- 1、[CV] Not All Images are Worth 16x16 Words: Dynamic Vision Transformers with Adaptive Sequence Length
- 2、[CV] Less is More: Pay Less Attention in Vision Transformers
- 3、[CV] StyTr2: Unbiased Image Style Transfer with Transformers
- 4、[CV] SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
- 5、[LG] Gotta Go Fast When Generating Data with Score-Based Models
- [CV] On the Bias Against Inductive Biases
- [LG] Exploring Sparse Expert Models and Beyond
- [CL] UCPhrase: Unsupervised Context-aware Quality Phrase Tagging
- [CL] Telling Stories through Multi-User Dialogue by Modeling Character Relations
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] Not All Images are Worth 16x16 Words: Dynamic Vision Transformers with Adaptive Sequence Length
Y Wang, R Huang, S Song, Z Huang, G Huang
[Tsinghua University & Huawei Technologies Ltd]
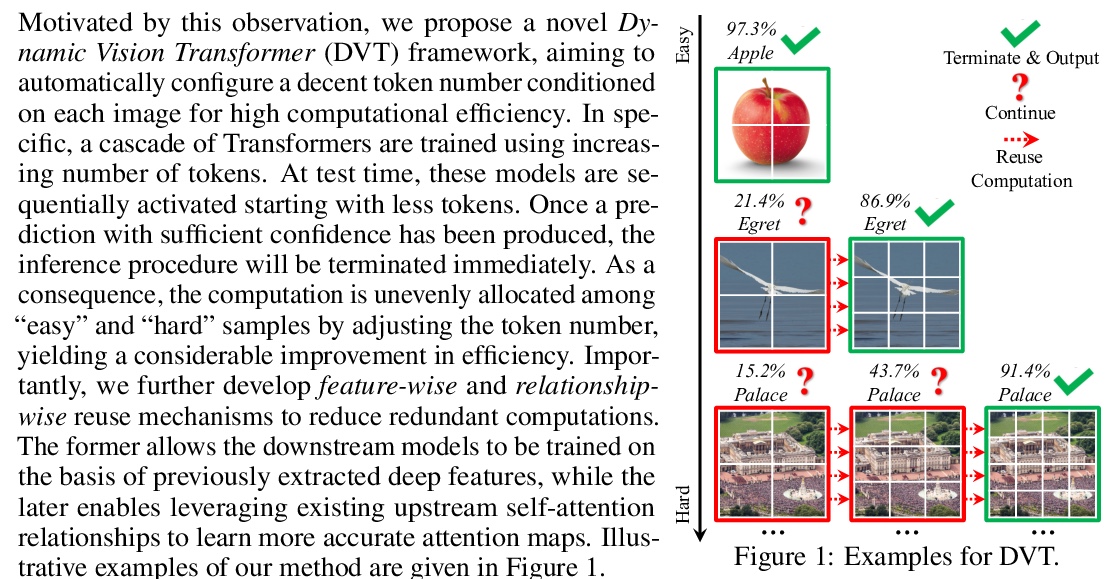
自适应序列长度动态视觉Transformer。视觉Transformers(ViT)在大规模图像识别中取得了显著成功,将每张2D图像分割成固定数量的图块,每个图块被视为一个token。一般来说,用更多的token来表示图像,会得到更高的预测精度,同时也会导致计算成本的急剧增加。为了在精度和速度之间取得适当的权衡,根据经验,token的数量被设定为16x16。本文认为每幅图像都有自己的特点,理想情况下,token数量应该以每个单独的输入为条件。事实上,存在相当数量的”简单”图像,仅用4x4的token数就可以准确预测,只有一小部分”困难”图像需要更精细的表示。受这一现象的启发,提出了一种动态Transformer,为每张输入图像自动配置适当数量的token。通过级联多个token数量增加的Transformer来实现,这些Transformers在测试时以自适应方式依次激活,一旦产生了足够自信的预测,推理就会终止。进一步设计了高效的特征重用和关系重用机制,跨越动态Transformer的不同组件,以减少冗余计算。在ImageNet、CIFAR-10和CIFAR-100上的大量实证结果表明,所提出方法在理论计算效率和实际推理速度上都明显优于竞争基线。
Vision Transformers (ViT) have achieved remarkable success in large-scale image recognition. They split every 2D image into a fixed number of patches, each of which is treated as a token. Generally, representing an image with more tokens would lead to higher prediction accuracy, while it also results in drastically increased computational cost. To achieve a decent trade-off between accuracy and speed, the number of tokens is empirically set to 16x16. In this paper, we argue that every image has its own characteristics, and ideally the token number should be conditioned on each individual input. In fact, we have observed that there exist a considerable number of “easy” images which can be accurately predicted with a mere number of 4x4 tokens, while only a small fraction of “hard” ones need a finer representation. Inspired by this phenomenon, we propose a Dynamic Transformer to automatically configure a proper number of tokens for each input image. This is achieved by cascading multiple Transformers with increasing numbers of tokens, which are sequentially activated in an adaptive fashion at test time, i.e., the inference is terminated once a sufficiently confident prediction is produced. We further design efficient feature reuse and relationship reuse mechanisms across different components of the Dynamic Transformer to reduce redundant computations. Extensive empirical results on ImageNet, CIFAR-10, and CIFAR-100 demonstrate that our method significantly outperforms the competitive baselines in terms of both theoretical computational efficiency and practical inference speed.
https://weibo.com/1402400261/KifRpmvWY

2、[CV] Less is More: Pay Less Attention in Vision Transformers
Z Pan, B Zhuang, H He, J Liu, J Cai
[Monash University]
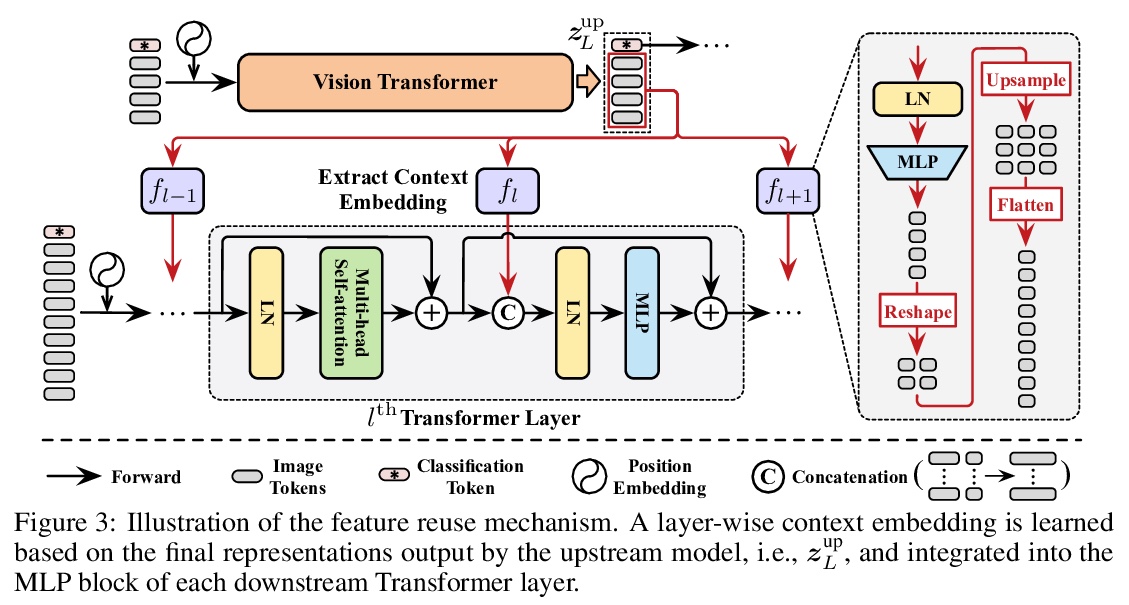
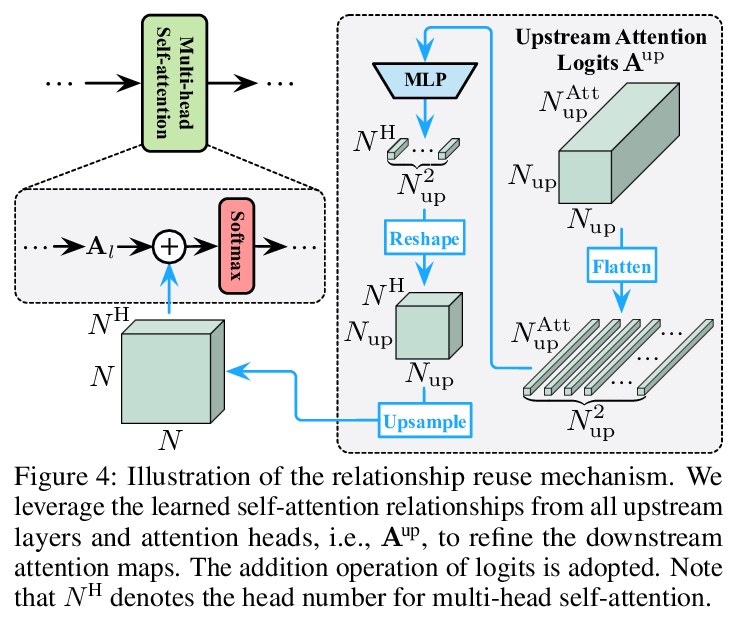
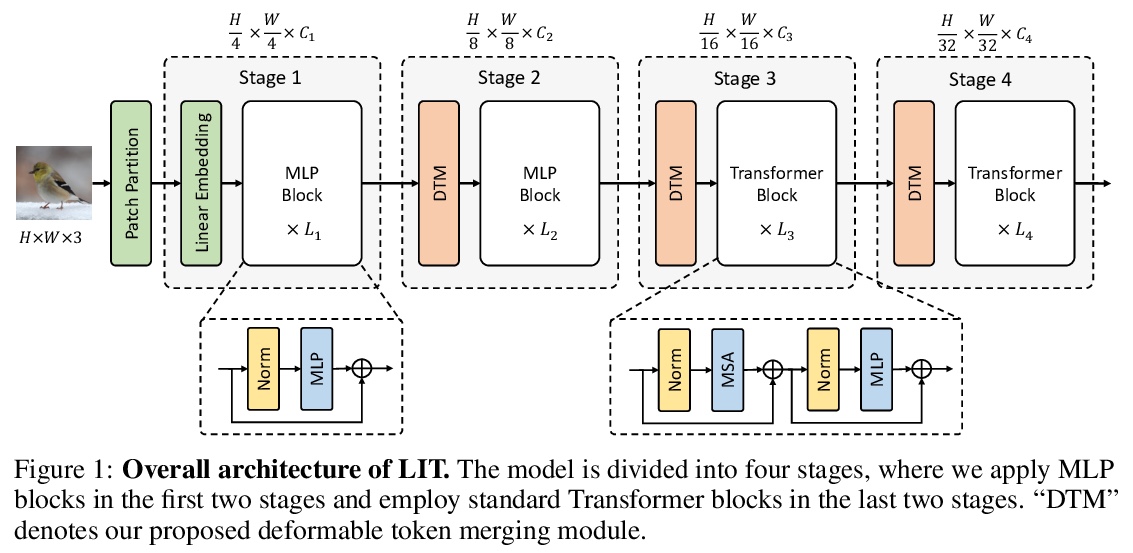
少即是多:更少注意力的视觉Transformer。Transformer已经成为深度学习的主流架构之一,特别是作为计算机视觉中卷积神经网络(CNN)的强大替代品。然而,由于长序列表示上的自注意力的二次复杂性,特别是对于高分辨率密集预测任务,之前工作中的Transformer训练和推理可能是非常昂贵的。本文提出一种新的少注意力Transformer(LIT),建立在卷积、全连接(FC)层和自注意力在处理图块序列方面具有几乎等价的数学表达方式的基础上,提出一种分层Transformer,用纯多层感知器(MLP)在早期阶段编码丰富的局部模式,同时应用自注意力模块捕捉更深层的依赖关系,进一步提出一种习得可变形token合并模块,以非均匀方式自适应融合信息块。所提出的LIT在图像识别任务上取得了很好的性能,包括图像分类、目标检测和实例分割,作为许多视觉任务的强大支柱。
Transformers have become one of the dominant architectures in deep learning, particularly as a powerful alternative to convolutional neural networks (CNNs) in computer vision. However, Transformer training and inference in previous works can be prohibitively expensive due to the quadratic complexity of self-attention over a long sequence of representations, especially for high-resolution dense prediction tasks. To this end, we present a novel Less attention vIsion Transformer (LIT), building upon the fact that convolutions, fully-connected (FC) layers, and selfattentions have almost equivalent mathematical expressions for processing image patch sequences. Specifically, we propose a hierarchical Transformer where we use pure multi-layer perceptrons (MLPs) to encode rich local patterns in the early stages while applying self-attention modules to capture longer dependencies in deeper layers. Moreover, we further propose a learned deformable token merging module to adaptively fuse informative patches in a non-uniform manner. The proposed LIT achieves promising performance on image recognition tasks, including image classification, object detection and instance segmentation, serving as a strong backbone for many vision tasks.
https://weibo.com/1402400261/KifUz2VAL

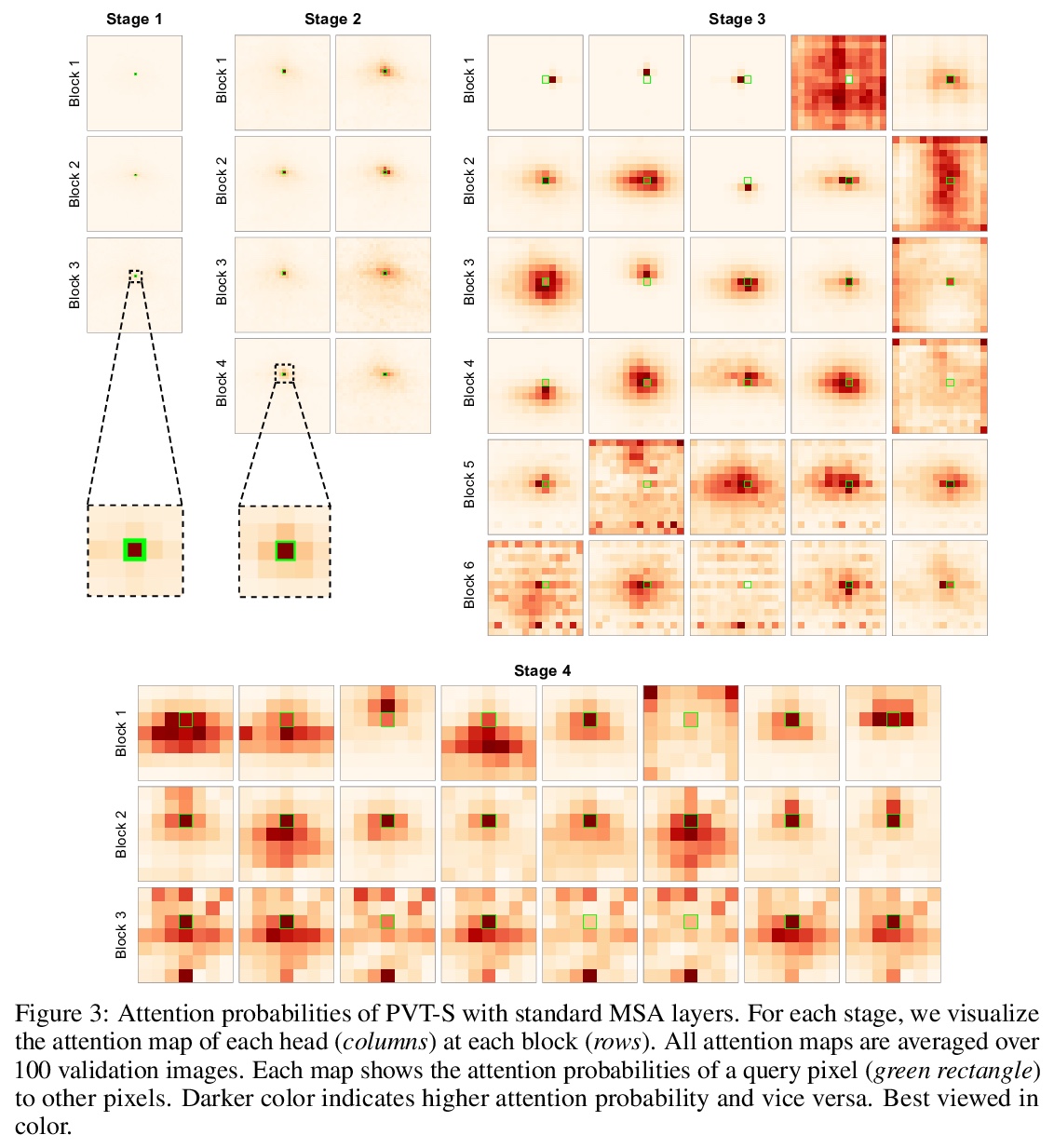
3、[CV] StyTr2: Unbiased Image Style Transfer with Transformers
Y Deng, F Tang, X Pan, W Dong, ChongyangMa, C Xu
[University of Chinese Academy of Sciences & Kuaishou Technology]
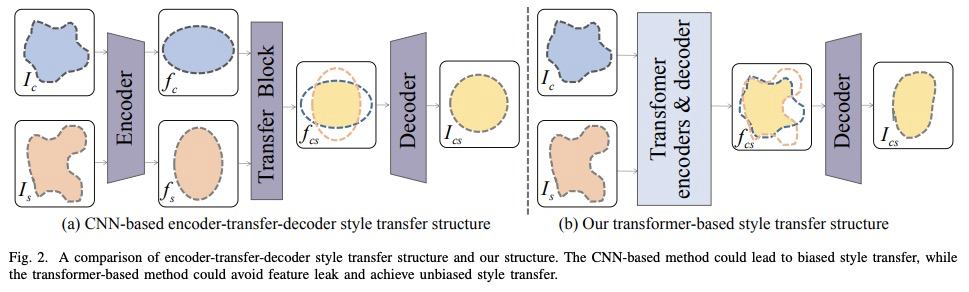
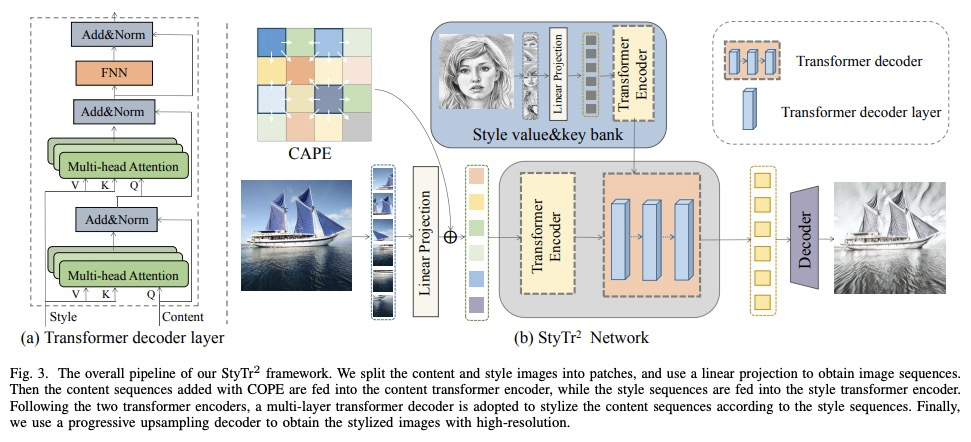
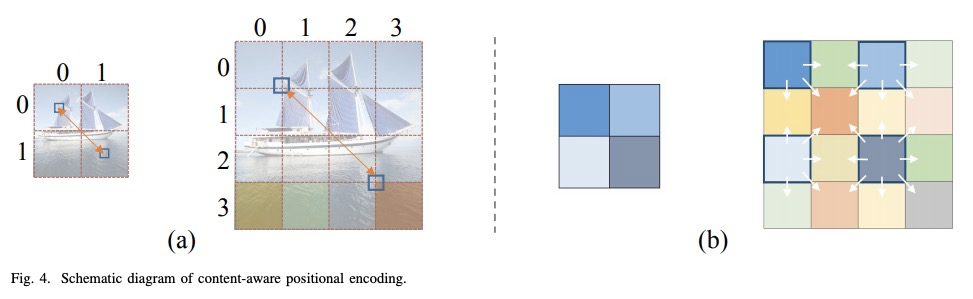
StyTr**2: 基于Transformer的无偏图像画风迁移。图像画风迁移的目标,是在保持原有内容的同时,在风格参考的指导下呈现具有艺术特征的图像。由于CNN的位置性和空间不变性,很难提取和保持输入图像的全局信息。因此,传统的神经画风迁移方法通常是有偏的,通过对同一参考风格图像进行多次画风迁移过程,可观察到内容的泄露。为解决这个关键问题,本文提出一种基于Transformer的方法StyTr2,将输入图像的长程依赖考虑在内,以实现无偏画风迁移。 与其他视觉任务的视觉Transformer相比,StyTr2包含两个不同的Transformer编码器,分别为内容和风格产生特定域序列。编码器之后,采用一种多层Transformer解码器,根据风格序列对内容序列进行风格化处理。分析了现有位置编码方法的不足,提出了尺度不变的内容感知位置编码(CAPE),更适合于图像画风迁移任务。定性和定量实验表明,与最先进的基于CNN和基于流的方法相比,所提出的StyTr2**是有效的。
The goal of image style transfer is to render an image with artistic features guided by a style reference while maintaining the original content. Due to the locality and spatial invariance in CNNs, it is difficult to extract and maintain the global information of input images. Therefore, traditional neural style transfer methods are usually biased and content leak can be observed by running several times of the style transfer process with the same reference style image. To address this critical issue, we take long-range dependencies of input images into account for unbiased style transfer by proposing a transformer-based approach, namely StyTr. In contrast with visual transformers for other vision tasks, our StyTr contains two different transformer encoders to generate domain-specific sequences for content and style, respectively. Following the encoders, a multi-layer transformer decoder is adopted to stylize the content sequence according to the style sequence. In addition, we analyze the deficiency of existing positional encoding methods and propose the content-aware positional encoding (CAPE) which is scale-invariant and more suitable for image style transfer task. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed StyTr compared to state-of-the-art CNN-based and flow-based approaches.
https://weibo.com/1402400261/KifYeyqAA

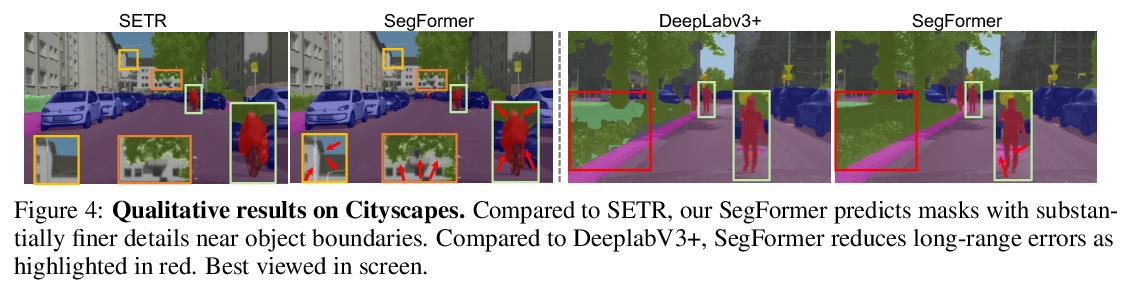
4、[CV] SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
E Xie, W Wang, Z Yu, A Anandkumar, J M. Alvarez, P Luo
[The University of Hong Kong & Nanjing University & NVIDIA]
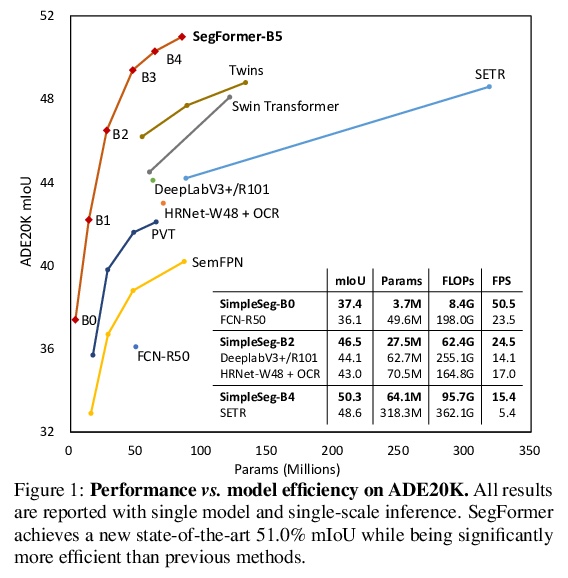
SegFormer: 基于Transformer的语义分割简单高效设计。提出SegFormer,一种简单、高效而强大的语义分割框架,将Transformer与轻量多层感知器(MLP)解码器统一起来。SegFormer有两个主要特点:1)包括一种新的分层结构Transformer编码器,输出多尺度特征,不需要位置编码,从而避免了位置编码的插值,当测试分辨率与训练不同时,插值会导致性能下降。2) 避免了复杂的解码器。所提出的MLP解码器聚合了来自不同层的信息,结合局部注意力和全局注意力,呈现出强大的表示。这种简单和轻量的设计,是在Transformer上进行高效分割的关键。扩展该方法,得到了从SegFormer-B0到SegFormer-B5的一系列模型,达到了比之前同类模型明显更好的性能和效率,SegFormer-B4在ADE20K上实现了50.3%的mIoU,参数为64M,比之前的最佳方法小5倍,好2.2%。最好的模型SegFormer-B5在Cityscapes验证集上实现了84.0%的mIoU,并在Cityscapes-C上显示了出色的零样本鲁棒性。
We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with lightweight multilayer perceptron (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding, thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from different layers, and thus combining both local attention and global attention to render powerful representations. We show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters, being 5× smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C.
https://weibo.com/1402400261/Kig1lqkhJ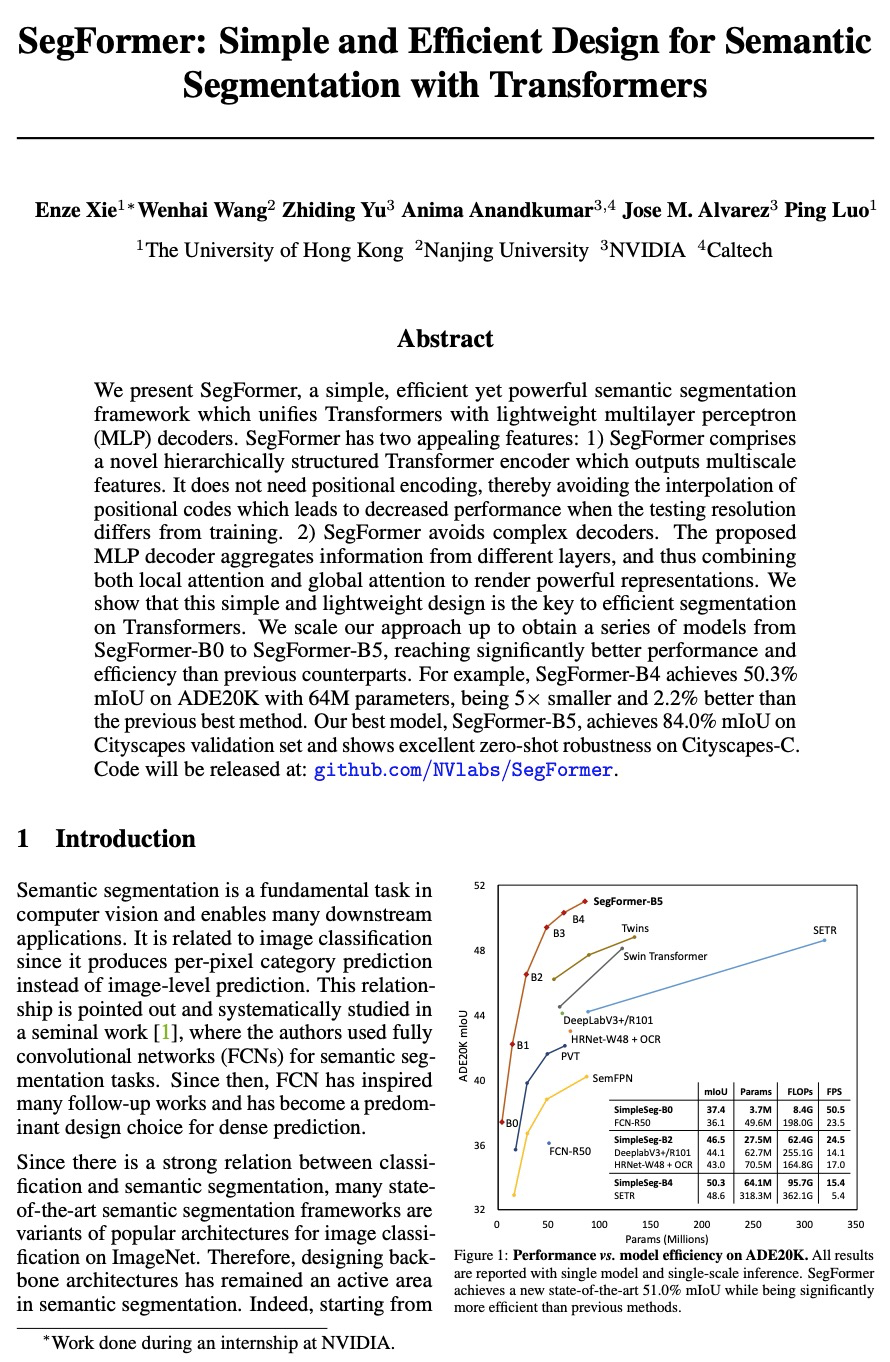
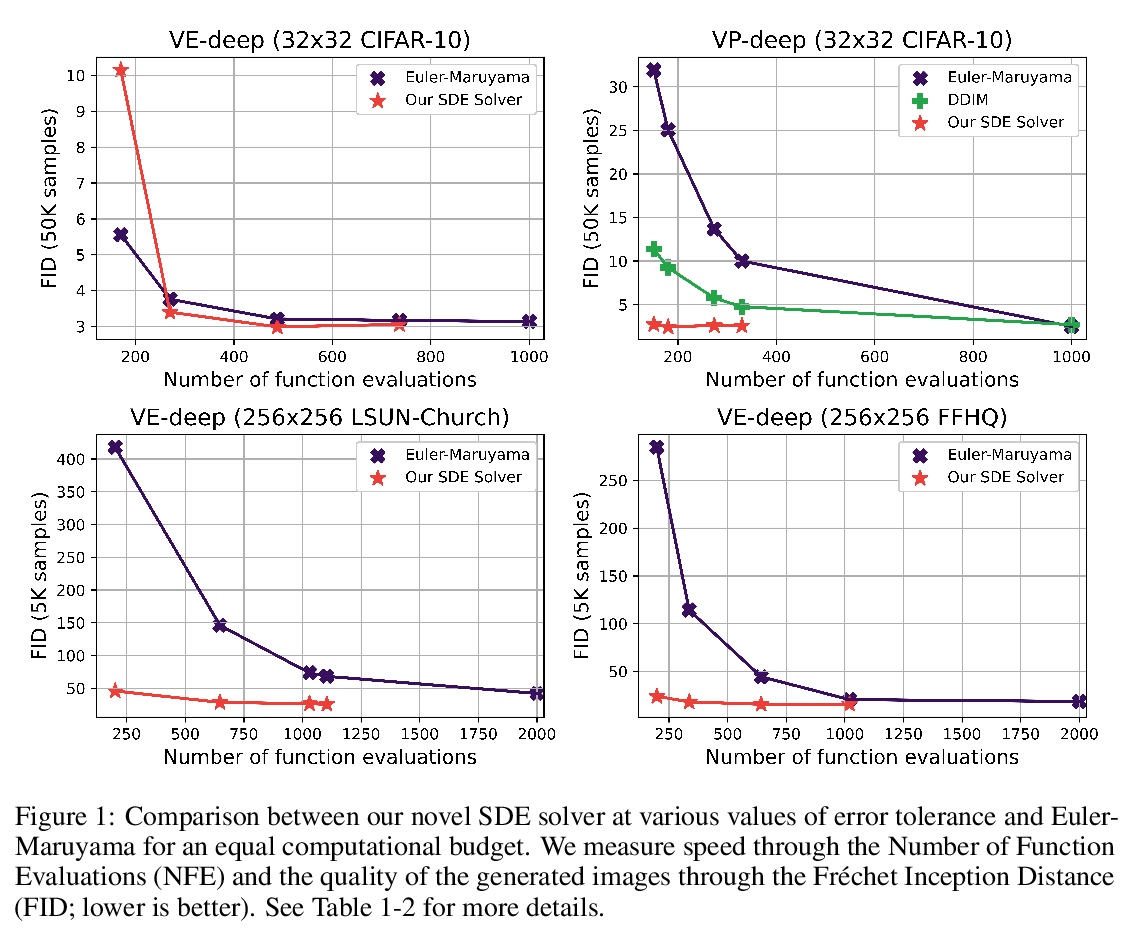
5、[LG] Gotta Go Fast When Generating Data with Score-Based Models
A Jolicoeur-Martineau, K Li, R Piché-Taillefer, T Kachman, I Mitliagkas
[University of Montreal & Simon Fraser University & Radboud University]
基于得分模型的加速数据生成。基于得分(去噪扩散)的生成模型,最近在生成现实的、多样化的数据方面获得了很大成功,这些方法定义了一个将数据转化为噪声的前向扩散过程,并通过逆向过程来生成数据(从噪声到数据)。不幸的是,由于数值SDE求解器需要大量的得分网络评估,目前基于得分的模型生成数据非常慢。本文旨在通过设计一种更有效的SDE求解器来加速这一过程。现有的方法依赖固定步长的EM求解器。简单用其他SDE求解器代替效果很差,要么导致低质量样本,要么变得比EM更慢。为解决该问题,设计了一种SDE求解器,自适应步长为基于分数的生成模型逐件定制,只需要进行两次得分函数评估,很少的拒绝样本,可得到高质量样本。该方法生成数据比EM快2到10倍,同时实现了更好或同等的样本质量。对于高分辨率图像,该方法得到了明显高于所有其他测试方法的高质量样本。SDE求解器有一个明显的好处,就是不需要调整步长。
Score-based (denoising diffusion) generative models have recently gained a lot of success in generating realistic and diverse data. These approaches define a forward diffusion process for transforming data to noise and generate data by reversing it (thereby going from noise to data). Unfortunately, current score-based models generate data very slowly due to the sheer number of score network evaluations required by numerical SDE solvers. In this work, we aim to accelerate this process by devising a more efficient SDE solver. Existing approaches rely on the Euler-Maruyama (EM) solver, which uses a fixed step size. We found that naively replacing it with other SDE solvers fares poorly they either result in low-quality samples or become slower than EM. To get around this issue, we carefully devise an SDE solver with adaptive step sizes tailored to score-based generative models piece by piece. Our solver requires only two score function evaluations, rarely rejects samples, and leads to high-quality samples. Our approach generates data 2 to 10 times faster than EM while achieving better or equal sample quality. For high-resolution images, our method leads to significantly higher quality samples than all other methods tested. Our SDE solver has the benefit of requiring no step size tuning.
https://weibo.com/1402400261/Kig4Eiu3N



另外几篇值得关注的论文:
[CV] On the Bias Against Inductive Biases
对归纳偏差的偏差
G Cazenavette, S Lucey
[CMU]
https://weibo.com/1402400261/Kig9OvEpM



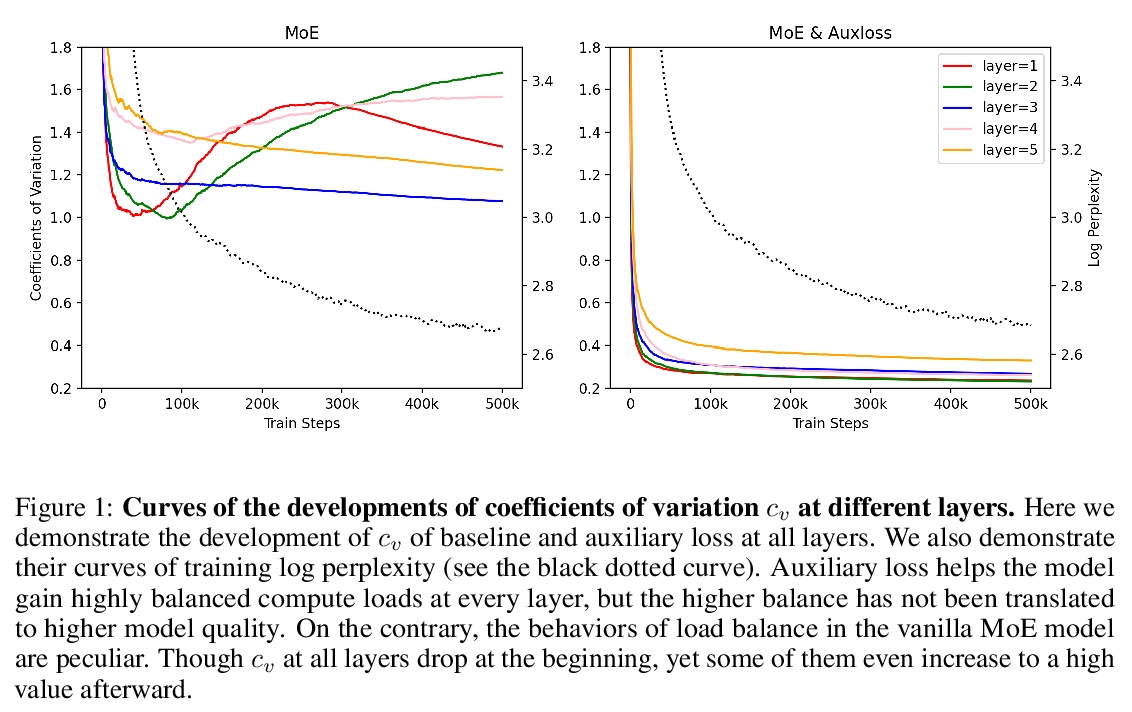
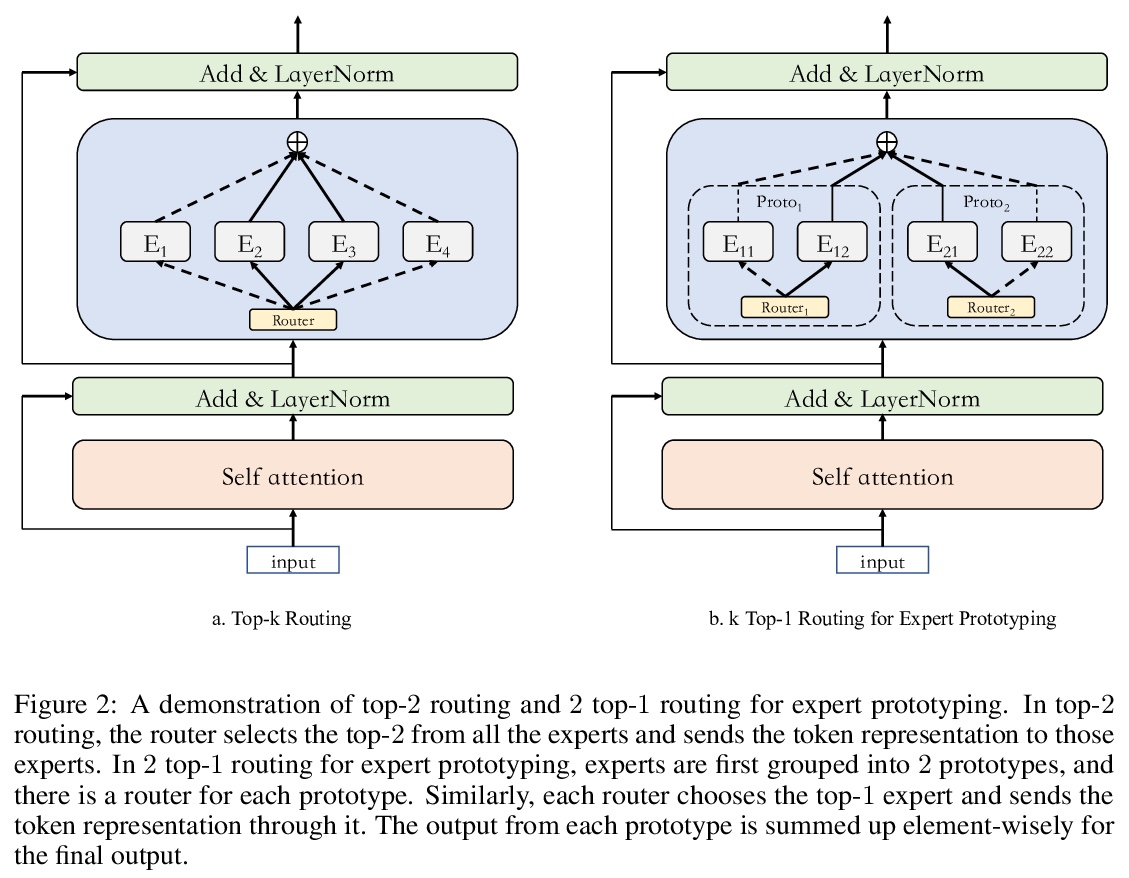
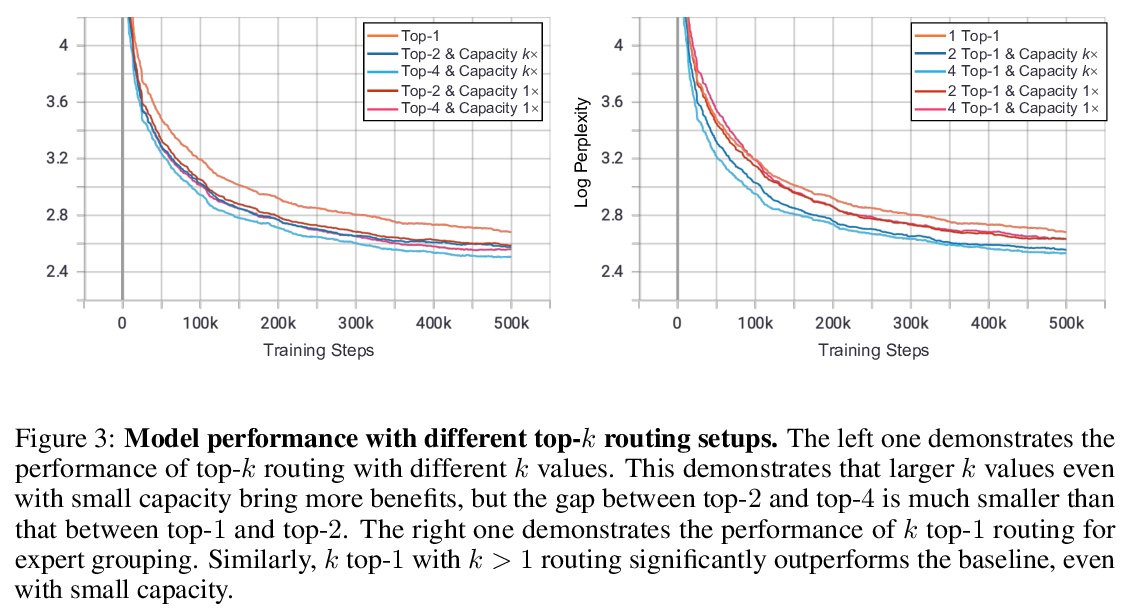
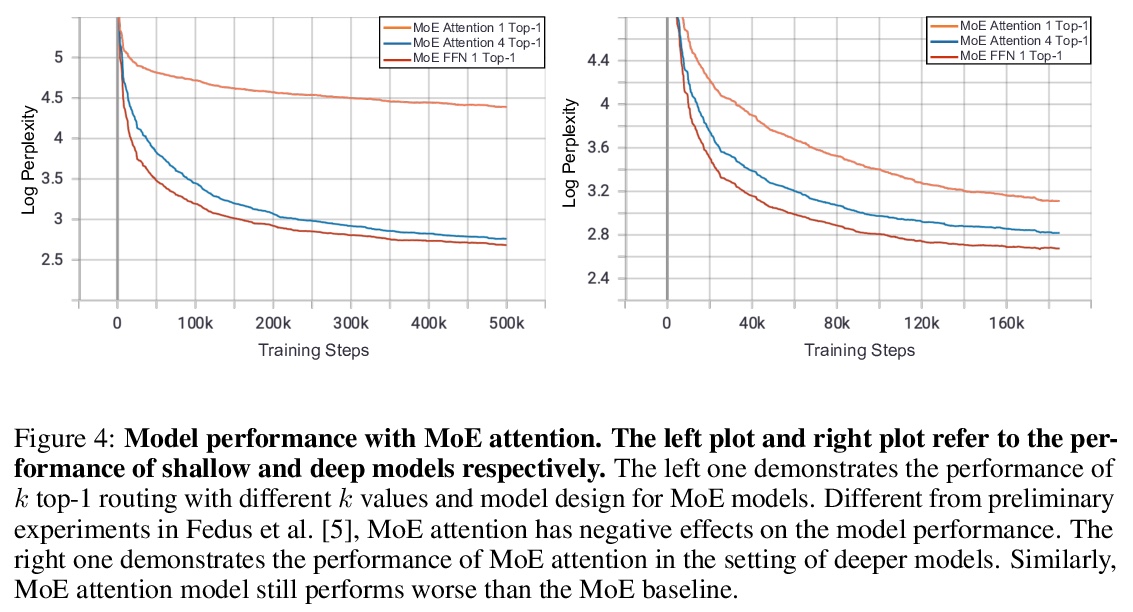
[LG] Exploring Sparse Expert Models and Beyond
稀疏专家模型探索
A Yang, J Lin, R Men, C Zhou, L Jiang, X Jia, A Wang, J Zhang, J Wang, Y Li, D Zhang, W Lin, L Qu, J Zhou, H Yang
[Alibaba Group]
https://weibo.com/1402400261/Kigc40dIJ
[CL] UCPhrase: Unsupervised Context-aware Quality Phrase Tagging
UCPhrase:无监督上下文感知高质量短语标记
X Gu, Z Wang, Z Bi, Y Meng, L Liu, J Han, J Shang
[University of Illinois at Urbana-Champaign & University of California San Diego]
https://weibo.com/1402400261/KigdXocvO


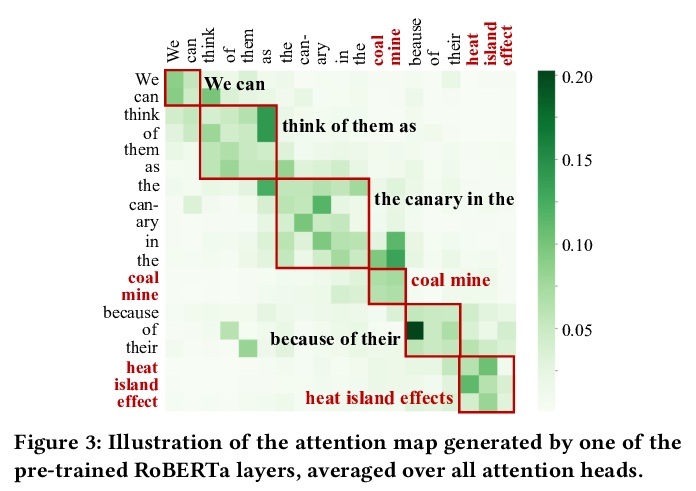
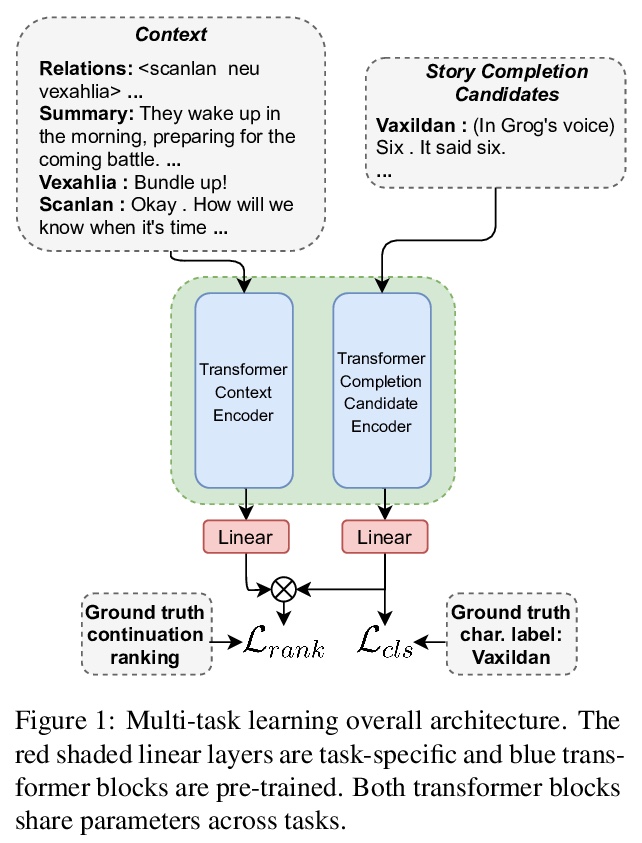
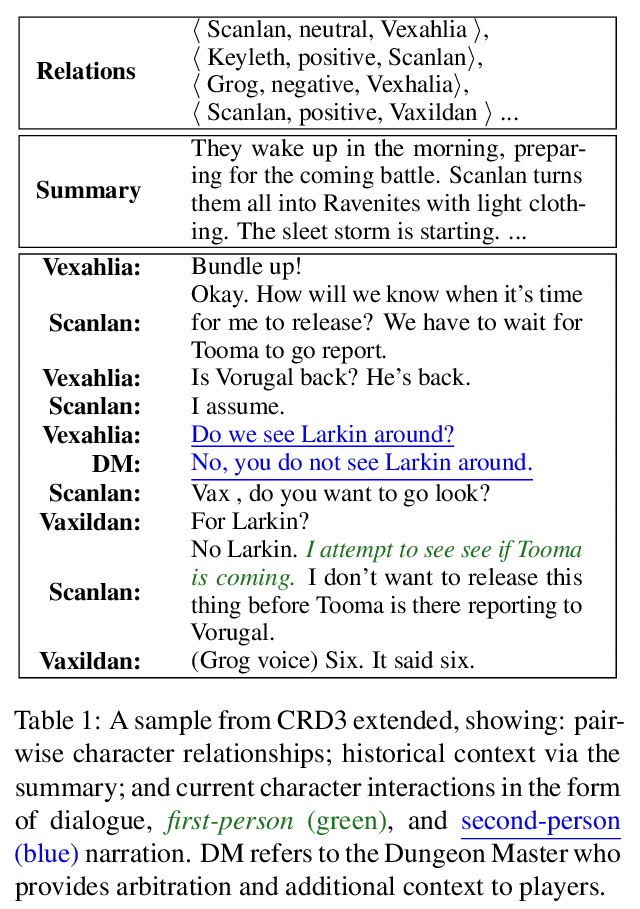
[CL] Telling Stories through Multi-User Dialogue by Modeling Character Relations
基于角色关系建模的多用户对话叙事
W M Si, P Ammanabrolu, M O. Riedl
[Georgia Institute of Technology]
https://weibo.com/1402400261/Kigfc9yqc

若有收获,就点个赞吧
0 人点赞
