- 1、[CV] TransPose: Towards Explainable Human Pose Estimation by Transformer
- 2、[RO] Improving the Generalization of End-to-End Driving through Procedural Generation
- 3、[CV] Self-supervised Pre-training with Hard Examples Improves Visual Representations
- 4、[CL] Universal Sentence Representation Learning with Conditional Masked Language Model
- 5、[LG] A Tutorial on Sparse Gaussian Processes and Variational Inference
- [CV] DeepSurfels: Learning Online Appearance Fusion
- [IT] Reproducible Workflow
- [LG] dalex: Responsible Machine Learning with Interactive Explainability and Fairness in Python
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
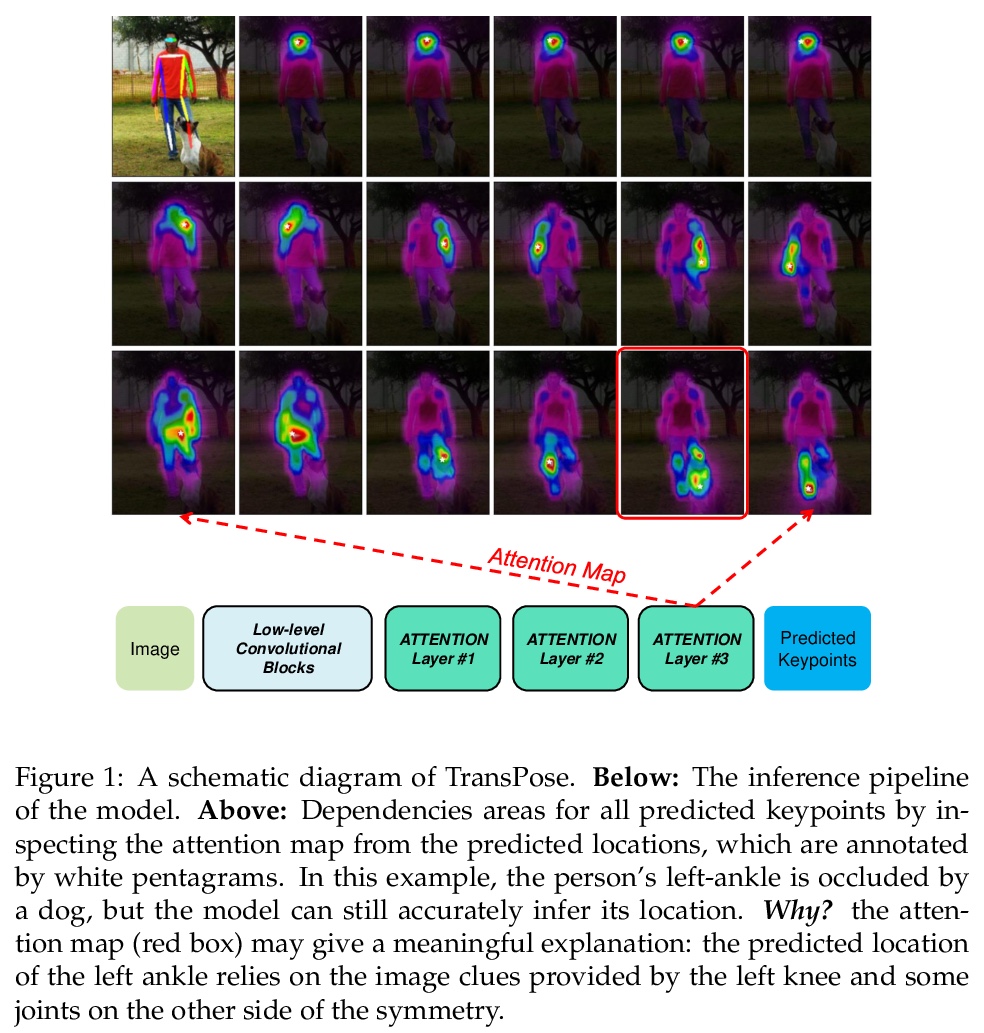
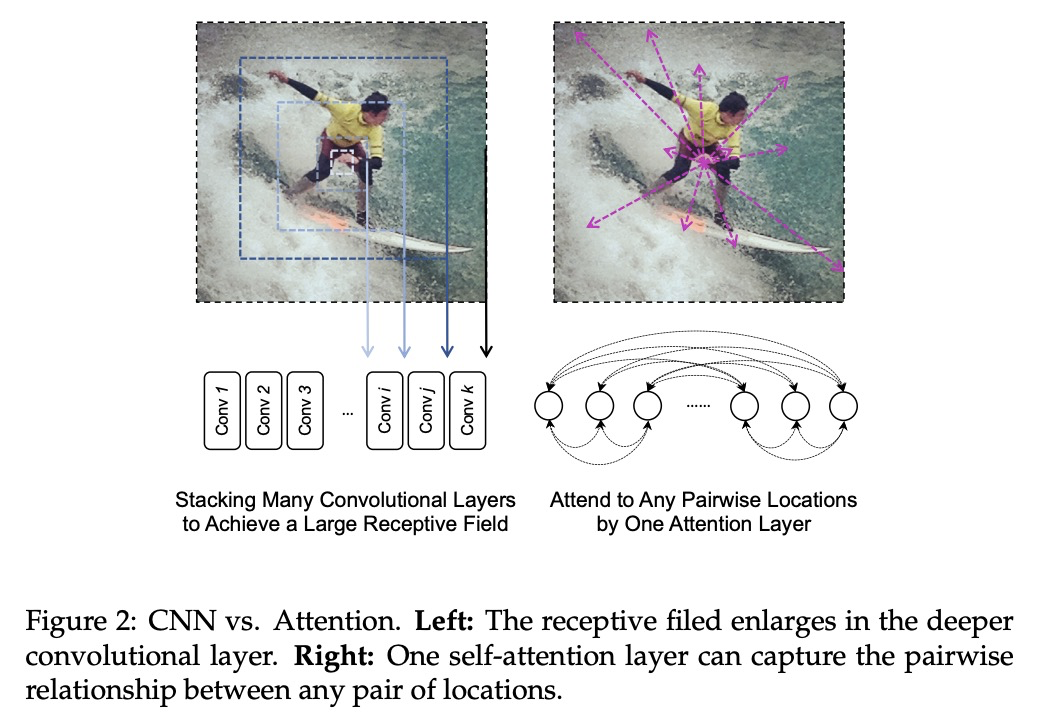
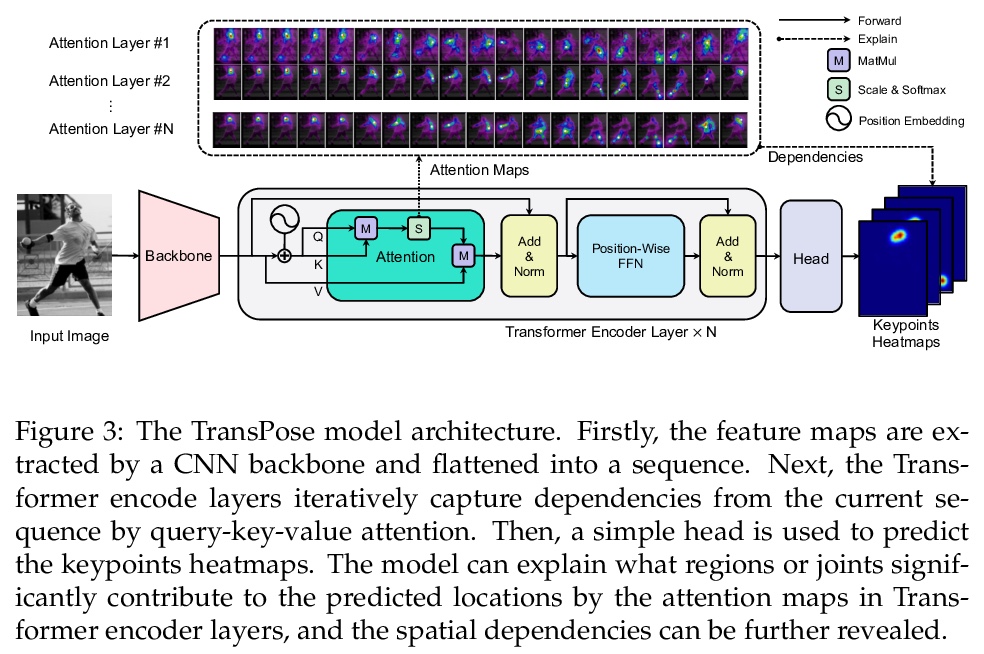
1、[CV] TransPose: Towards Explainable Human Pose Estimation by Transformer
S Yang, Z Quan, M Nie, W Yang
[Southeast University]
基于Transformer实现可解释的人体姿态估计。基于Transformer架构和低级卷积块,构建了TransPose,一种可解释的人体姿态估计模型。给定一张图像,Transformer中构建的注意力层,可捕捉关键点之间的长距离空间关系,并解释预测出的关键点位置,高度依赖哪些依赖关系。分析了在任务中使用注意力作为解释,来揭示空间依赖的合理性。所揭示的依赖性是特定于图像的,对不同的关键点类型、层深度或训练模型是可变的。实验表明,注意力机制在结构预测任务中对图像依赖的空间关系具有很好的捕捉和解释作用,TransPose可以准确预测关键点位置,在COCO数据集上实现了最先进性能,同时比主流的全卷积架构更可解释、更轻量和高效。
Deep Convolutional Neural Networks (CNNs) have made remarkable progress on human pose estimation task. However, there is no explicit understanding of how the locations of body keypoints are predicted by CNN, and it is also unknown what spatial dependency relationships between structural variables are learned in the model. To explore these questions, we construct an explainable model named TransPose based on Transformer architecture and low-level convolutional blocks. Given an image, the attention layers built in Transformer can capture long-range spatial relationships between keypoints and explain what dependencies the predicted keypoints locations highly rely on. We analyze the rationality of using attention as the explanation to reveal the spatial dependencies in this task. The revealed dependencies are image-specific and variable across different keypoint types, layer depths, or trained models. The experiments show that TransPose can accurately predict the positions of keypoints. It achieves state-of-the-art performance on COCO dataset, while being more interpretable, lightweight, and efficient than mainstream fully convolutional architectures.
https://weibo.com/1402400261/JANC5agnX
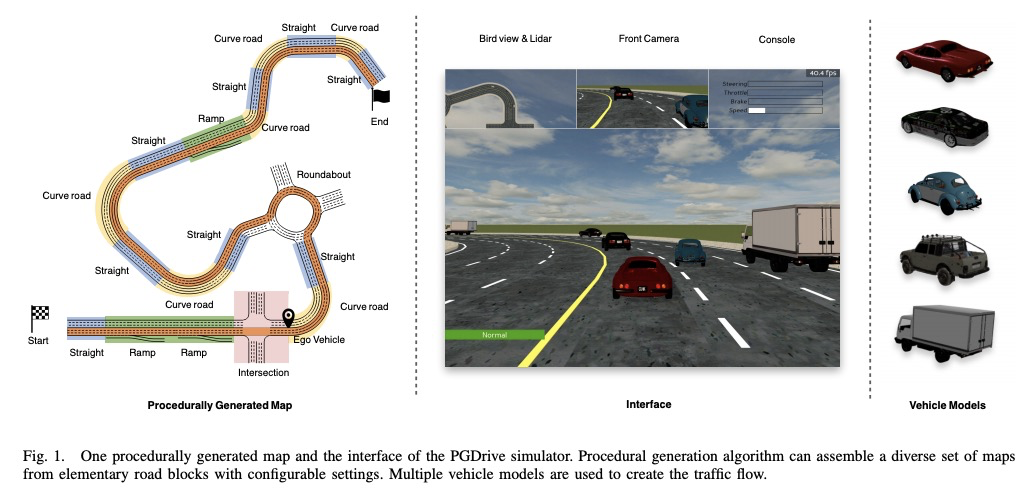
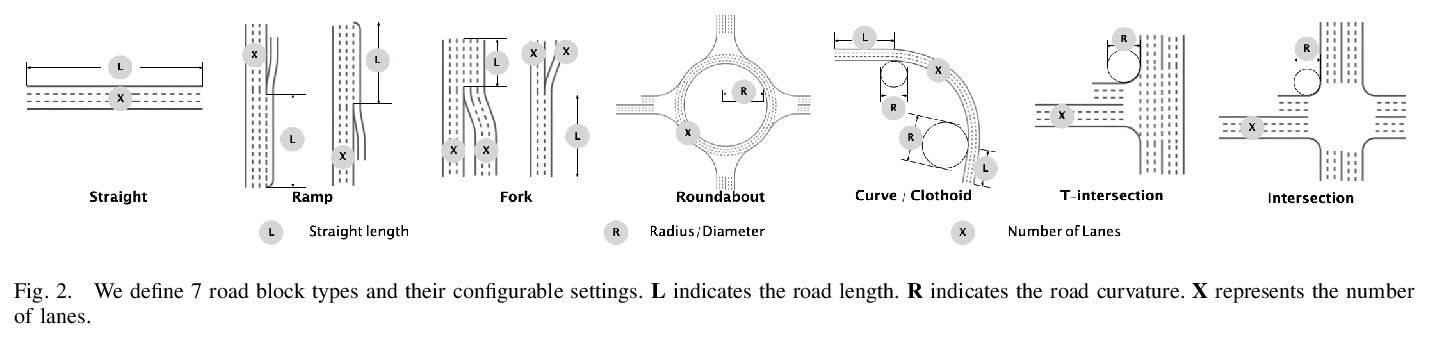
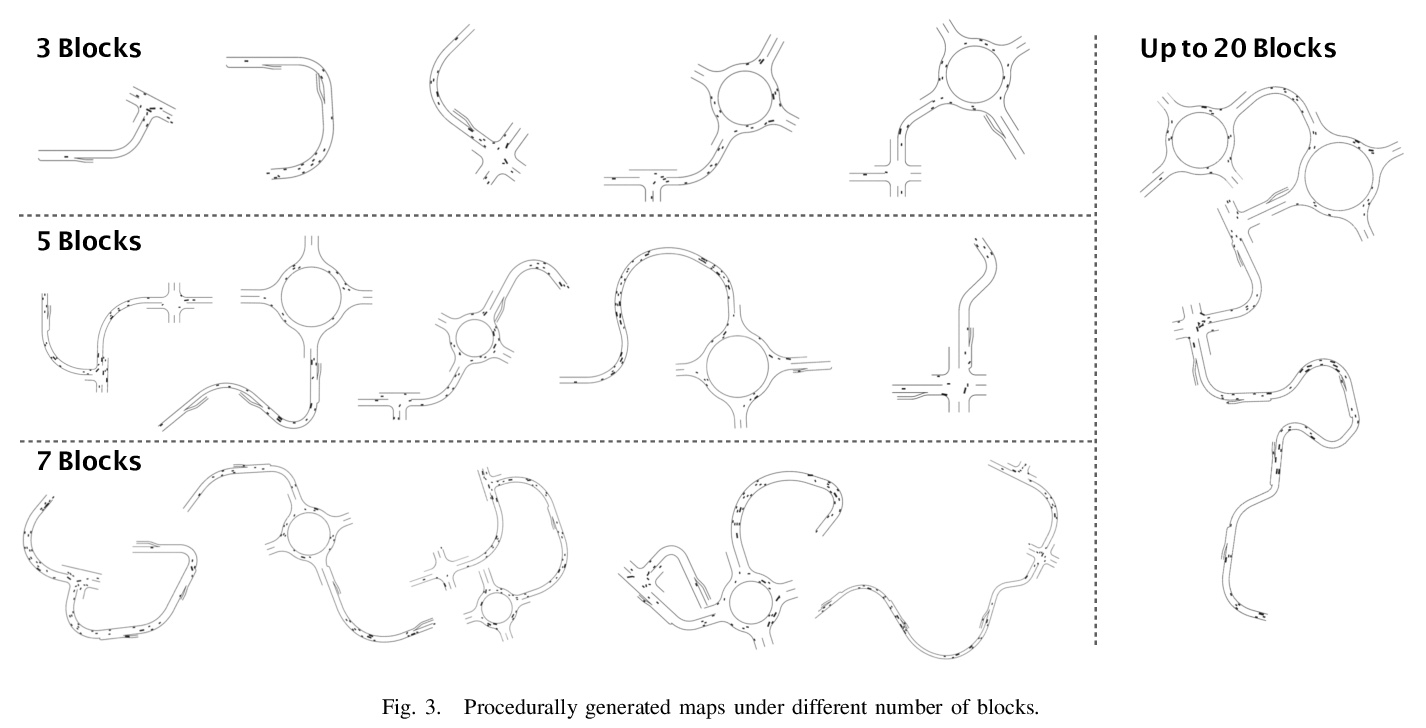
2、[RO] Improving the Generalization of End-to-End Driving through Procedural Generation
Q Li, Z Peng, Q Zhang, C Qiu, C Liu, B Zhou
[Chinese University of Hong Kong & SenseTime Group Limited & Zhejiang University]
用程序自动生成改善端到端驾驶的泛化性。为更好地评价和改进端到端驾驶的泛化性,引入一个开放的、高度可配置、具有程序自动生成特性的驾驶模拟器PGDrive,定义了多种基本路障,如坡道、岔路口和环岛,并进行了可配置设置,通过路块增量生成算法,从这些路块中组合出一系列多样化的地图,并进一步将其变成交互式环境。实验结果表明,增加训练环境的多样性可以大幅提高端到端驾驶的泛化性能。
Recently there is a growing interest in the end-to-end training of autonomous driving where the entire driving pipeline from perception to control is modeled as a neural network and jointly optimized. The end-to-end driving is usually first developed and validated in simulators. However, most of the existing driving simulators only contain a fixed set of maps and a limited number of configurations. As a result the deep models are prone to overfitting training scenarios. Furthermore it is difficult to assess how well the trained models generalize to unseen scenarios. To better evaluate and improve the generalization of end-to-end driving, we introduce an open-ended and highly configurable driving simulator called PGDrive. PGDrive first defines multiple basic road blocks such as ramp, fork, and roundabout with configurable settings. Then a range of diverse maps can be assembled from those blocks with procedural generation, which are further turned into interactive environments. The experiments show that the driving agent trained by reinforcement learning on a small fixed set of maps generalizes poorly to unseen maps. We further validate that training with the increasing number of procedurally generated maps significantly improves the generalization of the agent across scenarios of different traffic densities and map structures. Code is available at: > this https URL
https://weibo.com/1402400261/JANw8kqdz
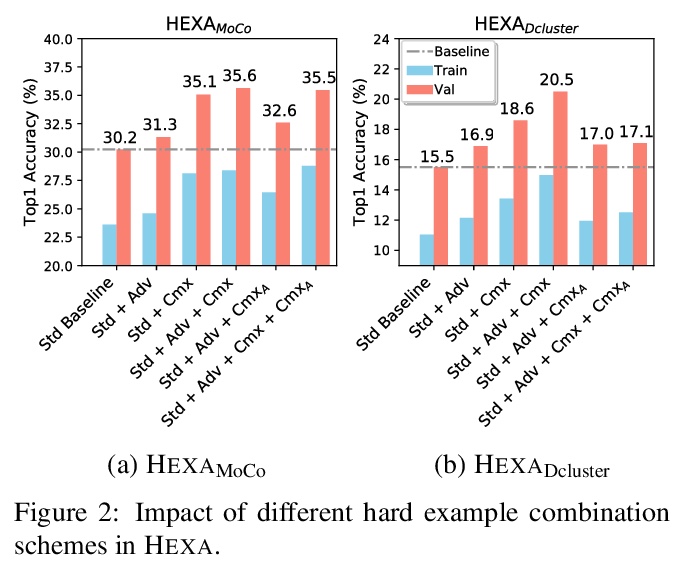
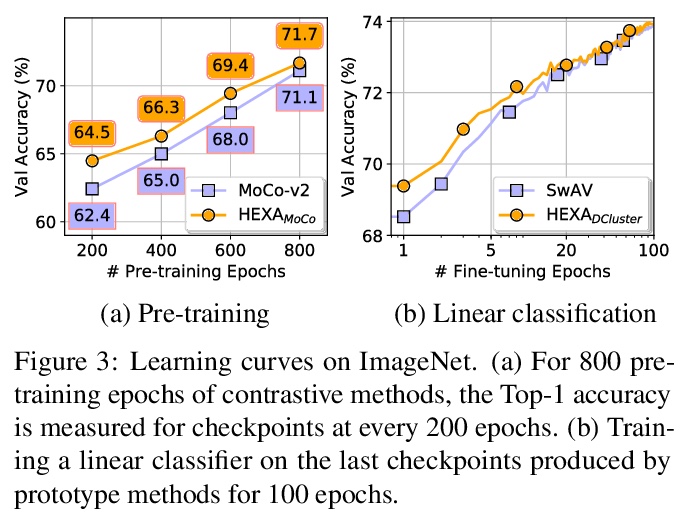
3、[CV] Self-supervised Pre-training with Hard Examples Improves Visual Representations
C Li, X Li, L Zhang, B Peng, M Zhou, J Gao
[Microsoft Research & The University of Texas at Austin]
用难样本自监督预训练改善视觉表示。将自监督预训练(SSP)视为伪标签分类任务,引入一个通用框架来生成更难的增强视图,以提升自监督学习模型的分辨能力。提出了两个新的算法变体:HEXAMoCo用于对比学习,HEXADCluster用于原型学习。HEXA变体在相同设置下,表现优于同类变体,具有明显的优势,实现了SoTA,验证了难样本有助于提高预训练模型的泛化能力。
Self-supervised pre-training (SSP) employs random image transformations to generate training data for visual representation learning. In this paper, we first present a modeling framework that unifies existing SSP methods as learning to predict pseudo-labels. Then, we propose new data augmentation methods of generating training examples whose pseudo-labels are harder to predict than those generated via random image transformations. Specifically, we use adversarial training and CutMix to create hard examples (HEXA) to be used as augmented views for MoCo-v2 and DeepCluster-v2, leading to two variants HEXA{MoCo} and HEXA{DCluster}, respectively. In our experiments, we pre-train models on ImageNet and evaluate them on multiple public benchmarks. Our evaluation shows that the two new algorithm variants outperform their original counterparts, and achieve new state-of-the-art on a wide range of tasks where limited task supervision is available for fine-tuning. These results verify that hard examples are instrumental in improving the generalization of the pre-trained models.
https://weibo.com/1402400261/JANJ9n3dd

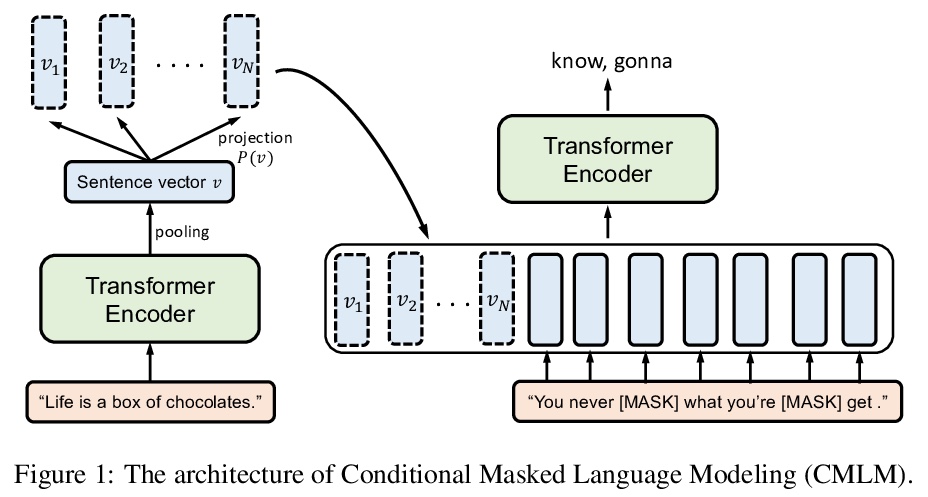
4、[CL] Universal Sentence Representation Learning with Conditional Masked Language Model
Z Yang, Y Yang, D Cer, J Law, E Darve
[Stanford University & Google AI]
基于条件掩蔽语言模型的通用句子表示学习。提出条件屏蔽语言建模(CMLM),基于大规模无标签语料库有效学习句子表示。通过对相邻句子的编码向量进行调节,将句子表示学习整合到MLM训练中。CMLM性能优于之前的英语句子嵌入模型,包括用(半)监督信号训练的模型。在多语言表示学习方面,将CMLM与bitext检索和跨语言NLI微调联合训练可达到最先进的性能。多语言表示具有相同的语言偏差,用主成分去除(PCR)可以通过分离语言识别信息和语义来消除偏差。作为一种完全无监督的学习方法,CMLM可以方便地扩展到更广泛的语言和领域。
This paper presents a novel training method, Conditional Masked Language Modeling (CMLM), to effectively learn sentence representations on large scale unlabeled corpora. CMLM integrates sentence representation learning into MLM training by conditioning on the encoded vectors of adjacent sentences. Our English CMLM model achieves state-of-the-art performance on SentEval, even outperforming models learned using (semi-)supervised signals. As a fully unsupervised learning method, CMLM can be conveniently extended to a broad range of languages and domains. We find that a multilingual CMLM model co-trained with bitext retrieval~(BR) and natural language inference~(NLI) tasks outperforms the previous state-of-the-art multilingual models by a large margin. We explore the same language bias of the learned representations, and propose a principle component based approach to remove the language identifying information from the representation while still retaining sentence semantics.
https://weibo.com/1402400261/JANMKrHs5
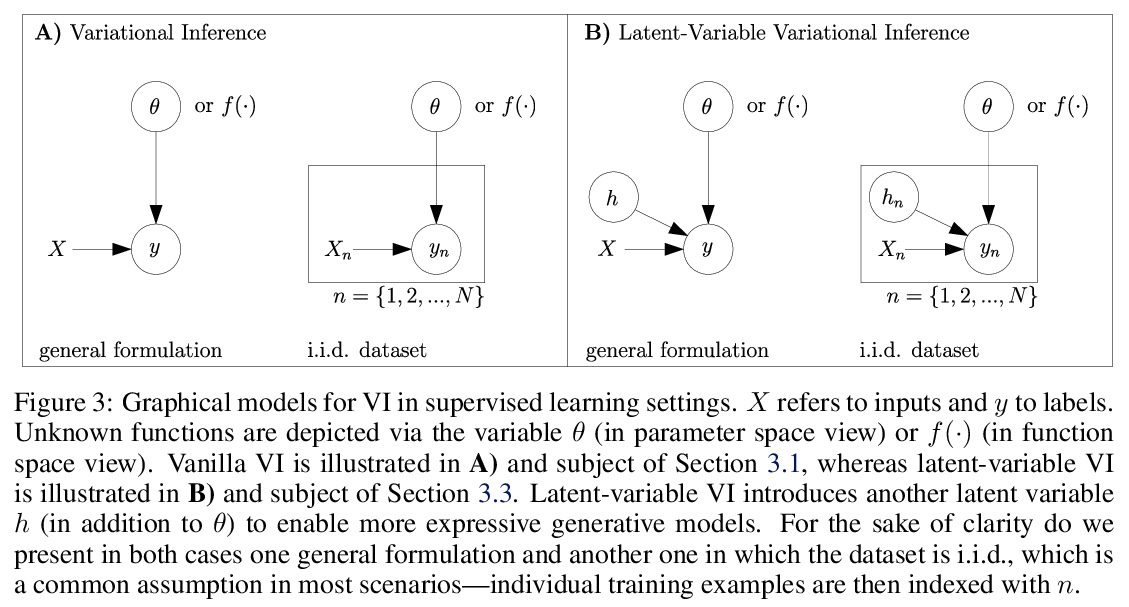
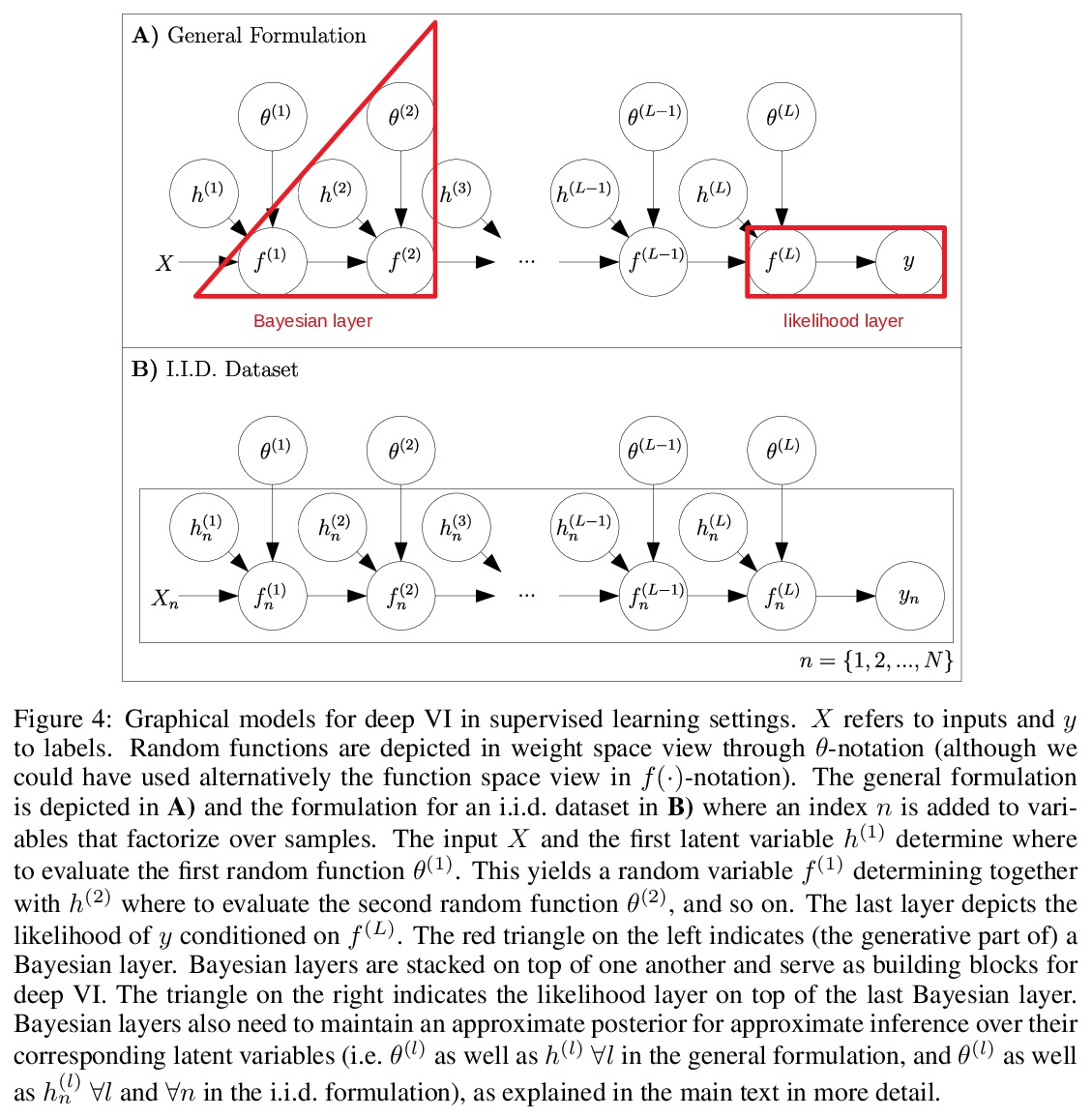
5、[LG] A Tutorial on Sparse Gaussian Processes and Variational Inference
F Leibfried, V Dutordoir, S John, N Durrande
[Secondmind]
稀疏高斯过程与变分推理教程。本教程目的是为没有高斯过程(GP)和变分推理(VI)方面知识的读者提供获取基础知识的途径。除了提供基础知识以外,还进行了适当的内容扩展,帮助读者了解更多的最新进展(如重要性加权VI以及内域、多输出和深度GP),这些进展可以作为新的研究思路的灵感。
Gaussian processes (GPs) provide a framework for Bayesian inference that can offer principled uncertainty estimates for a large range of problems. For example, if we consider regression problems with Gaussian likelihoods, a GP model can predict both the mean and variance of the posterior in closed form. However, identifying the posterior GP scales cubically with the number of training examples and requires to store all examples in memory. In order to overcome these obstacles, sparse GPs have been proposed that approximate the true posterior GP with pseudo-training examples. Importantly, the number of pseudo-training examples is user-defined and enables control over computational and memory complexity. In the general case, sparse GPs do not enjoy closed-form solutions and one has to resort to approximate inference. In this context, a convenient choice for approximate inference is variational inference (VI), where the problem of Bayesian inference is cast as an optimization problem — namely, to maximize a lower bound of the log marginal likelihood. This paves the way for a powerful and versatile framework, where pseudo-training examples are treated as optimization arguments of the approximate posterior that are jointly identified together with hyperparameters of the generative model (i.e. prior and likelihood). The framework can naturally handle a wide scope of supervised learning problems, ranging from regression with heteroscedastic and non-Gaussian likelihoods to classification problems with discrete labels, but also multilabel problems. The purpose of this tutorial is to provide access to the basic matter for readers without prior knowledge in both GPs and VI. A proper exposition to the subject enables also access to more recent advances (like importance-weighted VI as well as inderdomain, multioutput and deep GPs) that can serve as an inspiration for new research ideas.
https://weibo.com/1402400261/JANR8k1T9

另外几篇值得关注的论文:
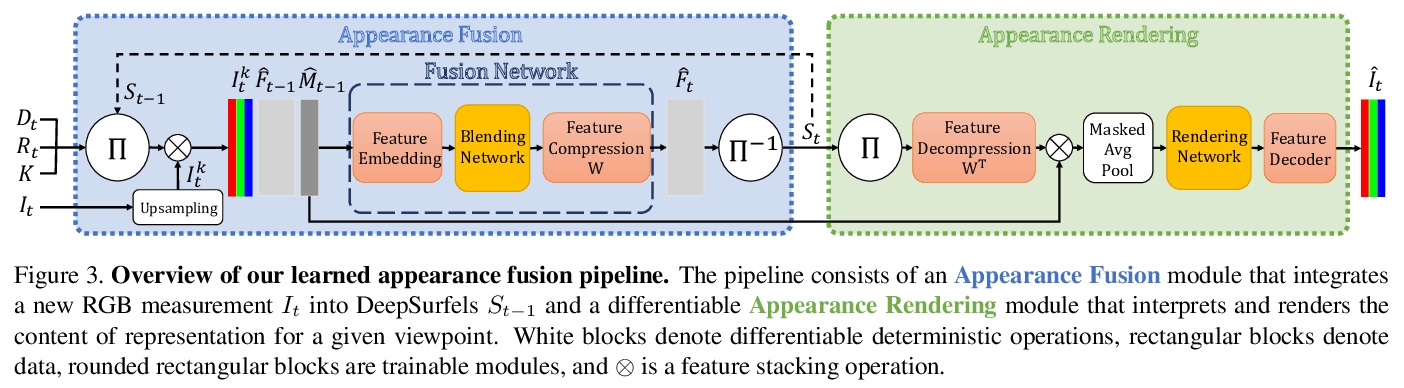
[CV] DeepSurfels: Learning Online Appearance Fusion
DeepSurfels:在线外观融合学习(一种新的几何和外观信息混合场景表示方法)
M Mihajlovic, S Weder, M Pollefeys, M R. Oswald
[ETH Zurich]
https://weibo.com/1402400261/JANUVdW4N


[IT] Reproducible Workflow
可复现工作流
A Prabhu, P Fox
[Rensselaer Polytechnic Institute]
https://weibo.com/1402400261/JANWYhBCa
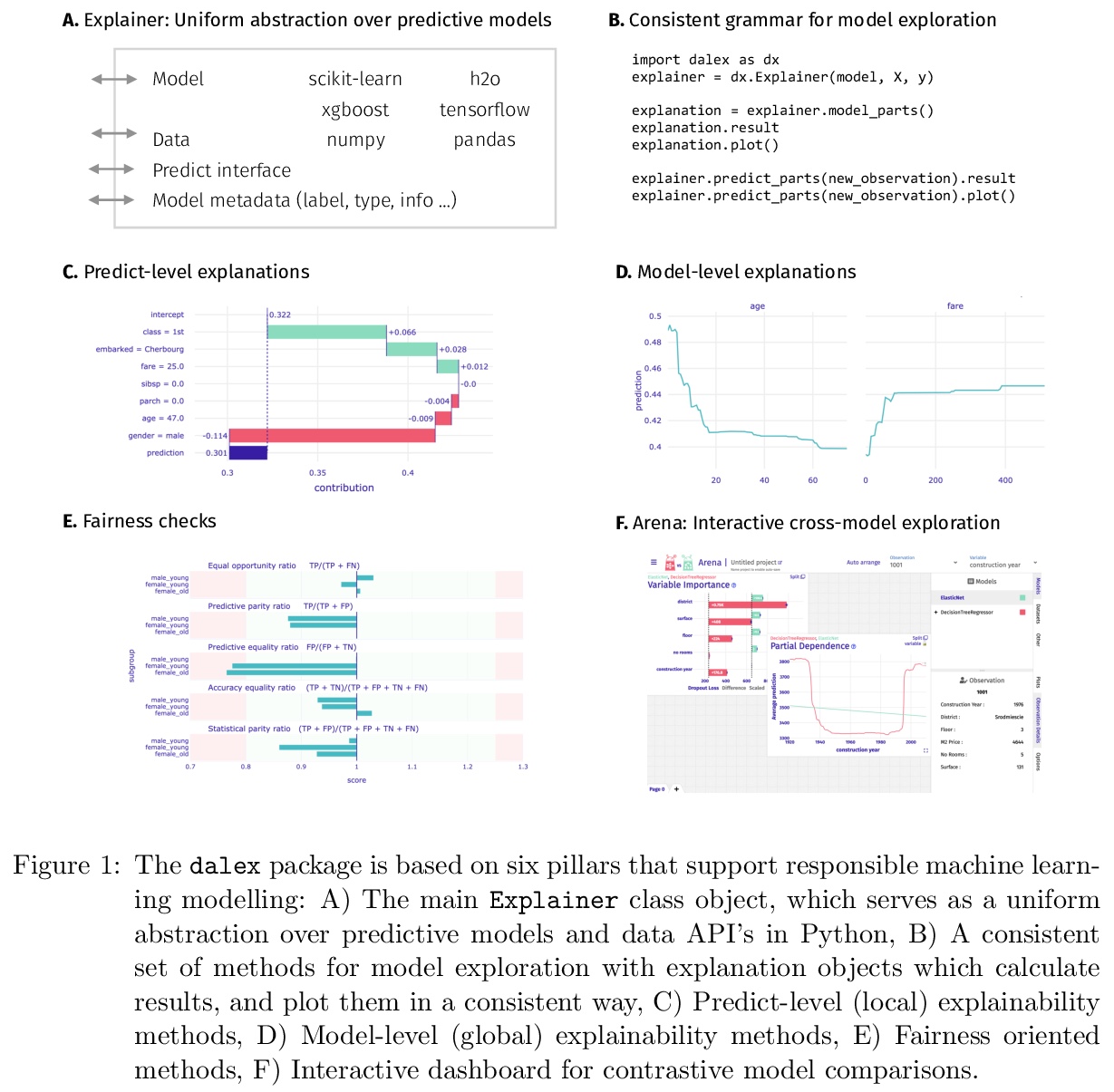
[LG] dalex: Responsible Machine Learning with Interactive Explainability and Fairness in Python
dalex:Python兼顾交互式可解释性与公平性的负责任机器学习库
H Baniecki, W Kretowicz, P Piatyszek, J Wisniewski, P Biecek
[Warsaw University of Technology]
https://weibo.com/1402400261/JANXPrJr

若有收获,就点个赞吧
0 人点赞
