- 1、[CL] Finetuning Pretrained Transformers into RNNs
- 2、[CV] Can Vision Transformers Learn without Natural Images?
- 3、[LG] FastMoE: A Fast Mixture-of-Expert Training System
- 4、[CV] Multi-view 3D Reconstruction with Transformer
- 5、[CV] One-Shot GAN: Learning to Generate Samples from Single Images and Videos
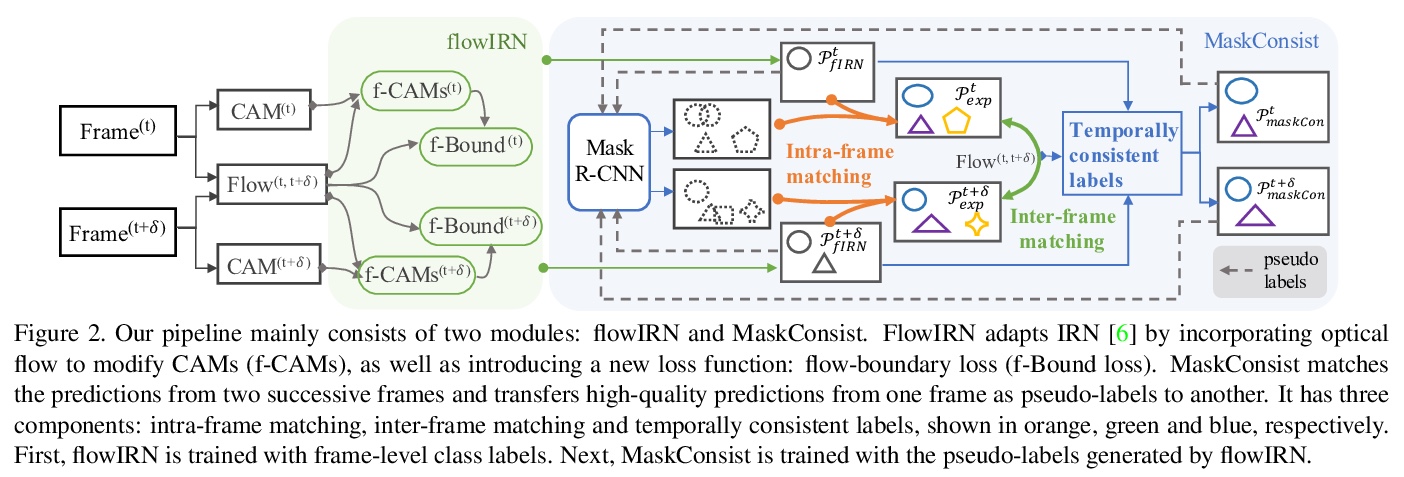
- [CV] Weakly Supervised Instance Segmentation for Videos with Temporal Mask Consistency
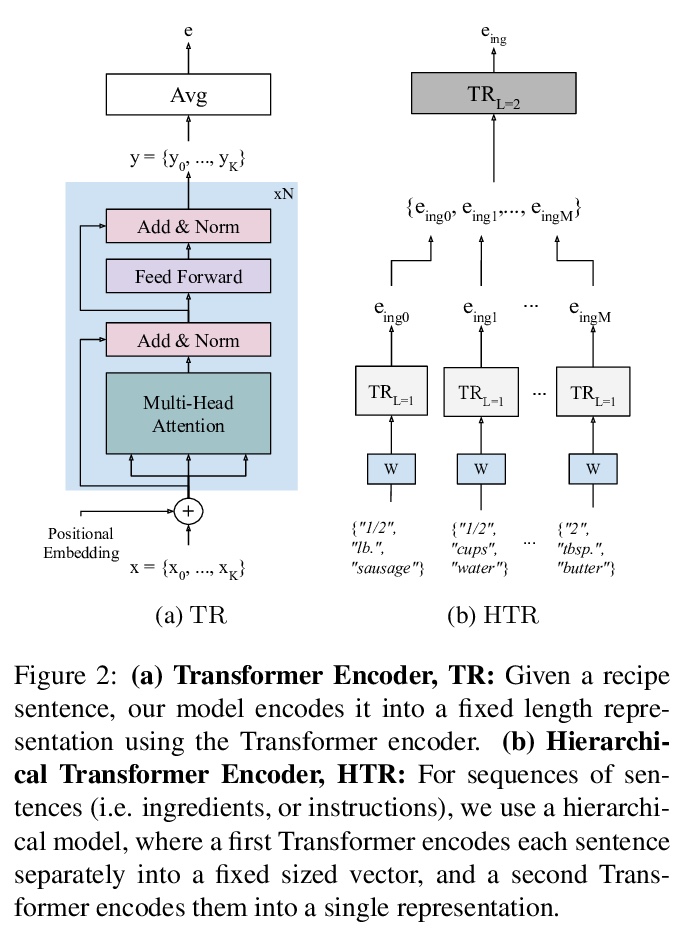
- [CV] Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning
- [CV] AcinoSet: A 3D Pose Estimation Dataset and Baseline Models for Cheetahs in the Wild
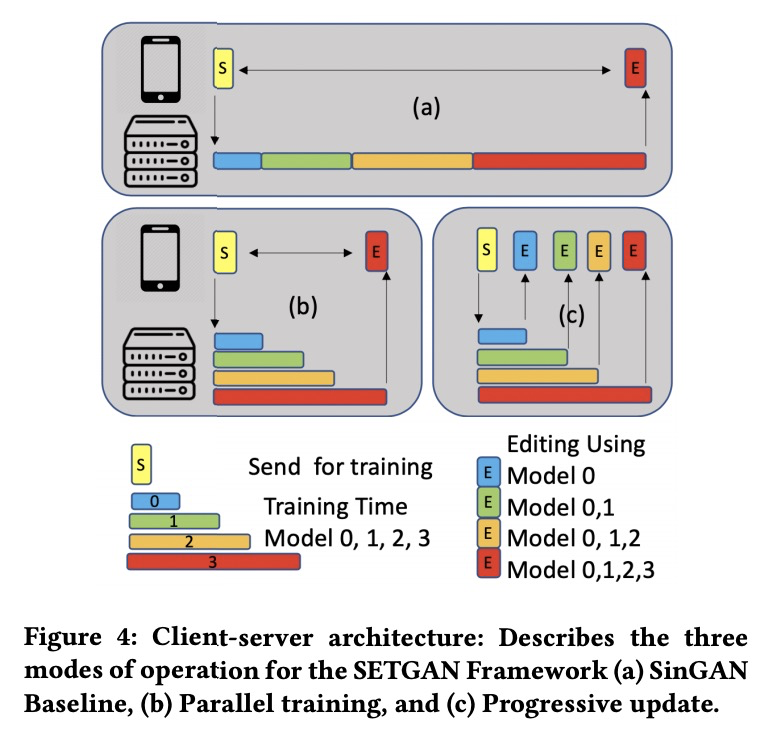
- [CV] SETGAN: Scale and Energy Trade-off GANs for Image Applications on Mobile Platforms
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] Finetuning Pretrained Transformers into RNNs
J Kasai, H Peng, Y Zhang, D Yogatama, G Ilharco, N Pappas, Y Mao, W Chen, N A. Smith
[University of Washington & Microsoft & DeepMind & Allen Institute for AI]
将预训练Transformer微调成RNN。提出T2S方法,用线性复杂度的递归对应模型替换softmax注意力,再进行微调,将预训练Transformer转换为其高效的递归对应模型,减少自回归生成的时间和内存成本,在保留精度的同时提高效率。通过学习到的特征图,T2S提供了比标准Transformer和其他递归变体更高的效率和准确性的权衡。与从头开始训练这些递归变体相比,微调需要的训练成本更低。
Transformers have outperformed recurrent neural networks (RNNs) in natural language generation. This comes with a significant computational overhead, as the attention mechanism scales with a quadratic complexity in sequence length. Efficient transformer variants have received increasing interest from recent works. Among them, a linear-complexity recurrent variant has proven well suited for autoregressive generation. It approximates the softmax attention with randomized or heuristic feature maps, but can be difficult to train or yield suboptimal accuracy. This work aims to convert a pretrained transformer into its efficient recurrent counterpart, improving the efficiency while retaining the accuracy. Specifically, we propose a swap-then-finetune procedure: in an off-the-shelf pretrained transformer, we replace the softmax attention with its linear-complexity recurrent alternative and then finetune. With a learned feature map, our approach provides an improved tradeoff between efficiency and accuracy over the standard transformer and other recurrent variants. We also show that the finetuning process needs lower training cost than training these recurrent variants from scratch. As many recent models for natural language tasks are increasingly dependent on large-scale pretrained transformers, this work presents a viable approach to improving inference efficiency without repeating the expensive pretraining process.
https://weibo.com/1402400261/K7UIPBfWD



2、[CV] Can Vision Transformers Learn without Natural Images?
K Nakashima, H Kataoka, A Matsumoto, K Iwata, N Inoue
[National Institute of Advanced Industrial Science and Technology (AIST) & Tokyo Institute of Technology]
视觉Transformer能在没有自然图像和人工标注的情况下完成预训练吗?提出公式驱动监督学习(FDSL)的框架,无需任何自然图像和人工注释即可训练视觉Transformer(ViT)。实验验证了所提出的框架在预训练阶段不使用任何自然图像的情况下,其性能部分优于SimCLRv2和MoCov2等复杂的自监督学习(SSL)方法。虽然不使用自然图像的ViT预训练产生的视觉与ImageNet预训练的ViT有些不同,但它可以在很大程度上解释自然图像数据集。
Can we complete pre-training of Vision Transformers (ViT) without natural images and human-annotated labels? Although a pre-trained ViT seems to heavily rely on a large-scale dataset and human-annotated labels, recent large-scale datasets contain several problems in terms of privacy violations, inadequate fairness protection, and labor-intensive annotation. In the present paper, we pre-train ViT without any image collections and annotation labor. We experimentally verify that our proposed framework partially outperforms sophisticated Self-Supervised Learning (SSL) methods like SimCLRv2 and MoCov2 without using any natural images in the pre-training phase. Moreover, although the ViT pre-trained without natural images produces some different visualizations from ImageNet pre-trained ViT, it can interpret natural image datasets to a large extent. For example, the performance rates on the CIFAR-10 dataset are as follows: our proposal 97.6 vs. SimCLRv2 97.4 vs. ImageNet 98.0.
https://weibo.com/1402400261/K7UNvv4uN



3、[LG] FastMoE: A Fast Mixture-of-Expert Training System
J He, J Qiu, A Zeng, Z Yang, J Zhai, J Tang
[Tsinghua University & Beijing Academy of Artificial Intelligence (BAAI)]
FASTMOE:快速Mixture-of-Experts模型训练系统。提出了FastMoE ,基于PyTorch与通用加速器的分布式Mixture-of-Experts模型训练系统。该系统提供了多层次的友好界面,供不同用户探索MoE架构的不同方面,既可以灵活设计模型,又可以轻松适应不同的应用,如Transformer-XL和Megatron-LM。与使用PyTorch直接实现MoE模型不同的是,FastMoE通过复杂的高性能加速对训练速度进行了高度优化。系统支持将不同的Expert放置在多个节点的多个GPU上,实现了Experts数量与GPU数量的线性放大。
Mixture-of-Expert (MoE) presents a strong potential in enlarging the size of language model to trillions of parameters. However, training trillion-scale MoE requires algorithm and system co-design for a well-tuned high performance distributed training system. Unfortunately, the only existing platform that meets the requirements strongly depends on Google’s hardware (TPU) and software (Mesh Tensorflow) stack, and is not open and available to the public, especially GPU and PyTorch communities.In this paper, we present FastMoE, a distributed MoE training system based on PyTorch with common accelerators. The system provides a hierarchical interface for both flexible model design and easy adaption to different applications, such as Transformer-XL and Megatron-LM. Different from direct implementation of MoE models using PyTorch, the training speed is highly optimized in FastMoE by sophisticated high-performance acceleration skills. The system supports placing different experts on multiple GPUs across multiple nodes, enabling enlarging the number of experts linearly against the number of GPUs. The source of FastMoE is available at > this https URL under Apache-2 license.
https://weibo.com/1402400261/K7UUooJWi




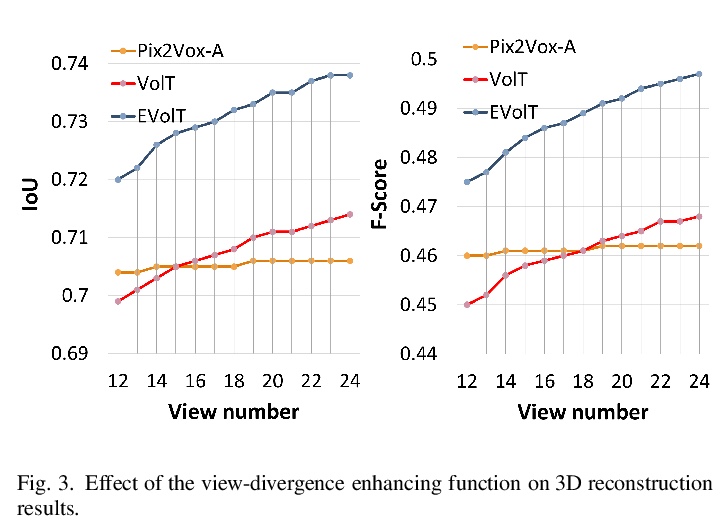
4、[CV] Multi-view 3D Reconstruction with Transformer
D Wang, X Cui, X Chen, Z Zou, T Shi, S Salcudean, Z. J Wang, R Ward
[University of British Columbia & University of Science and Technology of China & University of Michigan & NetEase Fuxi AI Lab]
基于Transformer的多视图3D重建。受最近基于自注意力的Transformer模型取得巨大成功的启发,将多视图3D重建重建重构为序列对序列预测问题,针对该任务提出一个新框架3D Volume Transformer(VolT)。与以往基于CNN的方法不同,将特征提取和视图融合统一在一个Transformer网络中。利用多个无序输入之间的自注意力探索视图之间的关系。提出了三个版本的方法(VolT、VolT+和EVolT)来探索多视图3D重建的视图和空间域关系。探讨了深度多视角信息的发散衰减问题,并提出了视图发散增强函数来进行缓解。在大规模3D重建基准数据集ShapeNet上,该方法比其他基于CNN的方法以更少的参数(减少70%)在多视图重建中达到了新的最先进精度。
Deep CNN-based methods have so far achieved the state of the art results in multi-view 3D object reconstruction. Despite the considerable progress, the two core modules of these methods - multi-view feature extraction and fusion, are usually investigated separately, and the object relations in different views are rarely explored. In this paper, inspired by the recent great success in self-attention-based Transformer models, we reformulate the multi-view 3D reconstruction as a sequence-to-sequence prediction problem and propose a new framework named 3D Volume Transformer (VolT) for such a task. Unlike previous CNN-based methods using a separate design, we unify the feature extraction and view fusion in a single Transformer network. A natural advantage of our design lies in the exploration of view-to-view relationships using self-attention among multiple unordered inputs. On ShapeNet - a large-scale 3D reconstruction benchmark dataset, our method achieves a new state-of-the-art accuracy in multi-view reconstruction with fewer parameters (> 70% less) than other CNN-based methods. Experimental results also suggest the strong scaling capability of our method. Our code will be made publicly available.
https://weibo.com/1402400261/K7UYhx4S8



5、[CV] One-Shot GAN: Learning to Generate Samples from Single Images and Videos
V Sushko, J Gall, A Khoreva
[Bosch Center for Artificial Intelligence & University of Bonn]
One-Shot GAN:从单张图片和视频中学习样本生成。提出了新的无条件生成模型One-Shot GAN,可学习从单个训练图像或视频片段中生成样本。提出一个双分支判别器架构,其中内容和布局分支被设计成分别判断内在内容和场景布局的真实性。这样就可以在保留原始样本背景的前提下,合成视觉上可信的、具有不同内容和布局的新场景组合。与之前的单图像GAN模型相比,One-Shot GAN可以生成更多样、更高质量的图像,同时也不局限于单一的图像设置。
Given a large number of training samples, GANs can achieve remarkable performance for the image synthesis task. However, training GANs in extremely low-data regimes remains a challenge, as overfitting often occurs, leading to memorization or training divergence. In this work, we introduce One-Shot GAN, an unconditional generative model that can learn to generate samples from a single training image or a single video clip. We propose a two-branch discriminator architecture, with content and layout branches designed to judge internal content and scene layout realism separately from each other. This allows synthesis of visually plausible, novel compositions of a scene, with varying content and layout, while preserving the context of the original sample. Compared to previous single-image GAN models, One-Shot GAN generates more diverse, higher quality images, while also not being restricted to a single image setting. We show that our model successfully deals with other one-shot regimes, and introduce a new task of learning generative models from a single video.
https://weibo.com/1402400261/K7V2bzKLc



另外几篇值得关注的论文:
[CV] Weakly Supervised Instance Segmentation for Videos with Temporal Mask Consistency
具有时间掩模一致性的视频弱监督实例分割
Q Liu, V Ramanathan, D Mahajan, A Yuille, Z Yang
[Johns Hopkins University & Facebook]
https://weibo.com/1402400261/K7V70zOIa


[CV] Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning
利用分层Transformer和自监督学习改进跨模态食谱检索
A Salvador, E Gundogdu, L Bazzani, M Donoser
[Amazon]
https://weibo.com/1402400261/K7V83Aj2f


[CV] AcinoSet: A 3D Pose Estimation Dataset and Baseline Models for Cheetahs in the Wild
D Joska, L Clark, N Muramatsu, R Jericevich, F Nicolls, A Mathis, M W. Mathis, A Patel
[University of Cape Town & University of Tsukuba]
AcinoSet:猎豹3D姿态估计数据集和基线模型
https://weibo.com/1402400261/K7V9CcVoF



[CV] SETGAN: Scale and Energy Trade-off GANs for Image Applications on Mobile Platforms
SETGAN:移动平台GAN图像应用规模与能耗的权衡
N K Jayakodi, J R Doppa, P P Pande
[Washington State University]
https://weibo.com/1402400261/K7VbUlS97



若有收获,就点个赞吧
0 人点赞
