- 1、[CV] The Invertible U-Net for Optical-Flow-free Video Interframe Generation
- 2、[CV] Spatial Dependency Networks: Neural Layers for Improved Generative Image Modeling
- 3、[CV] Generating Diverse Structure for Image Inpainting With Hierarchical VQ-VAE
- 4、[CV] Large-Scale Zero-Shot Image Classification from Rich and Diverse Textual Descriptions
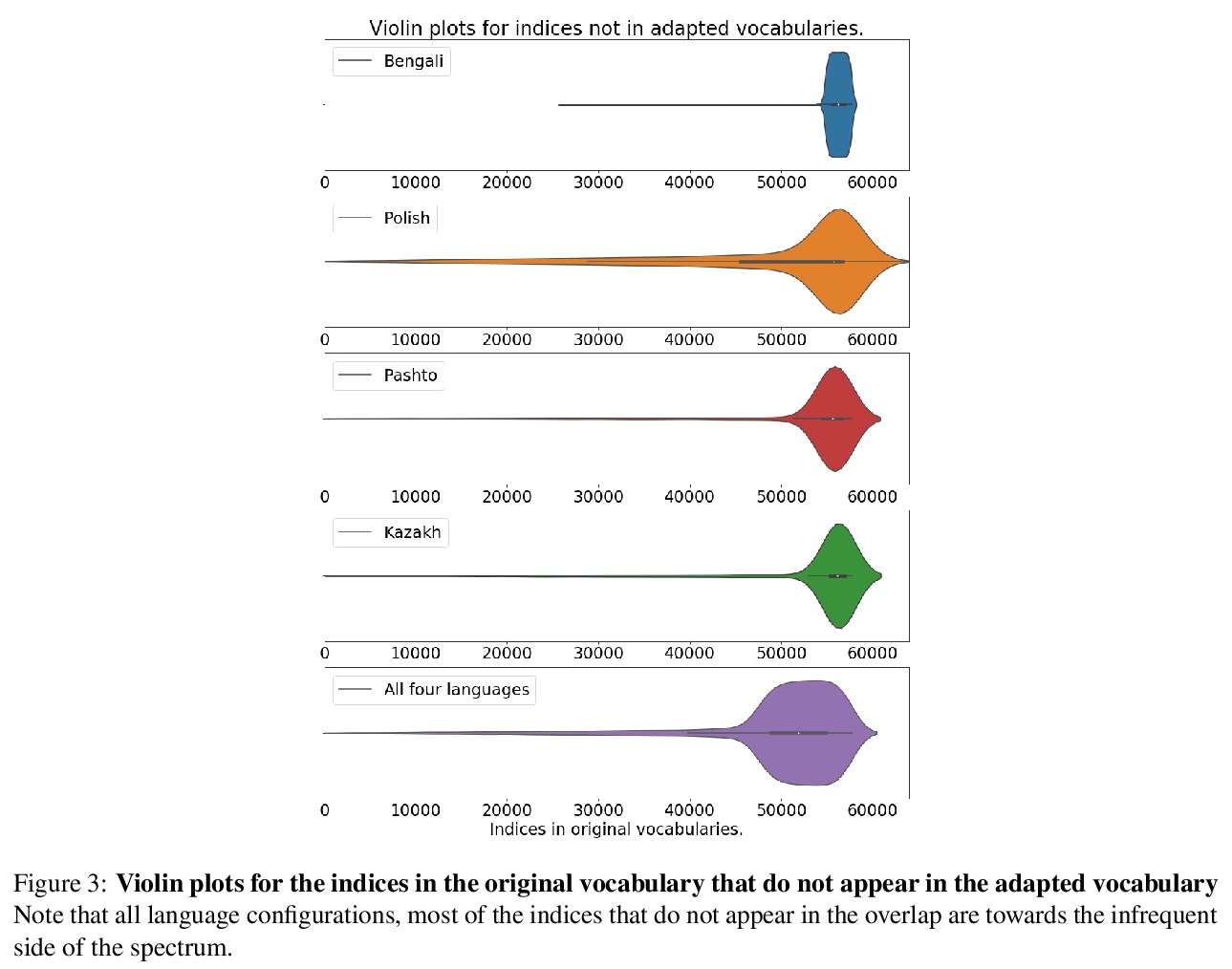
- 5、[CL] Towards Continual Learning for Multilingual Machine Translation via Vocabulary Substitution
- [LG] Modular Design Patterns for Hybrid Learning and Reasoning Systems: a taxonomy, patterns and use cases
- [LG] Provably Strict Generalisation Benefit for Equivariant Models
- [LG] Understanding invariance via feedforward inversion of discriminatively trained classifiers
- [LG] Rethinking Relational Encoding in Language Model: Pre-Training for General Sequences
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] The Invertible U-Net for Optical-Flow-free Video Interframe Generation
S Park, D Han, N Kwak
[Seoul National University]
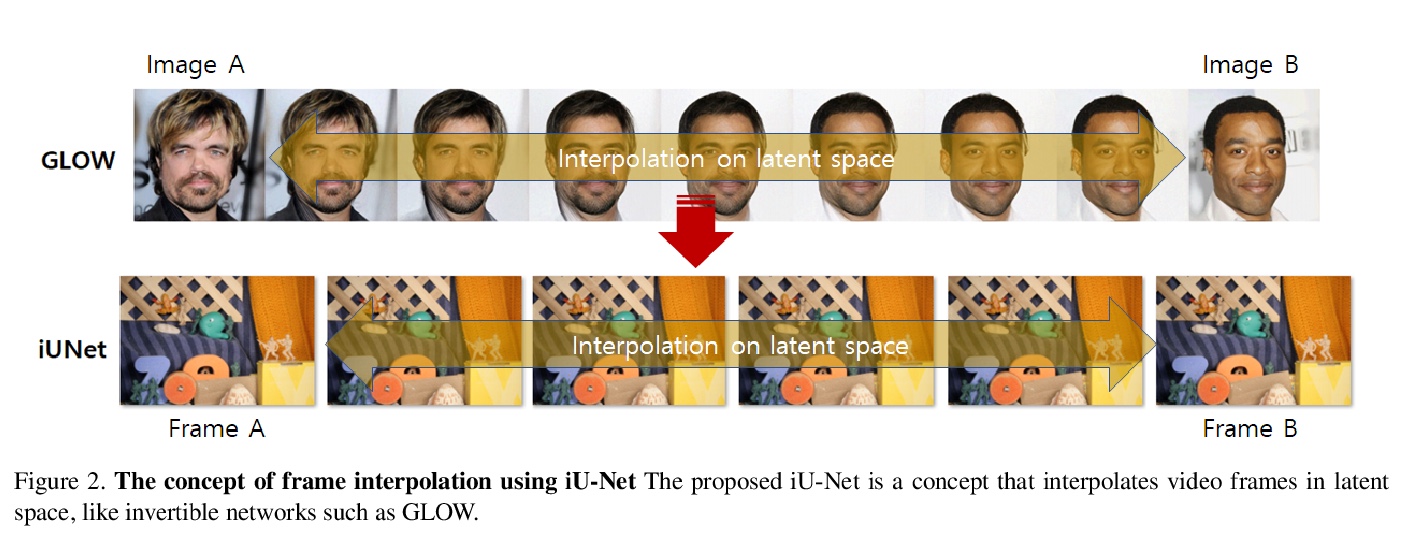
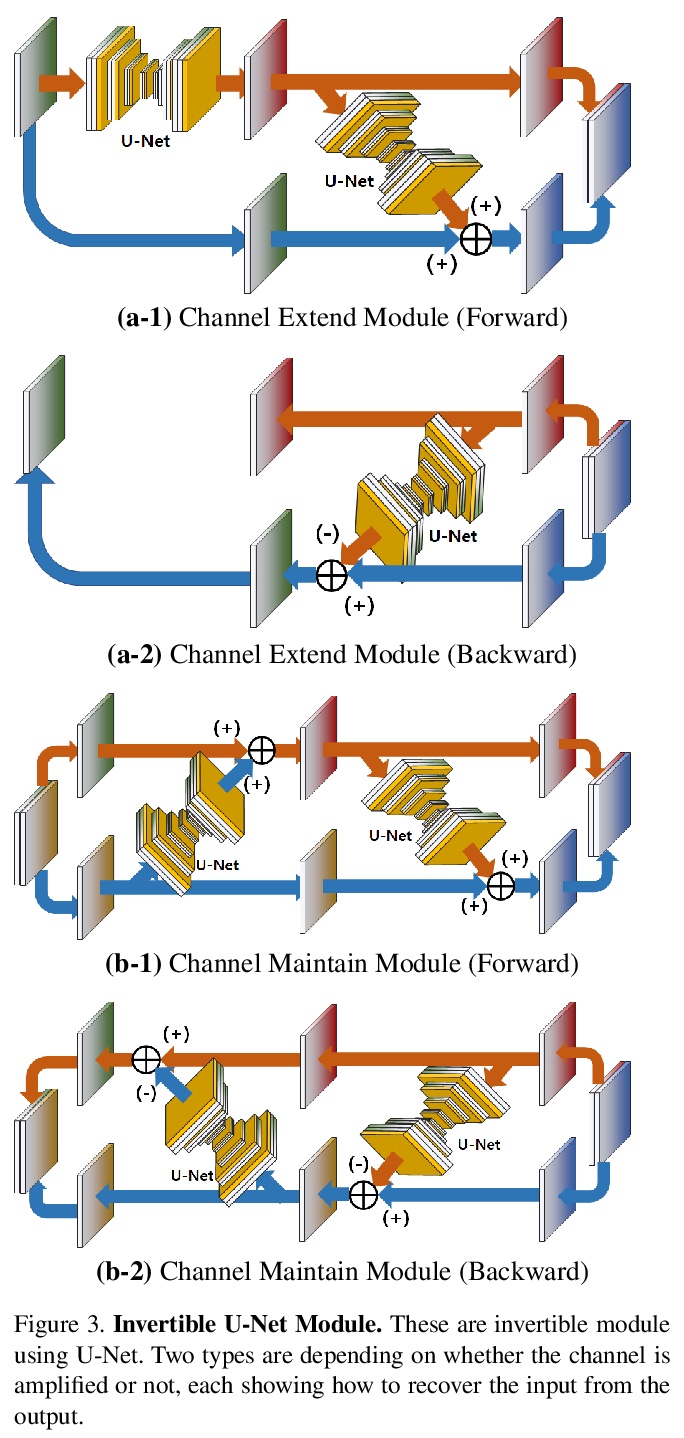
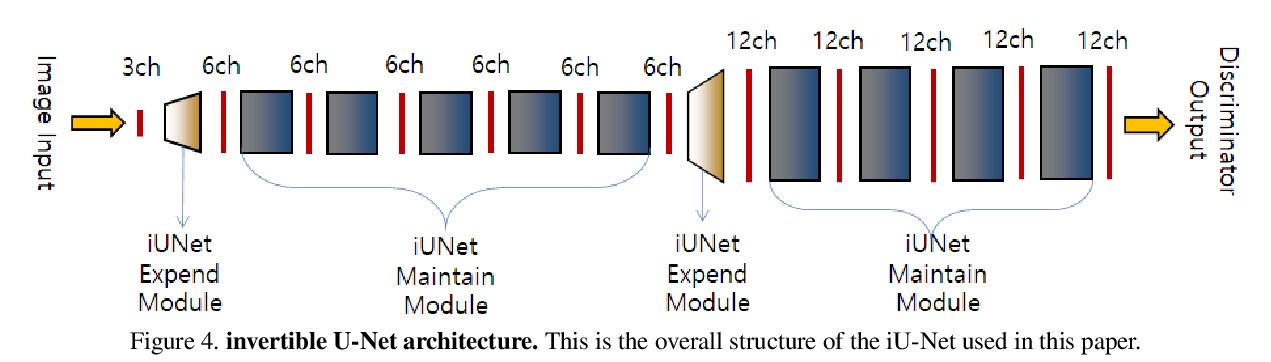
可逆U-Net非光流视频中间帧生成。提出一种利用视频数据本身生成中间帧的新方法,利用可逆深度神经网络,无需制造光流信息。提出一个可逆网络iU-Net,能产生更好的结果,利用Middlebury数据集证实了它的可行性。开发了一种在潜空间引发视频连续帧之间时间线性关系的损失,并提出一种能用训练好的可逆网络生成中景结果的算法。
Video frame interpolation is the task of creating an interface between two adjacent frames along the time axis. So, instead of simply averaging two adjacent frames to create an intermediate image, this operation should maintain semantic continuity with the adjacent frames. Most conventional methods use optical flow, and various tools such as occlusion handling and object smoothing are indispensable. Since the use of these various tools leads to complex problems, we tried to tackle the video interframe generation problem without using problematic optical flow. To enable this, we have tried to use a deep neural network with an invertible structure and developed an invertible U-Net which is a modified normalizing flow. In addition, we propose a learning method with a new consistency loss in the latent space to maintain semantic temporal consistency between frames. The resolution of the generated image is guaranteed to be identical to that of the original images by using an invertible network. Furthermore, as it is not a random image like the ones by generative models, our network guarantees stable outputs without flicker. Through experiments, we confirmed the feasibility of the proposed algorithm and would like to suggest invertible U-Net as a new possibility for baseline in video frame interpolation. This paper is meaningful in that it is the worlds first attempt to use invertible networks instead of optical flows for video interpolation.
https://weibo.com/1402400261/K7a17nBBe

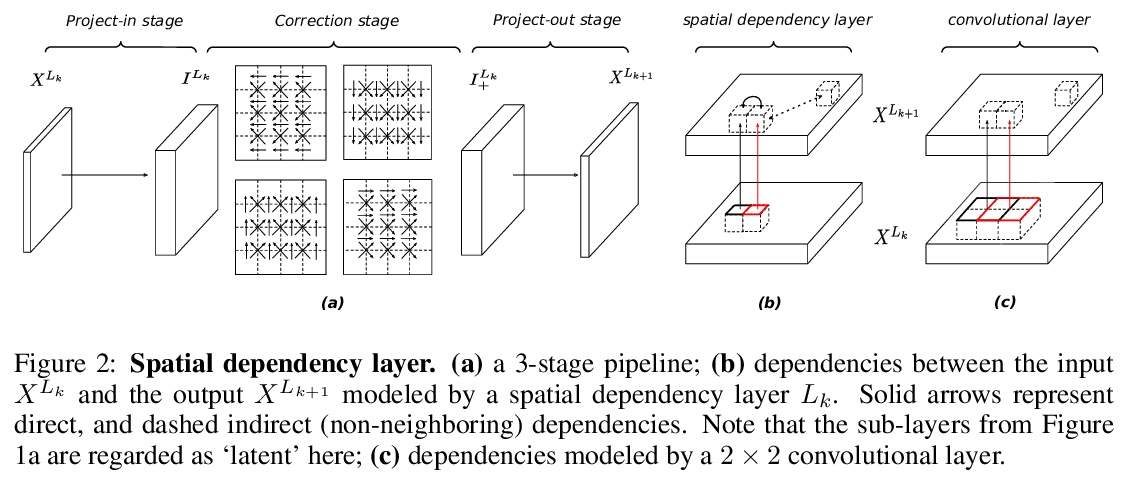
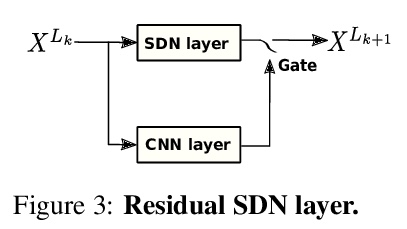
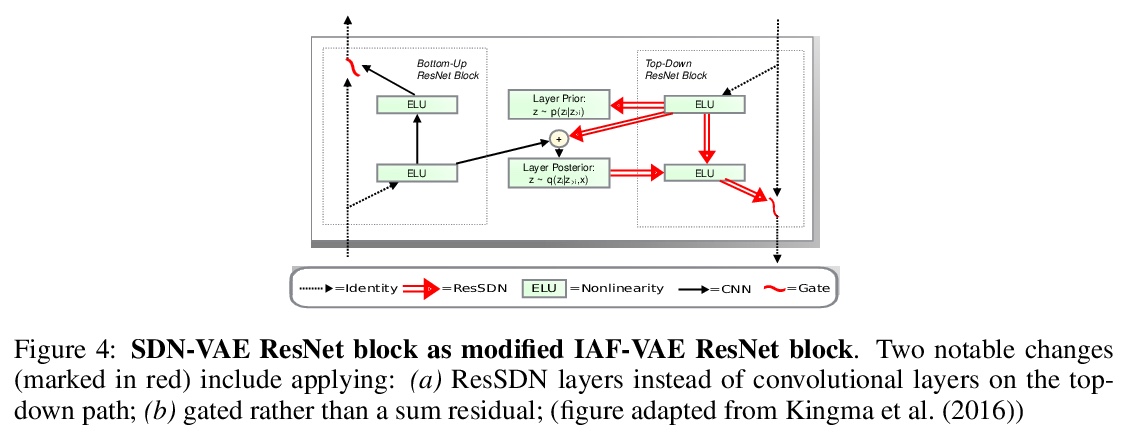
2、[CV] Spatial Dependency Networks: Neural Layers for Improved Generative Image Modeling
Đ Miladinović, A Stanić, S Bauer, J Schmidhuber, J M. Buhmann
[ETH Zurich & Swiss AI Lab IDSIA & Max-Planck Institute]
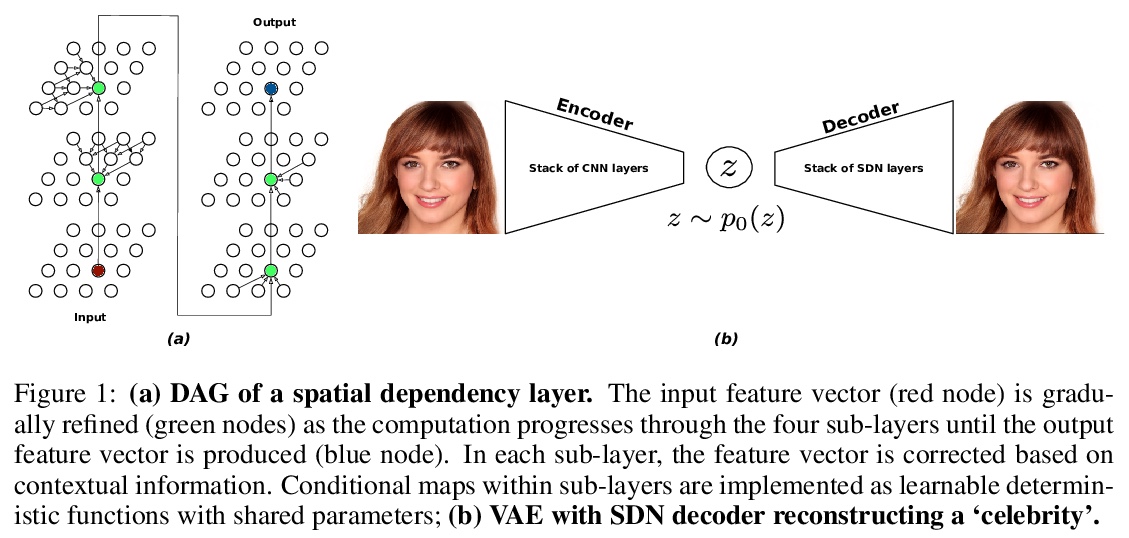
空间依赖网络:用于改进生成式图像建模的神经层。介绍了一种用于构建图像生成器(解码器)的新型神经网络,并将其应用于变分自编码器(VAE)。在空间依赖网络(SDN)中,深度神经网络每一级特征图都是以空间连贯方式计算的,用基于顺序门控的机制,将上下文信息分布在二维空间中。通过空间依赖层来增强分层VAE的解码器,相比基线卷积架构和同级模型中最先进技术,大大改善了密度估计。证明了SDN可通过合成高质量和一致性的样本来应用于大型图像。
How to improve generative modeling by better exploiting spatial regularities and coherence in images? We introduce a novel neural network for building image generators (decoders) and apply it to variational autoencoders (VAEs). In our spatial dependency networks (SDNs), feature maps at each level of a deep neural net are computed in a spatially coherent way, using a sequential gating-based mechanism that distributes contextual information across 2-D space. We show that augmenting the decoder of a hierarchical VAE by spatial dependency layers considerably improves density estimation over baseline convolutional architectures and the state-of-the-art among the models within the same class. Furthermore, we demonstrate that SDN can be applied to large images by synthesizing samples of high quality and coherence. In a vanilla VAE setting, we find that a powerful SDN decoder also improves learning disentangled representations, indicating that neural architectures play an important role in this task. Our results suggest favoring spatial dependency over convolutional layers in various VAE settings. The accompanying source code is given at > this https URL.
https://weibo.com/1402400261/K7a7iCGyR
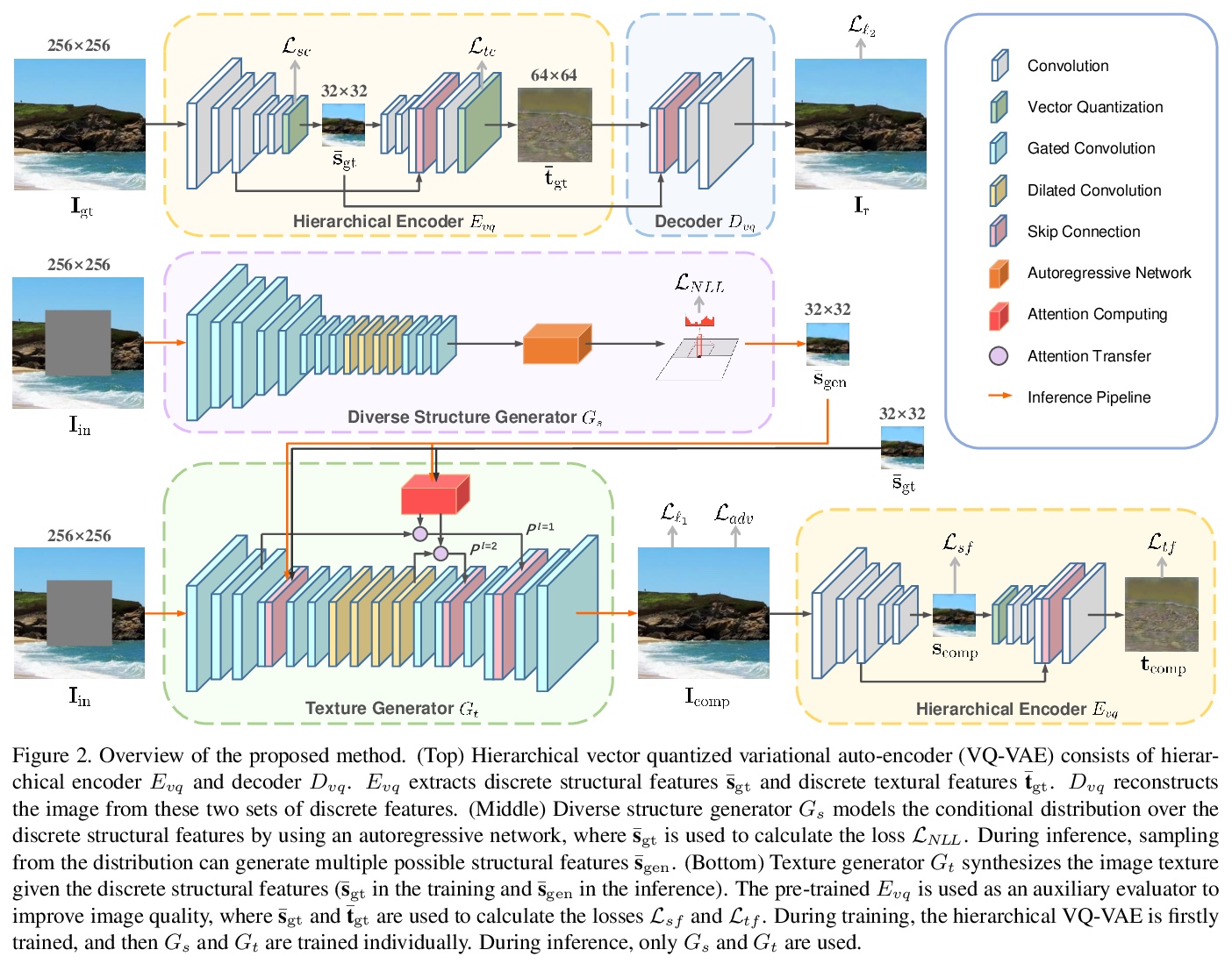
3、[CV] Generating Diverse Structure for Image Inpainting With Hierarchical VQ-VAE
J Peng, D Liu, S Xu, H Li
[University of Science and Technology of China & Noah’s Ark Lab,]
基于层次VQ-VAE的图像补全多样化结构生成。提出一种利用层次VQ-VAE生成多样化高质量图像的多解补全方法,先制定一个自回归分布来生成多样化结构,再为每一种结构合成图像纹理。提出一个结构关注模块,以确保合成的纹理与生成的结构一致。提出两种特征损失,分别用来提高结构一致性和纹理真实性。广泛的定性和定量比较显示了所提出方法在质量和多样性方面的优势。
Given an incomplete image without additional constraint, image inpainting natively allows for multiple solutions as long as they appear plausible. Recently, multiplesolution inpainting methods have been proposed and shown the potential of generating diverse results. However, these methods have difficulty in ensuring the quality of each solution, e.g. they produce distorted structure and/or blurry texture. We propose a two-stage model for diverse inpainting, where the first stage generates multiple coarse results each of which has a different structure, and the second stage refines each coarse result separately by augmenting texture. The proposed model is inspired by the hierarchical vector quantized variational auto-encoder (VQ-VAE), whose hierarchical architecture isentangles structural and textural information. In addition, the vector quantization in VQVAE enables autoregressive modeling of the discrete distribution over the structural information. Sampling from the distribution can easily generate diverse and high-quality structures, making up the first stage of our model. In the second stage, we propose a structural attention module inside the texture generation network, where the module utilizes the structural information to capture distant correlations. We further reuse the VQ-VAE to calculate two feature losses, which help improve structure coherence and texture realism, respectively. Experimental results on CelebA-HQ, Places2, and ImageNet datasets show that our method not only enhances the diversity of the inpainting solutions but also improves the visual quality of the generated multiple images. Code and models are available at: > this https URL.
https://weibo.com/1402400261/K7achcVOM


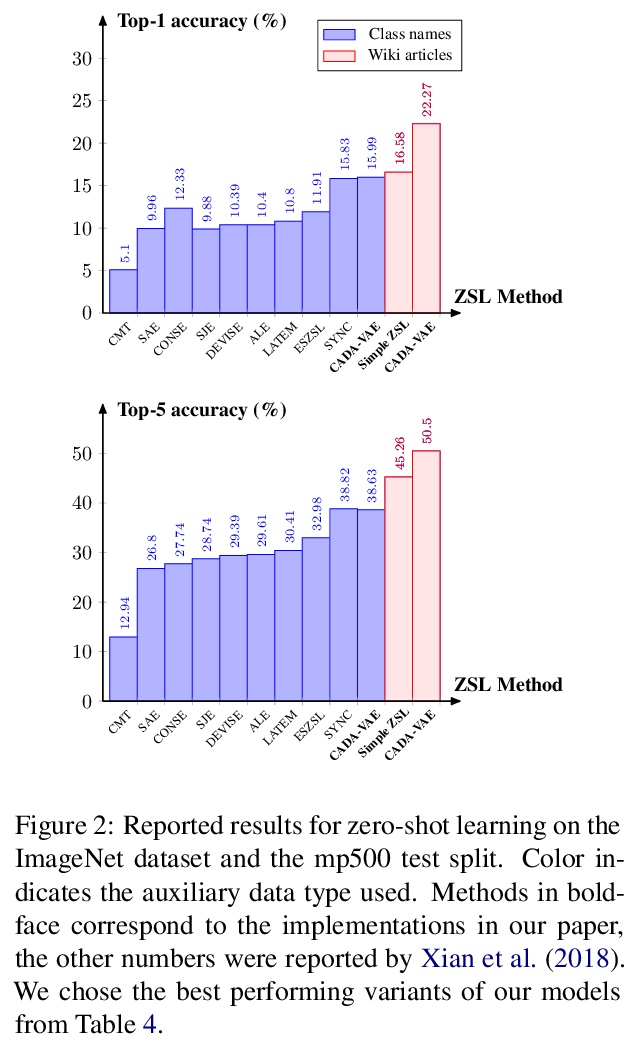
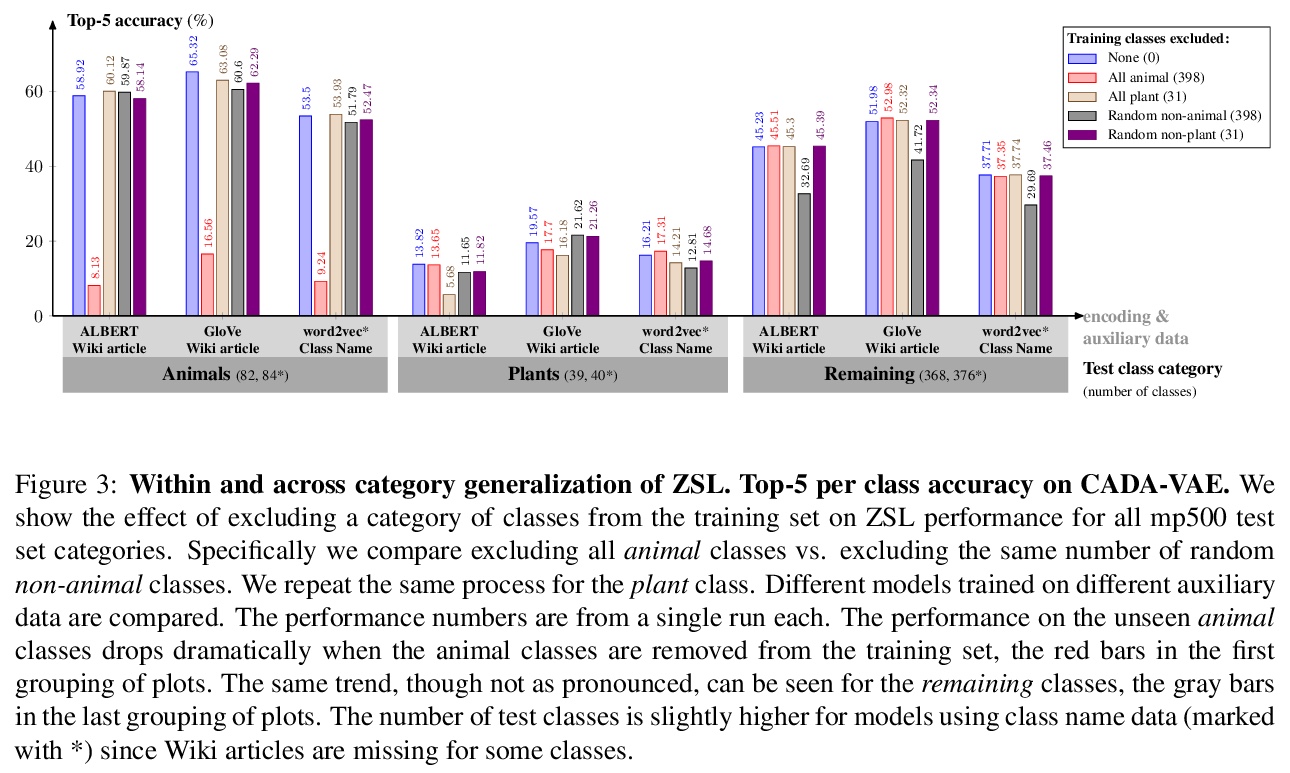
4、[CV] Large-Scale Zero-Shot Image Classification from Rich and Diverse Textual Descriptions
S Bujwid, J Sullivan
[KTH Royal Institute of Technology]
基于丰富多样文字描述的大规模零样本图像分类。创建了一个新数据集ImageNet-Wiki,将每个ImageNet类与其对应的维基百科文章进行匹配。实验表明,仅采用这些维基百科文章作为类描述,就能获得比之前方法高得多的零样本学习性能,即使是用这种类型的辅助数据的简单模型,也优于依靠类名词嵌入编码的标准特征的最先进模型。
We study the impact of using rich and diverse textual descriptions of classes for zero-shot learning (ZSL) on ImageNet. We create a new dataset ImageNet-Wiki that matches each ImageNet class to its corresponding Wikipedia article. We show that merely employing these Wikipedia articles as class descriptions yields much higher ZSL performance than prior works. Even a simple model using this type of auxiliary data outperforms state-of-the-art models that rely on standard features of word embedding encodings of class names. These results highlight the usefulness and importance of textual descriptions for ZSL, as well as the relative importance of auxiliary data type compared to algorithmic progress. Our experimental results also show that standard zero-shot learning approaches generalize poorly across categories of classes.
https://weibo.com/1402400261/K7agp5DTR

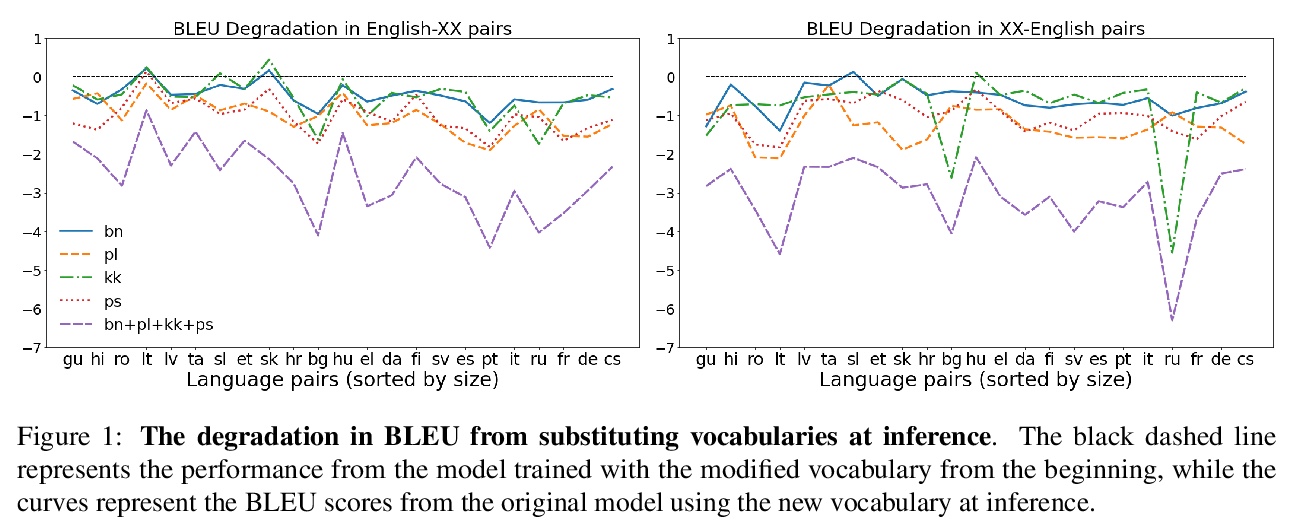
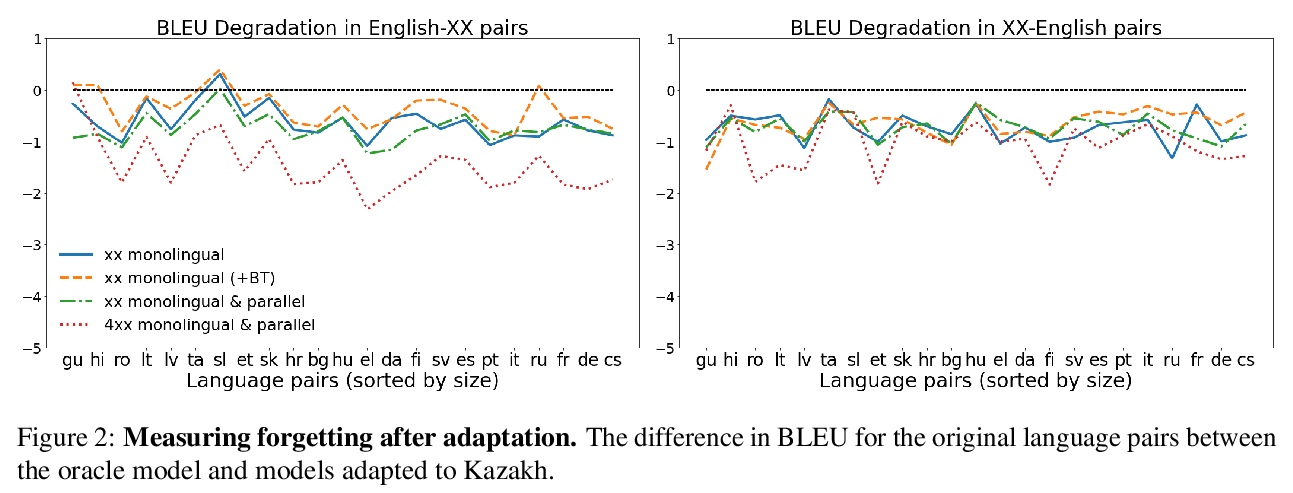
5、[CL] Towards Continual Learning for Multilingual Machine Translation via Vocabulary Substitution
X Garcia, N Constant, A P. Parikh, O Firat
[Google Research]
通过词汇替换实现多语言机器翻译的持续学习。提出一种直接的词汇自适应方案,以扩展多语言机器翻译模型的语言容量,为多语言机器翻译的高效持续学习铺平道路。所提方法适用于大规模数据集,适用于未见脚本的陌生语言,对原始语言对的翻译性能仅有轻微降低,即使在只拥有新语言单语数据的情况下,也能提供有竞争力的性能。
We propose a straightforward vocabulary adaptation scheme to extend the language capacity of multilingual machine translation models, paving the way towards efficient continual learning for multilingual machine translation. Our approach is suitable for large-scale datasets, applies to distant languages with unseen scripts, incurs only minor degradation on the translation performance for the original language pairs and provides competitive performance even in the case where we only possess monolingual data for the new languages.
https://weibo.com/1402400261/K7ajHhLwa
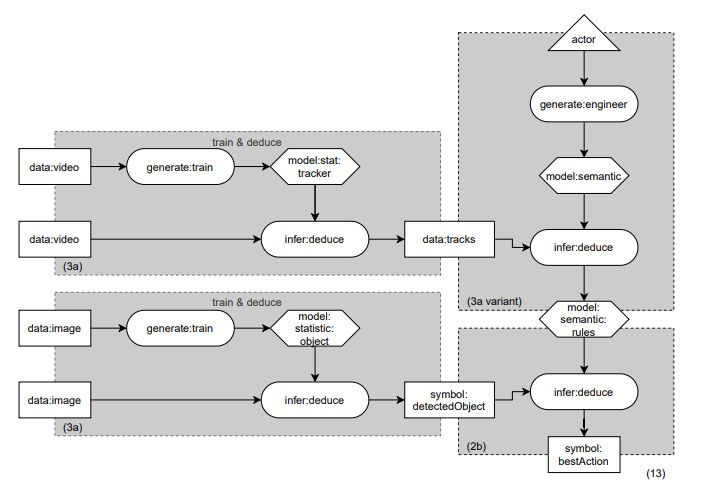
[LG] Modular Design Patterns for Hybrid Learning and Reasoning Systems: a taxonomy, patterns and use cases
混合学习和推理系统的模块化设计模式:分类、模式和用例。
M v Bekkum, M d Boer, F v Harmelen, A Meyer-Vitali, A t Teije
[TNO & Vrije Universiteit Amsterdam]
https://weibo.com/1402400261/K79UR629q
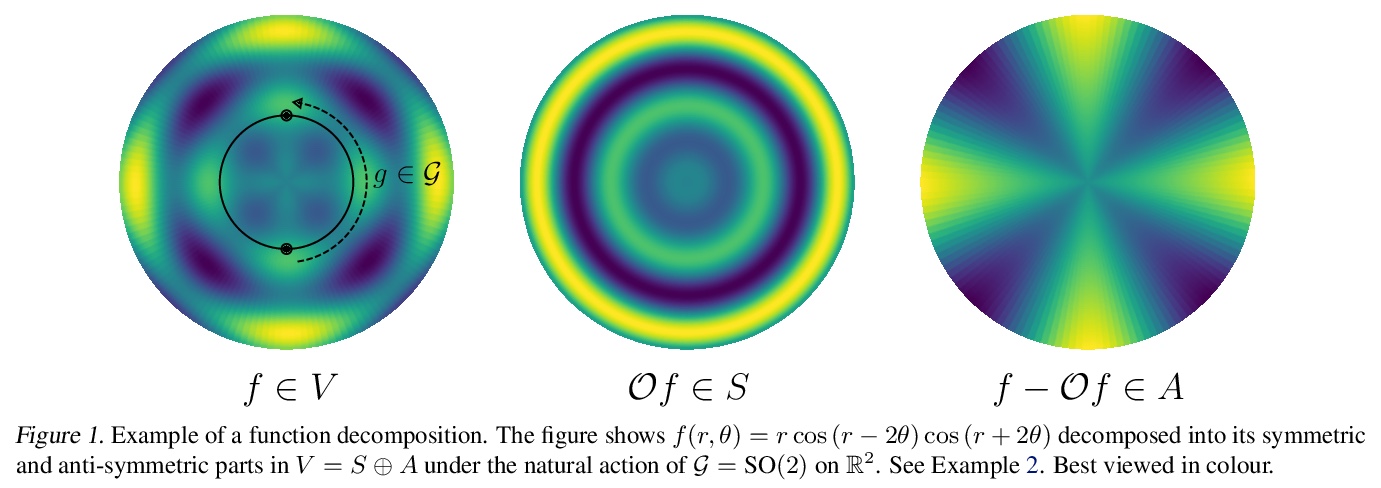
[LG] Provably Strict Generalisation Benefit for Equivariant Models
等价模型可证明严格泛化收益
B Elesedy, S Zaidi
[University of Oxford]
https://weibo.com/1402400261/K79Z1oOZV
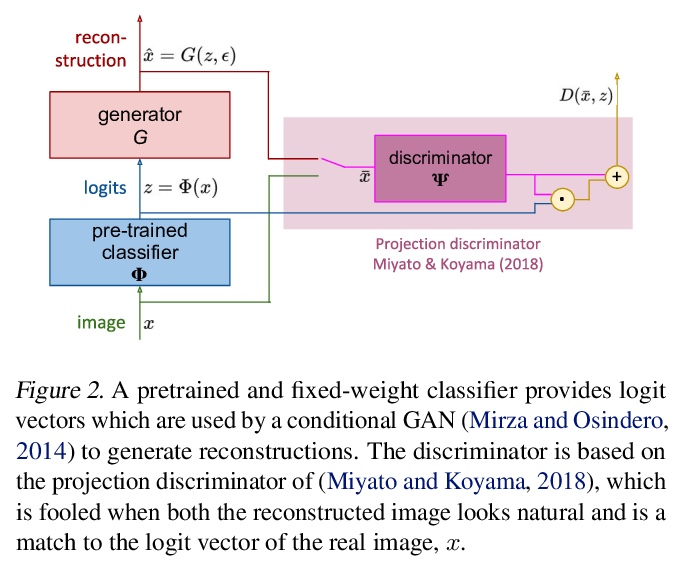
[LG] Understanding invariance via feedforward inversion of discriminatively trained classifiers
基于区分训练分类器前馈反演的不变性理解
P Teterwak, C Zhang, D Krishnan, M C. Mozer
[Boston University & Google Research]
https://weibo.com/1402400261/K7arHpzBM


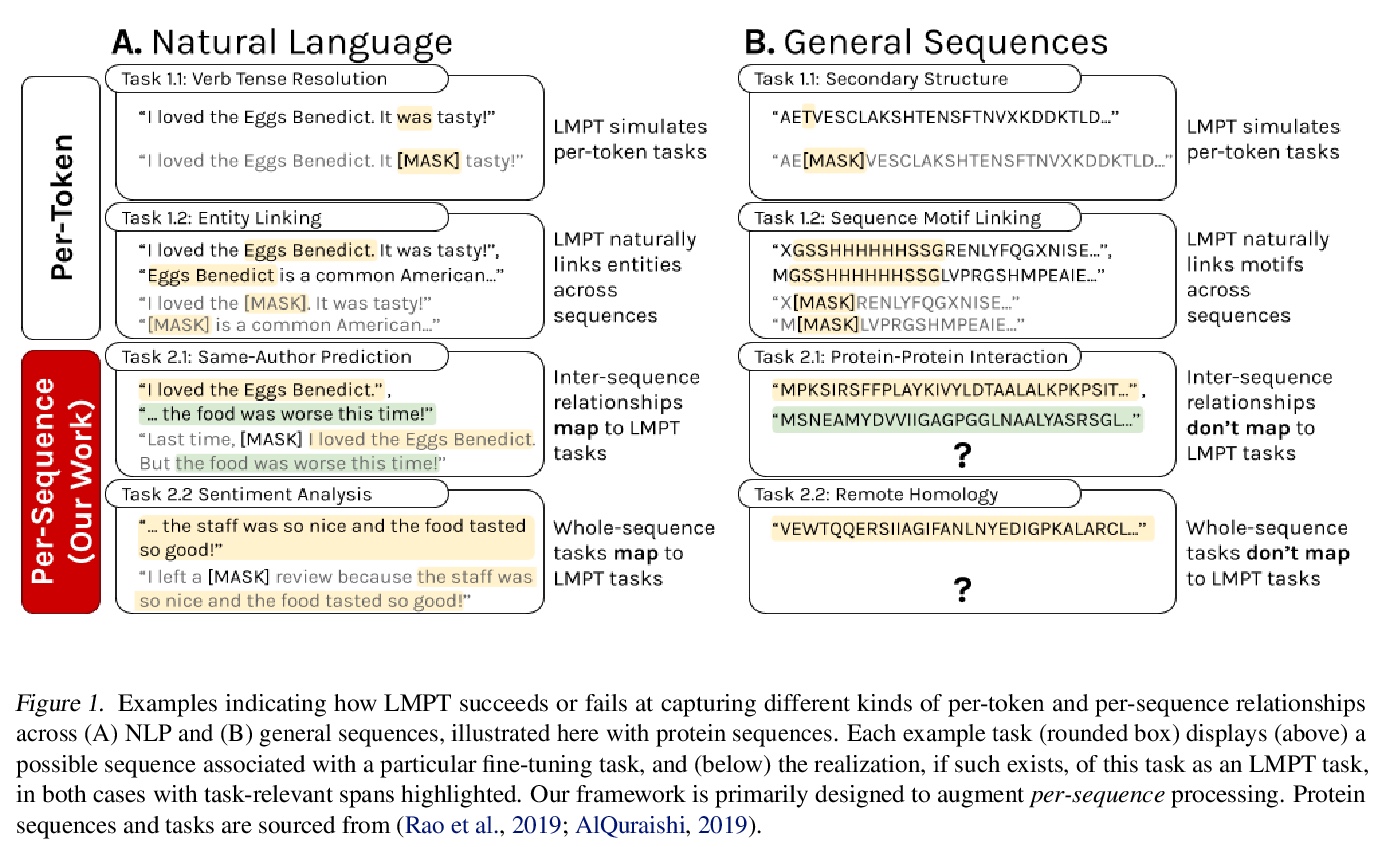
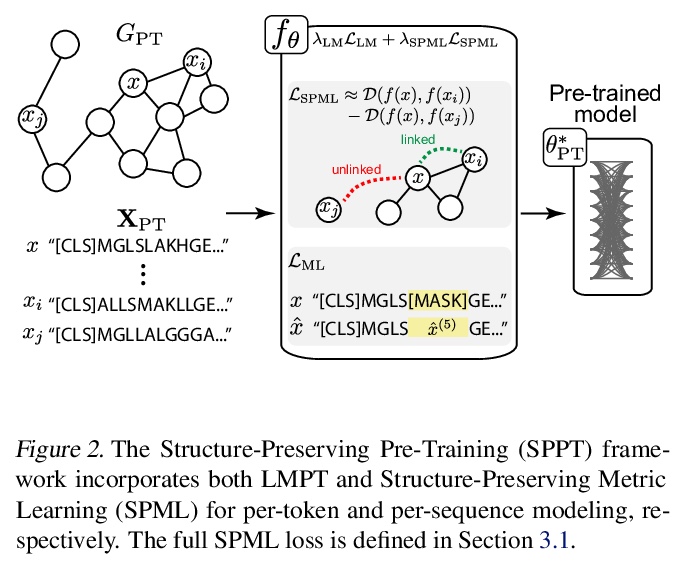
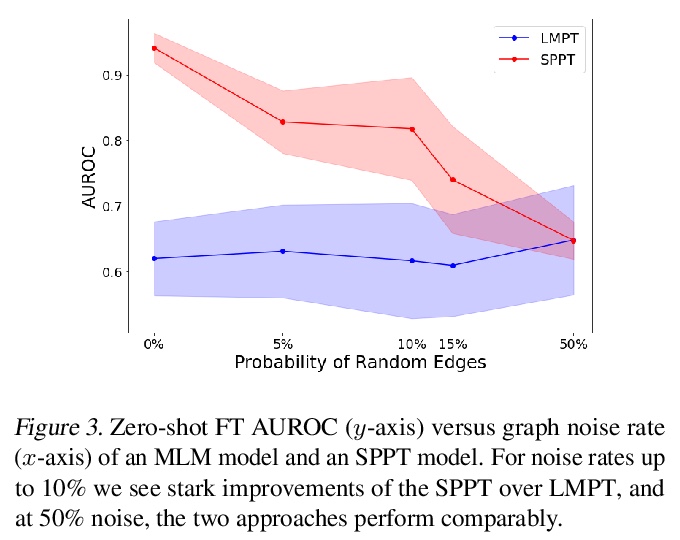
[LG] Rethinking Relational Encoding in Language Model: Pre-Training for General Sequences
语言模型中关系编码的反思:通用序列预训练
M B. A. McDermott, B Yap, P Szolovits, M Zitnik
[MIT & Harvard University]
https://weibo.com/1402400261/K7azTmErS

若有收获,就点个赞吧
0 人点赞
