- 1、[CV] How to represent part-whole hierarchies in a neural network
- 2、[CV] IBRNet: Learning Multi-View Image-Based Rendering
- 3、[CV] AniGAN: Style-Guided Generative Adversarial Networks for Unsupervised Anime Face Generation
- 4、[CL] Investigating the Limitations of the Transformers with Simple Arithmetic Tasks
- 5、[AI] Modular Object-Oriented Games: A Task Framework for Reinforcement Learning, Psychology, and Neuroscience
- [LG] Visualizing MuZero Models
- [CL] A Primer on Contrastive Pretraining in Language Processing: Methods, Lessons Learned and Perspectives
- [LG] Task-Agnostic Morphology Evolution
- [LG] SparseBERT: Rethinking the Importance Analysis in Self-attention
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] How to represent part-whole hierarchies in a neural network
G Hinton
[Google Research]
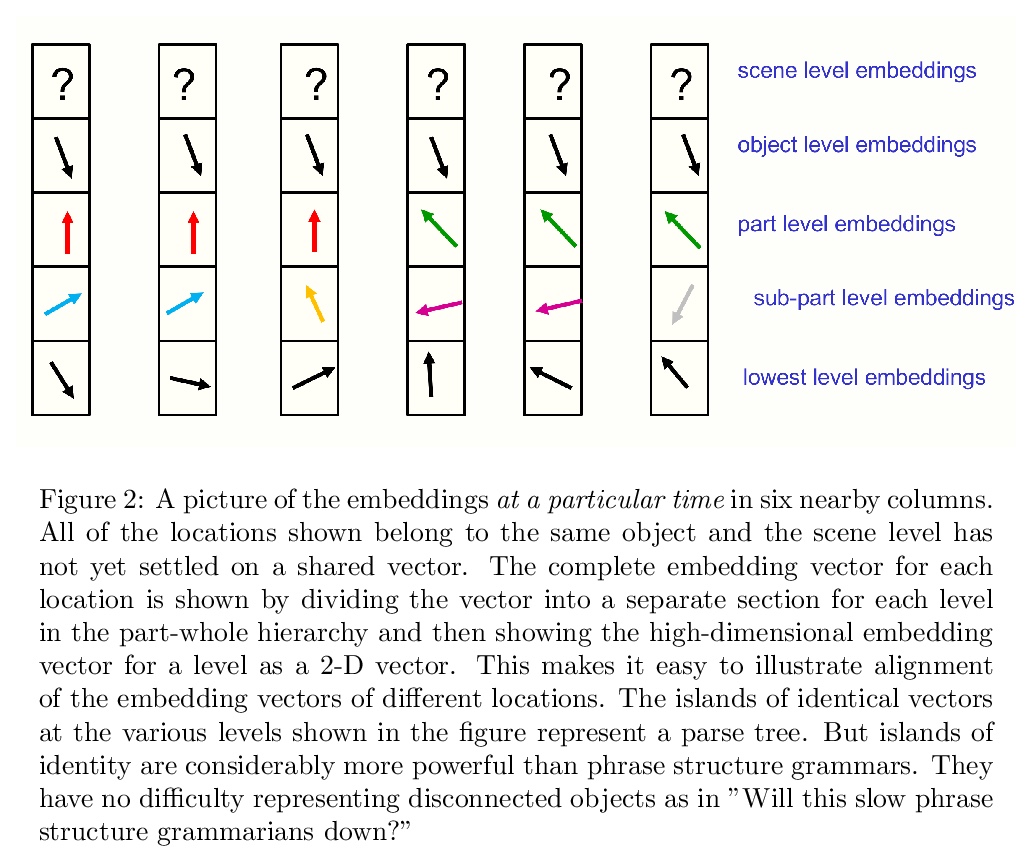
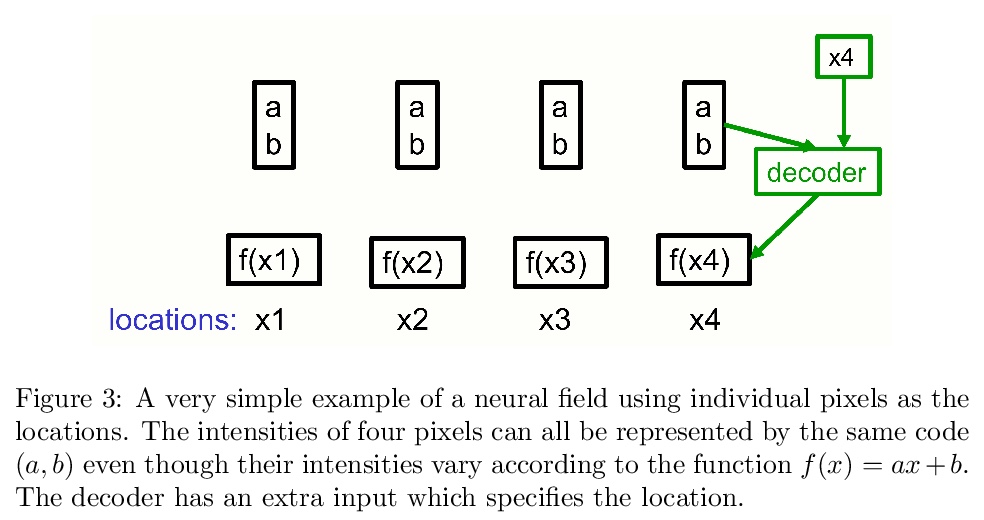
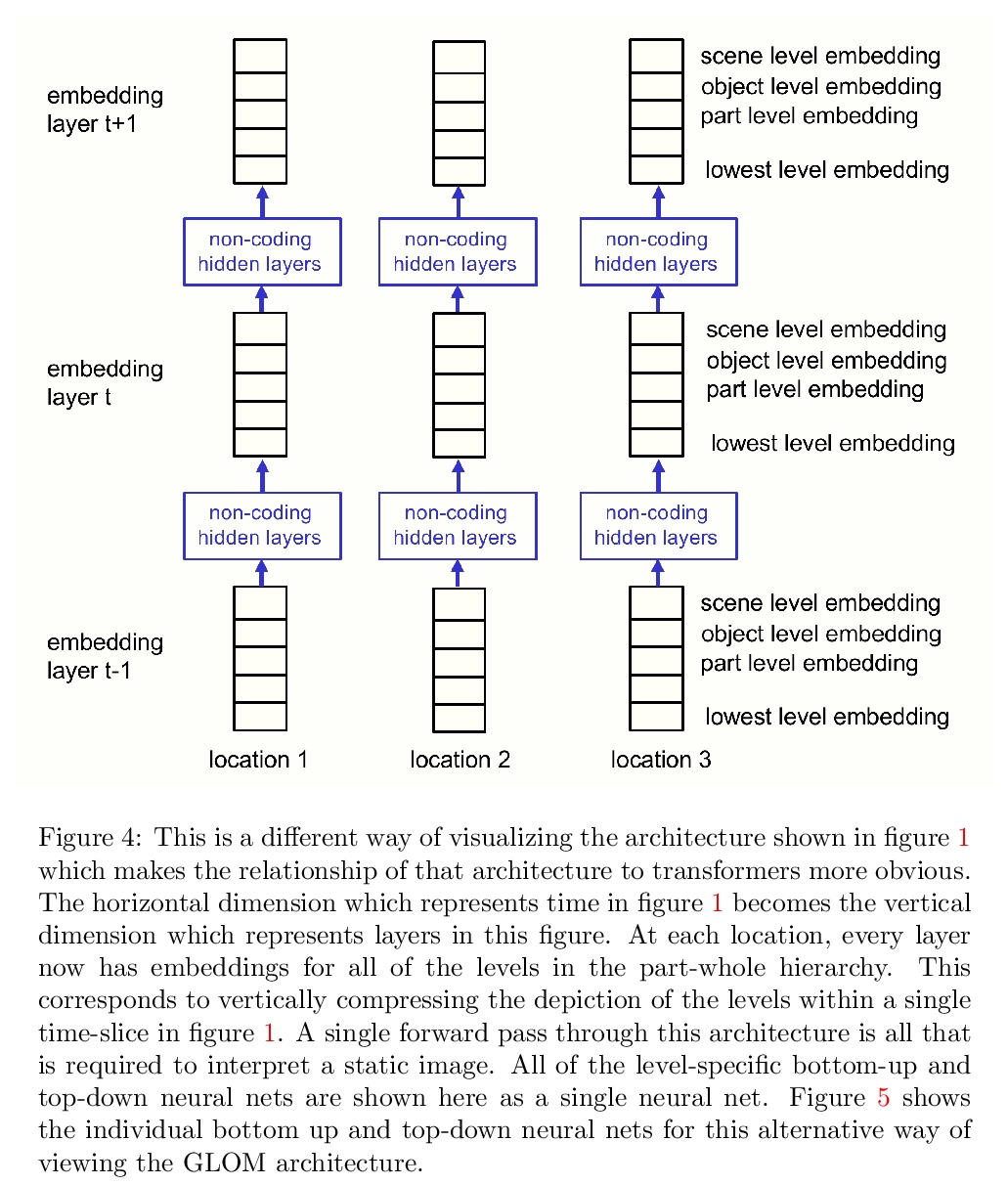
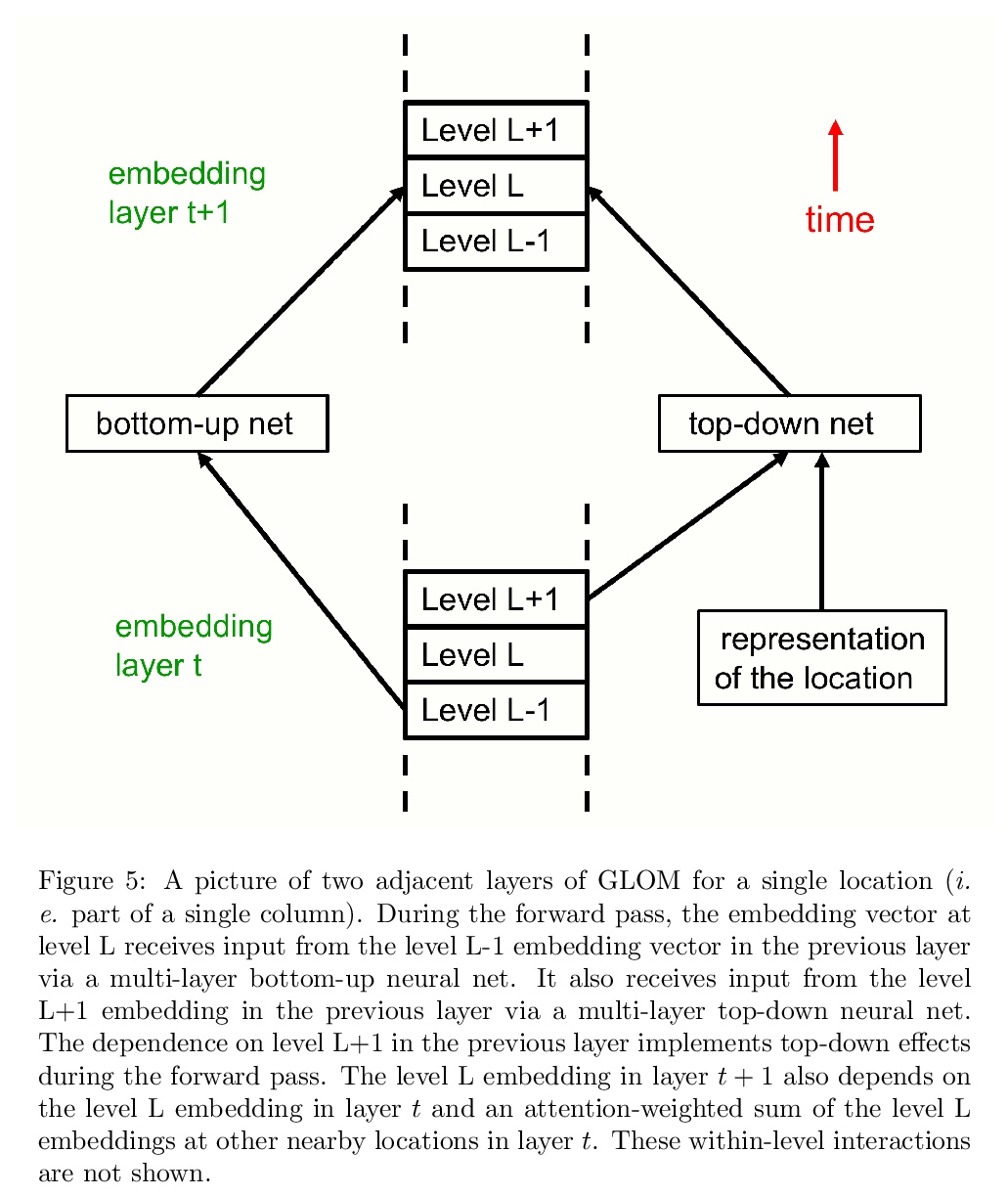
如何用神经网络表示部分-整体层次结构?提出一个关于表示的想法,将包括transformers、神经场、对比表示学习、蒸馏和胶囊等最新进展,整合到一个名为GLOM的假想系统中。GLOM回答了这样一个问题:具有固定架构的神经网络,如何将每幅图像解析成不同的部分-整体结构?想法很简单,就是用相同向量的岛来代表解析树中的节点。如GLOM可用,用于视觉或语言时,应该能显著提高类似transformer系统所产生的表示方法的可解释性。
This paper does not describe a working system. Instead, it presents a single idea about representation which allows advances made by several different groups to be combined into an imaginary system called GLOM. The advances include transformers, neural fields, contrastive representation learning, distillation and capsules. GLOM answers the question: How can a neural network with a fixed architecture parse an image into a part-whole hierarchy which has a different structure for each image? The idea is simply to use islands of identical vectors to represent the nodes in the parse tree. If GLOM can be made to work, it should significantly improve the interpretability of the representations produced by transformer-like systems when applied to vision or language
https://weibo.com/1402400261/K3Ogzhxco

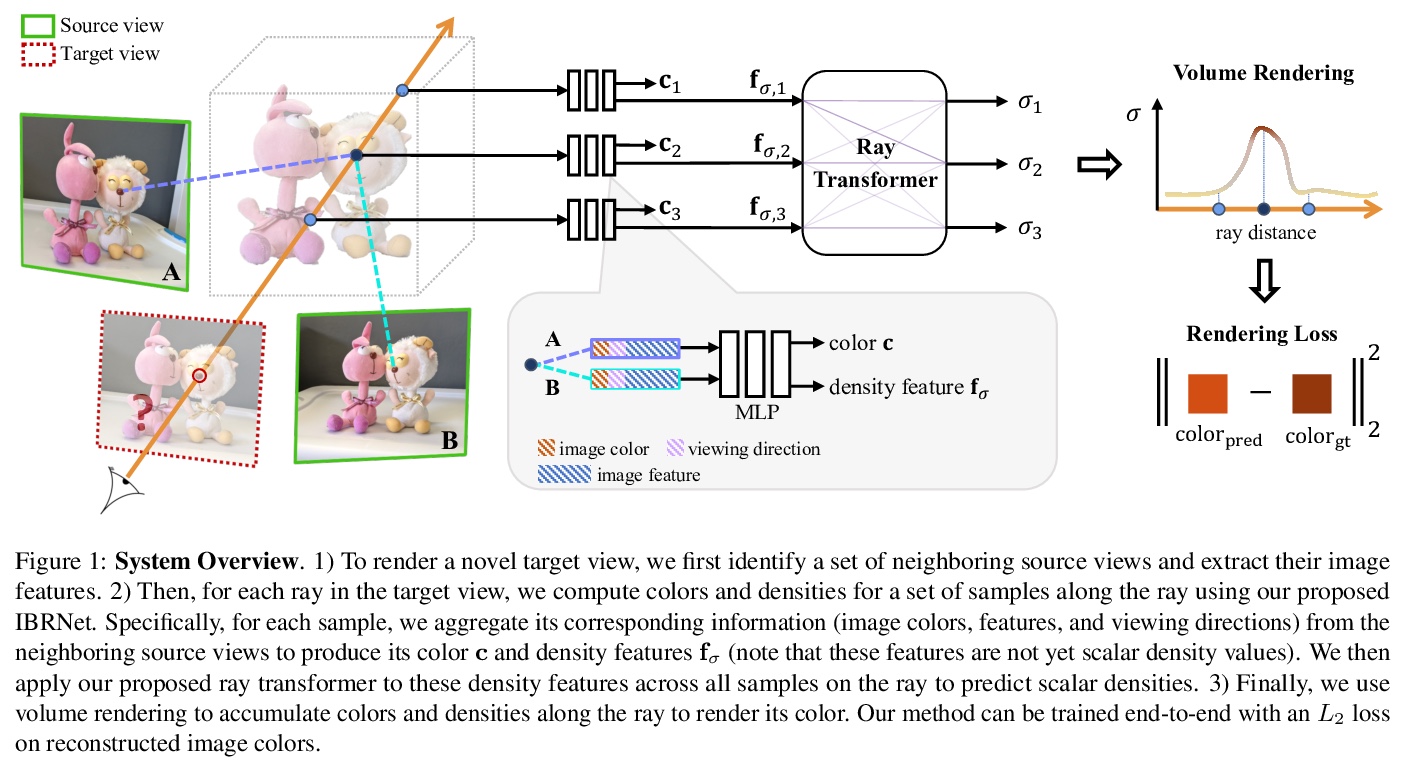
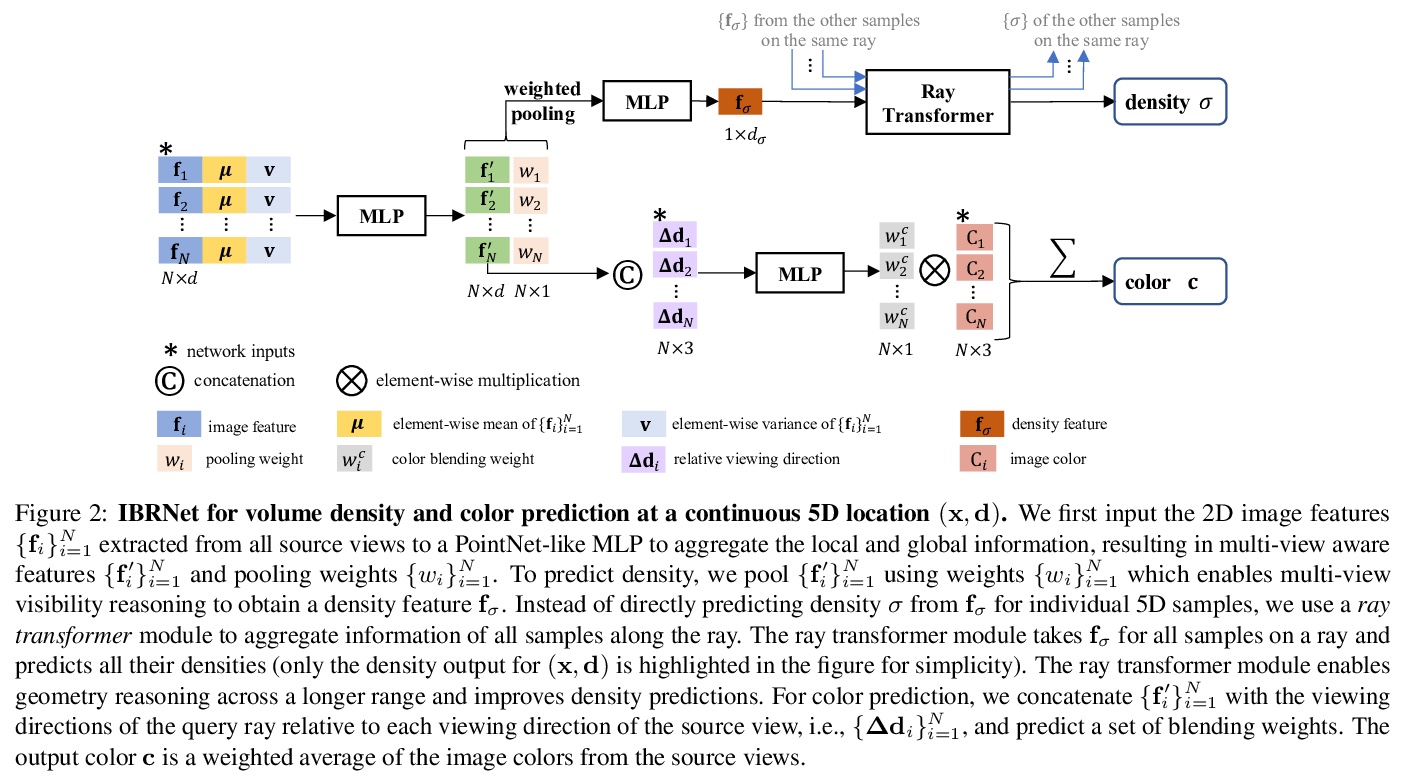
2、[CV] IBRNet: Learning Multi-View Image-Based Rendering
Q Wang, Z Wang, K Genova, P Srinivasan, H Zhou, J T. Barron, R Martin-Brualla, N Snavely, T Funkhouser
[Google Research]
IBRNet: 多视角图像渲染学习。提出一种基于学习的多视图图像渲染框架IBRNet,通过将附近图像像素与由多层感知器(MLP)和射线transformer组成的网络推断的权重和体密度进行混合,可以在连续的5D位置(3D空间位置和2D观看方向)估计辐射度和体密度,从多个源视图中快速提取外观信息,从多视图中连续预测空间中的颜色和密度,合成场景的新视图。该方法结合了基于图像的渲染(IBR)和神经网络渲染(NeRF)的优势,在复杂场景上实现最先进的渲染质量,无需预先计算几何体(与许多IBR方法不同)、存储昂贵的离散体(与神经网络体素表示法不同),或为每个新场景进行昂贵的训练(与NeRF不同)。如果在每个场景上进行微调,IBRNet与最先进的单场景神经网络渲染方法相比也具有竞争力。
We present a method that synthesizes novel views of complex scenes by interpolating a sparse set of nearby views. The core of our method is a network architecture that includes a multilayer perceptron and a ray transformer that estimates radiance and volume density at continuous 5D locations (3D spatial locations and 2D viewing directions), drawing appearance information on the fly from multiple source views. By drawing on source views at render time, our method hearkens back to classic work on image-based rendering (IBR), and allows us to render high-resolution imagery. Unlike neural scene representation work that optimizes per-scene functions for rendering, we learn a generic view interpolation function that generalizes to novel scenes. We render images using classic volume rendering, which is fully differentiable and allows us to train using only multi-view posed images as supervision. Experiments show that our method outperforms recent novel view synthesis methods that also seek to generalize to novel scenes. Further, if fine-tuned on each scene, our method is competitive with state-of-the-art single-scene neural rendering methods.
https://weibo.com/1402400261/K3OpRdvPr


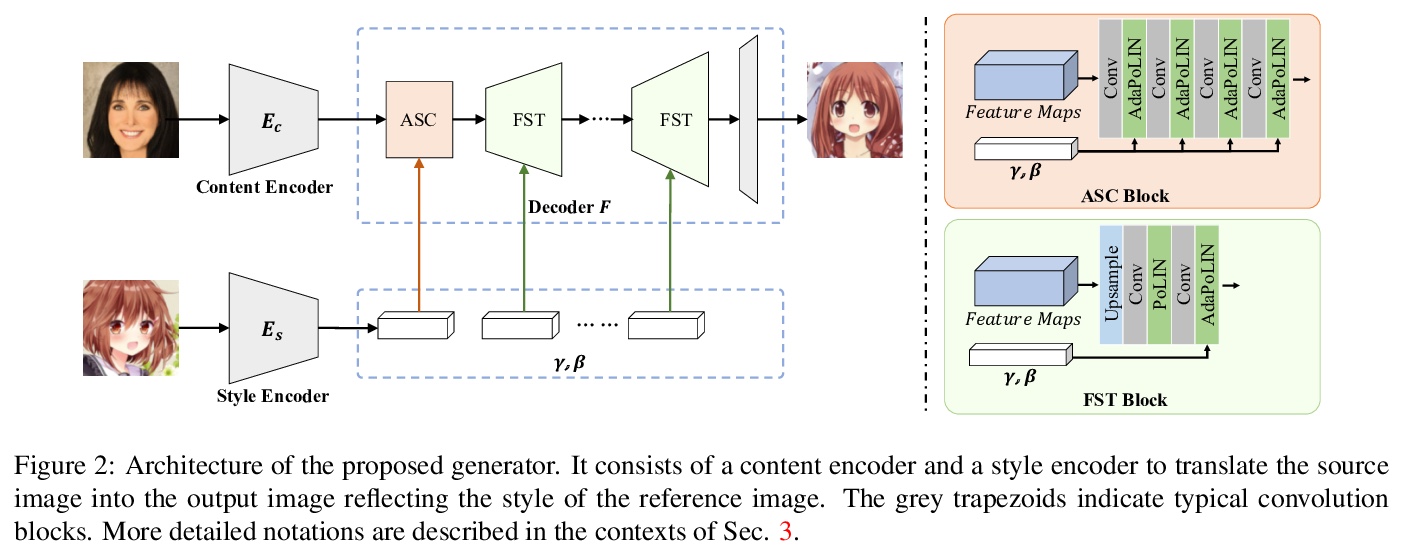
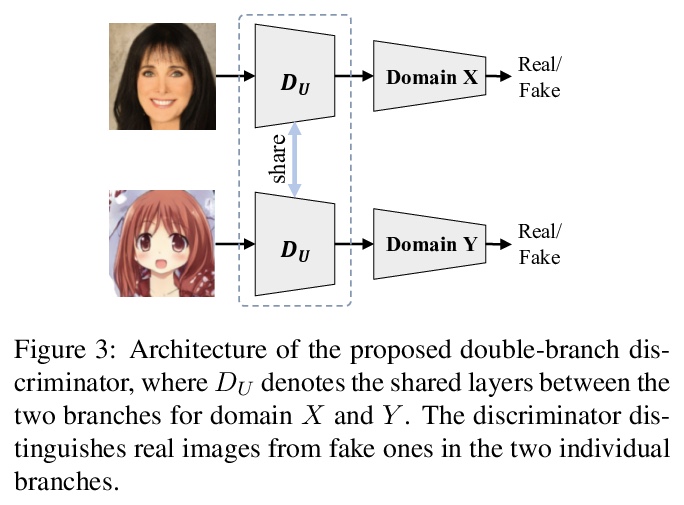
3、[CV] AniGAN: Style-Guided Generative Adversarial Networks for Unsupervised Anime Face Generation
B Li, Y Zhu, Y Wang, C Lin, B Ghanem, L Shen
[KAUST & ByteDance & National Tsing Hua University & Shenzhen University]
AniGAN:面向无监督动漫脸生成的风格引导生成式对抗网络。提出一种新的基于GAN的方法AniGAN,用于风格引导的人脸到动漫转换,合成与给定参考动漫脸风格一致的动漫脸。提出一种新的生成器架构和两个归一化函数,可有效地从参考动漫脸迁移风格,同时迁移颜色/纹理风格,保留源照片面部全局信息,将局部面部形状转换为类似动漫的形状。提出一个双分支判别器,帮助生成器生成高质量的动漫脸。
In this paper, we propose a novel framework to translate a portrait photo-face into an anime appearance. Our aim is to synthesize anime-faces which are style-consistent with a given reference anime-face. However, unlike typical translation tasks, such anime-face translation is challenging due to complex variations of appearances among anime-faces. Existing methods often fail to transfer the styles of reference anime-faces, or introduce noticeable artifacts/distortions in the local shapes of their generated faces. We propose Ani- GAN, a novel GAN-based translator that synthesizes highquality anime-faces. Specifically, a new generator architecture is proposed to simultaneously transfer color/texture styles and transform local facial shapes into anime-like counterparts based on the style of a reference anime-face, while preserving the global structure of the source photoface. We propose a double-branch discriminator to learn both domain-specific distributions and domain-shared distributions, helping generate visually pleasing anime-faces and effectively mitigate artifacts. Extensive experiments qualitatively and quantitatively demonstrate the superiority of our method over state-of-the-art methods.
https://weibo.com/1402400261/K3OyxAx9S

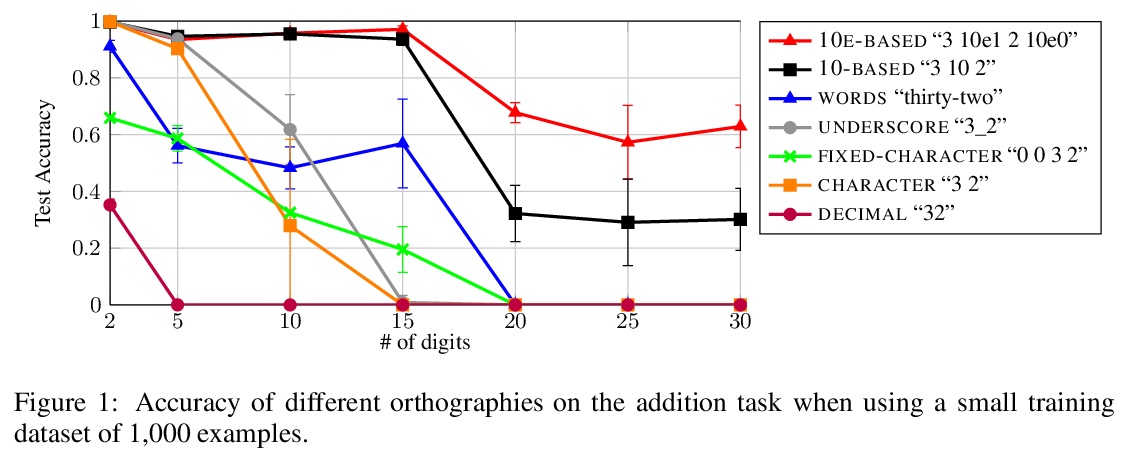
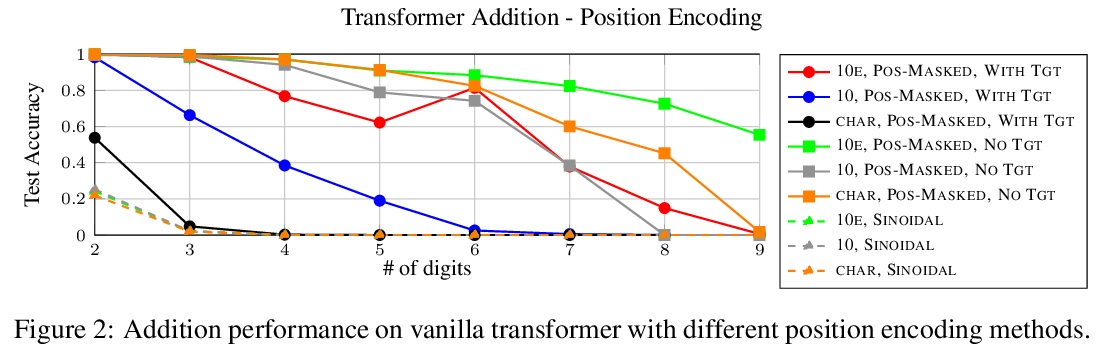
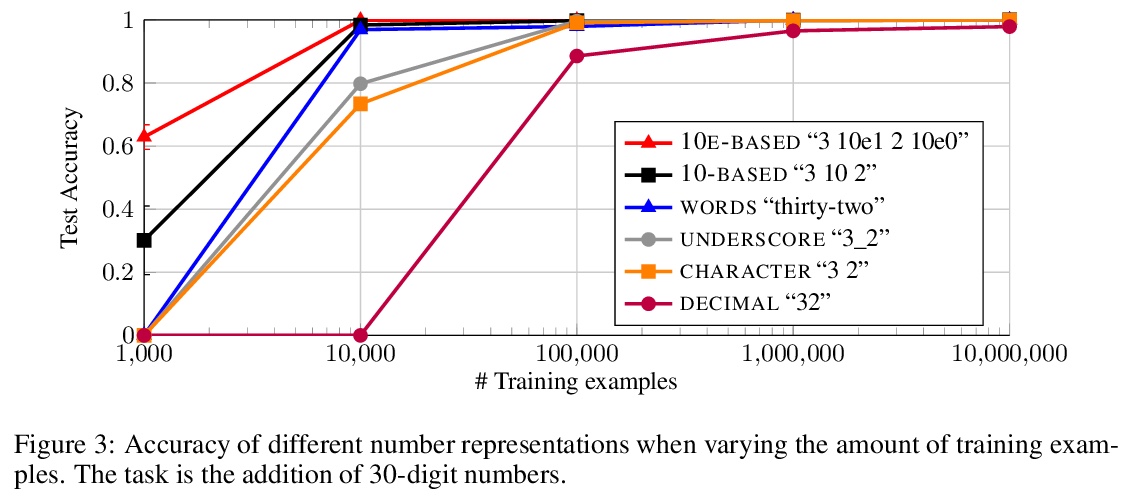
4、[CL] Investigating the Limitations of the Transformers with Simple Arithmetic Tasks
R Nogueira, Z Jiang, J Li
[University of Waterloo]
用简单算术任务调查Transformers的局限性。研究了数字的表面形式是否对序列到序列语言模型如何学习简单算术任务(如在广泛的数值范围内的加法和减法)有任何影响,发现数字表面形式的表示对模型准确率有很大影响。特别是,当使用子词(如”32”)时,模型无法学习五位数加法,用字符级表示(如”3 2”)时也很难学习。通过引入位置标记(如”3 10e1 2”),模型学会了准确加减高达60位的数字。由此得出结论,只要使用适当的表面形式表示,现代预训练语言模型可以从很少的例子中轻松学习算术。更好的符号表示可以使问题变得更容易,但是,仍然没有一个模型能够找到一个适用于任何输入长度的加减法问题的解决方案。这个结果加强了子词标记器和位置编码是当前Transformer设计中可能需要改进的组件的证据。此外还表明,无论参数和训练样本的数量如何,模型都无法学习到与训练过程中看到的数字长度无关的加法规则。
The ability to perform arithmetic tasks is a remarkable trait of human intelligence and might form a critical component of more complex reasoning tasks. In this work, we investigate if the surface form of a number has any influence on how sequence-to-sequence language models learn simple arithmetic tasks such as addition and subtraction across a wide range of values. We find that how a number is represented in its surface form has a strong influence on the model’s accuracy. In particular, the model fails to learn addition of five-digit numbers when using subwords (e.g., “32”), and it struggles to learn with character-level representations (e.g., “3 2”). By introducing position tokens (e.g., “3 10e1 2”), the model learns to accurately add and subtract numbers up to 60 digits. We conclude that modern pretrained language models can easily learn arithmetic from very few examples, as long as we use the proper surface representation. This result bolsters evidence that subword tokenizers and positional encodings are components in current transformer designs that might need improvement. Moreover, we show that regardless of the number of parameters and training examples, models cannot learn addition rules that are independent of the length of the numbers seen during training. Code to reproduce our experiments is available at > this https URL
https://weibo.com/1402400261/K3OG76Kzo
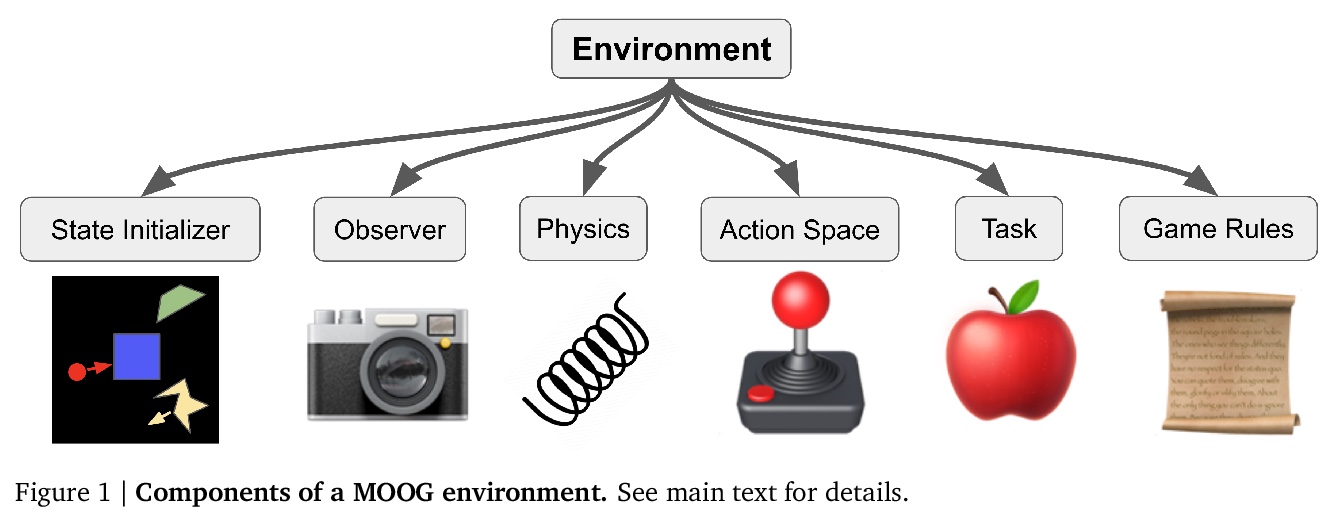
5、[AI] Modular Object-Oriented Games: A Task Framework for Reinforcement Learning, Psychology, and Neuroscience
N Watters, J Tenenbaum, M Jazayeri
[MIT]
模块化面向对象的游戏:强化学习、心理学和神经科学任务框架。近年来,研究模拟游戏的趋势在人工智能、认知科学、心理学和神经科学等领域得到了发展。这些领域的交叉点最近也有所增长,因为研究人员越来越多地使用人工智能体和人类或动物受试者来研究这种游戏。然而,实现游戏可能是一项耗时的工作,可能需要研究人员努力处理不容易定制的复杂代码库。此外,研究人工智能、人类心理学和动物神经生理学某种组合的跨学科研究人员,还面临着额外的挑战,因为现有的平台只针对其中一个领域设计。本文介绍了模块化面向对象的游戏,一个轻量级、灵活、可定制的Python任务框架,专供机器学习、心理学和神经生理学研究人员使用。其目标是满足以下标准:可用于强化学习,心理学和神经生理学,支持用于强化学习智能体的DeepMind dm_env和OpenAI Gym接口,以及用于心理学和神经生理学的MWorks接口;高度可定制化,环境物理、奖励结构、智能体界面等都可以定制;易于快速原型化任务,可在一个短文件中组成任务;轻量高效,大多数任务运行速度快;便于每次试验时程序化随机生成任务条件。
In recent years, trends towards studying simulated games have gained momentum in the fields of artificial intelligence, cognitive science, psychology, and neuroscience. The intersections of these fields have also grown recently, as researchers increasing study such games using both artificial agents and human or animal subjects. However, implementing games can be a time-consuming endeavor and may require a researcher to grapple with complex codebases that are not easily customized. Furthermore, interdisciplinary researchers studying some combination of artificial intelligence, human psychology, and animal neurophysiology face additional challenges, because existing platforms are designed for only one of these domains. Here we introduce Modular Object-Oriented Games, a Python task framework that is lightweight, flexible, customizable, and designed for use by machine learning, psychology, and neurophysiology researchers.
https://weibo.com/1402400261/K3OQoqY88
另外几篇值得关注的论文:
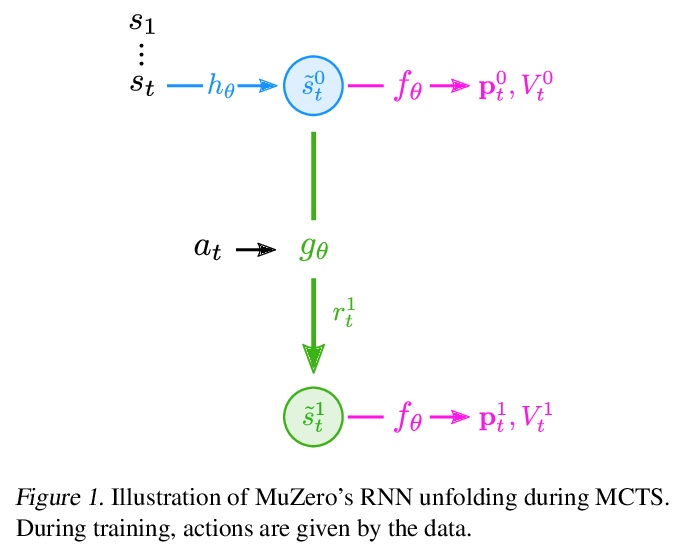
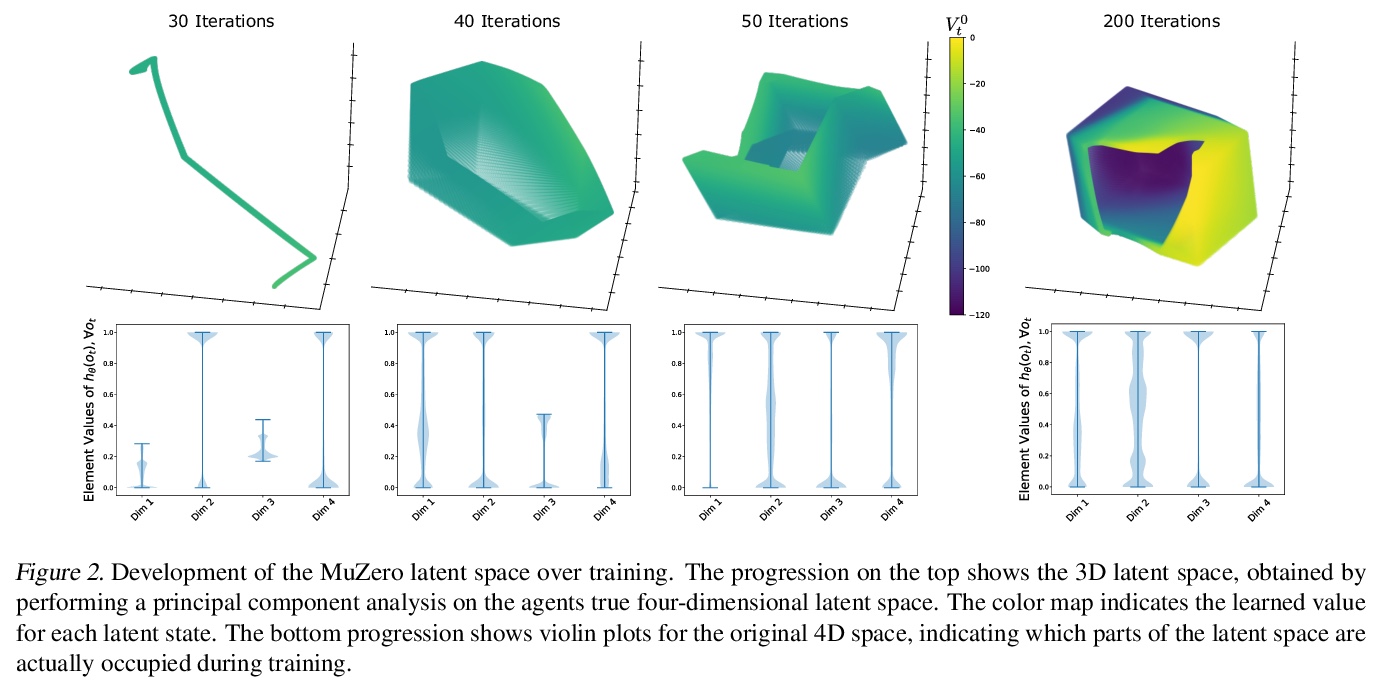
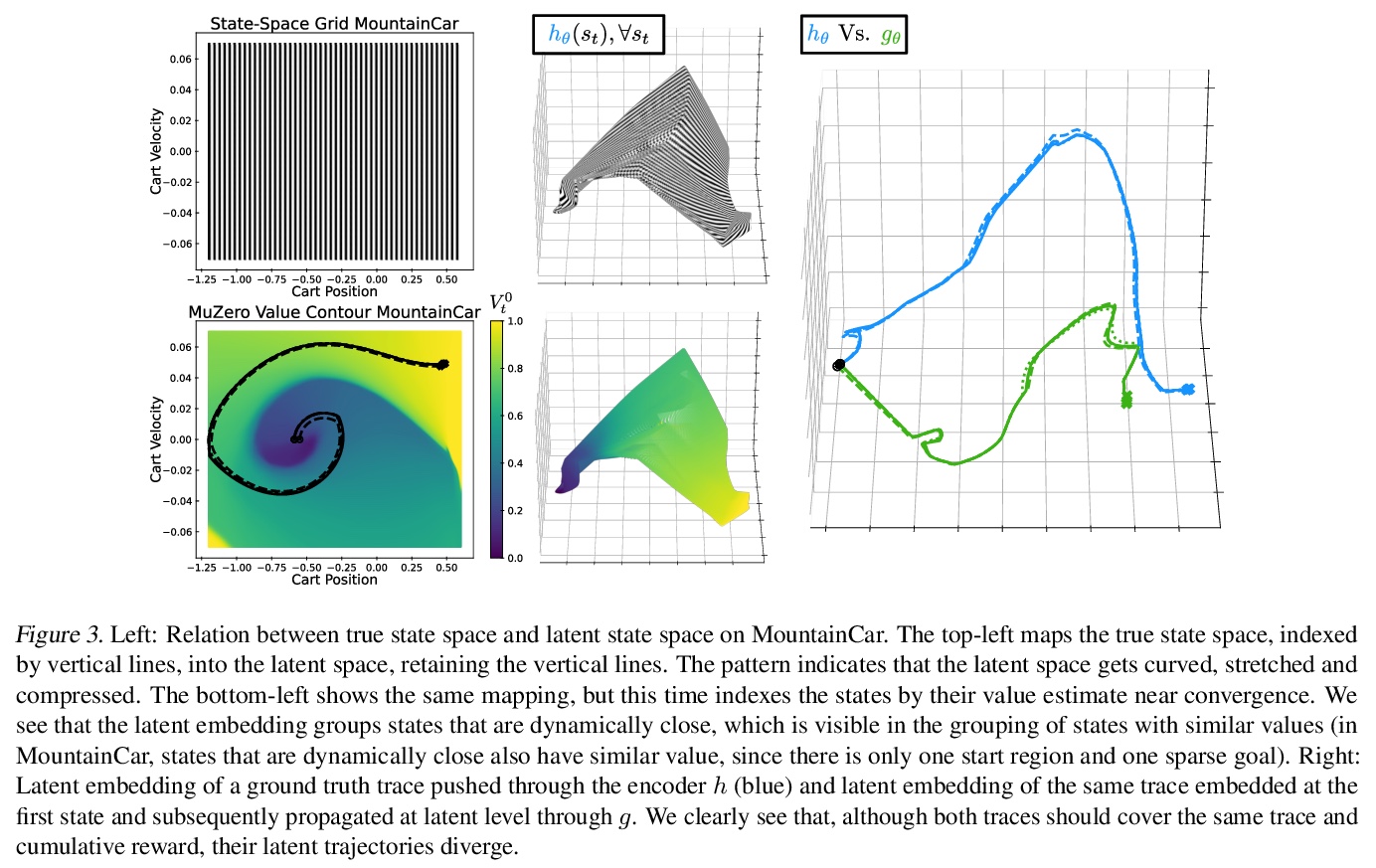
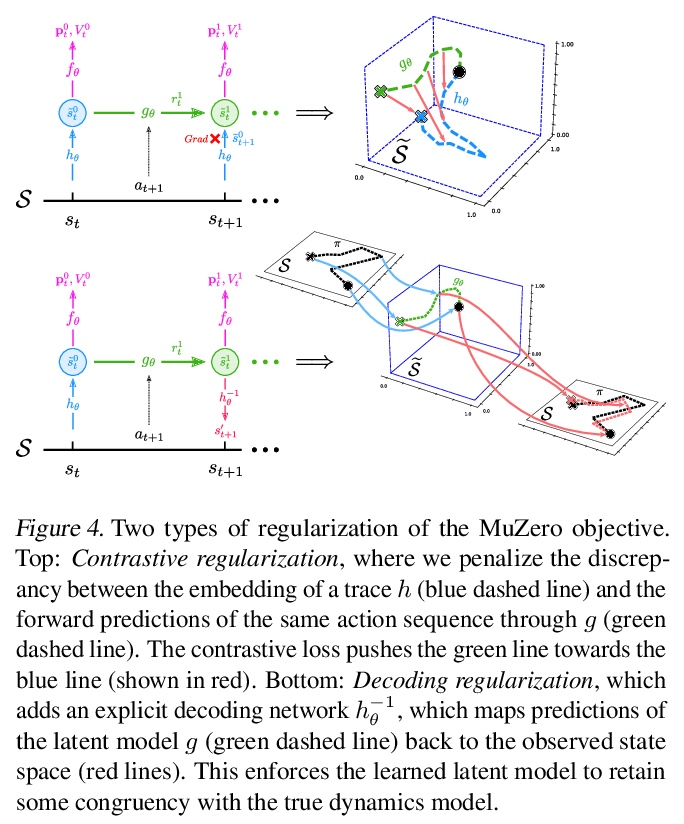
[LG] Visualizing MuZero Models
MuZero模型可视化
J A. d Vries, K S. Voskuil, T M. Moerland, A Plaat
[Leiden Institute of Advanced Computer Science]
https://weibo.com/1402400261/K3OVPAhCc
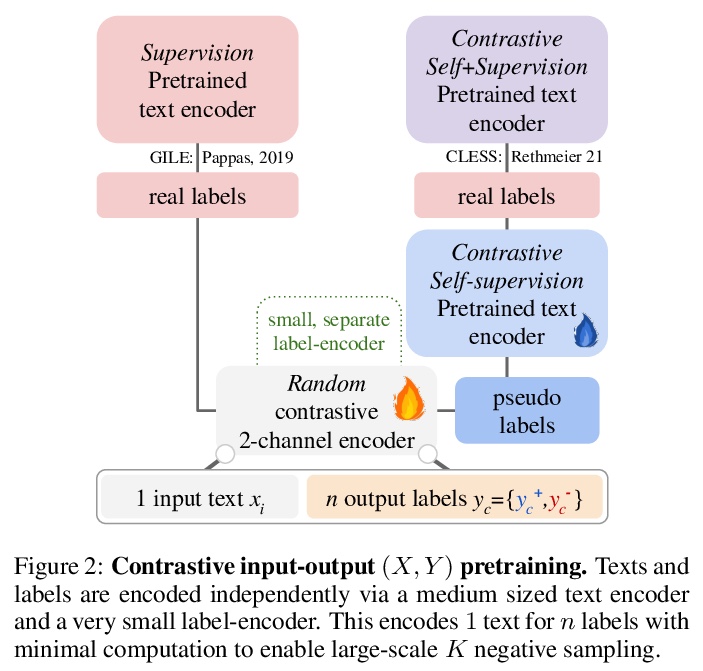
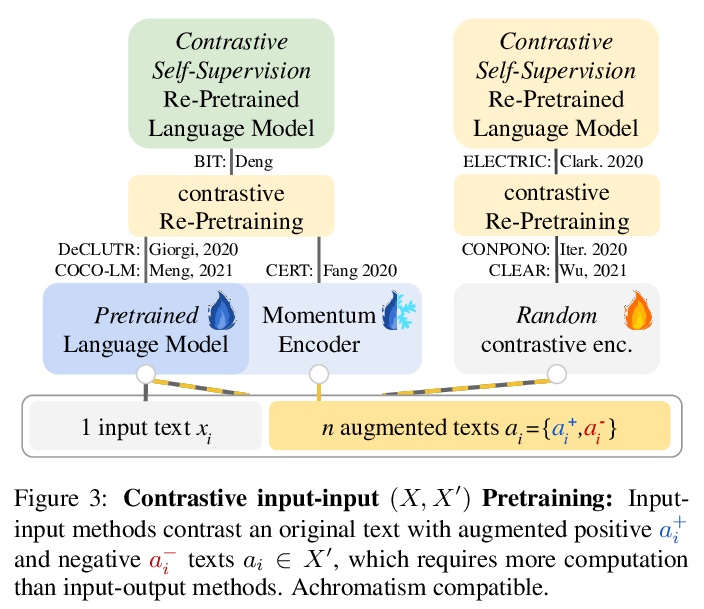
[CL] A Primer on Contrastive Pretraining in Language Processing: Methods, Lessons Learned and Perspectives
语言处理对比预处理入门:方法、经验和观点
N Rethmeier, I Augenstein
[German Research Center for AI & University of Copenhagen]
https://weibo.com/1402400261/K3OZwkabG
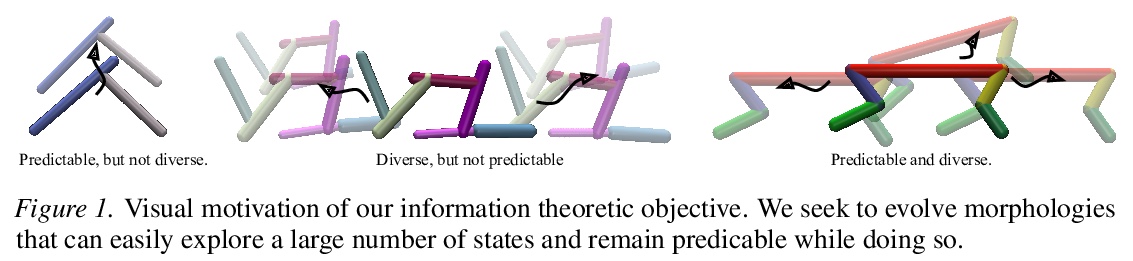
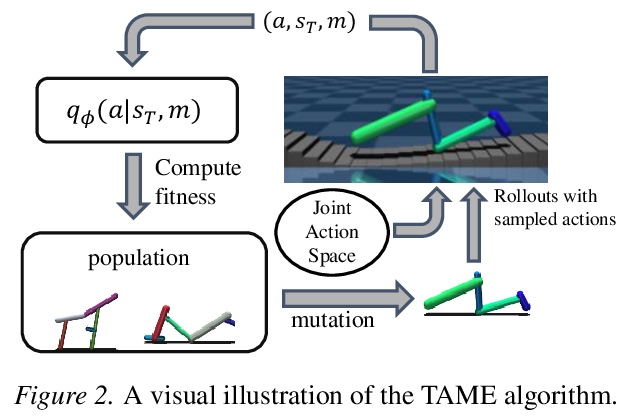
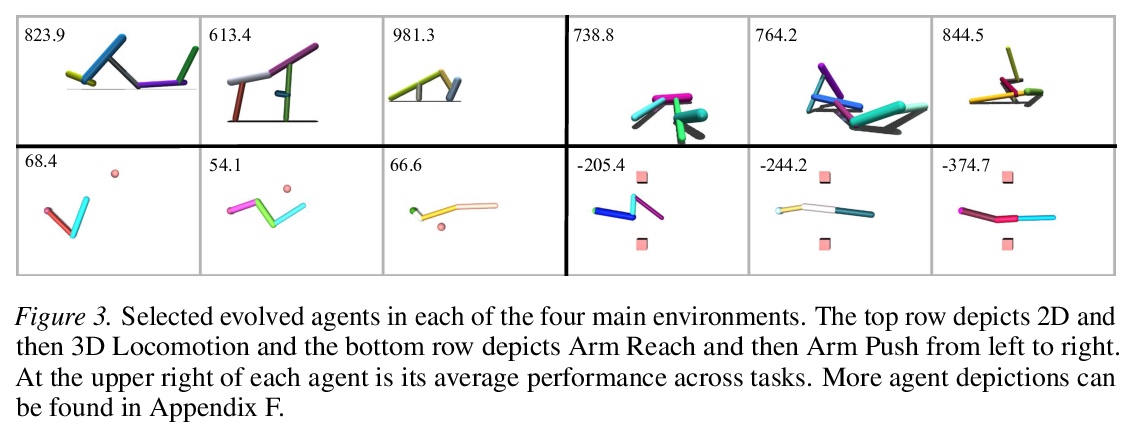
[LG] Task-Agnostic Morphology Evolution
任务无关的形态学进化
D J. H III, P Abbeel, L Pinto
[UC Berkeley & New York University]
https://weibo.com/1402400261/K3P0YppvL
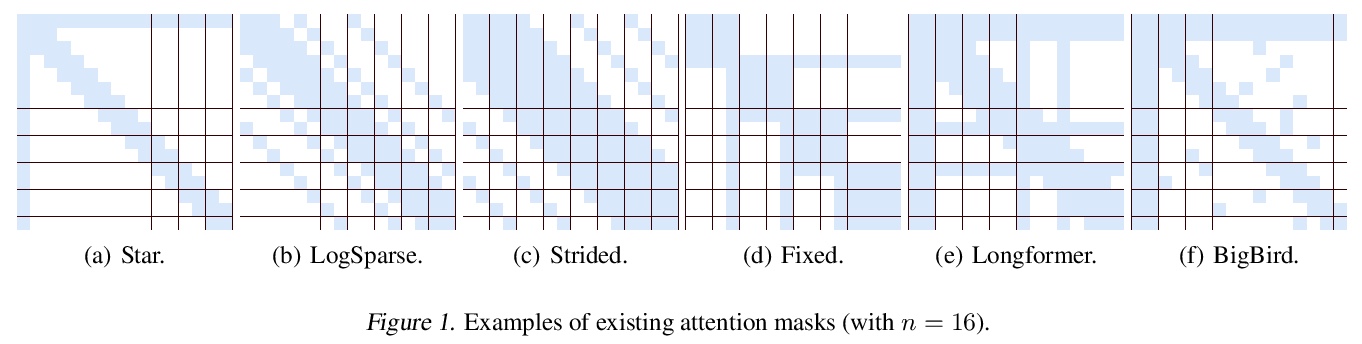
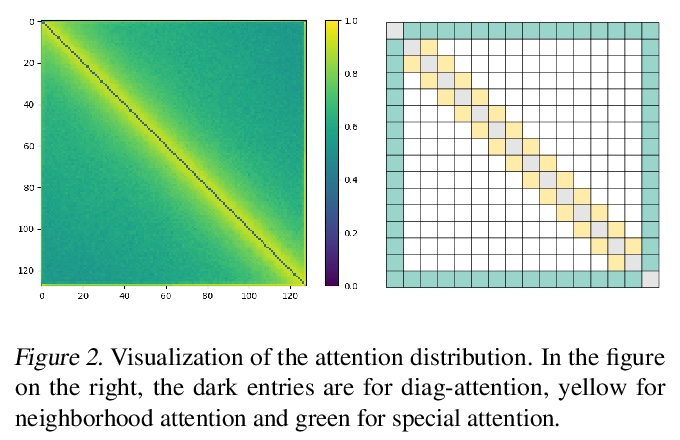
[LG] SparseBERT: Rethinking the Importance Analysis in Self-attention
SparseBERT:自注意力重要性分析的反思
H Shi, J Gao, X Ren, H Xu, X Liang, Z Li, J T. Kwok
[Hong Kong University of Science and Technology & The University of Hong Kong & Huawei Noah’s Ark & Lab Sun Yat-sen University]
https://weibo.com/1402400261/K3P2jebZF


若有收获,就点个赞吧
0 人点赞
