LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] *Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus
I Caswell, T Breiner, D v Esch, A Bapna
[Google Research]
1000种语言Web文本语料库真实场景语种识别(LangID)。LangID绝不是个已解决的问题,n-gram模型比普遍认为的要糟糕得多。本文分析了由n-gram模型缺陷、域不匹配、大量类不平衡、语言相似性和模型表达不足等原因所引发的各种错误模式,提出两类技术以减少错误:基于词列表的可调精度过滤器(为其发布了约500种语言的详细列表)和基于Transformer的半监督LangID模型,可将数据集的中值精度从5.5%提高到71.2%。
Large text corpora are increasingly important for a wide variety of Natural Language Processing (NLP) tasks, and automatic language identification (LangID) is a core technology needed to collect such datasets in a multilingual context. LangID is largely treated as solved in the literature, with models reported that achieve over 90% average F1 on as many as 1,366 languages. We train LangID models on up to 1,629 languages with comparable quality on held-out test sets, but find that human-judged LangID accuracy for web-crawl text corpora created using these models is only around 5% for many lower-resource languages, suggesting a need for more robust evaluation. Further analysis revealed a variety of error modes, arising from domain mismatch, class imbalance, language similarity, and insufficiently expressive models. We propose two classes of techniques to mitigate these errors: wordlist-based tunable-precision filters (for which we release curated lists in about 500 languages) and transformer-based semi-supervised LangID models, which increase median dataset precision from 5.5% to 71.2%. These techniques enable us to create an initial data set covering 100K or more relatively clean sentences in each of 500+ languages, paving the way towards a 1,000-language web text corpus.
https://weibo.com/1402400261/JrFX46Jkm
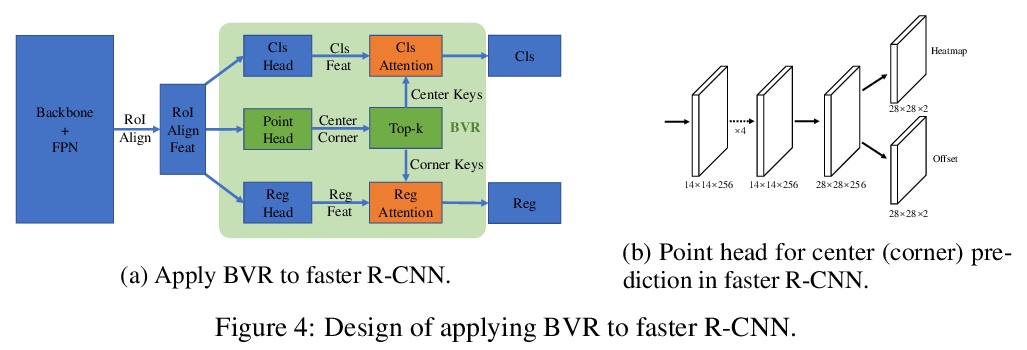
2、[CV] RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder
C Chi, F Wei, H Hu
[CAS & Microsoft Research Asia]
RelationNet++: 用Transformer解码器综合目标检测视觉表示。提出基于注意力的解码器模块BVR,类似于Transformer,以端到端的方式,将其他视觉表示方式,综合进构建在单一表示格式上的典型目标检测器。BVR在主流目标检测框架上显示出广泛的有效性,可实现1.5 ~ 3.0的AP提高。
Existing object detection frameworks are usually built on a single format of object/part representation, i.e., anchor/proposal rectangle boxes in RetinaNet and Faster R-CNN, center points in FCOS and RepPoints, and corner points in CornerNet. While these different representations usually drive the frameworks to perform well in different aspects, e.g., better classification or finer localization, it is in general difficult to combine these representations in a single framework to make good use of each strength, due to the heterogeneous or non-grid feature extraction by different representations. This paper presents an attention-based decoder module similar as that in Transformer~\cite{vaswani2017attention} to bridge other representations into a typical object detector built on a single representation format, in an end-to-end fashion. The other representations act as a set of \emph{key} instances to strengthen the main \emph{query} representation features in the vanilla detectors. Novel techniques are proposed towards efficient computation of the decoder module, including a \emph{key sampling} approach and a \emph{shared location embedding} approach. The proposed module is named \emph{bridging visual representations} (BVR). It can perform in-place and we demonstrate its broad effectiveness in bridging other representations into prevalent object detection frameworks, including RetinaNet, Faster R-CNN, FCOS and ATSS, where about > 1.5∼3.0 AP improvements are achieved. In particular, we improve a state-of-the-art framework with a strong backbone by about > 2.0 AP, reaching > 52.7 AP on COCO test-dev. The resulting network is named RelationNet++. The code will be available at > this https URL.
https://weibo.com/1402400261/JrG3FgvFs


3、[LG] **Understanding the Failure Modes of Out-of-Distribution Generalization
V Nagarajan, A Andreassen, B Neyshabur
[CMU & Google]
理解分布外泛化的失败模式。发现训练中的伪相关性,会在训练集引起两种不同的偏斜,一种是几何的,一种是统计的,会以互补的方式,让梯度下降经验风险最小化(ERM)依赖于伪相关性。
Empirical studies suggest that machine learning models often rely on features, such as the background, that may be spuriously correlated with the label only during training time, resulting in poor accuracy during test-time. In this work, we identify the fundamental factors that give rise to this behavior, by explaining why models fail this way {\em even} in easy-to-learn tasks where one would expect these models to succeed. In particular, through a theoretical study of gradient-descent-trained linear classifiers on some easy-to-learn tasks, we uncover two complementary failure modes. These modes arise from how spurious correlations induce two kinds of skews in the data: one geometric in nature, and another, statistical in nature. Finally, we construct natural modifications of image classification datasets to understand when these failure modes can arise in practice. We also design experiments to isolate the two failure modes when training modern neural networks on these datasets.
https://weibo.com/1402400261/JrGhY2U6y

 **
**
4、[LG] **Probabilistic Transformers
J R. Movellan
[Apple]
Transformer的概率解释。证明了Transformer是混合高斯模型的最大后验概率估计。**
We show that Transformers are Maximum Posterior Probability estimators for Mixtures of Gaussian Models. This brings a probabilistic point of view to Transformers and suggests extensions to other probabilistic cases.
https://weibo.com/1402400261/JrGoDd8Wo
5、[LG] *γ-Models: Generative Temporal Difference Learning for Infinite-Horizon Prediction
M Janner, I Mordatch, S Levine
[UC Berkeley & Google Brain]
γ模型——生成式时间差分学习无终止预测。利用时间差分学习的生成式自适应,训练无限概率野环境动力学预测模型。所得模型是无模型和基于模型机制的混合。像价值函数一样,包含关于长期的未来的信息;像标准的预测模型一样,独立于任务奖励。
We introduce the > γ-model, a predictive model of environment dynamics with an infinite probabilistic horizon. Replacing standard single-step models with > γ-models leads to generalizations of the procedures that form the foundation of model-based control, including the model rollout and model-based value estimation. The > γ-model, trained with a generative reinterpretation of temporal difference learning, is a natural continuous analogue of the successor representation and a hybrid between model-free and model-based mechanisms. Like a value function, it contains information about the long-term future; like a standard predictive model, it is independent of task reward. We instantiate the > γ-model as both a generative adversarial network and normalizing flow, discuss how its training reflects an inescapable tradeoff between training-time and testing-time compounding errors, and empirically investigate its utility for prediction and control.
https://weibo.com/1402400261/JrFPgEYx7

其他几篇值得关注的论文:
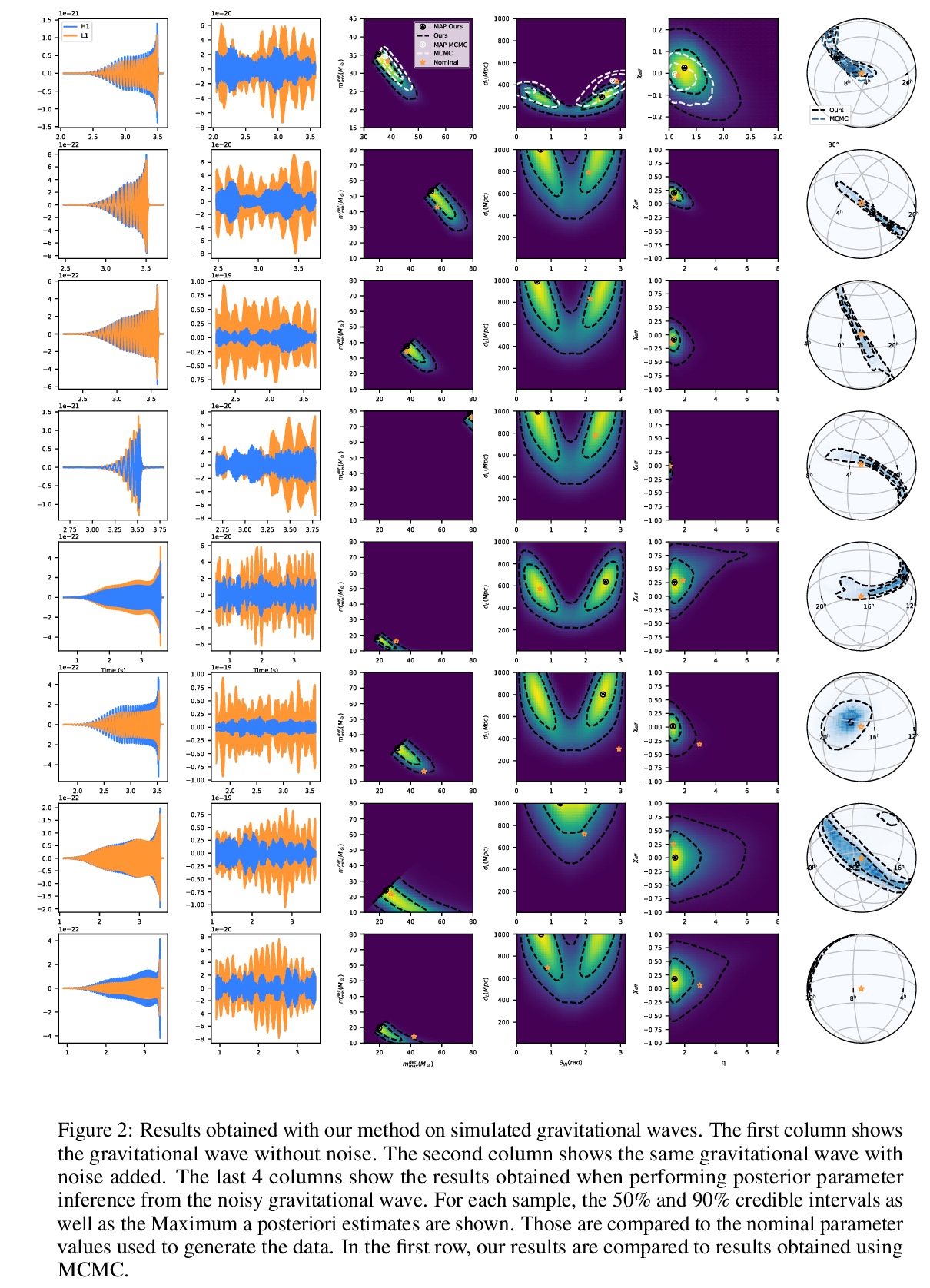
[LG] Lightning-Fast Gravitational Wave Parameter Inference through Neural Amortization
用神经网络高效推断引力波参数(加速三个数量级)
A Delaunoy, A Wehenkel, T Hinderer, S Nissanke, C Weniger, A R. Williamson, G Louppe
[University of Liège & University of Amsterdam & University of Portsmouth]
https://weibo.com/1402400261/JrGsFrIPz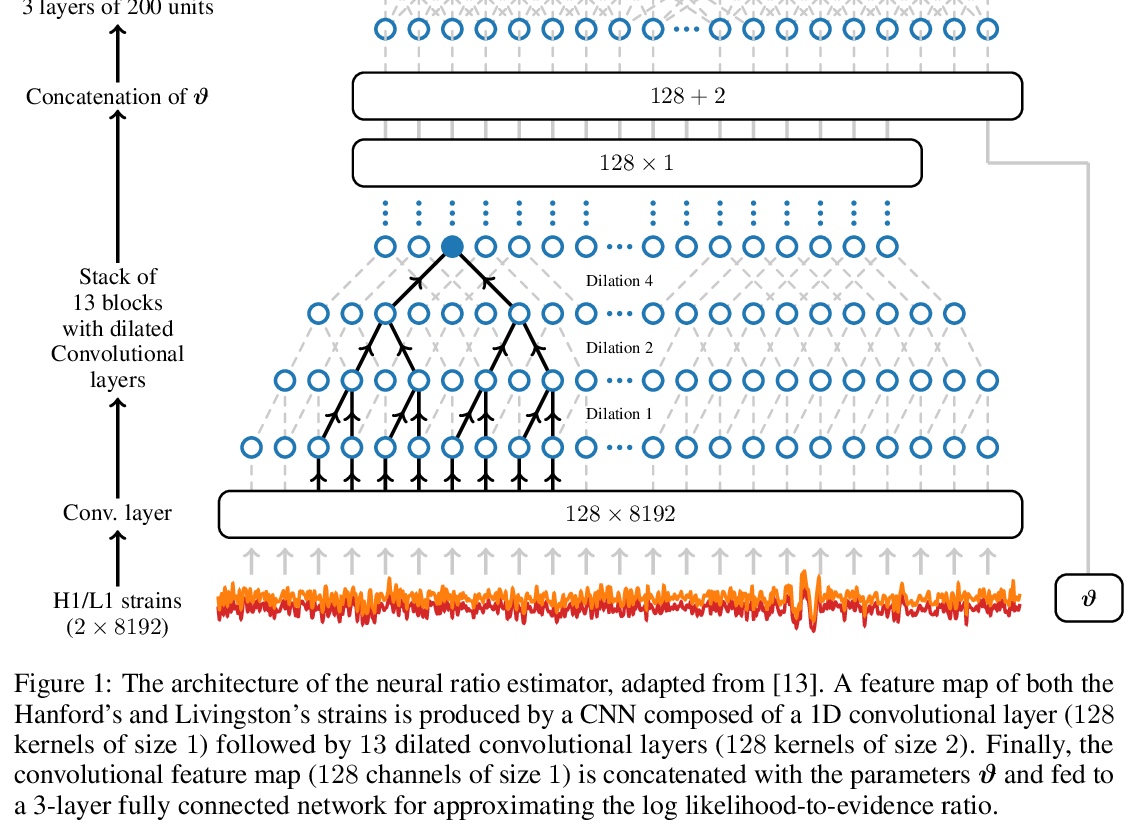
[CV] Cream of the Crop: Distilling Prioritized Paths For One-Shot Neural Architecture Search
百里挑一:One-Shot神经网络架构搜索优先路径蒸馏
H Peng, H Du, H Yu, Q Li, J Liao, J Fu
[Microsoft Research Asia & City University of Hong Kong & Chinese Academy of Sciences & Tsinghua University]
https://weibo.com/1402400261/JrGuKhRna

[LG] Matern Gaussian Processes on Graphs
图上的Matern高斯过程
V Borovitskiy, I Azangulov, A Terenin, P Mostowsky, M P Deisenroth, N Durrande
[St. Petersburg State University & Imperial College London]
https://weibo.com/1402400261/JrGyiFIe7


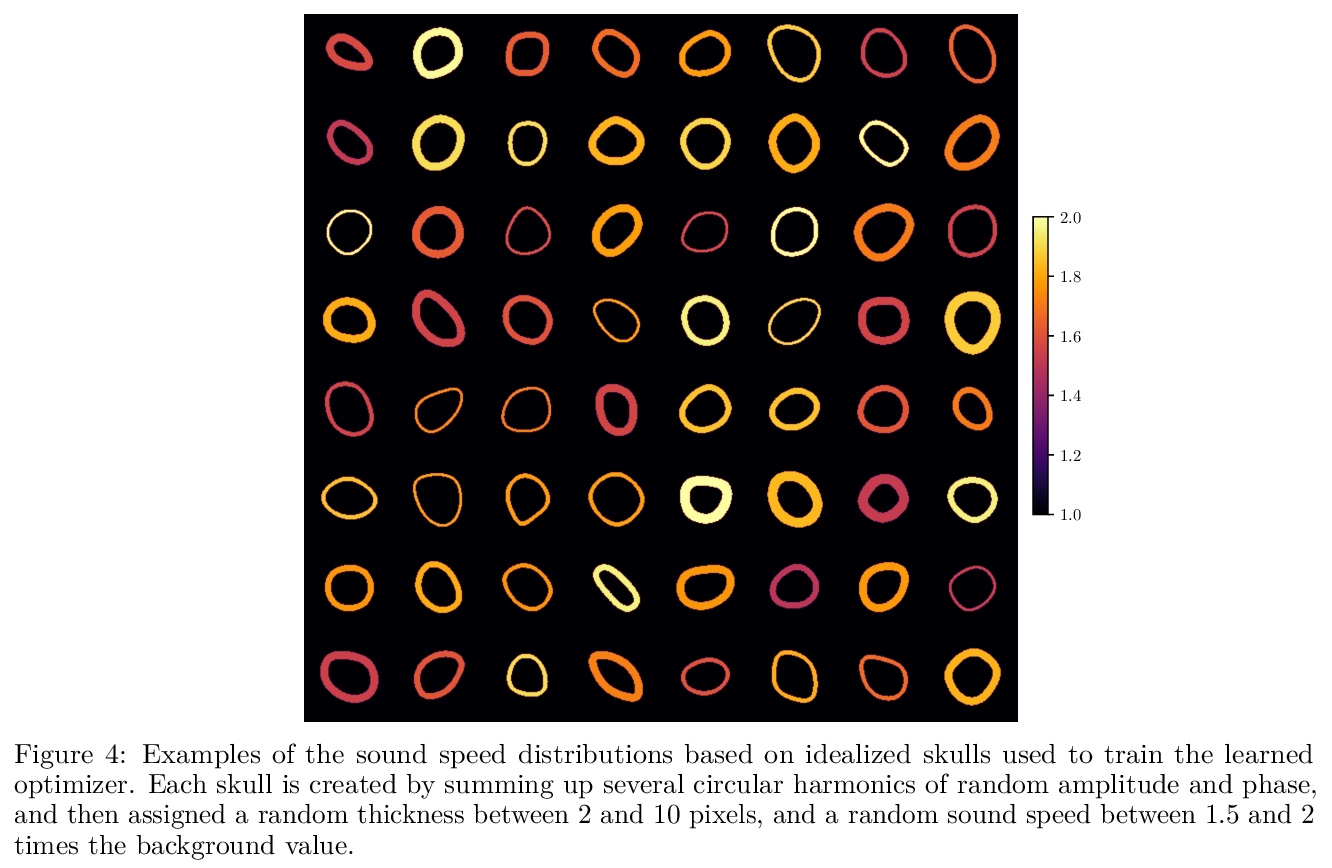
[LG] A Helmholtz equation solver using unsupervised learning: Application to transcranial ultrasound
无监督学习Helmholtz方程求解器:经颅超声应用
A Stanziola, S R. Arridge, B T. Cox, B E. Treeby
[University College of London]
https://weibo.com/1402400261/JrGCK9aQ2


[LG]Semi-Supervised Speech Recognition via Graph-based Temporal Classification
图时域分类半监督语音识别
N Moritz, T Hori, J L Roux
[Mitsubishi Electric Research Laboratories (MERL)]
https://weibo.com/1402400261/JrGHebx6g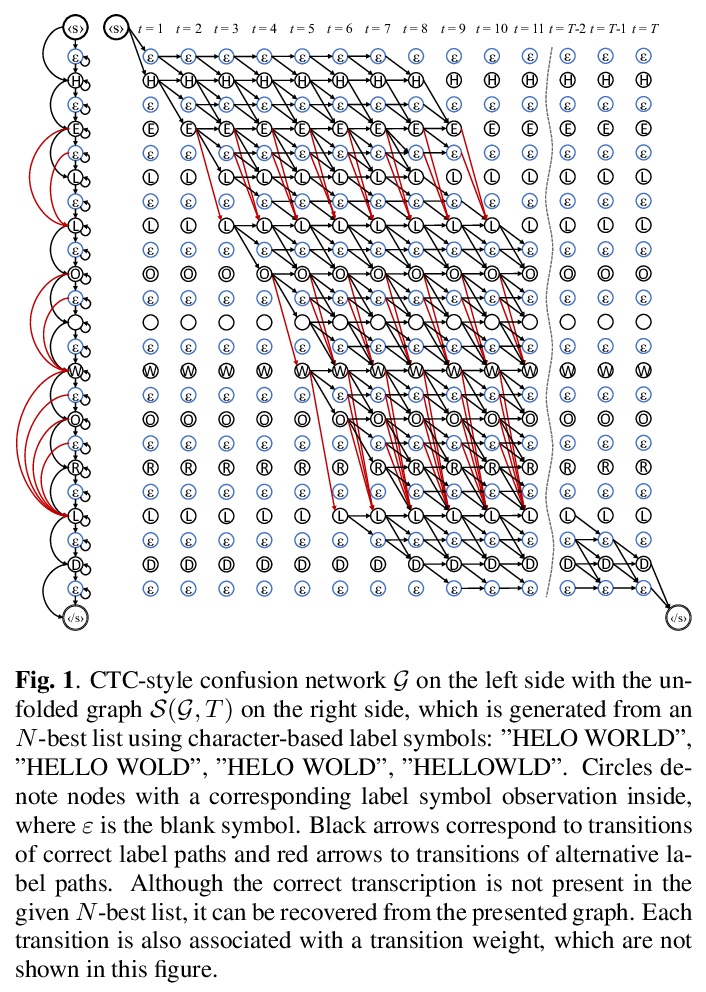

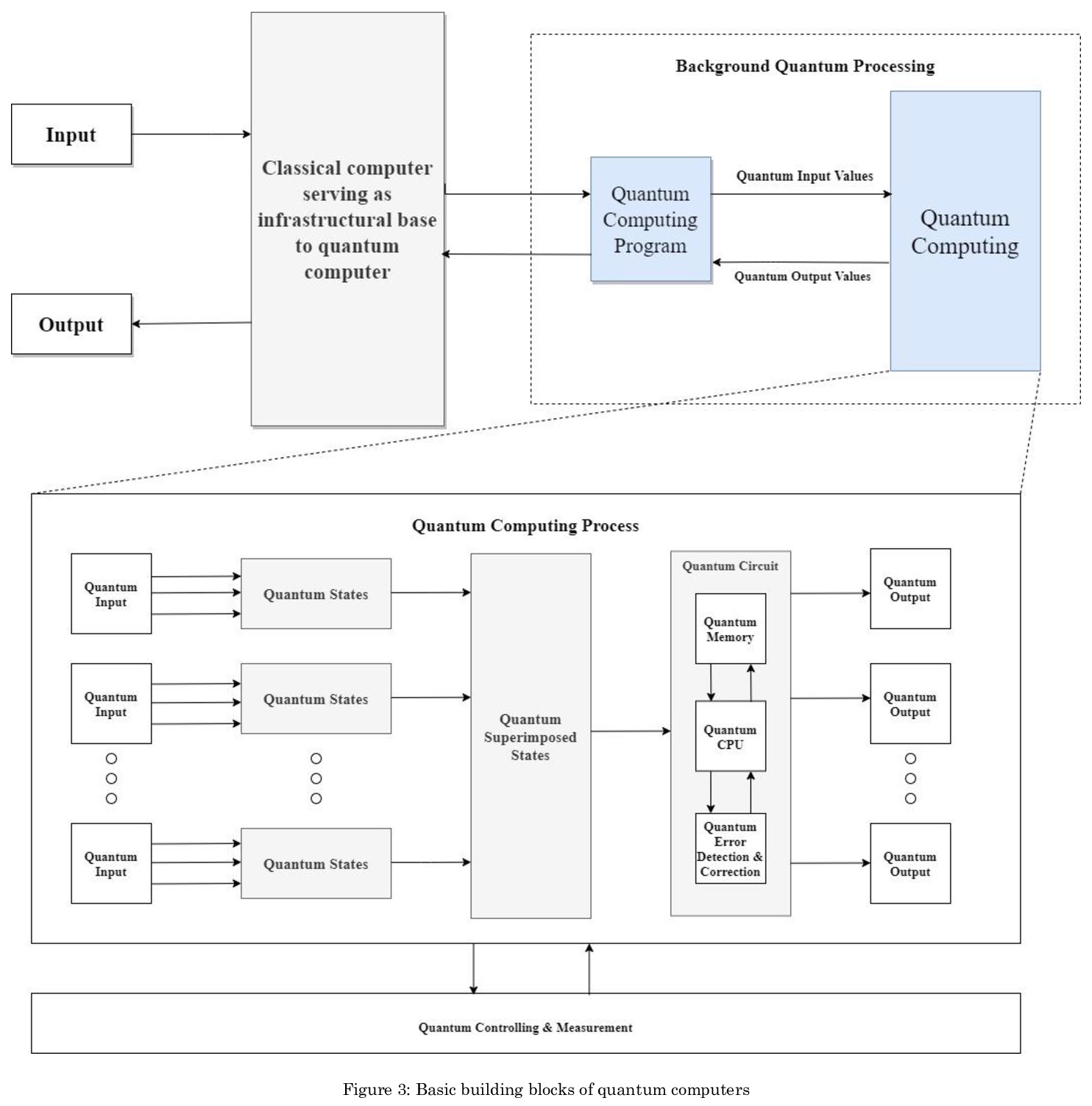
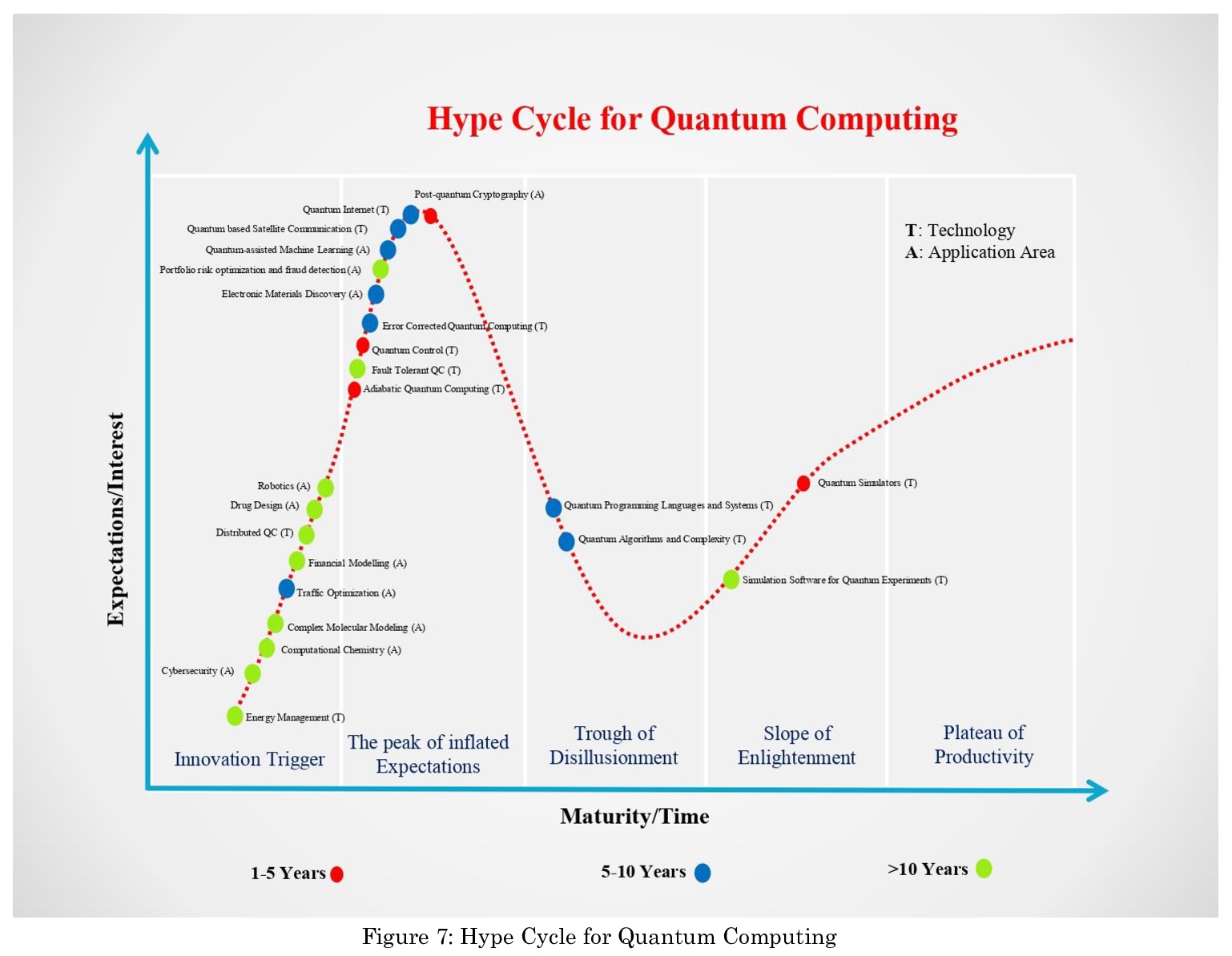
Quantum Computing: A Taxonomy, Systematic Review and Future Directions
量子计算:分类、系统综述与未来方向
S S Gill, A Kumar, H Singh, M Singh, K Kaur, M Usman, R Buyya
[Queen Mary University of London & University of Petroleum and Energy Studies & India and Indian Institute of Technology (IIT) & Qualite & SoftThe University of Melbourne]
https://weibo.com/1402400261/JrGGjuEFr





若有收获,就点个赞吧
0 人点赞
