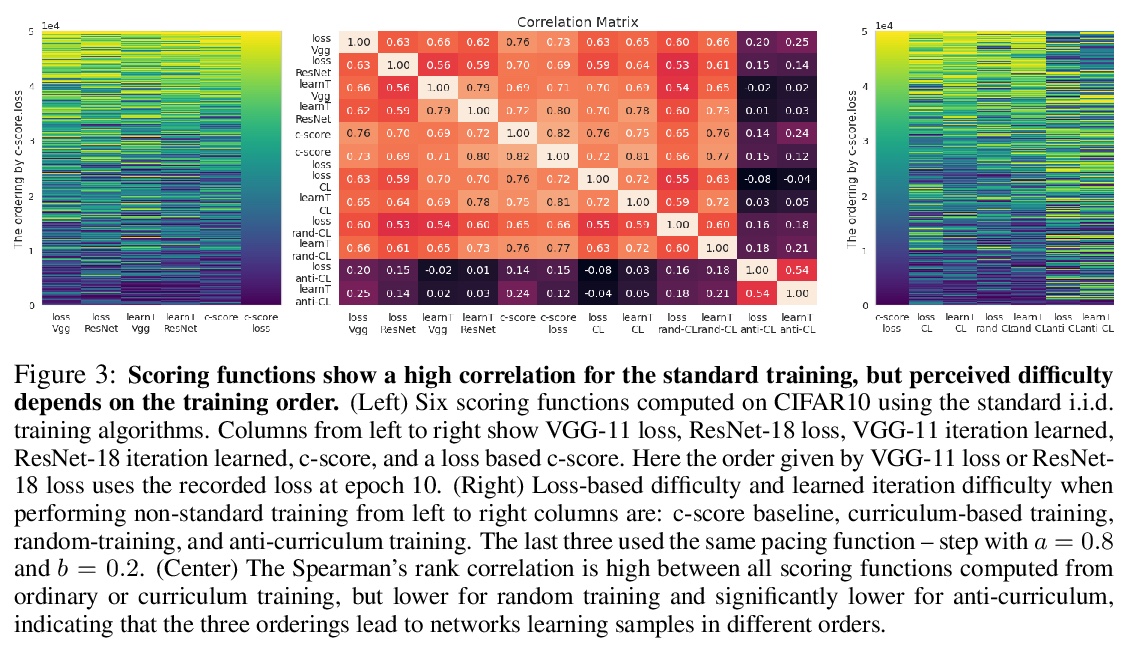
- 2、[LG] When Do Curricula Work?
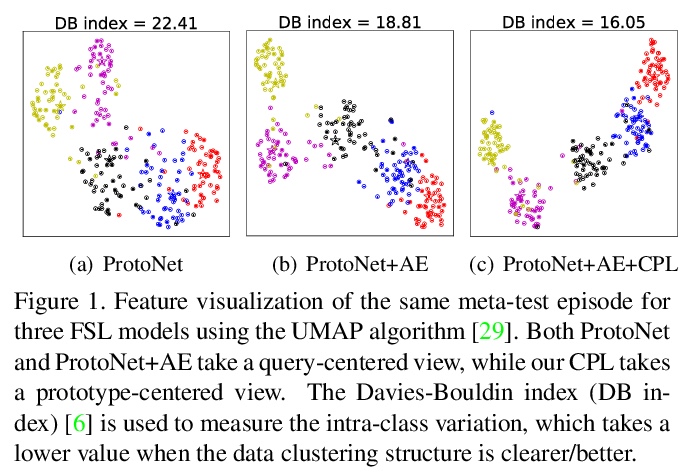
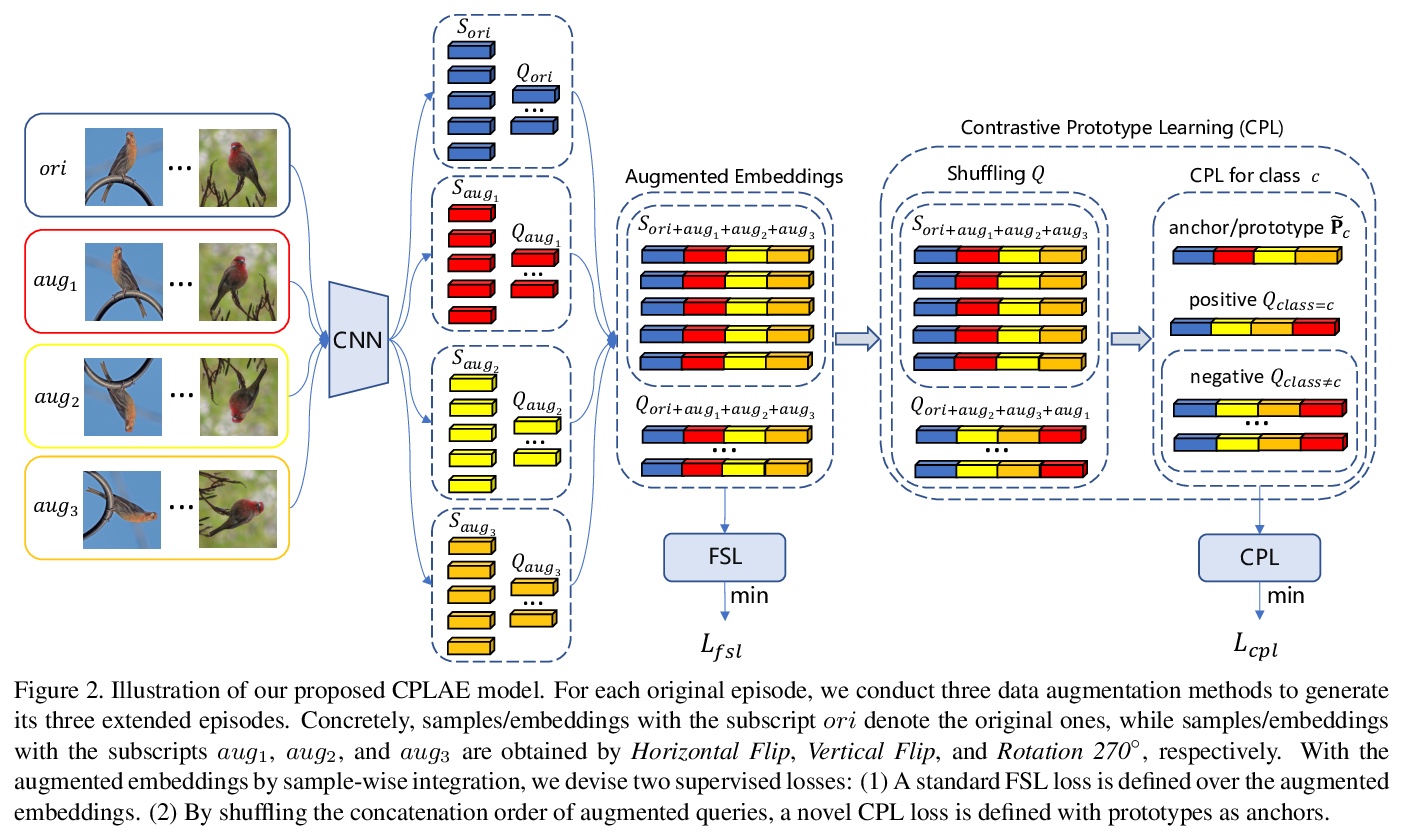
- 3、[CV] Contrastive Prototype Learning with Augmented Embeddings for Few-Shot Learning
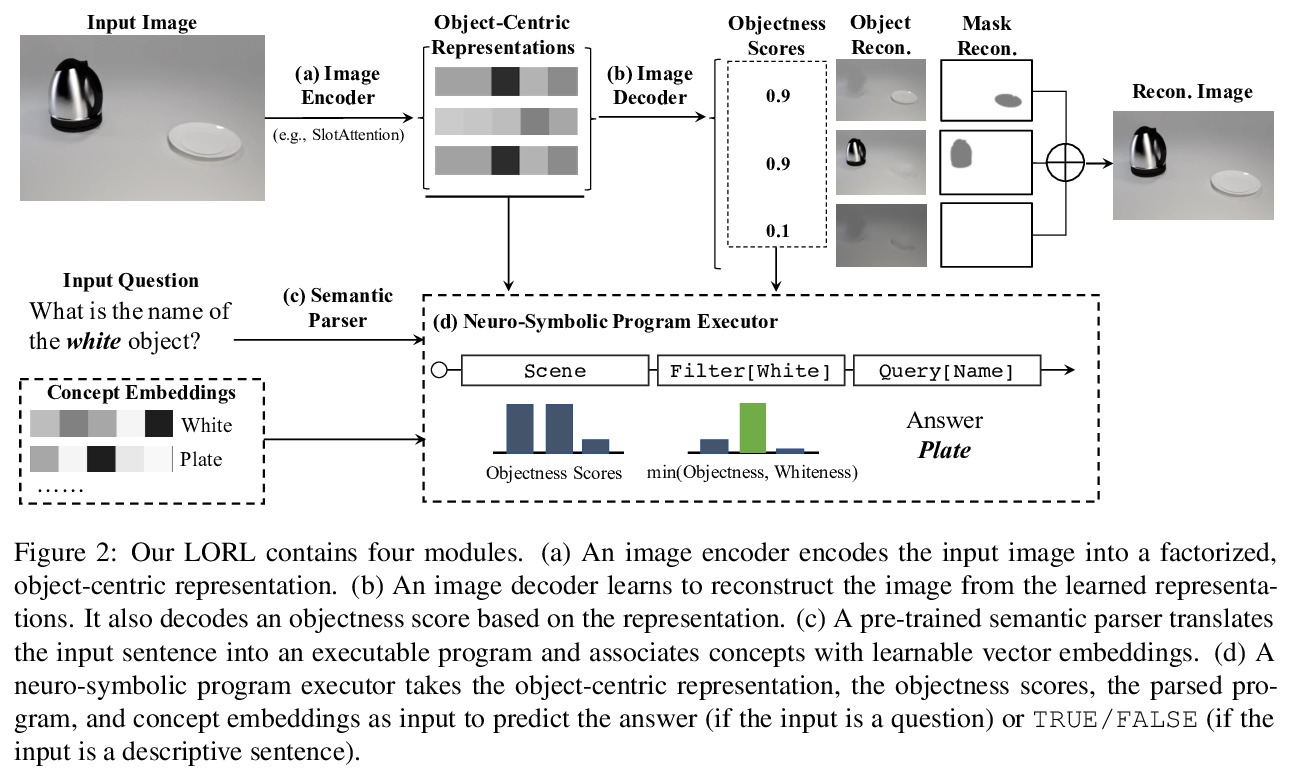
- 4、[LG] Language-Mediated, Object-Centric Representation Learning
- 5、[RO] A Framework for Efficient Robotic Manipulation
- [LG] Online Multivalid Learning: Means, Moments, and Prediction Intervals
- [CL] PAWLS: PDF Annotation With Labels and Structure
- [SI] Hypergraph clustering: from blockmodels to modularity
- [CL] Cross-lingual Visual Pre-training for Multimodal Machine Translation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Memory-Efficient Semi-Supervised Continual Learning: The World is its Own Replay Buffer
J Smith, J Balloch, Y Hsu, Z Kira
[Georgia Institute of Technology & Samsung Research America]
记忆高效的半监督持续学习:世界是它自己的重放缓冲器。针对类增量持续学习中复述(Rehearsal)需要大容量记忆的问题,提出半监督持续学习(SSCL)的概念,标记数据稀缺,但数据分布是真实的,通过标记超类结构来维持已标记和未标记集之间对象-对象相关性。提出用于SSCL环境的持续学习方法DistillMatch,基于伪标签、强数据增强、分布外检测和知识提炼等策略,可显著减少遗忘,与基线相比,在大多数指标上取得了优异的性能,并节省了大量的内存预算。
Rehearsal is a critical component for class-incremental continual learning, yet it requires a substantial memory budget. Our work investigates whether we can significantly reduce this memory budget by leveraging unlabeled data from an agent’s environment in a realistic and challenging continual learning paradigm. Specifically, we explore and formalize a novel semi-supervised continual learning (SSCL) setting, where labeled data is scarce yet non-i.i.d. unlabeled data from the agent’s environment is plentiful. Importantly, data distributions in the SSCL setting are realistic and therefore reflect object class correlations between, and among, the labeled and unlabeled data distributions. We show that a strategy built on pseudo-labeling, consistency regularization, Out-of-Distribution (OoD) detection, and knowledge distillation reduces forgetting in this setting. Our approach, DistillMatch, increases performance over the state-of-the-art by no less than 8.7% average task accuracy and up to a 54.5% increase in average task accuracy in SSCL CIFAR-100 experiments. Moreover, we demonstrate that DistillMatch can save up to 0.23 stored images per processed unlabeled image compared to the next best method which only saves 0.08. Our results suggest that focusing on realistic correlated distributions is a significantly new perspective, which accentuates the importance of leveraging the world’s structure as a continual learning strategy.
https://weibo.com/1402400261/JF3CwDM1z
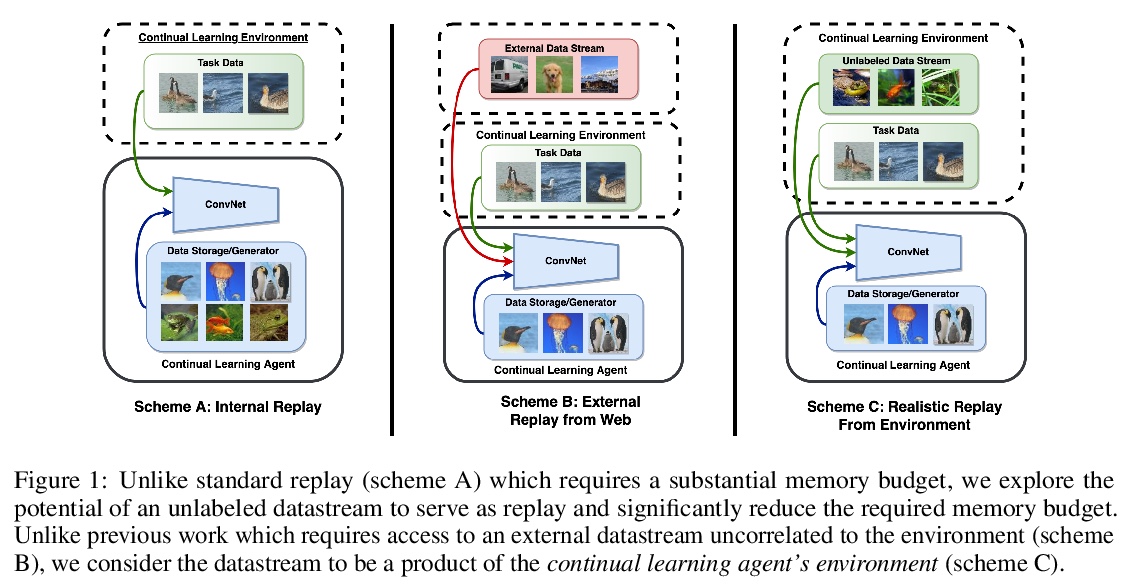
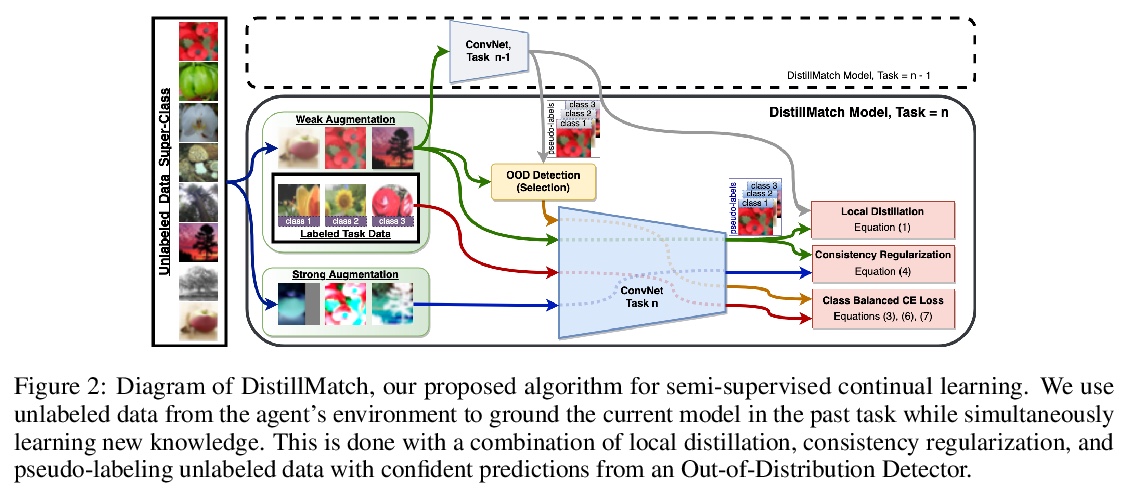
2、[LG] When Do Curricula Work?
X Wu, E Dyer, B Neyshabur
[University of Texas, Austin & Google]
关于课程(样本有序学习)有效性的实证研究。对数千次样本排序进行了大量实验,以研究三种学习方式的有效性:课程、反课程和随机课程(训练数据集大小随时间推移动态增加,样本随机排序)。结果表明,对标准基准数据集,课程集只有边际效益,而随机排序的样本表现与课程集和反课程集一样好、甚至更好,收益完全是由于动态训练集大小造成的。而在训练时间预算有限和存在噪声的嘈杂数据的情况下,课程学习比其他方法有明显的优势。
https://weibo.com/1402400261/JF3RubQZ8
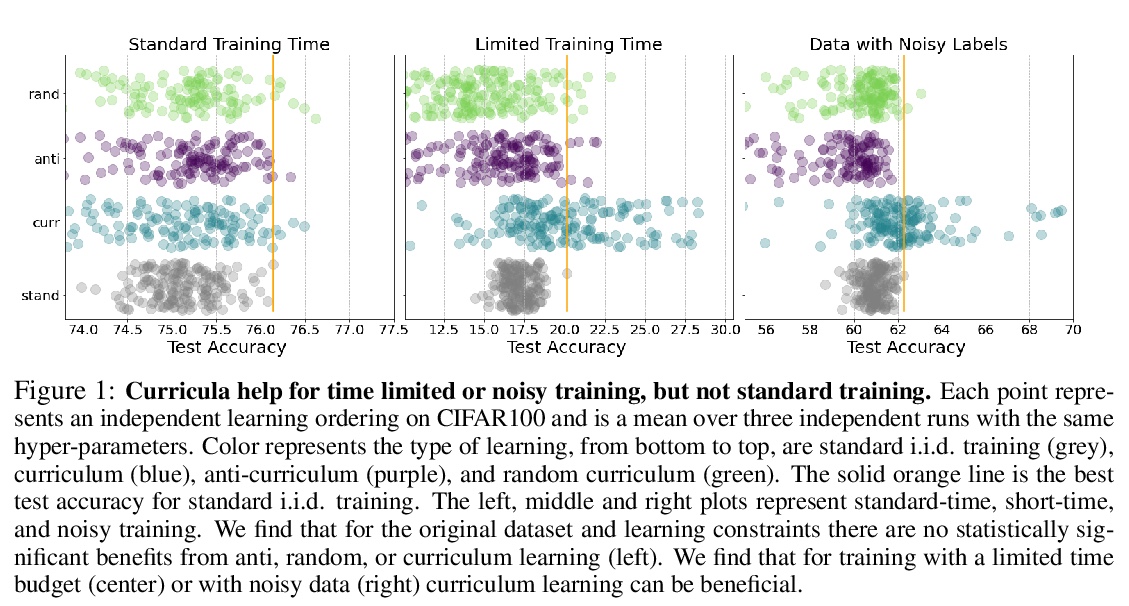
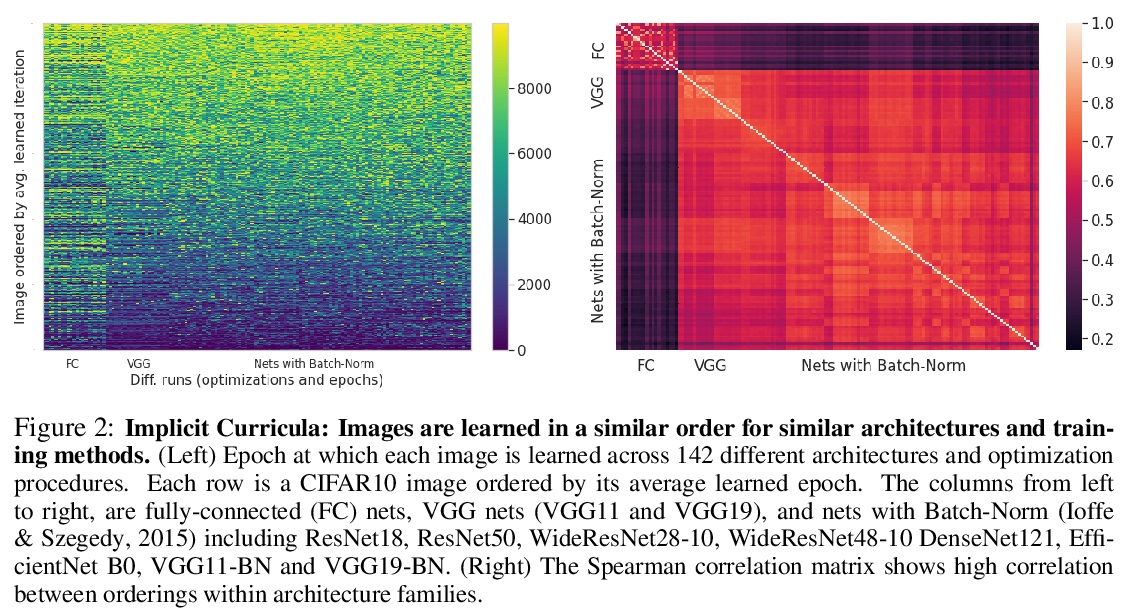
3、[CV] Contrastive Prototype Learning with Augmented Embeddings for Few-Shot Learning
Y Gao, N Fei, G Liu, Z Lu, T Xiang, S Huang
[Renmin University of China & University of Surrey & Alibaba Group]
基于增强嵌入对比原型学习的少样本学习。提出对比原型学习与增强嵌入(CPLAE)模型,用以解决少样本学习中训练数据缺乏的问题。与现有基于嵌入的元学习方法不同,引入了数据增强以形成增强嵌入空间,又引入了以支持集原型为中心的损失,作为传统查询中心化损失的补充。在三个广泛使用的基准上进行的大量实验表明,CPLAE达到了新的最先进水平,同时也表明,在有监督的和少样本的学习环境下,对比学习是有效的。
Most recent few-shot learning (FSL) methods are based on meta-learning with episodic training. In each meta-training episode, a discriminative feature embedding and/or classifier are first constructed from a support set in an inner loop, and then evaluated in an outer loop using a query set for model updating. This query set sample centered learning objective is however intrinsically limited in addressing the lack of training data problem in the support set. In this paper, a novel contrastive prototype learning with augmented embeddings (CPLAE) model is proposed to overcome this limitation. First, data augmentations are introduced to both the support and query sets with each sample now being represented as an augmented embedding (AE) composed of concatenated embeddings of both the original and augmented versions. Second, a novel support set class prototype centered contrastive loss is proposed for contrastive prototype learning (CPL). With a class prototype as an anchor, CPL aims to pull the query samples of the same class closer and those of different classes further away. This support set sample centered loss is highly complementary to the existing query centered loss, fully exploiting the limited training data in each episode. Extensive experiments on several benchmarks demonstrate that our proposed CPLAE achieves new state-of-the-art.
https://weibo.com/1402400261/JF3YY9r5R

4、[LG] Language-Mediated, Object-Centric Representation Learning
R Wang, J Mao, S J. Gershman, J Wu
[Stanford University & MIT CSAIL & Harvard University]
以语言为媒介,对象为中心的表示学习。重点研究语言如何支持目标分割,提出一种计算学习范式,即语言为媒介,以对象为中心的表示学习(LORL),将学习到的以对象为中心的表示与它们在图像中的视觉外观(蒙板),以及与语言中提供的概念—颜色、形状和材料等对象属性的词联系起来。LORL中,概念上相似的对象(如形状相似的对象)在嵌入空间中有聚类的趋势。在Shop-VRB-Simple和PartNet-Chairs上的实验表明,语言对学习更好的表示有显著贡献。这种行为在两种无监督的图像分割模型上是一致的。
We present Language-mediated, Object-centric Representation Learning (LORL), a paradigm for learning disentangled, object-centric scene representations from vision and language. LORL builds upon recent advances in unsupervised object segmentation, notably MONet and Slot Attention. While these algorithms learn an object-centric representation just by reconstructing the input image, LORL enables them to further learn to associate the learned representations to concepts, i.e., words for object categories, properties, and spatial relationships, from language input. These object-centric concepts derived from language facilitate the learning of object-centric representations. LORL can be integrated with various unsupervised segmentation algorithms that are language-agnostic. Experiments show that the integration of LORL consistently improves the object segmentation performance of MONet and Slot Attention on two datasets via the help of language. We also show that concepts learned by LORL, in conjunction with segmentation algorithms such as MONet, aid downstream tasks such as referring expression comprehension.
https://weibo.com/1402400261/JF43kfhrZ

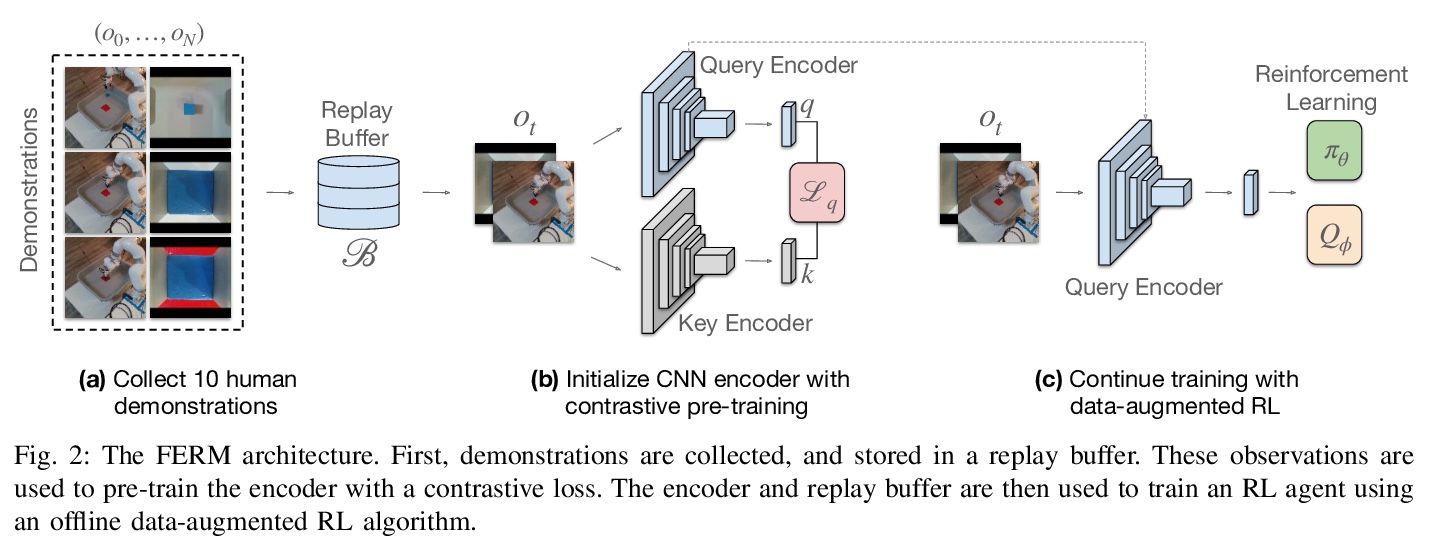
5、[RO] A Framework for Efficient Robotic Manipulation
A Zhan, P Zhao, L Pinto, P Abbeel, M Laskin
[UC Berkeley]
高效机器人操作框架。提出一个结合了演示、无监督学习和强化学习的框架FERM,利用数据增强和无监督学习,来实现具有稀疏奖励的机器人操纵策略的样本高效训练,学习现实世界中的复杂任务。只需给定10次演示,机械臂就能从像素中学习稀疏奖励的操纵策略,如伸手、拾取、移动、拉动大型物体、翻转开关和打开抽屉等,只需15-50分钟的真实世界训练时间。
Data-efficient learning of manipulation policies from visual observations is an outstanding challenge for real-robot learning. While deep reinforcement learning (RL) algorithms have shown success learning policies from visual observations, they still require an impractical number of real-world data samples to learn effective policies. However, recent advances in unsupervised representation learning and data augmentation significantly improved the sample efficiency of training RL policies on common simulated benchmarks. Building on these advances, we present a Framework for Efficient Robotic Manipulation (FERM) that utilizes data augmentation and unsupervised learning to achieve extremely sample-efficient training of robotic manipulation policies with sparse rewards. We show that, given only 10 demonstrations, a single robotic arm can learn sparse-reward manipulation policies from pixels, such as reaching, picking, moving, pulling a large object, flipping a switch, and opening a drawer in just 15-50 minutes of real-world training time. We include videos, code, and additional information on the project website.
https://weibo.com/1402400261/JF47x8ifI

另外几篇值得关注的论文:
[LG] Online Multivalid Learning: Means, Moments, and Prediction Intervals
在线多校验学习:均值、矩量和预测区间
V Gupta, C Jung, G Noarov, M M. Pai, A Roth
[University of Pennsylvania & Rice University ]
https://weibo.com/1402400261/JF3uNEdks

[CL] PAWLS: PDF Annotation With Labels and Structure
PAWLS:专门为PDF文档格式设计标签和结构标注工具
M Neumann, Z Shen, S Skjonsberg
[Allen Institute for Artificial Intelligence]
https://weibo.com/1402400261/JF3Mhdt7U



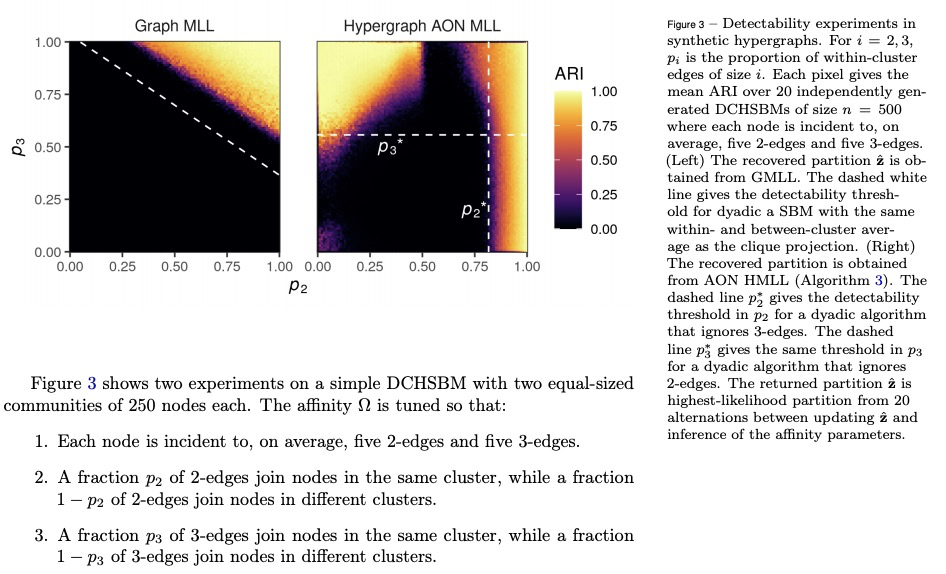
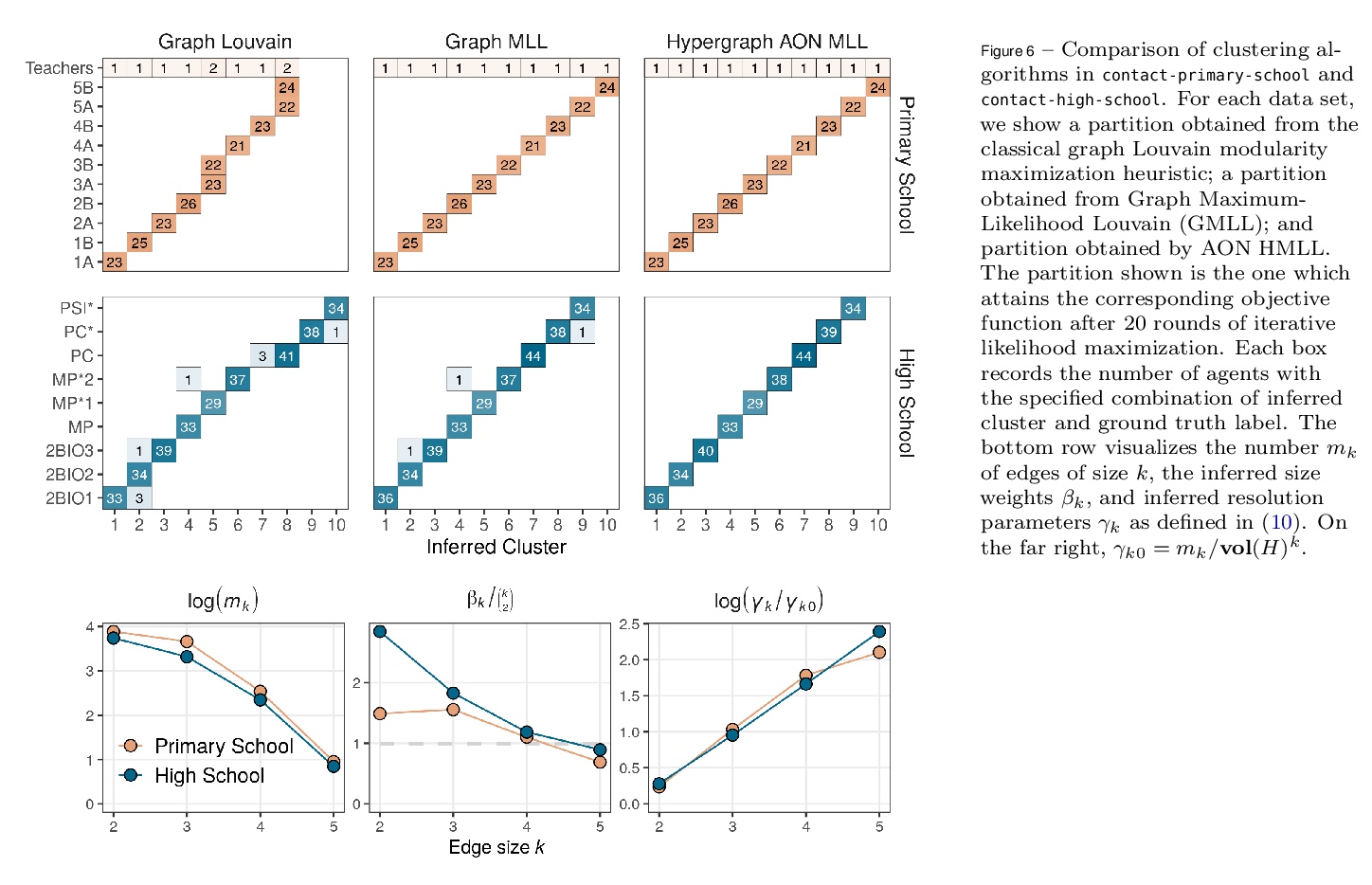
[SI] Hypergraph clustering: from blockmodels to modularity
超图聚类:从块模型到模块化
P S. Chodrow, N Veldt, A R. Benson
[University of California, Los Angeles & Cornell University]
https://weibo.com/1402400261/JF4bYx8vu
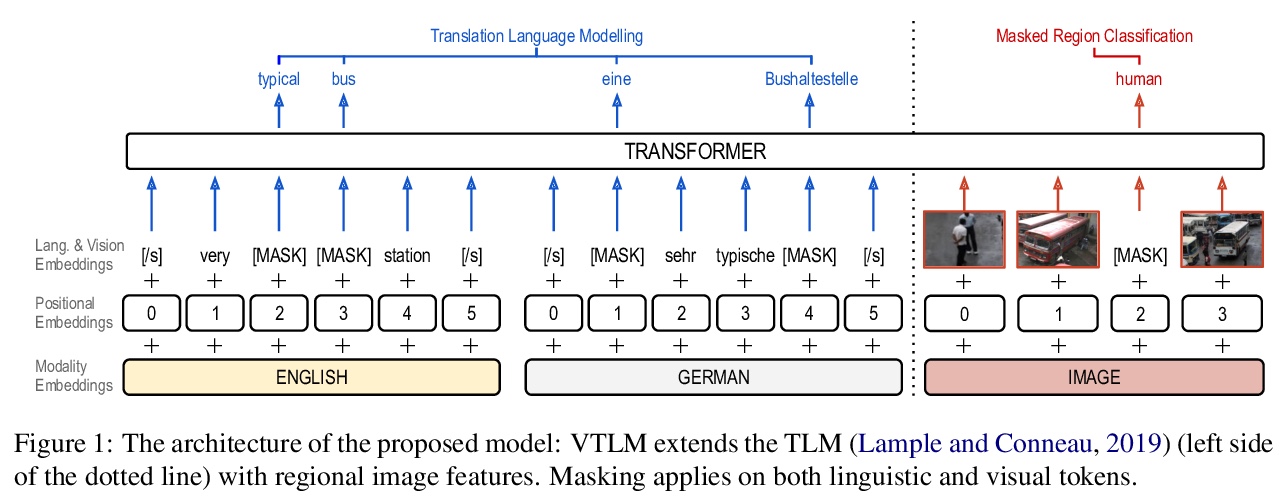
[CL] Cross-lingual Visual Pre-training for Multimodal Machine Translation
基于跨语言视觉预训练的多模态机器翻译
O Caglayan, M Kuyu, M S Amac, P Madhyastha, E Erdem, A Erdem, L Specia
[Imperial College London & Hacettepe University & Koc University]
https://weibo.com/1402400261/JF4dx8DY2

若有收获,就点个赞吧
0 人点赞
