LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] *Selective Inference for Hierarchical Clustering
L L. Gao, J Bien, D Witten
[University of Waterloo & University of Southern California & University of Washington]
层次聚类的选择性推理。提出一种选择性推理方法,用来测试从所有聚类方法得到的两聚类间的均值差异。通过考虑虚假设从数据中生成这一事实,来控制选择性的第一类统计错误率,描述了如何有效计算各种层次聚类得到聚类的精确P值。将该方法应用于仿真数据和单细胞RNA-seq数据,取得了良好的效果。
Testing for a difference in means between two groups is fundamental to answering research questions across virtually every scientific area. Classical tests control the Type I error rate when the groups are defined a priori. However, when the groups are instead defined via a clustering algorithm, then applying a classical test for a difference in means between the groups yields an extremely inflated Type I error rate. Notably, this problem persists even if two separate and independent data sets are used to define the groups and to test for a difference in their means. To address this problem, in this paper, we propose a selective inference approach to test for a difference in means between two clusters obtained from any clustering method. Our procedure controls the selective Type I error rate by accounting for the fact that the null hypothesis was generated from the data. We describe how to efficiently compute exact p-values for clusters obtained using agglomerative hierarchical clustering with many commonly used linkages. We apply our method to simulated data and to single-cell RNA-seq data.
https://weibo.com/1402400261/JxBzozMmF


2、** *[LG] A bounded-noise mechanism for differential privacy
Y Dagan, G Kur
[MIT]
差分隐私的有界噪声机制。解决了之前Thomas和Jon提出的开放问题,在每个k坐标加入有界独立噪声,以回答多重计数查询。
Answering multiple counting queries is one of the best-studied problems in differential privacy. Its goal is to output an approximation of the average > 1n∑ni=1x⃗ (i) of vectors > x⃗ (i)∈[0,1]k, while preserving the privacy with respect to any > x⃗ (i). We present an > (ϵ,δ)-private mechanism with optimal > ℓ∞ error for most values of > δ. This result settles the conjecture of Steinke and Ullman [2020] for the these values of > δ. Our algorithm adds independent noise of bounded magnitude to each of the > k coordinates, while prior solutions relied on unbounded noise such as the Laplace and Gaussian mechanisms.
https://weibo.com/1402400261/JxBDq34a7

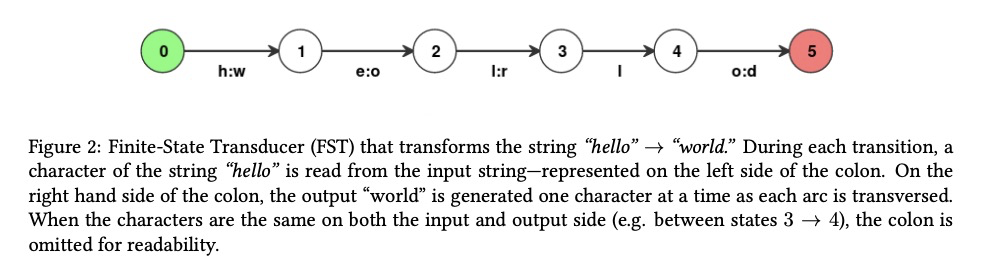
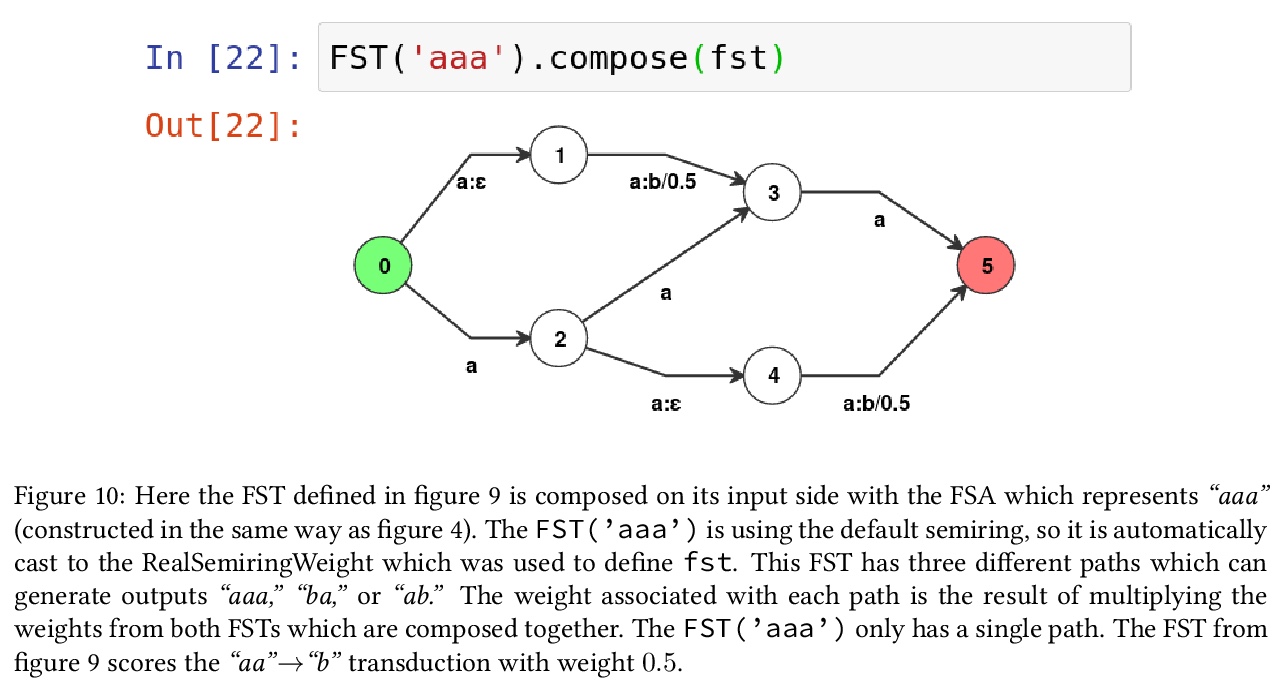
3、**[LG] MFST: A Python OpenFST Wrapper With Support for Custom Semirings and Jupyter Notebooks
M Francis-Landau
[Johns Hopkins University]
支持自定义半环的OpenFST的Python封装。介绍了一种新的Python库mFST,适用于基于OpenFST的有限状态机,支持Jupyter Notebooks。mFST开放了用于操作fst的所有OpenFST方法,也开放了OpenFST定义自定义半环的能力,非常适合开发需要学习FST权重或创建神经化FST的模型。**
This paper introduces mFST, a new Python library for working with Finite-State Machines based on OpenFST. mFST is a thin wrapper for OpenFST and exposes all of OpenFST’s methods for manipulating FSTs. Additionally, mFST is the only Python wrapper for OpenFST that exposes OpenFST’s ability to define a custom semirings. This makes mFST ideal for developing models that involve learning the weights on a FST or creating neuralized FSTs. mFST has been designed to be easy to get started with and has been previously used in homework assignments for a NLP class as well in projects for integrating FSTs and neural networks. In this paper, we exhibit mFST API and how to use mFST to build a simple neuralized FST with PyTorch.
https://weibo.com/1402400261/JxBIGuF6e
4、**[CV] MPG: A Multi-ingredient Pizza Image Generator with Conditional StyleGANs
F Han, G Hao, R Guerrero, V Pavlovic
[Rutgers University & Samsung AI Center]
基于条件式StyleGANs的多成分披萨图像生成器。提出多成分披萨生成器(MPG),一个条件式生成神经网络(GAN)框架,用于合成多标签图像,可以有效学习从特定成分组合中创建逼真披萨图像,并通过独立地改变样式噪声来操作视图。开发了新的条件处理技术,通过强制执行中间特征映射来学习粒度化标签信息。通过预测对应成分来对合成图像进行规则化,鼓励鉴别器区分匹配和不匹配的图像。**
Multilabel conditional image generation is a challenging problem in computer vision. In this work we propose Multi-ingredient Pizza Generator (MPG), a conditional Generative Neural Network (GAN) framework for synthesizing multilabel images. We design MPG based on a state-of-the-art GAN structure called StyleGAN2, in which we develop a new conditioning technique by enforcing intermediate feature maps to learn scalewise label information. Because of the complex nature of the multilabel image generation problem, we also regularize synthetic image by predicting the corresponding ingredients as well as encourage the discriminator to distinguish between matched image and mismatched image. To verify the efficacy of MPG, we test it on Pizza10, which is a carefully annotated multi-ingredient pizza image dataset. MPG can successfully generate photo-realist pizza images with desired ingredients. The framework can be easily extend to other multilabel image generation scenarios.
https://weibo.com/1402400261/JxBNerY00



5、** **[CV] NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis
P P. Srinivasan, B Deng, X Zhang, M Tancik, B Mildenhall, J T. Barron
[Google Research & MIT & UC Berkeley]
面向重打光和视图合成的神经反射率和可见度场。提出了一种从环境和间接照明场景图像中,恢复可靠神经体表示的方法,通过使用可见的MLP来近似部分体渲染集成,以一组由不受约束的已知光照照亮的场景图像作为输入,产生3D表示作为输出,该表示可以在任意光照条件下从新的视角呈现。
We present a method that takes as input a set of images of a scene illuminated by unconstrained known lighting, and produces as output a 3D representation that can be rendered from novel viewpoints under arbitrary lighting conditions. Our method represents the scene as a continuous volumetric function parameterized as MLPs whose inputs are a 3D location and whose outputs are the following scene properties at that input location: volume density, surface normal, material parameters, distance to the first surface intersection in any direction, and visibility of the external environment in any direction. Together, these allow us to render novel views of the object under arbitrary lighting, including indirect illumination effects. The predicted visibility and surface intersection fields are critical to our model’s ability to simulate direct and indirect illumination during training, because the brute-force techniques used by prior work are intractable for lighting conditions outside of controlled setups with a single light. Our method outperforms alternative approaches for recovering relightable 3D scene representations, and performs well in complex lighting settings that have posed a significant challenge to prior work.
https://weibo.com/1402400261/JxBSU6gBF


另外几篇值得关注的论文:
[CL] Grammar-Aware Question-Answering on Quantum Computers
量子计算机上的语法感知问答(QA)
K Meichanetzidis, A Toumi, G d Felice, B Coecke
[University of Oxford]
https://weibo.com/1402400261/JxBWcdYS6


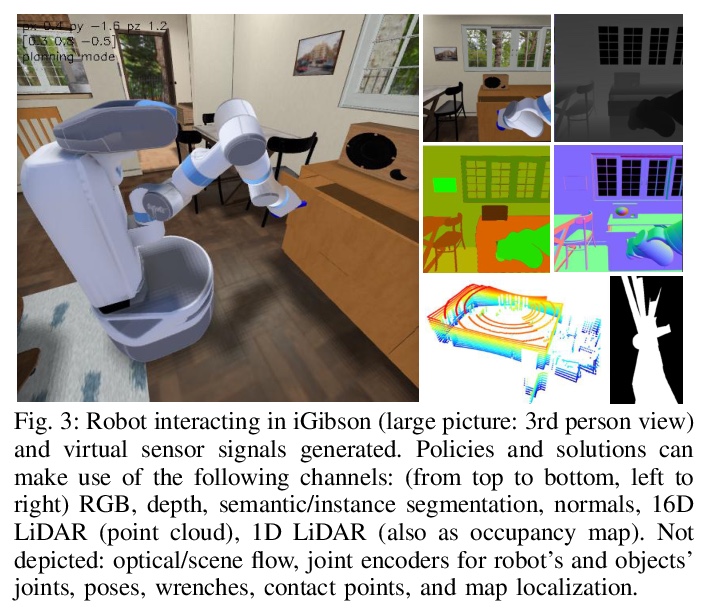
[CV] iGibson, a Simulation Environment for Interactive Tasks in Large RealisticScenes
iGibson:大型现实场景交互任务仿真环境
B Shen, F Xia, C Li, R Martín-Martín, L Fan, G Wang, S Buch, C D’Arpino, S Srivastava, L P. Tchapmi, M E. Tchapmi, K Vainio, L Fei-Fei, S Savarese
[Stanford University]
https://weibo.com/1402400261/JxBXwoVCv

[RO] Perspectives on Sim2Real Transfer for Robotics: A Summary of the R:SS 2020 Workshop
机器人的Sim2Real迁移:2020机器人学研讨会综述
S Höfer, K Bekris, A Handa, J C Gamboa, F Golemo, M Mozifian, C Atkeson, D Fox, K Goldberg, J Leonard, C. K Liu, J Peters, S Song, P Welinder, M White
[Amazon Robotics AI & NVIDIA Robotics & McGill University & Mila]
https://weibo.com/1402400261/JxC0llW3Q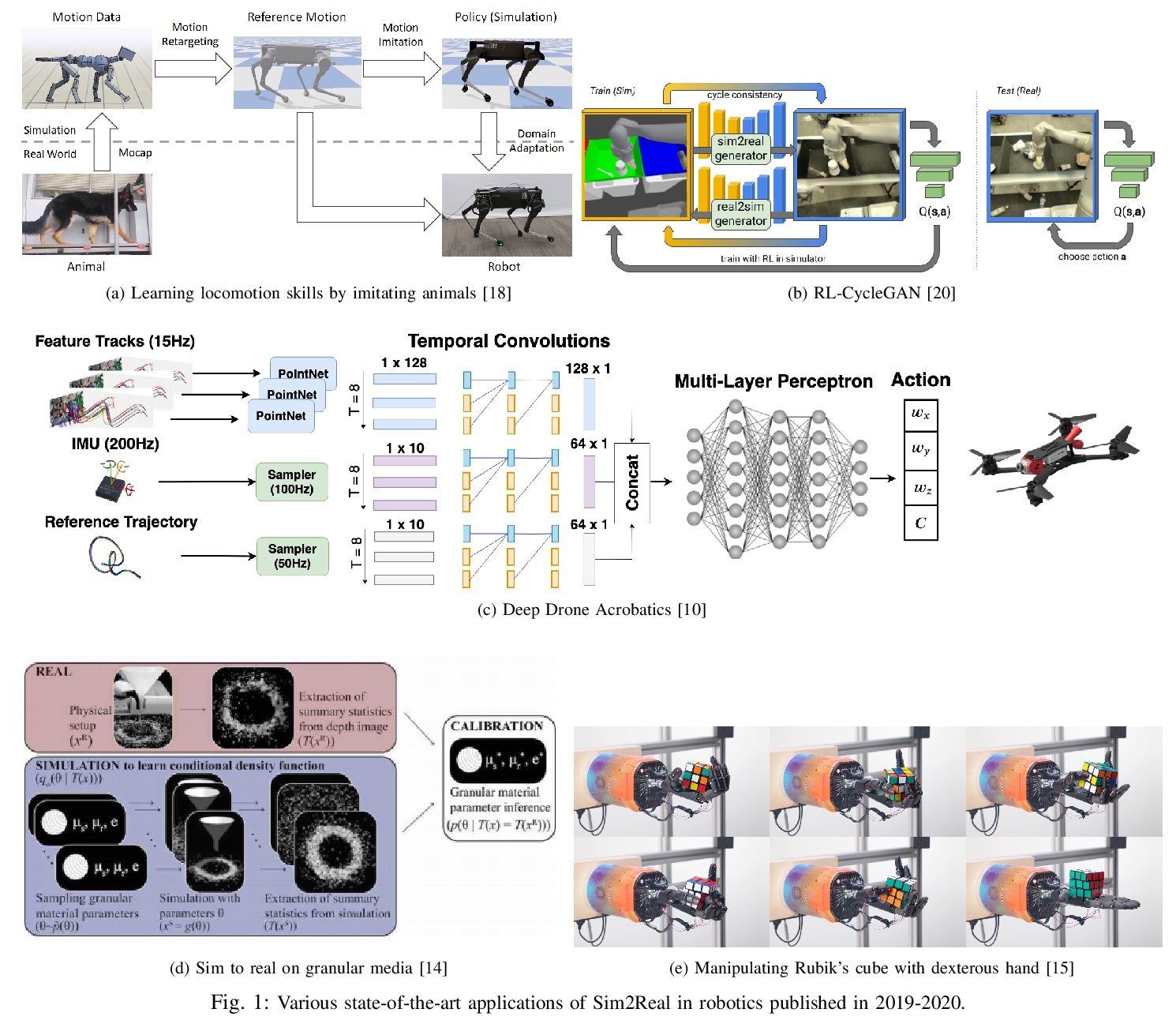
[CL] Pre-training Protein Language Models with Label-Agnostic Binding Pairs Enhances Performance in Downstream Tasks
用标签不可知结合对预训练蛋白质语言模型提高下游任务性能
M Filipavicius, M Manica, J Cadow, M R Martinez
[ETH Zürich & IBM Research Zürich] 



若有收获,就点个赞吧
0 人点赞
